
Chapter 2
Identifying Information Security Fundamentals
IN THIS CHAPTER
![]() Recognizing the pillars of information security
Recognizing the pillars of information security
![]() Identifying threats, vulnerabilities, and risks
Identifying threats, vulnerabilities, and risks
![]() Discovering how to control access to your data
Discovering how to control access to your data
![]() Exploring encryption
Exploring encryption
![]() Planning for and responding to security incidents
Planning for and responding to security incidents
In this chapter, you find out about the core security concepts crucial to passing the exam. You discover the most fundamental security topics and begin to set the stage for what you need to know to pass the exam. You need to understand a few foundational principles before embarking on your CCSP journey. This chapter serves as your information security primer.
 Although many CCSP candidates have already attained the CISSP or other security certifications, it’s not a requirement to sit for the CCSP exam. If you already hold one of these certifications — or if you already have a strong grasp of security topics — then you can probably skip this chapter and dive right into the CCSP domain chapters in Part 2.
Although many CCSP candidates have already attained the CISSP or other security certifications, it’s not a requirement to sit for the CCSP exam. If you already hold one of these certifications — or if you already have a strong grasp of security topics — then you can probably skip this chapter and dive right into the CCSP domain chapters in Part 2.
Exploring the Pillars of Information Security
Information security is the practice of protecting information by maintaining its confidentiality, integrity, and availability. These three principles form the pillars of information security, and they’re often referred to as the CIA triad (see Figure 2-1). Although different types of data and systems may prioritize one over the others, the three principles work together and depend on each other to successfully secure your information. After all, you can’t have a triangle with two legs!
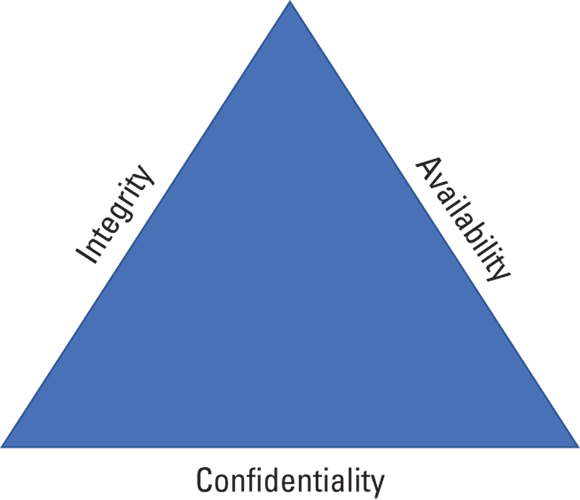
FIGURE 2-1: The CIA triad is the foundation of information security.
Confidentiality
Confidentiality entails limiting access to data to authorized users and systems. In other words, confidentiality prevents exposure of information to anyone who is not an intended party. If you receive a letter in the mail, the principle of confidentiality means that you’re the intended recipient of that letter; opening and reading someone else's letter violates the principle of confidentiality. The concept of confidentiality is closely related to the security best practice of least privilege, which asserts that access to information should only be granted on a need to know basis.
In order to enforce the principle of least privilege and maintain confidentiality, it’s important that you classify (or categorize) data by its sensitivity level. You can explore data classification in Chapter 4, but for this chapter, keep in mind that it plays a critical role in ensuring confidentiality. You must know what data you own and how sensitive it is before determining how to protect it and who to protect it from.
 Privacy is a hot topic that focuses on the confidentiality of personal data. Personal information such as names, birthdates, addresses, and Social Security numbers are referred to as personally identifiable information (PII). You can find out more about privacy in Chapter 8.
Privacy is a hot topic that focuses on the confidentiality of personal data. Personal information such as names, birthdates, addresses, and Social Security numbers are referred to as personally identifiable information (PII). You can find out more about privacy in Chapter 8.
Integrity
Integrity maintains the accuracy, validity, and completeness of information and systems. It ensures that data is not tampered with by anyone other than an authorized party for an authorized purpose. If your mail carrier opens your mail, destroys the letter inside, and seals it back up — well, you have a pretty mean mail carrier! In addition to not being a very nice person, your mail carrier has violated the principle of integrity: The letter did not reach the intended audience (you) in the same state that the sender sent it.
A checksum is a value derived from a piece of data that uniquely identifies that data and is used to detect changes that may have been introduced during storage or transmission. Checksums are generated based on cryptographic hashing algorithms and help you validate the integrity of data. You can find out more about cryptography in the “Deciphering Cryptography” section, later in this chapter, and hashing in Chapter 4.
Availability
Availability is all about ensuring that authorized users can access required data when and where they need it. Availability is sometimes the forgotten little sibling of the principles mentioned in the two preceding sections, but it has a special place in the cloud given that easy access to data is often a major selling point for cloud services. If your letter gets lost in the mail, then availability is a clear issue — the message that was intended for you to read is no longer accessible for you to read.
One of the most common attacks on availability is Distributed Denial of Service, or DDoS, which is a coordinated attack by multiple compromised machines causing disruption to a system’s availability. Aside from sophisticated cyber attacks, something as simple as accidentally deleting a file can compromise availability.
Availability is a major consideration for cloud systems.
Threats, Vulnerabilities, and Risks … Oh My!
They aren’t lions, tigers, or bears — but for many security professionals, threats, vulnerabilities, and risks are just as scary. Threats, vulnerabilities, and risks are interrelated terms describing things that may compromise the pillars of information security for a given system or an asset (the thing you’re protecting).
The field of risk management deals with identifying threats and vulnerabilities, and quantifying and addressing the risk associated with them. Being able to recognize threats, vulnerabilities, and risks is a critical skill for information security professionals. It’s important that you’re able to identify the things that may cause your systems and data harm in order to better plan, design, and implement protections against them.
Threats
A threat is anything capable of intentionally or accidentally compromising an asset’s security. Some examples of common threats include
- A fire wipes out your datacenter
- A hacker gains access to your customer database
- An employee clicks a link in a phishing email
Though only a few examples, the preceding short list shows how threats can come in all shapes and sizes and how they can be natural or manmade, malicious or accidental.
Vulnerabilities
A vulnerability is a weakness or gap existing within a system; it’s something that, if not taken care of, may be exploited in order to compromise an asset’s confidentiality, integrity, or availability. Examples of vulnerabilities include
- Faulty fire suppression system
- Unpatched software
- Lack of security awareness training for employees
Threats are pretty harmless without an associated vulnerability, and vice versa. A good fire detection and suppression system gives your data center a fighting chance, just like (you hope) thorough security awareness training for your organization’s employees will neutralize the threat of an employee clicking on a link in a phishing email.
Risks
Risk is the intersection of threat and vulnerability that defines the likelihood of a vulnerability being exploited (by a threat actor) and the impact should that exploit occur. In other words, risk is used to define the potential for damage or loss of an asset. Some examples of risks include
- A fire wipes out your data center, making service unavailable for five days
- A hacker steals half of your customer’s credit card numbers, causing significant reputational damage for your company
- An attacker gains root privilege through a phishing email and steals your agency’s Top Secret defense intelligence
Risk = Threat x Vulnerability. This simple equation is the cornerstone of risk management. Find out more about risk management in Chapter 8.
Securing Information with Access Control
So much of information security requires you to first have a strong understanding of who users are and then controlling their actions based on their identity. Think about it this way: The principle of confidentiality is pretty hard to enforce if you don’t first understand who does and doesn’t qualify as an authorized user, right? In this section, I introduce some key concepts associated with access control.
Identification is the act of establishing who (or what) someone (or something) is. In computing, identification is the process by which you associate a system or user with a unique identity or name, such as a username or email address.
Authentication takes identification a step further and actually validates a user’s identity. During authentication, you answer the question “Are you who you say you are?” before authorizing access to a system.
Passwords are the most obvious and common forms of authentication, but authenticators (things used to verify identity) can vary. Authenticators generally fit into one of three factors (or methods):
- Something you know: Passwords and PINs (Personal Identification Numbers) fall into this category.
- Something you have: Security tokens and smart cards are examples of this factor.
- Something you are: Examples of this factor includes fingerprints, iris scans, voice analysis, and other biometric methods.
Due to the imperfect nature of any one of the preceding factors, many organizations now require Two-Factor Authentication (2FA) or Multifactor Authentication (MFA). MFA has become standard practice for enforcing stronger validation of a user’s identity; because passwords can be hacked and security tokens can be stolen, the idea here is to require more than one form of authentication to reduce the risk of granting access to someone impersonating someone else.
Once you verify a user’s identity, you can determine what access to grant them. Authorization is the process of granting access to a user based on their authenticated identity and the policies you’ve set for them. You can control access to systems and data in many ways, but that topic is largely outside the scope of this book.
You can explore cloud-related access control in Chapters 3, 6, and 7.
Deciphering Cryptography
Cryptography is the science of encrypting and decrypting information to protect its confidentiality and/or integrity. It is easily one of the most daunting topics in the information security field, but it’s incredibly foundational for so much of what you do to protect data’s confidentiality and integrity. You don’t have to be a Math Ph.D. to grasp the most critical concepts of encryption, so the following sections tell you what you need to know.
Encryption and decryption
Encryption is the process of using an algorithm (or cipher) to convert plaintext (or the original information) into ciphertext. The ciphertext is unreadable unless it goes through the reverse process, known as decryption, which then allows an authorized party to convert the ciphertext back to its original form using the appropriate encryption key(s). An encryption key is a piece of information that allows the holder to encrypt and/or decrypt data.
Types of encryption
Encryption can either be symmetric-key or asymmetric-key. The two encryption types function very differently and are generally used for different applications.
Symmetric-key encryption (sometimes referred to as secret-key encryption) uses the same key (called a secret key) for both encryption and decryption (see Figure 2-2). Using a single key means the party encrypting the information must give that key to the recipient before they can decrypt the information. The secret key is typically sent to the intended recipient as a message separate from the ciphertext. Symmetric-key encryption is simple, fast, and relatively cheap.
 A notable drawback of symmetric-key encryption is it requires a secure channel for the initial key exchange between the encrypting party and the recipient.
A notable drawback of symmetric-key encryption is it requires a secure channel for the initial key exchange between the encrypting party and the recipient.- Asymmetric-key encryption (more commonly known as public-key encryption) operates by using two keys — one public and one private. The public key, as you might guess, is made publicly available for anyone to encrypt messages. The private key remains a secret of the owner and is required to decrypt messages that come in from anyone else (see Figure 2-3). Although public-key encryption is typically slower than its counterpart, it removes the need to secretly distribute keys and also has some very important uses (see the next section).
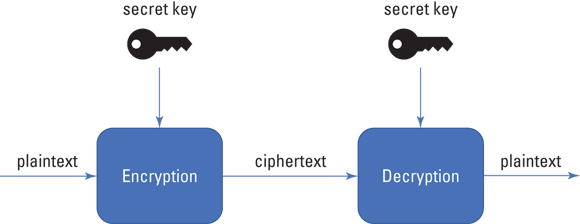
FIGURE 2-2: Using a symmetric-key for both encryption and decryption.
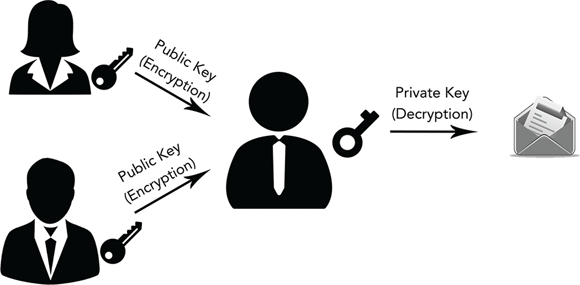
FIGURE 2-3: Utilizing asymmetric-key (or public-key) encryption and decryption.
Common uses of encryption
Encryption plays an important part in protecting information systems, and its applications are wide ranging. This section discusses some of the most common uses of encryption.
Data protection
Arguably the most widely used application of encryption is to protect the confidentiality of data. Data that has been encrypted (using strong algorithms) is protected from unauthorized viewers in the event it falls into the wrong person’s hand. You’ll typically see encryption used for data protection for both data-at-rest (things like files on a hard drive or in a database) and data-in-motion (communication over a network, for example).
Both symmetric-key and asymmetric-key encryption are commonly used in data protection applications.
Authentication
Usernames and passwords are often sent to some remote system for authentication and authorization. Encryption is commonly used to protect these sensitive credentials from eavesdroppers on the network who would intercept the credentials in transit and utilize them to impersonate an authorized user. Authentication is a standard use case for public-key encryption.
Network security
Transport Layer Security (TLS) is the standard technology used to encrypt traffic over a network, and it creates an encrypted link ensuring that all traffic between two points remains private. TLS has replaced its longstanding predecessor, Secure Sockets Layer (SSL), as the de facto standard and is used widely when privacy and data integrity need to be maintained between two systems.
While the nitty-gritty details of TLS is outside the scope of this book, you need to know that TLS connections use a combination of symmetric- and asymmetric-key encryption.
 Hypertext Transfer Protocol Secure (HTTPS) is TLS over HTTP and is the gold standard for protecting web communications. HTTPS is incredibly important for banking and other websites where users send and receive sensitive information and is now commonly used as a standard practice. Keep an eye on your browser’s address bar for https:// to ensure your session is encrypted.
Hypertext Transfer Protocol Secure (HTTPS) is TLS over HTTP and is the gold standard for protecting web communications. HTTPS is incredibly important for banking and other websites where users send and receive sensitive information and is now commonly used as a standard practice. Keep an eye on your browser’s address bar for https:// to ensure your session is encrypted.
Digital signatures
Much like your handwritten signature is used to verify your identity, a digital signature is a piece of information that asserts or proves the identity of a user. Digital signatures operate on a public-key scheme and require a sender to use their private key to electronically sign a message. Recipients can then use the sender’s public key to verify their identity.
Virtual Private Networks (VPNs)
Encryption provides a secure means for users to connect from one network to another. A virtual private network (VPN) encrypts communication between the two networks, over the Internet, to create a secure tunnel for communication. You commonly see VPNs used for people who telework by connecting to their organization’s network from home. Similar to the network security example in the earlier section, VPNs use a mix of symmetric-key and asymmetric-key encryption.
Crypto-shredding
Standard data deletion involves overwriting data with a series of zeroes, ones, or both. This process is both slow and not completely effective at ensuring bits and pieces of data aren’t left behind. A better process, known as crypto-shredding, involves encrypting data and then destroying the keys. With no key left behind to decrypt the data, it’s effectively considered deleted.
If you guessed that symmetric-key encryption is best for crypto-shredding, then you’d be correct! In addition to being simpler, faster, and cheaper, there’s only one key to delete!
Grasping Physical Security
“I’m an IT gal/guy. Why should I care about physical security?” I’m glad you asked! While most information security discussions focus on using technical controls to protect the data that resides on machines, the protection of physical assets is just as important.
An uncontrolled fire wiping out your data center may not compromise your data’s confidentiality or integrity, but what about availability? If it impacts one or more of the three pillars of information security, then you, as a security professional, definitely care about it. (For more on this topic, see the section “Exploring the Pillars of Information Security,” earlier in this chapter.)
Information security professionals are concerned with anything that impacts the confidentiality, integrity, or availability of data or systems. Don’t ignore legitimate risks that are present outside of the computer hardware and software.
In addition to the environmental considerations that come with physical security, keep in mind that you can spend all your time throwing sophisticated technical protections at your systems, but it means nothing if an attacker can simply pick the lock to your data center and walk out with a server! You can find out more about secure physical design in Chapter 5.
Realizing the Importance of Business Continuity and Disaster Recovery
You can’t always stop bad things from happening. The unfortunate reality is some factors will always be outside of your control — and when bad things do happen, business continuity and disaster recovery are paramount.
Business continuity (BC) refers to the policies, procedures, and tools you put in place to ensure critical business functions continue during and after a disaster or crisis. The goal of business continuity is to allow essential personnel the ability to access important systems and data until the crisis is resolved.
When you think of disasters and crises, you’re not only concerned with malicious cyberattacks but also accidental disruptions, natural disasters, and major system failures.
Disaster recovery (DR) is a subset of business continuity focusing on (you guessed it!) recovering your IT systems that are lost or damaged during a disaster. In other words, DR is the part of BC focused on restoring full operation of and access to hardware, software, and data as quickly as possible after a disaster. Unlike business continuity — whose focus is on making a business operational — disaster recovery focuses on activities like recovering off-site backups, for example.
Though business continuity and disaster recovery are closely related, they’re not the same. Business continuity broadly focuses on the procedures and systems you have in place to keep a business up and running during and after a disaster. Disaster recovery more narrowly focuses on getting your systems and data back after a crisis hits. The terms are often misused, so make note of the distinction.
You need to be aware of a couple important related metrics:
- Recovery Time Objective (RTO) is the amount of time within which business processes must be restored in order to avoid significant consequences associated with the disaster. In other words, RTO answers the question “How much time can pass before an outage or disruption has unacceptably affected my business?”
- Recovery Point Objective (RPO) is the maximum amount of data loss that’s tolerable to your organization. It answers the question “How much data can I lose before my business is unacceptably impacted by a disaster?” RPO plays an important role in determining frequency of backups.
Implementing Incident Handling
It would be great if you could just do your security magic, and nothing bad would ever happen. Unfortunately, you can’t fix every vulnerability or stop every threat … so it’s important that you’re prepared to handle whatever comes your way. The field of incident handling deals with preparing for, addressing, and recovering from security incidents.
I want to define some important terms up front. NIST SP 800-61 defines the following:
- An event is any observable occurrence in a system or network.
- Adverse events are events with negative consequences.
- A computer security incident is a violation or imminent threat of violation of computer security policies, acceptable use policies, or standard security practices.
While the focus in this section is specifically on computer security incidents, keep in mind that these principles apply to power failures, natural disasters, and so on.
Though every incident starts as an event (or multiple events), every event is not necessarily an incident. To take the distinction even further, not every event is even considered adverse or negative. Some examples of events include
- A website visitor downloads a file.
- A user enters an incorrect password.
- An Administrator is granted root access to a router.
- A firewall rejects a connection attempt.
- A server crashes.
Of the preceding events, only the last one is inherently adverse — and without further information, you can’t call any of them incidents. The following list includes some examples of incidents:
- A hacker encrypts all your sensitive data and demands a ransom for the keys.
- A user inside your organization steals your customers’ credit card data.
- An Administrator at your company is tricked into clicking on a link inside a phishing email, resulting in a backdoor connection for an attacker.
- Your HR system is taken offline by a Distributed Denial of Service (DDoS) attack.
Make sure you don’t use the terms event and incident interchangeably — they’re not the same. I have heard IT professionals refer to simple events as incidents, and that’s a great way to sound alarms that don’t need to be sounded!
Incident handling starts well before an incident even occurs and ends even after things are back to normal. The Incident Response (IR) Lifecycle (shown in Figure 2-4) describes the steps you take before, during, and after an incident. The key components of the IR Lifecycle are
- Preparation
- Detection
- Containment
- Eradication
- Recovery
- Post-Mortem
I cover the preceding concepts in the remaining sections.

FIGURE 2-4: The Incident Response (IR) Lifecycle.
Preparing for incidents
You can easily overlook preparation as part of the incident response process, but it’s a critical step for the rapid response to and recovery from incidents. This phase of incident handling includes things like
- Developing an Incident Response Plan. Your Incident Response Plan identifies procedures to follow when an incident occurs, as well as roles and responsibilities of all stakeholders.
- Periodically testing your Incident Response Plan. Determine your plan’s effectiveness by conducting table-top exercises and incident simulations.
- Implementing preventative measures to keep the number of incidents as low as possible. This process includes finding vulnerabilities in your systems, conducting threat assessments, and applying a layered approach to security controls (things like network security, host-based security, and so on) to minimize risk.
- Setting up incident analysis equipment. This process can include forensic workstations, backup media, and evidence-gathering accessories (cameras, notebooks and pens, and storage bags/bins to preserve crucial evidence and maintain chain of custody).
Detecting incidents
During this phase, you acknowledge an incident has indeed occurred, and you feverishly put your IR Plan into action. This phase is all about gathering as much information as possible and analyzing it to gain insights into the origin and impact of the breach. Some examples of activities during this phase are
- Conducting log analysis and seeking unusual behavior. A good Security Information and Event Management (SIEM) tool can help aggregate different log sources and provide more intelligent data for your analysis. You’re looking for the smoking gun, or at least a trail of breadcrumbs, that can alert you to how the attack took place.
- Identifying the impact of the incident. What systems were impacted? What data was impacted? How many customers were impacted?
- Notification of appropriate individuals. Your IR Plan should detail who to contact for specific types of incidents. During this phase, you’ll need to enact your communications plan to alert proper teams and stakeholders.
- Documentation of findings. The situation will likely be frantic, so organization is critical. You want to keep detailed notes of your findings, actions taken, chain of custody, and other relevant information. This activity helps with your post-mortem reporting later on and also helps with keeping track of important details that can assist in tracing the attack back to its origin. In addition, many incidents require reporting to law enforcement or other external parties; thorough notes and a strong chain of custody help support any investigations that may arise.
Depending on various factors (the nature of the incident, your industry, or any contractual obligations), you may be responsible for notifying customers, law enforcement, or even US-CERT (part of Department of Homeland Security). Make sure that you keep a comprehensive list of parties to notify in case of a breach.
Containing incidents
The last thing you want to deal with during an incident is an even bigger incident. Containment is extremely important to stop the bleeding and prevent further damage. It also allows you to use your incident response resources more efficiently and avoid exhausting your analysis and remediation capacity. Some common containment activities include
- Disabling Internet connectivity for affected systems
- Isolating/quarantining malware-infected systems from the rest of your network
- Reviewing and/or changing potentially compromised passwords
- Capturing forensic images and memory dumps from impacted systems
Eradicating incidents
By the time you reach this phase, your primary mission is to remove the threat from your system(s). Eradication involves eliminating any components of the incident that remain. Depending on the number of impacted hosts, this phase can be fairly short or last for quite some time. Here are some key activities during this phase:
- Securely removing all traces of malware
- Disabling or recreating impacted user and system accounts
- Identifying and patching all vulnerabilities (starting with the ones that led to the breach!)
- Restore known good backups
- Wipe or rebuild critically damaged systems
Recovering from incidents
The objective of the Recovery phase is to bring impacted systems back into your operational environment and fully resume business as usual. Depending on your organization’s IR Plan, this phase may be closely aligned or share steps with the Eradication phase. It can take several months to fully recover from a large-scale compromise, so you need to have both short-term and long-term recovery objectives that align with your organization’s needs. Some common recovery activities include
- Confirming vulnerabilities have been patched and fully remediated
- Validating systems are functioning normally
- Restoring systems to normal operations (for example, reconnecting Internet access, restoring connection to your production network, and so on)
- Closely monitoring systems for any remaining signs of undesirable activity
Conducting a Post-Mortem
After your systems are back up and running and the worst is over, you need to focus your attention on the lessons learned from the incident. The primary objective of the Post-Mortem phase is to document the lessons and implement the changes required to prevent a similar type of incident from happening in the future. All members of the Incident Response Team (and supporting personnel) should meet to discuss what worked, what didn’t work, and what needs to change within the organization moving forward. Here are some questions to consider during Post-Mortem discovery and documentation:
- What vulnerability (technical or otherwise) did this breach exploit?
- What could have been done differently to prevent this incident or decrease its impact on your organization?
- How can you respond more effectively during future incidents?
- What policies need to be updated, and with what content?
- How should you train your employees differently?
- What security controls need to be modified or implemented?
- Do you have proper funding to ensure you are prepared to handle future breaches?
For a more in-depth review of handling security incidents, refer to NIST’s Computer Security Incident Handling Guide (SP 800-61).
Utilizing Defense-in-Depth
One final security concept to explore is defense-in-depth, or layered security. These two terms describe the same idea of applying multiple, distinct layers of security technologies and strategies for greater overall protection. The thought behind this concept is that each layer will have its own strengths and weaknesses, which you’d like to complement one another; a weakness in one layer can be compensated by the strengths in other layers. By applying two or more of the control mechanisms discussed in this chapter (access control, cryptography, and physical security), you can implement defense-in-depth and gain greater overall protection. (I cover additional security controls that support defense-in-depth throughout the remainder of this book.)
Of course, this approach isn’t foolproof — vulnerabilities will still exist. However, a well-executed defense-in-depth approach makes it much harder for attackers to find and exploit vulnerabilities in your system, and much easier for you to detect an incident sooner rather than later. You explore the concept of defense-in-depth as it relates to the cloud throughout the rest of this book.