
This chapter describes IP addressing and routing protocols, and includes the following sections:
This chapter discusses Internet Protocol (IP) version 4 (IPv4) addressing design and routing protocol selection. After introducing why these topics are important, the address design considerations are explored. The factors that differentiate the available IPv4 routing protocols are described, followed by a discussion of the specific protocols. The considerations for choosing the routing protocol (or protocols) for your network complete this chapter.
Note
In this book, the term IP refers to IPv4. IP version 6 (IPv6), a successor to IPv4 not yet in common use, is introduced in Chapter 10, “Other Enabling Technologies.”
Note
Appendix B, “Network Fundamentals,” includes material that we assume you understand before reading the rest of the book. Thus, you are encouraged to review any of the material in Appendix B that you are not familiar with before reading the rest of this chapter.
Each chapter in the technologies section of this book discusses not only what you need to know but also why you need to know it. For IP addressing and routing, consider the following items:
The importance of IP—. IP is used throughout the public Internet and on most organizations’networks, and is therefore the most important routed protocol to the majority of businesses today. IP is not limited to sending traditional data such as files and e-mails—it forms the basis for many other technologies and solutions, as described in later chapters in this book. For example, IP telephony uses an IP network for voice traffic, eliminating many of the costs associated with long-distance calls and at the same time introducing other capabilities to your telephone network. (IP telephony is described in Chapter 7, “Voice Transport Design.”)
Toronto’s Pearson International Airport’s new terminal is a further example of how IP is being used as the foundation for an intelligent system. At this terminal, a variety of communications systems and applications were put onto a single, secure, IP-based network. For example, when a gate at the airport is used by one airline, the system provides access to that airline’s applications for check-in, baggage tracking, and so forth, and the IP phones provide that airline’s telephone service. When another airline uses the same gate later in the day, the configuration changes so that the new airline’s applications and telephone service can be accessed instead.[1] Cisco calls this a common-use network— a single communications infrastructure shared by all tenants of the terminal.[2]
The importance of proper IP addressing—. Correct IP addressing is crucial to making an IP network work, and if done properly, addresses can be summarized. Summarization ensures that the routing tables are smaller and therefore use less router memory, that the routing updates are smaller and use less network bandwidth, and that network problems can be localized (changes are sent to fewer routers). All of these benefits can result in a more stable network that adjusts faster to changes.
The importance of proper routing protocol selection—. Routers learn about paths to destinations from other routers by using a routing protocol. Many IP routing protocols are available to choose from, each with its own advantages and disadvantages. The key is to understand the requirements for your network, understand how the routing protocols work, and match the network requirements to the routing protocol specifications. In some cases, it might be appropriate to run multiple routing protocols. Understanding how they will interact and how to avoid problems in a mixed routing protocol environment is important to the successful operation of your network.
This section discusses IP addressing design. First, we examine how to determine how many IP addresses are needed in a network. We next discuss the use of private addresses. If private addresses are used in a network that also requires Internet connectivity, Network Address Translation (NAT) is also needed, so the various features of NAT are described. This is followed by a discussion of how routers use IP subnet masks. We next show you how to determine the subnet mask to use within a network. Assigning IP addresses in a hierarchical way allows them to be summarized, which has many benefits. These benefits are examined, and route summarization calculations are illustrated. The use of variable-length subnet masks (VLSMs) can help you to use your available IP address space more efficiently—an explanation of VLSMs concludes this section.
Note
Appendix B, “Network Fundamentals,” includes an introduction to IP addresses.
To determine how many IP addresses are required in your network, you should consider[3] the many different locations in your network that need addresses, including headquarters, branch and regional offices, telecommuters, and so forth. The number of devices in each location must be counted, including the network devices such as routers, switches, and firewalls; workstations; IP phones; network management stations; servers; and so forth. For each of these devices, determine how many interfaces need to be addressed and whether private or public addresses will be used.
A reserve for future growth should be added to the total number of addresses required. A 10 to 20 percent reserve is typically sufficient, but the reserve should be based on your knowledge of the organization. If you do not reserve enough space for future growth, you might have to reconfigure some of your routers (for example, to add new subnets or networks into route summarization calculations); in the worst case, you might have to re-address your entire network.
Recall that Requests For Comments (RFC) 1918, “Address Allocation for Private Internets,” defines the private IPv4 addresses as follows:
10.0.0.0 to 10.255.255.255
172.16.0.0 to 172.31.255.255
192.168.0.0 to 192.168.255.255
Note
RFC 3330, “Special-Use IPv4 Addresses,” describes IPv4 address blocks that have been assigned by the Internet Assigned Numbers Authority (IANA) for specialized purposes, and includes reference to the private addresses defined in RFC 1918.
The remaining Class A, B, and C addresses are public addresses. Private addresses are for use only within a company’s network; public addresses must be used when communicating on the public Internet. Internal private addresses must be translated to public addresses when data is sent out to the Internet, and these public addresses must be translated back to the private addresses when packets come in from the Internet.
Because only a finite number of public addresses are available, they are becoming scarce. Using private addresses internally on your network means that you will require fewer public addresses. However, public addresses are required for the Internet connections and for servers that must be accessible from the Internet—for example, File Transfer Protocol (FTP) servers that contain publicly accessible data, and web servers. Other devices internal to the network can use private addresses—they can connect to the Internet through a NAT device.
RFC 1631, “The IP Network Address Translator,” defines NAT. NAT can be provided by a variety of devices, including routers and firewalls.
Key Point
To configure NAT, you first define inside and outside interfaces on the NAT device. The inside interface connects to the internal network, while the outside interface connects to the Internet. You also define the addresses that are to be translated on each side.
For example, in the network in Figure 3-1, a person at PC 172.16.1.1 wants to access data on the FTP server at 192.168.7.2. A NAT device (in this case, a router) translates addresses on the inside network 172.16.0.0 to addresses on the outside network 10.1.0.0.

Note
Recall that the IP addresses shown in the examples in this book are private addresses. In practice, public addresses would be used on the Internet.
A NAT device has a NAT table, created either dynamically or with static entries configured by the network administrator. In Figure 3-1, the simple NAT table in the NAT router includes the following:
When a packet is sent from 172.16.1.1 to 192.168.7.2 (at 1 in Figure 3-1), it goes to the NAT router, which translates the source address (SA) 172.16.1.1 to 10.1.1.1 (at 2 in the figure). The packet then goes through the Internet and arrives at its destination, the FTP server. The server replies to 10.1.1.1 (at 3 in the figure). When the NAT router receives this packet, the router looks in its NAT table and translates the destination address (DA) from 10.1.1.1 to 172.16.1.1 (at 4 in the figure). The packet is then sent to its destination, the PC.
More complex translations might be necessary, for example, if some addresses in the inside network overlap addresses in the outside network. In this case, the NAT table would be expanded to include the following:
Outside global IP address—. The address that represents an outside host on the outside network
Outside local IP address—. The address that represents an outside host on the inside network
The example in Figure 3-1 shows a one-to-one translation from inside to outside addresses. NAT can also support address overloading, in which many inside addresses are translated into one outside address. In this case, the Transmission Control Protocol (TCP) and User Datagram Protocol (UDP) port numbers distinguish between the connections; the TCP and UDP port numbers are added to the NAT translation table.
When you configure the IP address of a router’s interface, you include the address and the subnet mask. The router uses this information not only to address the interface but also to determine the address of the subnet to which the interface is connected. The router then puts this subnet address in its routing table, as a connected network on that interface.
Key Point
To determine the network or subnet address to which a router is connected, the router performs a logical AND of the interface address and the subnet mask. Logically “ANDing” a binary 1 with any number yields that number; logically “ANDing” a binary 0 with any number yields 0.
Because subnet mask bits set to binary 0 indicate that the corresponding bits in the IP address are host bits, the result of this AND operation is that the host portion of the address is removed (zeroed out), and the subnet address (also called the subnet number) remains.
Table 3-1 illustrates an example of logically ANDing an IP address and subnet mask. The router puts the remaining subnet address in its routing table as the subnet to which the interface is connected.
Table 3-1. Example Calculation of Subnet Address
Network | Subnet | Subnet | Host | |
|---|---|---|---|---|
Interface IP Address 10.5.23.19 | 00001010 | 00000101 | 00010111 | 00010011 |
Subnet Mask 255.255.255.0 | 11111111 | 11111111 | 11111111 | 00000000 |
Subnet Address 10.5.23.0 | 00001010 | 00000101 | 00010111 | 00000000 |
When a packet arrives at the router, the router analyzes the destination address of the packet to determine which network or subnet it is on. The router looks up this network or subnet in its routing table to determine the interface through which it can best be reached; the packet is then sent out of the appropriate router interface. [If the router does not have a route to the destination subnet, the packet is rejected and an Internet Control Message Protocol (ICMP) error message is sent to the source of the packet.]
When addressing your network, you must determine the subnet mask to use. Because the subnet mask represents the number of bits of network, subnet, and host available for addressing, the subnet mask selected depends on the number of subnets required and the number of host addresses required on each of these subnets.
For example, consider the network shown in Figure 3-2. A total of 12 subnets exist in this network; each has a maximum of 10 device addresses. Some of the addresses are for router interfaces and some are for hosts (not shown in the figure); each device on each subnet needs to have its own IP address. You decide to use the private Class C network 192.168.3.0 to address this network.
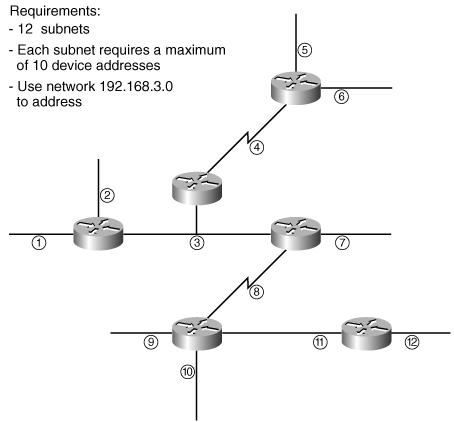
In a Class C address, only the last octet contains host bits, and therefore this is the only octet from which bits can be borrowed for subnets.
Key Point
Because IP addresses are binary, they are used in blocks of powers of 2 (2, 4, 8, and so on).
To determine the size of the block needed for the subnets, round the number of subnets required up to the next higher power of 2 (if it is not already a power of 2).
To determine the size of the block needed for the hosts, add 2—one for the subnet address (also referred to as the wire address) and one for the broadcast address—to the maximum number of hosts required per subnet, and round this number up to the next higher power of 2 (again, if it is not already a power of 2).
In the example in Figure 3-2, 12 subnets are needed; rounding up to the next power of 2 gives 16. Because 24 = 16, 4 bits are needed for the subnets. A maximum of 10 device addresses per subnet are needed; adding 2 and rounding up to the next power of 2 gives 16. Because 24 = 16, 4 bits are needed for the hosts. The subnet mask to use is therefore 255.255.255.240.
To determine the available subnet addresses, first write the network address in binary. Then, keeping the network bits as they are, use all combinations of the subnet bits. Remember that all the host bits are 0 in the subnet address, so leave the host bits set to 0. Finally, convert the binary number back to decimal. Figure 3-3 illustrates this process. (Note that any octets not changed in this process are left as decimal numbers, to save converting them twice.)

Thus, the first subnet address that can be used with a mask of 255.255.255.240 is 192.168.3.0; this can also be written as 192.168.3.0/28. The second subnet is 192.168.3.16/28, and so on.
To determine the device addresses on each subnet, first write the subnet address in binary. Next, keeping the network and subnet bits as they are, use all the combinations of the host bits. Remember that the address in which all host bits are 0 is the subnet address, and the address in which all host bits are 1 is the broadcast address. Finally, convert the binary number back to decimal. Figure 3-4 illustrates this process for the third subnet, 192.168.3.32/28. (Again, note that any octets not changed in this process are left as decimal numbers, to save converting them twice.)

Thus, the first device address on this subnet is 192.168.3.33/28, the second device address is 192.168.3.34/28, and so on. The last host address is 192.168.3.46/28. The broadcast address is 192.168.3.47/28. For example, the network marked as “3” in Figure 3-2 could be assigned the 192.168.3.32/28 subnet. The interfaces of the three routers on that subnet could be assigned addresses 192.168.3.33/28, 192.168.3.34/28, and 192.168.3.35/28.
A hierarchical IP address design means that addresses are assigned in a hierarchical manner, rather than randomly. The telephone network provides a good analogy. This network is divided into countries, which in turn are divided into areas and local exchanges. Phone numbers are assigned based on location. For example, in North America, 10-digit phone numbers represent a 3-digit area code, a 3-digit central office code, and a 4-digit line number. So if you are in Europe and you want to call someone in Canada, you dial his country code followed by his area code, central office, and line number. The telephone network switches in Europe recognize the country code and send the call to Canada; they don’t have to worry about the details of the phone number. The switches in Canada send the call to the appropriate area code, to the central office, and finally to the correct line.
This hierarchical structure allows the telephone switches to keep less detailed information about the network. For example, a central office (CO) switch only needs to know how to get to the numbers served by its equipment, and how to get to other COs and other area codes, but it doesn’t need to know how to get to the specific numbers in other COs. For example, 416 is the area code for downtown Toronto. Switches outside of Toronto only need to know how to get to 416; they don’t need to know how to get to each number in Toronto. Area code 416 can be considered to be a summary of Toronto.
An IP network can use a similar hierarchical structure to get comparable benefits. When routers only have summary routes instead of unnecessary details, their routing tables are smaller. Not only does this save memory in the routers, but it also means that routing updates are smaller and therefore use less bandwidth on the network. Hierarchical addressing can also result in a more efficient allocation of addresses. With some routing protocols (known as classful routing protocols), addresses can be wasted if they are assigned randomly (as explained further in the “Classifying Routing Protocols” section, later in this chapter.)
To illustrate, consider the network shown in Figure 3-5. Subnet addresses were assigned sequentially as the subnets were created, regardless of architecture, resulting in a random pattern. Consequently, when Router A sends its routing table to the other routers, it has no choice but to send all its routes.

Contrast this to the network in Figure 3-6, in which subnets were assigned in a hierarchical manner. Notice, for example, that all the subnets under Router A start with 10.1, while all under Router B start with 10.2. Therefore, the routers can summarize the subnets. When they communicate to other routers, they don’t send all the detailed routes; they just send the summary route. Not only does this save bandwidth on the network (because smaller updates are sent), but it also means that the routing tables in the core are smaller, which eases processing requirements. It also means that small local problems don’t need to be communicated network-wide. For example, if network 10.1.1.0 under Router A goes down, the summary route 10.1.0.0/16 does not change, so the routers in the core and other areas are not told about it. They do not need to process the route change, and the update does not use bandwidth on the network. (If traffic is routed to a device on that network that is down, Router A will respond with an error message, so the network can continue to function normally.)

The summary routes shown in Figure 3-6 are obvious—all the subnets under Router A start with 10.1 and thus the summary route is 10.1.0.0/16. It isn’t always this easy.
For example, consider a network in which Router A has the following subnet routes in its routing table: 192.168.3.64/28, 192.168.3.80/28, 192.168.3.96/28, and 192.168.3.112/28. Router B in the same network has the following subnet routes in its routing table: 192.168.3.0/28, 192.168.3.16/28, 192.168.3.32/28, and 192.168.3.48/28. What is the summary route for Router A’s subnets? While you might be tempted to use 192.168.3.0/24 because they all have the first three octets in common, this won’t work. If both Routers A and B reported the same 192.168.3.0/24 summary route, traffic would not necessarily go to the correct router, resulting in a nonfunctioning network. Instead, you have to determine the summary routes on nonoctet boundaries. Figure 3-7 illustrates how this is done.

To calculate the summary route, first write the subnet addresses in binary. Then, determine which network and subnet bits the addresses have in common—it can be helpful to draw a line at the end of the common bits. (Notice that the network portions of the addresses are all common, because they are all subnets of the same network.) In this case, the addresses have the first two subnet bits in common. The addresses should also encompass all combinations of the remaining subnet bits so that the summary route covers only these subnets; in this example, the addresses do cover all combinations of the remaining two subnet bits. Thus, if an address matches the network bits and the first two subnet bits of these addresses, it is on one of these four subnets. The summary route is written as the first address in the list with a prefix equal to the total number of common bits. In this example, the summary is 192.168.3.64/26. Similarly, the summary route for Router B is 192.168.3.0/26.
Consider the network in the upper portion of Figure 3-8. All the subnets are configured with a /24 mask, meaning that up to 28 - 2 = 254 hosts can be addressed. This can be useful on the LAN links. However, only two addresses will ever be required on each of the point-to-point serial WAN connections between the two routers, one for each of the routers. Therefore, the other 252 addresses available on each of these WAN subnets are wasted.

Figure 3-8. Using the Same Mask on LAN and WAN Links Can Waste Addresses; Using Different Masks Can Be a More Efficient Use of the Available Addresses
Key Point
A major network is a Class A, B, or C network.
A fixed-length subnet mask (FLSM) is when all subnet masks in a major network must be the same size.
A VLSM is when subnet masks within a major network can be different sizes.
The routing protocol in use in the network influences whether VLSMs can be used—we discuss why in the “Classifying Routing Protocols” section, later in this chapter. If a routing protocol supports VLSMs, IP addresses can be allocated more efficiently. For example, in the network shown in the lower portion of Figure 3-8, the LAN subnets use a /24 mask, while the WAN subnets use a more appropriate /30 mask. With a /30 mask, only 2 host bits exist, and therefore 22 - 2 = 2 host addresses are available. This is the exact number of addresses required, one for each of the routers.
Using VLSMs also means that the addressing plan can have more levels of hierarchy, resulting in routes that can be summarized easily. This in turn results in smaller routing tables and more efficient updates.
To see how VLSM addresses are calculated, consider the network in the upper portion of Figure 3-9, with one LAN requiring 150 addresses, two LANs requiring 100 addresses each, and two point-to-point WANs. You have been given the 10.5.16.0/20 address space to use in this network, and you have been asked to conserve as many addresses as possible (which also makes this exercise as challenging as possible).

For the left LAN, 150 addresses are needed; rounding up to the next power of 2 gives 256. Because 28 = 256, 8 host bits are needed. For the other two LANs, 100 addresses are needed; rounding up to the next power of 2 gives 128. Because 27 = 128, 7 host bits are needed for each LAN. The WANs require 2 host bits each.
Because at most 8 host bits are needed, the 10.5.16.0/20 address can be further subnetted into sixteen /24 subnets (leaving 8 host bits): 10.5.16.0/24, 10.5.17.0/24, and so on, up to 10.5.31.0/24, as shown at the top of Figure 3-10. Subnet 10.5.16.0/24 can be used to address the left LAN.

One of the unused /24 subnets, 10.5.17.0/24, can be further subnetted by 1 bit, resulting in 21 = 2 subnets, each with 7 host bits, as shown in the middle of Figure 3-10. The 10.5.17.0/25 and 10.5.17.128/25 subnets can be used to address the LANs on the right.
Another of the unused /24 subnets, 10.5.18.0/24, can be further subnetted by 6 bits, resulting in 26 = 64 subnets, each with 2 host bits, as shown at the bottom of Figure 3-10. Two of these subnets can be used to address the WANs. The resulting addresses are shown in the lower portion of Figure 3-9.
Key Point
Remember that only unused subnets should be further subnetted. In other words, if you use any addresses from a subnet, that subnet should not be further subnetted. In the example in the lower portion of Figure 3-9, one subnet, 10.5.16.0/24, is used on the left LAN. One of the unused subnets, 10.5.17.0/24, is further subnetted for use on the other two LANs. Another, as yet unused, subnet, 10.5.18.0/24, is further subnetted for use on the WANs.
Note
Because only two devices exist on point-to-point links, a specification has been developed (as documented in RFC 3021, “Using 31-Bit Prefixes on IPv4 Point-to-Point Links”) to allow the use of only 1 host bit on such links, resulting in a /31 mask. The two addresses created—with the host bit equal to 0 and with the host bit equal to 1—are to be interpreted as the addresses of the interfaces on either end of the link rather than as the subnet address and the directed broadcast address. Support for /31 masks is provided on some Cisco devices running IOS Release 12.2 and later; details regarding the support for this (and other features) on specific platforms and IOS releases are identified at the Cisco feature navigator site (http://www.cisco.com/go/fn).
Recall that routers work at the Open Systems Interconnection (OSI) model network layer, and that the main functions of a router are first to determine the best path that each packet should take to get to its destination, and second to send the packet on its way.
To determine the best path on which to send a packet, a router must know where the packet’s destination network is. Routers learn about networks by being physically connected to them or by learning about them either from other routers or from a network administrator. Routes configured by network administrators are known as static routes because they are hard-coded in the router and remain there—static—until the administrator removes them. Routes to which a router is physically connected are known as directly connected routes. Routers learn routes from other routers by using a routing protocol.
Key Point
A router uses a routing protocol to learn routes which it then puts in a routing table. A routed protocol is the type of packet forwarded, or routed, through a network.[4]
IP is a routed protocol; this section explores routing protocols that can be used for IP. First, we examine ways in which routing protocols are classified. We then discuss the different metrics that routing protocols use to determine the best way to get to each destination network. This is followed by a discussion of how convergence time and the ability to summarize routes are affected by the choice of routing protocol. The final portion of this section describes the specific IP routing protocols.
You can classify routing protocols in many ways. In the following sections, we describe four ways: interior versus exterior, distance vector versus link state versus hybrid, flat versus hierarchical routing, and classful versus classless routing.
An autonomous system (AS) is a network controlled by one organization; it uses interior routing protocols, called interior gateway protocols (IGPs) within it, and exterior routing protocols, called exterior gateway protocols (EGPs), to communicate with other autonomous systems.
When a network is using a distance vector routing protocol, all the routers send their routing tables (or a portion of their tables) to only their neighboring routers. The routers then use the received information to determine whether any changes need to be made to their own routing table (for example, if a better way to a specific network is now available). The process repeats periodically.
In contrast, when a network is using a link-state routing protocol, each of the routers sends the state of its own interfaces (its links) to all other routers (or to all routers in a part of the network, known as an area) only when there is a change to report. Each router uses the received information to recalculate the best path to each network and then saves this information in its routing table.
As its name suggests, a hybrid protocol borrows from both distance vector and link-state protocols. Hybrid protocols send only changed information (similar to link-state) but only to neighboring routers (similar to distance vector).
Key Point
In summary, link-state protocols send small updates everywhere only when a change occurs, while distance vector protocols send larger updates periodically only to neighboring routers. Hybrid routing protocols send small updates only to neighboring routers and only when a change occurs.
Link-state routers have knowledge of the entire network, while distance vector routers only know what their neighbors tell them.
Routers running distance vector routing protocols typically send updates in broadcast packets, while those running link-state and hybrid routing protocols send the updates in multicast packets. Recall that broadcast packets are received and processed by all devices on a network, so even servers and PCs that have no need to see routing updates are interrupted by those sent in broadcast packets. In contrast, special multicast addresses are defined for each routing protocol that uses them. Only routers that are configured for that routing protocol and therefore need to receive the updates receive and process them; other devices are not interrupted.
Routers running distance vector routing protocols have rules in place to help prevent routing loops.
Key Point
A routing loop occurs when packets bounce back and forth between routers because the routers are confused as to the best way to reach a destination network. These loops can occur if a network has changed but the routers have not yet all agreed on what the changed network looks like.
One of these rules for distance vector routing protocols is known as the split-horizon rule. This rule states that if a router has a route in its routing table (in other words, if a router is using a route) that it learned through an interface, it must not advertise that route out of that same interface (even to a different device on that interface). This works fine unless the routing protocol is being used in a nonbroadcast multiaccess (NBMA) network, such as Frame Relay. In an NBMA environment, multiple routers are connected to each other using multiple virtual circuits on one interface. For example, in the network in Figure 3-11, when Router A learns a route from Router B, it wants to pass it to Router C. However, the split-horizon rule prevents it from doing this, because Router A has only one physical interface, connected to both Routers B and C. (You can find ways around this problem, including defining multiple virtual subinterfaces, one for each virtual circuit, on the physical interface.)
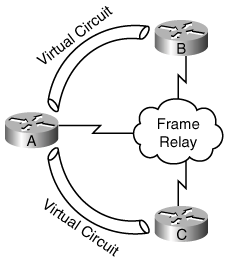
Figure 3-11. The Distance Vector Split-Horizon Rule Prevents Router A from Passing Routes Learned from Routers B to C
Distance vector routing protocols also use a hold-down mechanism to help prevent routing loops. When a router running a distance vector routing protocol receives information that a route to a destination has changed with the same or worse metric, it marks the route as being in a hold-down state; the new route is not put into the routing table until the hold-down timer expires, to give time for the other routers in the network to learn the new information.
Flat routing protocols have no way to restrict routes from being propagated within a major network (a Class A, B, or C network). In contrast, hierarchical routing protocols allow the network administrator to separate the network into areas and limit how routes are propagated between areas. This in turn reduces the routing table size and amount of routing protocol traffic in the network.
Routing protocols can be categorized as classful or classless.
Key Point
Routing updates sent by a classful routing protocol do not include the subnet mask.
Routing updates sent by a classless routing protocol include the subnet mask.
Because classful routing updates do not come with a subnet mask, devices must assume what the subnet mask associated with a received route is. If a router has an interface in the same major network as the received route, it assumes the same mask; otherwise, it assumes the default mask, based on the class of the address. The IP address design implications of using a classful routing protocol are as follows:
FLSMs must be used; in other words, all subnets of the same major network must use the same subnet mask.
All subnets of the same major network must be contiguous; in other words, all subnets of the same major network must be reachable from each other without going through a part of any other major network.
Classful routing protocols automatically summarize routes on the major network boundary.
Figure 3-12 uses subnet addresses from three major networks. The upper portion of the figure illustrates routes sent through a network using a classful routing protocol. Router B assumes that the mask of the 10.1.1.0 route sent by Router A must be the same as the mask on the 10.1.2.0 subnet to which it is connected, because the mask is not sent along with the route. Router B summarizes all subnets of network 10.0.0.0 when it sends routing information to Router C because it is sending the route on an interface that is in a different major network. For the same reason, Router C summarizes network 172.16.0.0 when it sends routing information to Router D.

Figure 3-12. Classful Routing Protocols Automatically Summarize on Major Network Boundaries; Classless Routing Protocols Do Not Have To
Classless routing protocols include the subnet mask information with routing updates, so devices do not have to make any assumptions about the mask that is being used. Therefore, classless routing protocols support VLSMs, and subnets of the same major network can be discontiguous. Classless routing protocols also allow route summarization to be manually configured and to be turned off if it is automatic on the major network boundary. The lower portion of Figure 3-12 illustrates the routing information that could be sent when using a classless routing protocol.
Figure 3-13 illustrates a discontiguous network. Three subnets of the major network 10.0.0.0 are allocated to the three LANs, and the three WANs are using subnets from the major network 172.16.0.0. If a classful routing protocol was used, Routers A, B, and C would all automatically summarize when sending routes to Router D—Router D would have three routes to network 10.0.0.0. Router D would therefore send traffic for any of the subnets of 10.0.0.0 to any of the other three routers, thinking that any of them can get to any of the available subnets; however, you can see from the topology that this is not true.

Figure 3-13. Classful Routing Protocols Do Not Support Discontiguous Networks; Classless Routing Protocols Do
Instead, if a classless routing protocol is used, the following could be configured on the routers:
Router A could report the route 10.1.1.0/24.
Router B could report the route 10.1.2.0/24.
Router C could report the route 10.1.3.0/24.
Router D could then send traffic for destinations on the three subnets to the correct router.
One of a router’s jobs is to determine the best path to each destination network. The routing protocol metric is the value that the routing protocol uses to evaluate which path is best. Metrics can include the following factors:
Hop count—. The number of hops, or other routers, to the destination network; the path with the least number of hops is preferred.
Bandwidth—. The path with the lowest bandwidth segment is the least preferred path.
Delay—. The path with the lowest accumulated delay (also called latency) is the preferred path.
Cost—. Usually inversely related to bandwidth; in other words, the path with the slowest links has the highest cost and is the least preferred path.
Load—. The utilization of the path (in other words, how much of the bandwidth is currently being used). For example, in the Cisco Interior Gateway Routing Protocol (IGRP) and Enhanced Interior Gateway Routing Protocol (EIGRP) metrics, load can be included as a number from 0 to 255, representing a 5-minute exponentially weighted average load. Load is not included by default in these calculations because it can be constantly changing.
Reliability—. The likelihood of successful packet transmission. For example, in IGRP and EIGRP metrics, reliability can be included as a number from 0 to 255, with 255 meaning 100 percent reliability and 0 meaning no reliability. Reliability is not included by default in these calculations because it can change often (for example, with heavy traffic load).
Some routing protocols use a composite metric, which is a combination of various factors. For example, IGRP and EIGRP use a metric that can include the bandwidth, delay, load, and reliability of the path. (However, by default, these protocols only use the bandwidth and delay in their metric calculations, as described in the “Routing Protocol Comparison” section, later in this chapter.)
Key Point
A lower metric value indicates a better path. For example, a path with a hop count of 2 is preferred over a path with a hop count of 5.
Note, however, that comparisons can only be made between the same metric type; for example, you cannot compare a hop count of 2 to a cost of 10.
On Cisco routers, all IP routing protocols support equal-cost (or equal-metric) load balancing, the ability to keep multiple paths, with the same metric, to the same destination network, and balance (or share) the load between those paths. By default, Cisco routers can keep up to four equal-cost paths and can be configured to keep up to six such paths.
Key Point
A network is converged when the routing tables in all the routers are synchronized so that they all contain a usable route to every available network.
Convergence time is the time it takes all the routers in a network to agree on the network’s topology, after that topology has changed.
Network design impacts convergence time significantly; in fact, proper network design is a must, or else the network might never converge.[5] Other factors that affect the convergence time include the routing protocol used, the size of the network (the number of routers), and various configurable timers.
For example, consider the type of routing protocol used. Assuming a proper design, link-state routing protocols usually converge quicker than distance vector routing protocols, because they immediately send the change to all other routers. Link-state routing protocols have a timer that prevents them from calculating the new routes immediately (so that many changes can be incorporated into one calculation); thus, they tend to converge within a few seconds.
Distance vector algorithms send updates periodically (every 30, 60, or 90 seconds is typical), so you might think that it takes a long time for changes to propagate. Fortunately, the distance vector routing protocols in use today are usually more intelligent and send flash updates. Flash updates, also called triggered updates, are sent as soon as something changes so that the routers are notified quickly. However, another mechanism prevents these routing protocols from converging fast—the hold-down mechanism (to prevent routing loops). When a router running a distance vector routing protocol receives information that a route to a destination has changed with the same or worse metric, it marks the route as being in a hold-down state; the new route is not put into the routing table until the hold-down timer expires. The hold-down timer is typically set to three times the periodic update timer; this gives time for the other routers in the network to learn the new information. Note, however, that a route in the hold-down state is still used to forward traffic. Therefore, if a link goes down and then comes up before the hold-down timer expires, it will be reachable. If the link remains down for the hold-down period, though, the router connected to the link will reply to any packets destined for devices on the link with an error message.
EIGRP is a hybrid routing protocol; it therefore has different convergence characteristics. EIGRP does not use periodic updates or hold-down timers; it does send flash updates to its neighboring routers, but only when necessary. EIGRP not only keeps the best routes in its routing table, but it also keeps all the routes to all destinations in another table, called a topology table. If the best route to a destination goes down, a router running EIGRP simply has to get the next-best route from the topology table, if one exists, and put it in its routing table; thus EIGRP can converge extremely fast. The router only has to talk to its neighboring routers if a suitable next-best route in its topology table doesn’t exist. This can occur, for example, if the downed link has resulted in a significant change in the network, or if specific routes are no longer reachable through any paths.
Note
The “Routing Protocol Comparison” section, later in this chapter, details the operation of each IP routing protocol.
The routing protocol choice affects summarization. As noted in the “Classful and Classless Routing Protocols” section earlier in this chapter, classful routing protocols automatically summarize on the major network boundary; this automatic behavior cannot be turned off. Some classless routing protocols also automatically summarize, but do allow summarization to be turned off and also allow summarization to be turned on at other boundaries.
The following routing protocols can be used for IP:
Routing Information Protocol (RIP), versions 1 and 2 (RIPv1 and RIPv2)
IGRP
EIGRP
Open Shortest Path First (OSPF)
Integrated Intermediate System-to-Intermediate System (IS-IS)
Border Gateway Protocol (BGP) Version 4 (BGP4)
Table 3-2 shows where these routing protocols fit in the various categories discussed earlier in this chapter. Each of the routing protocols is further described in the following sections. Later in this chapter, the “IPv4 Routing Protocol Selection” section describes how to choose which routing protocols you should use in your network, and what you need to consider if you decide to use more than one routing protocol.
Table 3-2. Routing Protocol Comparison Chart[6]
Characteristic | RIPv1 | RIPv2 | IGRP | EIGRP | OSPF | Integrated IS-IS | BGP-4 |
|---|---|---|---|---|---|---|---|
Interior | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
Exterior | ✓ | ||||||
Distance vector | ✓ | ✓ | ✓ | ✓[*] | ✓[**] | ||
Link-state | ✓[*] | ✓ | ✓ | ||||
Hierarchical topology required | ✓ | ✓ | |||||
Hierarchical topology supported | ✓ | ✓ | ✓ | ||||
Classless | ✓ | ✓ | ✓ | ✓ | ✓ | ||
Classful | ✓ | ✓ | |||||
VLSMs supported | ✓ | ✓ | ✓ | ✓ | ✓ | ||
Metric | Hops | Hops | Composite | Composite | Cost | Cost | Path Attributes |
Convergence time | Slow | Slow | Slow | Very Fast | Fast | Fast | Slow |
Automatic route summarization at classful network boundary | ✓ | ✓ | ✓ | ✓ | ✓ | ||
Ability to turn off automatic summarization | ✓ | ✓ | ✓ | ||||
Ability to summarize at other than classful network boundary | ✓ | ✓ | ✓ | ✓ | |||
Size of network supported | Small | Small | Medium | Large | Large | Very Large | Very Large |
[*] EIGRP is a hybrid routing protocol, with some distance vector and some link-state characteristics. [**] BGP is a path vector routing protocol. [***] RIPv2 summarization has some restrictions; for details, refer to “IP Summary Address for RIPv2” at http://www.cisco.com/en/US/products/sw/iosswrel/ps1830products_feature_guide09186a0080087ad1.html | |||||||
RIP is the original IP distance vector routing protocol. RIPv1 is classful and RIPv2 is classless. RIP’s metric is hop count; for each destination, it selects the path with the least number of routers. The hop count is limited to 15, so RIP is only suitable for small networks.
RIPv1 is not as popular as it once was. However, RIPv2 can still be used for small networks. The main advantage of using RIP is its simplicity, as explained in the following list:
It is easy to understand how it works.
It is easy to predict which way traffic will flow because RIP only uses hop count for its metric.
It is relatively easy to configure.
It is relatively easy to troubleshoot.
Both RIPv1 and RIPv2 automatically summarize at the major network boundary; RIPv2 allows this functionality to be turned off, so it supports discontiguous addressing. Other RIPv2 improvements over RIPv1 include its support for VLSMs, its use of multicast rather than broadcast for sending routing updates, and its support for authenticating routing updates to ensure that routes are only exchanged with authorized routers.
The main disadvantages of using RIP are its slow convergence (because it is a distance vector routing protocol) and the fact that it only uses hop count as its metric—it selects the path with the least number of routers to the destination, without regard to the speed of the links on the path. For example, RIP would choose a route that is two hops through a slow WAN connection rather than going three hops over Ethernet.
RIP’s snapshot routing feature allows it to be used on a dial-up network. This feature allows the router on each side of the connection to take a snapshot of the routing table while the link is up, and use that snapshot to update any other routers on its side of the connection while the link is down. The link is only brought up when necessary, for example, when data needs to be sent across it—during that time, the routing table can be updated.
IGRP is a Cisco-proprietary routing protocol developed by Cisco to include many improvements over RIP. As a classful distance vector routing protocol though, IGRP has relatively slow convergence, does not support VLSMs, and automatically summarizes routes at the classful network boundary. The distance vector split-horizon feature also restricts its ability to work on NBMA networks, such as Frame Relay.
However, IGRP’s metric provides a more useful gauge of a path’s suitability in most networks. IGRP uses a composite metric, with bandwidth, delay, load, and reliability all factored into the metric equation. Some constants are used in the metric calculation; with their default values, the IGRP metric formula is as follows:
metric = bandwidth + delay
The terms in this formula are defined as follows:
The bandwidth is 1,000,000 divided by the smallest bandwidth along the path—in other words, the slowest link—in kilobits per second (kbps).
The delay is the sum of all the outgoing delays along the path in microseconds, divided by 10.
Note
The hop count and the maximum transmission unit (MTU) are also carried along with IGRP routing updates. The MTU is the maximum packet size that can be sent without fragmentation.
A lower metric value indicates a better path—faster with the least amount of delay.
IGRP allows the network to be divided into what it calls autonomous systems, although this is a different use of the term than in the previous discussion of interior and exterior routing protocols. You can think of IGRP’s use of the term as being similar to groups: You can have different groups of routers running IGRP, and routing information is not shared among the groups unless you explicitly configure the routers to do so. For example, if your network is running IGRP and your organization acquires another organization that is also running IGRP, you might want to keep the two networks separate initially, and just share specific routes. The autonomous system numbers allow this to be accomplished easily.
Another feature introduced in IGRP is the ability to load-balance, or load-share, over unequal-cost paths, not just over equal-cost paths, as other routing protocols can do. For example, consider the network shown in Figure 3-14. From Router A’s perspective, network 172.16.2.0 can be reached in two ways—through the serial 0 (S0) interface at 64 kbps or through the serial 1 (S1) interface at 128 kbps. Ordinarily, the 128-kbps link would be chosen as the preferred path because it is faster, and all traffic would flow over that link. The 64-kbps link would not be used (unless and until the faster link became unavailable). IGRP allows unequal-cost load balancing so that traffic can flow across both links, in proportion to their speed. This makes better use of the available bandwidth.

Like RIP, IGRP is easy to configure and troubleshoot. However, because of its classful distance vector behavior, IGRP is seldom used in today’s networks; EIGRP is a better choice because it retains all of IGRP’s advantages and overcomes its disadvantages. In fact, Cisco will be discontinuing IGRP in future software releases, and recommends EIGRP in its place.[7]
EIGRP, as its name indicates, is an enhanced version of IGRP and is also Cisco-proprietary. EIGRP is a classless hybrid routing protocol that combines the best features of distance vector and link-state routing protocols. EIGRP performs well on LANs and WANs, including in NBMA environments; unlike distance vector routing protocols, EIGRP’s split-horizon feature can be turned off if necessary for use on an NBMA network.
Note
EIGRP is not appropriate for use on a dial-up network because it maintains the relationship with its neighboring routers by sending hello messages periodically. Doing this on a dial-up connection would mean that the link would have to remain up all the time.
EIGRP can be used to route not just IP but also Internetwork Packet Exchange (IPX) and AppleTalk routed protocols. Each of these routed protocols is handled completely independently. In this book, we only discuss the operation of EIGRP with respect to IP.
As a classless routing protocol, EIGRP supports VLSMs. It automatically summarizes on the classful network boundary, but this summarization can be turned off and summarization can be done at any other boundary in the network, by any of the EIGRP routers. This allows a hierarchical topology to be supported. Although this is good design practice, it is not required by EIGRP.
EIGRP is based on the Diffusing Update Algorithm (DUAL), which provides its very fast convergence. The following list of EIGRP terms helps to explain how EIGRP operates:
Neighbor table—. Each EIGRP router keeps a neighbor table to list the adjacent routers with which it has formed a neighbor relationship.
Topology table—. All routes learned to each destination, from all neighbors, are kept in the topology table.
Routing table—. Each EIGRP router chooses the best routes to each destination from its topology table and puts them in its routing table.
Successor—. A successor, also called a current successor, is a neighbor router that has the best route to a destination. Successor routes are kept in the routing table as well as in the topology table.
Feasible successor—. A feasible successor is a neighbor router that has a backup route to a destination. Feasible successor routes are chosen at the same time that successor routes are chosen, but they are only kept in the topology table. The DUAL algorithm only selects feasible successor routes that are loop-free; in other words, routes that do not loop back and go through the current router.
EIGRP routers exchange routes only with their neighboring routers—neighbor relationships are established and maintained with periodic, small, hello messages. Routing updates are only sent when a change occurs, and only the changed information from the routing table is sent. All EIGRP messages use multicast, rather than broadcast, to reduce interruptions of other network devices.
When an EIGRP router learns that a path it was using in its routing table (a successor route) has gone down, it looks in its topology table to see whether a usable backup route is available, through a feasible successor. If a route is available, the router copies that route to its routing table and starts using it—no further calculation or communication with other routers is required. As mentioned earlier, this can result in extremely fast convergence after a change in the network. An EIGRP router only has to send query messages to its neighbors—trying to find alternate routes to the destination now that the network has changed—if it doesn’t have a suitable backup route in its topology table.
The DUAL algorithm uses the same metric calculation as that used by IGRP, but the value is multiplied by 256 for EIGRP (because EIGRP uses 32 bits, instead of IGRP’s 24 bits, for the metric). EIGRP, like IGRP, supports both equal- and unequal-cost load balancing.
EIGRP uses much less bandwidth than IGRP because it only sends the routing table entries that have changed only when a change occurs, rather than sending the entire table periodically. The bandwidth used by the periodic hello messages can be a concern on slower WAN links with many neighbors (as can occur on an NBMA network), but normally this is not an issue.
EIGRP, like IGRP, is easy to configure. It uses the same autonomous system numbers as IGRP, and in fact can automatically share information with IGRP routers configured with the same autonomous system number. No special configuration is required for different types of Layer 2 media (as is the case for OSPF, as described in the next section).
OSPF is a standard (not Cisco-proprietary) routing protocol, developed to overcome RIP’s limitations. As a classless link-state routing protocol, it supports VLSMs and convergences quickly.
Note
The latest version of OSPF for IPv4, OSPF version 2, is described in RFC 2328, “OSPF Version 2.”
OSPF requires a hierarchical design. The OSPF network is called a domain or an autonomous system and is divided into areas. One backbone area exists, area 0, to which all other areas must be connected and through which all traffic between other areas must flow. Figure 3-15 illustrates an OSPF network. Traffic between Routers E and F in this figure, for example, must flow from area 1 through Router A, through the backbone area 0, and then into area 3 through Router C. (Even if another physical link existed between the routers in these areas, it could not be used.)
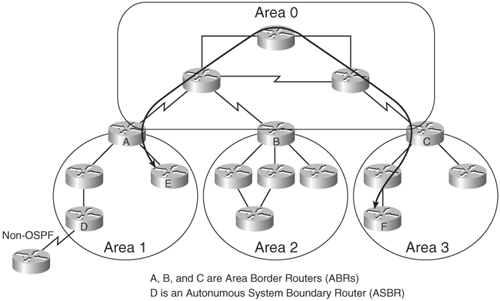
The routers that are on the boundary between area 0 and another area are called Area Border Routers (ABRs); Routers A, B, and C in Figure 3-15 are ABRs. ABRs are responsible for passing traffic to and from the backbone. Routers that are the interface between the current OSPF domain and other domains (for example, using static routes) are called Autonomous System Boundary Routers (ASBRs). Router D in the figure is an ASBR. The ASBR takes care of exchanging routing information between the current OSPF domain and the external domain.
An OSPF router communicates and maintains relationships with other routers using a hello protocol, similar to the one used by EIGRP. OSPF routing updates are sent in link-state advertisements (LSAs), describing the state of links (interfaces); LSAs are sent in multicast packets called link-state updates (LSUs). An OSPF router exchanges LSAs about all its links with all the routers in its area so that all routers in an area have the same information. Each router puts this information in its topology table and then runs the shortest path first (SPF) algorithm to calculate its shortest path to each destination network. These shortest paths are put in the routing table.
Different types of LSAs are sent, depending on the type of router (ABR, ASBR, and so on) that is sending the advertisement. An OSPF router sends an LSA whenever it detects a change; this can result in a lot of bandwidth being used if the network is not stable. OSPF routers receive LSAs and run the SPF algorithm whenever a change occurs in the network. Timers ensure that OSPF waits for a few seconds after receiving an LSA before running SPF so that multiple changes can be incorporated into one SPF calculation. This helps to limit the resources used by OSPF, but it also means that the convergence time is increased.
Note
The OSPF incremental SPF feature, introduced in Cisco Internet Operating System (IOS) Release 12.0(24)S, allows OSPF to converge faster when a network topology changes. Information on this feature is available in the “OSPF Incremental SPF” document.[9]
OSPF routers do not automatically summarize routes. By default, all routing information is sent to all OSPF routers in the domain, although it might be sent in a different LSA type. Manual summarization can be configured, but only on ABRs and ASBRs. Thus, a sound IP addressing design is important, to ensure that the ABR can summarize routes so that the routing protocol traffic between areas is kept to a minimum.
OSPF also supports defining different types of areas to limit the amount of routing traffic passing into areas. For example, on Cisco routers an OSPF area can be configured as a totally stubby area so that only a default route is passed into the area; traffic for any destinations external to the area is sent out on the default route. This configuration is useful for areas that do not connect to non-OSPF networks. The routers within the area then only have to keep minimal routing information, but can still get to all destinations.
OSPF treats different Layer 2 media differently, and special configuration is required for some Layer 2 media. For example, OSPF can run on NBMA networks, but it requires special configuration to do so. For use over dial-up links, an OSPF feature called demand circuit (DC) can be configured; it suppresses the hello messages.
The metric used by OSPF is called the cost, and it is inversely proportional to the bandwidth of the interface—in other words, slower links have a higher cost. On Cisco routers, the default cost calculation is as follows:
Cost = Reference bandwidth in Mbps / Bandwidth
The default reference bandwidth is 100 Mbps. The bandwidth in this formula is the bandwidth defined on the interface, which can be configured differently than its default. Using the default reference bandwidth value in the formula assumes a maximum bandwidth of 100 Mbps (resulting in a cost of 1). You can change the reference bandwidth value on the routers in the network if you have faster interfaces (it should be set to the same value on all routers to ensure a consistent calculation). You can also manually set the cost on each interface.
OSPF does not limit the number of hops that a routing update can travel in the network.
In “Designing Large-Scale IP Internetworks,”[10] Cisco recommends the following guidelines:
An area should have no more than 50 routers.
Each router should have no more than 60 OSPF neighbors.
A router should not be in more than three areas.
These values are recommended to ensure that OSPF calculations do not overwhelm the routers. Of course, the network design and link stability can also affect the load on the routers.
Integrated IS-IS is a link-state classless routing protocol that has the following similarities with OSPF:
It supports VLSMs.
It requires a hierarchical topology and defines areas.
It converges fast.
It does not summarize automatically but does allow manual summarization.
It uses the SPF algorithm to compute the best paths.
Note
Integrated IS-IS is defined in RFC 1195, “Use of OSI IS-IS for Routing in TCP/IP and Dual Environments.”
Many differences also exist between the two protocols. The main difference relates to the fact that IS-IS is the routing protocol for the OSI protocol suite, specifically to route Connectionless Network Protocol (CLNP) data. CLNP is a routed protocol of the OSI suite, just as IP is the routed protocol for the TCP/IP suite. Integrated IS-IS is an extended version of IS-IS used for IP. Recall that EIGRP also supports multiple routed protocols (IP, IPX, and AppleTalk); with EIGRP, each of these routed protocols is handled independently. With Integrated IS-IS, the IP routing information is included as part of the CLNP routing information. Therefore, OSI protocol suite addresses must be configured even if IS-IS is only being used for routing IP.
OSI protocol suite addresses, which are a maximum of 20 bytes long, are called network service access points (NSAPs). Each device, rather than each interface, has an address. Although Integrated IS-IS is used extensively by ISPs, OSI addresses are not widely understood, and therefore this routing protocol is not widely used outside of ISPs.
Another difference between IS-IS and OSPF is how areas are defined and used. The following OSI terminology and Figure 3-16 help to explain how Integrated IS-IS operates:
A domain is any part of an OSI network that is under a common administration; this is the equivalent of an autonomous system or domain in OSPF.
Within any OSI domain, one or more areas can be defined. An area is a logical entity formed by a set of contiguous routers and the links that connect them. All routers in the same area exchange information about all the hosts that they can reach.
The areas are connected to form a backbone. All routers on the backbone know how to reach all areas.
An end system (ES) is any nonrouting host or node.
An intermediate system (IS) is a router.
OSI defines Level 1, Level 2, and Level 3 routing. Level 1 (L1) ISs (routers) communicate with other L1 ISs in the same area. Level 2 (L2) ISs route between L1 areas and form a contiguous routing backbone. L1 ISs only need to know how to get to the nearest L2 IS. Level 3 routing occurs between domains.
L1 routers (ISs) are responsible for routing to ESs inside an area. They are similar to OSPF routers inside a totally stubby area.
L2 ISs only route between areas, similar to backbone routers in OSPF.
Level-1-2 (L1-2) routers can be thought of as a combination of an L1 router communicating with other L1 routers and an L2 router communicating with other L2 routers. L1-2 routers communicate between L2 backbone routers and L1 internal routers; they are similar to ABRs in OSPF. The backbone consists of both L2 and L1-2 routers.

Notice that the edge of an IS-IS area is on a link, rather than inside of a router, as is the case for OSPF. Also notice that it is easy to extend the IS-IS backbone and add on more areas. You just need to configure a router as L2 or L1-2 and connect it to another L2 or L1-2 router, and it is part of the backbone. This flexibility means that IS-IS is much easier to expand than OSPF. IS-IS also sends out less update packets than OSPF, resulting in less traffic and therefore allowing more routers per area.
IS-IS routes can only be summarized by L1-2 routers as they are sent into Level 2. All L1-2 routers in an area should perform the same summarization so that the other areas see only the summary routes; otherwise, traffic will flow to the router that is not summarizing, because it advertises more specific routes.
Note
If more than one entry in the routing table matches a particular destination, the longest prefix match—the most specific route that matches—in the routing table is used. Several routes might match one destination, but the one with the longest matching prefix is used.
Integrated IS-IS does not inherently support NBMA point-to-multipoint networks; in this case, multiple subinterfaces must be used to create multiple point-to-point networks.
IS-IS on Cisco routers assigns all interfaces a metric value of 10; it does not take into account the bandwidth of the link. This obviously is not appropriate in networks with varying link speed; in fact, it behaves similar to RIP’s hop count metric. The metric for IS-IS can be changed manually on each interface, and should be done so for proper routing behavior.
BGP4 is the exterior routing protocol, the EGP, for the TCP/IP suite and is used extensively throughout the Internet.
BGP is based on distance vector operation and uses a path vector as its metric. A path vector is a set of attributes of a path to a destination, including a list of AS numbers that the path goes through. The number of autonomous systems in this list can be thought of as being similar to a hop count, and can be used to affect the choice of which path is considered to be the best.
BGP is needed if an organization has more than one Internet connection and needs to determine which information should flow through each connection. BGP is also required if the AS allows packets to transit through it, from one AS to another AS; in this case, it is called a transit AS. An ISP is an example of a transit AS. Another reason to use BGP is if the AS must manipulate the flow of traffic entering or leaving the AS. In this latter case, BGP is being used as a policy-based protocol—policies can be defined to affect the way traffic flows through the AS.
In BGP, each AS is assigned an AS number. AS numbers are 16 bits, with values from 1 to 65535. Private AS numbers are 64512 through 65535; these are much like the private IP addresses and are not to be used on the Internet. (We only use private AS numbers in this book, just as we only use private IP addresses.)
BGP uses TCP to communicate. Any two routers that have formed a TCP connection to exchange BGP routing information—in other words, that have formed a BGP connection—are called BGP peers or neighbors.
BGP peers can be either internal or external to the AS. When BGP is running between routers within one AS, it is called internal BGP (IBGP). IBGP exchanges BGP information within the AS so that it can be passed to other autonomous systems. As long as they can communicate with each other, routers running IBGP do not have to be directly connected to each other. For example, if EIGRP is running within the AS, the routers will have routes to all destinations within the AS; they use this EIGRP routing information to send the BGP information to the routers that need it. You can think of IBGP running on top of the interior routing protocol (EIGRP in this example)—it uses the interior routing protocol to send its BGP information.
When BGP is running between routers in different autonomous systems, it is called external BGP (EBGP). Routers running EBGP are usually connected directly to each other.
Note
Understanding BGP operation is crucial to implementing it successfully. Many BGP parameters can be changed, and many BGP features can be configured—configuring and troubleshooting BGP can be complex. Because BGP typically involves connections to the Internet, errors can be catastrophic.
BGP4 is a classless routing protocol, so both the route and the prefix information are included in the routing updates. Thus, BGP4 supports VLSMs. It also supports classless interdomain routing (CIDR) addressing—blocks of multiple addresses (for example, blocks of Class C addresses) can be summarized, resulting in fewer entries in the routing tables.
This section describes the process of choosing routing protocols for your network and discusses the concepts of redistribution, filtering, and administrative distance.
To decide which routing protocol is best for your network, you need to first look at your requirements. You can then compare your requirements to the specifications for the available routing protocols, as detailed in the previous sections and summarized earlier in Table 3-2, and choose the routing protocol that best meets your needs.
Recall that Chapter 1, “Network Design,” described the hierarchical model in which a network is divided into three layers: core, distribution, and access. Because each layer provides different services, they typically have different routing requirements and therefore use different routing protocols. The specific network function performed at each of these layers is as follows:
Access layer—. Provides end-user and workgroup access to the resources of the network.
Distribution layer—. Implements the organization’s policies (including filtering of traffic) and provides connections between workgroups and between the workgroups and the core.
Core layer—. Provides high-speed links between distribution-layer devices and to core resources. The core layer typically uses redundancy to ensure high network availability.
Thus, the different routing protocols suitable at each layer are as follows:
In the core layer, a fast-converging routing protocol is required: EIGRP, OSPF, and IS-IS are the possible choices. OSPF and IS-IS require a hierarchical topology with areas defined; EIGRP supports a hierarchical topology but doesn’t require it. EIGRP is Cisco-proprietary, so it can only be supported if all routers are Cisco routers. IS-IS requires OSI addresses to be configured, which is not a common skill.
In the distribution layer, any of the interior routing protocols are suitable, depending on the specific network requirements. For example, if it is an all-Cisco network and has a mixture of link types so that VLSMs would be appropriate, EIGRP would be the logical choice. Because the distribution layer routes between the core and access layers, it might also have to redistribute (share with) and/or filter between the routing protocols running in those layers, as described in the next section.
The access layer typically includes RIPv2, IGRP, EIGRP, OSPF, or static routes. The devices in this layer are typically less powerful (in terms of processing and memory capabilities) and therefore support smaller routing tables—thus, the distribution layer should filter routes sent to this layer. Remember that EIGRP is not suitable for use in a dial-up network and that distance vector routing protocols have issues in NBMA networks.
Key Point
If two (or more) routing protocols are run in the same network, information from one routing protocol can be redistributed with, or shared with, another routing protocol. Routers that participate in more than one routing protocol perform the redistribution.
Redistribution can be bidirectional—the information from each routing protocol is shared with the other. It can also be performed in only one direction, with default routes used in the other direction. You must be careful not to introduce routing loops when you use redistribution.
Key Point
Routes can be filtered to prevent specific routes from being advertised. In other words, the router can exclude specific routes from the routing updates it sends to other specific routers.
Route filtering is useful when redistribution is being used, to help prevent routing loops.
For example, consider the network in Figure 3-17, with IGRP running in the upper part and RIPv2 running in the lower part. Both Routers A and B are configured to pass IGRP information into the RIPv2 network, and RIPv2 into the IGRP network, with the intention that all devices can reach all networks.
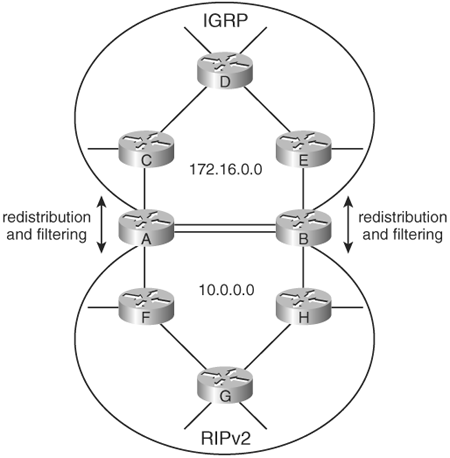
A problem can occur if both Routers A and B redistribute the full content of their routing tables, because more than one path exists between the IGRP and RIPv2 networks. For example, Router B can pass information about network 10.0.0.0 to Router E, which can pass it to Router D, which can pass it to Router C, which can pass it to Router A. Router A is connected to network 10.0.0.0, but depending on how the redistribution is configured, Router A might think that the path to some of the subnets of network 10.0.0.0 through Router C is better—through the IGRP network. If Router A passed this information to Router F, and so on, traffic from the RIPv2 part of the network might loop around the entire network before ending up where it started—in other words, the potential exists for a routing loop. Specific route filtering can be configured to avoid this—you must know your network and ensure that you are not introducing problems.
Because each routing protocol uses different metrics, you can’t compare one metric with another—for example, how do you compare whether 3 RIP hops are better than an OSPF cost of 10? Thus, when multiple routing protocols are run on Cisco routers, another parameter, called the administrative distance, compares the routing protocols.
Key Point
Cisco routers use the administrative distance in the path selection process when they learn two or more routes to the same destination network or subnet from different sources of routing information, such as different routing protocols. The administrative distance rates the believability of the sources of routing information.
The administrative distance is a value between 0 and 255; the lower the value, the higher the believability of the source of the routing information.
Table 3-4 lists the default administrative distance of the sources of routing information, including routing protocols, supported by Cisco routers.
Table 3-3. Administrative Distance of Routing Protocols
Route Source | Default Distance |
|---|---|
Connected interface, static route out an interface | 0 |
Static route to an address | 1 |
EIGRP summary route | 5 |
EBGP | 20 |
Internal EIGRP | 90 |
IGRP | 100 |
OSPF | 110 |
IS-IS | 115 |
RIPv1, RIPv2 | 120 |
External EIGRP | 170 |
Internal BGP | 200 |
Unknown | 255 |
For example, consider a router that receives a route to network 10.0.0.0 from RIPv2 (with an administrative distance of 120) and also receives a route to the same network from IGRP (with an administrative distance of 100). The router uses the administrative distance to determine that IGRP is more believable; the router therefore puts the IGRP route into its routing table.
The administrative distance can be changed from its default value, either for all routes from a routing protocol or for specific routes. This can help to eliminate routing loops.
In this chapter, you learned about IPv4 address design and routing protocol selection.
The following topics were explored:
Why proper IP addressing and protocol selection are critical to your business
IP address design issues, including private addresses and NAT, how subnet masks are used and selected, hierarchical addressing and summarization, and VLSMs
The various features of routing protocols in general, and the specifics for the IP routing protocols RIPv1, RIPv2, IGRP, EIGRP, OSPF, Integrated IS-IS, and BGP4
The process that chooses IP routing protocols for your network and the concepts of redistribution, filtering, and administrative distance
| 1. | Redford, R., “Intelligent Information Networks,” Keynote Address at the Cisco Technical Symposium 2004, Oct. 5, 2004, Toronto. |
| 2. | “Potential of IP Communications Takes Off at Toronto Pearson International Airport,” http://newsroom.cisco.com/dlls/partners/news/2004/f_hd_03-30.html. |
| 3. | Adapted from Teare, CCDA Self-Study: Designing for Cisco Internetwork Solutions (DESGN), Indianapolis, Cisco Press, 2004, Chapter 6. |
| 4. | Odom, CCNA Self-Study: CCNA INTRO Exam Certification Guide, Indianapolis, Cisco Press, 2004, p. 120. |
| 5. | Linegar, D. and Savage, D., Advanced Routing Protocol Deployment session, Cisco Technical Symposium 2004, Oct. 5, 2004, Toronto. |
| 6. | Adapted from Paquet and Teare, CCNP Self-Study: Building Scalable Cisco Internetworks (BSCI), Second Edition, Indianapolis, Cisco Press, 2003, pp. 32 and 118. |
| 7. | Linegar, D. and Savage, D., Advanced Routing Protocol Deployment session, Cisco Technical Symposium 2004, Oct. 5, 2004, Toronto. |
| 8. | Ibid. |
| 9. | “OSPF Incremental SPF,” http://www.cisco.com/univercd/cc/td/doc/product/software/ios120/120newft/120limit/120s/120s24/ospfispf.htm. |
| 10. | “Designing Large-Scale IPInternetworks,” http://www.cisco.com/univercd/cc/td/doc/cisintwk/idg4/nd2003.htm. |