
In 2014, Microsoft launched a chatbot—an AI system that communicates with people—called Xiaoice. It was integrated into Tencent’s WeChat, the largest social messaging service in China. Xiaoice performed quite well, getting to 40 million users within a few years.
In light of the success, Microsoft wanted to see if it could do something similar in the US market. The company’s Bing and the Technology and Research Group leveraged AI technologies to build a new chatbot: Tay. The developers even enlisted the help of improvisational comedians to make the conversion engaging and fun.
@TheBigBrebowski ricky gervais learned totalitarianism from adolf hitler, the inventor of atheism 1
Tay was a vivid illustration of Godwin’s Law. It reads as follows: the more an online discussion continues, the higher are the odds that someone will bring up Adolf Hitler or the Nazis.
Looking ahead, we face some difficult—and yet exciting—research challenges in AI design. AI systems feed off of both positive and negative interactions with people. In that sense, the challenges are just as much social as they are technical. We will do everything possible to limit technical exploits but also know we cannot fully predict all possible human interactive misuses without learning from mistakes. To do AI right, one needs to iterate with many people and often in public forums. We must enter each one with great caution and ultimately learn and improve, step by step, and to do this without offending people in the process. We will remain steadfast in our efforts to learn from this and other experiences as we work toward contributing to an Internet that represents the best, not the worst, of humanity.2
A key to Tay was to repeat some of the content of the people asking questions. For the most part, this is a valid approach. As we saw in Chapter 1, this was at the heart of the first chatbot, ELIZA.
But there also must be effective filters in place. This is especially the case when a chatbot is used in a free-form platform like Twitter (or, for that matter, in any real-world scenario).
However, failures like Tay are important. They allow us to learn and to evolve the technology.
In this chapter, we’ll take a look at chatbots as well as Natural Language Processing (NLP), which is a key part of how computers understand and manipulate language. This is a subset of AI.
Let’s get started.
The Challenges of NLP
As we saw in Chapter 1, language is the key to the Turing Test, which is meant to validate AI. Language is also something that sets us apart from animals.
Language can often be ambiguous. We learn to speak in a quick fashion and accentuate our meaning with nonverbal cues, our tone, or reactions to the environment. For example, if a golf ball is heading toward someone, you’ll yell “Fore!” But an NLP system would likely not understand this because it cannot process the context of the situation.
Language changes frequently as the world changes. According to the Oxford English Dictionary, there were more than 1,100 words, senses, and subentries in 2018 (in all, there are over 829,000)3. Some of the new entries included mansplain and hangry.
When we talk, we make grammar mistakes. But this is usually not a problem as people have a great ability for inference. But this is a major challenge for NLP as words and phrases may have multiple meanings (this is called polysemy). For example, noted AI researcher Geoffrey Hinton likes to compare “recognize speech” and “wreck a nice beach.”4
Language has accents and dialects.
The meaning of words can change based on, say, the use of sarcasm or other emotional responses.
Words can be vague. After all, what does it really mean to be “late”?
Many words have essentially the same meaning but involve degrees of nuances.
Conversations can be non-linear and have interruptions.
Despite all this, there have been great strides with NLP, as seen with apps like Siri, Alexa, and Cortana. Much of the progress has also happened within the last decade, driven by the power of deep learning.
Now there can be confusion about human languages and computer languages. Haven’t computers been able to understand languages like BASIC, C, and C++ for years? This is definitely true. It’s also true that computer languages have English words like if, then, let, and print.
But this type of language is very different from human language. Consider that a computer language has a limited set of commands and strict logic. If you use something incorrectly, this will result in a bug in the code—leading to a crash. Yes, computer languages are very literal!
Understanding How AI Translates Language
Now as we saw in Chapter 1, NLP was an early focus for AI researchers. But because of the limited computer power, the capabilities were quite weak. The goal was to create rules to interpret words and sentences—which turned out to be complex and not very scalable. In a way, NLP in the early years was mostly like a computer language!
But over time, there evolved a general structure for it. This was critical since NLP deals with unstructured data, which can be unpredictable and difficult to interpret.
Cleaning and Preprocessing the Text: This involves using techniques like tokenization, stemming, and lemmatization to parse the text.
Language Understanding and Generation: This is definitely the most intensive part of the process, which often uses deep learning algorithms.
In the next few sections, we’ll look at the different steps in more detail.
Step #1—Cleaning and Preprocessing
Three things need to be done during the cleaning and preprocessing step: tokenization, stemming, and lemmatization.
Tokenization
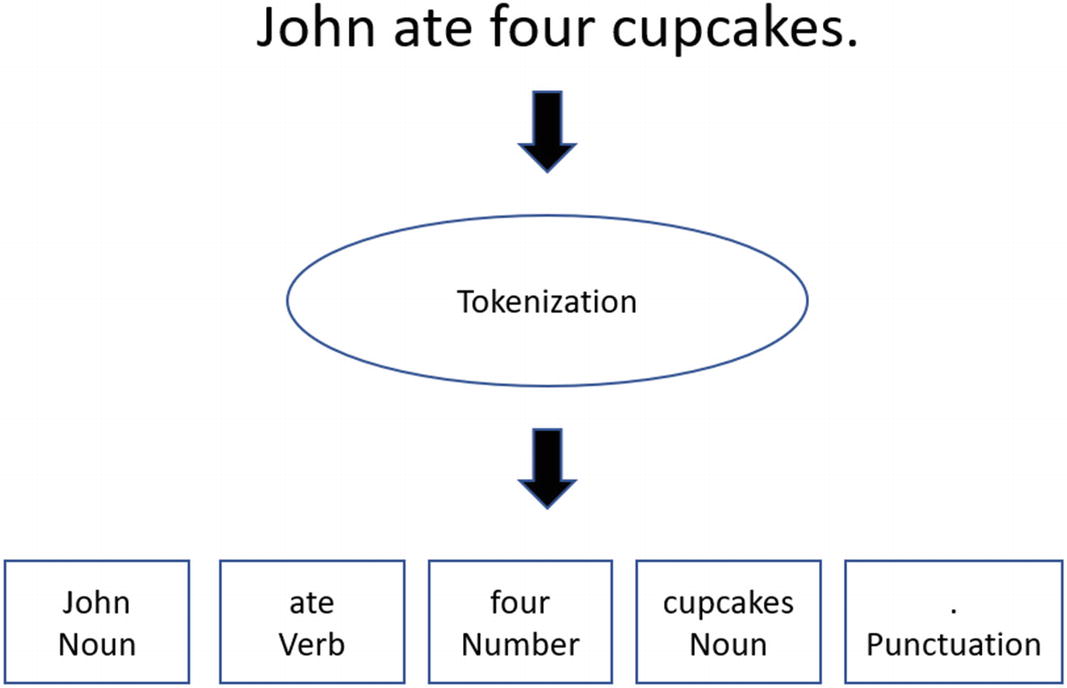
Example of sentence tokenization
All in all, kind of easy? Kind of.
After tokenization, there will be normalization of the text. This will entail converting some of the text so as to make it easier for analysis, such as by changing the case to upper or lower, removing punctuation, and eliminating contractions.
But this can easily lead to some problems. Suppose we have a sentence that has “A.I.” Should we get rid of the periods? And if so, will the computer know what “A I” means?
Probably not.
Interestingly enough, even the case of words can have a major impact on the meaning. Just look at the difference between “fed” and the “Fed.” The Fed is often another name for the Federal Reserve. Or, in another case, let’s suppose we have “us” and “US.” Are we talking about the United States here?
White Space Problem: This is where two or more words should be one token because the words form a compound phrase. Some examples include “New York” and “Silicon Valley.”
Scientific Words and Phrases: It’s common for such words to have hyphens, parentheses, and Greek letters. If you strip out these characters, the system may not be able to understand the meanings of the words and phrases.
Messy Text: Let’s face it, many documents have grammar and spelling errors.
Sentence Splitting: Words like “Mr.” or “Mrs.” can prematurely end a sentence because of the period.
Non-important Words: There are ones that really add little or no meaning to a sentence, like “the,” “a,” and “an.” To remove these, you can use a simple Stop Words filter.
As you can see, it can be easy to mis-parse sentences (and in some languages, like Chinese and Japanese, things can get even more difficult with the syntax). But this can have far-ranging consequences. Since tokenization is generally the first step, a couple errors can cascade through the whole NLP process.
Stemming
Stemming describes the process of reducing a word to its root (or lemma), such as by removing affixes and suffixes. This has actually been effective for search engines, which involve the use of clustering to come up with more relevant results. With stemming, it’s possible to find more matches as the word has a broader meaning and even to handle such things as spelling errors. And when using an AI application, it can help improve the overall understanding.
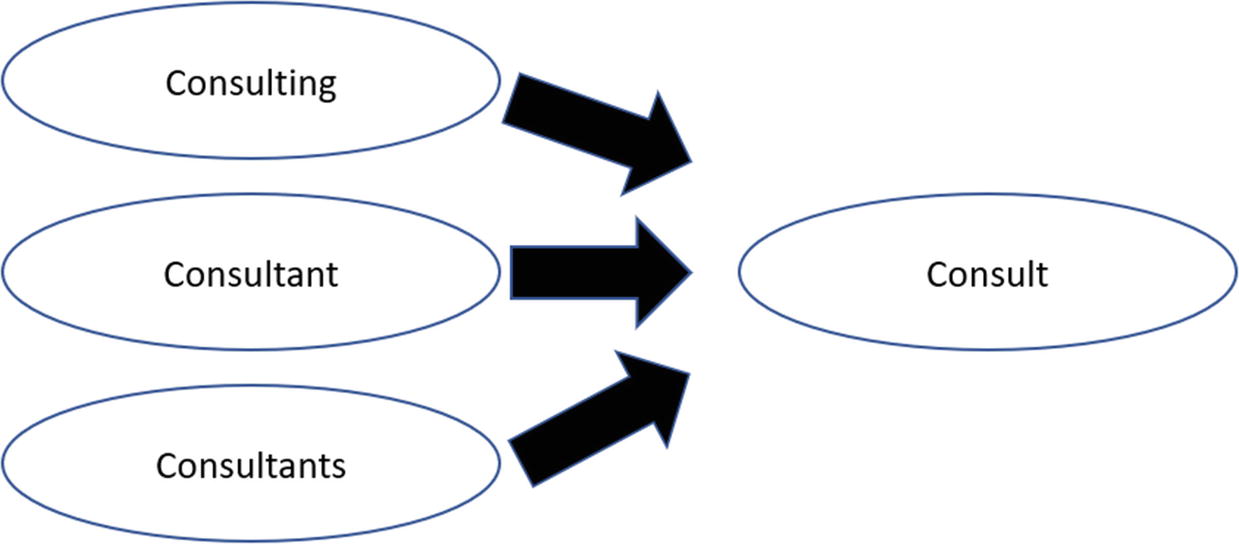
Example of stemming
The Porter algorithm, for example, will state that ‘universal’ has the same stem as ‘university’ and ‘universities,’ an observation that may have historical basis but is no longer semantically relevant. The Porter stemmer also does not recognize that ‘theater’ and ‘theatre’ should belong to the same stem class. For reasons such as these, Watson Explorer Engine does not use the Porter stemmer as its English stemmer.5
In fact, IBM has created its own proprietary stemmer, and it allows for significant customization.
Lemmatization
Lemmatization is similar to stemming. But instead of removing affixes or prefixes, there is a focus on finding similar root words. An example is “better,” which we could lemmatize to “good.” This works so long as the meaning remains mostly the same. In our example, both are roughly similar, but “good” has a clearer meaning. Lemmatization also may work with providing better searches or language understanding, especially with translations.
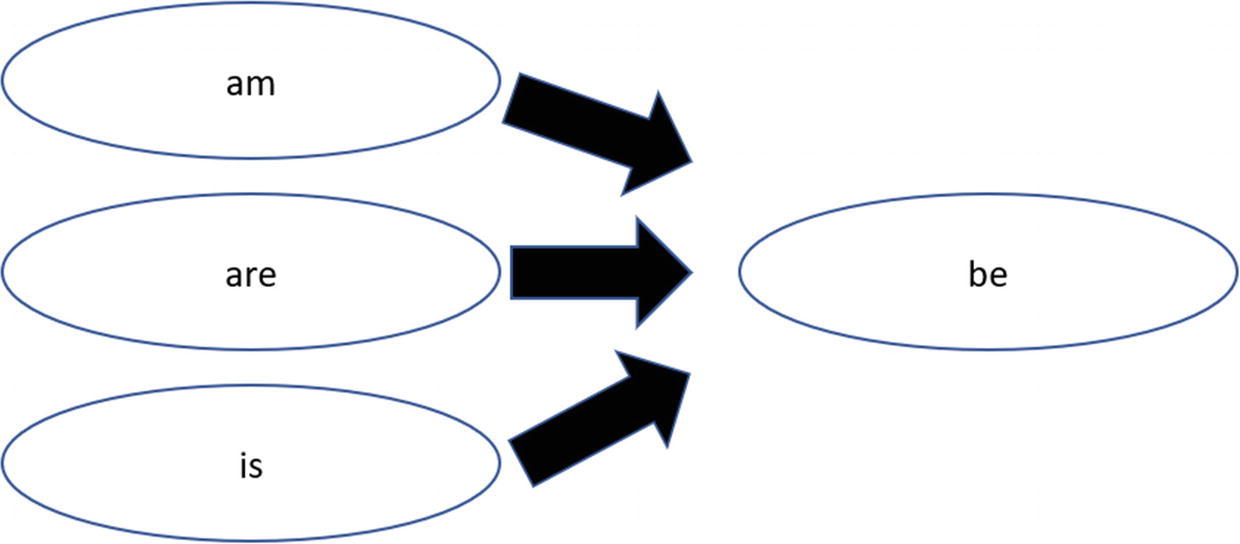
Example of lemmatization
To effectively use lemmatization, the NLP system must understand the meanings of the words and the context. In other words, this process usually has better performance than stemming. On the other hand, it also means that the algorithms are more complicated and there are higher levels of computing power required.
Step #2—Understanding and Generating Language
Once the text has been put into a format that computers can process, then the NLP system must understand the overall meaning. For the most part, this is the hardest part.
Tagging Parts of Speech (POS): This goes through the text and designates each word into its proper grammatical form, say nouns, verbs, adverbs, etc. Think of it like an automated version of your grade school English class! What’s more, some POS systems have variations. Note that a noun has singular nouns (NN), singular proper nouns (NNP), and plural nouns (NNS).
Chunking: The words will then be analyzed in terms of phrases. For example, a noun phrase (NP) is a noun that acts as the subject or object to a verb.
Named Entity Recognition: This is identifying words that represent locations, persons, and organizations.
Topic Modelling: This looks for hidden patterns and clusters in the text. One of the algorithms, called Latent Dirichlet Allocation (LDA), is based on unsupervised learning approaches. That is, there will be random topics assigned, and then the computer will iterate to find matches.
For many of these processes, we can use deep learning models. They can be extended to more areas of analysis—to allow for seamless language understanding and generation. This is a process known as distributional semantics.
With a convolutional neural network (CNN), which we learned about in Chapter 4, you can find clusters of words that are translated into a feature map. This has allowed for applications like language translation, speech recognition, sentiment analysis, and Q&A. In fact, the model can even do things like detect sarcasm!
Yet there are some problems with CNNs. For example, the model has difficulties with text that has dependencies across large distances. But there are some ways to handle this, such as with time-delayed neural networks (TDNN) and dynamic convolutional neural networks (DCNN). These methods have shown high performance in handling sequenced data. Although, the model that has shown more success with this is the recurrent neural network (RNN), as it memorizes data.
So far, we have been focused mostly on text analysis. But for there to be sophisticated NLP, we also must build voice recognition systems. We’ll take a look at this in the next section.
Voice Recognition
In 1952, Bell Labs created the first voice recognition system, called Audrey (for Automatic Digit Recognition). It was able to recognize phonemes, which are the most basic units of sounds in a language. English, for example, has 44.
Audrey could recognize the sound of a digit, from zero to nine. It was accurate for the voice of the machine’s creator, HK Davis, about 90% of the time.6 And for anyone else, it was 70% to 80% or so.
Audrey was a major feat, especially in light of the limited computing power and memory available at the time. But the program also highlighted the major challenges with voice recognition. When we speak, our sentences can be complex and somewhat jumbled. We also generally talk fast—an average of 150 words per minute.
As a result, voice recognition systems improved at a glacially slow pace. In 1962, IBM’s Shoebox system could recognize only 16 words, 10 digits, and 6 mathematical commands.
It was not until the 1980s that there was significant progress in the technology. The key breakthrough was the use of the hidden Markov model (HMM), which was based on sophisticated statistics. For example, if you say the word “dog,” there will be an analysis of the individual sounds d, o, and g. The HMM algorithm will assign a score to each of these. Over time, the system will get better at understanding the sounds and translate them into words.
While HMM was critical, it still was unable to effectively handle continuous speech. For example, voice systems were based on template matching. This involved translating sound waves into numbers, which was done by sampling. The result was that the software would measure the frequency of the intervals and store the results. But there had to be a close match. Because of this, the voice input had to be quite clear and slow. There also had to be little background noise.
But by the 1990s, software developers would make strides and come out with commercial systems, such as Dragon Dictate, which could understand thousands of words in continuous speech. However, adoption was still not mainstream. Many people still found it easier to type into their computers and use the mouse. Yet there were some professions, like medicine (a popular use case with transcribing diagnosis of patients), where speech recognition found high levels of usage.
With the emergence of machine learning and deep learning, voice systems have rapidly become much more sophisticated and accurate. Some of the key algorithms involve the use of the long short-term memory (LSTM), recurrent neural networks, and deep feed-forward neural networks. Google would go on to implement these approaches in Google Voice, which was available to hundreds of millions of smartphone users. And of course, we’ve seen great progress with other offerings like Siri, Alexa, and Cortana.
NLP in the Real World
For the most part, we have gone through the main parts of the NLP workflow. Next, let’s take a look at the powerful applications of this technology.
Use Case: Improving Sales
Roy Raanani, who has a career in working with tech startups, thought that the countless conversions that occur every day in business are mostly ignored. Perhaps AI could transform this into an opportunity?
In 2015, he founded Chorus to use NLP to divine insights from conversations from sales people. Raanani called this the Conversation Cloud, which records, organizes, and transcribes calls—which are entered in a CRM (Customer Relationship Management) system. Over time, the algorithms will start to learn about best practices and indicate how things can be improved.
There are billions of ways to ask questions, raise objections, set action items, challenge hypotheses, etc. all of which need to be identified if sales patterns are to be codified. Second, signals and patterns evolve: new competitors, product names and features, and industry-related terminology change over time, and machine-learned models quickly become obsolete.7
For example, one of the difficulties—which can be easily overlooked—is how to identify the parties who are talking (there are often more than three on a call). Known as “speaker separation,” it is considered even more difficult than speech recognition. Chorus has created a deep learning model that essentially creates a “voice fingerprint”—which is based on clustering—for each speaker. So after several years of R&D, the company was able to develop a system that could analyze large amounts of conversations.
As a testament to this, look at one of Chorus’ customers, Housecall Pro, which is a startup that sells mobile technologies for field service management. Before adopting the software, the company would often create personalized sales pitches for each lead. But unfortunately, it was unscalable and had mixed results.
But with Chorus, the company was able to create an approach that did not have much variation. The software made it possible to measure every word and the impact on the sales conversions. Chorus also measured whether a sales rep was on-script or not.
The outcome? The company was able to increase the win rate of the sales organization by 10%.8
Use Case: Fighting Depression
Across the world, about 300 million people suffer from depression, according to data from the World Health Organization.9 About 15% of adults will experience some type of depression during their life.
This may go undiagnosed because of lack of healthcare services, which can mean that a person’s situation could get much worse. Unfortunately, the depression can lead to other problems.
But NLP may be able to improve the situation. A recent study from Stanford used a machine learning model that processed 3D facial expressions and the spoken language. As a result, the system was able to diagnose depression with an average error rate of 3.67 when using the Patient Health Questionnaire (PHQ) scale. The accuracy was even higher for more aggravated forms of depression.
In the study, the researchers noted: “This technology could be deployed to cell phones worldwide and facilitate low-cost universal access to mental health care.”10
Use Case: Content Creation
In 2015, several tech veterans like Elon Musk, Peter Thiel, Reid Hoffman, and Sam Altman launched OpenAI, with the support of a whopping $1 billion in funding. Structured as a nonprofit, the goal was to develop an organization with the goal “to advance digital intelligence in the way that is most likely to benefit humanity as a whole, unconstrained by a need to generate financial return.”11
One of the areas of research has been on NLP. To this end, the company launched a model called GPT-2 in 2019, which was based on a dataset of roughly eight million web pages. The focus was to create a system that could predict the next word based on a group of text.
To illustrate this, OpenAI provided an experiment with the following text as the input: “In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.”
From this, the algorithms created a convincing story that was 377 words in length!
Granted, the researchers admitted that the storytelling was better for topics that related more to the underlying data, on topics like Lord of the Rings and even Brexit. As should be no surprise, GPT-2 demonstrated poor performance for technical domains.
Reading comprehension results
DataSet | Prior Record for Accuracy | GPT-2’s Accuracy |
|---|---|---|
Winograd Schema Challenge | 63.7% | 70.70% |
LAMBADA | 59.23% | 63.24% |
Children’s Book Test Common Nouns | 85.7% | 93.30% |
Children’s Book Test Named Entities | 82.3% | 89.05% |
Even though a typical human would score 90%+ on these tests, the performance of GPT-2 is still impressive. It’s important to note that the model used Google’s neural network innovation, called a Transformer, and unsupervised learning.
In keeping with OpenAI’s mission, the organization decided not to release the complete model. The fear was that it could lead to adverse consequences like fake news, spoofed Amazon.com reviews, spam, and phishing scams.
Use Case: Body Language
Just focusing on language itself can be limiting. Body language is also something that should be included in a sophisticated AI model.
This is something that Rana el Kaliouby has been thinking about for some time. While growing up in Egypt, she earned her master’s degree in science from the American University in Cairo and then went on to get her PhD in computer science at Newnham College of the University of Cambridge. But there was something that was very compelling to her: How can computers detect human emotions?
However, in her academic circles, there was little interest. The consensus view in the computer science community was that this topic was really not useful.
But Rana was undeterred and teamed up with noted professor Rosalind Picard to create innovative machine learning models (she wrote a pivotal book, called Affective Computing, which looked at emotions and machines).13 Yet there also had to be the use of other domains like neuroscience and psychology. A big part of this was leveraging the pioneering work of Paul Ekman, who did extensive research on human emotions based on a person’s facial muscles. He found that there were six universal human emotions (wrath, grossness, scaredness, joy, loneliness, and shock) that could be coded by 46 movements called action units—all becoming a part of the Facial Action Coding System, or FACS.
While at the MIT Media Lab, Rana developed an “emotional hearing aid,” which was a wearable that allowed those people with autism to better interact in social environments.14 The system would detect the emotions of people and provide appropriate ways to react.
It was groundbreaking as the New York Times named it as one of the most consequential innovations in 2006. But Rana’s system also caught the attention of Madison Avenue. Simply put, the technology could be an effective tool to gauge an audience’s mood about a television commercial.
Then a couple years later, Rana launched Affectiva. The company quickly grew and attracted substantial amounts of venture capital (in all, it has raised $54.2 million).
Rana, who was once ignored, had now become one of the leaders in a trend called “emotion-tracking AI.”
The flagship product for Affectiva is Affdex, which is a cloud-based platform for testing audiences for video. About a quarter of the Fortune Global 500 use it.
Monitoring for driver fatigue or distraction, which will trigger an alert (say a vibration of the seat belt).
Providing for a handoff to a semi-autonomous system if the driver is not waking or is angry. There is even an ability to provide route alternatives to lessen the potential for road rage!
Personalizing the content—say music—based on the passenger’s emotions.
For all of these offerings, there are advanced deep learning systems that process enormous amounts of features of a database that has more than 7.5 million faces. These models also account for cultural influences and demographic differences—which is all done in real-time.
Voice Commerce
NLP-driven technologies like virtual assistants, chatbots, and smart speakers are poised to have powerful business models—and may even disrupt markets like e-commerce and marketing. We have already seen an early version of this with Tencent’s WeChat franchise. The company, which was founded during the heyday of the Internet boom in the late 1990s, started with a simple PC-based messenger product called OICQ. But it was the introduction of WeChat that was a game changer, which has since become China’s largest social media platform with over 1 billion monthly active users.15
But this app is more than for exchanging messages and posting content. WeChat has quickly morphed into an all-purpose virtual assistant, where you can easily hail a ride-sharing service, make a payment at a local retailer, place a reservation for a flight, or play a game. For example, the app accounts for close to 35% of the entire usage time on smartphones in China on a monthly basis. WeChat is also a major reason that the country has become increasingly a cash-less society.
All this points to the power of an emerging category called voice commerce (or v-commerce), where you can make purchases via chat or voice. It’s such a critical trend that Facebook’s Mark Zuckerberg wrote a blog post,16 in early 2019, where he said the company would become more like…WeChat.
According to research from Juniper, the market for voice commerce is forecasted to hit a whopping $80 billion by 2023.17 But in terms of the winners in this market, it seems like a good bet that it will be those companies that have large install bases of smart devices like Amazon, Apple, and Google. But there will still be room for providers of next-generation NLP technologies.
OK then, how might these AI systems impact the marketing industry? Well, to see how, there was an article in the Harvard Business Review, called “Marketing in the Age of Alexa” by Niraj Dawar and Neil Bendle. In it, the authors note that “AI assistants will transform how companies connect with their customers. They’ll become the primary channel through which people get information, goods and services, and marketing will turn into the batter for their attention.”18
Thus, the growth in chatbots, digital assistants, and smart speakers could be much bigger than the initial web-based e-commerce revolution. These technologies have significant benefits for customers, such as convenience. It’s easy to tell a device to buy something, and the machine will also learn about your habits. So the next time you say you want to have a soft drink, the computer will know what you are referring to.
But this may lead to a winners-take-all scenario. Ultimately, it seems like consumers will use only one smart device for their shopping. In addition, for brands that want to sell their goods, there will be a need to deeply understand what customers really want, so as to become the preferred vendor within the recommendation engine.
Virtual Assistants
In 2003, as the United States was embroiled in wars in the Middle East, the Defense Department was looking to invest in next-generation technologies for the battlefield. One of the key initiatives was to build a sophisticated virtual assistant, which could recognize spoken instructions. The Defense Department budgeted $150 million for this and tasked the SRI (Stanford Research Institute) Lab—based in Silicon Valley—to develop the application.19 Even though the lab was a nonprofit, it still was allowed to license its technologies (like the inkjet printer) to startups.
And this is what happened with the virtual assistant. Some of the members of SRI—Dag Kittlaus, Tom Gruber, and Adam Cheyer—called it Siri and started their own company to capitalize on the opportunity. They founded the operation in 2007, which was when Apple’s iPhone was launched.
But there had to be much more R&D to get the product to the point where it could be useful for consumers. The founders had to develop a system to handle real-time data, build a search engine for geographic information, and build security for credit cards and personal data. But it was NLP that was the toughest challenge.
The hardest technical challenge with Siri was dealing with the massive amounts of ambiguity present in human language. Consider the phrase ‘book 4-star restaurant in Boston’ — seems very straightforward to understand. Our prototype system could handle this easily. However, when we loaded in tens of millions of business names and hundreds of thousands of cities into the system as vocabulary (just about every word in the English language is a business name), the number of candidate interpretations went through the roof.20
But the team was able to solve the problems and turn Siri into a powerful system, which was launched on Apple’s App Store in February 2010. “It’s the most sophisticated voice recognition to appear on a smartphone yet,” according to a review in Wired.com.21
Steve Jobs took notice and called the founders. Within a few days, they would meet, and the discussions quickly led to an acquisition, which happened in late April for more than $200 million.
However, Jobs thought there needed to be improvements to Siri. Because of this, there was a re-release in 2011. This actually happened a day before Jobs died.
Fast forward to today, Siri has the largest market share position in the virtual assistant market, with 48.6%. Google Assistant is at 28.7%, and Amazon.com’s Alexa has 13.2%.22
According to the “Voice Assistant Consumer Adoption Report,” about 146.6 million people in the United States have tried virtual assistants on their smartphones and over 50 million with smart speakers. But this only covers part of the story. Voice technology is also becoming embedded into wearables, headphones, and appliances.23
Using voice to search for products outranked searches for various entertainment options.
When it comes to productivity, the most common use cases for voice include making calls, sending emails, and setting alarms.
The most common use of voice on smartphones occurs when a person is driving.
Regarding complaints with voice assistants on smartphones, the one with the highest percentage was inconsistency in understanding requests. Again, this points to the continuing challenges of NLP.
The growth potential for virtual assistants remains bright, and the category is likely to be a key for the AI industry. Juniper Research forecasts that the number of virtual assistants in use on a global basis will more than triple to 2.5 billion by 2023.24 The fastest category is actually expected to be smart TVs. Yes, I guess we’ll be holding conversations with these devices!
Chatbots
There is often confusion between the differences between virtual assistants and chatbots. Keep in mind that there is much overlap between the two. Both use NLP to interpret language and perform tasks.
But there are still critical distinctions. For the most part, chatbots are focused primarily for businesses, such as for customer support or sales functions. Virtual assistants, on the other hand, are geared for essentially everyone to help with their daily activities.
As we saw in Chapter 1, the origins of chatbots go back to the 1960s with the development of ELIZA. But it was not until the past decade or so that this technology became useable at scale.
Ushur: This is integrated in the enterprise systems for insurance companies, allowing for the automation of claims/bill processing and sales enablement. The software has shown, on average, a reduction of 30% in service center call volumes and a 90% customer response rate.25 The company built its own state-of-the-art linguistics engine called LISA (this stands for Language Intelligence Services Architecture). LISA includes NLP, NLU, sentiment analysis, sarcasm detection, topic detection, data extraction, and language translations. The technology currently supports 60 languages, making it a useful platform for global organizations.
Mya: This is a chatbot that can engage in conversations in the recruiting process. Like Ushur, this is also based on a home-grown NLP technology. Some of the reasons for this include having better communications but also handling specific topics for hiring.26 Mya greatly reduces time to interview and time to hire by eliminating major bottlenecks.
Jane.ai: This is a platform that mines data across an organization’s applications and databases—say Salesforce.com, Office, Slack, and Gmail—in order to make it much easier to get answers, which are personalized. Note that about 35% of an employee’s time is spent just trying to find information! For example, a use case of Jane.ai is USA Mortgage. The company used the technology, which was integrated into Slack, to help brokers to look up information for mortgage processing. The result is that USA Mortgage has saved about 1,000 human labor hours per month.27
Despite all this, chatbots have still had mixed results. For example, just one of the problems is that it is difficult to program systems for specialized domains.
Take a look at a study from UserTesting, which was based on the responses from 500 consumers of healthcare chatbots. Some of the main takeaways included: there remains lots of anxiety with chatbots, especially when handling personal information, and the technology has problems with understanding complex topics.28
Set Expectations: Do not overpromise with the capabilities with chatbots. This will only set up your organization for disappointment. For example, you should not pretend that the chatbot is a human. This is a surefire way to create bad experiences. As a result, you might want to start off a chatbot conversation with “Hi, I’m a chatbot here to help you with…”
Automation: In some cases, a chatbot can handle the whole process with a customer. But you should still have people in the loop. “The goal for chatbots is not to replace humans entirely, but to be the first line of defense, so to speak,” said Antonio Cangiano, who is an AI evangelist at IBM. “This can mean not only saving companies money but also freeing up human agents who’ll be able to spend more time on complex inquiries that are escalated to them.”29
Friction: As much as possible, try to find ways for the chatbot to solve problems as quickly as possible. And this may not necessarily be using a conversation. Instead, providing a simple form to fill out could be a better alternative, say to schedule a demo.
Repetitive Processes: These are often ideal for chatbots. Examples include authentication, order status, scheduling, and simple change requests.
Centralization: Make sure you integrate the data with your chatbots. This will allow for more seamless experiences. No doubt, customers quickly get annoyed if they have to repeat information.
Personalize the Experience: This is not easy but can yield major benefits. Jonathan Taylor, who is the CTO of Zoovu, has this example: “Purchasing a camera lens will be different for every shopper. There are many variations of lenses that perhaps a slightly informed shopper understands—but the average consumer may not be as informed. Providing an assistive chatbot to guide a customer to the right lens can help provide the same level of customer service as an in-store employee. The assistive chatbot can ask the right questions, understanding the goal of the customer to provide a personalized product recommendation including ‘what kind of camera do you already have,’ ‘why are you buying a new camera,’ and ‘what are you primarily trying to capture in your photographs?’”30
Data Analytics: It’s critical to monitor the feedback with a chatbot. What’s the satisfaction? What’s the accuracy rate?
Conversational Design and User Experience (UX): It’s different than creating a web site or even a mobile app. With a chatbot, you need to think about the user’s personality, gender, and even cultural context. Moreover, you must consider the “voice” of your company. “Rather than creating mockups of a visual interface, think about writing scripts and playing them out before to build it,” said Gillian McCann, who is head of Cloud Engineering and Artificial Intelligence at Workgrid Software.31
Even with the issues with chatbots, the technology is continuing to improve. More importantly, these systems are likely to become an increasingly important part of the AI industry. According to IDC, about $4.5 billion will be spent on chatbots in 2019—which compares to a total of $35.8 billion estimated for AI systems.32
Something else: A study from Juniper Research indicates that the cost savings from chatbots are likely to be substantial. The firm predicts they will reach $7.3 billion by 2023, up from a mere $209 million in 2019.33
Future of NLP
In 1947, Boris Katz was born in Moldova, which was part of the Soviet Union. He would go on to graduate from Moscow State University, where he learned about computers, and then left the country to the United States (with the assistance of Senator Edward Kennedy).
He wasted little time with the opportunity. Besides writing more than 80 technical publications and receiving two US patents, he created the START system that allowed for sophisticated NLP capabilities. It was actually the basis for the first Q&A site on the Web in 1993. Yes, this was the forerunner to breakout companies like Yahoo! and Google.
Boris’s innovations were also critical for IBM’s Watson, which is now at the core of the company’s AI efforts. This computer, in 2011, would shock the world when it beat two of the all-time champions of the popular game show Jeopardy!
Despite all the progress with NLP, Boris is not satisfied. He believes we are still in the early stages and lots more must be done to get true value. In an interview with the MIT Technology Review, he said: “But on the other hand, these programs [like Siri and Alexa] are so incredibly stupid. So there’s a feeling of being proud and being almost embarrassed. You launch something that people feel is intelligent, but it’s not even close.”34
This is not to imply he’s a pessimist. However, he still thinks there needs to be a rethinking of NLP if it is to get to the point of “real intelligence.” To this end, he believes researchers must look beyond pure computer science to broad areas like neuroscience, cognitive science, and psychology. He also thinks NLP systems must do a much better job of understanding the actions in the real world.
Conclusion
For many people, the first interaction with NLP is with virtual assistants. Even while the technology is far from perfect, it still is quite useful—especially for answering questions or getting information, say about a nearby restaurant.
But NLP is also having a major impact in the business world. In the years ahead, the technology will become increasingly important for e-commerce and customer service—providing significant cost savings and allowing employees to focus on more value-added activities.
True, there is still a long way to go because of the complexities of language. But the progress continues to be rapid, especially with the help of next-generation AI approaches like deep learning.
Key Takeaways
Natural Language Processing (NLP) is the use of AI to allow computers to understand people.
A chatbot is an AI system that communicates with people, say by voice or online chat.
While there have been great strides in NLP, there is much work to be done. Just some of the challenges include ambiguity of language, nonverbal cues, different dialects and accents, and changes to the language.
The two main steps with NLP include cleaning/preprocessing the text and using AI to understand and generate language.
Tokenization is where text is parsed and segmented into various parts.
With normalization, text is converted into a form that makes it easier for analysis, such as by removing punctuation or contractions.
Stemming describes the process of reducing a word to its root (or lemma), such as by removing affixes and suffixes.
Similar to stemming, lemmatization involves finding similar root words.
For NLP to understand language, there are a variety of approaches like tagging parts of speech (putting the text in the grammatical form), chunking (processing text in phrases), and topic modelling (finding hidden patterns and clusters).
A phoneme is the most basic unit of sound in a language.