
Chapter 10. Building Systems with Reduced Risk
In Chapter 8, we learned how to mitigate risks that exist within your system and applications. However, there are things you can do to proactively build your applications with a reduced risk profile. This chapter reviews a few of these techniques. This is far from an exhaustive list, but it should at least get you thinking about risk reduction as you build and grow your applications.
Redundancy
Building in redundancy is an obvious step to improving the availability and reliability of your application. This inherently reduces your risk profile as well. However, redundancy can add complexity to an application, which can increase the risk to your application. So, it is important to control the complexity of the additional redundancy to actually have a measurable improvement to your risk profile.
Here are some examples of “safe” redundancy improvements:
-
Design your application so that it can safely run on multiple independent hardware components simultaneously (such as parallel servers or redundant data centers).
-
Design your application so that you can run tasks independently. This can help recovery from failed resources without necessarily adding significantly to the complexity of the application.
-
Design your application so that you can run tasks asynchronously. This makes it possible for tasks to be queued and executed later, without impacting the main application processing.
-
Localize state into specific areas. This can reduce the need for state management in other parts of your application. This reduction in the need for state management improves your ability to utilize redundant components.
-
Utilize idempotent interfaces wherever possible. Idempotent interfaces are interfaces that can be called repeatedly in order to assure an action has taken place, without the need to worry about the implications of the action being executed more than once. Idempotent interfaces facilitate error recovery by using simple retry mechanisms.
Examples of Idempotent Interfaces
Using the example of a car that has an interface to control how fast it goes, the following would be an example of an idempotent interface:
-
Set my current speed to 35 miles per hour
Whereas the following would be an example of a nonidempotent interface:
-
Increase my current speed by 5 miles per hour
The idempotent interfaces can be called multiple times, and only the first call has an effect. Successive or duplicate calls make no change to the speed of the car. Telling the car to go 35 miles per hour repeatedly has no effect over telling it just once. However, nonidempotent interfaces have an impact on the speed of the car each time they are called. Telling a car to increase speed by 5 miles per hour repeatedly will result in a car that is continuously going faster and faster.
With an idempotent interface, a “driver” of this automated car has to tell the car only how fast it should be going. If, for some reason, it believes the request to go 35 miles per hour did not make it to the car, it can simply (and safely) resend the request until it is sure the car received it. The driver can then be assured that the car is, in fact, going 35 miles per hour.
With a nonidempotent interface, if a “driver” of the car wants the car to go 35 miles per hour, it sends a series of commands instructing the car to accelerate until it’s going 35 miles per hour. If one or more of those commands fails to make it to the car, the driver needs some other mechanism to determine the speed of the car and decide whether to reissue an “increase speed” command. It cannot simply retry an increase speed command—it must figure out whether it needs to send the command. This is a substantially more complicated (and error-prone) operation.
Using idempotent interfaces lets the driver perform simpler operations that are less error prone than using a nonidempotent interface.
Redundancy Improvements That Increase Complexity
What are some examples of redundancy improvements that increase complexity? In fact, there are many that might seem useful, but their added complexity can cause more harm than good, at least for most applications.
Consider the example of building a parallel implementation of a system. This way if one of them fails, the other one can be used to implement the necessary features. Although this might be necessary for some applications for which extreme high availability is important (such as the space shuttle), it often is overkill and results in increased complexity, as well. Increased complexity means increased risk.
Another example is overtly separated activities. Microservices are a great model to impove the quality of your application and hence reduce risk. Chapter 12 contains more information on using services and microservices. However, if taken to an extreme, building your systems into too finely decomposed microservices can result in an overall increase in application complexity, which increases risk.
Independence
Multiple components utilizing shared capabilities or components may present themselves as independent components, but in fact, they are all dependent on a common compontent, as shown in Figure 10-1.

Figure 10-1. Dependency on shared components reduces independence
If these shared components are small or unknown, they can inject single point failures into your system.
Consider an application that is running on five independent servers. You are using five servers to increase availability and reduce the risk of a single server failure causing your application to become unavailable. Figure 10-2 shows this application.
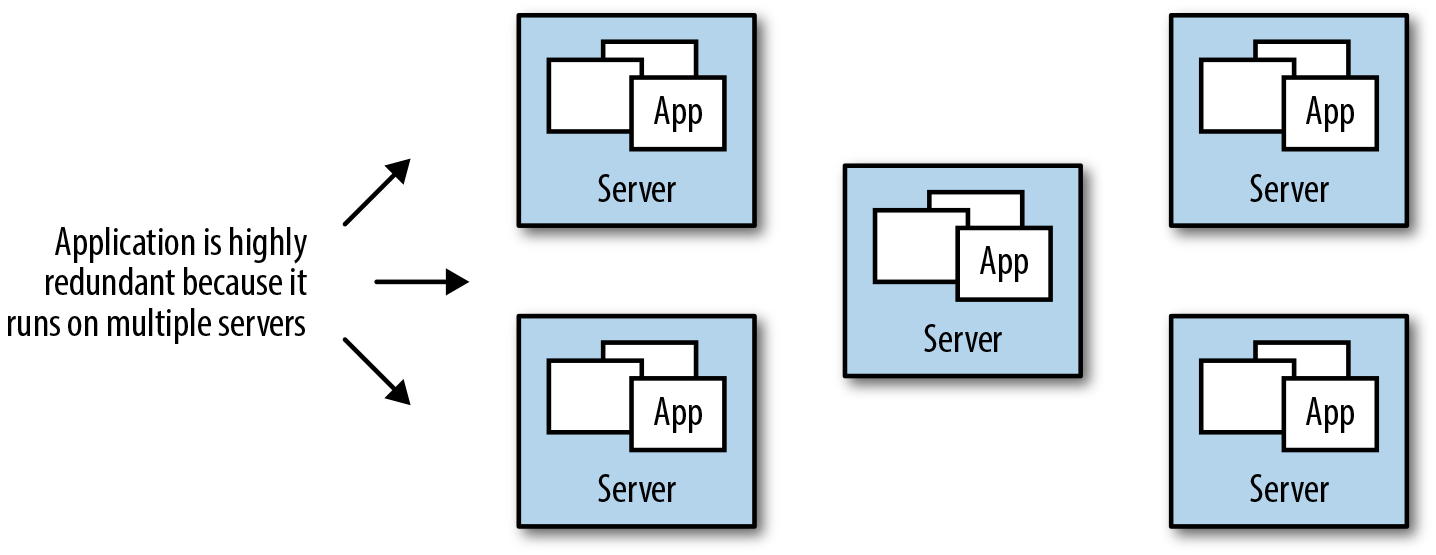
Figure 10-2. Independent servers…
But what happens if those five servers are actually five virtual servers all running on the same hardware server? Or if those servers are running in a single rack? What happens if the power supply to the rack fails? What happens if the shared hardware server fails?
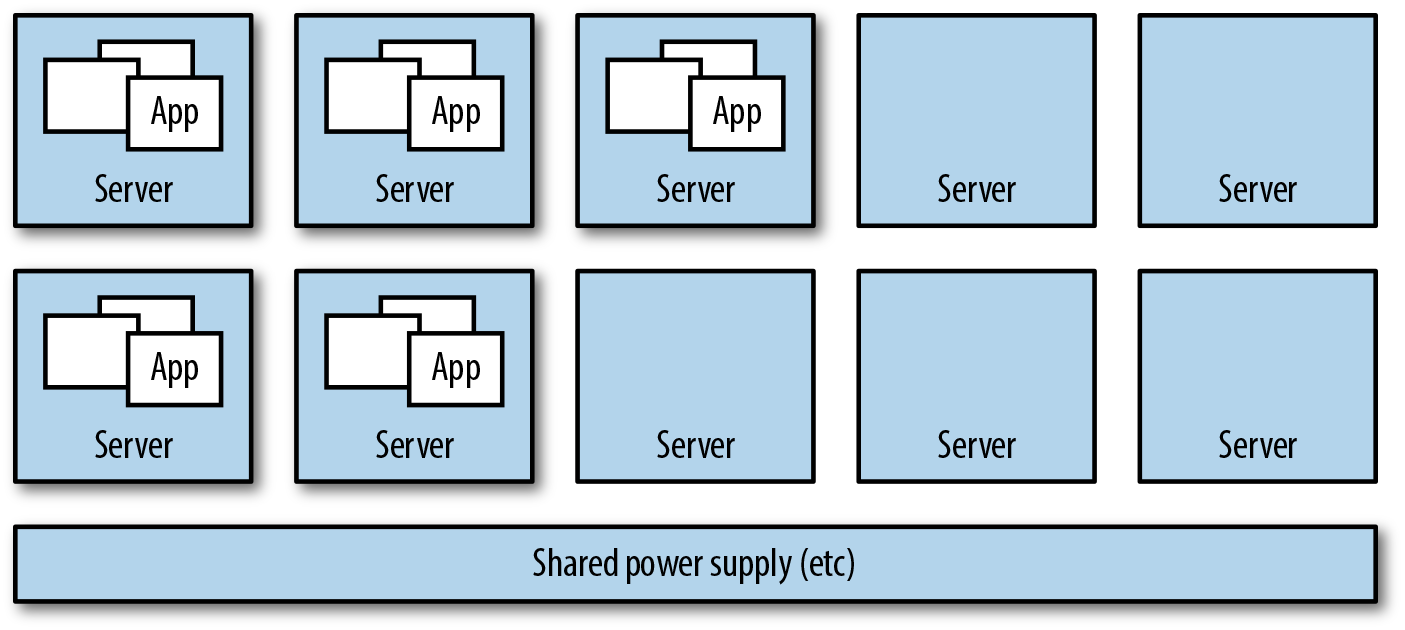
Figure 10-3. …aren’t as independent as you think
Your “independent servers” might not be as independent as you think.
Security
Bad actors have always been a problem in software systems. Security and security monitoring has always been a part of building systems, even before large-scale web applications came about.
However, web applications have become larger and more complicated, storing larger quantities of data and handling larger quantities of traffic. Combined with a higher usefulness to the data available within these applications, this has led to a huge increase in the number of bad actors attempting to compromise our applications. Compromises by bad actors can be directed at acquiring highly sensitive private data, or they can be directed at bringing down large applications and making them unavailable. Some bad actors do this for monetary gain, while others are simply in it for the thrill. Whatever the motivation, whatever the result, bad actors are becoming a bigger problem.
Web application security is well beyond the purview of this book.1 However, implementing high-quality security is imperative to both high availability and mitigating risk of highly scaled applications. The point here is that you should include security aspects of your application in your risk analysis and mitigation, as well as your application development process. However, the specifics of what that includes are beyond the scope of this book.
Simplicity
Complexity is the enemy of stability. The more complex a system becomes, the less stable it is. The less stable, the riskier it becomes and the lower the availability it is likely to have.
Although our applications are becoming larger and significantly more complicated, keeping simplicity in the forefront as you architect and build your application is critical to keep the application maintainable, secure, and low risk.
One common place where modern software construction principles tend to increase complexity more than perhaps is necessary is in microservice-based architectures. Microservice-based architectures reduce the complexity of individual components substantially, making it possible for the individual services to be easily understood and built using simpler techniques and designs. However, although they reduce the complexity of the individual microservice, they increase the number of independent modules (microservices) necessary to build a large-scale application. By having a larger number of independent modules working together, you increase the interdependence on the modules, and increase the overall complexity of the application.
It is important as you build your microservice-based application that you manage the trade-off between simpler individual services and more complex overall system design.
Self-Repair
Building self-righting and self-repairing processes into our applications can reduce the risk of availability outages.
As discussed in Chapter 3, if you strive for 5 nines of availability, you can afford no more than 26 seconds of downtime every month. Even if you only strive for 3 nines of availability, you can afford only 43 minutes of downtime every month. If a failure of a service requires someone to be paged in the middle of the night to find, diagnose, and fix the problem, those 43 minutes are eaten up very quickly. A single outage can result in missing your monthly 3 nines goal. And to maintain 4 nines or 5 nines, you have to be able to fix problems without any human intervention at all.
This is where self-repairing systems come into play. Self-repairing systems sound like high-end, complex systems, but they don’t have to be. A self-repairing system can be nothing more than including a load balancer in front of several servers that reroutes a request quickly to a new server if the original server handling a request fails. This is a self-repairing system.
There are many levels of self-repairing systems, ranging from simple to complex. Here are a few examples:
-
A load balancer that reroutes traffic to a new server when a previous server fails.
-
A “hot standby” database that is kept up to date with the main production database. If the main production database fails or goes offline for any reason, the hot standby automatically picks up the “master” role and begins processing requests.
-
A service that retries a request if it gets an error, anticipating that perhaps the original request suffered a transient problem and that the new request will succeed.
-
A queuing system that keeps track of pending work so that if a request fails, it can be rescheduled to a new worker later, increasing the likelihood of its completion and avoiding the likelihood of losing track of the work.
-
A background process (for example, something like Netflix’s Chaos Monkey) goes around and introduces faults into the system, and the system is checked to make sure it recovers correctly on its own.
-
A service that requests multiple, independently developed and managed services to perform the same calculation. If the results from all services are the same, the result is used. If one (or more) independent service returns a different result than the majority, that result is thrown away and the faulty service is shut down for repairs.
These are just some examples. Note that the more involved systems at the end of the list also add much more complexity to the system. Be careful of this. Use self-repairing systems where you can to provide significant improvement in risk reduction for a minimal cost in complexity. But avoid complicated systems and architectures designed at self-repair that provide a level of reliability higher than you really require, at the cost of increasing the risk and failures that the self-repair system itself can introduce.
Operational Processes
Humans are involved in our software systems, and humans make mistakes. By using solid operational processes, you can minimize the impact of humans in your system, and reducing access by humans to areas where their interaction is not required will reduce the likelihood of mistakes happening.
Use documented, repeatable processes to reduce one significant aspect of the human involvement problem—human forgetfulness: forgetting steps, executing steps out of order, or making a mistake in the execution of a step.
But documented repeatable processes only reduce that one significant aspect to the human involvement problem. Humans can introduce other problems. Humans make mistakes, they “fat finger” the keyboard, they think they know what they are doing when they really don’t. They perform unrepeatable actions. They perform unauditable actions. They can perform bad actions in emotional states.
The more you can automate the processes that humans normally perform in your production systems, the fewer mistakes that can be introduced, and the higher the likelihood that the tasks will work.
1 O’Reilly has many titles available about security and web security.