
XPath in the XML DOM
In the .NET Framework, you can make use of XPath expressions in two ways: through the XML DOM or by means of a new and more flexible API based on the concept of the XPath navigator.
In the former case, you use XPath expressions to select nodes within the context of a living instance of the XmlDocument class. As we saw in Chapter 5, the XmlDocument class is the .NET Framework class that renders a given XML document as a hierarchical object model (XML DOM). This approach keeps the API close to the old MSXML programming style and has probably been supplied mostly for compatibility reasons.
The alternative approach consists of creating an instance of the XPathDocument class and obtaining from it an XPath navigator object. The navigator object is a generic XPath processor that works on top of any XML data store that exposes the IXPathNavigable interface. Rendered through the XPathNavigator class, the XPath navigator object parses and executes expressions using its Select method. XPath expressions can be passed as plain text or as preprocessed, compiled expressions. As you can see, although the classes involved are different, the overall programming style is not much different from those pushed by MSXML and the .NET Framework XML DOM classes.
This said, though, the XPath navigator object represents a quantum leap from the SelectNodes method of the XmlDocument class. For one thing, it works on top of highly specialized document classes that implement IXPathNavigable and are optimized to perform both XPath queries and XSL transformations. In contrast, the XmlDocument class is a generic data container class that incorporates an XPath processor but is not built around it.
Several classes in the .NET Framework implement the IXPathNavigable interface, thus making their contents automatically selectable by XPath expressions. We’ll look at the navigation API in more detail in the section “The .NET XPath Navigation API,” on page 263. For now, let’s review the XPath support built into the XmlDocument class.
The XML DOM Node Retrieval API
When using XPath queries to query an XML DOM instance, you can use the SelectNodes method of the XmlDocument class. In particular, SelectNodes returns a collection that contains instances of all the XmlNode objects that match the specified expression. If you don’t need the entire node-set, but instead plan to use the query to locate the root of a particular subtree, use the SelectSingleNode method. SelectSingleNode takes an XPath expression and returns a reference to the first match found.
The SelectNodes and SelectSingleNode methods perform identical functionality to the methods available from the Component Object Model (COM)–based MSXML library that script and Microsoft Win32 applications normally use. It is worth noting that these methods are not part of the official W3C XML DOM specification but represent, instead, Microsoft extensions to the standard XML DOM.
At the application level, XML DOM methods and the XPath navigator supply different programming interfaces, but internally they run absolutely equivalent code.
The SelectNodes Internal Implementation
The SelectNodes method internally employs a navigator object to retrieve the list of matching nodes. The return value of the navigator’s Select method is then used to initialize an undocumented internal node list class named System.Xml.XPath .XPathNodeList. As you have probably guessed, this class inherits from XmlNodeList, which is a documented class. To verify this statement, compile and run the following simple code:
XmlDocument doc = new XmlDocument();
doc.Load(fileName);
XmlNodeList nodes = doc.SelectNodes("child::*");
Console.WriteLine(nodes.ToString());
The true type of the variable nodes is XPathNodeList. If you try to reference that type in your code, you get a compile error due to the protection level of the class.
What’s the difference between using SelectNodes and the XPath navigator object? The SelectNodes method uses a navigator that works on top of a generic XML document class—the XmlDocument class. The SelectNodes method’s navigator object is, in fact, created by the XmlDocument class’s CreateNavigator method. If you choose to publicly manage a navigator, you normally create it from a more specific and XPath-optimized document class—the XPathDocument class.
The XPath expression is passed to the navigator as plain text:
XmlNodeList SelectNodes(string xpathExpr, XmlNamespaceManager nsm)
Interestingly enough, however, if you use this overload of the SelectNodes method that handles namespace information, the XPath expression is first compiled and then passed to the processor.
As we’ll see in the section “Compiling Expressions,” on page 274, only compiled XPath expressions support namespace information. In particular, they get namespace information through an instance of the XmlNamespaceManager class.
The SelectSingleNode Internal Implementation
The SelectSingleNode method is really a special case of SelectNodes. Unfortunately, there is no performance advantage in using SelectSingleNode in lieu of SelectNodes. The following pseudocode illustrates the current implementation of the SelectSingleNode method:
public XmlNode SelectSingleNode(string xpathExpr)
{
XmlNodeList nodes = SelectNodes(xpathExpr);
return nodes[0];
}
The SelectSingleNode method internally calls SelectNodes and retrieves all the nodes that match a given XPath expression. Next it simply returns the first selected node to the caller. Using SelectSingleNode perhaps results in a more easily readable code, but doing so certainly does not improve the performance of the application when you need just one node.
In the next section, we’ll build a sample Microsoft Windows Forms application to start practicing with XPath expressions, thus turning into concrete programming calls all that theory about the XPath query language.
The Sample XPath Evaluator
The sample XPath Evaluator application is a Windows Forms application that loads an XML document and then performs an XPath query on it. The application’s user interface lets you type in both the context node and the query string. Next it creates an XML DOM for the document and calls SelectNodes.
The output of the expression is rendered as an XML string rooted in an arbitrary <results> node, as shown here:
<results> ... XML nodes that match ... </results>
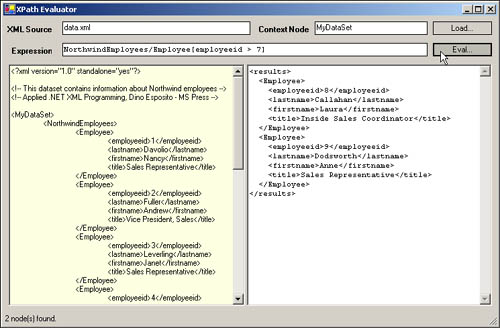
The sample application is shown in Figure 6-3. You can find the code listing for this application in this book’s sample files.
Figure 6-3. The XPath Evaluator sample application in action.

Initializing the Application
When the user clicks the Load button, a StreamReader object is used to load the specified XML document and refresh the left text box, which displays the contents of the XPath source document. I used the I/O API to read the document to preserve the newline characters. An alternative approach consists of loading the document into the XmlDocument class and then getting the source through the document element’s OuterXml property. In this case, however, what you get is a string of contiguous characters that does not display well in a fixed-width text box.
Setting the Context Node
As mentioned, the context node is the starting point of the query. The context node is important if you specify a relative expression. In this case, the context node—that is, the XmlNode object from which you call SelectNodes—determines the full path. The context node is simply ignored if the expression contains an absolute location path, in which case, the path must start from the XML root node.
The sample application first initializes the XML DOM and then sets the context node by calling SelectSingleNode on the document object. For the sake of generality, this application’s user interface accepts a reference to the context node using an XPath expression, as shown here:
XmlDocument doc = new XmlDocument(); doc.Load(xmlFile); XmlNode cxtNode = doc.SelectSingleNode(ContextNode.Text);
In a real-world situation, you normally know what the context node is (typically, the XML document root) and can locate it more efficiently using the ChildNodes collection. For example, the following code shows how to set the context node to the document’s root:
XmlNode cxtNode = doc.DocumentElement; XmlNodeList nodes = cxtNode.SelectNodes(xpathExpr);
Performing the XPath Query
After you type the XPath expression, you click the Eval button to run the query. Note that the node names in an XPath expression are case-sensitive and must perfectly match the names in the original source document.
After the processor has processed the node list, the output string is built by calling the BuildOutputString method and then displayed in the form’s results panel via the ShowResults method, as shown here:
string buf = "";
int nodeCount = 0;
XmlNodeList nodes = null;
try {
nodes = cxtNode.SelectNodes(xpathExpr);
nodeCount = nodes.Count;
} catch {}
if (nodes == null || nodeCount <= 0)
buf = "<results>No nodes selected</results>";
else
buf = BuildOutputString(nodes);
ShowResults(buf, nodeCount);
The results of the XPath query are rendered as an XML document. The root node is <results>, which contains the outer XML code of each node found.
Post-Processing the Node-Set
Post-processing the output of an XPath query is a relatively common task if you have to transfer the results to a different process or machine. In similar situations, you don’t have formatting concerns and can quickly arrange a final XML document, as follows:
StringBuilder sb = new StringBuilder("<results>");
foreach(XmlNode n in nodes)
sb.Append(n.OuterXml);
sb.Append("</results>");
return sb.ToString();
Our sample application intentionally follows a more sophisticated approach to display formatted output in the text box. In addition, this code turns out to be a useful exercise for understanding the logic of XML writers.
If you want to generate XML output in the .NET Framework, unless the text is short and straightforward, you have no good reason for not using XML writers. Using XML writers also provides automatic and free indentation. Don’t think that choosing an XML writer ties you to using a specific output stream. As the following code demonstrates, the output of an XML writer can be easily redirected to a string:
string BuildOutputString(XmlNodeList nodes)
{
// Create a string writer to hold the XML text. For efficiency,
// the string writer is based on a StringBuilder object.
StringBuilder sb = new StringBuilder("");
StringWriter sw = new StringWriter(sb);
// Instantiate the XML writer
XmlTextWriter writer = new XmlTextWriter(sw);
writer.Formatting = Formatting.Indented;
// Write the first element (No WriteStartDocument call is needed)
writer.WriteStartElement("results");
// Loop through the children of each selected node and
// recursively output attributes and text
foreach(XmlNode n in nodes)
LoopThroughChildren(writer, n);
// Complete pending nodes and then close the writer
writer.WriteEndElement();
writer.Close();
// Flush the contents accumulated in the string writer
return sw.ToString();
}
Let’s see what happens when we process the following XML document:
<MyDataSet> <NorthwindEmployees> <Employee> <employeeid>1</employeeid> <lastname>Davolio</lastname> <firstname>Nancy</firstname> <title>Sales Representative</title> </Employee> ⋮ </NorthwindEmployees> </MyDataSet>
This document is the same XML representation of the Northwind’s Employees database that we used in previous chapters. To see the application in action, let’s set MyDataSet (the root) as the context node and try the following expression:
NorthwindEmployees/Employee[employeeid > 7]
The XPath query has two steps. The first step restricts the search to all the <NorthwindEmployees> nodes in the source document. In this case, there is only one node with that name. The second step moves the search one level down and then focuses on the <Employee> nodes that are children of the current <NorthwindEmployees> context node. The predicate [employeeid > 7] includes in the final result only the <Employee> nodes with a child <employeeid> element greater than 7. The following XML output is what XPath Evaluator returns:
<results> <Employee> <employeeid>8</employeeid> <lastname>Callahan</lastname> <firstname>Laura</firstname> <title>Inside Sales Coordinator</title> </Employee> <Employee> <employeeid>9</employeeid> <lastname>Dodsworth</lastname> <firstname>Anne</firstname> <title>Sales Representative</title> </Employee> </results>
Figure 6-4 shows the user interface of XPath Evaluator when it is set to work on our sample document and expression.
Figure 6-4. The node set returned by XPath Evaluator.
Note
The preceding expression is an abbreviated form that could have been more precisely expressed as follows:
NorthwindEmployees/Employee/self::*[child::employeeid > 7]
You apply the predicate to the context node in person (self) and verify that the employeeid node on its children has a value greater than 7.
The contents of the final node-set is determined by the node that appears in the last step of the XPath expression. Predicates allow you to perform a sort of forward checking—that is, selecting nodes at a certain level but based on the values of child nodes. The expression NorthwindEmployees/Employee[employeeid > 7] is different from this one:
NorthwindEmployees/Employee/employeeid[node() > 7]
In this case, the node set consists of <employeeid> nodes, as shown here:
<results> <employeeid>8</employeeid> <employeeid>9</employeeid> </results>
Concatenating Multiple Predicates
An XPath expression can contain any number of predicates. If no predicate is specified, child::* is assumed, and all the children are returned. Otherwise, the conditions set with the various predicates are logically concatenated using a short-circuited AND operator.
Predicates are processed in the order in which they appear, and the next predicate always works on the node-set generated by the previous one, as shown here:
Employee[contains(title, ’Representative’)][employeeid >7]
This example set first selects all the <Employee> nodes whose <title> child node contains the word Representative. Next the returned set is further filtered by discarding all the nodes with an <employeeid> not greater than 7.
Accessing the Selected Nodes
The SelectNodes method returns the XPath node set through an XmlNodeList data structure—that is, a list of references to XmlNode objects. If you need simply to pass on this information to another application module, you can serialize the list to XML using a plain for-each statement and the XmlNode class’s OuterXml property.
Suppose, instead, that you want to access and process all the nodes in the result set. In this case, you set up a recursive procedure, like the following LoopThroughChildren routine, and start it up with a for-each statement that touches on the first-level nodes in the XPath node-set:
foreach(XmlNode n in nodes) LoopThroughChildren(writer, n);
The following procedure is designed to output the node contents to an XML writer, but you can easily modify the procedure to meet your own needs.
void LoopThroughChildren(XmlTextWriter writer, XmlNode rootNode)
{
// Process the start tag
if (rootNode.NodeType == XmlNodeType.Element)
{
writer.WriteStartElement(rootNode.Name);
// Process any attributes
foreach(XmlAttribute a in rootNode.Attributes)
writer.WriteAttributeString(a.Name, a.Value);
// Recursively process any child nodes
foreach(XmlNode n in rootNode.ChildNodes)
LoopThroughChildren(writer, n);
// Process the end tag
writer.WriteEndElement();
}
else
// Process any content text
if (rootNode.NodeType == XmlNodeType.Text)
writer.WriteString(rootNode.Value);
}
This version of the LoopThroughChildren routine is an adaptation of the routine we analyzed in Chapter 5.
A Better Way to Select a Single Node
In the section “The SelectSingleNode Internal Implementation,” on page 255, I pointed out that SelectSingleNode is not as efficient as its signature and description might suggest. This XML DOM method is expected to perform an XPath query and then return only the first node. You might think that the method works smartly, returning to the caller as soon as the first node has been found.
Unfortunately, that isn’t what happens. SelectSingleNode internally calls SelectNodes, downloads all the nodes (potentially a large number), and then returns only the first node to the caller. The inefficiency of this implementation lies in the fact that a significant memory footprint might be required, albeit for a very short time.
So in situations in which you need to perform an XPath query to get only a subset of the final node-set (for example, exactly one node), you can use a smarter XPath expression. The basic idea is that you avoid generic wildcard expressions like the following:
doc.SelectSingleNode("NorthwindEmployees/Employee");
Instead, place a stronger filter on the XPath expression so that it returns just the subset you want. For example, to get only the first node, use the following query:
doc.SelectSingleNode("NorthwindEmployees/Employee[position() = 1");
The same pattern can be applied to get a matching node in a particular position. For example, if you need to get the nth matching node, use the following expression:
doc.SelectSingleNode("NorthwindEmployees/Employee[position() < n+1");
Using such XPath expressions with SelectSingleNode does not change the internal implementation of the method, but those expressions require downloading a smaller subset of nodes prior to returning the first matching node to the caller.
The same XPath expression, if used with SelectNodes, returns a subset of the first n matching nodes:
doc.SelectNodes("NorthwindEmployees/Employee[position() < n+1");