
9
Exploring Real-World Scenarios
To better be able to focus on what real-world scenarios involve, first, it is important to holistically see the concept of identity within an enterprise.
To provide a broader view, first, this chapter will introduce all the features that a modern enterprise needs to consider regarding identity. This will help you to understand the implications and complexities to be expected in the real world.
The rest of the chapter will then present scenarios we come across in an enterprise when developing solutions, with a particular focus on modern applications. The examples that will be shown will demonstrate microservices applications designed with domain-driven design (DDD) principles in mind.
Most of the assets in a modern enterprise should be authenticated and authorized. The following are some use cases that are purposely very different from each other:
- Employees who need to access their mailbox
- Applications that need to query a database
- The mobile phone of an employee that needs to be registered to enable them to access sensitive information
- An enterprise application that an internal employee is required to access (e.g., an HR application)
- An enterprise application that customers are required to access to consume a service
- An unattended job or process that requires access to sensitive information
- An employee from an external company who needs to access resources within our company
- A customer from an external company who needs to access the API exposed by our company
Such a differing and complex landscape presents multiple scenarios that a typical medium-large company has to handle. It is quite normal for identity management to be inefficient due to the number of heterogeneous situations to handle. Moreover, digital transformation is evolving exponentially; large companies are known for their slowness and most of them cannot keep pace.
As an enterprise architect, it is important to distinguish between these two different levels of complexity: one where we have all the requirements a company needs to guarantee and secure the authentication and authorization of miscellaneous assets within the enterprise, and another where we have what has been the main focus of the book – the ability to guarantee a scalable and easy identity pattern when we, as architects, design an application.
We will cover the following main topics in this chapter:
- The identity features within an enterprise in the real world
- The implications of the company’s structure
- Frontend authentication challenges in the real world
- Backend authentication challenges in the real world
- Authentication challenges for microservices integration
The following section will present an exhaustive view of the identity-based features that a modern organization needs to care about. Going in-depth on each of the bullet points presented in the next section is out of the scope of this book; what is important to understand is how complex the company identity landscape is in the real world.
The identity features within an enterprise in the real world
For the sake of understanding all the complexities related to real-world scenarios and to better capture what a holistic view of identity in a big enterprise may look like, we are going to enumerate all the topics related to identity that a modern enterprise needs to consider:
- Privileged access management (PAM): PAM consists of identity strategies and technologies to manage the full life cycle of elevated (privileged) users who have access to highly confidential corporate or government information and can become targets for cybercriminals.
- Endpoint security: Endpoint security solutions protect user devices that can compromise corporate network security via the valuable identity data stored in them.
- Identity governance and administration (IGA): IGA systems merge identity administration (which addresses account and credentials administration, provisioning, and entitlement management) with identity governance (which addresses the segregation of duties, role management, analytics, and reporting).
- E-signatures and certifications: E-signatures are the digital equivalent of hand signatures and are a legally binding demonstration of consent. Digital certificates are electronic documents that validate claims made by an entity about identity.
- Network and infrastructure security: Network security solutions enable intelligent traffic filtering, performance monitoring, and threat detection to safeguard all the data traversing the network and respond to unauthorized network intrusions.
- Master data management (MDM): MDM helps companies maintain a single source of truth for digital assets, such as customer data. It ensures the accuracy, accessibility, and accountability of shared data across an enterprise.
- Workforce IAM: Workforce identity solutions provide full life cycle management and administration for an organization’s employees, partners, and contractors. Solutions include user registration, authentication, single sign-on (SSO), and access controls.
- Identity of Things: Identity of Things solutions focus on managing device identity credentials, permissions management, endpoint security, and data protection for billions of internet-connected devices.
- Consent management platform (CMP): CMPs obtain and manage proof of consent to collect, share, or sell personal data; they help companies comply with data privacy and protection regulations, such as GDPR and CCPA.
- Behavioral biometrics: Behavioral biometrics is a class of authentication solutions that use dynamic identifiers based on human behavioral patterns. Distinct from traditional biometrics, which uses absolute identifiers such as fingerprints and facial features, behavioral biometrics can be kinesthetic or device-based.
- Identity graphing and resolution: ID graphs map deterministic and probabilistic datasets to correlate online and offline identifiers with consumer identities. Identity resolution matches disparate records and data attributes to create a single, 360-degree customer view.
- Customer IAM (CIAM): CIAM solutions focus on identity management for end users and provide a centralized and managed view of each customer across registration, authentication, authorization, federation, and data capture.
- Biometrics: Biometrics measure a human’s physical characteristics to verify and authenticate an identity. Biometrics encompasses several physiological modalities, including fingerprints, faces, irises, palm veins, and voice.
- User-generated content (UGC) moderation: UGC moderation is how platforms protect their audiences from illegal and inappropriate content. UGC moderation can identify whether an account is human or non-human, providing the ability to remove bad actors before they have a chance to be disruptive.
- User and entity behavior analytics (UEBA): UEBA expands upon traditional cybersecurity tools, looks at the behavioral patterns of humans and machines (e.g., routers, servers, and endpoints), and applies algorithms to detect anomalies and potential threats.
- Mobile identity device intelligence: Mobile identity includes user data (e.g., biometrics and account information) and mobile device data (e.g., location data and device number). Together, solution providers can determine risk signals, prevent fraud, and improve customer experiences.
- Identity theft protection: Consumer identity theft protection solutions monitor personal data for anomalies (e.g., social security numbers and credit card accounts) and provide paths for identity restoration in the event of theft.
- Alternative credit and financial identity: Traditional credit scoring processes exclude millions of potential borrowers who don’t have a sufficient credit history to be scored. Alternative credit promotes financial inclusion by using a more comprehensive range of data attributes to determine a person’s creditworthiness.
- Fraud prevention and risk management (FPRM): FPRM solutions use risk-based approaches to analyze transaction history and network-related activity in order to identify potentially fraudulent or risky behavior patterns.
- Identity wallets: Identity wallets are smartphone-enabled applications that allow individuals to manage their digital identity credentials and data. Digital identity wallets offer control over what information is shared, when, and with whom, facilitating privacy, security, and consent management.
- Identity proofing: Identity proofing is a step up from identity verification and document authentication. It confirms that a user’s identity is associated with a real person and answers the question, “Are you really who you say you are?”
- Regulatory compliance transaction monitoring: Anti-money laundering (AML) transaction monitoring helps financial institutions and money service businesses monitor customer activity and information, such as transfers, deposits, and withdrawals, to prevent financial crime.
- Identity verification (IDV) and document verification: IDV is the process of confirming that a user’s identity is associated with a real person. IDV includes document authentication, which establishes an individual is who they say they are through a government-issued identity document.
- Self-sovereign identity (SSI): SSI promotes the usage of decentralized identifiers (DIDs) that are decoupled from federated solutions, centralized registries, and identity providers (IdPs). With SSI, individuals can maintain ownership of their own portable, interoperable, and consented digital identity attributes.
- Background screening: Background screening is the process of looking up and compiling the employment, criminal, commercial, and financial records of an individual or an organization.
- Enterprise master patient index (EMPI): EMPI solutions assist healthcare enterprises with managing patients’ holistic healthcare records, which may be housed across disparate databases, systems, or entities.
For the purpose of this book, it is not mandatory to understand each of the bullets proposed in the preceding list in depth, although it’s important to keep in mind the whole ecosystem of operations and processes beyond application authentication. In the upcoming section, we are going to review the implication of the company’s structure in terms of software design and choice of IdP.
The implications of the company’s structure
In Anchor, Trends in API Authentication, we have already seen the drawbacks for an organization to have, maintain, design, and pay for multiple IdPs to serve the multiple application architectures in its portfolio.
The purpose of this section is to understand the common reasons why this phenomenon occurs.
This aspect is usually connected to the structure of an organization. Mature companies already embrace DevOps, which is the practice of breaking down silos within an organization to ease collaboration and boost productivity. Companies that still work on silos with a lack of DevOps practices applied are more likely to suffer the IdP proliferation problem explained in Chapter 6, Trends in API Authentication, in the The multiple IdP dilemma section.
The reasons are straightforward: lack of communication and cooperation cannot produce a common strategy for a company, and this can result in different views on different areas that span design patterns, cloud providers, technology stacks, and, of course, identity strategies.
Such concepts are perfectly captured by Conway’s law:
Therefore, the very first step to moving toward a defined identity strategy in the application’s design is to focus on how the organization works.
This is where DevOps practices come into the picture; they can be leveraged to support an organization to be more efficient in the long term if properly applied. They can also be leveraged to break down silos, define common strategies, and, in general, enable a company to produce more homogeneous deliverables with shared principles, especially in terms of security and identity – typically across the whole application portfolio.
When it comes to speaking about DevOps, we find commonly agreed principles but we cannot find any “magic receipt” or “golden bullet” that explains in detail what steps a company needs to apply in order to boost their productivity with these theoretical principles.
The DevOps model an enterprise needs to adopt varies from company to company; if we want to summarize the DevOps principles, we can definitely find cooperation and collaboration as a common denominator within every successful DevOps model. Place collaboration at the center of the enterprise strategy, as it’s a concept that cannot be bypassed to successfully call an organization a DevOps organization.
If you want to explore effective delivery models for your own organization further, it is recommended to read the article at https://web.devopstopologies.com/. This article outlines the advantages and drawbacks of the most typical DevOps patterns and can be an important source of ideas to be refined further and applied to a company.
It is not uncommon in our job to meet customers with different approaches to DevOps and Agile practices.
Agile is a methodology to manage projects in a lean and faster fashion. Agile methodologies (Kanban and Scrum) distinguish themselves from legacy methodologies (Waterfall) with short iterative cycles that can tune the outcome of Agile projects in a few weeks, unlike a legacy methodology, in which tuning the outcome could mean re-evaluating the initial requirements of the project.
The typical scenario we find is where Agile project management concepts are forced within individual teams but every team is a silo by itself. Applying Agile concepts within a team is necessary but not sufficient to have well-defined company strategies and success in the long term. It is underestimated how important it is to have principles, guidelines, and blueprints shared across teams that need to cooperate well on high-level decisions.
Some may complain that Agile project management practices require the team to be self-sufficient, and the preceding statement (regarding cross-team cooperation) can limit the productivity of single teams and can be seen as an Agile anti-pattern. This is not true and it is a matter of trade-offs; dependencies between teams should be limited but not completely removed. This concept is paramount because a wide organization with hundreds of teams, different and potentially contradicting choices, and divergent architectural styles would lead an organization to the following potential drawbacks, among others:
- Economics: Paying multiple licenses for different products to serve the same purpose due to different choices or team philosophies.
- Heterogeneous skill sets: Different choices can lead to divergent types of tech adoption, which would, in turn, imply divergent skill sets across teams. This can limit the ability of a company to swap resources across teams according to market demand (as an example, one team could use Okta as an IdP, with the frontend coded using Angular technology and the backend in Node.js; another team could use Azure B2C as an IdP, with the frontend in Svelte technology and the backend in Java).
- Solutions maintainability: Adoption of different technology will force the production environment to deal with divergent problems of different natures at different points in time. This can span from a punctual technology bug that needs to be fixed to technology updates. The latter would occur at a different point in time according to the technology adopted and its life cycle. This has an impact on multiple areas – not just on identity or security but also on monitoring. For example, a company would have different ways to observe and monitor the solutions in production. All of these can lead to unsustainable maintenance for large firms.
In some circumstances, we noticed that a company still falls under a silo model (multiple teams and divergent strategies) due to a misinterpretation of the Agile principles that suggest a team be able to work independently. It is indeed important to understand that these principles don’t imply the teams don’t work together. It is important to design strategic decisions in a centralized way. If a strategic decision is made within a single team, the company may benefit in the short term but as said, there is definitely a high price to pay in the medium-long term due to the potential gaps between teams or silos, different decisions, different technologies to maintain, and, potentially, different IdPs being chosen. This simple concept may not be straightforward to every firm due to the interpretation (or misinterpretation) of Agile best practices.
If every single team works on its own strategy part independently, then they will likely produce different ways to approach topics such as security, identity, and the technology stack and reference architectures to follow. When this happens, we have a model similar to the one represented in the following figure:
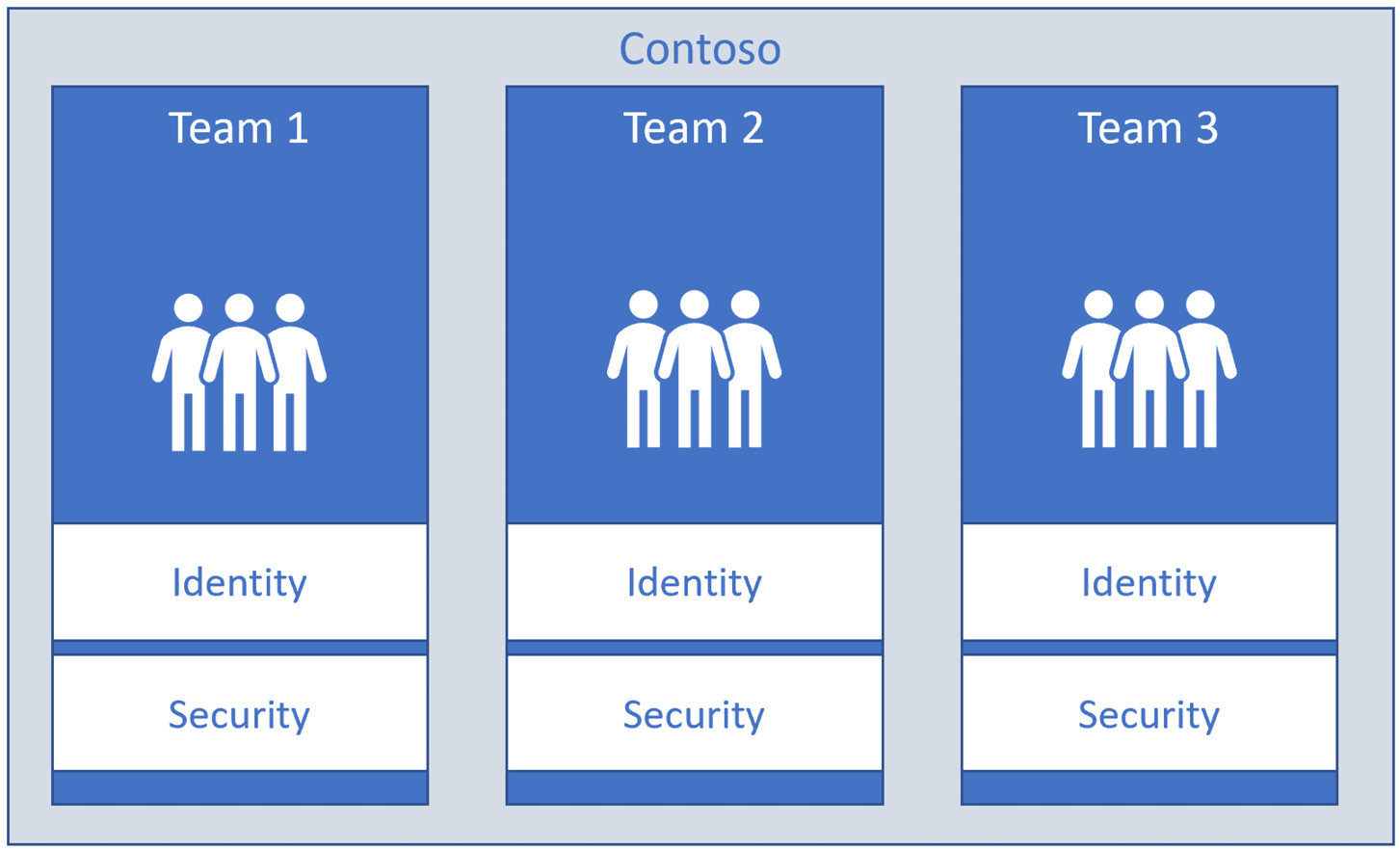
Figure 9.1 – Real-world example of independent teams, independent strategy
The preceding diagram provides an example to represent an organization with efficient teams with their own security standards, IdPs, and, potentially, identity protocols chosen.
The following diagram is an example of individual teams that share common strategies for high-level topics. Despite this slightly limiting the freedom an individual team can have, the end result of adopting this kind of model is an easier enterprise to maintain and there is a reduced cost to maintain the solution in the long term. The price to pay is that teams are not fully independent. As an example, they are not going to have the freedom to choose a specific IdP, to put in place different security practices, or even to choose the technology they wish; these high-level topics need to be mutually agreed upon:
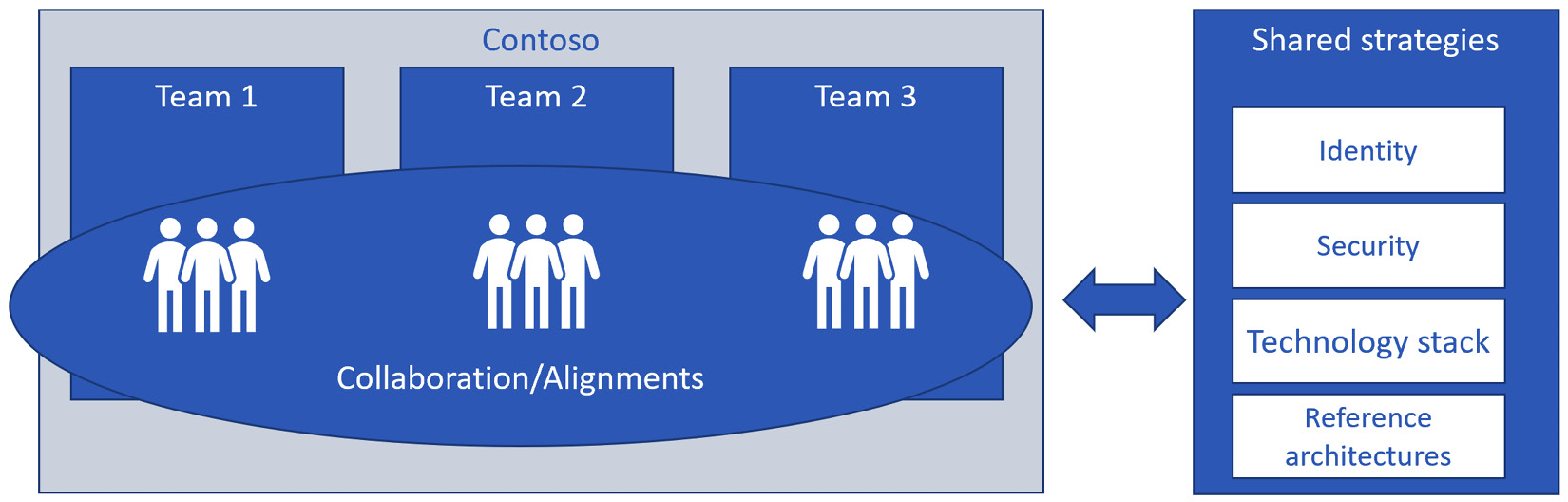
Figure 9.2 – Real-world example of independent teams, shared strategy
It is important to understand that any shared strategy reduces the freedom the Agile team is supposed to have and as such, it is recommended to force a shared strategy only on three or four pillars important for specific companies, such as the ones proposed in the preceding figure, and leave everything else up to individual teams. An extreme efficiency model (teams being 100% self-sufficient) leads to a proliferation of technology that, in the long term, requires more money and overhead to maintain. An extreme consistency-based model (teams follow shared strategies for all the choices) introduces processes and governance that lead to a static organization and remove most of the benefits of Agile project and product management. The trade-off between these extremes is important, and in any case, processes and governance practices need to be almost transparent for the model not to be an Agile anti-pattern.
This section didn’t cover any technical aspects, just aspects that are important to keep in mind that involve IdP choices and that can be extended to other common areas such as security. With these preconditions in mind, we can now return to the technical part and review frontend and backend authentication in the following sections.
Frontend authentication challenges in the real world
As outlined in Chapter 6, Trends in API Authentication, multiple IdPs for the same purpose within the same organization will lead to several side effects. When we refer to IdPs for the same purpose, we mean an IdP applied to common audiences or channels, such as consumer authentication, employee authentication, or app authentication, each of which represents a different purpose. The IdP for consumer authentication may be different from the one used for employee authentication; indeed, it would be inefficient to have multiple IdPs for employee authentication.
Mixing IDPs for the same purpose is hardly ever done on purpose. Most of the time, this anti-pattern occurs as a result of poor strategy in an organization and decisions siloed by team, as described in the previous section.
Just to give an example, let’s try to imagine an organization with multiple IdPs authenticating customers to their end services; it would create hassle and overhead for the company to manage, and moreover, it requires workarounds to mitigate user experience (UX) impact.
As an example, a customer or consumer who wants to access a service provided by a bank (e.g., the website of a bank) may use an IdP optimized to host consumer identities chosen by the architect who designed the bank’s platform. In a context such as this, customers may and should use an IdP for their customer identity. The same enterprise architect may have chosen a different IdP for the internal employees, which, in turn, may be different from the IdP chosen to host internal web applications that need to authenticate between each other (server-to-server authentication). This scenario is not optimal (we don’t have a unique IdP across the organization) but is acceptable and sometimes advisable for security purposes (we have different IdPs for different purposes, which, in turn, provides some security boundaries around different kinds of identity: customers, employee, and web app).
What would generate overhead is to have different IdPs for the same purpose. As an example, imagine a scenario where different internal applications need to authenticate with other internal applications that are hosted on another IdP. Another example that generates overhead is when the same customer needs to access a different service from the same company and its identity is hosted on a different IdP, which requires the customer to be hosted twice, having two different identities, and likely, two different passwords.
To understand the concept better, we’re going to have a look at a concrete example with a graphical diagram. Let’s imagine a company that provides both banking and insurance services to customers and, as such, has two web applications.
If customer-facing applications of this kind are developed by two different teams that implement two different IdPs, the high-level architecture would look like the example represented in the following figure:
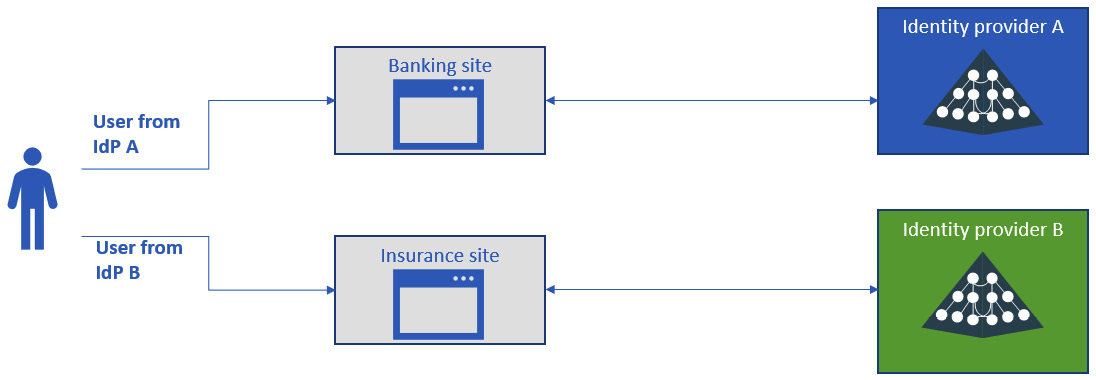
Figure 9.3 – Multiple customer-facing IdPs
This kind of scenario (as represented in the preceding figure) has the following two major drawbacks:
- Company overhead: Different IdPs to manage, different secrets, application registration, access token format, and any drift that two different IdPs may have
- UX: A user needs to use one identity for website A and another identity for website B, which leads to a more complicated experience and can impact the business due to fewer interactions with the customer
This scenario is not uncommon for many companies. Often, minor adjustments to the preceding architecture are performed to resolve any issues that might otherwise affect the UX and perception of the company’s brand. As a matter of fact, the preceding diagram requires the user, a customer of the bank, to have two different identities and to remember two different usernames and passwords, and likely two multi-factor authentications. When a situation such as that occurs, companies tend to mitigate the issue by adding an extra layer to the architecture, taking advantage of SSO techniques to enable the user to use just one identity for access, as represented in the following figure:
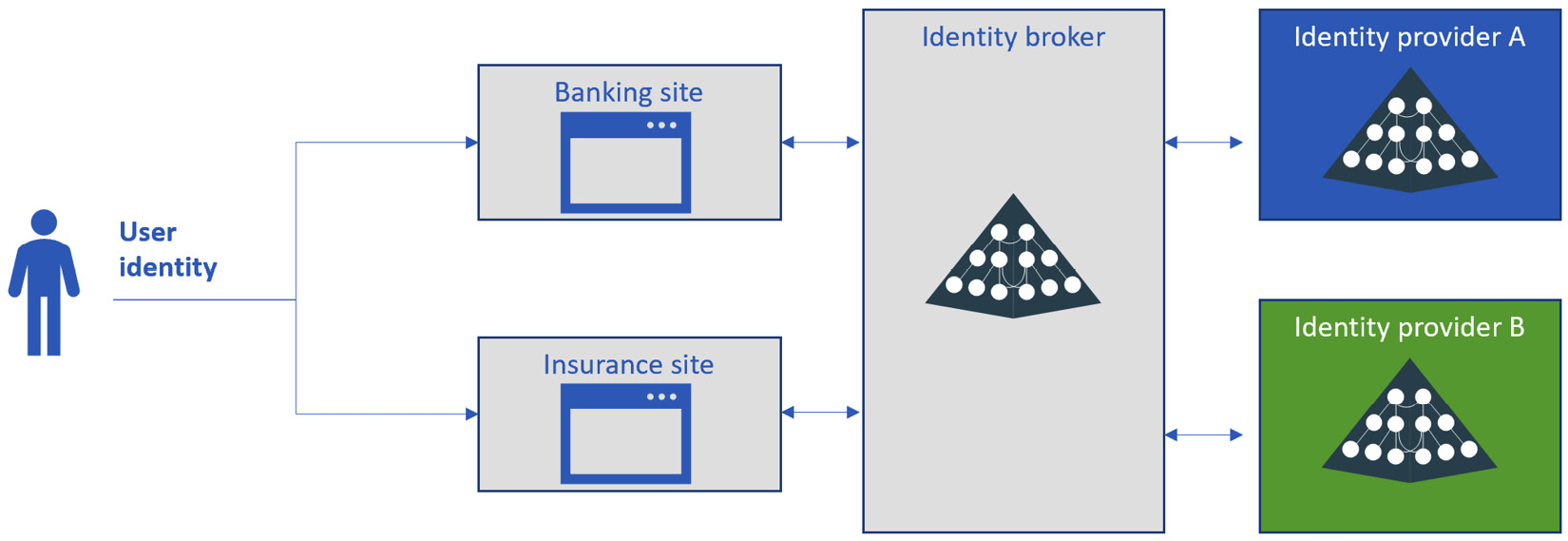
Figure 9.4 – Enhancing the UX with an identity broker
In the preceding figure, the identity broker is seen from both the applications (in this example, the banking site and the insurance site) as the reference IdP to be used to authenticate users to both platforms, even if, under the hood, the users belong to any two different IdPs.
From a high-level point of view, the workaround represented in the preceding figure is commonly implemented with any of the following two techniques that we have come across in our experience:
- Synchronization: With the synchronization option, the identity broker is a full IdP and the identities that belong to both IdP A and IdP B are copied into the identity broker. This is usually achieved with a third-party system that is designed to sync identities. This makes the identity broker completely self-sufficient to release tokens toward the applications in real time without referring to the source IdP that actually hosts the identities. This approach has sync overhead and requires always keeping the sync between the IdPs up to date.
- Token delegation: In the token delegation option, both applications still trust the identity broker as the IdP. Like the synchronization workaround, with token delegation, the complexity of having multiple IdPs is transparent from the application’s and the developer’s point of view. This time, the identity broker needs to check the user identities against the target IdP in real time, which, in the example in Figure 9.4, can be either IdP A or IdP B. It is important to note that in this kind of scenario, the identity broker completely relies on the other IdPs and is not able to release any token if these IdPs are not reachable for any reason. This has an impact on the service-level agreement (SLA) of the solution, which is directly proportional to the number of layers that belong to the solution.
In both cases, the access token released to the application (or to the user, according to the chosen protocol and flow) is forged and signed by the identity broker itself.
This is just an example of what companies tend to do to mitigate the proliferation of unwanted IdPs within their application portfolio. This workaround simplifies the application development, as well as the UX, more importantly, which, in turn, affects customers’ perception of the company.
From an enterprise architect standpoint, it is important to understand that the aforementioned scenario intrinsically generates overhead within the enterprise, which needs to cover multiple assets (IdPs) to serve the same purpose twice.
In fact, in this kind of scenario, the users of the companies are likely to be present on both IdP A and IdP B. It should be obvious that this pattern should be avoided, as long as there are no important security restrictions that recommend IdP segregation, which justifies the overhead addition.
The drawbacks to having multiple IdPs to host the customers of a company are, among others, as follows:
- Duplicates the effort to implement, monitor, and maintain multiple IdPs
- Decreases customer satisfaction and perception with the double IdP and the need to add an extra layer as a workaround (SSO, as shown in the example of the preceding figure)
- More complex architectures, which may include an identity broker or, in any case, an additional layer to implement, monitor, and maintain
- An impact on the SLA of the solution due to the extra layer(s) required
Let’s come back to the example of the two applications – the banking site and the insurance site – within the same company and see how the architecture would look with a unified IdP:
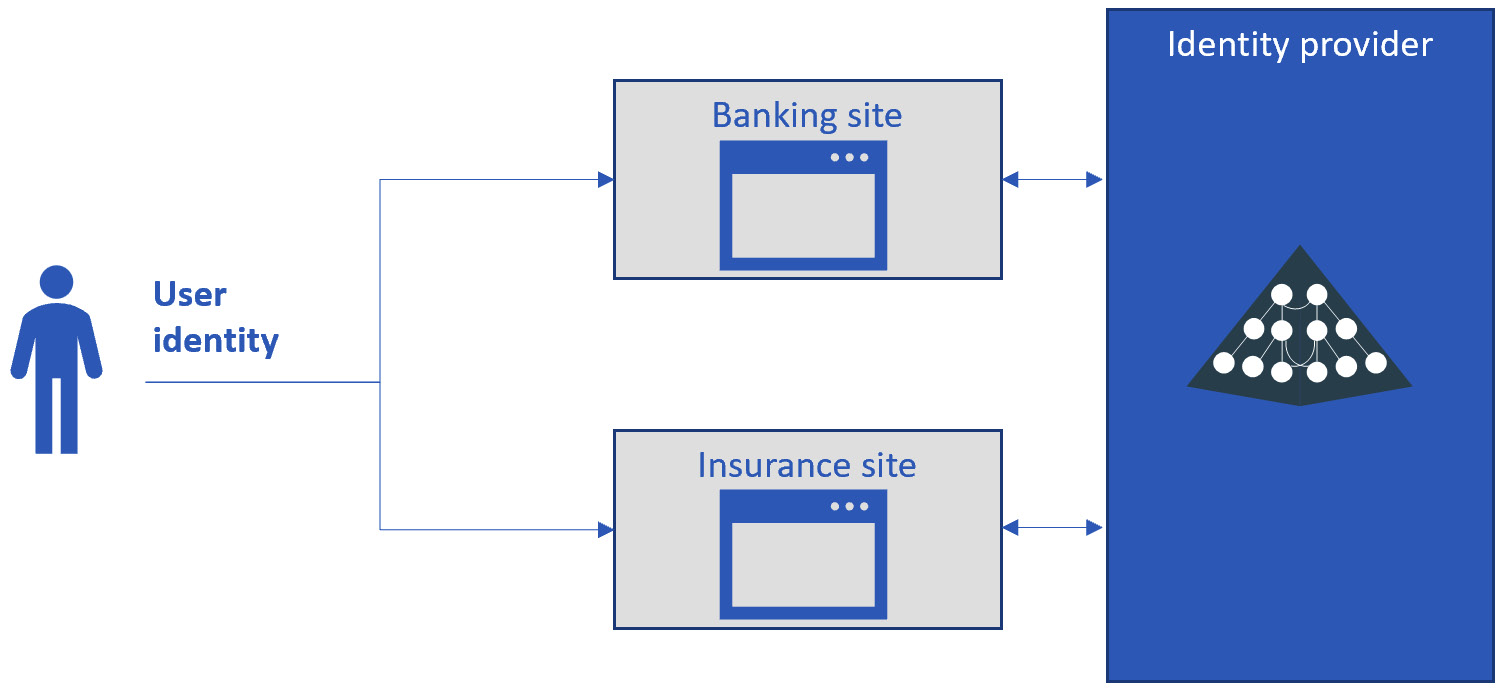
Figure 9.5 – A common IdP for consumers
As you can see, this proposed diagram contains fewer elements to produce a cleaner and more efficient architecture that is more reliable in the long term. This diagram, moreover, will likely have a better SLA due to fewer layers involved.
Before finishing this section, we want to outline once again an important aspect that we have covered: even by implementing the workaround of the identity broker and the addition of the extra layer, we are only going to be able to improve customer perception. Under the hood, the company still needs to deal with multiple identities and IdPs. This will result in a less reliable architecture. It is important to outline that although it may seem counterintuitive to a junior architect, adding layers to applications usually does not improve the reliability of the application; indeed, the overall reliability is generally reduced. This is because the more layers an application has, the more items are required to work (and need to be maintained) to enable the application to serve the requests, a scenario that a good enterprise architect wants to avoid.
In the next section, we are going to make similar considerations, but this time, for backend authentication instead. Backend authentication is a wider topic to analyze compared to the frontend due to the multiple ways an application can be designed. Because of its complexity, we have sliced the section into subsections, where each subsection is a different pattern, which will help you to appreciate the pros and cons of each of them.
Backend authentication challenges in the real world
In the previous section, we focused on how the number of IdPs used to authenticate the customer of a company can affect the design.
In this section, we are going to be focused on server-to-server authentication, a topic that is becoming even more important with cloud-born applications.
In the consumer example proposed in the previous section, having multiple IdPs for backend authentication (or server-to-server authentication) within an organization can lead to an even worse scenario than the one analyzed in the previous section.
Let’s forget user, consumer, or customer authentication for a minute; in other words, let’s forget the interactive authentication made by a human that was covered in the previous section, and let’s go deeper into analyzing backend authentication.
As covered in Chapter 1, Walkthrough of Digital Identity in the Enterprise, digital transformation and the cloud are impacting the way we design applications. Nowadays, new applications tend to be more distributed and, as such, composed of different slices, services, and layers. This means that we now have new challenges that weren’t relevant a few years ago.
To understand the argument better, let’s take an example of a monolith from the legacy era; in this case, the business logic sat on top of the same process that was supposed to serve views to the end user, as well as data classes. As a matter of fact, the most used pattern for legacy applications was based on Model-View-Controller (MVC). MVC is an architectural pattern implemented by different frameworks and technologies.
This kind of architectural pattern aims to distribute code components between three layers:
- Model: Code that is usually responsible (depending on the technology and framework chosen) for dealing with the database and materializing data into a concrete class usable inside the code.
- View: Code that is responsible for returning the view to the client.
- Controller: A component that is responsible for most of the business logic; it usually interacts with the view and the model.
With this common framework implementation, the pattern segregated the code. In the early 2000s, we assisted in the proliferation of MVC frameworks to support many different backend technologies: Java Spring, Ruby on Rails, ASP.NET, and CakePHP, just to mention a few of the most famous technologies. Anyway, the three layers (Model, View, and Controller) need to strictly interact with each other to enable the full logic of the application to work, and there is usually a strong dependency between code. This meant the MVC framework segregated the code, but not the hosting platform. This framework helped developers have clean and well-organized code, but it didn’t help from a hosting point of view, as this kind of code was usually compiled together and run on a single hosting platform. As a consequence, many developments on top of this kind of framework produced artifacts to run on top of a single application server known as a monolith.
In other words, a web application used to belong to the same compute process within the same application server. This means that no authentication was usually required between application components (e.g., the model didn’t need to authenticate against the controller, as it ran in the same process).
You may understand at this point that adopting an MVC framework led to code that was well-organized but wasn’t scalable, distributed, or able to scale independently. In the legacy world, authentication was still a hot topic, especially for integration (where an application needed to call an external API from the application itself) or in Service Oriented Architecture (SOA), but it is far from the requirements we have today in a world where most new applications are distributed by design.
In this new generation of cloud-born applications, we are dealing with applications that are distributed by design across different hosts, containers, and, generally, different processes; serverless applications are an extreme example of this. This means that, potentially, every time we have a portion of an application that needs to speak with another portion, authentication needs to occur.
To understand this concept better, let’s see an easy example aided by a diagram. We are going to consider a banking company that exposes a banking portal to its customers; we refer to the example proposed in the previous section again but elaborated further with a focus on backend authentication. This time, we are also going to represent greater complexity on the backend logic– we are going to split the backend into portions to simulate an extremely simplified distributed architecture:

Figure 9.6 – Backend authentication sample on a modern application
In the preceding example, the banking manager is a service that calls two different services to successfully work. The assumptions in these scenarios are the following:
- The banking application is an application composed of three backend services –Accounts, Cards, and Banking manager
- The backend services of the bank application authenticate each other via OAuth through the client credential flow
Before extending the use case to better apply to real-world complexities, let’s focus on how authentication can work in the backend components of the banking application. As explained in Chapter 5, Exploring Identity Patterns, in the OAuth client credential flow, whenever the Banking manager service in the example needs to communicate with the Accounts service, then it needs to connect to the IdP to obtain an access token first. These access tokens then need to be validated for the target service (in the preceding example, the Accounts service or Cards service). When the IdP releases the access token, the Banking manager service can finally submit the request to the Accounts service, and the latter is required to validate the token.
The first question you should think about is the following:
As usual, it’s a matter of requirements and trade-offs. If we want to fully follow the OAuth specifications, then we need to have one registration per service. Having a registration for every component of the application would require a specific token to the IdP for each component of the application. Each token will have its own audience (the claim in the token named “aud”) and scope fields. As such, the access token can only be spent on the specific service in the scope of the request (different IdPs may handle the aud claim differently). In other words, if the Banking manager service needs to communicate with both the Accounts and Cards services, it needs to obtain two distinct tokens from the IdP. The request for each token would be similar to the following snippet of an HTTP request:
POST /{tenant}/oauth2/v2.0/token HTTP/1.1
Host: hostname
Content-Type: application/x-www-form-urlencoded
client_id=1234567-8901-2345-6789-0123456678
&scope=AccountService
&client_secret=sampleCredentials
&grant_type=client_credentialsIn this example, a service or API with a client ID of 1234567-8901-2345-6789-0123456678 (which, in our example, will be Banking manager) is requesting a token to be used later to authenticate itself to AccountService, which is given in the scope field. The scope field, as explained, should be set according to the target service where the authentication needs to occur (some IdPs do not use the scope field but rather the resource for this purpose). In other words, and according to what is explained in the authentication flows chapter (Chapter 4, Authentication Flows), the token the IdP will emit will be forged according to the scope required. This affects the audience field of the access token that will be subsequently released by the IdP. In this scenario, the Accounts and Cards services will validate two different audiences (the aud field in the token released and signed by the IdP), and a token obtained from one service cannot be spent on the other one.
This simple example with three basic services outlines the following facts:
- If we want to establish a full mesh of authentication (each service can be authenticated against another random service), then we need to register every component of the application against the IdP so that we can obtain different client IDs and secrets.
- In this kind of example, it is requested that more logic is implemented on the caller, as each service requests its own specific access token.
- From a security standpoint, this approach is the best, as it guarantees security (one audience for one service). The price to pay is registering and managing multiple identities on the IdP side and writing further logic from the caller.
As already outlined, the sample application represented in Figure 9.6 is a simplified example. As a matter of fact, a typical cloud-native microservices application contains many more services.
Let’s now make our diagram more complete to make our application closer to a real-world scenario. A more concrete banking application that follows a microservices architecture would look like this. The example is still simplified but closer to the reality compared to what was reported previously:
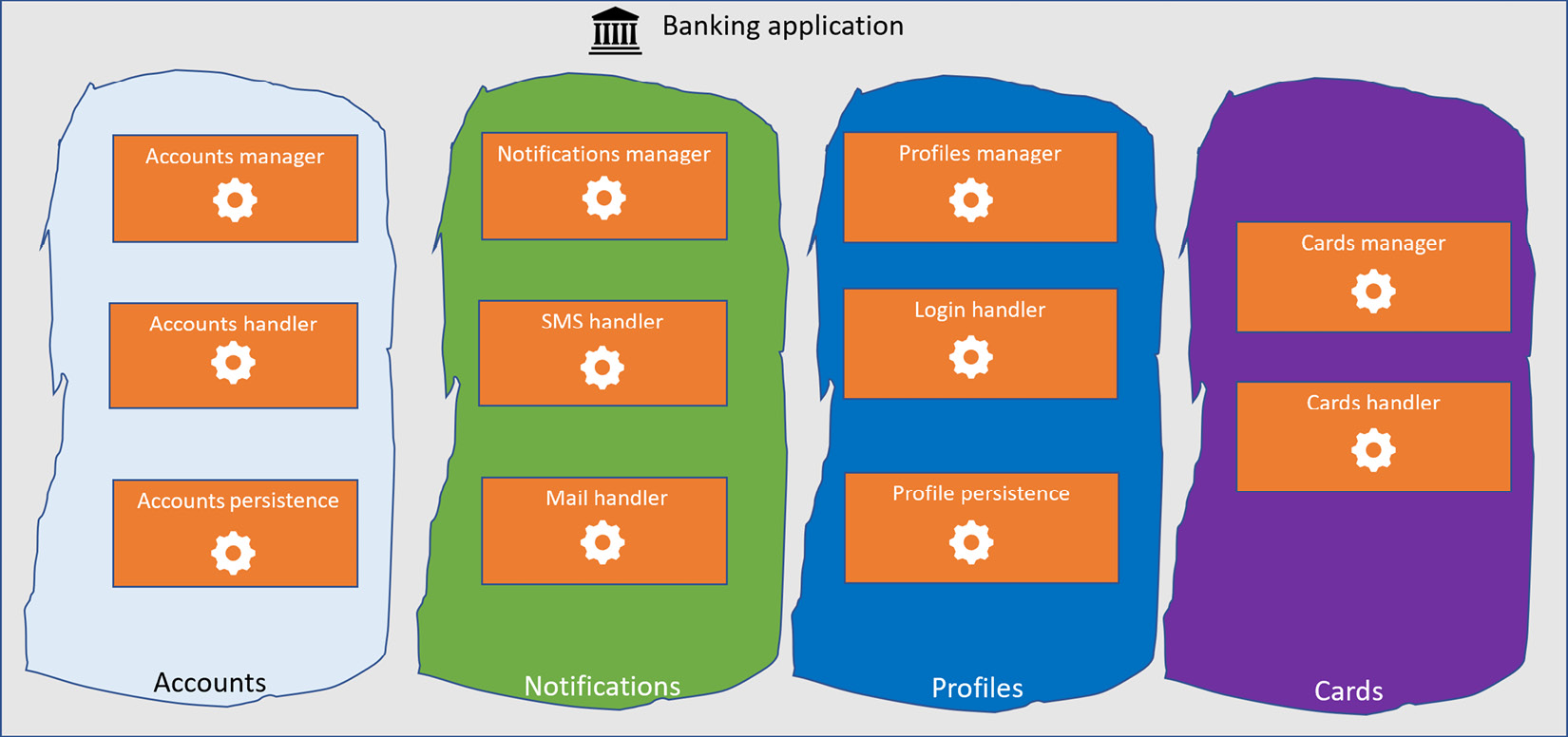
Figure 9.7 – Microservices application sample
Consistent microservices applications that follow the DDD pattern, as shown in the preceding figure, are divided into bounded contexts – in the example, four distinguished bounded contexts are present: Cards, Profiles, Notifications, and Accounts.
From a blueprint perspective, a pure microservices architecture cannot allow a service in a specific bounded context (e.g., Accounts) to interact with a service in a different bounded context (e.g., Notifications); this is to avoid the functionality of one bounded context relying on the response or functionality of a different bounded context and favor independence between the bounded domains. If domains can freely communicate with each other, then an issue on one domain can affect the functionality of another domain, and this would break the autonomous principle of a domain, as the DDD paradigm dictates. As a matter of fact, in this kind of architecture, there is usually a wide adoption of queues and publish/subscribe tools such as Kafka, Service Bus, or RabbitMQ, for example. They are adopted to enable one service to listen to the events of the others and act accordingly without any communication between the two occurring. In architecture designs, this approach is followed to increase independence across the service.
In the real world, it’s very hard to find fully decoupled domains and in some circumstances, a specific microservice within a domain is promoted to query on-demand services hosted in different domains, although this practice should be an exception that is limited as much as possible to ensure good reliability within the bounded context.
Let’s see, in the following sections, the implication of these designs on the IdP and the different ways to handle the identities in the service and their authentication. We are going to cover three potential identity patterns that can be applied to this application.
Pattern 1 – multiple IDPs
One benefit of the microservices approach is the ability to completely segregate the work between different teams and gain the maximum possible velocity and time to market by eliminating or mitigating all the dependencies and inefficiency across said teams.
This topic should sound familiar to you, as it directly connects to what was reported in the second section of this chapter, The implications of the company’s structure.
If the company is mature enough to fully embrace the microservices paradigm and have different teams associated with different bounded contexts (e.g., one team that works on the Cards functionalities and one team that works on the Accounts functionalities), then the information in the previous section about standard blueprints (which includes IdP adoption) needs to be considered to prevent situations such as the one shown in the following figure:
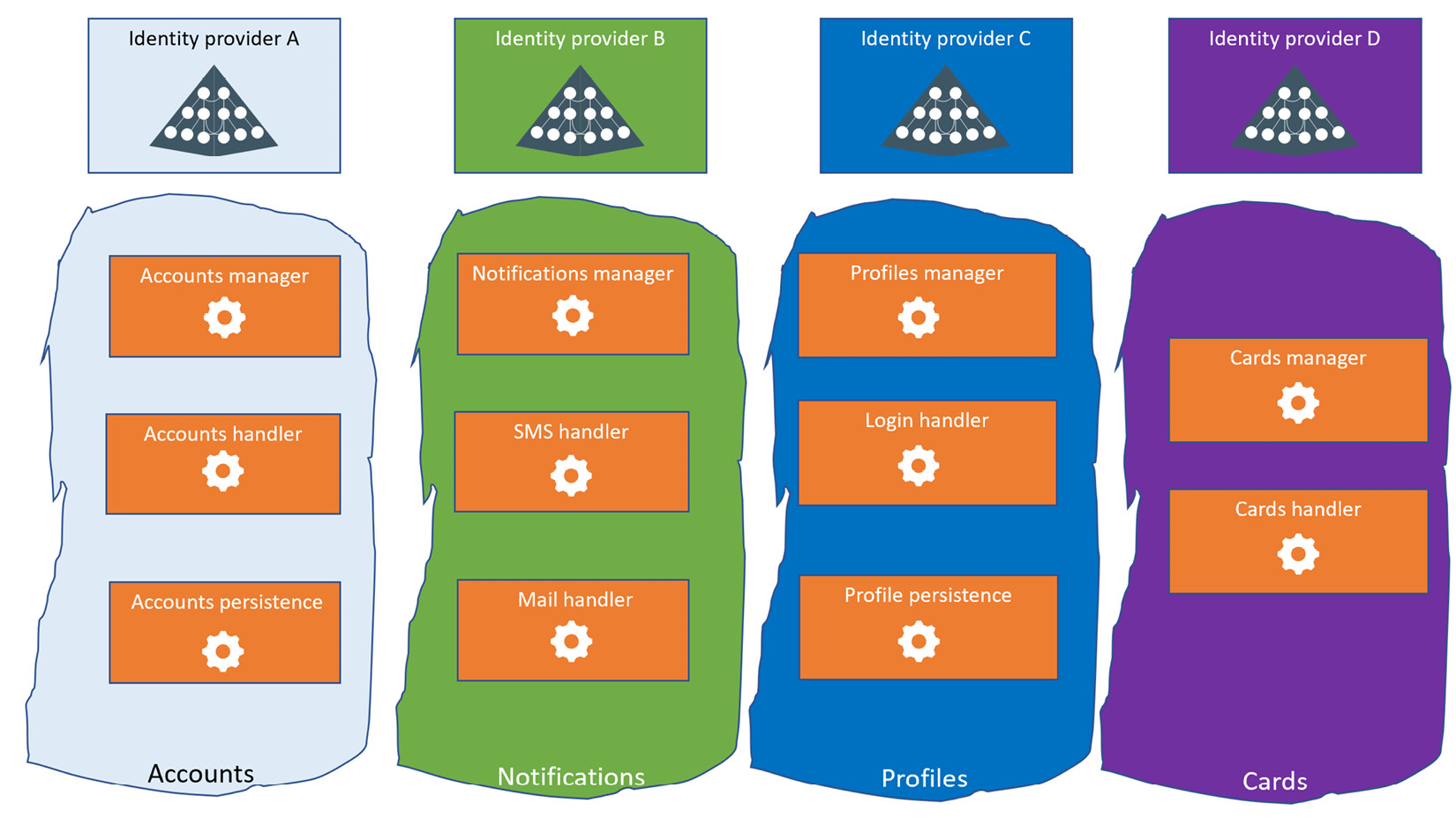
Figure 9.8 – Anti-pattern – multiple IdPs in different domain contexts
It is too easy to imagine the overhead a situation such as this would cause. These are the issues, among others:
- Multiple IdPs to maintain
- A heterogeneous registration process
- An audience field meaning changes according to the domain context
- A scope field meaning changes according to the domain context
In other words, this would cause the architecture to be unclean – the service should change the validation behavior according to the IdP.
As if that were not enough, each IdP may have its own slang and interpretation of the OAuth specs: it is common to see access tokens forged differently according to the IdP. The final result would be that the access token may contain different fields according to the source IdP and this would result in a cross-domain error when an integration test in the application included multiple bounded domains.
All in all, this kind of pattern is never recommended and should be avoided not just on the basis of the technical reasons explained in this section but also due to all the implications mentioned in the The implications of the company’s structure section.
Pattern 2 – a single IdP
In the previous section, we had the opportunity to appreciate a concrete real-world example that showed the implications of having multiple IdPs adopted by different teams on a microservices application.
If we imagine a microservices application that takes advantage of a single IdP, and we apply the principle of the full-meshed authentication mentioned in the Backend authentication challenges in the real world section, the architecture will look like the following example:

Figure 9.9 – Microservices application – single IdP
As stated in the previous section, the microservices in each domain context should have their own registration and require a specific token.
It’s worth noticing that although the diagram shown in Figure 9.9 is more complete than what was shown in Figure 9.6, it is a sample that may still be far from a real-world scenario: a complex and business-critical application could have dozens of domain contexts, and hundreds of microservices even. Guaranteeing all the permutations of possible authentication patterns within and, in rare cases, even across different domains will increase the complexity and the business logic that needs to be written and handled. This extension of the previous use case is not extreme: we need to consider that complex applications may rely on hundreds of microservices hosted on different functional domains. In a scenario such as this, even having a single IdP for each microservices application can become cumbersome. Registering each microservice to the IdP to ensure a full mesh of authentication within the services may not be practical and not even desirable; that’s where a trade-off between productivity, reliability, and security needs to be reached.
Moreover, it is worth noticing that a well-designed DDD application requires each microservice not to communicate outside of the domain context, and as such, introducing a full-mesh authentication pattern is unnecessary, as it would generate unjustified overhead.
From the security standpoint, if the hosting system is a container orchestrator such as Kubernetes or OpenShift, where the microservices sit on top of a software-defined network that is not reachable outside the cluster, then the severity of security may be relaxed a little, and authentication can be handled in one of the patterns that will be proposed in the following subsections.
All in all, this pattern is recommended for small applications where the number of microservices and bounded domains is limited and security requirements are very high; it would also be an option wherever DDD is not closely followed and microservices require mutual authentication out of the domain. It would not be recommended to adopt it as a standard pattern due to the proliferation of identities within the IdP and the overhead required in the maintenance of the solution and the related identities.
Pattern 3 – domain-based registration
This pattern may represent the best trade-off wherever a microservices application is managed by multiple teams associated with different domain boundaries.
The idea of this pattern is to have registered identities that don’t represent the microservices by themselves; instead, this pattern suggests registering domains. Each microservice that belongs to a specific domain will share its identity with the other microservices within the same domain. This approach has the following advantages:
- There is a specific audience and scope for each domain, which, on the other hand, represents the security boundaries established by the development team
- There is one registration per domain and not per microservice, which limits a lot of the required entities to be registered on the IdP
This is what it looks like:
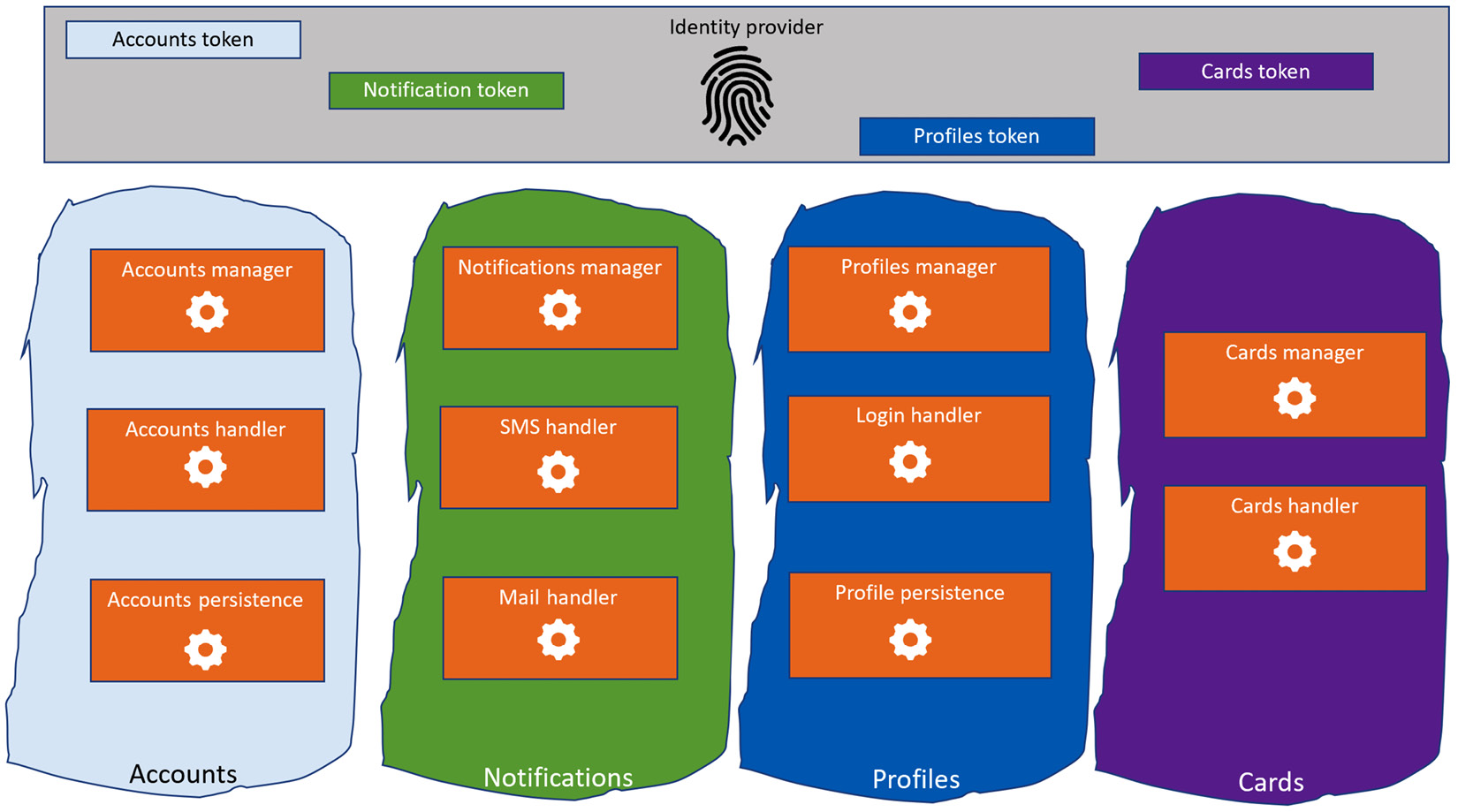
Figure 9.10 – Domain-based registration
As already explained, it’s important to outline once again that cross-domain communication in a pure microservices architecture should be rare or nonexistent; this means that on average, each service should only get the token required to communicate with the other microservices that co-exist within the same functional domain.
This approach will not be as secure as the one proposed in the previous section, where each microservice required a specific token. This is because, with a single token, an attacker could potentially access all the microservices within a functional domain. Regardless, it could represent the best trade-off between productivity, maintainability, and security for most applications.
From a security standpoint, moreover, it’s worth noticing that in a microservices architecture that works, the security footprint should not rely only on authentication but must be extended by a networking lockdown strategy, and as such, authentication requirements can be relaxed. As a matter of fact, functional domains in infrastructure such as Kubernetes or OpenShift should be hosted on specific namespaces and network restrictions can be paired with the authentication strategy to enhance the security footprint further and prevent unwanted cross-domain communication from both an authentication and network standpoint.
This pattern is the most practical in complex DDD architectures, as it limits the number of registrations to have and, at the same time, maintains a good degree of security.
Pattern 4 – application-based registration
This is the simplest possible pattern. It is the simplest because it requires the minimum number of registrations to the IdP. In this pattern, each application is registered once and each microservice within the application shares the same identity. In this pattern, only one identity is registered regardless of the complexity, the number of functional domains, and the magnitude of the microservices that compose the application.
This pattern is recommended in limited cases; it is advisable only when authentication between services in the same application is not required or when segregation and security are either not strict requirements or are completely handled by the networking area.
One of the advantages of the microservices application, as reported previously, is the ability to have self-sufficient teams. Having these teams adopt the same IdP is advisable. Having these teams share the same identity registration within the same IdP is not, as it may introduce an unnecessary dependency between them and involve sharing client IDs and secrets across teams, which is not advisable either.
The following figure provides a representation of this pattern:
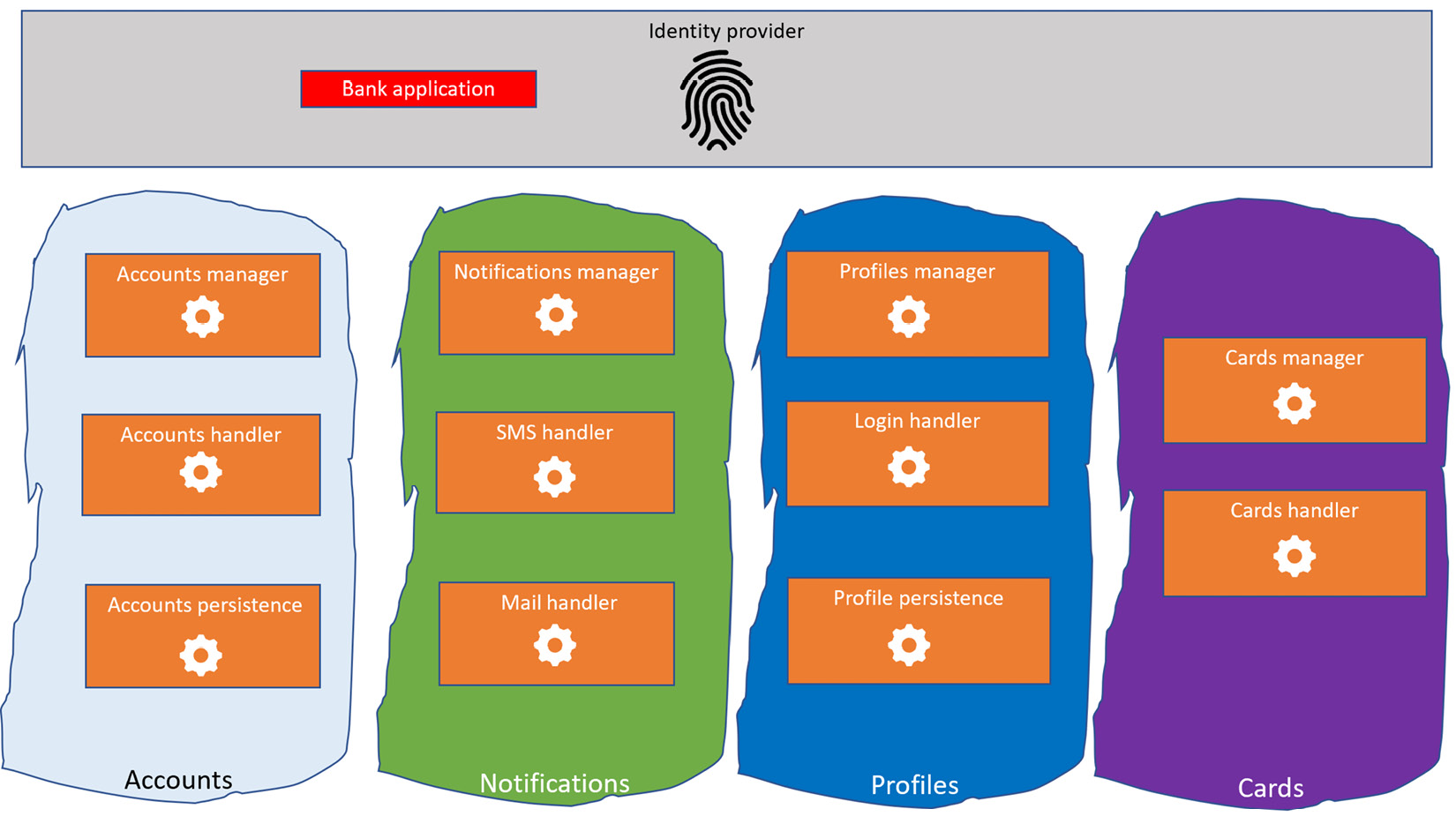
Figure 9.11 – Application-based registration
This pattern could become interesting whenever the backend service of the banking application should be accessible to an external system. This is because this external system doesn’t need to know the internal details and the functional domain of the microservices application; all it needs is to have a token to access the backend service of the banking application. This facilitation, of course, has security implications if only a generic token is used for all the authentication that an enterprise architect needs to evaluate in terms of its risks and benefits. In scenarios where security is important, this pattern is not preferred. This is because the same token that external applications consume is the one used internally by an application, and if network restrictions are not in place or configured properly, a system with a token can make an undesired query to microservices that are not supposed to be exposed.
Anyway, undoubtedly, this pattern allows the application to be exposed to external systems, as they can refer to a single token and the internal complexity can be hidden.
As such, it could be interesting to see the result of mixing this pattern (application-based registration) with the domain-based registration pattern to achieve the best of both and keep security high.
The next section will focus on this kind of combination.
Authentication challenges for microservices integration
All the patterns exposed so far have focused on internal authentication within a component of an application. We have seen scenarios where we wanted to authenticate each microservice and when we wanted to authenticate them based on the domain to which they belonged.
In real-world scenarios, the context is usually way more complex and we usually come up against integration requirements that require us to consider authentication beyond the remit of the patterns described so far.
The purpose of this chapter is to situate integration within the bigger picture and review how it is possible to combine the patterns explained so far to provide a more holistic solution. This chapter will focus on inbound integrations, which are the capabilities or APIs that the application needs to expose to external or third-party systems.
Inbound integrations are the calls to which the application is expected to reply, submitted from external systems. As such, inbound integrations are supposed to be developed as part of the application itself, unlike outbound integrations, which are indeed the APIs that the application needs to call – and, as such, are external and not part of the application development.
From a high-level perspective, an inbound integration pattern looks like the following diagram:

Figure 9.12 – Inbound integration
Inbound integrations are typically cumbersome during the application design. The reason behind that is that the application needs to have the capacity to scale not just for the core functionality that it needs to serve but also to serve queries from third-party components (inbound integrations). A spike of requests from third-party components should not degrade the performance of the core functionalities (which typically insist on the same database) and that’s the reason why inbound integration design usually requires careful attention on the part of an experienced enterprise architect. This is because we open our application to receive a query from external systems, and these external systems may introduce a load that can affect the performance of the whole application. Strategies such as horizontal scaling and design adjustments to prevent performance overhead from being introduced by third-party systems need to be carefully considered. This design aspect requires specific attention, despite being beyond the scope of this book.
To introduce the topic of inbound integration, first, it’s important to outline the full internal interactions that are needed in the application. Let’s take a step back and extend the domain-based registration design to introduce a frontend component that would query the backend microservices. This aspect hasn’t been outlined previously for two reasons:
- It simplifies the understanding of in-app authentication
- When it comes to discussing the design of the frontend for a microservices application, there are multiple options and permutations according to how closely the architect wishes to stick with the DDD guidance
For the sake of understanding, the example that follows will focus on the easiest approach.
The end-to-end authentication flows should look like the following:
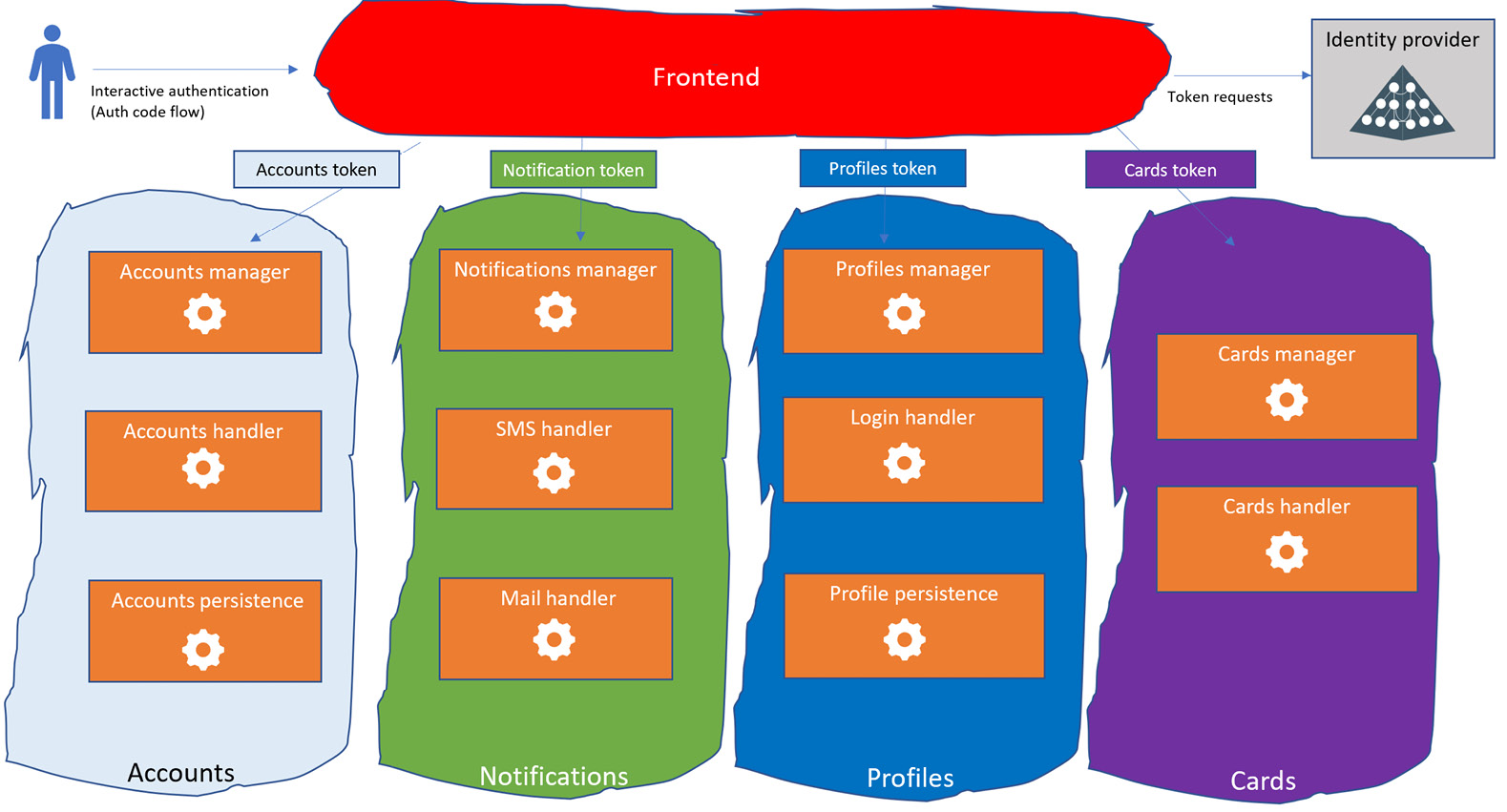
Figure 9.13 – Domain-based with a frontend component
What is shown in the preceding figure is an extension of the diagram proposed in domain-based registration; in this case, we also outline the frontend component, which is still considered an internal part of the application. It is important to understand that this kind of introduction, despite being widely adopted in real-world scenarios, drifts a little from a pure microservices design concept. The diagram shown depicts the frontend as a single entity. According to the DDD paradigm, from a design perspective, the frontend component should be divided into smaller chunks to extend the autonomy and the independence of the microservices approach to the frontend. This is usually achieved through the micro-frontend concept, which helps to promote the DDD paradigm further and avoid cross-domain functionality being hosted in a single component (which, in our case, is the frontend itself).
Figure 9.13 is the most common approach we have found across enterprises. As a matter of fact, most companies use it to focus on the microservices architecture on the backend side and do not extend the concept to the frontend layer. Situations in which micro-frontends could represent a benefit for your organization are out of the scope of this book; to further explore the benefits and the drawbacks of this approach, it is recommended to read this interesting article by Martin Fowler: https://martinfowler.com/articles/micro-frontends.html. In the case of micro-frontends, the functionality exposed to the GUI would belong to the domain itself and doesn’t need to be seen as an additional layer in the architecture.
In our simpler example, we can think of the frontend component as a backend for frontend (BFF). To those familiar with the pattern, for the sake of understanding, this section will consider a standard frontend that combines multiple domains to provide responses to an SPA.
Figure 9.13 represents a frontend layer, which integrates the concept expressed in the Pattern 3 – domain-based registration section of this chapter. In this case, every single domain has its own identity. As a consequence, a specific access token is required to grant authentication whenever the frontend needs to query the domains. The same applies to interactive authentication on the part of the user. In other words, this diagram shows two different OAuth flows: the interactive auth code grant flow, which is used to authenticate an end user that needs to use the application as reported in the Authorization code grant flow section in Chapter 4, Authentication Flows, and the client credential flow, which has already been discussed in the current chapter for server-to-server authentication within app components and detailed in the Client credential grant flow section in Chapter 4, Authentication Flows. Despite Figure 9.13 outlining a single IdP, it is possible, as said previously, that some organizations have one specific IdP for users/customers, and one adopted for server-to-server authentication. This aspect does not affect the understanding of this chapter, and Figure 9.13 has been simplified for a single IdP.
The diagram outlines how the frontend component, which is supposed to be considered part of the app, requires different tokens according to the backend service it needs to access. It is uncommon in microservices architecture for the frontend to access every backend service; the most typical design is that every domain has its own service that exposes the API that the frontend needs to consume, and other microservices within the domain are designed to support this “frontend-exposed microservice.” This is possible because the frontend layer is supposed to know the internal details of the application. The situation changes when the API queries are supposed to be received by an external system for inbound integration.
If we try to handle third-party systems or external applications by following the authentication pattern expressed so far, we would obtain a situation as in the figure shown here:

Figure 9.14 – Inbound integration anti-pattern
This design makes the integrations cumbersome for the following reasons:
- We show the application’s domain design to an external system, which should belong to our organization
- We force the external system to handle multiple tokens to query a single application
- We potentially enable the third-party system (if no network restrictions are in place) to query any microservices it wants, which is not desirable from a security perspective
In this case, getting an access token for the Cards domain or the Accounts domain may not have a clear meaning for an external actor who just wants to query the banking application. This approach would require showing unnecessary complexity to an external system and breaking the segregation of duties paradigm.
The preceding bullet list should make clear why internal authentication and external authentication should not be treated in the same way.
If the backend services need to be accessed by an external application (not the frontend of the application itself), an enterprise architect should evaluate how to hide the internal details of the application by mixing multiple patterns and introducing a network appliance, as shown in the following schema:
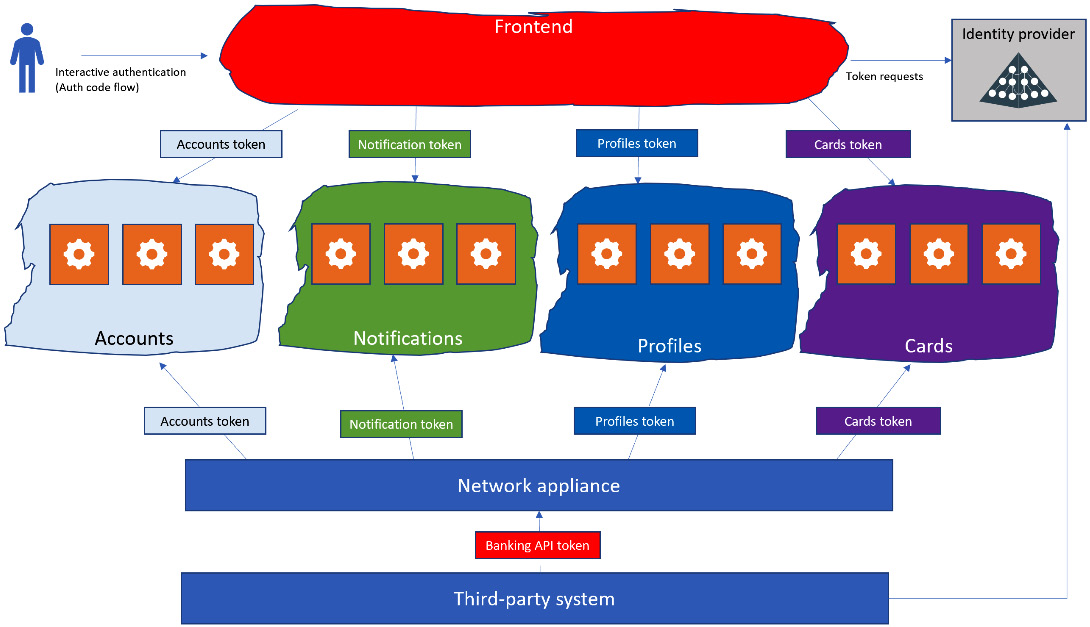
Figure 9.15 – Inbound integration pattern
This diagram shows a possible pattern to facilitate integration in a microservices application.
It enables the third-party system to not deal with the complexity of the application and not even know the application. All the third-party system needs to know is the API it needs to call and the token it needs to grab from the IdP. Moreover, the API can be exposed differently externally and internally thanks to a Level 7 network appliance, which has the goal of hiding the internal details of the application from external stakeholders. This layer, moreover, is responsible for validating a generic token for the integration and requires the proper internal token to the IdP. Some Level 7 network appliances provided by cloud providers have this capability. In the case that the Level 7 network appliance can’t ask for the internal token that is needed, it is still possible to build a similar architecture and secure the communication between the network appliance and the internal application using network restrictions, which is recommended in any case.
As a side note, the network appliance layer represented in the preceding figure is a logical component that may also belong to the same cluster that hosts the microservices of the application if platforms such as Kubernetes or OpenShift are adopted.
Summary
In this chapter, we had the opportunity to complement the theoretical explanations shared in previous chapters with practical examples of challenges, especially in the application design area, which is the critical area where new business is generated by companies.
In this book, we covered many areas related to identity management and we have done so on different levels: we moved through high-level views of how a company should have a common strategy for critical topics such as identity, and we had the opportunity to share the implications of ignoring how to set up an identity strategy correctly. We then touched on more pragmatic topics, such as the implications of an identity strategy in the application designed, and we even provided low-level information about the most common protocols used today and the possible application and flows of each protocol, as well as examples and patterns to adopt when it is time to design an application.
What should be clear at this stage is that identity is a wide topic that touches on many areas we didn't even explore in this book and that we attempted to enumerate at the beginning of the current chapter; nevertheless, the focus of an enterprise architect should be on guiding the development team, who are the ones that create new business value, and avoiding pitfalls and proliferations of tools and systems such as the IdP.
A solid and robust company that wants to do good business in the cloud world should be able to focus on generating new business value, avoiding complex systems with too many layers, and limiting the overhead generated by the maintenance of unnecessary layers such as multiple IdPs that are supposed to serve common goals.