
The SDDC will influence the way you might configure and setup vSphere in a data center. While any vSphere environment can be the base for an SDDC, it might make sense to revisit some of its settings and make them fit for the SDDC. Basically, there are two major approaches to think about:
- The management cluster and all the management relevant VMs and applications
- The environment running all your production/development or test VMs often referred to as payload
Both configurations are important and need to be well thought through. In a classic vSphere only environment, the need of a management cluster might be not as strong as in an SDDC environment, since all it runs is vCenter and maybe some virtual desktop managers (if applicable). So it can often be run on small vSphere hosts with a low-performance configuration. If you add monitoring like vRealize Operations and Log Insight the performance requirements of this cluster will rise since these two tools will require intense memory and CPU power to serve medium or large environments.
This is a general recommendation from VMware. Every bigger vSphere environment should have its separated manager cluster where all management VMs are installed onto. In an SDDC environment, all the required tools to run the SDDC will be added into the management cluster as well. Therefore, it is important to plan accordingly and provide it with all necessary resources.
So the requirements of your management cluster will change dramatically in an SDDC. If you also intend to add NSX to the picture, you need to run the NSX manager as well as think about a separate NSX Edge cluster.
Here is a list of VMs you will have to fit in your management cluster for a medium size SDDC installation:
- 2x vRealize Automation appliance
- 2x DEM worker for vRealize Automation
- 2x IaaS server for vRealize Automation
- 1x (or 2x) vRealize Orchestrator
- 1x (or 2x) vRealize Operations Manager
- 1x (or 2x) vRealize Log Insight
- 1x vRealize Business for Cloud
- 1x NSX Manager (if applicable) 3x NSX controller nodes
- 1x vRealize Code Stream (if applicable)
- 1x vCenter server
This means that your SDDC management server will have at least 16 management servers with different resource and performance requirements to host. Some of these services require extensive resources such as disk space or heavy CPU and memory workloads. Especially vRealize Operations and vRealize Log Insight can easily consume a couple of terabyte of storage and require high-performance CPU and memory configurations.
Because of this added duties, the management cluster gets more important and therefore needs well thought through high availability settings. vSphere HA should be configured to protect all necessary VMs to run and manage your SDDC. However, keep in mind that other management servers can run on this cluster as well. It is not exclusively reserved for VMware products.
If you plan to introduce a campus or metro cluster setup with shared storage between two data centers, this concept needs to be extended to the management cluster as well. This might be less important in a pure vSphere environment, but for the SDDC it is imperative to make sure the portal is high available and reachable. Just keep in mind that all consumers will have to go through the portal to manage their VMs and other ordered objects. If the portal is down, they have no option to interact with their installation.
Another important point here is the HA Restart Priority. The SDDC components may require a special restart order after an outage. Otherwise, they might be up but the portal is not running because of missing connection requirements. In the following screenshot, you will find a sample how to configure the restart priority for an SDDC management cluster:
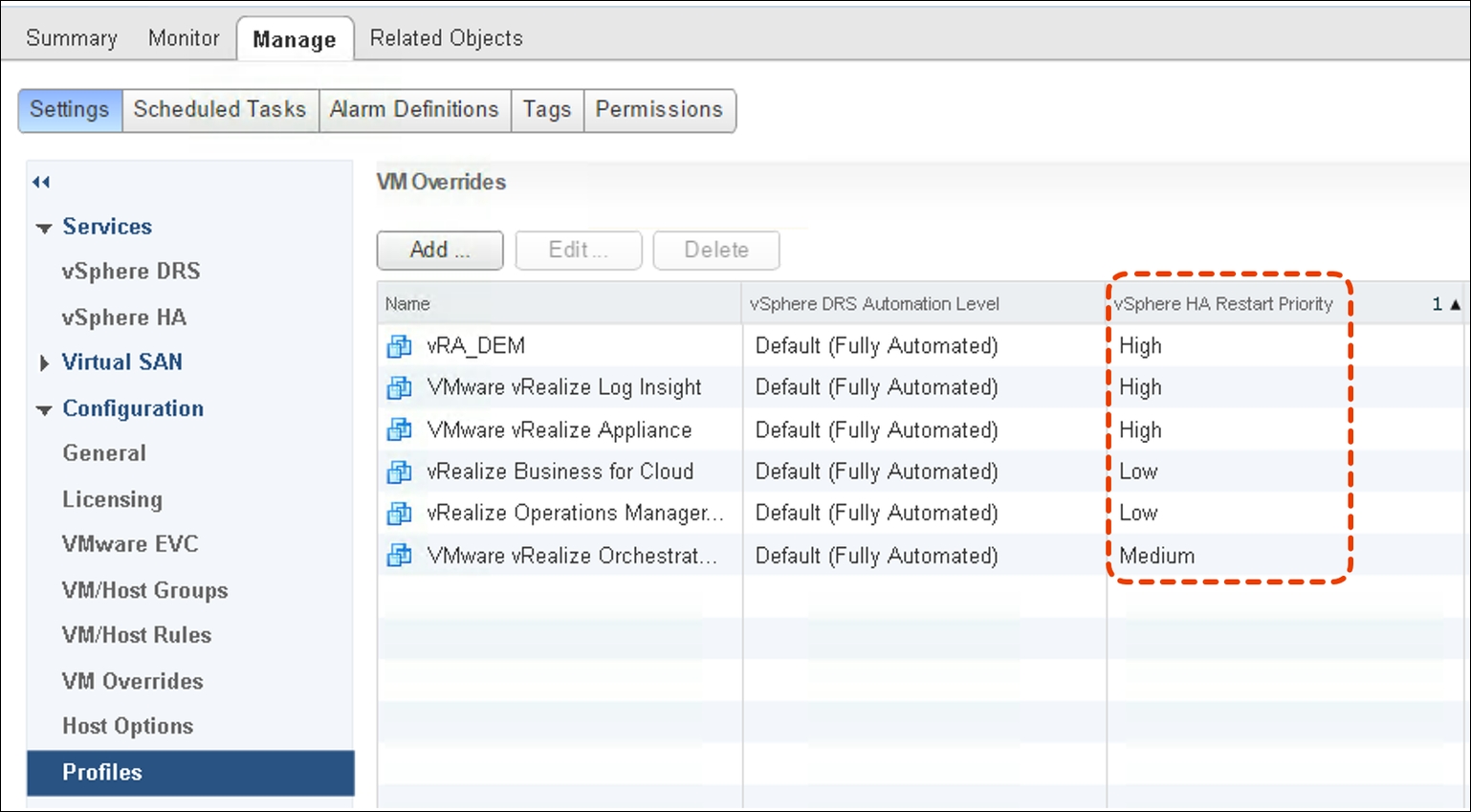
Obviously, vCenter is also important to be up and running as one of the first VMs, but that should be a given in any environment. Besides that, the logic for this startup priority is the following:
- Start vRealize Automation portal and Distributed Execution Mangers (DEM) first to bring up the portal and general functionality.
- Start vRealize Log Insight with the same priority in cases logs needs to be analyzed.
- Start up vRealize Orchestrator to make sure that any additional workflows or the XaaS components can work. Orchestrator can start and register itself fine if vRA is already running.
- Start up vRealize Operations and vRealize Business to restore capacity and analytics monitoring as well as chargeback and showback functionalities.
Tip
In the case of two data centers and a stretched management cluster, it might be very helpful to set an affinity rule to have all components running in the same data center. This will prevent random outages in case one of the data center sites has an issue. However, if you use a clustered vRA setup (as well as other components) make sure that each site runs one instance of it, instead of having both on one site!
It is strongly recommended to have at least three hosts in your management cluster. If you are using a campus or metro cluster setup, make sure that you use host groups and VM groups to distribute the VMs across both sites accordingly. Three hosts are important to also cover maintenance events. If vSphere upgrades need to be applied, the host often needs to be restarted or at least brought into maintenance mode. During these times your cluster resiliency is diminished. If you would only have two hosts, this means that there are no resources left in case of a failed of the other host. Therefore, it is strongly recommended to have at least a 2+1 configuration in place. However, in an NSX use case, the management cluster needs to have at least 6 hosts (3 per site) in order to house the additional required NSX controllers (3 per site, one per host).
Besides the separate management cluster, it might be useful to also create a separate management VDS. One of the reasons to do this is to limit the failure domain.
A VDS is nothing more than a software component to give access to the physical Network Interface Card (NIC) of a vSphere host. This is done by creating failover (NIC teaming) configurations as well as through adding so-called port groups. But such a switch also represents its own failure domain, which means in case something is going wrong with this VDS, it will only affect the management cluster. Limiting your failure domain is a passive move which will enhance your overall resiliency.
Another reason is often to add security. Since all port groups in a VDS can be used on all participating ESXi hosts, it might be possible to accidentally add a VM in the wrong port group. If this port group is part of the overall management network - severe harm could be done by accessing this network. To prevent this situation a separate management VDS helps to logically separate all the production networks from the management networks. Basically, it can also all be done with one single VDS, but some organizations may restrict this due to security regulations and force to have a separation of VDS.