
2. What Is the Berkeley Data Analytics Stack (BDAS)?
This chapter introduces the BDAS from AMPLabs (derived from “algorithms, machines, and people,” the three dimensions of their research) by first unfolding its motivation. It then goes on to discuss the design and architecture of BDAS, as well as the key components that make up BDAS, including Mesos, Spark, and Shark. The BDAS can help in answering some business questions such as
• How do you segment users and find out which user segments are interested in certain advertisement campaigns?
• How do you find out the right metrics for user engagement in a web application such as Yahoo’s?
• How can a video content provider dynamically select an optimal Content Delivery Network (CDN) for each user based on a set of constraints such as the network load and the buffering ratio of each CDN?
Motivation for BDAS
The “seven giants” categorization has given us a framework to reason about the limitations of Hadoop. I have explained that Hadoop is well suited for giant 1 (simple statistics) as well as simpler problems in other giants. The fundamental limitations of Hadoop are
• Lack of long-lived Map-Reduce (MR) jobs, meaning that MR jobs are typically short-lived. One would have to create fresh MR jobs for every iteration in a lot of these classes of computations.
• Inability to store a working set of data in memory—the results of every iteration would get stored in Hadoop Distributed File System (HDFS). The next iteration would need data to be initialized, or read, from HDFS to memory. The data flow diagram for iterative computing in Figure 2.1 makes this clearer.
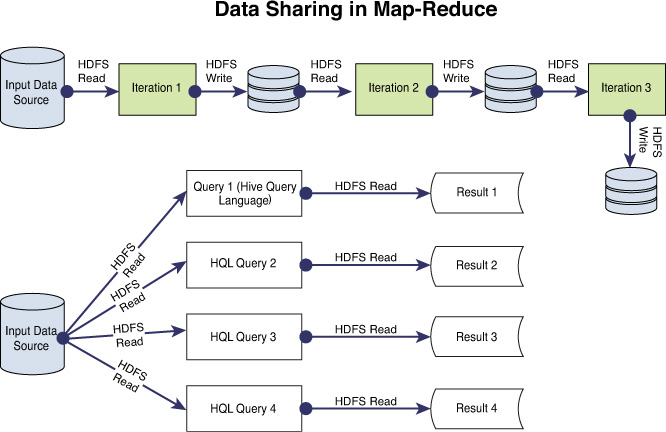
There are other kinds of computations/scenarios for which Hadoop is not well suited. Interactive querying is one such scenario. By its very nature, Hadoop is a batch-oriented system—implying that for every query, it would initiate a fresh set of MR jobs to process the query, irrespective of query history or pattern. The last kind of scenario is real-time computations. Hadoop is not well suited for these.
The main motivation for the BDAS comes from the previous incongruous use cases for Hadoop. Combining the capability to handle batch, interactive, and real-time computing into a single sophisticated framework that can also facilitate programming at a higher level of abstraction compared to existing systems resulted in the BDAS framework. Spark is the fulcrum of the BDAS framework. Spark is an in-memory cluster computing paradigm that exposes rich Scala and Python Application Programming Interfaces (APIs) for programming. These APIs facilitate programming at a much higher level of abstraction compared to traditional approaches.
Spark: Motivation
One of the main motivations for proposing Spark was to allow distributed programming of Scala collections or sequences in a seamless fashion. Scala is statically typed language that fuses object-oriented programming with functional programming. This implies that every value in Scala is an object and every operation a method call similar to object-oriented languages such as Smalltalk or Java. In addition, functions are first-class values, in the true spirit of functional programming languages such as machine learning (ML). Common sequences defined in the Scala library include arrays, lists, streams, and iterators. These sequences (all sequences in Scala) inherit from the scala.Seq class and define a common set of interfaces for abstracting common operations. Map and filter are commonly used functions in Scala sequences—they apply map and filter operations to the elements of the sequence uniformly. Spark provides a distributed shared object space that enables the previously enumerated Scala sequence operations over a distributed system (Zaharia et al. 2012).
Shark: Motivation
The other dimension for large-scale analytics is interactive queries. These types of queries occur often in a big data environment, especially where operations are semiautomated and involve end users who need to sift through the large data sets quickly. There are two broad approaches to solving interactive queries on massive data sets: parallel databases and Hadoop MR. Parallel databases distribute the data (relational tables) into a set of shared-nothing clusters and split queries into multiple nodes for efficient processing by using an optimizer that translates Structured Query Language (SQL) commands into a query plan. In case of complex queries involving joins, there might be a phase of data transfer similar to the shuffle phase of MR. Subsequently, the join operations are performed in parallel and the result is rolled up to produce the final answer, similar to the reduce phase of MR. Gamma (DeWitt et al. 1986) and Grace (Fushimi et al. 1986) were the earliest parallel database engines; recent ones include HP (HP Vertica 6.1) (Lamb et al. 2012), Greenplum (database 4.0), and Teradata (Aster Data 5.0). The comparison between MR and parallel database systems can be made along three axes:
• Schema: MR might not require a predefined schema, whereas parallel databases use a schema to separate data definition from use.
• Efficiency: Efficiency can be viewed as comprising two parts: indexing and execution strategy. With respect to indexing, parallel databases have sophisticated B-tree–based indexing for locating data quickly, whereas MR offers no direct support for indexing. With respect to execution strategy, MR creates intermediate files and transfers these from mappers to the reducers explicitly with a pull approach, resulting in performance bottlenecks at scale. In contrast, parallel databases do not persist the intermediate files to disk and use a push model to transfer data. Consequently, parallel databases might be more efficient for query execution strategy compared to MR.
• Fault tolerance (FT): Both MR and parallel databases use replication to handle FT. But MR has sophisticated mechanisms for handling failures during the computation which is a direct consequence of the intermediate file creation. The parallel databases do not persist intermediate results to disk. This implies that the amount of work to be redone can be significant, resulting in larger performance penalties under failure conditions.
The amount of work required to be redone is not significant in typical failure scenarios for the MR paradigm. In essence, the MR approach provides FT at a fine-grained level, but does not have efficient query execution strategies. Hadoop MR is not well suited for interactive queries. The reasoning behind this assertion is that Hive or Hbase, which might be typically used to service such queries in a Hadoop ecosystem, do not have sophisticated caching layers that can cache results of important queries—but instead might start fresh MR jobs for each query, resulting in significant latencies. This has been documented among others by Pavlo and others (Pavlo et al, 2009). The parallel database systems are good for optimized queries on a cluster of shared-nothing nodes, but they provide only coarse-grained FT—this implies that, for example, an entire SQL query might have to be rerun on the cluster in case of failures. The coarse-grained recovery point is true even in the case of some of the new low-latency engines proposed for querying large data sets such as Cloudera Impala, Google Dremel, or its open source equivalent, Apache Drill.
On top of the preceding limitations, parallel database systems also might not have sophisticated analytics such as those based on ML and graph algorithms. Thus, we arrive at the precise motivation for Shark: to realize a framework for SQL queries over a distributed system that can provide rich analytics as well as high performance (comparable to parallel databases) and fine-grained recovery (comparable to MR approaches).
Mesos: Motivation
Most frameworks such as Spark, Hadoop, or Storm need to manage the resources in the cluster efficiently. The frameworks need to run a set of processes in parallel on different nodes of the cluster. They also need to handle failures of these processes, nodes, or networks. The third dimension is that the resources of the cluster must be utilized efficiently. This might require monitoring the cluster resources and getting information about them quickly enough. The motivation for Mesos (Hindman et al. 2011) was to handle these dimensions as well as the ability to host multiple frameworks in a shared mode within the same cluster of nodes. In this case, the cluster management system would have to address the isolation of the different frameworks and provide certain guarantees in terms of resource availability to the respective frameworks. Although existing cluster managers, such as Ambari from Hortonworks or the Cloudera cluster manager, handle the entire lifetime management of cluster resources, they are tied to only specific frameworks (Hadoop) and do not address sharing cluster resources across multiple frameworks.
There are other use cases too that motivate the need for multiple frameworks to coexist in the same physical cluster. Consider a traditional data warehousing environment, where historical data from multiple sources is collected for offline queries or analytics. Hadoop can augment this environment in various ways, for example, by a more effective extract, transform, and load (ETL) process. It could also help in certain preprocessing (typically known as data wrangling, cleaning, or munging [Kandel et al. 2011]) of data, as well as in running certain analytics tasks more quickly. In the same environment, there is a strong need to run ML algorithms at scale. As I have explained before, Hadoop is not ideal for such use cases, and one may want to consider using Spark or even Message Passing Interface (MPI) to run such specialized analytics. In this case, the same data warehousing environment might have to run both Hadoop and MPI/Spark. These are ideal use cases for Mesos.
BDAS Design and Architecture
The BDAS architecture can be depicted as shown in Figure 2.2.
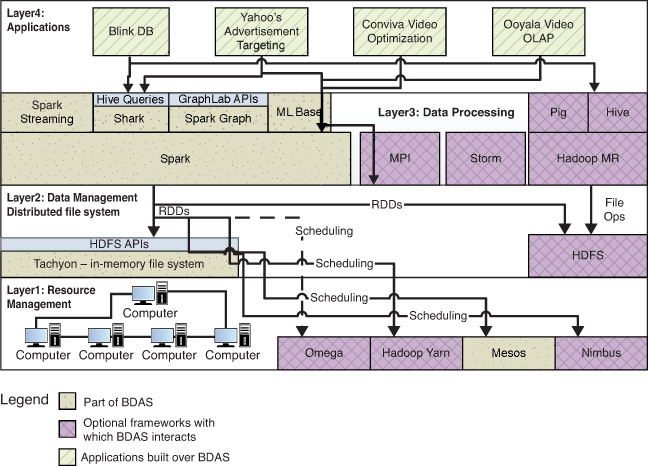
The figure divides the spectrum into three layers—resource management, data management, and data processing—with the applications built on top of the three layers. The lowest layer (Layer1) deals with the resources available, including the cluster of nodes and the capability to manage the resources efficiently. The frameworks in common use for resource management include Mesos, Hadoop Yarn, and Nimbus. Hadoop YARN (Yet Another Resource Negotiator) (Apache Software Foundation 2014) can be viewed as an applications scheduler or a monolithic scheduler, whereas Mesos is more of a framework scheduler or a two-level scheduler. Monolithic schedulers use a single scheduling algorithm for all jobs, whereas the framework scheduler assigns/offers processors to frameworks, which can internally schedule jobs at the second level. The other difference is that Mesos uses container groups to schedule frameworks, but Hadoop YARN uses UNIX processes. The initial version of YARN addresses memory scheduling only, whereas Mesos can schedule memory and CPUs. Nimbus has been used among others by the Storm project to manage the cluster resources. It is targeted more on cloud-aware applications and has evolved into a multicloud resource manager (Duplyakin et al. 2013). Omega is a shared-state scheduler from Google (Schwarzkopf et al. 2013). It gives each framework access to the whole cluster without locking, and it resolves conflicts, if any, using optimistic concurrency control. This approach tries to combine the advantages of monolithic schedulers (have complete control of cluster resources and not be limited to containers) and two-level schedulers (have a framework-specific scheduling policy).
Layer2 is the data management layer, which typically is realized through a distributed file system. BDAS is perfectly compatible with HDFS as the distributed file system in Layer2. This implies that the Resilient Distributed Datasets (RDDs) can be created from an HDFS file as well as through various transformations. Spark can also work with Tachyon, which is the in-memory file system from the AMPLab team. As can be inferred from Figure 2.2, the distributed file systems interact with the Layer1 cluster managers to make scheduling decisions. The implication of this statement is that the scheduling would be different for Spark over YARN as compared to Spark over Mesos. In the former case, the entire scheduling is done by YARN, whereas in the latter case, Spark is responsible for scheduling within its own containers.
Layer3 is the data processing layer. Spark is the key framework of BDAS in this layer because it is the in-memory cluster computing paradigm. Hadoop MR also sits in the same layer, as do Hive and Pig, which work over it. The other frameworks in this layer include MPI and Storm, which are not actually part of the BDAS. Spark streaming is the equivalent of Storm in BDAS. This implies that Spark streaming is also a Complex Event Processing (CEP) engine that allows the BDAS to perform real-time processing and analytics. Shark is built over Spark and provides an SQL interface to applications. The other interesting frameworks in this layer include SparkGraph, which provides a realization of GraphLab APIs over Spark, and MLbase, which provides an ML library over Spark.
The applications that have been built over the BDAS are in Layer4. These are the main applications:
• BLinkDB from AMPLabs: BLinkDB is a new database (DB) designed for running approximate queries on massive data sets that is built over Shark and Hive and consequently over Spark and Hadoop. The interesting feature of BLinkDB is the capability to specify error bounds and/or time bounds for a query. As a result, the BLinkDB returns results within the time bound and with appropriate error bounds compared to running the query on the whole data. For example, in one of the demos showcased in the Strata conference in New York in October 2013, the AMPLab folks showed that they could query a 4 TB dataset in less than 4 seconds with 80% error bounds.
• Ad customization and targeting from Yahoo: Yahoo has extensively experimented with Spark and Shark. Yahoo has built a Shark Software-as-a-Service (SaaS) application and used it to power a pilot for advertisement data analytics. The Shark pilot predicted which users (and user segments) are likely to be interested in specific ad campaigns and identified the right metrics for user engagement. Yahoo has also reengineered Spark to work over YARN. They have used Spark-YARN to run in a production 80-node cluster to score and analyze models. The Spark production cluster facilitates content recommendations based on historical analysis of users’ activity using a collaborative filtering algorithm.
• Video optimization from Conviva: Conviva is an end-user video content customizing company. It enables the end user to switch CDNs at runtime based on load and traffic patterns. Conviva has built a Spark-based optimization platform that enables end users to choose an optimal CDN for each user based on aggregate runtime statistics such as network load and buffering ratio for various CDNs. The optimization algorithm is based on the linear programming (LP)-based approach. The Spark production cluster supported 20 LPs, each with 4,000 decision variables and 500 constraints.
• The video Online Analytical Processing (OLAP) from Ooyala: Ooyala is another online video content provider. The key in the Ooyala system is its capability to have a via media for the two extremes in video content querying: having precomputed aggregates (in which case query resolution is only a look-up) or performing the query resolution completely on the fly (this can be very slow). They use Spark for the precomputed queries by realizing materialized views as Spark RDDs. Shark is used for on-the-fly ad hoc queries due to its capability to answer ad hoc queries at low latency. Both Shark and Spark read data (video events) that are stored in a Cassandra (C*) data store. The C* OLAP aggregate queries on millions of video events per day could be sped up significantly by using Spark/Shark, which was too slow on Cassandra.1
1 The OLAP queries that took nearly 130 seconds on Cassandra with DataStax Enterprise Edition 1.1.9 cluster took less than 1 second on a Spark 0.7.0 cluster.
Spark: Paradigm for Efficient Data Processing on a Cluster
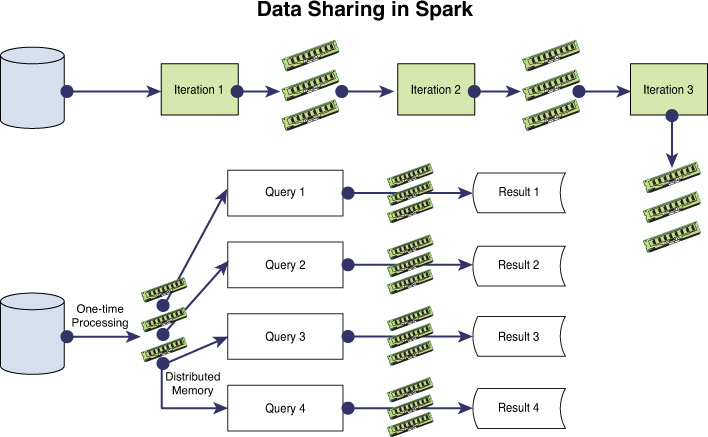
The data flow in Spark for iterative ML algorithms can be understood from an inspection of the illustration in Figure 2.3. Compare this to the data flow in Hadoop MR for iterative ML, which was shown in Figure 2.1. It can be seen that while every iteration involves read/write from/to HDFS in Hadoop MR, the Spark equivalent is much simpler. It requires only a single read from the HDFS into the distributed shared object space of Spark—creating an RDD from the HDFS file. The RDD is reused and can be retained in memory across the ML iterations, leading to significant performance gains. After the termination condition check determines that the iterations should end, the results can be saved back in HDFS by persisting the RDD. The following sections explain more details of Spark internals—its design, RDDs, lineage, and so forth.
Resilient Distributed Datasets in Spark
The concept of an RDD relates to our discussion for the motivation of Spark—the capability to let users perform operations on Scala collections across a distributed system. The important collection in Spark is the RDD. The RDD can be created by deterministic operations on other RDDs or data in stable storage (for example, from a file in HDFS). The other way of creating an RDD is to parallelize a Scala collection. The operations for creating RDDs are known as transformations in Spark. Compared to these operations, there are also other kinds of operations such as actions on RDDs. The operations such as map, filter, and join are typical examples of transformations. The interesting property of RDDs is the capability to store its lineage or the series of transformations required for creating it, as well as other actions on it. This implies that a Spark program can only make a reference to an RDD—which will have its lineage as to how it was created and what operations have been performed on it. The lineage provides the FT to RDDs—even if the RDD is lost, if the lineage alone is persisted/replicated, it is enough to reconstruct the RDD. The persistence as well as partitioning aspects of RDDs can be specified by the programmer. For instance, a partitioning strategy can be based on record keys.
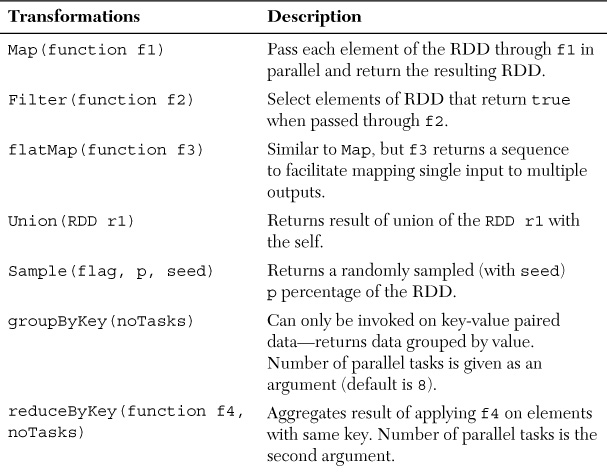
Various actions can be specified on RDDs. They include operations such as count, collect, and save, which can be respectively used for counting the elements, returning the records, and saving to disk/HDFS. The lineage graph stores both transformations and actions on RDDs. A set of transformations and actions is summarized in Table 2.1.

An example is given next to illustrate programming with RDDs in a Spark environment. This is a call data records (CDRs)–based influencer analytics application—based on CDRs, the idea is to build graphs of users and identify top-k influencers. The CDR structure is call id, caller, receiver, plantype, calltype, duration, time, date. The idea is to get the CDR file from HDFS, create an RDD, filter the records, and perform some operations on it, such as extracting certain fields through queries or performing aggregate operations such as count on it. The following is the Spark code snippet one might end up writing for this:
val spark = new SparkContext(<Mesos master>);
Call_record_lines = spark.textFile("HDFS://....");
Plan_a_users = call_record_lines.filter(_.
CONTAINS("plana")); // filter operation on RDDs.
Plan_a_users.cache(); // tells Spark runtime to cache
this RDD in memory, if there is room.
Plan_a_users.count();
%% Call data records processing.
RDDs are represented as a graph that enables simple tracking of the RDD lineage across the various transformations/actions possible. The RDD interface comprises five pieces of information as detailed in Table 2.2.

There are two types of dependencies between the RDDs: narrow and wide. Narrow dependencies arise in the case of map, for example. The child partition RDDs use only the RDDs of the parent partitions (one-to-one mapping from partitions in parent to partitions in child). Wide dependencies arise, for instance, in the case of a join. The mapping is many-to-one from each parent partition to child partitions. The types of dependencies influence the kind of pipelining that is possible on each cluster node. Narrow dependencies can be pipelined easier and transformations/actions applied on each element faster, because dependency is only on one parent. Wide dependencies can lead to inefficient pipelining and might require Hadoop MR shuffle-like transfers across the network. Recovery is also faster with narrow dependencies, because only lost parent partitions need to be recomputed, whereas in the case of wide dependencies, complete reexecution might be required.
Spark Implementation
Spark is implemented in about 20,000 lines of code in Scala, with the core about 14,000 lines. Spark can run over Mesos, Nimbus, or YARN as the cluster manager. Spark runs the unmodified Scala interpreter. When an action is invoked on an RDD, the Spark component known as a Directed Acyclic Graph (DAG) Scheduler (DS) examines the RDD’s lineage graph and constructs a DAG of stages. Each stage has only narrow dependencies, with shuffle operations required for wide dependencies becoming stage boundaries. DS launches tasks to compute missing partitions at different stages of the DAG to reconstruct the whole RDD. The DS submits the stages of task objects to the task scheduler (TS). A task object is a self-contained entity that comprises code and transformations, as well as required metadata. The DS is also responsible for resubmission of stages whose outputs are lost. The TS maps tasks to nodes based on a scheduling algorithm known as delay scheduling (Zaharia et al. 2010). Tasks are shipped to nodes—preferred locations, if they are specified in the RDD, or other nodes that have partitions required for a task in memory. For wide dependencies, the intermediate records are materialized on nodes containing the parent partitions. This simplifies fault recovery, similar to the materialization of map outputs in Hadoop MR.
The Worker component of Spark is responsible for receiving the task objects and invoking the run method on them in a thread pool. It reports exceptions/failures to the TaskSetManager (TSM). TSM is an entity maintained by the TS—one per task set to track the task execution. The TS polls the set of TSMs in first-in-first-out (FIFO) order. There is scope for optimization by plugging in different policies/algorithms here. The executor interacts with other components such as the Block Manager (BM), the Communications Manager (CM), and the Map Output Tracker (MOT). The BM is the component on each node responsible for serving cached RDDs and to receive shuffle data. It can also be viewed as a write-once key value store in each worker. The BM communicates with the CM to fetch remote blocks. The CM is an asynchronous networking library. The MOT is the component responsible for keeping track of where each map task ran and communicates this information to the reducers—the workers cache this information. When map outputs are lost, the cache is invalidated by using a “generation id.” The interaction between the components of Spark is depicted in Figure 2.4.
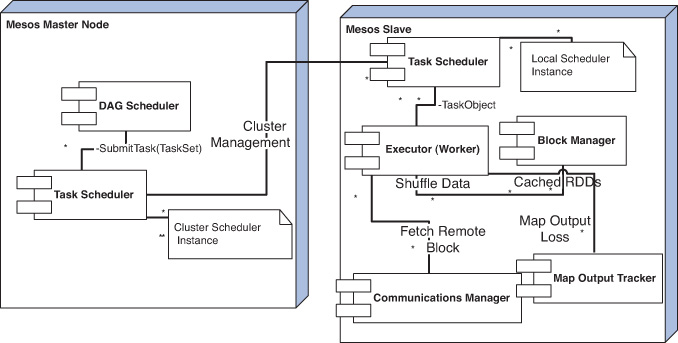
RDDs can be stored in three ways:
1. As deserialized Java objects in Java Virtual Machine (JVM) memory: This provides better performance because objects are in JVM memory itself.
2. As serialized Java objects in memory: This provides more memory-efficient representation, but at the cost of access speed.
3. On disk: This provides the slowest performance, but it’s required if RDDs are too large to fit into Random Access Memory (RAM).
Spark memory management uses the Least Recently Used (LRU) policy at RDD level for eviction in case the RAM is full. However, partitions belonging to the same RDD are not evicted—because typically, a single program could invoke computations on a large RDD and the system could end up thrashing if it evicts partitions from the same RDD.
The lineage graph has sufficient information to reconstruct lost partitions of the RDD. However, for efficiency reasons (it might take significant computation to reconstruct entire RDDs), check-pointing may be resorted to—the user has control over which RDDs to check-point. RDDs with wide dependencies can use check-pointing, because in this case, computing lost partitions might take significant communication and computation. RDDs that have only narrow dependencies are not good candidates for check-pointing.
Spark Versus Distributed Shared Memory Systems
Spark can be viewed as a distributed shared collection system, slightly different from traditional Distributed Shared Memory (DSM) systems such as those given in Stumm and Zhou (1990) or Nitzberg and Lo (1991). DSM systems allow individual memory locations to be read/written, whereas Spark allows only coarse-grained transformations on the RDDs. Although this restricts the kind of applications that can use Spark, it helps in realizing efficient FT. The DSM systems might need coordinated check-pointing to achieve FT, for instance, protocols such as the protocol presented in Boukerche et al. (2005). In contrast, Spark only needs to store the lineage graph for FT. Recovery would require the operations to be reconstructed on the lost partitions of RDDs—but this can be done in parallel for efficiency. The other fundamental difference between Spark and DSM systems is the straggler mitigation strategy available in Spark due to the read-only nature of RDDs—this allows backup tasks to be executed in parallel, similar to the speculative execution of MR (Dinu and Ng 2012). Straggler mitigation or backup tasks in a DSM are hard to realize due to the fact that both of the tasks might contend for the memory. The other advantage of Spark is that it allows RDDs to degrade gracefully when the RDDs exceed aggregate cluster memory. The flip side of Spark is that the coarse-grained nature of RDD transformations restricts the kind of applications that can be built. For instance, applications that need fine-grained access to shared state, such as distributed web crawlers or other web applications, might be hard to realize over Spark. Piccolo (Power and Li 2010), which provides an asynchronous data-centric programming model, might be a better choice for such applications.
Programmers can pass functions or closures to invoke the map, filter, and reduce operations in Spark. Normally, when Spark runs these functions on worker nodes, the local variables within the scope of the function are copied. Spark has the notion of shared variables for emulating “globals” using the broadcast variable and accumulators. Broadcast variables are used by the programmer to copy read-only data once to all the workers. (Static matrices in Conjugate Gradient Descent [CGD]-type algorithms can be broadcast variables.) Accumulators are variables that can only be added by the workers and read by the driver program—parallel aggregates can be realized fault-tolerantly. It can be noted that the globals are a special way of mimicking DSM functionality within Spark.
Expressibility of RDDs
The RDDs are restrictive in that they are efficient only for coarse-grained operations as discussed earlier in comparing Spark and DSM systems. But it turns out that the expressibility of RDDs is good enough for a number of applications. The AMPLabs team themselves have built the entire Pregel as a small library over Spark in just a few hundred lines of code. The list of cluster computing models expressible through RDDs and their operations are given here:
• Map-Reduce: This can be expressed as flatMap and reduceByKey operations on RDDs if there is a combiner. The simpler case can be expressed as flatMap and groupByKey operations.
• DryadLINQ: The DryadLINQ (Yu et al. 2008) provides operations way beyond MR by combining declarative and imperative programming. The bulk operators correspond to transformations in Spark. For instance, the Apply Dryad construct is similar to the map RDD transformation and the Fork construct is similar to the flatMap transformation.
• Bulk Synchronous Parallel (BSP): Computations in Pregel (Malewicz et al. 2010) comprise a series of iterations known as supersteps. Each vertex in the graph is associated with a user-defined compute function; Pregel ensures at each superstep that the user-defined compute function is invoked in parallel on each edge. The vertices can send messages through the edges and exchange values with other vertices. There is also the global barrier—which moves forward after all compute functions are terminated. Readers familiar with BSP can realize why Pregel is a perfect example of BSP—a set of entities computing in parallel with global synchronization and able to exchange messages. Since the same user function is applied to all vertices, the same can be expressed by having the vertices stored in an RDD and running a flatMap operation on them to generate a new RDD of messages. By joining this with the vertices RDD, message passing can be realized.
• Iterative Map-Reduce: The HaLoop work (Bu et al. 2010) also extends Hadoop for iterative ML algorithms. HaLoop not only provides a programming abstraction for expressing iterative applications, but also uses the notion of caching to share data across iterations and for fixpoint verification (termination of iteration), thereby improving efficiency. Twister (Ekanayake et al. 2010) is another effort similar to HaLoop. These are simple to express in Spark because it lends itself very easily to iterative computations. The AMPLabs team has implemented HaLoop in 200 lines of code.
Systems Similar to Spark
Nectar (Gunda et al. 2010), HaLoop (Bu et al. 2010), and Twister (Ekanayake et al. 2010) are the systems that are similar to Spark. HaLoop is Hadoop modified with a loop-aware TS and certain caching schemes. The caching is for both loop invariant data that are cached at the mappers and reducer outputs that are cached to enable termination conditions to be checked efficiently. Twister provides publish-subscribe infrastructure to realize a broadcast construct, as well as the capability to specify and cache static data across iterations. Both Twister and HaLoop are interesting efforts that extend the MR paradigm for iterative computations. They are, however, only academic projects and do not provide robust realizations. Moreover, the FT that Spark can provide using its lineage is superior and more efficient than what is provided in both Twister and HaLoop. The other fundamental difference is that Spark’s programming model is more general, with map and reduce being just one set of constructs supported. It has a much more powerful set of constructs, including reduceByKey and others described earlier.
Nectar is a software system targeted at data center management that treats data and computations as first-class entities (functions in DryadLINQ [Yu et al. 2008]) and provides a distributed caching mechanism for the entities. This enables data to be derived by running appropriate computations in certain cases and to avoid recomputations for frequently used data. The main difference between Nectar and Spark is that Nectar might not allow the user to specify data partitioning and might not allow the user to specify which data to be persisted. Spark allows both and is hence more powerful.
Shark: SQL Interface over a Distributed System
In-memory computation has become an important paradigm for massive data analytics. This can be understood from two perspectives. From one perspective, even when there are petabytes of data to be queried, due to spatial and temporal locality, the majority of queries (up to 95%) can be served by a cache as small as only 64GB on a cluster of nodes. This was observed in a study presented by Ananthanarayanan et al. (2012). The other perspective for in-memory computation is the fact that ML algorithms require to iterate over a working set of data and can be efficiently realized if the working set of data is in memory. Shark can be viewed as an in-memory distributed SQL system essentially.
Shark provides an SQL interface over Spark. The key features of Shark are its SQL interface and its capability to provide ML–based analytics, as well as its fine-grained FT for SQL queries and ML algorithms. The coarse-grained nature of RDDs works well even for queries, because Shark recovers from failures by reconstructing the lost RDD partitions across a cluster. The recovery is fine-grained, implying that Shark can recover in the middle of a query, unlike the parallel database systems, which would need to execute the whole query again.
Spark Extensions for Shark
Executing an SQL query over Spark RDDs follows the traditional three-step process from parallel databases:
1. Query parsing
2. Logical plan generation
3. Mapping the logical plan to a physical execution plan
Shark uses the Hive query compiler for query parsing. This generates an abstract syntax tree, which is then converted into a logical plan. The approach for logical plan generation in Shark is also similar to that of Hive. The physical plan generation is when both approaches are quite different. Whereas a physical plan in Hive might be a series of MR jobs, the physical plan in Shark is a DAG of staged RDD transformations. Due to the nature of Shark’s workload (ML and user-defined functions [UDFs], typical in Hive queries), the physical query plan might be difficult to obtain at compile time. This is true for data that are new (not loaded into Shark before). It must be noted that Hive and Shark can be used often to query such data. Hence, Shark has introduced the concept of Partial DAG Execution (PDE).
Partial DAG Execution
This is a technique to create query execution plans at runtime based on statistics collected, rather than generating a physical query execution plan at compile time. The statistics collected can include partition sizes and record counts for skew detection, frequently occurring items, and histograms to approximate data distribution of the RDD partitions. Spark materializes map output to memory before a shuffle stage—reduce tasks later use this output through the MOT component. Shark modifies this first by collecting statistics specific to a partition as well as globally. Another Shark modification enables the DAG to be changed at runtime based on the statistics collected. It must be noted that the Shark builds on top of query optimization approaches that work on a single node with the concept of the PDE, which is used to globally optimize the query in conjunction with local optimizers.
The statistics collection and subsequent DAG modification is useful in implementing distributed join operations in Shark. It provides two kinds of joins: shuffle join and map/broadcast join. Broadcast join is realized by sending a small table to all nodes, where it is joined locally with disjoint partitions of a large table. Both tables are hash-partitioned on the join key in the case of a shuffle join. The broadcast join works efficiently only when one table is small—now the reader can see why such statistics are useful in dynamic query optimization in Shark. The other way statistics are used for optimization in Shark is in determining the number of reducers or the degree of parallelism by examining partition sizes and fusing together smaller partitions.
Columnar Memory Store
The default approach used by Spark for storing RDDs (option 1 explained previously) is to store RDDs as deserialized Java objects in JVM memory itself. This has the advantage that they are natively available to JVM for faster access. But the disadvantage of this scheme is that it ends up creating a huge number of objects in the JVM memory. Readers should keep in mind that as the number of objects in the Java heap increases, the garbage collector (GC) takes more time for collection (Muthukumar and Janakiram 2006).2 Consequently, Shark has realized a columnar store that creates single objects out of entire columns of primitive types, while for complex types, it creates byte arrays. This drastically reduces the number of objects in memory and improves GC and performance of Shark consequently. It also results in improved space utilization compared to the naive approach of Spark.
2 Generational GCs are commonly used in modern JVMs. One kind of collection, known as a minor collection, is used to live-copy objects surviving the generation to the survivor and tenured spaces. The remaining objects can be collected. The other kind is the stop-the-world major collection, which is a compaction of the old generation. This is what I am referring to here.
Distributed Data Loading
Shark uses Spark executors for data loading, but customizes it. In particular, every table gets partitioned into splits, each of which is loaded by a Spark task. This task makes an independent decision on compression (whether this column needs to be compressed and, if so, what technique to use—whether it should be dictionary encoding or run-length encoding [Abadi et al. 2006]). The resultant compression metadata is stored for each partition. However, it must be noted that the lineage graph need not store the compression metadata and this could be computed as part of reconstruction of the RDD. As a result, Shark has been shown to be faster than Hadoop for loading data into memory and provides the same throughput as Hadoop loading data into HDFS.
Full Partition-Wise Joins
As known in the traditional database literature, a full partition-wise join can be realized by partitioning the two tables on the join column. Although Hadoop does not allow such co-partitioning, Shark facilitates the same using the “Distribute By” clause in the data definition. While joining two co-partitioned tables, Shark creates Spark map tasks and avoids the expensive Shuffle operation to achieve higher efficiency.
Partition Pruning
As known in the traditional database literature, partition pruning refers to the capability of the optimizer to cut down on unnecessary partitions when building the partition access list by analyzing the WHERE and FROM clauses in the SQL. Shark augments the statistics collected in the data loading process with range values and distinct values (for enum types), which are also stored as partition metadata, and guides pruning decisions at runtime—a process the Shark team names as map pruning.
Machine Learning Support
The capability to support ML algorithms is one of the key Unique Selling Points (USPs) of Shark. This is achieved as Shark allows the RDDs representing the query plan to be returned in addition to the query results. This implies that the user can initiate operations on this RDD—this is fundamental in that it makes the power of Spark RDDs available to Shark queries. It must be noted that ML algorithms are realizable on Spark RDDs, as illustrated by MLbase library presented in Kraska et al. (2013) or in subsequent chapters of this book.
Mesos: Cluster Scheduling and Management System
As explained earlier in the “Mesos: Motivation” section, the key motivation behind Mesos is that it helps manage cluster resources across frameworks (or application stacks). For example, there might be a business need to run Hadoop, Storm, and Spark on the same cluster of physical machines. In this case, existing schedulers might not allow such fine-grained resource sharing across frameworks. The Hadoop YARN scheduler is a monolithic scheduler and might allow several frameworks to run in the cluster. It might, however, become difficult to have framework-specific algorithms or scheduling policies, because there is only a single scheduling algorithm across multiple frameworks. For example, MPI employs a gang scheduling algorithm, whereas Spark employs delay scheduling. Running both over the same cluster can result in conflicting requirements and allocations. The other option is to physically partition the cluster into multiple smaller clusters and run the individual frameworks on smaller clusters. Yet another option is to allocate a set of virtual machines (VMs) for each framework. Virtualization has been known to be a performance bottleneck, especially for high-performance computing (HPC) systems, as shown in Regola and Ducom (2010). This is where Mesos fits in—it allows the user to manage cluster resources across diverse frameworks sharing the cluster.
Mesos is a two-level scheduler. At the first level, Mesos makes certain resource offers (in the form of containers) to the respective frameworks. At the second level, the frameworks accept certain offers and run their own scheduling algorithm to assign tasks to resources made available to them by Mesos. This might be a less efficient way of utilizing the cluster resources compared to monolithic schedulers such as Hadoop YARN. But it allows flexibility—for instance, multiple framework instances can run in the same cluster (Hadoop dev and Hadoop prod or Spark test and Spark prod). This cannot be achieved with any existing schedulers. Even Hadoop YARN is striving to support other frameworks such as MPI on the same cluster (refer to Hamster Jira, for instance, https://issues.apache.org/jira/browse/MAPREDUCE-2911). Moreover, as new frameworks are built—for example, Samza has been recently open sourced from LinkedIn—Mesos allows these new frameworks to be experimentally deployed in an existing cluster coexisting with other frameworks.
Mesos Components
The key components of Mesos are the master and slave daemons that run respectively on the Mesos master and Mesos slave, as depicted in Figure 2.5. Each slave also hosts frameworks or parts of frameworks, with the framework parts comprising two processes, the executor and the scheduler. The slave daemons publish the list of available resources as an offer to the master daemon. This is in the form of a list <2 CPUs, 8GB RAM>. The master invokes the allocation module, which decides to give framework1 all resources based on configurable policies. The master then makes a resource offer to the framework scheduler. The framework scheduler accepts the request (or can reject it, if it does not satisfy its requirements) and sends back the list of tasks to be run, as well as the resources necessary for those tasks. The master sends the tasks along with resource requirements to the slave daemon, which in turn sends the information to the framework executor, which launches the tasks. The remaining resources in the cluster are free to be allocated to other frameworks. Further, the process of resources being offered keeps repeating at intervals of time, whenever existing tasks complete and resources become available in the cluster. It must be noted that frameworks never specify the required resources and have the option of rejecting requests that do not satisfy their requirements. To improve the efficiency of this process, Mesos offers frameworks the capability to set filters, which are conditions that are always checked before the master can allocate resources. In practice, frameworks can use delay scheduling and wait for some time to acquire nodes holding their data to perform computations.
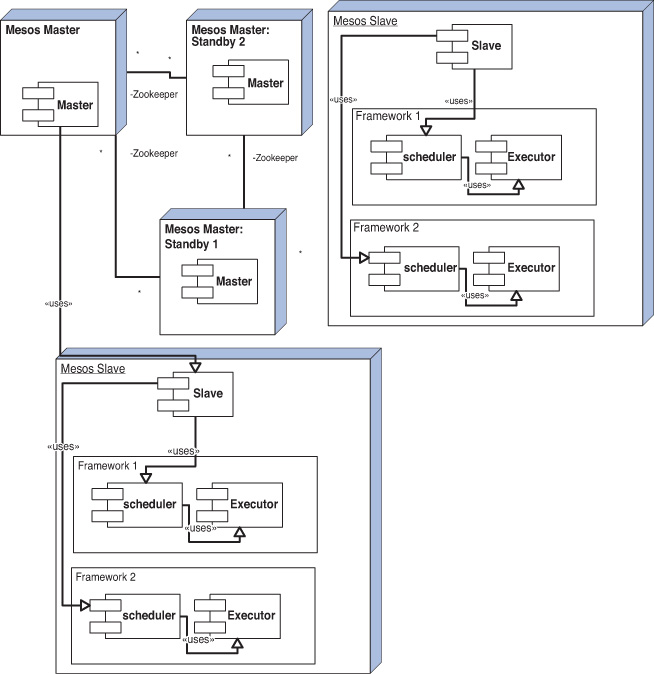
Mesos accounts the resources toward a framework as soon as the offer is made. The framework might take some time to respond to the offer. This ensures the resources are locked and available for this framework once the framework accepts the offer. The Resource Manager (RM) also has the capability to rescind the offer, if the framework does not respond for a sufficiently long time.
Resource Allocation
The allocation module is pluggable. There are two realizations currently—one is a policy known as Dominant Resource Fairness (DRF) proposed in Ghodsi et al. (2011). Fair schedulers such as those in Hadoop (https://issues.apache.org/jira/browse/HADOOP-3746) allocate resources at the grain of fixed-size partitions of nodes known as slots. This can be inefficient, especially in modern heterogeneous computing environments with multicore processors. The DRF is a generalization of the min-max fairness algorithm for heterogeneous resources. It must be noted that min-max fairness is a common algorithm, with variations such as the round-robin and weighted fair queuing, but is usually applied to homogenous resources. The DRF algorithm ensures that min-max can be applied across dominant resources of users. (The dominant resource of CPU-bound jobs is CPU, whereas the dominant resource of I/O-bound jobs is bandwidth.) The interesting properties of the DRF algorithm are given in the following list:
• It is fair and incentivizes users by guaranteeing that if all resources are statically and equally distributed, no user is preferred.
• Users do not benefit by lying about resource demands.
• It has paretto efficiency, in the sense that system resource utilization is maximal, subject to allocation constraints.
Frameworks can also read their guaranteed resource allocation through API calls. This is useful in situations in which Mesos must kill user tasks. If the framework is within its guaranteed resource allocation, its processes cannot be killed by Mesos, but if it goes above the threshold, Mesos can kill its processes.
Isolation
Mesos provides isolation by using Linux containers (http://lxc.sourceforge.net/) or Solaris containers. The traditional hypervisor-based virtualization techniques, such as Kernel-based Virtual Machine (KVM), Xen (Barham et al. 2003), or VMware, comprise VM monitors on top of a host operating system (OS), which provides complete hardware emulation of a VM. In this case, each VM has its own OS, which is completely isolated from other VMs. The Linux containers approach is an instance of an approach known as OS Level virtualization. OS Level virtualization creates a partition of the physical machine resources using the concept of isolated user-space instances. In essence, this approach avoids the guest OS necessary in hypervisor-based virtualization techniques. In other words, hypervisor works at the hardware abstraction level, whereas OS Level virtualization works at the system call level. However, the abstraction provided to users is that each user space instance runs its own separate OS. The various implementations of the OS Level virtualization work with slight differences, with Linux-VServer working on top of chroot,3 and OpenVZ working on top of kernel namespaces. Mesos uses LXC, which is based on cgroups (process control groups) for resource management and kernel namespaces for isolation. Detailed performance evaluation studies in Xavier et al. (2013) have shown the following:
3 People familiar with Unix can recollect that chroot is a command that changes the apparent root directory for the current process tree and creates an environment known as a “chroot jail” to provide isolation at the file level.
• The LXC approach is better (near native) than that of Xen on the LINPACK benchmark4 (Dongarra 1987) for CPU performance.
4 Available from www.netlib.org/benchmark/.
• The overhead of Xen is significant (nearly 30%) for memory using the STREAM benchmark (McCalpin 1995)5 compared to LXC, which gives near-native performance.
5 Available from www.cs.virginia.edu/stream/.
• LXC provides near-native performance for read, reread, write, and rewrite operations of the IOzone benchmark,6 whereas Xen has significant overheads.
6 Available from www.iozone.org/.
• LXC provides near-native performance on the NETPIPE benchmark7 for network bandwidth, whereas Xen has almost 40% additional overhead.
7 Available from www.scl.ameslab.gov/netpipe/.
• LXC has poorer isolation compared to Xen on the Isolation Benchmark Suite (IBS) due to its guest OS. A specific test known as the fork bomb test (which forks child processes repeatedly) shows that the LXC cannot limit the number of child processes created currently.
Fault Tolerance
Mesos provides FT for the master by running multiple masters in hot standby configuration of ZooKeeper (Hunt et al. 2010) and electing a new master in case of master failures. The state of the master comprises only the three pieces—namely, active slaves, active frameworks, and a list of running tasks. The new master can reconstruct the master’s state from the information in slaves and framework schedulers. Mesos also reports framework executors and tasks to the respective framework, which can handle the failure as per its policy independently. Mesos also allows frameworks to register multiple schedulers and can connect to a slave scheduler in case the master scheduler of the framework fails. However, frameworks would need to ensure that the different schedulers are in synchronization with respect to the state.
Closing Remarks
This chapter has discussed certain business use cases and their realization in the BDAS framework. It has explained the BDAS framework in detail with particular reference to Spark, Shark, and Mesos. Spark is useful for the use cases in which optimization is involved—such as in Ooyala’s need to improve the user experience of videos by dynamically choosing the optimal CDN based on constraints. It must be noted that optimization problems with a large number of constraints and variables are notoriously difficult to solve in a Hadoop MR environment, as discussed in the first chapter. Stochastic approaches are more Hadoopable. You should, however, keep in mind that the statement that optimization problems are not easily Hadoopable refers to difficulty of efficient realizations at scale.
The traditional parallel programming tools such as MPI or the new paradigms such as Spark are well-suited for such optimization problems and efficient realizations at scale. Several other researchers have also observed that Hadoop is not good for iterative ML algorithms, including the Berkeley folks who came up with Spark, the GraphLab folks, and the MapScale project team at the University of California–Santa Barbara. Professor Satish Narayana Srirama’s paper also talks about this in detail (Srirama et al. 2012). The primary reason is the lack of long-lived MR and the lack of in-memory programming support. Starting fresh MR jobs for every iteration, copying data from HDFS into memory, performing the iteration, writing back data to HDFS, checking for termination...repeating this for every iteration can incur overhead.
The MPI provides a construct known as All-Reduce, which allows for accumulation and broadcast of values across nodes of a cluster. The only work that addresses one kind of optimization problem and its efficient realization over Hadoop is from the Vowpal Wabbit group, which provides a Hadoop-based realization of the All-Reduce construct (Agarwal et al. 2013).
Shark is very useful for a slightly different set of use cases: performing low-latency ad hoc queries at scale without precomputing. This is especially evident in the kinds of queries at Ooyala on video data, such as top content for mobile users from a certain country or other dynamic trending queries.
Mesos was built as a resource manager that can manage resources of a single cluster running multiple frameworks such as Hadoop, Spark, or Storm. This is useful in data warehousing environments, for instance, where Hadoop might be used for ETLs and Spark for running ML algorithms.
References
Abadi, Daniel, Samuel Madden, and Miguel Ferreira. 2006. “Integrating Compression and Execution in Column-Oriented Database Systems.” In Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data (SIGMOD ‘06). ACM, New York, NY, USA, 671-682.
Agarwal, Alekh, Olivier Chapelle, Miroslav Dudík, and John Langford. 2013. “A Reliable Effective Terascale Linear Learning System.” Machine Learning Summit, Microsoft Research. Available at http://arxiv.org/abs/1110.4198.
Ananthanarayanan, Ganesh, Ali Ghodsi, Andrew Wang, Dhruba Borthakur, Srikanth Kandula, Scott Shenker, and Ion Stoica. 2012. “PACMan: Coordinated Memory Caching for Parallel Jobs.” In Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation (NSDI ‘12). USENIX Association, Berkeley, CA, USA, 20-20.
Apache Software Foundation. “Apache Hadoop NextGen MapReduce (YARN).” Available at http://hadoop.apache.org/docs/current2/hadoop-yarn/hadoop-yarn-site/. Last published February 11, 2014.
Barham, Paul, Boris Dragovic, Keir Fraser, Steven Hand, Tim Harris, Alex Ho, Rolf Neugebauer, Ian Pratt, and Andrew Warfield. 2003. “Xen and the Art of Virtualization.” In Proceedings of the Nineteenth ACM Symposium on Operating Systems Principles (SOSP ‘03). ACM, New York, NY, USA, 164-177.
Boukerche, Azzedine, Alba Cristina M. A. Melo, Jeferson G. Koch, and Cicero R. Galdino. 2005. “Multiple Coherence and Coordinated Checkpointing Protocols for DSM Systems.” In Proceedings of the 2005 International Conference on Parallel Processing Workshops (ICPPW ‘05). IEEE Computer Society, Washington, DC, USA, 531-538.
Bu, Yingyi, Bill Howe, Magdalena Balazinska, and Michael D. Ernst. 2010. “HaLoop: Efficient Iterative Data Processing on Large Clusters.” In Proceedings of the VLDB Endowment 3(1-2)(September):285-296.
DeWitt, David J., Robert H. Gerber, Goetz Graefe, Michael L. Heytens, Krishna B. Kumar, and M. Muralikrishna. 1986. “GAMMA—A High Performance Dataflow Database Machine.” In Proceedings of the 12th International Conference on Very Large Data Bases (VLDB ‘86). Wesley W. Chu, Georges Gardarin, Setsuo Ohsuga, and Yahiko Kambayashi, eds. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 228-237.
Dinu, Florin, and T. S. Eugene Ng. 2012. “Understanding the Effects and Implications of Computer Node Related Failures in Hadoop.” In Proceedings of the 21st International Symposium on High-Performance Parallel and Distributed Computing (HPDC ‘12). ACM, New York, NY, USA, 187-198.
Dongarra, Jack. 1987. “The LINPACK Benchmark: An Explanation.” In Proceedings of the 1st International Conference on Supercomputing. Elias N. Houstis, Theodore S. Papatheodorou, and Constantine D. Polychronopoulos, eds. Springer-Verlag, London, UK, 456-474.
Duplyakin, Dmitry, Paul Marshall, Kate Keahey, Henry Tufo, and Ali Alzabarah. 2013. “Rebalancing in a Multi-Cloud Environment.” In Proceedings of the 4th ACM Workshop on Scientific Cloud Computing (Science Cloud ‘13). ACM, New York, NY, USA, 21-28.
Ekanayake, Jaliya, Hui Li, Bingjing Zhang, Thilina Gunarathne, Seung-Hee Bae, Judy Qiu, and Geoffrey Fox. 2010. “Twister: A Runtime for Iterative MapReduce.” In Proceedings of the 19th ACM International Symposium on High-Performance Distributed Computing (HPDC ‘10). ACM, New York, NY, USA, 810-818.
Fushimi, Shinya, Masaru Kitsuregawa, and Hidehiko Tanaka. 1986. “An Overview of the System Software of a Parallel Relational Database Machine GRACE.” In Proceedings of the 12th International Conference on Very Large Data Bases (VLDB ‘86). Wesley W. Chu, Georges Gardarin, Setsuo Ohsuga, and Yahiko Kambayashi, eds. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 209-219.
Ghodsi, Ali, Matei Zaharia, Benjamin Hindman, Andy Konwinski, Scott Shenker, and Ion Stoica. 2011. “Dominant Resource Fairness: Fair Allocation of Multiple Resource Types.” In Proceedings of the 8th USENIX Conference on Networked Systems Design and Implementation (NSDI ‘11). USENIX Association, Berkeley, CA, USA, 24-24.
Gunda, Pradeep Kumar, Lenin Ravindranath, Chandramohan A. Thekkath, Yuan Yu, and Li Zhuang. 2010. “Nectar: Automatic Management of Data and Computation in Datacenters.” In Proceedings of the 9th USENIX Conference on Operating Systems Design and Implementation (OSDI ‘10). USENIX Association, Berkeley, CA, USA, 1-8.
Hindman, Benjamin, Andy Konwinski, Matei Zaharia, Ali Ghodsi, Anthony D. Joseph, Randy Katz, Scott Shenker, and Ion Stoica. 2011. “Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center.” In Proceedings of the 8th USENIX Conference on Networked Systems Design and Implementation (NSDI ‘11). USENIX Association, Berkeley, CA, USA, 22-22.
Hunt, Patrick, Mahadev Konar, Flavio P. Junqueira, and Benjamin Reed. 2010. “ZooKeeper: Wait-Free Coordination for Internet-Scale Systems.” In Proceedings of the 2010 USENIX Conference on USENIX Annual Technical Conference (USENIXATC ‘10). USENIX Association, Berkeley, CA, USA, 11-11.
Kandel, Sean, Jeffrey Heer, Catherine Plaisant, Jessie Kennedy, Frank van Ham, Nathalie Henry Riche, Chris Weaver, Bongshin Lee, Dominique Brodbeck, and Paolo Buono. 2011. “Research Directions in Data Wrangling: Visuatizations and Transformations for Usable and Credible Data.” Information Visualization 10(4)(October):271-288.
Kraska, Tim, Ameet Talwalkar, John C. Duchi, Rean Griffith, Michael J. Franklin, and Michael I. Jordan. 2013. “MLbase: A Distributed Machine-Learning System.” Conference on Innovative Data Systems Research (CIDR).
Lamb, Andrew, Matt Fuller, Ramakrishna Varadarajan, Nga Tran, Ben Vandiver, Lyric Doshi, and Chuck Bear. 2012. “The Vertica Analytic Database: C-Store 7 Years Later.” In Proceedings of the VLDB Endowment 5(12)(August):1790-1801.
Malewicz, Grzegorz,, Matthew H. Austern, Aart J.C Bik, James C. Dehnert, Ilan Horn, Naty Leiser, and Grzegorz Czajkowski. 2010. “Pregel: A System for Large-scale Graph Processing.” In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data (SIGMOD ‘10). ACM, New York, NY, USA, 135-146.
McCalpin, John D. 1995. “Memory Bandwidth and Machine Balance in Current High-Performance Computers.” IEEE Computer Society Technical Committee on Computer Architecture (TCCA) Newsletter.
Muthukumar, R. M., and D. Janakiram. 2006. “Yama: A Scalable Generational Garbage Collector for Java in Multiprocessor Systems.” IEEE Transactions on Parallel and Distributed Systems 17(2):148-159.
Nitzberg, Bill, and Virginia Lo. 1991. “Distributed Shared Memory: A Survey of Issues and Algorithms.” Computer 24(8)(August):52-60.
Pavlo, Andrew, Erik Paulson, Alexander Rasin, Daniel J. Abadi, David J. DeWitt, Samuel Madden, and Michael Stonebraker. 2009. “A Comparison of Approaches to Large-Scale Data Analysis.” In Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data (SIGMOD ‘09). Carsten Binnig and Benoit Dageville, eds. ACM, New York, NY, USA, 165-178.
Power, Russell, and Jinyang Li. 2010. “Piccolo: Building Fast, Distributed Programs with Partitioned Tables.” In Proceedings of the 9th USENIX Conference on Operating Systems Design and Implementation (OSDI ‘10). USENIX Association, Berkeley, CA, USA, 1-14.
Regola, Nathan, and Jean-Christophe Ducom. 2010. “Recommendations for Virtualization Technologies in High-Performance Computing.” In Proceedings of the 2010 IEEE Second International Conference on Cloud Computing Technology and Science (CLOUDCOM ‘10). IEEE Computer Society, Washington, DC, USA, 409-416.
Schwarzkopf, Malte, Andy Konwinski, Michael Abd-El-Malek, and John Wilkes. 2013. “Omega: Flexible, Scalable Schedulers for Large Compute Clusters.” In Proceedings of the 8th ACM European Conference on Computer Systems (EuroSys ‘13). ACM, New York, NY, USA, 351-364.
Srirama, Satish Narayana, Pelle Jakovits, and Eero Vainikko. 2012. “Adapting Scientific Computing Problems to Clouds Using MapReduce.” Future Generation Computer System 28(1)(January):184-192.
Stumm, Michael, and Songnian Zhou. 1990. “Algorithms Implementing Distributed Shared Memory.” Computer 23(5)(May):54-64.
Xavier, Miguel G., Marcelo V. Neves, Fabio D. Rossi, Tiago C. Ferreto, Timoteo Lange, and Cesar A. F. De Rose. 2013. “Performance Evaluation of Container-Based Virtualization for High-Performance Computing Environments.” In Proceedings of the 2013 21st Euromicro International Conference on Parallel, Distributed, and Network-Based Processing (PDP ‘13). IEEE Computer Society, Washington, DC, USA, 233-240.
Yu, Yuan, Michael Isard, Dennis Fetterly, Mihai Budiu, Úlfar Erlingsson, Pradeep Kumar Gunda, and Jon Currey. 2008. “DryadLINQ: A System for General-Purpose Distributed Data-Parallel Computing Using a High-Level Language.” In Proceedings of the 8th USENIX Conference on Operating Systems Design and Implementation (OSDI ‘08). USENIX Association, Berkeley, CA, USA, 1-14.
Zaharia, Matei, Dhruba Borthakur, Joydeep Sen Sarma, Khaled Elmeleegy, Scott Shenker, and Ion Stoica. 2010. “Delay Scheduling: A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling.” In Proceedings of the 5th European Conference on Computer Systems (EuroSys ‘10). ACM, New York, NY, USA, 265-278.
Zaharia, Matei, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, and Ion Stoica. 2012. “Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing.” In Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation (NSDI ‘12). USENIX Association, Berkeley, CA, USA, 2-2.