
Chapter 11. Why Use Services?
Traditionally, applications appear as single, large, distinct monoliths. The single monolith encompasses all business activities for a single application. To implement an improved piece of business functionality, an individual developer must make changes within the single application, and all developers making changes must make them within the same single application. Developers can easily step on one another’s toes, and make conflicting changes that result in problems and outages.
In a service-oriented architecture, individual services are created that encompass a specific subset of business logic. These individual services are interconnected to provide the entire set of business logic for the application.
The Monolith Application
Figure 11-1 shows an application that is a large, single entity with a complex, indecipherable infrastructure.
This is how most applications begin to look if they are constructed and grow as monolithic applications. In Figure 11-1, you see there are five independent development teams working on overlapping areas of the application. It is impossible to know who is working on what piece of the application at any point in time, and code-change collisions and problems are easy to imagine. Code quality and hence application quality and availability suffer. Additionally, it becomes more and more difficult for individual development teams to make changes without having to deal with the effect of other teams, incompatible changes, and a molasses effect to the organization as a whole.

Figure 11-1. A large, complex, monolithic application
The Service-Based Application
Figure 11-2 presents the same application constructed as a series of services.
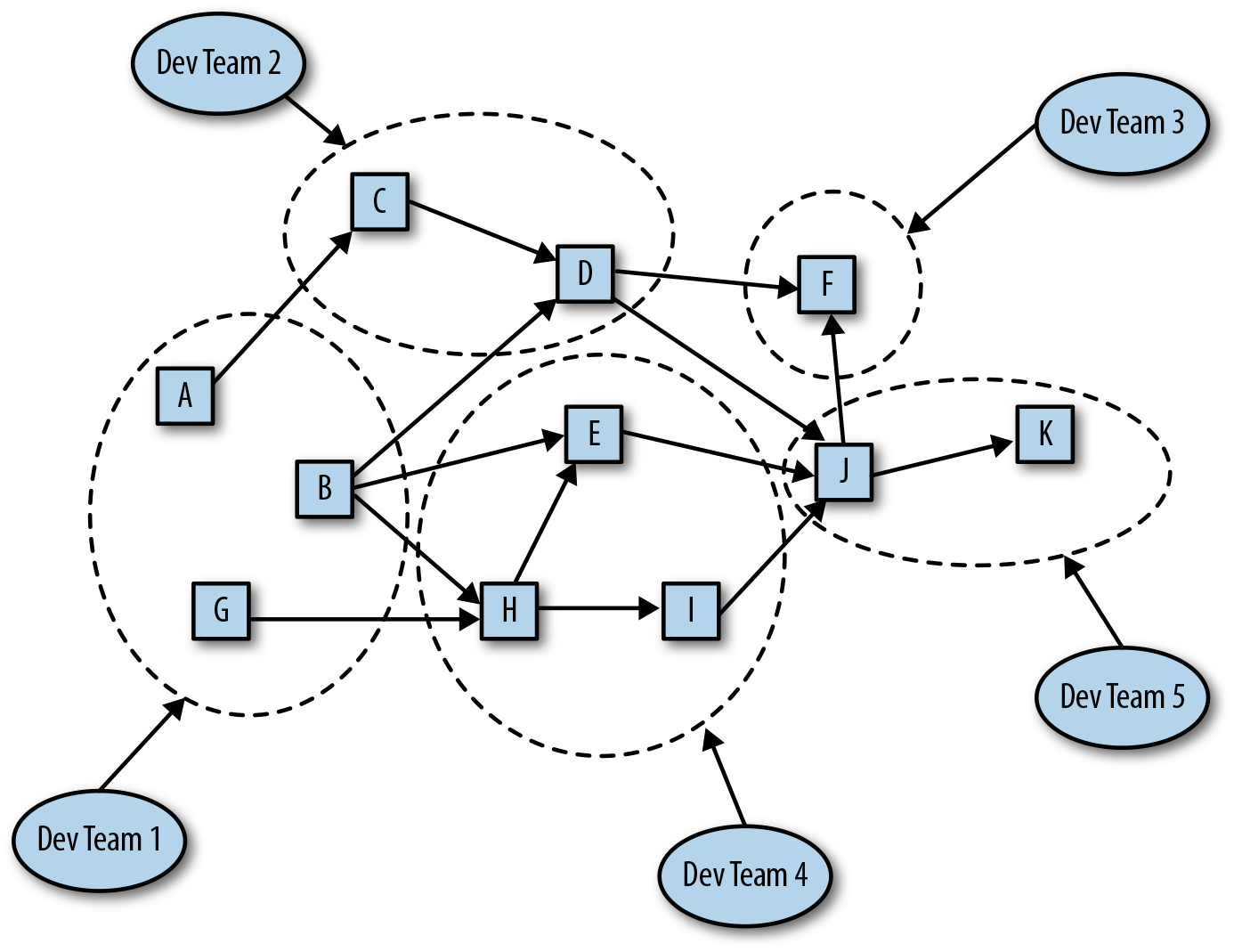
Figure 11-2. A large, complex, service-based application
Each service has a clear owner, and each team has a clear, nonoverlapping set of responsibilities.
Service-oriented architectures provide the ability to split an application into distinct domains that are each managed by individual groups within your organization. They enable the separation of responsibilities that are critical for building highly scaled applications, allowing work to be done independently on individual services without affecting the work of developers in other groups working on the same overall application.
When building highly scaled applications, service-based applications provide the following benefits:
- Scaling decisions
-
This makes it possible for scaling decisions to be made at a more granular level, which fosters more efficient system optimization and organization.
- Team assignment and focus
-
This lets you assign capabilities to individual teams in such a way that teams can focus on the specific scaling and availability requirements of their system in-the-small and have confidence that their decisions will have the appropriate impact at the larger scale.
- Complexity localization
-
Using service-based architectures, you can think about services as black boxes, making it so that only the owners of the service need to understand the complexity within that service. Other developers need only know what capabilities your service provides, without knowing anything about how it works internally. This compartmenting of knowledge and complexity facilitates the creation of larger applications and lets you manage them effectively.
- Testing
-
Service-based architectures are easier to test than monolithic applications, which increases your reliability.
Note
Service-oriented architectures can, however, increase the complexity of your system as a whole if the service boundaries are not designed properly. This complexity can lead to lower scalability and decreased system availability. So, picking appropriate service and service boundaries is critical.
The Ownership Benefit
Let’s take a look at a pair of services.
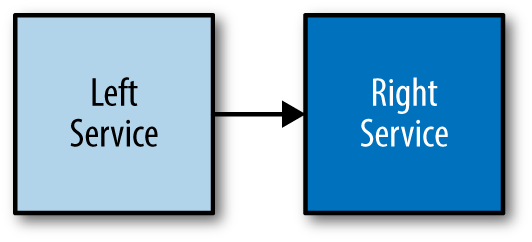
In Figure 11-3, we see two services owned by two distinct teams. The Left Service is consuming the capabilities exposed by the Right Service.

Figure 11-3. A pair of services
Let’s look at this diagram from the perspective of the Left Service owner. Obviously, that team needs to know the entire structure, complexity, connectedness, interactions, code, and so on for their service. But what does it need to know about the Right Service? As a start, the team needs to know the following:
-
The capabilities provided by the service.
-
How to call those capabilities (the API syntax).
-
The meanings and results of calling those capabilities (the API semantics).
That’s the basic information that the Left Service team needs to know. What don’t they need to know about the Right Service? Lots of things, for example:
-
They do not need to know whether the Right Service is a single service, or a construction of many subservices.
-
They do not need to know what services the Right Service depends on to perform its responsibilities.
-
They do not need to know what language(s) the Right Service is written in.
-
They do not need to know what hardware or system infrastructure is needed to operate the Right Service.
-
They do not even need to know who is operating the Right Service (however, they do need to know how to contact the owner in case there are issues with it).
The Right Service can be as complex or simple as needed, as shown in Figure 11-4. But to the owners of the Left Service, the Right Service can be thought of as nothing more than a black box, as shown in Figure 11-5. As long as they know what the interface to the box is (the API), they can use the capabilities the black box provides.

Figure 11-4. What’s inside the Right Service
To manage this, the Left Service must be able to depend on a contract that the Right Service provides. This contract describes everything the Left Service needs to use the Right Service.
The contract contains two parts:
- The capabilities of the service (the API)
-
-
What the service does
-
How to call it and what each call means
-
- The responsiveness of the service
-
-
How often can the API be used?
-
When can it be used?
-
How fast will the API respond?
-
Is the API dependable?
-
All of this information describes the contract that the owners of the Right Service provide to the Left Service describing how the Right Service operates. As long as the Right Service behaves to this contract, the Left Service doesn’t have to know or care anything about how the Right Service performs those commitments.
The last part of the contract, the responsiveness part, is called a service-level agreement, or SLA. It is a critical component in allowing the Left Service to depend on the Right Service without knowing anything about how the Right Service works.
We discuss SLAs in great detail in Chapter 18.
By having a clear ownership for each service, teams can focus on only those portions of the system for which they are responsible, along with the API contracts provided by the service owners of the services they depend on. This separation of responsibility makes it easier to scale your organization to contain many more teams; because the coupling between the teams is substantially looser, it doesn’t matter as much how far away (organizationally or physically) one team is from another. As long as the contracts are maintained, you can scale your organization as needed to build larger and more complicated applications.
The Scaling Benefit
Different parts of your application have different scaling needs. The component that generates the home page of your application will be used much more often than the component that generates the user settings page.
By using services with clear APIs and API contracts between them, you can determine and implement the scaling needs required for each service independently. This means that if your home page is the most frequently called page, you can provide more hardware to run that service than the service that manages your user settings page.
By managing the scaling needs of each service independently, you can do the following:
-
Provide more accurate scaling by having the team that owns the specific capability involved closely in the scaling decision.
-
Save system resources by not scaling one component simply because another component requires it.
-
Provide ownership of scaling decisions back to the team that knows the most about the needs of the service (the service owner).