
Overview of the DiffGram Format
A DiffGram is an XML serialization format that includes both the original values and the current values of each row in each table. In particular, a DiffGram contains the current instance of rows with the up-to-date values, plus a section where all the original values for changed rows are grouped.
Each row is given a unique identifier that is used to track changes between the two sections of the DiffGram. This relationship looks a lot like a foreign key relationship. The following listing outlines the structure of a DiffGram:.
<diffgr:diffgram xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" xmlns:diffgr="urn:schemas-microsoft-com:xml-diffgram-v1"> <DataSet> ... </DataSet> <diffgr:before> ... </diffgr:before> <diffgr:errors> ... </diffgr:errors> </diffgr:diffgram>
The <diffgr:diffgram> root node can have up to three children. The first is the DataSet object with its current contents, including newly added rows and modified rows but not deleted rows. The actual name of this subtree depends on the DataSetName property of the source DataSet object. If the DataSet object has no name, the subtree’s root is NewDataSet.
The subtree rooted in the <diffgr:before> node contains enough information to restore the original state of all modified rows. For example, it still contains any row that has been deleted as well as the original contents of any modified row. All columns affected by any change are tracked in the <diffgr:before> subtree.
The last subtree is <diffgr:errors>, which contains information about any errors that have occurred in a particular row. The DataRow class provides a few methods and properties that programmers can use to set an error on any column in the row. Errors can be set at any time, not necessarily when the data is entered. For example, in distributed applications, it’s typical for one user to create some data that another user has to validate. In this situation, the reviewer can set an error message on each column of a row to signal that something is wrong with that column. Amazingly, the Microsoft Windows Forms DataGrid control then detects any pending errors on displayed rows and marks them with a red exclamation point, providing the user with visual feedback that a particular column contains an error.
The following listing shows a sample DiffGram in which row 1 has been modified, row 2 has been deleted, row 3 has an error, and a new row has been added:
<diffgr:diffgram xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" xmlns:diffgr="urn:schemas-microsoft-com:xml-diffgram-v1"> <NorthwindInfo> <Employees diffgr:id="Employees1" msdata:rowOrder="0" diffgr:hasChanges="modified" employeeid="1" lastname="Davolio" firstname="Michela" /> <Employees diffgr:id="Employees4" msdata:rowOrder="3" diffgr:hasErrors="true" employeeid="4" lastname="Peacock" firstname="Margaret" /> <Employees diffgr:id="Employees10" msdata:rowOrder="9" diffgr:hasChanges="inserted" employeeid="10" lastname="Esposito" firstname="Dino" /> </NorthwindInfo> <diffgr:before> <Employees diffgr:id="Employees1" msdata:rowOrder="0" employeeid="1" lastname="Davolio" firstname="Nancy" /> <Employees diffgr:id="Employees2" msdata:rowOrder="1" employeeid="2" lastname="Fuller" firstname="Andrew" /> </diffgr:before> <diffgr:errors> <Employees diffgr:id="Employees3" diffgr:Error="Check out the first name!!!" /> </diffgr:errors> </diffgr:diffgram>
Some of the attributes and nodes that form a DiffGram come from a couple of Microsoft proprietary namespaces. The default prefixes are msdata and diffgr. In particular, the msdata namespace contains a number of attributes that are annotations for the data in the stream. We’ll look at these attributes and the entire structure of the DiffGram in the section “DiffGram Format Annotations,” on page 448.
The Current Data Instance
The first section of the DiffGram represents the current instance of the data. Although it’s not strictly mandatory from a syntax standpoint, of the three constituent subtrees, the data instance is the only subtree that you will always find in a DiffGram. A DiffGram without data is just the representation of an empty DataSet object. The <diffgr:before> and <diffgr:errors> subtrees are not present if the source DataSet object has no pending changes and errors.
A DiffGram is stateful and is like a superset of the ADO.NET XML normal form. The data instance is nearly identical to the normal form, which is a simple, stateless snapshot of data. The major difference between the DiffGram’s data instance and the normal form is that the DiffGram format does not include schema information. To make the overall DiffGram format truly stateful, you must combine the data with two other subtrees—the original data and the pending errors. By combining the contents of the three subtrees, a client can rebuild a faithful representation of the original DataSet contents.
Note
Like the normal form, not even the DiffGram can be considered a serialization format for the DataSet as an object. The DiffGram is a serialization format for the contents of a DataSet object. To be a valid serialization of the DataSet object itself, the DiffGram would need to contain schema information. Incidentally, the implementation of the ISerializable interface that both the DataSet object and the DataTable object provide manages to return a special version of the DiffGram format that differs from this because it incorporates schema information. You’ll learn how to build DiffGram documents that contain a schema in the section “The DiffGram Viewer Application,” on page 457.
Data Generator Objects
As mentioned, the data subtree in a DiffGram is similar to the ADO.NET normal form for XML we looked at in Chapter 9. In both cases, the XML code being generated by the WriteXml method represents a snapshot of the data currently stored in the DataSet object’s tables. The data written out faithfully tracks any pending updates and deletions that have occurred in the meantime. As Figure 10-1 shows, the similarity between the first block of a DiffGram and the XML normal form is not just cosmetic, nor it is due to a mere chance.
Figure 10-1. Components that work under the hood of the DataSet object’s WriteXml method.
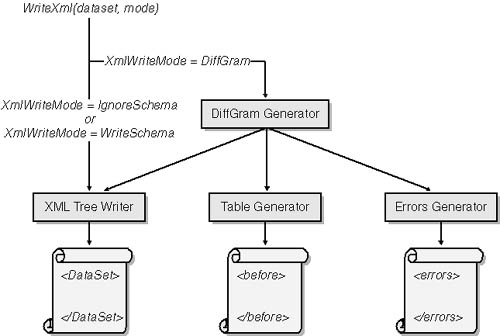
The same internal component, the XML tree writer, is used to generate both the ADO.NET XML normal form and the data instance block in a DiffGram. A pleasant side effect of this architecture is that all the mapping features for DataColumn objects we examined in Chapter 9 (see the discussion of the MappingType enumeration in the section “Customizing the XML Representation,” on page 411) are still valid in the context of a DiffGram. You can decide whether a given column is better rendered using an attribute or an element, or whether the column should be hidden altogether.
The Hidden Flag
The MappingType.Hidden flag reveals a slight difference in the XML code that WriteXml generates for DiffGrams. A column mapped as hidden text is still part of DiffGram’s data instance, but qualified with a particular attribute, as shown here:
<diffgr:diffgram
xmlns:msdata="urn:schemas-microsoft-com:xml-msdata"
xmlns:diffgr="urn:schemas-microsoft-com:xml-diffgram-v1">
<NorthwindInfo>
<Employees diffgr:id="Employees1" msdata:rowOrder="0"
msdata:hiddenemployeeid="1">
<lastname>Davolio</lastname>
<firstname>Nancy</firstname>
</Employees>
...
</NorthwindInfo>
</diffgr:diffgram>
For example, assume that you marked the employeeid column as hidden, as shown here:
DataColumn col = ds.Tables["Employees"].Columns["employeeid"]; col.ColumnMapping = MappingType.Hidden;
The employeeid column is not rendered as an <employeeid> element or an employeeid attribute, but a custom attribute is always used. The name of this attribute is hiddenXXX, where XXX represents the name of the column—in this case, hiddenemployeeid. The new attribute belongs to the msdata namespace.
Note
In the context of the DiffGram, the msdata:hiddenXXX attribute is a full replacement for the hidden column—in other words, the information is not hidden at all, but the name of the column is a bit camouflaged.
DiffGram Format Annotations
Another remarkable difference between the ADO.NET XML normal form and the DiffGram’s data instance is that the latter includes extra attributes such as id, hasChanges, hasErrors, and rowOrder. The extra attributes come from a couple of custom namespaces that are referenced at the beginning of the DiffGram. These special attributes are used to flag nodes, thus relating elements across the various sections—data instance, changes, and errors.
Table 10-1 lists all the DiffGram special attributes, also commonly referred to as annotations.
There’s no special reason for annotations to come from different namespaces—it’s just a more rational categorization. Attributes in the diffgr namespace relate elements from different blocks. Attributes in the msdata namespace represent working information that is useful to know when you’re processing the DiffGram.
Cross-Section Links
Each row rendered in a DiffGram is given a unique ID. The ID is automatically generated and consists of the table name followed by a one-based index—for example, Employees1, Employees2, and so on. The diffgr:id attribute is used as a key to retrieve the original data and the errors of a row from the <diffgr:before> and <diffgr:errors> sections.
The following DiffGram contains a modified row:
<diffgr:diffgram xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" xmlns:diffgr="urn:schemas-microsoft-com:xml-diffgram-v1"> <NorthwindInfo> <Employees diffgr:id="Employees1" msdata:rowOrder="0" diffgr:hasChanges="modified" employeeid="1" lastname="Davolio" firstname="Michela" /> ... </NorthwindInfo> <diffgr:before> <Employees diffgr:id="Employees1" msdata:rowOrder="0" employeeid="1" lastname="Davolio" firstname="Nancy" /> </diffgr:before> </diffgr:diffgram>
The same row can be referenced in any, or even all, of the DiffGram blocks. If the row is currently part of the DataSet object, you will find it in the data instance block. If the row has been updated or deleted, it will have a corresponding entry in the <diffgr:before> section. If error messages have been associated with any of the row’s columns, another record will be found in the <diffgr:errors> section. The diffgr:id attribute is used to pair related elements.
The msdata:rowOrder attribute is a simple zero-based index that tracks the ordinal position of the row in the source DataSet object. This information is not updated when a row is deleted. An msdata:rowOrder value of 1 indicates that the row was the second in the table when the DiffGram was created.
Catching Changes in the Data
The diffgr:hasChanges attribute indicates the type of change that has occurred in the row. This attribute can take any of the values listed in Table 10-2.
| Value | Description |
|---|---|
| descent | Indicates that the row received has one or more children from a parent/child relationship that have been modified. |
| inserted | Indicates that the row has been added. |
| modified | Indicates that the row has been modified. The original values are stored in the corresponding row in the <diffgr:before> section. |
An added row has no corresponding element in the <diffgr:before> section. A deleted row has no corresponding element in the data instance block, but there will be an entry in the <diffgr:before> block. Looking at the data instance, you can quickly and easily identify the modified and added rows—each has a diffgr:hasChanges attribute set to a self-explanatory value. But what about deleted rows?
By design, any hole in the sequence of msdata:rowOrder values denotes a deleted row. The msdata:rowOrder values must necessarily be consecutive. Let’s look more closely at how a DiffGram is actually loaded in memory and transformed into a DataSet object.
Reading Back DiffGrams
When reading a DiffGram, the DataSet object’s ReadXml method first loads the data instance and creates all the necessary tables and rows. Each row is put in the added or modified state, as appropriate. All the diffgr:id values are temporarily copied into an internal hash table defined as a property of the DataSet object. Each entry in the hash table references a DataRow object in the table being created.
Next ReadXml processes the <diffgr:before> section and reads the old values for the available rows. If a match can be found between a row in the <diffgr:before> section and a row already loaded in the table, the just-read values are stored as the original values of the table row. ReadXml looks for a match between the diffgr:id attribute in the <diffgr:before> section and the contents of the hash table. Figure 10-2 shows how the DataSet object is built.
Figure 10-2. The DataSet is built by reading the DiffGram sections one after the next and using the row IDs to pair elements in the various blocks.

If no match is found, ReadXml deduces that the row in the <diffgr:before> section was deleted from the table when it was at the position that the msdata:rowOrder attribute indicates. The method inserts a new row in the table at the same position and populates it with the values read from the <diffgr:before> section. Next the row is marked for deletion using the Delete method of the DataRow object.
The final step consists of reading the values from the <diffgr:errors> section and updating accordingly the RowError property of the corresponding DataRow object in the table.
The Row Commit Model
The DataSet, DataTable, and DataRow objects maintain a local cache of changes. When a row is modified, deleted, or added, its state changes to one of the values of the DataRowState enumeration. (See the .NET Framework documentation for details.) Similarly, when a row is added, modified, or deleted from a table, the internal state of the table is altered, resulting in pending changes for the affected rows.
Pending changes can be either accepted or rejected at the DataSet, DataTable, or DataRow level. Accepting a pending change means that the row (changes always involve a row) updates are committed to the table. Rejecting a pending change rolls back the state of the table, and the table appears as though the change never occurred.
A DiffGram can track pending changes—that is, in-memory changes that have not yet been committed. Table 10-3 lists the allowable states for a DataRow object.
| State | Description |
|---|---|
| Added | The row has been added to the table, but AcceptChanges has not yet been called. |
| Deleted | The row is marked for deletion from the parent table. |
| Detached | Either the row has been created but not yet added to the table, or the row has been removed from the rows collection. |
| Modified | Some columns within the row have been changed. |
| Unchanged | No changes have been made since the last call to AcceptChanges. This is also the state of all rows when the table is first created. |
The AcceptChanges method has the power to commit all the changes and accept the current values as the new original values of the table, clearing pending changes. RejectChanges rolls back all the pending changes. We’ll encounter the row commit model again in the section “A Save-And-Resume Application,” on page 464, when we look at save-and-resume applications.
The Original Data Section
The DiffGram has a layered structure in which current values, original values for the modified rows, and pending errors are stored in distinct sections. The state of the DataSet object is rebuilt by combining the contents of these sections. The original values are stored in the <diffgr:before> section as a change with respect to the current data instance.
The DataRow object maintains several versions of itself that are internally stored in an array of rows. The versions are grouped in the DataRowVersion enumeration, shown in Table 10-4.
Only the Current and Original versions are permanently stored in the DataRow object. The Proposed versions have a shorter life and are available only during the row edit phase. A row is in edit mode only during the time that elapses between two successive calls to the BeginEdit and EndEdit methods. When reading values from a DataRow object, you can also specify which of the available versions you want, as shown here:
if(row[0] == row[0, DataRowVersion.Original])
{...}
The <diffgr:before> section contains information that the ReadXml method will use to restore the Original version of each row referenced in the data instance. Newly added rows have no previous state and, subsequently, are not listed in the <diffgr:before> section.
Deleted rows are present only in the <diffgr:before> section, as they have no current data to show. Deleted rows are detected by matching the diffgr:id attribute of original rows in the DiffGram with the IDs of the rows in the current data instance. Rows in the <diffgr:before> section that have no counterpart in the current data instance are first inserted in the table and then deleted. Although this approach might appear a bit odd, it’s probably the most sensible way to add a logically deleted row to a DataTable object.
Note
The DataTable class provides two methods to delete child rows: Delete and Remove. The Delete method deletes the row logically by changing the state of the row. The row no longer appears in the Rows collection, but it is not detached from the DataTable object. The Remove method, on the other hand, performs a physical deletion and detaches the row from the table. The detached DataRow object is not automatically destroyed and remains valid as long as it does not go out of scope. (Out of scope objects are automatically garbage-collected and destroyed.) Valid DataRow objects can be readded to the same DataTable object (or to another DataTable object) at any time.
No matter how many columns in a row have effectively been updated, in the <diffgr:before> section, the original row is stored in its entirety. The XML layout of the row depends on the column mappings, as shown here:
<diffgr:before> <Employees diffgr:id="Employees2" msdata:rowOrder="1"> <employeeid>2</employeeid> <lastname>Fuller</lastname> <firstname>Andrew</firstname> </Employees> </diffgr:before>
Although this solution is clearly not optimal, because unchanged columns are stored twice, it closely reflects the internal architecture of the DataRow object and, as such, speeds up the restoration of the DataRow object in the destination DataTable object.
Note
The DataRow class maintains its various versions by implementing an array of subobjects—one for the current values, one for the original version, and one for intermediate proposed values. Other internal properties indicate at any moment which is the current version and what the state of the row is.
As a final note, consider that for each column in a DataRow object, only the original and the current values are tracked, and no intermediate values are buffered. For example, suppose that you perform the following operation on an unchanged row:
// 1 is the current value of the field row[0][field] = 2;
The row state changes to Modified, the original value (1) is persisted in the Original copy of the row, and the new value (2) is registered as the current value. Next the following code runs:
// 2 is the current value of the field // 1 is the original value of the field row[0][field] = 3; // 3 is NOW the current value of the field // 1 is the original value of the field
The original copy of the row remains intact, but the current version is updated. As a result, the intermediate value (2) is overwritten and is irreversibly lost.
Note
Building an automatic mechanism for tracking the entire history of a row is probably unnecessary in most cases. If you need a more powerful mechanism to track changes, you can build a parallel table of changes for each row in the table. Each entry in the custom table would point to a particular DataRow object and contain a collection of changes organized as you prefer.
Tracking Pending Errors
The DataRow class provides a few methods for handling row errors. You can set a general error message on the entire row, and you can set a column-specific message. To set a general error message, you use the RowError property. To set a column-specific message, you use the pair of methods SetColumnError and GetColumnError. Other helper methods available are GetColumnsInError and ClearErrors.
A column or row with an error is in no way different from a column or row without pending errors. In this context, an error is simply a description of contents that the user, or the application, finds erroneous and inconsistent. Nothing prevents you from using error properties as general-purpose cargo variables in which to store custom information and annotations.
Note
If you choose to use error properties as general-purpose cargo variables, keep in mind that some advanced Windows Forms and Web Forms controls can, in the presence of error flags, refresh their own user interfaces accordingly. For example, the Windows Forms DataGrid control displays a red exclamation mark on the columns in error, as shown here:

The DataRow Error Programming Interface
The tables in this section provide a quick overview of the properties and methods available in the DataRow class for setting and getting error messages. These messages are then tracked in the <diffgr:errors> section of the DiffGram. Table 10-5 lists the error-related properties of the DataRow class.
| Property | Description |
|---|---|
| HasErrors | Indicates whether the row contains errors |
| RowError | Gets or sets a custom error description for the row |
The HasErrors property is set to true when either the RowError property contains a value or at least one column is not associated with an empty message. If you want to know about all the columns with errors, use the GetColumnsInError method to obtain an array containing the DataColumn objects with errors.
Table 10-6 shows the error-related methods of the DataRow class.
| Method | Description |
|---|---|
| ClearErrors | Clears all the pending errors for the row. Does not distinguish between errors set using RowError and errors set using SetColumnError. |
| GetColumnError | Gets the error description for the specified column. |
| GetColumnsInError | Returns an array of the DataColumn objects with errors. |
| SetColumnError | Sets the error description for the specified column. |
Contents of the <diffgr:errors> Section
A table row is assigned an element in the <diffgr:errors> section if its HasErrors property returns true. In this case, the element that represents the row in the data section has an extra attribute, diffgr:hasErrors, as shown here:
<Employees diffgr:id="Employees1" msdata:rowOrder="0" diffgr:hasErrors="true"> <employeeid>1</employeeid> <lastname>Davolio</lastname> <firstname>Nancy</firstname> </Employees>
The preceding element is coupled with another element in the <diffgr:errors> section in which the error messages are tracked, as follows:
<diffgr:errors> <Employees diffgr:id="Employees1" diffgr:error="Must review"> <employeeid diffgr:error="Check the ID" /> <lastname diffgr:error="Sounds like the wrong name" /> </Employees> </diffgr:errors>
The diffgr:error attribute on the row node (<Employees> in the preceding sample code) contains the text stored in the RowError property. For each column with a custom error description, a new child element is created with the name of the column and a diffgr:error attribute. In the sample code, the employeeid and lastname columns contain errors. Note that the RowError property is not automatically filled when at least one column is in error.
Caution
The XML schema of the elements in the <diffgr:errors> section is not affected by column mappings, as is the case with the current data and the <diffgr:before> sections we examined earlier.