
Applets would not normally be allowed to work with files on the user’s system. Applications, of course, need to do this a lot. In this chapter we cover the methods for handling files and directories as well as the methods for actually writing and reading back information to and from files. This chapter also shows you the object serialization mechanism that is now in Java. This lets you store objects as easily as you can store text or numeric data.
Input/output techniques are not particularly exciting, but without the ability to read and write data, your applications and (occasionally) applets are severely limited. This chapter is about how to get input from any source of data that can send out a sequence of bytes and how to send output to any destination that can receive a sequence of bytes. These sources and destinations of byte sequences can be—and often are—files, but they can also be network connections and even blocks of memory. There is a nice payback to keeping this generality in mind: information stored in files and information retrieved from a network connection are handled in essentially the same way. (See Chapter 3 for information on how to work with networks.) Of course, while data is always ultimately stored in a series of bytes, it is often more convenient to think of it as having some higher-level structure such as being a sequence of characters or objects. We cover Java higher-level input/output facilities as well.
In Java, an object from which we can read a sequence of bytes is called an input stream. An object to which we can write a sequence of bytes is called an output stream. These are implemented in the abstract classes InputStream and OutputStream. Since byte-oriented streams are inconvenient for processing information stored in Unicode (recall Unicode uses two bytes per character), there is a separate hierarchy of classes for processing Unicode characters that inherit from the abstract Reader and Writer superclasses. These classes have read and write operations that are based on 2-byte Unicode characters rather than on single-byte characters.
You saw abstract classes in Chapter 5 of Volume 1. Recall that the point of an abstract class is to provide a mechanism for factoring out the common behavior of classes to a higher level. This leads to cleaner code and makes the inheritance tree easier to understand. The same game is at work with input and output in Java.
As you will soon see, Java derives from these four abstract classes a zoo of concrete classes: you can visit almost any conceivable input/output creature in this zoo.
The InputStream class has an abstract method:
public abstract int read() throws IOException
This method reads one byte and returns the byte read, or –1 if it encounters the end of the input source. The designer of a concrete input stream class overrides this method in order to provide useful functionality. For example, in the FileInputStream class, this method reads one byte from a file. The InputStream class also has non-abstract methods to read an array of bytes or to skip a number of bytes. These methods call the abstract read method, so that subclasses only need to override one method.
Similarly, the OutputStream class defines the abstract method
public abstract void write(int b) throws IOException
which writes one byte to an output file.
Both the read and write methods can block a thread until the byte is actually read or written. This means if the byte cannot immediately be read from or written to (usually because of a busy network connection), Java suspends the thread containing this call. This gives other threads the chance to do useful work while the method is waiting for the stream to again become available. (We discuss threads in Chapter 2.)
The available method lets you check the number of bytes that are currently available for reading. This means a fragment like the following is unlikely to ever block:
int bytesAvailable = System.in.available();
if (bytesAvailable > 0)
{ byte [] data = new byte [bytesAvailable];
System.in.read(data);
}When you have finished reading or writing to a stream, close it, using the appropriately named close method, because streams use operating system resources that are in limited supply. If an application opens many streams without closing them, system resources may become depleted. Closing an output stream also flushes the buffer used for the output stream: any characters that were temporarily placed in a buffer so that they could be delivered as a larger packet are sent off. In particular, if you do not close a file, the last packet of bytes may never be delivered. You can also manually flush the output with the flush method.
Even if a stream class provides concrete methods to work with the raw read and write functions, Java programmers seldom use them. This is because you rarely need to read and write streams of bytes. The data that you are interested in probably contain numbers, strings, and objects.
Java gives you many stream classes derived from the basic InputStream and OutputStream classes that let you work with data in the forms that you usually use rather than at the low, byte level.
java.io.InputStream

abstract int read()reads a byte of data and returns the byte read. The
readmethod returns a –1 at the end of the stream.int read(byte b[])reads into an array of bytes and returns the number of bytes read. As before, the
readmethod returns a –1 at the end of the stream.int read(byte b[], int off, int len)reads into an array of bytes. The
readmethod returns the actual number of bytes read, or –1 at the end of the stream.Parameters:
bthe array into which the data is read
offthe offset into
bwhere the first bytes should be placedlenthe maximum number of bytes to read
long skip(long n)skips
nbytes in the input stream. It returns the actual number of bytes skipped (which may be less thannif the end of the stream was encountered).int available()returns the number of bytes available without blocking. (Recall that blocking means that the current thread loses its turn.)
void close()closes the input stream.
void mark(int readlimit)The
markmethod puts a marker at the current position in the input stream. (Not all streams support this feature.) If more thanreadlimitbytes have been read from the input stream, then the stream is allowed to forget the marker.void reset()returns to the last marker. Subsequent calls to
readreread the bytes.boolean markSupported()returns
trueif the stream supports marking.
java.io.OutputStream
public abstract void write(int b)writes a byte of data.
public void write(byte b[])writes all bytes in the array
b.public void write(byte b[], int off, int len)Parameters:
bthe array from which to write the data
offthe offset into
bto the first byte that will be writtenlenthe number of bytes to write
public void close()closes the output stream.
public void flush()flushes the output stream, that is, sends any buffered data to its destination.
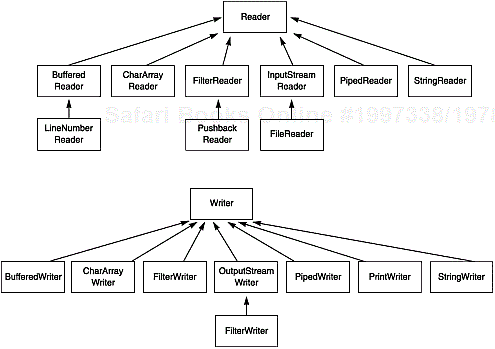
Unlike C, which gets by just fine with a single type FILE*, or VB, which has three file types, Java has a whole zoo of 58 (!) different stream types (see Figures 1-1 and 1-2). Library designers claim that there is a good reason to give users a wide choice of stream types: it is supposed to reduce programming errors. For example, in C, some people think it is a common mistake to send output to a file that was open only for reading. (Well, it is not that common, actually.) Naturally, if you do this, the output is ignored at run time. In Java and C++, the compiler catches that kind of mistake because an InputStream (Java) or istream (C++) has no methods for output.

(We would argue that, in C++ and even more so in Java, the main tool that the stream interface designers have against programming errors is intimidation. The sheer complexity of the stream libraries keeps programmers on their toes.)
C++ NOTE

C++ gives us more stream types than we want, such as istream, ostream, iostream, ifstream, ofstream, fstream, istream_with_assign, istrstream, and so on. The ANSI library takes away some of them and gives back others, such as wistream, to deal with wide characters, and istringstream, to handle string objects. But Java really goes overboard with streams and gives you the choice (or forces you to specify, depending on your outlook) of having buffering, lookahead, random access, text formatting, or binary data.
Let us divide the animals in the stream class zoo by how they are used. You have already seen the four abstract classes that are at the base of the zoo: InputStream, OutputStream, Reader, and Writer. You do not make objects of these types, but other functions can return them. For example, as you saw in Chapter 8 of Volume 1, the URL class has the method openStream that returns an InputStream. You then use this InputStream object to read from the URL. As we mentioned before, the InputStream and OutputStream classes let you read and write only individual bytes and arrays of bytes; they have no methods to read and write strings and numbers. You need more capable child classes for this. For example, DataInputStream and DataOutputStream let you read and write all the basic Java types.
For Unicode text, on the other hand, as we mentioned before, you use classes that descend from Reader and Writer. The basic methods of the Reader and Writer classes are similar to the ones for InputStream and OutputStream.
public abstract int read() throws IOException public abstract void write(int b) throws IOException
They work just as the comparable methods do in the InputStream and OutputStream classes except, of course, these methods return either a Unicode character (as an integer between 0 and 65535) or –1 when you have reached the end of the file.
Finally, there are streams that do useful stuff, for example, the ZipInputStream and ZipOutputStream that let you read and write files in the familiar ZIP compression format.
FileInputStream and FileOutputStream give you input and output streams attached to a disk file. You give the name or full pathname of the file in the constructor. For example,
FileInputStream fin = new FileInputStream("employee.dat");looks in the current directory for a file named "employee.dat". You can also use a File object:
File f = new File("employee.dat")
FileInputStream fin = new FileInputStream(f);Like the abstract InputStream and OutputStream classes, these classes only support reading and writing on the byte level. That is, we can only read bytes and byte arrays from the object in.
byte b = fin.read();
As we will see in the next section, if we just had a DataInputStream, then we could read numeric types:
DataInputStream din = . . .; double s = din.readDouble();
But just as the FileInputStream has no methods to read numeric types, the DataInputStream has no method to get data from a file.
Java uses a clever mechanism to separate two kinds of responsibilities. Some streams (such as the FileInputStream and the input stream returned by the openStream method of the URL class) can retrieve bytes from files and other more exotic locations. Other streams (such as the DataInputStream and the PrintWriter ) can assemble bytes into more useful data types. The Java programmer has to combine the two into what are often called filtered streams by feeding an existing stream to the constructor of another stream. For example, to be able to read numbers from a file, first create a FileInputStream and then pass it to the constructor of a DataInputStream.
FileInputStream fin = new FileInputStream("employee.dat");
DataInputStream din = new DataInputStream(fin);
double s = din.readDouble();The data input stream does not correspond to a new disk file. It accesses the data from the file attached to the file input stream, but it has a more capable interface.
If you look at Figure 1-1 again, you can see the classes FilterInputStream and FilterOutputStream. You combine their child classes into a new filtered stream to construct the streams you want. For example, by default, streams are not buffered. That is, every call to read contacts the operating system to ask it to dole out yet another byte. If you want buffering and data input, you need to use the following rather monstrous sequence of constructors:
DataInputStream din = new DataInputStream
(new BufferedInputStream
(new FileInputStream("employee.dat")));Notice that we put the DataInputStream last in the chain of constructors because we want to use the DataInputStream methods, and we want them to use the buffered read method.
Sometimes you need to keep track of the intermediate streams when chaining them together. For example, when reading input, you often need to peek at the next byte to see if it is the value that you expect. Java provides the PushbackInputStream for this purpose.
PushbackInputStream pbin = new PushbackInputStream
(new BufferedInputStream
(new FileInputStream("employee.dat")));Now you can speculatively read the next byte
int b = pbin.read();
and throw it back if it wasn’t what you wanted.
if (b != '<') pbin.unread(b);
But reading and unreading are the only methods that apply to the pushback input stream. If you want to look ahead and also read numbers, then you need both a pushback input stream and a data input stream reference.
DataInputStream din = new DataInputStream (pbin = new PushbackInputStream (new BufferedInputStream (new FileInputStream("employee.dat"))));
Of course, in the stream libraries of other programming languages, niceties such as buffering and lookahead are automatically taken care of, so it is a bit of a hassle in Java that one has to resort to stream filters in these cases. But you can also mix and match filter classes to construct truly useful sequences of streams. For example, you can read numbers from a compressed ZIP file by using the following sequence of streams (see Figure 1-3).

ZipInputStream zin = new ZipInputStream(new
FileInputStream("employee.zip"));
DataInputStream din = new DataInputStream(zin);(See the section on “ZIP file streams” later on in this chapter for more on Java’s ability to handle ZIP files.)
All in all, apart from the rather monstrous constructors that are needed to layer streams, the ability to mix and match streams is a very useful feature of Java!
java.io.FileInputStream
FileInputStream(String name)creates a new file input stream using the file whose pathname is specified by the
namestring.FileInputStream(File f)creates a new file input stream using the information encapsulated in the
Fileobject. (TheFileclass is described at the end of this chapter.)
java.io.BufferedInputStream
BufferedInputStream(InputStream in)creates a new buffered stream with a default buffer size. A buffered input stream reads characters from a stream without causing a device access every time. When the buffer is empty, a new block of data is read into the buffer.
BufferedInputStream(InputStream in, int n)creates a new buffered stream with a user-defined buffer size.
java.io.BufferedOutputStream
BufferedOutputStream(OutputStream out)creates a new buffered stream with a default buffer size. A buffered output stream collects characters to be written without causing a device access every time. When the buffer fills up, the data is written.
BufferedOutputStream(OutputStream out, int n)creates a new buffered stream with a user-defined buffer size.
java.io.PushbackInputStream
PushbackInputStream(InputStream in)constructs a stream with one-character lookahead.
PushbackInputStream(InputStream in, int size)constructs a stream with a push-back buffer of specified size.
void unread(int ch)pushes back a character, which is retrieved again by the next call to read. You can push back only one character at a time.
|
Parameters: |
|
the character to be read again |
You often need to write the result of a computation or read one back. The data streams support methods for reading back all of the basic Java types. To write a number, character, Boolean value, or string, use one of the following methods:
writeCharswriteIntwriteShortwriteLongwriteFloatwriteDoublewriteCharwriteBooleanwriteUTF
For example, writeInt writes an integer as a 4-byte binary quantity, and writeDouble writes a double as an 8-byte binary quantity. The resulting output is not humanly readable—see the section on the PrintWriter class later in this chapter for text output of numbers.
NOTE

There are two different methods of storing integers and floating-point numbers in memory, depending on the platform you are using. Suppose, for example, you are working with a 4-byte quantity, like an int or a float. This can be stored in such a way that the first of the 4 bytes in memory holds the most significant byte (MSB) of the value, the so-called big-endian method, or it can hold the least significant byte (LSB) first, which is called, naturally enough, the little-endian method. For example, the SPARC uses big-endian; the Pentium, little-endian. This can lead to problems. For example, when saving a file using C or C++, the data is saved exactly as the processor stores it. That makes it challenging to move even the simplest data files from one platform to another. In Java, all values are written in the big-endian fashion, regardless of the processor. That makes Java data files platform independent.
The writeUTF method writes string data using Unicode Text Format (UTF). UTF format is as follows. A 7-bit ASCII value (that is, a 16-bit Unicode character with the top 9 bits zero) is written as one byte:
0a6a5a4a3a2a1a0
A 16-bit Unicode character with the top 5 bits zero is written as a 2-byte sequence:
110a10a9a8a7a6 10a5a4a3a2a1a0
(The writeUTF method actually writes only the 11 lowest bits.)
All other Unicode characters are written as 3-byte sequences:
1110a15a14a13a12 10a11a10a9a8a7a6 10a5a4a3a2a1a0
This is a useful format for text consisting mostly of ASCII characters, because ASCII characters still take only a single byte. On the other hand, it is not a good format for Asiatic languages, for which you are better off directly writing sequences of double-byte Unicode characters. Use the writeChars method for that purpose.
Note that the top bits of a UTF byte determine the nature of the byte in the encoding scheme.
0xxxxxxx: ASCII10xxxxxx: Second or third byte110xxxxx: First byte of 2-byte sequence1110xxxx: First byte of 3-byte sequence
To read the data back in, use the following methods:
readIntreadDoublereadShortreadCharreadLongreadBooleanreadFloatreadUTF
NOTE
The binary data format is compact and platform independent. Except for the UTF strings, it is also suited to random access. The major drawback is that binary files are not readable by humans.
java.io.DataInput
boolean readBoolean()reads in a Boolean value.
byte readByte()reads an 8-bit byte.
char readChar()reads a 16-bit Unicode character.
double readDouble()reads a 64-bit double.
float readFloat()reads a 32-bit float.
void readFully(byte b[])reads bytes, blocks until all bytes are read.
Parameters:
bthe buffer into which the data is read
void readFully(byte b[], int off, int len)reads bytes, blocking until all bytes are read.
Parameters:
bthe buffer into which the data is read
offthe start offset of the data
lenthe maximum number of bytes read
int readInt()reads a 32-bit integer.
String readLine()reads in a line that has been terminated by a
EOF. Returns a string containing all bytes in the line converted to Unicode characters.long readLong()reads a 64-bit long integer.
short readShort()reads a 16-bit short integer.
String readUTF()reads a string of characters in UTF format.
int skipBytes(int n)skips bytes, blocks until all bytes are skipped.
|
Parameters: |
|
the number of bytes to be skipped |
java.io.DataOutput
void writeBoolean(boolean b)writes a Boolean value.
void writeByte(byte b)writes an 8-bit byte.
void writeChar(char c)writes a 16-bit Unicode character.
void writeChars(string s)writes a string as a sequence of characters.
void writeDouble(double d)writes a 64-bit double.
void writeFloat(float f)writes a 32-bit float.
void writeInt(int i)writes a 32-bit integer.
void writeLong(long l)writes a 64-bit long integer.
void writeShort(short s)writes a 16-bit short integer.
void writeUTF(String s)writes a string of characters in UTF format.
The RandomAccessFile stream class lets you find or write data anywhere in a file. Disk files are random access, but streams of data from a network are not. You open a random-access file either for reading only or for both reading and writing. You specify the option by using the string "r" (for read access) or "rw" (for read/write access) as the second argument in the constructor.
RandomAccessFile in = new RandomAccessFile("employee.dat", "r");
RandomAccessFile inOut
= new RandomAccessFile("employee.dat", "rw");A random-access file also has a file pointer setting that comes with it. The file pointer always indicates the position of the next record that will be read or written. The seek method sets the file pointer to an arbitrary byte position within the file. The argument to seek is a long integer between zero and the length of the file in bytes.
The getFilePointer method returns the current position of the file pointer.
To read from a random-access file, you use the same methods—such as readInt and readUTF —as for DataInputStream objects. That is no accident. These methods are actually defined in the DataInput interface that both DataInputStream and RandomAccessFile implement.
Similarly, to write a random-access file, you use the same writeInt and writeUTF methods as in the DataOutputStream class. These methods are defined in the DataOutput interface that is common to both classes.
The advantage of this setup is that you can write methods whose argument types are the DataInput and DataOutput interfaces.
class Employee
{ . . .
read(DataInput in) { . . . }
write(DataOutput out) { . . . }
}Note that the read method can handle either a DataInputStream or a RandomAccessFile object because both of these classes implement the DataInput interface. The same is true for the write method.
java.io.RandomAccessFile
RandomAccessFile(String name, String mode)Parameters:
namesystem-dependent file name
mode"r"for reading only, or"rw"for reading and writingRandomAccessFile(File file, String mode)Parameters:
filea
Fileobject encapsulating a system-dependent file name. (TheFileclass is described at the end of this chapter.)mode"r"for reading only, or"rw"for reading and writinglong getFilePointer()returns the current location of the file pointer.
void seek(long pos)sets the file pointer to
posbytes from the beginning of the file.public long length()returns the length of the file in bytes.
In the last section, we discussed binary input and output. While binary I/O is fast and efficient, it is not easily readable by humans. In this section, we will focus on text I/O. For example, if the integer 1234 is saved in binary, it is written as the sequence of bytes 00 00 04 D2 (in hexadecimal notation). In text format, it is saved as the string "1234". But as you know, there is a problem. Java uses Unicode characters. That is, the character encoding for the string "1234" really is 00 31 00 32 00 33 00 34 (in hex). However, at the present time most environments where your Java programs will run use their own character encoding. This may be a single-byte, a double-byte, or a variable-byte scheme.
For example, under Windows, the string would need to be written in ASCII, as 31 32 33 34, without the extra zero bytes. If the Unicode encoding were written into a text file, then it would be quite unlikely that the resulting file will be humanly readable with the tools of the host environment. To overcome this problem, as we mentioned before, Java now has a set of stream filters that bridges the gap between Unicode encoded text and the character encoding used by the local operating system. All of these classes descend from the abstract Reader and Writer classes, and the names are reminiscent of the ones used for binary data. For example, the InputStreamReader class turns an input stream that reads bytes in a particular character encoding into a reader that emits Unicode characters. Similarly, the OutputStreamWriter class turns a stream of Unicode characters into a stream of bytes in a particular character encoding.
For example, here is how you make an input reader that reads keystrokes from the console and automatically converts them to Unicode.
InputStreamReader in = new InputStreamReader(System.in);
This input stream reader assumes the normal character encoding used by the host system. For example, under Windows, it uses the ISO 8859-1 encoding (also known as ISO Latin-1 or, among Windows programmers, as “ANSI code”). You can choose a different encoding by specifying it in the constructor for the InputStreamReader. This takes the form
InputStreamReader(InputStream, String)
where the string describes the encoding scheme that you want to use. For example,
InputStreamReader in = new InputStreamReader(new
FileInputStream("kremlin.dat"), "8859_5");Table 1-1 lists the currently supported encoding schemes.
Of course, there are many Unicode characters that cannot be represented by these encoding schemes. If those characters are part of the stream, they are displayed by a ? in the output.
Because it is so common to want to attach a reader or writer to a file, there is a pair of convenience classes, FileReader and FileWriter, for this purpose. For example, the writer definition
FileWriter out = new FileWriter("output.txt");is equivalent to
OutputStreamWriter out = new OutputStreamReader(new
FileOutputStream("output.txt"));For text output, you want to use a PrintWriter. A print writer can print strings and numbers in text format. Just as a DataOutputStream has useful output methods but no destination, a PrintWriter must be combined with a destination writer.
PrintWriter out = new PrintWriter(new FileWriter("employee.txt"));You can also combine a print writer with a destination (output) stream.
PrintWriter out = new PrintWriter(new
FileOutputStream("employee.txt"));The PrintWriter(OutputStream) constructor automatically adds an OutputStreamWriter to convert Unicode characters to bytes in the stream.
To write to a print writer, you use the same print and println methods that you used with System.out. You can use these methods to print numbers (int, short, long, float, double ), characters, Boolean values, strings, and objects.
NOTE
Java veterans probably wonder whatever happened to the PrintStream class and to System.out. In Java1.0, the PrintStream class simply truncated all Unicode characters to ASCII characters by dropping the top byte. Conversely, the readLine method of the DataInputStream turned ASCII to Unicode by setting the top byte to 0. Clearly, that was not a clean or portable approach, and it was fixed with the introduction of readers and writers in Java 1.1. For compatibility with existing code, System.in, System.out, and System.err are still streams, not readers and writers. But now the PrintStream class internally converts Unicode characters to the default host encoding in the same way as the PrintWriter. And all constructors for PrintStream are now deprecated—simply use PrintWriter instead. That means that new Java code has exactly two objects of type PrintStream, namely, System.out and System.err. These act exactly like print writers when you use the print and println methods, but unlike print writers, you can also send raw bytes to them with the write(int) and write(byte[]) methods.
Table 1-1. Character encodings
|
|
ISO Latin-1 |
|
|
ISO Latin-2 |
|
|
ISO Latin-3 |
|
|
ISO Latin/Cyrillic |
|
|
ISO Latin/Arabic |
|
|
ISO Latin/Greek |
|
|
ISO Latin/Hebrew |
|
|
ISO Latin-5 |
|
|
Windows Eastern Europe / Latin-2 |
|
|
Windows Cyrillic |
|
|
Windows Western Europe / Latin-1 |
|
|
Windows Greek |
|
|
Windows Turkish |
|
|
Windows Hebrew |
|
|
Windows Arabic |
|
|
Windows Baltic |
|
|
Windows Vietnamese |
|
|
Original |
|
|
PC Greek |
|
|
PC Baltic |
|
|
PC Latin-1 |
|
|
PC Latin-2 |
|
|
PC Cyrillic |
|
|
PC Turkish |
|
|
PC Portuguese |
|
|
PC Icelandic |
|
|
PC Hebrew |
|
|
PC Canadian French |
|
|
PC Arabic |
|
|
PC Nordic |
|
|
PC Russian |
|
|
PC Modern Greek |
|
|
Windows Thai |
|
|
Japanese EUC |
|
|
JIS |
|
|
Macintosh Arabic |
|
|
Macintosh Latin-2 |
|
|
Macintosh Croatian |
|
|
Macintosh Cyrillic |
|
|
Macintosh Dingbat |
|
|
Macintosh Greek |
|
|
Macintosh Hebrew |
|
|
Macintosh Icelandic |
|
|
Macintosh Roman |
|
|
Macintosh Romania |
|
|
Macintosh Symbol |
|
|
Macintosh Thai |
|
|
Macintosh Turkish |
|
|
Macintosh Ukraine |
|
|
PC and Windows Japanese |
|
|
Standard UTF-8 |
For example, consider this code:
String name = "Harry Hacker";
double salary = 75000;
out.print(name);
out.print(' '),
out.println(salary);This writes the characters
Harry Hacker 75000
to the stream out. The characters are then converted to bytes and end up in the file employee.txt.
As you know, the println method always prints a line terminator. This is the string obtained by the call System.getProperty("line.separator"), such as "
" (Unix), "
" (DOS) or "
" (Macintosh). If the writer is set to auto flush mode, then all characters in the buffer are sent to their destination whenever println is called. (Print writers are always buffered.) By default, auto flushing is not enabled. You can enable or disable auto flushing by using the PrintWriter(Writer, boolean) constructor and passing the appropriate Boolean as the second argument.
PrintWriter out = new PrintWriter(new
FileWriter("employee.txt"), true); // auto flushThe print methods don’t throw exceptions. You can call the checkError method to see if something went wrong with the stream.
java.io.PrintStream
void print(Object obj)prints an object by printing the string resulting from
toString.Parameters:
objthe object to be printed
void print(String s)prints a Unicode string.
void println(String s)prints a string followed by a line terminator. Flushes the stream if the stream is in autoflush mode.
void print(char s[])prints an array of Unicode characters.
void print(char c)prints a Unicode character.
void print(int i)prints an integer in text format.
void print(long l)prints a long integer in text format.
void print(float f)prints a floating-point number in text format.
void print(double d)prints a double-precision floating-point number in text format.
void print(boolean b)prints a Boolean value in text format.
boolean checkError()returns
trueif a formatting or output error occurred. Once the stream has encountered an error, it is tainted and all calls tocheckErrorreturntrue.
java.io.PrintWriter
PrintWriter(Writer out)Creates a new
PrintWriter, without automatic line flushing.Parameters:
outa character-output writer
PrintWriter(Writer out, boolean autoFlush)Creates a new
PrintWriter.Parameters:
outa character-output writer
autoFlushif true, the
println()methods will flush the output bufferPrintWriter(OutputStream out)Creates a new
PrintWriter, without automatic line flushing, from an existingOutputStreamby automatically creating the necessary intermediateOutputStreamWriter.Parameters:
outan output stream
PrintWriter(OutputStream out, boolean autoFlush)Also creates a new
PrintWriterfrom an existingOutputStreambut allows you determine whether the writer autoflushes or not.Parameters:
outan output stream
autoFlushif true, the
println()methods will flush the output buffer
As you know:
To write data in binary format, you use a
DataOutputStream.To write in text format, you use a
PrintWriter.
Therefore, you might expect that there is an analog to the DataInputStream that lets you read data in text format. Unfortunately, Java does not provide such a class. (That is why we wrote our own Console class in Volume 1.) The only game in town for processing text input is the BufferedReader method—it has a method, readLine, that lets you read a line of text. You need to combine a buffered reader with an input source.
BufferedReader in = new BufferedReader(new
FileReader("employee.txt"));The readLine method returns null when no more input is available. A typical input loop, therefore, looks like this:
String s;
while ((s = in.readLine()) != null)
{do something with s;
}The FileReader class already converts bytes to Unicode characters. For other input sources, you need to use the InputStreamReader —unlike the PrintWriter, there is no automatic convenience method to bridge the gap between bytes and Unicode characters.
BufferedReader in2 = new BufferedReader(new InputStreamReader(System.in)); BufferedReader in3 = new BufferedReader(new InputStreamReader(url.openStream()));
To read numbers from text input, you need to read a string first and then convert it.
String s = in.readLine(); double x = new Double(s).doubleValue();
That works if there is a single number on each line. Otherwise, you must work harder and break up the input string. We will see an example of this later in this chapter.
TIP
Java now has StringReader and StringWriter classes that allow you to treat a string as if it were a data stream. This can be quite convenient if you want to parse both strings and data from a stream using the same code. The StringWriter classes, although more convenient, are not usually as efficient as using a StringBuffer class, however.
ZIP files are archives that store one or more files in (usually) compressed format. Java 1.1 can handle both GZIP and ZIP format. (See RFC 1950, RFC 1951, and RFC 1952 at ftp://ds.internic.net/rfc/.) In this section we concentrate on the more familiar (but somewhat more complicated) ZIP format and leave the GZIP classes to you if you need them. (They work in much the same way.)
NOTE
The classes for handling ZIP files are in java.util.zip and not in java.io, so remember to add the necessary import statement. Although not part of java.io, the GZIP and ZIP classes do subclass java.io.FilterInputStream and java.io.FilterOutputStream. The java.util.zip packages also contain classes for computing CRC checksums. (CRC stands for cyclic redundancy check and is a method to generate a hashlike code that the receiver of a file can use to check the integrity of data transmission.)
Each ZIP file has a header with information such as the name of the file and the compression method that was used. In Java, you use a ZipInputStream to read a ZIP file. You then look at the entries. The getNextEntry method returns an object of type ZipEntry that describes the entry. The read method of the ZipInputStream is modified to return –1, not at the end of the ZIP file but at the end of the current entry. You must then call closeEntry to read the next entry. Here is a typical code sequence to read through a ZIP file:
ZipInputStream zin = new ZipInputStream
(new FileInputStream(zipname));
ZipEntry entry;
while ((entry = zin.getNextEntry()) != null)
{ analyze entry;
read the contents of zin;
zin.closeEntry();
}
zin.close();To read the contents of a ZIP entry, you will probably not want to use the raw read method; usually, you will use the methods of a more competent stream filter. For example, to read a text file inside a ZIP file, you can use the following loop:
BufferedReader in = new BufferedReader
(new InputStreamReader(zin));
String s;
while ((s = in.readLine()) != null)
do something with s;The program in Example 1-1 lets you open a ZIP file. It then displays the files stored in the ZIP archive in the list box at the top of the screen. If you double-click on one of the files, the contents of the file are displayed in the text area, as shown in Figure 1-4.

Example 1-1. ZipTest.java
import java.awt.*;
import java.awt.event.*;
import java.io.*;
import java.util.*;
import java.util.zip.*;
import corejava.*;
public class ZipTest extends CloseableFrame
implements ActionListener
{ public ZipTest()
{ MenuBar mbar = new MenuBar();
Menu m = new Menu("File");
MenuItem m1 = new MenuItem("Open");
m1.addActionListener(this);
m.add(m1);
MenuItem m2 = new MenuItem("Exit");
m2.addActionListener(this);
m.add(m2);
mbar.add(m);
setMenuBar(mbar);
fileList.addActionListener(this);
add(fileList, "North");
add(fileText, "Center");
}
public void actionPerformed(ActionEvent evt)
{ String arg = evt.getActionCommand();
if (evt.getSource() == fileList)
{ loadZipFile(arg);
}
else if (arg.equals("Open"))
{ FileDialog d = new FileDialog(this,
"Open zip file", FileDialog.LOAD);
d.setFile("*.zip");
d.setDirectory(lastDir);
d.show();
String f = d.getFile();
lastDir = d.getDirectory();
if (f != null)
{ zipname = lastDir + f;
scanZipFile();
}
}
else if(arg.equals("Exit")) System.exit(0);
}
public void scanZipFile()
{ fileList.removeAll();
try
{ ZipInputStream zin = new ZipInputStream(new
FileInputStream(zipname));
ZipEntry entry;
while ((entry = zin.getNextEntry()) != null)
{ fileList.add(entry.getName());
zin.closeEntry();
}
zin.close();
}
catch(IOException e) {}
}
public void loadZipFile(String name)
{ try
{ ZipInputStream zin = new ZipInputStream(new
FileInputStream(zipname));
ZipEntry entry;
fileText.setText("");
while ((entry = zin.getNextEntry()) != null)
{ if (entry.getName().equals(name))
{ BufferedReader in = new BufferedReader(new
InputStreamReader(zin));
String s;
while ((s = in.readLine()) != null)
fileText.append(s + "
");
}
zin.closeEntry();
}
zin.close();
}
catch(IOException e) {}
}
public static void main(String args[])
{ Frame f = new ZipTest();
f.show();
}
private List fileList = new List();
private TextArea fileText = new TextArea();
private String lastDir = "";
private String zipname;
}NOTE
Java throws a ZipException when there is an error in reading a ZIP file. Normally this occurs when the ZIP file is corrupted.
To write a ZIP file, you open a ZipOutputStream. For each entry that you want to place into the ZIP file, you create a ZipEntry object. You pass the file name to the ZipEntry constructor; it sets the other parameters such as file date and decompression method automatically. You can override these settings if you like. Then, you call the putNextEntry method of the ZipOutputStream to begin writing a new file. Send the file data to the ZIP stream, and when you are done, call closeEntry. Repeat for all the files you want to store. Here is a code skeleton:
FileOutputStream fout = new FileOutputStream("test.zip");
ZipOutputStream zout = new ZipOutputStream(fout);
for all files
{ ZipEntry ze = new ZipEntry(file name);
zout.putNextEntry(ze);
send data to ze;
zout.closeEntry();
}
zout.close();NOTE
The files that are produced by the Java 1.1 ZipOutputStream methods are not proper ZIP archives. PKZip and WinZip 6.2 can extract the file names, but not the files themselves. WinZip 6.3 (which is in beta at the time that this book is written) “handles certain invalid zips more gracefully” and can handle ZIP files that are generated by the ZipOutputStream class. The same is true for JAR files (which were discussed in the applet chapter of Volume 1). JAR files are simply ZIP files with another entry, the so-called manifest.
ZIP streams are a good example of the power of the stream abstraction. Both the source and the destination of the ZIP data are completely flexible. You attach the most convenient reader to the ZIP file to read the data that is stored in compressed form, and that reader doesn’t even realize that the data is being decompressed as it is being requested. And the source of the bytes in ZIP formats need not be a file—the ZIP data can come from a network connection. In fact, the JAR files that we discussed in Chapter 10 of Volume 1 are ZIP formatted files. Whenever the class loader of an applet reads a JAR file, it uses a ZipInputStream to read and decompress data from the network.
java.util.zip.ZipInputStream
ZipInputStream(InputStream in)This constructor creates a
ZipInputStreamthat allows you to inflate data from the givenInputStream.Parameters
inthe underlying input stream
ZipEntry getNextEntry()returns a
ZipEntryobject for the next entry ornullif there are no more entries.void closeEntry()This method closes the current open entry in the ZIP file. You can then read the next entry using
getNextEntry().
java.util.zip.ZipOutputStream
ZipOutputStream(OutputStream out)This constructor creates a
ZipOutputStreamthat you use to write compressed data to the specifiedOutputStream.Parameters
outthe underlying output stream
putNextEntry(ZipEntry ze)writes the information in the given
ZipEntryto the stream and positions the stream for the data. The data can then be written to the stream usingwrite().Parameters
zethe new entry
void closeEntry()closes the currently open entry in the ZIP file. Use
putNextEntry()to start the next entry.void setLevel(int level)sets the default compression level of subsequent
DEFLATEDentries. The default value isDeflater.DEFAULT_COMPRESSION. Throws anIllegalArgumentExceptionif the level is not valid.Parameters
levela compression level, from 0 (
NO_COMPRESSION) to 9 (BEST_COMPRESSION)void setMethod(int method)sets the default compression method for this
ZipOutputStreamfor any entries that do not specify a method.Parameters
methodthe compression method, either
DEFLATEDorSTORED
java.util.zip.ZipEntry
ZipEntry(String name)Parameters
namethe name of the entry
long getCrc()returns the CRC32 checksum value for this
ZipEntry.String getName()returns the name of this entry.
long getSize()returns the uncompressed size of this entry, or –1 if the uncompressed size is not known.
boolean isDirectory()returns a Boolean that indicates whether or not this entry is a directory.
setMethod(int method)Parameters
methodthe compression method for the entry; must be either
DEFLATEDorSTOREDvoid setSize(long size)sets the size of this entry. Only required if the compression method is
STORED.Parameters:
sizethe uncompressed size of this entry
void setCrc(long crc)sets the CRC32 checksum of this entry. Use the
CRC32class to compute this checksum. Only required if the compression method isSTORED.Parameters:
crcthe checksum of this entry
java.util.zip.ZipFile
ZipFile(String name)This constructor creates a
ZipFilefor reading from the given string.Parameters
namea string that contains the pathname of the file
ZipFile(File file)This constructor creates a
ZipFilefor reading from the givenFileobject.Parameters
filethe file to read. The
Fileclass is described at the end of this chapterEnumeration entries()returns an
Enumerationobject that enumerates theZipEntryobjects that describe the entries of theZipFile.ZipEntry getEntry(String name)returns the entry corresponding to the given name, or
nullif there is no such entry.Parameters
namethe entry name
InputStream getInputStream(ZipEntry ze)returns an
InputStreamfor the given entry.Parameters
zea
ZipEntryin the ZIP fileString getName()returns the path of this ZIP file.
In the next four sections, we will show you how to put some of the creatures in the stream zoo to good use. For these examples, we will assume you are working with the Employee class and some of its derived classes, such as Manager. (See Chapters 4 and 5 of Volume 1 for more on these example classes.) We will consider four separate scenarios for saving an array of employee records to a file and then reading them back into memory.
Saving data of the same type (
Employee) in text formatSaving data of the same type in binary format
Saving and restoring polymorphic data (a mixture of
EmployeeandManagerobjects)Saving and restoring data containing embedded references (managers with pointers to other employees)
In this section, you will learn how to store an array of Employee records in the time-honored delimited format. This means that each record is stored in a separate line. Instance fields are separated from each other by delimiters. We use a vertical bar (| ) as our delimiter. (Acolon (: ) is another popular choice. Part of the fun is that everyone uses a different delimiter.) Naturally, we punt on the issue of what might happen if a | actually occurred in one of the strings we save.
NOTE
Especially on Unix systems, an amazing number of files are stored in exactly this format. We have seen entire employee databases with thousands of records in this format, queried with nothing more than the Unix awk, sort, and join utilities. (In the PC world, where excellent database programs are available at low cost, this kind of ad hoc storage is much less common.)
Here is a sample set of records:
Harry Hacker|35500|1989|10|1 Carl Cracker|75000|1987|12|15 Tony Tester|38000|1990|3|15
Writing records is simple. Since we write to a text file, we use the PrintWriter class. We simply write all fields, followed by either a | or, for the last field, a
. Finally, in keeping with the idea that we want the class to be responsible for responding to messages, we add a method, writeData, to our Employee class.
public void writeData(PrintWriter os) throws IOException
{ Format.print(os, "%s|", name);
Format.print(os, "%.14g|", salary);
Format.print(os, "%d|", hireDay.getYear());
Format.print(os, "%d|", hireDay.getMonth());
Format.print(os, "%d
", hireDay.getDay());
}To read records, we read in a line at a time and separate the fields. This is the topic of the next section, in which we use a utility class supplied with Java to make our job easier.
When reading a line of input, we get a single long string. We want to split it into individual strings. This means finding the | delimiters and then separating out the individual pieces, that is, the sequence of characters up to the next delimiter. (These are usually called tokens.) The StringTokenizer class in java.util is designed for exactly this purpose. It gives you an easy way to break up a large string that contains delimited text. The idea is that a string tokenizer object attaches to a string. When you construct the tokenizer object, you specify which characters are the delimiters. For example, we need to use
StringTokenizer t = new StringTokenizer(line, "|");
You can specify multiple delimiters in the string. For example, to set up a string tokenizer that would let you search for any delimiter in the set
" "
use the following:
StringTokenizer t = new StringTokenizer(line, " ");
(Notice that this means that any white space marks off the tokens.)
NOTE
These four delimiters are used as the defaults if you construct a string tokenizer like this:
StringTokenizer t = new StringTokenizer(line);
Once you have constructed a string tokenizer, you can use its methods to quickly extract the tokens from the string. The nextToken method returns the next unread token. The hasMoreTokens method returns true if more tokens are available.
NOTE
In our case, we know how many tokens we have in every line of input. In general, you have to be a bit more careful: call hasMoreTokens before calling nextToken because the nextToken method throws an exception when no more tokens are available.
java.util.StringTokenizer
StringTokenizer(String str, String delim)Parameters:
strthe input string from which tokens are read
delima string containing delimiter characters (any character in this string is a delimiter)
StringTokenizer(String str)constructs a string tokenizer with the default delimiter set
" ".boolean hasMoreTokens()returns
trueif more tokens exist.String nextToken()returns the next token; throws a
NoSuchElementExceptionif there are no more tokens.String nextToken(String delim)returns the next token, after switching to the new delimiter set. The new delimiter set is subsequently used.
int countTokens()returns the number of tokens still in the string.
Reading in an Employee record is simple. We simply read in a line of input with the readLine method of the BufferedReader class. Here is the code needed to read one record in a string.
BufferedReader in
= new BufferedReader(new FileReader("employee.dat"));
. . .
String line = in.readLine();Next, we need to extract the individual tokens. When we do this, we end up with strings, so we need to convert them into numbers when appropriate. To do this, we turn to the atoi and atof methods from the Format class in our corejava package.
Just as with the writeData method, we add a readData method of the Employee class. When you call
e.readData(in);
this method overwrites the previous contents of e. Note that the method may throw an IOException if the readLine method throws that exception. There is nothing this method can do if an IOException occurs, so we just let it propagate up the chain.
Here is the code for this method:
public void readData(BufferedReader in) throws IOException
{ String line = in.readLine();
if (line == null) return;
StringTokenizer t = new StringTokenizer(line, "|");
name = t.nextToken();
salary = Format.atof(t.nextToken());
int y = Format.atoi(t.nextToken());
int m = Format.atoi(t.nextToken());
int d = Format.atoi(t.nextToken());
hireDay = new Day(y, m, d);
}Finally, in the code for a program that tests these methods, the static method
void writeData(Employee[] e, PrintWriter out)
first writes the length of the array, then writes each record. The static method
readData(Employee[] BufferedReader in)
first reads in the length of the array, then reads in each record, as illustrated in Example 1-2.
Example 1-2. DataFileTest.java
import java.io.*;
import java.util.*;
import corejava.*;
public class DataFileTest
{ static void writeData(Employee[] e, PrintWriter os)
throws IOException
{ Format.print(os, "%d
", e.length);
int i;
for (i = 0; i < e.length; i++)
e[i].writeData(os);
}
static Employee[] readData(BufferedReader is)
throws IOException
{ int n = Format.atoi(is.readLine());
Employee[] e = new Employee[n];
int i;
for (i = 0; i < n; i++)
{ e[i] = new Employee();
e[i].readData(is);
}
return e;
}
public static void main(String[] args)
{ Employee[] staff = new Employee[3];
staff[0] = new Employee("Harry Hacker", 35500,
new Day(1989,10,1));
staff[1] = new Employee("Carl Cracker", 75000,
new Day(1987,12,15));
staff[2] = new Employee("Tony Tester", 38000,
new Day(1990,3,15));
int i;
for (i = 0; i < staff.length; i++)
staff[i].raiseSalary(5.25);
try
{ PrintWriter os = new PrintWriter(new
FileWriter("employee.dat"));
writeData(staff, os);
os.close();
}
catch(IOException e)
{ System.out.print("Error: " + e);
System.exit(1);
}
try
{ BufferedReader is = new BufferedReader(new
FileReader("employee.dat"));
Employee[] in = readData(is);
for (i = 0; i < in.length; i++) in[i].print();
is.close();
}
catch(IOException e)
{ System.out.print("Error: " + e);
System.exit(1);
}
}
}
class Employee
{ public Employee(String n, double s, Day d)
{ name = n;
salary = s;
hireDay = d;
}
public Employee() {}
public void print()
{ System.out.println(name + " " + salary
+ " " + hireYear());
}
public void raiseSalary(double byPercent)
{ salary *= 1 + byPercent / 100;
}
public int hireYear()
{ return hireDay.getYear();
}
public void writeData(PrintWriter os) throws IOException
{ Format.print(os, "%s|", name);
Format.print(os, "%.14g|", salary);
Format.print(os, "%d|", hireDay.getYear());
Format.print(os, "%d|", hireDay.getMonth());
Format.print(os, "%d
", hireDay.getDay());
}
public void readData(BufferedReader is) throws IOException
{ String s = is.readLine();
StringTokenizer t = new StringTokenizer(s, "|");
name = t.nextToken();
salary = Format.atof(t.nextToken());
int y = Format.atoi(t.nextToken());
int m = Format.atoi(t.nextToken());
int d = Format.atoi(t.nextToken());
hireDay = new Day(y, m, d);
}
private String name;
private double salary;
private Day hireDay;
}If you have a large number of employees, the storage technique used in the preceding section suffers from one limitation: it is not possible to read a record in the middle of the file without first reading all records that come before it. In this section, we will make all records the same length. This lets us implement a random-access method of reading back the information—we can get at any record in the same amount of time.
We will store the numbers in the instance fields in our classes in a binary format. This is done using the writeInt and writeDouble methods of the DataOutput interface. (This is the common interface of the DataOutputStream and the RandomAccessFile classes.)
However, since the size of each record must remain constant, we need to make all the strings the same size when we save them. The variable-size UTF format does not do this, and the rest of the Java library provides no convenient means for accomplishing this. We need to write a bit of code to implement two helper methods. We will call them writeFixedString and readFixedString. These methods read and write Unicode strings that always have the same length.
The writeFixedString method takes the parameter size. Then, it writes the specified number of characters, starting at the beginning of the string. (If there are too few characters, it pads the string using characters whose ASCII/Unicode values are zero.) Here is the code for the writeFixedString method:
static void writeFixedString
(String s, int size, DataOutput out)
throws IOException
{ int i;
for (i = 0; i < size; i++)
{ char ch = 0;
if (i < s.length()) ch = s.charAt(i);
out.writeChar(ch);
}
}The readFixedString method reads characters from the input stream until it has consumed size characters, or until it encounters a character with Unicode 0. Then, it should skip past the remaining zero characters in the input field.
For added efficiency, this method uses the StringBuffer class to read in a string. A StringBuffer is an auxiliary class that lets you preallocate a memory block of a given length. In our case, we know that the string is, at most, size bytes long. We make a string buffer in which we reserve size characters. Then we append the characters as we read them in.
NOTE
This is more efficient than reading in characters and appending them to an existing string. Every time you append characters to a string, Java needs to find new memory to hold the larger string: this is time consuming. Appending even more characters means the string needs to be relocated again and again. Using the StringBuffer class avoids this problem.
Once the string buffer holds the desired string, we need to convert it to an actual String object. This is done with the String(StringBuffer b) constructor. This constructor does not copy the characters in the string buffer. Instead, it freezes the buffer contents. If you later call a method that makes a modification to the StringBuffer object, the buffer object first gets a new copy of the characters and then modifies those.
static String readFixedString(int size, DataInput in)
throws IOException
{ StringBuffer b = new StringBuffer(size);
int i = 0;
boolean more = true;
while (more && i < size)
{ char ch = in.readChar();
i++;
if (ch == 0) more = false;
else b.append(ch);
}
in.skipBytes(2 * (size - i));
return b.toString();
}To write a fixed-size record, we simply write all fields in binary.
public void writeData(DataOutput out) throws IOException
{ DataIO.writeFixedString(name, NAME_SIZE, out);
out.writeDouble(salary);
out.writeInt(hireDay.getYear());
out.writeInt(hireDay.getMonth());
out.writeInt(hireDay.getDay());
}Reading the data back is just as simple.
public void readData(DataInput in) throws IOException
{ name = DataIO.readFixedString(NAME_SIZE, in);
salary = in.readDouble();
int y = in.readInt();
int m = in.readInt();
int d = in.readInt();
hireDay = new Day(y, m, d);
}In our example, each employee record is 100 bytes long because we specified that the name field would always be written using 40 characters. This gives us a breakdown as indicated in the following:
40 characters = 80 bytes for the name
1
double= 8 bytes3
int= 12 bytes
As an example, suppose we want to position the file pointer to the third record. We can use the following version of the seek method:
long int n = 3; int RECORD_SIZE = 100; in.seek((n - 1) * RECORD_SIZE);
To determine the total number of bytes in a file, use the length method. The total number of records is the length divided by the size of each record.
long int nbytes = in.length(); // length in bytes int nrecords = (int)(nbytes / RECORD_SIZE);
The test program shown in Example 1-3 writes three records into a data file and then reads them from the file in reverse order. To do this efficiently requires random access—we need to get at the third record first.
Example 1-3. RandomFileTest.java
import java.io.*;
import corejava.*;
public class RandomFileTest
{ public static void main(String[] args)
{ Employee[] staff = new Employee[3];
staff[0] = new Employee("Harry Hacker", 35000,
new Day(1989,10,1));
staff[1] = new Employee("Carl Cracker", 75000,
new Day(1987,12,15));
staff[2] = new Employee("Tony Tester", 38000,
new Day(1990,3,15));
int i;
try
{ DataOutputStream out = new DataOutputStream(new
FileOutputStream("employee.dat"));
for (i = 0; i < staff.length; i++)
staff[i].writeData(out);
out.close();
}
catch(IOException e)
{ System.out.print("Error: " + e);
System.exit(1);
}
try
{ RandomAccessFile in
= new RandomAccessFile("employee.dat", "r");
int n = (int)(in.length() / Employee.RECORD_SIZE);
Employee[] newStaff = new Employee[n];
for (i = n - 1; i >= 0; i--)
{ newStaff[i] = new Employee();
in.seek(i * Employee.RECORD_SIZE);
newStaff[i].readData(in);
}
for (i = 0; i < newStaff.length; i++)
newStaff[i].print();
}
catch(IOException e)
{ System.out.print("Error: " + e);
System.exit(1);
}
}
}
class Employee
{ public Employee(String n, double s, Day d)
{ name = n;
salary = s;
hireDay = d;
}
public Employee() {}
public void print()
{ System.out.println(name + " " + salary
+ " " + hireYear());
}
public void raiseSalary(double byPercent)
{ salary *= 1 + byPercent / 100;
}
public int hireYear()
{ return hireDay.getYear();
}
public void writeData(DataOutput out) throws IOException
{ DataIO.writeFixedString(name, NAME_SIZE, out);
out.writeDouble(salary);
out.writeInt(hireDay.getYear());
out.writeInt(hireDay.getMonth());
out.writeInt(hireDay.getDay());
}
public void readData(DataInput in) throws IOException
{ name = DataIO.readFixedString(NAME_SIZE, in);
salary = in.readDouble();
int y = in.readInt();
int m = in.readInt();
int d = in.readInt();
hireDay = new Day(y, m, d);
}
public static final int NAME_SIZE = 40;
public static final int RECORD_SIZE
= 2 * NAME_SIZE + 8 + 4 + 4 + 4;
private String name;
private double salary;
private Day hireDay;
}
class DataIO
{ public static String readFixedString(int size,
DataInput in) throws IOException
{ StringBuffer b = new StringBuffer(size);
int i = 0;
boolean more = true;
while (more && i < size)
{ char ch = in.readChar();
i++;
if (ch == 0) more = false;
else b.append(ch);
}
in.skipBytes(2 * (size - i));
return b.toString();
}
public static void writeFixedString(String s, int size,
DataOutput out) throws IOException
{ int i;
for (i = 0; i < size; i++)
{ char ch = 0;
if (i < s.length()) ch = s.charAt(i);
out.writeChar(ch);
}
}
}java.lang.StringBuffer
StringBuffer()constructs an empty string buffer.
StringBuffer(int length)constructs an empty string buffer with the initial capacity
length.StringBuffer(String str)constructs a string buffer with the initial contents
str.int length()returns the number of characters of the buffer.
int capacity()returns the current capacity, that is, the number of characters that can be contained in the buffer before it must be relocated.
void ensureCapacity(int m)enlarges the buffer if the capacity is fewer than
mcharacters.void setLength(int n)If
nis less than the current length, characters at the end of the string are discarded. Ifnis larger than the current length, the buffer is padded with'�'characters.char charAt(int i)returns the
i’th character (iis between0andlength()-1); throws aStringIndexOutOfBoundsExceptionif the index is invalid.void getChars(int from, int to, char a[], int offset)copies characters from the string buffer into an array.Parameters
fromthe first character to copy
tothe first character not to copy
athe array to copy into
offsetthe first position in
ato copy intovoid setCharAt(int i, char ch)sets the
i’th character toch.StringBuffer append(String str)appends a string to the end of this buffer (the buffer may be relocated as a result); returns
this.StringBuffer append(char c)appends a character to the end of this buffer (the buffer may be relocated as a result); returns
this.StringBuffer insert(int offset, String str)inserts a string at position
offsetinto this buffer (the buffer may be relocated as a result); returnsthis.StringBuffer insert(int offset, char c)inserts a character at position
offsetinto this buffer (the buffer may be relocated as a result); returnsthis.String toString()returns a string pointing to the same data as the buffer contents. (No copy is made.)
Using a fixed-length record format is a good choice if you need to store data of the same type. However, objects that you create in an object-oriented program are rarely all of the same type. For example, you may have an array called staff that is nominally an array of Employee records but contains objects that are actually instances of a child class such as Manager.
If we want to save files that contain this kind of information, we must first save the type of each object and then the data that defines the current state of the object. When we read this information back from a file, we must
Read the object type
Create a blank object of that type
Fill it with the data that we stored in the file
It is entirely possible to do this by hand, and the first edition of this book did exactly this. However, JavaSoft developed a powerful mechanism that allows this to be done with much less effort. As you will soon see, this mechanism, called object serialization, almost completely automates what was previously a very tedious process. (You will see later in this chapter where the term “serialization” comes from.)
To save object data, you first need to open an ObjectOutputStream object:
ObjectOutputStream out = new ObjectOutputStream(new
FileOutputStream("employee.dat"));Now, to save an object, you simply use the writeObject method of the ObjectOutputStream class as in the following fragment:
Employee harry = new Employee("Harry Hacker",
35000, new Day(1989, 10, 1));
Manager carl = new Manager("Carl Cracker",
75000, new Day(1987, 12, 15));
out.writeObject(harry);
out.writeObject(carl);To read the objects back in, first get an ObjectInputStream object:
ObjectInputStream in = new ObjectInputStream(new
FileInputStream("employee.dat"));Then, retrieve the objects in the same order in which they were written, using the readObject method.
Employee e1 = (Employee)in.readObject(); Employee e2 = (Employee)in.readObject();
When reading back objects, you must carefully keep track of the number of objects that were saved, their order, and their types. Each call to readObject reads in another object of the type Object. You, therefore, will need to cast it to its correct type.
If you don’t need the exact type, or you don’t remember it, then you can cast it to any superclass or even leave it as type Object. For example, e2 is an Employee object variable even though it actually refers to a Manager object. If you need to dynamically query the type of the object, you can use the getClass method that we described in Chapter 5 of Volume 1.
You can only write and read objects, not numbers. To write and read numbers, you use methods such as writeInt/readInt or writeDouble/readDouble. (The object stream classes implement the DataInput /DataOutput interfaces.) Of course, numbers inside objects (such as the salary field of an Employee object) are saved and restored automatically. (Recall that, in Java, strings and arrays are objects and can, therefore, be restored with the writeObject/readObject methods.)
There is, however, one change you need to make to any class that you want to save and restore in an object stream. The class must implement the Serializable interface:
class Employee implements Serializable { . . .}The Serializable interface has no methods, so you don’t need to change your classes in any way. In this regard, it is similar to the Cloneable interface that we also discussed in Chapter 5 of Volume 1. However, to make a class cloneable, you still had to override the clone method of the Object class. To make a class serializable, you do not need to do anything else. Why aren’t all classes serializable by default? We will discuss this in the section “Security.”
Example 1-4 is a test program that writes an array containing two employees and one manager to disk and then restores it. Once the information is restored, we give each employee a 100% raise, not because we are feeling generous, but because you can then easily distinguish employee and manager objects by their different raiseSalary actions. This should convince you that we did restore the correct type.
Example 1-4. ObjectFileTest.java
import java.io.*;
import corejava.*;
class ObjectFileTest
{ public static void main(String[] args)
{ try
{ Employee[] staff = new Employee[3];
staff[0] = new Employee("Harry Hacker", 35000,
new Day(1989,10,1));
staff[1] = new Manager("Carl Cracker", 75000,
new Day(1987,12,15));
staff[2] = new Employee("Tony Tester", 38000,
new Day(1990,3,15));
ObjectOutputStream out = new ObjectOutputStream(new
FileOutputStream("test1.dat"));
out.writeObject(staff);
out.close();
ObjectInputStream in = new
ObjectInputStream(new FileInputStream("test1.dat"));
Employee[] newStaff = (Employee[])in.readObject();
int i;
for (i = 0; i < newStaff.length; i++)
newStaff[i].raiseSalary(100);
for (i = 0; i < newStaff.length; i++)
newStaff[i].print();
}
catch(Exception e)
{ System.out.print("Error: " + e);
System.exit(1);
}
}
}
class Employee implements Serializable
{ public Employee(String n, double s, Day d)
{ name = n;
salary = s;
hireDay = d;
}
public Employee() {}
public void print()
{ System.out.println(name + " " + salary
+ " " + hireYear());
}
public void raiseSalary(double byPercent)
{ salary *= 1 + byPercent / 100;
}
public int hireYear()
{ return hireDay.getYear();
}
private String name;
private double salary;
private Day hireDay;
}
class Manager extends Employee
{ public Manager(String n, double s, Day d)
{ super(n, s, d);
secretaryName = "";
}
public Manager() {}
public void raiseSalary(double byPercent)
{ // add 1/2% bonus for every year of service
Day today = new Day();
double bonus = 0.5 * (today.getYear() - hireYear());
super.raiseSalary(byPercent + bonus);
}
public void setSecretaryName(String n)
{ secretaryName = n;
}
public String getSecretaryName()
{ return secretaryName;
}
private String secretaryName;
}java.io.ObjectOutputStream
ObjectOutputStream(OutputStream out)creates an
ObjectOutputStreamso that you can write to the specifiedOutputStream.void writeObject(Object obj)writes the specified object to the
ObjectOutputStream. The class of the object, the signature of the class, and the values of any field not marked astransientare written, as well as the non-static fields of the class and all of its supertypes.ObjectInputStream(InputStream is)creates an
ObjectInputStreamto read back object information from the specifiedInputStream.Object readObject()reads an object from the
ObjectInputStream. In particular, this reads back the class of the object, the signature of the class, and the values of the non-transient and non-static fields of the class and all of its superclasses. It does deserializing to allow multiple object references to be recovered.
Object serialization saves object data in a particular file format. Of course, you can use the writeObject/readObject methods without having to know the exact sequence of bytes that represents objects in a file. Nonetheless, we found studying the data format to be extremely helpful for gaining insight into the object streaming process. We did this by looking at hex dumps of various saved object files. However, the details are somewhat technical, so feel free to skip this section if you are not interested in the implementation.
Every file begins with the 2-byte “magic number”
AC ED
followed by the version number of the object serialization format, which is currently
00 05
(We will be using hexadecimal numbers throughout this section to denote bytes.) Then it contains a sequence of objects, in the order that they were saved.
String objects are saved as
742-byte length
characters
For example, the string “Harry” is saved as
7400 05H a r r y
The Unicode characters of the string are saved in UTF format.
When saving an object, the class of that object must be saved as well. The class description contains
The name of the class
The serial version unique ID, which is a fingerprint of the data field types and method signatures
A set of flags describing the serialization method
A description of the data fields
Java gets the fingerprint by:
First, ordering descriptions of the class, superclass, interfaces, field types, and method signatures in a canonical way
Then, applying the so-called Secure Hash Algorithm (SHA) to that data
SHA is a very fast algorithm that gives a “fingerprint” to a larger block of information. This fingerprint is always a 20-byte data packet, regardless of the size of the original data. It is created by a clever sequence of bit operations on the data that makes it essentially 100% certain that the fingerprint will change if the information is altered in any way. SHA is a U.S. standard, recommended by the National Institute for Science and Technology (NIST). (For more details on SHA, see, for example, Network and Internetwork Security, by William Stallings [Prentice-Hall].) However, Java only uses the first 8 bytes of the SHA code as a class fingerprint. It is still very likely that the class fingerprint will change if the data fields or methods change in any way.
Java can then check the class fingerprint in order to protect us from the following scenario: An object is saved to a disk file. Later, the designer of the class makes a change, for example, by removing a data field. Then, the old disk file is read in again. Now the data layout on the disk no longer matches the data layout in memory. If the data were read back in its old form, it could corrupt memory. Java takes great care to make such memory corruption close to impossible. Hence, it checks, using the fingerprint, that the class definition has not changed when restoring an object. It does this by comparing the fingerprint on disk with the fingerprint of the current class.
NOTE
Technically, as long as the data layout of a class has not changed, it ought to be safe to read objects back in. But Java is conservative and checks that the methods have not changed either. (After all, the methods describe the meaning of the stored data.) Of course, in practice, classes do evolve and it may be necessary for a program to read in older versions of objects. We will discuss this in the section “Versioning Objects.”
Here is how a class identifier is stored:
722-byte length of class name
class name
8-byte fingerprint
1-byte flag
2-byte count of data field descriptors
data field descriptors
78(end marker)superclass type (
70if none)
The flag byte is composed of three bit masks, defined in
java.io.ObjectStreamConstants:
static final byte SC_WRITE_METHOD = 1;
// class has writeObject method that writes additional data
static final byte SC_SERIALIZABLE = 2;
// class implements Serializable interface
static final byte SC_EXTERNALIZABLE = 4;
// class implements Externalizable interfaceWe will discuss the Externalizable interface later in this chapter; for now, all our example classes will implement the Serializable interface and have a flag value of 02.
Each data field descriptor has the format
1-byte type code
2-byte length of field name
field name
class name (if field is an object)
The type code is one of the following:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
object |
|
|
|
|
|
Boolean |
|
|
array |
When the type code is L, the field name is followed by the field type. Class and field name strings do not start with the string code 74, but field types do. Field types use a slightly different encoding of their names, namely, the format used by native methods. (See Chapter 10 for native methods.)
For example, the day field of the Day class is encoded as
I 00 03 d a y
Here is the complete class descriptor of the Day class:
72 00 0C c o r e j a v a . D a y 16 9A C1 B6 6E 7E C0 13 02 00 03 I 00 03 d a y I 00 05 m o n t h I 00 04 y e a r 78 70
These descriptors are fairly long. If the same class descriptor is needed again in the file, then an abbreviated form is used:
714-byte serial number
The serial number refers to the previous explicit class descriptor. We will discuss the numbering scheme later.
An object is stored as
73class descriptor
object data
For example, here is how a Day object is stored:
|
|
new object |
|
|
new class descriptor |
|
|
integer 1 |
|
|
integer 10 |
|
|
integer 1989 |
As you can see, the data file contains enough information to restore the Day object.
Arrays are saved in the following format:
75class descriptor
4-byte number of entries
entries
The array class name in the class descriptor is in the same format as that used by native methods (which is slightly different from the class name used by class names in other class descriptors). In this format, class names start with an L and end with a semicolon.
For example, here is an array of two Day objects.
75 | array |
72 | class descriptor |
00 0F | length |
[ L c o r e j a v a / D a y ; | class name |
FE . . . 36 02 | fingerprint and flag |
00 00 | no data fields |
78 | end marker |
70 | no superclass |
00 00 00 02 | number of entries |
73 | new object |
72 . . . 70 | new class |
00 00 00 01 | integer 1 |
00 00 00 0A | integer 10 |
00 00 07 C5 | integer 1989 |
73 | new object |
71 00 7E 00 02 | existing class + serial number |
00 00 00 0F | integer 15 |
00 00 00 0C | integer 12 |
00 00 07 C3 | integer 1987 |
Of course, studying these codes can be about as exciting as reading the average phone book. But it is still instructive to know that the object stream contains a detailed description of all the objects that it contains, with sufficient detail to be able to reconstruct both objects and arrays of objects.
We now know how to save objects that contain numbers, strings, or other simple objects (like the Day object in the Employee class). However, there is one important situation that we still need to consider. What happens when one object is shared by several objects as part of its state?
To illustrate the problem, let us make a slight modification to the Manager class. Rather than storing the name of the secretary, save a reference to a secretary object, which is an object of type Employee. (It would make sense to derive a class Secretary from Employee for this purpose, but we will not do that here.)
class Manager extends Employee
{ // previous code remains the same
private Employee secretary;
}This is a better approach to designing a realistic Manager class than simply using the name of the secretary—the Employee record for the secretary can now be accessed without having to search the staff array.
Having done this, you must keep in mind that the Manager object now contains a reference to the Employee object that describes the secretary, not a separate copy of the object.
In particular, two managers can share the same secretary, as is the case in Figure 1-5 and the following code:
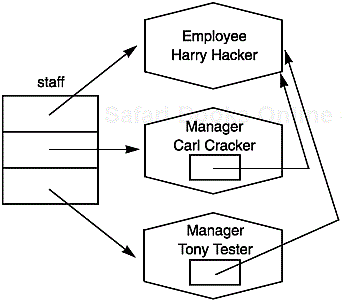
harry = new Employee("Harry Hacker", . . .);
Manager carl = new Manager("Carl Cracker", . . .);
carl.setSecretary(harry);
Manager tony = new Manager("Tony Tester, . . .);
tony.setSecretary(harry);Now suppose we write the employee data to disk. What we don’t want is that the Manager saves its information according to the following logic:
Save employee data
Save secretary data
Then, the data for harry would be saved three times. When reloaded, the objects would have the configuration shown in Figure 1-6.
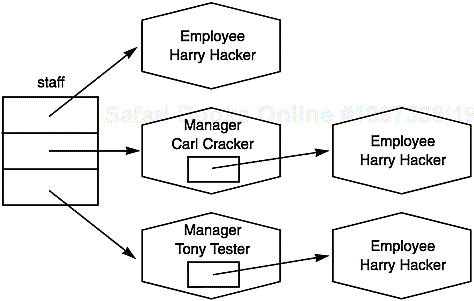
This is not what we want. Suppose the secretary gets a raise. We would not want to hunt for all other copies of that object and apply the raise as well. We want to save and restore only one copy of the secretary. To do this, we must copy and restore the original references to the objects. In other words, we want the object layout on disk to be exactly like the object layout in memory. This is called persistence in object-oriented circles.
Of course, we cannot save and restore the memory addresses for the secretary objects. When an object is reloaded, it will likely occupy a completely different memory address than it originally did.
Instead, Java uses a serialization approach. Hence, the name object serialization for this new mechanism. Remember:
All objects that are saved to disk are given a serial number (1, 2, 3, and so on, as shown in Figure 1-7).
When saving an object to disk, find out if the same object has already been stored.
If it has been stored previously, just write “same as previously saved object with serial number x”. If not, store all its data.
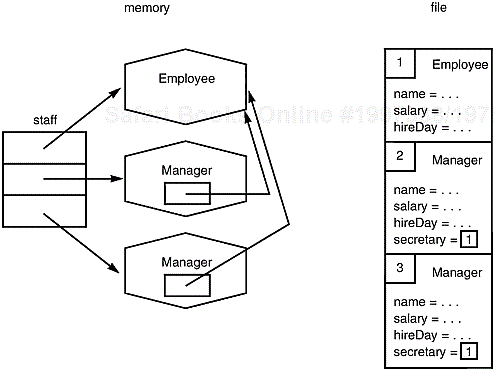
When reading back the objects, we simply reverse the procedure. For each object that we load, we note its sequence number and remember where we put it in memory. When we encounter the tag “same as previously saved object with serial number x”, we look up where we put the object with serial number x and set the object reference to that memory address.
Note that the objects need not be saved in any particular order. Figure 1-8 shows what happens when a manager occurs first in the staff array.

All of this sounds confusing, and it is. Fortunately, when using object streams, it is also completely automatic. Object streams assign the serial numbers and keep track of duplicate objects. The exact numbering scheme is slightly different from that used in the figures—see the next section.
NOTE
In this chapter, we use serialization to save a collection of objects to a disk file and retrieve it exactly as we stored it. Another very important application is the transmittal of a collection of objects across a network connection to another computer. Just as raw memory addresses are meaningless in a file, they are also meaningless when communicating with a different processor. Since serialization replaces memory addresses with serial numbers, it permits the transport of object collections from one machine to another. We will study that use of serialization in Chapter 5.
Example 1-5 is a program that saves and reloads a network of employee and manager objects (some of which share the same employee as a secretary). Note that the secretary object is unique after reloading—when staff[0] gets a raise, that is reflected in the secretary fields of the managers.
Example 1-5. ObjectRefTest.java
import java.io.*;
import java.util.*;
import corejava.*;
class ObjectRefTest
{ public static void main(String[] args)
{ try
{
Employee[] staff = new Employee[3];
Employee harry = new Employee("Harry Hacker", 35000,
new Day(1989,10,1));
staff[0] = harry;
staff[1] = new Manager("Carl Cracker", 75000,
new Day(1987,12,15), harry);
staff[2] = new Manager("Tony Tester", 38000,
new Day(1990,3,15), harry);
ObjectOutputStream out = new ObjectOutputStream(new
FileOutputStream("test2.dat"));
out.writeObject(staff);
out.close();
ObjectInputStream in = new
ObjectInputStream(new FileInputStream("test2.dat"));
Employee[] newStaff = (Employee[])in.readObject();
for (int i = 0; i < newStaff.length; i++)
newStaff[i].raiseSalary(100);
for (int i = 0; i < newStaff.length; i++)
newStaff[i].print();
}
catch(Exception e)
{ e.printStackTrace();
System.exit(1);
}
}
}
class Employee implements Serializable
{ public Employee(String n, double s, Day d)
{ name = n;
salary = s;
hireDay = d;
}
public Employee() {}
public void raiseSalary(double byPercent)
{ salary *= 1 + byPercent / 100;
}
public int hireYear()
{ return hireDay.getYear();
}
public void print()
{ System.out.println(name + " " + salary
+ " " + hireYear());
}
private String name;
private double salary;
private Day hireDay;
}
class Manager extends Employee
{ public Manager(String n, double s, Day d, Employee e)
{ super(n, s, d);
secretary = e;
}
public Manager() {}
public void raiseSalary(double byPercent)
{ // add 1/2% bonus for every year of service
Day today = new Day();
double bonus = 0.5 * (today.getYear() - hireYear());
super.raiseSalary(byPercent + bonus);
}
public void print()
{ super.print();
System.out.print("Secretary: ");
if (secretary != null) secretary.print();
}
private Employee secretary;
}This section continues the discussion of the output format of object streams. If you skipped the discussion before, you should skip this section as well.
All objects (including arrays and strings) and all class descriptors are given serial numbers as they are saved in the output file. This process is referred to as serialization since every saved object is assigned a serial number. (The count starts at 00 7E 00 00.
We already saw that a full class descriptor for any given class only occurs once. Subsequent descriptors refer to it. For example, in our previous example, the second reference to the Day class in the array of days was coded as
71 00 7E 00 02
The same mechanism is used for objects. If a reference to a previously saved object is written, it is saved in exactly the same way, that is, 71 followed by the serial number. It is always clear from the context whether the particular serial reference denotes a class descriptor or an object.
Finally, a null reference is stored as
70
Here is the commented output of the ObjectRefTest program of the preceding section. If you like, run the program, look at a hex dump of its data file test2.dat, and compare it with the commented listing. The important lines towards the end of the output (in bold) show the reference to a previously saved object.
AC ED 00 05 | file header |
75 | array staff (serial #1) |
72 | new class Employee[] (serial #0) |
00 0B | length |
[ L E m p l o y e e ; | class name |
FC BF 36 11 C5 91 11 C7 02 | fingerprint and flags |
00 00 | number of data fields |
78 | end marker |
70 | no superclass |
00 00 00 03 | number of entries |
73 | new object harry (serial #5) |
72 | new class Employee (serial #2) |
00 08 | length |
E m p l o y e e | class name |
3E BB 06 E1 38 0F 90 C9 02 | fingerprint and flags |
00 03 | number of data fields |
D 00 06 salary | |
L 00 07 hireDay | |
74 00 0E Lcorejava/Day; | (serial #3) |
L 00 04 name | |
74 00 12 Ljava/lang/String; | (serial #4) |
78 | end marker |
70 | no superclass |
40 E1 17 00 00 00 00 00 | 8-byte double salary |
73 | new object harry.hireDay (serial #7) |
72 | new class Day (serial #6) |
00 0C | length |
c o r e j a v a . D a y | |
16 9A C1 B6 6E 7E C0 13 02 | fingerprint and flags |
00 03 | 3 data fields |
I 00 03 day | |
I 00 05 month | |
I 00 04 year | |
78 | end marker |
70 | no superclass |
00 00 00 01 | 3 integers day, month, year |
00 00 00 0A | |
00 00 07 C5 | |
74 | string (serial #8) |
00 0C | length |
H a r r y H a c k e r | |
73 | new object staff[1] (serial #11) |
72 | new class Manager (serial #9) |
00 07 | length |
M a n a g e r | class name |
B1 C5 48 6B 95 EE BE C2 02 | fingerprint and flags |
00 01 | 1 data field |
L 00 09 secretary | |
74 00 0A Employee; | (serial #10) |
78 | end marker |
71 00 7E 00 02
| existing base class Employee--use serial #2 |
40 F2 4F 80 00 00 00 00 | 8-byte double salary |
73 | new object staff[1].hireDay (serial #12) |
71 00 7E 00 06
| existing class Day--use serial #6 |
00 00 00 0F | 3 integers day, month, year |
00 00 00 0C | |
00 00 07 C3 | |
74 | string (serial #13) |
00 0C | length |
C a r l C r a c k e r | |
71 00 7E 00 05
| existing object harry--use serial #5 |
73 | new object staff[2] (serial #14) |
71 00 7E 00 09
| existing class Manager-- use serial #9 |
40 E2 8E 00 00 00 00 00 | 8-byte double salary |
73 | new object staff[2].hireDay (serial #15) |
71 00 7E 00 06
| existing class Day--use serial #6 |
00 00 00 0F | 3 integers day, month, year |
00 00 00 03 | |
00 00 07 C6 | |
74 | string (serial #16) |
00 0B | length |
T o n y T e s t e r | |
71 00 7E 00 05
| existing object harry--use serial #5 |
It is usually not important to know the exact file format (unless you are trying to create an evil effect by modifying the data—see the next section). What you should remember is this:
The object stream output contains the types and data fields of all objects.
Each object is assigned a serial number.
Repeated occurrences of the same object are stored as references to that serial number.
Even if you only glanced at the file format description of the preceding section, it should become obvious that a knowledgeable hacker can exploit this information and modify an object file so that invalid objects will be read in when you go to reload the file.
Consider, for example, the Day class in the corejava package. That class has been carefully designed so that all of its constructors check that the day, month, and year fields never represent an invalid date. For example, if you try to build a new Day(1996, 2, 31), no object is created and an IllegalArgumentException is thrown instead.
However, this safety guarantee can be subverted through serialization. When a Day object is read in from an object stream, it is possible—either through a device error or through malice—that the stream contains an invalid date. There is nothing that the serialization mechanism can do in this case—it has no understanding of the constraints that define a legal date.
For that reason, Java’s serialization mechanism provides a way for individual classes to add validation or any other desired action instead of the default behavior. A serializable class can define methods with the signature
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException; private void writeObject(ObjectOutputStream out) throws IOException;
Then, the data fields are no longer automatically serialized, and these methods are called instead.
For example, let us add validation to the Day class. We don’t need to change the writing of Day objects, so we won’t implement the writeObject method.
In the readObject method, we first need to read the object state that was written by the default write method, by calling the defaultReadObject method. This is a special method of the ObjectInputStream class that can only be called from within a readObject method of a serializable class.
class Day
{ . . .
private void readObject(ObjectInputStream in)
throws IOException, ClassNotFoundException
{ in.defaultReadObject();
if (!isValid()) throw new IOException("Invalid date");
}
}If the day, month, and year fields do not represent a valid date (for example, because someone modified the data file), then we throw an exception.
NOTE
Another way of protecting serialized data from tampering is authentication. As we will see in Chapter 8, a stream can save a message digest (such as the SHA fingerprint) to detect any corruption of the stream data.
Classes can also write additional information to the output stream by defining a writeObject method that first calls defaultWriteObject and then writes other data. Of course, the readObject method must then read the saved data—otherwise, the stream state will be out of synch with the object. Also, the writeObject and readObject can completely bypass the default storage of the object data by simply not calling the defaultWriteObject and defaultReadObject methods.
In any case, the readObject and writeObject methods only need to save and load their data fields. They should not concern themselves with superclass data or any other class information.
Rather than letting the serialization mechanism save and restore object data, a class can define its own mechanism. To do this, a class must implement the Externalizable interface. This in turn requires it to define two methods:
public void readExternal(ObjectInputStream in) throws IOException, ClassNotFoundException; public void writeExternal(ObjectOutputStream out) throws IOException;
Unlike the readObject and writeObject methods that were described in the preceding section, these methods will be fully responsible for saving and restoring the entire object, including the superclass data. The serialization mechanism merely records the class of the object in the stream.
CAUTION

Unlike the readObject and writeObject methods, which are private and can only be called by the serialization mechanism, the readExternal and writeExternal methods are public. In particular, readExternal potentially permits modification of the state of an object.
Finally, there are certain data members that should never be serialized, for example, integer values that store file handles or handles of windows that are only meaningful to native methods. Such information is guaranteed to be useless when you reload an object at a later time or transport it to a different machine. In fact, improper values for such fields can actually cause native methods to crash. Java has an easy mechanism to prevent such fields from ever being serialized. Mark them with the keyword transient. Transient fields are always skipped when objects are serialized.
Beyond the possibility of data corruption, there is another potentially worrisome security aspect to serialization. Any code that can access a reference to a serializable object can:
Write that object to a stream
Then study the stream contents
and thereby know the values of all the data fields in the objects, even the private ones. After all, the serialization mechanism automatically saves all private data. Fortunately, this knowledge cannot be used to modify data. The readObject method does not overwrite an existing object but always creates a new object. Nevertheless, if you need to keep certain information safe from inspection via the serialization mechanism, you should take one of the following three steps:
Don’t make the class serializable.
Mark the sensitive data fields as
transient.Do not use the default mechanism for saving and restoring objects. Instead, define
readObject/writeObjectorreadExternal/writeExternalto encrypt the data.
In the past sections, we showed you how to save relatively small collections of objects via an object stream. But those were just demonstration programs. With object streams, it helps to think big. Suppose you write a program that lets the user produce a document. This document contains paragraphs of text, tables, graphs, and so on. You can stream out the document object with a single call to writeObject, and the paragraph, table and graph objects are automatically streamed out as well. One user of your program can then give the output file to another user who also has a copy of your program, and that program loads the entire document with a single call to readObject.
This is very useful, but your program will inevitably change, and you will release a version 1.1. Can version 1.1 read the old files? Can the users who still use 1.0 read the files that the new version is now producing? Clearly, it would be desirable if object files could cope with the evolution of classes.
At first glance it seems that this would not be possible. When a class definition changes in any way, then its SHA fingerprint also changes and you know that Java will refuse to read in objects with different fingerprints. However, a class can indicate that it is compatible with an earlier version of itself. To do this, one must first obtain the fingerprint of the earlier version of the class. You use the standalone serialver program that is part of the JDK to obtain this number. For example, running
serialver corejava.Day
prints out
corejava.Day: static final long serialVersionUID = 1628827204529864723L;
If you start the serialver program with the -show option, then it brings up a graphical dialog box (see Figure 1-9).
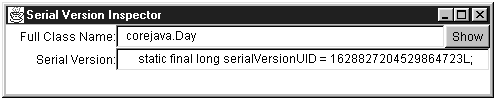
All later versions of the class must define the serialVersionUID constant to the same fingerprint as the original.
class Day // version 1.1
{ . . .
static final long serialVersionUID = 1628827204529864723L;
}When a class has a static data member named serialVersionUID, it will not compute the fingerprint manually but instead will use that value.
Once that static data member has been placed inside a class, the serialization system is now willing to read in different versions of objects of that class.
If only the methods of the class change, then there is no problem with reading the object new data. However, if data fields change, then you may have problems. For example, the old file object may have more or fewer data fields than the one in the program, or the types of the data fields may be different. In that case, Java makes an effort to convert the stream object to the current version of the class.
Java compares the data fields of the current version of the class with the data fields of the version in the stream. Of course, Java considers only the non-transient and non-static data fields. If two fields have matching names but different types, then Java makes no effort to convert one type to the other—the objects are incompatible. If the object in the stream has data fields that are not present in the current version, then Java ignores the data in the stream. If the current version has data fields that are not present in the streamed object, the added fields are set to their default (null for objects, zero for numbers).
Here is an example. Suppose we have saved a number of employee records on disk, using the original version (1.0) of the class. Now we change the Employee class to version 2.0 by adding a data field called department. Figure 1-10 shows what happens when a 1.0 object is read into a program that uses 2.0 objects. The department field is set to null. Figure 1-11 shows the opposite scenario: a program using 1.0 objects reads a 2.0 object. The additional department field is ignored.
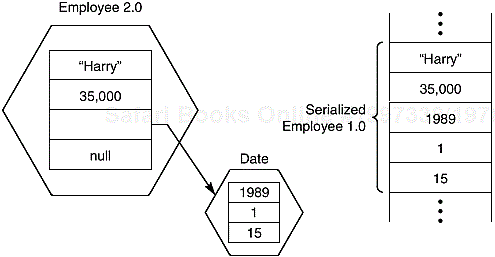
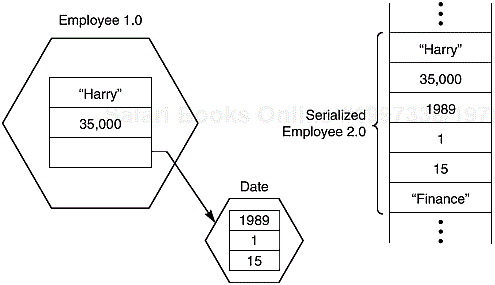
Is this process safe? It depends. Dropping a data field seems harmless—the recipient still has all the data that it knew how to manipulate. Setting a data field to null may not be so safe. Many classes work hard to initialize all data fields in all constructors to non-null values, so that the methods don’t have to be prepared to handle null data. It is up to the class designer to implement additional code in the readObject method to fix version incompatibilities or to make sure the methods are robust enough to handle null data.
We have learned how to read and write data from a file. However, there is more to file management than reading and writing. The File class encapsulates the functionality that you will need to work with the file system on the user’s machine. For example, you use the File class to find out when a file was last modified or to remove or rename the file. In other words, the stream classes are concerned with the contents of the file, whereas the File class is concerned with the storage of the file on a disk.
NOTE
As is so often the case in Java, the File class takes the least common denominator approach. For example, under Windows, you can find out if a file is write protected, but you cannot find out if it is a system or hidden file without using a native method (see Chapter 10).
The simplest constructor for a File object takes a (full) file name. If you don’t supply a pathname, then Java uses the current directory. For example:
File foo = new File("test.txt");gives you a handle on a file with this name in the current directory. (The current directory is the directory in which the program is running.) A call to this constructor does not create a file with this name if it doesn’t exist. Actually, creating a file from a File object is done with one of the stream class constructors. In fact, once you have a File object, the exists method in the File class tells you whether a file exists with that name. For example, the following trial program would almost certainly print “false” on anyone’s machine and yet it can print out a pathname to this nonexistent file.
import java.io.*;
public class test
{ public static void main(String args[])
{ File foo = new File( "sajkdfshds");
System.out.println(foo.getAbsolutePath());
System.out.println(foo.exists());
}
}There are two other constructors for File objects:
File(String path, String name)
which creates a File object with the given name in the directory specified by the path parameter. (If the path parameter is null, this constructor then creates a File object using the current directory.)
Finally, you can use an existing File object in the constructor:
File(File dir, String name)
where the File object represents a directory and, as before, if dir is null, the constructor creates a File object in the current directory.
Next, along with the exists method that you have already seen, there are isDirectory and isFile methods to tell you whether the file object represents a file or a directory. If the file object represents a directory, use list() to get an array of the file names in that directory. The program in Example 1-6 uses all these methods to print out the directory substructure of whatever path is entered on the command line. (It would be easy enough to change this into a utility class that returns a vector of the subdirectories for further processing.)
Example 1-6. FindDirectories.java
import java.io.*;
public class FindDirectories
{ public static void main(String args[])
{ if (args.length == 0) args = new String[] { ".." };
try
{ File pathName = new File(args[0]);
String[] fileNames = pathName.list();
for (int i = 0; i<fileNames.length; i++)
{ File tf = new File(pathName.getPath(),
fileNames[i]);
if (tf.isDirectory())
{ System.out.println(tf.getCanonicalPath());
main(new String [] { tf.getPath() });
}
}
}
catch(IOException e)
{ System.out.println("Error: " + e);
}
}
}Rather than listing all files in a directory, you can use a FileNameFilter object as a parameter to the list method to narrow down the list. These objects are simply instances of a class that satisfies the FilenameFilter interface.
NOTE
You may recall from Volume 1 that a FilenameFilter is supposed to be used to limit the choices shown in a file dialog box; however, that feature is not implemented in Java 1.1.
All a class needs to do to implement the FilenameFilter interface is define a method called accept(). Here is an example of a simple FilenameFilter class that only allows files with a specified extension:
import java.io.*;
public class ExtensionFilter implements FilenameFilter
{ private String extension;
public ExtensionFilter(String ext)
{ extension = "." + ext;
}
public boolean accept(File dir, String name)
{ return name.endsWith(extension);
}
}When writing portable programs, it is a challenge to specify file names with subdirectories. As it turns out, you can use a forward slash (the Unix and Mac separator) as the directory separator in Windows as well, but other operating systems might not permit this, so we don’t recommend that.
TIP
If you do use forward slashes as a directory separator in Windows, the getAbsolutePath method returns a file name that contains forward slashes, which will look strange to Windows users. Instead, use the getCanonicalPath method—it replaces the forward slashes with backslashes.
It is much better to use the information about the current directory separator that the File class stores in a static instance field called separatorChar. (In a Windows environment, this is a backslash (), while in a Unix or Macintosh environment, it is a forward slash (/)). For example:
File foo = new File("Documents" + File.separatorChar + "data.txt")Of course, if you use the second alternate version of the File constructor,
File foo = new File("Documents", "data.txt")then Java will supply the correct separator.
The API notes that follow give you what we think are the most important remaining methods of the File class; their use should be straightforward.
java.io.File
boolean canRead()indicates whether the file can be read by the current application.
boolean canWrite()indicates whether the file is writable or read only.
boolean delete()tries to delete the file; returns
trueif the file was deleted;falseotherwise.boolean exists()trueif the file or directory exists;falseotherwise.String getAbsolutePath()returns a string that contains the absolute pathname. Tip: Use
getCanonicalPathinstead.String getCanonicalPath()returns a string that contains the canonical pathname. In particular, redundant “.” directories are removed, the correct directory separator is used, and the capitalization preferred by the underlying file system is obtained.
String getName()returns a string that contains the file name of the
Fileobject (does not include path information).String getParent()returns a string that contains the parent directory of the file, or
nullif you are at the root.String getPath()returns a string that contains the pathname of the file.
boolean isDirectory()returns
trueif theFilerepresents a directory;falseotherwise.boolean isFile()returns
trueif theFileobject represents a file as opposed to a directory or a device.long lastModified()returns the time the file was last modified, or 0 if the file does not exist.
long length()returns the length of the file in bytes, or 0 if the file does not exist.
String[] list()returns an array of strings that contain the names of the files and directories contained by this
Fileobject, or null if thisFilewas not representing a directory.String[] list(FilenameFilter filter)returns an array of the names of the files and directories contained by this
Filethat satisfy the filter, ornullif none exist.Parameters:
filterthe
FilenameFilterobject to useboolean mkdir()makes a subdirectory off the directory represented by the
Fileobject. Returnstrueif the directory was successfully created;falseotherwise.boolean mkdirs()unlike
mkdir, creates the parent directories if necessary.boolean renameTo(File dest)returns
trueif the name was changed;falseotherwise.Parameters:
desta
Fileobject that specifies the new name