
Chapter 5
Domain 3: Cloud Platform and Infrastructure Security
IN THIS CHAPTER
![]() Understanding the components of cloud infrastructure
Understanding the components of cloud infrastructure
![]() Learning about secure data center design
Learning about secure data center design
![]() Learning how to identify and measure infrastructure risks
Learning how to identify and measure infrastructure risks
![]() Identifying countermeasures to cloud infrastructure risks
Identifying countermeasures to cloud infrastructure risks
![]() Planning and developing security controls to protect your infrastructure and platform
Planning and developing security controls to protect your infrastructure and platform
![]() Understanding your business continuity and disaster recovery requirements
Understanding your business continuity and disaster recovery requirements
![]() Developing and implementing a BC/DR strategy and plan
Developing and implementing a BC/DR strategy and plan
In this chapter, you explore all the practical matters of cloud platform and infrastructure security. You discover what makes up a cloud’s physical environment and how that relates to the virtual cloud environment. You also find out how cloud providers build and secure data centers and how you secure the systems you build within them. Domain 3 represents 17 percent of the CCSP certification exam.
Comprehending Cloud Infrastructure Components
Cloud infrastructure is made up of many parts, each playing its own important role. You can find many cloud infrastructure components in traditional data centers, but their application in cloud environments may be a little different. Aside from the infrastructure concepts that you're likely familiar with from traditional data center models, cloud infrastructure also introduces some unique components, which I describe throughout the rest of this section.
As you see in Figure 5-1, a cloud infrastructure is comprised of
- Physical environment
- Networking resources
- Compute resources
- Virtualization capabilities
- Storage resources
- Management plane
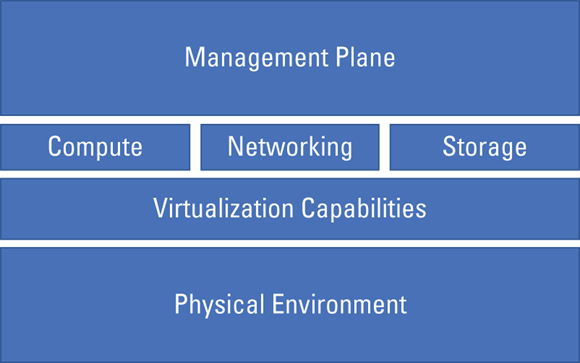
FIGURE 5-1: Overview of cloud infrastructure components.
I break down each of these key components in the following sections.
 The terms cloud infrastructure and cloud architecture are easy to use interchangeably, but they mean slightly different things. Cloud infrastructure includes all the tools and components needed to build a cloud, while cloud architecture is the blueprint that describes how those components work together to build the cloud. In other words, you can think of cloud infrastructure as your ingredient list and cloud architecture as your recipe.
The terms cloud infrastructure and cloud architecture are easy to use interchangeably, but they mean slightly different things. Cloud infrastructure includes all the tools and components needed to build a cloud, while cloud architecture is the blueprint that describes how those components work together to build the cloud. In other words, you can think of cloud infrastructure as your ingredient list and cloud architecture as your recipe.
Physical environment
While some less informed people may think that information in the cloud is stored in some fluffy virtual world, you and I know that the cloud has a physical environment. Cloud computing runs on actual hardware located in actual buildings. A single one of these buildings (or data centers) can house up to hundreds of thousands of servers, switches, and other hardware components. A single cloud environment is usually made up of several of these data centers located across multiple geographic locations.
NIST provides some helpful points to consider when securing physical environments. In NIST 800-53, the Physical and Environmental Protection control family provides guidance on the following areas that are particularly relevant to cloud infrastructures:
- Physical access authorization and control: Define and enforce controls for least privilege access to physical resources.
- Access control for transmission medium: Define security safeguards for power and network cables to prevent damage, disruption, tampering, and theft.
- Physical access monitoring: Develop capabilities to investigate and respond to physical security incidents. Monitoring can include things like physical access logs and security cameras that monitor data center ingress and egress points.
- Emergency power: This one is a biggie! Cloud computing is all about availability, and the last thing a CSP or cloud customer needs is a power outage making critical data unavailable.
- Fire and water damage protection: These guidelines are self-explanatory.
- Asset monitoring and tracking: Cloud providers must keep track of each and every server (and other hardware components) and ensure that they remain in authorized locations.
Although the underlying technologies in cloud computing are very similar to those in a traditional data center, the massive scale of cloud environments creates a unique and complex set of considerations for the physical environment. In addition to the preceding NIST-derived list, the following items are critical considerations for a cloud's physical environment:
- Data center location: Cloud Service Providers go through very detailed assessments when determining where to build their data centers. It's essential that CSPs pay special attention to the availability of resources, as well as threats (natural and manmade) associated with the potential locations.
- Sufficient and redundant power and cooling: With hundreds of thousands of servers providing services to potentially thousands of customers, cloud providers must ensure that they have enough electricity to power and enough cooling to safely run all that hardware. And if your primary power or cooling systems fail, you need to ensure that a reliable backup is in place.
- Sufficient and redundant network bandwidth: Similar to power and cooling, a CSP must ensure that they can support the data needs of all their customers with significant network bandwidth. Sufficient and redundant network bandwidth ensures that the cloud is always on and that customers can reliably access their cloud resources from anywhere in the world.
Having significant and redundant power, cooling, and bandwidth can get quite expensive, and providing suitable security for large physical environments is another huge expense. Because large public clouds serve many organizations, cloud customers are able to realize the benefits of economies of scale that they just couldn’t get by running their own data centers. I dive deeper into physical and environmental data center design in the upcoming section titled “Designing a Secure Data Center.”
Network and communications
Networking is the cornerstone of cloud computing because networks and communications provide the only way for cloud customers to access their cloud-based systems and applications (and their data!). Managing the physical network is completely the responsibility of the CSP, but every CCSP candidate should understand some key functionality in cloud networks, including the following concepts:
- Routing: The process of selecting for network traffic between endpoints on the cloud network or between the cloud network and an external network.
- Filtering: The process of selectively allowing or denying traffic or access to cloud resources.
- Rate limiting: The process of controlling the amount of traffic into or out of the cloud network.
- Address allocation: The process of assigning one or multiple IP addresses to a cloud resource, which can be done either statically or dynamically.
- Bandwidth allocation: The process of sharing network resources fairly between multiple users that share the cloud network. (I'm sure you can imagine how important this is for multitenant environments!)
Software-Defined Networking (SDN) is an approach to network management that enables a network to be centrally controlled (or programmed), providing consistent and holistic management across various applications and technologies. SDN architectures allow dynamic and efficient network configuration that improves network performance and gives cloud providers a centralized software-based view of their entire network infrastructure. As you can imagine, SDN technology is hugely important in cloud computing because it allows large CSPs to programmatically configure, manage, and secure network resources that would be a nightmare to manage through traditional network management techniques.
SDN sounds pretty cool, but you may be wondering exactly how it works. Figure 5-2 depicts a basic Software-Defined Networking architecture. As you see, SDN technology abstracts network control from network forwarding capabilities (like routing), thus creating two layers (control plus infrastructure) out of what is traditionally a combined function. The control plane contains the actual SDN control logic. This layer receives service requests from the application layer and is responsible for providing configuration and forwarding direction to network forwarding equipment in the infrastructure layer. The control plane is where the SDN magic happens; it’s here that SDNs logically optimize network traffic, thus allowing cloud providers to allocate network resources in an agile and highly scalable manner. This separation between the control and data planes also provides cloud administrators with a single interface to manage thousands of network devices, without needing to individually log in and manually manage those devices.
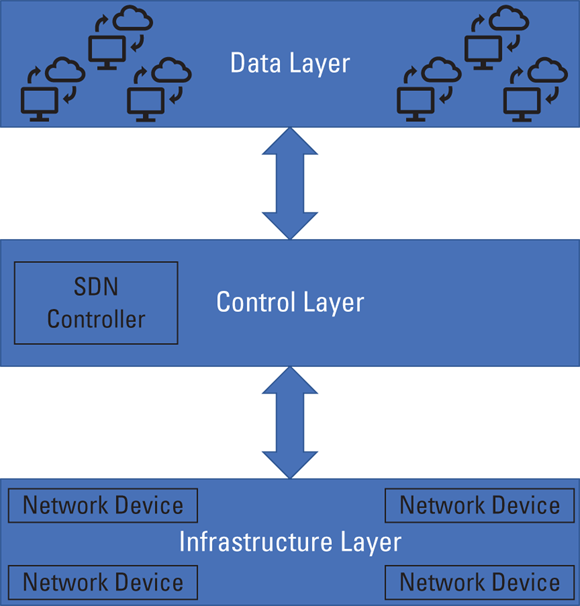
FIGURE 5-2: Software-Defined Networking (SDN) architecture.
Software-Defined Networking is a pivotal technology in cloud computing and forms the basis of many public cloud networks. With the amount of central control provided by SDN implementations, securing your Software-Defined Network is of the utmost importance. By virtualizing your entire network infrastructure, you increase your attack footprint and give attackers a central target (the SDN controller) that could be used to compromise your entire network. Pay special attention to securing SDN controllers through robust access policies, system hardening, and encrypted communications.
Compute
As the term cloud computing suggests, compute power is a big deal for cloud consumers! Compute resources take data, process it, and show you the output of that processing. Just like in traditional data center models, cloud-based computing comes down to compute (CPU) and processing (RAM) capabilities.
What's unique in cloud environments, however, is that these compute resources must be managed and allocated among multiple customers. Before tackling that challenge, you should be familiar with some common types of cloud compute assets, specifically virtual machines (VMs) and containers.
VMs
VMs are the most common compute mechanism in cloud computing environments. VMs emulate the functionality of physical hardware and allow cloud customers to run operating systems (OS) in a virtualized environment. In addition to the OS (and the OS kernel), your organization may include middleware or custom application code in your VM deployments.
Because virtual machines can include lots of different components, you need to pay close attention to how you asset manage, configuration manage, and vulnerability manage your VMs. Most large cloud platforms provide resources to support VM management, but it is ultimately the customer's responsibility to manage their Virtual Machine instances and the data processed within them.
One of the powerful features of cloud environments is the ability to scale resources, including VMs, up and down very quickly. While this ability is incredibly helpful to manage fluctuating resource needs, it can make asset management a nightmare. Agent-based solutions can be a big help in managing and securing your VM inventory.
Containers
Containers take the virtualization of VMs to the next step and package only the necessary code, configurations, and resources needed to run a particular application. Unlike VMs, containers don't run an entire OS — instead, they use the kernel of the VM or OS that they’re hosted on. In short: VMs provide virtual environments that allow organizations to run their applications, while containers isolate an application from its environment and allow the application to be run in multiple different environments. Containers are an increasingly popular technology, especially for multicloud or hybrid deployments.
 You may hear the term container and think of storage because … well, because containers in the real world are used to store things. Remember, however, that this compute technology is actually used to run applications and process information.
You may hear the term container and think of storage because … well, because containers in the real world are used to store things. Remember, however, that this compute technology is actually used to run applications and process information.
Because containers allow you to scale up and down resources even more rapidly than VMs, asset management and configuration management are even bigger security concern for containers. Most container technologies come with support for managing your container deployment lifecycle, but it's up to you to ensure that you aren't spinning up containers that haven't been properly patched or managed.
Reservations, limits, and shares
The use of reservations, limits, and shares allow you to allocate a single host’s compute resources.
A reservation guarantees that a cloud customer has access to a minimum amount of cloud compute resources, either CPU or RAM. Much like a restaurant reservation ensures that you have a seat when you need it (except Washington, D.C. restaurants that still make you wait 30 minutes), compute reservations are used to make sure that your VMs have the right amount of computing and processing power when they need it. Reservations are an important feature in cloud environments because they can help protect customers against Denial of Service due to other resource-intensive tenants.
A limit acts just the opposite of a reservation and sets a maximum amount of cloud compute resources that can be used. In cloud environments, limits can be set either for a VM or for a customer’s compute utilization as a whole. Limits can help customers ensure that they don’t use more resources than they’ve budgeted for, and they can also help ensure that a single cloud tenant doesn’t use a tremendous amount of resources at the harm of other tenants. Limits may be configured as fixed (for example, “use no more than 16GB of RAM”), but I’ve most often seen dynamic limits used in practice; dynamic limits allow customers to temporarily use additional resources depending on given circumstances or requirements being met.
 Limits are particularly useful in development environments, where cost may supersede any other consideration. Use limits in production environments very carefully to avoid potential Denial of Service.
Limits are particularly useful in development environments, where cost may supersede any other consideration. Use limits in production environments very carefully to avoid potential Denial of Service.
The concept of a share is used to mediate resource allocation contentions. Resource contention is just a fancy way of saying that there are too many requests and not enough resources available to supply all those requests. When resource contention occurs, share values are used to allocate resources to all tenants assigned a share value. Tenants with a higher share value receive a larger portion of available resources during this period.
You should understand what resource contention is for your exam and know that shares are one way to negotiate and remediate it. However, you should also know that this occurrence is fairly uncommon in most large, mature cloud providers. Two of the key cloud computing characteristics, rapid elasticity and resource pooling (see Chapter 3), are focused on ensuring that large amounts of customers are able to share cloud resources with minimal disruption. CSPs with routine resource contention are very likely not built at a scale large enough for their customer base.
Virtualization
Chapter 3 introduces the concept of virtualization. Virtualization is the process of creating software instances of actual hardware. VMs, for example, are software instances of actual computers. Software-Defined Networks, discussed earlier in this chapter, are virtualized networks. Nowadays, you can pretty much find any traditional hardware available as a virtualized solution.
Virtualization is the secret sauce behind cloud computing, as it allows a single piece of hardware to be shared by multiple customers. Concepts like multitenancy and resource pooling would not exist as they do today — and you wouldn’t be reading this book — if it weren’t for the advent of virtualization!
Virtualization offers many clear benefits. Following is a list of some of the most noteworthy:
- Increases scalability: Virtualized environments are designed to grow as your demand grows. Instead of buying new hardware, you simply spin up additional virtual instances.
- Allows faster resource provisioning: It’s much quicker and easier to spin up virtualized hardware from a console than it is to physically boot-up multiple pieces of hardware.
- Reduces downtime: Restoring or redeploying physical hardware takes a lot of time, especially at scale. Failover for virtualized resources can happen much more quickly, which means your systems remain up and running longer.
- Avoids vendor lock-in: Virtualization abstracts software from hardware, meaning your virtualized resources are more portable than their physical counterparts. Unhappy with your vendor? Pack up your VMs and move to another one!
- Saves time (and money): Virtualized resources can be easily centrally managed, reducing the need for personnel and equipment to maintain your infrastructure. In addition, less hardware usually means less money.
The preceding list reiterates why virtualization is such a critical technology and reminds you of the deep connection between virtualization and cloud computing.
The most common implementation of virtualization is the hypervisor (see Chapter 3). A hypervisor is a computing layer that allows multiple guest operating systems to run on a single physical host device. Figure 5-3 shows an overview of hypervisor architecture.
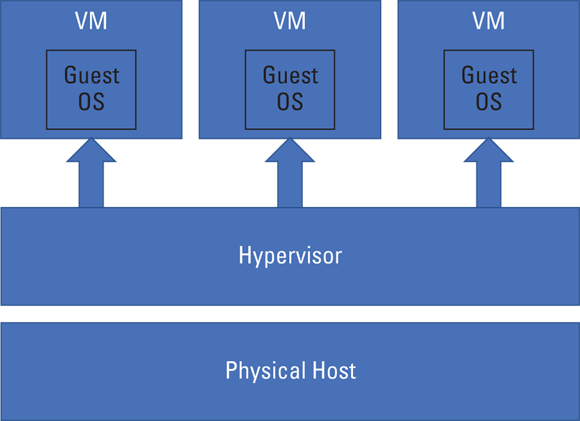
FIGURE 5-3: Hypervisor overview.
The hypervisor abstracts software from hardware and allows each of the guest OSes to share the host’s hardware resources, while giving the guests the impression that they’re all alone on that host. The two categories of hypervisors are Type 1 and Type 2. A Type 1 hypervisor is also known as a bare metal hypervisor, as it runs directly on the hardware (see Chapter 3). Type 2 hypervisors, however, run on the host’s operating system. Figure 5-4 shows a comparison of the two.
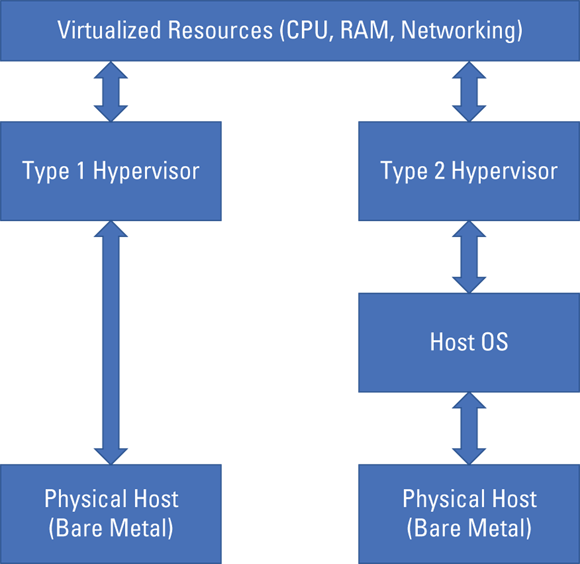
FIGURE 5-4: Type 1 versus Type 2 hypervisors.
Despite all the advantages of virtualization, and hypervisors specifically, you, as a CCSP candidate, should remember some challenges:
- Hypervisor security: The hypervisor is an additional piece of software, hardware, or firmware that sits between the host and each guest. As a result, it expands the attack surface and comes with its own set of vulnerabilities that the good guys must discover and patch before the bad guys get to them. If not fixed, hypervisor flaws can lead to external attacks on VMs or even VM-to-VM attacks, where one cloud tenant can access or compromise another tenant’s data.
- VM security: Virtual machines are nothing more than files that sit on a disk or other storage mechanism. Imagine your entire home computer wrapped up into a single icon that sits on your desktop — that’s pretty much what a virtual machine comes down to. If not sufficiently protected, a VM image is susceptible to compromise while dormant or offline. Use controls like Access Control Lists (ACLs), encryption, and hashing to protect the confidentiality and integrity of your VM files.
Network security: Network traffic within virtualized environments cannot be monitored and protected by physical security controls, such as network-based intrusion detection systems. You must select appropriate tools to monitor inter- and intra-VM network traffic.
 The concept of virtual machine introspection (VMI) allows a hypervisor to monitor its guest operating systems during runtime. Not all hypervisors are capable of VMI, but it’s a technique that can prove invaluable for securing VMs during operation.
The concept of virtual machine introspection (VMI) allows a hypervisor to monitor its guest operating systems during runtime. Not all hypervisors are capable of VMI, but it’s a technique that can prove invaluable for securing VMs during operation.- Resource utilization: If not properly configured, a single VM can exhaust a host’s resources, leaving other VMs out of luck. Resource utilization is where the concept of limits (discussed in the “Reservations, limits, and shares” section of this chapter) comes in handy. It’s essential that you manage VMs as if they share a pool of resources — because they do!
Storage
At the most fundamental technical level, cloud storage isn’t much different from traditional data center storage. Storage typically begins with Hard Disk Drives (HDD) or Solid State Drives (SSD), depending on the performance needed by a particular customer or workload. The drives are grouped and arranged into RAID (Redundant Array of Inexpensive Disks) or SAN (Storage Area Network) configurations and then virtualized for multitenant access. On their own, these storage units have no filesystem. Instead, a filesystem is created and applied by the guest OS whenever a tenant deploys a virtual machine.
In Chapter 4, you learn that IaaS cloud generally uses two categories of storage. Volume storage is similar to traditional block storage and is used when cloud storage is allocated to a VM and used as if it were a regular hard drive attached to that machine. Object storage is file storage that isn’t attached to any particular VM or application and is kept on a separate system that is accessed through APIs or web interfaces.
Make sure that you understand the differences between volume and object storage for your exam and for practical reasons. You should be able to identify the type of storage for a given cloud service, and you should know the key properties of each.
Volume storage
For volume storage, the hypervisor takes a chunk of the physical storage infrastructure and virtually assigns it to a VM. A logical unit number (LUN) is a unique identifier that’s used to label each individual chunk. A LUN can represent a single disk, a partition of a disk, or an array of disks, depending on how much storage space a cloud tenant provisions. In any case, LUNs are virtually mounted to the virtual machine for use as virtualized storage.
Volume storage is great when you need a fixed chunk of storage for with a filesystem, but keep in mind that volume storage can be used only with that filesystem and at runtime.
Object storage
Object storage is a bit newer of a concept than volume storage, and it gives developers additional options for storing and retrieving unstructured data. Instead of files being broken down into blocks, LUNs, or volumes, object storage deals with whole files that are accessed via network call. Object storage is ideal for images, documents, webpages, and any other data without a specific schema or structure.
Another key benefit of object storage is that cloud providers are able to charge for the exact amount of data you use (in other words: the total size of your objects is what you pay for), whereas with volume storage you’re likely to have volumes with more space allocated than you’re actually using at any given time. (Think of volume storage as having a 256GB hard drive with only 200GB being used.)
Management plane
The management plane, in cloud computing, is the interface and set of functions that supports and enables control of a cloud environment and the hosts within it. The management plane is typically restricted to highly privileged CSP administrators, with a limited subset of capabilities externalized to customer cloud admins.
Management planes not only allow you to start, stop, and pause your virtual hosts and services, but also allow you to provision the desired resources (CPU, memory, and storage, for example) for your environment. The management plane is the cloud administrator’s primary, centralized interface to connect with the cloud metastructure (see Chapter 3) and configure their environment.
Most modern cloud providers expose the management plane to customers through a set of APIs, CLIs, or proprietary web interfaces. (AWS refers to theirs as a management console, Google’s is named Cloud Console, while Microsoft’s is called the Azure Management Portal.) Regardless of what each company’s marketing departments might’ve come up with, management planes provide the interface and tools customers need to manage their cloud infrastructure, platforms, and applications.
As you can probably tell, the management plane is a very powerful tool — and with great power comes great responsibility! Because it provides a consolidated view and single-point access into your cloud environment, the management plane must be tightly locked down, with access granted to the fewest amount of people with absolute need for such permissions. In addition, all management plane access should be closely monitored, logged, and regularly audited for misuse.
Despite the increased risk associated with consolidated access, management planes offer security benefits by providing a holistic view of all your cloud resources. You’re able to examine all your cloud assets and know exactly what you’re running and how it’s configured at any given time. This level of transparency is hard to achieve in traditional data centers, which often require the use of multiple tools, interfaces, and processes to identify and manage your IT assets.
Designing a Secure Data Center
Cloud customers are moving their data to the cloud at a rapid rate. Many of these customers are thrilled by the opportunity to offload mundane infrastructure management and security responsibilities to companies who make their money doing just that. Other customers, however, are migrating to the cloud because of regulations like the Cloud First Policy in the United States. These organizations and others are often making the move to cloud with a great deal of anxiety — and understandably so. It’s easy to appreciate the reluctance an organization might have losing control and oversight of their own data centers; these companies have often done things a certain way for a very long time and have a high level of confidence in the way they secure their infrastructures. Giving that up to a CSP who says “Trust us, we’ve got this” is not always easy. Transparent CSPs share some (but not all) of the details behind how they secure their environments.
Whether you’re a cloud customer or a cloud provider, it’s essential that you understand the principles behind secure data center design. You should bear in mind that effective data center security involves a layered approach (or defense-in-depth, as I discuss in Chapter 2). This layered approach requires logical, physical, and environmental security controls that every CCSP candidate should understand.
Logical design
A data center’s network and software design is fundamentally important to keeping customer data secure. While logical data center security controls are discussed in-depth later in this chapter, this section is a good time to introduce the topic of zero trust.
NIST 800-207, zero trust architecture defines zero trust architecture as “a collection of concepts, ideas, and component relationships (architectures) designed to eliminate the uncertainty in enforcing accurate access decisions in information systems and services.” As I’m writing this book, NIST 800-207 is in draft, and I’m really hoping the final version has another definition. In short, though, zero trust architecture (ZTA) is a security model that’s built on the idea that no entity inside or outside of an organization’s security perimeter should be trusted. Instead of considering parties within the security perimeter as trusted, ZTA requires that identities and authorizations are always verified. This requirement prevents the common security risk associated with compromised accounts being used to pivot across a network.
ZTA relies on a number of existing technologies and processes to improve security; it leverages network micro-segmentation and granular access enforcement based on an entity’s location and other factors to verify its trustworthiness. Figure 5-5 depicts the overall zero trust security model.
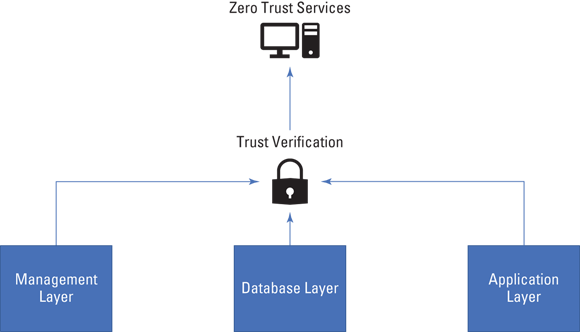
FIGURE 5-5: Zero trust architecture overview.
Physical design
The physical design of a data center includes the actual data center building and its contents, as well as the set of policies and procedures in place to prevent physical damage or compromise of the machines that store data. These policies and procedures should account for everything from natural disasters to nation-state attacks and other malicious actors.
Location, location, location!
Determining whether a data center is secure begins with its geographic location. A secure data center design should consider the following:
- Geographical features of the area (tall trees, for example, are a wonderful and free barrier)
- Risk of natural disasters and weather events
- Geopolitical risk (it’s worth noting if you’re building in a warzone, for example)
- Access to and costs of telecommunications infrastructure
- Availability of utilities and other essential resources
- Labor costs and availability
While you can prevent or mitigate some of these concerns, it’s best to avoid any unnecessary risk when building a multibillion dollar facility to store your customers’ sensitive information.
Buildings and structures
After you select the ideal location for your shiny new building, it’s important that you design the actual building structure to reduce access control and other physical risks. Some important considerations include
- Materials and thickness of the building’s walls
- Number of ingress and egress points
- Type of perimeter fencing
- Types of locks and alarms used on external and internal doors
- Redundant electrical and telecommunications suppliers
The preceding list is just a start, but can help you begin to focus your attention on the most important building security concerns. A Building Management System (BMS) is a hardware and software control system that is used to control and monitor a building’s electrical, mechanical, and HVAC systems. A BMS is an important part of the physical design of any data center and helps data center personnel monitor plumbing, power, lighting, ventilation, fire suppression, and other critical building systems.
Physical security monitoring
It may seem obvious, but one of the most important aspects of physical security is ensuring that only authorized people can access the building and its critical areas. A secure data center should have a list of all authorized personnel and monitor their access to building resources. Visitors, such as vendors, should be appropriately verified, logged, and monitored as well.
Don’t forget about tried and true security measures, such as video surveillance. All building entrances and exits should be monitored and recorded, and all internal doors to controlled areas (like areas with servers, HVAC systems, and so on) should be actively monitored by CCTV. As great as video surveillance is, it would be pretty useless without security staff on hand to respond to any alerts or suspicious activities; secure data centers have round-the-clock security patrols and personnel standing by to respond to potential threats.
Physical testing and auditing
No matter how great you design your physical controls, it is essential that you have a policy in place to periodically test them. Conduct physical penetration tests at least annually to ensure the ongoing effectiveness of your physical security mechanisms. In addition to testing you should do on your own, external audits (SOC, PCI, FedRAMP, and others) very often require that cloud data centers be physically audited by licensed or accredited auditors.
Environmental design
It’s essential that as a cloud security professional you pay attention to the environment in which your systems exist. When designing a secure data center, consider a few key environmental concepts:
Temperature: If you’ve ever left your computer running for a long time, you might’ve felt it get pretty hot. Now imagine a few hundred thousand of those computers, each running multiple users’ workloads — you’ve got your very own overheated data center! Temperature control is one of the absolute biggest concerns in a data center. Ensuring that servers don’t overheat is critical, and failure to properly manage temperature can lead to massive availability issues. Pay attention to where servers exhaust their heat and how you’re monitoring rack temperatures and make sure your cooling systems are regularly maintained.
The American Society of Heating, Refrigerating and Air-Conditioning Engineers (ASHRAE) recommends data center thermal ranges stay between 64 and 81°F. This range has risen over the years, as computing equipment becomes more resilient and energy efficient.- Humidity: Humidity is water in the air, and water is bad for electronics. Humidity should be monitored and controlled within data centers, with 50 to 60 percent being a typical recommended range for relative humidity. (ASHRAE recommends absolute minimum and maximum humidity of 20 percent and 80 percent, respectively.)
- Electrical monitoring: A secure data center should be designed to monitor electrical levels to not only trigger backup generators during outages, but also to watch for energy spikes that can damage sensitive equipment.
- Fire suppression: Fire suppression systems are an absolute must in data centers. Not only do they keep data center personnel safe, but they’re pivotal in preventing widespread outages and data loss should a fire occur. Hopefully, you never need them, but fire suppression systems are definitely “better safe than sorry” measures.
Analyzing Risks Associated with Cloud Infrastructure
Any IT infrastructure you use comes with a certain level of risk, and it’s always important to analyze those risks and determine the best ways to treat them. Many of the risks that come with cloud infrastructures are the same as traditional data center models, but some are unique to cloud environments. As a CCSP, you should know how to identify these unique risks, understand how to assess and analyze them, and be prepared with countermeasure strategies.
You should consider several categories of risk when evaluating cloud infrastructures. Some generally relevant categories are
- Organizational risks
- Compliance
- Legal risks
- Cloud infrastructure risks
- Virtualization risks
I provide an overview of the first three categories in the next section, “Risk assessment and analysis.” Cloud infrastructure and virtualization risks deserve sections of their own, which follow the next section.
Risk assessment and analysis
No matter what guidance you find in regulations, security blogs, or even this book, each cloud provider and cloud customer is ultimately responsible for performing their own tailored risk assessment and analysis. This section serves as a starting point for assessing organizational, compliance, and legal risks that cloud infrastructure presents for your organization.
Organizational risks
Organizational risks are inherently present whenever an organization outsources services to an external party — similar to third party or vendor risk. These risks may potentially impact business processes, existing company policies, or anything else that a company views as important.
A few noteworthy organizational risks to be mindful of are
- Reduced visibility and control: Customers who host and maintain their own infrastructure maintain complete control over their security (for better or for worse). If you run your own data center, you can change what you want when you want, and you have full visibility into your systems and services. Moving to the cloud means that you give up some of that control to the CSP. Customers must create a mature governance model prior to migrating to the cloud and find ways to mitigate or accept any residual risks related to control. Potential mitigations include SLA and contractual terms, as well as full utilization of monitoring tools available on your selected cloud provider.
- Staffing and operational challenges: Cloud migration can introduce challenges for existing IT staff who are not properly trained on cloud computing and security. Managing and operating a cloud environment may require substantial training for existing staff or even require entirely new personnel to be hired. The skills gap that may exist creates the potential for security risks that go unnoticed or unmanaged. Cloud customers must proactively evaluate their current staff and identify training and/or hiring needs prior to cloud migration.
- Vendor lock-in: Vendor lock-in becomes an issue when an organization has made significant investments in a cloud provider, but wants to move its data from that provider to another. The organization faces risks associated with greater time, effort, and cost to make the switch than planned. Vendor lock-in risk increases when cloud providers use nonstandard formats and APIs or lots of proprietary tools. Cloud customers can mitigate vendor lock-in risk by carefully evaluating potential CSPs for interoperability and open-source support.
- Financial management: Most organizations are accustomed to setting a strictly fixed IT budget every year; exceeding that budget usually means the CIO has some explaining to do. Even more confusing, though, some organizations actually have a use or lose policy that means if you fail to use all your IT funds this year, you can expect a lower budget next year. Moving to the cloud, where customers are billed for exactly what they use, can be a challenge for financial planning. Cloud utilization (and costs) can scale up and down on a monthly basis, rather than having a fairly consistent utilization from running your own data center. Further, on-demand self-service means that cloud customers must ensure that their users aren’t abusing the cloud services at their disposal.
Compliance and legal risks
Customers in highly regulated industries, such as financial services and healthcare, need to be concerned with data security and privacy regulations, like PCI DSS and HIPAA. When moving to the cloud, it is still the customer’s responsibility to ensure that their data meets those standards and regulations, as well as any contractual commitments they’ve made to their own customers. As part of these requirements, cloud customers may be required to know the following:
- Where does their regulated data reside
- Who accesses (or may access) the data
- How is their regulated data protected
When you move sensitive data to the cloud, you are relying on the CSP to protect it and help you meet your compliance obligations. Compliance and legal obligations are again where the Shared Responsibility Model comes into play, and cloud customers should look to their cloud provider for details on how they support compliance. By understanding a CSP’s role in compliance, customers can identify what responsibility they have to ensure their data is compliant with relevant regulations.
When moving to the cloud, you transfer some responsibility for protecting your infrastructure and systems. However, you’re not transferring liability. Unless your contract with the CSP states otherwise, you’re still legally responsible for ensuring compliance with legal regulations and requirements that impact your data.
Compliance is a huge point of contention for cloud customers, and it’s insanely important that you, as a customer, perform your due diligence when moving to the cloud. Some CSPs offer customers a document called a Customer Responsibility Matrix (CRM), which delineates the CSP’s responsibility from the customer’s responsibility for each requirement within a given regulation. CRMs are formally required for FedRAMP authorized CSPs, but I’ve seen them available to support HIPAA and other regulations as well.
Cloud vulnerabilities, threats, and attacks
Cloud environments, at a high level, experience the same types of threats and vulnerabilities as their on-premises peers. Cloud environments run applications, those applications have vulnerabilities, and bad guys try to exploit those vulnerabilities to compromise systems and data.
The nature of cloud infrastructure, however, lends it to some very specific types of risks. I introduce a few earlier in this chapter, and I cover the following threats and risks in the next few sections:
- Management plane compromise
- Incomplete data deletion and sanitization
- Insecure multitenancy
- Resource exhaustion
- Network, OS, and application vulnerabilities
Management plane compromise
The management plane is probably the most valuable attack target and the highest source of risk in a cloud environment. As a single interface with consolidated access to all your systems and resources, a management plane compromise can affect your entire cloud environment.
Because management planes are made available to customers through Internet-facing APIs, they’re widely exposed to attackers for exploitation. Malicious actors look for weak APIs and can exploit vulnerabilities to gain access to an organization’s cloud systems and data.
CSPs are responsible for securing their APIs — with special attention being given to management plane APIs. Cloud customers hold responsibility for ensuring that they use strong credentials and secure channels when accessing their cloud provider’s management console.
Incomplete data deletion and sanitization
When cloud customers delete their data, they’re relying on the cloud service provider to actually remove all traces of that data from the environment. Cloud customers have reduced visibility into where all components of their data resides, and they have very little ability to verify that all data has been securely deleted upon request.
Incomplete data deletion and sanitization can leave portions of a customer’s data available and potentially exposed to other CSPs tenants who share the same infrastructure. This potential data leakage is particularly concerning for customers managing sensitive information like PII, PHI, and cardholder data.
Whereas an organization operating their own data center is able to physically shred, incinerate, or pulverize storage media to ensure its destruction, cloud customers do not have this level of control. Instead, customers rely on SLAs, contracts, and data agreements in which CSPs commit to certain processes and timelines for secure data deletion. Customers must be mindful that data deletion and sanitization processes and terms differs from one CSP to another and must ensure that their selected CSP provides terms that meet the organization’s business needs, regulatory requirements, and legal commitments.
Insecure multitenancy
Multitenancy is a core property of public cloud, and it allows large CSPs to provide resources and services to thousands of customers in a scalable fashion. This architecture requires the cloud provider to use isolation controls to physically or logically separate each tenant from other tenants in the environment. Risks exist when these controls either do not exist or fail to function as intended.
Without proper separation between cloud tenants, an attacker can leverage one tenant’s resources to compromise another tenant’s environment. This compromise can include unauthorized access to data, Denial of Service, or other tenant-to-tenant attacks.
Securing multitenant infrastructures and ensuring effective separation between organizations is entirely the responsibility of the CSP. Logical controls, like strong encryption, are minimally required. In some cases, customers may require actual physical separation from other tenants and may request it through products like AWS Dedicated Hosts and Google’s sole-tenant nodes.
Resource exhaustion
Resource exhaustion is another risk related to multitenancy and resource pooling (see Chapter 3). Resource exhaustion presents itself when an organization is denied resources because the resources are being completely consumed by another tenant or tenants; resource exhaustion may be malicious or not. If one or more tenant within the shared environment provisions a large amount of CPU, RAM, or network bandwidth, it can leave other organizations lacking sufficient resources to process their workloads. Reservations, shares, and limits can be used to mitigate this risk.
Network, host, and application vulnerabilities
As with any computing system, cloud environments are made up of hardware and software that may contain security vulnerabilities. In terms of cloud infrastructure, CSPs are responsible for routine scanning and patching of hosts, network devices, databases and applications under their control.
Unpatched vulnerabilities present a risk to organizations and their data; unlike in traditional data centers, customers may not be aware of this risk because of the lack of insight they have into the CSP’s vulnerability management practices.
Chapter 6 provides examples of common cloud vulnerabilities.
Virtualization risks
In the “Virtualization” section of this chapter, I basically explain why virtualization is the greatest thing since sliced bread. No, I’m not going to take it all back — virtualization really is a phenomenal technology, without which we wouldn’t have the cloud computing we know and love today. What I do want to do is highlight some of the key risks that virtualization technology presents.
The complex nature of virtualization technologies means you have more things to understand (or misunderstand) and more room for things to go wrong. In 2015, the Cloud Security Alliance (CSA) published “Best Practices for Mitigating Risks in Virtualized Environments.” In the whitepaper, CSA identifies 11 virtualization risks that are broadly classified into three categories:
- Architectural
- Hypervisor software
- Configuration
I list those risks and discuss some of the most prevalent risks in each of the following sections.
Architectural risks
Architectural risks are directly related to the abstraction between physical hardware and virtualized systems. This abstraction creates an added layer of complexity that presents risks to virtual machines stored or running in a cloud environment.
Per CSA, some key architectural risks include
- Lack of visibility into and control over virtual networks: Virtualized traffic is not easily monitored with existing physical network monitoring tools.
- Resource exhaustion: This topic is discussed in the “Resource exhaustion” section of this chapter.
- Workloads of different trust levels on the same host: This risk is due to multitenancy and resource pooling. If sensitive data shares resources with less sensitive information, appropriate controls must exist to separate and appropriately categorize and secure each classification of data.
- Risk due to CSP APIs: This topic is discussed in the “Management plane compromise” section of this chapter.
Hypervisor software risks
As an essential component of virtualized systems, any vulnerabilities that exist within the hypervisor presents significant risk.
Per the CSA whitepaper, some key hypervisor risks include
- Hypervisor security: If not managed throughout its entire lifecycle, the hypervisor may contain exploitable vulnerabilities.
- Unauthorized access to the hypervisor: Because it’s the Holy Grail of virtualization, weak access control mechanisms present immense risk to cloud customers and their data.
- Account or service hijacking through the management portal: This topic is discussed in the “Management plane compromise” section of this chapter.
Configuration risks
Virtualization significantly speeds up the creation of computing environments. Without careful attention to secure configurations, large environments can be developed quickly and without proper security controls in place.
According to the CSA whitepaper, configuration risks include, but are not limited to
- VM sprawl: VM sprawl is the uncontrolled growth of VMs to the point where the cloud administrator can no longer effectively manage and secure them.
- Sensitive data within a VM: Because VMs are just files that can be moved from place to place, lack of strong security controls (like encryption and access control) poses a risk to any sensitive data contained within the VM.
- Security of offline and dormant VMs: This topic is discussed in the “Virtualization” section of this chapter.
While these risks are largely centered around virtual machines and the hypervisor, you should keep in mind that containers come with related virtualization risks. For example, a container’s underlying host OS may be compromised and pose risk to data within that container (or within the broader containerized environment)
Countermeasure strategies
After you understand the common risks present in cloud infrastructure, the next step is to identify some things you can do to mitigate those risks. It’s important that you develop and employ countermeasure strategies that are based on a defense-in-depth approach to combating risk. Your strategy should include logical, physical, and environmental protections — and layered controls for each of those categories. For example, physical protection of your data centers should include reinforced walls, strong locks, video cameras, security guards, and a tall perimeter, among other controls.
Another part of your countermeasure strategy should be to use not only preventative controls, but also detective measures. You should certainly try your best to prevent 100 percent of compromises from occurring, but more importantly, you must have mechanisms in place to detect any of those compromises that you’re not able to proactively stop. A strong combination of prevention and detection is key to an effective countermeasure strategy.
A key component of a strong countermeasure strategy is automation. Implementation, configuration, and management of security controls should be automated wherever possible. This automation helps ensure thorough coverage and also allows quicker validation of their effectiveness. Perhaps even more important, automation removes the human from the loop and prevents the killer effects of human error. When in doubt, automate, automate, automate!
As a cloud customer focusing all your attention on protecting virtual machine instances and the data in your environment is easy. However, an effective strategy must include due diligence in determining whether your cloud provider is effectively protecting the underlying infrastructure, including the hypervisor. Though you have less direct insight into infrastructure security than you would in a traditional server model, it is your right and responsibility to request and review your CSP’s security and compliance documentation.
Designing and Planning Security Controls
This chapter covers the core capabilities of cloud infrastructures and many of the risks associated with migrating your data to one of them. I’ve touched on some of the things you can do to mitigate those risks, but this section dives deeper into how you should design and plan your security controls. I dig into some of the earlier topics and help you understand the most important controls you can implement to ensure physical and environmental protection, as well as things you can do to secure your virtualized infrastructure.
Physical and environmental protection
Physical and environmental protection is focused on securing the actual data center by implementing security controls on its buildings, the physical infrastructure within them, and their immediate surroundings. Specific assets that require physical and environmental protection include
- Servers and their racks
- Networking equipment (routers, switches, firewalls, and such)
- HVAC systems
- Fire suppression systems
- Power distribution lines
- Telecommunications cables
- Backup generators
This list could go on and on, which goes to show the extreme importance behind physical security for a technology that is easy to view as strictly virtualized. In addition to the data center and its physical assets, physical protection must also extend to the end-user devices used to connect to the cloud environment. These devices can include desktops, laptops, mobile devices, and any other endpoint devices used by the customer. As a CCSP, you must remember that even physical protections have a shared responsibility.
The protections you need should be largely based on an assessment of the risks present in your specific situation. Among these risks, compliance risk should always be considered. Several regulations provide requirements for managing physical and environmental security; HIPAA, PCI DSS, and FedRAMP, among others, include relevant guidance for CSPs. In addition, cloud providers have recently been increasingly considered critical infrastructure by countries around the world. As such, CSPs are being further monitored and regulated by critical infrastructure regulations, like North American Electric Reliability Corporation Critical Infrastructure Protection (NERC CIP) in the United States.
For physical and environmental protection, security controls should minimally include
- Policies that address the purpose, scope, roles and responsibilities for physical and environmental protection
- Procedures that detail how to implement and address relevant policies
- Mechanisms to restrict access to data centers, server rooms, and other sensitive locations to authorized personnel and visitors (following the principle of least privilege)
- Background screening for any staff with access to critical systems or highly sensitive information
- Physical controls like fences, walls, trees, security guards, badge readers to deter unwanted access
- Fire suppression, water damage protection, temperature and humidity control, and other mechanisms to prevent natural disasters from causing preventable harm
- Backup power and redundant telecommunications capabilities
System and communication protection
Despite being highly virtualized, cloud infrastructures are still a collection of physical systems that communicate with each other and the outside world — much like within the traditional server model. Protecting these systems and communication channels again comes down to understanding the risks present in a particular environment, as well as evaluating the data being protected. Remember: Security follows the data!
Because following the data is so important when designing security controls, you should start by aligning your thinking with the cloud data lifecycle (see Chapter 4). By focusing on the state of the data you’re securing, you can better develop security controls that address the specific risks that exist at any given point. Take a look at some common controls for data at rest, data in transit, and data in use:
- Data at rest: The primary security control available for protecting confidentiality at rest is encryption. Protecting integrity and availability can be achieved through hashing controls and redundant storage, respectively.
- Data in transit: For data in transit, encryption is again a useful control for ensuring confidentiality; this type of data relies on encrypted transport protocols like HTTPS and TLS. Traffic isolation through VLANs and other network isolation controls can also help protect confidentiality, integrity, and availability for data in transit. DLP is another fantastic security control to consider for data in transit, as it helps prevent data leakage through a variety of channels.
- Data in use: Data in use can be protected through a combination of encryption, digital signatures, and access management controls across all APIs.
Some additional system and communications controls to consider include
Policies and procedures (again)
It’s really hard to know what to do and how to do it if none of that is documented. You should have a policy and set of procedures for any meaningful security function that must be enforced and/or repeated. Not only is this good security hygiene, but it’s also a compliance requirement for many regulations and industry certifications.- Isolation of security functions from nonsecurity functions
- Logging and monitoring of traffic through boundary protection devices, including firewalls and Intrusion Detection/Protection Systems (IDS/IPS)
You must have a firm grasp of where the responsibility for protecting cloud systems ends for the cloud service provider and where it begins for the cloud customer. Seek out documentation from your CSP regarding the Shared Responsibility Model and ensure that you understand what your responsibility is for your given service model and the specific cloud products and services you’re using.
Virtualization systems protection
As I mention throughout this book, virtualization is the foundational technology behind cloud infrastructure, and it allows compute, storage, and network resources to be shared among multiple cloud tenants. Considering how critical virtualized infrastructure is, it makes sense that the systems behind virtualization are primary sources of cloud-specific risk that require specific controls and protection.
Protecting virtualization systems starts with the hypervisor, and you can find out about many controls for hypervisor protection in this chapter. Another important area to focus on when planning security controls is the management plane. The management plane has full visibility and control over all virtualized resources, and it is exposed to cloud customers through Internet-facing APIs. Protecting those APIs and all associated CLIs or web front-ends is of the utmost importance. As a CCSP, it’s your job to break down all these components and understand the specific risks present in each before designing and implementing your security controls.
Virtualization security is a broad topic and includes many of the concepts discussed throughout this chapter. Key security controls that protect virtualization systems can be broadly grouped into three categories:
- Vulnerability and configuration management
- Access control
- Network management
Vulnerability and configuration management
Software vulnerabilities in the management plane and hypervisor are particularly concerning because of what we know about virtualization. In short, a vulnerability in one of these components may not only impact one customer, but potentially all tenants that share the underlying physical systems. For example, in a breakout attack, a hypervisor security flaw might allow one guest to break out of their VM and manipulate the hypervisor in order to gain access to other tenants.
To prevent breakout attacks and other software exploits, you must ensure that virtualization systems are hardened in accordance with vendor security guidelines and best practice recommendations. These best practices include disabling unnecessary services and applications that can increase the attack surface of your systems and also building comprehensive processes and controls for vulnerability remediation and patch management. You should automate as much of these processes as possible.
Pulling asset inventory information from your cloud APIs can help automate your vulnerability management and can ensure that you’re scanning and remediating your entire cloud environment.
The terms vulnerability management and patch management are sometimes used interchangeably, but they are not the same. Patch management is the part of configuration management that includes all processes for finding, testing, and applying software patches (or code changes) to your systems. Vulnerability management is the process of identifying, classifying, and fixing vulnerabilities that exist within your system. While some software patches may indeed result in vulnerabilities being fixed, many are related to product stability or other nonvulnerability related areas. Further, not all vulnerabilities can be fixed or mitigated by applying a patch. For example, some software weaknesses require disabling services or other manual configuration changes.
Access management
When it comes to access privileges, less is more — especially when controlling access to the hypervisor and management plane. Role-based access control (RBAC) should be enforced, and ideally only you (if you’re the CCSP responsible for your cloud environment), your cloud administrator, and very few others should have access to your CSP’s management console. The principle of least privilege means that you should set tight access restrictions that prevent unauthorized parties from modifying VM settings and accessing your sensitive resources and data.
Even with strict access controls in place, it’s important that you log, monitor, and audit the effectiveness of these controls. Any administrative access to virtualization systems should be tracked in very detailed logs that identify the following, at a minimum:
- Whether the access is successful or denied (multiple access denials is an indicator of foul play)
- Who originates the access (username, IP address, and so on)
- Where they are located (geolocation data can help identify misuse, especially if your management systems are generally accessed from specific locations)
- What access path was used (CLI or web console, for example)
- What privileged actions are taken (especially important to identify any pivots from one system to another)
Logging the proper details is a crucial control for detecting security compromises; preserving and analyzing those logs is just as important. Logs should be securely transported to and maintained on a separate system, where they are encrypted and tightly access controlled. Keeping your logs on a system that is separate from the systems being monitored adds a layer of protection against the logs being deleted or manipulated if the virtualization systems themselves are compromised.
Network management
Because network intrusions can affect hypervisors and management planes, proper network design is a fundamental requirement to protect virtualization systems. Secure network management includes suitable implementation and configuration of firewalls, IDS/IPS, and other security controls that prevent and detect anomalous or malicious network activity.
Connections to the management plane should occur over encrypted network sessions, for both cloud providers and cloud customers. Some regulations even mandate that specific encryption protocols or mechanisms be used for these connections. For example, US government agencies are required to use FIPS 140-2 validated cryptographic modules when connecting to the cloud, per FedRAMP requirements. I cover FedRAMP and FIPS 140-2 (and FIPS 140-3) in Chapter 3.
In the traditional data center model, network perimeters are pretty easily defined. You draw an imaginary line around your important internal stuff, and that’s your internal network. Another line drawn identifies the demilitarized zone (DMZ), which contains your perimeter devices that connect to the scary Internet. You may have some other zones in there, but the architecture at its core is this simple. In virtualized environments, the allocation of risk among systems differs from on-prem environments. When virtualization systems are not sufficiently protected by other controls, you can use additional trust zones as an added layer of protection.
I discuss the topic of zero trust in the “Logical design” section of this chapter. While zero trust is an emerging security concept that provides a great deal of protections for virtualized environments, the concept of trust zones has been around for a long time and must be understood for the CCSP exam.
A trust zone is a network segment that includes systems and assets that share the same level of trust. The DMZ and internal network in the preceding paragraph are common examples of trust zones. Network traffic within a trust zone can move freely, with few limitations. However, traffic into and out of a trust zone is closely monitored and tightly restricted. There are many strategies for developing trust zones, and it’s up to each CSP to identify the strategy that works best for their cloud. Figure 5-6 depicts one common example of a trust zone architecture that includes a web zone, data zone, and management zone. Use trust zones allows a cloud provider to plan security controls for each zone that meet the individual security needs of the systems in that particular zone.
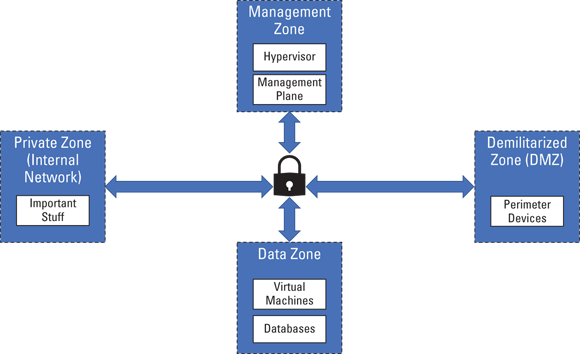
FIGURE 5-6: Example trust zone architecture.
As the preceding example shows, keeping your data zone (which may include customer VMs, databases, and so on) separate from your management zone (which includes the hypervisor and management plane) is a great idea. This segmentation helps ensure that a compromised customer VM is not able to affect other systems on the shared infrastructure.
When connecting into a management zone from another zone, you should connect from a bastion (or jump) host. A bastion host is a system that runs outside your security zone that is generally designed to serve a single-purpose (like connecting to the management zone) and has been extremely hardened for enhanced security. A bastion host might reside in your DMZ and be used to allow administrators access to the management zone via virtual private network (VPN). Because they are often the single connection into the highly sensitive management zone, bastion hosts must be stripped down of unnecessary functionality, protected with multifactor authentication, and monitored with auditing tools.
Identification, authentication, and authorization in cloud infrastructure
Any IT system requires you to manage identification, authentication, and authorization. Cloud infrastructure and platform environments are no exception, but you need to be aware of some cloud-specific nuances. I provide some background on these topics in Chapter 2, but this section takes a closer look.
Identification
Identification is essentially the act of giving a unique name or identifier to every entity within your environment; entities include users, servers, networking hardware, and other devices — anything that needs to be granted some level of permission to resources needs to be identified. A username is the most basic form of identification.
Just about every organization has an existing identity system or service, with Microsoft Active Directory being by far the most common in large organizations. Many smaller companies, academic institutions, and nonprofits choose open source identity standards instead of proprietary ones like Active Directory. Because large cloud providers must appeal to the masses, open standards like OpenID and OAuth have become the standards for cloud identity management.
You should be familiar with the OpenID and OAuth standards for your exam, and understand what they’re used for at a high level. The nitty-gritty details are outside the scope of this book, but are worth investigating further.
One thing customers don’t want is to be forced to manage two (or more) separate identity systems when they move to the cloud. Federation is the process of linking an entity’s identity across multiple separate identity management systems, like on-prem and cloud systems. Federation enables a cloud provider’s identity system to trust an organization’s existing identity profiles and attributes and use that identity information to manage access to cloud resources. Figure 5-7 shows a typical federated identity structure, where each party has its own identity provider, and each system that accepts identity information is known as a relying party. I cover federated identity in Chapter 6.
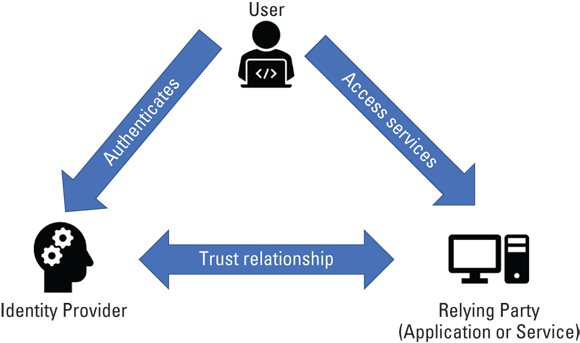
FIGURE 5-7: Federated identity overview.
Authentication
If identification is the act of uniquely naming an entity, authentication is the process of confirming that an entity is who they say they are. The password that is associated with your username is the most common mechanism used for authentication. Your password is something that only you should know (ask Netflix), which gives an authentication system reasonable confidence that it can confirm your identity when you enter it. Multifactor authentication (MFA) enforces stronger validation of a user’s identity, by requiring more than just a password (like a badge or fingerprint, for example). Using MFA is advisable whenever feasible, but should be considered a strict requirement for all privileged and high-risk access.
Authorization
Once your unique identity has been established and your credentials have been used to validate your identity, authorization is the process by which appropriate access privileges are granted. The relying party receives information about the entity from the identity provider and then makes the determination about what type of access to grant the entity, if any. The relying party determines this based on pre-set policies that govern which users and roles can access which resources.
You may come across tools like Okta, Onelogin, Azure Active Directory, and Duo. These (and many others) are examples of cloud-based identity management and active directory services that are growing increasingly popular.
Audit mechanisms
Auditing plays a major role in ensuring that IT systems comply with legal, regulatory, security, and other requirements. In a cloud environment, where many different customers share a single infrastructure, there is no way for an individual customer to do their own audits of a cloud environnent. I dive into audits in Chapter 8, but in this section, I cover two specific audit mechanisms: log collection and packet capture.
Log collection
Log collection within a cloud environment can be a mixed experience if you don’t know what to expect. While most cloud environments provide capabilities that enhance your ability access some logs and automate log management, your mileage will vary based on your service model and other factors.
On one hand, cloud environments make it super easy for customers to locate and centrally aggregate log data for all their assets via the management plane. Some CSPs even offer dedicated services for monitoring, storing, and analyzing your log files. AWS CloudWatch Logs, for examples, centralizes your DNS logs, EC2 logs, and log data from your other cloud-based systems. So, you can see how leveraging the power of the cloud can be a plus when it comes to log collection.
On the other hand, the types of logs you have access to in cloud environments never completely match what you can get when operating your own data center. Because of virtualization, you’re not able to access hypervisor logs, which would expose too much about other tenants in the shared environment. You are largely out of luck when it comes to collecting logs for the underlying infrastructure, and the types of log data available to you decreases as you move up the service category stack (from IaaS to PaaS to SaaS). With IaaS, you’ll get all the platform- and application-level logs, as well logs for your virtual hosts (VMs) and virtual network. The PaaS service model generally has access to the same log data minus the virtual host and network logs. SaaS customers capture the least amount of log data and are usually limited to access information and logs that capture data about application usage.
When organizations migrate to the cloud, they benefit by giving up lots of the management responsibilities that come with operating a data center. Along with this benefit, cloud customers are making the decision to let go of some of the control that they may be used to. As a CCSP, it’s your job to ensure that your organization understands what they’re gaining and losing as it pertains to log collection.
Packet capture
Cloud-based packet capture faces many of the same challenges mentioned for log collection (see preceding section) and is again dependent upon the cloud service category being deployed. IaaS customers are able to conduct packet capture activities on their virtual machines, but PaaS and SaaS customers are limited to what their CSP is willing to share. As a CCSP, you must ensure that your organization understands what data is available in a given cloud and make an informed decision as to whether it meets your company’s risk tolerance and business needs.
Planning Business Continuity (BC) and Disaster Recovery (DR)
I introduce business continuity and disaster recovery (collectively referred to as BCDR) in Chapter 2, and this section goes into the specific risks, requirements, and activities that go into creating, implementing, and testing your BCDR plans.
Certain characteristics and considerations of cloud infrastructures lend themselves very well to business continuity and disaster recovery; broad network access means that your organization is able to retrieve your critical data from just about anywhere, and large, geographically dispersed infrastructures provide you with levels of availability and resiliency that you just can’t match on-prem. As great as these features are, we are cloud security professionals, and as usual, we must consider risks and other factors as we plan for BC and DR in the cloud.
Risks related to the cloud environment
In this section, I cover two categories of risk as they pertain to business continuity and disaster recovery in cloud environments.
The first category is related to the risks that organizations face in traditional IT infrastructures that make cloud-based BCDR attractive, and the second category is focused on the risks involved in conducting BCDR in the cloud. For the latter, I also discuss some things you can do about those risks in order to create and implement a comprehensive and secure BCDR plan.
Risks to traditional IT
Risk exists in every form of computing, traditional server model and modern cloud computing alike. Whenever a risk can potentially disrupt an organization’s ability to access their important data or conduct critical business activities, the company’s business continuity and disaster recovery plan should address it. BCDR is an important set of activities that is required to minimize the business impact during and after potential disastrous events occur.
Many risks to traditional IT infrastructures can be completely solved or at least partially mitigated by migrating to the cloud. Those risks include, but are not limited to
- Natural disaster risks, including damage from
- Flood
- Fire
- Earthquake
- Hurricane
- Tornado
- Deliberate human risks
- DDoS attack
- Ransomware
- Arson
- Terrorist attack
- Employee strike
- Accidental human risks
- Fire
- Explosion
- Human error
- Indirect human risks
- Equipment failures
- Power outage
- Telecommunication outages
- Outage due to provider going out of business
While all these risks can potentially impact a cloud provider, the risk is substantially lower in cloud environments due to the vast nature of cloud infrastructures and the key characteristics of cloud.
Risks to cloud-based BCDR
Aside from risks that may trigger the use of a business continuity and disaster recovery plan, you must consider risks to a BCDR Plan itself. The following risks impact any BCDR Plan, including cloud-based:
- Cost and effort to maintain redundancy: Any BCDR plan requires some level of redundancy, which comes with a level of financial and operational risk. If you’re operating in a hot-hot configuration, you’ll need to ensure that both the primary and secondary sites are fully staffed, configured, and updated at all times. Maintaining this type of configuration requires that the primary and secondary locations remain in sync, which can be operationally challenging. Syncing primary and secondary locations is made easier with cloud infrastructures because the cloud allows near real-time syncing between regions, and you can have your data maintained in multiple regions automatically. This convenience does, however, come at a cost; the higher level of redundancy not only increases availability, but also your usage fees.
- Performance hit due to location change: If an outage to one cloud data center or region forces your resources to failover to another region, you can be faced with latency issues. Despite cloud infrastructures being developed and configured to run your workloads from multiple geographic regions, the way the Internet works means that the closer you are to your data, the faster you’ll be able to access it. Say that you’re a Texas-based company, your primary cloud region is in Oklahoma (very close to Texas), and your secondary region is in New York (kinda far from Texas). The latency and performance that you get when failing over to a region across the country may very well be noticeable (or even problematic, depending on the applications you’re running). This risk can impact the cloud customer’s perception of the CSP and may trickle down to affect any customers that use the cloud customer’s hosted services. You can mitigate these risks by selecting a cloud provider with multiple regions available to support your geographic needs.
- Decreased operations during/after failover: If you experience a complete outage of your primary site and must fully failover to your secondary site, you should be mindful of a couple potential risks:
- The speed at which you recover may present a risk to your business operations. This risk is generally less of a concern for cloud environments because of rapid elasticity, but full failover and recovery is dependent upon you properly maintaining backups of data and virtual machine instances. Again, cloud can help automate much of this risk, but it is your responsibility to configure these things according to your organization’s needs.
- If your applications contain custom code or API calls to/from external services or IP addresses, you run the risk of not maintaining proper functionality post-failover. This risk can be mitigated by ensuring primary configurations are saved and readily accessible should a BCDR event occur.
In addition to these risks, you need to consider certain risks that depend on the particular BCDR use-case. Three common BCDR use-cases leverage cloud:
- Scenario 1: Organizations use their existing IT infrastructure to run their primary workload, and have a cloud provider serve as their BCDR site. This scenario is a hybrid deployment.
- Primary: On-premise; Secondary: CSP
- Concerns: Cloud migration can be a complex process. If any organization procures a cloud provider strictly for BCDR purposes, they must ensure that their workloads are able to migrate to the cloud and operate seamlessly in a failover situation. Use of containers within the on-prem solution can provide added portability and help ensure compatibility when migrated.
- Scenario 2: Organizations run their infrastructure in a cloud environment, and use a separate region of the same cloud for BCDR.
- Primary: CSP; Secondary: CSP
- Concerns: This scenario generally comes with the least amount of risk. The organization must evaluate the CSP to ensure multiple cloud regions exist that will support their requirements. CSPs sometimes do not operate all cloud services in every region. Make sure that you select a secondary region that offers the functionality and performance that your organization needs to continue operating smoothly.
- Scenario 3: Organizations run their infrastructure in one cloud environment and use a completely separate cloud company for BCDR.
- Primary: CSP1; Secondary: CSP2
- Concerns: This scenario adds another potential risk, and that is the second provider’s compatibility and ability to execute as required. Depending on your service model and the types of services in use, you may have to accept minor differences in functionality during failover due to the two CSPs potentially offering different capabilities. Containers are very helpful in mitigating some of these risks in a multicloud solution.
No matter what your use-case is, BCDR is an important topic that deserves a lot of attention and planning. A full assessment of potential risks is a prerequisite to designing an appropriate BCDR plan for your organization.
Business requirements
BCDR planning should be based on business requirements that are collectively generated by management from several parts of the organization (including security). Your business must establish three important requirements for BCDR, whether on-premises, hybrid, or cloud-only. I introduce Recovery Time Objective (RTO) and Recovery Point Objective (RPO) in Chapter 2; those are the most commonly used BCDR business requirements. The third major concept is Recovery Service Level (RSL). Recovery Service Level is the percentage of total computing power, performance, or functionality needed during business continuity. In other words, RSL answers the question “What is the minimum percentage of my normal production that I need to maintain during a disaster?”
When determining your business requirements, it’s important that you do so without regard to any potential BCDR solutions. In other words, don’t derive these business requirements from the capabilities of potential CSPs. Instead, your organization must conduct a cost-benefit analysis and determine the potential cost (financial or reputational) to your business that is tolerable. This cost will translate into acceptable downtime (RTO), acceptable loss of data (RPO), or acceptable loss of functionality (RSL).
Business continuity/disaster recovery strategy
After your organization has evaluated all potential risks, and you identify BCDR requirements that meet your business needs, it’s time to develop your BCDR strategy. Your strategy should consider everything I cover earlier in this section and should help take you from concept through implementation. You can break down a BCDR strategy in a number of ways, but I like to use four phases:
- Scoping and assessment
- Creating/designing
- Implementing
- Testing and reporting
Scoping and assessment
The first phase in BCDR strategy development is scoping and assessment. During this phase, your organization’s primary goal is to establish the scope of your plan, generate your complete list of BCDR requirements and objectives, and assess any known risks. To help you understand, I break each of these out to better explain each step within Scoping and Assessment.
DEFINING YOUR SCOPE
When defining your BCDR scope, your organization should consider BCDR planning as an essential business function that is part of your Information Technology capability. Senior leadership from IT, Information Security, and other business areas should be included as you define key stakeholders, roles, and responsibilities, and as you continue to develop your plan. Scoping these components at the very beginning of your strategy can help you create a more comprehensive strategy with less need to gain stakeholder support down the line.
GENERATING YOUR REQUIREMENTS AND OBJECTIVES
Generating your BCDR requirements starts with identifying your critical business processes, systems, and data that need to be protected by BCDR. You must have a holistic inventory of your assets and should conduct threat and risk assessments on those assets to determine the business impact of losing access to them for a given period of time. Once you have this information, you should identify the RPO, RTO, and RSL, discussed earlier in the “Business requirements” section.
Getting caught up in the dollars and cents of business requirements is easy, but remember to consider any regulatory and contractual obligations that your organization has to satisfy. If your company has built cloud-based applications and sells to other companies or operates in certain industries or countries, you may very well have external requirements to consider.
So, after you have a comprehensive matrix of your critical assets and the risks to those assets and you have a thoroughly documented list of internal and external business requirements, you can start thinking about potential types of solutions that might meet your BCDR needs.
Don’t get too far ahead, though! During this step, you want to identify some key capabilities that a BCDR solution should have, but you don’t want to architect your solution just yet. Start by analyzing your current hosting environment and identifying critical capabilities that need to be maintained during business continuity or replicated during disaster recovery. Combine this analysis with your understanding of critical business processes and assets and the risks they face. With all this information in hand, you should have the framework for your BCDR plan and can start assessing risks that may be exposed during a BCDR event.
ASSESSING RISK
I talk about risk throughout this chapter and cover different areas of risk throughout this book. Risk assessment is an immensely important topic to understand, and you should recognize the nuances between different risk discussions. In the previous section, I talk about identifying risks that your critical assets face; these risks inform your prioritization of BCDR features and selection of a BCDR provider. In this step, your focus should be on assessing risks associated with your potential BCDR providers (rather than on your assets themselves). Some common risks and challenges to consider include
- Service migration: You must seek to understand the process a BCDR provider will use to migrate your services and data during failover. You may face longer than expected outages if the CSP lacks sufficient network infrastructure and bandwidth to migrate your workload within your desired RTO. You should also consider potential risks of getting data from your primary (on-prem or CSP) to the secondary (CSP) site. Not only must the BCDR site have sufficient bandwidth to support your recovery objectives, but you must have enough bandwidth between your primary and secondary sites to avoid length business outages.
- BCDR capacity: You must make sure that the secondary site can handle the same load as your primary. Secondary site capacity is generally less of a concern with an on-prem to CSP architecture, as CSPs almost always have more available resources than on-prem hosted solutions do. However, it’s important to consider capacity with CSP-CSP architectures, particularly when your BCDR site is a separate cloud provider altogether. Make sure that you understand and manage any risks associated with different SLAs between multiple cloud providers.
- Legal and compliance issues: Compliance with regulatory requirements and contractual obligations is a shared responsibility between CSP and cloud customer, but the liability ultimately falls on you as the data owner. When a BCDR event occurs, you need to assess potential risks as you move from one environment to another. For example, say that you manage HIPAA regulated PHI. If your BCDR provider does not support HIPAA regulations, then you could be in serious trouble. Risks even exist when you stay within the same cloud provider for BCDR. For example, many regulations include data location and data sovereignty requirements. If your data is required to remain in a particular country, you must be aware of your BCDR provider’s ability and commitment to meeting these obligations, even during failover.
OUTCOME
The expected outcome of the scoping and assessment phase is for your organization to
- Identify all stakeholders, including management from IT and other parts of the business
- Assign initial roles and responsibilities for the development and approval of your BCDR plan
- Identify and document all critical business processes and the systems and data necessary to support those processes
- Assess and document the risk to critical business processes, systems, and data
- Define business requirements, including RPO, RTO, RSL, and external requirements (legal, compliance, and so on)
- Identify controls and features necessary for a BCDR provider to mitigate business risks
- Assess the risk of all potential BCDR providers and identify initial mitigations
Creating, implementing, and testing your plan
After scoping your requirements and conducting a risk assessment of your initial BCDR plan, you’re ready to create, implement, and continuously test your plan. These phases rely heavily on the research, analysis, and planning that is conducted during the first phase of BCDR strategy development.
CREATING YOUR PLAN
The creation or design phase is where your organization identifies and fully evaluates BCDR options against the technical and business requirements you developed during the prior phase. It’s here that you dig into the details of each potential solution and identify the one that best fits your organization’s needs.
In addition to selecting a BCDR architecture that meets your technical requirements, your plan must also establish clear procedures to follow before, during, and after a BCDR event. You should establish the following items at a minimum:
- Technical requirements for the BCDR solution, including required services, features, and capacity
- Support requirements that must be included in SLAs and contracts with BCDR provider
- Definition of events, situations, and scenarios that trigger BCDR
- Procedures necessary to invoke the BCDR solution for Business Continuity
- Policies and procedures to test the BCDR, including the frequency of testing and step-by-step process required to ensure functionality
To be effective, all policies and procedures should include a RACI (Responsible, Accountable, Consulted, Informed) matrix that identifies all relevant teams and personnel and their associated roles and responsibilities. The specific personnel required will vary based on your organization structure, but examples of key business units to include are
- Information technology (including the CIO for approvals, at least)
- Legal
- Compliance
- Administrative support
- Operations
- Facilities management
- Physical security
- Crisis management
- Human resources
Lots of teams and people get involved during a crisis or disaster. It’s important that you have clear owners identified before the crisis hits so that you’re not left figuring out who’s responsible for what when tensions are high.
IMPLEMENTING YOUR PLAN
Okay, you’ve got a plan — that’s great! If you haven’t already, you need to make sure that your plan is fully vetted and approved by appropriate leadership within your organization. Once that’s done, you’re ready to bring your strategy to life and implement your plan.
Implementing your BCDR usually involves performing work on both your primary infrastructure and your BCDR infrastructure. The latter is pretty easy to understand, but many customers struggle with the notion that their on-prem or primary cloud implementation may need additional configurations or modifications to support BCDR preparedness. As a CCSP, you know better, and it’s partially up to you to help your organization see the rationale.
Typical implementation activities required on your primary infrastructure include
- Configuring necessary connections into the BCDR site, which may include programming API calls or even physical interconnects in some situations
- Implementing and configuring continuous or routine backup and replication activities that support your defined business requirements
- Implementing mechanisms that monitor for defined events and scenarios that should trigger BCDR
- Modifying change management procedures to ensure ongoing alignment between the primary and secondary infrastructures
For your BCDR infrastructure, you’re likely in a position that requires complete procurement and building out of capabilities to match your primary site. You must ensure that your BCDR site includes all the products and services that you need to ensure a near-seamless transition during failover. As a new environment, your BCDR infrastructure will need to be thoroughly tested after initial configuration.
TESTING YOUR PLAN
Once you create your BCDR plan and fully implement the required mechanisms and processes, you must test your plan to ensure that it’ll work during an actual BCDR event. The objective of BCDR testing is to ensure that the plan, as implemented, meets the RPO, RTO, and other business requirements your organization defined during initial planning. Testing is not a one-time event, but rather an ongoing activity that should ensure your plan stays relevant as your systems, processes, and risks change over time.
Most regulations and standard practices recommend BCDR testing at least annually, but some regulations and contractual commitments require more frequent testing. It’s also highly recommended that you do some form of BCDR testing anytime your environment sees a significant change that may impact your existing BCDR procedures.
You can conduct several different exercises to test the efficiency of your BCDR plan, and each requires a different level of vigor and effort to execute. The four most common testing methods include:
- Tabletop exercise: A tabletop exercise is a formal walkthrough of the BCDR plan by representatives of each business unit involved in BCDR activities. The walkthrough includes reviewing the plan itself, discussing each step in the process, and clarifying roles, responsibilities, and any open questions from stakeholders. As the simplest BCDR testing method, this method is not preferred for actual testing, but is better suited as a training exercise to get all stakeholders on the same page.
- Simulation exercise: A simulation exercise is an enhanced version of a tabletop exercise that leverages a predefined scenario. Participants again walk through the steps in the BCDR, this time adding specific actions that should be followed during the imaginary scenario. These exercises generally involve some form of simulated notifications and mobilization activities, but stops short of actual physical mobilization to alternate sites.
- Parallel test: A parallel test takes things to the next level and involves bringing the secondary site up to full operational capacity, while maintaining all operations in the primary site. Staff is mobilized to the alternate site along with any equipment and resources they’d bring during an actual event. This test is essentially a full drill that stops just shy of shutting off the primary infrastructure.
- Full-scale test: Here, it’s all systems go — well, actually it’s one system goes down and another goes up. During a full-scale test, all operations are shut down at the primary location and shifted to the BCDR site. This test is the only one that provides a complete view of what would happen during an actual BCDR, but it is very expensive to accomplish.
Regardless of the testing method selected, once testing is complete, a comprehensive report must be generated and published for all stakeholders to review the testing results, including what worked, what didn’t work, and any lessons learned. The report should include action items based on the lessons learned, with each action item being assigned an owner and tracked through completion. This report should serve as an input to revise the BCDR plan and the next BCDR testing exercise.