
In today’s world, customers are faced with multiple choices for every decision. Let’s assume that a person is looking for a book to read without any specific idea of what they want. There’s a wide range of possibilities for how their search might pan out. They might waste a lot of time browsing the Internet and trawling through various sites hoping to strike gold. They might look for recommendations from other people.
But if there was a site or app that could recommend books to this customer based on what they’d read previously, that would save time that would otherwise be spent searching for books of interest on various sites. In short, our main goal is to recommend things based on the user’s interests. And that’s what recommendation engines do.
A recommendation engine, also known as a recommender system or a recommendation system, is one of the most widely used machine learning applications; for example, it is used by companies like Amazon, Netflix, Google, and Goodreads.
This chapter explains recommendation systems and presents various recommendation engine algorithms and the fundamentals of creating them in Python 3.8 or greater using a Jupyter notebook.
What Are Recommendation Engines?
In the past, people generally purchased products recommended to them by their friends or the people they trust. This is how people used to make purchasing decisions when there was doubt about a product. But since the advent of the Internet, we are so used to ordering online and streaming music and movies that we are constantly creating data in the back end. A recommendation engine uses that data and different algorithms to recommend the most relevant items to users. It initially captures the past behavior of a user, and then it recommends items for future purchase or use.
There are scenarios where there is no historical data as well. For example, when a new user visits a site, there is no history of that user. So how does the website recommend products to this user? One way is by recommending bestselling products (i.e., the products that are trending). Another possible solution is to recommend the products that bring maximum profit to the business and any new products recently added to the site.
If you can recommend a few items to a customer based on their interests, it positively impacts the user experience and leads to frequent visits. Hence, intelligent recommendation engines are built by studying the past behavior of their users to enhance revenue.
Recommendation System Types
Data on a user’s likes and dislikes of items are essential to building a recommender engine that can suggest relevant items to the user. There are two feedback mechanisms through which users provide this required data.
Explicit feedback is the data that the user explicitly provides as feedback on an item. It is usually difficult to obtain this type of feedback from users, and companies try many innovative ways. A simple like or dislike button, star ratings, and even comments and reviews as text input can get user feedback on an item.
Implicit feedback is the data that the user implicitly or unknowingly provides through their actions. This can be in the form of pages visited, items viewed, the number of clicks, and all sorts of other activities performed on the site/platform, which can indicate their interest in certain items. This type of data is generally captured automatically through cookies and browsing history and doesn’t require any direct action from the users.
Types of Recommendation Engines
Market basket analysis (association rule mining)
Content-based filtering
Collaborative-based filtering
Hybrid systems
ML clustering
ML classification
Deep learning and NLP
Market Basket Analysis (Association Rule Mining)
Retailers predominantly use market basket analysis to reveal relationships between items. It works by looking for combinations of items that are often put together, allowing retailers to identify relationships between items that people buy.
There are several terms used in association analysis that are important to understand. Association rules are widely used to analyze retail basket or transaction data. They are intended to identify strong rules discovered in transaction data using interest measures based on the concept of strong rules.
Association rules are normally written like this: {bread} -> {butter}. This means a strong relationship exists between customers who bought bread and butter in the same transaction.
In the preceding example, {bread} is the antecedent and {butter} is the consequent. Both antecedents and consequences can have multiple items. In other words, {bread, milk} -> {butter, chips} is a valid rule.
Support is the relative frequency of the rule display. In many cases, you may want to seek high support to make sure it’s a worthwhile relationship. However, there may be cases where low support is useful if you are trying to find “hidden” relationships.
Confidence is a measure of the reliability of a rule. A 0.5 reliability in the preceding example means that bread and milk were purchased 50% of the time. The purchase also included butter and chips. For a product recommendation, 50% confidence may be perfectly acceptable, but this level may not be high enough in a medical situation.

An analysis of market basket rules. It includes four rules with support, confidence, and lift calculations. The rules are 1. A implies D. 2. C implies A. 3. A implies C. 4. B and C imply D.
Market basket analysis
Content-Based Filtering

An illustration depicts a content-based filtering method. It reveals new articles recommended, based on the text present in the article (text read by the user and similar articles are recommended to other users).
Content-based system
Let’s look at the popular example of Netflix and its recommendations to explore the workings in detail. Netflix saves all user viewing information in a vector-based format, known as the profile vector, which contains information on past viewings, liked and disliked shows, most frequently watched genres, star ratings, and so forth. Then there is another vector that stores all the information regarding the titles (movies and shows) available on the platform, known as the item vector. This vector stores information like the title, actors, genre, language, length, crew info, synopsis, and so forth.
The content-based filtering algorithm uses the concept of cosine similarity. In it, you find the cosine of the angle between two vectors—the profile and item vectors in this case. Suppose A is the profile vector and B is the item vector, then the (cosine) similarity between them is calculated as follows.

A formula states: sim open parenthesis A, B close parenthesis equals cos theta equals start fraction A dot B over either A OR B end fraction, here A is the profile vector and B is the item vector.
In a top N approach, the top N movies are recommended, where N is a threshold on the number of titles recommended.
In a rating scale approach, a threshold on the similarity value is set, and all the titles in that threshold are recommended.
Euclidean distance is the distance between two points measured by the length of the straight line connecting them. Hence if you can plot the profile and items in an n-dimensional Euclidean space, the similarity value is equal to the distance between them. The closer the item is, the more similar it is. So, the closest items to the profile are recommended. The following is the mathematical formula for calculating Euclidean distance.
 A formula for Euclidean distance. The square root of x subscript 1 minus x subscript 1 whole square plus up to plus x subscript N minus y subscript N whole square.
A formula for Euclidean distance. The square root of x subscript 1 minus x subscript 1 whole square plus up to plus x subscript N minus y subscript N whole square.Pearson’s correlation refers to how correlated or similar two things are. The higher the correlation, the higher the similarity. Pearson’s correlation is calculated using the formula shown in Figure 1-3.

A formula for Pearson's correlation. Sim of u, v is equal to the summation of r subscript u i minus r superscript hyphen subscript u and r subscript v i minus r superscript hyphen subscript v over square root of summation of r subscript u i minus r superscript hyphen subscript u whole square and the square root of summation of r subscript v i minus r superscript hyphen subscript v whole square is the end of the formula.
Formula
The major downside to this recommendation engine is that all suggestions fall into the same category, and it becomes somewhat monotonous. As the suggestions are based on what the user has seen or liked, we’ll never get new recommendations that the user has not explored in the past. For example, if the user has only seen mystery movies, the engine will only recommend more mystery movies.
To improve on this, you need a recommendation engine that not only gives suggestions based on the content but also on the behavior of users and on what other like-minded users are watching.
Collaborative-Based Filtering

An illustration depicts the collaborative-based filtering method. It recommends an item to user A based on the interests of a similar user B. Here displays an example with two users A and B.
Collaborative-based filtering
The similarity between users can be calculated again by all the techniques mentioned earlier. A user-item matrix is created individually for each customer, which stores the user’s preference for an item. Taking the same example of Netflix’s recommendation engine, the user aspects like previously watched and liked titles, ratings provided (if any) by the user, frequently watched genres, and so on are stored and used to find similar users. Once these similar users are found, the engine recommends titles that the user has not yet watched but users with similar interests have watched and liked.
This type of filtering is quite popular because it is only based on a user’s past behavior, and no additional input is required. It’s used by many major companies, including Amazon, Netflix, and American Express.
In user-user collaborative filtering, you find user-user similarities and offer suggestions based on what similar users chose in the past. Even though this algorithm is quite effective, since it requires high computations for getting all user-pair information and calculating the similarities, it takes a lot of time and resources. Hence for big customer bases, this algorithm is too expensive to use unless a proper parallelizable system is set up.
In item-item collaborative filtering, you try to find item similarities instead of similar users. An item look-alike matrix is generated for all the items that the user has previously chosen, and from this matrix, similar items are recommended. This algorithm is far less computationally expensive because the item-item look-alike matrix remains fixed over time with a fixed number of items. Hence recommendations are fetched much quicker for a new customer.
One of the drawbacks of this method happens when no ratings are provided for a particular item; then, it can’t be recommended. And reliable recommendations can be tough to get if a user has only rated a few items.
Hybrid Systems
So far, you have seen how content-based and collaborative-based recommendation engines work and their respective pros and cons. But the hybrid recommendation system combines content and collaborative-based filtering methods.
Hybrid recommendation systems can overcome the drawbacks of both content-based and collaborative-based to form one powerful recommendation system, both the individual methods fail to perform well when there is a lack of data to learn the relation between users and items, which is overcome in this hybrid approach.

A flow chart depicts the working mechanism of the hybrid recommendation system. It includes two inputs, one with C F-based recommender, the other with a content-based recommender, combiner, and R E C O.
Hybrid recommendation system
Generating recommendations separately by using content-based and collaborative-based and then combining them at the end
Adding the capabilities of the collaborative-based method to a content-based recommender engine
Adding the capabilities of the content-based method to a collaborative-based recommender engine
Several studies compare the performance of conventional methods to that of a hybrid system, showing that hybrid recommender engines generally perform better and provide more reliable recommendations.
ML Clustering
In today’s world, AI has become an integral part of all automation and technology-based solutions and the area of recommendation systems is no different. Machine learning-based methods are the upcoming high prospective methods that are quickly becoming a norm as more and more companies start adapting AI.
Machine learning methods are of two types: unsupervised and supervised. This section discusses the unsupervised learning method, which is the ML clustering–based method. The unsupervised learning technique uses ML algorithms to find hidden patterns in data to cluster them without human intervention (unlabeled data). Clustering is the grouping of similar objects into clusters. On average, an object belonging to one cluster is more similar to an object within that cluster than to an object belonging to another cluster.

A pie chart depicts the group-based similarity. It includes clustering to form groups of users similar to each other (cluster similar products or items).
Groups based on behavior
k-means clustering
fuzzy mapping
self-organizing maps (SOM)
a hybrid of two or more techniques
ML Classification
Again, clustering comes with its disadvantages. That’s where a classification-based recommendation system comes into play.
In classification based, the algorithm uses features of both items and users to predict whether a user will like a product or not. An application of the classification-based method is the buyer propensity model.
Propensity modeling predicts the chances of customers buying a particular item or any equivalent task. Also, for example, propensity modeling can help predict the likelihood that a sales lead will convert to a customer or not based on various features. The propensity score or probability is used to take action.
Collecting a combination of data about different users and items is sometimes difficult.
Classification is challenging.
The problem is training the models in real time.
Deep Learning
Deep learning is a branch of machine learning which is more powerful than ML-based algorithms and tends to produce better results. Of course, there are limitations, like the need for huge data or explainability, which we must overcome.
Various companies use deep neural networks (DNNs) to enhance the customer experience, especially if it’s unstructured data like images and text.
Restricted Boltzmann
Autoencoder based
Neural attention–based
Later chapters explore how machine learning and deep learning can be leveraged to build powerful recommender systems.
Now that you have a good understanding of the concepts, let’s start with a simple rule-based recommender system in this chapter before proceeding to the implementation in upcoming chapters.
Rule-Based Recommendation Systems
You build these recommendation systems with simple rules, such as popularity-based or buy again.
Popularity
A popularity-based rule is the simplest form: a product is recommended based on its popularity (most sold, most clicked, etc.). Let’s implement a quick one. For example, a song listened to by many people means it’s popular. It is recommended to others without any other intelligence being part of it.
Let’s take a retail dataset and implement the same logic.
Let’s import the data.

An output file depicts the popularity-based rule. It includes invoice number, stock code, description, quantity, invoice date, unit price, customer I D, and country. It has five rows of data.
The output
 An output file depicts the null value counts. It includes customer I D, description, country (null), unit price (null), invoice date (null), quantity (null), stock code (null), invoice number (null), and d type.
An output file depicts the null value counts. It includes customer I D, description, country (null), unit price (null), invoice date (null), quantity (null), stock code (null), invoice number (null), and d type.
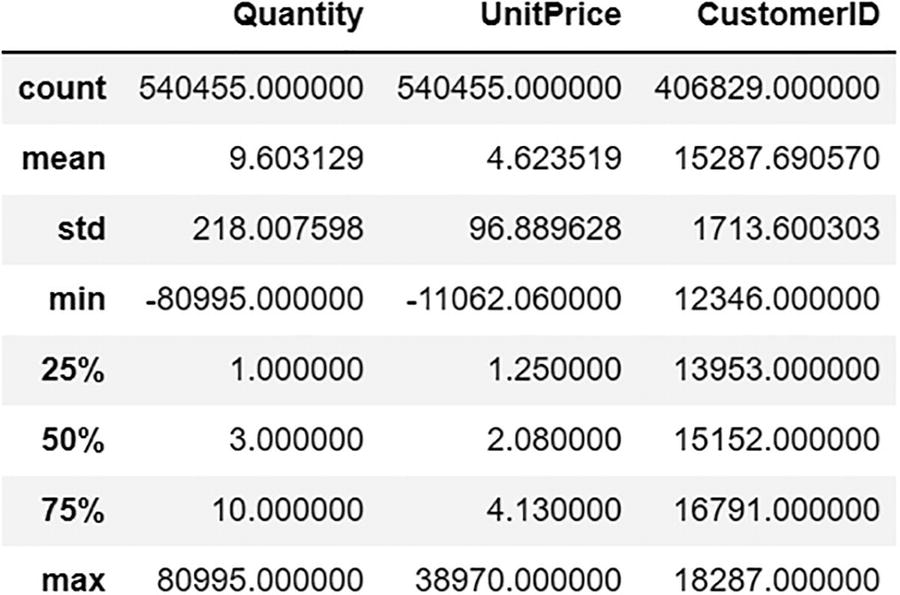
An output file depicts eight rows of data with some negative values (incorrect data). It includes quantity, unit price, and customer I D with two negative values in minimum.
The output contains negative values

An output file depicts eight rows of data with the popularity-based recommendation system. It includes quantity, unit price, and customer I D with count, mean, S T D, minimum, 25, 50, and 75 percent. Here 25 percent is highlighted.
shows the output after removing the negative values
Now that we cleaned up the data, let’s do some basic types of recommendation systems. These are not intelligent yet effective in some cases. Popularity-based recommendation systems could be a trending song. It could be a fast-selling item required for everyone, a recently released movie that gets traction, or a news article many users have read.
Sometimes it’s important to keep it simple because it gets you the most revenue. Let’s build a popularity-based system in the data we are using.
Global Popular Items
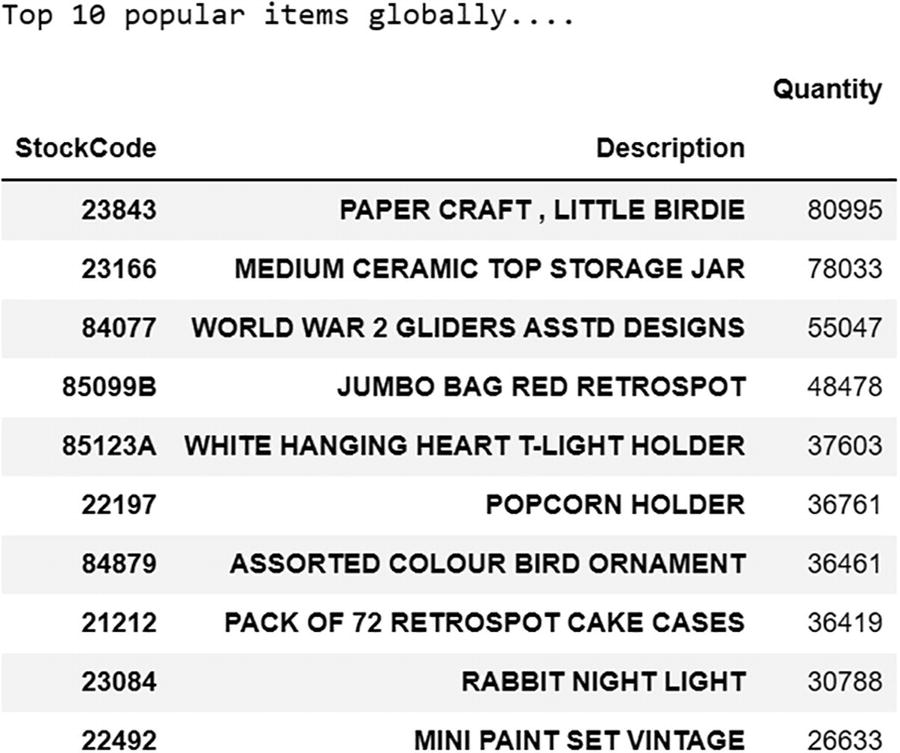
An output file depicts the top ten most popular items. It includes stock code, description, and quantity. paper craft, little birdie was the most bought item all over the region.
The output

A bar graph depicts items versus the quantity of the top ten most popular items globally. Papercraft, a little birdie has the highest range all over the region. medium ceramic top storage jar is the second highest item.
The output
Popular Items by Country

A bar graph depicts items versus the quantity of the top ten most popular items in U K. Papercraft, a little birdie has the maximum range with a quantity of 80000 approximately. Victorian glass hanging t-light has the minimum.
The output

A bar graph depicts items versus the quantity of the top ten most popular items in the Netherlands. Rabbit night light has a maximum range of 5000 quantities approximately. Space boy lunch box has the second highest range.
The output
Buy Again
Now let’s discuss buy again. It’s another simple recommendation simple calculated at the customer/user level. You might have seen “Watch again” on streaming platforms. It’s the same concept. You know a certain set of actions are done repeatedly by a customer, and we recommend the same action next time.
This is very useful in online grocery platforms because customers come back and buy the same item again and again.

An output file depicts the often-bought items by customer 17850. The 21 items include a white hanging T-light holder and white metal lantern and more.
The output
Summary
In this chapter, you learned about recommender systems—how they work, their applications, and the various implementation types. You also learned about implicit and explicit types and the differences between them. The chapter also explored market basket analysis (association rule mining), content-based and collaborative-based filtering, hybrid systems, ML clustering-based and classification-based methods, and deep learning and NLP-based recommender systems. Finally, you implemented simple recommender systems. Many other complex algorithms are explored in upcoming chapters.