
Chapter 19. Continuous Improvement
If your application is successful, you’ll need to scale it to handle larger traffic volumes. This requires more novel and complicated mechanisms to handle this increased traffic, and your application quality can suffer under the increased burdens.
Typically, application developers don’t build in scalability from the beginning. We often think we have done what was necessary to let our application scale to the highest levels we can imagine. But, more often than not, we find faults in our application that make scaling to larger traffic volumes and larger datasets less and less possible.
How can we improve the scalability of our applications, even when we begin to reach these limits? Obviously, the sooner we consider scalability in the lifecycle of an application, the easier it will be to scale. But at any point during the lifecycle, there are many techniques you can use to improve the scalability of your application.
This chapter discusses a few of these techniques.
Examine Your Application Regularly
Parts I and II provided extensive coverage on maintaining a highly available application and managing the risk inherent in the application. Before you can consider techniques for scaling your application, you must get your application availability and risk management in shape. Nothing else matters until you make this leap and make these improvements. If you do not implement these changes now, up front, you will find that as your application scales, you will begin to lose touch of how it’s working and random, unexpected problems will begin occurring. These problems will create outages and data loss, and will significantly affect your ability to build and improve your application. Furthermore, as traffic and data increases, these problems simply become worse. Before doing anything else, get your availability and risk management in order.
Microservices
In Part III, we discussed service- and microservice-oriented architectures. Although there are many different architectural decisions you need to make and architectural directions you need to set, make the decision early to move away from a monolithic or multimonolithic architecture and move instead to some form of a service-oriented architecture.
Service Ownership
While you move to a service-based architecture, also move to a distributed ownership model whereby individual development teams own all aspects of the services for which they are responsible. This distributed ownership will improve the ability of your application to scale to the appropriate size, from a code complexity standpoint, a traffic standpoint, and a dataset size standpoint. Ownership is discussed in greater detail in Chapter 15.
Stateless Services
As you build and migrate your application to a service-based architecture, be mindful of where you store data and state within your system.
Stateless services are services that manage no data and no state of their own. The entire state and all data that the service requires to perform its actions is passed in (or referenced) in the request sent to the service.
Stateless services offer a huge advantage for scaling. Because they are stateless, it is usually an easy matter to add additional server capacity to a service in order to scale it to a larger capacity, both vertically and horizontally. You get maximum flexibility in how and when you can scale your service if your service does not maintain state.
Additionally, certain caching techniques on the frontend of the service become possible if the cache does not need to concern itself with service state. This caching lets you handle higher scaling requirements with fewer resources.
Where’s the Data?
When you do need to store data, given what we just discussed in the preceding section, it might seem obvious to store data in as few services and systems as possible. It might make sense to keep all of your data close to one another to reduce the footprint of what services have to know and manage your data.
Nothing could be farther from the truth.
Instead, localize your data as much as possible. Have services and data stores manage only the data they need to manage to perform their jobs. Other data should be stored in different servers and data stores, closer to the services that require this data.
Localizing data this way provides a few benefits:
- Reduced size of individual datasets
-
Because your data is split across datasets, each dataset is smaller in size. Smaller dataset size means reduced interaction with the data, making scalability of the database easier. This is called functional partitioning. You are splitting your data based on functional lines rather than on size of the dataset.
- Localized access
-
Often when you access data in a database or data store, you are accessing all the data within a given record or set of records. Often, much of that data is not needed for a given interaction. By using multiple reduced dataset sizes, you reduce the amount of unneeded data from your queries.
- Optimized access methods
-
By splitting your data into different datasets, you can optimize the type of data store appropriate for each dataset. Does a particular dataset need a relational data store? Or is a simple key/value data store acceptable?
Data Partitioning
Data partitioning can mean many things. In this context, it means partitioning data of a given type into segments based on some key within the data. It is often done to make use of multiple databases to store larger datasets or datasets accessed at a higher frequency than a single database can handle.
There are other types of data partitioning (such as the aforementioned functional partitioning); however, in this section, we are going to focus on this key-based partitioning scheme.
A simple example of data partitioning is to partition all data for an application by account, so that all data for accounts whose name begins with A–D is in one database, all data for accounts whose name begins with E–K is in another database, and so on (see Figure 19-1).1 This is a very simplistic example, but data partitioning is a common tool used by application developers to dramatically scale the number of users who can access the application at once as well as scale the size of the dataset itself.
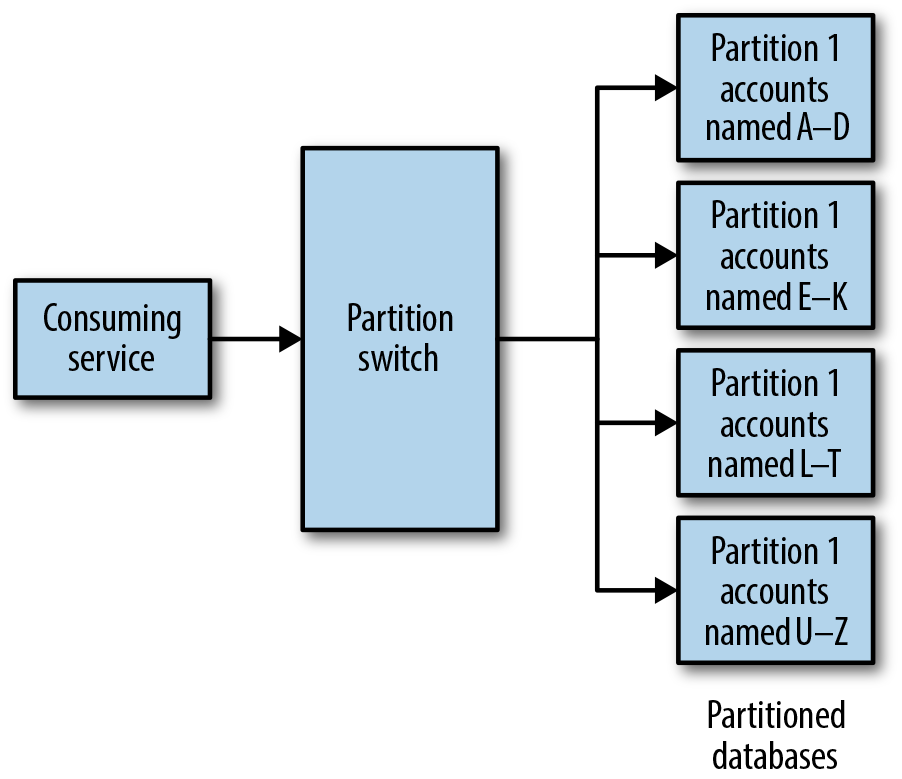
Figure 19-1. Example of data partitioning by account name
In general, you should avoid data partitioning whenever possible. Why? Well, whenever you partition data this way, you run into several potential issues:
-
You increase the complexity of your application because you now have to determine where your data is stored before you can actually retrieve it.
-
You remove the ability to easily query data across multiple partitions. This is specifically useful in doing business analysis queries.
-
Choosing your partitioning key carefully is critical. If you chose the wrong key, you can skew the usage of your database partitions, making some partitions run hotter and others colder, reducing the effectiveness of the partitioning while complicating your database management and maintenance. This is illustrated in Figure 19-2.
-
Repartitioning is occasionally necessary to balance traffic across partitions effectively. Depending on the key chosen and the type and size of the dataset, this can prove to be an extremely difficult task, an extremely dangerous task (data migration), and in some cases, a nearly impossible task.
In general, account name or account ID is almost always a bad partition key (yet it is one of the most common keys choosen). This is because a single account can change in size during the life of that account. An account might begin small and can easily fit on a partition with a significant number of small accounts. However, if it grows over time, it can soon cause that single partition to not be able to handle all of the load appropriately, and you’ll need to repartition in order to better balance account usage. If a single account grows too large, it can actually be bigger than what can fit on a single partition, which will make your entire partitioning scheme fail, because no rebalancing will solve that problem. This is demonstrated in Figure 19-2.
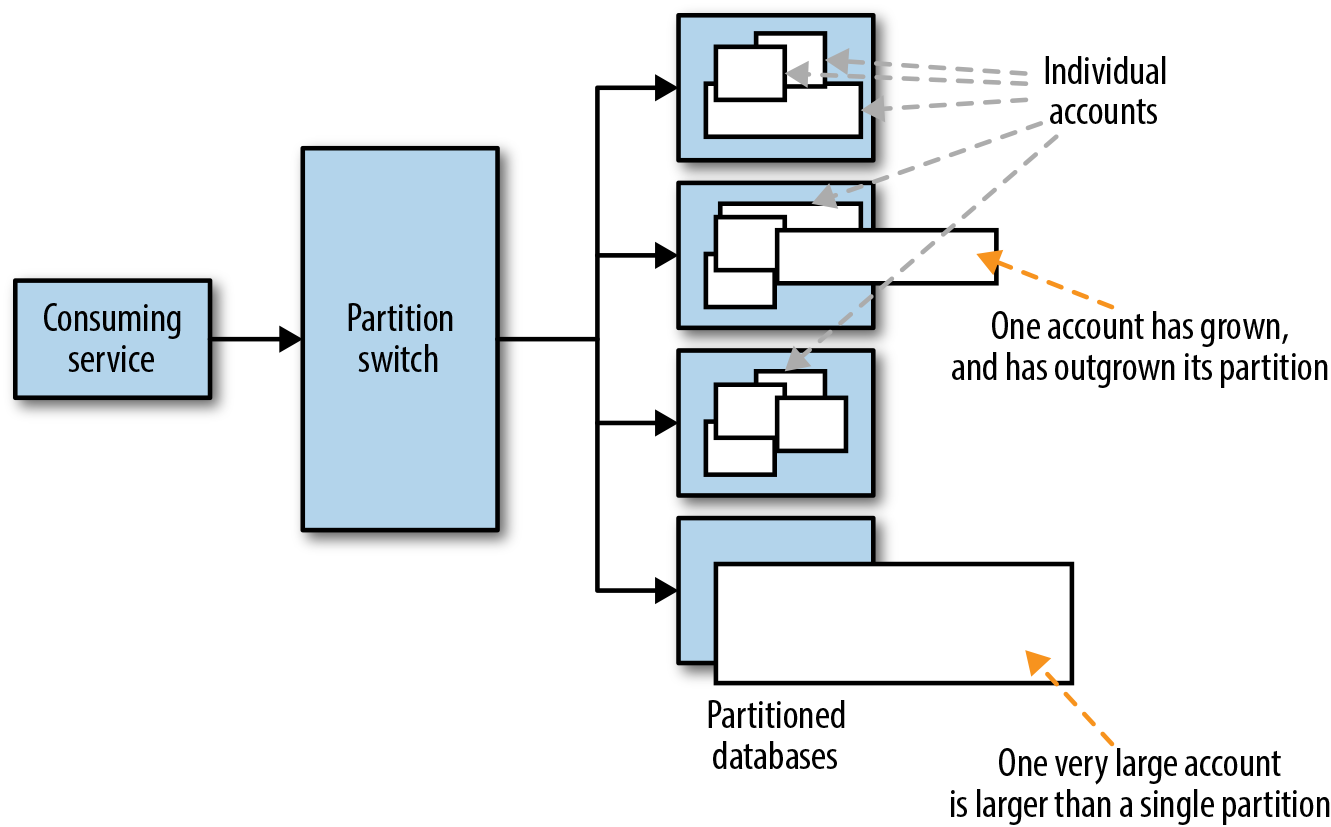
Figure 19-2. Example of accounts overrunning data partitions
A better partition key would be one that would result in consistently sized partitions as much as possible. Growth of partitions should be as independent and consistent as possible, as shown in Figure 19-3. If repartitioning is needed, it should be because all partitions have grown consistently and are too big to be handled by the database partition.
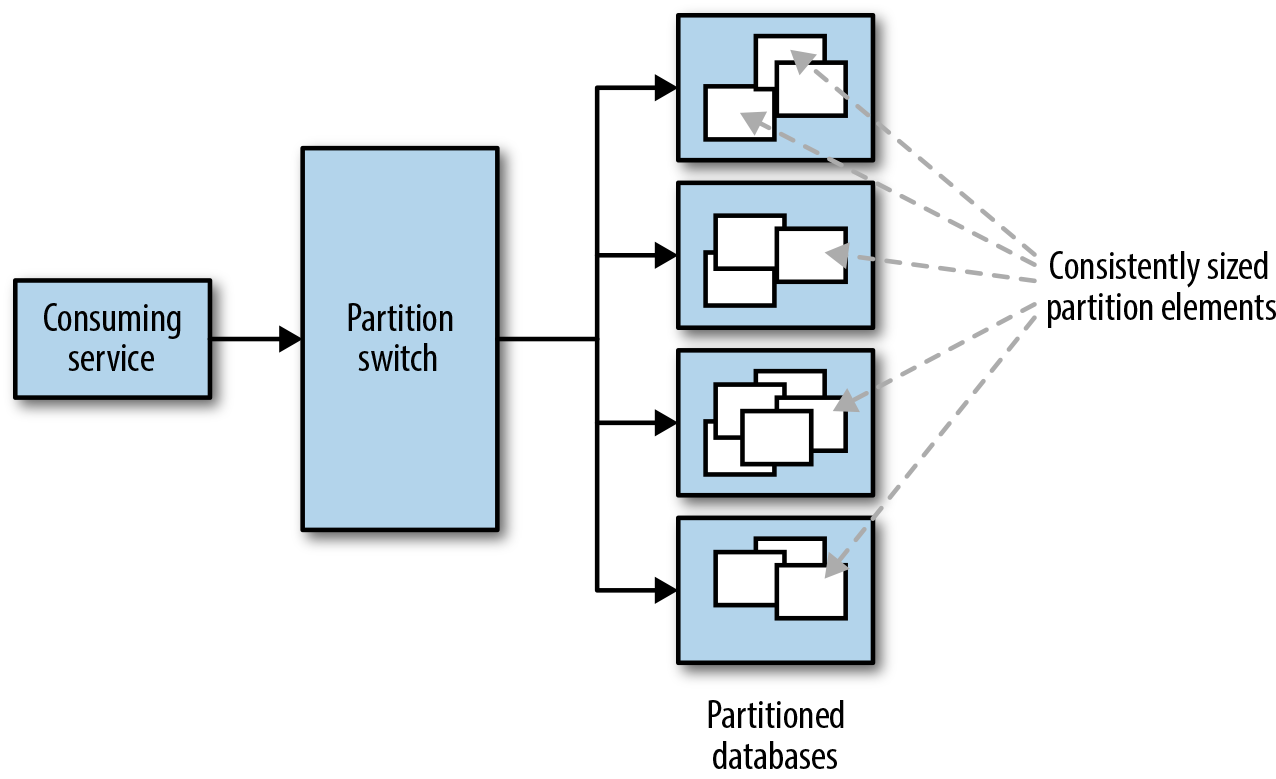
Figure 19-3. Example of consistently sized partitioned elements
One potentially useful partitioning scheme is to use a key that generates a significant number of small elements. Next, map these small partitions onto larger partitioned databases. Then, if repartitioning is needed, you can simply update the mapping and move individual small elements to new partitions, removing the need for a massive repartitioning of the entire system.2
The Importance of Continuous Improvement
Most modern applications experience growth in their traffic requirements, in the size and complexity of the application itself, and in the number of people working on the application.
Often, we ignore these growing pains until the pain reaches a certain threshold before we attempt to deal with it. However, by that point, it is usually too late. The pain has reached a serious level and many easy techniques to help reduce the growing pains are no longer available for you to use.
By thinking about how your application will grow long before it grows to those painful levels, you can preempt many problems and build and improve your applications so that they can handle these growing pains safely and securely.
1 A more likely account-based partitioning mechanism would be to partition by an account identifier rather than the account name. However, using account name makes this example easier to follow.
2 Selecting and utilizing appropriate partition keys is an art in and of itself, and is the subject of many books and articles.