
Chapter 7. Gaining Credibility through PageRank
Keywords mean different things in different contexts. For example, the word track is either a noun or a verb. The noun form refers to the sport involving foot races, the place where various races are held, an essential part of vehicles such as tanks, or a part of a rail line on which trains run. The verb form refers to the act of following game in hunting or checking on the progress of a project. And these are only a few of the uses of the word track. Not all words in the English language have multiple dictionary definitions, but those that don’t carry varied nuances, depending on the context. And puns, sarcasm, irony, and other forms of linguistic complexity are commonplace in natural language. The Web, of course, contains all of them.
In oral contexts, it is usually easy for us to determine what a person means when she uses a word with varying meanings. By paying attention to a string of words, utterances, and gestures from a speaker, we can usually determine the meaning of track, based on those contextual cues. In print contexts, we have all kinds of contextual cues at the macro level, including the cover of the publication, the table of contents, who the author is, and what magazine we’re reading. At the micro level, the part of speech is determined by the grammar of a sentence, and the surrounding sentences help determine, for example, whether track refers to the sport or the venue.
Because we learned language naturally, we can tune into these contextual cues to determine the usage of a word that has multiple meanings. It’s one of the marvels of humanity that we manage to communicate, tell jokes, write lyrics, and use language in innovative ways on a daily basis. But computers don’t have humans’ ability to pick up on contextual cues surrounding word forms. They rely on raw data—strings of letters, spaces, and punctuation marks—to parse the semantics of human language. Practitioners of Artificial Intelligence (AI) have tried for decades to get computers to mimic human language use, with limited success. The closest they have come is to attach all kinds of structure to the language and related code to help computers determine the context and parse the semantics. This structure is in the form of automated metadata.
On the Web, which is a giant repository of unstructured text, AI-like functions are still a work in progress.1 In the absence of sufficiently capable AI functions, search engines must somehow make sense of this mass of unstructured human text. At one time in the Web’s evolution, search engines relied exclusively on the semantics of the text on a Web page to determine the relevance of the page to a search query. But because of the complexity of the English language, this didn’t work too well.
1 Companies such as IBM have quietly been making progress on AI-like functions to enhance aspects of information retrievability. For example, the UIMA framework allows various linguistic applications such as XQuery, LSI, and LanguageWare to combine their power into one pipeline of enhanced linguistic information about unstructured text on the Web. But these are yet to be widely used and are not used by either Google or Bing to enhance their search engines.
Readers who used search in the mid-90s can attest to what an ineffective experience search was without any contextual cues to rely on. If you searched on the word track, you were likely to get pages with track in every part of speech, and every conceivable meaning. Sorting through this mess was easier than blind surfing, but not much. Standards groups such as the W3C tried to improve the retrievability of Web pages by adding metadata and other structure to HTML, and later, to XML. But many of these standards were quickly exploited by rogue page owners, to the point where the search experience for users didn’t improve much. In the case of metadata, for example, many page owners added irrelevant metadata just to pump up their traffic numbers.
The advent of Google was game changing, for two reasons. First, it required content transparency. It banned results from pages that used metadata spamming and other tricks to get better search visibility. In part because of metadata spamming, Google does not use metadata as part of its relevance algorithm. (However, it does use some metadata to build its search engine results page [SERP]). For example, it uses a page’s metadescription in the snippet it displays on its SERP—but not for ranking.) Second, and most importantly, Google engineers and architects figured out a way to use the structure of the Web to determine the context of a Web page for a given search query.2 It’s called PageRank, and it is an increasingly important aspect of writing for the Web. It’s also the reason that Google can ignore metadata for its SERP rankings and still lead the market in search usability. The basic idea is that links provide context for Web pages. The structure of the Web can be parsed by mapping its links. Google was the first company to do this, and this fact, more than any other, led to its market dominance.
2 Jon Kleinberg, a professor at Cornell, was perhaps the first to recognize that the Web is not just a repository of unstructured text. One can infer the Web’s structure by carefully mapping links from page to page and topic to topic. Google uses concepts from Kleinberg (1997) as the basis for its PageRank algorithm.
Following Google’s lead, other search engines, such as Yahoo and Bing, pay a lot more attention to links than they once did. Like Google’s, the Bing and Yahoo algorithms are trade secrets. But we can infer from our tests that links are also very important to other search engines, including Bing and Yahoo. But based on our extensive research, it is clear that neither Bing nor Yahoo pays as much attention to inbound links as Google. Still, optimizing for Google, which is the clear market leader, will not hurt you with Yahoo or Bing. So we focus on optimizing for Google in this book.
The following italicized passage is Google’s own definition of how it determines which pages are listed on its (SERP), and in what order:
• Page Rank Technology:PageRank reflects our view of the importance of Web pages by considering more than 500 million variables and 2 billion terms. Pages that we believe are important pages receive a higher PageRank and are more likely to appear at the top of the search results.
PageRank also considers the importance of each page that casts a vote, as votes from some pages are considered to have greater value, thus giving the linked page greater value. We have always taken a pragmatic approach to help improve search quality and create useful products, and our technology uses the collective intelligence of the Web to determine a page’s importance.
• Hypertext-Matching Analysis:Our search engine also analyzes page content. However, instead of simply scanning for page-based text (which can be manipulated by site publishers through meta-tags), our technology analyzes the full content of a page and factors in fonts, subdivisions and the precise location of each word. We also analyze the content of neighboring web (sic) pages to ensure the results returned are the most relevant to a user’s query. Source: www.google.com/corporate/tech.html3
3 According to Google representatives we spoke with, “PageRank is one of more than 200 signals we use to determine the rank of a Web site.”
What Google calls the “hypertext-matching analysis” aspect of its algorithm is covered in Chapter 4, in which keyword density, position and other factors—called on-page factors—determine the page relevance. PageRank then determines both the contextual relevance and the “importance” or credibility of a page.
Because Google doesn’t give us a lot of detail about its proprietary algorithm, it’s important to understand it from a more objective perspective. Rand Fishkin of SEOmoz.com surveyed the top experts in the field and came up with Figure 7.1 to demonstrate this.
Figure 7.1. The relative importance of external links to on-page keyword usage in the Google algorithm. Rand Fishkin surveyed 100 top SEO experts about what they thought were the most important reasons that pages rank highly in Google.
(Source: Rand Fishkin, SEOmoz, Inc, 2009- www.seomoz.org/article/search-ranking-factors)
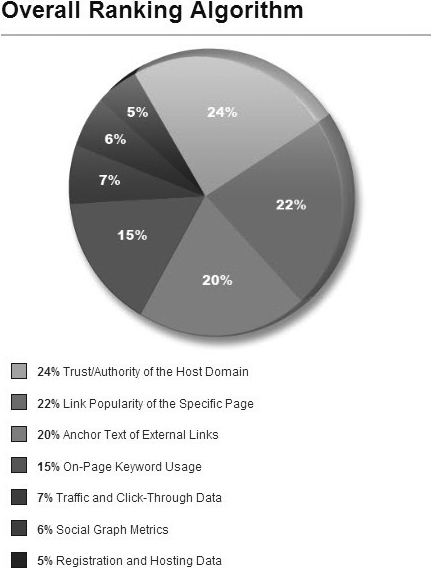
As Figure 7.1 shows, about 15 percent of Google’s algorithm uses on-page elements such as the heading and title tag to determine the semantics of the page itself. Link issues (authority and anchor text of external links) are roughly 42 percent of Google’s algorithm. (Google doesn’t release information about the exact weighting of different elements in PageRank. We can only infer it from the inputs and outputs of Google’s SERP.)
Of all the aspects of the Web that differentiate it from oral or print media, Hypertext is the most significant. The text on the Web might be unstructured, but the relationship between different pieces of text is highly structured. The links between pieces of text are the contextual cues that help determine the natural relevance of one piece of text to another. PageRank uses this feature of the Web to help determine the contextual relevance of a page to a search query, rather than using metadata and other artificial structures in a page’s code. Links help Google judge which pages are most contextually relevant to a search query.
If one page links to another and both have related on-page semantics, Google will consider them contextually relevant to each other. The more of these links to and from relevant pages that you have, the easier it is for Google to validate the relevance of your pages for the keywords you identify. In this way, links do a much better job of helping Google determine relevance than metadata does. Because it is much more difficult to create fake links than to fake metadata, links also provide Google with more reliable contextual information about a page.
PageRank doesn’t just help Google determine the contextual relevance of a page. It also helps Google evaluate its credibility. A link to a page is often described as a “vote of confidence for that page” (Moran and Hunt, 2005). Google users don’t care only about which pages are most linguistically relevant to their search query. They also want the most authoritative information on a topic. On-page semantics can’t help a machine determine authority. But links can. The more relevant links there are into a page, the more content owners determine that the page is credible. But Google doesn’t treat all links the same. Links from authoritative sites mean more than other links. Simply put, the quantity and quality of links into a page determine its PageRank, which then increases its visibility in Google accordingly. Unpacking how this works, and how to write for PageRank, is the subject of this chapter.
As we see in IBM, it is becoming increasingly difficult to get good visibility in Google with on-page attributes alone. Part of this is competition. Because it’s relatively easy to optimize your pages for keywords, more and more content owners are doing it. To compete with them, you must find ways of building links into your pages. Also, Google is not a static application. It has evolved over the years to create a better user experience, based on its own set of metrics. Because it’s relatively easy for site owners to manage what’s on their pages, Google doesn’t count these features as heavily as links. Even if links were as important as on-page elements, PageRank is gaining in importance in the market, as competition for high-demand words increases.
Becoming a Hub of Authority
Having links into your pages is called link equity or link juice. Suppose that Google assigns points on a scale of 0 to 10 to links, based on the credibility of a site. A highly credible site might warrant 10 points of link juice to the referred page. A lesser site might only garner one point. If two sites have identical page attributes (such as title tags, H1 tags, keywords in the URL, and keyword prominence and density), the one with more link juice will get higher visibility in the search results.
Again, Google does not release its PageRank algorithm, because it is its most important intellectual property. Also, because it’s evolving constantly, Google would have to publish changes to the weights and measures of the algorithm on an almost daily basis. But it has used PageRank as at least half its algorithm for so long that we can infer the basic workings of the PageRank portion of the algorithm. Also, how Google determines what pages are the most authoritative on a topic is continually changing with the landscape of the Web. But Google doesn’t make this determination itself; it uses the way content owners “vote” for sites they find credible by linking to them. A link to a site is a vote of confidence for it. Links from pages with the most link equity transfer the most link juice. A link from a page without much link equity doesn’t carry much link juice.
PageRank is designed to ensure that the most relevant, authoritative sites are listed at the top of search results. The primary way that a site gains authority is by publishing insightful, accurate, or definitive information in a compelling way, so that other sites will link to it. Content that does this is called link bait. There is no magic formula for publishing link bait. Good Web content speaks for itself. Link bait comes in many forms—such as white papers, bylined articles, and blogs from popular bloggers. One thing all link bait typically has in common is a byline: People consider the source when they decide to link to a piece of link bait. If two bloggers say the same thing, the one with more credibility in the community—the one with the bigger name—will tend to get the link. If you are just developing credibility in a community, the best way to create link bait is to write something insightful and original—something that no one else has written. If you do that repeatedly over time, eventually your stature in the community will increase and your content will be link bait, even when you are just synthesizing what others have written, in a compelling or interesting way.
Once you create link bait, there are ways of making sure that relevant, authoritative sites find and link to your link bait. The primary way is to find out what the community of people with similar interests is writing and then find your niche within that community. This is one area in which Web publishing resembles certain print contexts. Specifically, in academic publishing, the most effective way to get published is to read the writings of like-minded researchers on your topics of interest. If you find holes or gaps in their research, you design a research proposal to fill one of them. If your research makes a positive contribution to the literature for that topic and theoretical lens, you have a chance to get published in that journal. In this way, link juice is like citations in a print journal. The more citations an article has in the other writers’ bibliographies, the more credibility it has. A citation is very similar to a link in the sense that the writer who cites another is giving the other writer a vote of confidence.
To get other people to link to your content, you need to get a vote of confidence from them that your content is worth reading. It costs next to nothing to link to someone’s content (whereas publishers have to justify the expense of printing an article in an academic journal). But it is not without risk. Suppose that a content provider publishes a link and a description to your content and her regular visitors find the link irrelevant and have a negative experience with your content. A negative experience with your content is, by association, a negative experience with her content. This is the problem Google faces as it determines what to promote on its search results pages. For this reason, these votes of confidence are not easy to come by. You have to earn them by developing a relationship of trust with the referring site owner. And, of course, you need to create link bait, which is perhaps the biggest challenge.
The main similarity between academic print publishing and getting link equity is that for a particular topic, the Web is a collective effort of like-minded content owners. It takes many authors to fill a quarterly academic journal with good content. In a sense, these folks are collaborating on creating a body of knowledge related to a topic. Except in rare circumstances, content owners can’t “own” a whole topic. They need the help of others. And so do you if you wish to publish on the Web. You can’t do it by yourself.
If you try to become the expert on a topic and set out to publish the definitive reference on it, you will not likely succeed on the Web. Much of the work you publish already exists on the Web. And that information already has link equity in Google. Few people will link to your content if you try to publish the definitive reference in isolation. They will continue to link to the existing information unless your information is clearly superior. But they won’t know about your information if you publish it in isolation. They will only find out about it by visiting sites that link to your content, principally Google.
Of course, as we have been writing for several chapters now, Web publishing is different than print publishing in many ways. In one way it is easier to publish on the Web than in an academic journal. Academic journals are typically formal, fixed, rigid communities of insiders. But the Web is an informal community of diverse individuals from all walks of life. So there are fewer barriers to success on the Web. But the Web and academic journals do share one barrier to success: You must join a community of like-minded content producers if you have any hope of success.
In the print world, copyright is a big issue. Freelance writers hire lawyers to examine their contracts and try to ensure that they will ultimately own the rights to their intellectual property. Companies that own intellectual property are very guarded about their proprietary information. Much of it is confidential and is only shared on a need-to-know basis. This works for print because the object is to get the information into the hands of a select few to consume it. Printing information for people who don’t understand or appreciate it is a waste of time, labor, ink, and paper.
However, on the Web, it does not work to restrict information. If you protect your information behind firewalls accessed only by an exclusive group of individuals with passwords, very few people will find or want it. They will go elsewhere to find similar information, or they will create a free version themselves. Magazines have tried to force users to subscribe to their content on the Web, with little to no success. (One of this book’s authors—James Mathewson—was the editor of a magazine—ComputerUser—that tried that.) Given the abundance of free information, Web users simply will not tolerate a logon screen and will look elsewhere for similar content. Information wants to be free on the Web, because Web users expect it to be free and will not tolerate needing to pay for it.
On the Web, the value of content is directly proportional to how many links point to it. If you restrict access, you prevent links to your content and degrade its value. Even more of a problem for content owners who try to restrict their content is the fact that crawlers cannot get through firewalls. Content behind a firewall will not appear in Google. And no one will publish a link to a logon screen page. By restricting access to content, you reduce its value to virtually nil.
In terms of link juice, Wikipedia is the ultimate hub of authority. Millions of people link to it. It links to millions of sites. And it is listed as the top result in Google for almost every keyword you can think of. All because a few people got fed up and didn’t want to pay for basic information about subjects of interest.
How Wikipedia gained its status should be a lesson to all content owners on how to be a hub of authority. Among other things:
• Don’t try to do too much by yourself. Solicit help from colleagues both inside and outside of your company to link to your pages and to build pages to link to—filling holes as much with your own work as with the work of others.
• Be patient and persistent. Test your content as often as possible and adjust as necessary.
• Be transparent about your content, including acknowledging when it needs help (a large number of Wikipedia pages have this warning on them).
• Wherever possible, allow your users to contribute to your content, with reviews, feedback, comments, and the like.
How Not to Get Link Juice
Google is very vigilant about sniffing out scams that attempt to trick its algorithm to artificially improve a page’s ranking. In addition to pieces of code that expunge from its index pages suspected of keyword spamming or engaging in link-equity Ponzi schemes, it has hired more than 1,000 editors to audit the search results for high-demand keywords and ensure that the highest-visibility pages are authoritative.
Even if you’re not trying to trick Google but are honestly working to get link juice from content owners, you might unwittingly suffer the wrath of Google’s protections against link schemes. Because the majority of Google’s efforts to thwart dishonest Web site owners are based on code (rather than on content), you can inadvertently trigger the programs that scan for link building schemes.
The first impulse of folks trying to get link juice from similar sites is to simply request a link from them. By that we mean contacting the owners of a site and asking them to link to your content. In our experience, this is not very effective. The typical response contains at least one of the following: “I’ll link to your content if you put a link to my content on your home page,” or “I’ll link to your content if you pay me to do so.” If that’s the response you get, don’t act on it. If the owner doesn’t find your content relevant enough to link to it without link-swap or payment conditions, it’s not worth pursuing.
Effective sites don’t try to do too much, but rely on other sites for supporting information or commentary. In this way, links out of a site have value if they give users a more complete picture of the story the site is trying to tell. A site owner should want to link to you if it improves her users’ information experiences. If she demands something more than a better user experience for her visitors, it’s an indication that she’s not the kind of site owner you want to get links from.
Part of Google’s algorithm looks for reciprocal links (links to and from two related sites) and flags a page for elimination if it contains too many of them. Of course, sometimes links can be naturally reciprocal. Two content owners can legitimately admire each others’ work and share links. But that is the exception to the norm. If a content owner is not willing to recognize the value of your content for his users, he’s likely to own the kind of site that Google has on a watch list for link swapping schemes. Worse yet, you might not be aware of all his content activities. If he demands reciprocity in exchange for an innocent link request, what might he do with others?
A common way to gain link juice, which prompted Google to increase its vigilance towards link swapping is called a link farm. This is a group of sites that all link to each other in order to artificially improve their Google visibility. These sites send users round and round in a circle. But they don’t really care about users’ experience. Because Web advertising is often based on traffic, they just want the visibility they get from Google to increase their ad revenue, without concern for whether they are helping their users understand the content they’re looking for. These are the sites Google bans from its index for deceiving their users. If you inadvertently swap links with one of these sites, you might end up on Google’s naughty list as well.
Some unscrupulous sites will request links from you. You should be wary of them for the same reasons. Areas of the Web where link farms and other nefarious sites (such as porn and gambling sites) live are called bad neighborhoods. Whatever you do, make sure that your links don’t end up in a bad neighborhood. Google will penalize you severely for associating with them. They’re not always easy to spot, because they can be good at making themselves look like a legitimate site. There are some indicators, however. Link farms and bad neighborhoods commonly are based around the same Class C IP address. The Class C part of the address is the third of four sets of numbers in the IP string. If you see that many of the sites trying to develop a link swapping relationship with you have the same Class C address, ignore their requests (see Figure 7.2).
Figure 7.2. The Class C IP address refers to the third of the four sets of numbers in the address.
![]()
Because link swapping is mostly ineffective and risky, we don’t recommend expending much energy on it. Instead, we recommend focusing on developing your credibility within the community of site owners whose users share the interests of your users, as discussed below.
How to Leverage Existing Relationships to Get Link Juice
In general, we suggest that you develop recognition within the community of site owners related to your topic area. Some of the tactics you can use to develop this credibility are more effective than others. Because the Web is a social medium, in which content areas are built around communities of like-minded sites, taking advantage of the social nature of the Web is the most effective strategy. The two main tactics within this strategy are to
• Take advantage of existing relationships.
• Build new relationships through participation in social media sites such as LinkedIn, Twitter and Facebook. We will cover existing relationships in this section.
The first step in developing a link juice plan is to take an inventory of the people and organizations with whom you have an existing relationship. Chances are, you are not taking advantage of these communities as much as you can. These relationships include colleagues within your company who publish Web pages, colleagues within your company who publish press releases and other media-facing materials, colleagues within partner organizations, and friends and peers from professional or academic associations you belong to (see Figure 7.3).
Figure 7.3. The circles of effort for link building activity. Start at the center circle because it contains the easiest avenues of obtaining links, and work your way out.
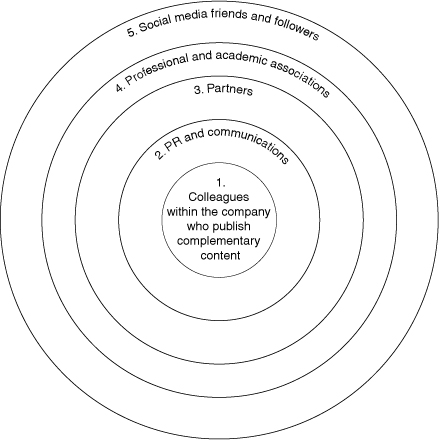
Start with colleagues in your company who develop content on similar or related topics. Find link opportunities to and from their sites and make link requests to them. Be sure to include instructions about the link text you want your colleagues to use in your request. As a refresher, recall that link text is text that is clickable. Google’s crawler looks at link text to determine the relevance of the link to the page it refers to. If the link text contains prominent keywords that also occur in the referred page, the crawler will determine that the link is indeed relevant and will pass that information to Google’s algorithms for analysis of how much link juice it warrants.
Links within your site to your own pages do not carry as much link juice as external links coming to your site. But they should be the easiest to get. And if you practice the litmus test that we advocate—asking yourself if the link helps the user’s experience—internal links can also help your users find relevant content on your site, which is the point of search engine optimization. So, as part of the basic blocking and tackling of Web publishing, always identify link partners within your company and collaborate to exchange links and descriptions with them, whenever it will improve the user experience for your audience. (We covered this in more detail in Chapter 6.)
If you work for a company, chances are that it publishes press releases announcing product launches and other events of interest to the general public. These are excellent avenues to getting external links. Media outlets often use press releases as the basis of articles about a company. If your press releases are optimized, they will have links to the most relevant pages on your Web site. These links often end up in articles on external sites. There is no better source of external links than this, if you use the right format for your press releases. See Figure 7.4 for an effective press release template.
Figure 7.4. A press release template that includes links and social media elements.
(Source: Swif Communications 2009)

Most companies work with partners to help them do a better job of serving their customers. The more closely you work with your partner, the better that service becomes. But for some reason, that close relationship does not always extend to the Web. Customers who come to a partner site looking for information on how the partner helps them use your product should naturally be interested in linking to information on your product. But few companies help their partners link appropriately. Of course, every link to a partner page from your page provides link juice for the partner page. And vice versa—every link into your site from partner pages brings your pages link juice. Besides internal linking, nothing should be easier than getting partners to link to your pages. And unlike internal links, links from partners can carry a lot of link juice. We recommend identifying partner opportunities and working with partners to build links into their pages (with the appropriate anchor, or link text).
A lot of writers and editors belong to professional groups or alumni organizations. Perhaps you attend conferences related to them. You will meet lots of like-minded people at these gatherings. Chances are, they have a Web site. If the site is closely related to your own, to the point where links between your site and a peer’s site would improve users’ experience, it is wise to take advantage of these relationships. Beyond conferences, social media sites such as LinkedIn and Facebook can help you keep in touch with your peers. We also recommend promoting new content in your site’s status updates and tweets as a way of keeping your peers informed about new content. If they have a related Web site and find your content useful for their audience, they will pick up the links. These kinds of natural links can really help your pages gain link juice, especially if you have a lot of friends who produce authoritative Web sites.
Using Social Media to Develop Linking Relationships
Before social media became popular, professional networking required a lot of hard work. People attended conferences, passing their business cards around. Perhaps they even presented. Another way to gain visibility was to publish. Whether in academic or professional journals, publishing helps people get noticed by peers. Speaking at conferences and publishing in journals were once the primary ways of gaining credibility among the community of experts on topics of expertise. Social media sites have changed all that.
Now experts have blogs and LinkedIn, Facebook, and Twitter accounts, and they get the word out on their latest work by posting or tweeting about it. Rather than needing to gain friends in their fields through hard weeks of travel, they can gain friends and followers daily, without leaving their desks. Not only can they promote their content, they can find good content to link to by following the right people on Twitter and making a select few of the people they follow friends on Facebook. Social media has automated the art of the conference, and it has accelerated the pace of finding potential collaboration partners.
You might be tempted to think that every link you create to your own content on Facebook or Twitter gets you link juice directly. To do this would be tantamount to creating content on Wikipedia in order to gain link juice. But although Wikipedia is the ultimate hub of authority, it will not directly get you any link juice. Why? Link juice is supposed to be a natural phenomenon. The folks at Google do not want to encourage people to publish content on one public site and link to it on another site just to get link juice. This is rigging the system. So they created an HTML attribute value, as part of the W3C 2.0 rel specification. It’s called the nofollow attribute value—a piece of code (rel=nofollow), which can be added to the HTML of a link and prevents it from passing link juice. All the links in Wikipedia are nofollow links, so you do not get any link juice if Wikipedia developers link to your page.
Other sites that typically carry the nofollow attribute value on links include Facebook, Twitter, YouTube, StumbleUpon, and Delicious. You cannot manufacture link juice for your own site by cleverly using social media sites to develop links into your content. Nonetheless, using social media sites is perhaps the most effective way to get link juice. How? Social media sites are places where you can connect with experts in your field and promote your content, much as you would do at a conference. If friends and followers find that your content helps them better serve their audience, they are likely to publish your link and pass it around to their friends and followers. Each of those links then carries the link juice appropriate to your friends’ or followers’ sites.
A Handy Tool to Find Nofollow Links
If you use Firefox, you can use the SearchStatus Firefox plug-in to find nofollow links. After installation, it displays information at the lower right of the browser screen (see Figure 7.5). The tool is currently offered at no cost and is easily downloaded from the Firefox plug-ins page (http://addons.mozilla.org/en-US/firefox/search?q=SearchStatus&cat=all). With the Highlight Nofollow links option checked, every site you visit will display with the nofollow links highlighted. Visit Wikipedia, and you will see that all links are highlighted in pink.
Figure 7.5. Firefox Search Status tool options menu.
In addition to being promotional vehicles, the main value of social media sites for your content is to help you find and connect with as many experts in your field as you can. One of the greatest difficulties in becoming a hub of authority is getting to know all the experts in your field. Suppose you are working on an important piece of content, but another expert in your field has proven that your research is a nonstarter. Unless you know about your colleague’s work, you might go ahead and do a lot of fruitless research. Developing a large and focused set of friends and followers can help you overcome this challenge.
Writing for social media sites is an emerging art form that deserves a chapter all its own (Chapter 8). But for the present, suffice it to say writing for social media is much less formal and much more conversational and pithy than writing for other Web pages. Like all writing, writing for social media is about writing for your audience. The difference is that you often know your audience very well in social media settings, so you can tailor it to their particular modes of expression. This might include puns, irony, or emotionally laden posts. On ordinary Web pages, you must respect the diversity of your audience by writing in compelling ways that leave little room for creative interpretation. Unless you have a vast set of friends and followers who are as diverse as an ordinary Web audience, social media sites allow you more freedom of expression.
Writing for social media also bears similarities to writing for ordinary Web pages. The primary similarity is that the most effective posts and tweets contain links to work you want to highlight—your own, and work from friends and followers.
The one constant on the Web is that the value of content is directly proportional to the quality and quantity of links into it. That is true on Twitter, Wikipedia, and, of course, Google.
Using the Power of the Web to Get Link Juice
In social media sites, you’ll notice that compared to other sites, they have a higher density of rich media content and a lower density of text. People use the social media sites to share videos via YouTube, presentations via SlideShare, photos via Flickr, and podcasts via iTunes. These rich media file sharing sites have innovative user interfaces that feature user reviews, social tagging—interfaces that allow users to attach tags in the form of words to pieces of content as a means of finding and sharing relevant content—and social bookmarking—interfaces that enable users to create and share bookmarks to favorite content. They become treasure troves of content that social media mavens use to spice up their posts and tweets.
Though this book is primarily about writing for the Web, we would be remiss if we did not mention that your content strategy needs to include using these social file sharing sites to connect with your audience, especially as a means of building links into your content. The best Web pages feature a mix of media: presentations, PDFs, videos, and podcasts. The emerging trend in Web design says that a Web page is more of a conduit for rich and social media content than a content vehicle in and of itself. But you can’t expect bloggers and tweeters to find and post your rich media content if you don’t also post it on the popular file sharing sites. Though many of these sites feature the nofollow attribute value on their links, many bloggers and other site owners frequent these sites looking for relevant, interesting content to complement their blogs or other posts. If they pick up your content, their link to your site will pass link juice.
The designers of the Web—the W3C, which is still led by Tim Berners-Lee after all these years—have developed technologies to extend the language of the Web and automate content publishing in the process. One such technology is colloquially called Really Simple Syndication (RSS). RSS lets you automatically distribute your content to people who have subscribed to it. So, if your content changes, your audience will be notified. Rather than needing to check back on your site in case content changes, they can wait for RSS to update them and only click in when you post new stuff.
A more valuable aspect of RSS is how it allows two site owners to share content without touching it. Suppose you have a daily news section on your site and a colleague is interested in posting that same feed on his site. He can post the RSS code for your feed, and his site will be automatically filled with links to your fresh content, which users can access by clicking. If you can develop a relationship with a content partner who is willing to post a feed of your content on her site, you are in content nirvana. All those links will pass link juice to your pages. This might not be as hard as you think. For example, your business partners might want to post your feeds on their sites to ensure that their users get the most up-to-date information from their business partner company.
Summary
• Keywords mean different things in different contexts. To determine the context of a Web page, Google uses PageRank, which measures the quantity and quality of links into its content.
• On the Web, the value of content is directly proportional to how many links point to it.
• PageRank also is a measure of the authority of a site: The more links into a page, the more prominent it is on the Web.
• To become a hub of authority, look to Wikipedia as a model of publishing: Don’t try to do too much, but engage with a community of subject matter experts who also own Web sites to produce a more complete content experience for the community’s users.
• Use social media sites to engage with the community of like-minded subject matter experts and expand your network of connections.
• Don’t expect to gain link juice directly from social media links, because most of those sites use the nofollow attribute.
• Even with the nofollow attribute, social media is the best way to gain indirect link juice, by publicizing content that might be relevant to your community and making it easy to link to it.
• Also consider posting rich media to file-sharing sites such as YouTube, iTunes, and SlideShare. Bloggers and others mine these sites for relevant videos, podcasts, and presentations.
• Use RSS feeds to help your audience subscribe to and share your content, thereby developing pass-along link juice.