
Chapter 17
Operationalizing Big Data
In This Chapter
![]() Making big data a part of your business/operating processes
Making big data a part of your business/operating processes
![]() Understanding big data workflows
Understanding big data workflows
![]() Ensuring the validity, veracity, and volatility of big data
Ensuring the validity, veracity, and volatility of big data
The benefits of big data to business are significant. But the real question is how do you make big data part of your overall business process so that you can operationalize big data? What if you can combine the traditional decision making process with big data analysis? How do you make big data available to decision makers so that they get the benefit from the myriad data sources that transform business processes? To make big data a part of the overall data management process requires that you put together a plan. In this chapter, we talk about what it takes to combine the results of big data analysis with your existing operational data. The combination can be a powerful approach to transforming your business.
Making Big Data a Part of Your Operational Process
The best way to start making big data a part of your business process is to begin by planning an integration strategy. The data — whether it is a traditional data source or big data — needs to be integrated as a seamless part of the inner workings of the processes.
Can big data be ancillary to the business process? The answer is yes, but only if little or no dependency exists between transactional data and big data. Certainly you can introduce big data to your organization as a parallel activity. However, if you want to get the most from big data, it needs to be integrated into your existing business operating processes. We take a look at how to accomplish this task. In the next section, we discuss the importance of data integration in making big data operational.
Integrating big data
Just having access to big data sources is not enough. Soon there will be petabytes of data and hundreds of access mechanisms for you to choose from. But which streams and what kinds of data do you need? The identification of the “right” sources of data is similar to what we have done in the past:
![]() Understand the problem you are trying to solve
Understand the problem you are trying to solve
![]() Identify the processes involved
Identify the processes involved
![]() Identify the information required to solve the problem
Identify the information required to solve the problem
![]() Gather the data, process it, and analyze the results
Gather the data, process it, and analyze the results
This process may sound familiar because businesses have been doing a variation of this algorithm for decades. So is big data different? Yes, even though we have been dealing with large amounts of operational data for years, big data introduces new types of data into people’s professional and personal lives. Twitter streams, Facebook posts, sensor data, RFID data, security logs, video data, and many other new sources of information are emerging almost daily. As these sources of big data emerge and expand, people are trying to find ways to use this data to better serve customers, partners, and suppliers. Organizations are looking for ways to use this data to predict the future and to take better actions. We look at an example to understand the importance of integrating big data with operating processes.
Healthcare is one of the most important and complex areas of investment today. It is also an area that increasingly produces more data in more forms than most industries. Therefore, healthcare is likely to greatly benefit by new forms of big data. The healthcare providers, insurers, researchers, and healthcare practitioners often make decisions about treatment options with data that is incomplete or not relevant to specific illnesses. Part of the reason for this disparity is that it is very difficult to effectively gather and process data for individual patients. Data elements are often stored and managed in different places by different organizations. In addition, clinical research that is being conducted all over the world can be helpful in determining the context for how a specific disease or illness might be approached and managed. Big data can help change this problem.
So, we apply our algorithm to a standard data healthcare scenario:
1. Understand the problem we are trying to solve:
a. Need to treat a patient with a specific type of cancer
2. Identify the processes involved:
a. Diagnosis and testing
b. Results analysis including researching treatment options
c. Definition of treatment protocol
d. Monitor patient and adjust treatment as needed
3. Identify the information required to solve the problem:
a. Patient history
b. Blood, tissue, test results, and so on
c. Statistical results of treatment options
4. Gather the data, process it, and analyze the results:
a. Commence treatment
b. Monitor patient and adjust treatment as needed
Figure 17-1 illustrates the process.
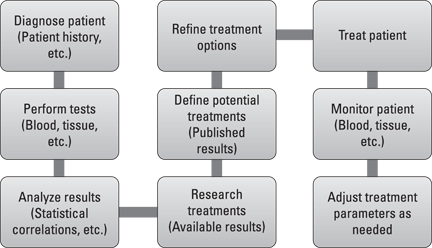
Figure 17-1: Process flow of the traditional patient diagnostic process.
This is how medical practitioners work with patients today. Most of the data is local to a healthcare network, and physicians have little time to go outside the network to find the latest information or practice.
Incorporating big data into the diagnosis of diseases
Across the world, big data sources for healthcare are being created and made available for integration into existing processes. Clinical trial data, genetics and genetic mutation data, protein therapeutics data, and many other new sources of information can be harvested to improve daily healthcare processes. Social media can and will be used to augment existing data and processes to provide more personalized views of treatment and therapies. New medical devices will control treatments and transmit telemetry data for real-time and other kinds of analytics. The task ahead is to understand these new sources of data and complement the existing data and processes with the new big data types.
So, what would the healthcare process look like with the introduction of big data into the operational process of identifying and managing patient health? Here is an example of what the future might look like:
1. Understand the problem we are trying to solve:
a. Need to treat a patient with a specific type of cancer
2. Identify the processes involved:
a. Diagnosis and testing (identify genetic mutation)
b. Results analysis including researching treatment options, clinical trial analysis, genetic analysis, and protein analysis
c. Definition of treatment protocol, possibly including gene or protein therapy
d. Monitor patient and adjust treatment as needed using new wireless device for personalized treatment delivery and monitoring. Patient uses social media to document overall experience.
3. Identify the information required to solve the problem:
a. Patient history
b. Blood, tissue, test results, and so on
c. Statistical results of treatment options
d. Clinical trial data
e. Genetics data
f. Protein data
g. Social media data
4. Gather the data, process it, and analyze the results:
a. Commence treatment
b. Monitor patient and adjust treatment as needed
Figure 17-2 identifies the same operational process as before, but with big data integrations.
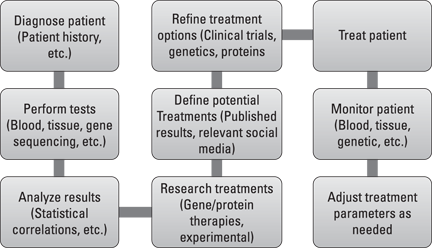
Figure 17-2: The healthcare diagnostic process leveraging big data.
This represents the optimal case where no new processes need to be created to support big data integrations. While the processes are relatively unchanged, the underlying technologies include the applications that will need to be altered to accommodate the impact of characteristics of big data, including the volume of data, the variety of data sources, and the speed or velocity required to process that data.
The introduction of big data into the process of managing healthcare will make a big difference in effectiveness to diagnosing and managing healthcare in the future. This same operational approach process can be applied to a variety of industries, ranging from oil and gas to financial markets and retail, to name a few. What are the keys to successfully applying big data to operational processes? Here are some of the most important issues to consider:
![]() Fully understand the current process.
Fully understand the current process.
![]() Fully understand where gaps exist in information.
Fully understand where gaps exist in information.
![]() Identify relevant big data sources.
Identify relevant big data sources.
![]() Design a process to seamlessly integrate the data now and as it changes.
Design a process to seamlessly integrate the data now and as it changes.
![]() Modify analysis and decision-making processes to incorporate the use of big data.
Modify analysis and decision-making processes to incorporate the use of big data.
Understanding Big Data Workflows
To understand big data workflows, you have to understand what a process is and how it relates to the workflow in data-intensive environments. Processes tend to be designed as high level, end-to-end structures useful for decision making and normalizing how things get done in a company or organization. In contrast, workflows are task-oriented and often require more specific data than processes. Processes are comprised of one or more workflows relevant to the overall objective of the process.
In many ways, big data workflows are similar to standard workflows. In fact, in any workflow, data is necessary in the various phases to accomplish the tasks. Consider the workflow in the preceding healthcare example. One elementary workflow is the process of “drawing blood.” Drawing blood is a necessary task required to complete the overall diagnostic process. If something happens and blood has not been drawn or the data from that blood test has been lost, it will be a direct impact on the veracity or truthfulness of the overall activity.
What happens when you introduce a workflow that depends on a big data source? Although you might be able to use existing workflows with big data, you cannot assume that a process or workflow will work correctly by just substituting a big data source for a standard source. This may not work because standard data-processing methods do not have the processing approaches or performance to handle the variety of complexity of the big data.
Workload in context to the business problem
The healthcare example focuses on the need to conduct an analysis after the blood is drawn from the patient. In the standard data workflow, the blood is typed and then certain chemical tests are performed based on the requirements of the healthcare practitioner. It is unlikely that this workflow understands the testing required for identifying specific biomarkers or genetic mutations. If you supplied big data sources for biomarkers and mutations, the workflow would fail. It is not big data aware and will need to be modified or rewritten to support big data.
The best practice for understanding workflows and the effect of big data is to do the following:
![]() Identify the big data sources you need to use.
Identify the big data sources you need to use.
![]() Map the big data types to your workflow data types.
Map the big data types to your workflow data types.
![]() Ensure that you have the processing speed and storage access to support your workflow.
Ensure that you have the processing speed and storage access to support your workflow.
![]() Select the data store best suited to the data types.
Select the data store best suited to the data types.
![]() Modify the existing workflow to accommodate big data or create new big data workflow.
Modify the existing workflow to accommodate big data or create new big data workflow.
After you have your big data workflows, it will be necessary to fine-tune these workflows so that they won’t overwhelm or contaminate your analysis. For example, many big data source do not include well-defined data definitions and metadata about the elements of those sources. In some cases, these data sources have not been cleaned. You need to make sure that you have the right level of knowledge about the big data sources that you are going to use.
Ensuring the Validity, Veracity, and Volatility of Big Data
High volume, high variety, and high velocity are the essential characteristics of big data. These characteristics are covered in detail in Chapter 1. But other characteristics of big data are equally important, especially when you apply big data to operational processes. This second set of “V” characteristics that are key to operationalizing big data includes
![]() Validity: Is the data correct and accurate for the intended usage?
Validity: Is the data correct and accurate for the intended usage?
![]() Veracity: Are the results meaningful for the given problem space?
Veracity: Are the results meaningful for the given problem space?
![]() Volatility: How long do you need to store this data?
Volatility: How long do you need to store this data?
Data validity
It stands to reason that you want accurate results. But in the initial stages of analyzing petabytes of data, it is likely that you won’t be worrying about how valid each data element is. That initial stream of big data might actually be quite dirty. In the initial stages, it is more important to see whether any relationships exist between elements within this massive data source than to ensure that all elements are valid.
However, after an organization determines that parts of that initial data analysis are important, this subset of big data needs to be validated because it will now be applied to an operational condition. When the data moves from exploratory to actionable, data must be validated. The validity of big data sources and subsequent analysis must be accurate if you are to use the results for decision making or any other reasonable purpose. Valid input data followed by correct processing of the data should yield accurate results. With big data, you must be extra vigilant with regard to validity. For example, in healthcare, you may have data from a clinical trial that could be related to a patient’s disease symptoms. But a physician treating that person cannot simply take the clinical trial results as though they were directly related to the patient’s condition without validating them.
A considerable difference exists between a Twitter data stream and telemetry data coming from a weather satellite. Why would you want to integrate two seemingly disconnected data sources? Imagine that the weather satellite indicates that a storm is beginning in one part of the world. How is that storm impacting individuals who live in the path of that storm? With about half a billion users, it is possible to analyze Twitter streams to determine the impact of a storm on local populations. Therefore, using Twitter in combination with data from a weather satellite could help researchers understand the veracity of a weather prediction.
Just because you have data from a weather satellite, that doesn’t mean the data is a truthful representation of the weather on the ground in a specific geography. If you want to get a truthful representation of the weather, you might correlate a social media stream (like Twitter) with the satellite data for a specific area. If people within the area publish observations about the weather and they align with the data from the satellite, you have established the veracity of the current weather. While veracity and validity are related, they are independent indicators of the efficacy of data and process.
Data volatility
If you have valid data and can prove the veracity of the results, how long does the data need to “live” to satisfy your needs? In a standard data setting, you can keep data for decades because you have, over time, built an understanding of what data is important for what you do with it. You have established rules for data currency and availability that map to your work processes. For example, some organizations might only keep the most recent year of their customer data and transactions in their business systems. This will ensure rapid retrieval of this information when required. If they need to look at a prior year, the IT team may need to restore data from offline storage to honor the request. With big data, this problem is magnified.
If storage is limited, you must look at the big data sources to determine what you need to gather and how long you need to keep it. With some big data sources, you might just need to gather data for a quick analysis. For example, if you are interested in the experiences of hybrid car owners, you might want to tap into Facebook and Twitter feeds to collect all the posts/tweets about hybrid cars. You could then store the information locally for further processing. If you do not have enough storage for all this data, you could process the data “on the fly” (as you are gathering it) and only keep relevant pieces of information locally. How long you keep big data available depends on a few factors:
![]() How much data is kept at the source?
How much data is kept at the source?
![]() Do you need to process the data repeatedly?
Do you need to process the data repeatedly?
![]() Do you need to process the data, gather additional data, and do more processing?
Do you need to process the data, gather additional data, and do more processing?
![]() Do you have rules or regulations requiring data storage?
Do you have rules or regulations requiring data storage?
![]() Do your customers depend on your data for their work?
Do your customers depend on your data for their work?
![]() Does the data still have value or is it no longer relevant?
Does the data still have value or is it no longer relevant?
Due to the volume, variety, and velocity of big data, you need to understand volatility. For some sources, the data will always be there; for others, this is not the case. Understanding what data is out there and for how long can help you to define retention requirements and policies for big data.
Big data and analytics can open the door to all kinds of new information about the things that are most interesting in your day-to-day life. As a consumer, big data will help to define a better profile for how and when you purchase goods and services. As a patient, big data will help to define a more customized approach to treatments and health maintenance. As a professional, big data will help you to identify better ways to design and deliver your products and services. This will only happen when big data is integrated into the operating processes of companies and organizations.