
Neural networks, specifically known as artificial neural networks (ANNs), were developed by the inventor of one of the first neurocomputers, Dr. Robert Hecht-Nielsen. He defines a neural network as follows: “…a computing system made up of a number of simple, highly interconnected processing elements, which process information by their dynamic state response to external inputs.”
Customarily, neutral networks are arranged in multiple layers. The layers consist of several interconnected nodes containing an activation function. The input layer, communicating to the hidden layers, delineates the patterns. The hidden layers are linked to an output layer.

A diagram illustrates how multiple input nodes are connected to a hierarchy of nodes in the hidden layers and the output node is predicted.
Neural network architecture
Backpropagation
Backpropagation, which usually substitutes an optimization method like gradient descent, is a common method of training artificial neural networks. The method computes the error in the outermost layer and backpropagates up to the input layer and then updates the weights as a function of that error, input, and learning rate. The final result is to minimize the error as far as possible.
Backpropagation Approach
Apply the input vector Xp = (xp1, xp2, …, xpN)t to the input units.

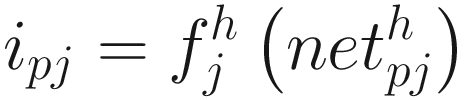





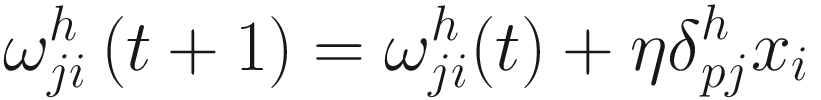
Other Algorithms

TensorFlow
People nowadays do not use raw TensorFlow code. They use the wrapper of Keras, which is code that uses data from several family surveys to determine the risk of delivery.
Network Architecture and Regularization Techniques
Before moving on to the next section, not that as you raise the number of hidden layers in your network, the accuracy improves, but the application consumes more memory. Typically, people employ two to three hidden layers.
The Adam optimizer is commonly chosen because it combines gradient descent and stochastic gradient descent. People may add the coefficient of the resulting equation in the loss function because a big coefficient indicates overfitting. Another option is to use a dropout layer, which ignores a certain percentage of neurons chosen at random during time learning. For the classification problem, an entropy function, which is a measurement of the chaos of the system, should be used in the loss function. For binary and multiclass classification, there are multiple versions.
Note that the PCA presented in Chapter 3 is used here with a 95 percent variance. That is the standard.
Updatable Model and Transfer Learning
In deep learning, declaring a model trainable is all that is required to create an updatable machine learning model, as mentioned in Chapter 3. The following code is an example of an anomaly detection system. Every cloud service offers network packet information, and any instrument, such as Suricata, can send a security alert. The following preprocessor code processes data and marks the network packet as alert or nonalert depending on the alert type.
You can find the data in the frame_packet_june_14.csv file in the Git repository of the book. Please refer to the following links:
https://github.com/Apress/advanced-data-analytics-python-2e/blob/main/eve.json
Note that PCA is not initialized with a 95 percent variance since we need the same number of parameters in each iteration; thus, we chose 15 as the number of parameters as the network packet had a total of 22 input parameters. PCA is not an updatable model. The development of an updatable feature selection model is still a research area.
This type of system is useful for a TV channel that wants to predict whether a user would churn. As they are not addicted to the channel, churn is defined as a user who does not renew their plan within 24 hours of it expiring. However, since hackers are continually trying new things, the network intrusion detection model always has new types of alerts. As a result, the system should cluster the data first, with each group representing a different type of alert. We have a classifier model for each category that determines if the alert is of that type.
Recurrent Neural Network
A recurrent neural network is an extremely popular kind of network where the output of the previous step goes to the feedback or is input to the hidden layer. It is an extremely useful solution for a problem like a sequence leveling algorithm or time-series prediction. One of the more popular applications of the sequence leveling algorithm is in an autocomplete feature of a search engine.
LSTM
In an RNN, the network takes feedback from past.X(t) = K × X(t − 1) = K2 × X(t − 2) = KN × X(t − N). Now, if K > 1, then KN is very large; otherwise, if K < 1, then KN is very small. To avoid this problem, network programmatically forgets some of its past state. LSTM does this.
This way, it can remember values over arbitrary intervals. LSTM works very well to classify, process, and predict time series given time lags of unknown duration. Relative insensitivity to gap length gives an advantage to LSTM over alternative RNNs, hidden Markov models, and other sequence learning methods.
RNN and HMM rely on the hidden state before emission/sequence. If we want to predict the sequence after 500 intervals instead of 5, LSTM can remember the states and predict properly.
To simplify this, suppose a person forgets old memories and remembers only recent things. But they need those memories from the past to perform some tasks in the future. This is the problem with traditional RNNs. Also, there is another person who remembers the important memories from the past along with the recent ones and deletes the useless memories from the past. This way, they can use that information to carry out the task more efficiently. This is the case with LSTM.
Each LSTM cell has three inputs, h{t − 1}, c{t − 1}, and xt, and two outputs, ht and ct. For a given time t, ht is the hidden state, ct is the cell state or memory, and xt is the current data point or input. The first sigmoid layer has two inputs, h{t − 1} and xt, where h{t − 1} is the hidden state of the previous cell. It is known as the forget gate as its output selects the amount of information of the previous cell to be included. The output is a number in [0,1], which is multiplied (pointwise) with the previous cell state c{t − 1}.
Reinforcement Learning
We’ll talk about reinforcement learning in this section. Learning from feedback is referred to as reinforcement learning. Reinforcement learning is one of three main types of machine learning approach alongside supervised and unsupervised machine learning. It’s used to learn models by performing specific tasks in a given environment. The program interacts with its surroundings and performs actions to move between different states. Actions are then either positively or negatively considered through reward or penalty. Successful actions are reinforced, and unsuccessful actions are penalized. A model will go through many different iterations to find the best possible sequence of actions to achieve a given goal. The following is the algorithm behind it.
TD0
Algorithm The TD(0) tabular algorithm is implemented by this function. After each transition, this function must be called.
X = Last state
Y = Next State
R = Instant reward connected with this transition
- V = Array of estimated value
![$$ delta =R+gamma left[V(Y)-V(X)
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484280058/9781484280058__9781484280058__files__images__458833_2_En_5_Chapter__458833_2_En_5_Chapter_TeX_Equj.png)
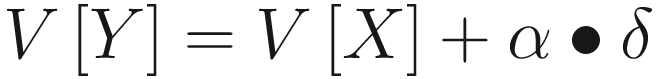
where α is step size.
return V
Please pass the following file in a command prompt while running this function:
You can use this method to boost accuracy in any regression problem by predicting error, but it’s a little trickier for classification.
TDλ
Algorithm This function uses replacing traces to perform the tabular TD(λ) algorithm. After each transition, this function must be called.
X= Last state
Y= Next state
R= Instant reward connected with this transition
V = Array of estimated value
- z= Array of eligibility traces

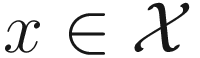 do:
do: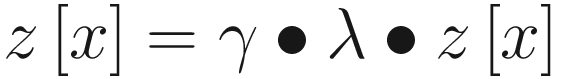
Example of Dialectic Learning
An algorithmic trader now wants to divide stock prices into three goal categories: same, up, and down. The class same denotes that the stock’s price has remained unchanged. The class up denotes that the stock’s price is going up. The class down denotes that the stock’s price is decreasing.
Ninety-seven percent of the data is classified as the class same. The time series is about 20,000 points long. For this type of problem, most people use biased sampling. We, on the other hand, did things differently. We divide the data into batches of 1,000 points and train the model with 1,000 data points to predict the following 100 in each iteration. In Keras, we use SoftMax regression with RNN with a sequence length of 100. We now calculate the probability of being up, down, or the same for each iteration. We also compute the probability distribution’s mean and standard deviation. We now use the following formula to determine the score for each class:
inc = (prob_increasing[j] - increasing_mean + k_inc*increasing_std)
dec = (prob_decreasing[j] - decreasing_mean + k_dec*decreasing_std)
same = (prob_same[j] - same_mean + k_same*same_std)
where K_inc, K_dec, and K_same are the constants initialized as 1.
So, most of the data is classified in same and the rest is in the other class.
wrong_count_pos_same = Count of points wrongly classified in the same class
total_count_acc_same = Count of points actually belonging to the same class
wrong_count_neg_same = Count of points wrongly not classified in the same class
total_count_acc_not_same = Count of points actually not in the class same
So, a dialectic was created between all candidate classes, and the points were adjusted depending on local trends of 100 points on top of the prediction based on the previous 1,000 points. This pattern improves the accuracy of classification with any model in stock point prediction. The original code is given next.
You can find the data in the dialectic_learning_data.csv and dialectic_learning_label.csv files in the Git repository of the book.
Convolution Neural Networks
Now we will discuss another kind of neural network: convolution neural networks.

A diagram defines how an input frame is convoluted, and features extracted. pooled, and classified through the fully connected layers to predict the output.
CNN architecture
Instead, we compute the output using convolutional filters applied to the input layer. When you use these convolutions, you get local connections, which means that every part of the input is linked to a portion of the output (we’ll explain this later in the chapter). In a CNN, each layer applies a separate set of filters, usually hundreds or thousands, and then merges the results.
In the first layer, detect edges using raw pixel data.
In the second layer, use these edges to recognize shapes (i.e., blobs).
In the top layers of the network, use these shapes to detect higher-level characteristics like face structures.
The last layer is a classifier, which makes predictions about the contents of the picture based on these higher-level characteristics.
Summary
This chapter is the heart of this book. We discussed neural networks such as RNN and CNN with reinforcement learning using real examples. In the next chapter, we will discuss some classical statistical methods to analyze time-series data, and the last chapter is all about how to scale your analytic application.