
2
The Cloud Era and Identity
This chapter will discuss the current technology landscape. It will provide a basic idea about the trends, the evolution of technology, and the typical challenges of identity management and governance at this moment in time. Knowing the current technology landscape promotes interoperability because then, organizations can easily collaborate by using common standards and enterprise architects are equipped with the means to design modern, secure, and reliable applications.
This chapter is focused on preparing you to better understand the technical details that will be provided in the upcoming sections.
In this chapter, we’ll cover the following topics:
- The cloud era
- Identity in the cloud era
- The challenges of identity
- The cloud identity
- A hybrid identity
- The future of identity
The cloud era
The cloud is boosting productivity and changing the components and tools used in application architectures, which, in turn, are affecting the way software is designed.
As a matter of fact, according to Gartner’s research, the total cloud market will reach something around 600,000,000,000 (billion) USD of overall revenue before 2023 with a double-digit percentage increase year by year.
As outlined in the previous chapter, user requirements are evolving, growing, and changing, and as a consequence, the technology paradigms, standards, and patterns are following the user requirements and evolving in parallel. In this chapter, we are going to have a detailed look at the impact market change has had on technology and software development, specifically identity.
We’ll start by viewing the present-day technology from a high-level point of view, regardless of the specific identity. If we think about IT a few years ago, there was the concept of a system administrator or infrastructure consultant and software developer or dev consultant. This distinction exists today as well but the line between them is getting more blurred every day. That is because, until a few years ago, companies used to have their own data center and needed system administrators to ensure the infrastructure worked properly; in the same way, they needed software developers to ensure the software was developed and that it worked. The cloud has developed and is changing our understanding of concepts.
Infrastructure is considered to be a commodity and not something companies need to administer anymore. System administrators are gradually pivoting their skills to support their companies in different and more efficient ways. Today, an infrastructure consultant is the one who takes care of either the Kubernetes cluster being properly configured or an infrastructure-as-code pipeline working correctly, rather than focusing on server configuration as happened in an on-premises environment. In the DevOps world, the system administrator works closely with software developers and their job roles merge at multiple junctures. If we think about it, an infrastructure-as-code pipeline is similar to a pipeline that follows the same principles of code development.
The following is a graph that is going to show how the most famous on-premises technology had been superseded by many cloud providers, according to Google’s search engine trends:
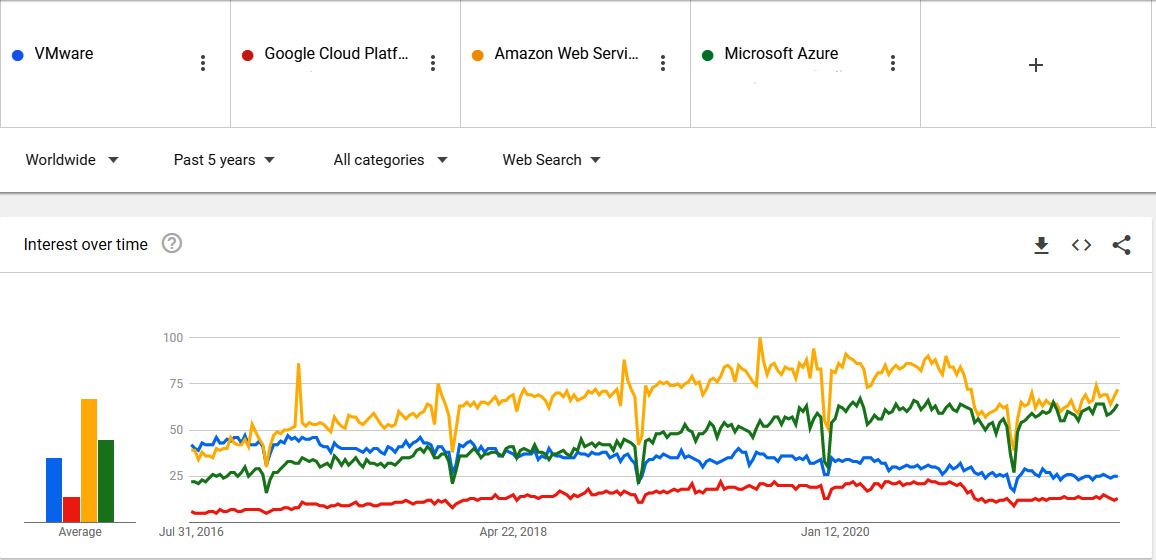
Figure 2.1 – Evolution of cloud trends over time versus the most famous on-premises virtualization according to Google trends
Let’s have a look at the implications and how identity fits into the picture.
Living in a cloud era doesn’t mean simply offloading some IT complexities to the cloud providers. Living in a cloud era is about the uptime of services and whether these services are accessible every time (ideally) and everywhere from heterogeneous devices.
Living in a cloud era also means that more services are exposed to the internet and, hence, more accessible. Additionally, it also means there is a user-centric approach where the ease of service adoption and productivity capabilities for an employee or a customer using the service is one of the most crucial aspects to consider because it is indirectly connected with monetization. All of this has a direct implication for security and identity, which are two highly coupled factors in the cloud era.
It is not possible to understand the impact of the cloud on identity if we don’t try to understand how security paradigms change in the cloud first.
In the pre-cloud era, we worked for different institutions such as banks, public administration, and commercial companies that used to have a very weak security posture in their internal network. They used to pay attention to and invest in enforcing the network perimeter with firewalls and making the system inaccessible from the outside. This made them feel safe. The fact, however, was that to ensure passwords were strong and best security practices were adopted, a constant inspection of the internal perimeter, in addition to process revision, was required, and the standards that needed to be followed were pretty expensive. That’s why many companies only focused their investments on firewalls, reverse proxies, and web application firewalls to prevent access from the outside. This has been the security approach of many companies in the pre-cloud era – a strong perimeter nobody could get past and usually very weak security defense within the company. We can compare it to a medieval city with very high and protected walls but with no weaponry or protection inside, where, if an attacker had entered, they could have killed everyone.
However, this practice wasn’t actually recommended, even in the past. The common suggestion was to have good security on the inside too and always work under the assumption that an attacker has already entered (a defense-in-depth approach). The reality, however, for most enterprises that we visited was different. We worked for several banks and government entities that had very simple passwords, which a hacker would have guessed in a couple of attempts. Despite our recommendations to enforce internal security processes, it never happened and wasn’t seriously perceived as a priority. We went back to these companies a few months ago and found that the company had finally migrated to the cloud and all our previous pieces of advice had finally been implemented.
Let’s have a look at the rationale behind this – why the cloud has been a driver to adopt an in-depth defense strategy within companies rather than just at the boundary.
Cloud services, especially Platform-as-a-Service (PaaS) ones, are created to be accessible through the public internet. Despite cloud providers providing a mechanism to insert PaaS into private networks, placing them in a network is usually expensive, and cloud services, in general, don’t have a network. The idea is to be able to develop a service quickly and make it easily available for internal users and consumers. This is where identity comes into play, as it is turning out to be one of the most important security measures to ensure services are not improperly accessed.
To get an idea of how the multi-factor authentication (which will be discussed in greater detail in later chapters) security measure trend has evolved over the last 5 years, refer to the graph, which outlines the trend according to Google (source: https://trends.google.com):
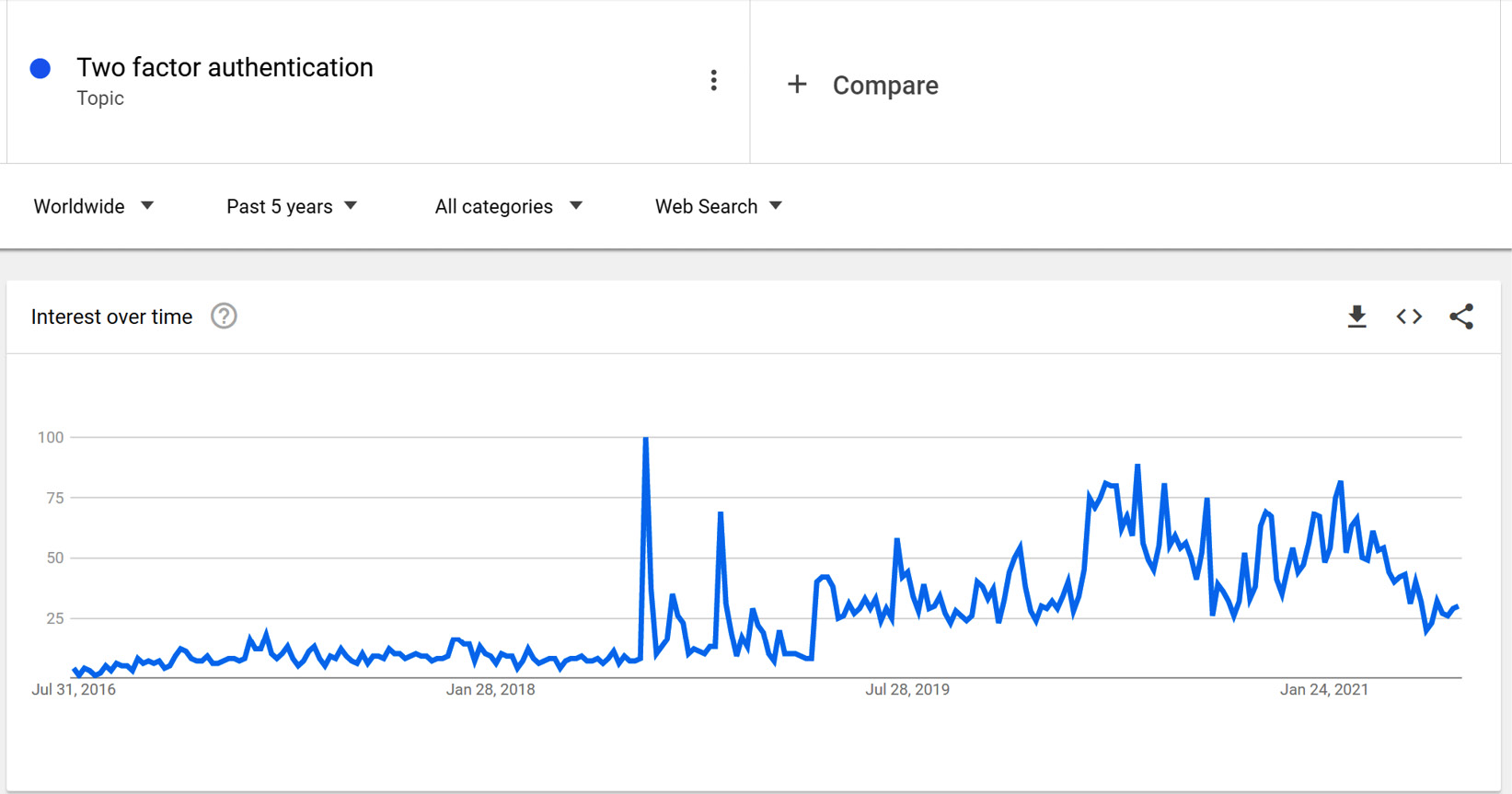
Figure 2.2 – The search trends for two-factor authentication on Google in the last 5 years
With the cloud, a stronger security mechanism is required for identity verification. This doesn’t mean that two-factor authentication is new. As a matter of fact, it existed even before the cloud era, and many providers made it available for on-premises installation. It’s just that it was not a priority for companies because of their security boundaries. That’s the reason why identity management is the foundation of modern security.
Zero-trust security principles are now widely adopted by many companies from different markets. This makes them more confident to embrace cloud technology, reduce time to market, become more agile, and reduce security exposure.
The cloud didn’t just pivot priorities in terms of security principles; it enabled a new protocol to be used in an open ecosystem (the internet) rather than in an internal enterprise accessible with VPN only (an intranet).
Figure 2.3 shows the trend comparison in the last 5 years, according to Google Trends, between an authentication protocol commonly used on-premises (Kerberos) with OAuth, which is a protocol commonly used on the public internet today that implements a delegation framework that authorizes applications to act on behalf of a user:
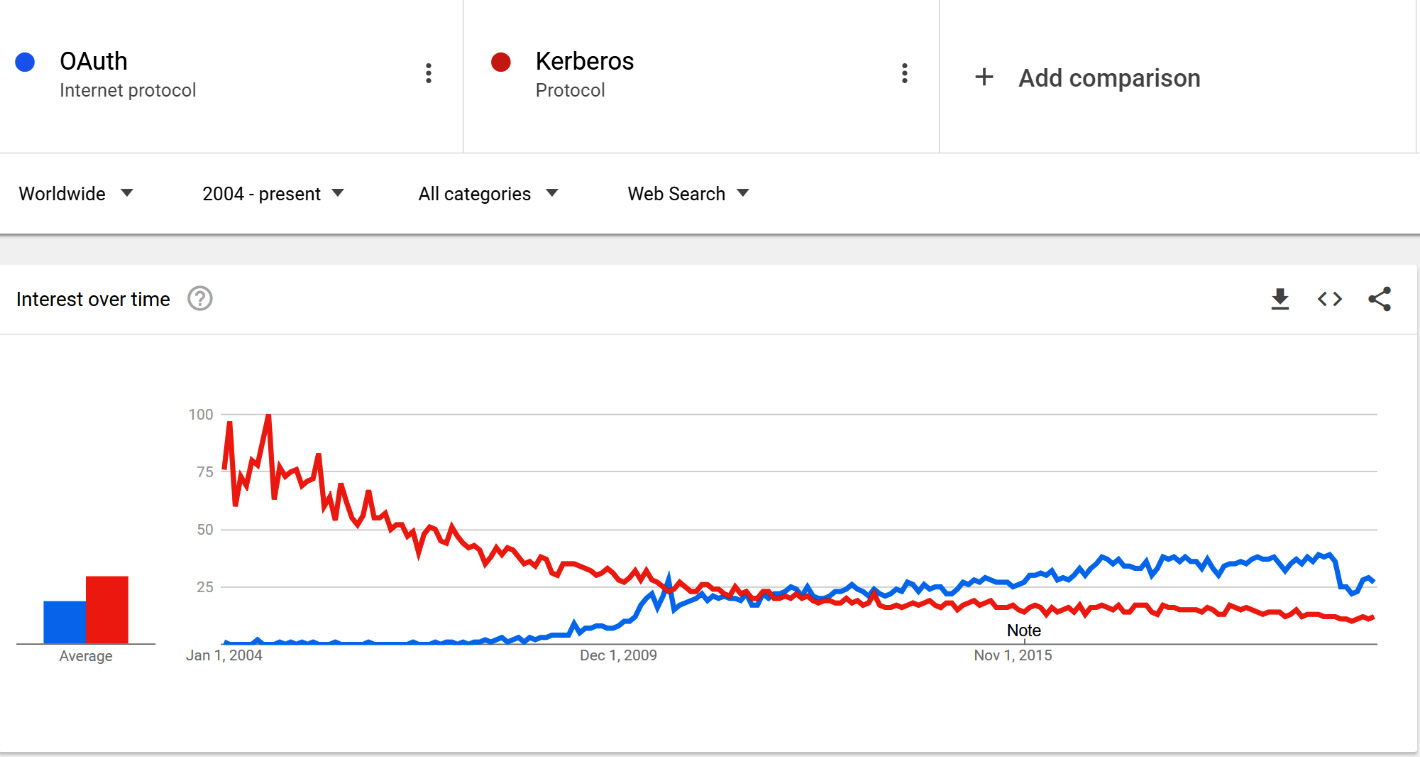
Figure 2.3 – Trend comparison between a historical enterprise protocol (Kerberos) versus OAuth
Another important implication of the cloud is that architectural design paradigms have changed – today, there is the concept of microservices applications, which are usually applications designed with independent components and an independent life cycle. Having these components decoupled means they can be built and deployed independently and can even be written in different programming languages, as they are usually interconnected through the HTTP protocol. They can also be developed by different independent software companies.
Gaining this kind of component granularity in a cloud solution will enable better scaling (each component can scale independently to the others) and control (developers do not need to know about the whole complexity of the application; they just need to know the contracts between components and about the single component they are developing). This means that every time an independent portion of the application needs to communicate with another independent block, authentication takes place, which, in turn, has an impact on identity. To seamlessly integrate microservices, a common identity system should be used to reduce complexity while increasing interoperability and trust between the different components of the application.
Another architectural trend is to distribute application components across different hosting platforms without letting developers worry about where their code is actually running, also known as a serverless application. This pattern is very similar to microservices. In microservices, the services often communicate through a public channel and not within an internal network, protected from external access. In times such as these, when a service communicates with another on a public channel, identity management is even more important from a security perspective because it is sometimes the only security mechanism in place. This can help us understand why reliable authentication is paramount for these kinds of architectures.
It is paramount for an enterprise to implement a clear identity governance strategy and, most importantly, adapt itself to a very fast-moving world, where protocols are evolving continuously, to guarantee further reliability and improve security principles.
Designing a next-generation identity system requires specific attention from enterprise architects who want to take advantage of cloud capabilities. Too often, different OAuth Identity Providers (IdPs), or even custom ones, are used by developers of the same enterprise without clear guidelines or criteria for which one to use and why. Other times, we can find situations where a single enterprise adopts one IdP to authenticate on a specific API and another IdP for a different one. This creates chaos and challenges whenever an application needs to take advantage of both.
That’s the reason why identity services and, as a consequence, authentication mechanisms need to be carefully designed in advance so that developers can take advantage of decisions taken by an architect with the full picture in mind.
Now that we have an idea about the importance of identity in the cloud era, it is time to take a closer look at what is out there and what pillars an enterprise needs to take into account to be cloud-ready and prepared for the future.
Identity in the cloud era
Nowadays, there are plenty of standards, protocols, and practices related to identity. Some of them have been outlined in the previous chapter and are must-know concepts for an identity expert. Regardless, these concepts can get very complicated.
Just to give a brief idea of what we are talking about, the following is a list (but not an exhaustive report) of the available standards at the time of writing. It is important to note that some of the standards or protocols we have mentioned are still in draft (under development) at the time of writing:
- Passwordless:
- World Wide Web Consortium (W3C):
- WebAuthn
- FIDO:
- Client to Authenticator Protocol (CTAP)
- World Wide Web Consortium (W3C):
- Authentication/authorization:
- OpenID Foundation:
- OpenID Connect
- Continuous Access Evaluation Protocol (CAEP)
- Shared Signals and Events
- FastFed
- OpenID Connect Federation (https://openid.net/specs/openid-connect-federation-1_0.html)
- IETF:
- OAuth
- System for Cross-Domain Identity Management (SCIM)
- Grant Negotiation and Authorization Protocol (GNAP)
- OpenID Foundation:
- Decentralized identity:
- DIF:
- Presentation Exchange
- Sidetree and ION
- Zero-knowledge proof protocol (https://www.blockchain-council.org/blockchain/zero-knowledge-proof-protocol/)
- Well-known Decentralized Identities (DID) configuration
- Credential Manifest
- IETF:
- JSONPath
- W3C:
- Decentralized Identifiers (DID-core) (https://www.w3.org/TR/did-core/)
- OpenID Foundation:
- Self-issued OpenID provider
- ISO
- Overview of existing Distributed Ledger Technology (DLT) systems for identity management
- Overview of trust anchors for DLT-based identity management
- DIF:
- Cards and security devices for personal identification:
- Information security, cybersecurity, and privacy protection:
- ISO:
- 27560: Privacy technologies – Consent record information structure
- 24760-2: A framework for identity management
- 29115: Entity authentication assurance framework
- 27554: Application of ISO 31000 for identity management-related risk
- ISO:
We have assisted a small number of enterprises that had applications with custom authentication protocols that didn’t follow any standard in their portfolio. This prevented smooth interoperability between the two authentication systems, which, for instance, would have been integrated if they had used a standard federation protocol instead. This is, of course, a bad practice, as we’re going to understand in the rest of this section.
We are living in an era where not only identity but also technology, in general, represents a core asset of almost every company in the world. Cloud solutions need to be reliable and scalable and, as such, standardization matters. Moreover, we are living in a cloud era where laptops, mobile devices, and sensors need to be to be authenticated and authorized seamlessly to the systems regardless of where they are in terms of physical location. If a company wants to provide these capabilities and be properly prepared in the cloud era, these are the points that need to be taken care of, which are true for identity as well:
- Standardization
- Portability
- Reliability
- Security
- Agility
We will try to understand why they are so important in the upcoming sections.
The pillars of a cloud company
Standardization is a core concept in IT, which is not only valid for identities but also forms the core principles for most things concerned with IT.
As we go through this section, we’ll see that the five core pillars of a cloud company are centered around the concept of standardization. Standardization is a necessary condition for all the other pillars to exist.
The following diagram will report the core pillars required by a company that wants to embrace the cloud. Standardization is the central one and all the other pillars are based around it:
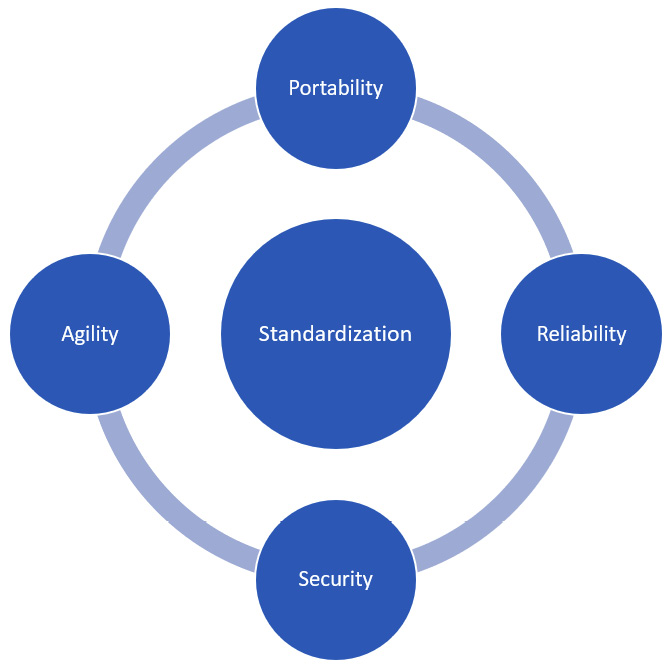
Figure 2.4 – The pillars of a cloud company
According to igi-global.com, this concept is defined as follows:
(https://www.igi-global.com/dictionary/interoperability-medical-devices-information-systems/28157)
This definition is true for enabling interoperability not only across different companies that need to adopt a common standard but also within a single company to ensure they adopt something that is well-proven and maintained by a group of experts.
Setting standards and rules that are universal for all companies across the board is important for a number of reasons, such as the following:
- Portability: Something can be portable to another platform if that platform follows the same standards.
- Reliability: Adopting standards that are well-tested and enterprise-ready provides more assurance and reliability of the overall solution wherever the standard is adopted.
- Security: If something is a standard, it often implies that it’s adopted widely and so is proven to be reliable and secure. Standardization often ensures that specs can be followed at scale by replicating the standard adoption, which, in turn, is a concept connected to the capability to be agile and is represented by the agility pillar.
- Interoperability: This enables companies or manufacturers to create products that can interact with each other.
To understand the concept better, let’s suppose there’s a company that developed its own authentication and authorization protocol for its own applications and defined it as a standard protocol to be adopted inside the company. Can we then say that they are following standards? Well, not really. A standard is supposed to be widely discussed and broadly adopted to become truly advantageous for its users. Just establishing a new standard developed by ourselves for our company does not guarantee that it is reliable and secure. Standards can indeed enhance reliability and security. In these instances, the employees or a restricted circle of people within the company who developed the standard cannot be asked to prove the reliability and security of the standard. In other words, this protocol would not be a standard outside of the company. Moreover, the company needs to maintain and invest effort, time, and money to keep the standard up to date in the cloud world, which evolves faster than ever. This is something that a company may want to avoid. Just as an example, let’s talk about the security aspect. A hacker may exploit our standard protocol in a way that the small group of people who developed it didn’t think about. A vulnerability exploit would require much more effort on a protocol adopted worldwide, where security exploits are usually published and fixed. The previous example is perfectly in line with security by obscurity and security by design, as system security should not depend on the secrecy of the implementation of its component. The same example can be extended to the reliability of a protocol. Generally speaking, something is more reliable if it is widely adopted and proven.
This is how the adoption of international or de facto standards that are widely adopted makes a positive difference in multiple ways. Contrary to the early days of IT, it is very rare nowadays to come across a company that wants to develop its own standards.
Agility and portability are other important factors to take into account. Since these terms are strictly connected, we are going to cover them together. Agility is the ability of a company to create efficiency with a low time to market. Portability is the capability of a company to move from one platform to another with zero or very little effort. Following a standard can enable a company to adopt a standard on multiple platforms and, as a consequence, move across cloud environments easily, rather than developing code or creating ad hoc customization. Let’s suppose our application adopts a standard authentication protocol; the company can decide years later to move to a different IdP or cloud vendor that has adopted the very same standard without hassle. This is also important since most companies want to avoid vendor lock-in and also be free to choose any vendor without technical restrictions. This is an example of agility enabled by embracing standardization.
Let’s take a look at the top challenges concerning identity.
The challenges of identity
When we think about the definition of a new specification, a new standard, or a new protocol in the identity area, we may imagine a lot of experts having multiple meetings to look for an optimal solution and define the perfect standard. What we tend to underestimate is that these experts cannot invent a new protocol without taking into account several technical constraints and the technical limitation of the market. In other words, their output is usually a trade-off. They need to consider how the browsers work, how HTTP works, what the behaviors of the browser on specific HTTP returning code are, and how the standard they are going to define usually sits on top of this. They cannot just invent what they believe is a perfect protocol from scratch.
This is because the history of IT and, more specifically, the internet clearly shows that de facto standards are much harder to bypass – we cannot force a model if this model requires a change in technology that is not yet implemented. In the early days of the internet, there was an attempt to force the adoption of the OSI stack. This didn’t work because TCP/IP was widely used at the time and that’s what became a standard.
We cannot, for instance, define a standard that implies behaviors a browser does not yet implement and force it. Likely, it will not work. Suppose we try to access an application we are not yet authenticated against and we want to prevent our username and password from being exposed to the application. We need a way for the user not to be prompted again for their credentials. One of the few ways to ensure the user is authenticated without submitting the password directly to the application is to take advantage of the HTTP status code 302. The related browser behavior is going to take the user to a different page and take advantage of another redirection to take the user back to the original application once they have provided their credentials to the IdP. This behavior will be better explained later in the book when we cover the technical aspects of OAuth flows.
It’s important to keep in mind that a spec represents a trade-off between the possibilities offered by the current technology standards and the objective of this spec. In the case of OAuth, we’re talking about a trade-off between the best grade of reliability and security for authentication and the features offered by the technologies, such as browsers and HTTP.
Another thing to consider when defining a new protocol is who is going to consume it. OAuth, for example, is a general-purpose protocol that is supposed to be consumed by both internet and enterprise users (see also the Digital transformation – the impact on the market section in Chapter 1, Walkthrough of Digital Identity in the Enterprise), unlike many other protocols, such as Kerberos, which are more enterprise-oriented. Making the protocol usable for both markets is another degree of complexity that makes the challenge for the authors even bigger. When creating the OAuth specification, just to give you an example, over the course of 22 revisions of the standard, the web and enterprise contributors continued to disagree on fundamental issues. The only way to resolve the disagreements and continue making progress was to pull out the conflicting issues and put them into their own drafts, leaving holes in the spec that were called extensible. All of this may create ambiguity and complexity during the definition of a standard, which, as you may understand, is not an easy job at all.
One thing that is worth noting is that at the moment of writing, there are some trends driven by important internet players (such as Google, Microsoft, and Apple) that may change certain behavior of browsers. There is a common wish to prevent third-party cookies from being used and the main browser makers are finding alternative ways to achieve a similar goal. This topic is out of the scope of this book; for further information, we recommend watching this interesting video that covers the topic in depth: https://www.youtube.com/watch?v=1g2uQfP1Q3U&t=138s. What we want to highlight here is that browsing is evolving as well, and as a consequence, the constraints are changing and new opportunities for even more effective, emergent protocols approach.
Once a spec becomes available, the next step is to understand the degree of adoption, and OAuth is one of, if not the, best trends in the area of identity.
In any case, regardless of the protocol that needs to be adopted, when we are focusing on the enterprise, one of the most important things is to define standards to be adopted and followed even within the company. When a company creates new applications that need to interact with each other or, as outlined in the The cloud era section, even parts of the application that interact with each other, this requires defining a common model, as a model is important for avoiding anarchy and keeping a good governance model. This is where the enterprise architect comes into the picture. They need to dictate what standards the company intends to adopt for each possible case, and they need to define guidelines. Let’s look at an example of why an enterprise architect must do this by contextualizing what is happening right now in the enterprise area.
Nowadays, companies are focusing on software development to support the business, rather than on infrastructure to support software development, and as a consequence, the skills required in IT are pivoting as well.
During our experiences, we noticed that, often, software development is outsourced to external companies, which are focused mainly on mere delivery. These external companies usually don’t focus on important aspects such as identity management and security. Their goal is to achieve the most with the minimum effort to increase the margin, or in other words, the dollars they are going to gain from a specific engagement. According to our experience, in these circumstances, it is likely that an external company will strictly follow only the basic requirements in the contracts and not always the best practices. This scenario is where a good enterprise architect of the company comes into play – they need to provide requirements that include quality, security, and extensibility of the solution. For example, suppose an external company or vendor has been contracted by your company for the development of an API. This API can be written in many different ways, but in order to take advantage of OAuth protocol capabilities, which will be outlined later in the book when we cover the technical part, it may be important for this API to handle different scopes. As a matter of fact, a consumer may be interested in only reading specific content and, as such, requires an access token that only has the read scope, which implicitly means that they are not allowed to write, in order to follow the least-privilege principle and best practice. If the API in question is not developed to handle a scenario such as this, it may not be possible to take full advantage of the OAuth protocol, which suggests the usage of scopes in the token instead.
The concept is broad, and what we’ve discussed is just the current context we have. You may have already read about some examples of other challenges in the chapter. There are challenges to defining an identity strategy, such as API reusability, so we are not going to focus further on that. We assume that at this point, you have a high-level idea of why having an identity strategy is important.
The cloud identity
In identity, standards are a serious thing. According to the Business Dictionary (https://businessdictionary.info/), a standard is defined as a “formulation, publication and implementation of guidelines, rules, and specification for common and repeated use, aimed at achieving the optimum degree of order or uniformity in a given context, discipline, or field.” This sentence encompasses brilliantly why standardization is so important – by adopting standards and protocols commonly agreed upon by a vast community of people, enterprises are enabled to make choices without having an active participation in the realization of the model that needs to be developed.
In the previous chapter, we talked about the cloud being a hugely transformational phenomenon that has greatly impacted our lives by making a plethora of services available to people in all parts of the world, all thanks to the distributed nature of cloud services.
Up-and-coming companies were provided with a series of ready-to-use tools that allowed them to start their journey to make a profit quickly (whatever that journey was) by using cloud-native services. New companies didn’t have the burden of managing and modernizing an existing IT infrastructure, which was likely to have been used by companies long before the cloud became the most common means of providing services to end users and organizations.
New companies started building their IT infrastructure from scratch (the so-called greenfield scenario) so they could pick up the best technology for their needs from a great number of available cloud services, including those needed to manage their identity assets and everything related to the authentication and authorization of their users. We may now have a good understanding of the importance of having a good identity strategy (this topic will be discussed in greater detail later in this chapter) – cloud services have simplified the adoption and implementation curve of information technologies. However, greater caution should be used when choosing the best service to accommodate your company’s identity needs because that means putting your most valuable asset in the hands of another company, which must be implicitly trusted and thoroughly scrutinized.
Nowadays, several actors provide authentication and identity services as PaaS or Software as a Service (SaaS). The most famous are Microsoft Azure Active Directory (AD), Google Identity, Amazon Cognito, and Okta.
Each of the preceding cloud IdPs has built its own implementation of the web authentication protocols described in the previous chapter by making different technical choices and, at the same time, agreeing on others, such as the adoption of the same token format (JSON Web Token) for OAuth and OpenID Connect protocols. Creating this kind of convention is fundamental for interoperability and healthy competition, where the real key differentiators between one technology and another are the additional features on top of the mere authentication and authorization capabilities defined in the protocol RFCs.
This does not mean that an enterprise architect should ignore how a protocol works just because another organization has already implemented and provided it as a commodity. On the contrary, deeper protocol knowledge and understanding highly simplifies and accelerates the adoption of cloud services because the architect can focus on and harness the real differentiators that a particular service provides as compared to its competitors.
Without diving into the details and the features of a specific cloud IdP (Chapter 8, Real-World Identity Provider – A Zoom-In on Azure Active Directory, is dedicated to Azure AD), let’s try to focus on the different types of identities that a cloud IdP can usually manage. As a matter of fact, an enterprise architect should understand the importance of and the difference between managing cloud-only identities and hybrid identities. Let’s focus on the former now.
A cloud identity directly originates in the cloud and seldom has an on-premises counterpart. As discussed previously, it is unlikely that a newly born company will have the hardware to host its servers. The best way of reducing the go-to-market curve in these particular and common scenarios is to purchase IT services directly from external organizations that provide them as SaaS either through a licensing or consumption model (no upfront costs, just Operating Expenses (OPEX)).
Imagine you are the IT administrator of an emerging start-up and you need to quickly start managing different IT assets of the new company. You will likely be asked at the very beginning to find a solution that allows the management of users and identities. As the passionate IT administrator that you are, you will likely start developing a solution by yourself at first, but once you understand the effort and the time needed to accomplish this endeavor, you will likely shift your ideas into using an existing end-to-end solution that provides a faster and more convenient way to start with (for those who are still interested in creating their own solution, there are several GitHub repositories that may help you with that, such as https://github.com/IdentityServer/IdentityServer4, now turned into a commercial solution).
Now, let’s say that you select the best cloud IdP that fits your requirements – for example, Azure AD. You then start creating all the identities one by one for the people that need an account to access your company’s assets. In the beginning, everything looks fine and you are proud of the great job you’ve done so far. As your company grows, you will, however, likely need to have some automation in place and delegate different business unit accounts and identities of your soon-to-be enterprise organization to different people and different tools. How can you handle this complexity?
Before answering this question, first, we need to distinguish between the concept of identities and user accounts (or simply users or accounts). Identity is a broader term that encompasses the whole life cycle and information regarding a person or employee within a company. This information may include the employee’s salary, family contacts, and contract duration, and, theoretically, all these pieces of information may live independently from the existence of a user account. Typically, the information around a person is stored in a Human Capital Management (HCM) system and it may span different tools and systems within a company.
A user account, on the other hand, can be defined as the security principal associated with a specific identity. A security principal is an entity usually used within an authentication system that can be assigned to one or more roles or permissions for other entities defined within the same authentication system. A user account is comprised of user credentials (typically, a username and a password), which, together with the account’s roles and permissions, are bound to a specific authentication system or IdP. Ideally, a unique IdP should be used to manage all user accounts in one company.
How do identities and user accounts relate to each other? Systems containing information about identities are usually the source of authority for the user accounts associated with them. This means that each identity might have one or more user accounts associated with it, although the best-case scenario is when each identity has only one user account.
If you’ve paid attention, it must be clear now that the problem we are talking about is user provisioning. The user provisioning process is basically the activity that relates identities and user accounts by automating the creation of accounts based on the information of the corresponding identity. A separate user provisioning tool can be used for this goal, which basically interacts with both the system where identities are stored (such as an HCM system) and the IdP (such as Azure AD) to synchronize the information from the former to the latter based on some business logic, such as assign the administrator role to all those identities that have a job role in the IT department. The Azure AD user provisioning tool is shown in the following screenshot:
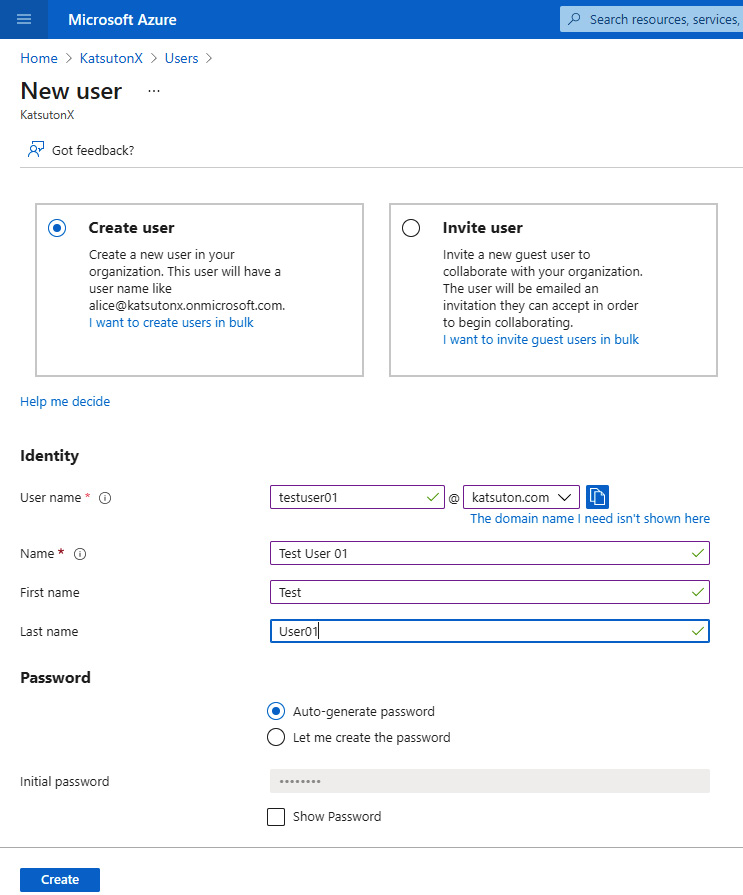
Figure 2.5 – Azure AD user creation example
The Google user provisioning tool is shown in the following screenshot:
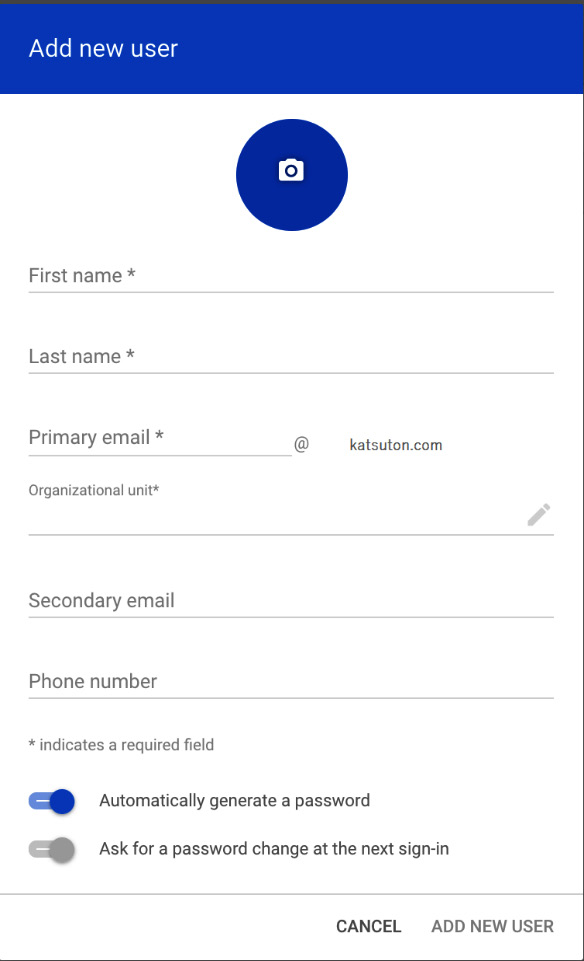
Figure 2.6 – Google user creation example
Using an external tool to manage user provision introduces complexity that an IT administrator has to add to the increasing number of tools that they use every day. If you think about this thoroughly, only the identity system (HCM system) and the IdPs are the systems strictly needed to enable an authentication process based on the user’s information; the user provisioning tool is just a commodity that interconnects them through some business logic.
Is there a way to get rid of a custom rule to reduce complexity by automating this provisioning? The answer is yes, and the solution is the SCIM protocol. SCIM is an open standard protocol for automating the exchange of user identity information between identity systems and IT systems (such as an IdP). SCIM ensures that the identities of employees added to an HCM system are automatically created in an IdP so that user attributes and their profiles are synchronized between the two systems and are also automatically updated accordingly when the source HCM system changes the status or the role of a user. SCIM has standardized the way a user can be provisioned between two systems by defining common endpoints such as /Users and /Groups. It uses common Representational State Transfer (REST) HTTP verbs to create, update, and delete objects and it defines a schema for frequently used attributes, such as the name of a group and the username, first name, last name, and email address of a user.
To get rid of a manual provisioning tool (which can still be used for complex scenarios involving more than two identity systems), the SCIM protocol must be implemented directly using the aforementioned HCM and identity system – the former, as a source of the information, should use the SCIM endpoints published by the identity system.
Luckily, most HCM and identity systems nowadays implement the SCIM protocol and enable integrated scenarios where an automated process is put in place so that the following occurs:
- A relationship is established between the identity in the HCM system and the user account in the IdP
- An automated process is triggered every time a user account needs an update because the corresponding identity has been created, modified, or deleted
- The proper administrative delegation has been set up correctly
The last point mentioned in this list is key to the success of the overall solution enabled by the SCIM protocol. Our main goal was to reduce complexity. How have we accomplished that? Business managers were already used to managing internal and external users under their business unit with an HCM system. A business manager is therefore the owner of the knowledge that provides insights about which resources a particular user is allowed to access, but they have no proficiency (and should not have that) in how an IT system or IdP works. This is where an IT administrator comes into the picture, who knows the technology very well but has no clue about what a user should actually have access to.
By enabling an automated process that integrates an HCM system with an identity system, SCIM highly reduces the complexity of managing user identity and an account’s life cycle by freeing the business managers from knowing how the underlying technologies work, and the IT administrators from knowing a user’s roles and permissions upfront. Once both actors agree on this automated process, they can continue doing their daily job within the scope of this new delegation and segregation of duties and tools.
Once a user account has been successfully created on an IdP, they can start accessing all the applications that trust this IdP using Single Sign-On (SSO). As seen in the previous chapter, when an application federates (trusts) an IdP, it means that it trusts the tokens (proof of authentication) that the IdP issues by checking its signature.
Typically, not all user accounts stored in the IdP (which could be very high in number) must be granted access to a particular application (even if sometimes this may happen) and therefore, the application has to find a way to authorize an authenticated user whose token has been correctly issued by the IdP. Authorization logic can be implemented either directly within the application or in the IdP.
In the case of the former, the application has to build a list of authorized users belonging to a particular IdP. This is usually done by importing CSV files or by manually maintaining a list of users together with their roles and permissions within the application’s local database. This is an error-prone approach that could lead to unsustainable and complex management of user accounts in the long term. The application team also cannot promptly react to the change in the status of a user in the IdP that may change their permissions within the application. When authorization is entirely delegated to the federated application, the IT administrators have limited control over the users’ access policies.
In the latter case, it’s the IT administrator that decides on and implements the authorization policies for the users stored in the IdP in order to allow or prevent them from accessing a specific application. Administrators, however, do not know whether or not a user requires access to an application – a business manager does.
This is where SCIM comes to the rescue (again). We already discussed earlier that SCIM can facilitate and automate the user provisioning process from an HCM system to an identity system. Well, SCIM can also be (and in fact, is) used to provision users from an identity system to applications. This is the most common approach used for modern SaaS applications that federate with most of the publicly available IdPs, such as Azure AD. With this approach, an IT administrator can (again) agree with the business manager upon a specific business logic that can automatically provision, de-provision, or update a user in a SaaS application with specific attributes or roles (for example, all the users that have the marketing department attribute can access the marketing portal). Of course, for the (SaaS) application to support this flow, it must implement and publish a SCIM endpoint.
How does all of this apply to external cloud identities as well? It is very common for an organization to collaborate with an external partner who may need access to an application offered by that company. External partner identities are likely stored in an external IdP that is not directly managed by us. How does user provisioning work in this case? There is no universal recipe for this scenario since it strictly depends on the implementation of the specific IdP, but generally speaking, the following considerations should apply:
- A federation between one company’s IdP and the external one can be put in place.
- External users can be created and represented within one company’s IdP as references or placeholders that contain a sort of link to the user in the external IdP that effectively stores user credentials. Having this representation allows you to define authorization policies directly in the application’s IdP.
- If an external user’s placeholder is not created, then the final applications will likely have to implement authorization policies within the application logic by making decisions only on information (claims) received within the proof of authentication (tokens) coming from the external IdP and relayed by the local IdP.
When it comes to all the applications that an organization offers to their customers, it is common to allow and configure an application to federate with several external IdPs, such as social IdPs, including Facebook, Google, and Microsoft, in order to let the user choose the account they prefer to log in with. This area is intended for consumers, not for the enterprise. For enterprise applications that target Business-to-Business (B2B) collaboration, controls are more strictly secured because the information managed by the applications is likely confidential. Access must, therefore, be granted only to the authorized company’s employees or external collaborators. This is one of the most common reasons why enterprises that manage both customers and B2B applications have different and separate IdPs – their need to have a more diligent security posture justifies greater management complexity.
To summarize, managing cloud identities can be complex, but most of this complexity is simplified today by modern cloud technologies (such as Identity-as-a-Service (IDaaS) solutions) that reduce the time to market of an enterprise identity solution considerably. IDaaS solutions can orchestrate all the aspects of user provisioning, authentication, authorization, and interaction with external IDaaS providers thanks to the standard protocols that most vendors implement today.
In the next chapter, we will extend the concept of cloud identities by explaining how their interaction and interoperability with on-premises legacy identity systems are a requirement for many enterprises. Next, we will understand what hybrid identities are.
A hybrid identity
As already touched on in the previous chapter, before the advent of the public internet and cloud technologies that gradually decentralized the services accessed by an organization outside of the organization’s perimeter, it was sufficient to provide users with an authentication model that granted access to internal assets. Information technology efforts were mainly focused on keeping the perimeter secure and preventing malicious users from breaching security defenses and, consequently, accessing sensitive assets within the organization’s internal network.
Let’s imagine the typical workday of an employee, Alice, in the early 2000s. Alice is a part of the engineering team of a big manufacturing company and she needs to use several services to fulfill her role and responsibilities. Alice turns on her Personal Computer (PC) first thing in the morning and logs into the operating system. She then starts her mail client to access her emails. Next, she starts the AutoCAD software, saves project files to a network file share, and finally, checks the internal human resources portal to check the travel policy so that she can safely book her flight for a business trip the month after.
Let’s analyze the different types of authentications involved in the aforementioned flow and which technologies were likely involved at that time:
- Operating system login: Windows was the most common operating system for corporate client computers that were used by users such as Alice. With Windows 2000 and Windows XP, log-in authentication started using AD as the user repository. As already seen in the previous chapter, NTLM and Kerberos protocols were used for this purpose. Within, an authentication server, called a Domain Controller, was implemented the Key Distribution Center role, which allowed Kerberos tickets to be issued to clients. This enabled SSO to other services that belonged to the same Kerberos realm (also known as a domain) of AD.
- Email client login: If Alice was lucky enough, the authentication within the email client (which would likely have been Outlook or Lotus Notes) was integrated with AD as well; if this was the case, then Alice would have seamlessly single signed-on to the client, which used Alice’s proof of authentication in the background to access the mail server (for example, Exchange Server).
- Network file share login: Depending on the operating system, network file shares were usually accessed through two different protocols – Service Message Block (SMB) for Windows and Network File System (NFS) for Linux. Both can be integrated with Kerberos; the former supports NTLM and the latter supports UNIX authentication.
- Human resources portal login: Web portals were the most flexible services in terms of user authentication technologies. You could find many different implementations – Kerberos or NTLM (Windows) authentication on Internet Information Services (IIS) web servers, local databases, and LDAP against a directory service, to mention just a few.
It becomes evident that the complexity of identity systems before the explosion of the public internet wasn’t negligible. For large enterprises, the transition to modern identity technologies was not straightforward because of the friction of the existing identity solutions they were already using. Technically speaking, it was not feasible to just get rid of the existing systems and fully embrace the new technologies because users still had to use those legacy systems to access the applications that strongly relied on them.
Another important aspect to mention is that organizations were reluctant to move their users’ information outside the safe perimeter that they had built over the years. Security, in fact, was changing too. It was slowly shifting to a new paradigm that didn’t value the frontline defenses that were used at that time anymore but put the users (and therefore the identities) at the center instead. Users were starting to access applications hosted outside their company’s boundaries and, very often, the user was doing that from their personal device outside their company’s network (for example, from their home or a public place such as a hotel). With the shift in trends and use cases that technology had to follow quickly, there were still those sticking to their perimeter and firewall model who didn’t believe that something was really changing, were just too lazy to roll up their sleeves, or, in some cases, simply didn’t have enough money (in terms of investments) to accommodate these changes.
It is not rare that identity and security travel on the same or parallel rails. One change to either of the two will inevitably affect the other one.
So, what about the brave and reckless people that took the leap of faith into changing their security and identity model instead? It wasn’t easy at the beginning. Well, it’s not that easy even today; otherwise, we would have not written this book!
Going back to the brave people, it was hard, because business users wanted to do the following:
- Seamlessly access the new technologies wherever they were hosted
- Continue to access the applications they were already using
- Have just one set of credentials to access all the applications
- Use SSO whenever possible
It was reasonable to a certain extent. This is where hybrid identities enter the picture. Hybrid identity is just a fancy term to describe identities that have a presence in more than one place. Today, hybrid identities are identities that have a presence both on-premises and in the cloud. The on-premises identity and the cloud twin should have a clear link that allows you to treat them as a single entity. This is needed if we would like to ensure the first two requirements mentioned previously are met. Keeping a single set of credentials and enabling SSO, on the other hand, can again be accomplished using federation between a cloud IdP and the on-premises one using SAML, WS-Federation, or OpenID Connect.
Wait a minute – why should we federate a cloud IdP with our on-premises one instead of federating cloud applications directly? The reason is that it is just more convenient to do so. Each time a new cloud application is added to a company’s portfolio, that application has to be federated with the on-premises IdP. Federating directly with the cloud IdP instead requires establishing the federation just once and all the cloud applications will benefit. Even third-party applications that already have a native integration with that cloud IdP can automatically leverage on-premises identities. This is, of course, just the natural outcome of the industry trends in how cloud IdPs have been designed. Consider Azure AD from Microsoft as an example. All Microsoft first-party applications, such as Azure, Office 365 (Microsoft 365), and Dynamics, are natively set up with Azure AD and cannot be set up on IdPs other than Azure AD (although it is possible to establish a federation between Azure AD and a third-party IdP). This is also true for other cloud services, such as Google Workspace and Google Identity, and, in general, this translates to having a single choice when it comes to harnessing these services with an organization’s existing users – federating commercial cloud IdPs with on-premises ones.
This solution allows us to concentrate identity management and governance into IdPs, which simplifies the task of provisioning users to cloud applications using SCIM in these implementations.
In most cases, this translates to choosing just a single cloud IdP in order to minimize the effort of contemporarily managing multiple identity systems at once. No matter the choice taken, the solution should be comprehensive of all the capabilities needed to manage identities regardless of their source of authority. Azure AD, for instance, allows you to manage both on-premises and cloud identities by providing a single pane of glass for hybrid identity management. Let’s talk about how this works by showing you a real-world example involving Alice again.
Alice’s company has started using Microsoft’s first-party cloud services, such as Microsoft 365 and Azure, and therefore, they now have an Azure AD tenant that manages authentication and authorization to these services. Azure AD allows you to create local cloud users, but Alice’s company would like to let their existing users who just have on-premises accounts use these services with their existing credentials and SSO. We need a way to synchronize these users to Azure AD and this is easily done with native tools, such as Azure AD Connect in this case, which takes accounts from on-premises AD environments and provisions them to Azure AD, which will therefore be aware of their existence and consequently enable their management. This is not a new concept. For years, enterprises were used to synchronizing on-premises identities among different identity systems. The cloud IdP is likely just another edge node within their existing user provisioning processes.
With the advance of the decades and the prevalent role of cloud technologies, the weight of an identity management strategy shifted more and more toward cloud IdPs. A cloud IdP very often needs to write back some information on the on-premises identity systems and manage the authorizations and access controls that once were done on-premises. This is needed to enable the transition to a full cloud identity model, which, nowadays, is believed to be the natural evolution of current on-premises solutions. On-premises solutions will most likely never disappear completely because of the nature of some workloads that will be kept on-premises for compliance with local regulatory requirements. Many workloads also have to be close to the edge for performance reasons (such as software that manages plants in a manufacturer). This is why hybrid identities are and will remain important now and in the future.
So, hybrid identities are just an extension of existing on-premises identities, a way to interconnect an on-premises user with its cloud counterpart. Now is an exciting time to work with identities. While most enterprises still struggle a bit to keep up with this new way of governing identities in a hybrid world, a new perspective is coming to light, thanks to the huge developments around blockchain technologies. Let’s try to understand what the concept of Decentralized Identities (DID) is and why this is important for the future of identity management in an enterprise.
The future of identity
Cloud, hybrid, and federated identities have been around for years and still many enterprises are struggling to fully harness their full potential. We hope that after reading this book, you will be one of those people that successfully survived the design and implementation stage of a good identity strategy in their organization.
However, technology is never static; it’s an ongoing stream of change that constantly veers toward the next breakthrough that will radically change our lives, so you may wonder what the next big thing for identity is.
First, let’s understand the factors that contribute to the need to have a different way of managing identities and the credentials associated with them. We already know that credentials are part of our daily lives. We are not just referring to digital credentials but to credentials as a broader concept, such as the government ID that your state has issued to you or the degree you received from your university. You normally use these credentials to benefit from and access specific services in the physical world that are only enabled because you have these credentials (for example, the proof of being a citizen of a state grants you the right to vote during elections). As a matter of fact, it is difficult to express things such as educational qualifications, healthcare data, and other kinds of verified machine-readable personal information on the web, which makes it difficult to benefit from the same commodities we usually benefit from in the real, physical world.
The joint efforts of several organizations contributed to developing different standards to support this view under the W3C umbrella:
- W3C DIDs
DIDs are a new type of identity that uses a common trusted ledger (blockchain) as a secure store to share users’ information among the different actors involved in the authentication process
- W3C Verifiable Credentials Data Model 1.0
Verifiable credentials describe the processes and protocols that all the parties involved in an authentication flow must adhere to in order to verify that the credentials (DIDs) used by the security principal are trustworthy and reliable
Together, these two standards have the potential to shape a new way of managing identities at scale so that it resembles how we use our credentials in the physical world today. Let’s see what they are, why we need them, and how they work.
Individuals (and organizations) use globally unique identifiers in a wide variety of contexts. The vast majority of these globally unique identifiers are not under the control of the individuals in question. They are issued by external authorities (for example, Facebook or Google) that control their whole life cycle without letting individuals such as you and me choose which context they can be used for. Moreover, these identifiers are tightly connected to the life of the organization that issued them, which means they can cease to exist if these organizations want them to. These identifiers are also often subject to identity theft, which leads to their improper use to the detriment of their real owner.
DIDs are a new type of identifier designed to enable individuals and organizations to generate globally unique identities. These new identifiers enable individuals and organizations to prove they own them by authenticating through cryptographic proof (e.g., digital signatures).
The DID specification does not require any particular technology or cryptography to implement the life cycle, including the creation of a DID. For example, implementers can create DIDs based on accounts registered in federated or centralized identity management systems, allowing almost all types of existing identity systems to support DIDs. This is fundamental to creating interoperability between the current centralized, federated systems and the DIDs. You can find an example of the structure of a DID in the following figure:

Figure 2.7 – An example of DID
A verifiable credential, on the other hand, is a way to digitally replace the information included within its physical counterpart. The addition of technologies, such as digital signatures, makes verifiable credentials more trustworthy.
While it is true that many verifiable credentials do use DIDs in the technical implementation of the specification, verifiable credentials and DIDs are not strictly interdependent.
A verifiable credential involves the interaction of the following actors or entities:
- Holder: An entity (typically an individual) that owns one or more verifiable credentials and generates verifiable presentations. A typical holder could be a student of a university, a citizen of a city, or an employee of a company.
- Issuer: An entity that issues claims about one or more subjects (see the following definition) and generates a verifiable credential from these claims. An issuer sends the verifiable credential to a holder that will use these credentials against a verifier as authentication proof. Examples of issuers include corporations, universities, governments, and individuals.
- Subject: This is the entity for whom the claims have been issued within the verifiable credential.
- Verifier: An entity that receives and processes one or more verifiable credentials. Examples of a verifier include employers and websites.
- Verifiable data registry: An entity (typically an information system) that is in charge of the creation and verification of identifiers, keys, and other relevant data, such as verifiable credential schemas, revocation registries, and issuer public keys. It is the decentralized repository containing verifiable information regarding issuers, holders, and verifiers, which is typically implemented through a distributed ledger.
The relationship between these entities is represented in the following figure:
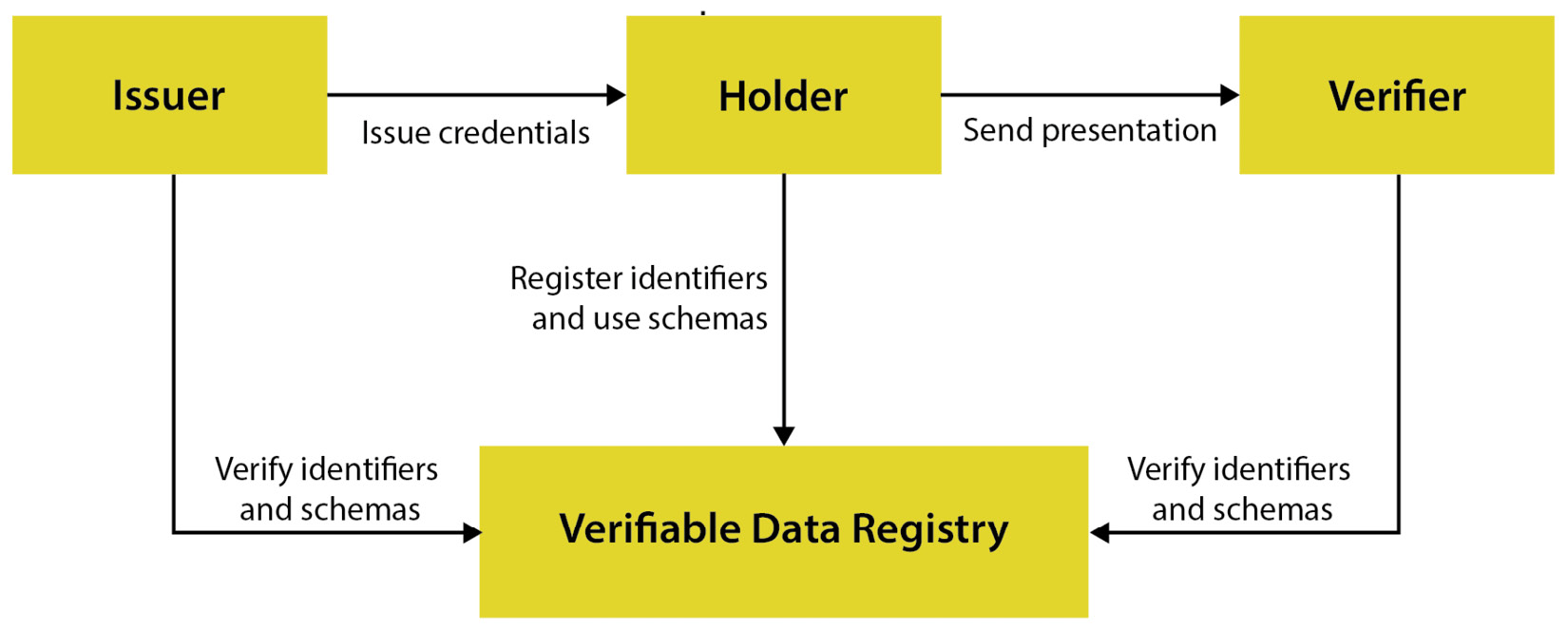
Figure 2.8 – Verifiable credentials example
DIDs and verifiable credentials are promising, and they have great potential to really change how we see and think about digital identities. Some vendors are starting to implement these standards and offer them as a service (for example, Azure AD). Maybe it’s too early to say whether they will be the new de facto standard for managing credentials in the future but we can surely say that today, they are the closest representation of the physical credentials we exchange and use every day to prove that we are who we say we are.
Summary
In this chapter, we explored the differences between cloud and hybrid identities, why they are important for an enterprise, and how they relate to each other. Synchronization protocols such as SCIM help an organization keep its different identity systems under control and allow them to seamlessly integrate legacy and modern identities. This chapter also provided an overview of the current state of technology, and we outlined the points that affect protocol creation, as well as the important pillars an enterprise-grade design needs to take into account. This helped us to not only understand what it is today but also the trends and the possible implications of the next-generation protocols that will be based on technology aspects not yet adopted. A great example of what we can expect in the future is represented by third-party cookie removal by browsers, which, in turn, will likely contribute to evolving protocols and standards.
With these concepts in mind, we are ready to take things a step further, contextualize them a little more in the present, and review the specs on the most used protocol that is adopted in the business world in the next chapter – OAuth.