
Recommender systems based on unsupervised machine learning algorithms are very popular because they overcome many challenges that collaborative, hybrid, and classification-based systems face. A clustering technique is used to recommend the products/items based on the patterns and behaviors captured within each segment/cluster. This technique is good when data is limited, and there is no labeled data to work with.

A graph of unsupervised learning exhibits the clustering outcome. A set of three clusters are represented along the x (x subscript 1) and y (x subscript 2) axis.
Clustering
Similar to each other in the same group
Dissimilar to the observations in other groups
There are mainly two important algorithms that are highly being used in the industry. Before getting into the projects, let’s briefly examine how algorithms work.
Approach
- 1.
Data collection
- 2.
Data preprocessing
- 3.
Exploratory data analysis
- 4.
Model building
- 5.
Recommendations

A set of 2 frameworks expose the steps involved to build a model based on similar user recommendations (top) and based on similar items recommendation (bottom).
Steps
Implementation
Data Collection and Downloading Required Word Embeddings
Let’s consider an e-commerce dataset. Download the dataset from the GitHub link of this book.
Importing the Data as a DataFrame (pandas)

A data frame exposes the output of the first 5 rows (0 to 4) of the records data. The data includes invoice number, stock code, quantity, delivery date, and ship mode are represented.
The output
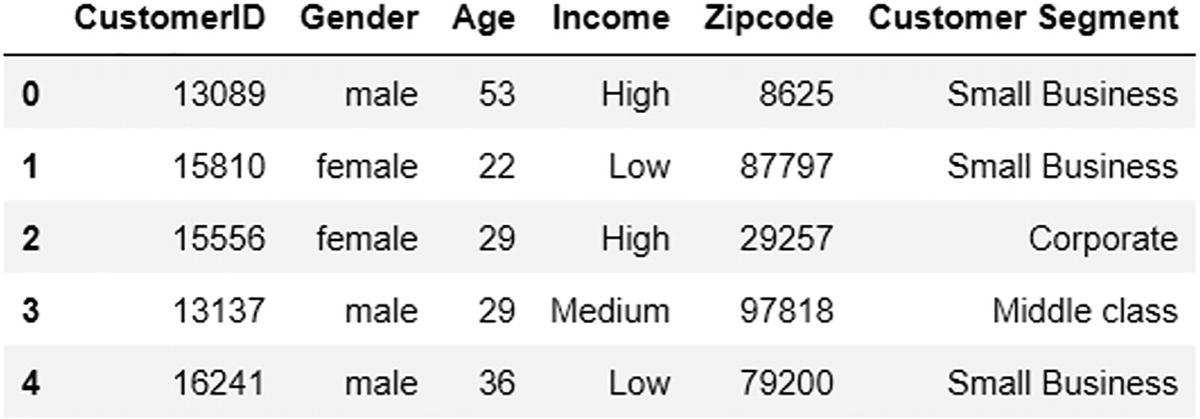
A data frame exposes the output of the first 5 rows (0 to 4) of customer data. The data includes customer I D, gender, age, income, zip code, and customer segment are represented.
The output

A data frame exposes the output of the first 5 rows (0 to 4) of product data. The data includes stock code, product name, description, category, brand, and unit price are represented.
The output
Preprocessing the Data
Before building any model, the initial step is to clean and preprocess the data.
Let’s analyze, clean, and merge the three datasets so that the merged DataFrame can be used to build ML models.
First, focus all customer data analysis to recommend products based on similar users.

A representation exposes the output of missing values. The selected data frame has 6 columns and 4372 rows. There are 0 columns that have missing values.
The output
Exploratory Data Analysis
Let’s explore the data for visualization using the Matplotlib package defined in sklearn.

A violin plot of ages frequency represents the output of distribution of the customer's age (from 20 to 60). The y-axis is indicated by age.
The output

A bar chart exposes the output of gender (male and female) count. The counts for male and female genders are observed with a similar range.
The output
The key insight from this chart is that data is not biased based on gender.

A bar chart shows the output of the number of customers (y-axis) and ages (x-axis). The age group 26 to 35 is observed with the highest number of customers.
The output
This analysis shows that there are fewer customers ages 18 to 25.
Label Encoding

A data frame exposes the output after encoding the values. The data of age, gender, customer _ segment, and income _ segment are represented.
The output
Model Building
This phase builds clusters using k-means clustering. To define an optimal number of clusters, you can also consider the elbow method or the dendrogram method.
K-Means Clustering

A graph represents the clustering of K means. There are 3 groups of clusters. It is observed that the clusters are plotted along - 1 and + 1.
k-means clustering
- 1.
Use the elbow method to identify the optimum number of clusters. This acts as k.
- 2.
Select random k points as cluster centers from the overall observations or points.
- 3.Calculate the distance between these centers and other points in the data and assign it to the closest center cluster that a particular point belongs to using any of the following distance metrics.
Euclidean distance
Manhattan distance
Cosine distance
Hamming distance
- 4.
Recalculate the cluster center or centroid for each cluster.
Repeat steps 2, 3, and 4 until the same points are assigned to each cluster, and the cluster centroid is stabilized.
The Elbow Method
The elbow method checks the consistency of clusters. It finds the ideal number of clusters in data. Explained variance considers the percentage of variance explained and derives an ideal number of clusters. Suppose the deviation percentage explained is compared with the number of clusters. In that case, the first cluster adds a lot of information, but at some point, explained variance decreases, giving an angle on the graph. At the moment, the number of clusters is selected.
The elbow method runs k-means clustering on the dataset for a range of values for k (e.g., from 1–10), and then for each value of k, it computes an average score for all clusters.
Hierarchical Clustering
- 1.
Hierarchical clustering starts by creating each observation or point as a single cluster.
- 2.
It identifies the two observations or points that are closest together based on the distance metrics discussed earlier.
- 3.
Combine these two most similar points and form one cluster.
- 4.
This continues until all the clusters are merged and form a final single cluster.
- 5.
Finally, using a dendrogram, decide the ideal number of clusters.

A hierarchical dendrogram exposes the clustering. The tree-like structure represents the relationship between all the data points in the system.
Hierarchical clustering
Usually, the distance between two clusters has been computed based on Euclidean distance. Many other distance metrics can be leveraged to do the same.
Let’s build a k-means model for this use case. Before building the model, let’s execute the elbow method and the dendrogram method to find the optimal clusters.

A graph of the K value (on the x-axis) versus W C S S (on the y-axis) exhibits the elbow method output. The trend in the graph decreases from 1 to 14 K value.
The output
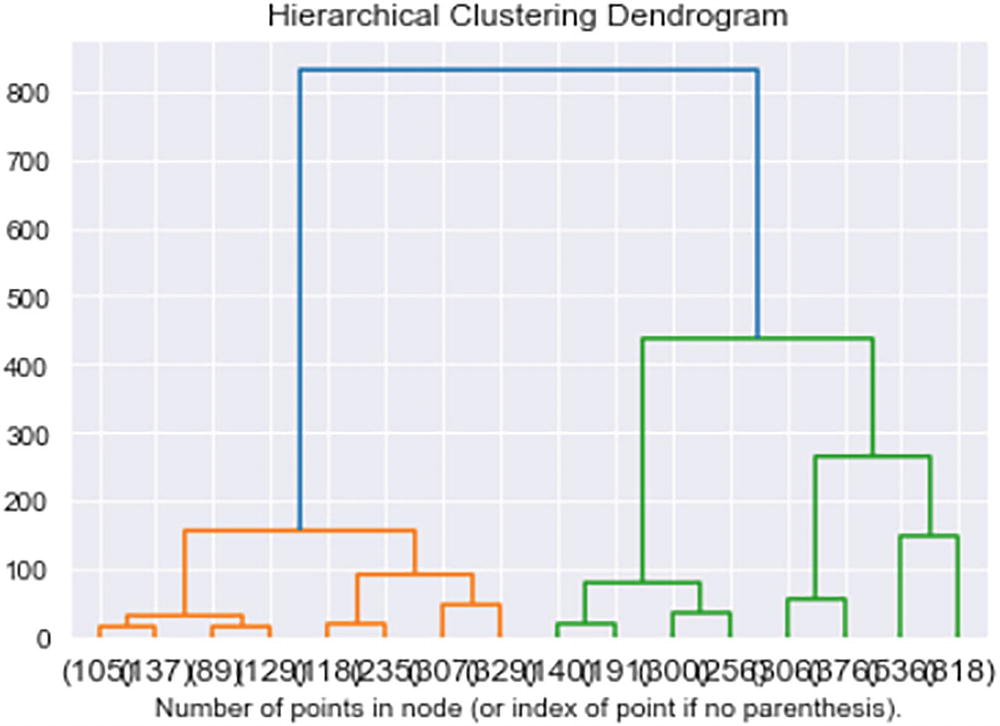
A hierarchical clustering dendrogram exposes the number of points in the node (or index of point if no parenthesis). It exhibits the relationship between all the data points in the system.
The output
The optimal or least number of clusters for both methods is two. But let’s consider 15 clusters for this use case.
You can consider any number of clusters for implementation, but it should be greater than the optimal, or the least, number of clusters from k-means clustering or dendrogram.

A data frame exposes the output of the df _ cluster after the creation of the clusters. The data includes customer I D, gender, age, income, zip code, and customer segment are represented.
The output

A data frame exposes the output of the df _ cluster after the selection of particular columns. The data includes customer I D, age, gender, income, and zip code are represented.
The output
Let’s perform some analysis on the cluster level.

A triple bar chart shows the output of customer segments (small business, corporate, and middle class) versus clusters. x and y axis is indicated by cluster and customer segment percentage.
The output

A triple bar chart exposes the data of cluster by percent income (high, medium, and low incomes). x and y axis indicate the clusters and income percentage respectively.
The output

A double bar chart exposes the gender percentage (for male and female) versus cluster. Cluster 9 for males is observed with the highest percentage and 14 for females has the highest percentage.
The output
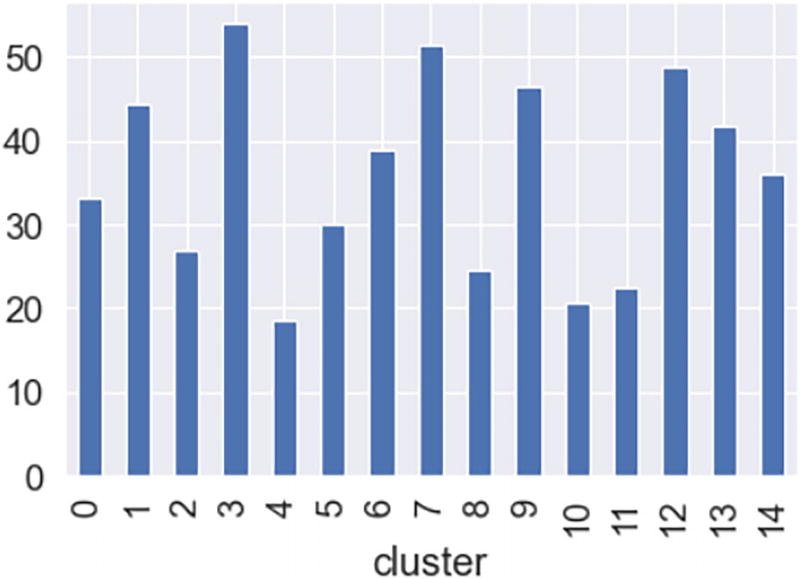
A bar chart exposes the output of the average in accordance with the cluster. The x-axis is indicated by the cluster. Cluster 3 has the highest average (above 50).
The output
Until now, all the data preprocessing, EDA, and model building have been performed on customer data.

A data frame exposes the output after unifying customer data with order data. The data includes stock code, customer I D, and cluster are represented.
The output

A data frame (37032 rows and 3 columns) exhibits the output after the formulation of score _ df. The data includes cluster, stock code, and score are represented.
The output
The score_df data is ready to recommend new products to a customer. Other customers in the same cluster have bought the recommended products. This is based on similar users.
Let’s focus on product data to recommend products based on similarity.

A data frame exposes the output of missing values. The data includes zero values, missing values, percentages of total values, total zero missing values, and data type represented.
The output

A representation of a data frame exhibits the output after the removal of missing values. The selected data frame has 6 columns and 3706 rows. There are 0 columns that have missing values.
The output
Let’s work on the Description column since we’re dealing with similar items.
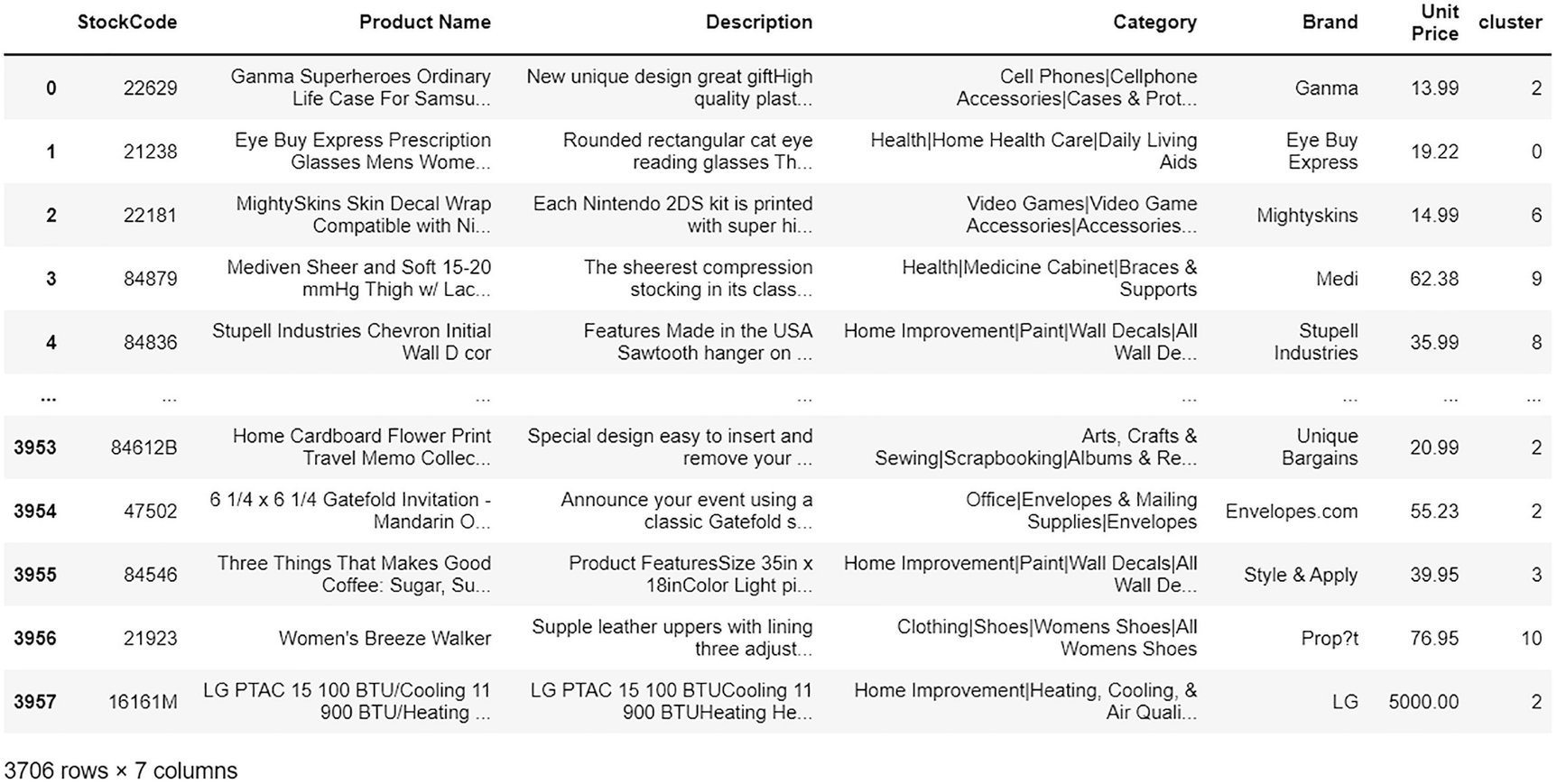
A data frame exposes the output after the formulation of clusters for product data. The data includes stock code, product name, description, category, brand, unit price, and cluster are represented.
The output
Now the df_product data is ready to recommend the products based on similar items.

A representation of the output exposes the top 5 stock codes - non-bought, top 5 stock codes - bought, recommendations for non-bought (highlighted), and stock code product - description cluster mapping.
The output
The first set highlights similar user recommendations. The second set highlights similar item recommendations.
Summary
In this chapter, you learned how to build a recommendation engine using unsupervised ML algorithms, which is clustering. Customer and order data were used to recommend the products/items based on similar users. The product data was used to recommend the products/items using similar items.