
4.2. Understanding Intrusion Detection Systems
Imagine that you have just come home from vacation. While you were gone, someone entered your house without your permission. How will you know it? Will the alarm be sounding, or will you notice the front door unlocked? Will you need to spot something missing, or will a rug out of place tip you off?
Real World Scenario: Know the Resources Available in LinuxSecurity information is readily found at a number of Linux-related sites. The first to check, and stay abreast of, is always the distribution vendor's site. Its pages usually provide an overview of Linux-related security issues with links to other relevant pages. You should also keep abreast of issues and problems posted at http://www.cert.org and http://www.linuxsecurity.com. You can find information on any Linux command through a number of utilities inherent in Linux:
|
In the original Walking Tall movies, the sheriff put small strips of clear tape on the hood of his car. Before getting in the vehicle, he would check the difficult-to-detect tape to see if it was broken—if it was, it tipped him off that someone had been messing beneath the hood, and that saved his life. Do you have clear tape on your network?
Intrusion detection systems (IDSs) are becoming integral parts of network monitoring. IDS is a relatively new technology, and it shows a lot of promise in helping to detect network intrusions. Intrusion detection (ID) is the process of monitoring events in a system or network to determine if an intrusion is occurring. An intrusion is defined as any activity or action that attempts to undermine or compromise the confidentiality, integrity, or availability of resources. Firewalls, as you may recall, were designed to prevent access to resources by an attacker. An IDS reports and monitors intrusion attempts.
NOTE
It should be inherently understood that every network, regardless of size, should utilize a firewall. On a home-based network, a personal software firewall can be implemented to provide protection against attacks.
Several key terms are necessary to explain the technology and facilitate the discussion in this section:
Activity
An activity is an element of a data source that is of interest to the operator. This could include a specific occurrence of a type of activity that is suspicious. An example might be a TCP connection request that occurs repeatedly from the same IP address.
Administrator
The administrator is the person responsible for setting the security policy for an organization. They're responsible for making decisions about the deployment and configuration of the IDS. The administrator should make decisions regarding alarm levels, historical logging, and session monitoring capabilities. They're also responsible for determining the appropriate responses to attacks and ensuring that those responses are carried out.
|

Alert
An alert is a message from the analyzer indicating that an event of interest has occurred. The alert contains information about the activity as well as specifics of the occurrence. An alert may be generated when an excessive amount of Internet Control Message Protocol (ICMP) traffic is occurring or when repeated logon attempts are failing. A certain level of traffic is normal for a network. Alerts occur when activities of a certain type exceed a preset threshold. For instance, you might want to generate an alert every time someone from inside your network pings the outside using the Ping program.
Analyzer
The analyzer is the component or process that analyzes the data collected by the sensor. It looks for suspicious activity among all the data collected. Analyzers work by monitoring events and determining whether unusual activities are occurring, or they can use a rule-based process that is established when the IDS is configured.
Data source
The data source is the raw information that the IDS uses to detect suspicious activity. The data source may include audit files, system logs, or the network traffic as it occurs.
Event
An event is an occurrence in a data source that indicates that a suspicious activity has occurred. It may generate an alert. Events are logged for future reference. They also typically trigger a notification that something unusual may be happening in the network. An IDS might begin logging events if the volume of inbound e-mail connections suddenly spiked; this event might be an indication that someone was probing your network. The event might trigger an alert if a deviation from normal network traffic patterns occurred or if an activity threshold was crossed.
Manager
The manager is the component or process the operator uses to manage the IDS. The IDS console is a manager. Configuration changes in the IDS are made by communicating with the IDS manager.
Notification
Notification is the process or method by which the IDS manager makes the operator aware of an alert. This might include a graphic display highlighting the traffic or an e-mail sent to the network's administrative staff.
Operator
The operator is the person primarily responsible for the IDS. The operator can be a user, administrator, and so on, as long as they're the primary person responsible.
Sensor
A sensor is the IDS component that collects data from the data source and passes it to the analyzer for analysis. A sensor can be a device driver on a system, or it can be an actual black box that is connected to the network and reports to the IDS. The important thing to remember is that the sensor is a primary data collection point for the IDS.
The IDS, as you can see, has many different components and processes that work together to provide a real-time picture of your network traffic. Figure 4.6 shows the various components and processes working together to provide an IDS. Remember that data can come from many different sources and must be analyzed to determine what's occurring. An IDS isn't intended as a true traffic-blocking device, though some IDSs can also perform this function; it's intended to be a traffic-auditing device.
Figure 4.6. The components of an IDS working together to provide network monitoring

IDSs use two primary approaches:
Signature-based-detection IDS
A signature-based system, also commonly known as misuse-detection IDS (MD-IDS), is primarily focused on evaluating attacks based on attack signatures and audit trails. Attack signatures describe a generally established method of attacking a system. For example, a TCP flood attack begins with a large number of incomplete TCP sessions. If the MD-IDS knows what a TCP flood attack looks like, it can make an appropriate report or response to thwart the attack.
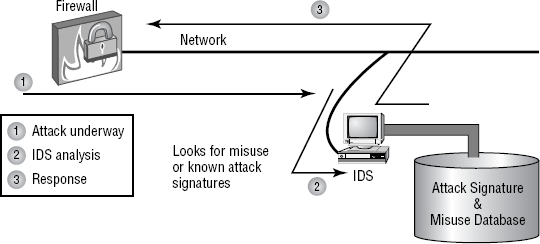
Figure 4.7 illustrates a signature-based IDS in action. Notice that this IDS uses an extensive database to determine the signature of the traffic. This process resembles an antivirus software process.
Figure 4.7. A signature-based IDS in action
Anomaly-detection IDS
An anomaly-detection IDS (AD-IDS) looks for anomalies, meaning it looks for things outside of the ordinary. Typically, a training program learns what the normal operation is and then can spot deviations from it. An AD-IDS can establish the baseline either by being manually assigned values or through automated processes that look at traffic patterns. One method is behavior-based, which looks for unusual behavior and then acts accordingly.
IDSs are primarily focused on reporting events or network traffic that deviate from historical work activity or network traffic patterns. For this reporting to be effective, administrators should develop a baseline or history of typical network traffic. This baseline activity provides a stable, long-term perspective on network activity. An example might be a report generated when a higher-than-normal level of ICMP responses is received in a specified time period. Such activity may indicate the beginning of an ICMP flood attack. The system may also report when a user who doesn't normally access the network using a VPN suddenly requests administrative access to the system. Figure 4.8 demonstrates an AD-IDS tracking and reporting excessive traffic in a network. The AD-IDS process frequently uses artificial intelligence or expert system technologies to learn about normal traffic for a network.
Figure 4.8. AD-IDS using expert system technology to evaluate risks

|
MD-IDS and AD-IDS are merging in most commercial systems. They provide the best opportunity to detect and thwart attacks and unauthorized access. Unlike a firewall, the IDS exists to detect and report unusual occurrences in a network, not block them.
The next sections discuss network-based and host-based implementations of IDS and the capabilities they provide. I'll also introduce honeypots and incident response.
4.2.1. Working with a Network-Based IDS
A network-based IDS (N-IDS) approach to IDS attaches the system to a point in the network where it can monitor and report on all network traffic. This can be in front of or behind the firewall, as shown in Figure 4.9.
NOTE
The best solution to creating a secure network is to place IDS in front of and behind the firewall. This double security provides as much defense as possible.
Placing the N-IDS in front of the firewall provides monitoring of all network traffic going into the network. This approach allows a huge amount of data to be processed, and it lets you see all the traffic coming into the network. Putting the N-IDS behind the firewall only allows you to see the traffic that penetrates the firewall. Although this approach reduces the amount of data processed, it doesn't let you see all the attacks that might be developing.
Figure 4.9. N-IDS placement in a network determines what data will be analyzed.

The N-IDS can be attached to a switch or a hub, or it can be attached to a tap. Many hubs and switches provide a monitoring port for troubleshooting and diagnostic purposes. This port may function in a manner similar to a tap. The advantage of the tap approach is that the IDS is the only device that will be using the tap. Figure 4.10 illustrates a connection to the network using a hub.
Figure 4.10. A hub being used to attach the N-IDS to the network

NOTE
Port spanning, also known as port mirroring, copies the traffic from all ports to a single port and disallows bidirectional traffic on that port. Cisco's Switched Port Analyzer (SPAN) is one example of a port spanning implementation.
In either case, the IDS monitors and evaluates all the traffic to which it has access.
Two basic types of responses can be formulated at the network level: passive and active. They're briefly explained in the following sections.
4.2.1.1. Implementing a Passive Response
A passive response is the most common type of response to many intrusions. In general, passive responses are the easiest to develop and implement. The following list includes some passive response strategies:
Logging
Logging involves recording that an event has occurred and under what circumstances it occurred. Logging functions should provide sufficient information about the nature of the attack to help administrators determine what has happened and to assist in evaluating the threat. This information can then be used to devise methods to counter the threat.
Notification
Notification communicates event-related information to the appropriate personnel when an event has occurred. This includes relaying any relevant data about the event to help evaluate the situation. If the IDS is manned full time, messages can be displayed on the manager's console to indicate that the situation is occurring.
Shunning
Shunning or ignoring an attack is a common response. This might be the case if your IDS notices an Internet Information Server (IIS) attack occurring on a system that's running another web-hosting service, such as Apache. The attack won't work because Apache doesn't respond the same way that IIS does, so why pay attention to it? In a busy network, many different types of attacks can occur simultaneously. If you aren't worried about an attack succeeding, why waste energy or time investigating it or notifying someone about it? The IDS can make a note of it in a log and move on to other more pressing business.
|
4.2.1.2. Implementing an Active Response
An active response involves taking an action based on an attack or threat. The goal of an active response is to take the quickest action possible to reduce an event's potential impact. This type of response requires plans for how to deal with an event, clear policies, and intelligence in the IDS in order to be successful. An active response will include one of the reactions briefly described here:
Terminating processes or sessions
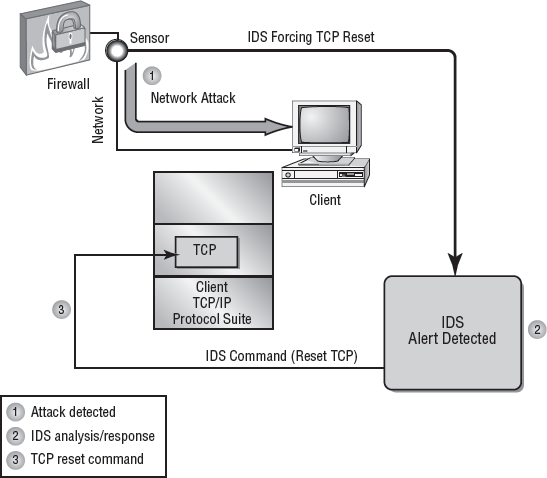
If a flood attack is detected, the IDS can cause the subsystem, such as TCP, to force resets to all the sessions that are under way. Doing so frees up resources and allows TCP to continue to operate normally. Of course, all valid TCP sessions are closed and will need to be reestablished—but at least this will be possible, and it may not have much effect on the end users. The IDS evaluates the events and determines the best way to handle them. Figure 4.11 illustrates TCP being directed to issue RST or reset commands from the IDS to reset all open connections to TCP. This type of mechanism can also terminate user sessions or stop and restart any process that appears to be operating abnormally.
Figure 4.11. IDS instructing TCP to reset all connections
Network configuration changes
If a certain IP address is found to be causing repeated attacks on the network, the IDS can instruct a border router or firewall to reject any requests or traffic from that address. This configuration change can remain in effect permanently or for a specified period. Figure 4.12 illustrates the IDS instructing the firewall to close port 80 for 60 seconds to terminate an IIS attack.
If the IDS determines that a particular socket or port is being attacked, it can instruct the firewall to block that port for a specified amount of time. Doing so effectively eliminates the attack but may also inadvertently cause a self-imposed DoS situation to occur by eliminating legitimate traffic. This is especially true for port 80 (HTTP or web) traffic.
Deception
A deception active response fools the attacker into thinking the attack is succeeding while the system monitors the activity and potentially redirects the attacker to a system that is designed to be broken. This allows the operator or administrator to gather data about how the attack is unfolding and the techniques being used in the attack. This process is referred to as sending them to the honeypot, and it's described later in the section "Utilizing Honeypots." Figure 4.13 illustrates a honeypot where a deception has been successful.
Figure 4.12. IDS instructing the firewall to close port 80 for 60 seconds to thwart an IIS attack

Figure 4.13. A network honeypot deceives an attacker and gathers intelligence.

The advantage of this type of response is that all activities are watched and recorded for analysis when the attack is completed. This is a difficult scenario to set up, and it's dangerous to allow a hacker to proceed into your network, even if you're monitoring the events.
This approach is frequently used when an active investigation is under way by law enforcement and they're gathering evidence to ensure a successful prosecution of the attacker. Deception allows you to gather documentation without risking live data.
|
4.2.2. Working with a Host-Based IDS
A host-based IDS (HIDS) is designed to run as software on a host computer system. These systems typically run as a service or as a background process. HIDSs examine the machine logs, system events, and applications interactions; they normally don't monitor incoming network traffic to the host. HIDSs are popular on servers that use encrypted channels or channels to other servers.
Figure 4.14 illustrates an HIDS installed on a server. Notice that the HIDS interacts with the logon audit and kernel audit files. The kernel audit files are used for process and application interfaces.
Figure 4.14. A host-based IDS interacting with the operating system

Two major problems with HIDS aren't easily overcome. The first problem involves a compromise of the system. If the system is compromised, the log files the IDS reports to may become corrupt or inaccurate. This may make fault determination difficult or the system unreliable. The second major problem with HIDS is that it must be deployed on each system that needs it. This can create a headache for administrative and support staff.
One of HIDS's major benefits is the potential to keep checksums on files. These checksums can be used to inform system administrators that files have been altered by an attack. Recovery is simplified because it's easier to determine where tampering has occurred.
Host-based IDSs typically respond in a passive manner to an incident. An active response would theoretically be similar to those provided by a network-based IDS.
4.2.3. Working with NIPS
As opposed to Network Intrusion Detection Systems (NIDSs), Network Intrusion Prevention Systems (NIPSs) focus on prevention. These systems focus on signature matches and then take a course of action. For example, if it appears as if an attack might be underway, packets can be dropped, ignored, and so forth. In order to be able to do this, the NIPS must be able to detect the attack occurring, and thus it can be argued that NIPS is a subset of NIDS.
NOTE
The line continues to blur between technologies. For example, NIST now refers to its releases as IDPS. While it is important to stay current on the terminology in the real world, know that the exam is frozen in time and you should be familiar with the older terminology for the questions you will face on it.
4.2.4. Utilizing Honeypots
A honeypot is a computer that has been designated as a target for computer attacks. The best way to visualize a honeypot is to think of Winnie the Pooh and the multiple times the cartoon bear has become stuck while trying to get the honey out of the jugs it is stored in. By getting stuck, he has incapacitated himself and become an easy target for anyone trying to find him.
|
The purpose of a honeypot is to allow itself to succumb to an attack. During the process of "dying," the system can be used to gain information about how the attack developed and what methods were used to institute the attack. The benefit of a honeypot system is that it draws attackers away from a higher-value system or allows administrators to gain intelligence about an attack strategy. See Figure 4.13 for a diagram of a honeypot implementation.
Honeypots aren't normally secured or locked down. If they come straight out of the box with an operating system and applications software, they may be configured as is. Elaborate honeypot systems can contain information and software that might entice an attacker to probe deeper and take over the system. If not configured properly, a honeypot system can be used to launch attacks against other systems.
There are several initiatives in the area of honeypot technology. One of the more interesting involves the Honeynet Project, which created a synthetic network that can be run on a single computer system and is attached to a network using a normal network interface card (NIC). The system looks like an entire corporate network, complete with applications and data, all of which are fake. As part of the Honeynet Project, the network was routinely scanned, worms were inserted, and attempts were made to contact other systems to infest them—all over the course of a three-day period. At the end of day three, the system had been infected by no fewer than three worms. This infestation happened without any advertising by the Honeynet Project.
NOTE
Additional information is available on the Honeynet Project at http://www.honeynet.org/misc/project.html.
Before you even consider implementing a honeypot or a honeynet-type project, you need to understand the concepts of enticement and entrapment:
Enticement
Enticement is the process of luring someone into your plan or trap. You might accomplish this by advertising that you have free software, or you might brag that no one can break into your machine. If you invite someone to try, you're enticing them to do something that you want them to do.
Entrapment
Entrapment is the process in which a law enforcement officer or a government agent encourages or induces a person to commit a crime when the potential criminal expresses a desire not to go ahead. Entrapment is a valid legal defense in a criminal prosecution.
While enticement is legally acceptable, entrapment isn't. Your legal liabilities are probably small in either case, but you should seek legal advice before you implement a honeypot on your network. You may also want to contact law enforcement or the prosecutor's office if you want to pursue legal action against attackers.
NOTE
Some security experts use the term tar pit in place of honeypot. The two phrases are interchangeable.
4.2.5. Understanding Incident Response
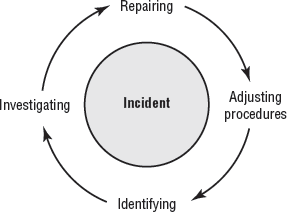
Forensics refers to the process of identifying what has occurred on a system by examining the data trail. Incident response encompasses forensics and refers to the process of identifying, investigating, repairing, documenting, and adjusting procedures to prevent another incident. Simply, an incident is the occurrence of any event that endangers a system or network. We need to discuss responses to two types of incidents: internal incidents and incidents involving law enforcement professionals. Figure 4.15 illustrates the interlocked relationship of these processes in an incident response. Notice that all the steps, including the first step, are related. Incidents are facts of life. You want to learn from them, and you want your organization to learn from them.
It's a good idea to include the procedures you'll generally follow in an incident response plan (IRP). The IRP outlines what steps are needed and who is responsible for deciding how to handle a situation. Carnegie Mellon pioneered this process.
Figure 4.15. Incident response cycle
NOTE
Law enforcement personnel are governed by the rules of evidence, and their response to an incident will be largely out of your control. You need to carefully consider involving law enforcement before you begin. There is no such thing as dropping charges. Once they begin, law enforcement professionals are required to pursue an investigation.
The term incident has special meanings in different industries. In the banking and financial areas, it's very specific and involves something that includes the loss of money. You wouldn't want to call a hacker attempt an incident if you were involved in a bank network because this terminology would automatically trigger an entirely different type of investigation.
The next five sections deal with the phases of a typical incident response process. The steps are generic in this example. Each organization will have a specific set of procedures that will generally map to these steps.
4.2.5.1. Step One: Identifying the Incident
Incident identification is the first step in determining what has occurred in your organization. An internal or external attack may have been part of a larger attack that has just surfaced, or it may be a random probe or scan of your network.
NOTE
An event is often an IDS-triggered signal. Operations personnel will determine if an event becomes an incident.
Many IDSs trigger false positives when reporting incidents. False positives are events that aren't really incidents. Remember that an IDS is based on established rules of acceptance (deviations from which are known as anomalies) and attack signatures. If the rules aren't set up properly, normal traffic may set off the analyzer and generate an event. You don't want to declare an emergency unless you're sure you have one.
One problem that can occur with manual network monitoring is overload. Over time, a slow attack may develop that increases in intensity. Manual processes typically will adapt, and they may not notice the attack until it's too late to stop it. Personnel tend to adapt to changing environments if the changes occur over a long period of time. An automated monitoring system, such as an IDS, will sound the alarm when a certain threshold or activity level occurs.
When a suspected incident pops up, first responders are those who must ascertain if it truly is an incident or a false alarm. Depending upon your organization, the first responder may only be the main security administrator, or could consist of a team of network and system administrators.
After you've determined that you indeed have an incident on your hands, you need to consider how to handle it. This process, called escalation, involves consulting policies, consulting appropriate management, and determining how best to conduct an investigation into the incident. Make sure that the methods you use to investigate the incident are consistent with corporate and legal requirements for your organization. Bring your human resources and legal departments into the investigation early, and seek their guidance whenever questions involving their areas of expertise appear.
A key aspect, often overlooked by system professionals, involves information control. When an incident occurs, who is responsible for managing the communications about the incident? Employees in the company may naturally be curious about a situation. A single spokesperson needs to be designated. Remember, what 1 person knows, 100 people know.
4.2.5.2. Step Two: Investigating the Incident
The process of investigating an incident involves searching logs, files, and any other sources of data about the nature and scope of the incident. If possible, you should determine whether this is part of a larger attack, a random event, or a false positive. False positives are common in an IDS environment and may be the result of unusual traffic in the network. It may be that your network is being pinged by a class of computer security students to demonstrate the return times, or it may be that an automated tool is launching an attack.
NOTE
It is sad but true: One reason administrators don't put as much security on networks as they could is because they do not want to have to deal with the false positives. While this is a poor excuse, it is still often used by administrators. As a security administrator, you must seek a balance between being overwhelmed with too much unneeded information and knowing when something out of the ordinary is occurring. It is an elusive balance that is easier to talk about than find, but it's one you must strive for.
You might find that the incident doesn't require a response if it can't be successful. Your investigation might conclude that a change in policies is required to deal with a new type of threat. These types of decisions should be documented, and if necessary, reconfigurations should be made to deal with the change.
Real World Scenario: The E-Mail IncidentYou're the administrator of a small network. This network has an old mail server that is used for internal and external e-mail. You periodically investigate log and audit files to determine the status of your systems and servers. Recently, you noticed that your e-mail log file has been reporting a large number of undeliverable or bounced e-mails. The addresses appear to be random. Upon examining the e-mail system, you notice that the outbound mail folder seems to be sending mail every second. A large number of files are being sent. After inspecting the workstations in the business, you determine that several of them have out-of-date antivirus software. How should you handle this situation? For starters, you may have one or more viruses or worms in your system. This type of virus sounds like a Simple Mail Transfer Protocol (SMTP) virus. Outlook and Outlook Express are the most popular virus spreaders in use today. A virus like Klez32 can gain access to the address directory and propagate itself using SMTP. You should investigate why the antivirus software is out-of-date, upgrade these systems as appropriate, and add server-based and mail-server virus-protection capabilities to your network. |
Real World Scenario: What If the Intrusion Is Now?Suppose a junior administrator rushes into your office and reports that an alert just notified him that the guest user account has logged in remotely. A suspected attack is occurring this very moment. What should you do? You should respond to an attack that's occurring at this moment the same way you would respond to one that happened before you knew about it. You need to determine what the account is doing and try to figure out who they are and where they're coming from. As you collect any information, you should treat it as evidence and keep careful watch over it. Although collecting as much information as possible is important, no one can be blamed for trying to protect their data. Damage and loss control are critical; while it may be admirable to catch a crook deleting your data, if you can keep the data from being deleted, you will stand a much better chance of still being employed tomorrow. As soon as it becomes apparent that data is at risk, you should disconnect the user. Catching a bad guy is a noble task, but the security of the data should be considered paramount. |
4.2.5.3. Step Three: Repairing the Damage
One of your first considerations after an incident is to determine how to restore access to resources that have been compromised. Then, of course, you must reestablish control of the system. Most operating systems provide the ability to create a disaster-recovery process using distribution media or system state files.
After a problem has been identified, what steps will you take to restore service? In the case of a DoS attack, a system reboot may be all that is required. Your operating system manufacturer will typically provide detailed instructions or documentation on how to restore services in the event of an attack.
If a system has been severely compromised, as in the case of a worm, it might not be possible to repair it. It may need to be regenerated from scratch. Fortunately, antivirus software packages can repair most of the damage done by the viruses you encounter. But what if you come across something new? You might need to start over with a new system. In that case, you're highly advised to do a complete disk drive format or repartition to ensure that nothing is lurking on the disk, waiting to infect your network again.
Real World Scenario: The Virus That Won't StopA virus recently hit a user in your organization through an e-mail attachment. The user updated all the programs in his computer and also updated his antivirus software; however, he's still reporting unusual behavior in his computer system. He's also receiving complaints from people in his e-mail address book because he's sending them a virus. You've been asked to fix the problem. The user has probably contracted a worm that has infected the system files in his computer. You should help him back up his user files to removable media. Then, completely reformat his drives and reinstall the operating system and applications. After you've replaced these, you can install new antivirus software and scan the entire system. When the scan is complete, help the user reinstall data files and scan the system again for viruses. This process should eliminate all viruses from system, application, and data files. |
NOTE
Just as every network, regardless of size, should have a firewall, it should also be protected by antivirus software that is enabled and current. ClamAV is an open source solution once available only for Unix-based systems that is now available for most operating systems.
4.2.5.4. Step Four: Documenting and Reporting the Response
During the entire process of responding to an incident, you should document the steps you take to identify, detect, and repair the system or network. This information is valuable; it needs to be captured in case an attack like this occurs again. The documentation should be accessible by the people most likely to deal with this type of problem. Many help-desk software systems provide detailed methods you can use to record procedures and steps. These types of software products allow for fast access.
If appropriate, you should report/disclose the incident to legal authorities and CERT (www.cert.org) so that others can be aware of the type of attack and help look for proactive measures to prevent this from happening again. At the CERT site, you can find detailed steps to take to recover after your computer has been compromised; this is located at http://www.cert.org/tech_tips/win-UNIX-system_compromise.html.
You might also want to inform the software or system manufacturer of the problem and how you corrected it. Doing so might help them inform or notify other customers of the threat and save time for someone else.
Real World Scenario: How Incident Response Plans WorkEmergency management (EM) personnel routinely stage fake emergencies to verify that they know what they should do in the event of an actual emergency. For example, if you live in a town with a train track that is routinely used by railcars carrying toxic chemicals, it isn't uncommon for EM personnel to stage a fake spill every couple of years. Those organizing the practice won't tell those responding what type of spill it is, or the severity of it, until they arrive at the scene. The organizers monitor and evaluate the responses to see that they're appropriate and where they can be improved. Responding to security incidents requires the same type of focus and training. You should plan a fake incident at your site, inform all those who will be involved that it's coming, and then evaluate their response. You should evaluate the following items:
Practice makes perfect, and there is no better time to practice your company's response to an emergency than before one really occurs. |
4.2.5.5. Step Five: Adjusting Procedures
After an incident has been successfully managed, it's a worthwhile step to revisit the procedures and policies in place in your organization to determine what changes, if any, need to be made.
Answering simple questions can sometimes be helpful when you're resolving problems. The following questions might be included in a policy or procedure manual:
How did the policies work or not work in this situation?
What did we learn about the situation that was new?
What should we do differently next time?
These simple questions can help you adjust procedures. This process is called a postmortem, and it's the equivalent of an autopsy.