
Writing a Custom XML Reader
We have one more topic to consider on the subject of XML readers, which opens up a whole new world of opportunities: creating customized XML readers. An XML reader class is merely a programming interface for reading data that appears to be XML. The XmlTextReader class represents the simplest and the fastest of all possible XML readers but—and this is what really matters—it is just one reader. Its inherent simplicity and effectiveness stems from two key points. First, the class operates as a read-only, forward-only, nonvalidating parser. Second, the class is assumed to work on native XML data. It has no need, and no subsequent overhead, to map input data internally to XML data structures.
Virtually any data can be read, traversed, and queried as XML as long as a tailor-made piece of code takes care of mapping that data to an XML Schema. This mapping code can then be buried in a method that simply returns one of the standard reader objects or creates a custom XML reader class.
Note
What’s the advantage of exposing data through XML? XML provides a kind of universal model for defining a set of information (infoset), the type and layout of constituent items (XML Schema), and the query commands (XPath). In the .NET Framework, XML readers provide an effective way to deal with hierarchical, XML-shaped data. Because XML is just a metalanguage used to describe information, and not a data repository itself, the key difference between standard XML readers and custom XML readers is in the location and the modality of intervention of the code that exposes data as XML. Such code is not part of the basic .NET XML reader classes but constitutes the core of custom XML readers.
Mapping Data Structures to XML Nodes
For a long time, INI files have been a fundamental part of Microsoft Windows applications. Although with the advent of Microsoft Win32 they were officially declared obsolete, a lot of applications have not yet stopped using them. Understanding the reasons for this persistence is not of much importance here, but when they were designing the .NET Framework, the Microsoft architects decided not to insert any managed classes to handle INI files. Although overall I agree with their decision, keep in mind that if you need to access INI files from within a .NET Framework application, you’ll find at your disposal only workarounds, not a direct solution.
You could, for instance, read and write the content of an INI file using file and I/O classes, or you might resort to making calls to the underlying Win32 unmanaged platform. Recently, however, I came across a rather illuminating MSDN article in which an even better approach is discussed. (See the section “Further Reading,” on page 74, for details and the URL.) The idea is this: Why not wrap the contents of INI files into an XML reader? INI files are not well-formed XML files, but a custom reader could easily map the contents of an INI file’s sections and entries to XML nodes and attributes.
In the next few sections of this chapter, you’ll learn how to build a custom XML reader working on top of comma-delimited CSV files.
Mapping CSV Files to XML
A CSV file consists of one or more lines of text. Each line contains strings of text separated by commas. Each line of a CSV file can be naturally associated with a database row in which each token maps to a column. Likewise, a line in a CSV file can also be correlated to an XML node with as many attributes as the comma-separated tokens. The following code shows a typical CSV file:
Davolio,Nancy,Sales Representative Fuller,Andrew,Sales Manager Leverling,Janet,Sales Representative
A good XML representation of this structure is shown here:
<csv> <row col1="Davolio" col2="Nancy" col3="Sales Representative" /> <row col1="Fuller" col2="Andrew" col3="Sales Manager" /> <row col1="Leverling" col2="Janet" col3="Sales Representative" /> </csv>
Each row in the CSV file becomes a node in the XML representation, while each token is represented by a node attribute. In this case, the XML schema is ever-changing because the number of attributes varies with the number of commas in the CSV file. The number of total columns can be stored as an extra property. You can opt for an automatically generated sequence of attribute names such as col1, col2, and so on, or if the CSV file provides a header with column names, you can use those names. Of course, there is no way to know in advance, and in general, whether the first row has to be read as the first data row or just the header. A possible workaround is adding an extra property that tells the reader how to handle the first row.
Using the XML schema described so far, you can use the following pseudocode to read about a given item of information in the second row:
XmlCsvReader reader = new XmlCsvReader("employees.csv");
reader.Read();
reader.Read();
Console.WriteLine(reader[1].Value);
Console.WriteLine(reader["col2"].Value);
Another reasonable XML schema for a CSV file is shown here:
<csv> <row> <column name="col1">Davolio</column> <column name="col2">Nancy</column> <column name="col3">Sales Representative</column> </row> <row> <column name="col1">Fuller</column> <column name="col2">Andrew</column> <column name="col3">Sales Manager</column> </row> <row> <column name="col1">Leverling</column> <column name="col2">Janet</column> <column name="col3">Sales Representative</column> </row> </csv>
Although more expressive, I find this format—an element normal form—to be a bit verbose, and more importantly, it would require more calls to Read or Skip methods to get to what you really need to know from CSV data—values.
Implementing a CSV-to-XML Reader
In this section, I’ll take you through building a custom CSV-to-XML reader. A custom XML reader is built starting from the abstract XmlReader class, as shown in the following code. You override all abstract methods and properties and, if needed, add your own overloads and custom members.
public class XmlCsvReader : XmlReader
{
⋮
}
The XmlCsvReader class we’re going to build is the reader class that processes CSV files as XML documents. Given the structure of a CSV file, not all methods and properties defined by the abstract XML reader interface make sense. For example, a CSV file does not contain namespaces or entities. Likewise, it does not need a name table property. Aside from these few exceptions, a large part of the XmlReader class basic interface is preserved.
The key method for our custom reader is still Read, and Value is the principal property. We’ll use a StreamReader object to access the file and move from line to line as the user calls Read. From an XML point of view, the structure of a CSV file is rather simple. It consists of just one level of nodes—the Depth property is always 0—and, subsequently, there is no possibility for nested nodes. As you can imagine, this fact greatly simplifies the development and the internal logic of the reader.
Important
If you look at the full source code for the XmlCsvReader class, you’ll notice that not all properties (see Table 2-1, on page 27) and methods (see Table 2-3, on page 30) defined for the XmlReader class are actually implemented or overridden. The reason is that although XmlReader is declared as an abstract class, not all methods and properties in the class are marked as abstract. Abstract methods and properties must be overridden in a derived class. Virtual methods and properties, on the other hand, can be overridden only if needed.
Notice that abstract and virtual are C# and C++ specific keywords. In Visual Basic .NET, to define an abstract class and a virtual method, you use the MustInherit and MustOverride keywords, respectively.
The Custom Reader’s Constructors
The XmlCsvReader class comes with a couple of constructors: one takes the name of the file to open, and one, in addition to the file name, takes a Boolean value indicating whether the contents of the first line in the CSV file contains titles of the columns, as shown here:
LastName,FirstName,Title
Davolio,Nancy,Sales Representative
Fuller,Andrew,Sales Manager
Leverling,Janet,Sales Representative
Both constructors reference an internal helper routine, InitializeClass, that takes care of any initialization steps.
public XmlCsvReader(string filename)
{
InitializeClass(filename, false);
}
public XmlCsvReader(string filename, bool hasColumnHeaders)
{
InitializeClass(filename, hasColumnHeaders);
}
private void InitializeClass(string filename, bool hasColumnHeaders)
{
m_hasColumnHeaders = hasColumnHeaders;
m_fileName = filename;
m_fileStream = new StreamReader(filename);
m_readState = ReadState.Initial;
m_tokenValues = new NameValueCollection();
m_currentAttributeIndex = -1;
m_currentLine = "";
}
In particular, the initialization routine creates a working instance of the StreamReader class and sets the internal state of the reader to the ReadState.Initial value. The CSV reader class needs a number of internal and protected members, as follows:
StreamReader m_fileStream; // Stream reader String m_fileName; // Name of the CSV file ReadState m_readState; // Internal read state NameValueCollection m_tokenValues; // Current element node String[] m_headerValues; // Current headers for CSV tokens bool m_hasColumnHeaders; // Indicates whether the // CSV file has titles int m_currentAttributeIndex; // Current attribute index string m_currentLine; // Text of the current CSV line
The currently selected row is represented through a NameValueCollection structure, and the current attribute is identified by its ordinal and zero-based index. In addition, if the CSV file has a preliminary header row, the column names are stored in an array of strings.
The Read Method
The CSV reader implementation of the Read method lets you move through the various rows of data that form the CSV file. First the method checks whether the CSV file has headers. The structure of the CSV file does not change regardless of whether headers are present. It’s the programmer who declares, using a constructor’s argument, whether the reader must consider the first row as the header row or just a data row. If the header row is present, it must be read only the first time a read operation is performed on the CSV file, and only if the read state of the reader is set to Initial.
public override bool Read()
{
// First read extracts headers if any
if (m_readState == ReadState.Initial)
{
if(m_hasColumnHeaders)
{
string headerLine = m_fileStream.ReadLine();
m_headerValues = headerLine.Split(‘,’);
}
}
// Read the new line and set the read state to interactive
m_currentLine = m_fileStream.ReadLine();
if (m_currentLine != null)
m_readState = ReadState.Interactive;
else
{
m_readState = ReadState.EndOfFile;
return false;
}
// Populate the internal structure representing the current element
m_tokenValues.Clear();
String[] tokens = m_currentLine.Split(‘,’);
for (int i=0; i<tokens.Length; i++)
{
string key = "";
if (m_hasColumnHeaders)
key = m_headerValues[i].ToString();
else
key = CsvColumnPrefix + i.ToString();
m_tokenValues.Add(key, tokens[i]);
}
// Exit
return true;
}
The header values are stored in an array of strings (m_headerValues), which is automatically created by the Split method of the .NET String object. The Split method takes a character and splits into tokens all the parts of the string separated by that character. For a line of text read out of a CSV file, the separator must be a comma.
The reader reads one row at a time and ensures that the internal reader state is set to Interactive to indicate that the reader is ready to process requests and to EndOfFile when the end of the stream is reached. The text read is split into components, and each component is copied as the value of a name/value pair. In the following example, the row is split into Davolio, Nancy, and Sales Representative:
LastName,FirstName,Title
Davolio,Nancy,Sales Representative
If the reader has been set to support header names, each value is stored with the corresponding header. The resulting name/value pairs are shown here:
LastName/Davolio FirstName/Nancy Title/Sales Representative
If no header row is present, the name of each value takes a default form: col1, col2, col3, and so on. You can customize the prefix of the header by setting the CsvColumnPrefix property. As you might have guessed, CsvColumnPrefix is a custom property defined for the XmlCsvReader class. The name/value pairs are stored in a NameValueCollection object, which is emptied each time the Read method is called.
The Name and Value Properties
The Name property represents the name of the current node—be it an element or an attribute node. Both the Name and the Value properties share a common design, as shown in the following code. Their content is determined by the node type.
public override string Name
{
get
{
if(m_readState != ReadState.Interactive)
return null;
string buf = "";
switch(NodeType)
{
case XmlNodeType.Attribute:
buf = m_tokenValues.Keys[m_currentAttributeIndex].ToString();
break;
case XmlNodeType.Element:
buf = CsvRowName;
break;
}
return buf;
}
}
If the reader is not in interactive mode, all properties return null, including Name. If the current node type is an attribute, Name is the header name for the CSV token that corresponds to the attribute index. For example, if the reader is currently positioned on the second attribute, and the CSV has headers as shown previously, the name of the attribute is FirstName. Otherwise, if the node is an element, the name is a string that you can control through the extra CsvRowName property. By default, the property equals the word row.
The Value property is implemented according to a nearly identical logic. The only difference is in the returned text, which is the value of the currently selected attribute if the node is XmlNodeType.Attribute or the raw text of the currently selected CSV line if the node is an element.
public override string Value
{
get
{
if(m_readState != ReadState.Interactive)
return "";
string buf = "";
switch(NodeType)
{
case XmlNodeType.Attribute:
buf = this[m_currentAttributeIndex].ToString();
break;
case XmlNodeType.Element:
buf = m_currentLine;
break;
}
return buf;
}
}
Who sets the node type? Actually, the node type is never explicitly set, but is instead retrieved from other data whenever needed. In particular, for this example, the index of the current attribute determines the type of the node. If the index is equal to -1, the node is an element simply because no attribute is currently selected. Otherwise, the node can only be an attribute.
public override XmlNodeType NodeType
{
get
{
if (m_currentAttributeIndex == -1)
return XmlNodeType.Element;
else
return XmlNodeType.Attribute;
}
}
The programming interface of an XML reader is quite general and abstract, so the actual implementation you provide (for example, for CSV files) is arbitrary to some extent, and several details can be changed at will. The NodeType property for a CSV file is an example of how customized the internal implementation can be. In fact, you return Element or Attribute based on logical conditions rather than the actual structure of the XML element read off disk.
Reading Attributes
Every piece of data in the CSV file is treated like an attribute. You access attributes using indexes or names. The methods in the XmlReader base interface that allow you to retrieve attribute values using a string name and a namespace URI are not implemented, simply because there is no notion of a namespace in a CSV file.
The following two function overrides demonstrate how to return the value of the currently selected attribute node by position as well as by name. The values of the current CSV row are stored as individual entries in the internal m_tokenValues collection.
public override string this[int i]
{
get
{
return m_tokenValues[i].ToString();
}
}
public override string this[string name]
{
get
{
return m_tokenValues[name].ToString();
}
}
The preceding code simply allows you to access an attribute using one of the following syntaxes:
Console.WriteLine(reader[i]); Console.WriteLine(reader["col1"]);
You can also obtain the value of an attribute using one of the overloads of the GetAttribute method. The internal implementation for the CSV XML reader GetAttribute method is nearly identical to the this overrides.
Moving Through Attributes
When you call the Read method on the CSV XML reader, you move to the first available row of data. If the first row is managed as the header row, the first available row of data becomes the second row. The internal state of the reader is set to Interactive—meaning that it is ready to take commands—only after the first successful and content-effective reading.
Any single piece of information in the CSV file is treated as an attribute. In this way, the Read method can move you only from one row to the next. As with real XML data, when you want to access attributes, you must first select them. To move among attributes, you will not use the Read method; instead, you’ll use a set of methods including MoveToFirstAttribute, MoveToNextAttribute, and MoveToElement.
The CSV XML reader implements attribute selection in a straightforward and effective way. Basically, the current attribute is tracked using a simple index that is set to -1 when no attribute is selected and to a zero-based value when an attribute has been selected. This index, stored in m_currentAttributeIndex, points to a particular entry in the collection of token values that represents each CSV row.
The CSV XML reader positions itself at the first attribute of the current row simply by setting the internal index to 0, as shown in the following code. It then moves to the next attribute by increasing the index by 1. In this case, though, you should also make sure that you’re not specifying an index value that’s out of range.
public override bool MoveToFirstAttribute()
{
m_currentAttributeIndex = 0;
return true;
}
public override bool MoveToNextAttribute()
{
if (m_readState != ReadState.Interactive)
return false;
if (m_currentAttributeIndex < m_tokenValues.Count-1)
m_currentAttributeIndex ++;
else
return false;
return true;
}
You can also move to a particular attribute by index, and you can reset the attribute index to -1to reposition the internal pointer on the parent element node.
public override void MoveToAttribute(int i)
{
if (m_readState != ReadState.Interactive)
return;
m_currentAttributeIndex = i;
}
public override bool MoveToElement()
{
if (m_readState != ReadState.Interactive)
return false;
m_currentAttributeIndex = -1;
return true;
}
A bit trickier code is required if you just want to move to a particular attribute by name. The function providing this feature is an overload of the MoveToAttribute method.
public override bool MoveToAttribute(string name)
{
if (m_readState != ReadState.Interactive)
return false;
for(int i=0; i<AttributeCount; i++)
{
if (m_tokenValues.Keys[i].ToString() == name)
{
m_currentAttributeIndex = i;
return true;
}
}
return false;
}
The name of the attribute—determined by a header row or set by default—is stored as the key of the m_tokenValues named collection. Unfortunately, the NameValueCollection class does not provide for search capabilities, so the only way to determine the ordinal position of a given key is by enumerating all the keys, tracking the index position, until you find the key that matches the specified name.
As you’ve probably noticed, almost all the methods and properties in the CSV reader begin with a piece of code that simply returns if the reader’s state is not Interactive. This is a specification requirement that basically dictates that an XML reader can accept commands only after it has been correctly initialized.
Exposing Data as XML
In a true XML reader, methods like ReadInnerXml and ReadOuterXml serve the purpose of returning the XML source code embedded in, or sitting around, the currently selected node. For a CSV reader, of course, there is no XML source code to return. You might want to return an XML description of the current CSV node, however.
Assuming that this is how you want the CSV reader to work, the ReadInnerXml method for a CSV XML reader can only return either null or the empty string, as shown in the following code. By design, in fact, each element has an empty body.
public override string ReadInnerXml()
{
if (m_readState != ReadState.Interactive)
return null;
return String.Empty;
}
In contrast, the outer XML text for a CSV node can be designed like a node with a sequence of attributes, as follows:
<row attr1="…" attr2="…" />
The source code to obtain this output is shown here:
public override string ReadOuterXml()
{
if (m_readState != ReadState.Interactive)
return null;
StringBuilder sb = new StringBuilder("");
sb.Append("<");
sb.Append(CsvRowName);
sb.Append(" ");
foreach(object o in m_tokenValues)
{
sb.Append(o);
sb.Append("=");
sb.Append(QuoteChar);
sb.Append(m_tokenValues[o.ToString()].ToString());
sb.Append(QuoteChar);
sb.Append(" ");
}
sb.Append("/>");
return sb.ToString();
}
The CSV XML Reader in Action
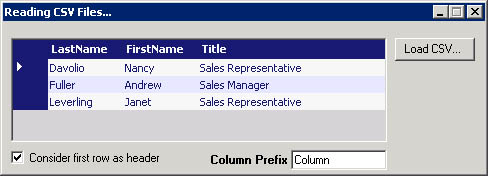
In this section, you’ll see the CSV XML reader in action and learn how to instantiate and use it in the context of a realistic application. In particular, I’ll show you how to load the contents of a CSV file into a DataTable object to appear in a Windows Forms DataGrid control. Figure 2-1 shows the application in action.
Figure 2-1. The CSV XML reader shows all the rows of a CSV file.

You start by instantiating the reader object, passing the name of the CSV file to be processed and a Boolean flag. The Boolean value indicates whether the values in the first row of the CSV source file must be read as the column names or as data. If you pass false, the row is considered a plain data row and each column name is formed by a prefix and a progressive number. You control the prefix through the CsvColumnPrefix property.
// Instantiate the reader on a CSV file
XmlCsvReader reader;
reader = new XmlCsvReader("employees.csv", hasHeader.Checked);
reader.CsvColumnPrefix = colPrefix.Text;
reader.Read();
// Define the target table
DataTable dt = new DataTable();
for(int i=0; i<reader.AttributeCount; i++)
{
reader.MoveToAttribute(i);
DataColumn col = new DataColumn(reader.Name, typeof(string));
dt.Columns.Add(col);
}
reader.MoveToElement();
Before you load data rows into the table and populate the data grid, you must define the layout of the target DataTable object. To do that, you must scroll the attributes of one row—typically the first row. You move to each of the attributes in the first row and create a DataColumn object with the same name as the attribute and specified as a string type. You then add the DataColumn object to the DataTable object and continue until you’ve added all the attributes. The MoveToElement call restores the focus to the CSV row element.
// Loop through the rows and populate a DataTable
do
{
DataRow row = dt.NewRow();
for(int i=0; i<reader.AttributeCount; i++)
{
row[i] = reader[i].ToString();
}
dt.Rows.Add(row);
}
while (reader.Read());
reader.Close();
// Bind the table to the grid
dataGrid1.DataSource = dt;
Next you walk through the various data rows of the CSV file and create a new DataRow object for each. The row will then be filled in with the values of the attributes. Because the reader is already positioned in the first row when the loop begins, you must use a do…while loop instead of the perhaps more natural while loop. At the end of the loop, you simply close the reader and bind the freshly created DataTable object to the DataGrid control for display.
Figure 2-2 shows the output generated by the sample application when it uses the values in the first row of the CSV file as column names.
Figure 2-2. The CSV XML reader now reads the column names from the first row in the source file.
Caution
I tried to keep this version of the CSV reader as simple as possible, which is always a good guideline. In this case, however, I went beyond my original intention and came up with a too simple reader! Don’t be fooled by the fact that the sample code discussed here works just fine. As I built it, the CSV reader does not expose the CSV document as a well-formed XML document, but rather as a well-formed XML fragment. There is no root node, and no clear distinction is made between start and end element tags. In addition, the ReadAttributeValue method is not supported. As a result, if you use ReadXml to load the CSV into a DataSet object, only the first row would be loaded. If you run the CsvReader sample included in this book’s sample files, you’ll see an additional button on the form labeled Use ReadXML, which you can use to see this problem in action. In Chapter 9, after a thorough examination of the internals of ReadXml, we’ll build an enhanced version of the CSV reader.
The DataGrid control shown in Figure 2-2 is read-only, but this does not mean that you can’t modify rows in the underlying DataTable object and then save changes back to the CSV file. One way to accomplish this result would be by using a customized XML writer class—a kind of XmlCsvWriter. You’ll learn how to create such a class in Chapter 4, while we’re looking at XML writers.
Note
The full source code for both the CSV XML reader and the sample application making use of it is available in this book’s sample files. The folder of interest is named CsvReader.
Important
The XmlTextReader class implements a visiting algorithm for the XML tree based on the so-called node-first approach. This means that for each XML subtree found, the root is visited first, and then recursively all of its children are visited, from the first to the last. Node-first is certainly not the most unique visiting algorithm you can implement, but it turns out to be the most sensible one for XML trees.
Another well-known visiting algorithm is the in-depth-first approach, which goes straight to the leaves of the tree and then pops back to outer parent nodes. The node-first approach is more effective for XML trees because it visits nodes in the order they are written to disk. Choosing to implement a different visiting algorithm would make the code significantly more complex and less effective from the standpoint of memory footprint. In short, you should have a good reason to plan and code any algorithm other than node-first.
In general, visiting algorithms other than node-first algorithms exist mostly for tree data structures, including well-balanced and binary trees. XML files are designed like a tree data structure but remain a very special type of tree.