
6. Mashups and External Server Communications
The Web is a big place. A very big place. With lots of smart people doing lots of smart and clever things. Sometimes other people get to use their smart ideas. Sometimes your needs are so specific that you have to write your own services. Whatever your needs, you will likely reach a point where the “out-of-the-box” offerings from OpenSocial on MySpace are just not enough to satisfy your needs. Thankfully, OpenSocial recognizes these needs and provides you with a mechanism or two for communicating with external servers.
In this chapter we’ll add two different features to our app that are dependent on external server communications. Each feature will use a different technique. We will make use of existing services on the Web to create a “mashup”-style app. Communication with your own servers, and securing those channels, will be covered when we discuss other styles of applications.
Communicating with External Servers
OpenSocial recognizes that it can’t be all things to all people. In fact, it’s designed to be just some things to all people—namely, an API for exposing social information. To that end it really is designed for use in external applications and mashups.
There are a multitude of techniques for communicating with external servers. If all you are doing is referencing static content, there are almost no constraints. If you want to do something a little more dynamic, like invoke a Web service, things are a little more complicated.
As we said before, static content on external servers has very little in the way of constraints. So long as you use a fully qualified address, the image file will resolve from any server. This is a common technique for large Web sites. They make use of a content delivery network, or CDN. A CDN may be simple or complex. A simple CDN just offloads the bandwidth that would be used to serve static content from the dynamic app servers, leaving more bandwidth and processing power for handling dynamic requests. Most browsers also throttle the number of concurrent connections back to a single domain, so this technique allows the browser to download more files at once; therefore the page loads faster.
Dynamic content is another story. There are a handful of well-established techniques for creating dynamic content, some legitimate, some nefarious. We’ll cover the well-established techniques here and touch on the nefarious ones in Chapter 13, Performance, Scaling, and Security.
Mashups
Mashups are a combination of one or more services in a new way to make a new service or product that is different from the original.
As companies have recognized the value of allowing external parties to use their services and infrastructure, the number of open APIs catering to mashup-style applications has proliferated widely. Several new business models have emerged, allowing larger providers to leverage their services and infrastructure for new revenue streams by providing so-called cloud services to third parties. This is in sharp contrast to the reaction to what we’ll call “proto-mashups” from the early days of the Web. Back then it was common practice for preportal aggregation sites to either deep-link to buried services within another site (for example, linking to buying concert tickets via TicketMaster from a band review site) or completely hijack a competitor’s content by using framesets to make their site look like the competitor’s.
Adding a Feed Reader to Our App
We’ll now extend our app by adding a feed reader. This feature allows your users to never have to leave their game to keep up with the latest happenings on the Web. In the interest of theatrics, we’ll do this as a contrasting implementation in three parts. We’ll add a standard set of feeds for the user to select from. Then we will demonstrate three different implementations using makeRequest:
• Manual display using the FEED content type
• Manual display using the DOM content type
• Raw text response of the feed with TEXT content type
Overview of gadgets.io.makeRequest
The call gadgets.io.makeRequest is the standard way for apps to call out to an external server. This is the only officially supported technique for making external server calls in the OpenSocial specification. It is also the only technique that is allowed on all three surfaces.
A makeRequest call is a powerful and flexible wrapper on top of the XMLHttpRequest (XHR) object built into all modern browsers. The makeRequest call wraps a batching mechanism on top of the XHR request and hides the ugly implementation details. If you have a special, well-known data type, it also provides several convenience formatters that will preprocess the response. You as the developer only need to supply a callback function that receives the response and does something useful with it.
As you may have gleaned, makeRequest uses the same underlying communication mechanism as all the built-in OpenSocial endpoints. The difference is that the makeRequest call is designed to handle external server communication. In order to get around the same-origin policy applied to all XHR calls, the call to an external server is bounced off a proxy server that lives within the msappspace.com jail domain.
The proxy is a resource shared by all apps on MySpace. As such, MySpace imposes some throttling restrictions on the number of requests an app may make within a certain time period. Particularly bad or sloppy apps have been known to take the proxy down entirely in the early days of the MySpace Open Platform. Now these apps are more likely to be suspended if they start adversely affecting the proxy servers’ performance. Even with this policy, the proxy is subject to slowed responses during peak load hours.
The makeRequest call may be invoked as follows:
gadgets.io.makeRequest(url, callback, opt_params)
where url indicates the URL of the service being invoked, callback is a function that is invoked when the data is received, and opt_params is an optional object hash of parameters to the request. By default, this call issues a GET request to url and invokes the function callback with the unprocessed raw text in the data response.
As we alluded to before, makeRequest is more than just a wrapper on top of an XHR request. It provides many optional parameters that, depending on what kind of data service you are invoking, can prove extremely useful. These parameters can specify things like content preprocessing, security authorization, raw headers, and a specific HTTP method.
For reference, optional parameters to gadgets.io.makeRequest are specified in Table 6.1. All optional keys are enum values from the enum gadgets.io.RequestParameters. In general, the string specified in the “Key” column will work, but it is good programming practice to use the enum value. For example, the key AUTHORIZATION is specified as gadgets.io.RequestParameters.AUTHORIZATION.
Table 6.1 Option Parameters to gadgets.io.makeRequest*


*Reprinted from Google (http://code.google.com/apis/opensocial/articles/makerequest-0.8.html) and used according to terms described in the Creative Commons 2.5 Attribution License (http://creativecommons.org/licenses/by/2.5/). Find the latest specification at www.opensocial.org or http://wiki.opensocial.org/index.php?title=Gadgets.io_(v0.9).
Response Structure
The response that is returned as a parameter to the callback method is a JSON object and follows a predictable structure. This structure includes error messages, raw response, security information, and processed data. Table 6.2 identifies the properties of the makeRequest response object.
Table 6.2 MySpace-Supported makeRequest Response Object Properties

The actual content of the data field varies depending on the CONTENT_TYPE specified in the initial request. In the case of a TEXT content type request, the value of data is the raw text response and matches the value of the text field. For all other content types, it is some sort of JSON object representation of the data.
Handling JSON Content
MySpace disallows the use of an eval statement, so the only two ways to process JSON data are by calling gadgets.json.parse or by using makeRequest. The CONTENT_TYPE parameter must be set to gadgets.io.ContentType.JSON for the response text to be processed as JSON.
When a makeRequest call is made with the JSON content type, the parsed JSON object is placed in the response data property. The content of the text property is the raw, unevaluated JSON text. This method works on any app surface (Home, Profile, or Canvas).
On the Canvas surface, only you can use a JSONP request to get JSON data (discussed later in this chapter in the section “Overview of JSONP”).
Handling Partial HTML Content
When making a request for partial HTML content to be rendered directly into the page, your best bet is to use the default TEXT format (gadgets.io.ContentType.TEXT). Since the raw HTML is written directly into the innerHTML of some element on the page, no processing is needed. This technique is analogous to Ruby on Rails’s partials or using the Ajax.Updater from the Prototype JavaScript library.
Handling RSS Feed Content
RSS feeds can be directly processed in the makeRequest call by specifying a CONTENT_TYPE of gadgets.io.ContentType.FEED. When this is done, the makeRequest response contains a processed JSON object that represents the feed. This can also be used in conjunction with the GET_SUMMARIES parameter to include summaries in the feed request.
RSS feeds are widely available services on the Internet. Many sites make use of this fact to act as content aggregators. Later in this chapter, under “Setup and Design of the Feed Reader,” we will use a feed to add our own news reader to our Tic-Tac-Toe game.
Handling XML Content
Raw XML content may be handled in one of two ways: by using the default TEXT format and managing your own XML processor in the browser, or by specifying a CONTENT_TYPE of gadgets.io.ContentType.DOM and having the XML document loaded into an actual DOMImplementation. This Document object is placed in the data property, and the raw response XML text is placed in the text property.
Once you have the content loaded into the data DOM object, you are able to use the full DOM API in all its glory. Statements like the following may be used to select nodes:
response.data.getElementsByTagName("item");
This can prove to be very useful when dealing with proprietary APIs. Even on occasion a well-known data type must be handled this way if the provider is not well conforming. This allows you as the developer to write more robust code, if you have a need.
Another way in which this is useful is when applying XSLT transforms to the XML for display. If you wish to look further into this technique, it involves using the following methods (depending on your browser):
• DOMDocument.transformNode() (Internet Explorer)
• XSLTProcessor.importStylesheet() and XSLTProcessor.transformToFragment() functions (Firefox and Safari)
Creating the XSLT object can be a little cumbersome because of browser compatibility issues. Maintaining the transforms can be problematic as in-browser debugging tools are poor at best and there are some minor implementation differences between browsers. It is not impossible, but we leave it to the reader to explore this technique.
“User’s Pick” Feed Reader
Our mashup example is a user-driven feed reader. The user can pick a feed from our market-tested and carefully peer-reviewed (read: random) drop-down list of available feeds. The user can then choose to do a one-time read or have the list refresh periodically, à la PointCast Network.
Setup and Design of the Feed Reader
This is a simple reader. The user can pick one of a preselected list of RSS source feeds from a drop-down. The user can also choose to have the feed continuously updated by selecting a check box.
The first step is building the UI for our feed reader. It will consist of a drop-down list, a format (content type) radio button selector, an action button, and a display surface.
For our feed reader we’ve selected the following RSS feeds:
• Digg
• CNET
• Lolcats
• Mashable
• Slashdot
• Hulu
Following is the HTML that constructs the user interface. Add this code to our app on the Canvas surface code immediately below the "myinfo" div element.

The basic elements we just added are
• Select list of feeds
• Request format radio buttons (for testing—will be removed later)
• Action button to load the feed
• Empty element "rssFeed" that will display the feed
Now that the UI is built (as shown in Figure 6.1), we need to add the loadFeed() function, which is called from the button click event. This function controls the makeRequest call for the feed. Add the following code in our JavaScript source block below the TTT object:

Figure 6.1 Feed reader user interface in our application.
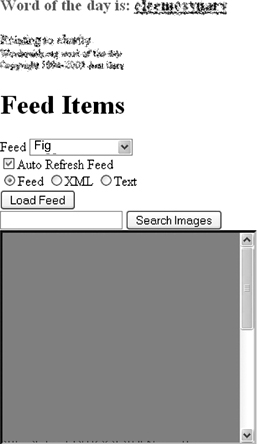
As listed, this call is hard-coded to pull the Digg feed and take the result in the FEED format. It also specifies to send down the first five entries. By default only the top three entries are loaded when the FEED content type is specified.
In this method is a callback reference to a function called feedCallback. This function processes the response and formats it for display. The simple implementation of the callback looks like this:

You will notice that the error handling from a makeRequest call is somewhat different from that of some of the other OpenSocial data calls. The makeRequest call holds its errors in a simple array, whereas the other OpenSocial calls use getter functions to test for errors. In that regard, the error handling from a makeRequest call is a little more straightforward. We just have to check the error’s property and make sure it is empty.
Our simple example must be expanded upon to satisfy the behavior specified earlier in this section. The first order of business is some display housecleaning and the addition of support for the user-selected values. The DOM elements are first cleaned up on each request. Because we are supporting multiple possible sources and multiple possible content type formats, the code must also read which items the user has selected.
The expanded listing of our code follows:




In order to carry the specified format value forward for the purpose of understanding how the response data is to be displayed, we have wrapped our callback in an anonymous function that passes down the response as well as the data format in a closure variable named format. Added to the listing are two convenience methods for getting correct values from the form fields.
Now we will move on to actual data display. The display is handled by a function showFeedResults. This function determines what format is being consumed and takes proper action. You can see the skeletal listing here:


FEED Content Type
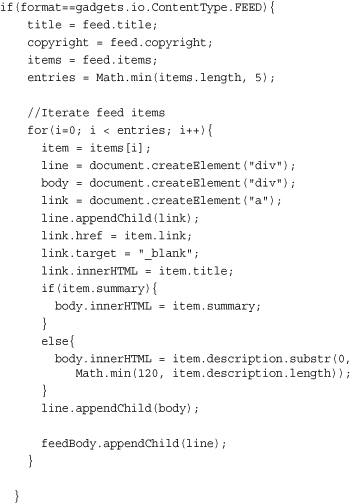
The FEED content type is the most obvious choice to use when processing an RSS feed. The makeRequest object automatically processes the raw XML feed data and parses it into a JSON object to be consumed. The structure of the JSON object mirrors the structure of the RSS feed. Constructing the display is a simple matter of iterating over the item array and building up our listings. Since all items are in JSON format, the code can directly access the values as properties.
In the case of our code, we build up DOM elements for each entry (item) in the feed. Each line consists of a hyperlinked title and a truncated description.
XML Content Type with Parsing
Why, you might ask yourself, would I want to manually parse an RSS feed as an XML document when there is a perfectly good feed reader built into makeRequest? The answer partially lies in the false premise of the question. Specifically, the feed reader built into makeRequest is not “perfectly good.” It is good, true, but it also has many flaws. Most noticeably, at the time of this writing, when it encounters a feed that doesn’t parse cleanly or is missing some required elements, it just dies. No error you can trap. No notification. It just dies, and the exception is swallowed. The irony of this situation is that this error occurs most often on feeds from FeedBurner, which was recently acquired by Google (Google also provides the underlying implementation code for gadgets.io.makeRequest).
The second half of why you, as a developer, might want to do things the hard way is a simple and unfortunate truism of developing against an external API: You can never fully trust the stability or robustness of someone else’s API. This is a general coding truth learned by the authors over many years and through many scars. To that end, we will be equipping you with some tools and skills to overcome life’s little challenges.
In the case of our code, it is almost identical in structure to process this as XML or as a JSON object. The only difference is in the use of the DOM API methods. Since the data coming back is a DOMImplementation, you are able to use all the familiar DOM API methods, such as getElementsByTagName. You are used to using the DOM API directly and aren’t one of those lazy developers who’s hooked on some fancy-schmancy JavaScript framework like jQuery or Prototype, aren’t you?
Since the elements in this DOM object do not have explicit ID values for selection, they must be selected by traversing the node tree. To that end, we have created a convenience method for safely extracting the value of an element from a selected DOMElement list, getFirstDomNodeContents, which is at the bottom of this code listing:


Because the use of the DOM (aka XML) content type is slightly more robust than the use of the FEED content type, your code can be designed to accommodate some error conditions. In the case of a FEED parse failure, the code simply dies. The underlying cause is often malformed or invalid XML in the feed. When the DOM content type is used, the response continues processing and allows your code to handle the error. A parsing error is reported, but the original response text is still placed in the text property of the response, so you have an opportunity to recover. This is where using the TEXT content type can come into play.
TEXT Content Type
If our feed encounters an error, we’ll simply display the raw response as text, along with an error message. We’ll also make available the TEXT content type for raw debugging and demonstration purposes.
In the case of an error in XML processing, the code changes the response format reported to showFeedResults as being TEXT. At this point we can just dump the results with a little escaping. Almost.


There are three curious lines in this code snippet. Instead of simply using a standard angle bracket escape sequence (> and <) when formatting the response text for display, our code needs to build them up. This is because of an oddity of the MySpace platform and how it saves app source. As part of the saving process, the code is run through a minimal security filter. This filter resolves any escape sequences in the app code to ensure that nothing nefarious slips past the reviewers. The usefulness and wisdom of running this sort of a processor over app code may be a subject that is open to debate. The reality is that this is a subtle yet significant “gotcha” that you must be aware of.
As an alternative, you can make use of the utility method gadgets.util.escapeString instead of performing manual string manipulation. This accomplishes encoding the markup without the headache of confusing the MySpace security filters.
Adding a Feed Refresh Option
Contrary to what you might think, the makeRequest parameter REFRESH_INTERVAL does not control an autorefresh. This is a directive to aid the container in understanding whether it can local-cache the results of a feed request. Instead we will use a simple setTimeout directive.
The first step is to create a new wrapper function for the load event that safely loads the Word of the Day feed and initializes the game. Each function call is wrapped in a try/catch to ensure that if one fails, it doesn’t kill the app entirely. We also have to change the gadget registerOnLoadHandler call to point to this new method.

Note that the call to gadgets.util.registerOnLoadHandler must be placed after the loadInitializer function is declared. Otherwise the function pointer will be undefined and the code won’t work. We’ve also placed every initialization call into a try/catch block. This is so that if one fails, it will not affect the other.
The next step is to tie the autorefresh check box (the code is not shown—the ID of "chkRefreshFeed") to a parameter and refactor out the actual makeRequest call into an independent function that can be invoked via a setTimeout call. The refactored function takes all the values we trapped as variables. This way, the setTimeout call can carry forward the calculated parameter values within closure variables and not lose the information. Any interval larger than zero is recognized as a call to autorefresh via a setTimeout call.


In the code we hard-coded the interval to three minutes (3 min * 60 sec/min * 1000 ms/sec). If you make this interval too short, your app will just start thrashing the proxy. If MySpace determines that your app is adversely affecting the proxy through too many calls within too short a time, your app could be subject to throttling (just disregarding or denying extra requests) or, in the worst case, suspension.
Feed Automation Candy
No proper push app (now commonly known as a feed reader) is complete without taking the user action out of the user experience. To that end, we’ll close this section out by adding a “Word of the Day” feature to our app. After all, nothing says Tic-Tac-Toe like the Word of the Day.
We need a few divs for data display ("wordoftheday", "wodDesc", and "wodcopyright"). Then we need to modify the loader function to also load the Word of the Day:

The implementation of getting the Word of the Day and displaying it should be fairly familiar by now. It entails a function to encapsulate the makeRequest call and a callback handler to display the results.

Secure Communication with Signed makeRequest
Secure communications are extremely important when calling home to your own servers. OpenSocial makes use of OAuth to make secure calls back to an external server. This technique involves the use of a shared secret in order to verify the source of the request and that the request hasn’t been altered. This topic is large and complex enough to warrant its own chapter so will not be covered here. See Chapter 8, OAuth and Phoning Home, for more information on secure server communications.
Adding an Image Search
The second feature we’ll add is an image search. In case your user is in the middle of an intense Tic-Tac-Toe session but suddenly receives a tweet on his or her phone about Angelina Jolie’s new beehive hairdo and needs to search for what that looks like, the user will be able to perform that search without ever leaving the game.
For this feature we’ll make use of the Yahoo! image search API. Many of the public APIs on the Web allow themselves to be called using a technique called JSONP. JSONP is a technique that allows JavaScript-only calls to an external server to be made in a way that removes the need for a proxy to make the call.
Overview of JSONP
You may or may not be familiar with JSONP. Do not confuse this with JSON (JavaScript Object Notation). JSONP stands for “JSON with padding.” While JSON and JSONP share some similar characteristics, JSONP is more akin to an XSS (cross-site scripting) attack used for good.
Most of the major client script libraries now have JSONP support, but we’re still going to describe the mechanism since it’s really not that complex. A JSONP call requires the current page’s code to manipulate the host page’s DOM to dynamically add a script tag. The source of this script tag is set to the remote server endpoint (REST/Web service). Since there is no cross-domain scripting policy in the browser for static content, the browser happily downloads the new script code.
However, unlike an XSS attack, for JSONP to work the server must cooperate. The magic pixie dust involves adding a callback method name to the query string of the JSONP request. The server then invokes the named JavaScript method by appending the method call to the body of the response. The actual response payload from the API call is wrapped as a parameter to the method call; hence the “padding.”
Warning
There are a few “gotchas” for using JSONP. Firefox blocks until the JSONP call returns. This gives you slower page execution, but you can reliably call methods in the returned script block without waiting for the callback. Since it works that way only in Firefox, you are ill advised to rely on this behavior and execute code prior to getting the callback. Internet Explorer and Safari begin full-page rendering and execution prior to handling any dynamically generated DOM elements, so they do not block on JSONP calls. The long and short is that you must make use of the callback.
So why bother using JSONP instead of makeRequest? Your JSONP calls will be both faster and more reliable. In essence, you are cutting out the middleman. A makeRequest call has to be proxied off to another server, then the proxy has to wait for the response and write it back if and when the answer comes. It creates more network hops and multiple points of failure. If the MySpace proxy goes down, all your makeRequest calls will fail. Your JSONP calls won’t even notice.
JSONP is much more restrictive in what can be done than makeRequest. As stated before, the MySpace terms of service disallow JSONP calls on any surface other than Canvas, so you are quite limited in when you can use it. The request may be only a GET call, so anything requiring form POST data is off the table. It is also restricted to JSON data, since the packet will be JavaScript. If your needs are simply for data on the Canvas, though, JSONP is a superior option.
Implementing the Image Search
For the user interface, we’ll add a text field and a button to invoke the search in our code. Results will be displayed in the same area as the RSS feed results.
<input id="imageTerm" />
<button onclick="searchImage()">Search Images</button><br />
The basic mechanism used in most instances is to manipulate the DOM to add a new script tag with the source pointed to the target URL. Many JavaScript libraries provide this mechanism, but it is easy enough to write your own. The de facto standard for services providing a JSONP mechanism is to specify the callback function name in a query string parameter named callback. This function creates a script tag and appends it to the head element.

The next step is to specify the entry point function and the callback to display results. The entry function pulls the search term from the input field imageTerm, constructs the search URL, and invokes the makeJsonpRequest function. The callback constructs DOM elements to display the search results.


Posting Data with a Form
Good old-fashioned forms remain an effective way to communicate with external servers. Using a form to send data involves either placing the form in an iframe inside your app or passing the current app’s URL along as a parameter to the form. In this way, the form can issue a redirect back to your app after processing. Many third-party payment gateways make use of this technique. We leave it to the reader to explore using forms as a mechanism to communicate with payment gateways.
From a MySpace-specific perspective, the terms of service allow form posts to external sites only from the Canvas view. This restriction can be circumvented by using a makeRequest call and specifying a method of gadgets.io.MethodType.POST (or gadgets.io.MethodType.GET for a query-string-encoded form) in the parameters to the makeRequest call.
Summary
There are pros and cons to the methods of external communication discussed in this chapter. gadgets.io.makeRequest is a shared resource and can become a single point of failure if the service is having issues. However, it offers many useful features such as built-in RSS feed support, along with being well defined by the OpenSocial specification. This is also the only mechanism that allows for signed and secure communications with an external server under your control. You should refer to Chapter 8, OAuth and Phoning Home, for a complete discussion of secure communications.
JSONP, on the other hand, is a bit of a hack. Browsers and the HTML specification weren’t really intended to do some of the things that JSONP does, and it’s limited in what it can do. Only GET requests are permitted; POST, DELETE, and other verbs aren’t possible. It’s also hard to debug JSONP requests; depending on where an error occurred, your callback function may never be executed. In that case, how do you know what went wrong? But what JSONP does, it does well. It’s a quick and easy way to make cross-domain requests from JavaScript.
HTML forms aren’t as exciting, but they are reliable. Form posts continue to be a common mechanism used to access third-party payment gateways.
In the end, it’s up to you to figure out which method you use to talk to external servers, given the specific needs of your app.
Note
Code listings and/or code examples for this chapter can be found on our Google Code page under http://opensocialtictactoe.googlecode.com.