
6.1 Introduction
In Chapter 5, I discussed several adaptive algorithms for computing principal and minor eigenvectors of the online correlation matrix Ak∈ℜnXn from a sequence of vectors {xk∈ℜn}. I derived these algorithms by applying the gradient descent on an objective function. However, it is well known [Baldi and Hornik 95, Chatterjee et al. Mar 98, Haykin 94] that principal component analysis (PCA) algorithms based on gradient descents are slow to converge. Furthermore, both analytical and experimental studies show that convergence of these algorithms depends on appropriate selection of the gain sequence {ηk}. Moreover, it is proven [Chatterjee et al. Nov 97; Chatterjee et al. Mar 98; Chauvin 89] that if the gain sequence exceeds an upper bound, then the algorithms may diverge or converge to a false solution.
Speed up the convergence of the algorithms, and
Automatically select the gain parameter based on the current data sample.
Objective Functions for Gradient-Based Adaptive PCA
Steepest descent (SD),
Conjugate direction (CD),
Newton-Raphson (NR), and
Recursive least squares (RLS).
These optimization methods lead to faster convergence of the algorithms compared to the gradient descent methods discussed in Chapters 4 and 5. They also help us compute a value of the gain sequence {ηk}, which is not available in the gradient descent method. The only drawback is the additional computation needed by these improved algorithms. Note that each optimization method when applied to a different objective function leads to a new algorithm for adaptive PCA.
The first objective function that is used extensively in signal processing applications for accelerated PCA is the Rayleigh quotient (RQ) objective function described in Sections 4.4 and 5.9. Sarkar et al. [Sarkar et al. 89; Yang et al. 89] applied the steepest descent and conjugate direction methods to this objective function to compute the extremal (largest or smallest) eigenvectors. Fu and Dowling [Fu and Dowling 94, 95] generalized the conjugate direction algorithm to compute all eigenvectors. Zhu and Wang [Zhu and Wang 97] also used a conjugate direction method on a regularized total least squares version of this objective function. A survey of conjugate direction-based algorithms on the RQ objective function is found in [Yang et al. 89].
The second objective function that is used for accelerated PCA is the penalty function (PF) objective function discussed in Sections 4.7 and 5.5. Chauvin [Chauvin 97] presents a gradient descent algorithm based on the PF objective function and analyzes the landscape of this function. Mathew et al. [Mathew et al. 94, 95, 96] also use this objective function to offer a Newton-type algorithm for adaptive PCA.
The third objective function used for accelerated PCA is the information theoretic (IT) objective function discussed in Sections 4.5 and 5.8. Miao and Hua [Miao and Hua 98] present gradient descent and RLS algorithms for adaptive principal sub-space analysis.
The fourth objective function used for accelerated PCA is the XU objective function given in Sections 4.6 and 5.4. For example, Xu [Xu 93], Yang [Yang 95], Fu and Dowling [Fu and Dowling 94], Bannour and Azimi-Sadjadi [Bannour and Azimi-Sadjadi 95], and Miao and Hua [Miao and Hua 98] used variations of this objective function. As discussed in Section 5.4, there are several variations of this objective function including the mean squared error at the output of a two-layer linear auto-associative neural network. Xu derives an algorithm for adaptive principal sub-space analysis by using gradient descent. Yang uses gradient descent and recursive least squares optimization methods. Bannour and Azimi-Sadjadi also describe a recursive least squares-based algorithm for adaptive PCA with this objective function. Fu and Dowling reduce this objective function to one similar to the RQ objective function, which can be minimized by the conjugate direction methods due to Sarkar et al. [Sarkar et al. 89; Yang et al. 89]. They also compute the minor components by using an approximation and by employing the deflation technique.
Outline of This Chapter
Gradient descent,
Steepest descent,
Conjugate direction,
Newton-Raphson, and
Recursive least squares.
I shall, however, use only one of these objective functions for the discussion in this chapter. I note that these analyses can be extended to the other objective functions in Chapters 4 and 5. My choice of objective function for this chapter is the XU deflation objective function discussed in Section 5.4.
Although gradient descent on the XU objective function (see Section 5.4) produces the well-known Xu’s least mean square error reconstruction (LMSER) algorithm [Xu 93], the steepest descent, conjugate direction, and Newton-Raphson methods produce new adaptive algorithms for PCA [Chatterjee et al. Mar 00]. The penalty function (PF) deflation objective (see Section 5.5) function has also been accelerated by the steepest descent, conjugate direction, and quasi-Newton methods of optimization by Kang et al. [Kang et al. 00].
I shall apply these algorithms to stationary and non-stationary multi-dimensional Gaussian data sequences. I experimentally show that the adaptive steepest descent, conjugate direction, and Newton-Raphson algorithms converge much faster than the traditional gradient descent technique due to Xu [Xu 93]. Furthermore, the new algorithms automatically select the gain sequence {ηk} based on the current data sample. I further compare the steepest descent algorithm with state-of-the-art methods such as Yang’s Projection Approximation Subspace Tracking (PASTd) [Yang 95], Bannour and Sadjadi’s recursive least squares (RLS) [Bannour et al. 95], and Fu and Dowling’s conjugate gradient eigenstructure tracking (CGET1) [Fu and Dowling 94, 95] algorithms.
The XU deflation objective function for adaptive PCA algorithms is given in the Section 5.4 equation (5.12) as
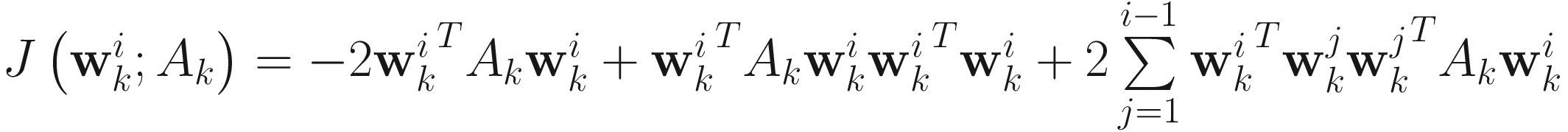 , (6.1)
, (6.1)
for i=1,…,p, where Ak∈ℜnXn is the online observation matrix. I now apply different methods of nonlinear minimization to the objective function 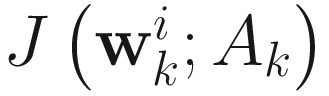 in (6.1) to obtain various algorithms for adaptive PCA.
in (6.1) to obtain various algorithms for adaptive PCA.
In Sections 6.2, 6.3, 6.4, and 6.5, I apply the gradient descent, steepest descent, conjugate direction, and Newton-Raphson optimization methods to the unconstrained XU objective function for PCA given in (6.1). Here I obtain new algorithms for adaptive PCA. In Section 6.6, I present experimental results with stationary and non-stationary Gaussian sequences, thereby showing faster convergence of the new algorithms over traditional gradient descent adaptive PCA algorithms. I also compare the steepest descent algorithm with state-of-the-art algorithms. Section 6.7 concludes the chapter.
6.2 Gradient Descent Algorithm
[Chatterjee et al. IEEE Trans. on Neural Networks, Vol. 11, No. 2, pp. 338-355, March 2000.]
The gradient
of (6.1) with respect to 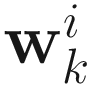 is
is
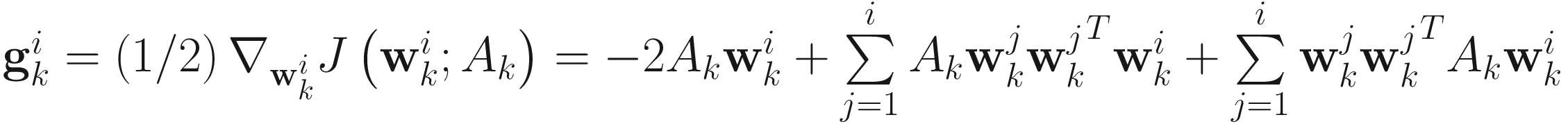 for i=1,…,p. (6.2)
for i=1,…,p. (6.2)
Thus, the XU deflation adaptive gradient descent algorithm for PCA (see Section 5.4.2) is
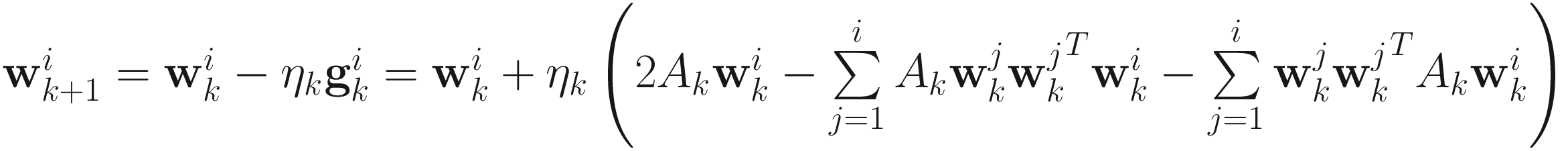 for i=1,…,p, (6.3)
for i=1,…,p, (6.3)
where ηk is a decreasing gain constant. We can represent Ak simply by its instantaneous value 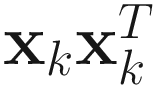 or by its recursive formula in Chapter 2 (Eq. 2.3 or 2.4). It is convenient to define a matrix
or by its recursive formula in Chapter 2 (Eq. 2.3 or 2.4). It is convenient to define a matrix ![$$ {W}_k=left[{mathbf{w}}_k^1dots {mathbf{w}}_k^p
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484280171/9781484280171__9781484280171__files__images__522202_1_En_6_Chapter__522202_1_En_6_Chapter_TeX_IEq7.png) (p≤n), for which the columns are the p weight vectors that converge to the p principal eigenvectors of Ak respectively. Then, (6.2) can be represented as (same as (5.14) in Section 5.4.2):
(p≤n), for which the columns are the p weight vectors that converge to the p principal eigenvectors of Ak respectively. Then, (6.2) can be represented as (same as (5.14) in Section 5.4.2):
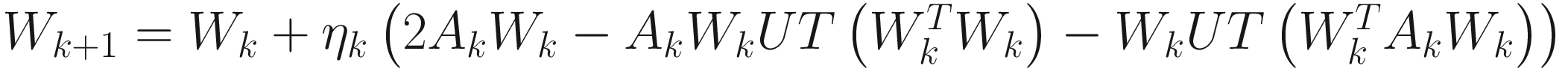 , (6.4)
, (6.4)
where UT[⋅] sets all elements below the diagonal of its matrix argument to zero, thereby making it upper triangular. Note that (6.2) is the LMSER algorithm due to Xu [Xu 93] that was derived from a least mean squared error criterion of a feed-forward neural network (see Section 5.4).
6.3 Steepest Descent Algorithm
[Chatterjee et al. IEEE Trans. on Neural Networks, Vol. 11, No. 2, pp. 338-355, March 2000.]
The adaptive steepest descent algorithm
for PCA is obtained from 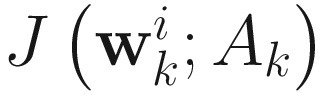 in (6.1) as
in (6.1) as
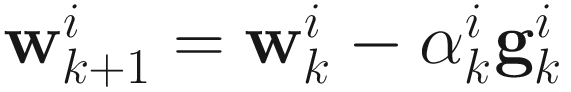 , (6.5)
, (6.5)
where 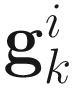 is given in (6.2) and
is given in (6.2) and 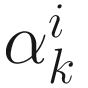 is a non-negative scalar minimizing
is a non-negative scalar minimizing 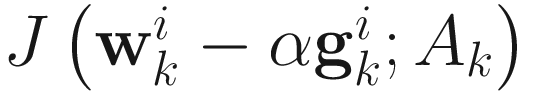 . Since we have an expression for
. Since we have an expression for 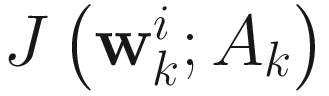 in (6.1), we minimize the function
in (6.1), we minimize the function 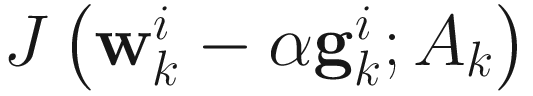 with respect to α and obtain the following cubic equation:
with respect to α and obtain the following cubic equation:
c3α3 + c2α2 + c1α + c0 = 0, (6.6)
where
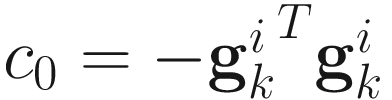 ,
, 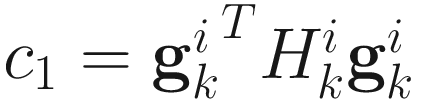 ,
, 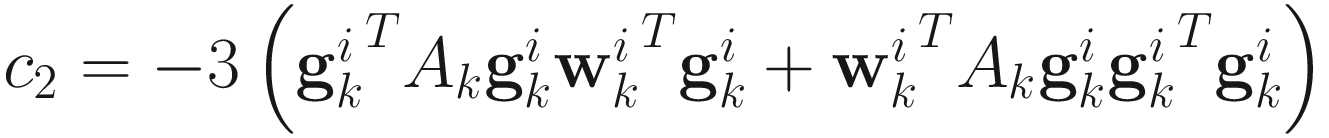 ,
, 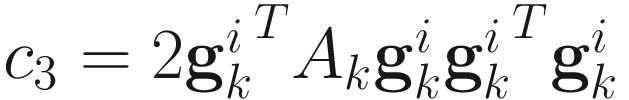 .
.
Here 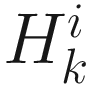 is the Hessian of
is the Hessian of 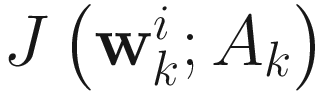 as follows:
as follows:
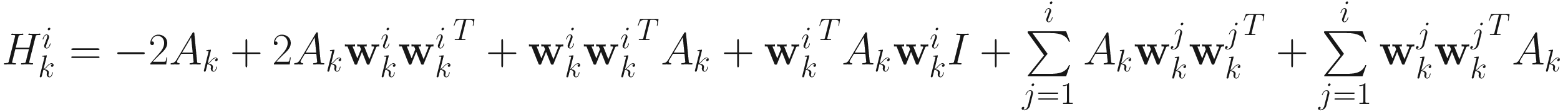 (6.7)
(6.7)
With known values of 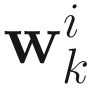 and
and 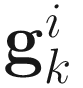 , this cubic equation can be solved to obtain α that minimizes
, this cubic equation can be solved to obtain α that minimizes 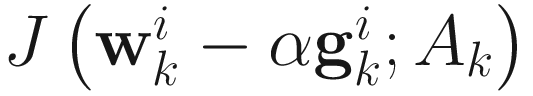 . A description of the computation of α is given in next section.
. A description of the computation of α is given in next section.
We now represent the adaptive PCA algorithm (6.5) in the matrix form. We define the matrices:
![$$ {W}_k=left[{mathbf{w}}_k^1,dots, {mathbf{w}}_k^p
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484280171/9781484280171__9781484280171__files__images__522202_1_En_6_Chapter__522202_1_En_6_Chapter_TeX_IEq26.png) ,
, ![$$ {G}_k=left[{mathbf{g}}_k^1,dots, {mathbf{g}}_k^p
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484280171/9781484280171__9781484280171__files__images__522202_1_En_6_Chapter__522202_1_En_6_Chapter_TeX_IEq27.png) , and
, and 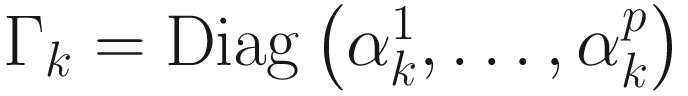 .
.
Then, the adaptive steepest descent PCA algorithm is
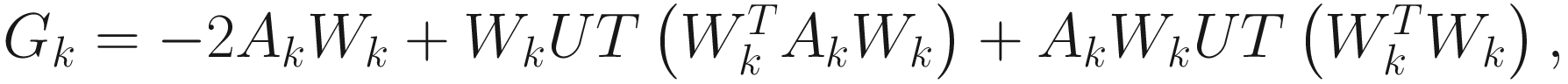
Wk + 1 = Wk − GkΓk. (6.8)
Here UT[·] is the same as in (6.4).
Computation of 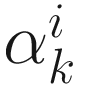 for Steepest Descent
for Steepest Descent
From J(wi;A) in (6.1), we compute α that minimizes J(wi − αgi; A), where
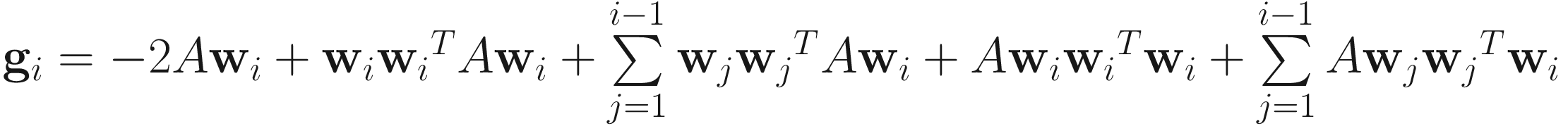 .
.
![$$ frac{d Jleft({mathbf{w}}_i-alpha {mathbf{g}}_i
ight)}{dalpha}=frac{1}{2} trleft[{
abla}_{{mathbf{w}}_i-alpha {mathbf{g}}_i}Jleft({mathbf{w}}_i-alpha {mathbf{g}}_i
ight)frac{d{left({mathbf{w}}_i-alpha {mathbf{g}}_i
ight)}^T}{dalpha}
ight]=-frac{1}{2}{mathbf{g}}_i^T{
abla}_{{mathbf{w}}_i-alpha {mathbf{g}}_i}Jleft({mathbf{w}}_i-alpha {mathbf{g}}_i
ight), $$](https://imgdetail.ebookreading.net/2023/10/9781484280171/9781484280171__9781484280171__files__images__522202_1_En_6_Chapter__522202_1_En_6_Chapter_TeX_Equa.png)
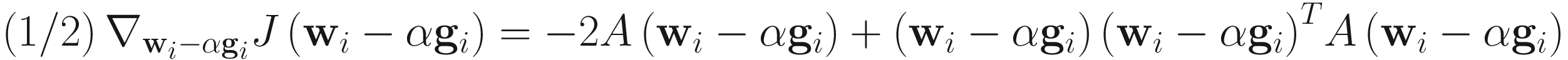
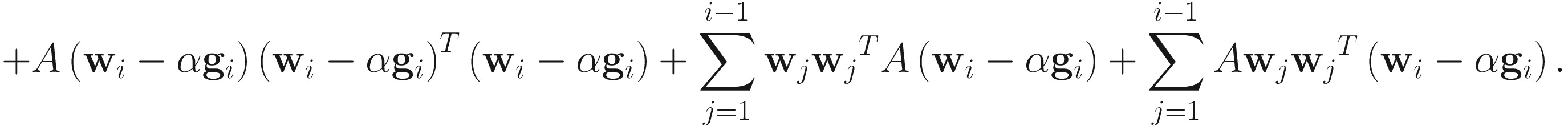
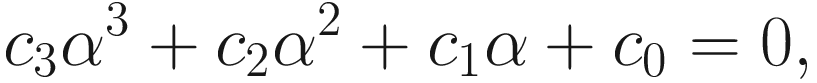
where
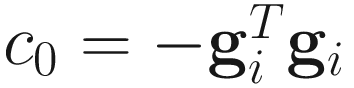 ,
, 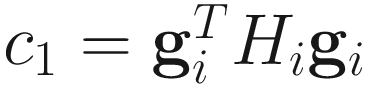 ,
, 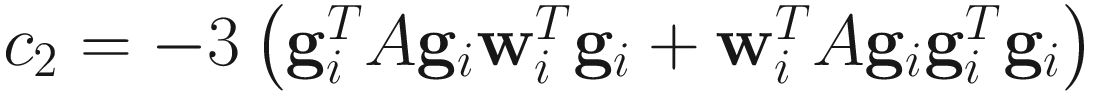 ,
, 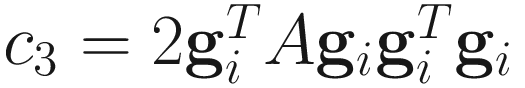 .
.
Here Hi is the Hessian of J(wi; A) given in (6.7).
It is well known that a cubic polynomial has at least one real root (two complex conjugate roots with a real root or three real roots). The roots can also be computed in closed form as shown in [Artin 91]. If a root is complex, then wi − αgi is complex, and clearly this is not the root we are looking for. If we have three real roots, then we can either take the root corresponding to minimum J(wi − αgi; A) or the one corresponding to 3c3α2 + 2c2α + c1 > 0.
Steepest Descent Algorithm Code
6.4 Conjugate Direction Algorithm
[Chatterjee et al. IEEE Trans. on Neural Networks, Vol. 11, No. 2, pp. 338-355, March 2000.]
The adaptive conjugate direction algorithm for PCA can be obtained as follows:
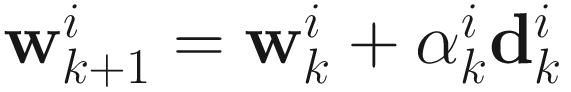
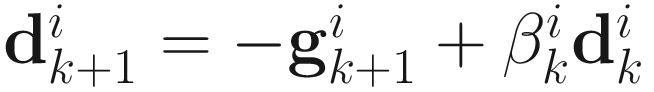 , (6.9)
, (6.9)
where 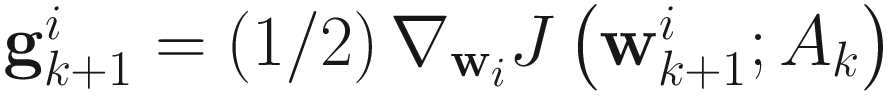 . The gain constant
. The gain constant 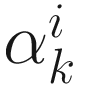 is chosen as α that minimizes
is chosen as α that minimizes 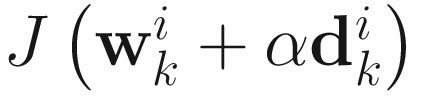 . Similar to the steepest descent case, we obtain the following cubic equation:
. Similar to the steepest descent case, we obtain the following cubic equation:
c3α3 + c2α2 + c1α + c0 = 0, (6.10)
where
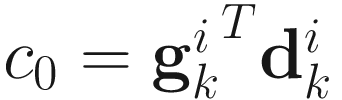 ,
, 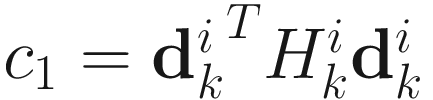 ,
, 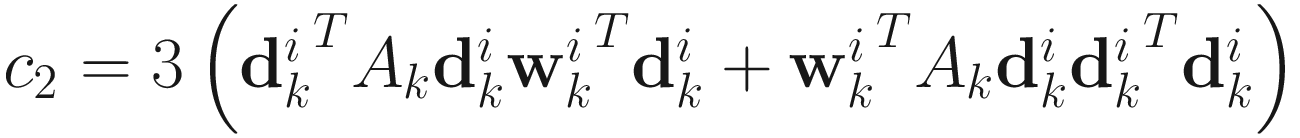 ,
, 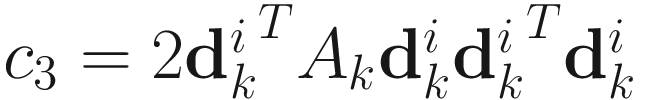 .
.
Here, 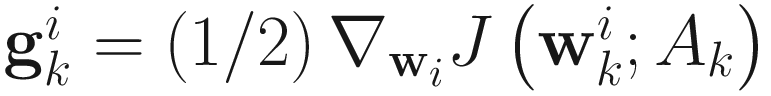 as given in (6.2). Equation (6.10) is solved to obtain α that minimizes
as given in (6.2). Equation (6.10) is solved to obtain α that minimizes 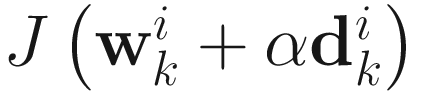 . For the choice of
. For the choice of 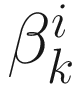 , we can use a number of methods such as Hestenes-Stiefel, Polak-Ribiere, Fletcher-Reeves, and Powell (described on Wikipedia).
, we can use a number of methods such as Hestenes-Stiefel, Polak-Ribiere, Fletcher-Reeves, and Powell (described on Wikipedia).
We now represent the adaptive conjugate direction PCA algorithm (6.9) in the matrix form. We define the following matrices:
![$$ {W}_k=left[{mathbf{w}}_k^1,dots, {mathbf{w}}_k^p
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484280171/9781484280171__9781484280171__files__images__522202_1_En_6_Chapter__522202_1_En_6_Chapter_TeX_IEq48.png) ,
, ![$$ {G}_k=left[{mathbf{g}}_k^1,dots, {mathbf{g}}_k^p
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484280171/9781484280171__9781484280171__files__images__522202_1_En_6_Chapter__522202_1_En_6_Chapter_TeX_IEq49.png) ,
, ![$$ {D}_k=left[{mathbf{d}}_k^1,dots, {mathbf{d}}_k^p
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484280171/9781484280171__9781484280171__files__images__522202_1_En_6_Chapter__522202_1_En_6_Chapter_TeX_IEq50.png) ,
,
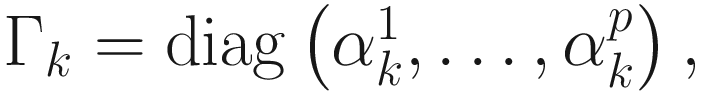 and
and 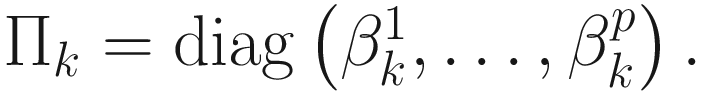
Then, the adaptive conjugate direction PCA algorithm is
Wk + 1 = Wk + DkΓk,
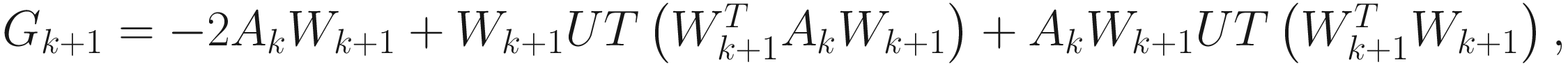
Dk + 1 = − Gk + 1 + DkΠk. (6.11)
Here UT[·] is the same as in (6.4).
Conjugate Direction Algorithm Code
6.5 Newton-Raphson Algorithm
[Chatterjee et al. IEEE Trans. on Neural Networks, Vol. 11, No. 2, pp. 338-355, March 2000.]
The adaptive Newton-Raphson algorithm for PCA is
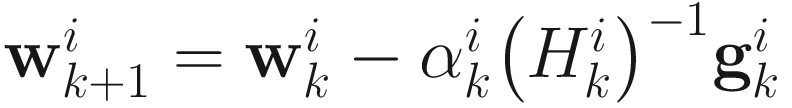 , (6.12)
, (6.12)
where 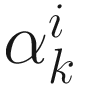 is a non-negative scalar and
is a non-negative scalar and 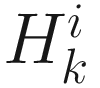 is the online Hessian given in (6.7). The search parameter
is the online Hessian given in (6.7). The search parameter 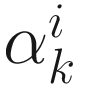 is commonly selected: (1) by minimizing
is commonly selected: (1) by minimizing 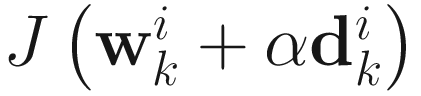 where
where 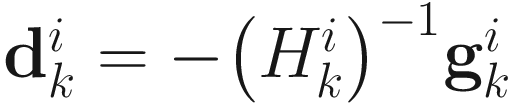 ; (2) as a scalar constant; or (3) as a decreasing sequence {
; (2) as a scalar constant; or (3) as a decreasing sequence {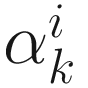 } such that
} such that 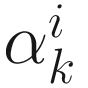 →0 as k→∞.
→0 as k→∞.
The main concerns in this algorithm are that 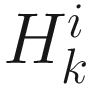 should be positive definite, and that we should adaptively obtain an estimate of
should be positive definite, and that we should adaptively obtain an estimate of 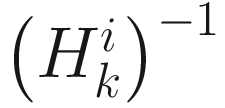 in order to make the algorithm computationally efficient. These two concerns are addressed if we approximate the Hessian by dropping the term
in order to make the algorithm computationally efficient. These two concerns are addressed if we approximate the Hessian by dropping the term 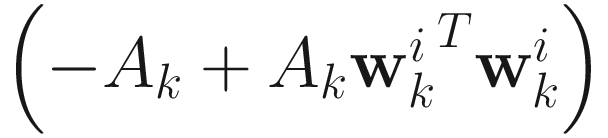 , which is close to 0 for
, which is close to 0 for 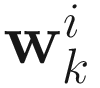 close to the solution. The new Hessian is
close to the solution. The new Hessian is
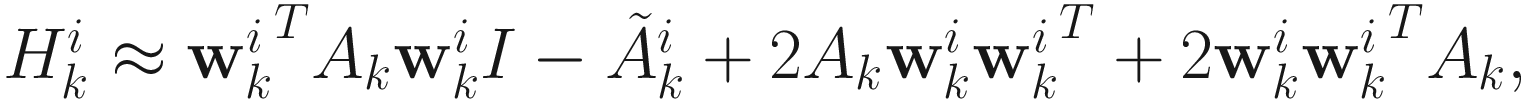 (6.13)
(6.13)
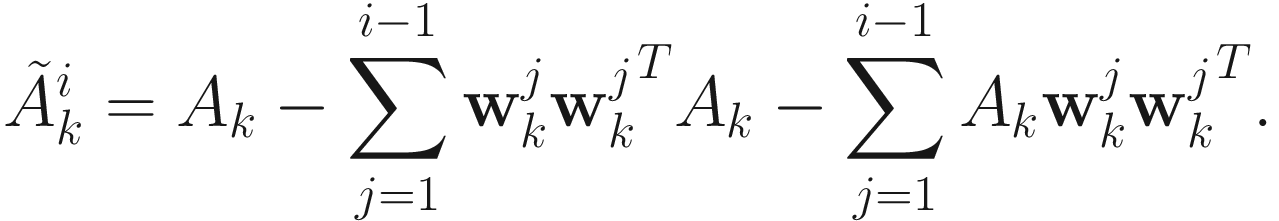
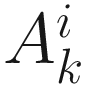 by an iterative equation in i as follows:
by an iterative equation in i as follows: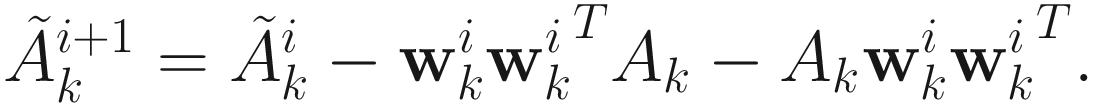
Inverting this Hessian consists of inverting the matrix 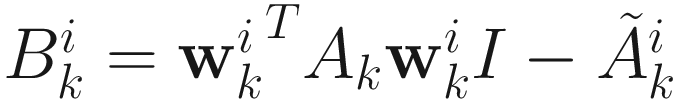 and two rank-one updates. An approximate inverse of this matrix
and two rank-one updates. An approximate inverse of this matrix 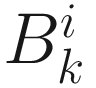 is given by
is given by
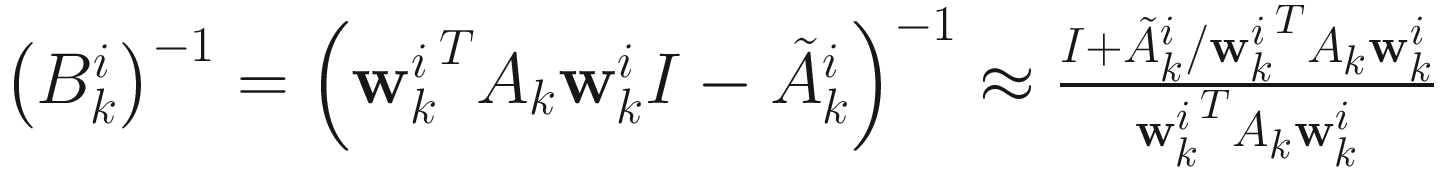 . (6.14)
. (6.14)
An adaptive algorithm for inverting the Hessian 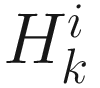 in (6.13) can be obtained by two rank-one updates. Let’s define
in (6.13) can be obtained by two rank-one updates. Let’s define
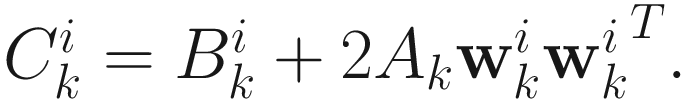 (6.15)
(6.15)
Then from (6.13), an update formula for 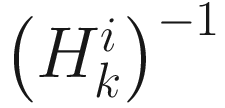 is
is
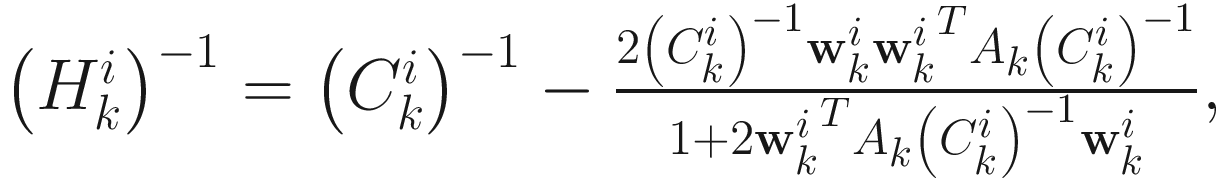 (6.16)
(6.16)
where 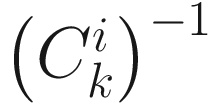 is obtained from (6.15) as
is obtained from (6.15) as
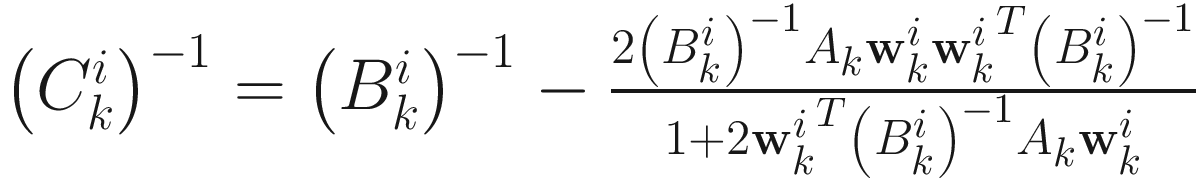 (6.17)
(6.17)
and 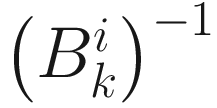 is given in (6.14).
is given in (6.14).
Newton-Raphson Algorithm Code
6.6 Experimental Results
I did two sets of experiments to test the performance of the accelerated PCA algorithms. I did the first set of experiments on stationary Gaussian data and the second set on non-stationary Gaussian data. I then compared the steepest descent algorithm against state-of-the-art adaptive PCA algorithms like Yang’s Projection Approximation Subspace Tracking, Bannour and Sadjadi’s Recursive Least Squares, and Fu and Dowling’s Conjugate Gradient Eigenstructure Tracking algorithms.
Experiments with Stationary Data
I generated 2000 samples of 10-dimensional Gaussian data (i.e., n=10) with mean zero and covariance given below. Note that this covariance matrix is obtained from the first covariance matrix in [Okada and Tomita 85] multiplied by 2. The covariance matrix is

The eigenvalues of the covariance matrix are
11.7996, 5.5644, 3.4175, 2.0589, 0.7873, 0.5878, 0.1743, 0.1423, 0.1213, 0.1007.

10-dimensional stationary random normal data
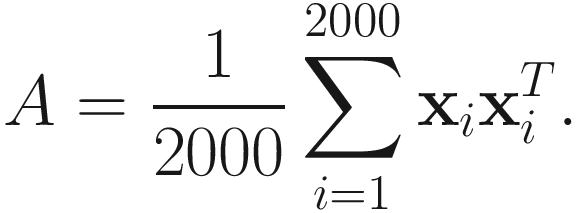
I refer to the eigenvectors and eigenvalues computed from this A by a standard numerical analysis method [Golub and VanLoan 83] as the actual values.
I used the adaptive gradient descent (6.4), steepest descent (6.8), conjugate direction (6.11), and Newton-Raphson (6.12) algorithms on the random data sequence {Ak}. I started all algorithms with W0 = 0.1*ONE, where ONE is a 10 X 4 matrix whose all elements are ones. In order to measure the convergence and accuracy of the algorithms, I computed the direction cosine at kth update of each adaptive algorithm as
Direction cosine (k) = 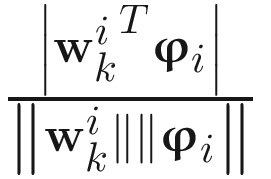 , (6.18)
, (6.18)
where 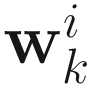 is the estimated eigenvector of Ak at kth update and ϕi is the actual eigenvector computed from all collected samples by a conventional numerical analysis method.
is the estimated eigenvector of Ak at kth update and ϕi is the actual eigenvector computed from all collected samples by a conventional numerical analysis method.
 . For the steepest descent, conjugate direction, and Newton-Raphson methods, I chose
. For the steepest descent, conjugate direction, and Newton-Raphson methods, I chose 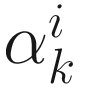 by solving a cubic equation as described in Sections 6.3, 6.4, and 6.5, respectively.
by solving a cubic equation as described in Sections 6.3, 6.4, and 6.5, respectively.
Convergence of the first four principal eigenvectors of A by the gradient descent (6.4) and steepest descent (6.8) algorithms for stationary data

Convergence of the first four principal eigenvectors of A by the gradient descent (6.4) and conjugate direction (6.11) algorithms for stationary data

Convergence of the first four principal eigenvectors of A by the gradient descent (6.4) and Newton-Raphson (6.12) algorithms for stationary data
It is clear from Figures 6-2 through 6-4 that the steepest descent, conjugate direction, and Newton-Raphson algorithms converge faster than the gradient descent algorithm in spite of a careful selection of ηk for the gradient descent algorithm. Besides, the new algorithms do not require ad-hoc selections of ηk. Instead, the gain parameters 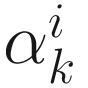 and
and 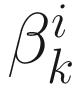 are computed from the online data sequence.
are computed from the online data sequence.
Comparison between the four algorithms show small differences between them for the first four principal eigenvectors of A. Among the three faster converging algorithms, the steepest descent algorithm (6.8) requires the smallest amount of computation per iteration. Therefore, these experiments show that the steepest descent adaptive algorithm (6.8) is most suitable for optimum speed and computation among the four algorithms presented here.
Experiments with Non-Stationary Data
In order to demonstrate the tracking ability of the algorithms with non-stationary data, I generated 500 samples of zero-mean 10-dimensional Gaussian data (i.e., n=10) with the covariance matrix stated before. I then abruptly changed the data sequence by generating 1,000 samples of zero-mean 10-dimensional Gaussian data with the covariance matrix below (the fifth covariance matrix from [Okada and Tomita 85] multiplied by 4):

The eigenvalues of this covariance matrix are
23.3662, 16.5698, 6.8611, 1.8379, 1.5452, 0.7010, 0.3851, 0.3101, 0.2677, 0.2278,

10-dimensional non-stationary random data with abrupt changes after 500 samples
I generated {Ak} from {xk} by using the algorithm (2.5 in Chapter 2) with β=0.995. I used the adaptive gradient descent (6.4), steepest descent (6.8), conjugate direction (6.11), and Newton-Raphson (6.12) algorithms on the random observation sequence {Ak} and measured the convergence accuracy of the algorithms by computing the direction cosine at kth update of each adaptive algorithm as shown in (6.18). I started all algorithms with W0 = 0.1*ONE, where ONE is a 10 X 4 matrix whose all elements are ones. Here again I computed the first four eigenvectors (i.e., p=4).
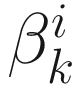 . For the steepest descent, conjugate direction, and Newton-Raphson methods, I chose
. For the steepest descent, conjugate direction, and Newton-Raphson methods, I chose 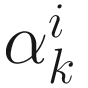 by solving a cubic equation as described in Sections 6.3 through 6.5.
by solving a cubic equation as described in Sections 6.3 through 6.5.
Convergence of the first four principal eigenvectors of two covariance matrices by the gradient descent (6.4) and steepest descent (6.8) algorithms for non-stationary data

Convergence of the first four principal eigenvectors of two covariance matrices by the gradient descent (6.4) and conjugate direction (6.11) algorithms for non-stationary data

Convergence of the first four principal eigenvectors of two covariance matrices by the gradient descent (6.4) and Newton-Raphson (6.12) algorithms for non-stationary data
Once again, it is clear from Figures 6-6 through 6-8 that the steepest descent, conjugate direction, and Newton-Raphson algorithms converge faster and track the changes in data much better than the traditional gradient descent algorithm. In some cases, such as Figure 6-6 for the third principal eigenvector, the gradient descent algorithm fails as the data sequence changes, but the new algorithms perform correctly.
Comparison between the four algorithms in Figure 6-8 show small differences between them for the first four principal eigenvectors. Once again, among the three faster converging algorithms, since the steepest descent algorithm (6.8) requires the smallest amount of computation per iteration, it is most suitable for optimum speed and computation.
Comparison with State-of-the-Art Algorithms
I compared the steepest descent algorithm (6.8) with Yang’s PASTd algorithm, Bannour and Sadjadi’s RLS algorithm, and Fu and Dowling’s CGET1 algorithm. I first tested the four algorithms on the stationary data described in Section 6.6.1.
- 1.
The steepest descent algorithm:
- 2.
Yang’s PASTd algorithm:
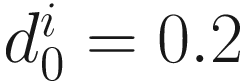 for i = 1, 2, …, p (p≤n).
for i = 1, 2, …, p (p≤n).- 3.
Bannour and Sadjadi’s RLS algorithm:
- 4.
Fu and Dowling’s CGET1 algorithm:
W0 = 0.1*ONE and 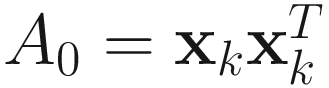 .
.
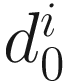 and P0 respectively. I, therefore, chose the initial values that gave the best results for most experiments. The results of this experiment are shown in Figure 6-9.
and P0 respectively. I, therefore, chose the initial values that gave the best results for most experiments. The results of this experiment are shown in Figure 6-9.
Convergence of the first four principal eigenvectors of A by steepest descent (6.8), PASTd, RLS, and CGET1 algorithms for stationary data
Observe from Figure 6-9 that the steepest descent and CGET1 algorithms perform quite well for all four principal eigenvectors. The RLS performed a little better than the PASTd algorithm for the minor eigenvectors. For the major eigenvectors, all algorithms performed well. The differences between the algorithms were evident for the minor (third and fourth) eigenvectors.

Convergence of the first four principal eigenvectors of two covariance matrices by the steepest descent (6.8), PASTd, RLS, and CGET1 algorithms for non-stationary data
Observe that the steepest descent and CGET1 algorithms perform quite well for all four principal eigenvectors. The PASTd algorithm performs better than the RLS algorithm in handling non-stationarity. This is expected since the PASTd algorithm accounts for non-stationarity with a forgetting factor of β=0.995, whereas the RLS algorithm has no such option.
6.7 Concluding Remarks
I presented an unconstrained objective function to obtain various new adaptive algorithms for PCA by using nonlinear optimization methods such as gradient descent, steepest descent, conjugate gradient, and Newton-Raphson. Comparison among these algorithms with stationary and non-stationary data show that the SD, CG, and NR algorithms have faster tracking abilities compared to the GD algorithm.
Further consideration should be given to the computational complexity of the algorithms. SD, CG, and NR algorithms have computational complexity of O(pn2). If, however, we use the estimate 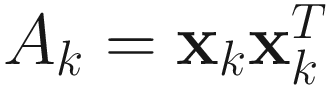 instead of (6.4) in the GD algorithm, then the computational complexity drops to O(pn), although the convergence gets slower. The CGET1 algorithm has complexity O(pn2). The PASTd and RLS algorithms have complexity O(pn). However, their convergence is slower than the SD and CGET1 algorithms as shown in Figures 6-9 and 6-10. Further note that the GD algorithm can be implemented by parallel architecture as shown by the examples in [Cichocki and Unbehauen 93].
instead of (6.4) in the GD algorithm, then the computational complexity drops to O(pn), although the convergence gets slower. The CGET1 algorithm has complexity O(pn2). The PASTd and RLS algorithms have complexity O(pn). However, their convergence is slower than the SD and CGET1 algorithms as shown in Figures 6-9 and 6-10. Further note that the GD algorithm can be implemented by parallel architecture as shown by the examples in [Cichocki and Unbehauen 93].