
11
Full-Text Index Queries
In the late 1980s, I worked as the Tech Support Manager for a growing medical billing software company. We had written most of our own internal support systems, accounting, payroll, and tech support incident management, not to mention our own software products. After a few years and hundreds of thousands of support calls later, we had accumulated what we considered to be a huge repository of support call notes and history. We found ourselves taking calls from customers whose issues seemed vaguely familiar. When a support technician received a call, he or she would page through support incident screens, looking for old records to help find resolutions to repeat problems, often to no avail. Our system didn't store data in a relational database so we couldn't use SQL or any other standard language to query data. All of our data lived in flat text files. While attending Comdex in Las Vegas, I found a company with an interesting product that did indexing over large volumes of text. This software could build searchable indexes for practically anything: encyclopedias, dictionaries, religious books, or hundreds of files in your file system. We quickly built this into our support system and it changed everything. When a customer called and told one of our support technicians they were getting error 3204 when they entered a new patient diagnosis, the technician could instantly find all incidents related to the same problem by simply typing a few keywords.
Free-form text indexing has been around for many years and has improved and matured since my experience as a Tech Support Manager. Relational databases have largely replaced old flat-file systems, but with that transition, we've actually lost some useful functionality—namely the ability to simply store a large volume of searchable text. Systems evolve to fill gaps and to meet users' needs. Today, most relational database products support the ability to store large volumes of data in a structure called binary large objects (BLOBs). SQL Server offers three different implementations of BLOB types in the data types Text, nText, and Image. When the Text and Image types were originally added to the SyBase and Microsoft SQL Server products in the early 1990s, they didn't support indexing or ordering. Even today, you cannot use these columns with a standard WHERE or ORDER BY clause — and for good reason. Can you imagine sorting rows using all of the text in a 15-page document?
Transact-SQL includes some simple tools for inexact text comparisons. This includes functionality such as Soundex phonetic and approximate word matching. By contrast, full-text indexing includes built-in logical operators, “near” matching, and ranked results. Whether you should choose to use full-text searches or standard SQL techniques depends on your specific needs.
Microsoft Search Service
To compensate for this shortcoming, Microsoft implemented a flexible, free-form text indexing technology very similar to the product I used to index our support call system. The Microsoft Search Service was originally adopted to index newsgroup servers and web sites. Because it was capable of indexing practically any volume of text stored in files, it was integrated into SQL Server several versions ago. Today, any SQL data type capable of storing text characters can be indexed for free-form searches using full-text indexing and the Microsoft Search Service. Keep in mind that this is not a capability of SQL Server, rather a separate service made accessible through extensions in both the SQL Server product and the Transact-SQL language. Because text in practically any form can be indexed, SQL Server can be used as a storage repository for content such as Office documents that can then be indexed and searched using full-text indexing. Word documents, for example, contain both text and binary markup information. This poses no problem because the non-textual data is simply ignored.
Full-text indexing works much differently than standard indexes in SQL Server. Indexed data is not stored in the database. Full-text catalogs store index data in separate catalog files on the server. When the index is populated, the search service weeds out all of the noise words such as “and” and “of.” All of the remaining words are added to a table-specific index stored within a catalog. Multiple columns can be added to the same index within a catalog.
Most of us use full-text searching every day. Although the Microsoft Search Service is not implemented on the same scale as the Google and Yahoo web search engines, the fundamental technology is the same. If you have used any of the leading web search services on-line, then you're already familiar with some of the things you can do with the Microsoft Search Service and full-text indexing.
Soundex Matching
One of the great challenges when mixing the nuance of language with the exactness of computing is to make sense of things that are similar to other things, but not exactly the same. My friend, Steve, who writes a humorous newspaper column, says that there are people who like things to be black and white, and there are other people who are OK with things in that gray area in between. For the gray people, driving 70 on a 60-mile-per-hour road is perfectly acceptable for the surgeon on his way to the hospital. This is not to say that the gray people are all about breaking rules and cheating their employers, they just have a different way of looking at things. Likewise, at times you may need to match a word or phrase that is similar to another, in that gray area between equal to and not equal to. One of the great challenges, for those of us who spend our lives in the world of Boolean logic, is to cope with the concept of inexact comparisons.
Soundex, as applied in SQL Server, is a standard used to compare words based on their phonetic equivalents, using a mathematical algorithm. This standard is based on the Consensus Soundex, developed by Robert Russell and Margaret Odell in the early 1900s. It was used by the United States Census in the 19th and early 20th centuries and in genealogical research to index and deal with spelling variations in surnames. Although the rules are based on English language phonetic rules, it does work with many words in different languages. Here's something to keep in mind: Just as the rules of spoken language can be a bit arbitrary, so is this. Soundex matching is pretty accurate, most of the time, but on occasion some exceptions may occur. Use it for search and matching features to be validated by a user, but don't bet the farm on every result.
The sound of a word is represented by a letter, representing the first sound, followed by a three-digit integer, each numeral representing adjacent consonant sounds. Before processing a word, the letters A, E, I, O, U, H, W, and Y are ignored unless they have a phonetic significance when combined with another letter. The first three prominent consonant sounds (after the first letter, if it's a consonant) are translated as shown in the following table.
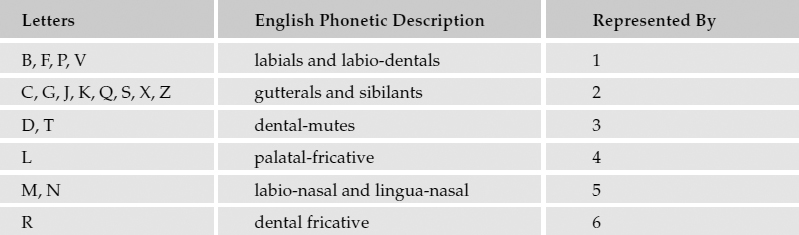
The resulting value is padded with zeros, if necessary. Here are some simple examples. The words “Two,” “To,” and “Too” all have the same pronunciation. I'll pass each to the Soundex function:
SELECT SOUNDEX(‘Two’) SELECT SOUNDEX (‘To’) SELECT SOUNDEX (‘Too’)
The result is the same for each word, T000, as shown in Figure 11-1.
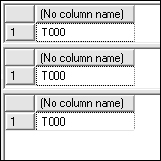
Figure 11-1
Because there are no consonants after the “T,” zeros are added. This happens to be the same value returned for Tea, Tee, Tow, Toe, and Toy. Using a more complex word, the result is more precise. For example, the Soundex value for the word “Microsoft” is M262: 2 for C, 6 for R, and 2 for S.
Try a few different words. Generally, I've found this to work reasonably well for comparing the closeness of words, but using the Soundex function for this purpose is not an exact science. For example, the word Seattle has a Soundex value of S340, which is the same for the word Settle. However, the word Subtle has a Soundex value of S134 because the algorithm missed the fact that the B is silent. This confirms what I've known all along, that people from Seattle are not very subtle.
The SOUNDEX() function returns a character string. With the exception of an exact match, you would need to parse this string and convert the numeric value to a numeric type. This would allow you to make quantitative comparisons. In this example, I use variables to hold the input and output values. The SOUNDEX() function output is parsed using the SUBSTRING() function to return only the numerical value. The difference is calculated and converted to a positive value using the ABS() function. Using this approach, I'll compare Redmond and Renton, two neighboring Washington State cities that many people (including my wife) often confuse:
DECLARE @Word1 VarChar(100) DECLARE @Word2 VarChar(100) DECLARE @Value1 Int DECLARE @Value2 Int DECLARE @SoundexDiff Int SET @Word1 = ‘Redmond’ SET @Word2 = ‘Renton’ SELECT @Value1 = CONVERT(Int, SUBSTRING(SOUNDEX(@Word1), 2, 3)) SELECT @Value2 = CONVERT(Int, SUBSTRING(SOUNDEX(@Word2), 2, 3)) SET @SoundexDiff = ABS(@Value1 − @Value2) PRINT @SoundexDiff
According to the SOUNDEX() function, these two words are quite different phonetically. My query returns a difference of 180. If you don't want to go to this much work and don't need such a granular comparison, all this effort isn't necessary.
The DIFFERENCE() Function
The DIFFERENCE() function is really just a wrapper around two SOUNDEX() function calls and some business logic to compare the values. It simplifies the comparison, reducing the result to a scale from 0 to 4, where the value 4 indicates a very close or exact match.
I'll use the DIFFERENCE() function to compare the words To and Two:
SELECT DIFFERENCE(‘To’, ‘Two’)
The result is 4, indicating a very close or exact match.
Using the DIFFERENCE() function to compare Redmond with Renton, as follows,
SELECT DIFFERENCE (‘Redmond’, ‘Renton’)
returns 3, meaning a similar but not-so-close match.
Managing and Populating Catalogs
Even though the task of managing full-text indexes belongs to the Microsoft Search Service, rather than SQL Server, all of the management work can be performed within the SQL Server management tools. These tasks are similar in SQL Server 2000 and SQL Server 2005. I'll start with the SQL Server 2000 Enterprise Manager and then move on to the SQL Server 2005 Management Studio. I'll briefly show you how to create and populate a full-text catalog. For detailed information on managing full-text indexes and catalogs, please refer to Professional SQL Server 2000 Programming and Professional SQL Server 2005 from Wrox Press.
SQL Server 2000
A few different methods are used to create a catalog and indexes. If you are using Enterprise Manager, you can use one of these methods to create a new full-text catalog:
- Right-click a database and choose New Full-Text Catalog to open the New Full-Text Catalog dialog window (see Figure 11-2).
- From the Tools menu, choose Full-Text Indexing to open the Full-Text Index Wizard.
- Right-click a table and, from the pop-up menu, select Full-Text Index Table
 Define Full-Text Indexing. If a catalog doesn't currently exist, you will be prompted to create one and then to define an index for the table.
Define Full-Text Indexing. If a catalog doesn't currently exist, you will be prompted to create one and then to define an index for the table.
Figure 11-2
This launches the Full-Text Indexing Wizard dialog shown in Figure 11-3.
Figure 11-3
Enter a name for the new catalog and finish the wizard, accepting all other default settings, as shown in Figure 11-4.
Figure 11-4
After a full-text catalog has been created, the console tree will have an icon added enabling you to manage full-text indexing for the database. Indexes can be created in a number of ways. One simple technique is to right-click a table icon in Enterprise Manager and then select Full-Text Index Table from the menu, choosing the Define Full-Text Indexing on a Table… option, as shown in Figure 11-5.
Figure 11-5
SQL Server 2005
Probably the most significant enhancement to full-text indexing in SQL Server 2005 is that the database engine can update indexes as data changes. This can make full-text indexing behave more like standard indexing and greatly reduce data latency. Just keep in mind that this feature can have a significant impact on overall server performance. This may not be a wise option in a busy transactional database environment unless you have a very capable server.
Implementing catalogs and indexes in the SQL Server Management Studio is very similar to using Enterprise Manager. The Full-Text Indexing Wizard contains several pages, and I'm not going to show them all. Begin by defining a new catalog for the AdventureWorks2000 database. Under the database, expand the Storage node and right-click Full-Text Catalogs. From the menu, select New Full-Text Catalog…, as shown in Figure 11-6.
Figure 11-6
The New Full-Text Catalog dialog is used to name, specify a file location, and set options for the new catalog file, as shown in Figure 11-7.
After creating a catalog, indexes can be created for tables. To create a new index, right-click a table icon and choose Full-Text Index ![]() Define Full-Text Index…, as shown in Figure 11-8.
Define Full-Text Index…, as shown in Figure 11-8.
When the Full-Text Indexing Wizard opens, navigate past the opening page. Because the wizard was launched from the Product table, it polls the table for a list of indexes. A unique index must exist in order to build a full-text index. Accept the default selection, which is the primary key for this table, as shown in Figure 11-9.
Next, a list of columns is displayed. These are candidates for full-text indexing. Check any columns that you would like to have included in the full-text index, as demonstrated in Figure 11-10.
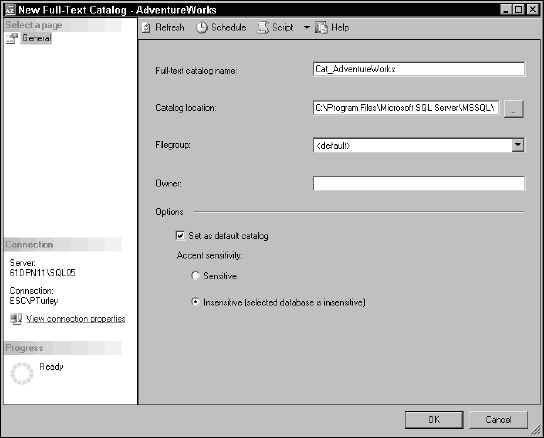
Figure 11-7
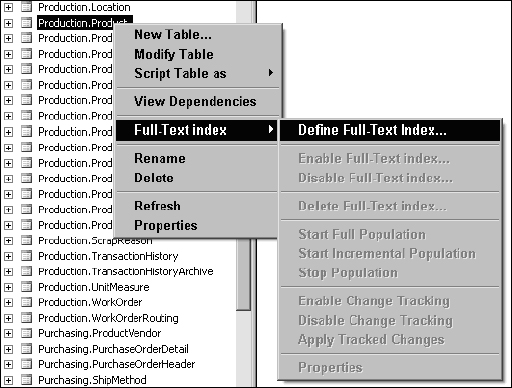
Figure 11-8
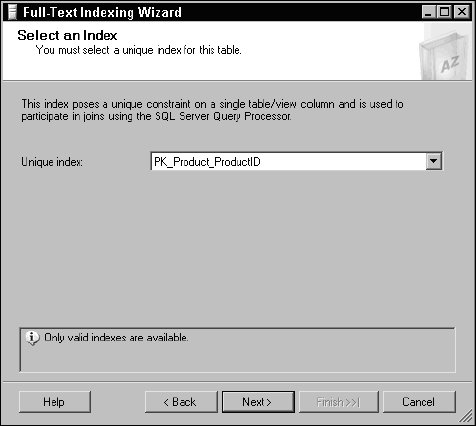
Figure 11-9
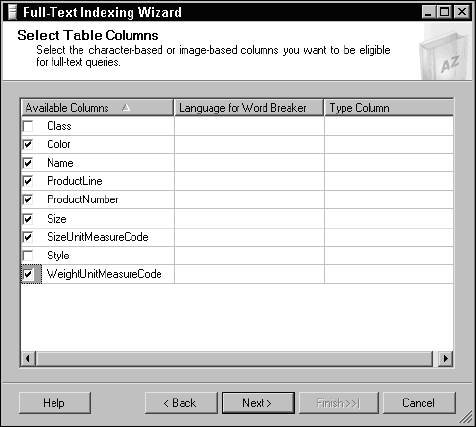
Figure 11-10
If you would like to have SQL Server track and automatically update this full-text index as data is modified, leave the Change Tracking option set to Automatically, as shown in Figure 11-11.
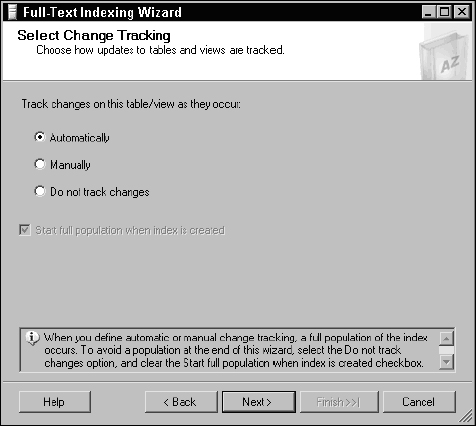
Figure 11-11
The page gives you the option to select an existing catalog or to create a new catalog. Because I created a catalog to store full-text indexes for this database, select the existing catalog, as shown in Figure 11-12.
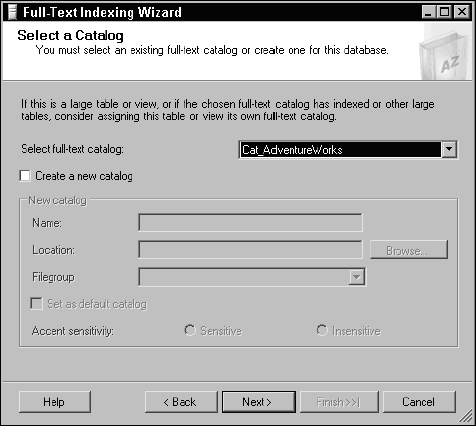
Figure 11-12
The next page allows you to manage full-text catalog population schedules. Creating a schedule invokes the SQL Server Agent service, which must be running for this option to function properly. Click Next to skip this page.
The following page displays summary information (see Figure 11-13). Using this dialog, you can review your selections and options. Because no settings have yet been applied, you can use the Next and Previous buttons to navigate to any page to make changes. Click the Finish button to apply your selections and build the next full-text index.
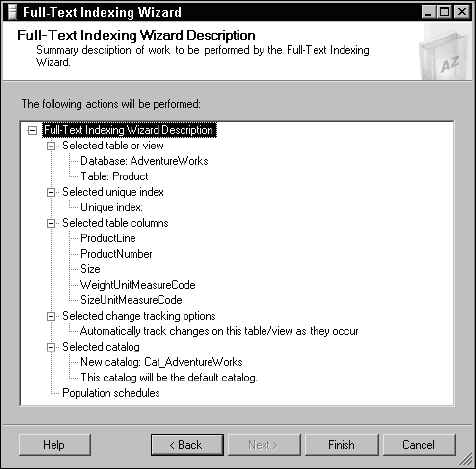
Figure 11-13
The final wizard page, shown in Figure 11-14, displays the progress of each step, as it is applied by the wizard.
Figure 11-14
Later in this chapter, I'm going to use some examples of full-text queries on the ProductReview table. Rather than using the wizard, create this index using the following script:
CREATE FULLTEXT INDEX ON ProductReview(Comments, ReviewerName) KEY Index PK_ProductReview_ProductReviewID
An optional statement can be used to explicitly control whether SQL Server tracks changes and whether it automatically populates and updates the index. You may want to disable change tracking to conserve server resources or to give yourself more control over this process.
To explicitly populate the index using change tracking, add this line to the end of the prior script:
WITH Change_Tracking Auto
To explicitly turn off change tracking, use this option:
WITH Change_Tracking OFF
In case you want to manually populate a full-text index that has not been set up for automatic population, use this option of the sp_fulltext_table system stored procedure:
sp_fulltext_table ‘ProductReview’, ‘start_full’
This stored procedure can be used in place of the Create FullText Index expression used previously and includes several related maintenance options.
Full-Text Query Expressions
Full-text indexing in SQL Server extends the Transact-SQL feature set by adding four languages predicates:
- CONTAINS
- FREETEXT
- CONTAINSTABLE
- FREETEXTTABLE
You'll recall that a predicate is simply a functional statement that yields a Boolean result. Predicates always return a true or false value. Functionally, these are really only two predicate statements with each having an alternate implementation that returns a SQL Server table object—rather than a standard result set—from the query. A predicate is simply an extension to the SQL language, used in a WHERE clause, that provides a conduit from SQL Server to the Microsoft Search Service. As far as you are concerned, you are working with SQL and communicating to the database engine. The reality is that these statements take your request outside of SQL Server and make requests against the search service. The only real evidence of this is in the way you must pass string values.
Quotes in Quotes
This is an interesting idiosyncrasy of the full-text query syntax. As you know, when passing text string values to Transact-SQL, these values are encapsulated in single quotes. This is still the case when using full-text predicates, however, these string values are then passed from SQL to the search service, which requires that values are passed within double quotes. This means that when you need to pass values to a full-text query expression (if the value contains spaces) you must pass a double-quoted value within single quotes, like this:
‘“My Value”’
This may seem a little strange but let me explain why this is necessary. Transact-SQL requires literal string values to be passed in single quotes. Before SQL Server reroutes the statement to the search service, it strips off the single quotes, passing values in the proper format for the search service, which requires literal values that include spaces to be enclosed in double quotes. When using logical operators within a full-text predicate call, you may need to pass multiple quoted values between operators, all of which are enclosed within single quotes for SQL to handle them, and each value in double quotes, as follows:
‘“My Value” OR “Your Value”’
Examples of the entire call syntax follow shortly, but I want to make sure you're comfortable with this requirement to pass double-quoted values (required by the Microsoft Search Service) within single quotes (required by SQL Server).
The CONTAINS Predicate
The CONTAINS predicate lets you find and return rows where one or any combination of indexed column values contains a specified value, or optionally a form of a specified word. The features of this predicate are as follows:
- Search criterion can apply to values in one or any number of specified column(s) contained in the full-text index.
- Search criterion can apply to values in all columns contained in the full-text index.
- The columns' text includes a word or string of characters located anywhere within the text. Matching text can include wildcards indicating that a word starts with, ends with, or contains a string of characters.
- Match may be based on a form of a specified word. For example, the text may include a plural, singular, different gender form, or different tense of the word.
The full-text indexing engine includes a vast thesaurus of words in different forms and inflections. This supports multiple languages if different language packs have been installed. To be able to apply language rules to the text, the engine needs to know what language to use. The language parameter for all predicates will accept either the language alias (friendly name) or the LCID, an integer value used internally. Full-text indexing recognizes the languages listed in the following table.
If the language parameter is omitted, the language will be derived from the column, table, or database.
I'll start with a simple example. I'm interested in returning all Product records where any indexed column contains the value “Black.” The first parameter to this function-like statement indicates the indexed columns I want to include in the search. The asterisk (*) represents all available columns. The second parameter is my search criteria:
SELECT * FROM Product WHERE CONTAINS(*, ‘“Black”’)
The results are shown in Figure 11-15.
Figure 11-15
As you can see, rows are returned where the word “Black” is contained in both the Name and Color columns. However, you may be wondering why the word “Black” was found in the middle of a field value when I didn't use any wildcard characters. Something to get used to when using full-text queries are the differences in behavior from this and the SQL LIKE operator. Full-text queries match whole words anywhere within a field without using wildcards. Wildcard matching is performed to match a substring, or part of a word. For example, I'll look for any rows that contain text beginning with the letters “crank”:
SELECT * FROM Product WHERE CONTAINS(*, ‘“crank*”’)
Note that the wildcard character isn't the percent symbol, %, as it is in Transact-SQL. It's the asterisk, *. The results are shown in Figure 11-16.
Figure 11-16
You can also specify a list of columns you want to include in the search by specifying a comma-delimited column list within parentheses:
SELECT * FROM Product WHERE CONTAINS((ProductNumber, Name, Color), ‘“Black”’)
The full-text indexing engine includes an internal thesaurus of words and their variations. This enables the CONTAINS predicate to match different forms of a word. This might include past-, future-, or present-tense, or different gender inflections. For example, performing a full-text search on the Product table for the word “tour” returns records containing the word “touring,” as shown in Figure 11-17.
SELECT * FROM Product WHERE CONTAINS(*, ‘FORMSOF(Inflectional, “Tour”)’)
Figure 11-17
Weighting Values
You can affect the outcome of word matching, and relative ranking of rows, by designating relative weight values for different words. A weight value is a numeric value between 0.0 and 1.0, accurate to one decimal position. Because these values are actually passed as a text string along with the rest of the search criteria, SQL Server doesn't really see this as a numerical type. These values are used only for relative comparison, so it's not necessary to make them add up to anything in particular. A weighted-value word list is passed to the ISABOUT() function, within the CONTAINS predicate expression:
ISABOUT (<word> weight (.75), <word> weight (.25))
The result of this weighting will affect whether or not some rows are included in the result set but may not otherwise be apparent when using the CONTAINS predicate. This is apparent, however, in the value of the calculated Rank column returned by the CONTAINSTABLE and FREETEXTTABLE predicates.
Ranked Results
Internally, the CONTAINS predicate calculates a qualifying ranking value for each row, based on exact and approximate word matching, logical operators, and explicit weighting value factors. Because the CONTAINS and FREETEXT predicates are only used to qualify selected rows returned in the result set, these techniques can't expose the ranking of each row. The CONTAINSTABLE and FREETEXTTABLE predicates do create a new result set, returned as a SQL table object. A new column, called Rank, is added to the result with the relative ranking value of each row.
The CONTAINSTABLE Predicate
Functionally, this is the CONTAINS predicate, wrapped by functionality that returns a SQL table object. Two additional columns are added to the result. The Key column is just a duplicate of the full-text index key column, which was specified when the full-text index was created. The Rank column appears, as I mentioned previously.
SELECT ProductID, Name, ProductNumber, Color, Rank
FROM Product INNER JOIN
CONTAINSTABLE(Product, *
, ‘ISABOUT (Black weight (.2), Blue weight (.8))’) AS ConTbl
ON Product.ProductID = ConTbl.[Key]
ORDER BY Rank DESC
Take a look at another example. Full-text queries are ideal for searching large volumes of text. The first thing I'll do is create a full-text index on the ProductReview table. This table contains a Comments column used to hold verbose text. After populating the index, the following query can be executed. Note the weight values for the two words:
SELECT Comments, Rank
FROM ProductReview INNER JOIN
CONTAINSTABLE(ProductReview, Comments
, ‘ISABOUT (terrible weight(.9), advertised weight(.l)) ’) AS ConTbl
ON ProductReview.ProductReviewID = ConTbl.[Key]
ORDER BY Rank DESC
When the query is executed, a rank value is calculated based on these words found in the Comments column and the relative weight values. Note the values in the Rank column shown in Figure 11-18.

Figure 11-18
Now I'll change the weight values (reversing.9 and.1) and execute the query again:
SELECT Comments, Rank FROM ProductReview INNER JOIN CONTAINSTABLE(ProductReview, Comments, ‘ISABOUT (terrible weight(.l), advertised weight(.9)) ’) AS ConTbl ON ProductReview.ProductReviewID = ConTbl.[Key] ORDER BY Rank DESC
The FREETEXT Predicate
Can a computer really understand what you want rather than simply give you exactly what you asked it for? The FREETEXT predicate attempts to do just that—to understand the meaning of a phrase or sentence. It does this by breaking a phrase down into individual words and then using the full-text indexing thesaurus to match all forms of these words, applying language rules. It may choose to return text that only contains forms of some of these words. As each row is considered for selection, an algorithm calculates a relative ranking value, used to qualify each record against the matching phrase.
The FREETEXT predicate takes few parameters, and the only optional parameter is the language. As with the CONTAINS predicate, if omitted, the language will be derived from the database. The ranking is not exposed in the result, and the order of records is unaffected by the ranking.
SELECT * FROM Product WHERE FREETEXT (*, ‘Yellow road bike’)
Not only are records returned where indexed columns contain the words “yellow,” “road,” and “bike,” but those records that contain any one of these words or forms of these words are also returned, as shown in Figure 11-19.
Figure 11-19
Logical Operators
Multiple words or text strings can be specified applying three different forms of logic, as explained in the following table.
| Operator | Logic |
| AND | Criteria on both sides of the operator must match. If two values were provided with the AND operator, a single column value in each qualifying row must match both of the values. |
| OR | Criteria on either side of the operator must match. If two values were provided with the OR operator, a single column value in each qualifying row must match any provided value. |
| NEAR | Like the AND operator, both values must match text in a single column value for qualifying rows. |
The FREETEXTTABLE Predicate
Like the CONTAINSTABLE predicate, FREETEXTTABLE is functionally the same as the FREETEXT predicate, but it returns a table with ranking values. Using the same technique as before, this table can be joined with the base table to return matching rows and the ranking values.
In this example, I've used a phrase that doesn't match any text exactly but several of the words may be found in the column text:
SELECT Comments, Rank
FROM ProductReview INNER JOIN
FREETEXTTABLE(ProductReview, Comments
, ‘mountain biking is new for me’) AS FtTbl
ON ProductReview.ProductReviewID = FtTbl.[Key]
ORDER BY Rank DESC
The result returns two rows with one row ranked significantly higher than the other, as shown in Figure 11-20.

Figure 11-20
The goal of free-text matching is to loosen the matching rules and provide some level of flexibility. Inevitably, this will return some rows that are simply not all that similar to the search text. To make the FREETEXT or FREETEXTTABLE predicate behave in a more predictable manner, you can force it to match the text exactly as it is presented by encapsulating the entire search text in double quotes:
Only one row matches this text exactly, as shown in Figure 11-21.
Figure 11-21
Summary
Often in our world of computer-managed precision and rigid logic, it's important to see past exact values and look for information with similar meaning and context. The SOUNDEX() and DIFFERENCE() functions were designed help you make inexact comparisons, matching words with the same or similar phonetic patterns. Using the SOUNDEX() function is actually an older and fairly unsophisticated technique for matching words based on basic phonetic language rules. It's simple and often useful for matching words that sound similar.
Full-text indexing is a very capable resource for searching and matching content within any text, large or small. The CONTAINS and FREETEXT predicates work very effectively where you may be storing very large volumes of notes, comments, or document content. The CONTAINS predicate gives you fairly precise control over matching logic but will also let you find words, text, and phrases that are grammatically similar to the words you search for. The FREETEXT predicate is generally used for soft-matching a phrase when you don't need text to match exactly, but to find text with similar meaning and content. The CONTAINSTABLE and FREETEXTTABLE predicates expand on their base predicates by returning SQL table types capable of presenting a ranked listing of qualifying values and integrating these features into more sophisticated queries.