
Chapter 3 - How Joins Work Inside the Aster Engine
“Every sunrise is a second chance.”
– Anonymous
Aster Join Quiz
Which Statement is NOT true?
1. Each Table in Aster has a Distribution Key, unless it is replicated.
2. The Distribution Key is the mechanism that allows Aster to physically distribute the rows of a table across the vworkers using a Hash Formula and the Hash Map.
3. Each vworker Sorts its rows by the Distribution Key, unless it is a Partitioned table, and then it sorts first by the Partition and then by Distribution Key.
4. For two rows to be Joined together, Aster insists that both rows are physically on the same vworker.
5. Aster will either Redistribute one or both of the tables to ensure the rows are on the same vworker. Once the matching rows are on the same vworker, the join can take place.
Do you know which statement above is False?
Aster Join Quiz Answer
Which Statement is NOT true?
1. Each Table in Aster has a Distribution Key, unless it is replicated.
2. The Distribution Key is the mechanism that allows Aster to physically distribute the rows of a table across the vworkers using a Hash Formula and the Hash Map.
3. Each vworker Sorts its rows by the Distribution Key, unless it is a Partitioned table, and then it sorts first by the Partition and then by Distribution Key.
4. For two rows to be Joined together, Aster insists that both rows are physically on the same vworker. ![]()
5. Aster will either Redistribute one or both of the tables to ensure the rows are on the same vworker. Once the matching rows are on the same vworker, the join can take place.
All statements above are true. Aster must have the matching rows on the same vworker in memory for the join to take place. You don’t see two people getting married in different locations do you? For a join or marriage to take place, both must be together.
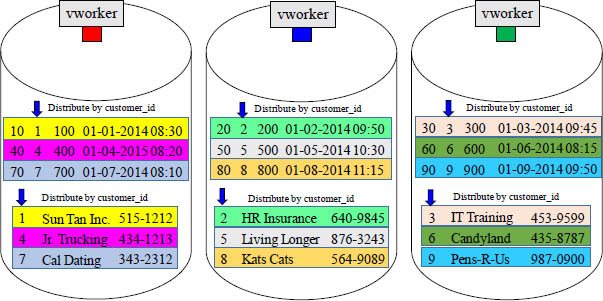
The Joining of Two Tables
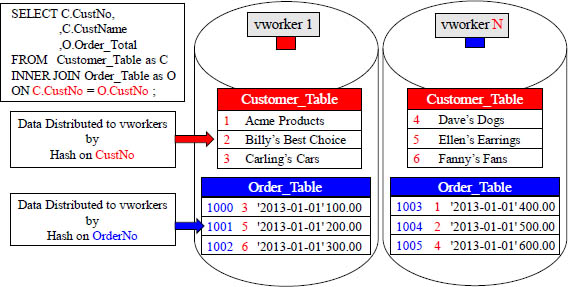
For a join to take place, all joining rows must be on the same vworker!
CustNo (1-6) (red) are the Join Condition (PK/FK). Each customer has placed one order. The matching join rows are on different vworkers because the tables were distributed by different Distribution Keys. How will Aster get the joining rows on the same vworker? Aster will redistribute the Order_Table by Cust_No in memory. The hash is consistent, so when the Order_Table is re-hashed, the matching rows will be co-located.
Aster Moves Joining Rows to the Same vworker
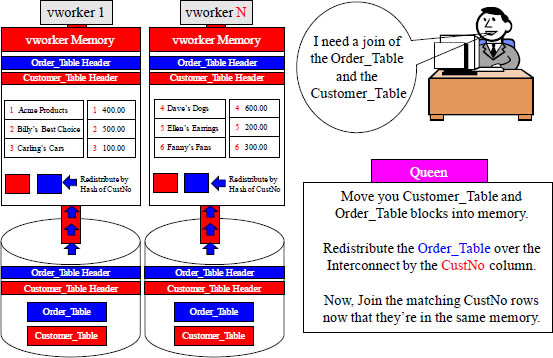
On joins, the matching rows must be on the same vworker, so hashing is how it is done.
Because of the Join Rule – Dimension Table are Replicated
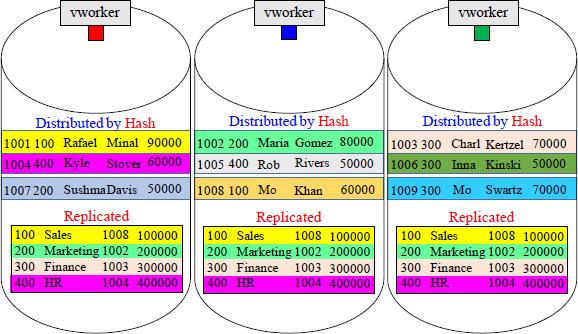
For two rows to be joined together, they must reside (physically) on the same vworker. That is why smaller tables are replicated. This guarantees a local join to the Fact table.
The Two Different Philosophies for Table Join Design
![]() One table is Distributed by Hash and the other is Distributed by Replication
One table is Distributed by Hash and the other is Distributed by Replication
![]() Both tables are Distributed by Hash on Customer_ID.
Both tables are Distributed by Hash on Customer_ID.
Both examples will have co-location of joins on the same vworker. Fact tables are always Distributed by Hash, but Dimension table can Distribute by Hash or Replication.
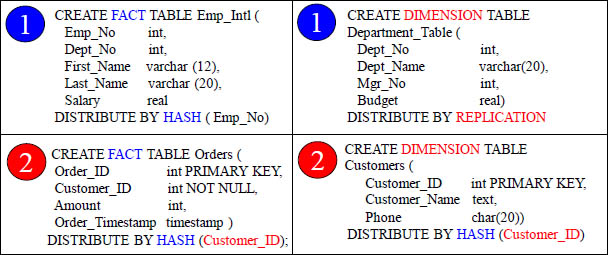
What Could You Do If Two Tables Joined 1000 Times a Day?
CREATE FACT TABLE Orders ( |
CREATE DIMENSION TABLE |
Give both tables the same Distribute By Hash column on the PK/FK join condition.
Each time these two tables are joined via the CustNo column, there will be no data movement because the matching CustNo rows will be on the same vworker. That is because CustNo is the Distribution Key for both tables, so the matching rows are hashed and distributed to the same vworker. This is the beauty of the Hash Formula.
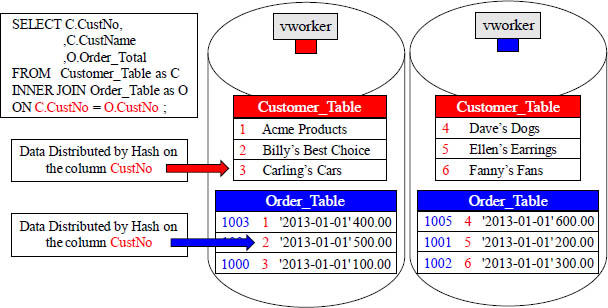
Fact and Dimension Tables can be Hashed by the same Key
Fact tables are large and usually distributed by hash. Dimension tables are usually small and often distributed by replication, but dimension tables can be distributed by hash. This is done to get vworker co-location. Above, you can see that both tables above where distributed by hash on the customer_id column. This locates the joining rows on the same vworker. Distribution design is based on what joins to what.
Joining Two Tables with the same PK/FK Distribution Key
The matching rows naturally distribute to the same vworkers
CustNo is the join condition (PK/FK) and the Distribution Key for both tables, so the matching customer numbers are on the same vworker. They were hashed there originally. Each customer has placed one order. Aster will have each vworker move their blocks into memory and perform the join.
A Join With Co-Location
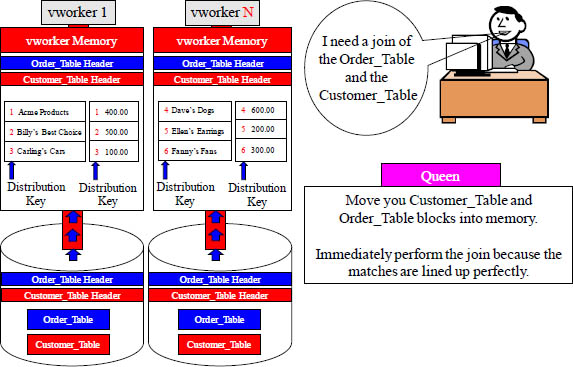
Both tables have the same Distribution Key, and it is the join condition of CustNo.
A Performance Tuning Technique for Large Joins
CREATE FACT TABLE Orders ( |
CREATE DIMENSION TABLE |
The Distribution Key are different and NOT both the PK/FK join condition.

Add an additional WHERE or AND clause using an index on one of the tables, and Aster will retrieve the row(s) first. Then, the join is done on only the matching row(s) thus saving enormous time and movement.
The Joining of Two Tables with an Additional WHERE Clause
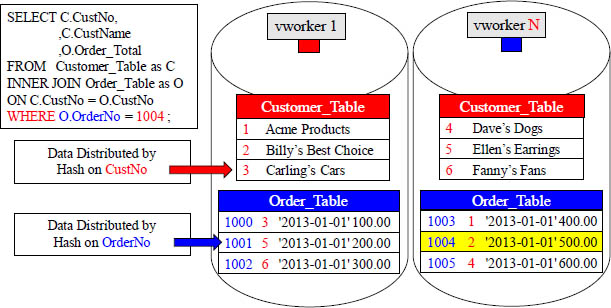
The single row OrderNo 1004 will be retrieved first and then joined.
Notice the join SQL at the top left, and notice the additional WHERE clause asking specifically for OrderNo 1004. Since OrderNo is the Distribution Key of the Order_Table, and we placed an index on that column, Aster will join that single row with its matching row thus saving enormous time and energy.
Aster Performs Joins Using Three Different Methods
![]() Hash Joins - A hash join is one where the smaller table is placed inside memory, so the joining of rows takes a single pass.
Hash Joins - A hash join is one where the smaller table is placed inside memory, so the joining of rows takes a single pass.
![]() Merge Joins - A merge join is the most scalable and likely to be used method of joining large tables. The merge join sorts both the tables on the columns being joined and then streams the top few rows from each table to do the join.
Merge Joins - A merge join is the most scalable and likely to be used method of joining large tables. The merge join sorts both the tables on the columns being joined and then streams the top few rows from each table to do the join.
![]() Nested Loop Joins - Nested loop joins are designed for a star schema join between a large fact table and a very small dimension table. It will filter down the smaller dimension table and then utilize an index on the fact table to join.
Nested Loop Joins - Nested loop joins are designed for a star schema join between a large fact table and a very small dimension table. It will filter down the smaller dimension table and then utilize an index on the fact table to join.
The ANALYZE command is how Aster creates statistics. Analyze tables after they are initially loaded, and then when they change by 10%. This helps the planner choose the best join plan.
A Hash Join is the fastest. A Merge Join is the slowest. A Nested Loop Join works great when one table is relatively smaller than the other AND the larger table has an index on the joining column.
The Hash Join
Hash Joins - A hash join is one where the smaller table is placed inside memory, so the joining of rows takes place in a single pass. The smaller tables are constructed once by gathering the unique values, and then the blocks are kept in memory. The larger table blocks are brought into memory (one at a time) and joined. This is the preferred method.
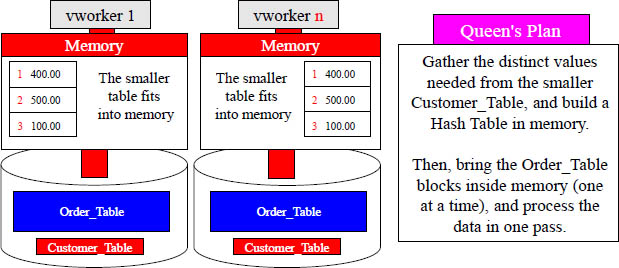
The DBA has control over the allocated (work_mem) amount of memory, so the more memory allocated, the more likely the Hash Join will take place. It is very important to run ANALYZE (Collect Statistics) on the smaller table to provide the optimizer confident that the smaller table is really small. A miscalculation about the smaller table's size could result in poor performance. Hash joins also work well when neither table is small but the smaller table’s joining column can be used to construct a hash table that fits in memory. Indexes do not help to speed up hash joins.
The Merge Join
Merge Joins - A merge join is the most scalable and likely to be used method of joining large tables. The merge join sorts both the tables on the columns being joined and then streams the top few rows from each table to do the join.
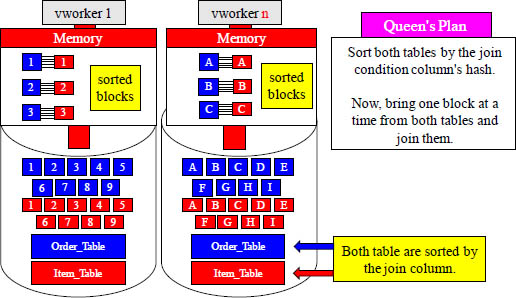
The merge join sorts both tables on the join column and then streams the top few rows from each table to do the join. This makes for excellent memory utilization. It is the actual sorting step that requires the most intensive memory use, and if the ANALYZE command hasn’t collected statistics, this could cause problems. If Aster thinks a table sorting will fit in memory, then it will use a quicksort algorithm. Else, it will use an external disk-based sorting algorithm (using at most work_mem amount of memory at any point during the sort).
Nested Loop Joins
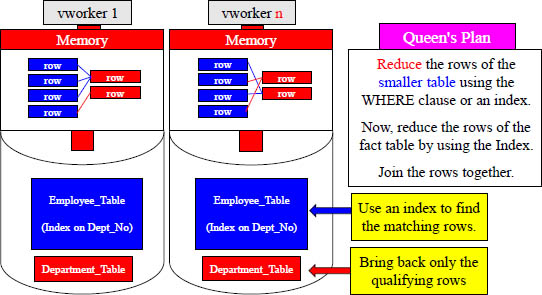
Nested loop joins are the fastest but can't always be used because all Aster Database deployments have the enable_nestedloop parameter set to off by default. It must be turned on by the DBA for Nested Joins to be eligible. Nested loop joins are very useful for performing a star-schema join between a large fact table and a dimension table, if the dimension is small or can be reduced with a WHERE clause or index. If there is an index on the join column of the fact table then Aster will use the index to minimize the rows of the fact table, and then the join takes place. What scares Aster is that if ANALYZE isn't run to collect the proper statistics, then problems could arise.