
Chapter 8 Caching and Performance
Performance problems are probably one of the biggest issues that applications on the Web face today. Actually, the problems that can occur are not confined solely to the Web, but that is where the focus lies for this book. This chapter outlines some of the steps you can take to incorporate good performance characteristics into your application early in the development lifecycle. Provided in this chapter are discussion points, options, and some examples on how to leverage the caching infrastructure provided by the WebSphere Application Server product line. Specifically this chapter presents two basic examples:
• Using the distributed map to save any custom Java objects
• Using servlet/JSP fragment caching to cache the HTML output of a servlet directly
Designing for Performance
The performance of your application can be looked at in several ways. The first part of any development cycle is to try to optimize your code so that it performs as well as possible. There are a lot of performance factors to take in to consideration, including some of the following:
• The use of string buffers versus string concatenation
• Creating objects that are never used within the code
• Lack of common logging or exception handling
• Overloading back-end resources
• Use of third-party libraries
• Minimizing memory usage, such as session information
The list can get pretty long and more information on these topics is available on the Web. Some of these topics are discussed in detail within this book, and many of these types of issues should come up within your code review process.
In deep code analysis, you can review code path length to ensure that you are optimizing the execution of your code. This helps ensure you are not performing unnecessary actions or using poorly performing features of the language. Often you might not be worried about a few unnecessary steps, but over time they can build up to take up a large chunk of your system resources. However, these types of issues are commonly not defined as part of the architecture of the system.
Other areas of concern are resources, third-party applications, and application frameworks that surround your own application. These might be items like databases, services, the operating system in use, or the application server itself in use. Tuning of these applications and environments is important to ensure that you are not handicapping the application before you even really get started. Chapter 2,“Setting a Standard,” which focuses on standards within the development cycle, offers suggestions for getting well-formed and hopefully performing code from your development team.
Architecture Concerns
Often you hear the statement that performance should be considered early in the design/development cycle. But actually architecting for performance can be challenging. Consider how distributed your architecture actually will be during the design cycle. Where will different components and layers sit within the infrastructure? How can you minimize requests to back-end systems such as databases or business logic components? Developers continue to learn new techniques, and ongoing enforcement of their adherences to best practices is necessary to ensure the same issue does not crop up more than once within a project or across the organization.
More than likely you will have user registries involved in the authentication and authorization of users within the application—how are those registries presented and accessed? LDAP protocol or perhaps a web service is used in many cases, but using a remote service during login can be quite expensive unless service-level agreements are in place with the providing service. Navigation and access control or authorization are also processes that sometimes require an external service.
Much broader issues need to be understood by the application architect when defining the application layers. Initial performance is a concern; that is, response time by a single user, but scalability is of perhaps a larger concern, because you do not want response time to go up as the user load increases.
Thinking about how your application or service will react under load is one of your main concerns. Should your application really make a database call for every request by every user? Can the database handle perhaps thousands of requests per minute, and how complex will the queries actually be? Remember that the database and other back-end services has to be able to scale with the application, so if your app suddenly becomes very popular will it overwhelm other systems that are not designed for this increased load?
Performance Terminology
When discussing performance it is always important that everyone uses and understands the same terms. Performance testing is a topic of great importance and unfortunately not something discussed in this chapter. But even without this detail we can agree on the proper terms. One of my favorite books on this topic is Performance Analysis for Java Web Sites (Joines, 2003). This book is a few years old but still very relevant to understanding the basic concepts of performance testing today.
You should have a general understanding of a few terms. I have taken these terms from my 2007 article in developerWorks (Bernal, 2007) for use here:
• Load:This is the amount of pressure against a Web site. This always makes me think of a water hose, either turned down to a trickle or turned all the way up to full blast. With Web sites, we talk about load in terms of concurrent users, which does not necessarily mean that every user is requesting a page at the exact same moment, which is a common misconception. It is better to think about load over time; for example, a number of users accessing the site within a specific time frame, perhaps over five minutes or per hour.
• Response time: This is the time it takes for the portal or site to respond to the request. This is really end-to-end time from the browser's perspective, and does not normally include time spent by the browser generating or displaying the page. Consider that in many applications response time generally will change (it will probably increase) as the load against the site increases, potentially increasing to the point where it is unacceptable to users. Response time is one measurement that gets a lot of attention, and tuning your portal to provide a consistent response time range with the expected volume of user load is your ultimate goal. Response time goals are chosen to follow industry standards; for example, a goal for the site might be to respond to 95% of page requests to respond within five seconds.
• Throughput: This is the rate at which a portal can respond to requests. Generally, you can think of this as either the hit rate or page rate of the system, with the page rate measurement being more consistent. Throughput, coupled with response time and a model of your users' activity, can help you determine how many users your system can handle (load) within a given timeframe. Throughput is often measured in relation to load, determining where the boundaries of the system might be as user load continues to grow.
These three main terms, working together, will help you understand how your portal might perform when you get to that phase in your development cycle.
Caching Considerations
Caching is the process of moving some resource that is needed closer to the location where you need it. Not a very scientific definition, I admit, but a cache doesn't always have to be about computer data. For example, you may keep a small cache of drinks in a mini-fridge within your home office, which saves you trips to the kitchen all the time. This is exactly the same type of performance-enhancing effect you want to achieve with your applications.
The goals of caching are simple. Achieve better performance, scalability, and availability of your applications by reducing the overall amount of data that is transferred or reducing round trips between your application and any data sources or other applications that provide data or information. Additionally, with interim (local) caching you can potentially reduce the amount of processing actually done within your application. This is similar to code path length reduction where you want to be as efficient as possible, but being able to do so is very heavily dependent upon the implementation. Coupled with this desire for efficiency is the need to ensure that security constraints are enforced.
Caching Design Options
![]()
The best caching is useless if users have access to data that should not be permitted. In fact, this brings up an interesting point. If you have very high security or personalization requirements, then you may have to take the performance hit and simply ensure that your hardware and infrastructure is large enough to handle the expected load. When thinking about caching you have many design options to consider including
• Staleness of cached data: This includes the likelihood that the underlying data will change, leaving a cache that is useless because it is not up to date. What happens when the cache is updated on a single server? Will the changes need to be replicated on other servers, or is there an approach that will allow the caches to be flushed and rebuilt when data changes? The performance impact of replicating data can be a large one.
• Cache loading policies: Here we want to talk about proactive versus reactive loading. Can data be pre-cached at startup so that it can be readily available, or should you fetch it upon first use? Memory and timeout considerations help drive this discussion along with how expensive it really is to retrieve the data initially.
• Size of the cache:Caches should probably never be unbounded. There is just too much opportunity for a problem to occur without your knowing the maximum size or amount of memory that your cache can consume. What makes sense for your cache: 100 entries or 1,000? You can make this design decision early, and hopefully it will help you better understand the details of your application.
• Cache key generation: The cache key is used to store and retrieve the data within a cache. This key is unique for each cache entry. Cache keys are usually based on the user or the data itself. For example, a zip code or customer ID may be the cache key that is used. In complex scenarios the cache key may be a combination of factors such as [user role + geographical location + department code]. This type of approach allows a complex caching capability that can be shared across groups of users. You need to determine whether the value of this complex caching outweighs the cost of running the SQL query.
• Expiration policies: Data changes over time, so caching can cause problems if the data in the cache is not updated appropriately. This issue goes hand in hand with the staleness of the data as discussed previously. Time-based expiration is the most often-used type of policy where the cache simply clears an entry after a given amount of time. Notification-based expiration is also an option, where some type of trigger allows you to clear the cache on demand. This approach may be good for data that does not change as often. For example, content-based repositories may only change a few times a week. Allowing for the ability to clear the cache on demand only when the content needs to be refreshed can be the right approach.
• Types of caches: Generically, you have two types of caches to think about: memory resident caches and disk resident caches. Memory resident is the most popular and generally provides the best performance. Again a consideration for any memory resident cache is the size of the cache and the size of each cache entry. Care should be taken with a disk resident cache policy. Writing to disk is generally expensive and may outweigh the benefit that you expect the cache to provide. If you need cached data to live beyond a server crash or restart then a disk resident approach can be a good option.
This list is not exhaustive but it should provide a good idea of the types of considerations you need to think about when designing your cache.
Sizing a Cache
Mentioned earlier is the idea that caches generally have a maximum size. That means there is a maximum number of entries that a cache can hold. So how do you determine this size? There is no set equation although I'm sure you could come up with some that are related to your environment. The problem is that the cache size should be driven partly by the amount of available memory within your system. Caches take up memory, so any tradeoff needs to be determined between the value of the cache and the amount of memory that it consumes.
Determining the size of each cache entry will make it easier to figure out the overall size of the cache. Weigh this figure against the total number of entries to be stored in the cache and whichever expiration policy needs to be put into place, to calculate some general memory consumption assumptions. The first problem is how to determine the size of the cache entry and whether the size will vary between each entry. Ways exist for analyzing the system heap to make this determination, but you can also build some sizeof() type of methods into your code, which can be turned on perhaps via a logging statement to gather the memory size of objects when necessary. Java 5 offers the possibility of providing instrumentations via agents to gather size data in a test mode scenario. When there is the possibility that the cache entry size is actually different between different cache entries, then you should calculate the average size to help determine the overall cache memory size. Additionally, the cache itself may provide some overhead, which you might need to consider. If you can determine the average size of each cache entry you might consider that number close enough unless you want to go digging through JVM heap dumps to calculate the total size with the most accuracy.
Additional caching tools are available, and the industry as a whole is catching up on the need for better tooling in this area. Of particular interest is the availability of viewing object cache instances within WebSphere Application Server. A preview product with this capability is available at http://www.ibm.com/developerworks/websphere/downloads/cache_monitor. html. Also for very large caches the Websphere Extended Deployment (XD) has advanced caching features for large-scale environments http://www-306.ibm.com/software/webservers/appserv/extend/?S_TACT=105AGX10&S_CMP=LP.
When Not to Cache
Sometimes a cache is not the best approach. But you should consider these times as carefully as when thinking about when to cache. Putting a cache in place after the fact can be very difficult, especially when it is an object- or data-level cache. Caches at the front end of your application that cache HTTP data are easier to implement later in the development cycle, but these types of caches have limitations when content is very personalized across users or groups or users.
Think about not caching when building the cache key is very expensive, or when the data will expire within a very short time period, say, under a minute. In some cases even a five minute cache can help under an extreme user load and may not be noticed by your business sponsors or the end user. Expensive cache keys are those that take a lot of processing or getting data from the back end to create; for example, if you have to retrieve the current user's customer ID, office location, position, title, and/or current role within the organization. This is an example of how you might personalize the data that is being displayed. While having these kinds of requirements is perfectly acceptable for the business, accounting for the performance impact that this type of calculation will need on a large scale is also important.
In some cases the business sponsor will make it clear that it does not want some data cached. For example, in the retail industry the application may display information about product recalls. This type of information has to be immediately sent to the field for local stores to begin removing products from the shelves. Perhaps in this case a more complex framework can be built to provide the required performance without sacrificing the urgency needed.
In any case, when a decision is made not to cache, then any performance hit must be discussed and accounted for. Back-end systems need to be tested or scaled to handle the increased load. The main point is that you have to pay for performance, in one way or another.
User Session Caching
Generally, the session is not considered a cache, but it can be a convenient location to store user data. Early in the life of Java programming using session state was a common practice. Programmers who are familiar with .Net programming are also comfortable with using session and application state to store information for their users. Putting information in a user session that needs to be saved between user requests is a no-brainer; everyone who has been building web applications for any length of time has done this, probably without even thinking too much about it.
There is a tendency for things to get out of hand when easy solutions like this one are around. Pretty soon everything gets stored in the session within the application. This can lead to a couple of key problems, one of which is session bloat, where more memory is used per user than should be. This reduces the amount of available memory that would allow your application to handle additional users. Remember that a user session is stored in memory until it expires. This is usually some set time after the last request has been made. Because you don't know if a user is reading some information on the current page, filling out a form, or has actually closed the browser window, you need to keep session information in memory until a set time period when you can assume the user will not be coming back.
The general recommendation is to keep the session timeout as short as possible. Again, there are perfectly legitimate reasons for maintaining a long session timeout. There are cases where a user will open a browser window in the morning and leave it open all day; however, the infrastructure must account for the cost of leaving objects in memory for long periods.
When things get out of hand there always tends to be a whiplash effect where new rules are put in place. In this case the new base rule that emerged was do not use the session for data storage. In many cases and with proper guidance, not using the session at all is probably better than overflowing it with too much data. But with proper guidance the rule can be tempered to something that provides a useful function without becoming the black hole of overloaded data. You can use advanced strategies such as storing session data to disk, or using lightweight session data to restore active data when needed; however, you should use these strategies on a case-by-case basis.
Caching in WebSphere Application Server
![]()
WebSphere Application Server and many WebSphere products provide a lot of caching capability to leverage within your application. One of the ways that WAS provides this ability is through a service called the dynamic cache. Dynamic caching or dynacache as it is often called, contains a number of interfaces and services that allow you to cache data in different ways. Figure 8.1 illustrates in a very simple way some of the capability that is provided in the Dynamic Cache service.

Figure 8.1 WebSphere dynamic caching
Dynacache provides the capability to cache the output of different objects within your application. For example, servlets and Java Server Pages often output HTML to the browser. Dynacache provides servlet/JSP fragment caching, which allows you to actually save the HTML fragments or the entire page, helping to reduce expensive calls to the same servlet over and over again. At the same time, dynacache also provides mechanisms for caching data objects that can be stored and retrieved locally instead of having to go back to the data source for the same information more than one time. Cacheable Command objects are another approach for data caching, where the CacheCommand interface can be implemented to provide a similar data caching ability. You can see in the diagram that other interfaces are available such as the capability to cache portlets or web service client results.
How does this capability fit together with your application? Figure 8.2 illustrates how you might use some of the capability within your web applications. Some data is cached natively or as objects, while other services cache the output of your application. The capabilities are usually mixed and matched to give you the best possible results depending upon the application requirements and your user base.
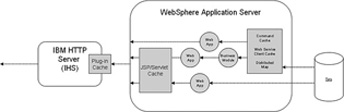
Figure 8.2 Where to cache
The ability to cache at several layers provides the best flexibility for an application. Figure 8.2 above does not illustrate every possible caching location. Additional opportunities exist for caching further out within the infrastructure. The general rule as stated at the beginning of this chapter is that the closer you can get to the end user with your caching the better off you will be in terms of performance. In Figure 8.2 several applications are sandwiched between different caching capabilities, something you might call back-end versus front-end caching. You can see that different applications take advantages of different capabilities, while some applications may not be able to use any of the features or services provided because of application requirements.
IBM HTTP Server and the Caching Plug-in
Static items are something that can cause a lot of churn within the application server. A server working hard to respond to requests for static items is that much less able to work on page requests to the system. Static items are just that: items that do not change very often, if at all. Images, style sheets (CSS), and script files such as Java script or JS files usually do not change on a day-to-day basis. These files specifically should be cached as close to the user as possible. Luckily, the browser does a lot of this work by caching static files between requests, but you still have to expect the initial hit from every new user as they request a page in your application.
In the early days of web programming developers generally tried to move static files to a different location, like perhaps out to the HTTP server itself where they would get served without ever bothering the application server for the request. This approach is fine, but it does put an additional burden on the developer to ensure that all URLs within the page access this external source. To help ease that burden and for those development teams who do not follow this approach, the WAS Web Server Plug-in using the ESI cache has been designed with some caching capability so that some types of files are cached automatically upon the initial request, and then subsequent requests are pulled from the cache and do not get routed back to the application server.
Although configuring and optimizing this cache will not usually save your Web site from performance problems, in some cases it can provide a substantial reduction in overall activity to the application server.
Using the Distributed Map
The distributed map (dMap) has become a very popular approach to caching data within WAS. It operates very similar to a HashMap might in Java, with the added benefit of being cluster aware if necessary. If you are familiar with using a Java collection such as a HashMap then you know how easy they are to use: You simply instantiate the object and start adding values. Using the dMap takes a little more foresight. You have to create an instance on the application server and then using JNDI you can get a handle to the correct Dmap instance that you need to use. Don't worry; you'll see how to do all this in the later example.
The one downside, if you are looking for one, is that there is no real security policy on the distributed map cache. That means that anyone can access the cache if he or she knows the name and look at data. This is generally not a problem within a controlled environment, but it may influence your decision.
Creating a New Distributed Map
Creating separate distributed map instances for different caching areas is a good idea. This approach allows you to separate where different data is cached and provides some opportunity for tuning caches independently based on the size of the cache and the data for each entry.
Object caching is something done internally to your code as opposed to the servlet/JSP caching that is provided to cache the HTML fragments that are output by your code. In this example you use the distributed map, which is an instance of an object cache, to cache internal data that you need to compute some value.
You can create a new object cache instance within the Integrated Solutions Console (admin console). Before creating a new instance you need to determine the scope of the instance. To do so:
1. In the scope drop-down box choose Cell scope for the instance.
2. To create a new instance navigate to Resources, Cache instances, Object cache instances, and click on the New button, as shown in Figure 8.3
To create a new orders instance enter the following values:
Name: orders
JNDI name: services/cache/orders
Description: Dmap cache for orders servlet
3. You can leave the rest of the settings as shown in Figure 8.4 as the default. Enabling disk offload of the cache would not be recommended unless you were very sure of what you were doing. Click OK to continue. The object cache instance is created.

Figure 8.3 Create a new object cache instance

Figure 8.4 Orders dMap
4. On the screen that appears, shown in Figure 8.5, save your changes by clicking on in the messages box.

Figure 8.5 Saving your changes
At this point the server should be restarted. After logging out of the admin console you can restart the server to pick up the changes.
NOTE
These examples are shown from a single server environment and not a clustered environment. In a clustered environment some slight differences exist, as you will be managing the environment from the Network Deployment application and not from the single admin console. Other differences are that you need to replicate your changes down to the application servers or nodes. Also, you may configure caches themselves to be setup in a replicated fashion so that cache changes stay in sync between hservers.
Watch the System.out log during the restart for a reference to the new cache entry.
[3/24/08 12:44:43:015 EDT] 0000000a ResourceMgrIm I WSVR0049I: Binding orders as services/cache/orders
Once the cache entry has been created successfully and you can see the entry being initialized in the logs, it is ready for use by your application.
Testing the Distributed Map
To test out the map I revised our old friend the ClassicModelsWeb application that was used in Chapter 2 with the EJB 3 example. To use this I have changed the interface slightly to allow you to actually input which order number you want to use. This allows you to request a specific order number and cache it as necessary. The algorithm to use is as follows:
1. The user submits a request to view a specific order.
2. The servlet checks the cache to see whether the order has been requested before.
3. If the order is in the cache, simply display the order information.
4. If the order is not in the cache, then request the order information from the database and cache the order for the next time it is requested.
Figure 8.6 shows the new index.html page that is used within the application. This page provides an input box for submitting the order number. Note: We have output to the bottom of the screen some of the order IDs for easier testing.
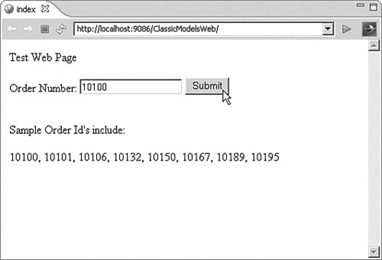
Figure 8.6 Submit an order request
The code for this page is pretty simple. A form is displayed that allows the entry of an order ID, and then a submit button allows for posting that ID to the OrdersTestServlet. The full example code is described in Appendix B,“Running the Examples,” along with the location where you can download all of the examples.
<body>
<p>TestWeb Page</p>
<form action="/ClassicModelsWeb/OrdersTestServlet" method="post">
Order Number:<input type="text" name="orderid" size="20">
<input type="submit" name="submit" value="Submit">
</form>
<p><br></p>
<p>SampleOrder Id's include:</p>
<p>10100, 10101, 10106, 10132, 10150, 10167, 10189, 10195</p>
</body>
Once the form is submitted the OrdersTestServlet takes over. Because you are posting the form data use a simple call in the doPost() to pass the information to the doGet() method in the servlet.
protected void doPost(HttpServletRequest request, HttpServletResponse
response) throws ServletException, IOException {
doGet(request,response);
}
The doGet() is where the real magic happens so let's examine this servlet in detail. It shows a mixture of System.out calls and PrintWriter options. The PrintWriter outputs data to the browser in the form of an HTML page. This allows you not to use a JSP and simplify the testing of this approach. Notice the System.out.printline call at the beginning of the method. This is actually used later in this chapter for enabling the servlet/JSP cache, which will cache the output of this servlet. It shows whether this method is even called during a request. More on that later in this chapter. For now let's just set things up for the rest of the method.
protected void doGet(HttpServletRequest request, HttpServletResponse
response) throws ServletException, IOException {
System.out.println("This is to check if I'm called…");
PrintWriter writer = response.getWriter();
response.setContentType("text/html");
writer.println("OrderTestServlet using OrderFacade(Local)
<br><br>");
The next step is to get the order ID from the request. This is the ID that is entered in the form and submitted to the servlet. You can use that ID as the cache key to store and retrieve information from the Dmap. You can use the dmap.get() method with the ID as the input parameter to attempt to retrieve an Order object from the map.
//get the submitted order ID from the request
Short orderid = Short.parseShort(request.getParameter("orderid"));
//get the requested order from the distributed map
writer.println("Checking dmap cache for order object" + orderid +
"…<br>");
Orders myOrder = (Orders)dMap.get(orderid);
Next, check whether you actually got something out of the Dmap. If you did that means this order has been requested before and has already been retrieved from the database. If you got a null, then you have to go back to the database and retrieve the information for this order. If the result is null then you do have to go retrieve the information. In this case you call the findOrdersByOrdernumber() method with the same order ID that was originally requested by the user. The next step is to now cache the result so next time, you don't have to go back to the database to look it up.
//check if we got an order out of the map
if (myOrder == null) {
//Order does not exist in dMap, go ahead and get it from the DB
writer.println("Not in dmap cache, retriving order data from
DB…<br>");
myOrder = ordersFacade.findOrdersByOrdernumber(orderid);
//Now place it in the map for next time.
writer.println("Storing retrieved order in dmap
cache…<br>");
dMap.put(orderid, myOrder);
If the Orders object is not null, that means you successfully retrieved the object from the Dmap. The code actually does not need this else section of the statement for any practical reasons, but you can make a note to the user explaining where you got the data.
}else {
writer.println("Order retrieved from dmap cache
successfully.</br>");
}
At this point in the code the Order object is available and should be stored in the cache for the next time this order is requested.
writer.println("<br><br>");
writer.println("Ordernumber: " +
myOrder.getOrdernumber() +
"<br>");
writer.println("Customernumber: " +
myOrder.getCustomernumber()+"<br>");
writer.println("Orderdate: " + myOrder.getOrderdate() +
"<br>");
writer.println("<br>order details<br>");
List<Orderdetails> orderDetails =
myOrder.getOrderdetailsCollection();
Iterator<Orderdetails>it = orderDetails.iterator();
Orderdetails od;
while (it.hasNext()) {
od = (Orderdetails) it.next();
writer.print("orderlinenumber: " + od.getOrderlinenumber()
+" ");
writer.println("item:
" + od.getProductcode() +"<br>");
}
The last part of the method is designed to display some more information on using the dMap cache. This section does a lookup of all the entries that are stored in the cache and then iterates through them to display the cache keys. Specifically, the dMap.keySet() method retrieves a set of keys for the entire cache.
writer.println("<br><br>Cache Keys:<br>");
Set set = dMap.keySet();
Iterator it1 = set.iterator();
while (it1.hasNext())
{String value = it1.next().toString();
writer.println("Key: " + value +"<br>");
}
}
The result of all this is shown in Figure 8.7. The request is submitted and the data is not found in the cache. This results in a lookup and then the data is displayed. This specific order ID has been retrieved from the database and is now to be stored in the cache for any future lookups.

Figure 8.7 Looking up in the cache
The final piece of code to look at in this example is where the distributed map is actually defined within the servlet. JNDI calls can be expensive, especially when they are used over and over unnecessarily. Because of this I have opted to define the map only once and then store the handle as an instance variable in the servlet. Generally the use of instance variables are frowned upon because a servlet is a multiuser type of object. But in this case a shared instance is okay because I am sharing the cache across all users. Other cases may call for abstracting the cache instance in a service or utility class.
I have broken my own rules here for better clarity and used System.out calls to handle the initialization of the servlet. Because it is only used once it lets me know whether the dMap has been set up correctly or not. The dMap is declared as an instance variable or globally within the class, and the initialization performs a context lookup on the JNDI name that we defined when creating the dMap in the admin console.
private DistributedMap dMap;
public OrdersTestServlet() {
super();
try
System.out.println("in constructor - getting dMap handle");
InitialContext ic = new InitialContext();
dMap =(DistributedMap)ic.lookup("services/cache/orders");
System.out.println("Cachesetup constructor…
Finished");
} catch (Exception e) {
System.out.println("Cachesetup.constructor - Exception");
e.printStackTrace();
}
}
On any subsequent requests for a particular order we should see the result shown in Figure 8.8. This shows that the order was successfully retrieved from the cache and is being used to display the data.
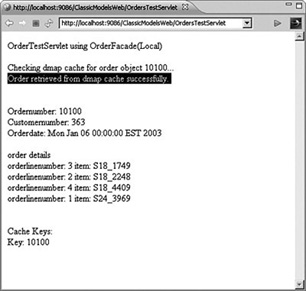
Figure 8.8 Order found in the cache
In this example all the caching occurred within the servlet class, or the presentation layer of this application. This may be fine for some applications, but more than likely you would provide this type of caching within a different layer within the architecture. The business logic layer or local service layer are good candidates for this type of caching.
HTML Fragment Caching
The servlet/JSP fragment caching component of dynacache can also be a powerful tool. In some cases this feature has been implemented to produce a multifold improvement in performance in an application. Fragment caching actually caches the HTML that a servlet or JSP component provides. This means that the next request for that servlet will result in a display from the cache and not the servlet. This protects the servlet from even being called on these subsequent requests. Be aware, however, that the closer to the end user that a cache exists, the less flexible the cache contents become. Caching at this high of a level is best for more generic or public data that is shared across all users, or at least large groups of users, or perhaps for content that is very expensive to generate and that you want to only create once for a given user and then keep it around for the length of that user session.
One good example is a public home or landing page. This generally is the page that everyone hits when they first access a Web site or application. Because there is no authentication the content is usually pretty generic and doesn't change often (maybe daily or weekly). This is a perfect candidate for a servlet cache. The first user to access the page triggers the cache. Any subsequent requests are displayed from the cache, which usually brings response time down to zero for these requests.
The default caching service has to be enabled to run at startup. You can accomplish this through the WebSphere Integrated Solutions Console by drilling down to the server that you are using and enabling the service at startup. Figure 8.9 shows the check box for turning on the dynamic caching service for a particular server.
Once dynacache is enabled it is ready to use with your application, and you need to tell it what applications to actually cache. This configuration is provided through the cachespec.xml file that is deployed with your application. The cachespec.xml configuration file is pretty powerful, which means that it can be confusing to new users. The cachespec.xml has several components that are discussed in detail in the WebSphere InfoCenter at http://publib.boulder.ibm.com/infocenter/wasinfo/v6r1/topic/com.ibm.websphere.nd. multiplatform.doc/info/ae/ae/rdyn_cachespec.html?resultof=%22%63%61%63%68%65%73%70%65%63%2e%78%6d%6c%22%20.

Figure 8.9 Turning on fragment caching
Specifically for this implementation, the cachespec.xml describes the fact that we are caching the output of the servlet called com.ibmpress.cm.web.OrdersTestServlet. class. This triggers the fact that we need to cache the output when this servlet is called. Additionally, we define a cache-id that provides the cache key for this particular servlet. The cache key in this case is the ordered parameter that is passed into the servlet from the initial request form. This allows us to cache the output of the servlet once for every unique order that is displayed.
Finally, we define a cache timeout of 180 seconds. This timeout is actually pretty short—only three minutes, but it is enough to perform a test without having to wait too long for the cache entries to time out.
<?xml version="1.0" ?>
<!DOCTYPE cache SYSTEM"cachespec.dtd">
<cache>
<cache-entry>
<class>servlet</class>
<name>com.ibmpress.cm.web.OrdersTestServlet.class</name>
<cache-id>
<component id="orderid" type="parameter">
<required>true</required>
</component>
<timeout>180<>/timeout>
</cache-id>
</cache-entry>
</cache>
That's it! Putting the cachespec.xml in place should allow this to start working as expected. For a web application the cachespec.xml file should be deployed within the WEB-INF directory of the war file.
Monitoring the Fragment Cache
For the earlier distributed map example there was no real way to monitor the cache entries. We added some code to the bottom of our servlet so that we could see which entries were cached during testing. But usually there is no out-of-the-box way to accomplish this. You would need to build a separate servlet that showed the state of all of your system caches. For the fragment cache this is not the case. There is an out-of-the-box way to view and monitor the state of this cache at any point in time. WebSphere Application Server comes bundled with an application called the CacheMonitor.ear, shown in Figure 8.10. This application needs to be deployed to the same server that you want to monitor and will show you the status of what is going on with the fragment cache.

Figure 8.10 Cache Monitor
The Cache Monitor can provide basic statistics about the fragment cache. Watching the base statistics can be enlightening. Of particular interest is the number of cache hits versus misses. If you are getting too many missed then you may adjust the size of your cache or look at the cache key that you are using for each entry. Figure 8.11 shows the cache entries themselves that have been stored in the servlet cache.

Figure 8.11 Cache entries
Drilling down into the actual cache contents will show you the actual entries that are being cached. Notice that each entry has a different order ID associated with it.
ESI Plug-in Caching
Not shown here is the enablement of the ESI (Edge Side Includes) cache within the HTTP Server plug-in. This plug-in allows for the caching of static entries that are usually displayed on a web page. Statics consist of images, Javascript files, or stylesheets that are generally used by all users, but are not something that the application server itself would need to provide every time. The plug-in is enabled by default when deployed so you receive the benefit of this approach without even trying, but the settings are configurable within the plugin-cfg.xml file that is deployed to the web server.
<?xml version-"1.0"?>
<Config>
<Property Name="esiEnable" Value="true"/>
<Property Name="esiMaxCacheSize" Value="1024"/>
<Property Name="esiInvalidationMonitor" Value="false"/>
There is an ESI monitor that is similar to the cache monitor that you deployed in this chapter that can show you what is being cached in the plug-in. The WebSphere Info Center can guide you on setting this up and tuning the plug-in.
Conclusion
So what is actually happening here? This is important because once an entry is in the cache, then any subsequent requests for that servlet with the same order ID will be drawn from the cache. This means that the servlet itself is not even called. You can imagine the performance improvement if your servlets are not even called much of the time. All of this is dependent upon the type of data you are displaying and the functional requirements of your application. Not every application will gain the same benefits with this type of caching.
Actually implementing a caching strategy requires not only understanding your application requirements, but also knowing what tools are available to you within the environment. You have seen two different approaches to caching using some of the features provided by the WebSphere infrastructure. Object-level caching can be done internally to your application and provides you with a handy holding space for data that you don't want to retrieve with every request.
Servlet caching is a way to store the entire HTML page or fragments of the page for reuse by groups of users. This approach is extremely fast, especially for public pages or Web sites. In addition the ESI web server plug-in cache can offload static images and other files from being served from WebSphere. This combination can be extremely powerful when incorporated into your application.
 Links to developerWorks Articles
Links to developerWorks Articles
A8.1 Revisiting Performance Fundamentals: http://www.ibm.com/developerworks/websphere/techjournal/0708_col_bernal/
0708_col_bernal.html
A8.2 Static and Dynamic Caching in WebSphere Application Server, Bill Hines, http://www.ibm.com/developerworks/websphere/techjournal/
0405_hines/0405_hines.html
References
Bernal (2007). “Revisiting Performance Fundamentals.” DeveloperWorks Technical Journal, Comment Lines Series. http://www.ibm.com/developerworks/websphere/techjournal/0708_col_bernal/0708_col_bernal.html
Joines, Willenborg, Hygh (2003). Performance Analysis for Java Web: Addison-Wesley Professional Computing Series.