
CHAPTER 13
Business Continuity and Disaster Recovery
In this chapter, you will learn about
• Business continuity methods
• Disaster recovery methods
• Backup and recovery
An organization’s data must be backed up, and key processes like payroll and billing need to be continually available even if the organization’s data center is lost due to a disaster. Choosing a disaster recovery method is an important step in a reliable cloud implementation. A cloud computing model can be seen as an alternative to traditional disaster recovery. Cloud computing offers a more rapid recovery time and helps to reduce the costs of a disaster recovery model.
Protecting organizational data requires different methods depending on the situation. Business continuity (BC) is the set of plans, procedures, and technologies necessary to ensure continued business operations or minimal disruption when incidents, technology failures, or mistakes happen.
BC is different from disaster recovery (DR) in that BC is a holistic way of keeping things running, while DR addresses major events that can take down a company if the right controls are not in place. Organizations typically have a disaster recovery plan (DRP) that can be followed for specific major events.
Backup and recovery are integral to both BC and DR. These functions are also useful for events that do not strain the business, such as when a user accidentally overwrites a nonurgent file and needs it recovered. Backup and recovery are used for significant and major events, as well as those not affecting business continuity and disaster recovery scenarios.
Business Continuity Methods
BC encompasses the activities that enable an organization to continue functioning, including offering services, delivering products, and conducting other activities deemed integral to running the business during and following a disruptive incident such as data corruption, employee mistakes, a malware breach, a malicious insider attack, a system hack, or a major component failure.
Business continuity is also concerned with recovering data or systems if and when they are harmed.
Business Continuity Plan
An organization makes its guidelines known through a business continuity plan (BCP), and it enacts its guidelines through business continuity management (BCM). BCM is the process the organization goes through to create procedures to deal with threats to data integrity, data exfiltration, data confidentiality, data availability, employee safety, asset integrity, brand image, and customer relationships. The process defines the threats to those organizational resources and outlines the safeguards and practices designed to protect them from harm.
BCM is concerned with protecting organizational resources from harm and relies on contingency and resiliency.
Contingency
A major portion of the BCP is concerned with contingency. Contingency planning involves establishing alternative practices, sites, and resources that can be used in an emergency or to establish high availability (discussed later in this section).
In the contingency component of the BCP, the organization establishes a generalized capability and readiness to cope effectively with whatever events compromise business operations. The BCP plans for, documents, and maps out steps to be taken if and when contingency events should occur.
Alternatives
Alternative preparations are the organization’s response if resilience and recovery arrangements prove inadequate to address the contingency event. Still, if a BCP is to be complete, it must have documented, planned for, and mapped out how it will handle alternatives when primary resources are unavailable. There are many factors to consider in a business continuity event, and some of those factors may affect whether certain parts of the plan will function as expected. When this happens, alternatives will be implemented.
Alternative Sites
Alternative sites are an essential part of business continuity. For example, hot and warm sites require replication to keep data consistent. Hot sites require continuous replication, while a warm site requires scheduled replication at certain points throughout the day, week, or month.
Using a remote site helps provide a more advanced business continuity solution, since the entire site is protected in case of a disaster. Multisite configurations rely on a backup site where a company can quickly relocate its computer equipment if a disaster occurs at its primary location and data center. The backup site needs to be either another location that the company owns and has available to implement additional equipment or a space that it rents from another provider for an annual or monthly fee.
There are three types of backup sites an organization can use: a cold site, a hot site, and a warm site. The difference between each site is determined by the administrative effort to implement and maintain them and the costs involved with each type.
Cold Site Of the three backup site options, the least expensive is the cold site. A cold site does not include any backup copies of data from the organization’s original data center. When an organization implements a cold site, it does not have readily available hardware at the site; it has only the physical space and network connectivity for recovery operations and is responsible for providing the hardware. Because there is no hardware at the backup site, the cost for a cold site is lower; however, not having readily available hardware at the cold site is also one of its downfalls. Since there is no hardware set up and ready to use at the backup site, it takes the organization longer to get up and operating after a disaster, which could end up costing it more than the extra expense of a warm or hot site, depending on the type of organization.
Hot Site A hot site, on the other hand, is a duplicate of the original site of the organization and has readily available hardware and a near-complete backup of the organization’s data. A hot site can have real-time synchronization between the original site and the backup site and can be used to mirror the original data center completely.
If the original site is affected by a disaster, the hot site is available for the organization to quickly relocate to, with minimal impact on the normal operations of the organization. A hot site is the most expensive type of alternative site to maintain. However, it is popular with organizations that need the highest level of disaster recovery, such as financial institutions and e-commerce providers.

EXAM TIP A hot site is the most expensive multisite configuration but provides the quickest recovery time in the event of a disaster.
Warm Site A warm site is somewhere on the continuum between a cold site and a hot site. It has readily available hardware but on a much smaller scale than the original site or a hot site. Warm sites will also have backups at the location, but they may not be complete backups, or they might be a few days old.
Determining an acceptable recovery time objective (RTO) for an organization helps a cloud administrator choose between the three types of backup sites. A hot site might have an RTO of a few hours, whereas a cold site might have an RTO of a day or more. It is important that the organization and the cloud administrator completely understand the RTO of an application or service and the cost required to operate at that RTO.
A hot site provides faster recovery time but also has a much higher cost than a warm site. A cold site costs the least to set up, but it takes the longest to implement in the event of a disaster. Understanding the benefits and costs of each of the three types of backup sites will help an organization determine which backup type best fits its needs and which backup strategy it should implement.
Site Mirroring
A mirror site is either a hosted website or set of files that is an exact copy of the original site and resides on one or more separate computers from the original. This mirror copy ensures that the website or files are accessible from multiple locations to increase availability and reduce network traffic on the original site. It is updated regularly to reflect changes in content from the original site.
A set of distributed mirrored servers can be set up to reflect geographic discrepancies, making it faster to download from various places throughout the world in what is known as a content delivery network (CDN). For example, a site that is heavily used in the United States might have multiple mirror sites throughout the country, or even a mirror site in Germany, so that end users who are trying to download the files can access a site that is in closer proximity to their location.
Sites that offer a large array of software downloads and have a large amount of network traffic can use mirror sites to meet the demand for the downloads and improve response time for the end user. For example, Microsoft often has multiple mirror sites available for users to download its software, and Download.com (http://download.cnet.com) often has mirror sites so that end users can retrieve files from a location that is closer to them.
Resiliency
The BCP should define how the organization will implement resiliency. Resiliency requires designing systems that can still service the company when problems arise. It accomplishes this primarily through redundancy. Cloud service providers achieve resiliency by architecting cloud and information systems that can withstand assault or faults. Security controls protect against assault (see Chapter 11), and redundancy protects against component failure or failure of integrated or dependent third-party systems such as the power grid, hosting provider, or key toolset.
Redundant components protect the system from a failure and can include power supplies, switches, network interface cards, and hard disks. An example of a redundant system is RAID, which employs methods to guard against single or multiple drive failure, depending on the RAID level. Review Chapter 2 if this seems unfamiliar.
Another example is NIC teaming, where two or more NICs are combined into one logical NIC. If the cable, NIC, or switch link for one fails, the others will still remain to service the server.
A redundant component means you have more of that component than you need. For example, a virtualization host computer might have two power supplies to make it redundant, but it can function with a single power supply. A data center may have four connections to four different ISPs, but it can function with any one of them, except that it would incur bursting charges for additional bandwidth used.
Redundant does not mean that there is not an impact to performance or a cost if a component fails; it means that service can be restored to working condition (although the condition may be in a degraded state) without the need for external components. Redundancy differs from fault tolerance (FT) in that FT allows the system to tolerate a fault and continue running in spite of it. Fault tolerance is discussed in more detail later in the chapter.
Once an organization has established the BCP and created redundant systems, it can implement high availability.
High Availability
High availability (HA) is a method of designing systems to ensure that they are continuously available for a predefined length of time. Organizations need to have their applications and services available to end users at all times. If end users cannot access a service or application, it is considered to be unavailable, and the period during which it is unavailable is commonly referred to as downtime.
Downtime comes in two different forms: scheduled downtime and unscheduled downtime. Scheduled downtime is downtime that has been predefined in a service contract that allows an administrator to perform routine maintenance on a system, like installing critical updates, firmware, or service packs.
Unscheduled downtime usually involves an interruption to a service or application due to a physical event, such as a power outage, hardware failure, or security breach. Most organizations exclude scheduled downtime from their availability calculation for an application or service as long as the scheduled maintenance does not affect the end users.
Having an infrastructure that is redundant and highly available helps an organization provide a consistent environment and a more productive workforce. Determining which systems require the investment to be highly available is up to each organization. There will be some systems or applications that do not need to be highly available and do not warrant the cost involved to make them so.
One of the benefits of a public cloud model is that the cost of making the systems highly available falls on the cloud provider and allows the cloud consumer to take advantage of that highly available system.
If a system is not highly available, it means that the system will fail if a single component fails. For example, suppose a system that is not highly available has a single power supply and that power supply fails. In that case, the entire system will be unavailable until the power supply can be replaced.
Determining which systems and which applications require redundancy can help reduce costs and administrative overhead. A policy should be created to determine the expected availability for each application. This will govern whether HA features are required on the systems housing the application.
An organization might use a scale of zero to four to rate the availability requirements of an application. In that scenario, an application that has a rating of zero would need to be available 99.99 percent, whereas an application with a rating of four might only have to be available 98 percent. Creating a scale allows an organization to prioritize its applications and appropriately distribute costs so that it can maximize its compute resources.
Fault Tolerance
FT allows a computer system to function as normal in the event of a failure in one or more of the system’s components. Fault-tolerant systems are designed for HA and reliability by installing redundant hardware components. For example, a virtualization host computer would have multiple CPUs, power supplies, and hard disks in the same physical computer. If a component fails, the spare component would take over without bringing the system down. However, having a system that is truly fault-tolerant does result in greater expense because the system requires additional components to achieve fault-tolerant status.
EXAM TIP Fault tolerance allows the system to tolerate a fault and to continue to run in spite of it.
Clustering Connecting multiple computers to provide parallel processing and redundancy is known as clustering. Clustering allows for two or more computers to be connected to act as a single computer. The computers are connected over a fast local area network (LAN), and each node (i.e., each computer used as a server) constituting the cluster runs its own operating system. Clusters can thereby improve performance and availability as compared to using a single computer, and clusters are often used in the cloud for Big Data analysis.
Geo-clustering Geo-clustering allows for the clustering of multiple redundant computers while those computers are located in different geographical locations. The cluster performs as one node to the outside world, but internally, it is distributed across multiple sites. Geo-clustering allows an organization to support enterprise-level continuity by providing a system that is location-independent. Geo-clustered sites could be contained within a single cloud but distributed across multiple regions, a multicloud solution, or a hybrid cloud solution. Some organizations that have existing regional data centers may opt for a hybrid cloud approach that also involves clustering of systems in their own regionally distributed data centers.
Geo-clustering requires that the devices in the cluster have a persistent connection to one another. In the case of multiple data centers, a wide area network (WAN) would be established between them. In a multicloud setup, a VPN might be used, whereas geographically distributed resources in the same cloud could use a VPC to connect them. In each of these cases, the nodes still appear as a single highly available system.
Failover Failover uses a constant communication mechanism between two systems called a heartbeat. As long as this heartbeat continues uninterrupted, failover to the redundant system will not initiate. If the heartbeat between the systems fails, the redundant system will take over processing for the primary system.
Failback When primary systems become operational again, the organization can initiate a failback. Failback is the process of restoring the processing back to the original node. If this were a failure situation, failback would revert processing to the node that had failed once it has been fixed.
Multipathing
Having a fault-tolerant system is a great start to achieving HA, but it is not the only requirement. When planning for HA, all aspects of the network must be considered. If the connection between the fault-tolerant systems is a single point of failure, then it is limiting the high availability of the system. Implementing multipathing allows for the configuration of multiple paths for connectivity to a device, providing redundancy for the system to connect to the others.
Figure 13-1 shows a sample network where each distribution switch is redundantly cabled to the core switches, which also are redundantly connected to two clustered firewalls. The servers and other endpoints would be connected to both switches for their subnet. This protects against a single NIC, cable, switch, or firewall failure.
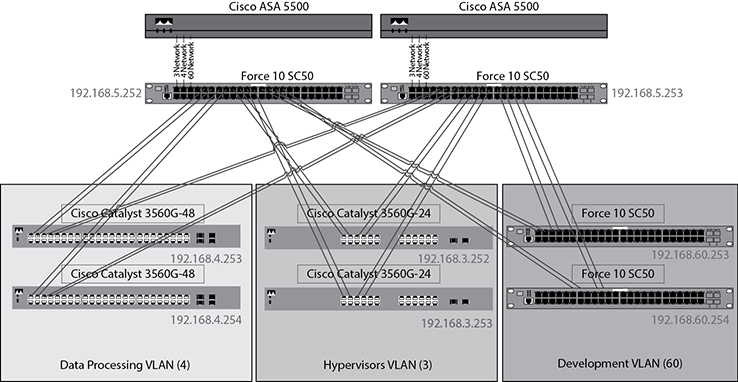
Figure 13-1 Redundant network connections
Load Balancing
Another component of HA is load balancing. Load balancing allows you to distribute a workload across multiple computers, networks, and disk drives. Load balancing helps to optimize workloads and resources, allowing for maximum throughput, and helps minimize response times for the end user. Load balancing can also help to create reliability with the use of multiple computers instead of a single computer and is delivered either with dedicated software or hardware.
Load balancing uses the resources of multiple systems to provide a single, specific Internet service. It can be used with any type of internal or public-facing TCP or UPD service to distribute the load of web or file requests between two or more servers. Load balancing can distribute incoming HTTP requests across multiple web servers in a server farm, which can help distribute the load across multiple servers to prevent overloading any single server. Suppose one of the servers in the server farm starts to become overwhelmed. In that case, load balancing begins to distribute HTTP requests to another node in the server farm so that no one node becomes overloaded.
Load balancers are supplied with an IP address and fully qualified domain name (FQDN) that is typically mapped through NAT and a firewall to an external DNS name for cloud resources. This IP address and FQDN represent the load balancer, but client connections are handled by one of the members of the load-balanced system. Internally the load balancer tracks the individual IP addresses of its members.
Load balancing can be performed on software that runs on each device or performed on a dedicated device.
Load Balancers Load balancers are devices that perform load balancing. Load balancers may be physical hardware, but more often, they are virtual appliances or services offered by cloud providers that can be easily added on to other services in your cloud.
Load balancers can be used to direct traffic to a group of systems to spread the traffic evenly across them. They operate at the OSI transport layer (layer 4). The advantage of cloud load balancers over software load balancing is that load balancers reduce the overhead of having software on each machine to manage the load balancing.
Load balancers make their decisions on which node to direct traffic to based on rulesets and node status obtained through health probes. The load balancer does not modify the URL. It just passes it on to the internal resource that best matches its load balancing rule.
Azure Load Balancer can be used to distribute the load across machines hosted in Microsoft Azure. In AWS, use Elastic Load Balancing.
Application Delivery Controller
Application delivery controllers (ADCs) have more functionality than a load balancer. ADC operates at the OSI application layer (layer 7) and can make delivery decisions based on the URL. Examples of ADC include the Azure Application Gateway (AGW), the AWS Application Load Balancer, and Citrix ADC. Some functions of an ADC include
• URL translation
• Content-based routing
• Hybrid cloud support
URL Translation ADCs allow companies to deploy a web application that runs on dedicated VMs for each client but maintain a single URL for the clients to access their instances. Each client would access the site from https://mainappurl.com/clientname/, and the ADC would interpret the client name in the URL and know which servers on the back end to direct the traffic to. In such cases, the ADC will rewrite the URL, translating https://mainappurl.com/clientname/ to the internal URL. This may seem simplistic, but as clients use the system, the URL string will be much longer, so the ADC needs to pick out that part of it and rewrite only a portion of the string.
For example, if a client Bob’s Hats connects to https://inventorycontrol.com/bobshats/, this might be internally translated to https://BHWeb01.clientsites.local. Later, a request for a resource in the session may look like this: https://inventorycontrol.com/bobshats/hatsearch/query.aspx?gender=mens&type=fedora. This would be translated to https://BHWeb01.clientsites.local/hatsearch/query.aspx?gender=mens&type=fedora.
Content-Based Routing In another example, you may have different types of data hosted on dedicated resources to better handle storage. If a request comes in for standard HTML content, the ADC can send them to one set of servers, whereas if a request comes in for video, the ADC will direct that traffic to a different set of servers. Each time it directs the traffic, it could still load-balance across the pool of video servers or web servers, but it makes that initial determination by looking at the application layer request to understand the content that is requested.
Another use of ADC is to terminate SSL/TLS sessions at the ADC so that back-end traffic is sent unencrypted. This method is used when trying to cut down on the SSL/TLS processing load on back-end web servers.

CAUTION Terminating SSL/TLS sessions at the ADC may seem like a good idea, but unencrypted sessions, even on the back end, do present a vulnerability that can be exploited if malicious code or unauthorized access is obtained to internal systems. This can result in a data breach or man in the middle attack.
Hybrid and Multicloud Support Hybrid and multiclouds are another area where ADCs are used. The ADC can distribute traffic between a combination of different cloud providers or local data centers based on traffic load or other factors. The ADC may require agent software to reside on resources so that it will have visibility into the health and other status of resources. You will also need to configure firewall rules to allow the ADC traffic, such as DNS lookups, health queries, and HTTP/HTTPS requests.
High Availability Network Functions
Without network connectivity, the cloud becomes useless to consumers. That is why it is so important to have reliable network resources. A primary method of establishing this reliability is through HA network functions.
HA in networking equipment involves improving resiliency at the device level and adding redundant units. HA networking equipment will often have FT components. These components are redundant or modular to increase resiliency if a component fails. Some FT components include
• Power supplies
• Control modules
• Interface cards
• Fan trays
A device configured for FT will have two or more of each of these components. Modular devices often allow for hot-swapping of components. This means that a hot-swap interface card or power supply can be removed and replaced while the device is running, with no interruption in service.
Another method of achieving HA is the use of link aggregation. Link aggregation combines two or more network interfaces into one logical unit. This allows the connection to achieve greater throughput because data can be transferred over all of the link aggregated ports at once. This throughput is equal to the total capacity of all the links aggregated. More importantly, link aggregation increases resiliency because the link will still operate, although at a slower speed, as long as one port in the link aggregation is operational.
Some networking equipment that is commonly configured for HA includes switches, routers, and firewalls.
Switches Switches connect servers and other resources to the network. As such, a switch failure would interrupt service to all the devices connected to it if redundant devices were not available. Switch resiliency can be achieved through FT, as described in the preceding section. This involves selecting devices with modular, hot-swappable, redundant components. Figure 13-2 shows the front of a modular switch. The interface cards have latches on the sides so that they can be released from the unit and swapped out. In the picture, the lower interface card has been pulled out so you can see how it slides into the unit. The power supplies at the top of the unit can be pulled and hot-swapped as well.

Figure 13-2 Modular switch front
Multiple switches can be cabled to each device, and then these switches are connected together. This is known as path resiliency. Switches must use protocols to allow for them to dynamically enable or disable links so that broadcast messages are not endlessly repeated over redundant pathways. Such protocols include Rapid Spanning Tree Protocol (RSTP) and Open Shortest Path First (OSPF).
Some switches are stackable. This does not mean that they can sit on top of one another. Stacking is a networking term where multiple devices are connected together at the backplane so that they operate as a single device. Stacking also offers higher throughput between the switches than could be achieved by cabling them together using some of the available switch ports.
Routers If you recall from Chapter 4, a router is used to connect multiple networks together and allows a network to communicate with the outside world. Without redundancy, a router failure would disrupt connectivity to an entire network. Router resiliency can be achieved as described in the preceding section, with modular, hot-swappable, redundant components.
You can also configure redundant devices to protect against device failure. There are three protocols that allow for multiple routers to operate as one default gateway. These protocols are known as First Hop Redundancy Protocols (FHRPs). These protocols are limited to a single subnet, so they do not modify the routing table or advertise networks other than the one used for the gateway.
The first of these is the Virtual Router Redundancy Protocol (VRRP). With VRRP, multiple routers share the same virtual IP address. These routers collectively are known as a virtual router. The devices that make up the virtual router are known as a VRRP group. One router in the group is the master, and the other routers are backups to that router. Each router is given a priority between 1 and 254, so that if the master fails, the one with the highest priority takes over as the master. The routers communicate with each other and determine their state (operational or not) over the multicast IP 224.0.0.18. These multicast packets will have 112 in the protocol field of the IPv4 header. VRRP is an open standard, so any router vendor can choose to support it. Some mainstream routers that support it include those from Juniper and Brocade.
Hot Standby Router Protocol (HSRP) is another protocol that operates much like VRRP. HSRP, however, is a Cisco proprietary protocol, so it is implemented when you are working with Cisco routers. However, due to the widespread use of Cisco routers, HSRP is a very well-known protocol. Some of the terminology is different, but the process is much the same as VRRP. Instead of a master device, the one that services requests is known as the active device. A standby device will take over if the master fails. Any other routers in the group are known as listening routers.
The third protocol is Gateway Load Balancing Protocol (GLBP). GLBP is another Cisco proprietary protocol. The advantage of GLBP over VRRP and HSRP is that, rather than having an active/standby model where only one router is doing the work and the others are just waiting, each of the routers in the GLBP group can route packets, so the load is shared among them. Figure 13-3 depicts how these three protocols operate. The status of each router is not shown in the diagram because that is how they differ. If it were a GLBP setup, each of the routers would be servicing traffic. If VRRP or HSRP were being used, one would service the traffic and the others would wait until it failed.

Figure 13-3 First Hop Redundancy Protocols
Firewalls Firewalls route traffic and enforce security rules governing the traffic flow. Similar to a router, without HA, a firewall failure would disrupt connectivity to an entire network. Routers can be configured for FT with modular, hot-swappable, redundant components to provide device resiliency. They can also be clustered together to protect against single device failure. Some clusters allow for both devices to service traffic together (active/active), whereas others operate with one servicing traffic while the other waits to take control if a failure occurs (active/passive).
Service-Level Agreements for BCP and HA
A service-level agreement (SLA) is a contract that specifies the level of uptime that will be supported by the service provider. SLAs are used with Internet service providers, cloud solutions, and a variety of other technology solutions.
Review the SLA damage clauses when purchasing a complete HA solution. SLAs include provisions for how the service provider will compensate customers if SLAs are not met. At a minimum, these include some monetary compensation for the time the system was down that may be credited toward future invoices. Sometimes the provider must pay fines or damages for lost revenue or lost customer satisfaction. Ensure that the SLA specifies the expected amount of uptime and that damages for SLA violations are sufficient to cover losses due to unexpected downtime.
Similarly, when providing a solution to customers, ensure that you construct SLAs that are consistent with the HA capabilities of your systems. For example, you would not want to create an SLA that states five 9s of availability if the underlying systems can only provide four 9s.
Disaster Recovery Methods
When an organization is choosing a disaster recovery method, it has to measure the level of service required. This means understanding how critical the application or server is and then determining the proper disaster recovery method. When implementing disaster recovery, it is important to form DRPs that will describe how the organization is going to deal with potential disasters such as fires, floods, earthquakes, complete site failure, or blackouts.
It is first necessary to focus on those applications or servers that are mission critical in the DRP. A mission-critical system is any system whose failure would result in the failure of business operations. These systems need to be identified and prioritized in the DRP so that recovery methods are documented commensurate with their criticality level so that losses are minimized.
Location is also important. The company will need to determine where to place the disaster recovery center. Geographic diversity should be taken into account when planning for a disaster that may affect a particular geographic region. Disasters come in many forms, including natural disasters, so placing the disaster recovery center in a location that is 1000 miles away might prevent the same natural disaster from destroying both the primary data center and the disaster recovery data center.
Corporate Guidelines/Documentation
Corporate guidelines should be established so that employees understand the company’s expectations for how a disaster will be handled and their own responsibilities if a disaster were to occur. Corporate guidelines are expressed through a set of plans and policies that have been approved by company leadership such as a CEO, CSO, CIO, or an executive group such as an information security steering committee.
The first of these documents is the DRP. An organization makes its DR guidelines known through the DRP, and it is likely the most comprehensive DR document. Other documents are usually created by departments in support of DR initiatives, such as employee rosters, emergency checklists, emergency contact numbers, system documentation, system dependency sheets, triage lists, and so forth. This section will focus mainly on the DRP, but it is good to be aware of some of the documents just mentioned.
After a discussion on the DRP, this section introduces metrics that the organization can use to determine when components might fail or cause problems. These metrics are good to know because they will likely appear in some of the documents mentioned previously. Lastly, DR defines parameters for what losses are acceptable during recovery in terms of how much data can be lost and how much time can be spent recovering. These are defined as the recovery time objective (RTO) and the recovery point objective (RPO). Both concepts are explained in their own subsection at the end of this section.
Disaster Recovery Plan
An organization makes its guidelines for how a disaster will be handled in a DRP. The DRP outlines the procedures to deal with large-scale threats to data, systems, and employees. The DRP defines the threats to those organizational resources and outlines the safeguards and practices designed to allow the company to operate in a different location, using different resources, while primary resources are being restored.
The DRP establishes a generalized capability and readiness to cope effectively with potential disasters. Disaster preparations constitute a last-resort response if resilience and recovery (elements of the BCP) should prove inadequate in practice. Still, if the DRP is to be complete, it must have documented, planned for, and mapped out contingencies.
A DRP typically contains the following sections:
• Business risk evaluation
• Impact analysis
• Roles and responsibilities
• Damage assessment process
• Disaster declaration process
• RTO and RPO (covered later in this section)
• Call trees
• Communication protocols
• Prearranged communication templates
• Testing methods
• Training methods
• Impact and likelihood of each identified disaster scenario
• Recovery steps for each identified disaster scenario
Disaster Recovery Metrics
Another factor to consider when planning for DR is hardware health metrics. Some important hardware health metrics include
• Mean time between failures (MTBF)
• Mean time to repair (MTTR)
• Self-monitoring, analysis, and reporting technology (SMART)
MTBF is the average length of time a device will function before it fails. MTBF can be used to determine approximately how long a hard drive will last in a server. It can also be used to project how long it might take for a particular hardware component to fail and thereby help with the creation of a DRP.
MTTR, on the other hand, is the average length of time that it takes to repair a failed hardware component. MTTR needs to be a factor in the DRP, as it is often part of the maintenance contract for the virtualization host computers. An MTTR of 24 hours or less would be appropriate for a higher-priority server, whereas a lower-priority server might have an MTTR of seven days.
Lastly, SMART is a set of hard disk metrics used to predict failures by monitoring over 100 metrics such as read error rate, spin-up time, start and stop count, reallocated sectors count, and seek error rate. SMART has predefined thresholds for each metric, and those thresholds are used to determine if a drive is in an OK, warning, or error status. All of these factors need to be considered in the DRP for the organization to have a successful disaster recovery environment.
RTO
The RTO is the maximum tolerable amount of time between an outage and the restoration of the service before an organization suffers unacceptable losses. RTO will involve many tasks. The following is the general sequence of tasks that must be performed:
1. Notify IT or cloud backup operations of the need for a restore.
2. Locate restoration archive or media that contains the required data, such as cloud storage, local storage, a remote data center, or tape. If tape, identify if the tape is on-site or off-site. If the tape is off-site, pick it up and bring it to the location where the restoration will take place.
3. Conduct the restore.
4. Validate the restore to confirm that the data is accessible, free from error, and ready for use. If errors are encountered, try restoring again. If errors continue, attempt the restore from another backup.
Figure 13-4 shows a flowchart of all the activities that could be required depending on where the data is located and how the activities contribute to RTO.

Figure 13-4 Restoration activities contributing to RTO
RPO
The RPO is the maximum amount of time in which data can be lost for a service due to a major incident. The RPO determines how often backups should take place. For example, if the RPO is 24 hours, then backups would occur daily.
The organization should not treat all data the same. Some data might need to have a different RPO because it has different availability needs. For example, a database of customer orders might have an RPO of one minute, whereas the RPO for web files might be 24 hours because updates are made no more than once per day and web files are also located in web developer repositories.
One of the things that should be considered and that can help meet expected RTO and RPO is redundancy. A redundant system can be used to provide a backup to a primary system in the case of failure.
Disaster Recovery Kit
A DR kit is a container packed with the essential items you will need in a disaster. One item should be the disaster recovery plan. Some other items to include are
• Water
• Dry food (nuts, protein bars, etc.)
• Flashlight
• First aid kit
• Batteries
• Whistle
• Cellular hotspot
• Charging brick
• Tool kit
Playbook
A DR playbook is a document that outlines the steps necessary for resolving a particular situation. This may sound like the DRP, but a playbook differs from a DRP in that a playbook only lists the steps required for one situation. For example, a DRP would list steps required in general for a disaster along with particulars for certain things, but it can be hard to find the information you need when a document gets so large. Playbooks, on the other hand, are shorter, situation-specific references that show employees what they need without all the extra details that do not pertain to the situation at hand. A company would develop playbooks for events like fires, floods, hurricanes, tornados, critical infrastructure failure, pandemics, or active shooter situations.
Network Diagram
A network diagram is a picture that explains how the network is laid out, how systems, such as firewalls, routers, switches, IoT, servers, and other computers, are interconnected. Each device is labeled with its name and possibly an IP address or other information on the system, such as the operating system, role, services, open ports, or subnet. There are two types of network diagrams: logical and physical.
Logical Network Diagram The logical network diagram is concerned with information flow and how systems communicate. Figure 13-5 shows a logical network diagram. It shows several networks that are each connected together. The resources on each server are defined, but the physical connections are not shown.
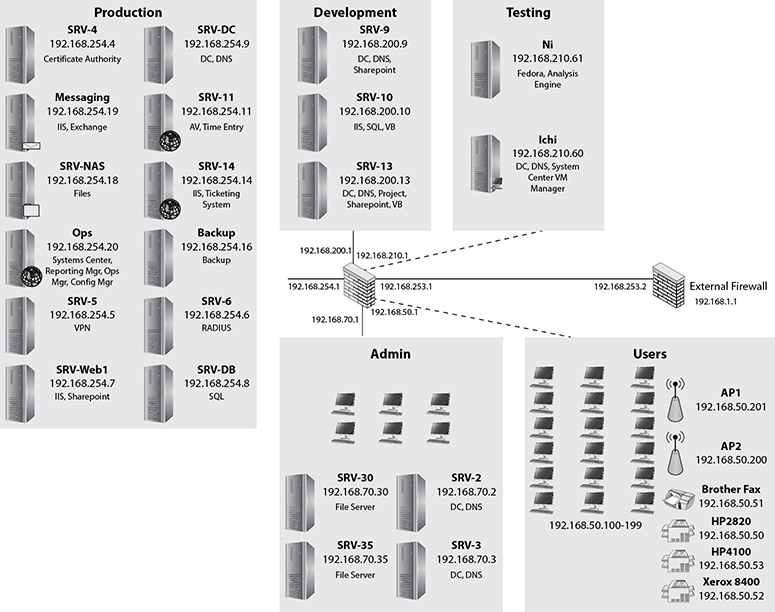
Figure 13-5 Logical network diagram
Physical Network Diagram The physical network diagram shows directly how systems are connected together. This includes the actual cabling and devices in between systems. It may also show how systems are laid out in proximity to one another.
If you were trying to track down which port on a patch panel where a user’s computer was connected, a logical diagram would not be of much use. It would only show you that the device was part of the network, but a physical network diagram could show the jack number of the wall port, the patch panel termination point, and the switch name and port number that the device is connected to.
Consider these examples of physical network diagrams. A switch port diagram is shown in Figure 13-6. This diagram includes labeling for LAG groups that are connected back to a core switch, a firewall, and an Internet filter. This diagram would help network engineers understand how the switch backbone is laid out and where to look if they were encountering issues with the switch fabric.

Figure 13-6 Switch port diagram
Figure 13-7 depicts a rack diagram of three racks in a data center. Each item is labeled with its model number. Most of the equipment is facing the front of the racks, but a few pieces are mounted facing the back side, and those are noted. This diagram would be helpful when planning for new equipment in the racks or when determining optimal data center cable runs. It would also help if you were to give instructions to a technician on where to find a server that has a spared drive or requires some other maintenance.
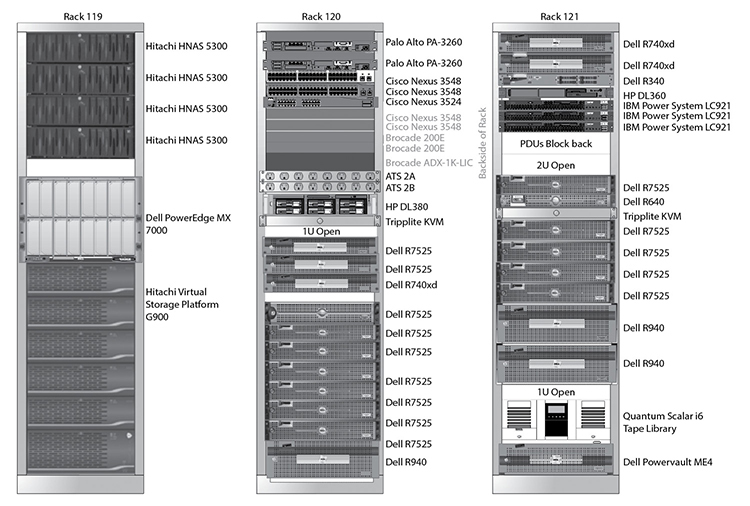
Figure 13-7 Rack diagram
Figure 13-8 shows a patch panel diagram. Each wall port is described with its purpose, color, and where it is patched in the wiring closet. If a port stopped working, technicians could use the diagram to determine where the port terminates in the wiring closet and then could troubleshoot the port, cable, or switch it is connected to.
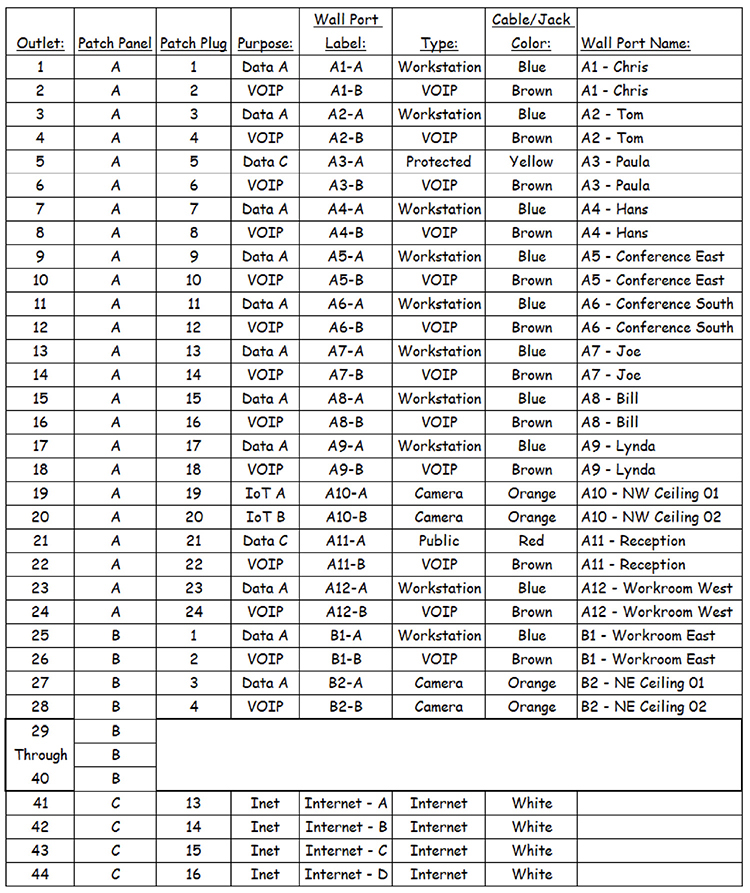
Figure 13-8 Patch panel diagram
Replication
Replication transfers data between two or more systems so that any changes to the data are made on each node in the replica set. A replica set consists of the systems that will all retain the same data. Replication can occur between systems at the same site, termed intrasite replication, or between systems at different sites, termed intersite replication. Multiple sites are used to protect data when a single site is unavailable and to ensure low-latency availability by serving data from sources that are close to the end user or application.
As discussed in Chapter 3, two forms of replication can be used to keep replica sets consistent. Synchronous replication writes data to the local store and then immediately replicates it to the replica set or sets. The application is not informed that the data has been written until all replica sets have acknowledged receipt and storage of the data. Asynchronous replication stores the data locally and then reports back to the application that the data has been stored. It then sends the data to replication partners at its next opportunity.
File Transfer
In lieu of some backups, an organization may choose to perform a file transfer or a scheduled synchronization of files instead. This is quite common in replication scenarios. It is important when synchronizing files for the intent of archiving that you configure them to not synchronize deletes. Additionally, changes on one side are going to be reflected on the other side, so synchronizations are not useful in preserving those changes.
A one-time file transfer is a great way to get a point-in-time copy for data that does not change so that you do not need to keep backing it up with every full backup that occurs. A one-time backup can be performed and then stored away for whenever it is needed. If data has remained unchanged since the one-time backup, the backup will still be consistent even though it has not been updated.
One-time backups can reduce space on backup drives and reduce the length of time required to perform backups. Ensure that if you do a one-time file transfer that you lock the files so that they cannot be changed in production. Otherwise, you might find at some later date that people have been changing the files but there is no active backup for the data.
Network Configurations
Network devices can take a long time to configure properly, but a saved configuration can be applied to a device in minutes. Save device configurations to a central location that is backed up regularly so that you will be able to retrieve device configurations and reapply them if necessary.
If you have a failed device but a spare is available, it can be placed into service, cabled up just like the failed unit, and then the configuration can be applied to it to make it functional.
CAUTION Ensure that you apply firmware updates to bring a device to the same firmware level before applying a configuration. Configuration files may not work correctly if the firmware versions differ between the one whose configuration was exported and the one you are importing it to.
Service-Level Agreements for DR
As mentioned earlier in this chapter, an SLA is a contract that specifies the level of uptime that will be supported by the service provider. SLAs should be obtained for each of the systems that will be relied upon for the DR solution. It would be a shame to fail over to a DR site only to find that the site did not meet availability expectations. Customers who have recently suffered a downtime do not want to experience other downtimes shortly thereafter, so you want to ensure that your DR site will provide the required service level.
Backup and Recovery
A backup set is a secondary copy of the organization’s data and is used to replace the original data in the event of a loss. The backup process needs to be monitored just like any other process that is running in the environment. Proper monitoring of the backup system helps to ensure that the data is available if there is a disaster.
Backups are only as good as their accompanying restore strategies. Testing the restoration process of all the backups in an organization should be done on a scheduled and routine basis. Backups can be fully automated with schedules, so that they can run without interaction from an administrator.
Proper DRP and data retention plans should be established to ensure that data loss is consistent with the RPO if a disaster occurs. The backup plan should include how the data is to be stored and if the data is going to be stored off-site, how long it is kept off-site and how many copies are kept at the off-site facility. The backup plan should also specify how the data will be recovered.
Selecting the appropriate backup solution is a critical piece of a properly configured disaster recovery implementation. Creating a backup is simply the process of copying and archiving data so that the data is available to be restored to either the original location or an alternative location should the original data be lost, modified, or corrupted.
Creating backups of data serves two primary purposes. The first purpose of a backup is to restore data that is lost because either it was deleted or it became corrupt. The second purpose of a backup is to enable the recovery of data from an earlier time frame.
An organization should have a data retention policy that specifies how long data needs to be kept. For example, if an organization has a data retention policy that specifies all data must be kept for two weeks, an end user who needs to have a document restored from ten days ago could do so.
When selecting a backup policy, several things need to be taken into consideration. First, the organization must determine how the backups will be stored, whether on tape, optical media, NAS, external disk, or a cloud-based storage system. Cloud storage can emulate a virtual tape library (VTL) so that existing on-premises backup solutions can see it.
If data is stored on removable media such as tapes, optical media, or external disks, first determine if the backups should be stored at an offsite location. Storing backups at an offsite location allows for recovery of the data in the event of a site disaster. After choosing a media type, the next step is to choose the style of backup.
Cloud backups exist in the cloud provider’s data center, so they are already outside of the organization and thus “off-site.” Cloud backups are an effective way to perform off-site backups without an extensive infrastructure. Files from cloud backups are easier to manage and often faster to retrieve than off-site tapes or removable media.
The available backup types are discussed next. Each backup type has its own set of advantages and disadvantages.
Backup Types
An organization can structure backups in multiple ways to strike a balance between the length of time it takes to conduct a backup and the length of time it takes to perform a restore operation. Backup types also offer different levels of recoverability, with some requiring the presence of another backup to be functional. The available backup types include the following:
• Full backup
• Differential backup
• Incremental backup
• Snapshot
• Bit-for-bit backup
• Imaging
Backups utilize features such as change or delta tracking and can be stored online or offline. We will discuss those topics before covering the various backup types.
Change/Delta Tracking
Some backup types archive information depending on whether it has been backed up recently or if it has changed since the last backup. File change status is tracked using a flag on files called the archive bit. When a full backup is performed, the archive bit is set to 0. If that file changes, the archive bit is set to 1.
Online and Offline Backups
Online backups are those that are available to restore immediately, while offline backups must be brought online before they are available to restore. Some offline backups include tape backups and removable hard drives. A backup tape is offline because it must be retrieved and inserted into a tape drive before it is available to restore. Similarly, a backup hard drive stored in a safe deposit box is offline.
Online backups include nearline and cloud backups. Nearline backups are written to media on the network, such as a NAS, a local backup server, or shared storage on a server. In the cloud, nearline storage is rated at a lower availability. (Google lists their nearline at 99.95 percent, whereas standard storage is 99.99 percent available.) These backups are online because they can be retrieved without having to insert media. Cloud backups are also online backups because they are always available. Both of these online options can be restored at any time.
Full Backup
A full system backup backs up the entire system, including everything on the hard drive. It makes a copy of all the data and files on the drive in a single process. A full backup takes up the most space on storage media because it does a full drive copy every time the backup is executed. Performing a full backup every day requires the same amount of space on the backup media as the drive being backed up without backup compression or deduplication. Multiple backup iterations usually have many duplicates and so deduplication ratios can be 100:1 or higher. A 100:1 reduction ratio reduces the space required for further backups by 99 percent. If a full backup takes 300GB, the next full backup would take 3GB with the 100:1 reduction ratio.
The benefit to a full backup is that an organization can take any of the backups from any day they were executed and restore data from a single backup media. The full backup resets the archive bit on all files on the computer to zero. Figure 13-9 shows an example of how a full system backup would look after four backups.
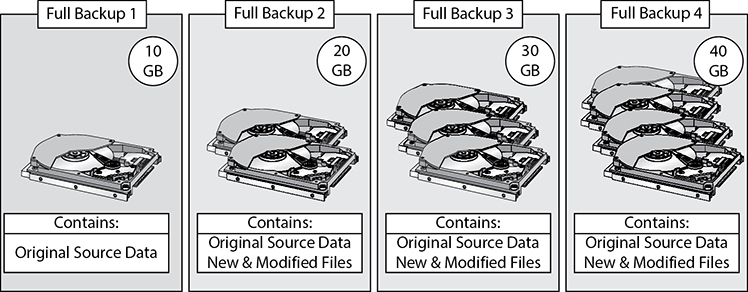
Figure 13-9 Illustration of a full system backup
Differential Backup
The differential backup backs up only those changes that were made since the last full backup was executed. To perform a differential backup, a full backup must have been performed on the data set previously.
After the full backup is executed, every differential backup executed thereafter will contain only the changes made since the last full backup. The differential backup knows which data has been changed because of the archive bit. Each changed file results in a file with an archive bit set to 1. The differential backup does not change the archive bit when it backs up the files, so each successive differential backup includes the files that changed since the last full backup because full backups do reset the archive bit.
One of the disadvantages to differential backups is that the time it takes to complete the backup will increase as files change between the last full backup. Another disadvantage is that if the organization wants to restore an entire system to a particular point in time, it must first locate the last full backup taken prior to the point of failure and the last differential backup since the last full backup.
For example, if full backups are taken every Friday night and differentials are taken each night in between, restoring a system on Wednesday to the Tuesday backup would require the full backup and the Tuesday differential. Figure 13-10 shows an example of how a differential backup looks after three days.

Figure 13-10 Illustration of a differential backup
EXAM TIP Differential backups require more space to store the backup and take more time to complete than an incremental backup. They are still faster to perform than a full backup. Differential backups require less time to perform a restoration than does an incremental backup.
Incremental Backup
An incremental backup also backs up only those files that have changed since the last backup was executed, but the last backup can be either a full backup or an incremental backup. Incremental backups do reset the archive bit to 0 when they back up files, so the next incremental backup does not back up that file again unless it has changed again. To perform an incremental backup, a full backup must have been carried out on the data set previously.
Backing up only files that have changed since the last backup makes incremental backups faster and requires less space than a full or differential backup. However, the time it takes to perform a restoration is longer because many backup files could need to be processed. Restores require the last full backup and all the incremental backups since the last full backup.
For example, if full backups are taken every Friday night, and incremental backups are taken each night in between, to restore a system on Wednesday to the Tuesday backup would require the full backup, Saturday incremental, Sunday incremental, Monday incremental, and Tuesday incremental. Figure 13-11 shows an example of how an incremental backup would look after three backups.

Figure 13-11 Illustration of an incremental backup
EXAM TIP Incremental backups require less space to store the backup than differential or full backups. Incremental backups also complete much more quickly but require more time to perform a restoration.
Table 13-1 shows the full, differential, and incremental backup types and their size, backup duration, and restore duration.

Table 13-1 Comparison of Full, Differential, and Incremental Backups
3-2-1 Rule
The 3-2-1 rule is a general principle to follow when designing backups. It requires that you keep at least three copies of your data, that two of the backups reside on different types of storage, and that at least one copy is stored off-site.
For example, you might have your production data hosted in the cloud and configure backups with a third-party cloud provider. You also have a backup job that makes a weekly copy of the backup to store on a removable hard drive rotation.
The 3-2-1 rule is easy to remember and very practical. If your data is lost or corrupted and you have to go to backup, you want to have some assurance that you will have another option if your backup fails. The second copy is that assurance. Furthermore, it is stored off-site because that helps to separate it from the same risks that the first backup copy faces. For example, if the cloud provider goes bankrupt, it wouldn’t help if you had multiple backup copies stored with them because they all would be inaccessible. Similarly, if all your backups are stored in a vault at the office and the building burns down, you want to have another copy at a different location to restore from.
Snapshot
A snapshot captures the state of a VM or volume at the specific time when the snapshot was taken. While similar to a backup, a snapshot should not be considered a replacement for traditional backups. A VM snapshot can be used to preserve the state and data of a VM at a specific point in time. A snapshot can be taken before a major software installation, and if the installation fails or causes issues, the VM can be restored to the state it was in when the snapshot was taken.
Other cloud data such as websites hosted in the cloud or cloud data stores perform storage snapshots that operate similarly to a VM snapshot except that they are only concerned with the data stored in the snapped location.
Multiple snapshots can be taken. A series of snapshots are organized into a snapshot chain. A snapshot keeps a delta file of all the changes after the snapshot was taken. The delta file records the differences between the current state of the disk and the state the disk was in when the snapshot was taken. A marker in the chain allows the cloud provider to know which points represent snapshots.
Snapshots and snapshot chains can be created and managed in a variety of different ways. It is possible to create snapshots, revert to any snapshot in the chain, mount snapshots as data stores to view individual files, or even delete snapshots.
Since snapshots are not a replacement for regular backups, they should only be kept for a short period, preferably a few days. A snapshot continues to record from its point of origin, so if the snapshot is kept for long periods, the file will continue to grow larger and might eventually become too large to remove or cause disk storage constraints. This can cause performance issues for the cloud resource. If there is a need to keep a snapshot longer than a few days, it is recommended to create a full system backup.
Bit-for-Bit Backups
Another type of backup is the bit-for-bit backup, which captures the entire hard drive bit by bit. Because the whole hard drive was captured, the image can be used to restore an entire server in the event of a disaster, allowing the image to be restored on new hardware.
Creating a bit-for-bit backup of a server differs from the file-based backups discussed earlier in that the file-based backups only allow you to restore what was configured to be backed up, whereas a bit-for-bit backup allows for the entire restoration of the server, including files, folders, and operating system. Even if a file backup contains all the data on a drive, it cannot restore partition tables and data to the exact places and states they were in when the backup was taken, and this can cause problems if you try to do a file-level restore on a server’s operating system drive or on transactional data such as e-mail mailboxes or databases.
Bit-for-bit backups can be scheduled much like other backup jobs and can be an excellent method for returning a system to a previous state. Bit-for-bit backups are typically used for physical machines in much the same way as a snapshot is used for VMs.
Imaging
Images are like bit-for-bit backups in that they are a bit-for-bit copy of the hard drive. However, images are usually taken as a one-time operation rather than a normal scheduled task. Images are taken of machines prior to deploying them to end users. Administrators may restore from the image if the user has issues with the machine at a later date. Some administrators may choose to restore rather than troubleshoot an issue if the issue appears complex. Applying an image can quickly and easily bring a system back to the organizationally approved operating system build and software set. Images can also be used to bring systems back to a standard approved state.
Images can be taken of machines that are prepped for deployments. Suppose the IT department receives 900 workstations with the same hardware configuration. They would configure the first one with all the software, configure it for use, update the system with the latest patches, and then harden the system. They would then image the system and deploy the image to the other 899 machines.
Images can be used for remote deployments as well. Similar to the situation just described, the IT department would configure the first machine with the software, configuration, and updates and then create an image. That image would be deployed to the network, and computers could PXE boot to the image repository, and the image would be deployed to them.
Clone
A clone is similar to an image, but it is often made as part of an ongoing process. A clone is a copy of the data on a logical or physical drive. Clones can be created through storage management software or via software tools. Figure 13-12 shows an example of a clone used as part of an ongoing backup operation. A clone is made of the production server data and kept synchronized using the storage software. When the backup server needs to write the data to tape, rather than copy the data over the network, the clone is split from the production volume so that new changes are not recorded to it and then mounted to the backup server. The backup server writes the data to tape and then takes the volume offline so that it can be resynced with the data volume.

Figure 13-12 Illustration of a clone used in backup operations
Backup Target
A backup target is a destination for a backup job. A backup target could be a local folder on another drive, a folder on the network, a cloud drive, a remote site, or a tape, for example. Choose a target that will offer low enough latency to complete backup jobs in the required amount of time and that is fast enough to meet the RTO.
Backup targets are sometimes confused with replicas. The two differ in that backup targets are the destination for a backup, whereas replicas are used to create a mirrored copy of the data between the initial target and a replica target.
Local
Local targets are those that are on the same network as the source data. These are also called nearline backups. Local targets include backups to another drive on the same machine, backups to a NAS on the local network, or backups to a file server on the local network. This could also include a local cloud appliance with local storage, which is then replicated to the cloud.
Remote
To help reduce downtime in case of a disaster, an organization can set up and configure backups or replication to another site or a cloud service that is off-premises. It is less likely that an event affecting the source data will also affect a remote target. For example, a forklift that knocks over a server rack in the data center would not affect the cloud backup. Remote targets include cloud backups, remote data centers, and tapes that are taken off-site.
Exercise 13-1: Cross-Region Replication
In this exercise, we will establish cross-region replication between two AWS S3 buckets.
1. Log in to your AWS account. You will be presented with the management console, which will show the available services you can choose from.
2. Go to the storage section and select S3.
3. You will be presented with a screen showing your existing buckets:
Enable replication for the source bucket
4. Select the cloud-example bucket we created in Exercise 3-1 by clicking on the blue hyperlinked name. If you do not have that bucket, please go back to Exercise 3-1 in Chapter 3 to create it.
5. The details of the cloud-example bucket will be displayed. Select the Properties tab, as shown here:
6. You can see that bucket versioning is disabled. We will enable it. Click the Edit button under Bucket Versioning.
7. When the Edit Bucket Versioning screen loads, select Enable, as shown next, and then click Save Changes.
Create a destination bucket and enable versioning
8. We will now create a destination bucket for the replication. Click the Buckets link on the left side of the screen. It is directly underneath the Amazon S3 label.
9. Choose Create Bucket.
10. Give the bucket a name. In this example, we call the bucket cloud-test-destination.
11. Select a different AWS region from the first bucket. In this example, the cloud-test bucket resides in the US East (Ohio) us-east-2 region. The replication bucket will reside in the US West (N. California) us-west-1 region.
12. Under bucket versioning, select the Enable radio button. Your selections should look like this:
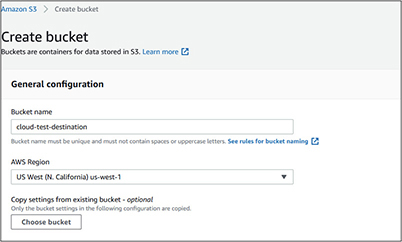

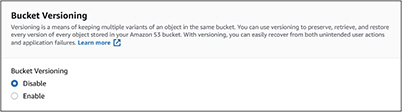
13. Scroll to the bottom of the page and select Create Bucket.
14. Select the Management tab.
15. Under Replication Rules, select Create Replication Rule.
16. Give it a name. For this exercise, we will call it cloud-test-bucket-replication.
17. Under Source Bucket, choose This Rule Applies To All Objects In The Bucket.
18. Under Destination, click the Browse S3 button to select the destination bucket we created in steps 8 to 13.
19. Choose the cloud-test-destination bucket by clicking the radio button next to it and click Choose Path.
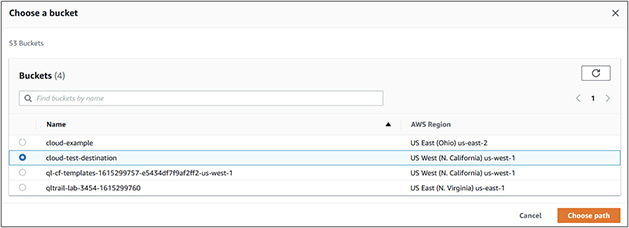
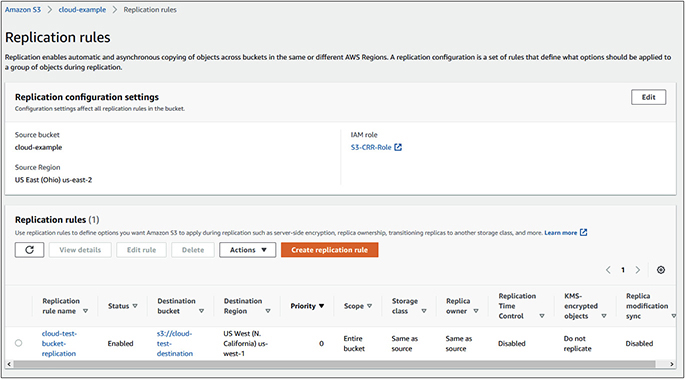
20. Scroll to the bottom of the screen and click Save. The replication rule will be displayed.
Upload files
21. You will be presented with the Buckets screen again. Open the cloud-example bucket.
22. Create three text files on your desktop called test1 , test2 , and test3 . Select those files and upload them to the bucket by clicking the Upload button, which will open the Upload screen, and then click Add Files, as shown here.

23. Click the Amazon S3 link in the upper left to return to the list of buckets.
24. Select the three text files and choose the Open button. The files will populate in the Upload screen.
25. Click Upload and the files will be placed into the bucket. The Upload Status screen will be displayed and you should see a status of Succeeded next to each of the files, as shown next.

26. Click the Close button, and the cloud-example bucket details will be displayed.
27. Click the Amazon S3 link in the upper left to return to the list of buckets.
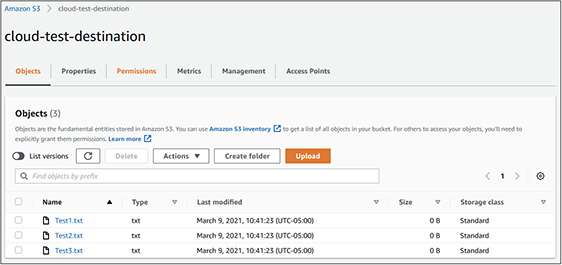
28. Open the cloud-test-destination bucket, and you will see that the three test files we uploaded are now in the destination bucket too.
Replicas
The closer the target is to the source, the faster the backup will run. It will also be faster to restore the data when the target is closer to the source. However, closer targets are riskier because an event that could disrupt services or corrupt the source data might also do the same to the local backup. You do not want to be in a situation where both production systems and backups are unavailable.
Typically, companies will perform a backup to a local data store in the same data center so that the backup job completes quickly and so the data is available close to the source if necessary. However, this data will then be replicated to a replica such as a cloud service, remote site, or tape.
Replicas help to improve reliability and FT. When replicating data, the data is stored on multiple storage devices at different locations so that if one location suffers a disaster, the other location is available with the exact same data. Remote sites are costly to own and operate, so cloud backups have become very popular as a replica.
Other Backup Considerations
Now that you understand the types of backups and where backups are stored, the next steps are to choose the right backup type for your organization and its RTO, configure the backups to store the right objects, and schedule backups to run at ideal times. Be aware that restoring data may require some dependencies such as backup software, catalogs, decryption keys, and licensing.
It is also important to ensure that connectivity from source to target is sufficient to back up the data in the required time frame and with minimal impact on other services that may be operating concurrently. Some companies may find that latency is preventing them from meeting backup windows, in which case they can employ edge sites to reduce the latency.
Next, procure the necessary equipment to conduct backups and restores. If you find that the cost of the equipment is prohibitive for your organization, look to contract with a third party or cloud provider to conduct backups. You will also want to be aware of the availability cost of performing backups or restores and make others aware of activities that could cause performance degradation. The availability cost is the performance impact incurred when backup or restore operations produce contention for available resources. Backup and restore operations could potentially prevent users from performing tasks, or they could make systems less desirable to use.
Backup Schedules
Backup jobs must run on a schedule to be effective. A one-time backup can be useful, but it does little to protect company information that changes rapidly. Scheduled jobs allow for backups to operate at regular intervals to back up the files that have changed since the last backup or to back up all files. The determination as to what is backed up in the job is based on the backup type discussed earlier, such as a full backup, incremental backup, differential backup, snapshot, or bit-for-bit backup.
Backup schedules should be structured such that they do not affect production activities. Backups can consume a lot of disk and network I/O. Compressed and encrypted backups consume CPU as well. Compression and decompression can place a heavy burden on the server and cause disruptions or poor performance for users if backups run during peak times.
Most backups will not require downtime, but they could still affect the performance of the VM and the applications that run on top of it. For this reason, it is best to plan backups for times when the load on the system is minimal.
For example, it would be a bad idea to back up a domain controller at the beginning of the day when users are logging into systems because that is when the domain controller must authenticate each request. Users would likely see service interruptions if a backup were to take place during such a peak time.
Virtualized and cloud systems may have users spread across the globe. Additionally, it may be necessary to coordinate resources with cloud vendors or with support personnel in different global regions. In such cases, time zones can be a large constraint for performing backups. It can be challenging to coordinate a time that works for distributed user bases and maintenance teams. In those cases, you might need to provision enough resources on machines so that backups can run concurrently with a full traffic load.
Configurations
As you choose a schedule for the backup jobs, you will also need to configure the appropriate backup type to minimize the impact on production systems and applications, yet meet backup frequency requirements, RTO, and RPO.
Some common scenarios include performing a full backup weekly and incrementals or differentials daily. Others might choose to do a full backup nightly with hourly incrementals or differentials. Bandwidth and system resources may determine which options are available to you. Of course, if company policy specifies a specific configuration, you may need to upgrade equipment to meet the requirements.
Objects
One of the most important decisions when designing backups is determining what to back up. Each item selected for backup is an object. Should you back up the company intranet? What about local machines if the policy states that data should only be stored on the network? The selection of backup objects is one that should be approved by data and application owners. Ensure that senior management sees the list and ensures that all data and application owners are represented. You may receive sign-off from the intranet application owner and the end-user support manager to back up local machines and the intranet, but if you forgot to include the e-mail application owner, you might be in trouble when the e-mail server goes down. We cannot stress how important it is to choose the right backup objects.
Dependencies
Just having a backup is not always enough. You also need to have the dependencies necessary to restore that backup in an emergency. Dependencies include backup software, catalogs, decryption keys, and licensing.
Backup software is the first dependency. Each vendor stores its backup data in a different format. Usually, one vendor’s backup software cannot read the backup software of another vendor, so you will need to have the backup software that initially created the backup or a newer version of the software to perform the restore.
Catalogs are also necessary. Catalogs are indexes of the data on backup media or backup files. When you want to restore data, you may not know which file contains the data you are looking for, so you query the backup system, and it uses a catalog to find the file or media, and then you can load that media or select that file to do the restore. The good news is that you can catalog media or files if the catalog does not exist. However, if you have 1000 backup files pulled from an old backup drive, the backup software will need to catalog all of them for you to know what is on each one.
Encryption is an important factor when storing backups. Many controls may be in place to protect data on production systems, but if backups are not encrypted, that data could be lost simply by exploiting the backup connection, backup media, or backup systems. For this reason, many companies encrypt their backups. To do the restore, you will need to provide the decryption keys, so keep these safe.
Licensing is also necessary for backup and restore operations. If you back up to a cloud service and then let the contract lapse, you will not be able to do a restore until you renew that license. Also, there is no guarantee that your backups will still be available if you let the contract lapse.
Connectivity
Backups, especially full ones, can take a lot of bandwidth depending on the size and type of the backup object. When migrating over a 1 Gbps or 10 Gbps Ethernet network, this is not as much of a concern, but bandwidth can be a huge constraint when performing backups over a low-speed WAN link such as a 5 Mbps Multiprotocol Label Switching (MPLS) connection.
Evaluate backup objects and their data sizes and then estimate how much time it will take to back them up over the bandwidth available. Be sure to factor in other traffic as well. You do not want the backup to affect normal business operations in the process.
Edge Sites
As information systems become more critical, companies are backing them up more often, even continuously. Latency can be an issue in ensuring timely backup completion when backing up to the cloud. The solution to latency with cloud backups is to select a vendor with edge sites close in proximity to the data that is being backed up. Edge sites are data centers closer to the customer.
Edge sites sometimes service requests and then synchronize back to the primary data center at a later time. Edge sites can also keep data close to the customer in their country of operation to meet data sovereignty requirements.
Equipment
You will need appropriate hardware to do the restoration. If the data is on tape media, you will need a compatible tape device to perform the restore. LTO drives can typically read two versions behind their stated version, and they can write to the stated version and one level down so that an LTO 7 drive can read LTO 5, 6, and 7, and it can write to LTO 6 and 7.
You will also need enough storage space to do a restore. If you archived data to free up space but then later need it, you might need to purchase and install more storage first. You will also need enough bandwidth to copy down data from cloud backups.
Availability
It is imperative to understand if the chosen backup requires downtime. Images of machines can sometimes fail when they are in use, so some image jobs are performed from boot disks when a server is offline.
Backups that require the system to be unavailable must be performed during a downtime. Downtime needs to be scheduled with stakeholders, such as end users and customers, and the stakeholders need to understand how long the downtime is expected to take.
If you anticipate performance degradation due to backups or restores, let stakeholders know. Some can adapt if they are aware of the issues, while some cannot, but they will at least know what is going on. A restore will likely be a higher priority than normal operations, but the helpdesk and other operations teams will need to be aware of the cause of the performance degradation.
Partners or Third Parties
You may use a third party or partner to perform backup services. The most common scenario is to use a cloud provider as the third-party backup service. It is important to understand your contract with the cloud vendor or other third party. Understand what their responsibilities are to you in the case of an emergency and how quickly data can be transferred from their site to yours.
If contracted, an IT service provider or CSP performs backups for you. You will need to determine whether they will be available overnight or on weekends to perform emergency work if necessary. You don’t want to be in a situation where you hire a firm to manage your backups, but then find that no one is available to do a restore when you need it.
Block-Level Backups and Transfers
Block-level backups reduce the time it takes to transfer data to the cloud. They are especially useful when dealing with large files. A block-level backup understands each of the individual blocks that make up the files in a backup set. When a file changes, the only data that is replicated to the cloud includes the individual blocks that changed, rather than the entire file. A large 60GB file might be divided into many small 512KB blocks. A small change to the file would result in some of those blocks changing, and those alone would be replicated to the cloud.
Restoration Methods
The whole point of having a backup is so that you can restore if necessary. While we all hope that day is far away, it helps to be prepared for how to handle it efficiently and effectively. There are a few methods you can use to restore data. They include
• Restoring in place An in-place restore will restore data to its original location on primary storage. The restore operation will overwrite the currently existing data with the data on the backup medium. Choose this option if the data you are overwriting no longer has value. For example, you may restore a database in place if the current database is corrupt and cannot be fixed. In-place restores are also used when granular selection is used, such as in the case of restoring only a few files.
• Restoring to an alternative location This restore places the data in a different location so that the currently existing data remains untouched. This is useful when you want to compare the restored data to the current data to merge it or overwrite selectively following the restore. For example, you might restore files from a backup to an alternative location and then allow users to pull data from the restored folder if they need it.
• Restoring files Restore operations do not have to restore all files that were backed up in the backup operation. File restores selectively choose one or more files from within a backup set to restore.
• Restoring snapshots Restoring snapshots rejects or undoes the changes made since the snapshot was taken. This is most often performed for virtual machines. You could take a snapshot before performing maintenance and then restore the snapshot if errors are encountered following the maintenance.
Archiving
Archiving is another important function to reduce the costs of storage and backup operations. Organizations keep a lot of data, and some data is kept on the off chance that it is ever needed. This data does not need to reside on primary storage and can be moved to the cloud or to archival media instead, such as a hard drive, tape, optical media, or a flash drive. Cloud archiving options offer inexpensive ways to archive data to a data store that is available whenever users have an Internet connection. Cloud archiving options are best for portable machines such as laptops or mobile devices because they do not need to be connected to the corporate network to be archived. This preserves valuable organizational data for users on the go.
Local storage administrators should ensure that the media chosen is adequately protected against harm and that it is logged and cataloged so that it can be found if and when needed. Cloud backups should be verified periodically to ensure that data can be effectively retrieved in an acceptable amount of time.
Chapter Review
This chapter covered methods for protecting data and systems against issues that may come up such as mistakes, component failures, malicious activity, and disasters. Business continuity (BC) encompasses the activities that enable an organization to continue functioning, including offering services, delivering products, and conducting other activities deemed integral to running the business, during and following a disruptive incident.
Achieving a highly available computing environment is something that takes careful planning and consideration. Multiple devices need to be considered and multiple components in each device need to be redundant and fault tolerant to achieve a highly available environment. High availability helps to prevent unplanned downtime and maintain service-level agreements. An organization can set up a multisite configuration to have a hot site, warm site, or cold site so that in the event something happens to the primary data center, the organization can migrate to a secondary data center and continue to operate.
Disaster recovery (DR) is the activities that are performed when a highly disruptive event occurs, such as an outage for a complete site, fires, floods, or hurricanes. These events cause damage to information resources, facilities, and possibly personnel. A proper disaster recovery plan (DRP) can help an organization plan for and respond to a disaster through replication and restoration at alternative sites. Metrics such as the recovery time objective (RTO) and the recovery point objective (RPO) help organizations specify how much data can be lost and how long it should take to restore data and bring systems back to a functioning state. These decisions should be made based on the potential impact on the business so that impact is limited to acceptable levels.
This chapter wrapped up by discussing backup and recovery. A backup set is a secondary copy of the organization’s data and is used to replace the original data in the event of a loss in a process known as restoration.
Questions
The following questions will help you gauge your understanding of the material in this chapter. Read all the answers carefully because there might be more than one correct answer. Choose the best response(s) for each question.
1. Which of the following would be considered a cold site?
A. A site with no heating system
B. A site that has a replication enabled
C. A site that is fully functional and staffed
D. A site that provides only network connectivity and a physical location
2. You are designing a disaster recovery plan that includes a multisite configuration. The backup site must include all necessary hardware and current backups of the original site. Which type of site do you need to design?
A. Cold site
B. Warm site
C. Hot site
D. Virtual site
3. Which of the following is a documented set of procedures that defines how an organization recovers and protects its IT infrastructure in the event of a disaster?
A. MTBF
B. MTTR
C. RPO
D. DRP
4. An organization recently had a disaster, and the data center failed over to the backup site. The original data center has been restored, and the administrator needs to migrate the organization back to the primary data center. What process is the administrator performing?
A. Failover
B. Failback
C. DRP
D. RTO
5. You have been tasked with distributing incoming HTTP requests to multiple servers in a server farm. Which of the following is the easiest way to achieve that goal?
A. Mirror site
B. Fault tolerance
C. Redundancy
D. Load balancing
6. When replicating data in a multisite configuration from the primary site to a backup site, which form of synchronization requires the system to wait before proceeding with the next data write?
A. Asynchronous replication
B. Synchronous replication
C. Failover
D. Mirror site
7. Which of the following terms can be used to describe a system that is location independent and provides failover?
A. Clustering
B. Load balancing
C. Geo-clustering
D. Failover
8. Which term is used to describe the target amount of time that a system can be down after a failure or a disaster occurs?
A. RPO
B. RTO
C. BCP
D. MTBF
9. Which of the following processes allows a system to automatically switch to a redundant system in the event of a disaster at the primary site?
A. Failback
B. DRP
C. Failover
D. Redundancy
10. Which of the following backup processes needs the last backup and all additional backups since that backup to perform a restore?
A. Incremental
B. Differential
C. Full
D. Image
11. Which of the following backups could be restored without any additional backups?
A. Incremental
B. Differential
C. Full
D. Image
12. What is the easiest method for an administrator to capture the state of a VM at a specific point in time?
A. Backup
B. Snapshot
C. Image
D. Clone
Answers
1. D. A cold site does not include any backup copies of data from the organization’s original data center. When an organization implements a cold site, it does not have readily available hardware at the site; the site only includes the physical space and network connectivity for recovery operations, and it is the organization’s responsibility to provide the hardware.
2. C. A hot site is a duplicate of the original site of the organization and has readily available hardware and a near-complete backup of the organization’s data. A hot site can contain a real-time synchronization between the original site and the backup site and can be used to completely mirror the organization’s original data center.
3. D. A DRP (disaster recovery plan) describes how an organization is going to deal with recovery in the event of a disaster.
4. B. Failback is the process of switching back to the primary site after the environment has been shifted to the backup site.
5. D. Load balancing distributes workloads across multiple computers to optimize resources and throughput and to prevent a single device from being overwhelmed.
6. B. Synchronous replication writes data to the local store and then immediately replicates it to the replica set or sets. The application is not informed that the data has been written until all replica sets have acknowledged receipt and storage of the data.
7. C. Geo-clustering uses multiple redundant systems that are located in different geographical locations to provide failover and yet appear as a single highly available system.
8. B. RTO (recovery time objective) is the target amount of time a system can be down after a failure or disaster.
9. C. Failover is the process of switching to a redundant system upon failure of the primary system.
10. A. An incremental backup backs up the files that have changed since the last full or incremental backup and requires all incremental backups to perform a restore.
11. C. A full backup backs up the entire system, including everything on the hard drive. It does not require any additional backups to perform a restore.
12. B. Snapshots can be used to capture the state of a VM at a specific point in time. They can contain a copy of the current disk state as well as memory state.