
8.1. Understanding Business Continuity
One of the oldest phrases still in use today is "the show must go on." Nowhere is that more true than in the world of business, where downtime means the loss of significant revenue with each passing minute. Business continuity is primarily concerned with the processes, policies, and methods that an organization follows to minimize the impact of a system failure, network failure, or the failure of any key component needed for operation—essentially, whatever it takes to ensure that the business continues, that the show does indeed go on.
Contingency and disaster-recovery planning make up a significant part of business continuity. The plans that you formulate for dealing with disasters are known as schemes and scheming is a key part of maintaining the infrastructure of a secure network. Utilities, high-availability environments, and disaster recovery are all parts of business continuity. In the following sections, we'll look at them and examine the roles that they play.
8.1.1. Utilities
Basic utilities such as electricity, water, and natural gas are key aspects of business continuity. In the vast majority of cases, electricity and water are restored—at least on an emergency basis—fairly rapidly. The damage created by blizzards, tornadoes, and other natural disasters is managed and repaired by utility companies and government agencies. Other disasters, such as a major earthquake or hurricane, can overwhelm these agencies, and services may be interrupted for quite a while. When these types of events occur, critical infrastructure may be unavailable for days, weeks, or even months.
Real World Scenario: The Importance of UtilitiesWhen the earthquake of 1989 occurred in San Francisco, California, portions of the city were without electricity, natural gas, and water for several months. Entire buildings were left unoccupied, not because of the earthquake, but because the infrastructure was badly damaged. This damage prevented many businesses whose information systems departments were located in those buildings from returning to operation for several weeks. Most of the larger organizations were able to shift the processing loads to other companies or divisions. |
When you evaluate your business's sustainability, realize that disasters do indeed happen. If possible, build infrastructures that don't have single points of failure or connection. After the September 11, 2001, terrorist attack on the World Trade Center (WTC), several ISPs and other companies became nonfunctional because the WTC housed centralized communications systems and computer departments.
Consider the impact of weather on your contingency plans. What if you needed to relocate your facility to another region of the country? How would you get personnel there? What personnel would be relocated? How would they be housed and fed during the time of the crisis? You should consider these possibilities in advance. Although the likelihood that a crippling disaster will occur is relatively small, you still need to evaluate the risk.
NOTE
The year 2005 was the year of the natural disaster. Starting with the tsunami that hit parts of Asia a few days before the start of the year and continuing through Hurricane Katrina that hit Louisiana and other parts of the South, it seemed as if there was a nonstop juggernaut of adversity underfoot. Many a business will never be able to recover from those catastrophes, while many paused for a short period of time, then were back up and running again.
As an administrator, you should always be aware of problems that can occur and have an idea of how you'll approach them. It's impossible to prepare for every emergency, but you can plan for those that could conceivably happen.
8.1.2. High Availability
High availability refers to the process of keeping services and systems operational during an outage. In short, the goal is to provide all services to all users, where they need them and when they need them. With high availability, the goal is to have key services available 99.999 percent of the time (also known as five nines availability).
Real World Scenario: Formulating Business Continuity PlansAs a security administrator, you'll need to think through a way to maintain business continuity should a crisis occur. Imagine your company is in each of the following three scenarios:
Just like in the real world, there are no right or wrong answers for these scenarios. However, they all represent situations that have happened and that administrators planned for ahead of time. |
There are several ways to accomplish this, including implementing redundant technology, fault-tolerant systems, and backup communications channels. A truly redundant system won't utilize just one of these methods but rather some aspect of all of them. The following sections address these topics in more detail.
8.1.2.1. Redundancy
Redundancy refers to systems that are either duplicated or that fail over to other systems in the event of a malfunction. Fail-over refers to the process of reconstructing a system or switching over to other systems when a failure is detected. In the case of a server, the server switches to a redundant server when a fault is detected. This allows service to continue uninterrupted until the primary server can be restored. In the case of a network, processing switches to another network path in the event of a network failure in the primary path.
NOTE
Fail-over systems can be very expensive to implement. In a large corporate network or e-commerce environment, a fail-over might entail switching all processing to a remote location until your primary facility is operational. The primary site and the remote site would synchronize data to ensure that information is as up-to-date as possible.
Many newer operating systems, such as Linux, Windows Server 2008, and Novell Open Enterprise Server, are capable of clustering to provide fail-over capabilities. Clustering involves multiple systems connected together cooperatively and networked in such a way that if any of the systems fail, the other systems take up the slack and continue to operate. The overall capability of the server cluster may decrease, but the network or service will remain operational.
NOTE
To appreciate the beauty of clustering, contemplate the fact that it is this technology upon which Google is built. Clustering not only allows the company to have redundancy, it also offers it the ability to scale as demand increases.
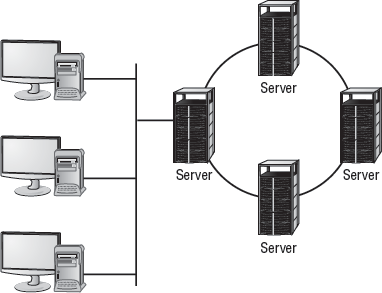
Figure 8.1 shows the clustering process in a network. In this cluster, each system has its own data storage and data-processing capabilities. The system that is connected to the network has the additional task of managing communication between the cluster and its users. Many clustering systems allow all the systems in the cluster to share a single disk system. In either case, reliability is improved when clustering technologies are incorporated in key systems.
Most ISPs and network providers have extensive internal fail-over capability to provide high availability to clients. Business clients and employees who are unable to access information or services tend to lose confidence. The trade-off for reliability and trustworthiness, of course, is cost: Fail-over systems can become prohibitively expensive. You'll need to carefully study your needs to determine whether your system requires this capability.
For example, if your environment requires a high level of availability, your servers should be clustered. This will allow the other servers in this network to take up the load if one of the servers in the cluster fails.
Figure 8.1. Server clustering in a networked environment
8.1.2.2. Fault Tolerance
Fault tolerance is primarily the ability of a system to sustain operations in the event of a component failure. Fault-tolerant systems can continue operation even though a critical component, such as a disk drive, has failed. This capability involves over-engineering systems by adding redundant components and subsystems.
Fault tolerance can be built into a server by adding a second power supply, a second CPU, and other key components. Several manufacturers (such as HP, Unisys, and IBM) offer fault-tolerant servers; these servers typically have multiple processors that automatically fail over if a malfunction occurs.
NOTE
In addition to fault-tolerant servers, you can have fault-tolerant implementations such as Tandem, Stratus, and HP. In these settings, multiple computers are used to provide the 100 percent availability of a single server.
There are two key components of fault tolerance you should never overlook: spare parts and electrical power. Spare parts should always be readily available to repair any system-critical component if it should fail. The redundancy strategy N+1 means that you have the number of components you need, plus one to plug into any system should it be needed. For example, a small company with five standalone servers that are all the same model should have a power supply in a box nearby to install in any one of the servers should there be a failure. (The redundancy strategy 1+1 has one spare part for every component in use.)
Since computer systems cannot operate in the absence of electrical power, it is imperative that fault tolerance be built into your electrical infrastructure as well. At a bare minimum, an uninterruptible power supply (UPS)—with surge protection—should accompany every server and workstation. That UPS should be rated for the load it is expected to carry in the event of a power failure (factoring in the computer, monitor, and any other device connected to it) and be checked periodically as part of your preventative maintenance routine to make sure the battery is operational. You will need to replace the battery every few years to keep the UPS operational.
A UPS will allow you to continue to function in the absence of power for only a short duration. For fault tolerance in situations of longer duration, you will need a backup generator. Backup generators run off of gasoline or diesel and generate the electricity needed to provide steady power. While some backup generators can come on instantly in the event of a power outage, most take a short time to warm up before they can provide consistent power, and thus you will find that you still need to implement UPSs within your organization.
8.1.2.3. Redundant Array of Independent Disks
Redundant Array of Independent Disks (RAID) is a technology that uses multiple disks to provide fault tolerance. There are several designations for RAID levels.
NOTE
RAID stands for not only Redundant Array of Independent Disks, but also Redundant Array of Inexpensive Disks. While the latter term has lost its popularity, you might still encounter it in some texts.
The most commonly implemented RAID levels are as follows:
RAID level 0
RAID 0 is disk striping. It uses multiple drives and maps them together as a single physical drive. This is done primarily for performance, not for fault tolerance. If any drive in a RAID 0 array fails, the entire logical drive becomes unusable.
RAID level 1
RAID 1 is disk mirroring. Disk mirroring provides 100 percent redundancy because everything is stored on two disks. If one disk fails, another disk continues to operate. The failed disk can be replaced, and the RAID 1 array can be regenerated. This system offers the advantage of 100 percent data redundancy at the expense of doubling the storage requirements. Each drive keeps an exact copy of all information, which reduces the effective storage capability to 50 percent of the overall storage. Some implementations of disk mirroring are called disk duplexing (duplexing is a less commonly used term). The only difference between mirroring and duplexing is one more controller card. With mirroring, one controller card writes sequentially to each disk. With duplexing, the same data is written to both disks simultaneously. Disk duplexing has much faster write performance than disk mirroring. Many hardware implementations of RAID 1 are actually duplexing but they are still generally referred to as mirrors.
|

RAID level 3
RAID 3 is disk striping with a parity disk. RAID 3 arrays implement fault tolerance by using striping (RAID 0) in conjunction with a separate disk that stores parity information. Parity information is a value based on the value of the data stored in each disk location. This system ensures that the data can be recovered in the event of a failure. The process of generating parity information uses the arithmetic value of the data binary. This process allows any single disk in the array to fail while the system continues to operate. The failed disk is removed, a new disk is installed, and the new drive is then regenerated using the parity information. RAID 3 is common in older systems, and it's supported by most Unix systems.
RAID level 5
RAID 5 is disk striping with parity and is one of the most common forms of RAID in use today. It operates similarly to disk striping, as in RAID 0. The parity information is spread across all the disks in the array instead of being limited to a single disk, as in RAID 3. Most implementations require a minimum of three disks and support a maximum of 32.
These four types of RAID drives, or arrays, are illustrated in Figure 8.2.
Figure 8.2. The four primary RAID technologies used in systems

|
|
RAID levels 0, 1, 3, and 5 are the most commonly implemented in servers today. RAID 5 has largely replaced RAID 3 in newer systems.
RAID levels are implemented either in software on the host computer or in the disk controller hardware. A RAID hardware-device implementation will generally run faster than a software-oriented RAID implementation because the software implementation uses the system CPU and system resources. Hardware RAID devices generally have their own processors, and they appear to the operating system as a single device.
Real World Scenario: How Many Disks Does RAID Need?As a security administrator, you must determine how many RAID disks you'll need. Compute how many disks will be needed for each scenario or the amount of storage capacity you'll end up with (answers appear at the end of each scenario).
|
You must do a fair amount of planning before you implement RAID. Within the realm of planning, you must be able to compute the number of disks needed for the desired implementation.
8.1.3. Disaster Recovery
Disaster recovery is the ability to recover system operations after a disaster. A key aspect of disaster-recovery planning is designing a comprehensive backup plan that includes backup storage, procedures, and maintenance. Many options are available to implement disaster recovery. The following sections discuss backups and the disaster-recovery plan.
|
8.1.3.1. Depending on Backups
Backups are duplicate copies of key information, ideally stored in a location other than the one where the information is currently stored. Backups include both paper and computer records. Computer records are usually backed up using a backup program, backup systems, and backup procedures.
The primary starting point for disaster recovery involves keeping current backup copies of key data files, databases, applications, and paper records available for use. Your organization must develop a solid set of procedures to manage this process and ensure that all key information is protected. A security professional can do several things in conjunction with system administrators and business managers to protect this information. It's important to think of this problem as an issue that is larger than a single department. The following are examples of key paper records that should be archived:
Board minutes
Board resolutions
Corporate papers
Critical contracts
Financial statements
Incorporation documents
Loan documents
Personnel information
Tax records
This list, while not comprehensive, gives you a place to start when you evaluate your archival requirements. Most of these documents can be easily converted into electronic form. However, keeping paper copies is strongly recommended because some government agencies don't accept electronic documentation as an alternative to paper documentation.
Computer files and applications should also be backed up on a regular basis. Here are some example of critical files that should be backed up:
Applications
Appointment files
Audit files
Customer lists
Database files
E-mail correspondence
Financial data
Operating systems
Prospect lists
Transaction files
User files
User information
Utilities
Again, this list isn't all-inclusive, but it provides a place to start.
In most environments, the volume of information that needs to be stored is growing at a tremendous pace. Simply tracking this massive growth can create significant problems.
NOTE
An unscrupulous attacker can glean as much critical information from copies as they can from the original files. Make sure your storage facilities are secure, and it is a good idea to add security to the backup media as well.
You might need to restore information from backup copies for any number of reasons. Some of the more common reasons are listed here:
Accidental deletion
Applications errors
Natural disasters
Physical attacks
Server failure
Virus infection
Workstation failure
The information you back up must be immediately available for use when needed. If a user loses a critical file, they won't want to wait several days while data files are sent from a remote storage facility. Several types of storage mechanisms are available for data storage:
Working copies
Working copy backups—sometimes referred to as shadow copies—are partial or full backups that are kept at the computer center for immediate recovery purposes. Working copies are frequently the most recent backups that have been made.
Typically, working copies are intended for immediate use. They are usually updated on a frequent basis.
NOTE
Working copies aren't usually intended to serve as long-term copies. In a busy environment, they may be created every few hours.
Many file systems used on servers include journaling. A journaled file system (JFS) includes a log file of all changes and transactions that have occurred within a set period of time (such as the last few hours). If a crash occurs, the operating system can check the log files to see what transactions have been committed and which ones have not.
This technology works well and allows unsaved data to be written after the recovery, and the system is usually successfully restored to its precrash condition.
Onsite storage
Onsite storage usually refers to a location on the site of the computer center that is used to store information locally. Onsite storage containers are available that allow computer cartridges, tapes, and other backup media to be stored in a reasonably protected environment in the building.
NOTE
As time goes on, tape is losing its popularity as a medium for backups to other technologies. The Security+ exam, however, is a bit dated and still considers tape the ideal medium.
Onsite storage containers are designed and rated for fire, moisture, and pressure resistance. These containers aren't fireproof in most situations, but they are fire rated: A fireproof container should be guaranteed to withstand damage regardless of the type of fire or temperature, whereas fire ratings specify that a container can protect the contents for a specific amount of time in a given situation.
If you choose to depend entirely on onsite storage, make sure the containers you acquire can withstand the worst-case environmental catastrophes that could happen at your location. Make sure, as well, that they are in locations where you can easily find them after the disaster and access them (near exterior walls, on the ground floor, and so forth).
NOTE
General-purpose storage safes aren't usually suitable for storing electronic media. The fire ratings used for safes generally refer to paper contents. Because paper does not catch fire until 451° Fahrenheit, electronic media is typically ruined well before paper documents are destroyed in a fire.
Offsite storage
Offsite storage refers to a location away from the computer center where paper copies and backup media are kept. Offsite storage can involve something as simple as keeping a copy of backup media at a remote office, or it can be as complicated as a nuclear-hardened high-security storage facility. The storage facility should be bonded, insured, and inspected on a regular basis to ensure that all storage procedures are being followed.
Determining which storage mechanism to use should be based on the needs of the organization, the availability of storage facilities, and the budget available. Most offsite storage facilities charge based on the amount of space you require and the frequency of access you need to the stored information.
8.1.3.2. Crafting a Disaster-Recovery Plan
A disaster-recovery plan, or scheme, helps an organization respond effectively when a disaster occurs. Disasters may include system failure, network failure, infrastructure failure, and natural disaster. The primary emphasis of such a plan is reestablishing services and minimizing losses.
In a smaller organization, a disaster-recovery plan may be relatively simple and straightforward. In a larger organization, it may involve multiple facilities, corporate strategic plans, and entire departments. In either case, the purpose is to develop the means and methods to restore services as quickly as possible and to protect the organization from unacceptable losses in the event of a disaster.
A major component of a disaster-recovery plan involves the access and storage of information. Your backup plan for data is an integral part of this process. The following sections address backup plan issues and backup types. They also discuss developing a backup plan, recovering a system, and using alternative sites. These are key components of a disaster-recovery plan: They form the heart of how an organization will respond when a critical failure or disaster occurs.
8.1.3.2.1. Understanding Backup Plan Issues
When an organization develops a backup plan for information, it must be clear about the value of the information. A backup plan identifies which information is to be stored, how it will be stored, and for what duration it will be stored. You must look at the relative value of the information you retain. To some extent, the types of systems you use and the applications you support dictate the structure of your plan.
Let's look at those different systems and applications:
Database systems
Most modern database systems provide the ability to globally back up data or certain sections of the database without difficulty. Larger-scale database systems also provide transaction auditing and data-recovery capabilities.
For example, you can configure your database to record in a separate file each addition, update, deletion, or change of information that occurs. These transaction or audit files can be stored directly on archival media, such as magnetic tape cartridges. In the event of a system outage or data loss, the audit file can be used to roll back the database and update it to the last transactions made.
Figure 8.3 illustrates the auditing process in further detail. In this situation, the audit file is directly written to a DAT tape that is used to store a record of changes. If an outage occurs, the audit or transaction files can be rolled forward to bring the database back to its most current state. This recovery process brings the database current to within the last few transactions. Although it doesn't ensure that all the transactions that were in process will be recovered, it will reduce potential losses to the few that were in process when the system failed.
Figure 8.3. Database transaction auditing process

Most database systems contain large files that have only a relatively few records updated in relation to the number of records stored. A large customer database may store millions of records—however, only a few hundred may be undergoing modification at any given time.
User files
Word-processing documents, spreadsheets, and other user files are extremely valuable to an organization. Fortunately, although the number of files that people retain is usually large, the number of files that change after initial creation is relatively small. By doing a regular backup on user systems, you can protect these documents and ensure that they're recoverable in the event of a loss. In a large organization, backing up user files can be an enormous task. Fortunately, most operating systems date-stamp files when they're modified. If backups that store only the changed files are created, keeping user files safe becomes a relatively less-painful process for an organization.
NOTE
Many organizations have taken the position that backing up user files is the user's responsibility. Although this policy decision saves administrative time and media, it isn't a good idea. Most users don't back up their files on a regular basis—if at all. With the cost of media being relatively cheap, including the user files in a backup every so often is highly recommended.
Applications
Applications such as word processors, transaction systems, and other programs usually don't change on a frequent basis. When a change or upgrade to an application is made, it's usually accomplished across an entire organization. You wouldn't necessarily need to keep a copy of the word-processing application for each user, but you should keep a single up-to-date version that is available for download and reinstallation.
NOTE
Some commercial applications require each copy of the software to be registered with a centralized license server. This may present a problem if you attempt to use a centralized recovery procedure for applications. Each machine may require its own copy of the applications for a recovery to be successful.
8.1.3.2.2. Knowing the Backup Types
Three methods exist to back up information on most systems:
Full backup
A full backup is a complete, comprehensive backup of all files on a disk or server. The full backup is current only at the time it's performed. Once a full backup is made, you have a complete archive of the system at that point in time. A system shouldn't be in use while it undergoes a full backup because some files may not get backed up. Once the system goes back into operation, the backup is no longer current. A full backup can be a time-consuming process on a large system.
|
Incremental backup
An incremental backup is a partial backup that stores only the information that has been changed since the last full or the last incremental backup. If a full backup were performed on a Sunday night, an incremental backup done on Monday night would contain only the information that changed since Sunday night. Such a backup is typically considerably smaller than a full backup. Each incremental backup must be retained until a full backup can be performed. Incremental backups are usually the fastest backups to perform on most systems, and each incremental backup tape is relatively small.
Differential backup
A differential backup is similar in function to an incremental backup, but it backs up any files that have been altered since the last full backup; it makes duplicate copies of files that haven't changed since the last differential backup. If a full backup were performed on Sunday night, a differential backup performed on Monday night would capture the information that was changed on Monday. A differential backup completed on Tuesday night would record the changes in any files from Monday and any changes in files on Tuesday. As you can see, during the week each differential backup would become larger; by Friday or Saturday night, it might be nearly as large as a full backup. This means the backups in the earliest part of the weekly cycle will be very fast, and each successive one will be slower.
NOTE
A differential backup backs up only files that have the archive bit turned on. At the conclusion of the backup, the archive bit is left on for those files so they are then included again in the next backup.
When these backup methods are used in conjunction with each other, the risk of loss can be greatly reduced, but you can never combine incremental and differential backups in the same set. One of the major factors in determining which combination of these three methods to use is time—ideally, a full backup would be performed every day. Several commercial backup programs support these three backup methods. You must evaluate your organizational needs when choosing which tools to use to accomplish backups.
Almost every stable operating system contains a utility for creating a copy of configuration settings necessary to reach the present state after a disaster. In Windows Vista, for example, this is accomplished with an Automated System Recovery (ASR) disk. Make certain you know how to do an equivalent operation for the operating system you are running.
As an administrator, you must know how to do backups and be familiar with all the options available to you.
8.1.3.2.3. Developing a Backup Plan
Several common models are used in designing backup plans. Each has its own advantages and disadvantages. Numerous methods have been developed to deal with archival backup; most of them are evolutions of the three models discussed here:
Grandfather, Father, Son method
The Grandfather, Father, Son method is based on the philosophy that a full backup should occur at regular intervals, such as monthly or weekly. This method assumes that the most recent backup after the full backup is the son. As newer backups are made, the son becomes the father, and the father, in turn, becomes the grandfather. At the end of each month, a full backup is performed on all systems. This backup is stored in an offsite facility for a period of one year. Each monthly backup replaces the monthly backup from the previous year. Weekly or daily incremental backups are performed and stored until the next full backup occurs. This full backup is then stored offsite and the weekly or daily backup tapes are reused (the January 1 incremental backup is used on February 1, and so on).
This method ensures that in the event of a loss, the full backup from the end of the last month and the daily backups can be used to restore information to the last day. Figure 8.4 illustrates this concept: The annual backup is referred to as the grandfather, the monthly backup is the father, and the weekly backup is the son. The last backup of the month becomes the archived backup for that month. The last backup of the year becomes the annual backup for the year. Annual backups are usually archived; this allows an organization to have backups available for several years and minimizes the likelihood of data loss. It's a common practice for an organization to keep a minimum of seven years in archives.
Figure 8.4. Grandfather, Father, Son backup method

The last full backup of the year is permanently retained. This ensures that previous years' information can be recovered if it's needed for some reason.
The major difficulty with this process is that a large number of tapes are constantly flowing between the storage facility and the computer center. In addition, cataloging daily and weekly backups can be complicated. It can become difficult to determine which files have been backed up and where they're stored.
Full Archival method
The Full Archival method works on the assumption that any information created on any system is stored forever. All backups are kept indefinitely using some form of backup media. In short, all full backups, all incremental backups, and any other backups are permanently kept somewhere.
This method effectively eliminates the potential for loss of data. Everything that is created on any computer is backed up forever. Figure 8.5 illustrates this method. As you can see, the number of copies of the backup media can quickly overwhelm your storage capabilities. Some organizations that have tried to do this have needed entire warehouses to contain their archival backups.
Figure 8.5. Full Archival backup method

Think about the number of files your organization has: How much storage media would be required to accomplish full archiving? The other major problem involves keeping records of what information has been archived. For these reasons, many larger companies don't find this to be an acceptable method of keeping backups.
Backup Server method
The costs of disk storage and servers have fallen tremendously over the past few years. Lower prices have made it easier for organizations to use dedicated servers for backup. The Backup Server method establishes a server with large amounts of disk space whose sole purpose is to back up data. With the right software, a dedicated server can examine and copy all the files that have been altered every day.
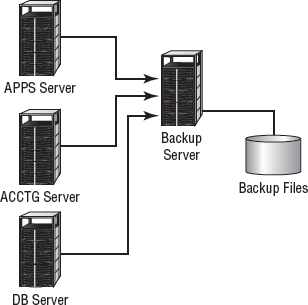
Figure 8.6 illustrates the use of backup servers. In this instance, the files on the backup server contain copies of all the information and data on the APPS, ACCTG, and DB servers. The files on the three servers are copied to the backup server on a regular basis; over time, this server's storage requirements can become enormous. The advantage of this method is that all backed-up data is available online for immediate access.
This server can be backed up on a regular basis, and the backups can be kept for a specified period. If a system or server malfunctions, the backup server can be accessed to restore information from the last backups performed on that system.
Backup servers don't need overly large processors; however, they must have large disk and other long-term storage media capabilities. Several software manufacturers take backup servers one additional step and create hierarchies of files: Over time, if a file isn't accessed, it's moved to slower media and may eventually be stored offline. This helps reduce the disk storage requirements, yet it still keeps the files that are most likely to be needed for recovery readily available
Figure 8.6. A backup server archiving server files
Many organizations utilize two or more of these methods to back up systems. The issue becomes one of storage requirements and retention requirements. In establishing a backup plan, you must ask users and managers how much backup (in terms of frequency, size of files, and so forth) is really needed and how long it will be needed.
NOTE
Make sure you obtain input from all who are dealing with governmental or regulatory agencies. Each agency may have different archival requirements, and compliance violations can be expensive. Both HIPAA and Sarbanes-Oxley are affecting—and driving—archival and disposal policies around the nation.
8.1.3.2.4. Recovering a System
When a system fails, you'll be unable to reestablish operation without regenerating all of the system's components. This process includes making sure hardware is functioning, restoring or installing the operating systems, restoring or installing applications, and restoring data files. It can take several days on a large system. With a little forethought, you may be able to simplify the process and make it easily manageable.
When you install a new system, make a full backup of it before any data files are created. If stored onsite, this backup will be readily available for use. If you've standardized your systems, you may need just one copy of a base system that contains all the common applications you use. The base system can usually be quickly restored, which allows for reconnection to the network for restoration of other software. Many newer operating systems now provide this capability, and system restores are very fast.
Figure 8.7 demonstrates this process further. Notice that the installation CDs are being used for the base OS and applications.
Figure 8.7. System regeneration process for a workstation or server

When the base system has been restored, data files and any other needed files can be restored from the last full backup and any incremental or differential backups that have been performed. The last full backup should contain most of the data on the system; the incremental backup or differential backups contain the data that has changed since the full backup.
Many newer operating systems, such as Windows Server 2008, allow you to create a model user system as a disk image on a server; the disk image is downloaded and installed when a failure occurs. This method makes it easier for administrators to restore a system than it would be to do it manually. It's all well and good to know how to make backups and the importance of doing so. There will come a time, however, when a recovery—the whole reason for disaster planning—will be necessary. As an administrator, you must be ready for this event and know how to handle it.
An important recovery issue is to know the order in which to progress. If a server is completely destroyed and must be re-created, ascertain which applications are the most important and should be restored before the others. Likewise, which services are most important to the users from a business standpoint and need to be available? Conversely, which are nice but not necessary to keep the business running? The answers will differ for every organization, and you must know them for yours.
8.1.3.2.5. Planning for Alternate Sites
Another key aspect of a disaster-recovery plan is to provide for the restoration of business functions in the event of a large-scale loss of service. You can lease or purchase a facility that is available on short notice for the purpose of restoring network or systems operations. These are referred to as alternate or backup sites.
If the power in your local area were disrupted for several days, how would you reestablish service at an alternate site until primary services were restored? Several options exist to do this; I'll briefly present them here. None of these solutions are ideal, but they are always considered to be significantly less costly—in terms of time—to implement than the estimated time of bringing your original site back up to speed. They are used to allow you to get your organization back on its feet until permanent service is available. An alternative site can be a hot site, a warm site, or a cold site:
Hot site
A hot site is a location that can provide operations within hours of a failure. This type of site would have servers, networks, and telecommunications equipment in place to reestablish service in a short time. Hot sites provide network connectivity, systems, and preconfigured software to meet the needs of an organization. Databases can be kept up-to-date using network connections. These types of facilities are expensive, and they're primarily suitable for short-term situations. A hot site may also double as an offsite storage facility, providing immediate access to archives and backup media.
Many hot sites also provide office facilities and other services so that a business can relocate a small number of employees to sustain operations.
NOTE
Given the choice, every organization would choose to have a hot site. Doing so is often not practical, however, on the basis of cost.
Warm site
A warm site provides some of the capabilities of a hot site, but it requires the customer to do more work to become operational. Warm sites provide computer systems and compatible media capabilities. If a warm site is used, administrators and other staff will need to install and configure systems to resume operations. For most organizations, a warm site could be a remote office, a leased facility, or another organization with which yours has a reciprocal agreement.
Warm sites may be for your exclusive use, but they don't have to be. A warm site requires more advanced planning, testing, and access to media for system recovery. Warm sites represent a compromise between a hot site, which is very expensive, and a cold site, which isn't preconfigured.
NOTE
An agreement between two companies to provide services in the event of an emergency is called a reciprocal agreement. Usually, these agreements are made on a best-effort basis: There is no guarantee that services will be available if the site is needed. Make sure your agreement is with an organization that is outside your geographic area. If both sites are affected by the same disaster, the agreement is worthless.
Cold site
A cold site is a facility that isn't immediately ready to use. The organization using it must bring along its equipment and network. A cold site may provide network capability, but this isn't usually the case; the site provides a place for operations to resume, but it doesn't provide the infrastructure to support those operations. Cold sites work well when an extended outage is anticipated. The major challenge is that the customer must provide all the capabilities and do all the work to get back into operation. Cold sites are usually the least expensive to put into place, but they require the most advanced planning, testing, and resources to become operational—occasionally taking up to a month to make operational.
NOTE
Almost anywhere can be a cold site; if necessary, users could work out of your garage for a short time. Although this may be a practical solution, it also opens up risks that you must consider. For example, while you're operating from your garage, will the servers be secure should someone break in?
Herein lies the problem. The likelihood that you'll need any of these facilities is low—most organizations will never need to use these types of facilities. The costs are usually based on subscription or other contracted relationships, and it's difficult for most organizations to justify the expense. In addition, planning, testing, and maintaining these facilities is difficult; it does little good to pay for any of these services if they don't work and aren't available when you need them.
|
Management must view the disaster-recovery plan as an integral part of its business continuity planning (BCP). Management must also provide the resources needed to implement and maintain an alternative site after the decision has been made to contract for the facilities.
Real World Scenario: Some Protection Is Better than None—Or Is It?You've been tasked with the responsibility of developing a recovery plan for your company to have in place in a critical infrastructure failure. Your CEO is concerned about the budget and doesn't want to invest many resources in a full-blown hot site. Several options are available to you in this situation. You need to evaluate the feasibility of a warm site, a cold site, or a reciprocal agreement with another company. The warm site and cold site options will cost less than a hot site, but they will require a great deal of work in the event of a failure. A reciprocal site may be a good alternative to both, if a suitable partner organization can be found. You may want to discuss this possibility with some of your larger vendors or other companies that may have excess computer capacity. No matter which direction you recommend, you should test and develop procedures to manage the transition from your primary site to an offsite facility. |