
Chapter 11. Antivirus Defense Techniques
“ But who is to guard the guards themselves?”
—Juvenal
This chapter is a collection of techniques that were deployed in antivirus software to protect against computer viruses. In particular, antivirus scanner techniques will be discussed, which have evolved with computer virus attacks during the last 15 years. During the long evolution of antivirus software, these common techniques became fine-tuned and widely used. Although other methods will likely emerge, those collected in this chapter have been in use long enough to remain the core of antivirus software for the foreseeable future.
I will provide examples of computer virus detection in order of increasing complexity:
• Simple pattern-based virus detection
• Exact identification
• Detection of encrypted, polymorphic, and metamorphic viruses1
I will also illustrate the use of generic and heuristic methods2 that can detect classes of computer viruses rather than only specific variants. This chapter also will familiarize you with repair techniques (including generic and heuristic methods) that are used to restore the clean state of infected files. State-of-the-art antivirus software uses sophisticated code emulation (virtual machine) for heuristics3 as well as complex virus detections. It is crucial to understand this critical component of the antivirus software because this is the “secret weapon” that has kept antivirus scanners alive for so long.
There are two basic kinds of scanners: on-demand and on-access scanners. On-demand scanning is executed only at the user's request. On-demand scanning can also be loaded from system startup points and similar locations to achieve better success in virus detection. On the other hand, on-access scanners are memory-resident. They load as a simple application and hook interrupts related to file and disk access, or they are implemented as device drivers that attach themselves to file systems4. For example, on Windows NT/2000/XP/2003 systems, on-access scanners are typically implemented as file-system filter drivers that attach themselves to file systems such as FAT, NTFS, and so on.
Figure 11.1 demonstrates a loaded file system filter driver attached to a set of file systems using a tool from OSR.
Figure 11.1. File system filter drivers attached to file system drivers.

On-access scanners typically scan files when they are opened, created, or closed. In this way, the virus infection can be prevented if a known virus is executed on the system. An interesting problem is caused by network infectors such as W32/Funlove. Funlove infects files across network shares. Thus the infections on the remote system will be detected only if the file is already written to the disk. This means that in some circumstances, even the on-access scanners have trouble stopping viruses effectively.
Note
This risk can be reduced further by scanning the disk cache before the file is written to the disk. Furthermore, other defense methods, such as behavior blocking or network intrusion prevention software, can be used.
This chapter focuses on techniques that prevent, detect, and repair viruses in files or file system areas. Other generic solutions are also subject of this chapter, including the following:
• On-demand integrity checkers
• On-access integrity shells
• Behavior blockers
• Inoculation
11.1 First-Generation Scanners
Most computer books discuss virus detection at a fairly simple level. Even newer books describe antivirus scanners as simple programs that look for sequences of bytes extracted from computer viruses in files and in memory to detect them. This is, of course, one of the most popular methods to detect computer viruses, and it is reasonably effective. Nowadays, state-of-the-art antivirus software uses a lot more attractive features to detect complex viruses, which cannot be handled using first-generation scanners alone. The next few sections show examples of detection and identification methods that can be applied to detect computer viruses.
Note
Not all the techniques can be applied to all computer viruses. However, doing so is not a requirement. It is enough to have an arsenal of techniques, one of which will be a good solution to block, detect, or disinfect a particular computer virus. This fact is often overlooked by security professionals and researchers, who might argue that if one technique cannot be used all the time, it is completely ineffective.
11.1.1 String Scanning
String scanning is the simplest approach to detecting computer viruses. It uses an extracted sequence of bytes (strings) that is typical of the virus but not likely to be found in clean programs. The sequences extracted from computer viruses are then organized in databases, which the virus scanning engines use to search predefined areas of files and system areas systematically to detect the viruses in the limited time allowed for the scanning. Indeed, one of the most challenging tasks of the antivirus scanning engine is to use this limited time (typically no more than a couple of seconds per file) wisely enough to succeed.
Consider the code snippet shown in Figure 11.2, selected from a variant of the Stoned boot virus using IDA (the interactive disassembler).
Figure 11.2. A code snippet of the Stoned virus loaded to IDA.
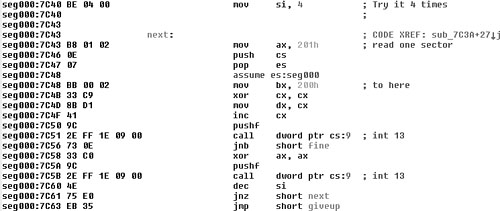
The actual code reads the boot sector of the diskettes up to four times and resets the disk between each try.
Note
The virus needs to call the original INT 13 disk handler because the virus monitors the same interrupt to infect diskettes whenever they are accessed. Thus the virus makes a call to CS:[09], right into the data areas in the front of the virus code at 0:7C09, where the original handler was previously stored. Indeed, there are a few bytes of data in the front section of the virus code, but the rest of the virus code remains constant.
This is a typical code sequence of the virus. The four attempts to read the first sector are necessary because older diskette drives were too slow to speed up. The virus uses the PUSH CS, POP ES instruction pair to set the disk buffer to the virus segment.
Notice that the code style appears to be a failing optimization attempt to set the contents of CX and DX registers, which are both parameters of the disk interrupt handler call.
Thus a possible pattern extracted from the Stoned virus is the following 16 bytes, which is the search string that was published in Virus Bulletin magazine:
0400 B801 020E 07BB 0002 33C9 8BD1 419C
Sixteen unique bytes is usually a long enough string to detect 16-bit malicious code safely, without false positives. Not surprisingly, computer virus research journals such as the Virus Bulletin published sequences that were typically 16 bytes long to detect boot and DOS viruses. Longer strings might be necessary to detect 32-bit virus code safely, especially if the malicious code is written in a high-level language.
The previous code sequence could appear in other Stoned virus variants. In fact, several minor variants of Stoned, such as A, B, and C, can be detected with the preceding string. Furthermore, this string might be able to detect closely related viruses that belong to a different family. On the one hand, this is an advantage because the scanner using the string is able to detect more viruses. On the other hand, this could be a serious disadvantage to the user because a completely different virus might be incorrectly detected as Stoned. Thus the user might think that the actual virus is relatively harmless, but the misidentified virus is probably much more harmful.
Identification problems might lead to harmful consequences. This can happen easily if the virus scanner also attempts to disinfect the detected-but-not-identified virus code. Because the disinfections of two different virus families—or even two minor variants of the same virus—are usually different, the disinfector can easily cause problems.
For example, some minor variants of Stoned store the original master boot sector on sector 7, but other variants use sector 2. If the antivirus program does not check carefully, at least in its disinfection code, whether the repair routine is compatible with the actual variant in question, the antivirus might make the system unbootable when it disinfects the system.
Several techniques exist to avoid such problems. For example, some of the simple disinfectors use bookmarks in the repair code to ensure that the disinfection code is proper for the virus code in question.
11.1.2 Wildcards
Wildcards are often supported by simple scanners. Typically, a wildcard is allowed to skip bytes or byte ranges, and some scanners also allow regular expressions.
0400 B801 020E 07BB ??02 %3 33C9 8BD1 419C
The preceding string would be interpreted the following way:
- Try to match 04 and if found continue.
- Try to match 00 and if found continue.
- Try to match B8 and if found continue.
- Try to match 01 and if found continue.
- Try to match 02 and if found continue.
- Try to match 0E and if found continue.
- Try to match 07 and if found continue.
- Try to match BB and if found continue.
- Ignore this byte.
- Try to match 02 and if found continue.
- Try to match 33 in any of the following 3 positions and if matched continue.
- Try to match C9 and if found continue.
- Try to match 8B and if found continue.
- Try to match D1 and if found continue.
- Try to match 41 and if found continue.
- Try to match 9C and if found report infection.
Wildcard strings are often supported for nibble bytes, which allow more precise matches of instruction groups. Some early-generation encrypted and even polymorphic viruses can be detected easily with wildcard-based strings.
Evidently, even the use of Boyer-Moore algorithm5 alone is not efficient enough for string scanners. This algorithm was developed for fast string searching and takes advantage of backward string matching. Consider the following two words of equivalent length:
CONVENED and CONVENER
If the two strings are compared from the front, it takes seven matches to find the first mismatch. Starting from the end of the string, the first attempt is a mismatch, which significantly reduces the number of matches that must be performed because a number of match positions can be ignored automatically.
Note
Interestingly, Boyer-Moore algorithm does not work very well in network IDS systems because the backward comparison can force out-of-packet comparison overhead.
Similar success, however, can be achieved based on bookmark techniques explained later. Furthermore, with the use of filtering6 and hashing algorithms, scanning speed can become virtually independent of the number of scan strings that need to be matched.
11.1.3 Mismatches
Mismatches in strings were invented for the IBM Antivirus. Mismatches allow N number of bytes in the string to be any value, regardless of their position in the string. For example, the 01 02 03 04 05 07 08 09 string with the mismatch value of 2 would match any of the following patterns, as shown in Figure 11.3.
Figure 11.3. A set of strings that differ in 2 mismatches.

Mismatches are especially useful in creating better generic detections for a family of computer viruses. The downside of this technique is that it is a rather slow scanning algorithm.
11.1.4 Generic Detection
Generic detection scans for several or all known variants of a family of computer viruses using a simple string (and in some cases an algorithmic detection that requires some special code besides standard scanning). When more than one variant of a computer virus is known, the set of variants is compared to find common areas of code. A simple search string is selected that is available in as many variants as possible. Typically, a generic string contains both wildcards and mismatches.
11.1.5 Hashing
Hashing is a common term for techniques that speed up searching algorithms. Hashing might be done on the first byte or 16-bit and 32-bit words of the scan string. This allows further bytes to contain wildcards. Virus researchers can control hashing even better by being selective about what start bytes the string will contain. For example, it is a good idea to avoid first bytes that are common in normal files, such as zeros. With further efforts, the researcher can select strings that typically start with the same common bytes, reducing the number of necessary matches.
To be extremely fast, some string scanners do not support any wildcards. For example, the Australian antivirus VET uses an invention of Roger Riordan7, which is based on the use of 16-byte scan strings (with no wildcards allowed) based on a 64KB hash table and an 8-bit shift register. The algorithm uses each 16-bit word of the string as an index into the hash table.
A powerful hashing was developed by Frans Veldman in TBSCAN. This algorithm allows wildcards in strings but uses two hash tables and a corresponding linked list of strings. The first hash table contains index bits to the second hash table. The algorithm is based on the use of four constant 16-bit or 32-bit words of the scan strings that do not have wildcards in them.
11.1.6 Bookmarks
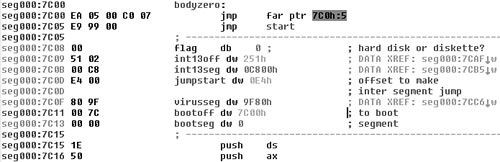
Bookmarks (also called check bytes) are a simple way to guarantee more accurate detections and disinfections. Usually, a distance in bytes between the start of the virus body (often called the zero byte of the body) and the detection string is calculated and stored separately in the virus detection record.
Good bookmarks are specific to the virus disinfection. For example, in the case of boot viruses, someone might prefer to select a set of bookmarks that point to references of the locations of the stored boot sectors. Staying with the previous example string for Stoned, the distance between the start of the virus body and the string is 0x41 (65) bytes. Now, look at the snippet of Stoned shown in Figure 11.4. The code reads the stored boot sector according to a flag. In case of the hard disk, the stored boot sector is loaded and executed from head 0, track 0, and sector 7 from drive C:. In case of the diskettes, the end of the root directory sector is loaded from head 0, track 3, and sector 1 from drive A:.
Figure 11.4. Another code snippet of the Stoned virus loaded to IDA.

The following could be a good set of bookmarks:
• The first bookmark can be picked at offset 0xFC (252) of the virus body, where the byte 0x07 can be found.
• The second bookmark can be selected at offset 0x107 (263) of the virus body, where the byte 0x03 can be found.
You can find these bytes at offset 0x7CFC and 0x7D07 in the preceding disassembly. Remember that the virus body is loaded to offset 0x7C00.
Note
In the case of file viruses, it is a good practice to choose bookmarks that point to an offset to the stored original host program header bytes. Additionally, the size of the virus body stored in the virus is also a very useful bookmark.
You can safely avoid incorrectly repairing the virus by combining the string and the detection of the bookmarks. In practice, it is often safe to repair the virus based on this much information. However, exact and nearly exact identification further refine the accuracy of such detection.
11.1.7 Top-and-Tail Scanning
Top-and-tail scanning is used to speed up virus detection by scanning only the top and the tail of a file, rather than the entire file. For example, the first and last 2, 4, or even 8KB of the file is scanned for each possible position. This is a slightly better algorithm than those used in early scanner implementations, which worked very similarly to GREP programs that search the content of the entire file for matching strings. As modern CPUs became faster, scanning speed typically became I/O bound. Thus to optimize the scanning speed, developers of antivirus programs looked for methods to reduce the number of disk reads. Because the majority of early computer viruses prefixed, appended, or replaced host objects, top-and-tail scanning became a fairly popular technique.
11.1.8 Entry-Point and Fixed-Point Scanning
Entry-point and fixed-point scanners made antivirus scanners even faster. Such scanners take advantage of the entry point of objects, such as those available via the headers of executable files. In structureless binary executables such as DOS COM files, such scanners follow the various instructions that transfer control (such as jump and call instructions) and start scanning at the location to which such instructions point.
Because this location is a common target of computer viruses, such scanners have major advantages. Other scanning methods, such as top-and-tail scanning, must mask the strings (or hashes of strings) to each scanned position of the scanned area, but entry-point scanners typically have a single position to mask their scan strings: the entry point itself.
Consider a 1KB-long size for a buffer called B. The number of positions to start a string match in B is 1,024–S, where S is the size of the shortest string to match. Even if the hashing algorithm of the scanner is so efficient that the scanner needs to perform a complete string search at a given position only 1% of the time, the number of computations could increase quickly, according to the number of strings. For example, with 1,000 strings, the scanner might need to make 10 complete matches for each possible position. Thus (1,024–S)x10 is a possible number of minimum matches required. Indeed, the 1,024–S multiplier can be dropped using fixed-point scanning with a single match position at the entry point. This is a very significant difference.
If the entry point does not have good enough strings, fixed-point scanning can come to the rescue. Fixed-point scanning uses a match position with each string. Thus it is possible to set a start position M (for example, the main entry point of the file) and then match each string (or hash) at positions M+X bytes away from this fixed point. Again, the number of necessary computations is reduced because X is typically 0. As a bonus, such scanners also can reduce significantly the disk I/O.
I used this technique in my own antivirus program. Each string of Pasteur required only a single, fixed start and ending byte, as well as a constant size. Wildcards were supported but only in a limited way. The strings were sorted into several tables according to object types. String matching picked the first byte of the entry point and checked whether there were any such start bytes for any strings using a hash vector. If there were no such first bytes, the next entry point was selected until there were no more entry points.
Because the size of each string was constant, the algorithm could also check whether the last byte of the string matched the corresponding location in the file being scanned. If the last byte of the string matched, only then was a complete string match performed. However, this rarely happened in practice. This trick is somewhat similar to the idea of the Boyer-Moore algorithm combined with simple hashing.
11.1.9 Hyperfast Disk Access
Hyperfast disk access was another useful technique in early scanner implementations. This was used by TBSCAN, as well as the Hungarian scanner VIRKILL, based on my inspiration. These scanners optimize scanning by bypassing operating system–level APIs to read the disk directly with the BIOS. Because MS-DOS was especially slow in handling FAT file systems, a ten-times-faster file I/O could be achieved using direct BIOS reads instead of DOS function calls. In addition, this method was often useful as an antistealth technique. Because file infector stealth viruses typically bypassed only DOS-level file access, the file changes could be seen via BIOS access in most, but not all, cases. Other scanners and integrity checkers even talked directly to the disk controllers for reasons of speed and security.
Unfortunately, nowadays these methods cannot be used easily (or at all) on all operating systems. Not only are there too many file systems that must be recognized and supported, there are also a variety of disk controllers, making such a task almost impossible.
11.2 Second-Generation Scanners
Second-generation scanners use nearly exact and exact identification, which helps to refine the detection of computer viruses and other malicious programs.
11.2.1 Smart Scanning
Smart scanning was introduced as computer virus mutator kits appeared. Such kits typically worked with Assembly source files and tried to insert junk instructions, such as do-nothing NOP instructions, into the source files. The recompiled virus looked very different from its original because many offsets could change in the virus.
Smart scanning skipped instructions like NOP in the host program and did not store such instructions in the virus signature. An effort was made to select an area of the virus body that had no references to data or other subroutines. This enhanced the likelihood of detecting a closely related variant of the virus.
This technique is also useful in dealing with computer viruses that appeared in textual forms, such as script and macro viruses. These computer viruses can easily change because of extra white spaces (such as the Space, CR/LF, and TAB characters, and so on). These characters can be dropped from the scanned buffers using smart scanning, which greatly enhances the scanner's detection capabilities.
11.2.2 Skeleton Detection
Skeleton detection was invented by Eugene Kaspersky. Skeleton detection is especially useful in detecting macro virus families. Rather than selecting a simple string or a checksum of the set of macros, the scanner parses the macro statements line to line and drops all nonessential statements, as well as the aforementioned white spaces. The result is a skeleton of the macro body that has only essential macro code that commonly appear in macro viruses. The scanner uses this information to detect the viruses, enhancing variant detection of the same family.
11.2.3 Nearly Exact Identification
Nearly exact identification is used to detect computer viruses more accurately. For example, instead of one string, double-string detection is used for each virus. The following secondary string could be selected from offset 0x7CFC in the previous disassembly to detect Stoned nearly exactly:
0700 BA80 00CD 13EB 4990 B903 00BA 0001
The scanner can detect a Stoned variant if one string is detected and refuse disinfection of the virus because it could be a possibly unknown variant that would not be disinfected correctly. Whenever both strings are found, the virus is nearly exactly identified. It could be still a virus variant, but at least the repair of the virus is more likely to be proper. This method is especially safe when combined with additional bookmarks.
Another method of nearly exact identification is based on the use of a checksum (such as a CRC32) range that is selected from the virus body. Typically, a disinfection-specific area of the virus body is chosen and the checksum of the bytes in that range is calculated. The advantage of this method is better accuracy. This is because a longer area of the virus body can be selected, and the relevant information can be still stored without overloading the antivirus database: The number of bytes to be stored in the database will be often the same for a large range and a smaller one. Obviously, this is not the case with strings because the longer strings will consume more disk space and memory.
Second-generation scanners also can achieve nearly exact identification without using search strings of any kind, relying only on cryptographic checksums8 or some sort of hash function.
To make the scanning engine faster, most scanners use some sort of hash. This led to the realization that a hash of the code can replace search string–based detection, provided that a safe hash in the virus can be found. For example, Icelander Fridrik Skulason's antivirus scanner, F-PROT9, uses a hash function with bookmarks to detect viruses.
Other second-generation scanners, such as the Russian KAV, do not use any search strings. The algorithm of KAV was invented by Eugene Kaspersky. Instead of using strings, the scanner typically relies on two cryptographic checksums, which are calculated at two preset positions and length within an object. The virus scanner interprets the database of cryptographic checksums, fetches data into scan buffers according to the object formats, and matches the cryptographic checksums in the fetched data. For example, a buffer might contain the entry-point code of an executable. In that case, each first cryptographic checksum that corresponds to entry-point code detections is scanned by calculating a first and a second cryptographic checksum. If only one of the checksums matches, KAV displays a warning about a possible variant of malicious code. If both cryptographic checksums match, the scanner reports the virus with nearly exact identification. The first range of checksum is typically optimized to be a small range of the virus body. The second range is larger, to cover the virus body nearly exactly.
11.2.4 Exact Identification
Exact identification9 is the only way to guarantee that the scanner precisely identifies virus variants. This method is usually combined with first-generation techniques. Unlike nearly exact identification, which uses the checksum of a single range of constant bytes in the virus body, exact identification uses as many ranges as necessary to calculate a checksum of all constant bits of the virus body. To achieve this level of accuracy, the variable bytes of the virus body must be eliminated to create a map of all constant bytes. Constant data bytes can be used in the map, but variable data can hurt the checksum.
Consider the code and data selected from the top of the Stoned virus shown in Figure 11.5. In the front of the code at the zero byte of the virus body, there are two jump instructions that finally lead the execution flow to the real start of virus code.
Figure 11.5. Variable data of the Stoned virus.
Right after the second jump instructions is the data area of the virus. The variables are flag, int13off, int13seg, and virusseg. These are true variables whose values can change according to the environment of the virus. The constants are jumpstart, bootoff, and bootseg; these values will not change, just like the rest of the virus code.
Because the variable bytes are all identified, there is only one more important item remaining to be checked: the size of the virus code. We know that Stoned fits in a single sector; however, the virus copies itself into existing boot and master boot sectors. To find the real virus body size, you need to look for the code that copies the virus to the virus segment, which can be found in the disassembly shown in Figure 11.6.
Figure 11.6. Locating the size of the virus body (440 bytes) in Stoned.

Indeed, the size of the virus is 440 (0x1B8) bytes. After the virus has copied its code to the allocated memory area, the virus code jumps into the allocated block. To do so, the virus uses a constant jumpstart offset and the previously saved virus segment pointed by virusseg in the data area at CS:0Dh (0x7C0D). Thus we have all the information we need to calculate the map of the virus.
The actual map will include the following ranges: 0x0–0x7, 0xD–0xE, 0x11–0x1B7, with a possible checksum of 0x3523D929. Thus the variable bytes of the virus are precisely eliminated, and the virus is identified.
To illustrate exact identification better, consider the data snippets of two minor variants of the Stoned virus, A and B, shown in Listing 11.1 and Listing 11.2, respectively. These two variants have the same map, so their code and constant data ranges match. However, the checksum of the two minor variants are different. This is because the virus author only changed a few bytes in the message and textual area of the virus body. The three-byte changes result in different checksums.
Listing 11.1. The Map of the Stoned.A Virus
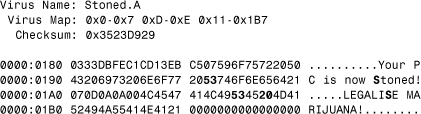
Listing 11.2. The Map of the Stoned.B Virus

Exact identification can differentiate precisely between variants. Such a level of differentiation can be found only in a few products, such as F-PROT9. Exact identification has many benefits to end users and researchers both. On the downside, exact identification scanners are usually a bit slower than simple scanners when scanning an infected system (when their exact identification algorithms are actually invoked).
Furthermore, it can be tedious to map the constant ranges of large computer viruses. This is because computer virus code frequently intermixes data and code.
11.3 Algorithmic Scanning Methods
The term algorithmic scanning is a bit misleading but nonetheless widely used. Whenever the standard algorithm of the scanner cannot deal with a virus, new detection code must be introduced to implement a virus-specific detection algorithm. This is called algorithmic scanning, but virus-specific detection algorithm could be a better term. Early implementation of algorithmic scanning was simply a set of hard-coded detection routines that were typically released with the core engine code.
Not surprisingly, such detection caused a lot of problems. First of all, the engine's code was intermixed with little special detection routines that were hard to port to new platforms. Second, stability issues commonly appeared; the algorithmic scanning could easily crash the scanner because virus-detection updates always need to be released in a hurry.
The solution to this problem is the virus scanning language10. In their simplest form, such languages allow seek and read operations in scanned objects. Thus an algorithmic string scan can be performed by seeking to a particular location forward from the beginning or backward from the end of the file or from the entry point, reading bytes such as a pattern of a call instruction, calculating the location to which the call instruction points, and matching string snippets one by one.
Algorithmic scanning is an essential part of modern antivirus architecture. Some scanners, such as KAV, introduced object code as part of an embedded virus-detection database. The detection routines for individual viruses are written in portable C language, and the compiled object code of such detection routines is stored in the database of the scanner. The scanner implements an operating system loader-like run-time linking of all virus specific–detection objects. These are executed one by one, according to a predefined call order. The advantage of this implementation of algorithmic scanning is better scanner performance. Its disadvantage is the risk of minor instability caused by real code running on the system, which might contain minor errors when the response to an emerging threat must be carried out quickly with a complex detection routine.
To eliminate this problem, modern algorithmic scanning is implemented as a Java-like p-code (portable code) using a virtual machine. Norton AntiVirus uses this technique. The advantage of this method is that the detection routines are highly portable. There is no need to port each virus-specific detection routine to new platforms. They can run on a PC as well as on an IBM AS/400, for example, provided that the code of the scanner and the virtual machine of the algorithmic scanning engine are ported to such platforms. The disadvantage of such scanners is the relatively slow p-code execution, compared to real run-time code. Interpreted code can often be hundreds of times slower than real machine code. The detection routines might be implemented as an Assembly-like language with high-level macros. Such routines might provide scan functions to look for a group of strings with a single search or convert virtual and physical addresses of executable files. Even more importantly, however, such scanners must be optimized with filtering, discussed in the next section. In addition, as a last line of defense, detection code can be implemented in an extensible scanning engine, using native code.
In the future, it is expected that algorithmic scanners will implement a JIT (just-in-time) system to compile the p-code-based detection routines to real architecture code, similarly to the .NET framework of Microsoft Windows. For example, when the scanner is executed on an Intel platform, the p-code-based detections are compiled to Intel code on the fly, enhancing the execution speed of the p-code—often by more than a hundred times. This method eliminates the problems of real-code execution on the system as part of the database, and the execution itself remains under control of the scanner because the detection routines consist of managed code.
11.3.1 Filtering
The filtering technique is increasingly used in second-generation scanners. The idea behind filtering is that viruses typically infect only a subset of known object types. This gives the scanner an advantage. For example, boot virus signatures can be limited to boot sectors, DOS EXE signatures to their own types, and so on. Thus an extra flag field of the string (or detection routine) can be used to indicate whether or not the signature in question is expected to appear in the object being scanned. This reduces the number of string matches the scanner must perform.
Algorithmic scanning relies strongly on filters. Because such detections are more expensive in terms of performance, algorithmic detection needs to introduce good filtering. A filter can be anything that is virus-specific: the type of the executable, the identifier marks of the virus in the header of the scanned object, suspicious code section characteristics or code section names, and so on. Unfortunately, some viruses give little opportunity for filtering.
The problem for scanners is obvious. Scanning of such viruses can cause certain speed issues for all products. A further problem is the detection of evolutionary viruses (such as encrypted and polymorphic viruses). Evolutionary viruses only occasionally can be detected with scan strings using wildcards.
Evolutionary viruses can be detected better using a generic decryptor11(based on a virtual machine) to decrypt the virus code and detect a possibly constant virus body under the encryption using a string or other known detection method. However, these methods do not always work. For example, EPO viruses and antiemulation viruses challenge such techniques. In such cases, early techniques such as decryptor/polymorphic engine analysis must be applied. Even viruses like W32/Gobi12 can be detected using such approach. (Decryptor analysis simply means that the defender needs to look into several polymorphic decryptors and match the code patterns of the decryptor within the polymorphic engine. This way, the decryptor itself can be detected in many cases using algorithmic detection.)
Algorithmic detection code typically loops a lot, which is processor-intensive. To give an example: In some cases, the highly optimized detection of the W95/Zmist13 virus must execute over 2 million p-code-based iterations to detect the virus correctly. Evidently, this kind of detection only works if the virus-infected file can somehow be quickly suspected and differentiated from noninfected files.
Although variants of the Zmist virus do not even mark infected objects, there are some opportunities to filter out files. Zmist implements several filters to avoid infecting some executables. For example, it only infects files with a set of section names it can recognize, and it does not infect files above a selected file size limit. The combination of such filters reduces the processing of files to less than 1% of all executable objects, which allows the relatively expensive detection algorithm to run effectively on all systems.
The following checks can be used for effective filtering:
• Check the number of zero bytes in an area of the file where the virus body is expected to be placed. Although some viruses use encryption, the frequency of encrypted and nonencrypted data can be very different. Such a technique is commonly used by crypto code-breakers. For example, the tail (last few kilobytes) of PE files often contain more than 50% zero bytes. In an encrypted virus, the number of zero bytes will be often less than 5%.
• Check the changes to the section header flags and sizes. Some viruses will flag sections to be writeable and others change similarly important fields to atypical values.
• Check the characteristics of the file. Some viruses do not infect command-line applications; others do not infect dynamic linked libraries or system drivers.
11.3.2 Static Decryptor Detection
Problems arise when the virus body is variably encrypted because the ranges of bytes that the scanner can use to identify the virus are limited. Various products use decryptor detection specific to a certain virus all the way in all code sections of program files. Obviously, the speed of scanning depends on the code section sizes of the actual applications. Such a detection method was used before generic decryptors were first introduced. By itself, this technique can cause false positives and false negatives, and it does not guarantee a repair solution because the actual virus code is not decrypted. However, this method is relatively fast to perform when used after an efficient filter.
Consider the code snippet from W95/Mad shown in Figure 11.7 and discussed in Chapter 7, “Advanced Code Evolution Techniques and Computer Virus Generator Kits.” The decryptor section of W95/Mad is in front of the encrypted virus body, right at the entry point of the infected PE files.
Figure 11.7. The decryptor of the W95/Mad virus.
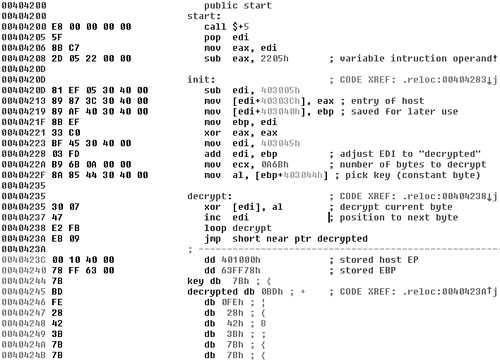
In this example, the operand of the SUB instruction located at 404208 is variable. Thus a wildcard-based string would need to be used from the entry point. The following string will be able to detect this decryptor, even in minor variants of the virus:
8BEF 33C0 BF?? ???? ??03 FDB9 ??0A 0000 8A85 ???? ???? 3007 47E2 FBEB
Because this virus only uses a single method (an XOR with a byte constant) to decrypt the virus body, complete decryption of the virus code is simple. The decryption can be achieved easily because the key length is short. In our example, the key is 7Bh. Notice the 7Bh bytes in the encrypted area of the virus—they are zero because 7Bh XOR 7Bh=0. We know the constant code under the single layer of encryption, so a plain-text attack is easy to do. This detection method is the subject of the following section.
Decryptor detection also can be used to detect polymorphic viruses. Even very strong mutation engines such as MtE use at least one constant byte in the decryptor. This is enough to start an algorithmic detection using an instruction size disassembler. The polymorphic decryptor can be disassembled using the instruction size disassembler, and the decryptor code can be profiled. MtE used a constant, conditional backward jump instruction at a variable location. The opcode of this instruction is 75h, which decodes to a JNZ instruction. The operand of the instruction always points backward in the code flow, identifying the seed of the decryptor. Then the seed itself can be analyzed for all the possible ways the virus decrypts its body, ignoring the junk operations.
It is time-consuming to understand advanced polymorphic engines for all possible encryption methods and junk operations, but often this is the only way to detect such viruses.
11.3.3 The X-RAY Method
Another group of scanners uses cryptographicdetection . In the previously mentioned example of W95/Mad, the virus uses a constant XOR encryption method with a randomly selected byte as a key stored in the virus. This makes decryption and detection of the virus trivial. Consider the snippet of W95/Mad's virus body in encrypted and decrypted form, shown in Listing 11.3 and Listing 11.4, respectively. In this particular sample, the key is 7Bh.
Listing 11.3. An Encrypted Snippet of W95/Mad

Listing 11.4. A Decrypted Snippet of W95/Mad

The virus can easily be decrypted by an algorithmic technique and exactly identified.
Researchers can also examine polymorphic engines of advanced viruses and identify the actual encryption methods that were used. Simple methods, such as XOR, ADD, ROR, and so on, are often used with 8-bit, 16-bit, and 32-bit keys. Sometimes the virus decryptor uses more than one layer encrypted with the same method (or even several methods) to encrypt a single byte, word, and double word.
Attacking the encryption of the virus code is called X-RAY scanning. This was invented by Frans Veldman for his TBSCAN product, as well as by several researchers independently about the same time. I first used X-RAY scanning to detect the Tequila virus. X-RAYing was a natural idea because decryption of the virus code to repair infections was necessary even for the oldest known, in-the-wild file viruses, such as Cascade. Vesselin Bontchev has told me that he saw a paper by Eugene Kaspersky describing X-RAY scanning for the first time.
X-RAY scanning takes advantage of all single-encryption methods and performs these on selected areas of files, such as top, tail, and near-entry-point code. Thus the scanner can still use simple strings to detect encrypted—and even some difficult polymorphic—viruses14. The scanning is a bit slower, but the technique is general and therefore useful.
The problem with this method appears when the start of the virus body cannot be found at a fixed position and the actual attack against the decryptor must be done on a long area of the file. This causes slowdown. The benefit to the method is the complete decryption of the virus code, which makes repair possible even if the information necessary for the repair is also stored in encrypted form.
Note
X-RAY can often detect instances of computer virus infections that have a bogus decryptor, provided that the virus body was placed in the file with an accurate encryption. Some polymorphic viruses generate bogus decryptors that fail to decrypt the virus, but the encryption of the virus body is often done correctly even in these types of samples. Such samples often remain detectable to X-RAY techniques but not to emulation-based techniques that require a working decryptor.
Some viruses, such as W95/Drill, use more than one encryption layer and polymorphic engine, but they can still be detected effectively. It is the combination of the encryption methods that matters the most. For example, it does not really matter if a virus uses polymorphic encryption with an XOR method only once or even as many as 100 times, because both of these can be attacked with X-RAYing. For example, the polymorphic engine, SMEG (Simulated “Metamorphic” Encryption Generator), created by the virus writer Black Baron, can be effectively detected using algorithmic detection that takes advantage of virus-specific X-RAY technique.
Note
Christopher Pile, the author of SMEG viruses, was sentenced to 18 months in prison in November of 1995, based on the Computer Misuse Act of the United Kingdom.
The Pathogen and Queeg viruses use the SMEG engine with XOR, ADD, and NEG methods in combination with shifting variable encryption keys.
The following sample detection of SMEG viruses was given to me by Eugene Kaspersky15 as an advanced X-RAY example. Kaspersky is one of the best in cryptoanalysis-oriented detection designs. He was able to detect extremely advanced encrypted and polymorphic engines using similar techniques.
SMEG viruses start with a long and variably polymorphic decryption routine. The polymorphic decryption loop is at the entry point of DOS COM and EXE files. However, the size of the decryptor is not constant. Because the decryptor's size can be long, the X-RAY decryption routine needs to use a start pointer p and increment that to hit each possible start position of the encrypted virus body placed after the decryptor to a nonconstant location.
The following five decryption methods must be implemented to decrypt the virus code, where s is the decrypted byte from a position pointed by p,t is the encrypted byte, k is the key to decrypt the byte t, and q is the key shifter variable that implements changes to the constant key. The variable s is equal to the decrypted byte by a selected method:
A. s=t XOR k, and then k=k+q
B. s=t ADD k, and then k=k+q
C. s=t XOR k, and then k=s+q
D. s=NEG (t XOR k), and then k=k+q
E. s=NOT (t XOR k), and then k=k+q
The following X-RAY function can be implemented to decrypt the encrypted virus body of SMEG viruses. Before the decoding can start, a buffer (buf[4096]) is filled with data for 0x800 (2,048 bytes) long. The algorithm implements key recovery based on the fact that the first few bytes of the SMEG virus body is E8000058 FECCB104 under the encryption. This is called a known plain-text attack in cryptography.
The key that encrypted the first byte of the virus can be recovered using the byte 0xE8, and the q key shifter variable can be recovered from the differences between the first and the second bytes using the five different methods. See Listing 11.5.
The first for loop is incrementing the p pointer to attempt to decrypt the virus body at each possible position. Because the length of the polymorphic decryptor does not exceed 0x700 (1792) bytes, the start of the encrypted virus body can be found in any of these positions.
Then the key initializations for five different methods are done according to two encrypted bytes next to each other, pointed by p. Next, a short decryption loop is executed that uses each of the five decryption methods and places the decrypted content to five different positions of the work buffer for further analysis.
Finally, the last loop checks each decrypted region for a possible match for the start of the string. When the decryption method is identified, the entire buffer can be decrypted and the virus easily identified.
Listing 11.5. X-RAY of the SMEG Viruses.

This code style minimizes the looping required to execute the virus decryption fast enough to be acceptable. Evidently, X-RAY methods have limitations when more than two layers of encryption are used with shifting keys. In such cases other methods, such as code emulations, are preferred.
Consider the sample snippets of the SME.Queeg virus shown in Listings 11.6 and 11.7.
Listing 11.6. Encrypted SMEG.Queeg

Listing 11.7. Decrypted SMEG.Queeg

As an exercise, try to identify which encryption/decryption methods were used to encrypt/decrypt this particular instance of the virus body. You can solve this exercise faster by taking advantage of the pair of zero bytes to recover the key and the delta. Realize that the sliding position of the virus body introduces complexity. For simplicity, noise bytes are not included in front of the encrypted code snippet.
Interestingly enough, virus writers also produced tools to perform X-RAYing. For example, in 1995 Virogen released a tool called VIROCRK (Super-Duper Encryption Cracker) to make it easier to read simple encrypted viruses. VIROCRK is limited in its X-RAYing. For example, it cannot attack sliding keys. However, it can decrypt many viruses quickly using plain text provided by the user.
I have seen X-RAY detection code written by Eugene Kaspersky for the W95/SK virus that was as long as 10KB of C code15. Not surprisingly, I prefer different methods to detect SK, using trial and error–based emulation instead. Well, lazy me!
11.4 Code Emulation
Code emulation is an extremely powerful virus detection technique. A virtual machine is implemented to simulate the CPU and memory management systems to mimic the code execution. Thus malicious code is simulated in the virtual machine of the scanner, and no actual virus code is executed by the real processor.
Some early methods of “code-emulation” used debugger interfaces to trace the code using the processor. However, such a solution is not safe enough because the virus code can jump out of the “emulated” environment during analysis.
Among the first antivirus programs was Skulason's F-PROT, which used software-based emulation for heuristic analysis. The third generation of F-PROT integrated the emulator and the scanning components to apply emulation to all computer viruses—particularly the difficult polymorphic viruses.
As an example, the registers and flags of a 16-bit Intel CPU can be defined with the following structures in C language:

The point of the code emulation is to mimic the instruction set of the CPU using virtual registers and flags. It is also important to define memory access functions to fetch 8-bit, 16-bit, and 32-bit data (and so on). Furthermore, the functionality of the operating system must be emulated to create a virtualized system that supports system APIs, file and memory management, and so on.
To mimic the execution of programs, the data from executable files is first fetched into memory buffers. Then a giant switch() statement of the emulator can analyze each instruction opcode, one by one. The current instruction, pointed by the virtual register IP (instruction pointer) is decoded, and the related virtual function for each instruction is executed. This changes the content of the virtual machine's memory, as well as the virtual registers and flags. The instruction pointer register IP is incremented after each executed instruction, and the iterations are counted.
Consider the code snippet of a 16-bit CPU emulator shown in Listing 11.8. First, the code selects the next instruction for execution with an internal read_mem() function that will access the already fetched buffers according to CS (code segment). Next, a while loop executes instructions according to preset conditions, such as the number of iterations. The execution also stops if the emulator experiences a fatal emulation error.
Listing 11.8. A Sample Snippet of a 16-Bit Intel CPU Emulator
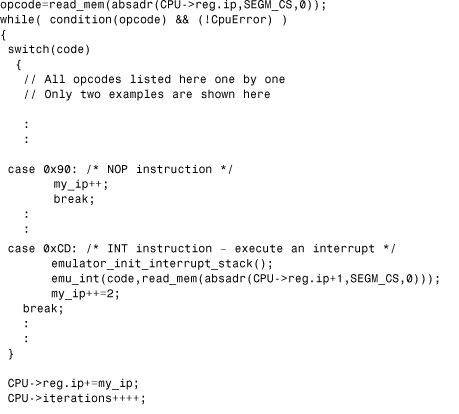
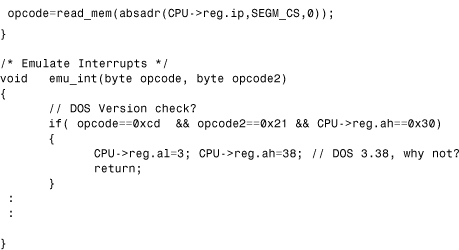
This example illustrates how the CPU emulator encounters a NOP and INT instruction during emulation. When a NOP (no operation) is executed, the IP register needs to be incremented. When an INT instruction is executed, the code in Listing 11.8 demonstrates what the emulator does when the DOS get version call is executed.
First, the state of the CPU stack is set, given that the INT instruction sets a return address on the top of the stack. The emu_int() function should normally handle most interrupt calls, but in this example only the DOS version check is handled and the false 3.38 DOS version is returned to the caller of the interrupt. As a result, a program executed in the virtual machine will receive the false version numbers when running in the virtual system. This illustrates that everything is under the emulator's control. Depending how well the emulator can mimic the real system functionality, the code has more or fewer chances to detect the fact that it is running in a virtual environment. Of course, the preceding code is over-simplified, but it demonstrates the typical structure of a generic CPU emulator. The 32-bit emulators differ only in complexity.
Polymorphic virus detection can be done by examining the content of the virtual machine's memory after a predefined number of maximum iterations, or whenever other stop conditions are met. Because polymorphic viruses decrypt themselves, the virus will readily present itself in the virtual machine's memory if emulated long enough. The question arises of how to decide when to stop the emulator. The following common methods are used:
• Tracking of active instructions: Active instructions are those instructions that change an 8-bit, 16-bit, or 32-bit value in the virtual machine's memory. The instruction becomes active when two memory modifications occur next to each other in memory. This is a typical decryption pattern in memory. Although not all decryptors can be profiled with this technique, it covers the most common cases. The emulator can execute instructions up to a predefined number of iterations, such as a quarter of a million, half a million, or even a million iterations, but only if the code continuously generates active instructions. Short decryptors typically generate a lot of active instructions, whereas longer decryptors with a lot of inserted junk will use active instructions less frequently. For example, this technique was used in the IBM Antivirus.
• Tracking of decryptor using profiles: This method takes advantage of the exact profile of each polymorphic decryptor. Most polymorphic engines use only a few instructions in their decryptor. Thus the first time an instruction is executed that is not in the profile, the first decrypted instruction is executed. This moment can be used to stop the emulator and attempt virus detection.
• Stopping with break points: Several predefined break points can be set for the emulator as conditions. For example, an instruction or a hash of a few instructions can be used from each polymorphic virus to stop the execution of the emulator whenever the decrypted virus body is likely to be executed. Other conditions can include the first interrupt or API call because polymorphic viruses typically do not use them in their decryptors (but some antiemulation viruses do use them).
First, the location of emulations need to be identified. For example, each known entry point of a program can be emulated. Moreover, each possible decryptor location is identified (this method can assume false decryptor detection because the detection of the decryptor itself will not produce a virus warning). Then the decryptor is executed for an efficient number of iterations, and the virus code is identified in the virtual machine of the scanner by checking for search strings (or by using other, previously discussed methods) in the “dirty” pages of the virtual machine's memory.
Note
A memory page becomes dirty when it is modified. Each modified page has a dirty flag, which is set the first time a change occurs in the page.
Such detection can be much faster than X-RAY-based scanning. However, it depends on the actual iterations of the decryptor loop. With short decryptors, the method will be fast enough to be useful. In the case of longer decryption loops (which have a lot of garbage instructions), even partial decryption of the virus code might not be fast enough because the number of necessary iterations can be extremely high, so the decryption of the virus would take more than several minutes in the virtual machine. This problem is also the greatest challenge for emulator-based virus heuristics.
11.4.1 Encrypted and Polymorphic Virus Detection Using Emulation
Consider the example in Listing 11.9, which shows an emulation of an encrypted virus { W95,W97M} /Fabi.9608 in a PE file. This virus places itself at the entry point of infected files. Emulation of the entry-point code will result in a quick decryption of virus code in the virtual machine's memory. Although this virus is not polymorphic, the basic principle of polymorphic virus detection is the same.
Fabi initializes the ESI pointer to the start of the encrypted virus body. The decryption loop decrypts each 32-bit word of the body with a 32-bit key. This key is set randomly but is also shifted in each decryption loop. At iteration 12, the virus generates an active instruction because two 32-bit words in memory are changed next to each other as the XOR instruction decrypts them. This can signal an emulator to continue emulation of the decryption loop, which will stop after about 38,000 iterations.
Note
Detection of the virus is possible before the constant virus body is completely decrypted. However, exact identification of this virus using emulation would require this many iterations to be executed in the virtual machine.
Listing 11.9. The Emulation of the W95/Fabi Virus


When this particular instance of the virus is loaded for emulation, the virus is still encrypted in the memory of the virtual machine, as shown in Listing 11.10.
Note
The decryptor is in front of the encrypted virus body, and the decryption begins at virtual address 40522A (in this example), pointed by ESI.
Listing 11.10. The Front of W95/Fabi.9608 in Encrypted Form
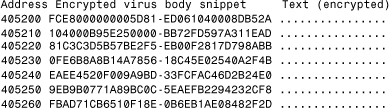
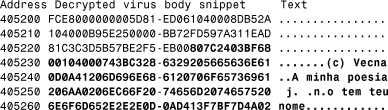
After a few thousand iterations, the virus is decrypted. The scanner can use any of the previously mentioned techniques to detect or identify the virus easily in the virtual machine's dirty pages. String scans are typically done periodically after a number of predefined iterations during emulation, so the complete decryption of the virus does not need to happen. Then the emulation can be further extended for exact identification.
The emulation of Fabi reveals the name of its creator, Vecna, with a Portuguese message that translates to “My poetry” (see Listing 11.11).
Listing 11.11. The Front of W95/Fabi.9608 in Decrypted Form
This technique is the most powerful detection method for polymorphic viruses. It can be applied to metamorphic viruses that use encryption layers. An antivirus product that does not support code emulation is ineffective against most polymorphic viruses because response time is seriously affected by complex polymorphic viruses. This is a danger to those scanners that do not implement emulation because polymorphic computer worms leave little room for prolonged response. Indeed, there are wildly adopted scanners that do not support emulation technology that will not be able to respond to complex threats.
The key idea in using the emulator relies on the trial-and-error detection approach. A computer file might be emulated from more than a hundred possible entry points, one after another, attempting to find viruses. Such detections are not cost effective in the long run, and they can only survive if the average computer's CPU performance can keep up with the increasing performance hunger of the code emulation. As scanners evolve, the effectiveness of the scanner on old platforms decreases. For example, emulation of Pentium CPUs on 8086 or even 286 processors is too slow to be effective nowadays. In addition, handheld devices have very limited CPU power, and thus complex mobile threats will be more challenging to detect and repair on the native platform. (For example, imagine a polymorphic virus running on a Pocket PC using an ARM processor. Such a virus would be slow, but the antivirus would be even slower.)
11.4.2 Dynamic Decryptor Detection
A relatively new scanning technique uses a combination of emulation and decryptor detection. For viruses with longer loops, such as W32/Dengue, virus emulation cannot perform very fast. The possible entry point of the virus decryptor can be identified in a virus-specific manner. During emulation, for example, specific algorithmic detection can check which areas of the virtual machine's memory have been changed. If there is a suspicious change, additional scanning code can check which instructions were executed during a limited number of iterations. Furthermore, the executed instructions can be profiled and the essential set of decryptor instructions can be identified. For example, a virus that always uses XOR decryption will execute a lot of XOR instructions in its decryptor. At the same time, certain instructions will never be executed, which can be used as exclusions. The combination of inclusions and exclusions will yield an excellent profile of polymorphic decryptors. This can be used by itself to detect the virus with enough filtering in place to keep false positives to the minimum, making the decryptor detection more fully proved and quick enough.
This technique cannot be used to repair the virus because the virus code must be emulated for a longer time (up to several minutes in bad cases) to decrypt the virus code completely using the emulator.
It appears that entry point–obscuring polymorphic viruses are a big problem for all kinds of scanning techniques that seek to be time and cost effective. Heuristic methods are not completely useless against such viruses. Modern emulation-based heuristics16 have a chance to detect such viruses because the decryptor of the virus is often represented at or near the entry point. Therefore, the decryptor will often be reached via emulation.
Note
Complete control of the scanning engine and emulator is mandatory to detect difficult polymorphic viruses effectively. If the actual scanning is not data-driven (p-code interpretation or some sort of executable object as part of the database) so that standalone code must be updated for detection, the actual scanner will not meet expectations because it cannot be updated fast enough. In that case, the virus researcher is in great trouble—and customers will be in trouble, too17.
A relatively new dynamic technique to detect polymorphic viruses is done by using code optimalization techniques18 in an attempt to reduce the polymorphic decryptor to a certain core set of instructions, removing the junk. This technique works very effectively with simple polymorphic viruses. Suppose that emulation is used to detect a virus that has many jump instructions inserted into its polymorphic decryptor. Suppose further that the jump instructions are the only “garbage” instructions in the polymorphic decryptor. The code flow of the decryptor can be optimized in each loop of the decryptor as the emulator executes it. Each jump that points to another jump is identified as nonessential in the code, so the jumps can be removed one by one. Table 11.1 demonstrates a pseudo-decryption loop that uses jump garbage instructions J1..Jn and essential instructions I1..In. A possible optimalization of such loops is the removal of each jump instruction that points to another jump.
Table 11.1. A Pseudo-Decryption Loop and Optimization Phases

Similarly, the code of other junk instructions that do not play a role in changing state can be removed from the code flow, which makes emulation of the polymorphic code faster and provides a profile of the decryptor for identification.
Of course, just like any other method, code optimalization–based decryptor detection has its limitations and cannot be applied universally. For example, the complex polymorphic garbage of the MtE mutation engine (as discussed in Chapter 7) cannot be optimized effectively. Other problems appear when multiple encryptions are used on top of each other, dependent on one another.
11.5 Metamorphic Virus Detection Examples
There is a level of metamorphosis beyond which no reasonable number of strings can be used to detect the code that it contains. At that point, other techniques must be used, such as examination of the file structure or the code stream, or analysis of the code's behavior.
To detect a metamorphic virus perfectly, a detection routine must be written that can regenerate the essential instruction set of the virus body from the actual instance of the infection. Other products use shortcuts to try to solve the problem, but such shortcuts often lead to an unacceptable number of false positives. This section introduces some useful techniques.
11.5.1 Geometric Detection
Geometric detection17 is the virus-detection technique based on alterations that a virus has made to the file structure. It could also be called the shape heuristic because it is far from exact and prone to false positives. An example of a geometric detection is W95/Zmist. When this virus infects a file using its encrypted form, it increases the virtual size of the data section by at least 32KB but does not alter the section's physical size.
Thus a file might be reported as being infected by W95/ZMist if the file contains a data section whose virtual size is at least 32KB larger than its physical size. However, such a file structure alteration also can be an indicator of a runtime-compressed file. File viruses often rely on a virus infection marker to detect already infected files and avoid multiple infections. Such an identifier can be useful to the scanner in combination with the other infection-induced geometric changes to the file. This makes geometric detection more reliable, but the risk of false positives only decreases; it never disappears.
11.5.2 Disassembling Techniques
To assemble means to bring together, so to disassemble is to separate or take apart. In the context of code, to disassemble is to separate the stream into individual instructions. This is useful for detecting viruses that insert garbage instructions between their core instructions. Simple string searching cannot be used for such viruses because instructions can be quite long, and there is a possibility that a string can appear “inside” an instruction, rather than being the instruction itself. For example, suppose that one wished to search for the instruction CMP AX, “ZM.” This is a common instruction in viruses, used to test whether a file is of the executable type. Its code representation is
66 3D 4D 5A
and it can be found in the stream
90 90 BF 66 3D 4D 5A
However, when the stream is disassembled and displayed, notice that what was found is not the instruction at all:
NOP
NOP
MOV EDI, 5A4D3D66
The use of a disassembler can prevent such mistakes, and if the stream were examined further
90 90 BF 66 3D 4D 5A 90 66 3D 4D 5A
when disassembled and displayed, it can be seen that the true string follows shortly after:
NOP
NOP
MOV EDI, 5A4D3D66
NOP
CMP AX, "ZM"
When combined with a state machine, perhaps to record the order in which “interesting” instructions are encountered, and even when combined with an emulator, this technique presents a powerful tool that makes a comparatively easy task of detecting such viruses as W95/ZMist and the more recent W95/Puron19. (The Puron virus is based on the Lexotan engine.)
Lexotan and W95/Puron execute the same instructions in the same order, with only garbage instructions and jumps inserted between the core instructions, and no garbage subroutines. This makes them easy to detect using only a disassembler and a state machine.
Sample detection of W95/Puron is shown in Listing 11.12.
Listing 11.12. Focusing the Scanning on "Interesting" Instructions

ACG20, by comparison, is a complex metamorph that requires an emulator combined with a state machine. Sample detection is included in the next section.
11.5.3 Using Emulators for Tracing
Earlier in this chapter, emulation was discussed as being useful in detecting polymorphic viruses. It is very useful for working with viruses because it allows virus code to execute in an environment from which it cannot escape. Code that runs in an emulator can be examined periodically or when particular instructions are executed. For DOS viruses, INT 21h is a common instruction to intercept. If used properly, emulators are still very useful in detecting metamorphic viruses. This is explained better through the following examples.
11.5.3.1 Sample Detection of ACG
Listing 11.13 shows a short example code of an instance of ACG.
Listing 11.13. A Sample Instance of ACG

When the INT 21 is reached, the registers contain ah=4a and bx=1000. This is constant for one class of ACG viruses. Trapping enough similar instructions forms the basis for detection of ACG.
Not surprisingly, several antivirus scanner products do not support such detection. This shows that traditional code emulation logic in older virus scanner engines might not be used “as-is” to trace code on such a level. All antivirus scanners should go in the direction of interactive scanning engine developments.
An interactive scanning engine model is particularly useful in building algorithmic detections of the kind that ACG needs.
11.5.3.2 Sample Detection of Evol
Chapter 7 discussed the complexity of the Evol virus. Evol is a perfect example of a virus that deals with the problem of hiding constant data as variable code from generation to generation. Code tracing can be particularly useful in detecting even such a level of change. Evol builds the constant data on the stack from variable data before it passes it to the actual function or API that needs it.
At a glance, it seems that emulation cannot deal with such viruses effectively. However, this is not the case. Emulators need to be used differently by allowing more flexibility to the virus researcher to control the operations of the emulator using a scanning language that can be used to write detection routines. Because viruses such as Evol often build constant data on the stack, the emulator can be instructed to run the emulation until a predefined limit of iterations and to check the content of the stack after the emulation for constant data built by the virus. The content of the stack can be very helpful in dealing with complex metamorphic viruses that often decrypt data on the stack.
11.5.3.3 Using Negative and Positive Features
To speed detection, scanners can use negative detection. Unlike positive detection, which checks for a set of patterns that exist in the virus body, negative detection checks for the opposite. It is often enough to identify a set of instructions that do not appear in any instance of the actual metamorphic virus.
Such negative detection can be used to stop the detection process when a common negative pattern is encountered.
11.5.3.4 Using Emulator-Based Heuristics
Heuristics have evolved much over the last decade21. Heuristic detection does not identify viruses specifically but extracts features of viruses and detects classes of computer viruses generically.
The method that covers ACG in our example is essentially very similar to a DOS heuristic detector. If the DOS emulator of the scanner is capable of emulating 32-bit code (which is generated by ACG), it can easily cover that virus heuristically. The actual heuristics engine might track the interrupts or even implement a deeper level of heuristics using a virtual machine (VM) that simulates some of the functions of the operating system. Such systems can even “replicate” the virus inside their virtual machine on a virtual file system built into the VM of the engine. Such a system has been implemented in some AV scanner solutions and was found to be very effective, providing a much better false positive ratio. This technique requires emulation of file systems. For example, whenever a new file is opened by the emulated program (which is a possible virus), a virtual file is given to it. Then the emulated virus might decide to infect the virtual file offered to it in its own virtual world.
The heuristics engine can take the changed virtual file from one VM and place it in another VM with a clean state. If the modified virtual file changes other virtual files offered in the new VM similarly to previously experienced virus-like changes in the first VM, then the virus replication itself is detected and proved by the heuristic analyzer. Modern emulators can mimic a typical Windows PC with network stacks and Internet protocols. Even SMTP worm propagation can be proved in many cases22.
Nowadays, it is easy to think of an almost perfect emulation of DOS, thanks to the computing speed of today's processors and the relatively simple single-threaded OS. However, it is more difficult to emulate Windows on Windows built into a scanner! Emulating multithreaded functionality without synchronization problems is a challenging task. Such a system cannot be as perfect as a DOS emulation because of the complexity of the OS. Even if we use a system like VMWARE to solve most of the challenges, many problems remain. Emulation of third-party DLLs is one problem that can arise. Such DLLs are not part of the VM and, whenever virus code relies on such an API set, the emulation of the virus will likely break.
Performance is another problem. A scanner must be fast enough or people will not use it. Faster is not always better when it comes to scanners, although this might seem counterintuitive to customers. Even if we had all the possible resources to develop a perfect VM to emulate Windows on Windows inside a scanner, we would have to compromise regarding speed—resulting in an imperfect system. In any case, extending the level of emulation of Windows inside the scanner system is a good idea and leads to better heuristics reliability. Certainly, the future of heuristics relies on this idea.
Unfortunately, EPO viruses (such as Zmist) can easily challenge such a system. There is a full class of antiemulation viruses. Even the ACG virus uses tricks to challenge emulators. The virus often replicates only on certain days or under similar conditions. This makes perfect detection, using pure heuristics without attention to virus-specific details, more difficult.
If an implementation ignores such details, the virus could be missed. Imagine running a detection test on a Sunday against a few thousand samples that only replicate from Monday to Friday. Depending on the heuristic implementations, the virus could be easily missed. Viruses like W32/Magistr23 do not infect without an active Internet connection. What if the virus looks for www.antiheuristictrick.com? What would the proper answer to such a query be? Someone could claim that a proper real-world answer could be provided, but could you really do that from a scanner during emulation? Certainly it cannot be done perfectly.
There will be viruses that cannot be detected in any emulated environments, no matter how good the system emulator is. Some of these viruses will be metamorphic, too. For such viruses, only specific virus detection can provide a solution. Heuristic systems can only reduce the problem against masses of viruses.
The evolution of metamorphic viruses is one of the great challenges of this decade. Clearly, virus writing is evolving in the direction of modern computer worms. From the perspective of antivirus researchers and security professionals, this is going to be a very interesting and stressful time.
11.6 Heuristic Analysis of 32-Bit Windows Viruses
Heuristic analysis has proved to be a successful way to detect new viruses. The biggest disadvantage of heuristic analyzer–based scanners is that they often find false positives, which is not cost-effective for users. In some ways, however, the heuristic analyzer is a real benefit.
For instance, a modern scanner cannot survive without a heuristic scanner for macro viruses24. In the case of binary viruses, heuristic scanning also can be very effective, but the actual risk for a false positive is often higher than that of good macro heuristics.
The capabilities of a heuristic analyzer must be reduced to a level where the number of possible false positives is not particularly high, while the scanner is still able to catch a reasonable number of new viruses. This is not an easy task. Heuristic scanning does not exist in a vacuum. Heuristics are very closely related to a good understanding of the actual infection techniques of a particular virus type. Different virus types require completely different rules on which the heuristic analyzer logic can be built.
Obviously, heuristic analyzers designed to catch DOS viruses or boot viruses are useless in detecting modern Win32 viruses. This section is an introduction to some of the ideas behind the heuristics of Windows viruses25.
The usual method of binary heuristics is to emulate the program execution and look for suspicious code combinations. The following sections introduce some heuristic flags which, for the most part, are not based on code emulation, but which describe particular structural problems unlikely to happen in PE programs compiled with a 32-bit compiler (such as Microsoft, Borland, or Watcom programs). Although not very advanced, structural checking is an effective way to detect even polymorphic viruses such as W95/Marburg or W95/HPS.
Shapes of programs can be used to detect a virus heuristically if they look suspicious enough.
11.6.1 Code Execution Starts in the Last Section
The PE format has a very important advantage: Different functional areas, such as code data areas, are separated logically into sections. If you look back to the infection techniques described in Chapter 4, “Classification of Infection Strategies,” you will see that most Win32 viruses change the entry point of the application to point to the last section of the program instead of the .text (CODE) section. By default, the linker merges all the object code into the .text section. It is possible to create several code sections, but this does not happen by default compiling, and most Win32 applications will never have such a structure. It looks very suspicious if the entry point of the PE image does not point to the code section.
11.6.2 Suspicious Section Characteristics
All sections have a characteristic that describes certain attributes and that holds a set of flags indicating the section's attributes. The code section has an executable flag but does not need writeable attributes because the data is separated. Very often the virus section does not have executable characteristics but has writeable only or both executable and writeable. Both of these cases must be considered suspicious. Some viruses fail to set the characteristic field and leave the field at 0. That is also suspicious.
11.6.3 Virtual Size Is Incorrect in PE Header
The SizeOfImage is not rounded up to the closest section alignment value by most Windows 95 viruses. Windows 95's loader allows this to happen; Windows NT's does not. It is suspicious enough, therefore, if the SizeOfImage field is incorrect. However, this also could happen as a result of incorrect disinfection.
11.6.4 Possible “Gap” Between Sections
Some viruses, such as W95/Boza and W95/Memorial, round the file size up to the nearest file alignment before adding a new section to it, in a way very similar to DOS EXE infectors. However, the virus does not describe this size difference as in the last section header of the original program. For Windows NT's loader, the image looks like it has a gap in its raw data and is therefore not considered a valid image. Many Windows 95 viruses have this bug, making it a good heuristic flag.
11.6.5 Suspicious Code Redirection
Some viruses do not modify the entry-point field of the code. Instead, they put a jump (JMP) to the entry-point code area to point to a different section. It is very suspicious to detect that the code execution chain jumps out from the main code section to some other section close to the entry point of the program.
11.6.6 Suspicious Code Section Name
It is suspicious if a section that normally does not contain code, such as .reloc, .debug, and so on, gets control. Code executed in such sections must be flagged.
11.6.7 Possible Header Infection
If the entry point of a PE program does not point into any of the sections but points to the area after the PE header and before the first section's raw data, then the PE file is probably infected with a header infector. This is an extremely useful heuristic to detect W95/CIH-style virus infections and virus-corrupted executables.
11.6.8 Suspicious Imports from KERNEL32.DLL by Ordinal
Some Win95 viruses patch the import table of the infected application and add ordinal value–based imports to it. Imports by ordinal from KERNEL32.DLL should be suspicious, but some Windows 95 programmers do not understand that there is no guarantee that a program that imports from system DLLs by ordinals will work in a different Windows 95 release, and these programmers still use them. In any case, it is suspicious if GetProcAddress() or GetModuleHandleA() functions are imported by ordinal values.
11.6.9 Import Address Table Is Patched
If the import table of the application has GetProcAddress() and GetModuleHandleA() API imports and imports these two APIs by ordinal at the same time, then the import table is patched for sure. This is suspicious.
11.6.10 Multiple PE Headers
When a PE application has more than one PE header, the file must be considered suspicious because the PE header contains many nonused or constant fields. This is the case if the lfanew field points to the second half of the program and it is possible to find another PE header near the beginning of the file. (See Chapter 4 for more details on the lfanew-style infection.)
11.6.11 Multiple Windows Headers and Suspicious KERNEL32.DLL Imports
Structural analysis can detect prepending viruses by searching for multiple new executable headers, such as 16-bit NE and 32-bit PE. This can be done by checking whether the real image size is bigger than the actual representation of the code size as described in the header. As long as the virus does not encrypt the original header information at the end of the program, the multiple Windows headers can be detected. Additionally, the import table must be checked for a combination of API imports. If there are KERNEL32.DLL imports for a combination of GetModuleHandle(), Sleep(), FindFirstFile(), FindNextFile(), MoveFile(), GetWindowsDirectory(), WinExec(), DeleteFile(), WriteFile(), CreateFile(), MoveFile(), CreateProcess(), the application is probably infected with a prepender virus.
11.6.12 Suspicious Relocations
This is a code-related flag. If the code contains instructions that can be used to determine the actual start address of the virus code, it should be flagged. For instance, a CALL instruction detected for the next possible offset is suspicious. Many Win95 viruses use the form of E80000's (CALL next address) 32-bit equivalent form E800000000, similar to DOS virus implementations.
11.6.13 Kernel Look-Up
Code that operates with hard-coded pointers to certain system areas, such as the KERNEL32.DLL or the VMM's memory area, is suspicious. Such viruses often search for the PE�� mark at the same time in their code, which should also be detected.
During program emulation, an application accessing a range of memory can be flagged. For example, a direct code sequence to implement a GetProcAddress() functionality is common both in computer viruses and in exploit code. Direct access to ranges of memory that belong to the KERNEL32.DLL header area is very common in the start-up code of computer viruses—but atypical in normal programs.
11.6.14 Kernel Inconsistency
The consistency of KERNEL32.DLL can be checked by using one API from IMAGEHLP.DLL, such as CheckSumMappedFile() or MapFileAndCheckSum().
In this way, viruses that infect KERNEL32.DLL but do not recalculate the checksum field for it (such as W95/Lorez, W95/Yourn) can be detected easily.
11.6.15 Loading a Section into the VMM Address Space
Unfortunately, it is possible to load a section into the ring 0 memory area under Windows 9x systems. The Virtual Machine Manager (VMM) memory area starts at address 0xC0001000. At 0xC0000000 there is a page that is not used. A few viruses, such as the W95/MarkJ.825 virus, get a hold of this unused page. The virus adds a new section header into the section table of the host program. This new section specifies the virtual address of the section that will point to 0xC0000000 of memory. The system loader allocates this page automatically when the infected application is executed. In turn, the virus code enjoys kernel-mode execution. The system loader could easily refuse this page allocation, but Windows 9x's implementations do not contain such a feature. Therefore, it must be considered suspicious when any section's virtual address points into the VMM area.
11.6.16 Incorrect Size of Code in Header
Most viruses do not touch the SizeOfCode field of the PE header when adding a new executable section. If the recalculated size of all code sections is not the same as in the header, there is a chance that new executable sections have been patched into the executable.
11.6.17 Examples of Suspicious Flag Combinations
Listing 11.14 gives examples of the preceding flags in real viruses such as W32/Cabanas, W95/Anxiety, W95/Marburg, and W95/SGWW.
Listing 11.14. First-Generation Win32 Heuristics

11.7 Heuristic Analysis Using Neural Networks
Several researchers have attempted to use neural networks to detect computer viruses. Neural networks are a sub-field of artificial intelligence26, 27, so the subject is very exciting. Difficult polymorphic EPO viruses such as Zhengxi have been detected successfully using a trained neural network28.
In general, a trained neural network seems to be overkill for detecting a single virus because of the amount of data and computations required. Even a well-optimized neural network scanner can decrease overall scanning performance by about 5%. Thus it is more interesting that neural networks can be applied to heuristic computer virus detection. In practice, IBM researchers have successfully applied neural networks to heuristic detection of boot29 and Win32 viruses30.
One of the key problems of any heuristic is the false positive ratio. If the heuristic is too alarming, people will not use it. IBM researchers demonstrated that single-layer classifiers yield the best results with a voting system. Figure 11.8 shows a typical single-layer classifier with a threshold31.
Figure 11.8. Single-layer classifier with threshold.
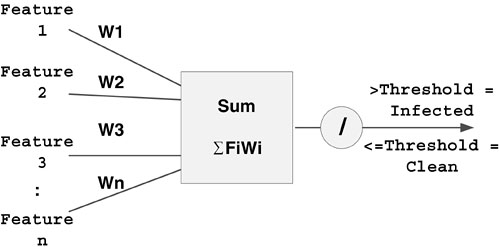
Neural networks can easily be overtrained, which is a pitfall of the method. Overtrained networks remember the training set extremely well, but they do not work with new sample sets. In other words, they fail to detect new viruses. To eliminate this problem, multiple neural networks are trained using distinct features. In addition, a voting system is used so that more than one network must agree about a positive detection. In the first experiments, IBM used four neural networks with voting, but it turned out that the best result was achieved when five networks out of eight agreed on a positive.
The basic idea of the training is the selection of n-grams (sequences a couple of bytes long) of the constant part of viruses that indicate an infection. The selection of n-grams for neural network training is the unique feature of IBM's solution. For example, 4-byte sequences can be used to train the network. To train the networks better, a corpus database is used to check whether the n-grams extracted from the constant virus body areas of known computer viruses appear more than a threshold T. If the threshold is exceeded, the n-gram is not used.
The training input vector to the network is constructed using each n-gram with corresponding values. The values have counts for each n-gram feature and the correct output value of 0 or 1 for the neural network. IBM used back-propagation training software to train the networks, and the outputs of each network were saved. Outputs were squashed through a sigmoid output unit, which generated values in the 0.0 to 1.0 range:
sigmoid(x) = 1.0 / (1.0+exp(-x));
The threshold of the sigmoid output was set to 0.65 for 4-byte n-grams.
When the network data is available, it is introduced to a scanner the following way. The neural network heuristic is called whenever an area of the file is scanned. Thus whenever the scanner scans the area of a file, such as a 4KB buffer selected around the entry point of PE files, the heuristics can trigger if enough networks vote positive.
Neural network–based heuristics depend on a good training set. With more 32-bit Windows viruses in the training set, the automatically trained heuristic produces slightly better results. In practice, neural network heuristics are very effective against closely related variants of viruses that were used in the original training set. They also yield good results against new families of computer viruses that are similar enough to the feature set of known viruses in the training set. It is also important to select n-grams of the virus from the entire virus body. Some antivirus vendors attempted to train neural networks with n-grams selected from emulated instructions of the virus body. However, looping virus code can often generate instruction sets (n-grams) similar to normal programs, yielding an unacceptable false positive ratio.
IBM's neural network engine was released in the Symantec antivirus engine. The neural network engine produced so few false positives that it was used in default scanning (it does not depend on any user-configurable options).
11.8 Regular and Generic Disinfection Methods
Traditionally, antivirus scanners have only been able to disinfect viruses that have been analyzed beforehand by product developers32. Producers of antivirus products were pretty much able to keep up with new viruses, adding detection and disinfection routines, until about 1996. It has been a logical expectation of users of antivirus programs that a detected virus is always repaired to restore the clean state of the host programs. Although full backups provide easy restoration of all infected programs, they are not always available unless a backup strategy is in place or is an integrated part of a disaster recovery system.
The situation quickly changed after 15,000 additional viruses were generated overnight using the PS-MPC kit. Even the producers of exact identification scanners and disinfectors had to admit that generic methods were necessary to clean viruses.
As the number of viruses continues to grow, more and more viruses are only detected because the developers do not consider every virus important enough to necessitate specific disinfection routines. Unfortunately, some users will eventually get infected by such viruses.
It is possible (but difficult) to disinfect unknown viruses. There are several approaches to this problem: One method is to trace the execution of a possibly infected program with debugger interfaces until the virus has restored the host to its original state33. This method works but cannot be considered truly reliable. An alternative is to emulate the program and collect information on its execution, using this information with generic rules to perform rule-based disinfection. Although this is difficult to implement, it produces surprisingly good results for DOS viruses and also can be applied to other classes of viruses, such as Win32 viruses.
How many viruses can be removed in this way? Testing a generic disinfector is a very difficult task. Testing how many particular viruses it can handle does not make sense because it is a generic antivirus product. It is more important to test how many different types of viruses it can handle by using such methods. A figure of 60% is quite possible, at least for DOS viruses. Most antivirus programs (such as my old program, Pasteur) do not even come close to this percentage of disinfection because there have been no sufficient resources to write disinfection by hand for each virus variant.
Generic methods explained in this chapter can be used as a disinfection solution without using heuristics to detect the virus in the first place. In such a case, the virus is detected and identified by normal methods, but it is repaired generically. This method was used effectively against virus generation kits by several antivirus products, including the Solomon engine34, 35 used by NAI. Generic disinfection can reduce the size of the antivirus database greatly because less virus variant-specific data needs to be stored.
11.8.1 Standard Disinfection
Before we can talk about generic disinfection, we should understand how a virus is repaired by the antivirus program. Virus infection techniques are the subject of Chapter 4, where it was demonstrated that in most cases, a virus adds itself to the end of the host file. If this is the case, the virus modifies the beginning of the program to transfer control to itself. Unless the virus is very primitive, it saves the beginning of the file within the virus code because it will be necessary to execute the victim file correctly after infection (see Listing 11.15).
Listing 11.15. A Simple DOS COM Infector Virus
Every virus adds new functionalities to the victim. The infected victim will execute the virus code, which will infect other files or system areas or go resident in memory. The virus code then “repairs” the beginning of the victim in memory and starts it. This sounds very simple. Unfortunately, it is only simple from the point of view of the virus, which modifies a few bytes in the victim file and saves a piece of the file's original code in the virus body (in this example: CCC).
In the early years, there were no problems with conventional disinfection. We had enough time to analyze viruses because there were only a few. We could spend weeks with every new sample until we had all the information necessary to clean it successfully.
Basically, the cleaning process is as easy as the infection. The following is all we need to know:
• How to find the virus (in most cases, with a search string selected from the virus)
• Where the original beginning of the host file (CCC) can be found in the virus
• The size of the virus body in bytes
If we have all this information, we can easily remove the virus: “Let's read the original beginning from the virus code and put it back in its original place and then truncate the file at its original end, calculating where this is from the virus size.” That's it! This method might have been interesting for the first ten viruses, but everyone who has spent years with viruses finds it just too tedious.
So we developed so-called goat systems to replicate virus samples automatically. These systems save time. We can calculate the place of the original bytes in the virus body by comparing many infected samples to uninfected ones, using a special utility. This system works as long as the virus is not encrypted, self-mutating, or polymorphic. Of course, it must not have an antigoat mechanism or a new infection technique that our disinfector does not know how to handle. If one of these problems occurs, we must analyze the virus manually. If we are lucky, this is enough. If not, we must change our antivirus strategy by adding new functions to it or by modifying already existing ones. This can take a lot of time and is therefore not efficient enough.
11.8.2 Generic Decryptors
Most of the better antivirus products have a generic decryptor to combat polymorphic viruses, so it appears we can solve the biggest problem that way. We can decrypt the virus so we can use the old search-string technique once again, which is great. Basically, the generic decryptor method is a part of the generic disinfection technique.
11.8.3 How Does a Generic Disinfector Work?
The idea of doing generic disinfection without any information stored about the original file was first developed by Frans Veldman in his TBCLEAN program.
The generic disinfection method is simple but great: The disinfector loads the infected file and starts to emulate it until the virus restores the infected file to its “original” form and is ready to execute it. So the generic disinfector uses the virus to perform the most important part of the cleaning process. As Veldman said, “Let the virus do the dirty work!” The virus has the beginning of the original file. All we need to do is copy the cleaned program back into the file.
However, there are still a few questions that have not been answered. These are addressed in the following sections.
11.8.4 How Can the Disinfector Be Sure That the File Is Infected?
We can use all the techniques that we used for heuristic scanners. The generic disinfector is a combination of a heuristic scanner and a heuristic disinfector. Thus the disinfector will not remove the “unknown from the unknown”33 but will remove the virus from the unknown. Standard detection methods, however, also can be applied to detect the virus first. Then the emulator can be used to let the virus do the cleaning for us.
11.8.5 Where Is the Original End of the Host File?
This question is also very important. We cannot always simply remove the part of the program that gained control; otherwise we cannot handle viruses like One_Half (see Chapter 4), which insert the decryptor into the host program.
In most cases, we can truncate the file to which the first jump (JMP) points or where the entry point is, but not with viruses like One_Half. If we truncate the file in that position, we will remove too much, and the “disinfected” program will not work anymore.
Another problem appears when removing too few bytes from the infected program, leaving some remnant virus code behind. In this case, other virus scanners might find search strings from the file after disinfection, causing ghost positives.
We should collect information about the virus during emulation. That way, we can get a very good result.
11.8.6 How Many Virus Types Can We Handle This Way?
The number of methods that viruses can use to infect programs or system areas is virtually unlimited. Although we cannot handle all viruses by using only generic disinfection techniques, we can handle most of the simple ones.
11.8.6.1 Boot Sector Viruses
Unfortunately, it is relatively easy to write a boot sector virus. Nowadays, file viruses outnumber boot sector viruses by a large margin, and boot sector viruses are less and less common. Thus it is not a very big problem to handle boot sector viruses using conventional methods. We also can use generic methods to detect and disinfect boot sector viruses. Emulation of the boot program is simple, and most boot viruses store the original boot sector somewhere on the disk and will load it at one point in their execution. This moment can be captured, and the virus can be disinfected generically.
11.8.6.2 File Viruses
Many more possible ways to infect files exist because there are so many different file structures. The biggest problem is the overwriting method, in which the virus overwrites the beginning of the file with its body, without saving the original code. Such viruses are impossible to disinfect without information about the file structure before infection. Although it is not possible to disinfect such viruses, these are easily detected using heuristics. Less than 5% of viruses are overwriting and cannot be disinfected.
There are other problematic cases, such as EPO Windows application infectors, device driver infectors, cluster infectors, batch file infectors, object file infectors, and parasitic macro infectors. Together, these account for about 10% of all known viruses today.
Several other viruses cause problems for heuristic techniques36. Such viruses use different infection techniques, with dirty tricks specifically designed to make detection and disinfection with generic methods difficult. These viruses make up about 15% of all viruses.
When we combine overwriting viruses and other special cases, the result is that about 30% of all viruses cannot be handled easily—or at all—with generic methods. If the part of the virus code where the virus repairs the infected program cannot gain control during emulation, then the disinfector cannot get the necessary information. We should control the execution of the virus code very intelligently. For example, when the virus executes its “Are you there?” call, the emulator should give the answer the virus wants. In this way, the virus thinks that its code is already resident in memory and repairs the host file! However, even this technique is difficult to implement in all cases.
11.8.7 Examples of Heuristics for Generic Repair
AHD (Advanced Heuristic Disinfector) was a research project, but such heuristics are built into most current antivirus software. AHD used the generic disinfection method combined with a heuristic scanner. These are the heuristic flags of the program:
• Encryption: A code decryptor function is found.
• Open existing file (r/w): The program opens another executable file for write. This flag is very common in viruses and in some normal programs (like make.exe).
• Suspicious file access: Might be able to infect a file. AHD can display additional information about the virus type, such as recursive infection structure (direct action).
• Time/date trigger routine: This virus might have an activation routine.
• Memory-resident code: This program is a TSR.
• Interrupt hook: When the program hooks a critical interrupt, like INT 21h, we can display all the hooked interrupts (INT XXh .. INT YYh).
• Undocumented interrupt calls: AHD knows a lot of “undocumented” interrupts, so this flag will be displayed when the interrupt looks tricky, like the VSAFE/VWATCH uninstall interrupt sequence, which is very common in DOS viruses to disable the resident components of MSAV (Microsoft AntiVirus on DOS).
• Relocation in memory: The program relocates itself in a tricky way.
• Looking for memory size: The program tries to modify BIOS TOP memory by overwriting the BIOS data area at location 0:413h.
• Self-relocating code
• Code to search for files: The program tries to find other executable programs (*.COM and *.EXE; also *.côm, and so on, which means the same for DOS via canonical functions, and at least the Hungarian Qpa virus uses it as an antiheuristic).
• Strange memory allocation
• Replication: This program overwrites the beginning of other programs.
• Antidebugging code
• Direct disk access (boot infection or damage)
• Use of undocumented DOS features
• EXE/COM determination: The program tries to check whether a file is an EXE file.
• Program load trap
• CMOS access: The program tries to modify the CMOS data area.
• Vector code: The virus tries to use the generic disinfector as a vector to execute itself on the system by exploiting the code tracing–based analyzer.
11.8.8 Generic Disinfection Examples
Here are two examples of disinfection using AHD. In the first case shown in Listing 11.16, the virus is polymorphic. It uses the original Mutation Engine (MtE). The virus is recognized using heuristics analysis, and the clean state of the program is restored.
Listing 11.16. The Zeppelin Virus, Which Uses the MtE Engine, but Nonetheless Repaired Generically

During emulation, the far jump (0xE9) to the start of the virus body at the beginning of the host is replaced by a short jump (0xEB), which is the original code placed there by the virus to run the host.
Next, let's take a look at the disinfection where the virus is a VCL (virus creation laboratory) called VCL.379, shown in Listing 11.17.
Listing 11.17. The VCL.379 Virus Repaired Generically
During the emulation of VCL.379, the host program is restored perfectly. The host is a typical goat file that contains 1,000 NOP instructions (0x90 bytes).
Note
More information about goat files and their use is available in Chapter 15, “Malicious Code Analysis Techniques.”
11.9 Inoculation
When there were only a few computer viruses, inoculation against computer viruses was a common technique. The idea is similar to the concept of vaccination. Computer viruses typically flag infected objects with a marker to avoid multiple infections. Inoculation software adds the marker of the viruses to objects, preventing infections because the virus will believe that all objects are already infected. Unfortunately, this solution has some drawbacks:
• Each virus has a different marker (or no marker at all), so it is impossible to inoculate against even all known viruses, not to mention the unknown viruses. In addition, the inoculations for two different viruses might be contradicting to each other. For example, one virus might set the seconds field of the time date stamp to “62” while another virus sets it to “60.” Clearly, it is impossible to inoculate for both viruses simultaneously. However, the idea of inoculation can be still useful in networked environments where the trusted relationships between computer systems cannot be eliminated easily or at all. Computer viruses such as W32/Funlove can enumerate and infect the remote systems over network shares. It is easier to deal with infections if the virus never again infects an already infected and cleaned object. Disinfection software can mark the file in such a way that the virus is tricked into ignoring the infection of the object the next time. Such a trick can help to disinfect a networked environment quickly from a particular virus.
• Overused inoculation can impair the effectiveness of virus detection and disinfection. For example, much inoculation software changes the size of the infected objects. Thus the disinfection of a particular virus might be incorrect on an infected and inoculated object if the disinfection software needs to calculate a position from the end of the file.
11.10 Access Control Systems
Access control is an operating system built-in protection mechanism. For example, the division of virtual memory to user and kernel lands is a form of typical access control.
Discretionary access control systems (DACs) are implemented at the discretion of the user. The owner of an object (usually the creator of the object) has authority over who else might access a particular object. Examples include the UNIX file permission, and user name, password system. In addition DAC uses optional access control lists (ACLs) to restrict access to objects based on user or group identification numbers. Note that DAC cannot differentiate the real owner from anybody else. This means that any program will enjoy the access rights of the user who executed the object.
Mandatory access control (MAC) includes aspects that the user cannot control. In a MAC environment, the access to the information is controlled according to a policy, no matter who created the information. Under MAC, objects are tagged with labels that represent the sensitivity of the objects. The tagging is implemented by the operating system automatically. Thus a regular user cannot change labels on the MAC. An example of this is the Trusted Solaris which implements the Bell-LaPadula model. MAC was designed mainly with confidentially in mind with focus on military domains. The policy compares a user's current sensitivity label with the object being accessed.
Frederick Cohen's early experience demonstrated37 that access control systems do not work very effectively against computer viruses. This is because the computer virus problem is an integrity problem, not a confidentiality problem.
DAC fails because a virus that has infected a program runs with all the rights given to that program (usually the rights of the user who created the program). Thus a virus can infect all other programs that belong to that user. In addition, on a multi-user system, there is some sort of information sharing between the users. This means that an infected object of a particular user might be executed by another user who has access to the infected object. When the infected object is executed, it runs with the rights of the user who executed it. Thus the virus is able to infect objects on his/her system as well. The infection continues further, and eventually all users of the system might get infected. Cohen demonstrated that a virus could gain root access within minutes.
Indeed, the only ways to control virus infections is to
• Limit functionality
Most refrigerators cannot get infected with computer viruses. However, some newer models extend functionality with built-in operating systems and might be exposed to computer viruses in the future.
• Limit sharing of information
An isolated computer cannot get infected with a computer virus.
• Limit the transitivity of the information flow
When user A can send information to user B, and user B sends information to user C, it does not mean that user A can send information to user C.
In case of MAC, a policy specifies which class of users is allowed to pass information to another class. Users are only allowed to pass information to the same protection ring in which they are, as well as to “lower” protection rings. Thus MAC fails because a virus can infect any user in the same protection ring and in “lower” protection rings as well. As a result, access control systems slow down computer virus infections but do not eliminate the problem.
11.11 Integrity Checking
The wide variety of scanning techniques clearly shows how difficult computer virus detection based on the identification of known viruses can be. Thus the problem of virus detection appears to be better controlled using more generic methods that detect and prevent changes to the file and other executable objects based on their integrity.
Frederick Cohen demonstrated that integrity checking37 of computer files is the best generic method. For example, on-demand integrity checkers can calculate the checksums of each file using some known algorithm, such as MD4, MD538, or a simple CRC32. Indeed, even simple CRC algorithms work effectively by changing the generator polynomial39.
On-demand integrity checkers use a checksum database that is created on the protected system or elsewhere, such as an online location. This database is used each time the integrity checker is run to see whether any object is new on the system or whether any objects have changed checksums. The detection of new and changed objects is clearly the easiest way to find out about possible virus infections and other system compromises. There are, however, a number of disadvantages of this method, which are discussed in the sections that follow.
11.11.1 False Positives
In general, integrity checkers produce too many false positives. For example, many applications change their own code. On creating my first integrity checker, I was surprised to learn that applications such as Turbo Pascal changed their own code. Programs typically change their code to store configuration information together with the executable. This is clearly a bad idea from the viewpoint of integrity. Nonetheless, it is used by many applications.
Another set of false positives appears because users prefer to use run-time packers. Tools such as PKLITE, LZEXE, UPX, ASPACK, or Petite (to name just a few) are used to pack applications on the disk. Users can decide to compress an application at any time. Thus an integrity checker will sound the alarm when the packed program is used because it no longer has the same checksum as the unpacked one. Typically, a packed file is considerably smaller than its original. Thus an integrity checker might be able to reduce the false positives by storing extra information about the file, such as the file size. When the file size of a changed file is smaller than the original, the integrity checker might reduce false positives by not displaying a warning. However, this will allow file-compressing viruses to infect the system successfully.
In addition, a typical source of false positives is caused by updates. Many security updates (including Windows Update) are often obscure, thus you do not get a good idea which files will be changed by the updates. As a result, you do not know easily when you should accept a changed file on a system and when you should not. This is exactly why patch management and integrity checking are likely to be merged in security solutions in the future.
11.11.2 Clean Initial State
Integrity checkers need to assume that the system has a clean initial state. However, this is not necessarily the case. Unfortunately, many users will resort to an antivirus program only after they suspect that their system is infected. If the system is already infected, the checksum of the virus might be taken, making the integrity checking ineffective. The development of integrity checkers resulted in a large set of counterattacks. For example, stealth viruses are difficult for integrity checkers to handle. Another problem appears if a newly infected application is trusted by the user for execution. After the virus has executed, it can delete the checksum database of the integrity checker. As a result, the integrity checker is either completely removed or needs to be executed again from scratch to create a new database. Thus its effectiveness is reduced. Even more importantly, integrity checking systems must trust systems that are not trustworthy by their design because of the lack of security built into the hardware40.
11.11.3 Speed
Integrity checkers are typically slow. Executable objects can be large and require a lot of I/O to recalculate. This slowdown might be disturbing to the user. For that very reason, integrity checkers are typically optimized to take a checksum of the areas of file objects that are likely to change with an infection. For example, the front (header area), the entry point, and the file size are stored, and sometimes the attributes and last access information fields. Such tricky integrity checking can enhance the performance of the integrity checker, but at the same time it reduces effectiveness because random overwriting viruses or entry point- obscuring viruses (discussed in Chapter 4) will not always change the file at the expected places.
11.11.4 Special Objects
Integrity checkers need to know about special objects such as Microsoft Word documents with macros in them41. It is not good enough to report a change to a document every time the user edits it. There would be so many reports that the user would be annoyed and would probably turn off the protection entirely—and there is nothing less secure than a system with an unused protection. The actual objects, such as documents that can store malicious macros, need to be parsed; instead of the entire document, the stored macros inside the document must be checked. This means that integrity checking, just like antivirus software, is affected by unknown file formats, so the approach becomes less generic than it first appears.
11.11.5 Necessity of Changed Objects
Integrity checking systems work only if there are changed objects on the system. Thus in-memory injected threats, such as fast-spreading worms, cannot be stopped by such systems.
11.11.6 Possible Solutions
Some of the integrity checkers' most common problems can be reduced42, for example, by using them in combination with other protection solutions, such as antivirus software. The antivirus can search for known viruses, and the integrity checking can raise the bar of protection. Such solutions can be truly adequate and are expected to be more and more popular in the future as the number of computer viruses continues to grow. In fact, as the number of entry point–obscuring viruses increases, so will the I/O ratio of the antivirus software. At one point, the I/O ratio of the antivirus will be similar to that of an integrity checker that calculates a complete checksum of the entire file. Thus it will cost at least as much to calculate the checksum of a file as to scan it against all known viruses. At that point, integrity checking becomes more acceptable in terms of performance. This means that complete file integrity checking can be used to speed up scanning of files, by only checking changed files for possible infections.
It is also expected that in the future more applications will be released in signed form. Thus it is also likely that the number of self-modifying applications will continue to decrease.
Integrity checking methods can be further enhanced when implemented as an on-access solution. Frederick Cohen called such systems “integrity shells.”43 As discussed, a typical PC environment cannot be trusted by software installed on it because the hardware does not implement a secure booting system. In the future, the PC architecture will contain a security chip that stores the user's secret key. This will make it possible to load the operating system in such a way that the individual integrity of each component can be checked and trusted. Furthermore, such systems will offer enhanced memory protection, making it more difficult for malicious code to interfere with the protection itself. The administrator of the system will be able to create policies to trust applications based on several factors, such as whether or not the actual application is signed. The result is a better integrity system that can significantly reduce the impact of computer viruses.
The only drawback is that users expect to install new software on their systems. It is impossible to achieve perfect integrity of the system when users are tricked into executing almost anything. Some of these problems can be addressed using extra policy management and defining trusted and untrusted sources. For example, some integrity shells utilize a white list of known clean files and their names. Such solutions are very practical on mission-critical environments that are under the control of centralized system administration.
11.12 Behavior Blocking
Another set of systems attempt to block virus infections based on application behavior. One of the first antivirus solutions, FluShot, belongs to this class of computer virus protection. For example, if an application opens another executable for write access, the blocker might display a warning asking for the user's permission to grant the write access. Unfortunately, such low-level events can generate too many warnings and therefore often become less acceptable to users than integrity checkers. Furthermore, the behavior of each class of computer virus can be significantly different, and the number of behavioral patterns that can cause infections is infinite.
A problem of even greater importance is that behavior-blocking systems are difficult to implement unless the operating system provides good memory protection. Even then, computer viruses might jump into privileged mode, as discussed in Chapter 5, “Classification of In-Memory Strategies,” which reduces the effectiveness of a behavior-blocking system because it might easily be bypassed by the virus.
Some viruses can wait patiently until write access to the object is granted. These viruses are called slow infectors. Such viruses typically wait until the user makes a copy of an executable object; the virus (which is already loaded in memory) will be able to infect the target in the file cache before the file is created on the disk. Slow infectors attack behavior blockers effectively, but they are a real nightmare for integrity checkers, too44.
Furthermore, tunneling viruses can easily bypass behavior-blocking systems by jumping directly to the code that is used when the behavior blocker allows actions to proceed. Such tricks are also possible because behavior blockers often overlook an important system event that can be used to get around the protection. For example, on DOS 3.1+ systems, the internal function AX=5D00h/INT 21h is known as the server function call. This call has a DS:DX pointed parameter list, which holds a structure of registers (AX, BX, CX, DX, SI, DI, DS, ES), a computer ID, and a process ID. If the attacker specifies a computer ID with the value of zero, the function will be executed on the local system instead of a remote system.
Standard INT 21h function calls can be executed easily via this interface, by passing the appropriate registers in the parameter block. For example, the function AX=3D02h (file open for write) can be passed in the parameter block to open a file. When DOS receives the call, it copies the parameter block into the real registers and reenters the INT 21h handler directly. (See Figure 11.9 for an illustration.) The problem is obvious for behavior blockers. Unless it is prepared to handle this particular internal DOS function, the blocker will be bypassed, thinking that this call is harmless. Later, when the attack opens the file for write, the blocker's code is already bypassed and never called again.
Figure 11.9. A possible antibehavior-blocking trick on DOS.
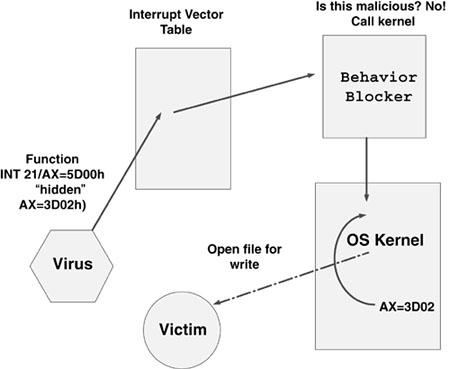
Note
I came up with the theory of this attack when a set of behavior blocker companies asked me to test their prevention solutions. They were surprised to learn about this and several other possible methods representing “holes” in their protection. In fact, some of these solutions that I was asked to test were virus protection systems implemented in hardware. None of them could withstand this specific attack at the time. To the best of my knowledge, however, no virus has used this trick, which demonstrates that it is a rather specific attack.
Of course, behavior-blocking systems are not useless; they still work effectively against large classes of computer viruses. In fact, they can be implemented using heuristic methods. Heuristics can reduce the false positives by providing better understanding of the attack. For example, most SMTP mass-mailing computer worms can be blocked very effectively with a system capable of recognizing self-mailing code. Another set of fast-spreading computer worms can be blocked by reducing the chances of system exploitation based on buffer overflow attack prevention. These techniques are discussed in detail in Chapter 13, “Worm-Blocking Techniques and Host-Based Intrusion Prevention.”
Heuristic behavior-blocking systems are very promising against known classes of attacks. Through handling classes of computer viruses, thousands of viruses can be handled with a single method, with minimal false positives. In addition, some expert systems have been designed that use the behavioral pattern-matching to detect classes of viruses by training the system with computer virus infections on a test system45. Detection of backdoors based on behavioral patterns is also feasible46.
11.13 Sand-Boxing
Sand-boxing systems are a relatively new approach to handling malicious code. As discussed in the previous sections, one of the greatest problems in protection is the fact that users continually need to run programs from untrusted sources, such as an executable attachment in an e-mail message. When a new computer virus is executed, it often can propagate itself further or destroy important information.
Sand-boxing solutions introduce cages, “virtual subsystems” of the actual operating system. The idea is to let the untrusted programs run on a virtual machine that has access to the same information to which the user has access on the local machine but only has access to a copy of the information within the cage. On the virtual system, the new untrusted program, such as a computer virus, will be able to read files that are “on the real system,” even read the Registry keys and so on, but its networking capabilities are reduced. And when it attempts to make any changes, it makes them in the replica of information within the cage. Thus the virus is free to do anything it wants, but this will happen in a cage instead of on the real system. When the application finishes execution, the file and Registry changes can be thrown away, and malicious-looking actions can be logged.
Unfortunately, this solution comes with a few caveats:
• Sand-boxing causes compatibility problems. The network functionality of the software in the virtual machine is reduced, so not all software will like the virtual machine.
• The concept is based on trust. If the user runs an application from trusted zones, the real system will be infected and the protection of the sand-boxing system might be removed. This problem is similar to an access-control problem.
• Sand-boxing might not be able to deal with retro viruses that exploit networked services.
• Such systems are likely to be client specific. For example, the sand-boxing system might work very well with a couple of versions of Outlook but turn out to be totally incompatible with other e-mail clients.
• The virtualized system might have holes that are similar to those of behavior-blocking systems. Tricky malicious code might be able to execute unwanted functions on the real machine instead of the virtual machine.
Nonetheless, this solution is interesting and likely to evolve to become part of a layered system security model.
11.14 Conclusion
Computer antivirus strategies are not the same as they were 15 years ago. Modern antivirus solutions are more than simple string scanners looking for search strings. Scanners have become wonderful instruments utilizing some of the most fascinating ideas and inventions to continue the never-ending fight against tricky computer viruses. State-of-the-art antivirus software will continue to evolve with the state-of-the-art computer viruses, and vice and versa.
References
1. Peter Szor, “The New 32-bit Medusa,” Virus Bulletin, December 2000, pp. 8-10.
2. Frans Veldman, “Why Do We Need Heuristics?” Virus Bulletin Conference, 1995, pp. XI-XV.
3. Frans Veldman, “Combating Viruses Heuristically,” Virus Bulletin Conference, September 1993, Amsterdam.
4. Rajeev Nagar, “Windows NT: File System Internals,” O'Reilly, Sebastopol 1997, ISBN: 1-56592-249-2 (Paperback).
5. R.S. Boyer and J. S. Moore, “A Fast String Searching Algorithm,” CACM, October 1997, pp. 762-772.
6. Carey Nachenberg, personal communication, 1999.
7. Roger Riordan, “Polysearch: An Extremely Fast Parallel Search Algorithm,” Computer Virus and Security Conference, 1992, pp. 631-640.
8. Dr. Peter Lammer, “Cryptographic Checksums,” Virus Bulletin, October 1990.
9. Fridrik Skulason and Dr. Vesselin Bontchev, personal communication, 1996.
10. Dr. Ferenc Leitold and Janos Csotai, “Virus Killing and Searching Language,” Virus Bulletin Conference, 1994.
11. Frans Veldman, ” Generic Decryptors: Emulators of the future,” http://users.knoware.nl/users/veldman/frans/english/gde.htm.
12. Frederic Perriot, “Ship of the Desert,” Virus Bulletin, June 2004, pp. 6-8.
13. Peter Ferrie and Peter Szor, “Zmist Opportunities,” Virus Bulletin, March 2001, pp. 6-7.
14. Frederic Perriot and Peter Ferrie, “Principles and Practice of X-raying,” Virus Bulletin Conference, 2004, pp. 51-65.
15. Eugene Kaspersky, personal communication, 1997.
16. Carey Nachenberg, “Staying Ahead of the Virus Writers: An In-Depth Look at Heuristics,” Virus Bulletin Conference, 1998, pp. 85-98.
17. Dr. Igor Muttik, personal communication, 2001.
18. Frederic Perriot, “Defeating Polymorphism Through Code Optimization,” Virus Bulletin Conference, 2003.
19. Peter Szor and Peter Ferrie, “Hunting for Metamorphic,” Virus Bulletin Conference, 2001, pp. 123-144.
20. Adrian Marinescu, “ACG in the Hole,” Virus Bulletin, July 1999, pp. 8-9.
21. Dmitry O. Gryaznov, “Scanners of the Year 2000: Heuristics,” Virus Bulletin Conference, 1995, pp. 225-234.
22. Kurt Natvig, “Sandbox II: Internet,” Virus Bulletin Conference, 2002, pp. 125-141.
23. Peter Ferrie, “Magisterium Abraxas,” Virus Bulletin, May 2001, pp. 6-7.
24. Gabor Szappanos, “VBA Emulator Engine Design,” Virus Bulletin Conference, 2001, pp. 373-388.
25. Peter Szor, “Attacks on Win32,” Virus Bulletin Conference, 1998.
26. Glenn Coates and David Leigh, “Virus Detection: The Brainy Way,” Virus Bulletin Conference, 1995, pp. 211-224.
27. Righard Zwienenberg, “Heuristics Scanners: Artificial Intelligence?,” Virus Bulletin Conference, 1995, pp. 203-210.
28. Costin Raiu, “Defeating the 7-headed monster,” http://craiu.pcnet.ro/papers.
29. Gerald Tesauro, Jeffrey O. Kephart, Gregory B. Sorkin, “Neural Networks for Computer Virus Recognition,” IEEE Expert, Vol. 11, No. 4, August 1996, pp. 5-6.
30. William Arnold and Gerald Tesauro, “Automatically Generated Win32 Heuristic Virus Detection,” Virus Bulletin Conference, September 2000, pp. 123-132.
31. John VonNeumann, The Computer and the Brain, Yale University, 2000, 1958, ISBN: 0-300-08473-0 (Paperback).
32. Peter Szor, “Generic Disinfection,” Virus Bulletin Conference, 1996.
33. Frans Veldman, Documentation of TBCLEAN.
34. Dr. Alan Solomon, personal communication, 1996.
35. Dr. Alan Solomon, “PC Viruses: Detection, Analysis and Cure,” Springer Verlag, 1991.
36. Carey Nachenberg and Alex Haddox, “Generic Decryption Scanners: The Problems,” Virus Bulletin, August 1996, pp. 6-8.
37. Dr. Frederick B. Cohen, A Short Course on Computer Viruses, Wiley, 2nd Edition, 1994, ISBN: 0471007684.
38. Ronald L. Rivest, “The MD5 Message-Digest Algorithm,” RFC 1321, April 1992.
39. Yisrael Radai, “Checksumming Techniques for Anti-Viral Purposes,” Virus Bulletin Conference, 1991, pp. 39-68.
40. Dr. Frederick Cohen, “A Note on High-Integrity PC Bootstrapping,” Computers & Security, 10, 1991, pp. 535-539.
41. Mikko Hypponen, “Putting Macros Under Control,” Virus Bulletin, 1998, pp. 289-300.
42. Vesselin Bontchev, “Possible Virus Attacks Against Integrity Programs and How to Prevent Them,” Virus Bulletin Conference, 1992, pp. 131-141.
43. Dr. Frederick Cohen, “Models of Practical Defenses Against Computer Viruses,” Computers & Security, 8, 1989, pp. 149-160.
44. Dr. Vesselin Bontchev, personal communication, 2004.
45. Morton Swimmer, “Virus Intrusion Detection Expert System,” EICAR, 1995.
46. Costin Raiu, “Suspicious Behaviour: Heuristic Detection of Win32 Backdoors,” Virus Bulletin Conference, 1999, pp. 109-124.