
Chapter 12. Business Continuity Planning
Terms you’ll need to understand:
![]() Business continuity
Business continuity
![]() Hot site
Hot site
![]() Warm site
Warm site
![]() Cold site
Cold site
![]() Criticality prioritization
Criticality prioritization
![]() Maximum tolerable downtime (MTD)
Maximum tolerable downtime (MTD)
![]() Remote journaling
Remote journaling
![]() Electronic vaulting
Electronic vaulting
![]() Qualitative assessment
Qualitative assessment
![]() Quantitative assessment
Quantitative assessment
![]() Database shadowing
Database shadowing
Topics you’ll need to master:
![]() Development and processing of contingency plans
Development and processing of contingency plans
![]() Completing business impact analyses
Completing business impact analyses
![]() Creation of backup strategies
Creation of backup strategies
![]() Integrating management responsibilities
Integrating management responsibilities
![]() Steering team responsibilities
Steering team responsibilities
![]() Testing emergency plans
Testing emergency plans
![]() Notifying employees of procedures
Notifying employees of procedures
![]() Testing issues and concerns
Testing issues and concerns
Introduction
Most of this book has focused on ways in which security incidents can be prevented. This chapter addresses the need to prepare for, and how to respond to, disasters that could put your company out of business. Notable recent events, such as tsunamis in Japan and Southeast Asia, 9/11 in New York, Pennsylvania, and Washington, D.C., Hurricane Katrina in New Orleans, earthquakes in China, and Hurricane Ike in Houston, continue to highlight the need for organizations to be adequately prepared. Even after these calamitous events, Disaster Recovery Institute (DRI) reports that most United States companies still spend, on average, only 3.7% of their IT budget on disaster recovery planning, whereas best practice calls for 6%.
For a company to be successful under duress of hardship or catastrophe, it must plan how to protected time sensitive business operations and the IT assets that support these business operations in the face of these major disruptions. A business continuity plan (BCP) identifies how a business would respond and recover in the wake of serious damage, and evolves only as the result of a risk assessment that identifies potentials for serious damage. It is an unfortunate reality that this critical planning for disasters and disruptions is an often-overlooked area of IT security.
ExamAlert
Note: ISC2 covers business continuity (BC) in the Security Operations domain, but there is a lot to cover, so I have placed BC into this chapter. Remember that for the exam you will be given 250 questions from the 8 domains. You will not be asked or need to know which domain they are based on.
Some key elements of this chapter include project management and planning, business impact analysis (BIA), continuity planning design and development, and BCP testing and training.
Threats to Business Operations
A disaster is something that many of us would prefer not to think about. Many might see it as an unpleasant exercise or something that is safe to ignore. Sadly, disasters and incidents are something that we all will find occasion to deal with, and the threats they pose vary. For example, mainframes face a different set of threats than distributed systems, just as computers connected to modems face a different set of threats than do wireless-connected computers. This means that planning must be dynamic: able to change with time and circumstance.
Threats can be man-made or natural, accidental or intentional; however, regardless of the cause, threats have the potential to cause an incident with the same end result. Incidents and disruptions come in many forms. Those foolish enough not to prepare could witness the death of their business. Categories of threats that should be provided for include:
![]() Man-made/political—Disgruntled employees, riots, vandalism, accidents, theft, crime, protesters, and political unrest
Man-made/political—Disgruntled employees, riots, vandalism, accidents, theft, crime, protesters, and political unrest
![]() Technical—Outages, malicious code, worms, hackers, electrical power problems, equipment outages, utility problems, and water shortages
Technical—Outages, malicious code, worms, hackers, electrical power problems, equipment outages, utility problems, and water shortages
![]() Natural—Earthquakes, storms, fires, floods, hurricanes, tornados, and tidal waves
Natural—Earthquakes, storms, fires, floods, hurricanes, tornados, and tidal waves
Each of these can cause an interruption in operations and should be defined in your company disaster recovery plan (DRP). The DRP should address the impact of a disaster or disruption on time-sensitive business processes and on critical services and resources that support those business processes. Each company will be different. Disruption of services can be categorized as follows:
![]() Minor—Operations are disrupted for several hours to less than a day.
Minor—Operations are disrupted for several hours to less than a day.
![]() Intermediate—Operations are disrupted for a day or longer. The organization might need a secondary site to continue operations.
Intermediate—Operations are disrupted for a day or longer. The organization might need a secondary site to continue operations.
![]() Major—The entire facility is unusable. Ancillary sites will be required while the original site is rebuilt or a new facility is found or built.
Major—The entire facility is unusable. Ancillary sites will be required while the original site is rebuilt or a new facility is found or built.
Business Continuity Planning (BCP)
There are many different approaches to BCP. Some companies address these processes separately, whereas others focus on a continuous process that interweaves the plans. The National Institute of Standards and Technology (NIST) (www.csrc.nist.gov) offers a good example of the contingency process in Special Publication 800-34: Continuity Planning Guide for Information Technology Systems. In NIST SP 800-34, the BCP/DRP process is defined as:
1. Develop the contingency planning policy statement.
2. Conduct the BIA (business impact analysis).
3. Identify preventive controls.
4. Develop recovery strategies.
5. Develop an IT contingency plan.
6. Test the plan, train employees, and hold exercises.
7. Maintain the plan.
Before we go further, let’s define the terms disaster and business continuity. A disaster is any sudden, unplanned calamitous event that brings about great damage or loss. Entire communities have concerns following a disaster; however, businesses face special challenges because they have responsibilities to protect the lives and livelihoods of their employees, and to guard company assets on behalf of shareholders. In the business realm, a disaster can be seen as any event that prevents the continuance of critical business functions for a predetermined period of time. In other words, the estimated outage might force the declaration of a disaster.
ExamAlert
For the exam keep in mind that human safety always comes first and has priority over all other concerns.
Business continuity is the process of sustaining operation of a critical business function (CBF) to keep the company in business for the long term. (A DRP is part of a BCP, but deals with more with technology and short-term issues: “What do we do right now to stop the bleeding and get critical systems and services running?” The overall BCP, by contrast, lays out what a company does to stay in business and return to normal operations. The CISSP candidate must know the difference for the exam.) The goal of business continuity is to reduce or prevent outage time and optimize operations. The Business Continuity Institute (www.thebci.org), a professional body for business continuity management, defines it as a holistic management process that identifies potential impacts that threaten an organization, provides a framework for building resilience, ensures an effective response, and safeguards its reputation, brand, value, and the interests of its key stakeholders.
Although there are competing methodologies that can be used to complete the BCP/DRP process, this chapter will follow steps that most closely align with reference documentation recommended by ISC2. Figure 12.1 illustrates an overview of the process, the steps for which are as follows:
1. Project initiation
2. Business impact analysis (BIA)
3. Recovery strategy
4. Plan design and development
6. Testing
7. Monitoring and maintenance
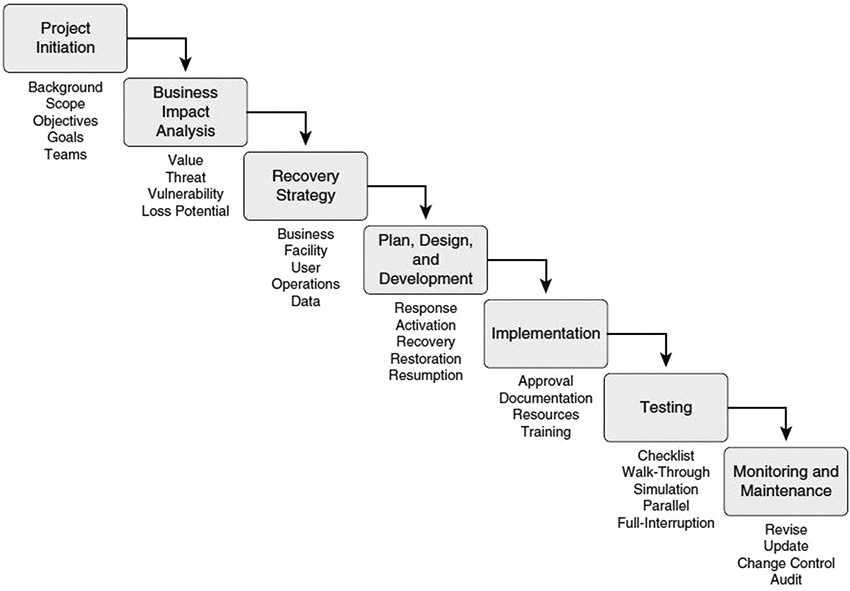
We will discuss each of these steps individually.
Project Management and Initiation
Before the BCP process can begin, it is essential to have the support of senior management, because they are responsible for:
![]() Setting the budget
Setting the budget
![]() Determining the team leader
Determining the team leader
![]() Starting the BCP process
Starting the BCP process
Without senior management support, you will not have funds to successfully complete the project, and resulting efforts will be marginally successful, if at all. One way to gain their support this is to prepare and present a seminar for them that overviews the risks the organization faces, identifies basic threats, and documents the costs of potential outages. This is a good time to remind them that, ultimately, they are legally responsible. Customers, shareholders, stockholders, or anyone else could bring civil suits against senior management if they feel the company has not practiced due care.
Senior management must choose a team leader. This individual must have enough credibility with senior management to influence them in regard to BCP results and recommendations. After the team leader is appointed, an action plan can be established and the team can be assembled. Members of the team should include representatives from management, legal staff, recovery team leaders, the information security team, various business units, the networking team, and the physical security team. It is important to include asset owners and the individuals that would be responsible for executing the plan.
Next, determine the project scope. A properly defined scope is of tremendous help in maximizing the effectiveness of the BCP plan. You cannot protect everything and you really do not need to, either. For example if you are planning for a company that has offices in California, Florida, New York, and Montana you would not have contingency plans for hurricanes for all offices.
Be sensitive to interoffice politics, which, if it gets out of control, can derail the entire planning process. Another problem to avoid is project creep, which occurs when more and more items that were not part of the original project plan are added to it. This can delay completion of the project or cause it to run over budget.
The BCP benefits from adherence to traditional project plan phases. Issues such as resources (personnel and financial), time schedules, budget estimates, and any critical success factors must be managed. Schedule an initial meeting to kick off the process.
Finally, the team is ready to get to work. The team can expect a host of duties and responsibilities:
![]() Identifying regulatory and legal requirements that must be complied with
Identifying regulatory and legal requirements that must be complied with
![]() Identifying all possible threats and risks
Identifying all possible threats and risks
![]() Estimating the probability of these threats and correctly identifying their loss potential
Estimating the probability of these threats and correctly identifying their loss potential
![]() Performing a BIA
Performing a BIA
![]() Outlining the priority in which departments, systems, and processes must be up and running
Outlining the priority in which departments, systems, and processes must be up and running
![]() Developing the procedures and steps to resume business functions following a disaster
Developing the procedures and steps to resume business functions following a disaster
![]() Assigning crisis situation tasks to employee roles or individuals
Assigning crisis situation tasks to employee roles or individuals
![]() Documenting plans, communicating plans to employees, and performing necessary training and drills
Documenting plans, communicating plans to employees, and performing necessary training and drills
It’s important for everyone on the team to realize that the BCP is the most important corrective control the organization will have, and to use the planning period as an opportunity to shape it. The BCP is more than just corrective controls; the BCP is also about preventive and detective controls. These three elements are:
![]() Preventive—Including controls to identify critical assets and prevent outages
Preventive—Including controls to identify critical assets and prevent outages
![]() Detective—Including controls to alert the organization quickly in case of outages or problems
Detective—Including controls to alert the organization quickly in case of outages or problems
![]() Corrective—Including controls to restore normal operations as quickly as possible
Corrective—Including controls to restore normal operations as quickly as possible
Business Impact Analysis
The next task is to create the BIA, the role of which is to measure the impact each type of disaster could have on critical or time-sensitive business functions. It is necessary to evaluate time as a metric, just as you would the importance of the function. For example, paying employees is not critical from the perspective of business activities, but if you don’t pay them on time, your company will still go out of business because it will lose its employees.
The BIA is an important step in the process because it considers all threats and the implications of those threats. As an example, the city of Galveston, Texas is on an island known to be prone to hurricanes. Although it might be winter in Galveston and the possibility of a hurricane is extremely low, it doesn’t mean that planning can’t take place to reduce the potential negative impact if and when a hurricane arrives. The steps for accomplishing this require trying to think through all possible disasters, assess the risk of those disasters, quantify the impact, determine the loss, and identify and prioritize operations that would require disaster recovery planning in the event of those disasters.
The BIA is tasked with answering three vital questions:
![]() What is most critical?—The prioritization must be developed to address what processes are most critical to the organization.
What is most critical?—The prioritization must be developed to address what processes are most critical to the organization.
![]() How long an outage can the company endure?—The downtime estimation is performed to determine which processes must resume first, second, third, and so on, and to determine which systems must be kept up and running.
How long an outage can the company endure?—The downtime estimation is performed to determine which processes must resume first, second, third, and so on, and to determine which systems must be kept up and running.
![]() What resources are required?—Resource requirements must be identified and require correlation of system assets to business processes. As an example, a generator can provide backup power, but requires fuel to operate.
What resources are required?—Resource requirements must be identified and require correlation of system assets to business processes. As an example, a generator can provide backup power, but requires fuel to operate.
Note
Criticality prioritization is something that companies do all the time. Consider the last time you phoned your favorite computer vendor to order new equipment. How long were you placed on hold? Most likely, your call was answered within a few minutes. Contrast that event with the last time you phoned the same company to speak to the help desk. How long was the wait? Most likely, much longer.
The development of multiple scenarios should provide a clear picture of what is needed to continue operations in the event of a disaster. The team creating the BIA will need to look at the organization from many different angles and use information from a variety of sources. Different tools can be used to help gather data. Strohl Systems’ BIA Professional and SunGard’s Paragon software can automate portions of the data input and collection process. Although the CISSP exam will not require that you know the names of various tools, it is important to understand how the BIA process works, and it helps to know tools that are available.
Whether the BIA process is completed manually or with the assistance of tools, its completion will take some time. Any time individuals are studying processes, techniques, and procedures they are not familiar with, a learning curve will be involved.
As you might be starting to realize, creation of a BIA is no easy task. It requires not only the knowledge of business processes but also a thorough understanding of the organization itself, including IT resources, individual business units, and the interrelationships of each. This task will require the support of senior management and the cooperation of IT personnel, business unit managers, and end users. The general steps within the BIA are:
1. Determine data-gathering techniques.
2. Gather business impact analysis data.
3. Identify critical business functions and resources that support these functions.
4. Verify completeness of data.
5. Establish recovery time for operations.
6. Define recovery alternatives and costs.
Note
A vulnerability assessment is often included in a BIA. Although the assessment is somewhat similar to the risk-assessment process discussed in Chapter 9, “Security Assessment and Testing,” this assessment focuses on providing information specifically for the business continuity plan.
Assessing Potential Loss
There are different approaches to assessing potential loss. One of the most popular methods is the use of a questionnaire. This approach requires the development of a questionnaire distributed to senior management and end users. The objective of the questionnaire is to maximize the identification of potential loss by the people engaged in business processes that would be jeopardized by a disaster. This questionnaire might be distributed and independently completed or filled out during an interactive interview process. Figure 12.2 shows a sample questionnaire.

The questionnaire can also be completed in a round table setting. In fact, this sort of group completion can add synergy to the process, as long as the dynamics of the group allow for open communication and the required key individuals can all schedule and meet to discuss the impact specific types of disruptions would have on the organization. The importance of the inclusion of all key individuals must be emphasized because management might not be aware of critical key tasks for which they do not have direct oversight.
A questionnaire is a qualitative technique for assessing risk. Qualitative assessments are scenario-driven and do not attempt to assign dollar values to anticipated loss. A qualitative assessment ranks the seriousness of an impact using grades or classes, such as low, medium, high, or critical. As an example:
![]() Low—Minor inconvenience that customers might not notice. Outages could last for up to 30 days without any real inconvenience.
Low—Minor inconvenience that customers might not notice. Outages could last for up to 30 days without any real inconvenience.
![]() Medium—Loss of service would impact the organization after a few days to a week. Longer outages could affect the company’s bottom line or result in the loss of customers.
Medium—Loss of service would impact the organization after a few days to a week. Longer outages could affect the company’s bottom line or result in the loss of customers.
![]() High—Only short-term outages of a few minutes to hours could be endured. Longer outages would have a severe financial impact. Negative press might also reduce outlook for future products and services.
High—Only short-term outages of a few minutes to hours could be endured. Longer outages would have a severe financial impact. Negative press might also reduce outlook for future products and services.
![]() Critical—Outage of any duration cannot be endured. Systems and controls must be in place or be developed to ensure redundancy so that no outage occurs.
Critical—Outage of any duration cannot be endured. Systems and controls must be in place or be developed to ensure redundancy so that no outage occurs.
This sort of grading process enables a quicker progress in the identification of risks, and provides a means of classifying processes that might not easily equate to a dollar value. This will also help you to understand the appropriate recovery techniques or technologies based on the level of criticality. Table 12.1 provides an example of this.

The BIA can also be undertaken using a quantitative approach. This method of analysis attempts to assign a monetary value to all assets, exposures, and processes identified during the risk assessment. These values are used to calculate the material impact of a potential disaster, including both loss of income and expenses. A quantitative approach requires:
1. Estimation of potential losses and determination of single loss expectancy (SLE)
2. Completion of a threat frequency analysis and calculation of the annual rate of occurrence (ARO)
3. Determination of the annual loss expectancy (ALE)
The process of performing a quantitative assessment is covered in much more detail in Chapter 4, “Security and Risk Management”. It is important that a quantitative study include all associated costs resulting from a disaster, such as:
![]() Lost productivity
Lost productivity
![]() Delayed or canceled orders
Delayed or canceled orders
![]() Cost of repair
Cost of repair
![]() The value of the damaged equipment or lost data
The value of the damaged equipment or lost data
![]() The cost of rental equipment
The cost of rental equipment
![]() The cost of emergency services
The cost of emergency services
![]() The cost to replace equipment or reload data
The cost to replace equipment or reload data
Both quantitative and qualitative assessment techniques require the BIA team to examine how the loss of service or data would affect the company. Each method is seeking to reduce risk and plan for contingencies, as shown in Figure 12.3.
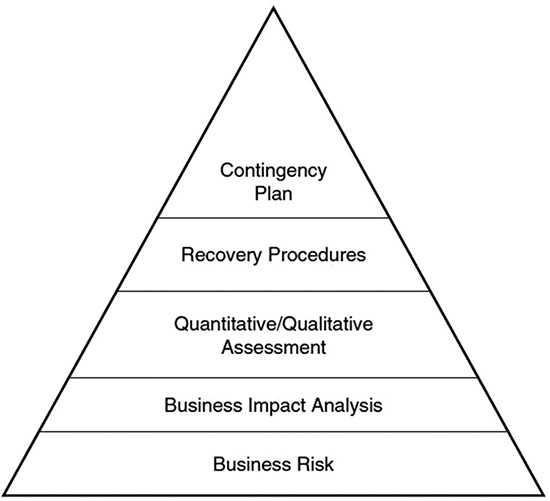
The severity of an outage is generally measured by considering the maximum tolerable downtime (MTD) that the organization can survive without that resource, function, or service.
Tip
Know terms like MTD and understand their meaning for the exam.
Will there be a loss of revenue or operational capital, or will the organization be held legally liable? Although the team might be focused on what the immediate effect of an outage would be, costs are not necessarily immediate. Many organizations are under regulatory requirements; the result of an outage could be a legal penalty or fine. Or an organization’s reputation could be tarnished.
MTD is a measurement of the longest time that an organization can survive without a specific business function.
Reputation Has Its Value
![]() Cisco—An industry leader of quality networking equipment.
Cisco—An industry leader of quality networking equipment.
![]() Ruth’s Chris Steak House—An upscale eatery known for serving high-quality steaks seared at 1800° Fahrenheit.
Ruth’s Chris Steak House—An upscale eatery known for serving high-quality steaks seared at 1800° Fahrenheit.
![]() Rolls-Royce—Known for high-quality luxury automobiles.
Rolls-Royce—Known for high-quality luxury automobiles.
![]() Enron—A symbol of corporate fraud and corruption.
Enron—A symbol of corporate fraud and corruption.
![]() Yugo—A low-quality car released in the United States in the mid-1980s.
Yugo—A low-quality car released in the United States in the mid-1980s.
![]() Volkswagen—A well-known auto maker that was scarred by a public relations thrashing over its “Dieselgate” scandal.
Volkswagen—A well-known auto maker that was scarred by a public relations thrashing over its “Dieselgate” scandal.
Perhaps your vision of the companies listed is different than what was documented. The intent of the listing is to demonstrate that well-known corporate names do generate visions when people hear and read them. Companies work hard for years to gain a level of respect and positive reputation. Catastrophes don’t just happen. Most occur because of human error or as the result of a series of overlooked mistakes. Will a mistake be fatal to your organization? Reputations can be easily damaged. That is why disaster recovery is so important. The very future of your organization may rest on it.
Recovery Strategy
A recovery strategy involves planning for failure by using methods of resiliency. Developing a successful recovery strategy requires senior management’s support. To judge the best strategy to recover from a given interruption, the team must evaluate and complete:
1. Detailed documentation of all costs associated with each possible alternative.
2. Quoted cost estimates for any outside services that might be needed.
3. Written agreements with chosen vendors for all outside services.
4. Possible resumption strategies in case there is a complete loss of the facility.
5. Documentation of findings and conclusions as a report to management of chosen recovery strategy for feedback and approval.
This information is used to determine the best course of action based on the analysis of data from the BIA. With so much to consider, it is helpful to divide the organization’s recovery into specific areas, functions, or categories:
![]() Business process recovery
Business process recovery
![]() Facility and supply recovery
Facility and supply recovery
![]() User recovery
User recovery
![]() Operations recovery
Operations recovery
![]() Data and information recovery
Data and information recovery
Business Process Recovery
Business processes can be interrupted due to the loss of personnel, critical equipment, supplies, or office space; or from uprisings, such as strikes. As an example, in 2005 after Katrina, New Orleans had a huge influx of workers in the city rebuilding homes, offices, and damaged buildings. Fast food restaurants were eager to meet the demand these workers had for burgers, fries, tacos, and fried chicken. However, there was insufficient low-cost housing for the fast food industry’s employees. The resulting shortage forced fast food restaurants to pay bonuses of up to $6,000 to entice potential employees to the area. It is worth noting that even if the facility is intact after a disaster, people are still required and are an important part of the business process recovery.
Workflow diagrams and documents can assist business process recovery by mapping relationships between critical functions to evaluate interdependencies. Often, a critical process cannot be done because a related process was left out of the workflow. For example, you bring in the hardware, software, electric supply, and a system engineer to restore a computerized business process; however, you do not have any network cables to connect the equipment. Now all the vendors are closed because of the storm; therefore, no five-dollar networking cables are available! A process flow can identify what needs to be done and what parts and components are needed. The process order for a widget illustrates a sample flow:
1. Is the widget in stock?
2. Which warehouse has the widget?
3. When can the widget be shipped?
4. Confirm capability to fulfill order with customer and provide total.
5. Process credit card information.
6. Verify funds were deposited in the bank.
7. Ship item to customer.
8. Restock widget for subsequent sales.
A more detailed listing would be appropriate for industrial use, but you get the idea. Building these types of flowcharts allows organizations to examine the resources required for each step and the functions that are critical for continued business operations.
Facility and Supply Recovery
Facility and supply interruptions can be caused by fire, loss of inventory, transportation or telecommunications problems, or even heating, ventilating, and air conditioning (HVAC) problems. An emergency operations center (EOC) must be established and redundant services enabled for rapid recovery from interruptions. Many options are available, from a dedicated offsite facility, to agreements with other organizations for shared space, to the option of building a prefab building and leaving it empty as a type of cold backup site. The following sections examine some of these options.
Subscription Services
Building and running data-processing facilities is expensive. Organizations might opt instead to contract their EOC facility needs to a subscription service. The CISSP exam categorizes these subscription services as hot, warm, and cold sites.
A hot site is ready to be brought online quickly. It is fully configured and is equipped with the same systems as the regular production site. It can be made operational within just a few hours. A hot site will need staff, data, and procedural documentation. Hot sites are a high-cost recovery option, but can be justified when a short recovery time is required. As a subscription service, a range of associated fees exist, including monthly cost, subscription fees, testing costs, and usage or activation fees. Contracts for hot sites need to be closely examined because some charge extremely high activation fees to discourage subscribers from utilizing the facility for anything less than a true disaster. To get an idea of the types of costs involved, www.drj.com reports that subscriptions for hot sites average 52 months in duration and costs can be as high as $120,000 per month.
Caution
Is one backup site enough? It’s possible that during a disaster, the backup site might not be available. That is why many organizations use a backup to the backup site. Such a site is known as a tertiary site.
Regardless of what fees are involved, the hot site needs to be periodically tested. These tests should evaluate processing abilities as well as security. The physical security of the hot site should be at the same level or greater than the primary site. Finally, it is important to remember that the hot site is intended for short-term usage only. As a subscriber-based service, there might be others in line for the same resource once your contract ends. The organization should have a plan to recover primary services quickly or move to a secondary location.
Caution
Hot sites should not be externally identifiable, as this will increase their risk of sabotage and other potential disruptions.
For those companies lacking the funds to spend on a hot site or in situations where a short-term outage is acceptable, a warm site might be acceptable. A warm site has data equipment and cables, and is partially configured. It could be made operational within a few hours to a few days. The assumption with a warm site is that necessary computer equipment and software can be procured in spite of the disaster. Although the warm site might have some computer equipment installed, it is typically of lower processing power than the primary site. The costs associated with a warm site are slightly lower than those of a hot site. The warm site is a popular subscription alternative, as shown in Figure 12.4.

In situations where even longer outages are acceptable, a cold site might be the right choice. A cold site is basically an empty room with only rudimentary electrical power and computing capability. Although it might have a raised floor and some racks, it is nowhere near ready for use. It might take several weeks to a month to get the site operational. Cold sites offer the least preparedness when compared to hot and warm subscription services discussed. Associated costs are also much lower than for hot or warm sites, averaging between $500 and $2,000 per month.
Tip
Cold sites are a good choice for the recovery of non-critical services.
Redundant Sites
The CISSP exam considers redundant sites to be sites owned by the company. Although these might be either partially or totally configured, the CISSP exam does not typically expect you to know that level of detail. A redundant site is capable of handling all operations if another site fails. Although there is an increased cost, it offers the company fault tolerance and this is necessary if you cannot withstand the downtime. If the redundant sites are geographically dispersed, the possibility of more than one being damaged is reduced. For low- to medium-priority services, a distance of 10 to 20 miles from the primary site is considered acceptable. If the loss of services, for even a very short time, could cost the organization millions of dollars, the redundant site should be farther away. Therefore, redundant sites that are meant to support highly critical services should not be in the same geographical region or subject to the same types of natural disasters as the primary site.
For organizations that have multiple sites dispersed in different regions of the world, multiple processing centers might be an option. Multiple processing centers allow a branch in one area to act as backup for a branch in another area.
Mobile Sites
Mobile sites are another processing alternative. Mobile sites are usually tractor-trailer rigs that have been converted into data-processing centers. These sites contain all the necessary equipment and are mobile, permitting transport to any business location quickly. Rigs can also be chained together to provide space for data processing and provide communication capabilities. Mobile units are a good choice for areas where no recovery facilities exist and are commonly used by the military, large insurance agencies, and others for immediate response during a disaster. They work well in getting critical services up and running, and commonly provide tactical satellite services, but are not a long-term solution.
Note
Mobile sites are a non-mainstream alternative to traditional recovery options. Mobile sites typically consist of fully contained tractor-trailer rigs that come with all the facilities needed for a data center. Units can be quickly moved to any site and are perfect for storms, whose boundaries are hard to predict.
Whatever recovery method is chosen, regular testing is important to verify that the redundant site meets the organization’s needs, and that the team can handle the workload to meet minimum processing requirements.
Reciprocal Agreement
The reciprocal agreement option requires two organizations to pledge assistance to one another in case of disaster. The support requires sharing space, computer facilities, and technology resources. On paper, this appears to be a cost-effective approach, but it has its drawbacks. Each party to this agreement must place its trust in the other organization to provide aid in case of a disaster. However, people who are not victims may become hesitant to follow through when a disaster actually occurs.
Also, confidentiality requires special consideration. This is because the damaged organization is placed in a vulnerable position while needing to trust the other party’s housing of the victim’s confidential information. Legal liability can also be a concern; for example, one company agrees to help the other and as a result is hacked. Finally, if the two parties of the agreement are geographically near one another, there is the danger that disaster could strike both, thereby rendering the agreement useless.
The biggest drawbacks to reciprocal agreements are that they are hard to enforce and that, many times, incompatibilities in company hardware, software, and even cultures are not discovered until after a disaster strikes.
User Recovery
User recovery is primarily about what employees need so that they can do their jobs. Requirements include:
![]() Procedures, documents, and manuals
Procedures, documents, and manuals
![]() Communication system
Communication system
![]() Means of mobility and transportation to and from work
Means of mobility and transportation to and from work
![]() Workspace and equipment
Workspace and equipment
![]() Alternate site facilities
Alternate site facilities
![]() Basic human requirements like food and water, sanitation facilities, rest, money, and morale
Basic human requirements like food and water, sanitation facilities, rest, money, and morale
At issue here is the fact that a company might be able to get employees to a backup facility after a disaster, but if there are no phones, desks, or computers, the employees’ ability to work will be severely limited.
User recovery can even include food. As an example, my brother-in-law works for a large chemical company on the Texas Gulf Coast. During storms, hurricanes, or other disasters, he is required to stay at work as part of the emergency operations team. His job is to stay at the facility regardless of time; the disaster might last two days or two weeks. During a simulation test several years ago, it was discovered that someone had forgotten to order food for the facility where the employees were to remain for the duration of the drill. Luckily, the 40 or so hungry employees were not really in a disaster, and were able to order pizza and have it delivered. Had it been a real disaster, no takeout would have been available.
Operations Recovery
Operations recovery addresses interruptions caused by the loss of capability due to equipment failure. Redundancy solves this potential loss of availability, such as redundant equipment, Redundant Array of Inexpensive Disks (RAID), backup power supplies (BPS), and other redundant services.
Hardware failures are one of the most common disruptions that can occur. Preventing this disruption is critical to operations. The best place to start planning hardware redundancy is when equipment is purchased. At purchase time, there are two important numbers that the buyer must investigate:
![]() Mean time between failure (MTBF)—Used to calculate the expected lifetime of a device. A higher MTBF means the equipment should last longer.
Mean time between failure (MTBF)—Used to calculate the expected lifetime of a device. A higher MTBF means the equipment should last longer.
![]() Mean time to repair (MTTR)—Used to estimate how long it would take to repair the equipment and get it back into production. Lower MTTR numbers mean the equipment requires less repair time and can be returned to service sooner.
Mean time to repair (MTTR)—Used to estimate how long it would take to repair the equipment and get it back into production. Lower MTTR numbers mean the equipment requires less repair time and can be returned to service sooner.
A formula for calculating availability is
MTBF / (MTBF + MTTR) = Availability
To maximize availability of critical equipment, an organization can consider obtaining a service level agreement (SLA). There are all kinds of SLAs. In this situation, the SLA is a contract between a company and a hardware vendor, in which the vendor promises to provide a certain level of protection and support. For a fee, the vendor agrees to repair or replace the covered equipment within the contracted time.
Fault tolerance can be used at the server or drive level. For servers, there is clustering, which is technology that allows for high availability; it groups multiple servers together, so that they are viewed logically as a single server. Users see the cluster as one unit. The advantage is that if one server in the cluster fails, the remaining active servers pick up the load and continue operation.
Fault tolerance on the drive level is achieved primarily with RAID, which provides hardware fault tolerance and/or performance improvements. This is accomplished by breaking up the data and writing it across one or more disks. To applications and other devices, RAID appears as a single drive. Most RAID systems have hot-swappable disks. This means that faulty drives can be removed and replaced without turning off the entire computer system. If the RAID system uses parity and is fault tolerant, the parity data can be used to reconstruct the newly replaced drive. The technique for writing the data across multiple drives is called striping. Although write performance remains almost constant, read performance is drastically increased. RAID has humble beginnings that date back to the 1980s at the University of California. RAID is discussed in depth in Chapter 10, “Security Operations.”
Although operations can be disrupted because of the failure of equipment, the loss of communications can also disrupt critical processes. Protecting communication with fault tolerance can be achieved through redundant WAN links, diverse routing, and alternate routing. Whatever method is chosen, the organization should verify capacity requirements and acceptable outage times. The primary methods for network protection include:
![]() Diverse routing—This is the practice of routing traffic through different cable facilities. Organizations can obtain both diverse routing and alternate routing, but the cost is not low. Many telecommunications companies use buried facilities. These systems usually enter a building through the basement and can sometimes share space with other mechanical equipment. Recognize that this sharing adds to the risk of potential failure. Also, many cities have aging infrastructures, which is another potential point of failure.
Diverse routing—This is the practice of routing traffic through different cable facilities. Organizations can obtain both diverse routing and alternate routing, but the cost is not low. Many telecommunications companies use buried facilities. These systems usually enter a building through the basement and can sometimes share space with other mechanical equipment. Recognize that this sharing adds to the risk of potential failure. Also, many cities have aging infrastructures, which is another potential point of failure.
![]() Alternate routing—Also called redundant routing, this provides use of another transmission line if the regular line is busy or unavailable. This can include using a dialup connection instead of a dedicated connection, cell phone instead of a landline, or microwave communication instead of a fiber connection.
Alternate routing—Also called redundant routing, this provides use of another transmission line if the regular line is busy or unavailable. This can include using a dialup connection instead of a dedicated connection, cell phone instead of a landline, or microwave communication instead of a fiber connection.
![]() Last mile protection—This is a good choice for recovery facilities; it provides a second local loop connection, and is even more redundantly capable if an alternate carrier is used.
Last mile protection—This is a good choice for recovery facilities; it provides a second local loop connection, and is even more redundantly capable if an alternate carrier is used.
![]() Voice communication recovery—Many organizations are highly dependent on voice communications, and some have started making the switch to Voice over IP (VoIP) for both voice and fax communication because of the cost savings. But some landlines should always be maintained to provide backup capability; they are still the most reliable form of voice communication.
Voice communication recovery—Many organizations are highly dependent on voice communications, and some have started making the switch to Voice over IP (VoIP) for both voice and fax communication because of the cost savings. But some landlines should always be maintained to provide backup capability; they are still the most reliable form of voice communication.
Networks are susceptible to the same types of outages as equipment. If operations recovery concerns are not addressed, these outages can be a real problem for companies that rely heavily on networks to deliver data when needed.
Free Space Optics (FSO) is an emerging technology that can be used to obtain high bandwidth, short haul, redundant links. FSO uses LED and/or laser light to transmit data between two points and is inexpensive, easy to install, and works great on campus WANs (see en.wikipedia.org/wiki/Free_Space_Optics).
Data and Information Recovery
The focus here is on recovering the data. Solutions to data interruptions include backups, offsite storage, and/or remote journaling. Because data processing is essential to most organizations, the data and information recovery plan is critical. The objective of the plan is to back up critical software and data, which permits quick restores with minimum loss of content. Policy should dictate when backups are performed, where the media is stored, who has access to the media, and what the reuse or rotation policy will be. Types of backup media include tape reels, tape cartridges, removable hard drives, solid state storage, disks, and cassettes.
Tape and optical systems still have the majority of market share for backup systems. Common types of media include:
![]() 8mm tape
8mm tape
![]() CDR/W media (recommended for temporary storage only)
CDR/W media (recommended for temporary storage only)
![]() Digital Audio Tape (DAT)
Digital Audio Tape (DAT)
![]() Digital Linear Tape (DLT)
Digital Linear Tape (DLT)
![]() Quarter Inch Tape (QIC)
Quarter Inch Tape (QIC)
![]() Write Once Read Many (WORM)
Write Once Read Many (WORM)
Another technology worth mentioning is MAID (massive array of inactive disks). MAID offers a distributed hardware storage option for the storage for data and applications. It was designed to reduce the operational costs and improve long-term reliability of disk-based archives and backups. MAID is similar to RAID except that it provides power management and advanced disk monitoring. MAID might or might not stripe data and/or supply redundancy. The MAID system powers down inactive drives, reduces heat output, reduces electrical consumption, and increases the disk drive’s life expectancy.
In addition to defining the media type, the organization must determine how often and what type of backups should be performed. Answers will vary depending on the cost of the media, the speed of the restoration needed, and the time allocated for backups. Backup methods include:
![]() Full backup—During a full backup, all data is backed up. No data files are skipped or bypassed. All items are copied to one tape, set of tapes, or backup media. If a restoration is required, only data set is needed. A full backup resets the archive bit on all files.
Full backup—During a full backup, all data is backed up. No data files are skipped or bypassed. All items are copied to one tape, set of tapes, or backup media. If a restoration is required, only data set is needed. A full backup resets the archive bit on all files.
![]() Differential backup—A differential backup is a partial backup performed in conjunction with a full backup. Any restoration requires the last full backup and the most recent differential backup. This method takes less time than a full backup per each backup, but increases the restoration time because both the full and differential backups will be needed. A differential backup does not reset the archive bit on files.
Differential backup—A differential backup is a partial backup performed in conjunction with a full backup. Any restoration requires the last full backup and the most recent differential backup. This method takes less time than a full backup per each backup, but increases the restoration time because both the full and differential backups will be needed. A differential backup does not reset the archive bit on files.
![]() Incremental backup—An incremental backup is faster yet to perform. It backs up only those files that have been modified since the previous incremental (or full) backup. A restoration requires the last full backup and all incremental backups since the last full backup. An incremental backup resets the archive bit on files.
Incremental backup—An incremental backup is faster yet to perform. It backs up only those files that have been modified since the previous incremental (or full) backup. A restoration requires the last full backup and all incremental backups since the last full backup. An incremental backup resets the archive bit on files.
![]() Continuous backup—Some backup applications perform continuous backups, and keep a database of backup information. These systems are useful when a restoration is needed because the application can provide a full restore, point-in-time restore, or restore based on a selected list of files such as file synchronization programs from a source to a target that can be on any schedule.
Continuous backup—Some backup applications perform continuous backups, and keep a database of backup information. These systems are useful when a restoration is needed because the application can provide a full restore, point-in-time restore, or restore based on a selected list of files such as file synchronization programs from a source to a target that can be on any schedule.
ExamAlert
Test questions regarding different backup types can be quite tricky. Make sure you clearly know the difference before the exam. Backups can also be associated with DRP planning metrics such as RPO, RTP, and MTTR.
Backup and Restoration
Backups need to be stored somewhere and backups are needed quickly when it’s time to restore not just the data, but applications and configurations settings as well. Where the backup media is stored can have a real impact on how quickly data can be restored and brought back online. The media should be stored in more than one physical location so that the possibility of loss is reduced. These remote sites should be managed by a media librarian. It is this individual’s job to maintain the site, control access, rotate media, and protect this valuable asset. Unauthorized access to the media is a huge risk because it could impact the organization’s capability to provide uninterrupted service. Who transports the media to and from the remote site is also an important concern. Important backup and restoration considerations include:
![]() Maintenance of secure transportation to and from the site
Maintenance of secure transportation to and from the site
![]() Use of bonded delivery vehicles
Use of bonded delivery vehicles
![]() Appropriate handling, loading, and unloading of backup media
Appropriate handling, loading, and unloading of backup media
![]() Use of drivers trained on proper procedures to pick up, handle, and deliver backup media
Use of drivers trained on proper procedures to pick up, handle, and deliver backup media
![]() Legal obligations for data, such as encrypted media, and separation of sensitive data sets, such as credit card numbers and CVCs
Legal obligations for data, such as encrypted media, and separation of sensitive data sets, such as credit card numbers and CVCs
![]() 24/7 access to the backup facility in case of an emergency
24/7 access to the backup facility in case of an emergency
It is recommended that companies contract their offsite storage needs with a known firm that demonstrates control of their facility and is responsible for its maintenance. Physical and environmental controls at offsite storage locations should be equal to or better than the organization’s own facility. A letter of agreement should specify who has access to the media and who is authorized to drop it off or pick it up. There should also be agreement on response times that will be met in case of disaster. Onsite storage should maintain copies of recent backups to ensure the capability to recover critical files quickly.
Backup media should be securely maintained in an environmentally controlled facility with physical control appropriate for critical assets. The area should be fireproof, and anyone depositing or removing media should have a record of their access logged by a media librarian.
Table 12.2 shows some sample functions and their recovery times.

Software itself can be vulnerable, even when good backup policies are followed, because sometimes software vendors go out of business or no longer support needed applications. In these instances, escrow agreements can help.
Caution
Escrow agreements are one possible software-protection mechanism. Escrow agreements allow an organization to obtain access to the source code of business-critical software if the software vendor goes bankrupt or otherwise fails to perform as required. Given the myriad of compilers and operating systems, escrow is now requiring everything required to build the product including operating systems, all tools, compilers, and so on.
Data Replication Techniques
Data replication can be handled by two basic techniques, each of which provides various capabilities:
![]() Synchronous replication—This technique uses as an atomic write operation. An atomic write operation will either complete on both sides, or will be abandoned. Its strength is that it guarantees no data loss.
Synchronous replication—This technique uses as an atomic write operation. An atomic write operation will either complete on both sides, or will be abandoned. Its strength is that it guarantees no data loss.
![]() Asynchronous replication—This technique updates as allowed, but may have small performance degradation. Its downside is that the remote storage facility may not have the most recent copy of data; therefore, some data may be lost in case of an outage.
Asynchronous replication—This technique updates as allowed, but may have small performance degradation. Its downside is that the remote storage facility may not have the most recent copy of data; therefore, some data may be lost in case of an outage.
Media-Rotation Strategies
Although most backup media is rather robust, no backup media can last forever. This means that media rotation is another important part of backup and restoration. Additionally, backup media needs to be periodically tested. Backups will be of little use if you find out during a disaster that they have malfunctioned and no longer work.
These media-rotation strategies are most often applied to tape backups:
![]() Simple—A simple tape-rotation scheme uses one tape for every day of the week and then repeats the pattern the following week. One tape can be for Monday, one for Tuesday, and so on. You add a set of new tapes each month and then archive the previous month’s set. After a predetermined number of months, you put the oldest tapes back into use.
Simple—A simple tape-rotation scheme uses one tape for every day of the week and then repeats the pattern the following week. One tape can be for Monday, one for Tuesday, and so on. You add a set of new tapes each month and then archive the previous month’s set. After a predetermined number of months, you put the oldest tapes back into use.
![]() Grandfather-father-son (GFS)—This scheme typically uses one tape for monthly backups, four tapes for weekly backups, and four tapes for daily backups (assuming you are using a five-day work week). It is called grandfather-father-son because the scheme establishes a kind of hierarchy. The grandfather is the single monthly backup, the fathers are the four weekly backups, and the sons are the four daily backups.
Grandfather-father-son (GFS)—This scheme typically uses one tape for monthly backups, four tapes for weekly backups, and four tapes for daily backups (assuming you are using a five-day work week). It is called grandfather-father-son because the scheme establishes a kind of hierarchy. The grandfather is the single monthly backup, the fathers are the four weekly backups, and the sons are the four daily backups.
![]() Tower of Hanoi—This tape-rotation scheme is named after a mathematical puzzle. It involves using five sets of tapes, each set labeled A through E. Set A is used every other day; set B is used on the first non-A backup day and is used every 4th day; set C is used on the first non-A or non-B backup day and is used every 8th day; set D is used on the first non-A, non-B, or non-C day and is used every 16th day; and set E alternates with set D.
Tower of Hanoi—This tape-rotation scheme is named after a mathematical puzzle. It involves using five sets of tapes, each set labeled A through E. Set A is used every other day; set B is used on the first non-A backup day and is used every 4th day; set C is used on the first non-A or non-B backup day and is used every 8th day; set D is used on the first non-A, non-B, or non-C day and is used every 16th day; and set E alternates with set D.
Other Data Backup Methods
Other alternatives that exist for further enhancing a company’s resiliency and redundancy are listed below. Some organizations use these techniques by themselves; others combine these techniques with other backup methods.
![]() Database shadowing—Databases are a high-value asset for most organizations. File-based incremental backups can read only entire database tables and are considered too slow. A database shadowing system uses two physical disks to write the data to. It creates good redundancy by duplicating the database sets to mirrored servers. Therefore, this is an excellent way to provide fault tolerance and redundancy. Shadowing mirrors changes to the database as they occur.
Database shadowing—Databases are a high-value asset for most organizations. File-based incremental backups can read only entire database tables and are considered too slow. A database shadowing system uses two physical disks to write the data to. It creates good redundancy by duplicating the database sets to mirrored servers. Therefore, this is an excellent way to provide fault tolerance and redundancy. Shadowing mirrors changes to the database as they occur.
![]() Electronic vaulting—Electronic vaulting makes a copy of database changes to a secure backup location. This is a batch-process operation copying all current records, transactions, and/or files to the offsite location. To implement vaulting, an organization typically loads a software agent onto the systems to be backed up, and then, periodically, the vaulting service accesses the software agent on these systems to copy changed data.
Electronic vaulting—Electronic vaulting makes a copy of database changes to a secure backup location. This is a batch-process operation copying all current records, transactions, and/or files to the offsite location. To implement vaulting, an organization typically loads a software agent onto the systems to be backed up, and then, periodically, the vaulting service accesses the software agent on these systems to copy changed data.
![]() Remote journaling—Remote journaling is similar to electronic vaulting, except that information is duplicated to the remote site as it is committed on the primary system. By performing live data transfers, this mechanism allows alternate sites to be fully synchronized and fault tolerant at all times. Depending on configuration, it is possible to configure remote journaling to record only the occurrence of transactions and not the actual content of the transactions. Remote journaling can provide a very high level of redundancy.
Remote journaling—Remote journaling is similar to electronic vaulting, except that information is duplicated to the remote site as it is committed on the primary system. By performing live data transfers, this mechanism allows alternate sites to be fully synchronized and fault tolerant at all times. Depending on configuration, it is possible to configure remote journaling to record only the occurrence of transactions and not the actual content of the transactions. Remote journaling can provide a very high level of redundancy.
![]() Storage area network (SAN)—SAN supports disk mirroring, backup and restore, archiving, and retrieval of archived data in addition to data migration from one storage device to another. A SAN can be implemented locally or use storage at a redundant facility.
Storage area network (SAN)—SAN supports disk mirroring, backup and restore, archiving, and retrieval of archived data in addition to data migration from one storage device to another. A SAN can be implemented locally or use storage at a redundant facility.
![]() Cloud computing backup—This can offer a cost-savings alternative to traditional backup techniques. These should be carefully evaluated, as there are many concerns when using cloud-based services. Cloud backups can be deployed in a variety of configurations, as an on-site private cloud or an off-site public or private cloud.
Cloud computing backup—This can offer a cost-savings alternative to traditional backup techniques. These should be carefully evaluated, as there are many concerns when using cloud-based services. Cloud backups can be deployed in a variety of configurations, as an on-site private cloud or an off-site public or private cloud.
Caution
Remember that if using off-site public cloud storage, you should look at encrypting the backup.
Choosing the Right Backup Method
It is not easy to choose the right backup method. To start the process, the team must consider how long an outage the organization can endure and how current the restored information must be. These two recovery requirements are technically called:
![]() Recovery point objective (RPO)—Defines how much data an organization can afford to lose. The greater the RPO, the more tolerant the process is to interruption.
Recovery point objective (RPO)—Defines how much data an organization can afford to lose. The greater the RPO, the more tolerant the process is to interruption.
![]() Recovery time objective (RTO)—Specifies the maximum acceptable time to recover the data. This same metric would be used to evaluate the application that stores the data or the time it would take to transfer the data to the alternate site. The goal for DRP would be to determine the time it would take to get the data up and running, regardless of whether it was at the primary or alternate site. The greater the RTO, the longer the recovery process can take and the more tolerant the organization is to interruption. Figure 12.5 illustrates how the RTO can be used to determine acceptable downtime.
Recovery time objective (RTO)—Specifies the maximum acceptable time to recover the data. This same metric would be used to evaluate the application that stores the data or the time it would take to transfer the data to the alternate site. The goal for DRP would be to determine the time it would take to get the data up and running, regardless of whether it was at the primary or alternate site. The greater the RTO, the longer the recovery process can take and the more tolerant the organization is to interruption. Figure 12.5 illustrates how the RTO can be used to determine acceptable downtime.

Tip
For the exam you must know the terms RPO and RTO.
The RPO and RTO metrics are very important. What you should realize about them both is that the lower the time requirements are, the higher the maintenance cost will be to provide for reduced restoration capabilities. For example, most banks have a very small RPO because they cannot afford to lose any processed information. Think of the recovery strategy calculations as being designed to meet the required recovery time frames. We can write this as MTD = RTO + WRT, where MTD is the maximum tolerable downtime, and WRT is the work recovery time, which is simply the remainder of the MTD used to restore all business operations. This is shown in Figure 12.6.

The work recovery time (WRT) is the remainder of the MTD used to restore all business operations.
Plan Design and Development
The BCP process is now ready for its next phase—plan design and development. In this phase, the team designs and develops a detailed plan for the recovery of critical business systems. The plan should be directed toward major catastrophes. Worst-case scenarios are planned for on the assumption that the entire facility has been destroyed. If the organization can handle these types of events, less severe events that render the facility unusable only for a time, can be readily dealt with.
The BCP should be a guide for implementation. The plan should include information on both long-term and short-term goals and objectives:
1. Identify time-sensitive critical functions and priorities for restoration.
2. Identify support systems needed by time-sensitive critical functions.
3. Estimate potential outages and calculate the minimum resources needed to recover from the catastrophe.
4. Select recovery strategies and determine which vital personnel, systems, and equipment will be needed to accomplish the recovery. There must be a team for the primary site and the alternate site.
5. Determine who will manage the restoration and testing process.
6. Determine what type of funding and fiscal management is needed to accomplish these goals.
The plan should also detail how the organization will contact and mobilize employees, provide for ongoing communication between employees, interface with external groups and the media, and provide employee services. Each of these items is discussed next.
Personnel Mobilization
The process for contacting employees in case of an emergency needs to be worked out before a disaster. The process chosen depends on the nature and frequency of the emergency. Outbound dialing systems and call trees are widely used. An outbound dialing system stores the numbers to be called in an emergency. These systems can provide various services, such as:
![]() Call rollover—If one number gets no response, the next is called.
Call rollover—If one number gets no response, the next is called.
![]() Leave a recorded message—If an answering machine answers, a message can be left for the individual.
Leave a recorded message—If an answering machine answers, a message can be left for the individual.
![]() Request a call back—Even if a message is left, the system will continue to call back until the user calls in to the predefined phone number.
Request a call back—Even if a message is left, the system will continue to call back until the user calls in to the predefined phone number.
A call tree is a communication system in which the person in charge of the tree calls a lead person on every “branch”, who in turn calls all the “leaves” on that branch. If call trees are used, the team will want to verify that there is a feedback mechanism built in. As an example, the last person on any branch of the tree calls and confirms that he or she got the message. This can help ensure that everyone has been contacted. Call trees can be automated with VoIP and public switched telephone networks (PSTNs) and online services.
Personnel mobilization can also be triggered by emails to tablets, smartphones, and so on. Such systems require the email server to be functioning.
It is also important to plan for executive succession planning. The company needs to be able to continue even if key personnel are not available. The company should have measures in place that account for the potential loss of key individuals. If there is no executive succession planning, the loss of key individuals could mean the organization may not be able to continue.
Interface with External Groups
A public affairs officer (PAO) typically will decide how to interact with external groups. This can affect the long-term reputation of your business. Damaging rumors can easily start, and it is important to have protocols in place for dealing with incidents, accidents, and catastrophes. The organization must decide how to deal with response teams, the fire department, the police department, ambulance, and other emergency response personnel. If you do not tell the pubic what you want them to know, the media will decide for you. In a world of social media, your employees or former employees may even contribute to this cause; therefore, have a policy and a canned statement for your PAO.
A media spokesperson should be identified to deal with the media. Negative public opinion can be costly. It is important to have a properly trained spokesperson to speak and represent the organization. The media spokesperson must be in the communication path to have the facts before speaking or meeting with the press. He or she should engage with senior management and legal counsel prior to making any public statement.
Meeting with the media during a crisis is not something that should be done without preparation. The corporate plan should include generic communiqués that address each possible incident. The spokesperson will also need to know how to handle tough questions. Liability should never be assumed; the spokesperson should simply state that an investigation has begun. Tackling these tough issues up front will allow the company to have a preapproved framework should a real disaster occur.
Employee Services
Companies have an inherent responsibility to employees and to their families. This means that paychecks must continue and that employees need to be taken care of. Employees must be trained in what to do in case of emergencies and in what they can expect from the company. Insurance and other necessary services must continue.
Caution
The number-one priority of any BCP or DRP plan is to protect the safety of employees.
Before a disaster, senior management must determine who is in charge during a disaster to avoid chaos and confusion. Employees must know what is expected of them and who is in charge. You don’t want the CFO telling the person in charge what to do, so make the decision now, in policy. Tragically, people die during a disaster, so it’s important to have a succession of command.
Furthermore, someone must have the authority to allocate emergency funding as needed. After Hurricane Katrina, the U.S. Congress passed 48 C.F.R. § 13.201(b) (2005), which increased the limit on FEMA-issued credit cards to $250,000. The idea was to allow government employees to acquire needed items quickly and without delay. Of course, although funding is important, controls must also be in place to ensure that funds are not misappropriated.
Insurance
Insurance is one option that companies can consider to remove a portion of the risk the team has uncovered during the BIA. Just as protection insurance can be purchased by individuals for a host of reasons, companies can purchase protection insurance for such things as:
![]() Outages
Outages
![]() Data centers
Data centers
![]() Hacker or cyber insurance (which might include potential penalties and fines)
Hacker or cyber insurance (which might include potential penalties and fines)
![]() Software recovery
Software recovery
![]() Business interruption
Business interruption
![]() Documents, records, and important papers
Documents, records, and important papers
![]() Errors and omissions
Errors and omissions
![]() Media transportation
Media transportation
Insurance is not without its drawbacks, such as high premiums, delayed claim payout, denied claims, and problems proving real financial loss. Also, most insurance policies pay for only a percentage of any actual loss and do not pay for lost income, increased operating expenses, or consequential loss. It is also important to note that many insurance companies will not ensure companies who have not exercised due care with the implementation of a DRP and BCP.
Implementation
The BCP team is now nearing the end of the plan’s development process, and is ready to submit a completed plan for implementation. The plan is the result of all information gathered during the project initiation, the BIA, and the recovery strategies phase. A final checklist for completeness ensures the plan addresses all relevant factors, such as:
![]() Calculating what type of funding and fiscal management is needed to accomplish the stated goals
Calculating what type of funding and fiscal management is needed to accomplish the stated goals
![]() Determining the procedures for declaring a disaster and under what circumstances this will occur
Determining the procedures for declaring a disaster and under what circumstances this will occur
![]() Evaluating potential disasters and calculating the minimum resources needed to recover from the catastrophe
Evaluating potential disasters and calculating the minimum resources needed to recover from the catastrophe
![]() Determining critical functions and priorities for restoration
Determining critical functions and priorities for restoration
![]() Identifying what recovery strategy and equipment will be needed to accomplish the recovery
Identifying what recovery strategy and equipment will be needed to accomplish the recovery
![]() Identifying individuals that are responsible for each function in the plan
Identifying individuals that are responsible for each function in the plan
![]() Determining who will manage the restoration and testing process
Determining who will manage the restoration and testing process
The completed plan should be presented to senior management for approval. References for the plan should be cited in all related documents so that the plan is maintained and updated whenever there is a change or update to the infrastructure. When senior management approves the plan, it must be released and disseminated to employees. Awareness training with the individuals who would be responsible for carrying out the plan is critical and will help make sure that everyone understands what their tasks and responsibilities are when an emergency occurs.
Awareness and Training
The goal of awareness and training is to make sure all employees are included and internal and external personnel that are involved in the plan, including contractors and consultants, are involved to ensure they know what to do in case of an emergency. It is certain that you will require support from external agencies, such as law enforcement, and they will likely not have time to participate in your training; however, having a face-to-face meeting with them and getting to know them prior to a disaster is a good idea, so you understand their resources and capabilities.
If employees are untrained, they might simply stop what they’re doing and run for the door anytime there’s an emergency. Even worse, they might not leave when an alarm has sounded, even though the plan requires that they leave because of possible danger. Instructions should be written in easy-to-understand language that uses common terminology. The organization should design and develop training programs to make sure each employee knows what to do and how to do it. Employees assigned to specific tasks should be trained to carry them out. If possible, plan for cross-training of teams so that team members are familiar with a variety of recovery roles and responsibilities.
Caution
Although some companies might feel that the BCP development job is done once the plan is complete, it is important to remember that no demonstrated recovery exists until the plan has been tested.
Testing
This final phase of the process is to test and maintain the BCP. Training and awareness programs are also developed during this phase. The test of the disaster-recovery plan is critical. Without performing a test, there is no way to know whether the plan will work. Testing transforms theoretical plans into reality. Testing should be repeated at least once a year.
Tests should start with the easiest parts of the plan and then build to more complex items. The initial tests should focus on items that support core processing, and they should be scheduled during a time that causes minimal disruption to normal business operations. As a CISSP candidate, you should be aware of the five different types of BCP tests:
![]() Checklist—Although this is not considered a replacement for a live test, a checklist is a good first test. A checklist test is performed by sending copies of the plan to different department managers and business unit managers for review. Each recipient reviews the plan to make sure nothing was overlooked.
Checklist—Although this is not considered a replacement for a live test, a checklist is a good first test. A checklist test is performed by sending copies of the plan to different department managers and business unit managers for review. Each recipient reviews the plan to make sure nothing was overlooked.
![]() Structured walkthrough—This test, also known as a tabletop test, is performed by having the members of the emergency management team and business unit managers meet in a conference to discuss the plan. The plan then is “walked through” line by line. This gives all attendees a chance to see how an actual emergency would be handled and to discover discrepancies. By reviewing the plan in this way, errors and omissions might become apparent.
Structured walkthrough—This test, also known as a tabletop test, is performed by having the members of the emergency management team and business unit managers meet in a conference to discuss the plan. The plan then is “walked through” line by line. This gives all attendees a chance to see how an actual emergency would be handled and to discover discrepancies. By reviewing the plan in this way, errors and omissions might become apparent.
Tip
The primary advantage of the structured walkthrough is to discover discrepancies between different departments.
![]() Simulation—This is a drill involving members of the response team acting in the same way they would if there had been an actual emergency. This test proceeds to the point of recovery or to relocation to the alternate site. The primary purpose of this test is to verify that members of the response team can perform the required duties with only the tools they would have available in a real disaster.
Simulation—This is a drill involving members of the response team acting in the same way they would if there had been an actual emergency. This test proceeds to the point of recovery or to relocation to the alternate site. The primary purpose of this test is to verify that members of the response team can perform the required duties with only the tools they would have available in a real disaster.
![]() Parallel—A parallel test is similar to a structured walkthrough but actually invokes operations at the alternate site. Operations at the new and old sites are run in parallel.
Parallel—A parallel test is similar to a structured walkthrough but actually invokes operations at the alternate site. Operations at the new and old sites are run in parallel.
![]() Full interruption—This plan is the most detailed, time-consuming, and disruptive to your business. A full interruption test mimics a real disaster, and all steps are performed to complete backup operations. It includes all the individuals who would be involved in a real emergency, both internal and external to the organization. Although a full interruption test is the most thorough, it is also the scariest because it can be so disruptive as to create its own disaster.
Full interruption—This plan is the most detailed, time-consuming, and disruptive to your business. A full interruption test mimics a real disaster, and all steps are performed to complete backup operations. It includes all the individuals who would be involved in a real emergency, both internal and external to the organization. Although a full interruption test is the most thorough, it is also the scariest because it can be so disruptive as to create its own disaster.
The CISSP exam will require you to know the differences of each test type. You should also note the advantages and disadvantages of each.
The final step of the BCP process is to combine all this information into the BCP plan and inter-reference it with the organization’s other emergency plans. Although the organization will want to keep a copy of the plan onsite, there should be another copy offsite. If a disaster occurs, rapid access to the plan will be critical.
Caution
Access to the plan should be restricted so that only those with a need to know can access the entire plan. This is because access to the plan could become a playbook for an attack.
Monitoring and Maintenance
When the testing process is complete, a few additional items still need to be considered. This is important because some might falsely believe that the plan is completed once tested. That’s not true. All the hard work that has gone into developing the plan can be lost if controls are not put into place to maintain the current level of business continuity and disaster recovery. Life is not static and neither should the organization’s BCP plans be. The BCP should be a living document, subject to constant change.
To ensure the plan is maintained, first build in responsibility for the plan. This can be done by
![]() Job descriptions—Individuals responsible for the plan should have this responsibility detailed in their job description. Management should work with HR to have this information added to the appropriate documents. The best way to enforce a plan is to have someone to hold accountable.
Job descriptions—Individuals responsible for the plan should have this responsibility detailed in their job description. Management should work with HR to have this information added to the appropriate documents. The best way to enforce a plan is to have someone to hold accountable.
![]() Performance reviews—The accomplishment (or lack of accomplishment) of appropriate plan maintenance tasks should be discussed in the responsible individual’s periodic evaluations.
Performance reviews—The accomplishment (or lack of accomplishment) of appropriate plan maintenance tasks should be discussed in the responsible individual’s periodic evaluations.
![]() Audits—The audit team should review the plan and make sure that it is current and appropriate. The audit team will also want to inspect the offsite storage facility and review its security, policies, and configuration.
Audits—The audit team should review the plan and make sure that it is current and appropriate. The audit team will also want to inspect the offsite storage facility and review its security, policies, and configuration.
Table 12.3 lists the individuals responsible for specific parts of the BCP process.

Disaster recovery implications for monitoring, maintaining, and recovery should be made a part of any discussions for procuring new equipment, modifying current equipment, new employment of key personnel, or for making changes to the infrastructure. The best method to accomplish this is to add BCP review into all change management procedures. If changes are required to the approved plans, they must also be documented and structured using change management, and the plan should be updated and distributed if even 10% of the plan, employees, or company are affected by the change. A change control document should be kept with the plan at all times, using good version control. A centralized command and control structure eases this burden.
Tip
Senior management is ultimately responsible for the BCP. This includes funding, project initiation, overall approval, and support.
Exam Prep Questions
1. You are an information assurance manager for a large company that wants to develop a BCP. You would like have your team thoroughly test the plan to ensure that when the company faces a natural disaster, it will survive. The company relies heavily on e-commerce and must ensure that in the event a server fails, customers will still be able to complete financial transactions online. You have already implemented redundancy for the web application servers, and you have deployed a database activity monitor and a web application firewall. Your concern is that backup systems come on if the primary system fails. You would like to test these systems but do not want to take primary systems offline. What best explains the type of test you are recommending?
![]() A. Tabletop/walkthrough
A. Tabletop/walkthrough
![]() B. Simulation
B. Simulation
![]() C. Parallel
C. Parallel
![]() D. Full interruption
D. Full interruption
2. Which of the following groups is responsible for project initiation?
![]() A. Functional business units
A. Functional business units
![]() B. Senior management
B. Senior management
![]() C. BCP team members
C. BCP team members
![]() D. Middle management
D. Middle management
3. When an organization starts to plan for business continuity and disaster recovery it will likely be a very large, complex, and multi-disciplinary project that would bring key associates within the organization together. What best describes the role of senior management?
![]() A. They will plan for money for the DR project manager, technology experts, process experts, or other financial requirements from various departments within the organization
A. They will plan for money for the DR project manager, technology experts, process experts, or other financial requirements from various departments within the organization
![]() B. To be willing to make the discussion to make DRP a priority, commit and allow staff the time, and set hard dates for completion.
B. To be willing to make the discussion to make DRP a priority, commit and allow staff the time, and set hard dates for completion.
![]() C. To manage the multi-disciplinary people to keep them all on the same page
C. To manage the multi-disciplinary people to keep them all on the same page
![]() D. To be experts and understand specific processes that require a special skill set
D. To be experts and understand specific processes that require a special skill set
4. Which of the following is not considered an advantage of a mutual aid agreement?
![]() A. Low cost
A. Low cost
![]() B. Enforcement
B. Enforcement
![]() C. Documentation
C. Documentation
![]() D. Testing
D. Testing
5. Which of the following uses batch processing?
![]() A. Remote journaling
A. Remote journaling
![]() B. Hierarchical storage management
B. Hierarchical storage management
![]() C. Electronic vaulting
C. Electronic vaulting
![]() D. Static management
D. Static management
6. Which of the following BCP tests carries the most risk?
![]() A. Full interruption
A. Full interruption
![]() B. Parallel
B. Parallel
![]() C. Walkthrough
C. Walkthrough
![]() D. Checklist
D. Checklist
7. Which of the following is the best definition of a software escrow agreement?
![]() A. Provides the vendor with additional assurances that the software will be used per licensing agreements
A. Provides the vendor with additional assurances that the software will be used per licensing agreements
![]() B. Specifies how much a vendor can charge for updates
B. Specifies how much a vendor can charge for updates
![]() C. Gives the company access to the source code under certain conditions
C. Gives the company access to the source code under certain conditions
![]() D. Provides the vendor access to the organization’s code if there are questions of compatibility
D. Provides the vendor access to the organization’s code if there are questions of compatibility
8. Which of the following will a business impact analysis provide?
![]() A. Determining the maximum outage time before the company is permanently damaged
A. Determining the maximum outage time before the company is permanently damaged
![]() B. Detailing how training and awareness will be performed and how the plan will be updated
B. Detailing how training and awareness will be performed and how the plan will be updated
![]() C. Establishing the need for BCP
C. Establishing the need for BCP
![]() D. Selecting recovery strategies
D. Selecting recovery strategies
9. Mike had a server crash on Thursday morning. Bob performed a backup in which he used the complete backup from Sunday and several other tapes from Monday, Tuesday, and Wednesday. Which tape-backup method was used?
![]() A. Full restore
A. Full restore
![]() B. Structured restore
B. Structured restore
![]() C. Differential restore
C. Differential restore
![]() D. Incremental restore
D. Incremental restore
10. Which of the following tape-rotation schemes involves using five sets of tapes, with each set labeled A through E?
![]() A. Tower of Hanoi
A. Tower of Hanoi
![]() B. Son-father-grandfather
B. Son-father-grandfather
![]() C. Complex
C. Complex
![]() D. Grandfather-father-son
D. Grandfather-father-son
11. If the recovery point objective (RPO) is low, which of the following techniques would be the most appropriate solution?
![]() A. Clustering
A. Clustering
![]() B. Database shadowing
B. Database shadowing
![]() C. Remote journaling
C. Remote journaling
![]() D. Tape backup
D. Tape backup
12. You have been assigned to the BCP team responsible for backup options and offsite storage. Your company is considering the purchase of software from a small startup operation that has a proven record for unique software solutions. To mitigate the potential for loss, which of the following should you recommend?
![]() A. Clustering
A. Clustering
![]() B. Software escrow
B. Software escrow
![]() C. Insurance
C. Insurance
![]() D. Continuous backup
D. Continuous backup
13. Which of the following is one of the most important steps that is required before developing a business continuity plan?
![]() A. Perform a BIA
A. Perform a BIA
![]() B. Perform quantitative and qualitative risk assessment
B. Perform quantitative and qualitative risk assessment
![]() C. Get senior management buy-in
C. Get senior management buy-in
![]() D. Determine membership of the BCP team
D. Determine membership of the BCP team
14. When developing a business continuity plan, what should be the number-one priority?
![]() A. Minimizing outage times
A. Minimizing outage times
![]() B. Mitigating damage
B. Mitigating damage
![]() C. Documenting every conceivable threat
C. Documenting every conceivable threat
![]() D. Protection of human safety
D. Protection of human safety
15. Which of the following could be used to determine MTD for a vital function?
![]() A. Payroll
A. Payroll
![]() B. Product support
B. Product support
![]() C. Purchasing
C. Purchasing
![]() D. Research and development
D. Research and development
Answers to Exam Prep Questions
1. C. The correct answer is C, because a parallel test sets up recovery servers and runs select or limited transactions to see if the servers work while keeping primary servers up and running. Answer A is incorrect because a tabletop/walkthrough test would consist of a group of experts meeting in person to step through recovery procedures and discuss issues along the away. Answer B is incorrect because a simulation is a group of experts that go through a disaster script scenario to observe how the procedures work. Answer D is incorrect because a full interruption test is a when the recovery team brings down the primary servers and brings up the backup servers so that a business processes can continue.
2. B. Although the other groups listed have responsibilities in the BCP process, senior management is responsible for project initiation, overall approval, support, and is ultimately responsible and held liable. Answer A is incorrect because the functional business units are responsible for implementation, incorporation, and testing. Answer C is incorrect because the BCP team members are responsible for planning, day-to-day management, and implementation and testing of the plan. Answer D is incorrect because middle management is responsible for the identification and prioritization of critical systems.
3. B. The best answer is B. If senior management does not get behind the DRP and fully support it, the DRP will more than likely fail. Answer A is not the best answer because this describes the roles of a budget manager or budget department. Answer C is not the best answer because this describes the roles of a project manager. Answer D is not the best answer as it describes the roles of a subject matter expert.
4. B. The parties to this agreement must place their trust in the reciprocating organization to provide aid in the event of a disaster. However, the non-victim might be hesitant to follow through if such a disaster occurred. None of the other answers represents a disadvantage because this is a low-cost alternative, it can be documented, and some tests to verify that it would work can be performed.
5. C. Electronic vaulting makes a copy of data to a backup location. This is a batch-process operation that functions to keep a copy of all current records, transactions, or files at an offsite location. Remote journaling is similar to electronic vaulting, except that information is processed continuously in parallel, so answer A is incorrect. Hierarchical storage management provides continuous online backup, so answer B is incorrect. Static management is a distractor and is not a valid choice, so answer D is incorrect.
6. A. A full interruption is the test most likely to cause its own disaster. All the other answers listed are not as disruptive, so answers B, C, and D are incorrect.
7. C. A software escrow agreement allows an organization to obtain access to the source code of business-critical software if the software vendor goes bankrupt or otherwise fails to perform as required. Answer A is incorrect because an escrow agreement does not provide the vendor with additional assurances that the software will be used per licensing agreements. Answer B is incorrect because an escrow agreement does not specify how much a vendor can charge for updates. Answer D is incorrect because an escrow agreement does not address compatibility issues; it grants access to the source code only under certain conditions.
8. A. A BIA is a process used to help business units understand the impact of a disruptive event. Part of that process is determining the maximum outage time before the company is permanently crippled. The other answers are part of the BCP process but are not specifically part of the BIA portion, so answers B, C, and D are incorrect.
9. D. Incremental backups take longer to restore. Answer A is incorrect because a full backup backs up everything and, therefore, takes the longest time to create. Answer B is incorrect because the term structured addresses how a backup is carried out, not the method used. Answer C is incorrect because a differential backup does not reset the archive bit. It takes increasingly longer each night, but would require a shorter period to restore because only two restores would be needed: the last full and the last differential.
10. A. The Tower of Hanoi involves using five sets of tapes, with each set labeled A through E. Set A is used every other day. Set B is used on the first non-A backup day and is used every 4th day. Set C is used on the first non-A or non-B backup day and is used every 8th day. Set D is used on the first non-A, non-B, or non-C day and is used every 16th day. Set E alternates with set D. Answer B is incorrect because son-father-grandfather is a distractor. Answer C is incorrect because complex does not refer to a specific backup type. Answer D is incorrect because grandfather-father-son includes four tapes for weekly backups, one tape for monthly backups, and four tapes for daily backups; this does not match the description in the question.
11. D. The RPO is the earliest point at which recovery can occur. If the company has a low RPO, tape backup is acceptable because there is a low need to capture the most current data. If the backup occurs at midnight and the failure is at noon the next day, 12 hours of data has been lost. Answers A, B, and C are incorrect because each of these would be used when a higher RPO, or more current data, is required.
12. B. The core issue here is that the software provider is a small startup that may not be around in a few years. If this were to happen, your company must protect itself so that it has access to the source code. Escrow agreements allow an organization to obtain access to the source code of business-critical software if the software vendor goes bankrupt or otherwise fails to perform as required. Answers A, C, and D are incorrect because clustering and continuous backup do nothing to provide the company access to the source code should they cease to exist, and, while insurance is an option, the expense is not necessary if the organization has rights and access to the code should something occur.
13. C. Before the BCP/DRP process can begin, you must get senior management buy-in. Answers A, B, and D are important but activities like developing the team occur after management buy-in, and the risk assessment process is performed during the BIA.
14. D. The protection of human safety is always the number-one priority of a CISSP. Answers A, B, and C are incorrect. Minimizing outages is important but not number one. Preventing damage is also important, but protection of human safety is number one. It not possible to identify and place a dollar amount on every conceivable threat.
15. A. Payroll is typically considered a vital process. While most employees may come to work for a while without a check, this would most likely not continue for very long. Answers B, C, and D are incorrect because while product support could be vital, it is not for many companies. Also, many companies may be able to survive without purchasing for a short period of time, and R&D looks to long-term revenues.
Need to Know More?
Business Continuity Institute: thebci.org/
Cloud backup strategies: searchdatabackup.techtarget.com/tip/The-pros-and-cons-of-cloud-backup-technologies
Recovery point objective: www.disaster-resource.com/articles/03p_068.shtml
Disaster recovery best practices: www.pcmag.com/article2/0,2817,2288745,00.asp
Availability in relation to MTBF: www.barringer1.com/ar.htm
Electronic vaulting: www.disaster-resource.com/articles/electric_vault_rapid_lindeman.shtml
Free space optics: www.lightpointe.com/free-space-optics-technology-overview.html
Common disaster recovery terms and concepts: defaultreasoning.com/2013/12/10/rpo-rto-wrt-mtdwth/
Recovery strategies: www.disaster-recovery-guide.com/
Disaster recovery planning: www.utoronto.ca/security/documentation/business_continuity/dis_rec_plan.htm