
5
Host Security Controls
CERTIFICATION OBJECTIVES
5.03 Endpoint Security Software
5.05 Asset Management (Inventory Control)
The security of an organization’s computer systems and networks is not accomplished by applying security at only one point in the network. So far, this text has discussed a number of different aspects of security that occur at a number of different places in the network. This chapter will concentrate on securing the individual hosts that make up the network. It is at this point that the user interacts with the network, and many of the security features we discuss here will be well known to users.
CERTIFICATION OBJECTIVE 5.01
Host-based Firewalls
In your car, the firewall sits between the passenger compartment and the engine. It is a fireproof barrier that protects the passengers within the car from the dangerous environment under the hood. A computer firewall serves a similar purpose—it is a protective barrier that is designed to shield the computer (the system, user, and data) from the “dangerous” environment it is connected to. This dangerous and hostile environment is the network, which in turn is most likely connected to the Internet. A firewall can reside in different locations. A network firewall will normally sit between the Internet connection and the network, monitoring all traffic that is attempting to flow from one side to the other. A host-based firewall serves a similar purpose but instead of protecting the entire network, and instead of sitting on the network, it resides on the host itself and only protects the host. Whereas a network firewall will generally be a hardware device running very specific software, a host-based firewall is a piece of software running on the host.
Firewalls examine each packet sent or received to determine whether or not to allow it to pass. The decision is based on the rules that the administrator of the firewall has set. These rules, in turn, should be based on the security policy for the organization. For example, if certain websites are prohibited based on the organization’s Internet Usage Policy (or the desires of the individual who owns the system), sites such as those containing adult materials or online gambling can be blocked. Typical rules for a firewall will specify any of a combination of things, including the source and/or destination IP address, the source and/or destination port (which in turn often identifies a specific service such as e-mail), a specific protocol (such as TCP or UDP), and the action that the firewall is to take if a packet matches the criteria laid out in the rule. Typical actions include allow, deny, and alert. The rules in a firewall are examined in order and rules will continue to be checked until a match is found or until no more rules are left. Because of this, the very last rule in the set of rules will generally be the “default” rule, which will specify the activity to take if no other rule was matched. The two extremes for this last rule are to deny all packets that didn’t match another rule and to allow all packets. The first is safer from a security standpoint; the second is a bit friendlier because it means that if there isn’t some rule specifically denying this access, then it will be allowed.
A screen capture of the simple firewall supplied by Microsoft for its XP operating system is shown in Figure 5-1. As can be seen, the program provides some simple options to choose from in order to establish the level of filtering desired. A finer level of detail can be obtained by going into the Advanced option, but most users never worry about anything beyond this initial screen. In the newer Windows operating systems, the firewall is based on the Windows Filtering Platform. This service allows applications to tie into the operating system’s packet processing to provide the ability to filter packets that match specific criteria. It can be controlled through a management console found in the Control Panel under Windows Firewall. It allows the user to select from a series of basic settings, but will also allow advanced control, giving the user the option to identify actions to take for specific services, protocols, ports, users, and addresses.
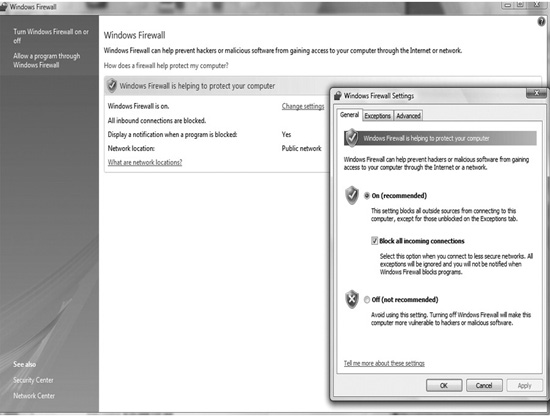
FIGURE 5-1 The firewall found in the Windows XP operating system
For Linux-based systems, a number of firewalls are available, with the most commonly used one being iptables, which replaced the previous most commonly used package, called ipchains. Iptables provides the functionality to accomplish the same basic functions as those found in commercial network-based firewalls. Common functionality includes the ability to accept or drop packets, to log packets for future examination, and to reject a packet, along with returning an error message to the host sending the package. As an example of the format and construction of firewall rules used by iptables, the rules that would allow WWW (port 80) and SSH (port 22) traffic would look like the following:

The specifics of these commands is as follows: -A tells iptables to append the rule to the end of the chain; -p identifies the protocol to match (in this case, TCP); -i identifies the input interface; --dport and --sport specify the destination and source ports respectively; -m state --state NEW states the packet should be the start of a new connection, and -j ACCEPT tells iptables to stop further processing of the rules and hand the packet over to the application.
An important note to make that is not always considered, is that a firewall can filter packets that are either entering or leaving the host or network. This allows an individual or organization the opportunity to monitor and control what leaves the host or network, not just what enters it. This is related to, but is not entirely the same as, data exfiltration, which we will discuss later in this chapter.
Another consideration from the organization’s point of view is the ability to centrally manage the organization’s host firewalls if they are used. The issue here is whether you really want your users to have the ability to set their own rules on their hosts or whether it is better to have one policy that governs all user machines. If you let the users set their own rules, not only can they allow access to sites that might be prohibited based on the organization’s usage policy, but they might also inadvertently block important sites that could impact the functionality of the system.

Understanding that firewall rules are checked in a specific order is critical for the correct implementation of those rules. You would not want to have the default rule, allowing (or denying) all other traffic, be placed first in your rule set because none of the other rules would ever be checked. Watch carefully the creation and placement of rules that include “any ip address, any port, or any protocol.”
Special-purpose host-based firewalls, such as host-based application firewalls, are also available for use. The purpose of an application firewall is to monitor traffic originating from or traveling to a specific application. Application firewalls can be more discriminating beyond simply looking at source/destination IP addresses, ports, and protocols. Application firewalls will understand something about the type of information that is generated by or sent to the specific application and can, in fact, make decisions on whether to allow or deny information based on the contents of the connection. A host-based application firewall will generally be used in conjunction with a packet-filtering host-based firewall instead of replacing it completely. This provides an additional level of filtering to better protect the host because they act on the application layer, which means they can inspect the contents of the traffic, allowing them to block specified content such as certain websites, malicious logic, and attempts to exploit known logical flaws in client software.

CERTIFICATION OBJECTIVE 5.02
Trusted OS
The concept of a trusted operating system has been around since even before the days of the DoD Trusted Computer System Evaluation Criteria, known as the “Orange Book.” In the early days of computer security, the belief was that if a trusted computing base (TCB) could be built, it would be able to prevent security issues from occurring. In other words, if we could just build a truly secure computer system, we could eliminate the issue of security problems. Although this sounds like a reasonable goal, the reality of the situation quickly asserted itself—that is, no matter how secure we think we have made the system, something always seems to happen that allows a security event to occur. The discussion turned from attempting to create a completely secure computer system to creating a system in which we can place a certain level of trust. Thus, the concept behind the Orange Book in which different levels were defined related to varying levels of trust that could be placed in systems certified at those levels.
The Orange Book, although containing many interesting concepts that are as valid today as they were when the document was created, has been replaced by other criteria used in the evaluation of computer systems and components. Most notably is the Common Criteria, which is a multinational program in which evaluations conducted in one country are accepted by others subscribing to the tenets of the Common Criteria as well. At the core of both the Orange Book and the Common Criteria is this concept of building a computer system or device in which we can place a certain amount of trust and thus feel more secure about the protection of our systems and the data they process. The problem with this concept is that common operating systems have evolved over the years to maximize ease of use, performance, and reliability. The desire for a general-purpose platform on which to install and run any number of other applications does not lend itself to a trusted environment in which high assurance often equates to a more restrictive environment. This leads to a generalization that if you have an environment requiring maximum flexibility, a trusted platform is not the way to go.
In general, somebody wanting to utilize a trusted operating system probably has a requirement for a multilevel environment. Multilevel security is just what its name implies. On the same system you might, for example, have users who have Secret clearance as well as others who have Top-Secret clearance. You will also have information that is Secret and other information that is Top-Secret stored on the system. The operating system is going to have to ensure that individuals who have only a Secret clearance are never exposed to information that is Top-Secret. Implementation of such a system requires a method to provide a label on all files (and a similar mechanism for all users) that declares the security level of the data. The trusted operating system will have to make sure that information is never copied from a document labeled Top-Secret to a document labeled Secret because of the potential for disclosing information. In the Common Criteria, the requirements for implementing such a system is described in the Labeled Security Protection Profile. In the older Orange Book, this level of security was enabled through the implementation of Mandatory Access Control (MAC). Some vendors have gone through the process of obtaining a certification verifying compliance with the requirements for multilevel security, resulting in products such as Trusted Solaris. Other products have not gone through the certification, but may still provide an environment of trust allowing for this level of separation. An example of this is SELinux.
Microsoft, which has seen many vulnerabilities discovered in its Windows operating systems, attempted to address this issue of trust with its Next-Generation Secure Computing Base (NGSCB) effort. This effort highlighted what has been stated about trusted platforms because it offered users the option of a more secure computing environment, but this came at the expense of giving up a level of control as to what applications and files could be run on an NGSCB PC. The Microsoft initiative was announced in 2002 and given the code name Palladium. It would have resulted in a secure “fortress” designed to provide enhanced data protection while ensuring digital rights management and content control. Two years later, Microsoft announced it was shelving the project because of waning interest from consumers, but then turned around and said it wasn’t dead completely but was just not going to take as prominent a role.
A little clarification is important at this point. Another term that is often heard related to the subject of trusted computing is trustworthy computing. The two are not the same. A trusted system is one in which a failure of the system will break the security policy upon which the system was designed. A trustworthy system, on the other hand, is one that will not fail. Trustworthy computing is not a new concept, but it has taken on a larger presence due to the Microsoft initiative by the same name. This initiative is designed to help instill more public trust in the company’s software by focusing on the four key pillars of security, privacy, reliability, and business integrity.
Make sure you understand the concept of multilevel security; it is not simply implemented by normal access control mechanisms, such as is seen in most Windows- and Unix-based operating systems. Multilevel security implements multiple classification levels, and the operating system has to maintain separation between these levels of all data and users.
CERTIFICATION OBJECTIVE 5.03
Endpoint Security Software
Endpoint security refers to an approach to security in which each device (that is, endpoint) is responsible for its own security. We have already discussed one such implementation of endpoint security: the host-based firewall. Instead of relying on a separate device connected to the network to perform all filtering functions for all systems on the network, the host-based firewall implements filtering at the endpoint. Often, other security mechanisms such as virtual private networks (VPNs) will make it harder for network security devices (such as intrusion detection systems) to do their job because the contents of packages will be encrypted. Therefore, if examination of the contents of a packet is important, it will need to be done at the endpoint. A number of very common software packages are also designed to push protection to the devices, such as anti-malware, antivirus, anti-spyware, and spam-filtering software. We will discuss each of these in greater detail.
Antivirus
Antivirus software is designed specifically to prevent virus infection or, barring that, to detect an infected file and to hopefully remove the infection. A computer virus is a program that replicates itself by attaching to other programs. Then, when these other programs are run, the virus is invoked and will attempt to spread. Not all viruses have a malicious intent, but most do.
Antivirus programs can accomplish their goal in a number of ways. One way, known as signature detection, has the antivirus package look for patterns of data known to e part of a virus. This works well for viruses that are already known and that do not evolve or change (the term polymorphic virus is used to describe viruses that modify themselves as they infect other programs in order to avoid signature-based antivirus programs). Another method to detect viruses that may have changed is to analyze code, allowing for slight variations of known viruses. This will generally allow the antivirus software to detect viruses that are a variant of an older virus—this is actually very common—and new viruses that have not been seen before are often referred to as zero-day (or 0-day) viruses or threats. This method is often referred to as heuristic-based detection. Another method is to actually attempt to predict what a file will do by running it in a sandbox to see how it acts. A sandbox is a tightly controlled environment that only allows certain access by the program to control the potential for undesirable activity. If the code attempts to do anything that appears to be malicious, an alarm is generated and the program is either deleted or quarantined. If no malicious activity is detected, the file is allowed. This method is sometimes referred to as file emulation. Because virus detection is an inexact science, two possible types of errors can occur. A false-positive error is one in which the antivirus program decides that a certain file is malicious when, in fact, it is not. A false-negative occurs when the antivirus software decides that a file is safe when it actually does contain malicious content. Obviously, the desire is to limit both of these errors. The challenge is to “tighten” the system to a point so that it catches all (or most) viruses while rejecting as few benign programs as possible.
When selecting an antivirus vendor, one important factor to consider is how frequently the database of virus signatures is updated. With variations of viruses and new viruses occurring on a daily basis, it is important that your antivirus software uses the most current list of virus signatures in order to stand a chance of protecting your systems. Most antivirus vendors offer signature updating for some specified initial period of time. At the conclusion of this period, a renewal will be required in order to continue to obtain information on new threats. Although it is tempting to let this ongoing expense lapse, it is not generally a good idea because your system would then only be protected against viruses that are known up to the point when you quit receiving updates.
A common question to ask is, how effective is antivirus protection? The effectiveness varies between specific vendors, but against known viruses, tests have shown that most antivirus software has performed between 80- and 99-percent effective in detecting viruses. Against zero-day threats, the results have been much less spectacular, with effectiveness falling below 50 percent.
As a final note, many programs that are advertised as antivirus software will often actually detect more than just viruses. As technology has advanced, the need to detect other common threats, including worms, Trojan horses, spyware, adware, and rootkits, has led to newer technologies including anti-spyware and anti-malware.
Anti-spyware
Spyware is a special breed of malicious software. It is designed to collect information about the users of the system without their knowledge. The type of information that may be targeted by spyware includes Internet surfing habits (sites that have been visited or queries that have been made), user IDs and passwords for other systems, and personal information that might be useable in an identity theft attempt.
A special type of spyware is keyloggers. A keylogger will record all keystrokes that an individual makes, thus providing an exact image of the activity of the user. Although keyloggers are often part of malicious software installed on a system as a result of an individual running a program or clicking a link that they should not have, keyloggers can also be installed by the owner of a computer in order to monitor employees or other individuals who use the system.
Anti-spyware is designed to perform a similar function to antivirus software, except its purpose is to prevent, or detect and remove, spyware infections. A well-known example of anti-spyware software is Windows Defender, which can be downloaded from Microsoft. Anti-spyware software can be employed in a real-time mode to prevent infection by scanning all incoming data and files, attempting to identify spyware before it can be activated on the system. Alternatively, anti-spyware software can be run periodically to scan all files on your system in order to determine if it has already been installed. It will concentrate on operating system files and installed programs. Similar to antivirus software, anti-spyware software looks for known patterns of existing spyware. As a result, anti-spyware software also relies on a database of known threats and requires frequent updates to this database in order to be most effective. Some anti-spyware software does not rely on a database of signatures but instead scans certain areas of an operating system where spyware often resides.
Writers of spyware have gotten clever in their attempts to evade anti-spyware detection. Some now have a pair of programs that run (if you were not able to prevent the initial infection) and monitor each other so that if one of the programs is killed, the other part of the pair will immediately respawn it. Some spyware also watches special operating system files (such as the Windows Registry), and if the user attempts to restore certain keys the spyware has modified or attempts to remove registry items it has added, it will quickly set them back again. One trick that may help in removing persistent spyware is to reboot the computer in safe mode and then run the anti-spyware package to allow it to remove the installed spyware.
Anti-malware
The term malware is short for malicious software and encompasses a number of different pieces of programming designed to inflict damage on a computer system or its data, to deny use of the system or its resources to authorized users, or to steal sensitive information that may be stored on the computer. Malware includes viruses, worms, Trojan horses, keystroke loggers, spyware, and other malicious software. Malware is not the same thing as defective software or software containing errors in it. A security vulnerability that is a result of poor programming practices may result in loss of data, or a program written incorrectly that destroys data inadvertently is not considered malware because the intent of the software was not to cause these problems. Instead, software of this sort is just bad software.
For malware to be effective, its nefarious purpose generally needs to be hidden from the user. This can be done by attaching the malware to another program (which is what a virus does) or it can be part of the program itself, but just hidden (such as a Trojan horse). One of the things that malware will often do is to attempt to replicate itself (in the case of worms and viruses, for example) and often the nefarious purpose may not immediately manifest itself so that the malware can accomplish maximum penetration before it performs its destructive purpose.
In order to combat these security threats, security vendors have created software packages designed to prevent infection of a system, or to detect an infection on a system and to remove it. Obviously the preferred route is to prevent infection in the first place. Anti-malware packages that are designed to prevent installation of malware on a system provide what is known as real-time protection because in order to prevent infection it must spot an attempt to infect a system and prevent it from occurring. Anti-malware packages designed to detect and remove malware will scan the computer system, examining all files and programs, including important operating system files (such as the Registry in Windows-based systems). Real-time protection requires the anti-malware package be run continuously, whereas detect-and-remove anti-malware packages can be run on an occasional basis.
Know the different types of malware and the different software applications that will defend against them. Not all products will protect against all types of malware. Some may be designed to protect against spyware, others viruses, and still others may do both.
Spam Filters
Spam is the term used to describe unsolicited bulk e-mail messages. It is also often used to refer to unsolicited bulk messages sent via instant messaging, Usenet newsgroups, blogs, or any other method that can be used to send a large number of messages. E-mail spam is also sometimes referred to as unsolicited bulk e-mail (UBE). It frequently contains commercial content, and this is the reason for sending it in the first place—for quick, easy mass marketing. Increasingly today, e-mail spam is sent using botnets, which are networks of compromised computers that are referred to as bots or zombies. The bots on the compromised systems will stay inactive until they receive a message that activates them, at which time they can be used for mass mailing of spam or other nefarious purposes such as a denial-of-service attack on a system or network. Networks of bots (referred to as botnets) can include thousands or even tens of thousands of computer systems.
Spam is generally not malicious but rather is simply annoying, especially when numerous spam e-mail messages are received daily. Preventing spam from making it to your inbox so that you don’t have to deal with it is the goal of spam filters. Spam filters are basically special versions of the more generic e-mail filters. Spam filtering can be accomplished in several different ways. One simple way is to look at the content of the e-mail and search for special keywords that are often found in spam (such as various drugs that are commonly found in mass-mailing advertising such as Viagra and Cialis). The problem with keyword searches is the issue discussed before of false positives. Filtering on the characters “cialis” would also cause an e-mail with the word specialist to be filtered because the letters are found within it. Users are generally much more forgiving of an occasional spam message slipping through the filter rather than having valid e-mail filtered, so this is a critical issue. Usually, when an e-mail has been identified as spam, it will be sent to a special “quarantine” folder. The user can then periodically check the folder to ensure that legitimate e-mail has not been inadvertently filtered.
Another method for filtering spam is to keep a “black list” of sites that are known to be friendly to spammers. If e-mail is received from an IP address for one of these sites, it will be filtered. The lists may also contain known addresses for botnets that have been active in the past. An interesting way to populate these blacklists is through the use of spamtraps. These are e-mail addresses that are not real in the sense that they are not assigned to a real person or entity. They are seeded on the Internet so that when spammers attempt to collect lists of e-mail addresses by searching through websites and other locations on the Internet for e-mail addresses, these bogus e-mail addresses are picked up. Any time somebody sends an e-mail to them, because they are not legitimate addresses, it is highly likely that the e-mail is coming from a spammer and the IP address from which the e-mail was generated can be placed on the black list.
One note for users: It highly recommended that you never respond to a spam e-mail. Responding to such an e-mail provides confirmation to the spammer that the e-mail address is legitimate and is being used by a legitimate user who is reading the e-mail. Individuals who want to avoid having their e-mail harvested from websites can use a method such as modifying their address in such a way that human users will quickly recognize it as an e-mail but automated programs may not. An example of this for a user with the e-mail of [email protected] might be john(at) abcxyzcorp(dot)com.
The more generic e-mail filters can be used to block spam but also other incoming, or outgoing, e-mails. They may block e-mail from sites known to send malicious content (such as viruses), may block based on keywords that might indicate that the system is being used for other-than-official purposes, or could filter outgoing traffic based on an analysis of the content to ensure that sensitive company data is not sent (or at least not sent in an unencrypted manner).

One method that spammers use to slip words by filters that check for keywords is to not include text in the body of the e-mail but rather take a screen capture of the advertisement and include it as an image. Doing this means that the filter simply sees the body as including an image. Some organizations address this by not allowing pictures in the body of incoming e-mail messages, but filtering based on this alone may result in false-positive errors.
CERTIFICATION OBJECTIVE 5.04
Host Hardening
Implementing a series of endpoint security mechanisms as described in the previous section is one approach to securing a computer system. Another, more basic approach is to conduct host-hardening tasks designed to make it harder for attackers to successfully penetrate the system. Often this starts with the basic patching of software, but before attempting to harden the host, the first step should be to identify the purpose of the system—what function does this system provide? Whether the system is a PC for an employee or a network server of some sort, before you can adequately harden the system, you need to know what its intended purpose is. There is a constant struggle between usability and security. In order to determine what steps to take, you have to know what the system will be used for—and possibly of equal importance, what it is not intended to be used for. Defining the standard operating environment for your organization’s systems is your first step in host hardening. This allows you to determine what services and applications are unnecessary and can thus be removed. In addition to unnecessary services and applications, similar efforts should be made when hardening a system to identify unnecessary accounts and to change the names and passwords for default accounts. Shared accounts should be discouraged, and if possible two-factor authentication can be used. An important point to remember is to always use encrypted authentication mechanisms. The access to resources should also be carefully considered in order to protect confidentiality and integrity. Deciding who needs what permissions is an important part of system hardening. This extends to the limiting of privileges, including restricting who has root or administrator privileges and more simply who has write permissions to various files and directories.
Standard Operating Environment
It is generally true that the more secure a system is, the less useable it becomes. This is true if for no other reason than hardening your system should include removing applications that are not needed for the system’s intended purpose, which, by definition, means that it is less useable (because you will have removed an application).
If you’ve done a good job in determining the purpose for the system, you should be able to identify what applications and which users need access to the system. Your first hardening step will then be to remove all users and services (programs/applications) not needed for this system. An important aspect of this is identifying the standard environment for employees’ systems. If an organization does not have an identified standard operating environment (SOE), administrators will be hard pressed to maintain the security of systems because there will be so many different existing configurations. If a problem occurs requiring massive re-imaging of systems (as sometimes occurs in larger security incidents), organizations without an identified SOE will spend an inordinate amount of time trying to restore the organization’s systems and will most likely not totally succeed. This highlights another advantage of having an SOE—it greatly facilitates restoration or re-imaging procedures.
A standard operating environment will generally be implemented as a disk image consisting of the operating system (including appropriate service packs and patches) and required applications (also including appropriate patches). The operating system and applications should include their desired configuration. For Windows-based operating systems, the Microsoft Deployment Toolkit (MDT) can be used to create deployment packages that can be used for this purpose. An example of an SOE is the United States Government Configuration Baseline (USGCB), maintained by NIST. The purpose of this baseline is to create security configuration baselines for widely deployed products in federal agencies. A baseline such as the USGCB provides a starting point from which your organization can adapt to meet your own circumstances and requirements.
A key concept to remember is to limit the services available on a system. This is true no matter what the operating system is. The more services that are available (and the more applications that are running), the more vulnerabilities you will need to be concerned with because each application may have one or more vulnerabilities that can be exploited. If you don’t need a specific service, don’t keep it around; otherwise, you may be needlessly exposing your system to possible exploitation.
Security/Group Policy Implementation
Group Policy is a feature of Windows-based operating systems. It is a set of rules that provides for centralized management and configuration of the operating system, user configurations, and applications in an Active Directory environment. The result of a Group Policy is to control what users are allowed to do on the system. From a security standpoint, Group Policy can be used to restrict activities that could pose possible security risks, limit access to certain folders, and disable the ability for users to download executable files, thus protecting the system from one avenue through which malware can attack. The Windows Vista operating system introduced 2,400 Group Policy settings, including ones addressing items such as power management and settings for printers, Internet Explorer, and security. The security settings include nine different types: Account Policies, Local Policies, Event Log, Restricted Groups, Systems Services, Registry, File System, Public Key Policies, and Internet Protocol Security Policies on Active Directory. The Group Policy Management Console (GPMC) provides a method to manage all aspects of Group Policy and is in fact the primary access point to Group Policy. The GPMC provides the capability to perform functions such as importing and exporting Group Policy Objects (GPOs), copying and modifying GPOs, and backing up and restoring GPOs.
With Windows 7, over 150 new standard policy settings were made available to administrators, and Group Policies can be managed from the Windows PowerShell command line. This is also available in Windows Server 2008 R2. The System Starter GPOs that are now included in Windows Server 2008 R2 and Windows 7 are read-only starter GPOs that provide a baseline of recommended Group Policy settings for a specific scenario. Together, these all serve to provide more generic capabilities for these systems from the start.
System Starter GPOs are available for several scenarios for Windows Server 2008. These include Windows Vista Enterprise Client, Windows Vista Specialized Security Limited Functionality Client, Windows XP Service Pack 2 Enterprise Client, and Windows XP SP2 Specialized Security Limited Functionality Client. They provide a baseline of recommended settings for these different scenarios and can greatly reduce the time required to create your organization’s Group Policy Objects.
Command Shell Restrictions
Restricting the ability of users to perform certain functions can help ensure that they don’t deliberately or inadvertently cause a breach in system security. This is especially true for operating systems that are more complex and provide greater opportunities for users to make a mistake. One very simple example of restrictions placed on users is those associated with files in UNIX-based operating systems. Users can be restricted so that they can only perform certain operations on files, thus preventing them from modifying or deleting files that they should not be tampering with. A more robust mechanism used to restrict the activities of users is to place them in a restricted command shell.
A command shell is nothing more than an interface between the user and the operating system providing access to the resources of the kernel. A command-line shell provides a command-line interface to the operating system, requiring users to type the commands they want to execute. A graphical shell will provide a graphical user interface for users to interact with the system. Common UNIX command-line shells include the Bourne shell (sh), Bourne-Again shell (bash), C shell (csh), and Korn shell (ksh).
A restricted command shell will have a more limited functionality than a regular command-line shell. For example, the restricted shell might prevent users from running commands with absolute pathnames, keep them from changing environment variables, and not allow them to redirect output. If the bash shell is started with the name rbash or if it is supplied with the --restricted or -r option when run, the shell will become restricted—specifically restricting the user’s ability to set or reset certain path and environment variables, redirect output using the “>” and similar operators, to specify command names containing slashes, and to supply filenames with slashes to various commands.
Warning Banners
Warning banners do not actually harden the host like the other mechanisms discussed that make it harder for attackers to gain unauthorized access to the system or its resources or to force the system to perform certain activities. They are, nonetheless, important elements of an organization’s security program and play an important role. A warning banner is simply a short statement alerting individuals (authorized or unauthorized) of what is considered proper use of the system, that the system is subject to monitoring (if it is), what the expectation of privacy is for users of the system (generally no expectation of privacy), and that improper use of the system may result in prosecution. For government systems, it is a requirement that a warning banner be used, and for other environments the banner serves to provide some weight to any legal procedures taken against individuals who may violate security policies or who gain unauthorized access to the system. Because the banners are designed to provide a legal notification and warning, care should be taken to not have them appear as “welcome” messages, which could be misconstrued as inviting individuals to, in fact, access the system. An example of the type of banner that is often used follows, taken from a Department of Commerce instruction on Screen Warning Banners:
“This is a (Agency) computer system. (Agency) computer systems are provided for the processing of Official U.S. Government information only. All data contained on (Agency) computer systems is owned by the (Agency) and may be monitored, intercepted, recorded, read, copied, or captured in any manner and disclosed in any manner, by authorized personnel. THERE IS NO RIGHT OF PRIVACY IN THIS SYSTEM. System personnel may give to law enforcement officials any potential evidence of crime found on (Agency) computer systems. USE OF THIS SYSTEM BY ANY USER AUTHORIZED OR UNAUTHORIZED CONSTITUTES CONSENT TO THIS MONITORING, INTERCEPTION, RECORDING, READING, COPYING, OR CAPTURING AND DISCLOSURE.”
The capitalized, italicized, and underlined sections in this example are as the Department of Commerce provided in its guidance. The guidance also specifically stated that the use of the word welcome anywhere in a banner should be removed so as not to imply authorization to be used by anyone and to allow for “easier prosecution.” Notice how the warning banner covers all of the points mentioned earlier, namely: 1) the system is for processing of U.S. Government information only (that is, this is the purpose of this system), 2) individuals using the system have no right to privacy, and 3) use of the system (by either authorized or unauthorized individuals) constitutes consent to monitoring.
As a final note, banners also act like signs that warn of the presence of a guard dog, surveillance cameras, or other physical security mechanisms. The sign may in fact deter individuals from attempting to gain access to a guarded facility (or in the case of computer banners, access to the computer system or network) because they realize they stand a good chance of being caught.
Restricted Interfaces
The idea behind a restricted interface is to limit the types of things a user can do and thus restrict the potential the user may have of circumventing some security feature. As previously mentioned, interfaces can be command line or graphical in nature. In either case, the interface provided to the user (such as was discussed with the rbash example) can be limited to only allow certain activities. Applications generally have an interface provided that will allow the user to interact with the application program in some specific, and limited, manner. As another example, starting with Windows Server 2003, the RestrictRemoteClients Registry key was added to eliminate remote anonymous access to Remote Procedure Call (RPC) interfaces on the system.
CERTIFICATION OBJECTIVE 5.05
Asset Management (Inventory Control)
Asset management encompasses the business processes that allow an organization to support the entire life cycle of the organization’s assets (such as the IT and security systems). This covers a system’s entire life, from acquisition to disposal, and acquisition covers not just the actual purchase of the item, but the request, justification, and approval process as well. For software assets, it also includes software license management and version controls (to include updates and patches for security purposes).
An obvious reason for implementing some sort of asset management system is to gain control of the inventory of systems and software. There are other reasons as well, including increasing accountability to ensure compliance (with such things as software licenses, which may limit the number of copies of a piece of software that the organization can be using) and security (consider the management controls needed to ensure that a critical new security patch is installed). From a security standpoint, knowing what hardware the organization owns and what operating systems and applications are running on them is critical to being able to adequately protect the network and systems. Imagine that a new vulnerability report is released providing details on a new exploit for a previously unknown vulnerability. A software fix that can mitigate the impact has been developed. How do you know whether this report is of concern to you if you have no idea what software you are running and where in the organization it resides?
The components of an inventory control or asset management system include the software to keep track of the inventory items, possibly wireless devices to record transactions at the moment and location at which they occur, and a mechanism to tag and track individual items. Common methods of tagging today include barcodes or Radio-Frequency Identification (RFID) or barcode tags. Such tags have gone a long way toward increasing the speed and accuracy of physical inventory audits. RFID tags are more expensive than barcodes but have the advantage of not needing a line-of-sight to be able to read them (in other words, a reader doesn’t have to actually see the RFID tag in order to be able to read it, so it can be placed in out-of-the-way locations on assets).
As a final note, the database of your software and hardware inventory is going to be critical for you to manage the security of your systems, but it could also be an extremely valuable piece of information for others as well. Obviously, vendors would love to know what you have in order to try and sell you other/additional products, but more importantly, attackers would love to have this information to make their lives easier because your database would give them a good start on identifying possible vulnerabilities to attempt to exploit. Because of this, you should be careful to protect your inventory list. For those who need or are interested in assistance with their inventory management, there are software products on the market that assist in automating the management of your hardware and software inventory.
A good inventory control system is often overlooked from a security perspective, but it shouldn’t be. It is absolutely critical that you know what hardware and software your organization is using. Without this knowledge, if a new vulnerability is announced, you will have no way of knowing if you need to be concerned about it.
CERTIFICATION OBJECTIVE 5.06
Data Exfiltration
We briefly discussed data exfiltration earlier. Basically, data exfiltration, which may also be call data extrusion, is the unauthorized transfer of information from (out of) a computer. Most of the attention in computer security is focused on preventing attackers from gaining unauthorized access to your systems, but what happens if they are successful? Data exfiltration is an attempt to limit the damage that can be caused to your organization by limiting the information that can be removed from your system. It can also apply to authorized users (that is, “insiders”) who may also be attempting to remove information from your system in an unauthorized manner. Attackers, once they gain access to a system, may be inside for months before they are detected. During this time, they will attempt to gain access to valuable data such as credit card or banking information. It may in fact be the downloading of large files containing such information that tips off an organization to the fact that they have been penetrated. In one well-known case called “Night Dragon,” attackers were able to gain access to sensitive internal desktops and servers at several global oil, energy, and petrochemical companies. They enabled direct communication from these machines to the Internet and then downloaded e-mail archives and other sensitive documents.
Obviously, we would like to prevent an attack from being successful, but we must also plan for the possibility that our efforts to prevent intrusions will fail. Our efforts should then turn to methods to prevent data loss (also known as data leakage prevention), which can be accomplished through content monitoring. If done correctly, data loss prevention through content monitoring can catch both inadvertent and intentional exposure of sensitive information. One way this is accomplished is by performing packet inspections on network transmissions including e-mail and web traffic. It is important to look not just at the header information, but the content of the packets to see what it is that is being transferred out of the system. Key words and patterns (such as a series of 10-digit numbers that might indicate social security numbers are being sent) can be looked for in the contents of the packets to spot sensitive information that is being transmitted. Also, simply paying attention to the size of files that are being sent may alert an organization to the transfer of large databases or files containing sensitive information. If an individual wants to avoid detection via electronic monitoring for data loss, one technique is to simply encrypt the file before it is sent out. This prevents the key word detection method, and although the transfer of a large file may be noted, its contents would not be known. If an individual wants to avoid having the target for sending a file to remain unknown, then posting it to a special social media site set up for this purpose, or to a blog site, will allow for somebody to download it later without the organization knowing where the document was sent to. In actual studies of cases of data exfiltration, the use of encrypted channels for data extraction were rare. Much more common was the use of services such as FTP and HTTP. Most frequently used was the remote access application that had been exploited to gain initial entry to the system.
Data exfiltration is not limited to network transmissions. A large document can also be printed and carried out of a facility. Alternatively, a document can be stored on a USB storage device or burned to a CD or DVD and then taken from the organization. Detecting data loss via these routes can be quite a bit harder, especially if the document is limited in size to a single page or just a few pages. The person wishing to remove the data from the organization doesn’t even have to leave with the printed page if a fax machine is available in the organization. Preventing the loss of data due to employees trying to get the information out can be very difficult and ultimately will depend on personnel security measures.
Covert Channels
An interesting topic included in discussions on data exfiltration is the concept of convert channels. Covert channels are mechanisms used to transmit information using methods not originally intended for data transmission. An example might be the service load of a program upon a system. Consider a system in which one individual was not allowed access to a file that another individual did have. The authorized individual wants to send the file to the unauthorized individual but doesn’t want normal system logging or monitoring to detect the transfer. If at specific intervals the system load is checked, and if the load at the time checked is at or near 100 percent, this could represent a “1.” If it is not at or near 100 percent, it could represent a “0.” Over an extended period of time, the entire contents of the file could be passed from the authorized user to the unauthorized user by transmitting the file one bit at a time via this system-load scheme, with the unauthorized user checking the system load at prearranged time intervals. This would be an example of a covert timing channel. Another type of covert channel involves writing to a storage location not normally used for transmission of information (for example, using filenames to transfer information). This is known as a covert storage channel. Another example might be the use of unused fields in packet headers to transmit information. Because the field as defined for the protocol is unused, whatever is placed in it will be ignored by other systems.
Elimination of a potential covert channel can be very difficult and basically is the responsibility of the developer of a system. Careful design, coding, and testing can help to ensure that the possibility of a covert channel is minimized. Detection of the use of a covert channel can also be extremely difficult because the existence of the channel (such as the system-load covert timing channel previously discussed) does not mean that anybody is exploiting it. Careful monitoring and profiling of a system can help to identify abnormal behavior, which might indicate that a covert channel is being used. Because other methods of data exfiltration are so much easier to exploit, and can also be very difficult, covert channels are generally not on the top of security administrators lists of security issues to be concerned about. Many other issues should be addressed first.
Covert channels are a very interesting aspect of computer security, but they are not something most can do much about. Know what they are, know how they can be utilized for data exfiltration, but realize that there is not much you can do about them once a system is deployed—this is really an issue of design, development, and testing.
Steganography
A somewhat related field to covert channels is the concept of steganography. Covert channels are methods used to hide the transmission of information between two parties. Steganography is the technique of hiding messages (data) in plain sight, such that nobody but the sender and the receiver even suspects that a message was sent. This is different from cryptography, which effectively hides a message, but the fact that a hidden message is being sent is obvious because you can see the encrypted message. An encrypted e-mail, for example, will appear as a bunch of scrambled text and special characters. It is obvious that something is there—you just don’t know what it is. Steganography, on the other hand, is used to pass a message between two parties in a manner such that another observer would not realize that a message was sent. This has the advantage over cryptography of not arousing suspicion because it is not obvious that a secret message was transmitted. An example of this might be the sentence “Sandy enjoyed long lists of fanciful fall shoes, handbags, and rings entered sequentially” found in an e-mail. Although the sentence is somewhat interesting, depending on what else was in the e-mail it could easily go unnoticed. If, however, you take the first letter of each word in the sentence, you would have the message “sell off shares.” This is an example of a message hidden in plain sight and example of one type of steganography.
The best known method to hide data electronically is to hide information with image files, although any sort of file can be used, including audio and text. A common technique to do this is to take the least significant bit for each pixel and alter it to send a message one bit at a time. Because we are altering the least significant bit of a picture, pixels are changed only in a very small way—one that is generally not discernable with the human eye. With the size of images today, a considerable amount of information can be hidden inside of a picture. Detecting a steganographic image is extremely challenging, and determining what is contained in the image is even more challenging—especially because the message itself could also be encrypted before it is hidden inside the image. For those interested in seeing how this process works, a number of steganographic tools are available on the Internet. A related topic to steganography is the use of digital watermarks to authenticate the source of a document or image. Sometimes, the first indication that you may be losing information through data exfiltration via steganography will be the discovery of steganographic tools on a system. Again, as in the case of covert channels, because there are so many other easier ways to transmit data, steganography should not be on the top of your list of security concerns. It is something you should be aware of, however.
CERTIFICATION OBJECTIVE 5.07
HIPS/HIDS
Earlier we discussed the use of firewalls to block or filter network traffic to a system. Although this is an important security step to take, it is not sufficient to cover all situations. Some traffic may be totally legitimate based on the firewall rules you set, but may result in an individual being able to exploit a vulnerability within the operating system or an application program. Firewalls are prevention technology; they are designed to prevent a security incident from occurring. Intrusion detection systems (IDSs) were initially designed to detect when your prevention technologies failed, allowing an attacker to gain unauthorized access to your system. Later, as IDS technology evolved, these systems became more sophisticated and were placed in-line so that they did not simply detect when an intrusion occurred but rather could prevent it as well. This led to the development of intrusion prevention systems (IPSs).
Early IDS implementations were designed to monitor network or system activity, looking for signs that an intrusion had occurred. If one was detected, the IDS would notify administrators of the intrusion, who could then respond to it. Two basic methods were used to detect intrusive activity. The first, anomaly-based detection, is based on statistical analysis of current network or system activity versus historical norms. Anomaly-based systems build a profile of what is normal for a user, system, or network, and any time current activity falls outside of the norm, an alert is generated. The type of things that might be monitored include the times and specific days a user may log into the system (for example, do they ever access the system on weekends or late at night?), the type of programs a user normally runs, the amount of network traffic that occurs, specific protocols that are frequently (or never) used, and what connections generally occur. If, for example, a session is attempted at midnight on a Saturday, when the user has never accessed the system on a weekend or after 6:00 P.M., this might very well indicate that somebody else is attempting to penetrate the system.
The second method to accomplish intrusion detection is based on attack signatures. A signature-based system relies on known attack patterns and monitors for them. Certain commands or sequences of commands may have been identified as methods to gain unauthorized access to a system. If these are ever spotted, it indicates that somebody is attempting to gain unauthorized access to the system or network. These attack patterns are known as signatures, and signature-based systems have long lists of known attack signatures that they monitor for. The list will occasionally need to be updated to ensure that the system is using the most current and complete set of signatures.
Advantages and disadvantages are associated with both types of systems, and some implementations actually combine both methods in order to try and cover all possible avenues of attack. Signature-based systems suffer from the tremendous disadvantage that they, by definition, must rely on a list of known attack signatures in order to work. If a new vulnerability is discovered (a 0-day exploit), there will not be a signature for it and therefore signature-based systems will not be able to spot it. There will always be a lag between the time a new vulnerability is discovered and the time when vendors are able to create a signature for it and push it out to their customers. During this period of time, the system will be at risk to an exploit taking advantage of this new vulnerability. This is one of the key points to consider when evaluating different vendor IDS and IPS products—how long does it take them to push out new signatures?
Because anomaly-based systems do not rely on a signature, they have a better chance of detecting previously unknown attacks—as long as the activity falls outside of the norm for the network, system, or user. One of the problems with systems that strictly use anomalous activity detection is that they need to constantly adapt the profiles used because user, system, and network activity changes over time. What may be normal for you today may no longer be normal if you suddenly change work assignments. Another issue with strictly profile-based systems is that a number of attacks may not appear to be abnormal in terms of the type of traffic they generate and therefore may not be noticed. As a result, many systems combine both types so that all the aforementioned advantages can be use to create the best-possible monitoring situation.
IDS and IPS also have the same issues with false-positive and false-negative errors as was discussed before. Tightening an IDS/IPS so that it will spot all intrusive activity, so that no false-negatives occur (that is, so no intrusion attempts go unnoticed) means that the number of false-positives (that is, activity identified as intrusive that in actuality is not) will more than likely increase dramatically. Because an IDS generates an alert when intrusive activity is suspected and because an IPS will block the activity, falsely identifying valid traffic as intrusive will cause either legitimate work to be blocked or an inordinate number of alert notifications that administrators will have to respond to. Frequently, when the number of alerts generated is high, and most turn out to be false-positives, administrators will get into the extremely poor habit of simply ignoring the alerts. Tuning your IDS/IPS for your specific environment is therefore an extremely important activity.
Just as we discussed in the case of firewalls, an IDS or IPS can be placed in various places. One of them is on the host itself. When they are installed at this level, they are known as host-based intrusion detection systems (HIDSs) or host-based intrusion prevention systems (HIPSs). Some of the original IDSs were HIDSs because they were run on large mainframe computers before the use of PCs became widespread. In addition to monitoring network traffic to and from the system, an HIDS/HIPS may also monitor the programs running on the host and the files that are being accessed by them. It may also monitor regions of memory to ensure only appropriate areas have been modified, and may also keep track of specific information on files, including generating a checksum or hash for them to determine if they have been modified. It is interesting to note that due to its function, an HIDS/HIPS may itself become the object of an intruder who wants to go unnoticed and therefore may attempt to modify the HIDS/HIPS and its data. In addition to human intruders, an HIDS/HIPS may also be useful in detecting and preventing certain types of malware from adversely impacting the host.
CERTIFICATION OBJECTIVE 5.08
NIPS/NIDS
In addition to host-based IDS and IPS, another place where these devices can be located is on the network. Systems deployed in this manner are known as network-based intrusion detection systems (NIDS) and network-based intrusion prevention systems (NIPS). A common question asked is, which type of system should be used, an NIPS/NIDS or HIPS/HIDS? The answer depends on your environment, because each has its advantages and disadvantages. A host-based system is focused on what is happening on and to the host it is monitoring. As such, it will not notice what is going on in the network in general. A network-based system, on the other hand, will have a “bird’s-eye view” of what is going on overall in the network but will not see what is actually occurring within each of the individual hosts. So, for example, an intruder that attempts a single login using a known default user ID/password combination on a host before trying it on all other hosts in a network will probably not be noticed (because systems are often not tuned to alert on single occurrences of failed logins) by an HIPS/HIDS, but an NIPS/NIDS could notice this activity occurring on all systems throughout the network. An NIPS/NIDS, on the other hand, has some of the same issues that firewalls do in terms of their effectiveness in the face of encrypted traffic. Detection of specific attacks that require inspection of the contents of network packets will not be successful if the packets are encrypted, but an HIPS/HIDS would have a chance of detecting the attack at the host level.
An NIPS/NIDS identifies intrusion attempts by examining network traffic, potentially looking at both the header and contents of packets that are being transmitted. It can monitor both inbound and outbound traffic. The reason for monitoring inbound traffic is obvious, but outbound traffic monitoring may also provide clues that a system on the network has been penetrated because it may detect signs of activity such as unusual downloading of large or sensitive files (the issue of data exfiltration, discussed previously).
A sample rule might follow the pattern of this example from Snort, a common Linux-based NIPS:
alert tcp any any -> any any (msg: “example howdy alert rule”; content: “howdy”)
In this example, we tell the system to generate an alert if it sees any TCP packet coming from any source IP address or port going to any source IP address or port where the word “howdy” is found in the contents of the packet. The message we’d like it to alert us with if the word is found is “example howdy alert rule.”
Where to place an NIPS/NIDS system is always an interesting question. Generally the discussion comes down to whether to place it inside the organization’s firewall (on the inside of the network), outside of the organization’s firewall (on the outside of the network), or in both locations. Placing the device on the outside of the firewall will mean that it can see all traffic destined for the network and will be able to see any attempted intrusive activity. It may also mean an extremely high number of alerts. Placing it on the inside of the firewall means that a certain amount of traffic will not be seen because the firewall will filter it. This will cut down on the number of alerts generated, but it also means that a number of attempted attacks will be missed that could provide early indicators of unusual interest in your organization’s network. Putting one on both sides and tuning them for their specific location, so as to look for specific types of traffic, will allow you to see all attempts without being overloaded with too many alerts.
Intrusion detecting/prevention systems are common security mechanisms employed today. You should know the different methods used to accomplish intrusion detection/prevention and the different locations where intrusion detection/prevention can take place. In particular, make sure you understand the strengths and weaknesses of each approach and for each location that an IDS/IPS can be deployed.
One of the best known and most common network intrusion detection/prevention system is Snort. Snort is an open-source product that combines both signature- and anomaly-based inspection. Although the program is open source, the all-important real-time database of rules is not. The official rules for Snort are generated by Sourcefire Vulnerability Team and distributed by subscription to their customers.

CERTIFICATION SUMMARY
In this chapter, we covered eight very important objectives on the CASP. All of these center around providing security controls at the individual host level. Whether the individual host being protected is an individual’s home computer or a user’s system in a corporation, there are certain basic protection mechanisms that can and should be employed. For corporations, additional security mechanisms should be considered.
You first learned about firewalls, which are used to monitor and filter dangerous traffic. Firewalls can be deployed at both the host and network level, with the basic principles of operation being the same wherever they are deployed.
The next objective covered the topic of trusted operating systems. The idea of providing a level of trust versus attempting to provide complete security was introduced. Basically, a completely secure (and yet still useable) system is not feasible. Instead, we want to implement systems where we provide a certain level of trust that the system will function as desired.
Next, we discussed a variety of mechanisms that can provide security at the “endpoint”—that is, the host. These mechanisms center around programs that look for and protect against a variety of malicious software (malware). Common packages included antivirus and anti-spyware filters.
The topic of hardening individual hosts was discussed next. Examples include command shell restrictions, restricted interfaces, and security/group policy implementation. The idea behind all these is to provide additional protection, and thus to “harden” individual hosts so that they are less likely to be penetrated.
The topic of asset management (inventory control) was also discussed because it involves the control of individual pieces of hardware and software. Although it may first appear that this is not a security-related topic, in order for any organization to effectively secure its many systems, it first must know what systems (hardware and software) it has.
Data exfiltration is an extremely important topic because the target of intruders is generally the data contained in a system. Should other security mechanisms fail to prevent an intruder from obtaining unauthorized access to your systems, you will want to have in place mechanisms that can prevent data from being lost, thus securing the most valuable asset—the information your systems process and store.
Finally, you learned about another common security tool that is used to detect and possible prevent intrusions from occurring. HIPS/HIDS and NIPS/NIDS are all part of the same category of devices and are designed to spot (and in the case of IPS, prevent) intrusive activity. As in the case of firewalls, these devices can be located at the network and the individual host levels.
 TWO-MINUTE DRILL
TWO-MINUTE DRILL
Host-based Firewalls
![]() Firewalls are devices designed to monitor traffic, allowing only certain types of traffic to pass.
Firewalls are devices designed to monitor traffic, allowing only certain types of traffic to pass.
![]() Firewalls can be located at the network or the individual host level.
Firewalls can be located at the network or the individual host level.
![]() A set of rules will govern what traffic is allowed to pass and what will be denied. The rules are processed sequentially.
A set of rules will govern what traffic is allowed to pass and what will be denied. The rules are processed sequentially.
![]() Common fields to base rules on include the source/destination IP address, the source/destination port, and the type of network traffic.
Common fields to base rules on include the source/destination IP address, the source/destination port, and the type of network traffic.
Trusted Operating Systems
![]() Frequently, the desire to have a trusted operating system is a result of the need for a multilevel security environment.
Frequently, the desire to have a trusted operating system is a result of the need for a multilevel security environment.
![]() A totally secure operating system is probably not feasible. Instead, we discuss how much trust we can place in the system.
A totally secure operating system is probably not feasible. Instead, we discuss how much trust we can place in the system.
![]() A trusted system is not the same thing as a trustworthy system. A trustworthy system is one that will not fail.
A trusted system is not the same thing as a trustworthy system. A trustworthy system is one that will not fail.
Endpoint Security Software
![]() Endpoint security refers to an approach to security in which each device (that is, endpoint) is responsible for its own security.
Endpoint security refers to an approach to security in which each device (that is, endpoint) is responsible for its own security.
![]() Antivirus software is designed specifically to prevent virus infection or, barring that, to detect an infected file and to hopefully remove the infection.
Antivirus software is designed specifically to prevent virus infection or, barring that, to detect an infected file and to hopefully remove the infection.
![]() Spyware is a special breed of malicious software designed to collect information about the users of the system without their knowledge.
Spyware is a special breed of malicious software designed to collect information about the users of the system without their knowledge.
![]() Preventing spam from making it to your inbox so that you don’t have to deal with it is the goal of spam filters. Spam filters are basically special versions of the more generic e-mail filters.
Preventing spam from making it to your inbox so that you don’t have to deal with it is the goal of spam filters. Spam filters are basically special versions of the more generic e-mail filters.
Host Hardening
![]() Before attempting to harden the host, the first step is to identify what is the purpose of the system—what function does this system provide?
Before attempting to harden the host, the first step is to identify what is the purpose of the system—what function does this system provide?
![]() A standard operating environment will generally be implemented as a disk image consisting of the operating system (including appropriate service packs and patches) and required applications (also including appropriate patches).
A standard operating environment will generally be implemented as a disk image consisting of the operating system (including appropriate service packs and patches) and required applications (also including appropriate patches).
![]() Group Policy is a feature of Windows-based operating systems. It is a set of rules that provides for centralized management and configuration of the operating system, user configurations, and applications in an Active Directory environment.
Group Policy is a feature of Windows-based operating systems. It is a set of rules that provides for centralized management and configuration of the operating system, user configurations, and applications in an Active Directory environment.
![]() Command shells can be restricted so as to limit the ability of users to perform certain functions that will help ensure they don’t deliberately or inadvertently cause a breach in system security.
Command shells can be restricted so as to limit the ability of users to perform certain functions that will help ensure they don’t deliberately or inadvertently cause a breach in system security.
![]() Warning banners do not actually harden the host like the other mechanisms discussed that make it harder for attackers to gain unauthorized access to the system or its resources.
Warning banners do not actually harden the host like the other mechanisms discussed that make it harder for attackers to gain unauthorized access to the system or its resources.
Asset Management (Inventory Control)
![]() Asset management encompasses the business processes that allow an organization to support the entire life cycle of the organization’s assets (such as the IT and security systems).
Asset management encompasses the business processes that allow an organization to support the entire life cycle of the organization’s assets (such as the IT and security systems).
![]() Knowing what hardware the organization owns and what operating systems and applications are running on them is critical to being able to adequately protect the network and systems.
Knowing what hardware the organization owns and what operating systems and applications are running on them is critical to being able to adequately protect the network and systems.
Data Exfiltration
![]() Data exfiltration, which may also be call data extrusion, is the unauthorized transfer of information from (out of) a computer.
Data exfiltration, which may also be call data extrusion, is the unauthorized transfer of information from (out of) a computer.
![]() Covert channels are mechanisms used to transmit information using methods not originally intended for data transmission. An example might be the service load of a program upon a system.
Covert channels are mechanisms used to transmit information using methods not originally intended for data transmission. An example might be the service load of a program upon a system.
HIPS/HIDS and NIPS/NIDS
![]() Intrusion detection systems (IDSs) were initially designed to detect when your prevention technologies failed, allowing an attacker to gain unauthorized access to your system.
Intrusion detection systems (IDSs) were initially designed to detect when your prevention technologies failed, allowing an attacker to gain unauthorized access to your system.
![]() Intrusion prevention systems (IPSs) are an outgrowth of IDS and are designed to not just detect intrusions, but as inline devices to prevent intrusions from happening.
Intrusion prevention systems (IPSs) are an outgrowth of IDS and are designed to not just detect intrusions, but as inline devices to prevent intrusions from happening.
![]() IDS and IPS can be either host-based (HIDS/HIPS) or network-based (NIDS/NIPS).
IDS and IPS can be either host-based (HIDS/HIPS) or network-based (NIDS/NIPS).
![]() Tuning your IDS/IPS is important to limit the number of false-positives (alerts generated when no intrusion actually occurred) while at the same time not allowing any intrusions to go unnoticed.
Tuning your IDS/IPS is important to limit the number of false-positives (alerts generated when no intrusion actually occurred) while at the same time not allowing any intrusions to go unnoticed.
SELF TEST
The following questions will help you measure your understanding of the material presented in this chapter. Read all the choices carefully because there might be more than one correct answer. Choose all correct answers for each question.
1. In a firewall, where should you place a “default” rule stating that any packet with any source/destination IP address and any source/destination port should be allowed?
A. It should be the first rule so that it will always be checked.
B. It doesn’t matter where it is placed as long as you have it in the rules somewhere.
C. You should never have a rule like this in your rule set.
D. It should be the last rule checked.
2. Which is a common firewall found and used on Linux-based machines?
A. iptables
B. Snort
C. Defender
D. Checkpoint
3. You need to generate a rule that allows web-destined traffic to pass through your firewall. Which of the following rules will do that?

4. An operating system is said to implement multilevel security if it:
A. Introduces multiple levels of authorization such that users must authenticate themselves every time they wish to access a file
B. Includes multiple layers of security, such as having both firewalls and intrusion detection/prevention systems built into it
C. Implements a system where information and users may have multiple levels of security and the system is trusted to prevent users from accessing information they are not authorized to see
D. Can be said to be both trustworthy and reliable
5. If you require a trusted operating system environment, as described in this chapter, which of the following operating systems might you consider deploying?
A. Windows 2008 Server
B. SELinux
C. Redhat Linux
D. Windows 7
6. Which of the following is a program that replicates itself by attaching to other programs?
A. Spyware
B. Trojan horse
C. Virus
D. Worm
7. As a parent, you may actually be interested in monitoring the activities of your child on your computer system. If you are interested in determining what activities your child is involved in on the computer, which of the following pieces of software might you be tempted to install?
A. Trojan horse
B. Phishing software
C. Firewall
D. Keylogger
8. What is one of the major issues with spam filters that rely solely on keyword searches to determine what to filter?
A. Keyword searches are too labor intensive and therefore take too long to accomplish (thus slowing the system response time down).
B. Keyword searches may filter e-mail you don’t want to filter because the keyword may be found as part of legitimate text.
C. It is hard to define the keywords.
9. From a security standpoint, why is having a standard operating environment (SOE) important?
A. Without an SOE, administrators will be hard pressed to maintain the security of systems because there could easily be so many different existing configurations that they would not be able to ensure all are patched and secured correctly.
B. Having an SOE has nothing to do with security and is purely an administrative tool.
C. Having an SOE allows administrators to take advantage of large-scale, bulk ordering of software, thus saving funds.
D. Having an SOE is essential in order to implement Active Directory correctly.
10. If you want to implement a restricted shell in a UNIX environment, which of the following would you use?
A. ksh
B. csh
C. rbash
D. sh
11. What are two technologies you might utilize in your inventory control efforts?
A. RFID
B. TCP/IP protocol suite
C. Barcodes
D. Telephone modems
12. From a security standpoint, why might you want to protect your database of inventory items?
A. Regenerating it if it is lost can be costly.
B. Losing something like this would be an indication of a lack of general security procedures and processes.
C. Because it would contain information on the hardware and software platforms that your organization uses, it would provide an attacker with information that could be used to determine vulnerabilities you might be susceptible to.
D. If a software or hardware vendor obtained a copy of it, you might find yourself inundated with sales calls trying to sell you any number of products.
13. If you are in a banking environment, what type of information might you look for in traffic that is leaving your organization in order to protect against data exfiltration by somebody who may have gotten unauthorized access to your system?
A. Files containing strings of 10 digit numbers (which might be social security numbers) or numbers that might represent bank accounts
B. Large data files being sent out of your organization in an unencrypted manner
C. Files, or even e-mail, that contain numerous occurrences of numbers that could be phone numbers or ZIP codes
D. Files or e-mail that contain sequences of digits that could be credit or debit card numbers
14. In a standard office environment, which of the following covert channels should you routinely be checking for?
A. Covert timing channels
B. Covert storage channels
C. Both covert timing and storage channels
D. Neither
15. Which type of intrusion detection/prevention system is based on statistical analysis of current network or system activity versus historical norms?
A. Signature-based
B. Abnormal behavior–based
C. Pattern deviation–based
D. Anomaly-based
16. What will cause the following Snort rule to generate an alert?
![]()
A. An e-mail from our system to any other system with the word “hack” in it
B. An e-mail to our system from any other system’s e-mail server with the word “hack” in it
C. A message to our e-mail system from any system with the word “hack” in it
D. None of the above
LAB QUESTION
You have just taken over as the security administrator at a regional financial institution. One of your employees comes to you and complains that the previous administrator had recently changed the rules for the intrusion detection system and since then the organization has been getting thousands of alerts daily. The other employees have simply taken to deleting all of the alert notifications because they simply do not have the time to check them all out. The employee who has come to you is not comfortable with this situation and thinks something should be done. What do you tell the employee and what steps should be taken to address the situation? The specific IDS that is being used is Snort.
SELF TEST ANSWERS
1. ![]() D. You should have this as the last rule so that if none of the other rules are invoked, the system will fall through to this one and know what to do.
D. You should have this as the last rule so that if none of the other rules are invoked, the system will fall through to this one and know what to do.
![]() A, B, and C are incorrect. The placement of such a rule is critical. It needs to go last because as soon as it is checked, it will be invoked and no rules following it will ever be checked. You should include it because you need to tell the system what you want it to do if none of the other rules are invoked (you want to tell it either to deny all other packets or to allow them).
A, B, and C are incorrect. The placement of such a rule is critical. It needs to go last because as soon as it is checked, it will be invoked and no rules following it will ever be checked. You should include it because you need to tell the system what you want it to do if none of the other rules are invoked (you want to tell it either to deny all other packets or to allow them).
2. ![]() A. This is the specific firewall we discussed in the chapter, and it is found in releases of Linux.
A. This is the specific firewall we discussed in the chapter, and it is found in releases of Linux.
![]() B, C, and D are incorrect. Snort is an intrusion prevention system we talked about in the chapter. Defender is a Windows-based system used to protect against spyware and other unwanted software, and Checkpoint is a network firewall that we did not discuss.
B, C, and D are incorrect. Snort is an intrusion prevention system we talked about in the chapter. Defender is a Windows-based system used to protect against spyware and other unwanted software, and Checkpoint is a network firewall that we did not discuss.
3. ![]() D. This is the sample rule we showed in the chapter that allows web traffic to pass. Remember that web traffic is destined for port 80.
D. This is the sample rule we showed in the chapter that allows web traffic to pass. Remember that web traffic is destined for port 80.
![]() A, B, and C are incorrect. Each of these packets is incorrect (A and C specify the incorrect destination port and B does not state ACCEPT).
A, B, and C are incorrect. Each of these packets is incorrect (A and C specify the incorrect destination port and B does not state ACCEPT).
4. ![]() C. This is a description of multilevel security. Generally, when somebody wants to utilize trusted operating systems, it is because they want to implement multiple levels of security on the system.
C. This is a description of multilevel security. Generally, when somebody wants to utilize trusted operating systems, it is because they want to implement multiple levels of security on the system.
![]() A, B, and D are incorrect because none of them describe multilevel security.
A, B, and D are incorrect because none of them describe multilevel security.
5. ![]() B. SELinux is the only one of the operating systems listed that implements Mandatory Access Controls, which allow for multiple levels of security.
B. SELinux is the only one of the operating systems listed that implements Mandatory Access Controls, which allow for multiple levels of security.
![]() A, C, and D are incorrect because they are not designed to provide multiple levels of security.
A, C, and D are incorrect because they are not designed to provide multiple levels of security.
6. ![]() C. This is the definition of a virus.
C. This is the definition of a virus.
![]() A, B, and D are incorrect. A is incorrect because it does not necessarily replicate itself by attaching to another program. It is software designed to monitor and report on the activities of the individuals who use the system. B is incorrect because a Trojan horse is a piece of software that appears to be one thing but is hiding some other purpose. It does not need to attach itself to another program because it is designed with the hidden purpose from the start. D is incorrect because a worm does not attach itself to another program to replicate itself.
A, B, and D are incorrect. A is incorrect because it does not necessarily replicate itself by attaching to another program. It is software designed to monitor and report on the activities of the individuals who use the system. B is incorrect because a Trojan horse is a piece of software that appears to be one thing but is hiding some other purpose. It does not need to attach itself to another program because it is designed with the hidden purpose from the start. D is incorrect because a worm does not attach itself to another program to replicate itself.
7. ![]() D. Although you should be careful where you obtain it from, a keylogger will record all keystrokes that your child makes, allowing you to determine what they are doing on the computer.
D. Although you should be careful where you obtain it from, a keylogger will record all keystrokes that your child makes, allowing you to determine what they are doing on the computer.
![]() A, B, and C are incorrect. A is incorrect because this is not the purpose of a Trojan horse. B is incorrect because this question has nothing to do with phishing. D is incorrect because, although a firewall may allow you to monitor certain aspects of what your child is doing (what Internet sites are visited, for example), it will not allow you to see everything the child is doing.
A, B, and C are incorrect. A is incorrect because this is not the purpose of a Trojan horse. B is incorrect because this question has nothing to do with phishing. D is incorrect because, although a firewall may allow you to monitor certain aspects of what your child is doing (what Internet sites are visited, for example), it will not allow you to see everything the child is doing.
8. ![]() B. Filtering based solely on keywords could mean you filter e-mail that contains legitimate occurrences of the string you are searching for. The chapter used the example of filtering on “cialis,” which is often found in spam related to the sale of drugs; yet this pattern is also found in the word “specialist.” Thus, you might filter a perfectly legitimate e-mail.
B. Filtering based solely on keywords could mean you filter e-mail that contains legitimate occurrences of the string you are searching for. The chapter used the example of filtering on “cialis,” which is often found in spam related to the sale of drugs; yet this pattern is also found in the word “specialist.” Thus, you might filter a perfectly legitimate e-mail.
![]() A and C are incorrect. A is incorrect because processing time is really not an issue with e-mail, which can have its delivery delayed by a few seconds without any problem. C is incorrect because you can generate a list of keywords that can be useful in filtering. It may be a challenge to determine all the words you might want to search for, but the real issue is the one already described.
A and C are incorrect. A is incorrect because processing time is really not an issue with e-mail, which can have its delivery delayed by a few seconds without any problem. C is incorrect because you can generate a list of keywords that can be useful in filtering. It may be a challenge to determine all the words you might want to search for, but the real issue is the one already described.
9. ![]() A. This is the key. If your organization has a large number of systems, without having a standard operating environment, configuration control could quickly get out of hand, and maintaining the security of numerous, disparate systems would become untenable.
A. This is the key. If your organization has a large number of systems, without having a standard operating environment, configuration control could quickly get out of hand, and maintaining the security of numerous, disparate systems would become untenable.
![]() B, C, and D are incorrect. B and D are simply not true. C is incorrect because, although there is a bit of truth to it in that a single, similar environment implemented throughout a large organization may indeed allow for savings via bulk orders, it is not the reason an SOE is important to security.
B, C, and D are incorrect. B and D are simply not true. C is incorrect because, although there is a bit of truth to it in that a single, similar environment implemented throughout a large organization may indeed allow for savings via bulk orders, it is not the reason an SOE is important to security.
10. ![]() C. rbash invokes the bash shell in restricted mode.
C. rbash invokes the bash shell in restricted mode.
![]() A, B, and D are incorrect because they are not restricted shells.
A, B, and D are incorrect because they are not restricted shells.
11. ![]() A and C. Both were specifically mentioned as technologies that can be useful in tracking individual inventory items.
A and C. Both were specifically mentioned as technologies that can be useful in tracking individual inventory items.
![]() B and D are incorrect. Neither really provides technology specifically designed for the purpose of marking and tracking inventory.
B and D are incorrect. Neither really provides technology specifically designed for the purpose of marking and tracking inventory.
12. ![]() C. Knowing what hardware and software you have provides an attacker a tremendous boost in terms of determining what attacks to try against you.
C. Knowing what hardware and software you have provides an attacker a tremendous boost in terms of determining what attacks to try against you.
![]() A, B, and D are incorrect. They are incorrect in terms of a reason why the list would be important from a security standpoint. All of them, however, are true to a certain extent for other reasons.
A, B, and D are incorrect. They are incorrect in terms of a reason why the list would be important from a security standpoint. All of them, however, are true to a certain extent for other reasons.
13. ![]() A, B, C, and D. All of these might very well be indicators of information being sent out of your organization that should not be. Even e-mails that are not encrypted and that contain more than one account or credit card number could indicate a problem.
A, B, C, and D. All of these might very well be indicators of information being sent out of your organization that should not be. Even e-mails that are not encrypted and that contain more than one account or credit card number could indicate a problem.
14. ![]() D. In a normal office environment that is not processing classified information or dealing with excessively sensitive information, covert channels are simply something that you don’t need to worry about. This is not to say that you don’t worry about data exfiltration. You need to worry about it, just not data exfiltration via covert channels.
D. In a normal office environment that is not processing classified information or dealing with excessively sensitive information, covert channels are simply something that you don’t need to worry about. This is not to say that you don’t worry about data exfiltration. You need to worry about it, just not data exfiltration via covert channels.
![]() A, B, and C are incorrect because of the reason just explained.
A, B, and C are incorrect because of the reason just explained.
15. ![]() D. This is the definition of anomaly-based detection.
D. This is the definition of anomaly-based detection.
![]() A, B, and C are incorrect. The description does not apply to any of them.
A, B, and C are incorrect. The description does not apply to any of them.
16. ![]() D. This is somewhat of a trick question. Because the Snort rule states “log” and not “alert,” no alert will be generated, even if the rule is invoked. Snort will simply log the occurrence.
D. This is somewhat of a trick question. Because the Snort rule states “log” and not “alert,” no alert will be generated, even if the rule is invoked. Snort will simply log the occurrence.
![]() A, B, and C are incorrect. However, C is close in that everything else is correct, if the rule had stated “alert” instead of “log.”
A, B, and C are incorrect. However, C is close in that everything else is correct, if the rule had stated “alert” instead of “log.”
LAB ANSWER
First of all, from a managerial perspective, the employee should be thanked and congratulated for not being comfortable with the security situation the way it was and for wanting to address the issue.
After that, you need to determine what the employee meant by “changed the rules.” Does the organization subscribe to a signature service, and if so, which one? Or, did the previous administrator attempt to load a set of rules downloaded from some place and then attempt to add additional ones deemed necessary? As was mentioned, there are subscription services for Snort, but there are also other sites where you can obtain rules for free, although they may not be as up to date as the subscription services.
Next, you will want to take a look at the alerts you are receiving. What are they? Can they be grouped into specific categories or types? Are most of them related? If so, what rules are causing these alerts and do they really apply to your environment?
Another thing you should probably look out for is the use of “any” in specific fields. Default values in Snort may set the HOME_NET variable to “any,” which will cause problems because now any IP address will be considered the “home” when in reality only your system (network) should be the home. A number of other default variables should be examined as well. What may have happened is that the previous administrator “reset” the configuration and now the system simply needs to be tuned.