
Serializing DataSet Objects
Like any other .NET Framework object, a DataSet object is stored in memory in a binary format. Unlike other objects, however, the DataSet object is always remoted and serialized in a special XML format, called a DiffGram. (We’ll look at the DiffGram format and the relative API in more detail in Chapter 10.) When the DataSet object trespasses across the boundaries of the application domains (AppDomains), or the physical borders of the machine, it is automatically rendered as a DiffGram. At its destination, the DataSet object is silently rebuilt as a binary and immediately usable object.
In ADO.NET, serialization of an object is performed either through the public ISerializable interface or through public methods that expose the object’s internal serialization mechanism. As .NET Framework objects, ADO.NET objects can plug into the standard .NET Framework serialization mechanism and output their contents to standard and user-defined formatters. The .NET Framework provides a couple of built-in formatters: the binary formatter and the Simple Object Access Protocol (SOAP) formatter. A .NET Framework object makes itself serializable by implementing the methods of the ISerializable interface—specifically, the GetObjectData method, plus a particular flavor of the constructor. According to this definition, both the DataSet and the DataTable objects are serializable.
In addition to the official serialization interface, the DataSet object supplies an alternative, and more direct, series of methods to serialize and deserialize itself, but in a class-defined XML format only. To serialize using the standard method, you create instances of the formatter object of choice (binary, SOAP, or whatever) and let the formatter access the source data through the methods of the ISerializable interface. The formatter obtains raw data that it then packs into the expected output stream.
In the alternative serialization model, the DataSet object itself starts and controls the serialization and deserialization process through a group of extra methods. The DataTable object does not offer public methods to support such an alternative and embedded serialization interface, nor does the DataView object.
In the end, both the official and the embedded serialization engines share the same set of methods. The overall architecture of DataSet and DataTable serialization is graphically rendered in Figure 9-1.
Figure 9-1. Both the DataSet object and the DataTable object implement the ISerializable interface for classic .NET Framework serialization. The DataSet object also publicly exposes the internal API used to support classic serialization.
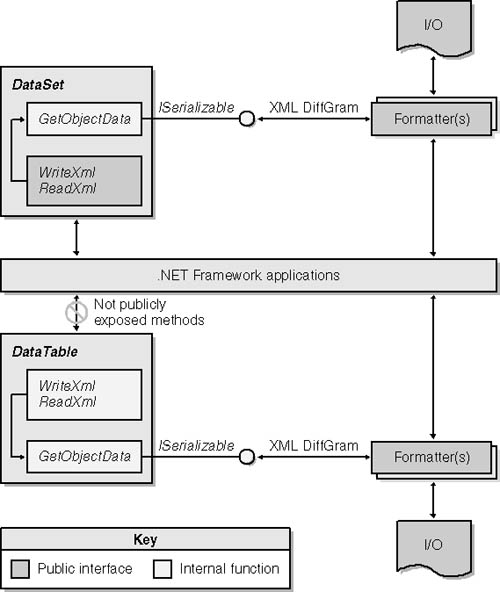
All the methods that the DataSet object uses internally to support the .NET Framework serialization process are publicly exposed to applications through a group of methods, one pair of which clearly stands out—ReadXml and WriteXml. The DataTable object, on the other hand, does not publish the same methods, although this feature can be easily obtained with a little code. (I’ll demonstrate this in the section “Serializing Filtered Views,” on page 417.)
As you can see in the architecture depicted in Figure 9-1, both objects always pass XML data to .NET Framework formatters. This means that there is no .NET Framework–provided way to serialize ADO.NET objects in binary formats. We’ll return to this topic in the section “Custom Binary Serialization,” on page 424.
The DataSet Object’s Embedded API for XML
Table 9-1 presents the DataSet object methods you can use to work with XML, both in reading and in writing. This list represents the DataSet object’s internal XML API, which is at the foundation of the serialization and deserialization processes for the object.
| Method | Description |
|---|---|
| GetXml | Returns an XML representation of the data currently stored in the DataSet object. No schema information is included. |
| GetXmlSchema | Returns a string that represents the XML schema information for the data currently stored in the object. |
| ReadXml | Populates the DataSet object with the specified XML data read from a stream or a file. During the process, schema information is read or inferred from the data. |
| ReadXmlSchema | Loads the specified XML schema information into the current DataSet object. |
| WriteXml | Writes out the XML data, and optionally the schema, that represents the DataSet object to a storage medium—that is, a stream or a file. |
| WriteXmlSchema | Writes out a string that represents the XML schema information for the DataSet object. Can write to a stream or a file. |
Note that GetXml returns a string that contains XML data. As such, it requires more overhead than simply using WriteXml to write XML to a file. You should not use GetXml and GetXmlSchema unless you really need to obtain the DataSet representation or schema as distinct strings for in-memory manipulation. The GetXmlSchema method returns the DataSet object’s XML Schema Definition (XSD) schema; there is no way to obtain the DataSet object’s XML-Data Reduced (XDR) schema.
As Table 9-1 shows, when you’re working with DataSet and XML, you can manage data and schema information as distinct entities. You can take the XML schema out of the object and use it as a string. Alternatively, you could write the schema to a disk file or load it into an empty DataSet object. Alongside the methods listed in Table 9-1, the DataSet object also features two XML-related properties: Namespace and Prefix. Namespace specifies the XML namespace used to scope XML attributes and elements when you read them into a DataSet object. The prefix to alias the namespace is stored in the Prefix property. The namespace can’t be set if the DataSet object already contains data.
Writing Data as XML
The contents of a DataSet object can be serialized as XML in two ways that I’ll call stateless and stateful. Although these expressions are not common throughout the ADO.NET documentation, I believe that they capture the gist of the two XML schemas that can be used to persist a DataSet object’s contents. A stateless representation takes a snapshot of the current instance of the data and renders it according to a particular XML schema (defined in Chapter 1 as the ADO.NET normal form). A stateful representation, on the other hand, contains the history of the data in the object and includes information about changes as well as pending errors. Keep in mind that stateless and stateful refer to the data in the DataSet object but not to the DataSet object as a whole.
In this chapter, we’ll focus on the stateless representation of the DataSet object, with just a glimpse at the stateful representation—the DiffGram format. In Chapter 10, we’ll delve into the DiffGram’s structure and goals.
The XML representation of a DataSet object can be written to a file, a stream, an XmlWriter object, or a string using the WriteXml method. It can include, or not include, XSD schema information. The actual behavior of the WriteXml method can be controlled by passing the optional XmlWriteMode parameter. The values in the XmlWriteMode enumeration determine the output’s layout. The overloads of the method are shown in the following listing:
public void WriteXml(Stream, XmlWriteMode); public void WriteXml(string, XmlWriteMode); public void WriteXml(TextWriter, XmlWriteMode); public void WriteXml(XmlWriter, XmlWriteMode);
WriteXml provides four additional overloads with the same structure as this code but with no explicit XmlWriteMode argument.
The stateless representation of the DataSet object takes a snapshot of the current status of the object. In addition to data, the representation includes tables, relations, and constraints definitions. The rows in the tables are written only in their current versions, unless you use the DiffGram format—which would make this a stateful representation. The following schema shows the ADO.NET normal form—that is, the XML stateless representation of a DataSet object:
<DataSetName> <xs:schema ... /> <Table #1> <field #1>...</field #1> <field #2>...</field #2> </Table #1> <Table #2> <field #1>...</field #1> <field #2>...</field #2> <field #3>...</field #3> </Table #2> ⋮ </DataSetName>
The root tag is named after the DataSet object. If the DataSet object has no name, the string NewDataSet is used. The name of the DataSet object can be set at any time through the DataSetName property or via the constructor upon instantiation. Each table in the DataSet object is represented as a block of rows. Each row is a subtree rooted in a node with the name of the table. You can control the name of a DataTable object via the TableName property. By default, the first unnamed table added to a DataSet object is named Table. A trailing index is appended if a table with that name already exists. The following listing shows the XML data of a DataSet object named NorthwindInfo:
<NorthwindInfo> <Employees> <employeeid>1</employeeid> <lastname>Davolio</lastname> <firstname>Nancy</firstname> </Employees> ⋮ <Territories> <employeeid>1</employeeid> <territoryid>06897</territoryid> </Territories> ⋮ </NorthwindInfo>
Basically, the XML representation of a DataSet object contains rows of data grouped under a root node. Each row is rendered with a subtree in which child nodes represent columns. The contents of each column are stored as the text of the node. The link between a row and the parent table is established through the name of the row node. In the preceding listing, the <Employees>…</Employees> subtree represents a row in a DataTable object named Employees.
Modes of Writing
Table 9-2 summarizes the writing options available for use with WriteXml through the XmlWriteMode enumeration.
| Write Mode | Description |
|---|---|
| DiffGram | Writes the contents of the DataSet object as a DiffGram, including original and current values. |
| IgnoreSchema | Writes the contents of the DataSet object as XML data without a schema. |
| WriteSchema | Writes the contents of the DataSet object, including an in-line XSD schema. The schema can’t be inserted as XDR, nor can it be added as a reference. |
IgnoreSchema is the default option. The following code demonstrates the typical way to serialize a DataSet object to an XML file:
StreamWriter sw = new StreamWriter(fileName); dataset.WriteXml(sw); // Defaults to IgnoreSchema sw.Close();
Tip
In terms of functionality, calling the GetXml method and then writing its contents to a data store is identical to calling WriteXml with XmlWriteMode set to IgnoreSchema. Using GetXml can be comfortable, but in terms of raw overhead, calling WriteXml on a StringWriter object is slightly more efficient, as shown here:
StringWriter sw = new StringWriter(); ds.WriteXml(sw, XmlWriteMode.IgnoreSchema); // Access the string using sw.ToString()
The same considerations apply to GetXmlSchema and WriteXmlSchema.
Preserving Schema and Type Information
The stateless XML format is a flat format. Unless you explicitly add schema information, the XML output is weakly typed. There is no information about tables and columns, and the original content of each column is normalized to a string. If you need a higher level of type and schema fidelity, start by adding an in-line XSD schema.
In general, a few factors can influence the final structure of the XML document that WriteXml creates for you. In addition to the overall XML format—DiffGram or a plain hierarchical representation of the current contents—important factors include the presence of schema information, nested relations, and how table columns are mapped to XML elements.
Note
To optimize the resulting XML code, the WriteXml method drops column fields with null values. Dropping the null column fields doesn’t affect the usability of the DataSet object—you can successfully rebuild the object from XML, and data-bound controls can easily manage null values. This feature can become a problem, however, if you send the DataSet object’s XML output to a non-.NET platform. Other parsers, unaware that null values are omitted for brevity, might fail to parse the document. If you want to represent null values in the XML output, replace the null values (System.DBNull type) with other neutral values (for example, blank spaces).
Writing Schema Information
When you serialize a DataSet object, schema information is important for two reasons. First, it adds structured information about the layout of the constituent tables and their relations and constraints. Second, extra table properties are persisted only within the schema. Note, however, that schema information describes the structure of the XML document being created and is not a transcript of the database metadata.
The schema contains information about the constituent columns of each DataTable object. (Column information includes name, type, any expression, and all the contents of the ExtendedProperties collection.)
The schema is always written as an in-line XSD. As mentioned, there is no way for you to write the schema as XDR, as a document type definition (DTD), or even as an added reference to an external file. The following listing shows the schema source for a DataSet object named NorthwindInfo that consists of two tables: Employees and Territories. The Employees table has three columns—employeeid, lastname, and firstname. The Territories table includes employeeid and territoryid columns. (These elements appear in boldface in this listing.)
<xs:schema id="NorthwindInfo" xmlns="" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata"> <xs:element name="NorthwindInfo" msdata:IsDataSet="true"> <xs:complexType> <xs:choice maxOccurs="unbounded"> <xs:element name="Employees"> <xs:complexType> <xs:sequence> <xs:element name="employeeid" type="xs:int" /> <xs:element name="lastname" type="xs:string" /> <xs:element name="firstname" type="xs:string" /> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="Territories"> <xs:complexType> <xs:sequence> <xs:element name="employeeid" type="xs:int" /> <xs:element name="territoryid" type="xs:string" /> </xs:sequence> </xs:complexType> </xs:element> </xs:choice> </xs:complexType> </xs:element> </xs:schema>
The <xs:choice> element describes the body of the root node <NorthwindInfo> as an unbounded sequence of <Employees> and <Territories> nodes. These first-level nodes indicate the tables in the DataSet object. The children of each table denote the schema of the DataTable object. (See Chapter 3 for more information about XML schemas.)
The schema can be slightly more complex if relations exist between two or more pairs of tables. The msdata namespace contains ad hoc attributes that are used to annotate the schema with ADO.NET–specific information, mostly about indexes, table relationships, and constraints.
In-Line Schemas and Validation
Chapter 3 hinted at why the XmlValidatingReader class is paradoxically unable to validate the XML code that WriteXml generates for a DataSet object with an in-line schema, as shown here:
<DataSetName>
<schema>...</schema>
<Table1>...</Table1>
<Table2>...</Table2>
<DataSetName>
In the final XML layout, schema information is placed at the same level as the table nodes, but includes information about the common root (DataSetName, in the preceding code) as well as the tables (Table1 and Table2). Because the validating parser is a forward-only reader, it can match the schema only for nodes placed after the schema block. The idea is that the parser first reads the schema and then checks the compliance of the remainder of the tree with the just-read information, as shown in Figure 9-2.
Figure 9-2. How the .NET Framework validating reader parses a serialized DataSet object with an in-line schema.

Due to the structure of the XML document being generated, what comes after the schema does not match the schema! Figure 9-3 shows that the validating parser we built in Chapter 3 around the XmlValidatingReader class does not recognize (I’d say, by design) a serialized DataSet object when an in-line schema is incorporated.
Figure 9-3. The validating parser built in Chapter 3 does not validate an XML DataSet object with an in-line schema.

Is there a way to serialize the DataSet object so that its XML representation remains parsable when an in-line schema is included? The workaround is fairly simple.
Serializing to Valid XML
As you can see in Figure 9-2, the rub lies in the fact that the in-line schema is written in the middle of the document it is called to describe. This fact, in addition to the forward-only nature of the parser, irreversibly alters the parser’s perception of what the real document schema is. The solution is simple: move the schema out of the DataSet XML serialization output, and group both nodes under a new common root, as shown here:
<Wrapper> <xs:schema> ... </xs:schema> <DataSet> ⋮ </DataSet> </Wrapper>
Here’s a code snippet that shows how to implement this solution:
XmlTextWriter writer = new XmlTextWriter(file);
writer.Formatting = Formatting.Indented;
writer.WriteStartElement("Wrapper");
ds.WriteXmlSchema(writer);
ds.WriteXml(writer);
writer.WriteEndElement();
writer.Close();
If you don’t use an XML writer, the WriteXmlSchema method would write the XML declaration in the middle of the document, thus making the document wholly unparsable. You can also mark this workaround with your own credentials using a custom namespace, as shown here:
writer.WriteStartElement("de", "Wrapper", "dinoe-xml-07356-1801-1");
Figure 9-4 shows the new document displayed in Microsoft Internet Explorer.
Figure 9-4. The DataSet object’s XML output after modification.

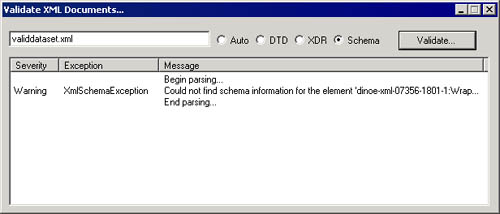
Figure 9-5 shows that this new XML file (validdataset.xml) is successfully validated by the XmlValidatingReader class. The validating parser raises a warning about the new root node; this feature was covered in Chapter 3.
Figure 9-5. The validating parser raises a warning but accepts the updated XML file.
A reasonable concern you might have is about the DataSet object’s ability to read back such a modified XML stream. No worries! The ReadXml method is still perfectly able to read and process the modified schema, as shown here:
DataSet ds = new DataSet();
ds.ReadXml("ValidDataset.xml", XmlReadMode.ReadSchema);
ds.WriteXml("standard.xml");
Note
Although paradoxical, this behavior (whether it’s by design or a bug) does not deserve much hype. At first glance, this behavior seems to limit true cross-platform interoperability, but after a more thoughtful look, you can’t help but realize that very few XML parsers today support in-line XML schemas. In other words, what appears to be a clamorous and incapacitating bug is actually a rather innocuous behavior that today has a very limited impact on real applications. Real-world cross-platform data exchange, in fact, must be done using distinct files for schema and data.
Customizing the XML Representation
The schema of the DataSet object’s XML representation is not set in stone and can be modified to some extent. In particular, each column in each DataTable object can specify how the internal serializer should render its content. By default, each column is rendered as an element, but this feature can be changed to any of the values in the MappingType enumeration. The DataColumn property that specifies the mapping type is ColumnMapping.
Customizing Column Mapping
Each row in a DataTable object originates an XML subtree whose structure depends on the value assigned to the DataColumn object’s ColumnMapping property. Table 9-3 lists the allowable column mappings.
| Mapping | Description |
|---|---|
| Attribute | The column is mapped to an XML attribute on the row node. |
| Element | The column is mapped to an XML node element. The default setting. |
| Hidden | The column is not included in the XML output unless the DiffGram format is used. |
| SimpleContent | The column is mapped to simple text. (Only for tables containing exactly one column.) |
The column data depends on the row node. If ColumnMapping is set to Element, the column value is rendered as a child node, as shown here:
<Table> <Column>value</Column> ⋮ </Table>
If ColumnMapping is set to Attribute, the column data becomes an attribute on the row node, as shown here:
<Table Column="value"> ⋮ </Table>
By setting ColumnMapping to Hidden, you can filter the column out of the XML representation. Unlike the two preceding settings, which are maintained in the DiffGram format, a column marked with Hidden is still serialized in the DiffGram format, but with a special attribute that indicates that it was originally marked hidden for serialization. The reason is that the DiffGram format is meant to provide a stateful and high-fidelity representation of the DataSet object.
Finally, the SimpleContent attribute renders the column content as the text of the row node, as shown here:
<Table>value</Table>
For this reason, this attribute is applicable only to tables that have a single column.
Persisting Extended Properties
Many ADO.NET classes, including DataSet, DataTable, and DataColumn, use the ExtendedProperties property to enable users to add custom information. Think of the ExtendedProperties property as a kind of generic cargo variable similar to the Tag property of many ActiveX controls. You populate it with name/value pairs and manage the contents using the typical and familiar programming interface of collections. For example, you can use the DataTable object’s ExtendedProperties collection to store the SQL command that should be used to refresh the table itself.
The set of extended properties is lost at serialization time, unless you choose to add schema information. The WriteXml method adds extended properties to the schema using an ad hoc attribute prefixed with the msprop namespace prefix. Consider the following code:
ds.Tables["Employees"].ExtendedProperties.Add("Command",
EmployeesCommand.Text);
ds.Tables["Territories"].ExtendedProperties.Add("Command",
TerritoriesCommand.Text);
When the tables are serialized, the Command slot is rendered as follows:
<xs:element name="Employees" msprop:Command="..."> <xs:element name="Territories" msprop:Command="...">
ExtendedProperties holds a collection of objects and can accept values of any type, but you might run into trouble if you store values other than strings there. When the object is serialized, any extended property is serialized as a string. In particular, the string is what the object’s ToString method returns. This can pose problems when the DataSet object is deserialized.
Not all types can be successfully and seamlessly rebuilt from a string. For example, consider the Color class. If you call ToString on a Color object (say, Blue), you get something like Color [Blue]. However, no constructor on the Color class can rebuild a valid object from such a string. For this reason, pay careful attention to the nonstring types you store in the ExtendedProperties collection.
Rendering Data Relations
A DataSet object can contain one or more relations gathered under the Relations collection property. A DataRelation object represents a parent/child relationship set between two DataTable objects. The connection takes place on the value of a matching column and is similar to a primary key/foreign key relationship. In ADO.NET, the relation is entirely implemented in memory and can have any cardinality: one-to-one, one-to-many, and even many-to-one.
More often than not, a relation entails table constraints. In ADO.NET, you have two types of constraints: foreign-key constraints and unique constraints. A foreign-key constraint denotes an action that occurs on the columns involved in the relation when a row is either deleted or updated. A unique constraint denotes a restriction on the parent column whereby duplicate values are not allowed. How are relations rendered in XML?
If no schema information is required, relations are simply ignored. When a schema is not explicitly required, the XML representation of the DataSet object is a plain snapshot of the currently stored data; any ancillary information is ignored. There are two ways to accurately represent a DataRelation relation within an XML schema: you can use the <msdata:Relationship> annotation or specify an <xs:keyref> element. The WriteXml procedure uses the latter solution.
The msdata:Relationship Annotation
The msdata:Relationship annotation is a Microsoft XSD extension that ADO.NET and XML programmers can use to explicitly specify a parent/child relationship between non-nested tables in a schema. This annotation is ideal for expressing the content of a DataRelation object. In turn, the content of an msdata:Relationship annotation is transformed into a DataRelation object when ReadXml processes the XML file.
Let’s consider the following relation:
DataRelation rel = new DataRelation("Emp2Terr",
ds.Tables["Employees"].Columns["employeeid"],
ds.Tables["Territories"].Columns["employeeid"]);
ds.Relations.Add(rel);
The following listing shows how to serialize this relation to XML:
<xs:schema id="NorthwindInfo" ... >
<xs:annotation>
<xs:appinfo>
<msdata:Relationship name="Emp2Terr"
msdata:parent="Employees"
msdata:child="Territories"
msdata:parentkey="employeeid"
msdata:childkey="employeeid" />
</xs:appinfo>
</xs:annotation>
<xs:element name="NorthwindInfo" msdata:IsDataSet="true">
⋮
</xs:element>
</xs:schema>
This syntax is simple and effective, but it has one little drawback—it is simply targeted to describe a relation. When you serialize a DataSet object to XML, you might want to obtain a hierarchical representation of the data, if a parent/child relationship is present. For example, which of the following XML documents do you find more expressive? The sequential layout shown here is the default:
<Employees employeeid="1" lastname="Davolio" firstname="Nancy" /> <Territories employeeid="1" territoryid="06897" /> <Territories employeeid="1" territoryid="19713" />
The following layout provides a hierarchical view of the data—all the territories’ rows are nested below the logical parent row:
<Employees employeeid="1" lastname="Davolio" firstname="Nancy"> <Territories employeeid="1" territoryid="06897" /> <Territories employeeid="1" territoryid="19713" /> </Employees>
As an annotation, msdata:Relationship can’t express this schema-specific information. Another piece of information is still needed. For this reason, the WriteXml method uses the <xs:keyref> element to describe the relationship along with nested type definitions to create a hierarchy of nodes.
The XSD keyref Element
In XSD, the keyref element allows you to establish links between elements within a document in much the same way a parent/child relationship does. The WriteXml method uses keyref to express a relation within a DataSet object, as shown here:
<xs:keyref name="Emp2Terr" refer="Constraint1"> <xs:selector xpath=".//Territories" /> <xs:field xpath="@employeeid" /> </xs:keyref>
The name attribute is set to the name of the DataRelation object. By design, the refer attribute points to the name of a key or unique element defined in the same schema. For a DataRelation object, refer points to an automatically generated unique element that represents the parent table, as shown in the following code. The child table of a DataRelation object, on the other hand, is represented by the contents of the keyref element.
<xs:unique name="Constraint1"> <xs:selector xpath=".//Employees" /> <xs:field xpath="employeeid" /> </xs:unique>
The keyref element’s contents consist of two mandatory subelements—selector and field—both of which contain an XPath expression. The selector subelement specifies the node-set across which the values selected by the expression in field must be unique. Put more simply, selector denotes the parent or the child table, and field indicates the parent or the child column. The final XML representation of our sample DataRelation object is shown here:
<xs:unique name="Constraint1"> <xs:selector xpath=".//Employees" /> <xs:field xpath="employeeid" /> </xs:unique> <xs:keyref name="Emp2Terr" refer="Constraint1"> <xs:selector xpath=".//Territories" /> <xs:field xpath="@employeeid" /> </xs:keyref>
This code is functionally equivalent to the msdata:Relationship annotation, but it is completely expressed using the XSD syntax.
Nested Data and Nested Types
The XSD syntax is also important for expressing relations in XML using nested subtrees. Neither msdata:Relationship nor keyref are adequate to express the relation when nested tables are required. Nested relations are expressed using nested types in the XML schema.
In the following code, the Territories type is defined within the Employees type, thus matching the hierarchical relationship between the corresponding tables:
<xs:element name="Employees"> <xs:complexType> <xs:sequence> ⋮ <xs:element name="Territories" minOccurs="0" maxOccurs="unbounded"> <xs:complexType> <xs:sequence> <xs:element name="employeeid" type="xs:int" /> <xs:element name="territoryid" type="xs:string" /> </xs:sequence> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType> </xs:element>
By using keyref and nested types, you have a single syntax—the XML Schema language—to render in XML the contents of any ADO.NET DataRelation object. The Nested property of the DataRelation object specifies whether the relation must be rendered hierarchically—that is, with child rows nested under the parent—or sequentially—that is, with all rows treated as children of the root node.
Important
When reading an XML stream to build a DataSet object, the ReadXml method treats the <msdata:Relationship> annotation and the <xs:keyref> element as perfectly equivalent pieces of syntax. Both are resolved by creating and adding a DataRelation object with the specified characteristics. When ReadXml meets nested types, in the absence of explicit relationship information, it ensures that the resultant DataSet object has tables that reflect the hierarchy of types and creates a DataRelation object between them. This relation is given an auto-generated name and is set on a pair of automatically created columns.