
Accessing Validity of Argumentation of Agents of the Internet of Everything
Boris Galitsky⁎; Anna Parnis† * Oracle Corporation, Redwood Shores, CA, United States
† Department of Biology, Technion-Israel Institute of Technology, Haifa, Israel
Abstract
Agents of the Internet of Everything (IoE) exchange messages, make certain decisions, and provide arguments for them. In this IoE environment validation of the validity of argumentation patterns in messages, as well as their truthfulness, authenticity, and consistency, is essential. We formulate a problem of domain-independent assessment of argumentation validity based on rhetorical analysis of text. Argumentation structure is discovered in the form of discourse trees extended with edge labels for communicative actions. Extracted argumentation structure is represented as a defeasible logic program and is subject to dialectical analysis to establish the validity of the arguments for the main claim being communicated. We evaluate the accuracy of each step of this argumentation processing pipeline as well as its overall performance.
Keywords
Argumentation; Complexity; Logic; Affect
11.1 Introduction
One of the key features of the Internet of Everything (IoE) is communication in a complex system that includes people, robots, and machines. According to Chambers (2014), IoE connects humans, data, processes, and entities to enhance business communication and facilitate employment, well-being, education, and health care between various communities of people. As billions of people are anticipated to be connected the validity, truthfulness, and authenticity of the textual messages being delivered have become essential requirements. To make decisions based, in particular, on textual messages, the claims and their argumentation need to be validated in a domain-independent manner. The validation of claims in IoE messages needs to be done based on argumentation patterns rather than on costly domain-dependent ontologies, which are hard to scale.
Intentional or unintentional untruthful claims and/or their faulty argumentation can lead to accidents, and machines should be able to recognize such claims and their arguments as a part of tackling human errors (Galitsky, 2015; Lawless, Mittu, Sofge, & Russell, 2017). Frequently human errors are associated with extreme emotions, so we aim at detecting and validating both affective and logical argumentation patterns. Intentional disinformation in a message can also be associated with a security breach (Munro, 2017).
When domain knowledge is available and formalized, truthfulness of a claim can be validated directly. However, in most environments such knowledge is unavailable and other implicit means need to come into play, such as writing style and writing logic (which are domain independent). Hence we employ the discourse analysis in our message validation pipeline and explore which discourse features can be leveraged for argumentation validity analysis.
When an author attempts to provide a logical or affective argument for something, a number of argumentation patterns can be employed. The basic points of argumentation are reflected in the rhetorical structure of text where an argument is presented. A text without argument, with an affective argument and with a logical one would have different rhetoric structures (Moens, Boiy, Palau, & Reed, 2007). When an author uses an affective argument instead of logical arguments it does not necessarily mean that his argument is invalid.
We select customer relationship management (CRM) as an important domain of IoE. One of the trickiest areas of CRM, involving a number of conflicting agents, is handling customer complaints (Galitsky & de la Rosa, 2011). In customer complaints the authors are upset with the products or services they received, as well as how customer support communicated with them. Complainants frequently write complaints in very strong, emotional language, which may distort the logic of argumentation, therefore making a judgment on complaint validity difficult. Both affective and logical argumentation is heavily used.
Banking is one of the industries one would expect to pioneer Internet of Things (IoT) technologies. In the personal finance domain, customers would expect a fully automated CRM environment that would solve 100% of their issues. In banking’s customer complaints, customers usually explain what was promised and advertised, and what they ended up receiving. Therefore a typical complaint arises when a customer attempts to communicate this discrepancy with the bank and does not receive an adequate response. Most complaint authors mention misinformation provided by company agents, a reluctance to accept responsibility, and a denial of a refund or compensation to a customer. At the same time, frequently, customers write complaints attempting to get compensation for allegedly problematic service.
Judging by complaints, most complainants are in genuine distress due to a strong deviation between what they expected from a service, what they received, and how it was communicated. Most complaint authors report incompetence, flawed policies, ignorance, indifference to customer needs, and misrepresentation from the customer service personnel. The authors have frequently exhausted the communicative means available to them; confused, they may seek recommendations from other users. They often advise other customers to avoid particular financial services. Multiple affective argumentation patterns are used in complaints; the most frequent is an intense description by a complainant of a deviation from what was expected, according to common sense, to what actually happened. This pattern covers both valid and invalid argumentation.
We select rhetoric structure theory (RST) (Mann & Thompson, 1988) as a means to represent discourse features associated with logical and affective argumentation. Nowadays, the performance of both rhetoric parsers and argumentation reasoners has dramatically improved (Feng & Hirst, 2014). Taking into account the discourse structure of conflicting dialogs, one can judge the authenticity and validity of these dialogs in terms of its affective argumentation. In this work we will evaluate the combined argument validity assessment system that includes both the discourse structure extraction and reasoning about it with the purpose of the validation of a complainant’s claim. Either approach on argument detection from text or on reasoning about formalized arguments has been undertaken (Galitsky & Pampapathi, 2003; Symeonidis, Chatzidimitriou, Athanasiadis, & Mitkas, 2007), but not the whole text assessment pipeline required for IoT systems.
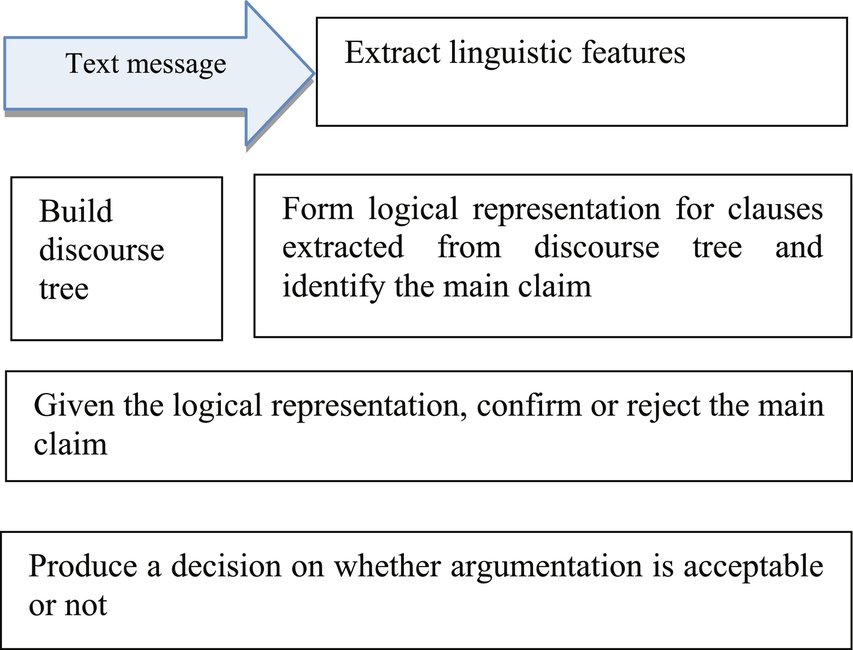
Most of the modern techniques treat computational argumentation as specific discourse structures and perform detection of arguments of various sorts in text, such as classifying a text paragraph as argumentative or nonargumentative (Moens et al., 2007). A number of systems recognize components and structures of logical arguments (Sardianos, Katakis, Petasis, & Karkaletsis, 2015; Stab & Gurevych, 2014). However, these systems do not rely on discourse trees (DTs); they only extract arguments and do not apply logical means to evaluate them. A broad corpus of research deals with logical arguments irrespectively of how they may occur in natural language (Bondarenko, Dung, Kowalski, & Toni, 1997). A number of studies addressed argument quality in logic and argumentation theory (Damer, 2009; van Eemeren, Grootendorst, & Henkemans, 1996); however, the number of systems that assess the validity of arguments in text is very limited (Cabrio & Villata, 2012). This number is especially low for studies concerning affective argumentation. Most argument mining systems are either classifiers that recognize certain forms of logical arguments in text, or reasoners over the logical representation of arguments (Amgoud, Besnard, & Hunter, 2015). Conversely, in this project we intend to build the whole argumentation pipeline, augmenting an argument extraction from text with its logical analysis (Fig. 11.1). This pipeline is necessary to deploy an argumentation analysis in a practical decision support system.
The concept of automatically identifying argumentation schemes was first discussed by Walton, Reed, and Macagno (2008). Ghosh, Muresan, Wacholder, Aakhus, and Mitsui (2014)) investigate argumentation discourse structure of a specific type of communication—online interaction threads. Identifying argumentation in text is connected to the problem of identifying truth, misinformation, and disinformation on the web (Galitsky, 2015; Pendyala & Figueira, 2015; Pisarevskaya, Litvinova, & Litvinova, 2017). Lawrence and Reed (2015) combined three types of argument structure identification: linguistic features, topic changes, and machine learning.
To represent the linguistic features of text, we use the following sources:
- (1) Rhetoric relations between the parts of the sentences, obtained as a DT, and
- (2) Speech acts and communicative actions, obtained as verbs from the VerbNet resource.
To assess the logical validity of an extracted argument, we apply the Defeasible Logic Program (DeLP) (Garcia & Simari, 2004), part of which is built on the fly from facts and clauses extracted from these sources. We integrate argumentation detection and validation components into a decision support system that can be deployed, for example, in the CRM domain. To evaluate our approach to extraction and reasoning for argumentation, we chose the dispute resolution/customer complaint validation task because affective argumentation analysis plays an essential role in it.
11.2 Representing Argumentative Discourse
We start with a political domain and give an example of conflicting agents providing their interpretation of certain events. These agents provide argumentation for their claims; we will observe how formed rhetoric structures correlate with their argumentation patterns. We focus on the Malaysia Airlines Flight 17 example with the agents exchanging affective arguments: Dutch investigators, The Investigative Committee of the Russian Federation, and the self-proclaimed Donetsk People’s Republic. It is a controversial conflict where each agent attempts to blame its opponent. Keywords indicating sentiments are underlined. To sound more convincing, each agent does not just formulate its claim, but postulates it in a way to attack the claims of its opponents. To do that, each agent does its best to match the argumentation style of opponents, defeat their claims, and apply negative sentiments to them.
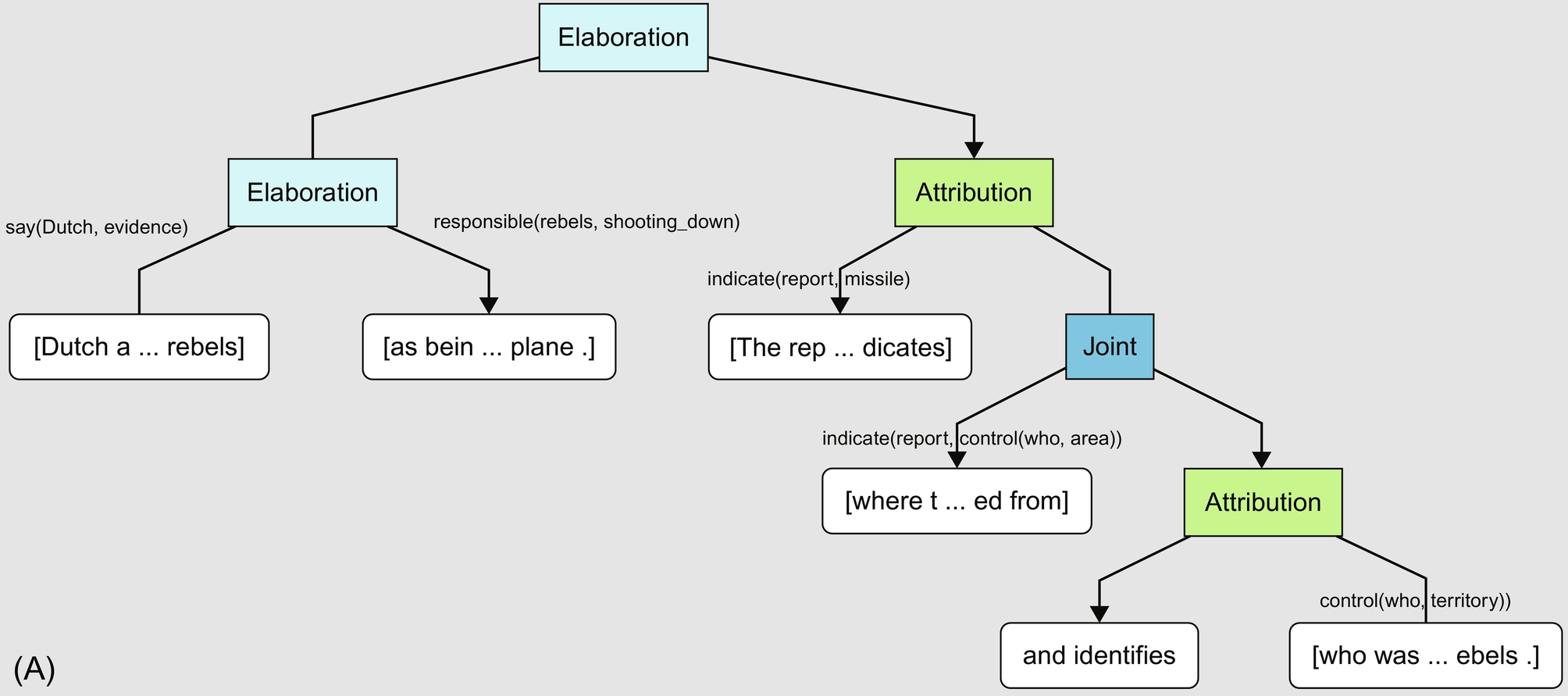
Dutch accident investigators say that strong evidence points to pro-Russian rebels as being fully responsible for shooting down plane. The report indicates where the missile was fired from and identifies who was in control of the territory and pins the downing of MH17 on the pro-Russian rebels (Fig. 11.2A).
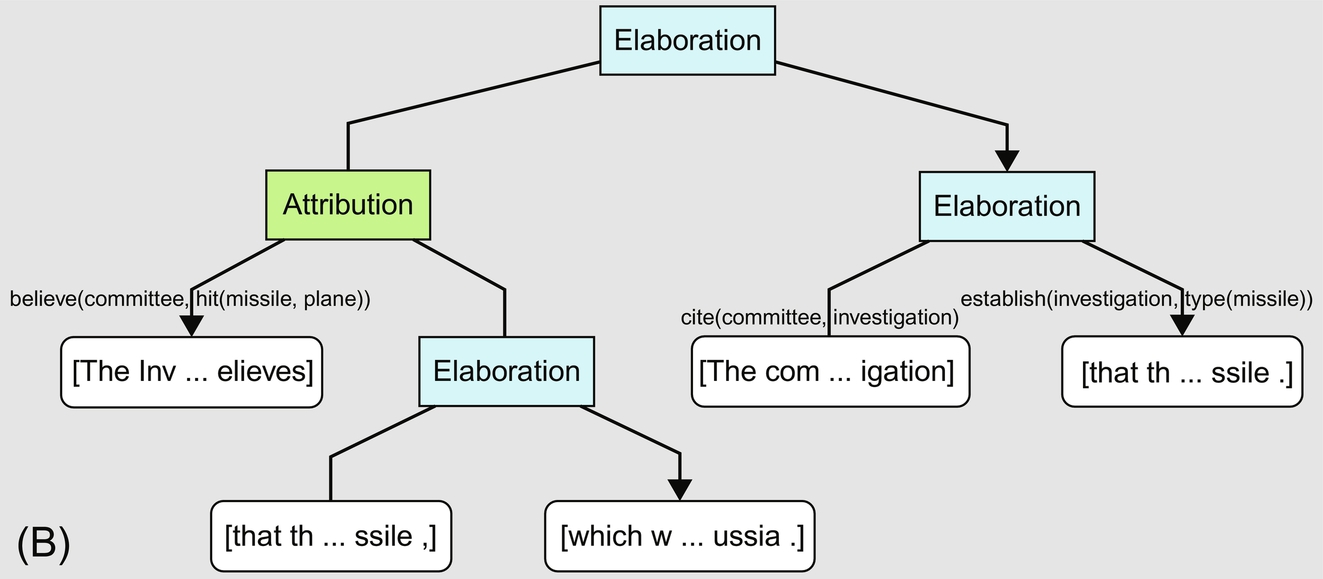
The Investigative Committee of the Russian Federation believes that the plane was hit by a missile, which could not be produced in Russia. The committee cites an investigation that established the type of the missile and disagrees with Dutch accident investigators (Fig. 11.2B).
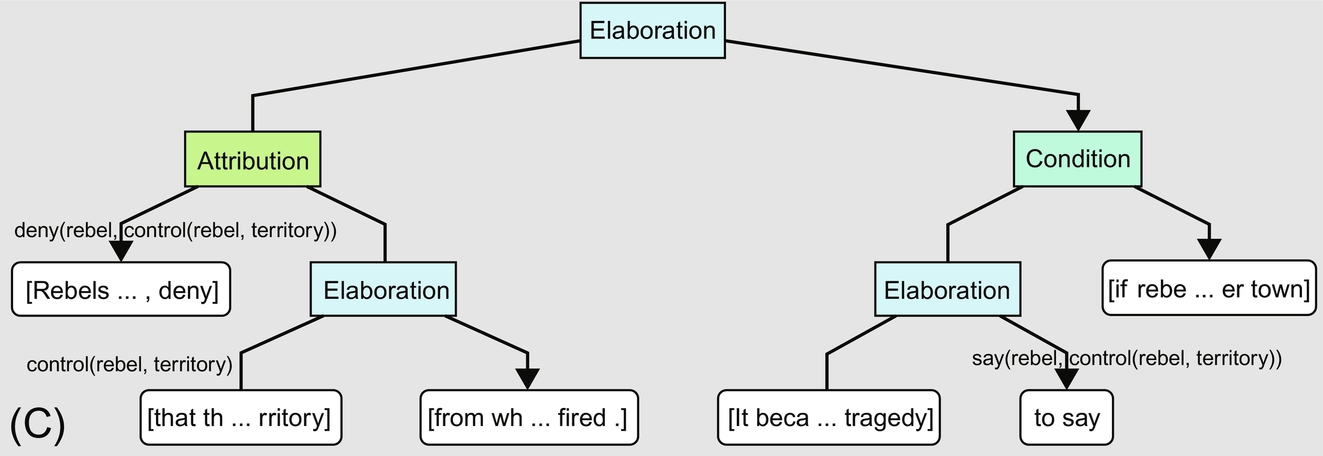
Rebels, the self-proclaimed Donetsk People's Republic, deny that they controlled the territory from which the missile was allegedly fired. They confirm that it became possible only after three months after the tragedy to say if rebels controlled one or another town and the claim of Dutch accident investigators is flawed (Fig. 11.2C).
To show the structure of arguments one needs to merge discourse relations with information from speech acts. We need to know the discourse structure of interactions between agents, and what kinds of interactions they are. For argument identification we do not need to know the domain of interaction (here, aviation), the subjects of these interaction, what are the entities, but we need to take into account the mental, domain-independent relations between them. We accomplish this by introducing the concept of communicative discourse tree (CDT).
CDT is a DT with labels for edges that are the VerbNet expressions for verbs (which are communicative actions or CA; Galitsky & Kuznetsov, 2008). Arguments of verbs are substituted from text according to VerbNet frames (Kipper, Korhonen, Ryant, & Palmer, 2008). The first and possibly second argument is instantiated by agents. The consecutive arguments are instantiated by noun or verb phrases, which are the subjects of CA. For example, the nucleus node for elaboration relation (on the left of Fig. 11.2A) is labeled with say(Dutch, evidence), and the satellite is labeled with responsible(rebels, shooting_down). These labels are not intended to express that the subjects of elementary discourse units (EDUs) are evidence and shooting_down but instead are intended for matching this CDT with others for the purpose of finding similarity between them.
Notice that in the CDTs for three paragraphs expressing the views of conflicting parties (Fig. 11.2A–C), communicative actions with their subjects contain the main claims of the respective party, and the DTs without these labels contain information on how these claims are logically packaged. To summarize, a typical CDT for a text with argumentation includes rhetoric relations other than “elaboration” and “join,” and a substantial number of communicative actions. However, these rules are complex enough so that the structure of CDT matters and tree-specific learning is required (Galitsky, Ilvovsky, & Kuznetsov, 2015).
11.3 Detecting Invalid Argumentation Patterns
Starting from the autumn of 2015, we became interested in the controversy about Theranos, the health-care company that hoped to make a revolution in blood tests. Some sources including the Wall Street Journal started claiming that the company’s conduct was fraudulent. The claims were made based on the whistleblowing of employees who left Theranos. At some point the US Food and Drug Administration got involved, and as the case developed, we were improving our argumentation mining and reasoning techniques (Galitsky, 2016; Galitsky, Ilvovsky, & Kuznetsov, 2018) while keeping an eye on Theranos’ story. As we scraped from the websites the discussions about Theranos back in 2016, the audience believed that the case was initiated by Theranos’ competitors who felt jealous about the proposed efficiency of the blood test technique promised by Theranos. However, our argumentation analysis technique was showing that Theranos’ argumentation patterns mined at their website were faulty and our finding confirmed the case, which led to the massive fraud verdict. SEC (2018) says that Theranos’ CEO Elizabeth Holmes raised more than $700 million from investors “through an elaborate, years-long fraud” in which she exaggerated or made false statements about the company’s technology and finances.
Let us imagine that we need to index the content about Theranos for answering questions about it. If a user leans towards Theranos and not its opponents, then we want to provide answers favoring Theranos’ position. Good arguments of its proponents, or bad arguments of its opponents would also be good. Table 11.1 shows the flags for various combinations of agency, sentiments, and argumentation for tailoring search results for a given user with certain preferences of entity A versus entity B. The far right grayed side of the column in the table has opposite flags for the second and third row. For the fourth row, only the cases with generally accepted opinion-sharing merits are flagged to be shown.
Table 11.1
 |
In a product recommendation domain, texts with positive sentiments are used to encourage a potential buyer to make a purchase. In a domain such as politics, the logical structure of sentiment vs. argument vs. agency is much more complex.
We build an RST representation of the arguments and observe if a DT is capable of indicating whether a paragraph communicates both a claim and possesses argumentation that backs it up. We will then explore what needs to be added to a DT so that it is possible to judge if it expresses an argumentation pattern or not.
This is the beginning of Theranos’ story, according to Carreyrou (2016):
Since October [2015], the Wall Street Journal has published a series of anonymously sourced accusations that inaccurately portray Theranos. Now, in its latest story (“U.S. Probes Theranos Complaints,” Dec. 20), the Journal once again is relying on anonymous sources, this time reporting two undisclosed and unconfirmed complaints that allegedly were filed with the Centers for Medicare and Medicaid Services (CMS) and U.S. Food and Drug Administration (FDA).
Fig. 11.3A shows the communicative discourse tree (CDT) for the following paragraph (Carreyrou, 2016):
But Theranos has struggled behind the scenes to turn the excitement over its technology into reality. At the end of 2014, the lab instrument developed as the linchpin of its strategy, handled just a small fraction of the tests then sold to consumers, according to four former employees.
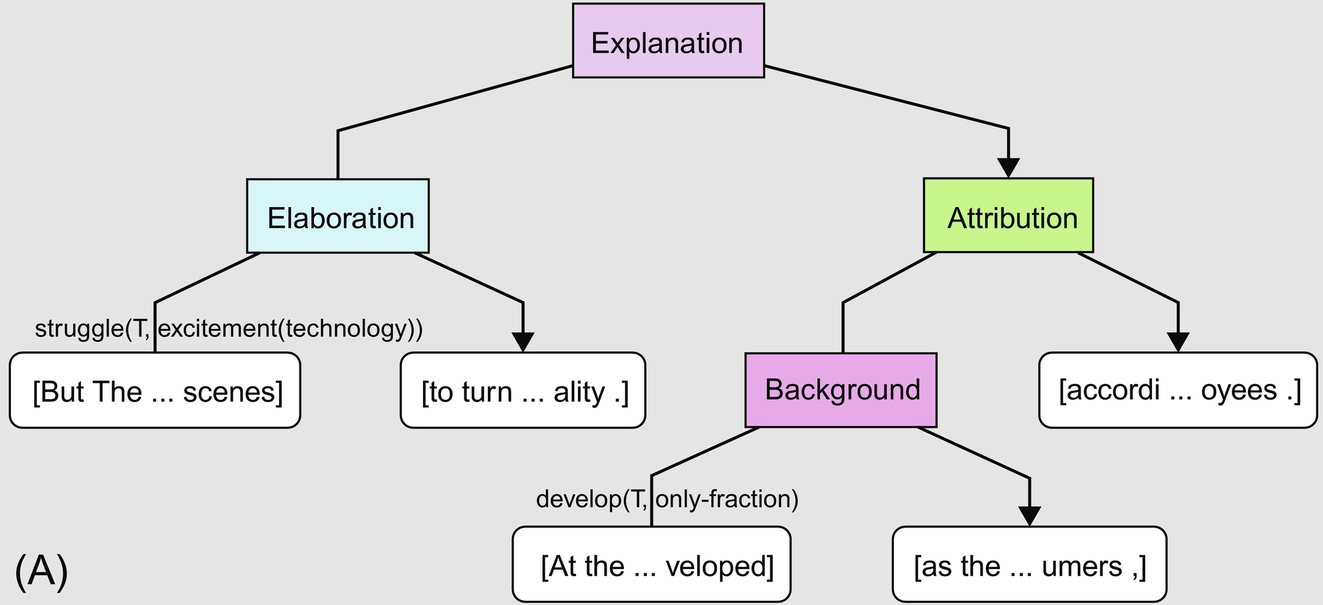
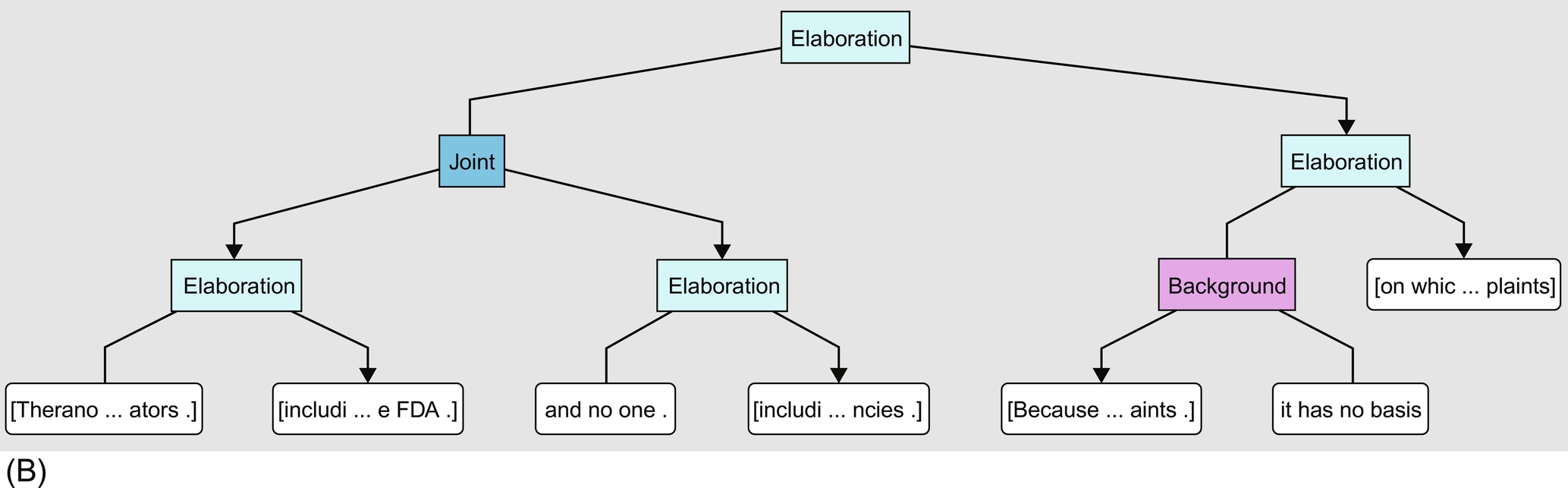
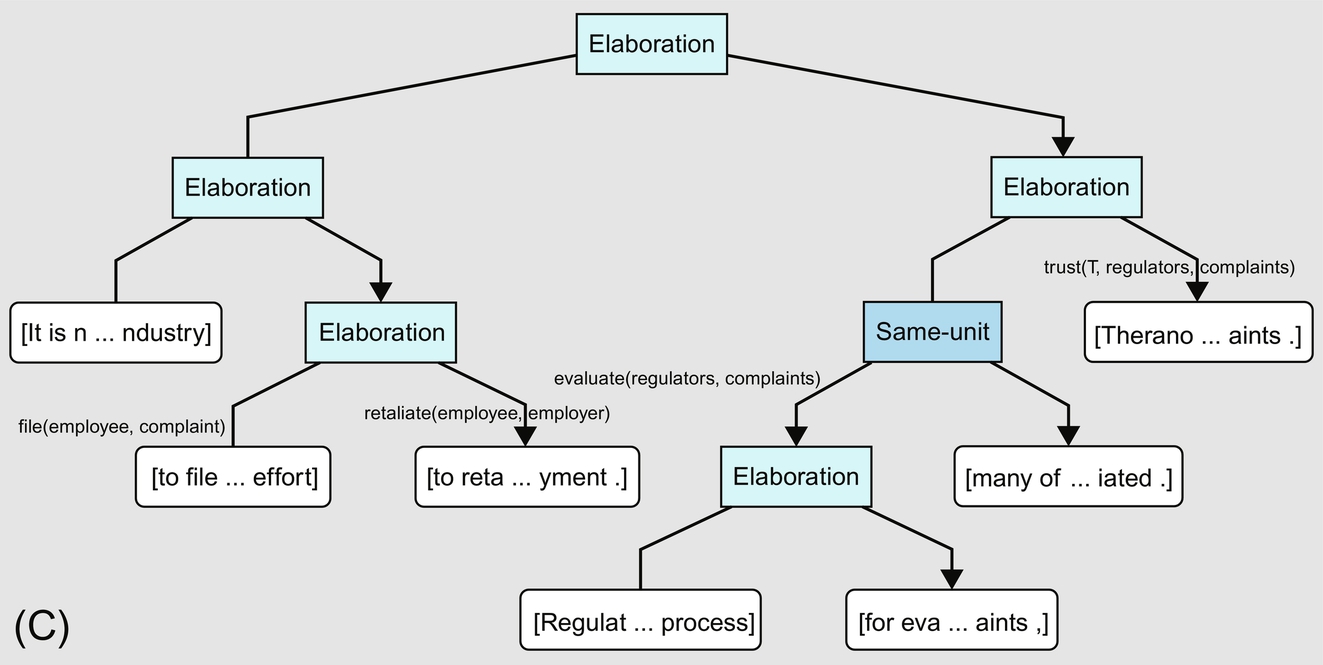
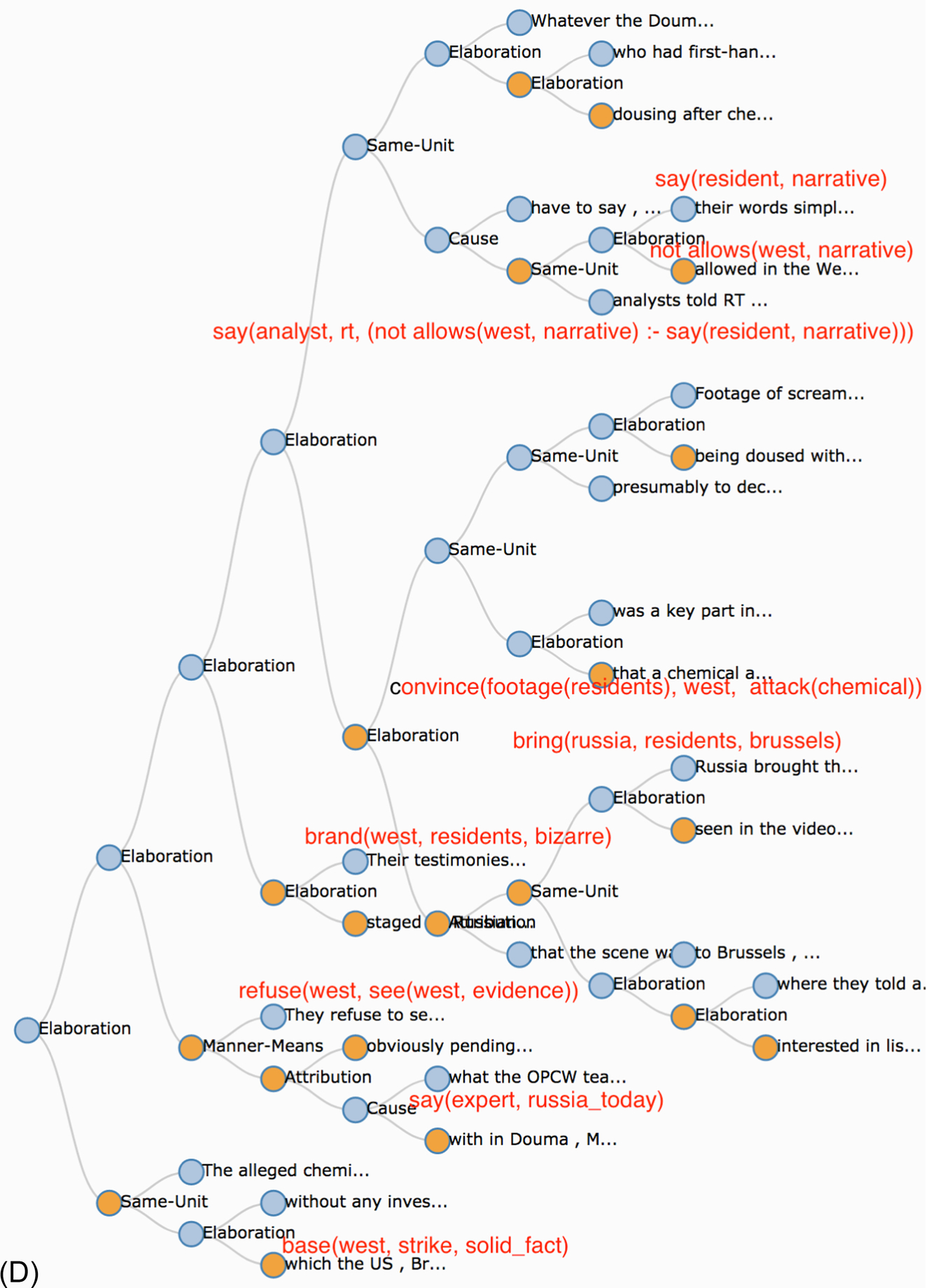

Please notice the labels for communicative actions are attached to the edges of DTs (on the left and in the middle-bottom).
In the following paragraph Theranos attempts to rebuke the claim of WSJ, but without communicative actions it is unclear from the DT (see Fig. 11.3B):
Theranos remains actively engaged with its regulators, including CMS and the FDA, and no one, including the Wall Street Journal, has provided Theranos a copy of the alleged complaints to those agencies. Because Theranos has not seen these alleged complaints, it has no basis on which to evaluate the purported complaints.
We proceed to a CDT for an attempt by Theranos to acquit itself (Fig. 11.3C):
It is not unusual for disgruntled and terminated employees in the heavily regulated health care industry to file complaints in an effort to retaliate against employers for termination of employment. Regulatory agencies have a process for evaluating complaints, many of which are not substantiated. Theranos trusts its regulators to properly investigate any complaints.
In another example, the objective of the author is to attack a claim that the Syrian government used chemical weapon in the spring of 2018. An acceptable proof would be to share a certain observation, associated from the standpoint of peers, with the absence of a chemical attack. For example, if it is possible to demonstrate that the time of the alleged chemical attack coincided with the time of a very strong rainfall that would be a convincing way to attack this claim. However, since no such observation was identified the source, Russia Today (2018), resorted to plotting a complex mental states concerning how the claim was communicated, where it is hard to verify most statements about the mental states of the involved parties. We show the text split into EDU as done by discourse parser (Joty, Carenini, Ng, & Mehdad, 2013):
This article (RussiaToday, 2018) has not found counter-evidence for the claim of the chemical attack it attempts to defeat, instead it says that the opponents are not interested in observing this counter-evidence. The main statement of the article is that a certain agent “disallows” a particular kind of evidence thereby attacking the main claim, rather than providing and backing up this evidence. Instead of defeating a chemical attack claim, the article builds a complex image of the conflicted mental states of the residents, Russian agents taking them to Brussels, the West, and a Middle-East expert (see Fig. 11.3D).
Our other example of controversial news is a Trump–Russia link accusation (BBC, 2018). For a long time the claim could not be confirmed, so the story was repeated over and over again to maintain the reader’s expectation that it would be instantiated one day. There is neither confirmation nor rejection that the dossier exists and the goal of the author is to make the audience believe that such dossier exists without misrepresenting events. To achieve this goal the author can attach a number of hypothetical statements about the existing dossier to a variety of mental states to impress upon the reader the authenticity and validity of the topic (see Fig. 11.3E).
11.4 Recognizing Communicative Discourse Trees for Argumentation
Argumentation analysis needs a systematic approach to learn associated discourse structures. The features of CDTs could be represented in a numerical space so that argumentation detection can be conducted; however, structural information on DTs would not be leveraged. Also, features of argumentation can potentially be measured in terms of maximal common sub-DTs, but such nearest-neighbor learning is computationally intensive and too sensitive to errors in DT construction. Therefore a CDT-kernel learning approach is selected, which applies support vector machine (SVM) learning to the feature space of all sub-CDTs of the CDT for a given text where an argument is being detected.
Tree kernel (TK) learning for strings, parse trees, and parse thickets is a well-established research area nowadays. The CD-TK counts the number of common sub-trees as the discourse similarity measure between two DTs. A version of TK has been defined for discourse analysis (Joty & Moschitti, 2014). Wang, Su, and Tan (2010) used the special form of TK for discourse-relation recognition. In this study, we extend the TK definition for the CDT, augmenting DT kernel by the information on CAs. TK-based approaches are not very sensitive to errors in parsing (syntactic and rhetoric) because erroneous sub-trees are mostly random and will unlikely be common among different elements of a training set.
A CDT can be represented by a vector V of integer counts of each sub-tree type (without taking into account its ancestors):
V(T) = (# of subtrees of type 1, …, # of subtrees of type I, …, # of subtrees of type n). This representation results in a very high dimensionality since the number of different sub-trees is exponential in size. Thus it is computationally infeasible to directly use the feature vector '(T). To solve the computational issue, a tree kernel function is introduced to calculate the dot product between the previously mentioned high-dimensional vectors efficiently. Given two tree segments CDT1 and CDT2, the tree kernel function is defined:
K (CDT1, CDT2) = < V(CDT1), V(CDT2) > = ∑i V(CDT1)[i], V(CDT2)[i] = ∑n1 ∑n2 ∑i Ii(n1)⁎ Ii(n2),
Where n1 ∈ N1, n2 ∈ N2 and N1 and N2 are the sets of all nodes in CDT1 and CDT2, respectively; Ii (n) is the indicator function; and Ii (n) = {1 iff a subtree of type i occurs with a root at a node; 0 otherwise}. Further details for using TK for paragraph-level and discourse analysis are available in Galitsky (2017).
Only the arcs of the same type of rhetoric relations (presentation relation, such as antithesis, subject matter relation, such as condition, and multinuclear relation, such as List) can be matched when computing common sub-trees. We use N for a nucleus or situations presented by this nucleus, and S for a satellite or situations presented by this satellite. Situations are propositions, completed actions or actions in progress, and communicative actions and states (including beliefs, desires, approve, explain, reconcile, and others). Hence we have the following expression for RST-based generalization “ˆ” for two texts text1 and text2:
text1 ˆ text2 = ∪i,j (rstRelation1i, (…,…) ˆ rstRelation2j (…,…)),
where i ∈ (RST relations in text1) and j ∈ (RST relations in text2). Further, for a pair of RST relations their generalization looks as follows:
rstRelation1(N1, S1) ˆ rstRelation2 (N2, S2) = (rstRelation1ˆ rstRelation2)(N1ˆN2, S1ˆS2).
We define CA as a function of the form verb (agent, subject, cause), where verb characterizes some type of interaction between involved agents (e.g., explain, confirm, remind, disagree, deny, etc.), subject refers to the information transmitted or the object described, and cause refers to the motivation or explanation for the subject. To handle the meaning of words expressing the subjects of CAs, we apply word2vec models (Mikolov, Chen, Corrado, & Dean, 2015).
To compute similarity between the subjects of CAs, we use the following rule. If subject1 = subject2, then subject1ˆsubject2 = < subject1, POS(subject1), 1 >. Otherwise, if they have the same part-of-speech, subject1ˆsubject2 =<⁎,POS(subject1), word2vecDistance(subject1ˆsubject2)>.
If a part-of-speech is different, the generalization is an empty tuple. It cannot be further generalized.
We combined Stanford NLP parsing, coreferences, entity extraction, DT construction (discourse parser; Surdeanu, Hicks, & Valenzuela-Escarcega, 2016; Joty et al., 2013), VerbNet, and Tree Kernel builder into one system, which is available at https://github.com/bgalitsky/relevance-based-on-parse-trees.
11.5 Assessing Validity of Extracted Argument Patterns Via Dialectical Analysis
To convince an addressee, a message needs to include an argument and its structure needs to be valid. Once an argumentation structure extracted from text is represented via CDT, we need to verify that the main point (target claim) communicated by the author is not logically attacked by her other claims. To assess the validity of the argumentation, a DeLP approach is selected. It is an argumentative framework based on logic programming (Alsinet, Chesñevar, Godo, & Simari, 2008; Garcia & Simari, 2004); we present an overview of the main concepts associated with it.
A DeLP is a set of facts, strict rules Π of the form (A:-B), and a set of defeasible rules Δ of the form A-<B, whose intended meaning is “if B is the case, then usually A is also the case.” Let P =(Π, Δ) be a DeLP program and L a ground literal. Let us now build an example of a DeLP for legal reasoning about facts extracted from text (Fig. 11.4). A judge hears an eviction case and wants to make a judgment on whether rent was provably paid (deposited) or not (denoted as rent_receipt). An input is a text where a defendant is expressing his point. Underlined words form the clause in DeLP, and the other expressions formed the facts (Fig. 11.5). This is an example from the author’s personal experience:
The landlord contacted me, the tenant, and the rent was requested. However, I refused the rent since I demanded repair to be done. I reminded the landlord about necessary repairs, but the landlord issued the three-day notice confirming that the rent was overdue. Regretfully, the property still stayed unrepaired.

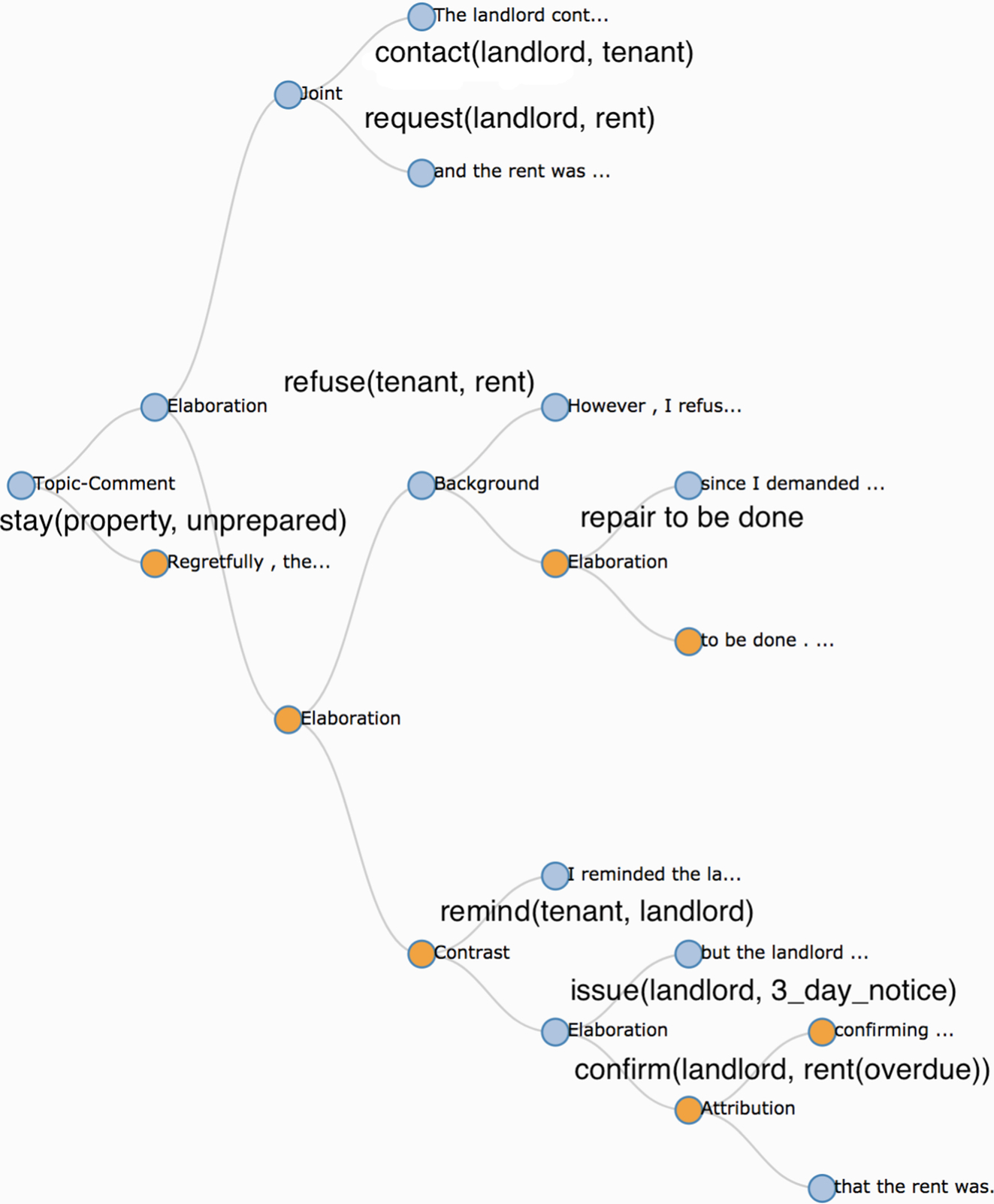
A defeasible derivation of L from P consists of a finite sequence L1, L2, …, Ln = L of ground literals, such that each literal Li is in the sequence because:
- (a) Li is a fact in Π, or
- (b) there exists a rule Ri in P (strict or defeasible) with head Li and body B1, B2, …, Bk and every literal of the body is an element Lj of the sequence appearing before Lj (j < i).
Let h be a literal, and P = (Π, Δ) a DeLP program. We say that < A, h > is an argument for h if A is a set of defeasible rules of Δ, such that:
- 1. there exists a defeasible derivation for h from (Π ∪ A);
- 2. the set (Π ∪ A) is noncontradictory; and
- 3. A is minimal: there is no proper subset A0 of A such that A0 satisfies conditions (1) and (2).
Hence an argument < A, h > is a minimal noncontradictory set of defeasible rules obtained from a defeasible derivation for a given literal h associated with a program P.
We say that < A1, h1 > attacks < A2, h2 > if there exists a sub-argument < A, h > of < A2, h2 >, (A ⊆ A1) such that h and h1 are inconsistent (i.e., Π ∪ {h, h1} derives complementary literals). We will say that < A1, h1 > defeats < A2, h2 > if < A1, h1 > attacks < A2, h2 > at a sub-argument < A, h > and < A1, h1 > is strictly preferred (or not comparable to) < A, h >. In the first case we will refer to < A1, h1 > as a proper defeater, whereas in the second case it will be a blocking defeater. Defeaters are arguments that in their turn can be attacked by other arguments, as is the case with a human dialogue. An argumentation line is a sequence of arguments where each element in a sequence defeats its predecessor. In the case of DeLP there are a number of acceptability requirements for argumentation lines in order to avoid fallacies (such as circular reasoning by repeating the same argument twice).
Target claims can be considered DeLP queries solved in terms of dialectical trees, which subsumes all possible argumentation lines for a given query. The definition of a dialectical tree provides us with an algorithmic view for discovering implicit self-attack relations in users’ claims. Let < A0, h0 > be an argument (target claim) from a program P. A dialectical tree for < A0, h0 > is defined as follows:
- 1. The root of the tree is labeled with < A0, h0 >.
- 2. Let N be a nonroot vertex of the tree labeled < An, hn > and Λ =[< A0, h0 >, < A1, h1 >, …, < An, hn >] (the sequence of labels of the path from the root to N). Let [< B0, q0 >, < B1, q1 >, …, < Bk, qk >] all attack < An, hn >.
For each attacker < Bi, qi > with acceptable argumentation line [Λ,< Bi, qi >], we have an arc between N and its child Ni.
A labeling on the dialectical tree can be then performed as follows:
- 1. All leaves are to be labeled as U-nodes (undefeated nodes).
- 2. Any inner node is to be labeled as a U-node whenever all of its associated children nodes are labeled as D-nodes.
- 3. Any inner node is to be labeled as a D-node whenever at least one of its associated children nodes is labeled as U-node.
After performing this labeling, if the root node of the tree is labeled as a U-node, the original argument at issue (and its conclusion) can be assumed as justified or warranted.
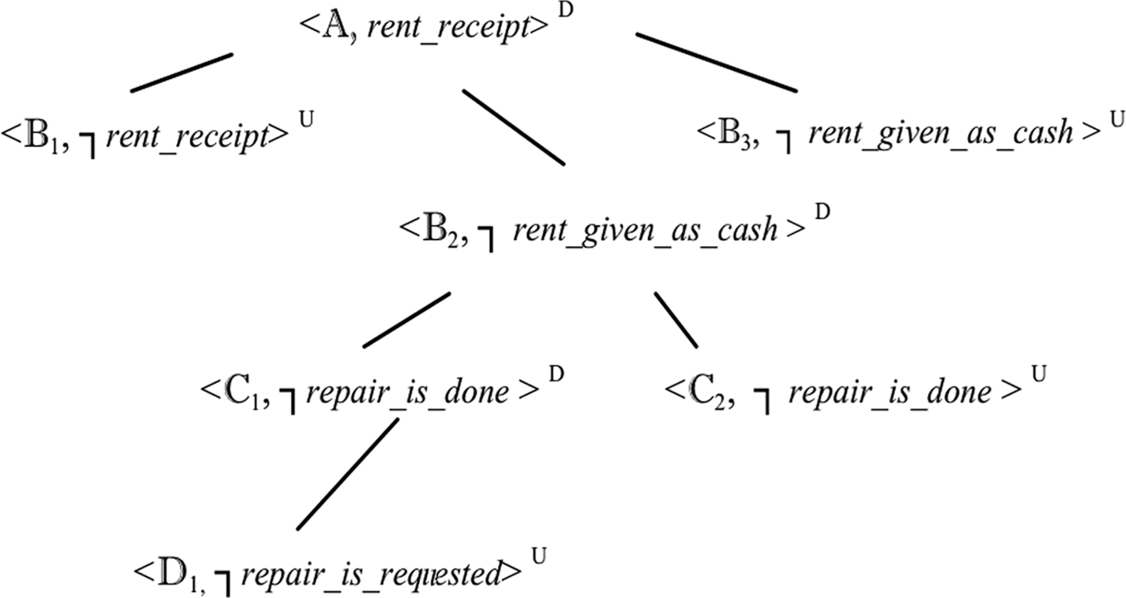
In our DeLP example, the literal rent_receipt is supported by:
< A, rent_receipt > = <{ (rent_receipt -< rent_deposit_transaction), (rent_deposit_transaction -< tenant_short_on_money)}, rent_receipt > and there exist three defeaters for it with three respective argumentation lines:
< B1, ┐rent_deposit_transaction > = <{(┐rent_deposit_transaction -< tenant_short_on_money, three_days_notice_is_issued)}, rent_deposit_transaction >.
< B2,┐rent_deposit_transaction > = <{( ┐ rent_deposit_transaction -< tenant_short_on_money, repair_is_done), (repair_is_done -< rent_refused) }, rent_deposit_transaction >.
< B3, ┐rent_deposit_transaction > = <{(┐rent_deposit_transaction -< rent_is_overdue )}, rent_deposit_transaction >.
The first two are proper defeaters and the last one is a blocking defeater. Observe that the first argument structure has the counter-argument, <{rent_deposit_transaction -< tenant_short_on_money}, rent_deposit_transaction), but it is not a defeater because the former is more specific. Thus no defeaters exist and the argumentation line ends there.
B3 above has a blocking defeater <{(rent_deposit_transaction -< tenant_short_on_money)},
rent_deposit_transaction >, which is a disagreement sub-argument of < A, rent_receipt > and it cannot be introduced since it gives rise to an unacceptable argumentation line. B2 has two defeaters that can be introduced: < C1, ┐repair_is_done >, where C1 = {(┐repair_is_done -< rent_refused, repair_is_done),
(repair_is_done -< rent_is_requsted)}, a proper defeater, and < C2, ┐repair_is_done >, where C2 ={(┐repair_is_done -< repair_is_requested)} is a blocking defeater. Hence one of these lines is further split into two; C1 has a blocking defeater that can be introduced in the line
< D1, ┐repair_is_done >, where D1 = <{(┐repair_is_done -< stay_unrepaired)}. D1 and C2 have a blocking defeater, but they cannot be introduced because they make the argumentation line unacceptable. Hence the state rent_receipt cannot be reached, as the argument supporting the literal rent_receipt is not warranted. The dialectical tree for A is shown in Fig. 11.6.
Having shown how to build a dialectic tree, we are now ready to outline the algorithm for validation of the domain-specific claim for arguments extracted from text:
- 1. Build a DT from input text;
- 2. Attach communicative actions to its edges to form CDT;
- 3. Extract subjects of communicative actions attached to CDT and add to “Facts” section;
- 4. Extract the arguments for rhetoric relation contrast and communicative actions of the class disagree and add to “Clauses Extracted FromText” section;
- 5. Add a domain-specific section to DeLP; and
- 6. Having the DeLP formed, build a dialectical tree and assess the claim.
We use the Tweety (2016) system for DeLP implementation (Thimm, 2014).
11.6 Intense Arguments Dataset
The purpose of this dataset is to collect texts where authors do their best to bring their points across by employing all means to show that they are right and their opponents are wrong. Complainants are emotionally charged writers who describe the problems they have encountered with a financial service and how they attempted to solve them.
Most complaint authors report incompetence, flawed policies, ignorance, indifference to customer needs, and misrepresentation from the customer service personnel (Galitsky, González, & Chesñevar, 2009). The focus of a complaint is a proof that the proponent is right and his/her opponent is wrong, followed by a resolution proposal and a desired outcome.
Complaints revealed the shady practices of banks during the financial crisis of 2007, such as manipulating an order of transactions to charge the highest possible amount of insufficient fund fees. Moreover, banks attempted to communicate this practice as a necessity to process a wide amount of checks. This is the most frequent topic of customer complaints, so one can track a manifold of argumentation patterns applied to this topic.
For a given topic, such as insufficient funds fee, this dataset provides many distinct ways of argumentation that this fee is unfair. Therefore our dataset allows for systematic exploration of the topic-independent clusters of argumentation patterns to observe a link between argumentation type and overall complaint validity. Other argumentation datasets, including legal arguments, student essays, Internet argument corpus, fact-feeling, and political debates, have a strong variation of topics so it is harder to track a spectrum of possible argumentation patterns per topic. Unlike professional writing in legal and political domains, the messages produced by complainants have a simple motivational structure, a transparency of their purpose, and occur in a fixed domain and context. In our dataset, the affective arguments play a critical rule for the well-being of authors subject to an unfair charge of a large amount of money or eviction from their home. Therefore the authors attempt to provide as strong argumentation as possible to back up their claims and strengthen their cases.
11.7 Evaluation of Detection and Validation of Arguments
The objective of argument detection task is to identify all kinds of arguments, not only the ones associated with customer complaints. We formed the positive dataset from textual customer complaints dataset (Galitsky et al., 2009; Github, 2018) scraped from consumer advocacy site PlanetFeedback.com. This dataset is used for both argument detection (first step) and argument validity (second step) tasks. For argument detection we attempt to identify if a given paragraph of text contains an argument, in a domain-independent manner. For argument validation, in the second step, if we detected an argument in the first step we try to validate it having the domain-ontology built in a given vertical domain such as a landlord-tenant dispute. If an argument has not been detected in the first step, we have nothing to validate.
For the negative dataset, only for the affective argument detection task, we used Wikipedia, factual news sources, and also the component of Lee’s (2001) dataset that includes such sections of the corpus as: [“tells”], instructions for how to use software; [“tele”], instructions for how to use hardware; and [news], a presentation of a news article in an objective, independent manner, and others. Further details on the data set are available in Galitsky et al. (2015).
Each row indicates a method used to detect the presence of argumentation in a paragraph. We start with baseline methods based on keywords and their frequencies (second and third row on the top, Table 11.2). The second column shows precision (P), the third recall, and the fourth F1 measure. Frequently, a coordinated pair of communicative actions (so that at least one has a negative sentiment polarity related to an opponent) is a hint that logical argumentation is present. This naïve approach is outperformed by the top-performing TK-learning CDT approach by 29%. SVM TK of CDT outperforms SVM TK for RST + CA and RST + full parse trees (Galitsky et al., 2018) by about 5% due to noisy syntactic data, which is frequently redundant for argumentation detection.
Table 11.2
| Method/sources | P | R | F1 |
|---|---|---|---|
| Bag-of-words | 57.2 | 53.1 | 55.07 |
| WEKA-Naïve Bayes | 59.4 | 55.0 | 57.12 |
| SVM TK for RST and CA (full parse trees) | 77.2 | 74.4 | 75.77 |
| SVM TK for DT | 63.6 | 62.8 | 63.20 |
| SVM TK for CDT | 82.4 | 77.0 | 79.61 |

The SVM TK approach provides an acceptable F-measure but does not help to explain how exactly the affective argument identification problem is solved, providing only final scoring and class labels. The nearest-neighbor maximal common sub-graph algorithm is much more fruitful in this respect (Galitsky et al., 2015). Comparing the bottom two rows, we observe that it is possible, but infrequent, to express an affective argument without CAs.
Assessing logical arguments extracted from text, we were interested in cases where an author provides invalid, inconsistent, self-contradicting cases. That is important for CRM systems focused on customer retention and facilitating communication with a customer (Galitsky et al., 2009). The domain of residential real estate complaints was selected and a DeLP thesaurus was built for this domain. An automated complaint-processing system can be essential, for example, for property-management companies in their decision-support procedures (Constantinos, Sarmaniotis, & Stafyla, 2003).
In our validity assessment, we focus on target features (claims) related to how a given complaint needs to be handled, such as compensation_required, proceed_with_eviction, rent_receipt, and others. A system decision is determined by whether the claim is validated or not: if it is validated, then the decision support system demands compensation, and if not validated, it decides that compensation should not be demanded (for the compensation_required claim).
Validity assessment results are shown in Table 11.3. These results are computed together for the detection and validation steps. In the first and second rows, we show the results of the simplest complaint with a single rhetoric relation such as contrast with a single CA indicating an extracted argumentation attack relation respectively. In the third row we assess complaints of average complexity, and in the bottom row, the most complex, longer complaints in terms of their CDTs are given. The third column shows detection accuracy for invalid argumentation in complaints in a stand-alone argument validation system. Finally, the fourth column shows the accuracy of the integrated argumentation extraction and validation system.
Table 11.3
| Types of complaints | P | R | F1 of validation | F1 of total |
|---|---|---|---|---|
| Single rhetoric relation of type contrast | 87.3 | 15.6 | 26.5 | 18.7 |
| Single communicative action of type disagree | 85.2 | 18.4 | 30.3 | 24.8 |
| Two or three specific relations or communicative actions | 80.2 | 20.6 | 32.8 | 25.4 |
| Four and above specific relations or communicative actions | 86.3 | 16.5 | 27.7 | 21.7 |

In these results recall is low because in the majority of cases the invalidity of claims is due to factors other than being self-defeated. Precision is relatively high since if a logical flaw in an argument is established, most likely the whole claim is invalid because other factors besides argumentation (such as false facts) contribute as well. As the complexity of a complaint and its DT grows, F1 first improves, since more logical terms are available, and then goes back down, as there is a higher chance of a reasoning error due to a noisier input.
For decision support systems it is important to maintain a low false-positive rate. It is acceptable to miss invalid complaints, but for a detected invalid complaint, confidence should be rather high. If a human agent is recommended to look at a given complaint as invalid, his/her expectations should be met most of the time. Although F1-measure of the overall argument detection and validation system is low in comparison with modern recognition systems, it is still believed to be usable as a component of a CRM decision-support system.
11.8 Conclusions
In this study we explored the possibility of validating messages in an IoE environment. We observed that by relying on DT data one can reliably detect patterns of logical and affective argumentation. CDTs become a source of information to form a defeasible logic program to validate an argumentation structure. Although the performance of the former being about 80% is significantly above that of the latter (29%), the overall pipeline can be useful for detecting cases of invalid affective argumentation, which is important in decision support for CRM.
To the best of our knowledge this is the first study building a whole argument validity pipeline including everything from text to a validated claim, which is a basis of IoE decision support. Hence, although the overall argument validation accuracy is fairly low, there is no existing system to compare this performance against.
In this chapter to support IoE message validation we attempted to combine the best of both worlds: argumentation mining from text and reasoning about the extracted argument. Whereas applications of either technology are limited, the whole argumentation pipeline is expected to find a broad range of applications. In this work we focused on a very specific legal area such as customer complaints, but it is easy to see a decision support system employing the proposed argumentation pipeline in other domains of CRM.
Message validation is essential not only in decision making, but also in security IoT applications. Computational models of message validation are associated with autonomy and trust such as the trust of autonomous machines in human behavior or the trust of humans in autonomous machine behavior. Proper claim validation enables the handling of threats to autonomy and trust (cyber attacks, competitive threats, deception) and the fundamental barriers to system survivability (Russell, Moskowitz, & Raglin, 2017; Sibley, Coyne, & Sherwood, 2017). Validation and verification play important roles in autonomous systems. Analytic validation and verification techniques, and model checking can assist with the design of autonomous IoT control agents in an efficient and reliable manner. This can mean earlier identification of false claims in messages and the detection of other errors.
An important finding of this study is that argumentation structure can be discovered via the features of extended discourse representation, combining information on how an author organizes his/her thoughts with information on how involved agents communicate these thoughts. Once a CDT is formed and identified as being correlated to argumentation, a defeasible logic program can be built from this tree and the dialectical analysis can validate the main claim.
Although validating agents’ messages, affective argument should not be confused with an appeal to emotion, a logical fallacy characterized by the manipulation of the recipient’s emotions in order to win an argument, especially in the absence of factual evidence. This kind of appeal to emotion is a type of red herring and encompasses several logical fallacies.