
A time series is a series of data points arranged chronologically. Most commonly, the time points are equally spaced. A few examples are the passenger loads of an airline recorded each month for the past two years or the price of an instrument in the share market recorded each day for the last year. The primary aim of time-series analysis is to predict the future value of a parameter based on its past data.
Classification of Variation
Traditionally, time-series analysis divides the variation into three major components, namely, trends, seasonal variations, and other cyclic changes. The variation that remains is attributed to “irregular” fluctuations or error term. This approach is particularly valuable when the variation is mostly comprised of trends and seasonality.
Analyzing a Series Containing a Trend

A graph plots the international airline passenger data in thousands. It plots an increasing trend from around 100 in Jan 49 to 600 in Jan 60.
A time series with trends
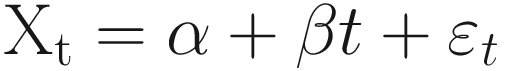
Here, α,β are constants, and εt denotes a random error term with a mean of 0. The average level at time t is given by mt= (α + βt). This is sometimes called the trend term.
Curve Fitting
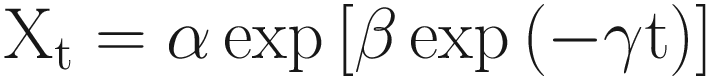
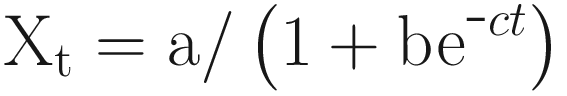
Both these curves are S-shaped and approach an asymptotic value as t → ∞, with the Gompertz curve generally converging slower than the logistic one. Fitting the curves to data may lead to nonlinear simultaneous equations.
For all curves of this nature, the fitted function provides a measure of the trend, and the residuals provide an estimate of local fluctuations where the residuals are the differences between the observations and the corresponding values of the fitted curve.
Removing Trends from a Time Series
Differentiating a given time series until it becomes stationary is a special type of filtering that is particularly useful for removing a trend. You will see that this is an integral part of the Box-Jenkins procedure. For data with a linear trend, a first-order differencing is usually enough to remove the trend.

A trend can be exponential as well. In this case, you will have to do a logarithmic transformation to convert the trend from exponential to linear.
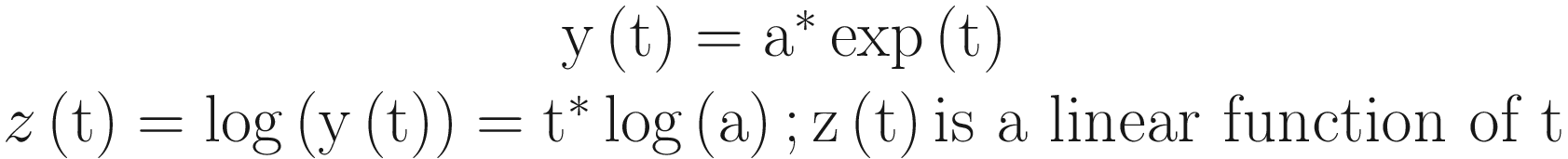
Analyzing a Series Containing Seasonality
Many time series, such as airline passenger loads or weather readings, display variations that repeat after a specific time period. For instance, in India, there will always be an increase in airline passenger loads during the holiday of Diwali. This yearly variation is easy to understand and can be estimated if seasonality is of direct interest. Similarly, like trends, if you have a series such as 1, 2, 1, 2, 1, 2, your obvious choices for the next values of the series will be 1 and 2.

In this model, every point is realized as a weighted average of the previous point and seasonality. So, X(t+1) will be calculated as a function X(t-1) and S(t-2) and square of α. In this way, the more you go on, the α value increases exponentially. This is why it is known as exponential smoothing. The starting value of St is crucial in this method. Commonly, this value starts with a 1 or with an average of the first four observations.

Here, b1, often referred to as the permanent component, is the initial weight of the seasonality; b2 represents the trend, which is linear in this case.
However, there is no standard implementation of the Holt-Winters model in Python. It is available in R (see Chapter 1 for how R’s Holt-Winters model can be called from Python code).
Removing Seasonality from a Time Series
By filtering
By differencing
By Filtering
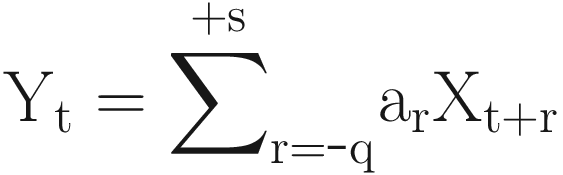
To smooth out local fluctuations and estimate the local mean, you should clearly choose the weights so that ∑ar = 1; then the operation is often referred to as a moving average. They are often symmetric with s = q and aj = a-j. The simplest example of a symmetric smoothing filter is the simple moving average, for which ar = 1 / (2q+1) for r = -q, …, + q.
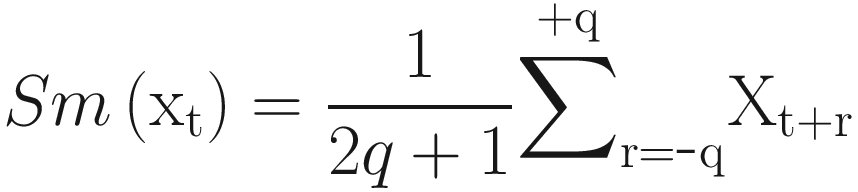
The simple moving average is useful for removing seasonal variations, but it is unable to deal well with trends.
By Differencing
Differencing is widely used and often works well. Seasonal differencing removes seasonal variation.

Similar to trends, you can convert the multiplicative seasonality to additive by log transformation.
Now, finding time period T in a time series is the critical part. It can be done in two ways, either by using an autocorrelation function in the time domain or by using the Fourier transform in the frequency domain. In both cases, you will see a spike in the plot. For autocorrelation, the plot spike will be at lag T, whereas for FT distribution, the spike will be at frequency 1/T.
Transformation
Up to now I have discussed the various kinds of transformation in a time series. The three main reasons for making a transformation are covered in the next sections.
To Stabilize the Variance
The standard way to do this is to take a logarithmic transformation of the series; it brings closer the points in space that are widely scattered.
To Make the Seasonal Effect Additive
If the series has a trend and the volume of the seasonal effect appears to be on the rise with the mean, then it may be advisable to modify the data so as to make the seasonal effect constant from year to year. This seasonal effect is said to be additive. However, if the volume of the seasonal effect is directly proportional to the mean, then the seasonal effect is said to be multiplicative, and a logarithmic transformation is needed to make it additive again.
To Make the Data Distribution Normal
In most probability models, it is assumed that distribution of data is Gaussian or normal. For example, there can be evidence of skewness in a trend that causes “spikes” in the time plot that are all in the same direction.
To transform the data in a normal distribution, the most common transform is to subtract the mean and then divide by the standard deviation. I gave an example of this transformation in the RNN example in Chapter 5; I’ll give another in the final example of the current chapter. The logic behind this transformation is it makes the mean 0 and the standard deviation 1, which is a characteristic of a normal distribution. Another popular transformation is to use the logarithm. The major advantage of a logarithm is it reduces the variation and logarithm of Gaussian distribution data that is also Gaussian. Transformation may be problem-specific or domain-specific. For instance, in a time series of an airline’s passenger load data, the series can be normalized by dividing by the number of days in the month or by the number of holidays in a month.
Cyclic Variation
In some time series, seasonality is not a constant but a stochastic variable. That is known as cyclic variation. In this case, the periodicity first has to be predicted and then has to be removed in the same way as done for seasonal variation.
Irregular Fluctuations
A time series without trends and cyclic variations can be realized as a weekly stationary time series. In the next section, you will examine various probabilistic models to realize weekly time series.
Stationary Time Series
Normally, a time series is said to be stationary if there is no systematic change in mean and variance and if strictly periodic variations have been done away with. In real life, there are no stationary time series. Whatever data you receive by using transformations, you may try to make it somehow nearer to a stationary series.
Stationary Process
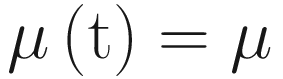
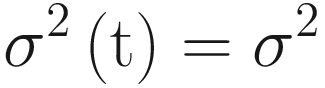
They are both constants, which do not depend on the value of t.
A weekly stationary time series is a stochastic process where the mean is constant and autocovariance is a function of time lag.
Autocorrelation and the Correlogram
Quantities called sample autocorrelation coefficients act as an important guide to the properties of a time series. They evaluate the correlation, if any, between observations at different distances apart and provide valuable descriptive information. You will see that they are also an important tool in model building and often provide valuable clues for a suitable probability model for a given set of data. The quantity lies in the range [-1,1] and measures the forcefulness of the linear association between the two variables. It can be easily shown that the value does not depend on the units in which the two variables are measured; if the variables are independent, then the ideal correlation is zero.
A helpful supplement in interpreting a set of autocorrelation coefficients is a graph called a correlogram. The correlogram may be alternatively called the sample autocorrelation function.
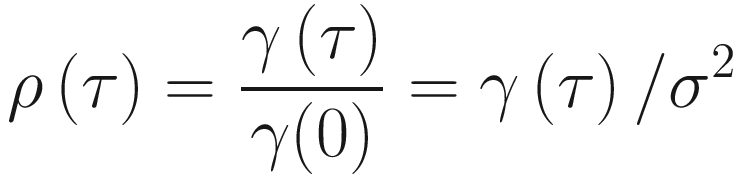
Estimating Autocovariance and Autocorrelation Functions
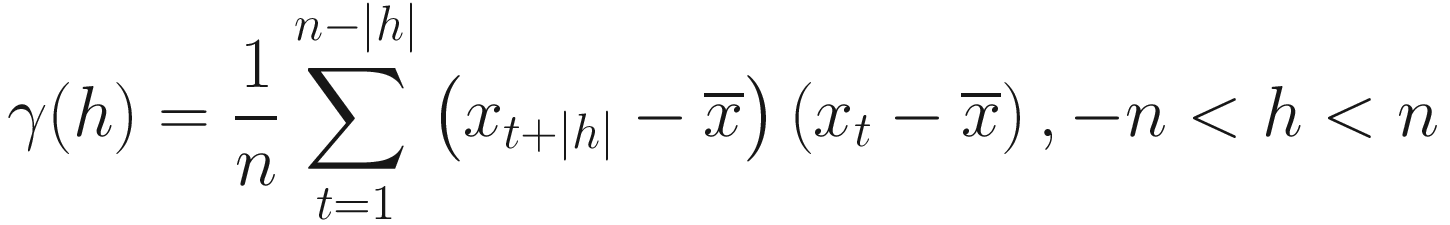

A pair of simulated discrete-time sequences for autocorrelation and partial autocorrelations. Both plots have the highest peak of 0 at 1 point 0.
Sample autocorrelations
Time-Series Analysis with Python
A complement to SciPy for statistical computations including descriptive statistics and estimation of statistical models is provided by Statsmodels, which is a Python package. Besides the early models, linear regression, robust linear models, generalized linear models, and models for discrete data, the latest release of scikits.statsmodels includes some basic tools and models for time-series analysis, such as descriptive statistics, statistical tests, and several linear model classes. The linear model classes include autoregressive (AR), autoregressive moving-average (ARMA), and vector autoregressive models (VAR).
Useful Methods
Let’s start with a moving average.
Moving Average Process




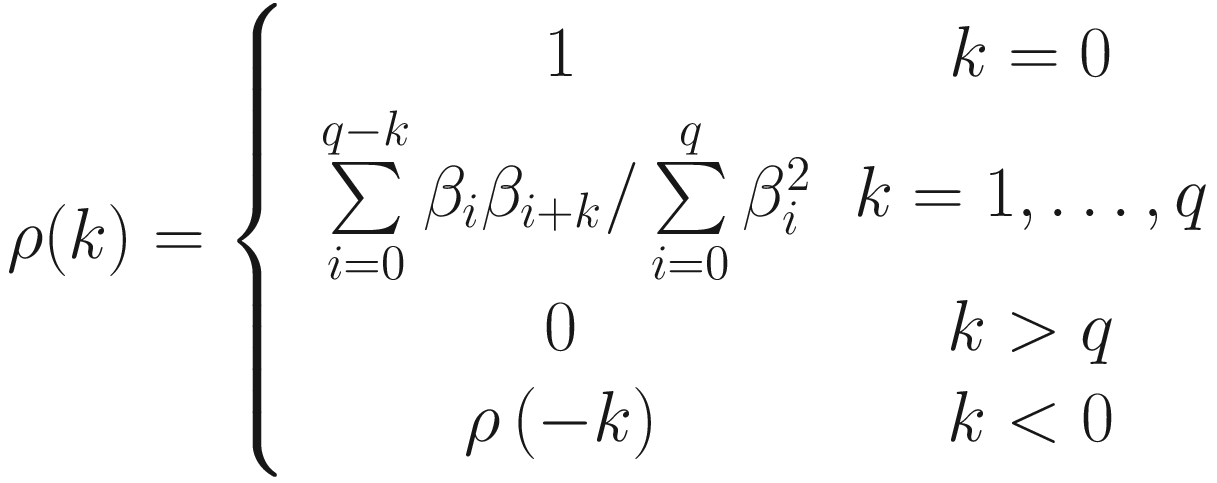
Fitting Moving Average Process


A graph of price versus period. It plots 2 increasing trends for the moving average of actual and interval at 6. The actual has the highest peak at 9.
Example of moving average
Autoregressive Processes




A simulated graph of time series and A R model. It plots a fluctuating trend with multiple crests and troughs.
A time series and AR model
Estimating Parameters of an AR Process

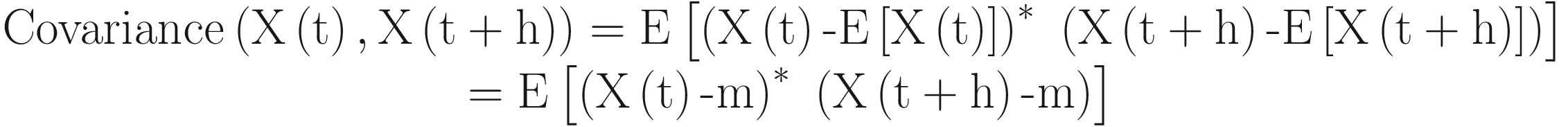
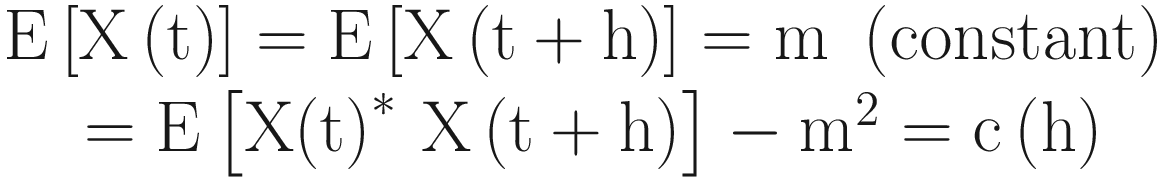
Here, m is constant, and cov[X(t),X(t+h)] is the function of only h(c(h)) for the weakly stationary process. c(h) is known as autocovariance.
Similarly, the correlation (X(t),X(t+h) = ρ(h) = r(h) = c(h) = c(0) is known as autocorrelation.

Correlation(X(t),X(t)) = a1 * correlation (X(t),X(t-1)) + …. + ap * correlation (X(t),X(t-p))+0
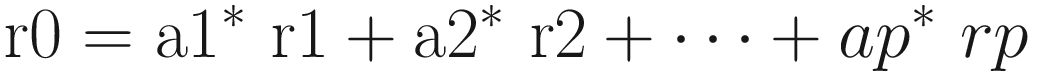

So, for an n-order model, you can easily generate the n equation and from there find the n coefficient by solving the n equation system.
First order: a1 = r1
Second order:

Mixed ARMA Models

The following example code was taken from the stat model site to realize time-series data as an ARMA model.
- 1.
After specifying the order of a stationary ARMA process, you need to estimate the parameters.
- 2.Assume the following:
The model order (p and q) is known.
The data has zero mean.
- 3.
If step 2 is not a reasonable assumption, you can subtract the sample mean Y and fit a 0 mean ARMA model, as in Ø(B)Xt = θ(B)at where Xt = Yt – Y. Then use Xt + Y as the model for Yt.
Integrated ARMA Models
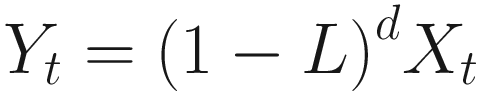
ARIMA models are designated by the level of autoregression, integration, and moving averages.
This does not assume any pattern uses an iterative approach of identifying a model.
The model “fits” if residuals are generally small, randomly distributed, and, in general, contain no useful information.
Here is the example code for an ARIMA model.
The Fourier Transform

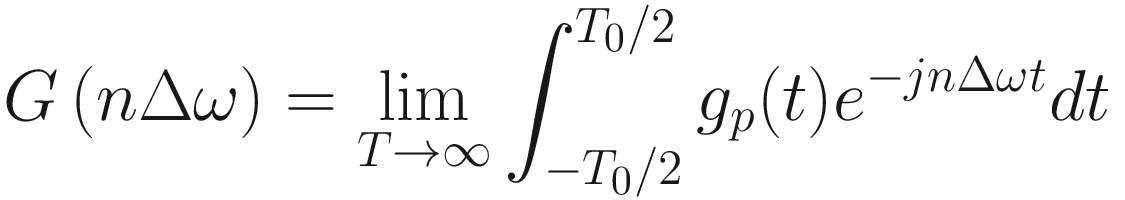
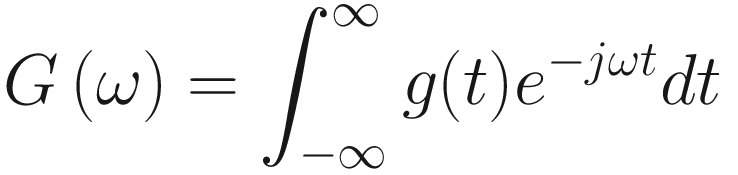
G(w) is known as a Fourier transform of g(t).

An Exceptional Scenario
In the airline or hotel domain, the passenger load of month t is less correlated with data of t-1 or t-2 month, but it is more correlated for t-12 month. For example, the passenger load in the month of Diwali (October) is more correlated with last year’s Diwali data than with the same year’s August and September data. Historically, the pick-up model is used to predict this kind of data. The pick-up model has two variations.
![$$ extrm{X}left( extrm{t}
ight)= extrm{X}left( extrm{t}hbox{-} 1
ight)+left[ extrm{X}left( extrm{t}hbox{-} 12
ight)hbox{-} extrm{X}left( extrm{t}hbox{-} 13
ight)
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484280058/9781484280058__9781484280058__files__images__458833_2_En_6_Chapter__458833_2_En_6_Chapter_TeX_Equaj.png)
![$$ extrm{X}left( extrm{t}
ight)= extrm{X}{left( extrm{t}hbox{-} 1
ight)}^{ast } left[ extrm{X}left( extrm{t}hbox{-} 12
ight)/ extrm{X}left( extrm{t}hbox{-} 13
ight)
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484280058/9781484280058__9781484280058__files__images__458833_2_En_6_Chapter__458833_2_En_6_Chapter_TeX_Equak.png)
Studies have shown that for this kind of data the neural network–based predictor gives more accuracy than the time-series model.
In high-frequency trading in investment banking, time-series models are too time-consuming to capture the latest pattern of the instrument. So, they on the fly calculate dX/dt and d2X/dt2, where X is the price of the instruments. If both are positive, they blindly send an order to buy the instrument. If both are negative, they blindly sell the instrument if they have it in their portfolio. But if they have an opposite sign, then they do a more detailed analysis using the time-series data.
As I stated earlier, there are many scenarios in time-series analysis where R is a better choice than Python. So, here is an example of time-series forecasting using R. The beauty of the auto.arima model is that it automatically finds the order, trends, and seasonality of the data and fits the model. In the forecast, we are printing only the mean value, but the model provides the upper limit and the lower limit of the prediction in forecasting.
Missing Data
One important aspect of time series and many other data analysis work is figuring out how to deal with missing data. In the previous code, you fill in the missing record with the average value. This is fine when the number of missing data instances is not very high. But if it is high, then the average of the highest and lowest values is a better alternative.
Summary
Following feature engineering, we’ll go over some basic statistics, particularly time-series models. One thing to keep in mind is that you may apply any supervised machine learning model on time-series data if you transform feature vectors (1xn) to the matrix (kxn), where each k element of each row is the latest k observation of the first column.