
In the previous chapters, we looked at fully connected networks and all the problems you encounter while training them. The network architecture we used, one where each neuron in a layer is connected to all the neurons in the previous and next layers, is not good at many fundamental tasks like image recognition, speech recognition, time series prediction, and many more. Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) are the most advanced architectures used today. This chapter looks at convolution and pooling, the basic building blocks of CNNs. We also discuss a complete, although basic, implementation of CNNs in Keras. RNNs are discussed, although briefly, in the next chapter.
Kernels and Filters
- The following kernel will allow the detection of horizontal edges
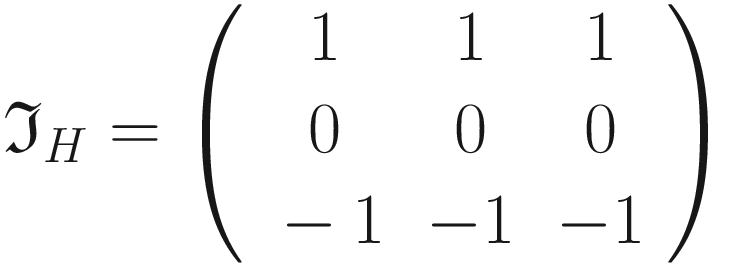
- The following kernel will allow the detection of vertical edges
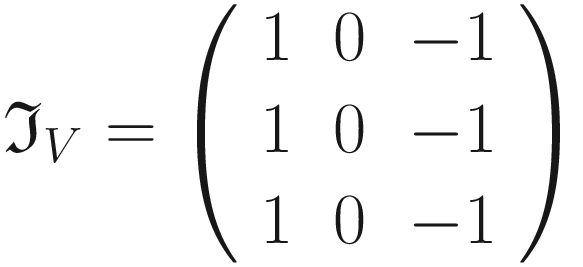
- The following kernel will allow the detection of edges when luminosity changes drastically
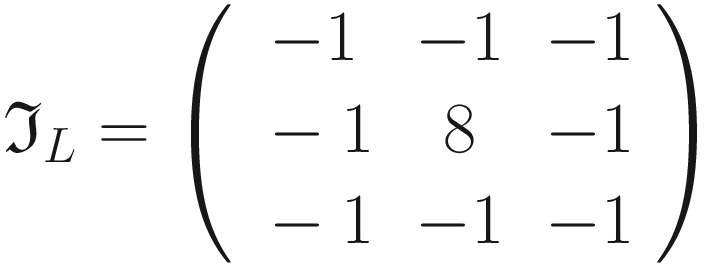
- The following kernel will blur edges in an image
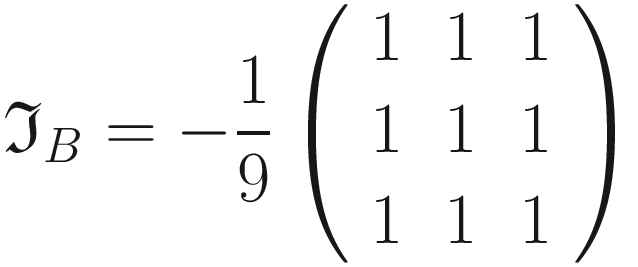
In the next sections, we will apply convolution to a test image with the filters and you will see the effect.
Convolution
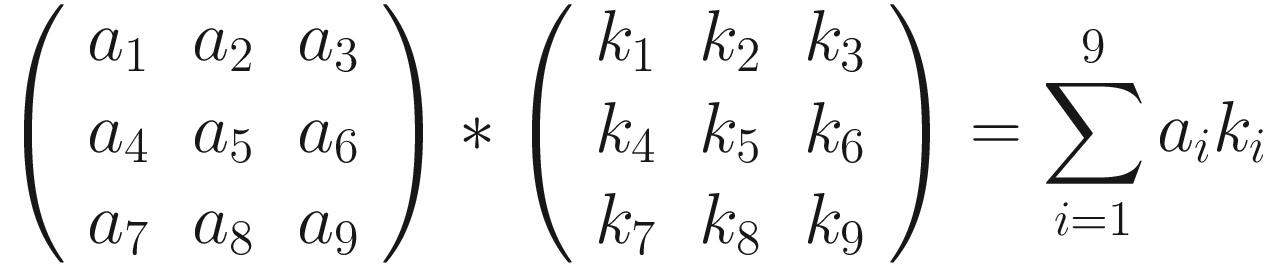
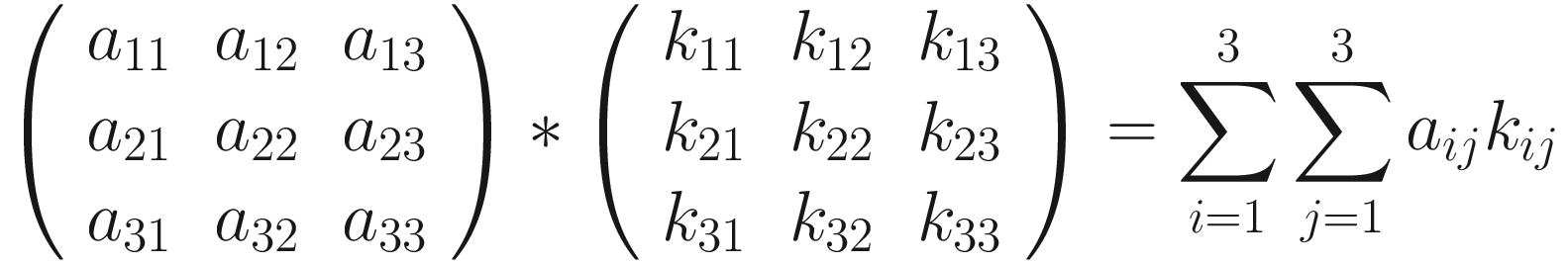
The first version has the advantage of making the fundamental idea very clear: each element from one tensor is multiplied by the correspondent element (the element in the same position) of the second tensor. Then all the values are summed to get the result.
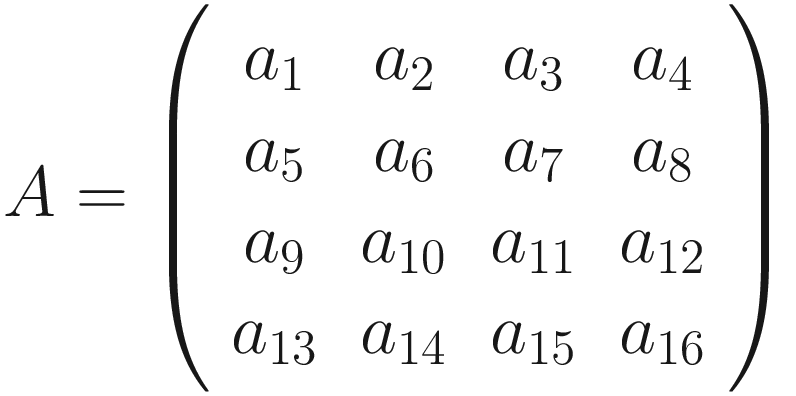

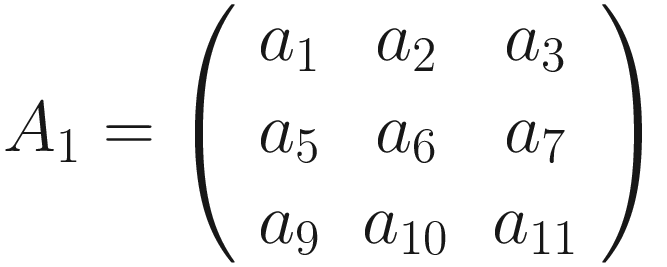

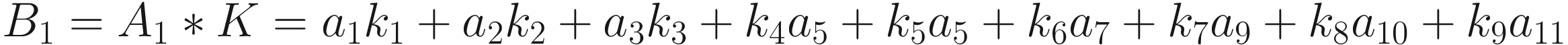

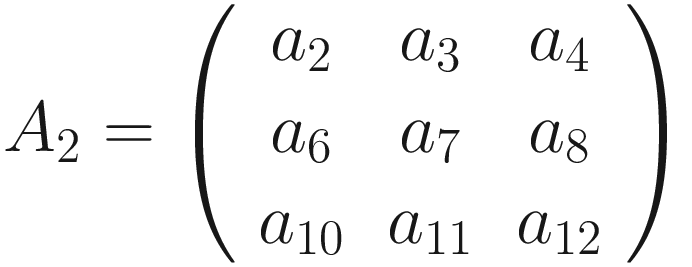
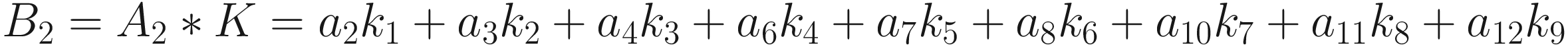
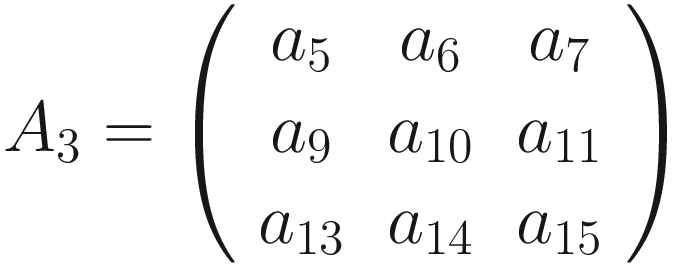
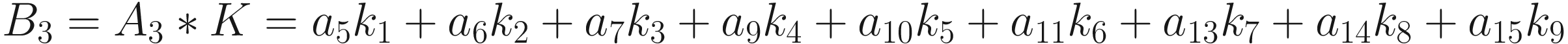
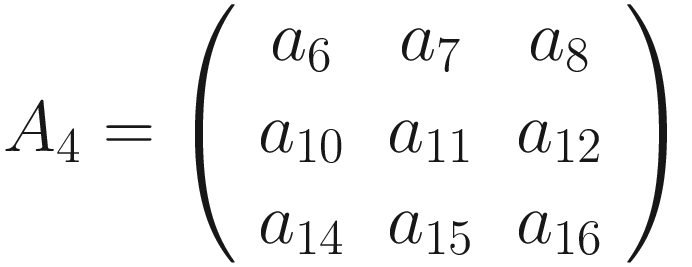
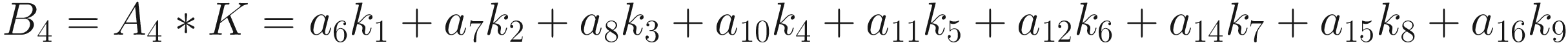
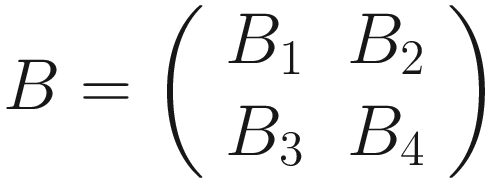
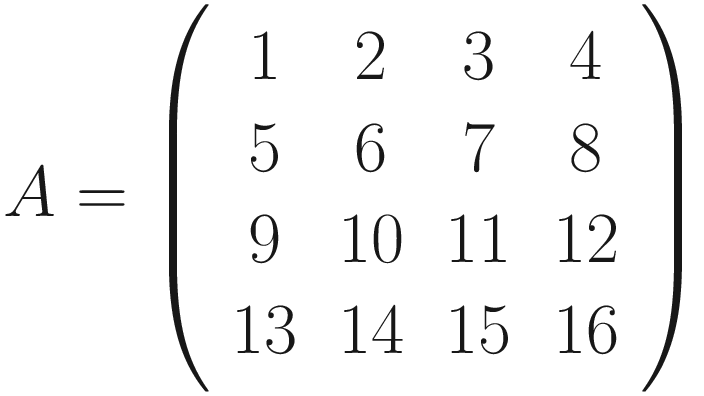
The same process can be applied when the tensor A is bigger. You will simply get a bigger resulting B tensor, but the algorithm to get the elements Bi is the same. Before moving on, there is still a small detail that we need to discuss, and that is the concept of stride. In the process above we moved our 3 × 3 region one column to the right and one row down. The number of rows and columns, in this example 1, is called stride and is often indicated with s. Stride s = 2 means simply that we shift our 3 × 3 region two columns to the right and two rows down.
Something else that we need to discuss is the size of the selected region in the input matrix A. The dimensions of the selected region that we shifted around in the process must be the same as the kernel used. If you use a 5 × 5 kernel, you need to select a 5 × 5 region in A. In general, given a nK × nK kernel, you will select a nK × nK region in A.
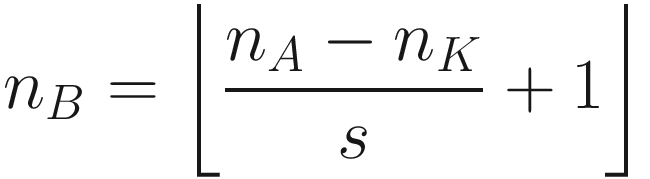
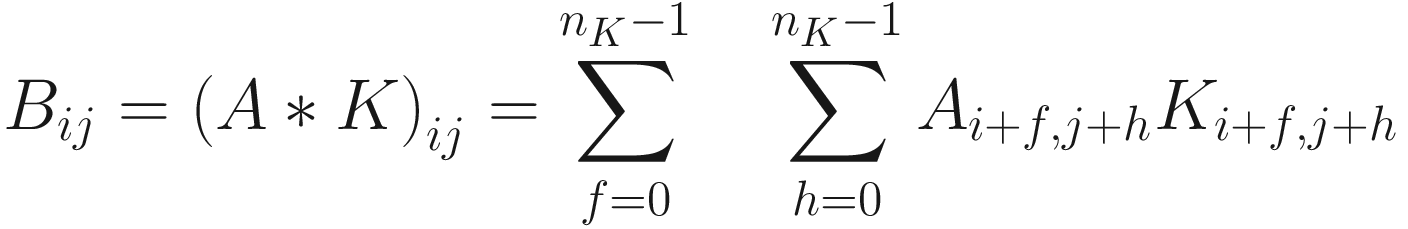
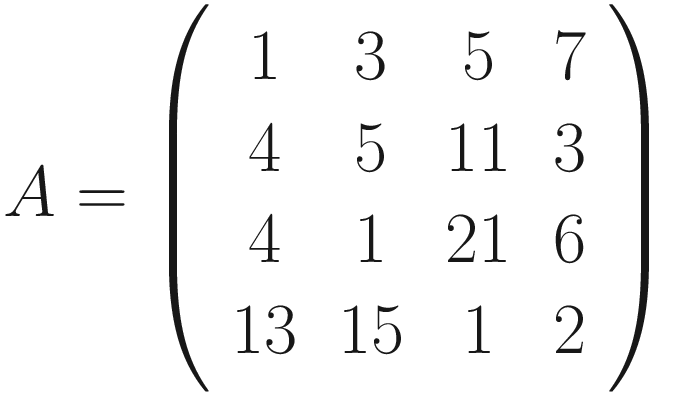
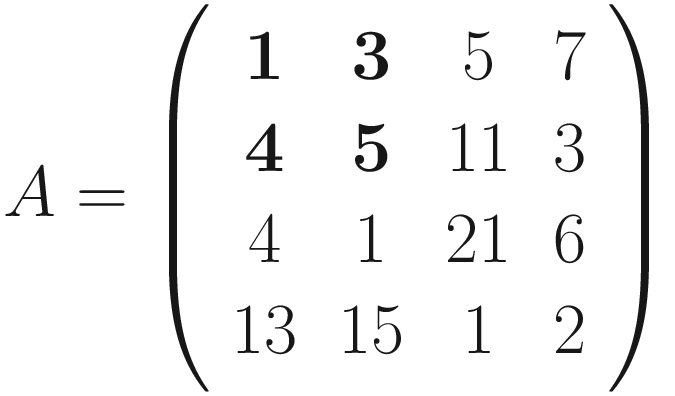
The formula is cryptic and is very difficult to understand. Let’s see some more examples to grasp the meaning better. Figure 7-1 shows how convolution works. Suppose you have a 3 × 3 filter. Then, in the figure, you can see that the top-left nine elements of the matrix A, marked by a square drawn with a black continuous line, are the ones used to generate the first element of the matrix B1 according to the formula. The elements marked by the square drawn with a dotted line are the ones used to generate the second element B2, and so on.

A visual explanation of convolution
 for example you can see in Figure 7-2 which element of A gets multiplied by which element in
for example you can see in Figure 7-2 which element of A gets multiplied by which element in  and the result for the element B1, that is nothing more than the sum of all the multiplications
and the result for the element B1, that is nothing more than the sum of all the multiplications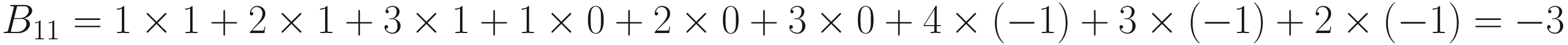

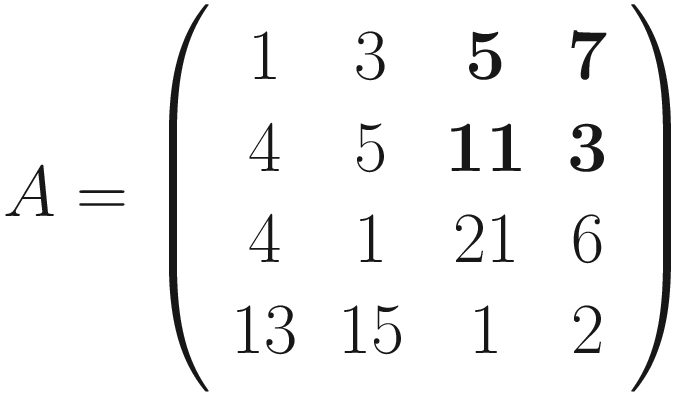
A visualization of convolution with the kernel 

A visual explanation of convolution with stride s = 2
 can be seen in Figure 7-4. If s > 1, what can happen, depending on the dimensions of A, is that at a certain point you cannot shift your window on matrix A (the black square you can see in Figure 7-3 for example) anymore, and you cannot cover the matrix A completely. Figure 7-4 shows that you need an additional column on the right of matrix A (marked by many X) to be able to perform the convolution operation. In Figure 7-4, we chose s = 3, and since we have nA = 5 and nK = 3, B will be a scalar as a result:
can be seen in Figure 7-4. If s > 1, what can happen, depending on the dimensions of A, is that at a certain point you cannot shift your window on matrix A (the black square you can see in Figure 7-3 for example) anymore, and you cannot cover the matrix A completely. Figure 7-4 shows that you need an additional column on the right of matrix A (marked by many X) to be able to perform the convolution operation. In Figure 7-4, we chose s = 3, and since we have nA = 5 and nK = 3, B will be a scalar as a result: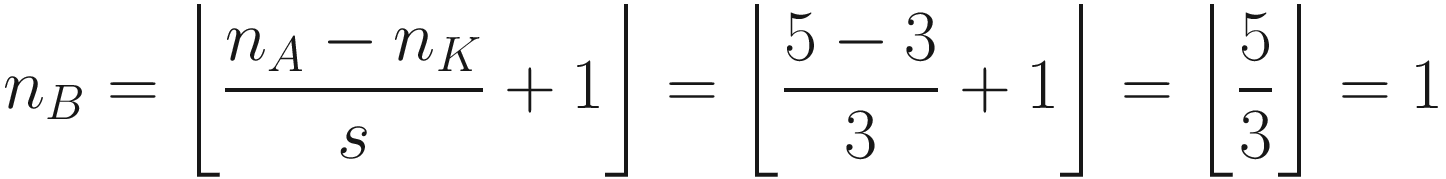

A visual explanation why the floor function is needed when evaluating the resulting matrix B dimensions
You can see from Figure 7-4 how, with a 3 × 3 region, you can only cover the top-left region of A, since with stride s = 3 you would end up outside A. Therefore, you can consider one region only for the convolution operation, thus ending up with a scalar for the resulting tensor B.
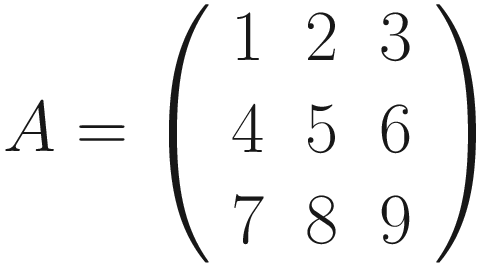
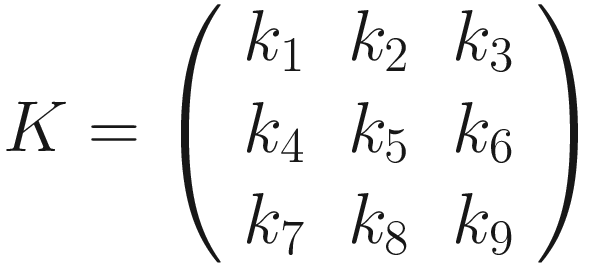
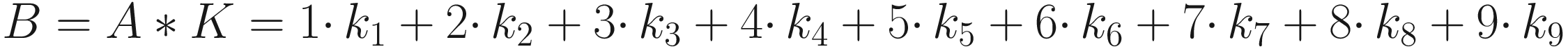
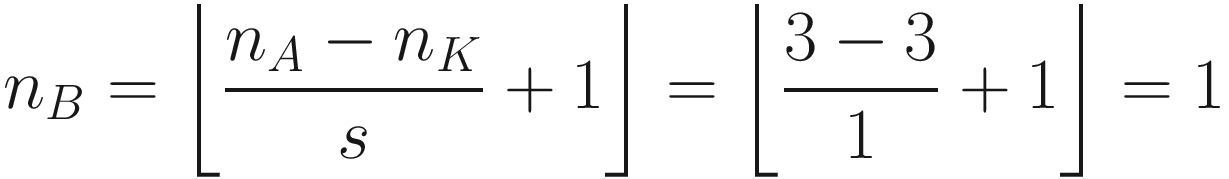
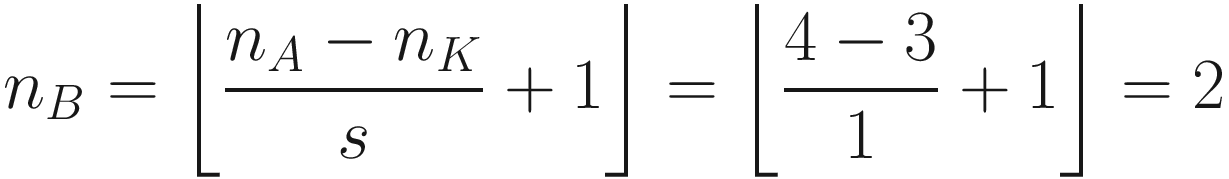
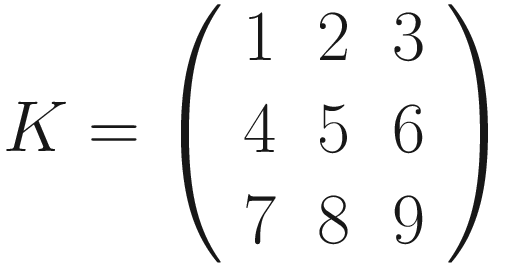
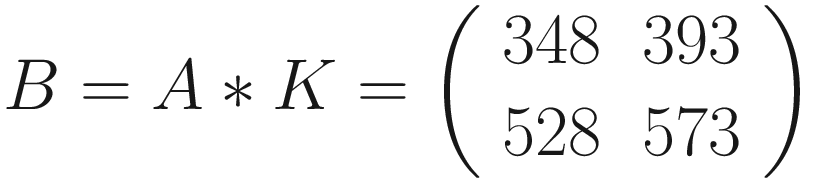
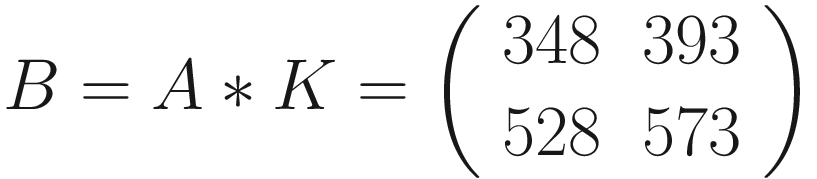
Note that the formula for the convolution works only for stride s = 1, but can be easily generalized for other values of s.
Examples of Convolution

The chessboard image generated with code
Now let’s try to apply convolution to this image with the different kernels and with stride s = 1.
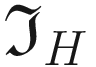 will detect the horizontal edges. This can be applied with the code
will detect the horizontal edges. This can be applied with the code
The result of performing a convolution between the kernel 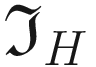 and the chessboard image
and the chessboard image

 with the code
with the code
The result of performing a convolution between the kernel 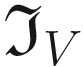 and the chessboard image
and the chessboard image
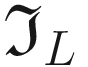

The result of performing a convolution between the kernel 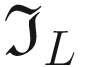 and the chessboard image
and the chessboard image
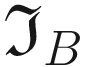

The effect of the blurring kernel 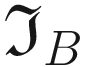 . On the left is the blurred image and on the right is the original one
. On the left is the blurred image and on the right is the original one
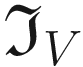 . We can perform the convolution with the code
. We can perform the convolution with the code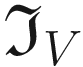 has clearly detected the sharp transition in the original matrix, marking with a vertical black line where the transition from black to white happens. For example, consider B11 = 0
has clearly detected the sharp transition in the original matrix, marking with a vertical black line where the transition from black to white happens. For example, consider B11 = 0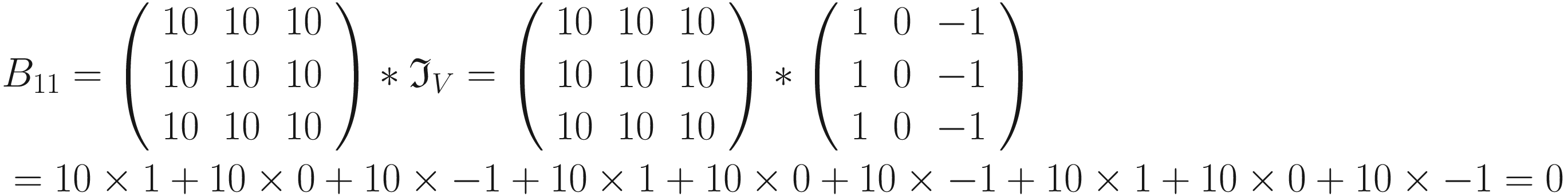
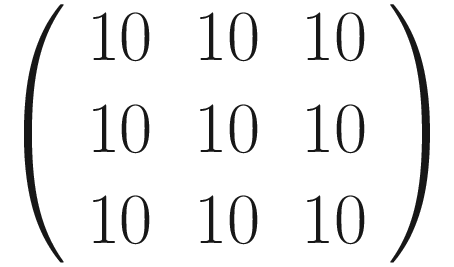
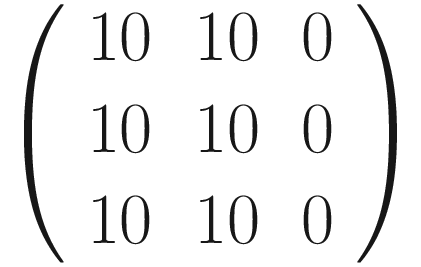
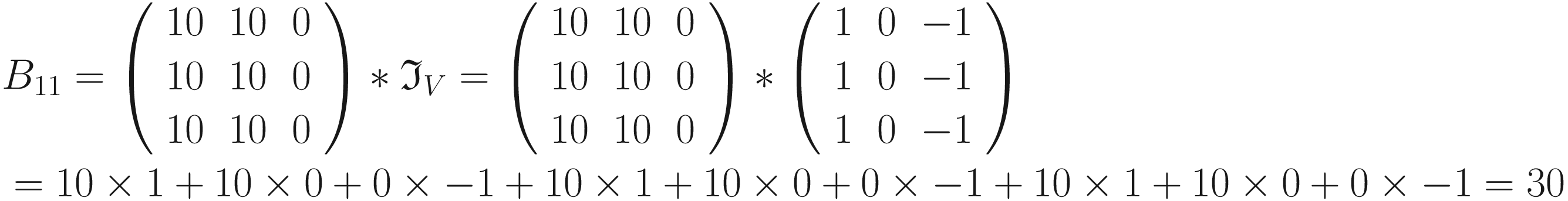
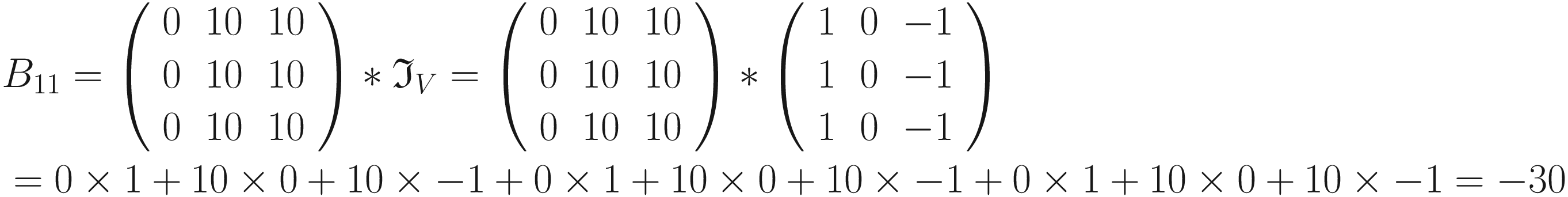

The result of the convolution of the matrix ex_mat with the kernel 
Note how, as expected, the output matrix is 5 × 5 since the original matrix is 7 × 7 and the kernel is 3 × 3.
Pooling
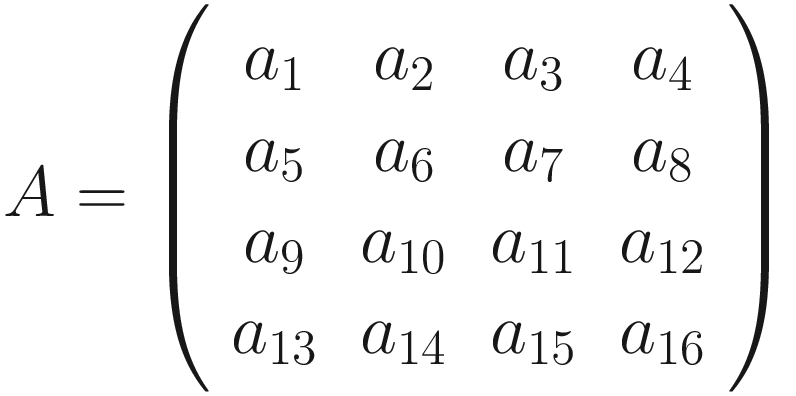

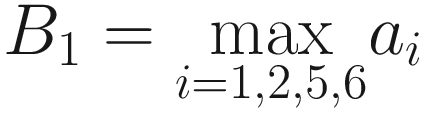
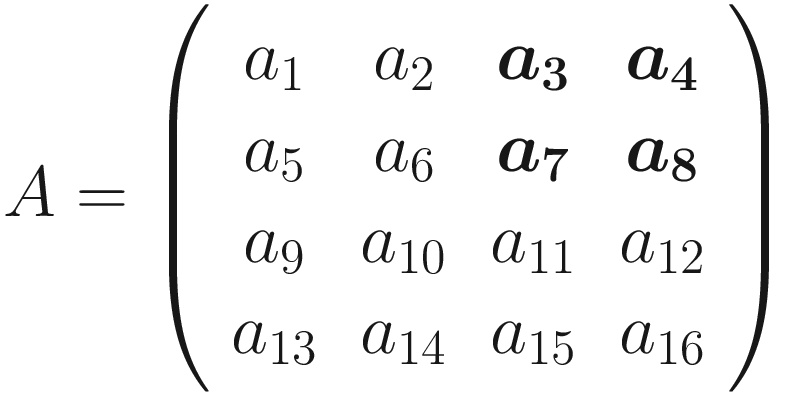
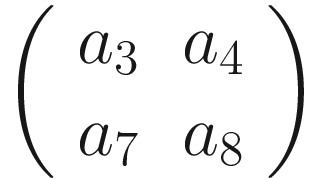
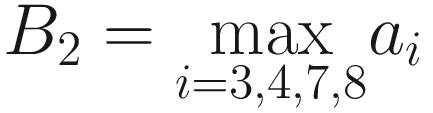
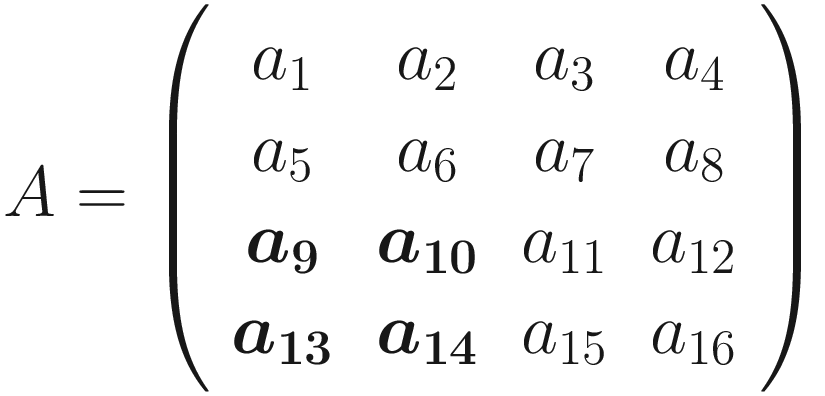
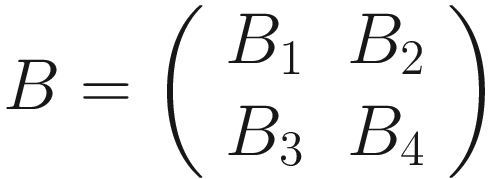
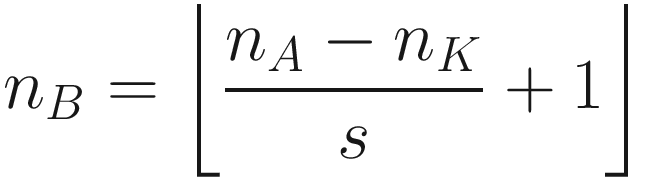

A visualization of pooling with stride s = 2
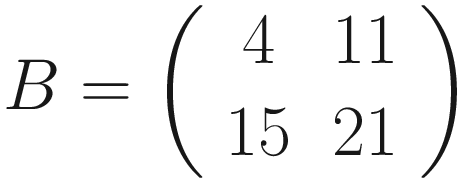
and so on. It’s worth mentioning another way of doing pooling, although not as widely used as max pooling, and that’s average pooling. Instead of returning the maximum of the selected values, it returns the average.
The most common pooling operation is max pooling. Average pooling is not as widely used, but can be found in specific network architectures.
Padding
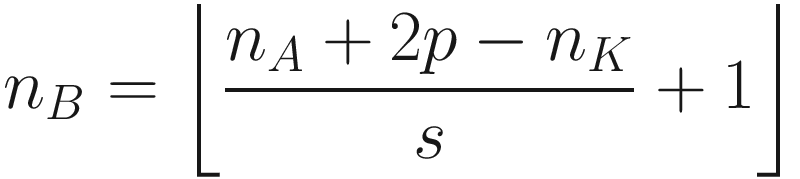
When dealing with real images, you always have color images, coded in three channels: RGB. That means that you need to do convolution and pooling in three dimensions: width, height, and color channel. This will add a layer of complexity to the algorithms.
Building Blocks of a CNN
Convolutional layers
Pooling layers
Fully connected layers
Fully connected layers are exactly what you have already seen in all previous chapters: a layer where neurons are connected to all neurons of previous and subsequent layers. You know them already. But the first two require some additional explanation.
Convolutional Layers
A convolutional layer takes as input a tensor (it can be three-dimensional, due to the three color channels). For example, an image of certain dimensions. It then applies a certain number of kernels, typically 10, 16, or even more, adds a bias, applies the ReLU activation functions (for example) to introduce non-linearity to the result of the convolution, and produces an output matrix, B. If you remember the notation we used in the previous chapters, the result of the convolution will have the role of W[l]Z[l − 1], which we discussed in Chapter 3.
 of dimensions nB × nB × nc. That means that
of dimensions nB × nB × nc. That means that![$$ {overset{sim }{B}}_{i,j,1}kern1em forall i,jin left[1,{n}_B
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484280201/9781484280201__9781484280201__files__images__463356_2_En_7_Chapter__463356_2_En_7_Chapter_TeX_Equbb.png)
![$$ {overset{sim }{B}}_{i,j,2}kern1em forall i,jin left[1,{n}_B
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484280201/9781484280201__9781484280201__files__images__463356_2_En_7_Chapter__463356_2_En_7_Chapter_TeX_Equbc.png)
will be the output of convolution with the second kernel, and so on. The convolution layer is nothing more than something that transforms the input into an output tensor. But what are the weights in this layer? The weights, or the parameters that the network learns during the training phase, are the elements of the kernel themselves. We discussed that we have nc kernels, each of nK × nK dimensions. That means that we have 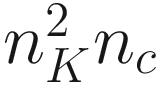 parameters in a convolutional layer.
parameters in a convolutional layer.
The number of parameters that you have in a convolutional layer, 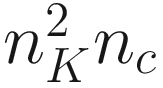 , is independent of the input image size. This fact helps reduce overfitting, especially when dealing with large input images.
, is independent of the input image size. This fact helps reduce overfitting, especially when dealing with large input images.

A representation of a convolutional layer1
Of course, a convolutional layer must not necessarily be placed immediately after the inputs. A convolutional layer may get as input the output of any other layer of course. Keep in mind that your input image will usually have dimensions nA × nA × 3, since an image in color has three channels: Red, Green, and Blue. A complete analysis of the tensors involved in a CNN when considering color images goes beyond the scope of this book. Very often in diagrams, the layer is simply indicated as a cube or a square.
Pooling Layers
A pooling layer is usually indicated with POOL and a number: for example, POOL1. It takes as input a tensor and gives as output another tensor after applying pooling to the input.
A pooling layer has no parameter to learn, but it introduces additional hyper-parameters: nK and stride s. Typically, in pooling layers you do not use padding, since one of the reasons to use pooling is to reduce the dimensionality of the tensors.
Stacking Layers Together

A representation of how to stack convolutional and pooling layers

A representation of a CNN similar to the LeNet-5 network
An Example of a CNN
Convolution layer 1 (CONV1): Six filters 5 × 5, stride s = 1.
We then apply ReLU to the output of the previous layer.
Max pooling layer 1 (POOL1) with a window 2 × 2, stride s = 2.
Convolution layer 2 (CONV2): 16 filters 5 × 5, stride s = 1.
We then apply ReLU to the output of the previous layer.
Max pooling layer 2 (POOL2) with a window 2 × 2, stride s = 2.
Fully Connected Layer with 128 neurons with activation function ReLU.
Fully Connected Layer with ten neurons for classification of the Zalando dataset.
Softmax output neuron.
Remember that the convolutional layer will require the two-dimensional image, and not a flattened list of gray values of the pixels.
One of the biggest advantages of CNNs is that they use the two-dimensional information contained in the input image, this is why the input of convolutional layers are two-dimensional images, and not a flattened vector.
When building CNNs in Keras, a single line of code (and a Keras method) will correspond to a different layer. The build_model function creates a CNN stacking Conv2D (which builds a convolutional layer) and MaxPooling2D (which builds a max pooling layer) layers. The stride is a tuple since it gives the stride in different dimensions (for rows and columns). In our examples we have gray images, but we could also have RGB, for example. That would mean having more dimensions: the three color channels.
Note that the output of every convolutional and pooling layer is a 3D tensor of shape (height, width, number_of_filters). The first dimension (i.e., the number of batches), is set to None since the network does not know it yet and thus it can be applied to every set of samples, of any length. The width and height dimensions decrease as you go deeper into the network. The number of output channels for each Conv2D layer is controlled by the first function argument. Typically, as the width and height decrease, you can afford (computationally) to add more output filters to each Conv2D layer.
To complete the model, we added two Dense layers. They take vectors as input (which are 1D), while the current output is a 3D tensor. This is why you first need to flatten the 3D output to 1D, then add one or more Dense layers on top.
If you run this code (it took roughly four minutes on a medium performance laptop), it will start, after just one epoch, with a training accuracy of 76.3%. After ten epochs it will reach a training accuracy of 91% (88% on the dev set). We have trained our network here only for ten epochs. You can get much higher accuracy if you train longer. Additionally, note that we have not done any hyper-parameter tuning so this would get you much better results if you spent time tuning the parameters.
Kernel size
Stride
Padding
Those will need to be tuned to get optimal results. Typically, researchers tend to use existing architectures for specific tasks that have been already optimized by other practitioners and are well documented in papers.
Conclusion
You should now have a basic understanding of how CNN networks work, and on what principles they work on. Convolutional neural networks are used extensively in multiple forms for various tasks, from classification (as you have seen here) to object localization, object segmentation, instance segmentation, and much more. This chapter just scratched the surface. But you should understand the building blocks of CNNs and should be able to understand how more complex architecture is built and structured.
Exercises
Try to build a multiclass classification model like the one you saw in this chapter, but using the MNIST database of handwritten digits instead.
Try to change the network’s parameters to see if you can get a better accuracy. Change kernel size, stride, and padding.
References
[1] https://goo.gl/hM1kAL, last accessed 19.07.2021.
[2] https://goo.gl/FodLp5, last accessed 21.07.2021.
[3] https://goo.gl/8Ja3n2, last accessed 21.07.2021.