
2
SQL Server Fundamentals
Where does SQL Server fit in the grand scheme of business applications? At one time, this was a simple question with a simple answer. Today, SQL Server is at the core of many different types of applications and business solutions large and small. Just last week I was fortunate enough to attend a developers' conference on the Microsoft Corporate Campus in Redmond, Washington, and sit at the feet of the Chairman and Chief Architect of Microsoft, Bill Gates. He spoke of his vision for the next generation of products. He said that the current evolution of software technologies is as significant to the industry as was the first generation of Windows. He talked about the importance of XML web services, smart clients, and the pieces that make them all work together. The new generation of servers and operating systems will blend file storage and document and data management in a seamless, uniform approach; and at the core of all of this Microsoft technology is SQL Server. Under the hood, this is not the same SQL Server as it was in years past. SQL Server 2005 is a complex, multipurpose data storage engine, capable of doing some very sophisticated things. This new-and-improved SQL Server can manage complex binary streams, hierarchies, cubes, files, and folders in addition to text, numbers, and other simple data types. Mr. Gates didn't have a perfect answer to every question posed but he certainly had a clear vision for the future of Microsoft products and related technologies—and that future includes SQL Server playing a major role.
For the purposes of this book we're only concerned with using SQL Server to store and manage relational data. This is what it was designed for years ago — and what it does even better today. However, SQL Server 2005 can also be used to store and manage application objects in the form of XML. On the surface, SQL Server 2005 and SQL Server 2000 behave much the same way for the same Transact-SQL statements. For our purposes, the most significant differences are simply the tools that you use, not the statements you use to perform operations. The SQL part of SQL Server has evolved some over the years but fundamentally is not so different.
Who Uses SQL Server?
Not very long ago, enterprise databases were hidden away on large servers that were never visible to the casual business computer user. Any interaction with these systems was performed only by members of the elite order of database administrators. These highly revered professionals worked in large, noisy, sealed server rooms on special consoles and workstations. Even after many companies migrated their database systems from mainframe and mid-range computer platforms to PC-based servers, the databases were still hands-off and carefully protected from all but a select few.
A generation of smaller-scale database products evolved to fill the void left for the casual application developer and power user. Products such as the following became the norm for department-level applications because they were accessible and inexpensive:
- dBase
- FoxPro
- Paradox
- Clipper
- Clarion
- FileMaker
- Access
The big databases were in another class and were simply not available outside of formal IT circles. They were complicated and expensive. Database administrators and designers used cumbersome command-line script to create and manage databases. It was a full-time job; DBAs wrote the script to manage the databases and application developers wrote the code for the applications that ran against them. Life was good. Everyone was happy. However, there is only one real constant in the IT world and that is change. In the past five years, there have been significant changes in the world of application development, database design, and management.
I recall attending the launch event for SQL Server 7.0. Steve Ballmer, the President of Microsoft Corporation, was on the road to introduce this significant product release. After demonstrating several simple, wizard-based features, he asked for all of the career database administrators to stand up. There were probably 1500 people in the audience and 100 or so DBAs came to their feet. He said, “I'd like to do you all a favor and give you some career advice.” He paused with a big smile before he continued, “Learn Visual Basic”. Needless to say, there were several uneasy DBAs leaving the launch event that day. Steve's advice was evidence of the harsh reality of changing times. Today, SQL Server (and other related Microsoft products) represents a toolkit in the hands of a different kind of business IT professional; not a full-time DBA, specialized Business Analyst, or single-minded Application Developer, but a Solution Architect who creates a variety of software solutions consisting of all these pieces. From the initial requirement gathering and solution concept to the database design, component architecture, and user-interface construction, the Database Solution Developer often covers all these bases. Just a quick note to help clarify Mr. Ballmer's point: What do SQL Server and Visual Basic have to do with one another? Chapter 14 answers this question more completely by showing you some examples of complete application solutions. In short, solving business problems requires the use of multiple tools, SQL and programming languages working together to solve complex business problems.
Although we have certainly seen a lot of recent change in the database world, I won't be so naïve to say that traditional database servers are going away. On the contrary, most large companies have centralized most of their data on large-scale servers and the largest corporate databases are now in the ballpark of 10–20 terabytes in size. In just the past few years, these volumes have been doubling about every three years. There are really two separate trends: Corporate, mission-critical data is growing more than ever, stored on large-scale (albeit physically much smaller) servers, managed by full-time database administrators. The other trend is that small-scale, regional data marts (relatively small, reporting databases) and data silos (specialized, departmental databases) have emerged. Unlike the ad-hoc, desktop databases of the past decade, these are stored on department-level database servers. They are managed and used primarily by business unit power users, rather than career IT folks.
A new class of SQL Server user has recently emerged. Computer power users now have access to SQL Server using a variety of tools. Bill Gates refers to these individuals as the “knowledge worker” of the twenty-first century. Desktop applications such as Microsoft Excel and Access can easily be used as front-ends for SQL Server. In fact, Access gives users the ability to create and manage database objects much like an administrator would using SQL Server Enterprise Manager and Management Studio. This means that more casual users have the ability to create and utilize these powerful databases that were available only to highly trained professionals a few years ago. Of course, this also means that untrained users can use these powerful tools to make a big mess. Yes, this means that more users now have the tools to create poorly designed databases, more efficiently than ever before.
Hopefully, your organization has standards and policies in place to manage production database servers and to control access to sensitive data. With a little guidance and the appropriate level of security access, SQL Server can be a very useful tool in the hands of new users who possess some fundamental skills.
SQL Server Editions and Features
A brief comparison of the various editions of SQL Server 2000 and SQL Server 2005 follows.
SQL Server 2000
Two editions of SQL Server 2000 exist that may be used for production databases: Standard and Enterprise. The Standard Edition is a more economical investment for most small businesses. It is full-featured, but lacks some scalability and availability features that make the Enterprise Edition more attractive for very large-scale business environments and servers, such as supporting a larger number of processors and more memory, as well as a few database objects specifically targeted toward the large enterprise. The Developer Edition IS the Enterprise Edition — that's right, it is actually the same code with some specific adaptations. The Developer Edition will run on a desktop operating system, such as Windows 2000 Professional and Windows XP, and is limited to 10 concurrent connections. With these exceptions, all SQL Server features in the Developer Edition should behave like the Enterprise Edition. Keep this in mind if you plan to implement the Standard Edition that doesn't support a few advanced features available in the Developer Edition.
SQL Server 2005
Several new features and capabilities have been added to SQL Server 2005. Some of the most notable features include native XML storage and query support, and integration with the .NET Common Language Runtime. The comparative editions of this version of SQL Server haven't really changed much. In addition to the Standard, Developer, and Enterprise editions, there is a variety of the product called the SQL Server 2005 Express Edition. This is essentially the replacement for the SQL Server 2000 Desktop Engine (MSDE) that shipped with versions of Office and Access in the past. It's a lightweight version of the SQL Server engine, intended to run on a desktop computer with a limited number of connections. As our friends at Microsoft continue to gently nudge users away from the Access JET database engine and toward SQL Server, their products will continue to become more aligned and standardized. Like the more serious editions, SQL Server Express can be managed from within Access, Visual Studio, or the SQL Server client tools.
The SQL language has been enhanced in a few places but is generally unchanged. Because Transact-SQL conforms to the industry standard ANSI SQL standard, you will find only a few minor additions to the supported syntax in SQL Server 2005.
Relational Database Engine
Big differences exist between a true RDBMS Relational Database Management System (RDBMS) and a file-based database product. Although a true RDBMS product, such as SQL Server, does store its data in files managed by the file system, the data in these files cannot be accessed directly. The concepts of relational integrity have been applied to file-based databases for several years. Programmers wrote these rules into their program code. The difference is that the RDBMS system contains this code to enforce business rules and doesn't allow a user or developer to work around them once a database has been designed with certain rules applied.
The language used to access nearly all relational database products is SQL. The dialect of SQL used in Microsoft SQL Server is called Transact-SQL. Using SQL is the front door to the data in a database and the administrative objects of the database server. Specialized programmatic interfaces also exist that developers can use to access a database with the appropriate security clearance. Unlike file-based databases, RDBMS systems are designed so there is no “back door” to a database.
Semantics
The words used to describe data concepts are often different, depending a great deal upon the context of the discussion. Data lives in tables. Usually, a table represents some kind of business entity, such as a Product or Customer, for example. Each item in a table is called a row or record. For our purposes, these mean the same thing. I may use these words interchangeably throughout the book. Envision several rows in an Excel worksheet representing different products. Each product has a manufacturer, supplier, packaging quantity, and price. In Excel, these values would be contained in different cells. In a table, separate values are referred to as a column or field. As far as we're concerned, these words have the same meaning as well. How do you decide how data should be organized into tables and columns? That is the fine art of database design and is often no easy task. To arrive at an optimal database design, you must first have a thorough understanding of the business process and the how data will be used.
So, what is data, really? We often hear the words information and data used to mean the same thing. In reality, they are very different concepts. We, as humans, generally concern ourselves with meaningful information we can use day-to-day. Information has a context — it makes sense to us. If my wife were to give me a call and ask that I stop by the store on the way home from work and pick up eggs and milk, I should have enough information to accomplish this simple task. I have a few informational items to contend with in this scenario: the store, eggs, and milk. If we were to ask some people in the database business about these simple things, we might get some interesting (or not so interesting) answers. For example, my friend Greg, a city geographic information systems (GIS) expert employed by the city government, might point out that in his database, the store is a building with an address, property plot number, city zoning record, water, sewer, and electrical service locations. It has latitude and longitude coordinates, a business license, and tax record. If we were to talk to someone in the grocery business, they might tell us that eggs and milk exist in a products table in their point of sale and inventory management database systems. Each is assigned a product record ID and UPC codes. The product supplier, vendors, shipping companies, and the dairies likely have their own systems and deal with these items in different ways. However, as a consumer, I'm not concerned with such things. I just need to stop by the store and pick up the eggs and milk.
Here's the bottom line: data is just numbers and letters in a database or computer application somewhere. At some point, all of that cryptic data was probably useful information until it was entered into the database. For the database designer or programmer, these values may be meaningful. For the rest of us, it isn't useful at all until it gets translated back into something we understand — information.
Changing Terminology
One of the greatest challenges in our relatively new world of technology is how we use common language to communicate both technical and non-technical concepts. Even when dealing with the same system, terminology often changes as you progress through the different stages of the solution design and construction. These stages are generally as follows:
- Conceptual or Architectural Design
- Logical Design
- Physical Design
Conceptual Design
As you approach the subject of automating business processes through the use of databases and software, one of the first and most important tasks is to gather business requirements from users and other business stakeholders. Beginning with non-technical, business, and user-centric language, you must find terms to describe each unit of pertinent information to be stored and processed. A complete unit of information is known as an entity. Business entities generally represent a whole unit that can stand on its own. For example, a customer and a product are examples of entities. Another conceptual unit of information is an attribute. This unit of information describes a characteristic of an entity. An attribute may be something as simple as the color or price of a product. It could also be something more complex such as the dimensions of a package. The important thing during conceptual design is to deal with the simple and conceptual aspects and not all of the implementation details. This way you leave your options open to consider creative ways to model and manage the data according to your business requirements.
In most processes, different terms may be used to describe the same or similar concepts. For example, in an order processing environment, the terms customer, shopper, and purchaser could mean the same thing. Under closer evaluation, perhaps a shopper is a person who looks for products and a customer is a person who actually purchases a product. In this case, a shopper may become a customer at some point in the process. In some cases, a customer may not actually be a person. A customer could also be an organization. It's important to understand the distinction between each entity and find agreeable terms to be used by anyone dealing with the process, especially non-technical users and business stakeholders. Conceptual design is very free-form and often takes a few iterations to reveal all of the hidden requirements.
Along with the entity and attribute concepts, another important notion is that of an instance. You may have 100,000 customers on record, but as far as your database system is concerned, these customers don't really exist until you need to deal with their information. Sure, these people do exist out in customer land, but your unfeeling database system couldn't care less about customers who are not currently engaged in buying products, spending money, or updating their billing information. Your system was designed to process orders and purchase products — that's it. If a customer isn't involved in ordering, purchasing, or paying, the system pays no attention. When a customer places an order, you start caring about this information and your order processing system needs to do something with the customer information. At this point, your system reaches into the repository of would-be customers and activates an instance of a specific customer. The customer becomes alive just long enough for the system to do something useful with it and then put it back into cold storage, moving on to the next task.
Logical Design
This stage of design is the transition between the abstract, non-specific world of conceptual design and the very specific, technical world of physical design. After gaining a thorough understanding of business requirements in the language of users, this is an opportunity to model the data and the information flow through the system processes. With respect to data, you should be able to use the terms entity, attribute, and instance to describe every unit of data. Contrasted with conceptual design, logical design is more formalized and makes use of diagramming models to confirm assumptions made in conceptual design. Prototyping is also part of the logical design effort. A quick mock-up database can be used to demonstrate design ideas and test business cases. It's important, though, that prototypes aren't allowed to evolve into the production design. As Fredrick P. Brooks said in his book, The Mythical Man Month, “Plan to throw one away. You will do that, anyway. Your only choice is whether to try to sell the throwaway to customers”. When you finally happen upon a working model, throw it out and start fresh. This gives you the opportunity to design a functional solution without the baggage of evolutionary design. In logical design, you decide what you're going to build and for what purpose.
In particular, logical database design involves the definition of all the data entities and their attributes. For example, you know that a customer entity should have a name, a shipping location, and a line of credit. Although you realize that the customer's name may consist of a first name, middle initial, and last name, this is unimportant in this stage of design. Likewise, the customer's location may consist of a street address, city, state, and zip code; you also leave these details for the physical design stage. The point during this stage is to understand the need and recognize how this entity will behave with other data entities and their attributes.
Physical Design
One of the greatest reasons to have a formal design process is to find all of the system requirements before attempting to build the solution. Requirements are like water. They're easier to build on when they're frozen. An attempt to define requirements as you go along will inevitably lead to disastrous results. Ask any seasoned software professional. I guarantee their response will be preceded with either a tear or a smile.
Physical design is like drawing the blueprints for a building. It's not a sketch or a rough model. It is the specification for the real project in explicit detail. As your design efforts turn to the physical database implementation, entities may turn into tables and attributes into columns. However, there is not always a one-to-one correspondence between conceptual entities and physical tables. The value of appropriate design is to find similarities and reduce redundant effort. You will likely discover the need for more detail than originally envisioned.
In a recent project, I needed to design a database system to manage a youth activity. The requirements specified both youth and adult entities. Due to the similarities between these entities, I created a single table of members with a flag to indicate the member type as either an adult member or youth member.
Relationships
Although I briefly discussed entity relationships in Chapter 1, I want to devote a little more time expounding on the concepts to add clarity to the current topic of design. The purpose of nearly all database systems is to model elements in our physical world. To do this effectively, you need to consider the associations that exist between the various entities you want to keep track of. This concept of an item or multiple items being related to a different item or multiple items is known as cardinality or multiplicity. To illustrate this concept, just look around you. Nearly everything fits into some kind of collection or set of like objects. The leaves on a tree, the passengers in a car, and the change in your pocket are all examples of this simple principle. These are sets of similar objects in a collection and associated with some kind of container or attached to some type of parent entity. Relationships can be described and discovered using common language. As you describe associations, listen for words such as is, have, and has. For example a customer has orders. Now turn it around: an order has a customer. By looking at the equation from both sides, you've discovered a one-to-many relationship between customers and orders.
Relationships generally can be grouped into three different types of cardinality:
- One-to-one
- One-to-many
- Many-to-many
The one-to-one and one-to-many relationships are fairly easy to define using a combination of foreign key and unique constraints, but many-to-many relationships cannot actually be defined using two tables. To reduce redundancy, minimize data storage requirements, and facilitate these relationships, you apply standard rules of normalization (the rules of normal form), which are described briefly in this section.
Primary Keys
According to the first rule of normal form (1NF), which says that each column contains a single type of information, a single value, and there are no repeating groups of data, it is imperative that each row (or record) be stamped with a unique key value. This key could either be a meaningful value that is useful for other reasons, or a surrogate key, a value generated only for the sake of uniqueness. The uniqueness of a record depends entirely on the primary key. Be very cautious and think twice (or three times) before choosing to use non-surrogate key values. I've designed more than a few database systems where it seemed to make sense to use an intelligent value for the primary key (for example, social security number, address, phone number, product code, and so on) and later wished I had just generated a unique value for the key. Most experienced database folks have horror stories to share about such experiences.
I'll briefly share an experience of my own. A few years ago, I was asked to design a database solution for a large fire department to manage the wellness and immunization records of their employees. They had some existing data and used social security numbers to identify each person in their personnel table. Trying to avoid problems and accommodate future requirements, I asked the project sponsor if every one of their employees would always have an SSN on file. She said that this was absolute—every employee would always have an SSN and that this could always be used as an identifier for an employee. I made the SSN the primary key of the Person table and constructed an entire application around it. A year later the client called me on the phone with a problem. She explained that they had been contracted by the volunteer fire department in a small town to manage their health wellness records and that when she entered new volunteer firefighters the system was throwing an error (something about a primary key violation). I asked about social security numbers and she told me that these were unavailable for volunteer personnel. As I began to remind her of our earlier conversation, she interrupted me and repeated our exchange word-for-word: “You asked me if all of our employees had social security numbers. These aren't our employees”. I had not asked if they would be managing personnel records other than their own employees. Lesson learned: Use surrogate keys or have a very good reason not to.
Two common forms of surrogate key values exist. An identity key type is simply an integer value that is automatically incremented by the database system. This will serve as a unique value as long as all data is entered into a single instance of the database. In distributed systems consisting of multiple, disconnected databases, it can be a bit challenging to keep these values unique. The other type of automatically generated key uses a special data type called a unique identifier or globally unique identifier (GUID). This SQL data type is equipped to store a very large numeric value automatically generated by the system. A complex algorithm is used to produce a value, partially random and partially predictable. The result is what I call a big ugly number, guaranteed to be unique — any time and anywhere. The chances of this value being duplicated are astronomically improbable.
Foreign Keys
One purpose for keys is to relate the records in one table to those in another table. A column in the table containing related records is designated as a foreign key. This means that it contains the same values found in the primary key column(s) of the primary table. Unlike a primary key, a foreign key doesn't have to be unique. Using the Customer/Order example, one customer can have multiple orders but one order only has one customer. This describes a one-to-many relationship. The primary key column of the Customer table is related to the foreign key column of the Order table through a relationship known as a foreign key constraint. Later, in Chapter 6, you see how this relationship is defined in Transact-SQL.
Normalization Rules
Because this is not a book about database design, I will not engage in a lengthy discussion on the background behind these rules. Volumes have been written on these subjects. On the surface, a short discussion on database design is an important prerequisite to using the Transact-SQL language. The problem with this is that it's nearly impossible to engage in a short discussion on a topic that is so conceptual and subject to individual style and technique. Like so many “simple” concepts in this industry, this one can be debated almost endlessly. Having written and rewritten this section a few times now, I have decided not to walk through an example and align this with the true rules of normal form, as so many books on this subject do. Rather, I'll briefly present the definitions of each rule and then walk you through an example of distilling an unnormalized database into a practical, normalized form without the weighty discussion of the rules.
Unless you have a taste for mathematical theory, you may not even be interested in the gory details of normalized database design. Throughout this book, I discuss query techniques for normalized and de-normalized data. It would be convenient to say that when a person designs any database, he should do so according to certain rules and patterns. In fact, a number of people do prescribe one single approach regardless of the system they intend to design. Everyone wants to be normal, right? Well, maybe not. Perhaps it will suffice to say that most folks want their data to be normal. But, what does this mean in terms of database design? Are different values stored in one table or should they be stored in multiple tables with some kind of association between them? If the latter approach is taken, how are relationships between these tables devised? This is the subject of a number of books on relational database design. If you are new to this subject and find yourself in the position of a database designer, I would recommend that you pick up a book or research this topic to meet your needs. This subject is discussed in greater detail in Rob Viera's books on SQL Server programming, mentioned at the beginning of the previous chapter. I'll discuss some of the fundamentals here but this is a complex topic that goes beyond the scope of the SQL language.
In the early 1970s, a small group of mathematicians at IBM proposed a set of standards for designing relational data systems. In 1970, Dr. Edger (E. F.) Codd wrote a paper entitled “A Relational Model of Data for Large Shared Data Banks” for the Association of Computing Machinery. He later published 12 principles for relational database design in 1974. These principles described the low-level mechanics of relational database systems as well as the higher-level rules of entity-relation design for a specific database. Dr. Codd teamed with others who also wrote papers on these subjects including Chris (CJ) Date and Raymond F. Boyce. Boyce and Codd are now credited as the authors of relational database design. Codd's original 12 principles of design involved using set calculus and algebraic expressions to access and describe data. One of the goals of this effort was to reduce data redundancy and minimize storage space requirements. Something to consider is that, at the time, data was stored on magnetic tape, paper punch cards, and, eventually, disks ranging from 5 to 20 megabytes in capacity. As the low-level requirements were satisfied by file system and database products, these 12 rules were distilled into the five rules of normal form taught in college classes today.
In short, the rules of normal form, or principles of relational database design, are aimed at the following objectives:
- Present data to the relational engine that is set accessible
- Label and identify unique records and columns within a table
- Promote the smallest necessary result set for data retrieval
- Minimize storage space requirements by reducing redundant values in the same table and in multiple tables
- Describe standards for relating records in one table to those in another table
- Create stability and efficiency in the use of the data system while creating flexibility in its structure
To apply these principles, tables are created with the fewest number of columns (or fields) to define a single entity. For example, if your objective is to keep track of customers who have ordered products, you will store only the customer information in a single table. The order and product information would be stored their own respective tables.
The idea behind even this lowest form of normalizations is to allow straightforward management of the business rules and the queries that implement these rules against data structures that are flexible to accommodate these changes.
The real purpose of first normal form is to standardize the shape of the entity (relation)—to form a two-dimensional grid that is easily accessed and managed using set-based functions in the data engine.
It's really quite difficult to take a table and apply just one rule. One of the tenets of all the rules of normal form is that each rule in succession must conform to its predecessor. In other words, a design that conforms to second normal form must also conform to first normal form. Also, to effectively apply one, you may also be applying a subsequent rule. Although each of these rules describes a distinct principle, they are interrelated. This means that generally speaking, normalization, up to a certain level, is kind of a package deal.
First Normal Form — 1NF
The first rule of normal form states that an entity shouldn't contain duplicate types of attributes. This means that a table shouldn't contain more than one column that represents the same type of non-distinct value.
To convert flat data to First Normal Form, additional tables are created. Duplicate columns are eliminated and the corresponding values are placed into unique rows of a second table. This rule is applied to reduce redundancy along the horizontal axis (columns).
Second Normal Form — 2NF
This rule states that non-key fields may not depend on a portion of the primary key. These fields are placed into a separate table from those that depend on the key value.
To meet Second Normal Form, you must satisfy First Normal Form and decompose attributes that have partial dependencies to the key attribute.
Without a composite key or by correcting a partial dependency by constructing a new entity with its Reference Key, you arrive at Second Normal Form. Then move to the transitive dependencies of Third Normal Form.
Third Normal Form — 3NF
The first rule states that rows are assigned a key value for identification. This rule takes this principle one step further by stating that the uniqueness of any rule depends entirely upon the primary key. My friend Rick, who teaches and writes books on this topic, uses a phrase to help remember this rule: “The uniqueness of a row depends on the key, the whole key, and nothing but the key; so help me Dr. Codd”.
In some cases it makes sense for the primary key to be a combination of columns. Redundant values along multiple rows should be eliminated by placing these values into a separate table as well. Compared with First Normal Form, this rule attempts to reduce duplication along the vertical axis (rows).
Fourth and Fifth Normal Form
Boyce and Codd built their standards — Boyce-Codd Normal Form (BCNF) — on earlier ideals that recognized only those discussed thus far. You must satisfy First and Second and Third Normal Form before moving on to satisfy subsequent forms. In fact, it is the process of the First, Second, and Third Normal Forms that drives the need for BCNF. Through the decomposition of attribute functional dependencies, many-to-many relationships develop between some entities. This is sometimes inaccurately left in a state where each entity involved has duplicate candidate keys in one or more of the entities.
Attributes upon which non-key attributes depend are candidate keys. BCNF deals with the dependencies within candidate keys. The short version of what could be a lengthy and complex discussion of mathematical theory is that fourth and fifth normal forms are used to resolve many-to-many relationships. On the surface this seems to be a simple matter — and for our purposes, we'll keep it that way. Customers can buy many different products and products can be purchased by multiple customers. Concerning ourselves with only customers and products, these two entities have a many-to-many relationship. The fact is that you cannot perform many-to-many joins with just two tables. This requires another table, sometimes called a bridge or intermediary table, to make the association. The bridge table typically doesn't need its own specific key value because the combination of primary key values from the two outer tables will always be unique (keep in mind that this is not a requirement of this type of association but is typically the case). Therefore, the bridge table conforms to third normal form by defining its primary key as the composite of the two foreign keys, each corresponding to the primary keys of the two outer, related tables. Fifth normal form is a unique variation of this rule, which factors in additional business logic, disallowing certain key combinations. For our purposes, this should suffice.
Other Normal Forms
A number of disciplines and conceptual approaches to data modeling and database design exist. Among others, these include Unified Modeling Language (UML) and Object Role Modeling (ORM). These include additional forms that help to manage special anomalies that might arise to describe constraints within and between groups or populations of information. The forms that qualify these descriptions usually move into user-defined procedures added to the database and not the declarative structures that have been addressed so far.
Transforming Information into Data
In the real world, the concepts and information you deal with exist in relationships and hierarchies. Just look around you and observe the way things are grouped and associated. As I write this, I'm sitting on a ferry boat. The ferry contains several cars, and cars have passengers. If I needed to store this information in a relational database, I would likely define separate tables to represent each of the entities I just mentioned. These are simple concepts but when applied at all possible levels, some of the associations may take a little more thought and cautious analysis. At times the business rules of data are not quite so straightforward. Often, the best way to discover these rules (and the limits of these rules) is to ask a series of “what if” questions. Given the ferry/car/passenger scenario, what if a passenger came onto the ferry in one car and left in another? What if she walked on and then drove off? Is this important? Do we care? These questions are not arbitrarily answered by a database designer but through the consensus of designers and system stakeholders.
At some point you will need to decide upon the boundaries of your business rules. This is where you decide that a particular exception or condition is beyond the scope of your database system. Don't treat this matter lightly. It is imperative to define specific criteria while also moving quickly past trivial decision points so that you can move forward and stay on schedule. This is the great balancing act of project management.
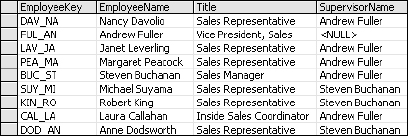
When you attempt to take this information and store it in a flat, two-dimensional table as rows and columns, you can't help but create redundant or repeating values. Take a look at a simple example using data from the Northwind sample database. The table in Figure 2-1 shows employee records. Each employee has a name and may have two addresses and two phone numbers. Most employees also have a supervisor. This is the way this data might appear in a simple spreadsheet.

The <NULL> text is SQL Server's way of telling you that there is nothing in that field. Each employee has a name, title, one or two residence locations, a home and work phone number, and a supervisor. This data is easy to read in this form but it may be difficult to use in a proper database system.
Applying Normalization Rules
Using the previous Employees table, look for violations of the first rule of normal form. Is there more than one column containing information about the same type of attributes? Beginning with the numbered Address and CityLine fields, each “location” consists of a column for the address and another column for the city, state, and zip code. Because there are two pairs of these columns, this may be a problem. Each phone number is a single column, designated as either the home or work phone. How would I make a single list of all phone numbers? What happens if I need to record a mobile phone for an employee? I could add a third column to the table. How about a fourth? How about the Title column? The Supervisor column may be viewed as a special case but the fact is that the EmployeeName and Supervisor columns store the same type of values. They both represent employees.
I can move all of these columns into separate tables but how do I keep them associated with the employee? This is accomplished through the use of keys. A key is just a simple value used to associate a record in one table to a record in another table (among other things). To satisfy the first rule of normal form, I'll move these columns to different tables and create key values to wire up the associations. In the following example, I have removed the address and city information and have placed it into a separate table.
I have devised a method to identify each employee with a six-character character key, using part of their last and first names. I chose this method because this was once a very popular method for assigning key values. This allows me to maintain the associations between employees and their addresses. In this first iteration (see Figure 2-2), I use this method to make a point. This is a relatively small database for a small company and I don't have any employees with similar first and last names, so this method ought to work just fine, right? Hold that thought for now.
I do the same thing with the new Addresses table (see Figure 2-3). Each address record is assigned an EmployeeKey value to link it back to the Employees table.
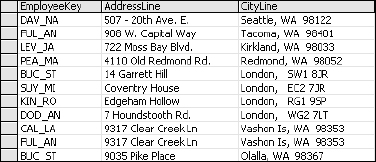
Figure 2-3
I have lost a significant piece of information in doing this. I've flattened the address information so I no longer have one address designated as either primary or secondary for an employee. I'll get to this later. For now, I'm only concerned with adhering to the first rule of normal form. Besides, does the information in the old Address1 and CityLine1 columns imply that this is the employee's primary residence? Did I have a complete understanding of the business rules when I began working with this data? Unfortunately, in most ad-hoc projects, it is more often a case of making things up as we go along.
For the phone numbers I'll do the same thing as before, move the phone number values into their own table and then add the corresponding key value to associate them with the employee record. I'm also going to add a column to designate the type of phone number this represents (see Figure 2-4). I could use this as an argument to do the same thing with the addresses, but I'll hold off for now.
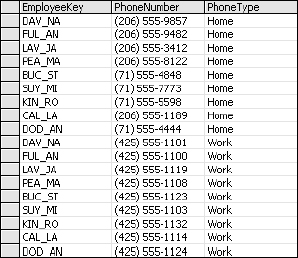
Figure 2-4
Now that I have three tables with common column values, do I have a relational database? Although it may be true that this is related data, it's not a fully relational database. The key values only give me ability to locate the related records in other tables, but this does nothing to ensure that my data stays intact. Take a look at what I have done so far (see Figure 2-5). The presence of the same key value in all three of these tables is an implied relationship. There is currently no mechanism in place for the database to prevent users from making silly mistakes (such as deleting an employee record without also removing the corresponding address and phone information, for example). This would create a condition, common in early database systems, called orphaned records.
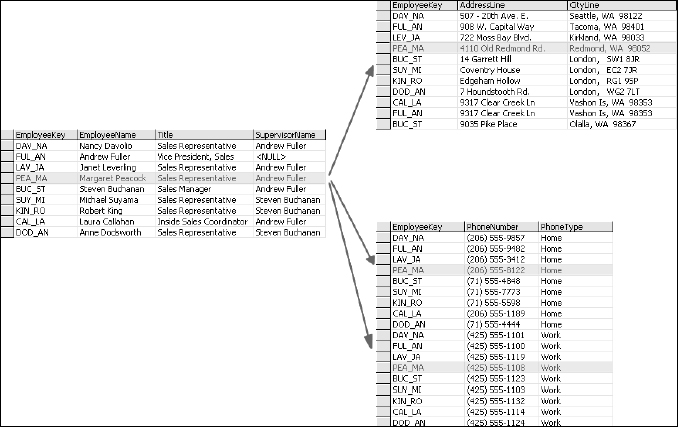
Before continuing, I must correct a horrible indiscretion. I told you that this business of using parts of different field values (such as the first and last name) to form a meaningful unique key was once a common practice. This is because database system designers in the past often had to create a system where users had to provide a special number to look up a record. To make this easier, they would come up with some kind of intelligent, unique value. It might include characters from a customer or patient's name, or perhaps a series of numbers with digits in specific positions representing an account type or region. For example, when was the last time you called the bank or the telephone company and was asked for your account number? This happens to me all the time. It amazes me that the companies in possession of the most sophisticated, state-of-the-art technology on the planet require me to memorize my account number. How about looking up my account using my name, address, phone number, mother's maiden name, or any of the other information they required when I set up my account?
Using this simple name-based key may have seemed like the right thing to do at the time but the fact is that it will likely get me into a whole lot of trouble down the road. I worked for a company that used this approach in a small, commercial application. The program even appended numbers to the end of the keys so there could be nearly a hundred unique key values for a given last name/first name combination. What they didn't anticipate was that their product would eventually become the most popular medical billing software in the country and would be used in business environments they couldn't possibly have imagined. Eventually this got them into trouble and they had to completely re-architect the application to get around this limitation. One customer, a medical office in the Chicago area, had so many patients with the same or similar names, that they actual ran out of key values.
Thinking Ahead
I'll resolve the EmployeeKey issue by changing it to an auto-sequencing integer called an identity (see Figure 2-6). This is known as a surrogate key, which simply means that key values are absolutely meaningless as far as the user is concerned. The database assigns numbers that will always be unique within this column. The purpose of the key is to uniquely identify each row, not to give employees or users something to memorize.
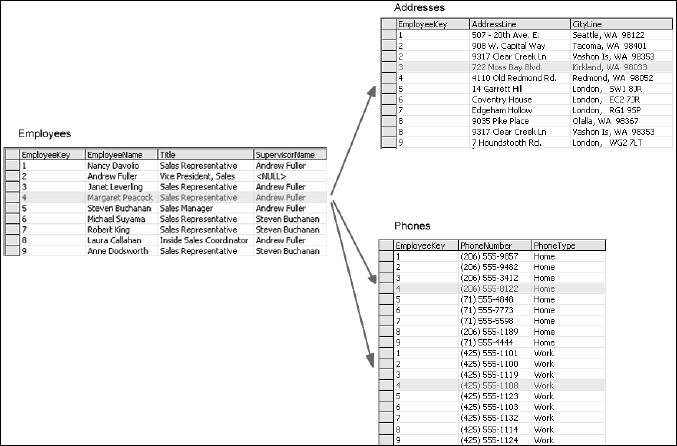
Figure 2-6
The next step is to designate the EmployeeKey in the Employees table as a primary key and the related keys as foreign keys. The foreign key constraints cause the database engine to validate any action that could cause these relationships to be violated. For example, the database would not allow an employee record to be deleted if there were existing, related address or phone records. Related tables are often documented using an entity-relation diagram (ERD). The diagram in Figure 2-7 shows the columns and relationships between these tables.
There is still work to do. The SupervisorName is also a violation of first normal form because it duplicates some employee names. This is a special case, however, because these names already exist in the Employees table. This can be resolved using a self-join, or relationship on the same table (see Figure 2-8).
The supervisor designation within the Employees table is now just an integer value referring to another employee record.
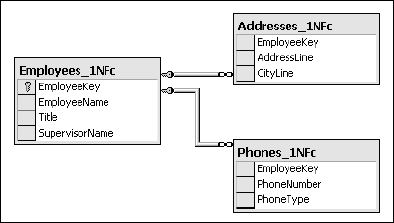
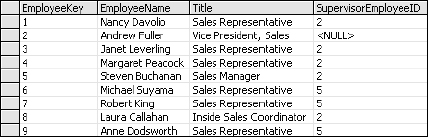
Figure 2-8
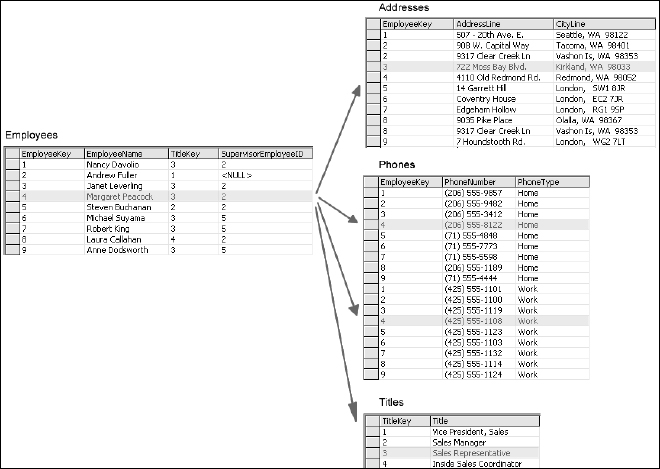
The Title column is also in violation of first normal form and could be moved into its own table, as well. A title isn't uniquely owned by an employee, but each employee only has one title. To discern this relationship, you must look at it from both directions:
- One employee has one title
- One title can have multiple employees
This is a one-to-many relationship from the title to the employee. Resolving this is a simple matter of placing one instance of each title value in a separate table, identified by a unique primary key. A similar column is added to the Employees table as a non-unique foreign key (see Figure 2-9).
You should see a pattern developing. This is an iterative process that will typically send you in one of two directions in each cycle. You will either continue to move these values into related tables with related keys or you will find discrepancies between your business rules and the data, and then head back to the drawing board to correct the data and table structure.
Multiple Associations
I know that a title can be associated with more than one employee, but what happens if an address is shared by more than one individual? This is a problem in the current database model. I can't use one primary key value and have multiple associations going in both directions. The only way I can do this is to create a primary key that includes two separate values: one for the employee key and one for the address key. However, I can't do this using either of these two tables. If I add the EmployeeKey to the Addresses table, I'm back to the original problem, where I would have duplicate address rows. Because a record in the Addresses table will no longer be directly tied to a record in the Employees table, I must remove the EmployeeKey and create a new primary key for this table and remove the duplicate values. Now the Addresses table conforms to first normal form and third normal form.
Many-to-many relationships are solved using a separate table, often called a join or bridge table. Often, this table contains no user-readable values, only keys to bridge one table to another. However, you may recall that we have a missing bit of information. Remember when I moved the address information from the Address1/CityLine1 columns and Address2/CityLine2 columns into the Address table? I said that we had no way to trace these back to their roots and recall which location was the employee's primary residence? I can now resolve this within the bridge table by adding an additional column (see Figure 2-10).
The new AddressType column is used to indicate the type of residence. This allows employees to share addresses while eliminating redundant address records. Does the AddressType column violate first normal form? Technically, yes. This could be an opportunity to optimize the database even more by creating yet another table for these values. It looks like there would only be three address type records related to the nine employees (see Figure 2-11).

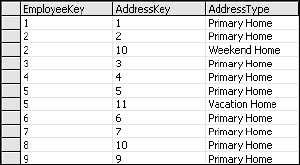
Figure 2-11
A simple query is used to obtain detail information about employees at a common address:
SELECT EmployeeName, AddressLine, CityLine, AddressType
FROM Employees
INNER JOIN EmployeeAddresses
ON Employees.EmployeeKey = EmployeeAddresses.EmployeeKey
INNER JOIN Addresses
ON EmployeeAddresses.AddressKey = Addresses.AddressKey
WHERE Addresses.AddressKey = 10
It looks like the Vice President of Sales and the Inside Sales Coordinator share a residence only on weekends (see Figure 2-12).

Figure 2-12
Multi-valued Columns
The last issue with which I must contend is that of having multiple values stored in a single column. There are quite a few examples in these tables. For example, the EmployeeName column in the Employees table contains both the first and last name, the AddressLine column in the Addresses table includes all parts of a street address, and the CityLine contains the city name, U.S. state, and zip code/postal code. Before I just willy-nilly start parsing all the values into separate columns, it's important for me to consider how this data will be used and the advantages and disadvantages of breaking it into pieces. Here are some sample questions that could help to define these business requirements:
- Will the employee first name and last name ever be used separately?
- Will I ever need to sort on one single value (such as last name)?
- Does every employee have a first name and last name? Do they only have a first name and last name (middle names/initials, hyphenated names, and so on)?
- Is there any value or need in separating parts of the address line (will I need a list of streets, and so on)?
- If I separate parts of the AddressLine or CityLine into separate columns, do I need to accommodate international addresses?
Apparently I do need to consider addresses in at least two locales because I have locations in the UK and the U.S., so I will need to think beyond only one style of address. So, suppose that I have consulted my sponsoring customer and have learned that it would be useful to store separate first names and last names and we don't care about middle names or initials. We also don't plan to accommodate anyone without a first and last name. We have no need to break up the address line. This practice is highly uncommon outside of specialized systems and would be very cumbersome to maintain. We would benefit from storing the city, postal code or zip code, and state or province. It would also be useful to store the country, which is currently not included. Storing geographic information can be tricky due to the lack of consistency across international regions. This may require that you devise your own synonyms for different regional divisions (such as city, township, municipality, county, state, province, and country). In distributing these values into separate columns, you may find even more redundancies. Should these be further normalized and placed into separate tables? Does this ever end? I'll site one example where the city, state, and zip code is normalized. I maintain a system that stores U.S. addresses and stores only the zip code on the individual's record. A separate table contains related city and state information obtained from the U.S. Postal Service.
I won't bore you will the mechanics of separating all of these fields. The process is quite straightforward and very similar to what's already been done. Figure 2-13 shows the completed data model, based on the original flat table.
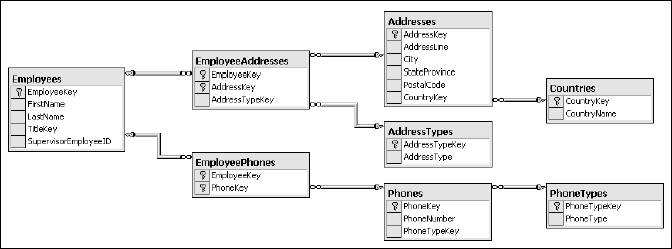
Figure 2-13
To Normalize or to De-normalize?
Depending on how a database is to be used (generally, it will be used for data input or for reporting), it may or may not be appropriate to apply all of the rules just presented. The fact of the matter is that fully normalized databases require some gnarly, complex queries to support reporting and business analysis requirements. To fully comply with all of the rules of normal form often adds more overhead to the application. Without going into detail, here's something to think about: If you are designing a new database system to support a typical business process, you will usually want to follow these rules completely and normalize all of your data structures. After a time, when you have a large volume of data to extract and analyze through reports and business intelligence tools, you may find it appropriate to create a second database system for this purpose. In this database, you will strategically break the rules of normal form, creating redundant values in fewer, larger tables. Here's the catch: Only after you fully understand the rules of normal form will you likely know when and where you should break them.
Question Authority
You should ask yourself an important question as you encounter each opportunity to normalize: “Why?” Know why you should apply the rules and what the benefits and cost are. One of the challenges of applying normalization rules is to know just how far to go and to what degree it makes sense to apply them. At times it just makes sense to break some of the rules. There are good arguments to support both sides of this issue and without a complete understanding of business requirements I would be hard pressed to make a general statement about how data elements (such as phone numbers, titles, or addresses) should always be managed. In short, you need to understand the business requirements for your application and then apply the appropriate level of database normalization to reach that goal. If ever in doubt, it's usually best to err on the side of keeping the rules.
Client/Server Processes
SQL Server is a true client/server database. This means that application logic is processed both on the application client computer and the database server. The client process is typically encapsulated within an application that needs to submit or access data. In addition to the standard operating system and network protocols, a set of special components is installed on both the client and server computers, allowing the client to send requests and receive results. Server-side components enable SQL Server to receive and respond to the client requests, as illustrated in Figure 2-14.
The Mechanics of Query Processing
To drive a car, it's not essential to understand how the engine works. However, if you want to be able to drive a car well (and perhaps maintain and tune it for optimal performance), it's helpful to have a fundamental understanding of the engine mechanics and to know what's going on inside. Likewise, it's possible to use SQL Server without fully understanding its mechanics, but if you want to create queries that work efficiently, it will help to understand what goes on within the relational database engine and the query processor.
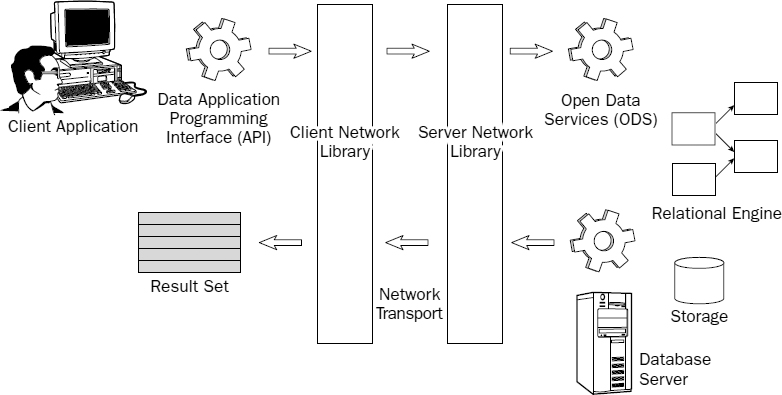
When a SQL statement is presented to the database engine, it begins to analyze the request and break it down into steps. Based on characteristics of the data stored in tables, decisions are made resulting in the selection of appropriate operations. Many factors are considered including the table structures, existence of indexes, and the relative uniqueness of relevant data values.
It would be inefficient for the query-processing engine to analyze all of the data prior to each query, so SQL Server gathers statistical information it uses to make these decisions. In essence, SQL Server learns from previous query executions and adapts as the data changes (see Figure 2-15). In theory, queries will continue to be optimized and updated as time goes on.
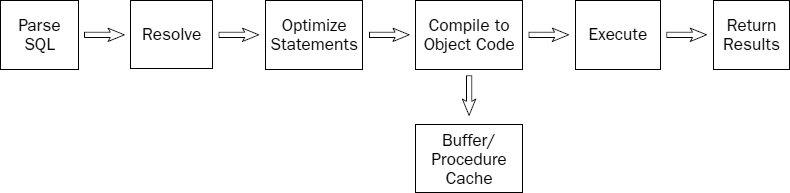
Figure 2-15
Complex queries are broken down into individual steps — smaller queries — that process granular operations. This list of steps and operations is known as an execution plan. The query's syntax may actually be rewritten by the query optimizer into a standard form of SQL. SQL Server doesn't actually execute SQL — that's just how we talk to it. Before SQL Server can send instructions to the computer's processor, these commands must be compiled into low-level computer instructions, or object code. The optimized, compiled query is placed into an in-memory cache. Depending on how the query is created (for example, it may be saved as a view or stored procedure), the execution plan and cache are saved with that object in the database, called procedure cache. Even ad-hoc queries may benefit from this process. The cached compiled query and execution plan is held into memory as buffer cache and reused until the user and client application's connection is closed. This way, if the same query is executed multiple times, it should run faster and more efficiently after the first time. In SQL Server 2005, the same mechanism is used to manage both buffer cache and procedure cache. Here's a closer look at this process, also illustrated in Figure 2-16:
- First the query text is flat-lined and translated into a standardized form of SQL.
- Objects and then permissions are resolved, replacing object names with data-specific numeric identifiers and security context. These identifiers streamline conversations between the relation and storage engine.
- The query is semantically translated from SQL to Tabular Data Stream (TDS), the native language of the SQL Server net libraries. In this translation, operations are simplified and optimized. More than 300 possible semantic operations exist.
- Compiled version of the plan and call are placed into the buffer.
- The relational engine spawns threads for calling logical and physical I/O and operational execution. Database object locks are placed and managed by the transactional engine.

Figure 2-16
The Adventure Works Cycles Database
Through the remainder of the book, you'll be working with the Adventure Works Cycles sample database. This is a new sample database included with SQL Server 2005. There have actually been several different versions of this database as it evolved from the first edition in 2004 and then through the SQL Server 2005 beta test period. The version that installs with SQL Server 2005 is a little more complex than deemed appropriate for this book, so I decided to use the SQL Server 2000 version for the examples. It will work with both SQL Server 2000 and SQL Server 2005.
You can download and install the AdventureWorks2000 sample database from the support site for this book at Wrox Press. You will find this at http://www.wrox.com/go/begintransact-SQL. To install the sample database, follow these steps:
- Click the Download button and then click Open in the File Download dialog and follow the directions in the InstallShield Wizard.
- Double-check that the AdventureWorks2000 database has been added to the list of available databases on your server. Right-click the Databases node and choose Refresh.
If the new database is not displayed on the database tree, the database file may need to be attached manually. This is easy to do using the following steps:
- For SQL Server 2000, in Enterprise Manager, right-click the Databases node and select All Tasks
 Attach Database. In the Attach Database dialog, click the small ellipsis (...) button and then browse for the file. The AdventureWorks2000_Data.MDF file should be at C:Program FilesMicrosoft SQL ServerMSSQLData. Select the file and click OK.
Attach Database. In the Attach Database dialog, click the small ellipsis (...) button and then browse for the file. The AdventureWorks2000_Data.MDF file should be at C:Program FilesMicrosoft SQL ServerMSSQLData. Select the file and click OK. - For SQL Server 2005, the procedure is similar. Right-click the database server node in the SQL Server Management Studio object browser and select Attach Database. Browse to the database file and then click OK.'
- For SQL Server 2000, in Enterprise Manager, right-click the Databases node and select All Tasks
The AdventureWorks2000 database is also an optional installation component with SQL Server Reporting Services for SQL Server 2000. An evaluation version of Reporting Services is available for download from Microsoft.
Summary
SQL Server is a product widely used by a lot of different people in many different ways. At its core is the relational database engine, and sitting on this foundation are a wealth of features and capabilities. The way that SQL Server databases are designed and administered has changed as the client applications have improved and been integrated into Microsoft's suite of solution development tools. SQL Server is now accessible to business users in addition to technical professionals.
You read about the conceptual, logical, and physical phases of solution design and how they apply to designing a database. A relational database stores data in separate tables, associated through primary key/foreign key relationships that implement the rules of normal form. You saw how flat, spreadsheet-like data is transformed into a normalized structure by applying these rules. Normalizing data structures is not an absolute necessity for all databases and it sometimes is prudent to ignore the rules to simplify the design. Both normalizing and de-normalizing a database design come at a cost that must be carefully considered and kept in balance with the business rules for the solution. These business rules and the user's requirements ultimately drive the capabilities and long-term needs of a project.
You also learned about the client/server database execution model and how SQL Server uses both client-side and server-side components to process requests and to execute queries. The execution and procedure cache allow SQL Server to optimize performance by compiling execution plans for ad-hoc queries and prepared stored procedures.