
This chapter briefly discusses four technologies and includes the following sections:
This chapter briefly describes four technologies that can be incorporated into your network design. In addition to the information provided in this chapter and because these topics are only briefly covered here, references to additional information on each of these topics are also included.
The chapter first introduces how IP multicast technology enables networks to send data to a group of end stations in the most efficient way. Next, the chapter describes the factors that affect the availability of a network and ways that it can be improved. Storage networking, that is, enabling storage devices to be accessed over the network, is then explored. The chapter concludes with a discussion of IP version 6 (IPv6), the next generation of the Internet Protocol.
Note
Appendix B, “Network Fundamentals,” includes material that we assume you understand before reading the rest of the book. Thus, we encourage you to review any of the material in Appendix B that you are not familiar with before reading the rest of this chapter.
Many types of data can be transferred between devices over an IP network, including, for example, document files, voice, and video. However, a traditional IP network is not efficient when sending the same data to many locations; the data is sent in unicast packets and is therefore replicated on the network for each destination. For example, if a CEO’s annual video address is sent out on a company’s network for all employees to watch, the same data stream must be replicated for each employee. Obviously, this would consume many resources, including precious WAN bandwidth.
IP multicast technology enables networks to send data to a group of destinations in the most efficient way. The data is sent from the source as one stream; this single data stream travels as far as it can in the network. Devices only replicate the data if they need to send it out on multiple interfaces to reach all members of the destination group.
Multicast groups are identified by Class D IP addresses, which are in the range from 224.0.0.0 to 239.255.255.255. IP multicast involves some new protocols for network devices, including two for informing network devices which hosts require which multicast data stream and one for determining the best way to route multicast traffic. These three protocols are described in the following sections.
IGMP is used between hosts and their local routers. Hosts register with the router to join (and leave) specific multicast groups; the router is then aware that it needs to forward the data stream destined to a specific multicast group to the registered hosts.
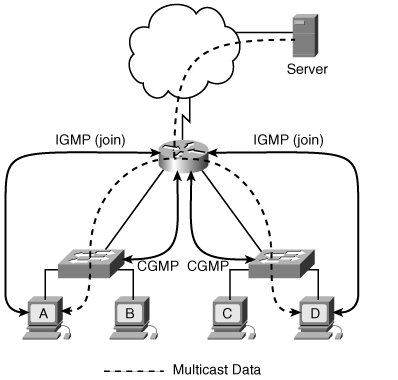
In a typical network, hosts are not directly connected to routers but are connected to a Layer 2 switch, which is in turn connected to the router. IGMP is a network layer, Layer 3, protocol. Thus, Layer 2 switches do not participate in IGMP and are therefore not aware of which hosts attached to them might be part of a particular multicast group. By default, Layer 2 switches flood multicast frames to all ports (except the port from which the frame originated), which means that all multicast traffic received by a switch would be sent out on all ports, even if only one device on one port required the data stream. Cisco therefore developed CGMP, which is used between switches and routers. The routers inform each of their directly connected switches of IGMP registrations that were received from hosts through the switch, in other words, from hosts accessible through the switch. The switch then forwards the multicast traffic only to ports that those requesting hosts are on, rather than flooding the data to all ports. (Switches, including non-Cisco switches, can alternatively use IGMP snooping to eavesdrop on the IGMP messages sent between routers and hosts to learn similar information.)
Figure 10-1 illustrates the interaction of these two protocols. Hosts A and D register, using IGMP, to join the multicast group to receive data from the server. The router informs both switches of these registrations, using CGMP. When the router forwards the multicast data to the hosts, the switches ensure that the data only goes out of the ports on which hosts A and D are connected. The ports on which hosts B and C are connected do not receive the multicast data.
PIM is used by routers that are forwarding multicast packets. The “protocol independent” part of the name indicates that PIM is independent of the unicast routing protocol (for example, Enhanced Interior Gateway Routing Protocol [EIGRP] or Open Shortest Path First [OSPF]) running in the network. PIM uses the normal routing table, populated by the unicast routing protocol, in its multicast routing calculations.
Note
EIGRP, OSPF, and so forth are called unicast routing protocols because they are used for creating and maintaining unicast routing information in the routing table. Recall, though, that they use multicast packets (or broadcast packets in some protocols) to send their routing update traffic.
(Note that a variant of OSPF, called multicast OSPF, supports multicast routing. Cisco routers do not support multicast OSPF.)
When a router is forwarding a unicast packet, it looks up the destination address in its routing table and forwards the packet out of the appropriate interface. However, when forwarding a multicast packet, the router might have to forward the packet out of multiple interfaces, toward all the receiving hosts. Multicast-enabled routers use PIM to dynamically create distribution trees that control the path that IP multicast traffic takes through the network to deliver traffic to all receivers. The following two types of distribution trees exist:
Source tree—. A source tree is created for each source sending to each multicast group. The source tree has its root at the source and has branches through the network to the receivers.
Shared tree—. A shared tree is a single tree that is shared between all sources for each multicast group. The shared tree has a single common root, called a rendezvous point (RP).
Multicast routers consider the source address of the multicast packet as well as the destination address, and use the distribution tree to forward the packet away from the source toward the destination. Forwarding multicast traffic away from the source, rather than to the receiver, is called Reverse Path Forwarding (RPF). To avoid routing loops, RPF uses the unicast routing table to determine the upstream (toward the source) and downstream (away from the source) neighbors and ensures that only one interface on the router is considered to be an incoming interface for data from a specific source. (For example, data received on one router interface and forwarded out another interface can loop around the network and come back into the same router on a different interface; RPF ensures that this data is not forwarded again.)
PIM operates in one of the following two modes:
Sparse mode—. This mode uses a “pull” model to send multicast traffic. Sparse mode uses a shared tree and therefore requires an RP to be defined. Sources register with the RP. Routers along the path from active receivers that have explicitly requested to join a specific multicast group register to join that group. These routers calculate, using the unicast routing table, whether they have a better metric to the RP or to the source itself; they forward the join message to the device with which they have the better metric.
Dense mode—. This mode uses a “push” model that floods multicast traffic to the entire network. Dense mode uses source trees. Routers that have no need for the data (because they are not connected to receivers that want the data or to other routers that want it) request that the tree is pruned so that they no longer receive the data.
Note
Further information on IP multicast can be found at http://www.cisco.com/go/ipmulticast.
When we think of network availability, we must go back to the business objectives and requirements—the first step in the design process—to see what purpose the network has in the organization. For example, availability can mean that the online customer services must be available 24 hours a day, 7 days a week. Or, it can mean that the IP phone system must be as available as the public switched telephone network (PSTN) system.
Thus, when we think of increasing the network availability, or achieving high availability, we must also reference the business objectives. One definition of high availability is as follows:
The ability to define, achieve, and sustain ‘target availability objectives’ across services and/or technologies supported in the network that align with the objectives of the business.[1]
Availability is usually measured as either the percentage of time that the network is up or by the amount of time the network is down. For example, two common formulas for availability are as follows:[2]
Availability = MTBF / (MTBF + MTTR), where
MTBF = Mean time between failure—the average amount of time that the network is up (between failures).
MTTR = Mean time to repair—the average amount of time it takes to get the network functioning again after a failure has occurred.
The type of network connections, for example, whether devices are connected in parallel or in series, can make this calculation more complex.
Availability = (Total User Time – Total User Outage Time) / Total User Time, where
Total User Time = Total amount of user time that the network should be accessible = Number of users * Total measurement time.
Total User Outage Time = Sum of the amount of time that each user was unable to access the system during the measurement time.
Table 10-1 illustrates some availability percentages and describes how they translate to the amount of downtime in a year. High availability usually means that the network is down for less than 5 minutes in a year, which equates to a 99.999% availability (also known as five nines availability).
Table 10-1. Availability Can Be Translated into Network Downtime
Availability, % | Downtime per Year |
|---|---|
99.000 | 3 days, 15 hours, 36 minutes |
99.500 | 1 day, 19 hours, 48 minutes |
99.700 | 26 hours, 17 minutes |
99.900 | 8 hours, 46 minutes |
99.950 | 4 hours, 23 minutes |
99.990 | 53 minutes |
99.999 | 5 minutes |
99.9999 | 30 seconds |
When you consider increasing the availability of your network, the cost of doing so should be weighed against the cost of downtime. For example, ensuring that an online ordering system is highly available avoids the opportunity costs of lost sales and therefore might be worth the expense. In contrast, ensuring that every user is always able to dial in to the corporate network without getting a busy signal might not be worth the loss in productivity of a few users having to retry making the connection.
The reasons for network problems must also be considered. Many times, only the design and the technologies used are considered in availability analysis; however, a network can experience problems for other reasons. For example, one study[3] found that the relative distribution of the common causes of network outages is as follows:
User and process errors (including change management and process issues): 40%
Software and applications (including software, performance, and load issues): 40%
Technology (including design, hardware, and links): 20%
Thus, design and equipment issues should be considered, but other factors must also be taken into account. Therefore, increasing the availability of your network can include implementing the following measures:
Using redundant links between devices, including between redundant devices
Using redundant components within devices, for example, installing redundant network interface cards (NICs) in mission-critical servers or redundant processors in network devices
Having a simple, logical network design that is easily understood by the network administrators and having processes and procedures for naming and labeling equipment, and for implementing changes to anything within the network
Having processes and procedures in place for monitoring the network for potential problems and for correcting those problems before they cause the network to fail
Ensuring the appropriate physical and environmental conditions for all equipment and the availability of appropriate spare parts
For redundancy, recall from Chapter 2, “Switching Design,” that a Layer 2 switched network with redundant links can have problems because of the way that switches forward frames. Thus, the Spanning-Tree Protocol (STP) logically disables part of the redundant network for regular traffic while still maintaining the redundancy in case an error occurs. When multiple virtual LANs (VLANs) exist algorithms such as per-VLAN spanning tree (PVST) can also be implemented. With PVST, switches have one instance of STP running per VLAN. PVST can result in load balancing across the redundant links by allowing different links to be forwarding for each VLAN.
In Chapter 3, “IPv4 Routing Design,” you see that routed (Layer 3) networks inherently support redundant paths, so a protocol such as STP is not required. All the IP version 4 (IPv4) routing protocols can load-balance over multiple paths of equal cost; EIGRP and Interior Gateway Routing Protocol (IGRP) can also load-balance over unequal-cost paths.
Some of the other protocols that can be enabled on network devices for increasing availability include the following:
Hot Standby Router Protocol (HSRP)—. The Cisco HSRP allows a group of routers to appear as a single virtual router to the hosts on a LAN. The group is assigned a virtual IP address (and is either assigned or autoconfigures, based on the group number, a virtual Media Access Control [MAC] address); hosts on the LAN have the virtual address as their default gateway. One router is elected as the active router and processes packets addressed to the virtual address. If the active router fails, another router takes over this responsibility, and routing continues transparently to the hosts.
Virtual Router Redundancy Protocol (VRRP)—. VRRP is a standard protocol, similar to the Cisco HSRP. A group of routers represent a single virtual router; the IP address of the virtual router is the same as configured on one of the real routers. That router, known as the master virtual router, is initially responsible for processing packets addressed to the IP address. If the master virtual router fails, one of the backup virtual routers (as determined by a priority) takes over, and routing continues transparently to the hosts.
Gateway Load Balancing Protocol (GLBP)—. GLBP is another protocol that allows redundancy of routers on a LAN, similar to HSRP. The difference is that GLBP allows load balancing over the redundant routers, using a single virtual IP address and multiple virtual MAC addresses, so that all hosts are configured with the same default gateway. All routers in the group participate in forwarding packets simultaneously, making better use of network resources.
Nonstop Forwarding (NSF) with Stateful Switchover (SSO)—. In Cisco devices that support two route processors, the SSO feature allows one to be active while the other is in standby mode. Configuration data and routing information are synchronized between the two, and if the active route processor fails, the other takes over. During the switchover, the NSF feature ensures that packets continue to be forwarded along the previous routes, with no packet loss.
Server Load Balancing (SLB)—. The Cisco SLB feature provides IP server load balancing. A virtual server address represents a group of real servers. When a client initiates a connection to the virtual server address, the SLB function chooses a real server for the connection, based on a load-balancing algorithm.
Note
Further information on increasing network availability can be found at http://www.cisco.com/go/availability.
Storage networking can be defined as “the hardware and software that enables storage to be consolidated, shared, and accessed over a networked infrastructure.”[4]
As networks are being used for more functions by more organizations and individuals, the amount of data that is created and must be stored is quickly increasing. This data includes documents, online transaction details, financial information, e-learning courses, corporate videos, and so forth.
Before storage networking, data was stored either on embedded disks within servers or on separate disks directly attached to servers, known as directly attached storage (DAS). Neither of these solutions is scalable because they are limited by the capacity of the server. They are also not reliable because access to the data depends on the server being available.
Storage networking allows data to be accessed over the network and is therefore not restricted by or dependent on a particular server.
Two complementary storage networking models exist:
Network-attached storage (NAS)
Storage area network (SAN)
An NAS device is considered an “appliance” that is installed directly onto a LAN and provides file-oriented access to data. The data stored on these high-performance devices is physically separate from the servers themselves and thus can be accessed by many different protocols. For example, files can be accessed with IP applications (such as Hypertext Transfer Protocol [HTTP] and File Transfer Protocol [FTP]), and the devices can also support file-sharing protocols such as the Network File System (NFS). NAS provides scalability and reliability but can also produce a lot of traffic because data travels between the NAS device, the server, and the client requesting it, all on the LAN.
In contrast, a SAN is a dedicated, high-performance network infrastructure that is deployed between servers and disks (called storage resources), as illustrated in Figure 10-2. The disks are interconnected in a separate network that is accessible from the servers. Clients communicate with servers over the LAN (and over a WAN), while servers communicate with disks over the SAN.
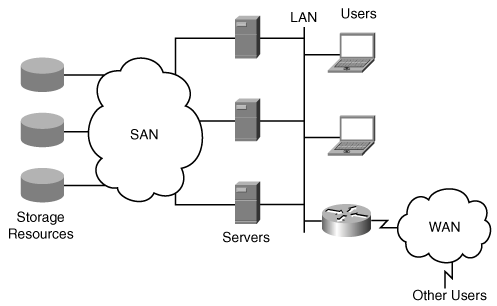
SAN technology allows a mixture of server platforms and storage devices. Within a SAN, a Fibre Channel infrastructure is typically used. Fibre Channel provides high-speed connectivity over relatively long distances, allowing functions such as backups to be performed quickly on a dedicated network.
Because Fibre Channel is not a well-known technology and is expensive to implement, the following two alternative SAN protocols, which use IP, have been developed:
Fibre Channel IP (FCIP)
Small Computer Systems Interface over IP (iSCSI)
FCIP interconnects SAN islands over an IP network by providing a transparent connection between the Fibre Channel networks. With FCIP, Fibre Channel frames are encapsulated within IP packets, creating a tunnel between two Fibre Channel devices connected to the IP network. The IP network provides the connectivity between the SAN islands, including over a WAN. The IP network uses the Transmission Control Protocol (TCP) to provide reliable delivery.
The iSCSI protocol is based on the Small Computer Systems Interface (SCSI) standard that has been around for a long time for communication between PCs and their attached devices, such as printers, disk drives, and so forth. SCSI uses block-oriented access, in which data is formatted into blocks before being sent. SCSI commands, for example, for reading and writing blocks of data, are also used in Fibre Channel technology.
The iSCSI protocol enables servers to communicate with Fibre Channel storage over an IP infrastructure by encapsulating the SCSI commands and data into IP packets and using TCP’s reliable services. Routers with iSCSI capabilities connect iSCSI devices to Fibre Channel storage.
Note
Further information on storage and SANs can be found at http://www.cisco.com/go/san and http://www.cisco.com/go/storage, and in the Cisco Press books Storage Networking Fundamentals: An Introduction to Storage Devices, Subsystems, Applications, Management, and File Systems, by Farley, and Storage Area Network Fundamentals, by Gupta.
IPv6 is the next generation of IP, created to overcome the limitations of IPv4. Although IPv4 has served the Internet well, IPv4 addresses were not allocated efficiently—a global shortage of addresses exists, especially in the developing world. The use of private IPv4 addresses and Network Address Translation (NAT) (explained in Chapter 3) has meant that we have been able to cope so far. However, as more people become connected to the Internet with more devices, the ever-increasing need for IP addresses isn’t about to disappear.
IPv4 and IPv6 have some similarities and some differences. To compare them, we start with the IPv6 packet header, as illustrated in Figure 10-3.
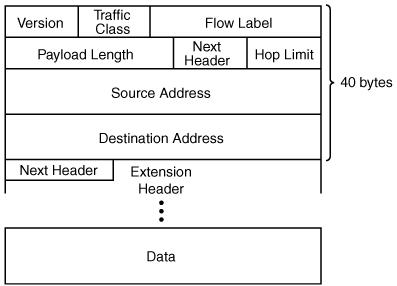
One noticeable difference between the two versions of the Internet Protocol is the size of the address: IPv6 addresses are 128 bits long, four times larger than IPv4 addresses. Those network administrators who struggled with calculating IPv4 subnet masks might wonder how they will cope with 128-bit IPv6 addresses. However, there is good news—these 128-bit addresses don’t have to be typed into devices; rather, IPv6 devices can automatically configure their own addresses (with minimal typing on your part). IPv6 devices can even have multiple addresses per interface.
Other fields of note in the IPv6 header are as follows:
Traffic class—. This 8-bit field is similar to IPv4’s type of service (ToS) field, which marks traffic for quality of service (QoS).
Flow label—. This 20-bit field is new in IPv6. It can be used by the source of the packet to tag the packet as being part of a specific flow. This feature allows routers to handle traffic on a per-flow basis, rather than per-packet, providing faster processing. The flow label can also be used to provide QoS.
Hop limit—. This 8-bit field is similar to the IPv4 Time to Live (TTL) field. It is decremented by each router that the packet passes through; if it ever reaches 0, a message is sent back to the source of the packet and the packet is discarded.
Rather than using dotted decimal format, IPv6 addresses are written as hex numbers with colons between each set of four hex digits (which is 16 bits); we like to call this the “coloned hex” format. An example address is as follows:
2035:0001:2BC5:0000:0000:087C:0000:000A
Fortunately, you can shorten the written form of IPv6 addresses. Leading 0s within each set of four hex digits can be omitted, and a pair of colons can be used, once within an address, to represent any number of successive 0s. For example, the previous address can be shortened to the following:
2035:1:2BC5::87C:0:A
Similar to how IPv4 subnet masks can be written as a prefix (for example, /24), IPv6 uses prefixes to indicate the number of bits of network or subnet.
The following are the three main types of IPv6 addresses:
Unicast—. Similar to an IPv4 unicast address, an IPv6 unicast address is for a single interface. A packet that is sent to a unicast address goes to the interface identified by that address.
Anycast—. An IPv6 anycast address is assigned to a set of interfaces on different devices. A packet that is sent to an anycast address goes to the closest interface (as determined by the routing protocol being used) identified by the anycast address.
Multicast—. An IPv6 multicast address identifies a set of interfaces on different devices. A packet sent to a multicast address is delivered to all the interfaces identified by the multicast address.
Broadcast addresses do not exist in IPv6.
There are three main types of unicast addresses,[5] as follows:
Global unicast address—. Similar to IPv4 public unicast addresses, IPv6 global unicast addresses can be used on any network. Addresses in this group are defined by the prefix 2000::/3—in other words, the first 3 bits of the hex number 2000, which is binary 001, identify this group of addresses. A global unicast address typically has three fields: a 48-bit global prefix, a 16-bit subnet ID, and a 64-bit interface identifier (ID). The interface ID contains the 48-bit MAC address of the interface, written in an extended universal identifier 64-bit (EUI-64) format.
Site-local unicast address—. These addresses are similar to IPv4 private addresses. They are identified by the FEC0::/10 prefix (binary 1111 1110 11), and they have a 16-bit subnet and a 64-bit interface ID in EUI-64 format.
Link-local unicast address—. This type of address is automatically configured on an interface by using the link-local prefix FE80::/10 (binary 1111 1110 10) and the interface ID in the EUI-64 format. Link-local addresses allow multiple devices on the same link to communicate with no address configuration required.
The IPv6 stateless autoconfiguration process allows IPv6 devices to be automatically configured and renumbered. Routers send out advertisements that include the prefix (/64) to be used on the network. The device then automatically concatenates its MAC address, in EUI-64 format, with this prefix to create its own address.
A few other types of unicast addresses exist; they are used for communicating between IPv4 and IPv6 devices or transporting IPv6 packets over an IPv4 network. These addresses would be used when migrating from IPv4 to IPv6.
Note
Further information on IPv6 can be found at http://www.cisco.com/go/ipv6.
In this chapter, you learned about four technologies that can be useful in your networks; the following topics were presented:
IP multicast, which enables data to be sent from a source to a group in the most efficient way. The data travels from the source as one stream as far as it can in the network. Devices only replicate the data if they need to send it out on multiple interfaces to reach all members of the destination group.
Increasing network availability, based on the business objectives, by using redundancy and having the appropriate processes and procedures in place.
Storage networking, which allows data to be accessed over the network instead of being embedded in or directly attached to servers.
IPv6, the next generation of IP, which was created to overcome the limitations of IPv4.
| 1. | “Designing and Managing High Availability IP Networks,” Networkers 2004 Session NMS-2T20, http://www.cisco.com/warp/public/732/Tech/grip/docs/deploymanage.pdf. |
| 2. | “Availability Measurement,” Networkers 2004 Session NMS-2201, http://www.cisco.com/warp/public/732/Tech/grip/docs/availmgmt.pdf. |
| 3. | Gartner Group, as reported in “Availability Measurement,” Networkers 2004 Session NMS-2201, http://www.cisco.com/warp/public/732/Tech/grip/docs/availmgmt.pdf. |
| 4. | “Cisco AVVID Network Infrastructure for Storage Networking,” http://www.cisco.com/warp/public/cc/so/neso/stneso/tech/avvis_wp.pdf. |
| 5. | “The ABCs of IP Version 6,” http://www.cisco.com/application/pdf/en/us/guest/products/iosswrel/c1127/cdccont_0900aecd8018e369.pdf. |