
Chapter 10. Security Operations
Terms you’ll need to understand:
![]() Redundant array of inexpensive disks
Redundant array of inexpensive disks
![]() Clustering
Clustering
![]() Distributed computing
Distributed computing
![]() Cloud computing
Cloud computing
![]() Media management
Media management
![]() Least privilege
Least privilege
![]() Mandatory vacations
Mandatory vacations
![]() Due care / due diligence
Due care / due diligence
![]() Privileged entities
Privileged entities
![]() Trusted recovery
Trusted recovery
![]() Clipping level
Clipping level
![]() Resource protection
Resource protection
Topics you’ll need to master:
![]() Understanding disaster recovery processes and plans
Understanding disaster recovery processes and plans
![]() Understanding foundational security concepts
Understanding foundational security concepts
![]() Defining different types of RAID
Defining different types of RAID
![]() Understanding backup and recovery
Understanding backup and recovery
![]() Describing different types of anti-malware tools
Describing different types of anti-malware tools
![]() Implement disaster recovery processes
Implement disaster recovery processes
![]() Auditing and monitoring
Auditing and monitoring
Introduction
Readers preparing for the ISC2 Certified Information Systems Security Professional exam and those reviewing the security operations domain must know resources that should be protected: principles of best practices, methods to restrict access, protect resources, and monitor activity, and response to incidents.
This domain covers a wide range of topics involving operational security best practices. Security professionals apply operational controls to daily activities to keep systems running smoothly and facilities secure. This domain reviews these controls, and shows how their application to day-to-day activities can prevent or mitigate attacks.
The process starts before an employee is hired. Employers should perform background checks, reference checks, criminal history reports, and educational verification. Among many on-boarding tasks, after someone is hired, the new employee must be trained on corporate policies.
Additional controls need to be put in place to limit the ability and access the employee has. Access is a major control that should be limited to just what is needed to complete required tasks; this kind of limit is referred to as least privileges. Job rotation, dual control, and mandatory vacations are some more examples of these types of controls.
Controls are not just about people. Many of the controls discussed in this chapter are technical in nature. These controls include intrusion prevention, network access control, anti-virus, RAID and security information, and event management. Each is used in a unique way so that we can seek to prevent, detect, and recover from security incidents and exposures. Keep in mind that violations to operational security aren’t always malicious; sometimes things break or accidents happen. Therefore, operational security must also be prepared to deal with these unintended occurrences by building in system resilience and fault tolerance.
Foundational Security Operations Concepts
Ask any seasoned security professional what it takes to secure its networks, systems, applications, and data, and the answer will most likely involve a combination of operational, technical, and physical controls. This process starts before you ever hire your first employee. Employees need to know what is expected of them. Accounts need to be configured, users need to have the appropriate level of access approved, and monitoring must be implemented. These are the topics that will be discussed in the first section.
Managing Users and Accounts
One foundational control to increase accountability is to enforce specific roles and responsibilities within an organization. Most organizations have clearly defined controls that specify what each job role is responsible for. Some common roles within organizations are:
![]() Librarian—Responsible for all types of media, including CDs, DVDs, USB thumb drives, solid state hard drives, and so on. Librarians must track, store, and recall media as needed. They also must document whether the media is encrypted, when the media was stored, when it was retrieved, and who accessed it. If media moves offsite, librarians track when it was sent and when it arrived. They might also be asked to assist in an audit to verify what type of media is still being held at a vendor’s site.
Librarian—Responsible for all types of media, including CDs, DVDs, USB thumb drives, solid state hard drives, and so on. Librarians must track, store, and recall media as needed. They also must document whether the media is encrypted, when the media was stored, when it was retrieved, and who accessed it. If media moves offsite, librarians track when it was sent and when it arrived. They might also be asked to assist in an audit to verify what type of media is still being held at a vendor’s site.
![]() Data entry specialist—Although most data entry activities are now outsourced, in the not-too-distant past, these activities were performed in-house at an information processing facility. During that time, a full-time data entry specialist was assigned the task of entering all data. (Bar codes, scanning, and web entry forms have also reduced the demand for these services.)
Data entry specialist—Although most data entry activities are now outsourced, in the not-too-distant past, these activities were performed in-house at an information processing facility. During that time, a full-time data entry specialist was assigned the task of entering all data. (Bar codes, scanning, and web entry forms have also reduced the demand for these services.)
![]() Systems administrator—Responsible for the operation and maintenance of the LAN and associated components, such as Windows Server 2012 R2, Linux, or even mainframes. Although small organizations might have only one systems administrator, larger organizations might have many.
Systems administrator—Responsible for the operation and maintenance of the LAN and associated components, such as Windows Server 2012 R2, Linux, or even mainframes. Although small organizations might have only one systems administrator, larger organizations might have many.
![]() Quality assurance specialist—Can fill either of two roles: quality assurance or quality control. Quality assurance employees make sure programs and documentation adhere to standards; quality control employees perform tests at various stages of product development to make sure the products are free of defects.
Quality assurance specialist—Can fill either of two roles: quality assurance or quality control. Quality assurance employees make sure programs and documentation adhere to standards; quality control employees perform tests at various stages of product development to make sure the products are free of defects.
![]() Database administrator—Responsible for the organization’s data and maintains the data structure. The database administrator has control over all the data; therefore, detective controls and supervision of duties must be closely observed. This role is usually filled by a senior information systems employee because these employees have control over the physical data database, implementation of data definition controls, and definition and initiation of backup and recovery.
Database administrator—Responsible for the organization’s data and maintains the data structure. The database administrator has control over all the data; therefore, detective controls and supervision of duties must be closely observed. This role is usually filled by a senior information systems employee because these employees have control over the physical data database, implementation of data definition controls, and definition and initiation of backup and recovery.
![]() Systems analyst—Involved in the system development life cycle (SDLC) process responsible for determining the needs of users and developing the requirements and specifications for the design of needed software.
Systems analyst—Involved in the system development life cycle (SDLC) process responsible for determining the needs of users and developing the requirements and specifications for the design of needed software.
![]() Network administrator—Responsible for maintenance and configuration of network equipment, such as routers, switches, firewalls, wireless access points, and so on.
Network administrator—Responsible for maintenance and configuration of network equipment, such as routers, switches, firewalls, wireless access points, and so on.
![]() Security architect—Responsible for examining the security infrastructure of the organization’s network.
Security architect—Responsible for examining the security infrastructure of the organization’s network.
Job titles can be confusing because different organizations tend to use different titles for identical positions and in smaller organization they tend to combine duties under one position or title. For example, some network architects are called network engineers. The critical concept for a security professional is to understand that, to avoid conflicts of interest, certain roles should not be combined. Table 10.1 lists some examples of role combinations and whether it’s okay to combine them.

The titles and descriptions in Table 10.1 are just examples and many companies might describe these differently or assign more or less responsibility to any one job role. To better understand the effect of role combinations that can conflict, consider a small company that employs one person as both the network administrator and the security administrator. This represents a real weakness because of the conflict of interest in the range of duties that a security administrator and a network administrator must perform. This conflict arises because a network administrator is tasked with keeping the system up and running, keeping services available, while a security administrator is tasked with turning services off, blocking them, and denying users access. A CISSP should be aware of such incompatibilities and be concerned about the risks that can arise when certain roles are combined. Finally, any employee of the organization who has elevated access requires careful supervision. These individuals should be considered privileged entities.
Privileged Entities
A privileged entity is anyone that has a higher level of access than the normal user. Privileged entities can include mainframe operators, security administrators, network administrators, power users, or anyone with higher than normal levels of access. It important that sufficient controls be placed on these entities so that misuse of their access is deterred or, if their access is misused, it can be detected and corrected.
Controlling Access
Before hiring employees, you must make sure that you have the right person for the right job. Items such as background checks, reference checks, education/certification checks, or even Internet or social media checks might be run before new-hire orientation ever occurs. New employees might be asked to sign nondisclosure agreements (NDAs), agree to good security practices, and agree to acceptable use policies (AUPs).
When employees are on-boarded there are a number of controls that can be used to control access and privilege. First there is separation of duties. It describes the process of dividing duties so that more than one person is required to complete a task. Job rotation can be used to maintain redundancy, back up key personnel, and even help identify fraudulent activities. The principle of least privilege is another important concept that can go a long way toward an organization achieving its operational security goals. Least privilege means that individuals should have only enough resources to accomplish their required tasks.
Even activities such as mandatory vacations provide time for audits and to examine user activity for illicit activities. Each of these items will need to be backed up by policies, procedures, and training. Keep in mind that organizations benefit when each employee actively participates in the security of the organization.
Clipping Levels
No one has the time to investigate every event or anomaly that might occur but there must still be systems in place to log and monitor activities. One such technique is a clipping level. A clipping level is set to identify an acceptable threshold for the normal mistakes a user might commit. Events that occur with a frequency in excess of the clipping level lead to administrative notification and investigation.
The clipping level allows the user to make an occasional mistake, but if the established level is exceeded, violations are recorded or some type of response occurs. The network administrator might allow users to attempt to log in three times with an incorrect password. If the user can’t get it right on the third try, the account is locked and he or she is forced to call the help desk for support. If an administrator or help desk staffer is contacted to reset a password, a second type of authentication should be required to protect against a social engineering attack. Chapter 9, “Security Assessment and Testing,” covers social engineering in more detail.
Tip
To prevent social engineering attacks, individuals who need to have their password reset by automated means should be required to provide strong authentication such as user ID, PIN, or two or more cognitive passwords. For systems with higher security, physical retrieval or in-person verification should be used for password recovery.
Resource Protection
When you think of resource protection you might think of servers or other tangible assets. But resources can be both tangible and intangible. Tangible assets include equipment and buildings, whereas intangible assets can include such things as patents, trademarks, copyrights, and even brand recognition. Loss of a trade secret to a competitor can be just as, or more, devastating than an employee stealing a laptop. This means the organization must take reasonable care to protect all items of value.
Due Care and Due Diligence
Due care is focused on taking reasonable ongoing care to protect the assets of an organization. Due diligence is the background research. As an example, before accepting credit cards you might want to research the laws that govern their use, storage, and handling. Therefore, due diligence would be associated with reviewing the controls highlighted within PCI-DSS. Actually, due diligence was first used as a result of the United States Securities Act of 1933.
Organizations and their senior management are increasingly being held to higher levels of due care and due diligence. Depending on the law, senior management can be held responsible for criminal and/or financial damages if they are found negligent. The Sarbanes-Oxley Act of 2002 and the Federal Information Security Management Act have increased an organization’s liability for maintaining industry compliance. As an example, United States federal sentencing guidelines allow for fines in excess of $200 million dollars.
A legal challenge to an organization’s due diligence often results in the court system looking at what a “prudent person” would have done, and this is in fact referred to as the reasonably prudent person rule. For example, a prudent person would implement PCI-DSS controls for credit card transactions for a retail store using a point of sale (POS) device with over 80,000 transactions a year. The reasonably prudent person is a legal abstraction; in the context of cyber-security, it would be a professional, well trained, certified, educated individual with common sense in cyber-defense.
Note
While PCI is a major standard for control of financial information, the Group of Eight (G8) started as a forum for the governments of eight of the world’s largest economies to discuss issues related to commerce. Today, it has grown to 20 members.
Asset Management
Asset management is the process of identifying all the hardware and software assets within an organization, including the organization’s employees. There is no way to assess risk, or to consider what proper operational controls are, without good asset management. Asset management not only helps an organization gain control of its software and hardware assets, but also increases an organization’s accountability. Consider the process of hardening, patching, and updating. This process cannot be effectively managed without knowing what operating systems and/or software a company owns, and on what systems those products are installed.
System Hardening
Once we know what assets we have, system hardening is used to eliminate all applications, processes, and services that are not required for the business to function. When attackers attempt to gain access to a system, they typically look for systems that are highly vulnerable or that have “low-hanging fruit.” This phrase describes services and applications that are easily exploitable, often because they are unnecessary and unmanaged. The purpose of system hardening is to reduce the attack surface by removing anything that is not needed, or at least to isolate vulnerable services away from sensitive systems. After a system has been reduced to its bare essentials, there are fewer avenues for a potential attacker to exploit.
System hardening applies to all platforms. But consider for a moment the Nimda attack of 2001. Nimda focused on Microsoft web servers, and it used TFTP to upload the malware to the web server. Simply removing the TFTP service would have gone a long way toward protecting these vulnerable web servers. While most everyone does this now, little thought was given to this process then. Commonly removed services nowadays include FTP, Telnet, file and print sharing, NetBIOS, DNS, and SNMP.
Hardening should also be considered from a hardware perspective. Hardware components such as CD drives, DVD drives, and USB ports should be disabled or removed. Also, hardening can be extended to the physical premise itself. Wiring closets should be locked, data centers should have limited access, and network equipment such as switches, routers, and wireless access points should be physically secured.
Note
After performing many security assessments, one of the first things I now look for when I enter a facility is the lack of physical controls; this includes wireless access points, telecommunication equipment, servers, and riser rooms. If an asset is physically accessible to an intruder, it is insecure.
Once a system has been hardened and approved for release a baseline needs to be approved. Baselining is simply capturing a configuration or image at a point in time and understanding the current system security configuration. All our work up to this point would do little good if the systems are not maintained in a secure state. This is where change management comes into play.
Change and Configuration Management
Companies put a lot of effort into securing assets and hardening systems. To manage required system changes, controls must be put in place to make sure all changes are documented and approved. This is accomplished with the change management process. Any time a change is to be made, it is important to verify what is being requested, how it will affect the systems, and what unexpected actions might occur. Most companies will not directly deploy patches without first testing them to see what changes will occur after the patch has been installed. It is important to ensure that changes do not somehow diminish or reduce the security of the system. Configuration management should also provide a means to roll back or undo any applied changes should negative effects occur because of the change. Although change management processes can be implemented slightly differently in various organizations, a generic process can be defined:
1. Request a change.
2. Approve the change.
3. Catalog the change.
4. Schedule the change.
5. Prepare a means to roll back the change if needed.
6. Implement the change.
7. Test or confirm the change.
8. Report the completion of the change to the appropriate individuals/groups.
Tip
While some might question the need to have a rollback plan, things can go wrong. A good example of this can be seen in 2010 when a McAfee Antivirus update caused Windows XP systems to blue screen. See www.eweek.com/c/a/Security/Buggy-McAfee-Security-Update-Takes-Down-Windows-XP-Machines-827503/.
Despite the fact that each organization might implement change management differently, there can be no argument over the value of using comprehensive change management. The primary benefits of change management include:
![]() Verification that change is implemented in an orderly manner through formalized testing
Verification that change is implemented in an orderly manner through formalized testing
![]() Verification that the user base is informed of impending/completed changes
Verification that the user base is informed of impending/completed changes
![]() Review of the effects of changes on the system after implementation
Review of the effects of changes on the system after implementation
![]() Mitigation of any adverse impact that changes might have had on services, systems, or resources
Mitigation of any adverse impact that changes might have had on services, systems, or resources
Trusted Computer System Evaluation Criteria (TCSEC), frequently referred to as the Orange Book, specifies that change management is a requirement at the A1, B3, and B2 levels (see Table 10.2). The Orange Book defines operational assurance in terms of a system’s architecture, its capability to provide system integrity, its resistance to known attacks (such as covert channels), its provision of facility management, and its capability to provide trusted recovery. Although it’s safe to say the measurement of assurance has progressed way beyond the Orange Book, TCSEC does provide a basis for discussing assurance through the use of operational controls.
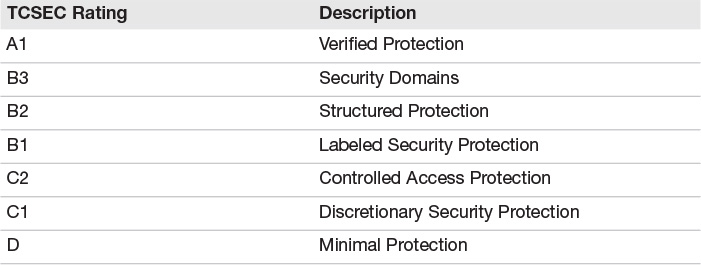
Take a moment to review Chapter 5, “Security Engineering,” to review more about Orange Book levels and their meaning, and about more current specifications like Common Criteria. Change management can also be used to demonstrate due care and due diligence.
Trusted Recovery
Trusted recovery is one of the assurance requirements found in the Orange Book. Administrators of B3-A1 systems must be able to restore the systems to a secure state whenever a failure occurs. Failures can occur in all types of operating systems. Many older readers may remember Windows NT and the blue screen of death (BSOD) that administrators were tasked with dealing with. These system failures usually required a reboot to recover. Administrators that experienced these issues had to understand what caused the failure and how to recover the system to a usable state. Luckily, the BSOD is encountered much less frequently now than in those early years. A system failure can be categorized as a system reboot, an emergency system restart, or a system cold start. The Orange Book describes these as follows:
![]() System reboot—Performed after shutting down the system in a controlled manner in response to a trusted computer base (TCB) failure. For example, when the TCB detects the exhaustion of space in some of its critical tables or finds inconsistent object data structures, it closes all objects, aborts all active user processes, and restarts with no user process in execution.
System reboot—Performed after shutting down the system in a controlled manner in response to a trusted computer base (TCB) failure. For example, when the TCB detects the exhaustion of space in some of its critical tables or finds inconsistent object data structures, it closes all objects, aborts all active user processes, and restarts with no user process in execution.
![]() Emergency system restart—Occurs after a system fails in an uncontrolled manner in response to a TCB or media failure. In such cases, the TCB and user objects on nonvolatile storage belonging to processes active at the time of the TCB or media failure may be left in an inconsistent state.
Emergency system restart—Occurs after a system fails in an uncontrolled manner in response to a TCB or media failure. In such cases, the TCB and user objects on nonvolatile storage belonging to processes active at the time of the TCB or media failure may be left in an inconsistent state.
![]() System cold start—Occurs when unexpected TCB or media failures take place. The recovery procedures cannot bring the system to a consistent state, so intervention by administrative personnel is required to bring the system to a consistent state from maintenance mode.
System cold start—Occurs when unexpected TCB or media failures take place. The recovery procedures cannot bring the system to a consistent state, so intervention by administrative personnel is required to bring the system to a consistent state from maintenance mode.
Tip
Whereas modern client/server systems use the term reboot, mainframes use the term initial program load (IPL). Historically, when a mainframe had to have a configuration change, it was said to be re-IPL’d.
Any failure that endangers the security of a system must be understood and investigated. It is critical that the environment be protected during recovery. Consider a Windows 2008 or 2012 Server. Did you ever notice that when you shut down a Windows Server, you are asked why? This screen is an example of an operational control.
To protect the environment during the reboot/restart process, access to the server must be limited. This prevents anyone from having an opportunity to disrupt the process. Some example recovery limits include:
![]() Prevent system from being booted from network, CD/DVD, or USB
Prevent system from being booted from network, CD/DVD, or USB
![]() Log restarts so that auditing can be performed
Log restarts so that auditing can be performed
![]() Block complementary metal-oxide semiconductor (CMOS) changes to prevent tampering
Block complementary metal-oxide semiconductor (CMOS) changes to prevent tampering
![]() Deny forced shutdowns
Deny forced shutdowns
Remote Access
As transportation, utilities, and other associated costs associated with traditional 9-to-5 employees continue to rise, more and more companies are permitting employees to telecommute, access resources remotely, and use cloud computing. Companies might also have sales reps and others that need remote access. These requirements lead companies to enable remote access to their networks.
Remote access also offers an attacker a potential means of gaining access to the protected network. Therefore, companies need to implement good remote access practices to mitigate risk. Some basic remote access controls include the following:
![]() Implementing caller ID
Implementing caller ID
![]() Using a callback system
Using a callback system
![]() Disabling unused authentication protocols
Disabling unused authentication protocols
![]() Using strong authentication
Using strong authentication
![]() Implementing remote and centralized logging
Implementing remote and centralized logging
![]() Using VPNs and encryption
Using VPNs and encryption
Media Management, Retention, and Destruction
Resource protection techniques do not just include when the resource is being used. It also includes disposal. If the media is held on hard drives, magnetic media, or thumb drives, it must eventually be sanitized. Sanitization is the process of clearing all identified content, such that no data remnants can be recovered. When sanitization is performed, none of the original information can be recovered. Some of the methods used for sanitization include drive wiping, zeroization, degaussing, and physical destruction:
![]() Drive wiping is the act of overwriting all information on the drive. It allows the drive to be reused.
Drive wiping is the act of overwriting all information on the drive. It allows the drive to be reused.
![]() Zeroization involves overwriting the data with zeros. Zeroization is defined as a standard in ANSI X9.17.
Zeroization involves overwriting the data with zeros. Zeroization is defined as a standard in ANSI X9.17.
![]() Degaussing is used to permanently destroy the contents of the hard drive or magnetic media. Degaussing works by means of a powerful magnet that uses its field strength to penetrate the media and polarize the magnetic particles on the tape or hard disk platters. After media has been degaussed, it cannot be reused.
Degaussing is used to permanently destroy the contents of the hard drive or magnetic media. Degaussing works by means of a powerful magnet that uses its field strength to penetrate the media and polarize the magnetic particles on the tape or hard disk platters. After media has been degaussed, it cannot be reused.
![]() Physical destruction may be required to sanitize newer solid-state drives.
Physical destruction may be required to sanitize newer solid-state drives.
Telecommunication Controls
Guglielmo Marconi probably had no idea that his contributions to the field of radio would lead to all the telecommunications systems available today. Even though a CISSP is not going to be tasked with building the first ship-to-shore radio system like Marconi did, he/she must be aware of current telecommunication systems and understand their usage and potential vulnerabilities. These systems include items such as cloud computing, email systems, facsimile (fax) machines, public branch exchanges (PBXs), whitelisting, sandboxing, and anti-malware.
Cloud Computing
Cloud computing uses Internet-based systems to perform on-demand computing. Users only have to pay for the services and computing resources they require. They can increase usage when more computing resources are needed or reduce usage when the services are not needed. Some of the most common types of cloud computing are:
![]() Monitoring as a Service (MaaS)—Allows IT and other organizations to remotely monitor and manage networks, applications, and services.
Monitoring as a Service (MaaS)—Allows IT and other organizations to remotely monitor and manage networks, applications, and services.
![]() Communication as a Service (CaaS)—The service provider seamlessly integrates multiple communication devices or channels for voice, video, IM, and email as a single solution.
Communication as a Service (CaaS)—The service provider seamlessly integrates multiple communication devices or channels for voice, video, IM, and email as a single solution.
![]() Infrastructure as a Service (IaaS)—Enables organizations to rent storage and computing resources, such as servers, networking technology storage, and data center space.
Infrastructure as a Service (IaaS)—Enables organizations to rent storage and computing resources, such as servers, networking technology storage, and data center space.
![]() Platform as a Service (PaaS)—Provides access to platforms that let organizations develop, test, and deploy applications. It is a cloud computing service delivery model that delivers a set of software. In PaaS, the user’s application resides entirely on the cloud from its development to delivery.
Platform as a Service (PaaS)—Provides access to platforms that let organizations develop, test, and deploy applications. It is a cloud computing service delivery model that delivers a set of software. In PaaS, the user’s application resides entirely on the cloud from its development to delivery.
![]() Software as a Service (SaaS)—Allows the use of applications running on the service provider’s environment. It is a cloud service model that delivers prebuilt applications over the Internet on an on-demand basis. If an organization wants to use the software for a short duration, SaaS delivers a single application to multiple customers within the organization using a multi-tenant architecture.
Software as a Service (SaaS)—Allows the use of applications running on the service provider’s environment. It is a cloud service model that delivers prebuilt applications over the Internet on an on-demand basis. If an organization wants to use the software for a short duration, SaaS delivers a single application to multiple customers within the organization using a multi-tenant architecture.
Cloud computing models generally fall into one of the categories shown here:
![]() Private—All of the cloud and its components are managed by a single organization.
Private—All of the cloud and its components are managed by a single organization.
![]() Community—Cloud components are shared by multiple organizations and managed by one of them, or by a third party.
Community—Cloud components are shared by multiple organizations and managed by one of them, or by a third party.
![]() Public—Open for any organization or user to use, public in nature, and managed by third-party providers.
Public—Open for any organization or user to use, public in nature, and managed by third-party providers.
![]() Hybrid—This service model has components of more than one of the private, community, and public service models.
Hybrid—This service model has components of more than one of the private, community, and public service models.
ExamAlert
For the exam you will need to know not just cloud computing types like SaaS and MaaS but also their various categories.
Email provides individuals the ability to communicate electronically through the Internet or a data communications network. Email is the most used Internet application. Just take a look around the office and see how many people use a BlackBerry or another device that provides email services. Email is not a new Internet technology and, as such, it comes with some security concerns. Email was designed in a different era and, by default, sends information via cleartext. Anyone able to sniff such traffic can read it. Email can be easily spoofed so that the true identity of the sender is masked. Email is also a major conduit for spam, phishing, and viruses.
Email functions by means of several underlying services, which can include the following:
![]() SMTP—Used to send mail and to relay mail to other SMTP mail servers. SMTP uses TCP port 25. Messages sent through SMTP have two parts: an address header and message text. All types of computers can exchange messages with SMTP.
SMTP—Used to send mail and to relay mail to other SMTP mail servers. SMTP uses TCP port 25. Messages sent through SMTP have two parts: an address header and message text. All types of computers can exchange messages with SMTP.
![]() POP—Currently at version 3. POP3 is the one of the protocols that can be used to retrieve messages from a mail server. POP3 performs authentication in cleartext on TCP port 110. An alternative to POP3 is IMAP.
POP—Currently at version 3. POP3 is the one of the protocols that can be used to retrieve messages from a mail server. POP3 performs authentication in cleartext on TCP port 110. An alternative to POP3 is IMAP.
![]() IMAP—Used as a replacement for POP, operates on TCP port 143, and is designed to retrieve messages from an SMTP server. IMAP4 is the current version and offers several advantages over POP. IMAP has the capability to work with email remotely. Many of today’s email users might need to access email from different locations and devices, such as PDAs, laptops, and desktops. IMAP provides this functionality so that multiple clients can access the email server and leave the email there until it’s deleted.
IMAP—Used as a replacement for POP, operates on TCP port 143, and is designed to retrieve messages from an SMTP server. IMAP4 is the current version and offers several advantages over POP. IMAP has the capability to work with email remotely. Many of today’s email users might need to access email from different locations and devices, such as PDAs, laptops, and desktops. IMAP provides this functionality so that multiple clients can access the email server and leave the email there until it’s deleted.
Tip
An updated version of POP that provides authentication is known as Authenticated Post Office Protocol (APOP).
Basic email operation consists of the SMTP service being used to send messages to the email server. To retrieve email, the client application, such as Outlook, might use POP or IMAP, as seen in Figure 10.1.

In sum, anyone who uses email needs to be aware of the security risks. Spam is an ongoing problem, and techniques like graylisting can be used to deal with it. The sending of sensitive information by cleartext email is another area of concern. If an organization has policies that allow email to be used for sensitive information, encryption should be mandatory. This will require an evaluation of the needs of the business. Several solutions exist to meet this need. One is Pretty Good Privacy (PGP). Other options include link encryption or secure email standards like Secure Multipurpose Internet Mail Extensions (S/MIME) or Privacy Enhanced Mail (PEM).
Whitelisting, Blacklisting, and Graylisting
Other good technical controls are whitelisting, blacklisting, and graylisting. A whitelist is used to determine what is allowed access or can be performed. Anything that is not included on the whitelist is prohibited.
Blacklists operate in the opposite way. Blacklisting consists of banning or denying. As a real-world example, just about anyone is allowed in a casino to gamble. However, some individuals may be specifically prohibited (this happened to actor Ben Affleck in 2014: nypost.com/2014/05/02/ben-affleck-banned-for-life-from-vegas-casino/). In the network sense, the prohibition might be against a list of users, access, or resources. The problem with blacklisting is that as the list continues to grow it requires more ongoing maintenance and oversight.
Finally, there are graylists. Graylists are used by many email administrators as a technique to deal with spam. When a graylist is implemented it will reject any email sender that is unknown. If the mail is from a legitimate email server it will be retransmitted after a period of time. This moves the graylisted email off the graylist and on to the whitelist, and at that time places the email in the inbox of the receiving account. The email is not necessarily blacklisted or deleted until the user evaluates the decision and makes a human decision to reject or accept the sender.
ExamAlert
Exam candidates should understand blacklists, graylists, and whitelists.
Fax
Fax machines can present some security problems if they are being used to transmit sensitive information. These vulnerabilities reside throughout the faxing process and include the following:
![]() When the user feeds the document into the fax machine for transmission, wrongdoers have the opportunity to intercept and decode the information while in transit.
When the user feeds the document into the fax machine for transmission, wrongdoers have the opportunity to intercept and decode the information while in transit.
![]() When the document arrives at its destination, it is typically printed and deposited into a fax tray. Anyone can retrieve the printed document and review its contents.
When the document arrives at its destination, it is typically printed and deposited into a fax tray. Anyone can retrieve the printed document and review its contents.
![]() Many fax machine use ribbons. Anyone with access to the trash can retrieve the ribbons and use them as virtual carbon copies of the original documents.
Many fax machine use ribbons. Anyone with access to the trash can retrieve the ribbons and use them as virtual carbon copies of the original documents.
![]() Fax machines can also allow unauthorized connections using dial-up. As an example, a contractor could attempt to use a fax phone port to access personal accounts or bypass firewalls.
Fax machines can also allow unauthorized connections using dial-up. As an example, a contractor could attempt to use a fax phone port to access personal accounts or bypass firewalls.
Fax systems can be secured by one or more of the following techniques:
![]() Fax servers—Can send and receive faxes and then hold the fax in electronic memory. At the recipient’s request, the fax can be forwarded to the recipient’s email account or can be printed.
Fax servers—Can send and receive faxes and then hold the fax in electronic memory. At the recipient’s request, the fax can be forwarded to the recipient’s email account or can be printed.
![]() Fax encryption—Provides fax machines the capability to encrypt communications. Fax encryption requires that both the transmitting and receiving device support a common protocol.
Fax encryption—Provides fax machines the capability to encrypt communications. Fax encryption requires that both the transmitting and receiving device support a common protocol.
![]() Fax activity logs—Implement activity logs and review exception reports to detect any anomalies.
Fax activity logs—Implement activity logs and review exception reports to detect any anomalies.
Caution
Although fax servers have solved many security problems, they have their own challenges. Many use hard drives where companies store a large amount of commonly used administrative documents and forms. Others allow HTTP and/or FTP access to the print queue, where someone can capture the files. These issues must be addressed before effective security can be achieved.
PBX
PBX systems are used by private companies and permit users to connect to a public switched telephone network (PSTN). The PBX can be used to assign extensions, provide voice mail, and special services for internal users and customers. The issue with PBXs is that, like other organizational resources, a PBX can be a potential target. Some PBX issues are:
![]() PBX without the default password changed
PBX without the default password changed
![]() PBX used by attackers to call in to public address lines and make announcements that might be inappropriate
PBX used by attackers to call in to public address lines and make announcements that might be inappropriate
![]() PBX allowing callers to call out and make free long distance phone calls that are charged to the company
PBX allowing callers to call out and make free long distance phone calls that are charged to the company
PBX hacking is not as prevalent as in the past, but a PBX can still pose a threat to operational security. If criminals can crack the security of the PBX system, it’s possible for them to sell the victim’s phone time. These charges are usually discovered after 30 to 60 days, but this window of opportunity allows the criminal to run up thousands of dollars in phone charges. Any attack will require time, money, and effort to repair. Individuals that target PBX and phone systems are known as phreakers.
Phreakers
Long before modern-day hacking existed, phreakers were practicing their trade. Phreaking is the art of hacking phone systems. Although this might sound like a rather complicated affair, back in the early 1970s it was discovered that free phone calls could be made by playing a 2600Hz tone into a phone. The 2600Hz tone allowed the phreaker to bypass the normal billing process. The first device tailored to this purpose was known as a blue box. Some of the other box devices used by phreakers were:
![]() Red box—Duplicates tones of coins being dropped into pay phone.
Red box—Duplicates tones of coins being dropped into pay phone.
![]() Gold box—Connects to two lines so that one is called into, while the other is used for outbound communication. Such devices were designed to prevent line tracing.
Gold box—Connects to two lines so that one is called into, while the other is used for outbound communication. Such devices were designed to prevent line tracing.
![]() Orange box—Spoofs caller ID information on the called party’s phone.
Orange box—Spoofs caller ID information on the called party’s phone.
Most of these boxes were invented in the 1970s and used until the early 1990s. Most won’t work on modern telephone systems. New telephone system networks use out-of-band (OOB) signaling, in which one channel is used for the voice conversation and a separate channel is used for signaling. With OOB, it is no longer possible to just play tones into the mouthpiece to signal equipment within the network. Although these tools are primarily historical, phreakers can still carry out activities like caller ID spoofing, or might even target VoIP phone systems for DoS attacks or sniffing attacks.
Two other techniques attackers can use are slamming and cramming; both terms are used with telephony. Slamming refers to switching users’ long-distance phone carriers without their knowledge. Cramming relates to unauthorized phone charges. One cramming technique is to send a fake SMS message that, when clicked on, authorizes the attacker to bill the victim for a small amount each month. Sometimes these charges can seem incidental, but multiplied by hundreds or thousands of users can add up to a great deal of money.
Anti-malware
Malware is a problem that computer users are faced with on a daily basis. Training users in safe computing practices is a good start, but anti-malware tools are still needed to protect the organization’s computers. When you find suspected malware there are generally two ways to examine it: static analysis and active analysis. While static analysis requires you to decompile or disassemble the code, active analysis requires the suspected malware to be executed. Because executing malware on a live, production environment can be dangerous, it is typically done on a stand-alone system or virtual machine, referred to as a sandbox. The sandbox allows you to safely view or execute the suspected malware or any untrusted code while keeping it contained. Keep in mind that even when malware is run in a sandbox, there is always some possibility that it may escape and infect other systems.
Along with testing malware you will want to try and prevent malware from ever executing on your systems. This is where anti-malware software comes in. Anti-malware software should be installed on servers, workstations, and even portable devices. It can use one or more techniques to check files and applications for viruses and other types of common malware. These techniques include:
![]() Signature scanning—In a similar fashion to IDS pattern-matching systems, signature scanning looks at the beginning and end of executable files for known virus signatures. Virus creators attempt to circumvent the signature scanning process by making viruses polymorphic.
Signature scanning—In a similar fashion to IDS pattern-matching systems, signature scanning looks at the beginning and end of executable files for known virus signatures. Virus creators attempt to circumvent the signature scanning process by making viruses polymorphic.
![]() Heuristic scanning—Heuristic scanning examines computer files for irregular or unusual instructions. As an example, think of your word processing program. It probably creates, opens, and updates text files. If the word processor attempts to format the C drive, this is something that a heuristics scanner would quickly identify as unusual activity for a word processor. In reality, antivirus vendors must strike a balance with heuristic scanning because they do not want to produce too many false positives or false negatives. Many antivirus vendors use a scoring technique that evaluates many types of behaviors. Only when the score exceeds a threshold (also called a clipping level) will the antivirus program actually flag an alert.
Heuristic scanning—Heuristic scanning examines computer files for irregular or unusual instructions. As an example, think of your word processing program. It probably creates, opens, and updates text files. If the word processor attempts to format the C drive, this is something that a heuristics scanner would quickly identify as unusual activity for a word processor. In reality, antivirus vendors must strike a balance with heuristic scanning because they do not want to produce too many false positives or false negatives. Many antivirus vendors use a scoring technique that evaluates many types of behaviors. Only when the score exceeds a threshold (also called a clipping level) will the antivirus program actually flag an alert.
![]() Integrity checking—Integrity checkers work by building a database of checksums or hashed values. Periodically, new scans are performed and the results are compared to the stored results. Although it is not always effective for data files, this technique is useful for executables because their contents rarely change. For example, the MD5sum of the Linux bootable OS Kali Linux 5.0 is a66bf35409f4458ee7f35a77891951eb. Any change to the Kali.iso would change this hashed value, which would easily be detected by an integrity checker.
Integrity checking—Integrity checkers work by building a database of checksums or hashed values. Periodically, new scans are performed and the results are compared to the stored results. Although it is not always effective for data files, this technique is useful for executables because their contents rarely change. For example, the MD5sum of the Linux bootable OS Kali Linux 5.0 is a66bf35409f4458ee7f35a77891951eb. Any change to the Kali.iso would change this hashed value, which would easily be detected by an integrity checker.
![]() Activity blockers—An activity blocker intercepts a virus when it starts to execute and blocks it from infecting other programs or data. Activity blockers are usually designed to start at boot up and continue until the computer shuts down.
Activity blockers—An activity blocker intercepts a virus when it starts to execute and blocks it from infecting other programs or data. Activity blockers are usually designed to start at boot up and continue until the computer shuts down.
Honeypots and Honeynets
A honeypot can be used to trap, jail, or even examine a hackers’ activities. A honeypot is really nothing more than a fake system. A honeynet is an entire network of fake systems. One of the primary uses of a honeypot is to deflect an attack. The idea is that the hacker is drawn to the honeypot while the real system avoids attack.
Honeypots can also be used to gather research about hackers’ activities. You can see a good example of this at old.honeynet.org/papers/forensics/index.html. There is more information on honeypots in Chapter 9.
Caution
Honeypots are used for diversion and analysis of an attacker’s tactics, tools, and methods. Honeypots are simply fake systems or networks. A key issue is to avoid entrapment because entrapment can itself be illegal. Warning banners can help avoid claims of entrapment by clearly noting that those who use or abuse the system will be monitored and potentially prosecuted.
Patch Management
Patch management is important in helping to identify problems and getting them updated in an expedient manner to reduce overall risk of a system compromise. Patch management is key to keeping applications and operating systems secure. The organization should have a well developed patch management testing and deployment system in place. The most recent security patches should be tested and then installed on host systems as soon as possible. The only exception is when an immediate installation would interfere with business requirements.
Before a patch can be tested and deployed it must first be verified. Typical forms of verification include digital signatures, digital certificates, or some form of checksum and/or integrity verification. This is a critical step that must be performed before testing and deployment to make sure that it has not been maliciously or accidentally altered. Once testing is complete deployment can begin. Change management protocols should be followed throughout this process.
System Resilience, Fault Tolerance, and Recovery Controls
Plan to fail because things will surely go wrong; it is just a matter of when. Therefore, understanding how to react and recover from errors and failures is an important part of operational security.
Good operational security practices require security planners to perform contingency planning. Contingency planning requires that you develop plans and procedures that can be implemented when things go wrong. Although covered in detail in Chapter 12, “Business Continuity Planning,” this subject is mentioned here because it is closely tied to operations security. Contingency planning should occur after you’ve identified operational risks and performed a risk analysis to determine the extent of the impact of the possible adverse events. Backup, fault tolerance, and recovery controls are discussed in the sections that follow.
Backups
Three types of backup methods exist: full, incremental, and differential. The method your organization chooses depends on several factors:
![]() How much data needs to be backed up?
How much data needs to be backed up?
![]() How often should the backup occur?
How often should the backup occur?
![]() Where will the backups be stored?
Where will the backups be stored?
![]() How much time do you have to perform each backup?
How much time do you have to perform each backup?
Each backup method has benefits and drawbacks. Full backups are the most comprehensive, but take the longest time to create. So, even though it might seem best to do a full backup every day, it might not be possible due to the time and expense.
Tip
Two basic methods can be used to back up data: automated and on-demand. Automated backups are scheduled to occur at a predetermined time. On-demand backups can be scheduled at any time.
Full Backups
During a full backup, all data is backed up, and no files are skipped or bypassed; you simply designate which server to back up. A full backup takes the longest to perform and the least time to restore because only one backup dataset is required.
Differential Backups
Using differential backup, a full backup is typically done once a week and a differential backup, which backs up all files that have changed since the last full backup, is done more frequently, typically daily. If you need to restore, you need the last full backup and the most recent differential backup.
Differential backups make use of files’ archive bit. The archive bit indicates that the file is ready for archiving, or backup. A full backup clears the archive bit for each backed up file. Then if anyone makes changes to one of these files, its archive bit is toggled on. During a differential backup, all the files that have the archive bit on are backed up, but the archive bit is not cleared until the next full backup. Because more files will likely be modified during the week, the differential backup time will increase each day until another full backup is performed; still, this method takes less time than a daily full backup. The value of a differential backup is that only two backup datasets are required; the full and the differential.
Incremental Backups
With this backup strategy, a full backup is scheduled for once a week (typically) and only files that have changed since the previous full backup or previous incremental backup are backed up more frequently (usually daily).
Unlike a differential backup, in an incremental backup the archive bit is cleared on backed up files; therefore, incremental backups back up only changes made since the last incremental backup. This is the fastest backup option, but it takes the longest to restore, because the full backup must be restored, then all the incremental backups, in order.
Tape Rotation Schemes
Tapes and other media used for backup will eventually fail. It is important to periodically test backup media to verify its functionality. Some tape rotation methods include Tower of Hanoi and grandfather-father-son (GFS). This scheme performs a full backup once a week, known as the father. The daily backups, which can be differential or incremental, are known as the son. The last full backup of the month is retained for a year and is known as the grandfather.
Fault Tolerance
Fault tolerance requires a redundant system so that in the event of a failure, a backup system can take its place. Some common devices used for fault tolerance include tape and hard drives. Tape-based systems are an example of a sequential access storage device (SASD). Should you need information from a portion of the tape, the tape drive must be traversed to the required position for the information to be accessed. Hard drives are an example of a direct access storage device (DASD). The advantage of a DASD is that information can be accessed much more quickly. One option that can be used to speed up the sequential process when large amounts of data need to be backed up is a redundant array of independent tapes (RAIT). RAIT is efficient for instances where large numbers of write operations are needed for massive amounts of data. RAIT stripes the data across multiple tapes much like a RAID array and can function with or without parity.
A technology similar to RAIT is massive array of inactive hard drives (MAID). This technology uses hard drives instead of tape drives and could be useful in situations where the hard drives are inactive for the majority of time and powered up only when the transfer of data is needed. Although the controller stays active, the drives are inactive most of the time. Because the drives are inactive, power consumption is reduced and life expectancy is increased.
Storing and managing all this data can become a massive task for many organizations. Companies might have tape drives, MAID, RAID, optical jukeboxes, and other storage solutions to manage. To control all these systems, many companies now use storage area networks (SANs). Although SANs are not common in small companies, large organizations with massive amounts of data can use them to provide redundancy, fault tolerance, and backups. The beauty of the system is that the end user does not have to know the location of the information—the user must only make the request for the data and the SAN will retrieve and recover it.
It is not just data that can be made fault tolerant. Computer systems can also benefit. Redundant servers can be used and the computing process can be distributed to utilize the power of many computers. Two such concepts are:
![]() Clustering—A means of grouping computers and moving to a greater level of usability over redundant servers. Whereas a redundant server waits until it’s needed, a clustered server is actively participating in responding to the server’s load. Should one of the clustered servers fail, the remaining servers can pick up the slack. An example of a clustered system can be seen at www.beowulf.org.
Clustering—A means of grouping computers and moving to a greater level of usability over redundant servers. Whereas a redundant server waits until it’s needed, a clustered server is actively participating in responding to the server’s load. Should one of the clustered servers fail, the remaining servers can pick up the slack. An example of a clustered system can be seen at www.beowulf.org.
Note
When is a cluster not a cluster? When it is referred to as a server farm. A server farm can be used as a cluster of computers. Such clusters can be used for complex tasks or in instances where supercomputers might have been used in the past.
![]() Distributed computing—This technique is similar to clustering except there is no central control. Distributed computing, also known as grid computing, can be used for processes that require massive amounts of computer power. Because grid computing is not under a centralized control, processes that require high security should not be considered. Distributed computing also differs from clustering in that distributed computers can add or remove themselves as they please.
Distributed computing—This technique is similar to clustering except there is no central control. Distributed computing, also known as grid computing, can be used for processes that require massive amounts of computer power. Because grid computing is not under a centralized control, processes that require high security should not be considered. Distributed computing also differs from clustering in that distributed computers can add or remove themselves as they please.
Note
An example of distributed computing can be seen in projects such as www.distributed.net. This project asks that users download a small application that makes use of their computers’ spare processing power. This project was able to crack the RC4 encryption algorithm by brute force in July, 2002, after 1,757 days.
RAID
Redundant Array of Inexpensive Disks (RAID) is one critical piece. RAID offers capacity benefits and can be used for fault tolerance and for performance improvements. Another important part of contingency planning, backup, and recovery is some type of data backup system. All hard drives and data storage systems fail. It’s not a matter of if, but when. Although there are many types of RAID, Table 10.3 lists and describes the nine most common types.

It is worth mentioning that RAID Level 0 is for performance only, not for redundancy. The most expensive RAID solution to implement is RAID Level 1 because all the data on disk A is mirrored to disk B. Mirroring also has another disadvantage; if data on disk A is corrupted, data on disk B will also become corrupted. The most common form of RAID is RAID 5. What makes RAID 5 striping so useful is that it offers a balance of performance and usability. RAID 5 stripes both data and parity information across three or more drives, whereas RAID 3 uses a dedicated parity drive.
Striping the data and parity across all drives removes the drive stress that the dedicated parity drive inflicts. Fault tolerance is provided by ensuring that, should any one drive die, the other drives maintain adequate information to allow for continued operation and eventual rebuilding of the failed drive (once replaced).
When is RAID not RAID? When it is Just a Bunch of Disks (JBOD). JBOD is somewhat like a poor man’s RAID, but it is really not RAID at all. JBOD can use existing hard drives of various sizes. These are combined together into one massive logical disk. There is no fault tolerance and no increase in speed. The only benefit of JBOD is that you can use existing disks and if one drive fails, you lose the data on only that drive. Both of these advantages are minimal, so don’t expect to see too many organizations actually use this technique. To better understand how these technologies map to each other, take a moment to review Figure 10.2.

ExamAlert
Fault tolerance and RAID are important controls. For the exam, you should be able to define RAID and describe specific levels and each level’s attributes. For example, RAID 1 has the highest cost per byte; RAID 5 is the most widely used.
Recovery Controls
Recovery controls are those applied after the fact. They are administrative in nature and are useful for contingency planning and disaster recovery. Most of us know contingency planning. As an example, while writing this book, I had a hard drive failure. Although I was lucky to have backed up the data, I still needed to finish the chapter and get it emailed by the deadline. My contingency plan was to use my laptop until I could get the desktop system back up and running. Even though most major organizations have much more detailed contingency plans than this, it is important to have some plan in place. The process of recovery is to have a mechanism to restore lost services after a disruptive event. Some of the issues that need to be considered to make sure recovery goes smoothly include elimination of single points of failure, mean time between failures (MTBF), and mean time to repair (MTTR).
A single point of failure is never a good thing. Single points of failure can be found everywhere from power supplies, hard drives, servers, telecommunication lines, firewalls, and even facility power. As an example, to keep power flowing, a company might use power leads from two substations and also have a backup generator on site. The idea is to try to avoid any single point of failure.
MTBF is a product’s average time until failure. Engineers will often discuss MTBF in terms of the bathtub curve (see Figure 10.3). This graphic example of average time before failure looks at the average rate of failure of a population of devices. Whereas some devices will fail early, most will last until the end of service.

Devices that survive until their end of life will start to fail at an increasing rate as they wear out. Good operational control practices dictate that companies should have some idea how long a device is calculated to last. This helps the organization plan for replacement before outages occur and services are disrupted.
For those items that fail before the expected end of service, a second important variable is MTTR. The MTTR is the amount of time it will take to get the item repaired. As an example, a product that can be repaired in-house will typically have a much lower MTTR than a product that needs to be shipped back to its manufacturer in China. One way companies deal with such unknowns is to use service-level agreements (SLAs).
Monitoring and Auditing Controls
Computer resources are a limited commodity provided by the company to help meet its overall goals. Although many employees would never dream of placing all their long-distance phone calls on a company phone, some of those same individuals have no problem using computer resources for their own personal use. Consider these statistics from Personal Computer World: according to information on its site, one-third of time spent online at work is not work-related, and more than 75% of streaming radio downloads occur between 5 a.m. and 5 p.m.
Accountability must be maintained for network access, software usage, and data access. In a high-security environment, the level of accountability should be substantial, and users should be held responsible by logging and auditing their activities.
Good practice dictates that audit logs be transmitted to a remote centralized site. Centralized logging makes it easier for the person assigned the auditing task to review the data. Exporting the logs to a remote site also makes it harder for hackers to erase or cover their activity. If there is a downside to all this logging, it is that all the information must be recorded and reviewed. A balance must be found between collecting audit data and maintaining a manageable log size. Reviewing it can be expedited by using audit reduction and correlation tools, such as SIEM. These tools parse the data and eliminate unneeded information. Another useful tool is a variance detection tool. These tools look for trends that fall outside the realm of normal activity. As an example, if an employee normally enters the building around 7 a.m. and leaves about 4 p.m. but is seen entering at 3 a.m., a variance detection tool would detect this abnormality.
Auditing and monitoring require accountability because if you don’t have accountability, you cannot perform an effective audit. True security relies on the capability to verify that individual users perform specific actions. Without the capability to hold individuals accountable, organizations can’t enforce security policies. Some of the primary ways to establish accountability are as follows:
![]() Auditing user activity
Auditing user activity
![]() Monitoring application controls
Monitoring application controls
![]() Security information and event management
Security information and event management
![]() Emanations
Emanations
![]() Network access control
Network access control
![]() Tracking the movement of individuals throughout the organization’s physical premises
Tracking the movement of individuals throughout the organization’s physical premises
Auditing User Activity
Auditing produces audit trails. These trails can be used to re-create events and verify whether security policies have been violated. The biggest disadvantage of the audit process is that it is detective in nature and that audit trails are usually examined after an event. Some might think of audit trails only as something that corresponds to logical access, but auditing can also be applied to physical access. Audit tools can be used to monitor who entered a facility and what time certain areas were accessed. The security professional has plenty of tools available that can help isolate activities of individual users.
Many organizations monitor network traffic to look for suspicious activity and anomalies. Some monitoring tools enable administrators to examine just packet headers, whereas others can capture all network traffic. Snort, Wireshark, and TCPdump are several such tools. Regardless of the tools used to capture and analyze traffic, administrators need to make sure that policies are in place detailing how such uncovered activities will be handled. Warning banners and AUPs go a long way in making sure that users are adequately informed of what to expect when using company resources.
ExamAlert
Exam candidates should understand the importance of monitoring employees and that tools that examine activity are detective in nature.
Tip
A warning banner is the verbiage a user sees at the point of entry into a system. Its purpose is to identify the expectations that users accessing those systems will be subjected to. The banners also aid in any attempt to prosecute those who violate the AUPs. A sample AUP is shown here:
WARNING: Unauthorized access to this system is forbidden and will be prosecuted by law. By accessing this system, you agree that your actions may be monitored if unauthorized use is suspected.
Monitoring Application Transactions
Good security is about more than people. A big part of a security professional’s day is monitoring controls to ensure that people are working according to policy. With so much of today’s computing activity occurring on servers that are connected to the Internet, these systems must be monitored.
In the modern world it is very possible that the output of one system might be the input of another. In such situations, data must be checked to verify the information from both the sending and receiving applications. Input controls can be automated or manual. Consider the last time you were at your local discount store. If there was an item that did not ring up as the correct price, you might have had to wait for the clerk to signal a supervisor to correct the error. Before the correction could occur, the supervisor had to enter a second-level password to authorize the price correction. This is an example of a manual authorization input control.
Process controls are another item that should be monitored. Process controls should be designed to detect problems and initiate corrective action. If procedures are in place to override these controls, their use should be logged and periodically reviewed. Individuals who have the ability to override these controls should not be the same ones responsible for reviewing the log; this is an example of separation of duties.
Output controls are designed to provide assurance of the results of data that has completed processing. Output controls should be designed to ensure that processing executed correctly and the data is distributed and archived in a secure manner. Sensitive data should have sufficient controls to monitor access and usage. These controls will vary, depending on whether the information is centrally stored or distributed to end-user workstations.
All input, processed, and output data should be monitored. Inputs must be validated. Consider the example of a dishonest individual browsing an e-commerce website and entering a quantity of –1 for an expensive item worth $2,450.99. Hopefully, the application has been written in such a way as to not accept a negative quantity for any items advertised. Otherwise, the merchant could end up crediting money back to the dishonest customer. Figure 10.4 shows an example of an application that lacks this control.

Note
One good example of an output control can be seen in many modern printer configurations. For example, some employee evaluation reviews might be configured so that they can be printed only to the supervisor’s printer. Another example can be seen in products such as Adobe’s Acrobat, which can limit printing of PDFs or embed password controls to limit who can open or edit PDFs.
Security Information and Event Management (SIEM)
Security information and event management (SIEM) is a relatively new technology that seeks to collect and analyze auditable events. SIEM allows for centralized logging and log analysis, and can work with a variety of log data, such as Netflow, Sflow, Jflow, and syslog. Most SIEM products support controls for confidentiality, integrity, and availability of log data. While SIEM can be used to spot attacks and security incidents, it can also be used for the day-to-day operational concerns of a network. SIEM can be used to detect misconfigured systems, unresponsive servers, malfunctioning controls, and failed applications. SIEM can also handle the storage of log data by disregarding data fields that are not significant to computer security, thereby reducing network bandwidth and data storage. Most SIEM products support two ways of collecting logs from log generators:
![]() Agentless—The SIEM server receives data from the hosts without needing to have any special software (agents) installed on those hosts.
Agentless—The SIEM server receives data from the hosts without needing to have any special software (agents) installed on those hosts.
![]() Agent Based—An agent program is installed on the hosts and may be used to generic log input such as Syslog and SNMP.
Agent Based—An agent program is installed on the hosts and may be used to generic log input such as Syslog and SNMP.
Network Access Control
IDS and IDP can be seen as just the start of access control and security. The next step in this area is Network Access Control (NAC). NAC has grown out of the trusted computer movement and has the goal of unified security. NAC offers administrators a way to verify that devices meet certain health standards before allowing them to connect to the network. Laptops, desktop computers, or any device that doesn’t comply with predefined requirements can be prevented from joining the network or can even be relegated to a controlled network where access is restricted until the device is brought up to the required security standards. Currently, there are several different incarnations of NAC available, which include the following:
![]() Infrastructure-based NAC—Requires an organization to upgrade its hardware and/or operating systems.
Infrastructure-based NAC—Requires an organization to upgrade its hardware and/or operating systems.
![]() Endpoint-based NAC—Requires the installation of software agents on each network client. These devices are then managed by a centralized management console.
Endpoint-based NAC—Requires the installation of software agents on each network client. These devices are then managed by a centralized management console.
![]() Hardware-based NAC—Requires the installation of a network appliance. The appliance monitors for specific behavior and can limit device connectivity should noncompliant activity be detected.
Hardware-based NAC—Requires the installation of a network appliance. The appliance monitors for specific behavior and can limit device connectivity should noncompliant activity be detected.
Keystroke Monitoring
Keystroke monitoring can be accomplished with hardware or software devices and is used to monitor activity. These devices can be used for both legal and illegal activity. As a compliance tool, keystroke monitoring allows management to monitor a user’s activity and verify compliance. The primary issue of concern is the user’s expectation of privacy. Policies and procedures should be in place to inform the user that such technologies can be used to monitor compliance. A sample AUP is shown here:
This acceptable use policy defines the boundaries of the acceptable use of this organization’s systems and resources. Access to any company system or resources is a privilege that may be wholly or partially restricted without prior notice and without consent of the user. In cases of suspected violations or during the process of periodic review, employees can have activities monitored. Monitoring may involve a complete keystroke log of an entire session or sessions as needed to vary compliance with company polices and usage agreements.
Unfortunately, key logging is not just for the good guys. Hackers can use the same tools to monitor and record an individual’s activities. Although an outsider to a company might have some trouble getting one of these devices installed, an insider is in a prime position to plant a keystroke logger. Keystroke loggers come in two basic types:
![]() Hardware keystroke loggers are usually installed while users are away from their desks and are completely undetectable, except for their physical presence. Just take a moment to consider when you last looked at the back of your computer. Even if you see it, a hardware keystroke logger can be overlooked because it resembles a dongle or extension. These devices are even available in wireless versions that can communicate via 802.11b/g and Bluetooth, or that can be built into the keyboard. You can see one example of a Bluetooth keystroke logger at www.wirelesskeylogger.com/products.php.
Hardware keystroke loggers are usually installed while users are away from their desks and are completely undetectable, except for their physical presence. Just take a moment to consider when you last looked at the back of your computer. Even if you see it, a hardware keystroke logger can be overlooked because it resembles a dongle or extension. These devices are even available in wireless versions that can communicate via 802.11b/g and Bluetooth, or that can be built into the keyboard. You can see one example of a Bluetooth keystroke logger at www.wirelesskeylogger.com/products.php.
![]() Software keystroke loggers sit between the operating system and the keyboard. Most of these software programs are simple, but some are more complex and can even email the logged keystrokes back to a preconfigured address. What they all have in common is that they operate in stealth mode and can grab all the text, mouse clicks, and even all the URLs that a user enters.
Software keystroke loggers sit between the operating system and the keyboard. Most of these software programs are simple, but some are more complex and can even email the logged keystrokes back to a preconfigured address. What they all have in common is that they operate in stealth mode and can grab all the text, mouse clicks, and even all the URLs that a user enters.
Emanation Security
The United States government was concerned enough about the possibility of emanations that the Department of Defense started a program to study it. Research actually began in the 1950s with the result being TEMPEST technology. The fear was that attackers might try to sniff the stray electrical signals that emanate from electronic devices. Devices that have been built to TEMPEST standards, such as cathode ray tube (CRT) monitors, have had TEMPEST-grade copper mesh, known as a Faraday cage, embedded in the case to prevent signal leakage. This costly technology is found only in very high-security environments.
TEMPEST is now considered somewhat dated; newer technologies such as white noise and control zones are now used to control emanation security. White noise uses special devices that send out a stream of frequencies that make it impossible for an attacker to distinguish the real information. Control zones are facilities, walls, floors, and ceilings designed to block electrical signals from leaving the zone. Eavesdropping on the contents of a CRT by emanation leakage is referred to as Van Eck phreaking.
Controlling Physical Access
No monitoring plan is complete without implementing controls that monitor physical access. Some common facility access controls include:
![]() Watching CCTV to monitor who enters or leaves the facility and correlating these logs with logical access and for the access control polices for systems and faculties for the company security policy.
Watching CCTV to monitor who enters or leaves the facility and correlating these logs with logical access and for the access control polices for systems and faculties for the company security policy.
![]() Installing card readers or biometric sensors on server room doors to maintain a log of who accesses the area.
Installing card readers or biometric sensors on server room doors to maintain a log of who accesses the area.
![]() Mounting alarm sensors on doors and windows to detect possible security breaches.
Mounting alarm sensors on doors and windows to detect possible security breaches.
![]() Using mantraps and gates to control traffic and log entry to secured areas. Remember that mantraps are double doors used to control the flow of employees and block unauthorized individuals.
Using mantraps and gates to control traffic and log entry to secured areas. Remember that mantraps are double doors used to control the flow of employees and block unauthorized individuals.
ExamAlert
Make sure you know the difference between audit and accountability for the exam. Audit controls are detective controls, which are utilized after the fact, and are usually implemented to detect fraud or other illegal activities. Accountability is the capability to track actions, transactions, changes, and resource usage to a specific user within the system. This is accomplished in part by having unique identification for each user, using strong authentication mechanisms and logging events.
Intrusion Detection Systems
Intrusion detection systems play a critical role in the protection of the IT infrastructure. Intrusion detection involves monitoring network traffic, detecting attempts to gain unauthorized access to a system or resource, and notifying the appropriate individuals so that counteractions can be taken. An IDS is designed to function as an access control monitor. Intrusion detection is a relativity new technology and was really born in the 1980s when James Anderson put forth the concept in a paper titled “Computer Security Threat Monitoring and Surveillance.”
An IDS can be configured to scan for attacks, track a hacker’s movements, alert an administrator to ongoing attacks, and highlight possible vulnerabilities that need to be addressed. The key to what type of activity the IDS will detect is dependent on where the intrusion sensors are placed. This requires some consideration because, after all, a sensor in the DMZ will work well at detecting misuse there but will prove useless against attackers inside the network. Even when you have determined where to place sensors, they still require specific tuning. Without specific tuning, the sensor will generate alerts for all traffic that matches some given criteria, regardless of whether the traffic is indeed something that should generate an alert. An IDS must be trained to look for suspicious activity. That is why I typically tell people that an IDS is like a 3-year-old. They require constant care and nurturing, and don’t do well if left alone.
Although the exam will examine these systems in a very basic way, modern systems are a mix of intrusion detection and intrusion prevention, so they are referred to as intrusion detection and prevention (IDP) systems. IDP systems are designed to identify potential incidents, log information, attempt to stop the event, and report the event. Many organizations even use IDP systems for activities such as identifying problems with security policies, documenting threats, and deterring malicious activity that violates security policies. NIST 800-94 is a good resource to learn more (csrc.nist.gov/publications/nistpubs/800-94/SP800-94.pdf).
A huge problem with an IDS is that it is an after-the-fact device—the attack has already taken place. Other problems with IDS are false positives and false negatives. False positives refer to when the IDS has triggered an alarm for normal traffic. For example, if you go to your local mall parking lot, you’re likely to hear some car alarms going off that are experiencing false positives. False positives are a big problem because they desensitize the administrator. False negatives are even worse. A false negative occurs when a real attack occurs but the IDS does not pick it up.
ExamAlert
A false negative is the worst type of event because it means an attack occurred, but the IDS failed to detect it.
IDS systems can be divided into two basic types: network-based intrusion detection systems (NIDS) and host-based intrusion detection systems (HIDS).
![]() Network based (NIDS)—These devices attach to the LAN and sniff for traffic that has been flagged to be anomalous.
Network based (NIDS)—These devices attach to the LAN and sniff for traffic that has been flagged to be anomalous.
![]() Host based (HIDS)—This form of IDS resides on the host device and examines only the traffic going to or coming from the host computer.
Host based (HIDS)—This form of IDS resides on the host device and examines only the traffic going to or coming from the host computer.
Network-Based Intrusion Detection Systems
Much like a protocol analyzer operating in promiscuous mode, NIDSs capture and analyze network traffic. These devices diligently inspect each packet as it passes by. When they detect suspect traffic, the action taken depends on the particular NIDS. Alarms could be triggered, sessions could be reset, or traffic could be blocked. Among their advantages are that they are unobtrusive, they have the capability to monitor the entire network, and they provide an extra layer of defense between the firewall and the host. Their disadvantages include the fact that attackers can send high volumes of traffic to attempt to overload them, they cannot decrypt or analyze encrypted traffic, and they can be vulnerable to attacks. (Sometimes attackers will send low levels of traffic to avoid tripping the IDS threshold alarms.) Tools like NMAP have this capability built-in. Things to remember about NIDS include the following:
![]() They monitor network traffic in real time.
They monitor network traffic in real time.
![]() They analyze protocols and other relevant packet information.
They analyze protocols and other relevant packet information.
![]() They integrate with a firewall and define new rules as needed.
They integrate with a firewall and define new rules as needed.
![]() When used in a switched environment, they require the user to perform port spanning.
When used in a switched environment, they require the user to perform port spanning.
![]() They send alerts or terminate an offending connection.
They send alerts or terminate an offending connection.
![]() When encryption is used, a NIDS will not be able to analyze the data traffic.
When encryption is used, a NIDS will not be able to analyze the data traffic.
Host-Based Intrusion-Detection Systems
HIDS are more closely related to a virus scanner in their function and design because they are applications that reside on the host computer. Running quietly in the background, they monitor traffic and attempt to detect suspicious activity. Suspicious activity can range from attempted system file modification to unsafe activation of ActiveX commands. Although they are effective in a fully switched environment and can analyze network-encrypted traffic, they can take a lot of maintenance, cannot monitor network traffic, and rely on the underlying operating system because they do not control core services. Things to remember about HIDS include the following:
![]() HIDS consume some of the host’s resources.
HIDS consume some of the host’s resources.
![]() HIDS analyze encrypted traffic.
HIDS analyze encrypted traffic.
![]() HIDS send alerts when unusual events are discovered.
HIDS send alerts when unusual events are discovered.
![]() HIDS are in some ways just applications running on the local host, which is subject to attack.
HIDS are in some ways just applications running on the local host, which is subject to attack.
Signature-Based, Anomaly-Based, and Rule-Based IDS Engines
Signature-based, anomaly-based, and rule-based IDS systems are the three primary types of analysis methods used by IDS systems. These types take different approaches to detecting intrusions.
Signature-based engines rely on a database of known attacks and attack patterns. This system examines data to check for malicious content, which could include fragmented IP packets, streams of SYN packets (DoS), or malformed Internet Control Message Protocol (ICMP) packets. Anytime data is found that matches one of these known signatures, it can be flagged to initiate further action. This might include an alarm, an alert, or a change to the firewall configuration. Although signature-based systems work well, their shortcoming is due to the fact that they are only as effective as their most current update. Anytime there is a new or varied attack, the IDS will be unaware of it and will ignore the traffic. The two subcategories of signature-based systems are:
![]() Pattern-based—Looks at specific signatures that packets are compared to. Snort started as a pattern-matching IDS.
Pattern-based—Looks at specific signatures that packets are compared to. Snort started as a pattern-matching IDS.
![]() State-based—A more advanced design that has the capability to track the state of the traffic and data as it moves between host and target.
State-based—A more advanced design that has the capability to track the state of the traffic and data as it moves between host and target.
An anomaly-based IDS observes traffic and develops a baseline of normal operations. Intrusions are detected by identifying activity outside the normal range of activities. As an example, if Mike typically tries to log on only between the hours of 8 a.m. to 5 p.m., and now he’s trying to log on 5,000 times at 2 a.m., the IDS can trigger an alert that something is wrong. The big disadvantage of a behavior-based IDS system is that an activity taught over time is not seen as an attack, but merely as normal behavior. These systems also tend to have a high number of false positives. The three subcategories of anomaly-based systems are:
![]() Statistical-based—Compares normal to abnormal activity.
Statistical-based—Compares normal to abnormal activity.
![]() Traffic-based or Signature-based—Triggers on abnormal packets and data traffic or by comparing to a database of well known attack signatures.
Traffic-based or Signature-based—Triggers on abnormal packets and data traffic or by comparing to a database of well known attack signatures.
![]() Protocol-based—Possesses the capability to reassemble packets and look at higher layer activity. If the IDS knows the normal activity of the protocol according to the RFC, it can pick out abnormal activity. Protocol-decoding intrusion detection requires the IDS to maintain state information. As an example, DNS is a two-step process; therefore, if a protocol-matching IDS sees a number of DNS responses that occur without a DNS request having ever taken place, the system can flag that activity as cache poisoning.
Protocol-based—Possesses the capability to reassemble packets and look at higher layer activity. If the IDS knows the normal activity of the protocol according to the RFC, it can pick out abnormal activity. Protocol-decoding intrusion detection requires the IDS to maintain state information. As an example, DNS is a two-step process; therefore, if a protocol-matching IDS sees a number of DNS responses that occur without a DNS request having ever taken place, the system can flag that activity as cache poisoning.
A rule-based (also called behavior-based) IDS involves rules and pattern descriptors that observe traffic and develop a baseline of normal operations. Intrusions are detected by identifying activity outside the normal range. This expert system follows a four-phase analysis process:
1. Preprocessing
2. Analysis
3. Response
4. Refinement
All IDS systems share some basic components:
![]() Sensors—Detect and send data to the system.
Sensors—Detect and send data to the system.
![]() Central monitoring system—Processes and analyzes data sent from sensors.
Central monitoring system—Processes and analyzes data sent from sensors.
![]() Report analysis—Offers information about how to counteract a specific event.
Report analysis—Offers information about how to counteract a specific event.
![]() Database and storage components—Perform trend analysis and store the IP address and information about the attacker.
Database and storage components—Perform trend analysis and store the IP address and information about the attacker.
![]() Response box—Inputs information from the previously listed components and forms an appropriate response.
Response box—Inputs information from the previously listed components and forms an appropriate response.
ExamAlert
Carefully read any questions that discuss IDS. Remember that several variables can change the outcome or potential answer. Take the time to underline such words as network, host, signature, and behavior to help clarify the question.
Sensor Placement
Your organization’s security policy should detail the placement of your IDS system and sensors. The placement of IDS sensors requires some consideration. IDS sensors can be placed externally, in the DMZ, or inside the network. A sensor in any of these locations will require specific tuning. Without it, the sensor will generate alerts for all traffic that matches a given criterion, regardless of whether the traffic is indeed something that should generate an alert.
ExamAlert
Although an anomaly-based IDS can detect new attacks, signature-based and rule-based IDS cannot.
Intrusion Prevention Systems
Intrusion prevention systems (IPSs) build on the foundation of IDS and attempt to take the technology a step further. IPSs can react automatically and actually prevent a security event from happening, preferably without user intervention. IPS is considered the next generation of IDS and can block attacks in real time. The National Institute of Standards and Technology (NIST) now uses the term IDP (intrusion detection and prevention) to define modern devices that maintain the functionality of both IDS and IPS devices. These devices typically perform deep inspection and can be applied to devices that support OSI Layer 3 to OSI Layer 7 inspection.
Responding to Operational Security Incidents
There can be many different types of incidents, from unauthorized disclosure, to theft of property, to outage by DoS, to the detection of an intrusion. What all of these activities have in common is that they should be driven by a preexisting procedure and policy. You will need to have created a team to deal with the investigation. The team will need to understand how to properly handle the crime scene. As an example, does the team understand how to protect evidence and maintain it in the proper chain of custody? You will also need to have established specific roles and responsibilities within the team, including a team lead to be in charge of the response to any incident.
You must establish contacts within the organization. As an example, if an employee is discovered to have been hacking, the supervisor may want to fire the employee, but must first discuss the issue with Human Resources and the legal department. Even when an incident has been contained and is in the recovery phase you will need to think about what lessons can be learned and how you will report and document your findings. What all this points to is a specific incident response policy.
Incident Response
The most important thing to understand when it come to incident response is that every company needs to have a plan before something unfortunate occurs. This methodology is shown here:
![]() Preparation—Create an incident response team to address incidents.
Preparation—Create an incident response team to address incidents.
![]() Identification—Determine what has occurred.
Identification—Determine what has occurred.
![]() Mitigation and containment—Halt the effect of the incident and prevent it from spreading further.
Mitigation and containment—Halt the effect of the incident and prevent it from spreading further.
![]() Investigation—Determine what the problem is and who is responsible.
Investigation—Determine what the problem is and who is responsible.
![]() Eradication—Eliminate the problem.
Eradication—Eliminate the problem.
![]() Recovery—Clean up any residual effects.
Recovery—Clean up any residual effects.
![]() Follow-up and resolution—Improve security measures to prevent or reduce the impact of future occurrences.
Follow-up and resolution—Improve security measures to prevent or reduce the impact of future occurrences.
Both incident response and forensics are very similar, except that incident response is more focused on finding the problem and returning to normal activities, whereas forensics is more focused on the legal aspects and potentially prosecuting the accused. Also, only some companies can justify forensic investigation due to the potential cost. Both incident response and forensics are discussed in detail in Chapter 9. Outsourcing forensic investigation is quite common.
The Disaster Recovery Life Cycle
Closely related to incident response is disaster recovery. Disaster recovery’s purpose is to get a damaged organization restarted so that critical business functions can resume. When a disaster occurs, the process of progressing from the disaster back to normal operations includes:
![]() Crisis management
Crisis management
![]() Recovery
Recovery
![]() Reconstitution
Reconstitution
![]() Resumption
Resumption
When disasters occur, the organization must be ready to respond. Federal and state government entities typically use a Continuity of Operations (COOP) site. The COOP is designed to take on operational capabilities when the primary site is not functioning. The length of time that the COOP site is active, and the criteria in which the COOP site is enabled, depend upon the business continuity and disaster recovery plans. Both governmental and non-governmental entities typically make use of a checklist to manage continuity of operations. Table 10.4 shows a sample disaster recovery checklist.

ExamAlert
The disaster recovery manager should direct short-term recovery actions immediately following a disaster.
Individuals responsible for emergency management will need to assess damage and perform triage. Areas impacted the most will need attention first. Protection of life is a priority while working to mitigate damage. Recovery from a disaster will entail sending personnel to the recovery site. When employees and materials are at the recovery site, interim functions can resume operations. This might entail installing software and hardware. Backups might need to be loaded and systems might require configuration.
Each step might not occur in series. As an example, while the recovery process is taking place, teams will also be dispatched to the disaster site to start the cleanup, salvage, and repair process. When those processes are complete, normal operations can resume.
When operations are moved from the alternate operations site back to the restored site, the efficiency of the restored site must be tested. In other words, processes should be sequentially returned, from least critical to most critical. In the event that a few glitches need to be worked out in the restored facility, you can be confident that your most critical processes are still in full operation at the alternate site.
Flat Tires Are a Fact of Life
![]() Crisis management—On realizing I had a flat, I pulled safely off the freeway.
Crisis management—On realizing I had a flat, I pulled safely off the freeway.
![]() Recovery—Working quickly, I jacked up the car and replaced the flat tire with the emergency spare that GM generously provides.
Recovery—Working quickly, I jacked up the car and replaced the flat tire with the emergency spare that GM generously provides.
![]() Reconstitution—Back on the freeway, I was able to limp along with my 50-miles-per-hour-rated spare until I could reach a tire repair shop.
Reconstitution—Back on the freeway, I was able to limp along with my 50-miles-per-hour-rated spare until I could reach a tire repair shop.
![]() Resumption—As expected, the technician confirmed that the tire could not be fixed. But for only $149 plus a few fees, he could get me back on the road. I headed home with the new tire on the car and my wallet a little emptier.
Resumption—As expected, the technician confirmed that the tire could not be fixed. But for only $149 plus a few fees, he could get me back on the road. I headed home with the new tire on the car and my wallet a little emptier.
Teams and Responsibilities
Individuals involved in disaster recovery must deal with many things; when called to action, their activities center on emergency response, assessing the damage, recovery operations, and restoration. Figure 10.5 illustrates an example of disaster recovery activities.

The salvage team is responsible for the reconstruction of damaged facilities. This includes cleanup, recovery of assets, creation of documentation for filing insurance or legal actions, and restoration of paper documents and electronic media. The recovery team has the necessary authority and responsibility to get the alternate site up and running. This site will be used as a stand-in for the original site until full operations can be restored. Although the CISSP exam will not require an in-depth understanding of all the teams and their responsibilities in a real disaster, a few additional teams and their roles are as follows:
![]() Emergency response team—The first responders for the organization. They are tasked with evacuating personnel and saving lives.
Emergency response team—The first responders for the organization. They are tasked with evacuating personnel and saving lives.
![]() Emergency management team—Executives and line managers that are financially and legally responsible. They must also handle the media and public relations.
Emergency management team—Executives and line managers that are financially and legally responsible. They must also handle the media and public relations.
![]() Damage assessment team—These individuals are the estimators. They must determine the damage and estimate the recovery time.
Damage assessment team—These individuals are the estimators. They must determine the damage and estimate the recovery time.
![]() Communications team—Responsible for installing communications (data, voice, phone, fax, radio, video) at the recovery site.
Communications team—Responsible for installing communications (data, voice, phone, fax, radio, video) at the recovery site.
![]() Security team—Manages the security of the organization during the time of crisis. They must maintain order after a disaster.
Security team—Manages the security of the organization during the time of crisis. They must maintain order after a disaster.
![]() Emergency operations team—These individuals reside at the alternative site and manage systems operations. They are primarily operators and supervisors that are familiar with system operations.
Emergency operations team—These individuals reside at the alternative site and manage systems operations. They are primarily operators and supervisors that are familiar with system operations.
![]() Incident response team—This team responds to incidents and acts as a central clearinghouse for information.
Incident response team—This team responds to incidents and acts as a central clearinghouse for information.
![]() Transportation team—This team is responsible for notifying employees that a disaster has occurred, and is also in charge of providing transportation, scheduling, and lodging for those needed at the alternate site.
Transportation team—This team is responsible for notifying employees that a disaster has occurred, and is also in charge of providing transportation, scheduling, and lodging for those needed at the alternate site.
![]() Coordination team—This team is tasked with managing operations at different remote sites and coordinating the recovery efforts.
Coordination team—This team is tasked with managing operations at different remote sites and coordinating the recovery efforts.
![]() Finance team—Provides budget control for recovery and provides accurate accounting of costs.
Finance team—Provides budget control for recovery and provides accurate accounting of costs.
![]() Administrative support team—Provides administrative support and might also handle payroll functions and accounting.
Administrative support team—Provides administrative support and might also handle payroll functions and accounting.
![]() Supplies team—Coordinates with key vendors to maintain needed supplies.
Supplies team—Coordinates with key vendors to maintain needed supplies.
Caution
Physical security is always of great importance after a disaster. Precautions such as guards, temporary fencing, and barriers should be deployed to prevent looting and vandalism.
Exam Prep Questions
1. You have been given an attachment that was sent to the head of payroll and was flagged as malicious. You have been asked to examine the malware. You have decided to execute the malware inside a virtual environment. What is the best description of this environment?
![]() A. Honeypot
A. Honeypot
![]() B. Hyperjacking
B. Hyperjacking
![]() C. Sandbox
C. Sandbox
![]() D. Decompiler
D. Decompiler
2. Which of the following is not a security or operational reason to use mandatory vacations?
![]() A. It allows the organization the opportunity to audit employee work.
A. It allows the organization the opportunity to audit employee work.
![]() B. It ensures that the employee is well rested.
B. It ensures that the employee is well rested.
![]() C. It keeps one person from easily being able to carry out covert activities.
C. It keeps one person from easily being able to carry out covert activities.
![]() D. It ensures that employees will know that illicit activities could be uncovered.
D. It ensures that employees will know that illicit activities could be uncovered.
3. What type of control is an audit trail?
![]() A. Application
A. Application
![]() B. Administrative
B. Administrative
![]() C. Preventative
C. Preventative
![]() D. Detective
D. Detective
4. Which of the following is not a benefit of RAID?
![]() A. Capacity benefits
A. Capacity benefits
![]() B. Increased recovery time
B. Increased recovery time
![]() C. Performance improvements
C. Performance improvements
![]() D. Fault tolerance
D. Fault tolerance
5. Separation of duties is related to which of the following?
![]() A. Dual controls
A. Dual controls
![]() B. Principle of least privilege
B. Principle of least privilege
![]() C. Job rotation
C. Job rotation
![]() D. Principle of privilege
D. Principle of privilege
6. Phreakers target which of the following resources?
![]() A. Mainframes
A. Mainframes
![]() B. Networks
B. Networks
![]() C. PBX systems
C. PBX systems
![]() D. Wireless networks
D. Wireless networks
7. You recently emailed a colleague you worked with years ago. You noticed that the email you sent him was rejected and you have been asked to resend it. What has happened with the message transfer agent?
![]() A. Whitelist.
A. Whitelist.
![]() B. Graylist.
B. Graylist.
![]() C. Blacklist
C. Blacklist
![]() D. Black hole
D. Black hole
8. Your organization has experienced a huge disruption. In this type of situation which of the following is designed to take on operational capabilities when the primary site is not functioning?
![]() A. BCP
A. BCP
![]() B. Audit
B. Audit
![]() C. Incident response
C. Incident response
![]() D. COOP
D. COOP
9. Which RAID type provides data striping but no redundancy?
![]() A. RAID 0
A. RAID 0
![]() B. RAID 1
B. RAID 1
![]() C. RAID 3
C. RAID 3
![]() D. RAID 4
D. RAID 4
10. Which of the following is the fastest backup option but takes the longest to restore?
![]() A. Incremental
A. Incremental
![]() B. Differential
B. Differential
![]() C. Full
C. Full
![]() D. Grandfathered
D. Grandfathered
11. Which of the following types of intrusion detection systems could be best described as one that compares normal to abnormal activity?
![]() A. Pattern-based.
A. Pattern-based.
![]() B. Statistical-based.
B. Statistical-based.
![]() C. Traffic-based.
C. Traffic-based.
![]() D. Protocol-based.
D. Protocol-based.
12. Which of the following processes involves overwriting the data with zeros?
![]() A. Formatting
A. Formatting
![]() B. Drive-wiping
B. Drive-wiping
![]() C. Zeroization
C. Zeroization
![]() D. Degaussing
D. Degaussing
13. What type of RAID provides a stripe of mirrors?
![]() A. RAID 1
A. RAID 1
![]() B. RAID 5
B. RAID 5
![]() C. RAID 10
C. RAID 10
![]() D. RAID 15
D. RAID 15
14. Which of the following is the name of a multidisk technique that offers no advantage in speed and does not mirror, although it does allow drives of various sizes to be used and can be used on two or more drives?
![]() A. RAID 0
A. RAID 0
![]() B. RAID 1
B. RAID 1
![]() C. RAID 5
C. RAID 5
![]() D. JBOD
D. JBOD
15. You have been assigned to a secret project that requires a massive amount of processing power. Which of the following techniques is best suited for your needs?
![]() A. Redundant servers
A. Redundant servers
![]() B. Clustering
B. Clustering
![]() C. Distributed computing
C. Distributed computing
![]() D. Cloud computing
D. Cloud computing
Answers to Exam Prep Questions
1. C. A virtual environment where you can safely execute suspected malware is called a sandbox. Answer A is incorrect because a honeypot is a fake vulnerable system deployed to be attacked. Answer B is incorrect because hyperjacking is a type of attack against a virtual system. Answer D is incorrect because a decompiler is used to disassemble an application.
2. B. Mandatory vacations are not primarily for employee benefit, but to better secure the organization’s assets. Answers A, C, and D are incorrect. As answer A states, this gives the organization the opportunity to audit employee work. In answer C, it keeps one person from easily being able to carry out covert activities. In answer D, it ensures that employees will know that illicit activities could be uncovered. Each is a valid reason to use mandatory vacations.
3. D. Audit trails are considered a detective type of control. Answers A, B, and C are incorrect because audit trails are not an application, administrative, or preventive control.
4. B. RAID provides capacity benefits, performance improvements, and fault tolerance; therefore, answers A, C, and D are incorrect. Although RAID might reduce recovery time, it certainly won’t increase it.
5. B. Separation of duties is closely tied to the principle of least privilege. Separation of duties is the process of dividing duties so that more than one person is required to complete a task, and each person has only the minimum resources needed to complete the task. Answer A is incorrect because dual controls are implemented to require more than one person to complete an important task. Answer C is incorrect because job rotation is used to prevent collusion. Answer D is incorrect because the principle of privilege would be the opposite of what is required.
6. C. Phreakers target phone and voice systems (PBX). Answer A is incorrect because mainframes are typically not a target of phreakers. Answer B is incorrect because networks might be a target of hackers, but phreakers target phone systems. Answer D is incorrect because wireless networks are targeted by war drivers or hackers, not phreakers.
7. B. When graylisting is implemented it will reject any email sender that is unknown. Mail from a legitimate email server will be retransmitted after a period of time. This moves the graylisted email off the hold list and on to the whitelist and at that time places the email in the inbox of the receiving account. Whitelisting only approves what is on an allowed list whereas blacklisting blocks specific items. Black holes silently discard or drop traffic without informing the source.
8. D. COOP is designed to take on operational capabilities when the primary site is not functioning. Business continuity plans generally focus on the continuation of business services in the event of any type of interruptions. Therefore, answers A, B, and C are incorrect.
9. A. RAID 0 provides data striping but no redundancy. Answers B, C, and D are incorrect because RAID 1 provides disk mirroring, RAID 3 provides byte-level striping with a dedicated parity disk, and RAID 4 is considered a dedicated parity drive.
10. A. Incremental backup is the fastest backup option, but takes the longest to restore. Answers B, C, and D are incorrect: A grandfathered backup is not a valid answer, a differential backup takes less time overall but longer to restore, and a full backup takes the longest to perform, though it’s the fastest to restore.
11. B. Statistical-based IDS compares normal to abnormal activity. Pattern-, traffic-, and protocol-based IDS do not; therefore, answers A, C, and D are incorrect.
12. C. Zeroization overwrites the data with all zeros. Answer A is incorrect because formatting does not remove any data on the file allocation table (FAT). Answer B is incorrect because drive-wiping writes patterns of ones and zeros. Answer D is incorrect because degaussing works by means of a magnetic field.
13. C. RAID 10 provides a stripe of mirrors. RAID 1 offers only striping. RAID 5 is seen as a combination of good, cheap, and fast because it provides data striping at the byte level, good performance, and good fault tolerance. RAID 15 is the combination of RAID 1 and RAID 5.
14. D. JBOD can use existing hard drives of various sizes. These are combined together into one massive logical disk. There is no fault tolerance and no increase in speed. The only benefit of JBOD is that you can use existing disks and if one drive fails, you lose the data on only that drive. Answers A, B, and C are incorrect because RAID 0, 1, and 5 do not match the description provided.
15. B. Clustering is a means of grouping computers and moving to a greater level of usability. Answer A is incorrect because a redundant server waits until it’s needed before being used. Answer C is incorrect because distributed computing is not centrally controlled and, as such, should not be used for sensitive or classified work. Answer D is incorrect because placing sensitive information in the cloud could be a real security concern.
Need to Know More?
Snort IDS: www.it.uu.se/edu/course/homepage/sakdat/ht05/assignments/pm/programme/Introduction_to_snort.pdf
Understanding TCSEC: www.fas.org/irp/nsa/rainbow/tg022.htm
The Open Source Security Testing Methodology Manual: to www.isecom.org/
Employee fraud controls: www.cricpa.com/CRI_Anti-Fraud%20Controls.pdf
Remote access best practices: technet.microsoft.com/en-us/library/cc780755.aspx
Clustering: arxiv.org/abs/cs/0004014
Antivirus techniques: searchsecurity.techtarget.com/tip/How-antivirus-software-works-Virus-detection-techniques
Keystroke-monitoring ethics and laws: www.privacyrights.org/fs/fs7-work.htm
Historical keystroke-monitoring recommendations: csrc.nist.gov/publications/nistbul/csl93-03.txt
Cloud computing security issues: www.infoworld.com/article/2613560/cloud-security/cloud-security-9-top-threats-to-cloud-computing-security.html