
A Read/Write XML Streaming Parser
XML readers and writers work in separate compartments and in an extremely specialized way. Readers just read, and writers just write. There is no way to force things to go differently, and in fact, the underlying streams are read-only or write-only as required. Suppose that your application manages lengthy XML documents that contain rather volatile data. Readers provide a powerful and effective way to read that contents. Writers, on the other hand, offer a fantastic tool to create that document from scratch. But if you want to read and write the document at the same time, you must necessarily resort to a full-fledged XML Document Object Model (XML DOM). What can you do to read and write an XML document without loading it entirely into memory?
In Chapter 5, I’ll tackle the XML DOM model of a parser, which is the classic tool for performing read/write operations on an XML tree. The strength of the XML DOM parsers, but also their greatest drawback, lies in the fact that an XML DOM parser loads the whole XML document in memory, creates an ad hoc image of the tree, and lets you perform any sort of modification and search on the mapped nodes. Keeping the nitty-gritty details of XML DOM warm for Chapter 5, in this section, we’ll look at how to set up a mixed type of streaming parser that works as a kind of lightweight XML DOM parser.
The idea is that this parser will allow you read the contents of a document one node at a time as with an XML (validating) reader but that, if needed, it can also perform some simple updates. By simple updates, I mean simply changing the value of an existing attribute, changing the contents of a node, or adding new attributes or nodes. For more complex operations, realistically nothing compares to XML DOM parsers.
Designing a Writer on Top of a Reader
In the .NET Framework, the XML DOM classes make intensive use of streaming readers and writers to build the in-memory tree and to flush it out to disk. Thus, readers and writers are definitely the only XML primitives available in the .NET Framework. Consequently, to build up a sort of lightweight XML DOM parser, we can only rely, once more, on readers and writers.
The inspiration for designing such a read/write streaming parser is database server cursors. With database server cursors, you visit records one after the next and, if needed, can apply changes on the fly. Database changes are immediately effective, and actually the canvas on which your code operates is simply the database table. The same model can be arranged to work with XML documents.
You will use a normal XML (validating) reader to visit the nodes in sequence. While reading, however, you are given the opportunity to change attribute values and node contents. Unlike the XML DOM, changes will have immediate effect. How can you obtain these results? The idea is to use an XML writer on top of the reader.
You use the reader to read each node in the source document and an underlying writer to create a hidden copy of it. In the copy, you can add some new nodes and ignore or edit some others. When you have finished, you simply replace the old document with the new one. You can decide to write the copy in memory or flush it in a temporary medium. The latter approach makes better use of the system’s memory and saves you from possible troubles with the application’s security level and zones. (For example, partially trusted Windows Forms applications and default running ASP.NET applications can’t create or edit disk files.)
Built-In Support for Read/Write Operations
When I first began thinking about this lightweight XML DOM component, one of key points I identified was an efficient way to copy (in bulk) blocks of nodes from the read-only stream to the write stream. Luckily enough, two somewhat underappreciated XmlTextWriter methods just happen to cover this tricky but boring aspect of two-way streaming: WriteAttributes and WriteNode.
The WriteAttributes method reads all the attributes available on the currently selected node in the specified reader. It then copies them as a single string to the current output stream. Likewise, the WriteNode method does the same for any other type of node. Note that WriteNode does nothing if the node type is XmlNodeType.Attribute.
The following code shows how to use these methods to create a copy of the original XML file, modified to skip some nodes. The XML tree is visited in the usual node-first approach using an XML reader. Each node is then processed and written out to the associated XML writer according to the index. This code scans a document and writes out every other node.
XmlTextReader reader = new XmlTextReader(inputFile);
XmlTextWriter writer = new XmlTextWriter(outputFile);
// Configure reader and writer
writer.Formatting = Formatting.Indented;
reader.MoveToContent();
// Write the root
writer.WriteStartElement(reader.LocalName);
// Read and output every other node
int i=0;
while(reader.Read())
{
if (i % 2)
writer.WriteNode(reader, false);
i++;
}
// Close the root
writer.WriteEndElement();
// Close reader and writer
writer.Close();
reader.Close();
You can aggregate the reader and the writer in a single new class and build a brand-new programming interface to allow for easy read/write streaming access to attributes or nodes.
Designing the XmlTextReadWriter Class
The XmlTextReadWriter class does not inherit from XmlReader or XmlWriter but, instead, coordinates the activity of running instances of both classes—one operating on a read-only stream, and one working on a write-only stream. The methods of the XmlTextReadWriter class read from the reader and write to the writer, applying any requested changes in the middle.
The XmlTextReadWriter class features three constructors, shown in the following code. These constructors let you indicate an input file and an optional output stream, which can be a stream as well as a disk file. If the names of input and output files coincide, or if you omit the output file, the XmlTextReadWriter class uses a temporary file to collect the output and then automatically overwrites the input file. The net effect of this procedure is that you simply modify your XML document without holding it all in memory, as XML DOM does.
public XmlTextReadWriter(string inputFile) public XmlTextReadWriter(string inputFile, string outputFile) public XmlTextReadWriter(string inputFile, Stream outputStream)
The internal reader and writer are exposed through read-only properties named Reader and Writer, as shown here:
public XmlTextReader Reader
{
get {return m_reader;}
}
public XmlTextWriter Writer
{
get {return m_writer;}
}
For simplicity, I assume that all the XML documents the class processes have no significant prolog (for example, processing instructions, comments, declarations, and DOCTYPE definitions). On the other hand, the primary goal of this class is to provide for quick modification of simple XML files—mostly filled with any kind of settings. For more complete read/write manipulation of documents, you should resort to XML DOM trees.
Configuring the XmlTextReadWriter Class
Immediately after class initialization, the reader and the writer are configured to work properly. This process entails setting the policy for white spaces and setting the formatting options, as shown here:
m_reader = new XmlTextReader(m_InputFile); m_writer = new XmlTextWriter(m_OutputStream, null); m_reader.WhitespaceHandling = WhitespaceHandling.None; m_writer.Formatting = Formatting.Indented; // Skip all noncontent nodes m_reader.Read(); m_reader.MoveToContent();
I recommend that you configure the reader to ignore any white space so that it never returns any white space as a distinct node. This setting is correlated to the autoformatting feature you might need on the writer. If the reader returns white spaces as nodes and the writer indents any node being created, the use of the writer’s WriteNode method can cause double formatting.
As you can see in the preceding code, the XmlTextReadWriter class also moves the internal reader pointer directly to the first contents node, skipping any prolog node found in the source.
The XmlTextReadWriter Programming Interface
I designed the XmlTextReadWriter class with a minimal programming interface because, in most cases, what you really need is to combine the features of the reader and the writer to create a new and application-specific behavior such as updating a particular attribute on a certain node, deleting nodes according to criteria, or adding new trees of nodes. The class provides the methods listed in Table 4-9.
| Method | Description |
|---|---|
| AddAttributeChange | Caches all the information needed to perform a change on a node attribute. All the changes cached through this method are processed during a successive call to WriteAttributes. |
| Read | Simple wrapper around the internal reader’s Read method. |
| WriteAttributes | Specialized version of the writer’s WriteAttributes method. Writes out all the attributes for the specified node, taking into account all the changes cached through the AddAttributeChange method. |
| WriteEndDocument | Terminates the current document in the writer and closes both the reader and the writer. |
| WriteStartDocument | Prepares the internal writer to output the document and adds default comment text and the standard XML prolog. |
A read/write XML document is processed between two calls to WriteStartDocument and WriteEndDocument, shown in the following code. The former method initializes the underlying writer and writes a standard comment. The latter method completes the document by closing any pending tags and then closes both the reader and the writer.
public void WriteStartDocument()
{
m_writer.WriteStartDocument();
string text = String.Format("Modified: {0}",
DateTime.Now.ToString());
m_writer.WriteComment(text);
}
public void WriteEndDocument()
{
m_writer.WriteEndDocument();
m_reader.Close();
m_writer.Close();
// If using a temp file name, overwrite the input
if (m_ReplaceFile)
{
File.Copy(m_tempOutputFile, m_InputFile, true);
File.Delete(m_tempOutputFile);
}
}
If you are not using a distinct file for output, WriteEndDocument also overwrites the original document with the temporary file in which the output has been accumulated in the meantime.
You can use any of the methods of the native interfaces of the XmlTextWriter and XmlTextReader classes. For simplicity, however, I endowed the XmlTextReadWriter class with a Read method and a NodeType property. Both are little more than wrappers for the corresponding method and property on the reader. Here’s how you initialize and start using the XmlTextReadWriter class:
XmlTextReadWriter rw = new XmlTextReadWriter(inputFile); rw.WriteStartDocument(); // Process the file rw.WriteEndDocument();
What happens between these two calls depends primarily on the nature and the goals of the application. You could, for example, change the value of one or more attributes, delete nodes, or replace the namespace. To accomplish whatever goal the application pursues, you can issue direct calls on the interface of the internal reader and writer as well as use the few methods specific to the XmlTextReadWriter class.
Bear in mind that reading and writing are completely distinct and independent processes that work according to slightly different models and strategies. When the reader is positioned on a node, no direct method can be called on the writer to make sure that just the value or the name of that node is modified. The following pseudocode, for example, does not correspond to reality:
if (reader.Value >100) writer.Value = 2*reader.Value;
To double the value of each node, you simply write a new document that mirrors the structure of the original, applying the necessary changes. To change the value of a node, you must first collect all the information about that node (including attributes) and then proceed with writing. One of the reasons for such an asymmetry in the reader’s and writer’s working model is that XML documents are hierarchical by nature and not flat like an INI or a CSV file. In the section “A Full-Access CSV Editor,” on page 192, I’ll discuss a full read/write editor for CSV files for which the preceding pseudocode is much more realistic.
Testing the XmlTextReadWriter Class
Let’s review three examples of how the XmlTextReadWriter class can be used to modify XML documents without using the full-blown XML DOM. Looking at the source code, you’ll realize that a read/write streaming parser is mostly achieved by a smart and combined use of readers and writers.
By making assumptions about the structure of the XML source file, you can simplify that code while building the arsenal of the XmlTextReadWriter class with ad hoc properties such as Value or Name and new methods such as SetAttribute (which would be paired with the reader’s GetAttribute method).
Changing the Namespace
For our first example, consider the problem of changing the namespace of all the nodes in a specified XML file. The XmlTextReadWriter parser will provide for this eventuality with a simple loop, as shown here:
void ChangeNamespace(string prefix, string ns)
{
XmlTextReadWriter rw;
rw = new XmlTextReadWriter(inputFile);
rw.WriteStartDocument();
// Modify the root tag manually
rw.Writer.WriteStartElement(rw.Reader.LocalName);
rw.Writer.WriteAttributeString("xmlns", prefix, null, ns);
// Loop through the document
while(rw.Read())
{
switch(rw.NodeType)
{
case XmlNodeType.Element:
rw.Writer.WriteStartElement(prefix,
rw.Reader.LocalName, null);
rw.Writer.WriteAttributes(rw.Reader, false);
if (rw.Reader.IsEmptyElement)
rw.Writer.WriteEndElement();
break;
}
}
// Close the root tag
rw.Writer.WriteEndElement();
// Close the document and any internal resources
rw.WriteEndDocument();
}
The code starts by manually writing the root node of the source file. Next it adds an xmlns attribute with the specified prefix and the URN. The main loop scans all the contents of the XML file below the root node. For each element node, it writes a fully qualified new node whose name is the just-read local name with a prefix and namespace URN supplied by the caller, as shown here:
rw.Writer.WriteStartElement(prefix, rw.Reader.LocalName, null);
Because attributes are unchanged, they are simply copied using the writer’s WriteAttributes method, as shown here:
rw.Writer.WriteAttributes(rw.Reader, false);
The node is closed within the loop only if it has no further contents to process. Figure 4-13 shows the sample application. In the upper text box, you see the original file. The bottom text box contains the modified document with the specified namespace information.
Figure 4-13. All the nodes in the XML document shown in the bottom text box now belong to the specified namespace.

Updating Attribute Values
The ultimate goal of our second example is changing the values of one or more attributes on a specified node. The XmlTextReadWriter class lets you do that in a single visit to the XML tree. You specify the node and the attribute name as well as the old and the new value for the attribute.
In general, the old value is necessary just to ensure that you update the correct attribute on the correct node. In fact, if an XML document contains other nodes with the same name, you have no automatic way to determine which is the appropriate node to update. Checking the old value of the attribute is just one possible workaround. If you can make some assumptions about the structure of the XML document, this constraint can be easily released.
As mentioned, the update takes place by essentially rewriting the source document, one node at a time. In doing so, you can use updated values for both node contents and attributes. The attributes of a node are written in one shot, so multiple changes must be cached somewhere. There are two possibilities. One approach passes through the addition of enrichment of a set of properties and methods that more closely mimics the reader. You could expose a read/write Value property. Next, when the property is written, you internally cache the new value and make use of it when the attributes of the parent node are serialized.
Another approach—the one you see implemented in the following code—is based on an explicit and application-driven cache. Each update is registered using an internal DataTable object made up of four fields: node name, attribute name, old value, and new value.
rw.AddAttributeChange(nodeName, attribName, oldVal, newVal);
The same DataTable object will contain attribute updates for each node in the document. To persist the changes relative to a specified node, you use the XmlTextReadWriter class’s WriteAttributes method, shown here:
public void WriteAttributes(string nodeName)
{
if (m_reader.HasAttributes)
{
// Consider only the attribute changes for the given node
DataView view = new DataView(m_tableOfChanges);
view.RowFilter = "Node=‘" + nodeName + "‘";
while(m_reader.MoveToNextAttribute())
{
// Begin writing the attribute
m_writer.WriteStartAttribute(m_reader.Prefix,
m_reader.LocalName, m_reader.NamespaceURI);
// Search for a corresponding entry
// in the table of changes
DataRow[] rows =
m_tableOfChanges.Select("Attribute=‘" +
m_reader.LocalName + "‘ AND OldValue=‘" +
m_reader.Value + "‘");
if (rows.Length >0)
{
DataRow row = rows[0];
m_writer.WriteString(row["NewValue"].ToString());
}
else
m_writer.WriteString(m_reader.Value);
}
}
// Move back the internal pointer
m_reader.MoveToElement();
// Clear the table of changes
m_tableOfChanges.Rows.Clear();
m_tableOfChanges.AcceptChanges();
}
The following code, called by a client application, creates a copy of the source document and updates node attributes:
void UpdateValues(string nodeName, string attribName,
string oldVal, string newVal)
{
XmlTextReadWriter rw;
rw = new XmlTextReadWriter(inputFile, outputFile);
rw.WriteStartDocument();
// Modify the root tag manually
rw.Writer.WriteStartElement(rw.Reader.LocalName);
// Prepare attribute changes
rw.AddAttributeChange(nodeName, attribName, oldVal, newVal);
// Loop through the document
while(rw.Read())
{
switch(rw.NodeType)
{
case XmlNodeType.Element:
rw.Writer.WriteStartElement(rw.Reader.LocalName);
if (nodeName == rw.Reader.LocalName)
rw.WriteAttributes(nodeName);
else
rw.Writer.WriteAttributes(rw.Reader, false);
if (rw.Reader.IsEmptyElement)
rw.Writer.WriteEndElement();
break;
}
}
// Close the root tag
rw.Writer.WriteEndElement();
// Close the document and any internal resources
rw.WriteEndDocument();
}
Figure 4-14 shows the output of the sample application from which the preceding code is excerpted.
Figure 4-14. The code can be used to change the value of the forecolor attribute from blue to black.

Adding and Deleting Nodes
A source XML document can also be easily read and modified by adding or deleting nodes. Let’s look at a couple of examples.
To add a new node, you simply read until the parent is found and then write an extra set of nodes to the XML writer. Because there might be other nodes with the same name as the parent, use a Boolean guard to ensure that the insertion takes place only once. The following code demonstrates how to proceed:
void AddUser(string name, string pswd, string role)
{
XmlTextReadWriter rw;
rw = new XmlTextReadWriter(inputFile, outputFile);
rw.WriteStartDocument();
// Modify the root tag manually
rw.Writer.WriteStartElement(rw.Reader.LocalName);
// Loop through the document
bool mustAddNode = true; // Only once
while(rw.Read())
{
switch(rw.NodeType)
{
case XmlNodeType.Element:
rw.Writer.WriteStartElement(rw.Reader.LocalName);
if ("Users" == rw.Reader.LocalName && mustAddNode)
{
mustAddNode = false;
rw.Writer.WriteStartElement("User");
rw.Writer.WriteAttributeString("name", name);
rw.Writer.WriteAttributeString("password", pswd);
rw.Writer.WriteAttributeString("role", role);
rw.Writer.WriteEndElement();
}
else
rw.Writer.WriteAttributes(rw.Reader, false);
if (rw.Reader.IsEmptyElement)
rw.Writer.WriteEndElement();
break;
}
}
// Close the root tag
rw.Writer.WriteEndElement();
// Close the document and any internal resources
rw.WriteEndDocument();
}
To delete a node, you simply ignore it while reading the document. For example, the following code removes a <User> node in which the name attribute matches a specified string:
while(rw.Read())
{
switch(rw.NodeType)
{
case XmlNodeType.Element:
if ("User" == rw.Reader.LocalName)
{
// Skip if name matches
string userName = rw.Reader.GetAttribute("name");
if (userName == name)
break;
}
// Write in the output file if no match has been found
rw.Writer.WriteStartElement(rw.Reader.LocalName);
rw.Writer.WriteAttributes(rw.Reader, false);
if (rw.Reader.IsEmptyElement)
rw.Writer.WriteEndElement();
break;
}
}
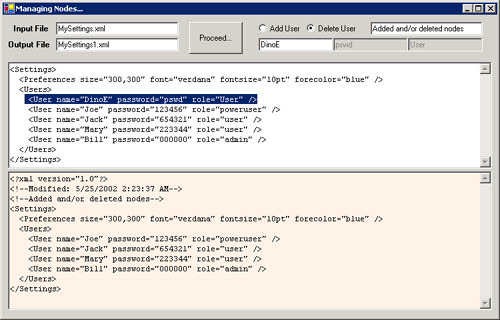
Figure 4-15 shows this code in action. The highlighted record has been deleted because of the matching value of the name attribute.
Figure 4-15. A sample application to test the class’s ability to add and delete nodes.
Note
The entire sample code illustrating the XmlTextReadWriter class and its way of working is available in this book’s sample files. The all-encompassing Microsoft Visual Studio .NET solution is named XmlReadWriter.
A Full-Access CSV Editor
In Chapter 2, we looked at the XmlCsvReader class as an example of a custom XML reader. The XmlCsvReader class enables you to review the contents of a CSV file through nodes and attributes and the now-familiar semantics of XML readers. In this section, I’ll go one step further and illustrate a full-access CSV reader capable of reading and writing—the XmlCsvReadWriter class.
The new class inherits from XmlCsvReader and modifies only a few methods and properties. The XmlCsvReadWriter class works by using a companion output stream in which each row read and modified is then persisted prior to reading a new row. The XmlCsvReadWriter class is declared as follows:
public class XmlCsvReadWriter : XmlCsvReader
{
public XmlCsvReadWriter(
string filename, bool hasColumnHeaders, bool enableOutput)
{ ... }
...
}
The class has a new constructor with a third argument—the Boolean value enableOutput, which specifies whether the class should use a hidden output stream. Basically, by setting enableOutput to true, you declare your intent to use the class as a reader/writer instead of a simple reader. When this happens, the constructor creates a temporary file and a stream writer to work on it. At the end of the reading, this output file contains the modified version of the CSV and is used to replace the original file. A new property, named EnableOutput, can be used to programmatically enable and disable the output stream.
Shadowing the Class Indexer
The Item indexer property—that is, the property that permits the popular reader[index] syntax—is declared as read-only in the abstract XmlReader base class. This means that any derived class can’t replace that property with another one that is read/write. However, the XmlCsvReader class provides a total implementation of the abstract functionality defined in XmlReader. So when deriving from XmlCsvReader, you can simply shadow the base Item property and replace it with a brand-new one with both get and set accessors.
The following code is at the heart of the new CSV reader/writer class. It extends the Item property to make it work in a read/write fashion. The get accessor is identical to the base class. The set accessor copies the specified value in the m_tokenValues collection, in which the attributes of the current CSV row are stored. (See Chapter 2 for more details about the internal architecture of the CSV sample XML reader.)
new public string this[int i]
{
get
{
return base[i].ToString();
}
set
{
// The Item[index] property is read-only, so
// use the Item[string] overload
string key = m_tokenValues.Keys[i].ToString();
m_tokenValues[key] = value;
}
}
Notice the use of the new keyword to shadow the same property defined on the base class. This trick alone paves the road for the read/write feature.
Note
The new keyword is C#-specific. To achieve the same effect with Microsoft Visual Basic .NET, you must use the Shadows keyword. Also note that, when it comes to overloading a method in a derived class, you don’t need to mark it in any way if the language of choice is C#. If you use Visual Basic .NET, the overload must be explicitly declared using the Overloads keyword.
In addition, bear in mind that a standard NameValueCollection object allows you to update a value only if you can pass the key string to the indexer, as shown here:
public string this[int] {get;}
public string this[string] {get; set;}
The new Item indexer property allows you to write code, as the following code snippet demonstrates:
for(int i=0; i<reader.AttributeCount; i++)
{
if (reader[i] == "Sales Representative")
reader[i] = "SalesMan";
...
}
The reader’s Read method copies the contents of the current CSV row in the input stream, and from there the indexer will draw the values to return. When updated, the indexer overwrites values in the internal memory collection. When will changes actually be persisted to the CSV output stream?
Persisting Changes During the Next Read
The Read method moves the internal pointer of an XML reader one element ahead. An XML CSV reader moves that pointer to the next row. The contents of the newly selected row is buffered into a local and transient structure—the m_tokenValues collection—for further use and investigation.
However, when the Read method is called to move ahead, all the changes on the current element have been performed. This is a great time to persist those changes to the output stream if a stream is enabled. After that, you go on as usual with the Read base class’s implementation, as shown here:
public override bool Read()
{
if (!EnableOutput)
return base.Read();
// If we’re not reading the first row, then save the
// current status to the output stream. (If we’re reading the
// first row, then the token collection is empty and there’s
// nothing to persist.
if (m_tokenValues.Count >0)
{
// If writing the first row, and used the first source
// row for headers, now add that prior to writing the
// first data row.
if (HasColumnHeaders && !m_firstRowRead)
{
m_firstRowRead = true;
string header = "";
foreach(string tmp in m_tokenValues)
header += tmp + ",";
m_outputStream.WriteLine(header.TrimEnd(‘,’));
}
// Prepare and write the current CSV row
string row = "";
foreach(string tmp in m_tokenValues)
row += m_tokenValues[tmp] + ",";
m_outputStream.WriteLine(row.TrimEnd(‘,’));
}
// Move ahead as usual
return base.Read();
}
If the first row in the source CSV file has been interpreted as the headers of the columns (HasColumnHeaders property set to true), this implementation of the Read method ensures that the very first row written to the output stream contains just those headers. After that, the current contents of the m_tokenValues collection is serialized to a comma-separated string and is written to the output stream. Once this has been done, the Read method finally moves to the next line.
Closing the Output Stream
When you close the reader, the output stream is also closed. In addition, because the output stream was writing to a temporary file, that file is also copied over by the source CSV replacing it, as shown here:
public override void Close()
{
base.Close();
if (EnableOutput)
{
m_outputStream.Close();
File.Copy(m_tempFileName, m_fileName, true);
File.Delete(m_tempFileName);
}
}
The net effect of this code is that any changes entered in the source CSV document are cached to a temporary file, which then replaces the original. The user won’t perceive anything of these workings, however.
The CSV Reader/Writer in Action
Let’s take a sample CSV file, read it, and apply some changes to the contents so that they will automatically be persisted when the reader is closed. Here is the source CSV file:
LastName,FirstName,Title,Country Davolio,Nancy,Sales Representative,USA Fuller,Andrew,Sales Manager,USA Leverling,Janet,Sales Representative,UK Suyama,Michael,Sales Representative,UK
The idea is to replacing the expression Sales Representative with another one—say, Sales Force. The sample application, nearly identical to the one in Chapter 2, loads the CSV file, applies the changes, and then displays it through a desktop DataGrid control, as follows:
// Instantiate the reader on a CSV file
XmlCsvReadWriter reader;
reader = new XmlCsvReadWriter("employees.csv",
hasHeader.Checked);
reader.EnableOutput = true;
reader.Read();
// Define the schema of the table to bind to the grid
DataTable dt = new DataTable();
for(int i=0; i<reader.AttributeCount; i++)
{
reader.MoveToAttribute(i);
DataColumn col = new DataColumn(reader.Name,
typeof(string));
dt.Columns.Add(col);
}
reader.MoveToElement();
// Loop through the CSV rows and populate the DataTable
do
{
DataRow row = dt.NewRow();
for(int i=0; i<reader.AttributeCount; i++)
{
if (reader[i] == "Sales Representative")
reader[i] = "Sales Force";
row[i] = reader[i].ToString();
}
dt.Rows.Add(row);
}
while (reader.Read()); // Persist changes and move ahead
// Flushes the changes to disk
reader.Close();
// Bind the table to the grid
dataGrid1.DataSource = dt;
If the contents of a specified CSV attribute matches the specified string, it is replaced. The change occurs initially on an internal collection and is then transferred to the output stream during the execution of the Read method. Finally, the reader is closed and the output stream flushed. Figure 4-16 shows the program in action.
Figure 4-16. The original CSV file has been read and updated on disk.
