
In the summer of 1996, Sun released the first version of the JDBC (Java database connectivity) kit. This package lets Java programmers connect to a database, query it, or update it, using the industry standard query language. We think this is one of the most important developments in Java programming. It is not just that databases are among the most common use of hardware and software today. After all, there are a lot of products running after this market; so why do we think Java has the potential to make a big splash? The reason we think that Java and JDBC have an essential advantage over other database programming environments is this:
Programs developed with Java and the JDBC are platform independent and vendor independent.
The same Java database program can run on a PC, a workstation, or a Java-powered terminal (“network computer”). You can move your data from one database to another, for example, from Microsoft SQL Server to Oracle, and the same program can still read your data. This is in sharp contrast to the database programming typically done on personal computers today. It is all too common that one writes database applications in a proprietary database language, using a database management system that is available only from a single vendor. The result is that you can run the resulting application only on one or two platforms. We believe that because of their universality, Java and JDBC will eventually replace proprietary database languages, such as Borland’s PAL, or the various incompatible BASIC derivatives used by vendors such as Powersoft, Oracle, and Microsoft for accessing databases.
Having said this, we still must caution you that the JDK offers no tools for database programming with Java. We are only beginning to see the form designers, query builders, and report generators that database developers have come to expect. Similarly, there are only beginning to appear the kinds of database controls that you find for Visual Basic or Delphi. However, we are confident that many more tools will be released in the near future. Judging from the C++ marketplace, it is likely that all “corporate” or “professional” versions of Java development environments will ship with database integration tools (such as the currently available Visual Café and JBuilder Professional and Enterprise editions).
In this chapter, we:
Explain some of the ideas behind JDBC—the “Java database connectivity API”
Give you enough details and examples so that you can get started in actually using JDBC
The first part of this chapter gives you an overview of how JDBC is put together. The last part gives you example code that illustrates the major JDBC features.
NOTE

Over the years, many technologies were invented to make database access more efficient and failsafe. Standard databases support indexes, triggers, stored procedures, and transaction management. JDBC supports all these features, but we do not discuss them in this chapter. One could write an entire book on advanced database programming in Java, and (many) such books are or will be written. The material in this chapter will give you enough information to effectively deal with a departmental database in Java and to make it easy to go further with the JDBC if you want to.
From the start, the people at JavaSoft were aware of the potential Java showed for working with databases. They began working on extending Java to deal with SQL access to databases roughly as soon as the JDK went into beta testing. (They started working in November 1995.) What they first hoped to do was to extend Java so that it could talk to any random database, using only “pure” Java. It didn’t take them very long to realize that this is an impossible task: there are simply too many databases out there, utilizing too many protocols. Moreover, while database vendors were all in favor of JavaSoft providing a standard network protocol for database access, they were only in favor of it if JavaSoft decided to use their network protocol.
What all the database vendors and tool vendors did agree on was that it would be useful if JavaSoft provided a purely Java API for SQL access along with a device manager to allow third-party drivers to connect to specific databases. Database vendors could provide their own drivers to plug into the driver manager. There would then be a simple mechanism for registering third-party drivers with the device manager—the point being that all they needed to do was follow the requirements laid out in the device manager API.
After a fairly long period of public discussion, the API for database access became the JDBC API, and the rules for writing device drives were encapsulated in the JDBC driver API. (The JDBC driver API is of interest only to database vendors and database tool providers; we don’t cover it here.)
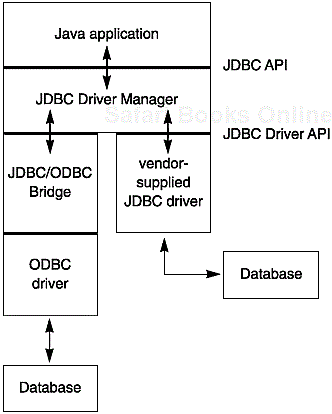
This protocol follows the very successful model of Microsoft’s ODBC, which provided a C-programming language interface to structured query language (SQL), which is the standard for accessing relational databases. Both the JDBC and ODBC, in turn, are based on the X/Open SQL call-level interface specification. In the end, the idea behind the JDBC is the same as with ODBC: Programs written using the JDBC API would talk to the JDBC driver manager, which, in turn, would use the drivers that were plugged into it at that moment to talk to the actual database.
NOTE
A list of JDBC drivers currently available can be found at: http://splash.javasoft.com/jdbc/jdbc.drivers.html
More precisely, the JDBC consists of two layers. The top layer is the JDBC API. This API communicates with the JDBC manager driver API, sending it the various SQL statements. The manager should (transparently to the programmer) communicate with the various third-party drivers that actually connect to the database and return the information from the query or perform the action specified by the query.
NOTE
The JDBC specification will actually allow you to pass any string to the underlying driver. The driver can pass this string to the database. This feature allows you to use specialized versions of SQL that may be supported by the driver and its associated database.
All this means the Java/JDBC layer is all that most programmers will ever have to deal with. Figure 4-1 illustrates what happens.
In summary, the ultimate goal of the JDBC is to make possible the following:
Programmers can write applications in Java to access any database, using standard SQL statements—or even specialized extensions of SQL—while still following Java language conventions. (JavaSoft insists that all JDBC drivers support at least the entry-level version of SQL 92.)
Database vendors and database tool vendors can supply the low-level drivers. Thus, they can optimize their drivers for their specific situation.
NOTE
If you are curious as to why JavaSoft just didn’t adopt the ODBC model, their response, as given at the JavaOne Conference in May 1996, was:
ODBC is hard to learn.
ODBC has a few commands with lots of complex options. The Java style is to have simple and intuitive methods, but to have lots of them.
ODBC relies on the multiple use of
void*pointers and other C features that are not natural in Java.It was felt to be too hard to map ODBC to Java because of the frequent use of multiple pointers and pointer indirection.
Just as one can use Java for both applications and applets, one can use the JDBC-enhanced version of Java in both applications and applets. When that version is used in an applet, all the normal security restrictions apply. The JDBC continues to assume that all Java applets are untrusted.
In particular, applets that use JDBC would only be able to open a database connection from the server from which they are downloaded. They can make neither explicit nor implicit use of local information. Although the JDBC extensions of the Java security model allow one to download a JDBC driver and register it with JDBC device manager on the server, that driver can be used only for connections from the same server the applet came from. That means the Web server and the database server must be the same machine, which is not a typical setup. Of course, the Web server can have a proxy service that routes database traffic to another machine. When signed Java applets become possible, this restriction could be loosened. To summarize: You can use JDBC with applets, but you must manage the server carefully.
Applications, on the other hand, have complete freedom. They can give the application total access to files and remote servers. We envision that JDBC applications will be very common.
Finally, there is a third possible use for the JDBC-enhanced version of Java. This possibility is somewhat speculative, and we do not give any examples of it here. But the thinking at JavaSoft is that this will be an important area in the future, so we want to briefly mention it. The idea is sometimes referred to as the “three tier model,” meaning that a Java application (or applet) calls on a middleware layer that in turn accesses the data. This approach would work best with RMI (see Chapter 5) or an object request broker for the communication between the client and the middle layer, with JDBC between the middle tier and a back-end database. Especially through the use of better compilation techniques (just-in-time compilers and native compilers), Java is becoming fast enough that it can be used to write the middleware layer. (You might want to check out www.weblogic.com to see more on one company’s implementation of this idea.)
JDBC is an interface to SQL, which is the interface to essentially all modern relational databases. Desktop databases usually have a graphical user interface that lets users manipulate the data directly, but server-based databases are accessed purely through SQL. Most desktop databases have an SQL interface as well, but it often does not support the full range of ANSI SQL92 features, the current standard for SQL.
The JDBC package can be thought of as nothing more than an application programming interface (API) for communicating SQL statements to databases. We will give a short introduction to SQL in this section. If you have never seen SQL before, you may not find this material sufficient. If so, you should turn to one of the many books on the topic. (One online book service lists 123 books on SQL, ranging from the expected SQL for Dummiesto one titled (we kid you not) SQL for Smarties—which is actually not a bad book.) We recommend Client/Server Databases, by James Martin and Joe Leben [Prentice-Hall, 1995], or the venerable and opinionated book A Guide to the SQL Standard, by C.J. Date [Addison-Wesley, 1996].
A modern relational database can be thought of as a bunch of named tables with rows and columns that can be joined on certain common columns. The rows contain the actual data (these are usually called records). The column headers in each table correspond to the field names.
Figure 4-2 shows a sample table that contains a set of books on HTML that is adopted from a useful, essentially complete, list of HTML books maintained by Cye H. Waldman at http://wwwiz.com/books/.

Figure 4-3 shows the result of linking this table with a table of publishers. Both the book table and the publisher table contain a numerical code for the publisher. The publisher table contains the publisher’s name and Web page URL. When we link both tables on the publisher code, we obtain a query result. Each row in the result contains the information about a book, together with the publisher name and Web page URL. Note that the publisher names and URLs are duplicated across several rows since we have several rows with the same publisher.
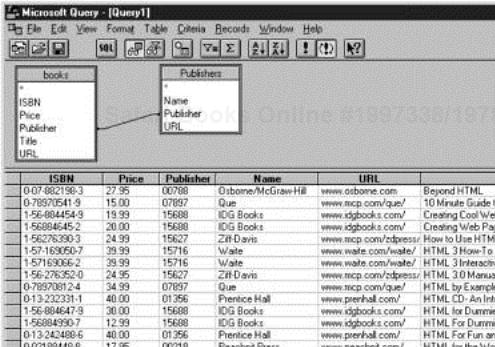
The benefit of using a relational database and the linking strategy for queries is to avoid unnecessary duplication of data in the database tables. For example, a native database design might have had columns for the publisher name and URL right in the book table. But then the database itself, and not just the query result, would have many duplicates of these entries. If a publisher’s Web address changed, all entries would need to be updated. Clearly, this is somewhat error prone. In the relational model, we distribute data into multiple tables such that no information is ever unnecessarily duplicated. For example, each publisher URL is contained only once in the publisher table. If the information needs to be combined, then the tables are joined.
In this example, we used the Microsoft Query tool to inspect and link the tables. Microsoft Query is a part of Microsoft Office, so if you have Office, you already have a copy. Many other vendors have similar tools. Microsoft Query is a graphical tool that lets us express queries in a simple form by connecting column names and filling information into forms. Such tools are often called query by example (QBE) tools. In contrast, a query that uses SQL is written out in text, using the SQL syntax. For example:
SELECT Books.ISBN, Books.Price, Books.Title, Books.Publisher_Id, Publishers.Name, Publishers.URL FROM Books, Publishers WHERE Books.Publisher_Id = Publishers.Publisher_Id
This is a complex query. In the remainder of this section, we will learn how to write such queries. If you are already familiar with SQL, just skip this section.
By convention, SQL keywords are written in all caps, although this is not necessary.
The SELECT operation is quite flexible. You can simply select all elements in the Books table with the following query:
SELECT * FROM Books
The FROM statement is required in every SQL SELECT statement. The FROM clause tells the database which tables to examine to find the data.
You can choose the columns that you want.
SELECT ISBN, Price, Title, FROM Books
You can restrict the rows in the answer with the WHERE clause.
SELECT ISBN, Price, Title, FROM Books WHERE Price <= 29.95
Be careful with the “equals” comparison. SQL uses = and <>, not == or !=, as in Java, for equality testing.
The WHERE clause can also use pattern matching, using the LIKE operator. The wildcard characters are not the usual * and ?, however. Use a % for zero or more characters and an underscore for a single character. For example:
SELECT ISBN, Price, Title, FROM Books WHERE Title NOT LIKE '%HTML%'
Note that strings are enclosed in single quotes, not double quotes. A single quote inside a string is denoted as a pair of single quotes. For example,
SELECT Title, FROM Books WHERE Books.Title LIKE '%''%'
reports all titles that contain a single quote.
You can select data from multiple tables.
SELECT * FROM Books, Publishers
Without a WHERE clause, this query is not very interesting. It lists all combinations of rows from both tables. In our case, where Books has 37 rows and Publishers has 18 rows, the result is a table with 37 × 18 entries and lots of duplications. We really want to constrain the query to say that we are only interested in matching books with their publishers.
SELECT * FROM Books, Publishers WHERE Books.Publisher_Id = Publishers.Publisher_Id
This query result has 37 rows, one for each book, since each book has a publisher in the Publisher table.
Whenever you have multiple tables in a query, the same column name can occur in two different places. That happened in our example. There is a publisher code column called Publisher_Id in both the Books and the Publishers table. To resolve ambiguities, you must prefix each column name with the name of the table to which it belongs, such as Books.Publisher_Id.
Now you have seen all SQL constructs that were used in the query at the beginning of this section:
SELECT Books.ISBN, Books.Price, Books.Title, Books.Publisher_Id, Publishers.Name, Publishers.URL FROM Books, Publishers WHERE Books.Publisher_Id = Publishers.Publisher_Id
SQL can be used to change the data inside a database as well, by using so-called action queries (i.e., queries that move or change data). For example, suppose you want to reduce by $5.00 the current price of all books that do not have HTML 3 in their title.
UPDATE Books SET Price = Price - 5.00 WHERE Title NOT LIKE '%HTML 3%'
Similarly, you can change several fields at the same time by separating the SET clauses with commas. There are many other SQL keywords you can use in an action query. Probably the most important besides UPDATE is DELETE, which allows the query to delete those records that satisfy certain criteria. Finally, SQL comes with built-in functions for taking averages, finding maximums and minimums in a column, and a lot more. Consult a book on SQL for more information.
Of course, before you can query and modify data, you must have a place to store data and you must have the data. There are two SQL statements you need for this purpose. The CREATE TABLE command makes a new table. You specify the name and data type for each column. For example,
CREATE TABLE Books ( Title CHAR(60), ISBN CHAR(13), Publisher_Id CHAR(5), URL CHAR(80), Price DECIMAL(6,2) )
Table 4-1 shows the most common SQL data types.
Table 4-1. SQL Data Types
|
Data Types |
Description |
|---|---|
|
|
typically, a 32-bit integer |
|
|
typically, a 16-bit integer |
|
|
fixed-point decimal number with |
|
|
digits and |
|
|
a floating-point number with |
|
|
typically, a 32-bit floating point number |
|
|
typically, a 64-bit floating point number |
|
|
fixed-length string of length |
|
|
variable-length strings of maximum length |
|
|
calendar date, implementation dependent |
|
|
time of day, implementation dependent |
|
|
date and time of day, implementation dependent |
Again, we are not discussing in this book many of the clauses you can add to the CREATE TABLE command that deal with database information, such as keys and constraints.
Typically, to insert values into a table, you use the INSERT statement:
INSERT INTO Books
VALUES ('Beyond HTML', '0-07-882198-3', '00788', '', 27.95)You need a separate INSERT statement for every row being inserted in the table unless you embed a SELECT statement inside an INSERT statement. (Consult an SQL book for examples of how to embed a statement.)
If you install the software from the CD-ROM, you will already have the JDBC package installed. You can also obtain the newest JDBC version from Sun and combine it with your existing Java installation. Be sure that the version numbers are compatible, and carefully follow the installation directions.
Of course, you need a database program that is compatible with JDBC. You will also need to create a database for your experimental use. We assume you will call this database COREJAVA. Create a new database, or have your database administrator create one with the appropriate permissions. You need to be able to create, update, and drop tables.
Some database vendors already have JDBC drivers, so you may be able to install one, following your vendor’s directions. For those databases that do not have a JDBC driver, you need to go a different route. Since ODBC drivers exist for most databases, JavaSoft decided to write (with the help of Intersolv) a JDBC-to-ODBC bridge. To make a connection between such a database and Java, you need to install the database’s ODBC driver and the JDBC-to-ODBC bridge.
NOTE
As of this writing, the JDBC to ODBC bridge works only with Solaris and Windows 95/NT. Versions for other platforms are expected to be available at a later date. The bridge does not work with Microsoft J++ 1.x—the Microsoft virtual machine uses a nonstandard native calling convention that is not compatible with the native bridge code.
The JDBC-to-ODBC bridge has the advantage of letting people use the JDBC immediately. It has the disadvantage of requiring yet another layer between the database and the JDBC, although in most cases, performance will be acceptable. Most major vendors have announced plans to come out with native drivers that plug directly into the JDBC driver manager that will give you access to the most popular databases. (For example, Weblogic, which was alluded to earlier, has a few native drivers available.) We suggest you contact your database vendor to find out if (more likely, when) a native JDBC driver will be available for your database. But for experimentation and in most other cases, the bridge works just fine. In this chapter, we developed the examples by using the bridge and a) Microsoft SQL server running on NT Workstation 4.0, b) Microsoft Access running on Windows 95, and c) Borland Interbase running on Windows 95.
If your database doesn’t have direct JDBC support, you need to install the ODBC driver for your database. Directions for this vary widely, so consult your database administrator or, if all else fails, the vendor documentation.
NOTE
Some databases support SQL through a proprietary mechanism, not JDBC. For example, Borland has a BDE engine and Microsoft has a Jet engine that give somewhat better performance than ODBC for local databases. These mechanisms are not compatible with Java. If you are looking in vain for ODBC drivers, you may not have installed or purchased the correct driver.
You then need to make your experimental database into an ODBC data source. In Windows, use the ODBC control in the control panel. Click on Add. You will see a list of available ODBC drivers. Click on the one that contains your new database. Fill out the resulting dialog box with the name of the database and the location of the server. When you are done, you should see your database listed as a data source. (If you create your test database with Microsoft Access, then you need to close the Access database before you can establish an ODBC connection to it.)
If you have Microsoft Query, use it to test your configuration. Start the Query program and make a new query. You will see a list of all data sources. If you see COREJAVA, then your setup is correct. Of course, there are no tables in the database yet. We will see how to use Java to create tables in the next section.
If you have never installed a client/server database before, you may find that setting up the database and the ODBC driver is somewhat complex and that it can be difficult to diagnose the cause for failure. It may be best to seek expert help if your setup is not working correctly. When working with Microsoft SQL Server, we found it to be a real lifesaver to have a book on server and database administration such as Microsoft BackOffice Administrator Survival Guide, by Arthur Knowles [Sams Publications, 1996]. The same is undoubtedly true on other platforms as well.
Programming with the JDBC classes is, by design, not very different from programming with the usual Java classes: you build objects from the JDBC core classes, extending them by inheritance if need be. This section takes you through the details.
When connecting to a database, you must specify the data source and you may need to specify additional parameters. For example, network protocol drivers may need a port, and ODBC drivers may need various attributes.
As you might expect, JDBC uses a syntax similar to ordinary Net URLs to describe data sources. Here is an example of the syntax you need:
jdbc:odbc:corejava
This command would access an ODBC data source named corejava, using the JDBC-ODBC bridge. The general syntax is:
jdbc:subprotocol name:other_stuff
where a subprotocol is the specific driver used by JDBC to connect to the database.
NOTE
JavaSoft has said that it will act as a temporary registry for JDBC subprotocol names. To reserve a subprotocol name, send a message to [email protected].
The format for the other_stuff
parameter depends on the subprotocol used. JavaSoft recommends that if you are using a network address as part of the other_stuff
parameter, you use the standard URL naming convention of //hostname:port/other. For example:
jdbc:odbc://whitehouse.gov:5000/Cat;PWD=Hillary
would connect to Cat database on port 5000 of whitehouse.gov, using the ODBC attribute value of PWD set to “Hillary.”
The DriverManager is the class responsible for loading database drivers and creating a new database connection. You need to load the driver manager code so that your program can use it. For example, to load the JDBC-to-ODBC bridge driver, you use the command
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
// force loading of driverIf you have a driver from another vendor, then find out the class name of that driver and load it instead.
For practical programming, you need not be particularly interested in the details of driver management. After loading the driver, you can just open a database connection with the following code:
String url = "jdbc:odbc:corejava";
String user = "Cay";
String password = "wombat";
Connection con = DriverManager.getConnection(url,
user, password);The JDBC manager will try to find a driver than can use the protocol specified in the database URL by iterating through the available drivers currently registered with the device manager.
The connection object you get via a call to getConnection lets you use JDBC drives to manage SQL queries. You can execute queries and action statements, commit, or roll back transactions.
To make a query, you first create a Statement object. The Connection object that you obtained from the call to DriverManager.getConnection can create statement objects.
Statement stmt = con.createStatement();
You can then execute a query simply by using the executeQuery object of the Statement class and supplying the SQL command for the query as a string. Note that you can use the same Statement object for multiple, unrelated queries.
Of course, you are interested in the result of the query. The executeQuery object returns an object of type ResultSet that you use to walk through the result a row at a time.
ResultSet rs = stmt.executeQuery("SELECT * FROM Books")The basic loop for analyzing a result set looks like this:
while (rs.next())
{ look at a row of the result set
}When inspecting an individual row, you will want to know the contents of each column. A large number of accessor methods give you this information.
String isbn = rs.getString(1);
float price = rs.getDouble("Price");There are accessors for every Java type, such as getString and getDouble. Each accessor has two forms, one that takes a numeric argument and one that takes a string argument. When you supply a numeric argument, you refer to the column with that number. For example, rs.getString(1) returns the value of the first column in the current row. (Unlike array indexes, database column numbers start at 1.) When you supply a string argument, you refer to the column in the result set with that name. For example, rs.getDouble("Price") returns the value of the column with name Price. Using the numeric argument is a bit more efficient, but the string arguments make the code easier to read and maintain.
Java will make reasonable type conversions when the type of the get method doesn’t match the type of the column. For example, the call rs.getString("Price") yields the price as a string.
NOTE
SQL data types and Java data types are not exactly the same. See Table 4-2 for a listing of the basic SQL data types and their Java equivalents.
Table 4-2. SQL data types and their corresponding Java types
|
SQL data type |
Java data type |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
java.sql.DriverManager

static Connection getConnection(String url, String user, String password)establishes a connection to the given database and returns a
Connectionobject.
|
Parameters: |
|
the URL for the database |
|
|
the database logon ID | |
|
|
the database logon password |
java.sql.Connection
Statement createStatement()creates a statement object that can be used to execute SQL queries and updates without parameters.
void close()immediately closes the current connection.
interface java.sql.Statement
ResultSet executeQuery(String sql)executes the SQL statement given in the string and returns a
ResultSetto view the query result.Parameters:
sqlthe SQL query
int executeUpdate(String sql)executes the SQL INSERT, UPDATE, or DELETE statement specified by the string. Also used to execute DDL (Data Definition Language) statements. Returns the number of records affected.
Parameters:
sqlthe SQL statement
void cancel()cancels a JDBC statement that is being executed by another thread.
java.sql.ResultSet
boolean next()makes the current row in the result set move forward by one. Returns
falseafter the last row. Note that you must call this method to advance to the first row.XxxgetXxx(int columnNumber)XxxgetXxx(String columnName)(
Xxxis a type such asint,double,String,Date,etc.)return the value of the column with column index
cor with column names, converted to the specified type. Not all type conversions are legal. See the JDBC documentation for details.int findColumn(String columnName)gives the column index associated with a column name.
void close()immediately closes the current result set.
SQLException
Most JDBC methods throw this exception, and you must be prepared to catch it. The following methods give more information about the exceptions.
String getSQLState()gets the SQLState formatted, using the X/Open standard.
int getErrorCode()gets the vendor-specific exception code.
SQLException getNextException()gets the exception chained to this one. It may contain more information about the error.
We now want to write our first, real, JDBC program. Of course, it would be nice if we could execute some of the fancy queries that we discussed earlier. Unfortunately, we have a problem: right now, there is no data in the database. And you won’t find a database file on the CD-ROM that you can simply copy onto your hard disk for the database program to read, because no database file format lets you interchange SQL relational databases from one vendor to another. SQL does not have anything to do with files. It is a language to issue queries and updates to a database. How the database executes these statements most efficiently and what file formats it uses toward that goal is entirely up to the implementation of the database. Database vendors try very hard to come up with clever strategies for query optimization and data storage, and different vendors arrive at different mechanisms. Thus, while SQL statements are portable, the underlying data representation is not.
To get around our problem, we provide you with a small set of data in a series of text files. The first program we give reads such a text file and creates a table whose column headings match the first line of the text file and whose column types match the second line. The remaining lines of the input file are the data, and we insert the lines into the table. Of course, we use SQL statements and JDBC to create the table and insert the data.
At the end of this section, you can see the code for the program that reads a text file and populates a database table. Even if you are not interested in looking at the implementation, you must run this program if you want to execute the more interesting examples in the next two sections. Run the program as follows:
java MakeDB Books.txt java MakeDB Authors.txt java MakeDB Publishers.txt java MakeDB BooksAuthors.txt
The following steps provide an overview of the program.
Connect to the database.
If there is no command line, then ask for the input file.
Extract the table name from the file by removing the extension of the input file (e.g.,
Books.txtis stored in the tableBooks).Read in the column names, using the
readLinemethod that reads a line and splits it into an array of tokens. This is done using theStringTokenizerclass that you saw in Chapter 1.Read in the column types.
Use the
createTablemethod to make a string command of the form:CREATE TABLE Name ( Column1 Type1, Column2 Type2, ... )
Pass this string to the
executeUpdatemethod:stmt.executeUpdate(command);
Here, we use
executeUpdate, notexecuteQuery, because this statement has no result. (It is a DDL SQL statement.)For each line in the input file, execute an
INSERTstatement, using theinsertIntomethod. The only complications are that strings must be surrounded by single quotes and that single quotes inside strings must be duplicated.After all elements have been inserted, run a
SELECT * FROM Namequery, using theshowTablemethod to show the result. This method shows that the data has been successfully inserted.
Example 4-1 provides the code for these steps.
Example 4-1. MakeDB.java
import java.net.*;
import java.sql.*;
import java.io.*;
import java.util.*;
class MakeDB
{ public static void main (String args[])
{ try
{ Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
// force loading of driver
String url = "jdbc:odbc:corejava";
String user = "Cay";
String password = "password";
Connection con = DriverManager.getConnection(url,
user, password);
Statement stmt = con.createStatement();
String fileName = "";
if (args.length > 0)
fileName = args[0];
else
{ System.out.println("Enter filename: ");
fileName = new BufferedReader
(new InputStreamReader(System.in)).readLine();
}
int i = 0;
while (i < fileName.length()
&& (Character.isLowerCase(fileName.charAt(i))
|| Character.isUpperCase(fileName.charAt(i))))
i++;
String tableName = fileName.substring(0, i);
BufferedReader in = new BufferedReader(new
FileReader(fileName));
String[] columnNames = readLine(in);
String[] columnTypes = readLine(in);
createTable(stmt, tableName, columnNames,
columnTypes);
boolean done = false;
while (!done)
{ String[] values = readLine(in);
if (values.length == 0) done = true;
else insertInto(stmt, tableName,
columnTypes, values);
}
showTable(stmt, tableName, columnNames.length);
stmt.close();
con.close();
}
catch (SQLException ex)
{ System.out.println ("SQLException:");
while (ex != null)
{ System.out.println ("SQLState: "
+ ex.getSQLState());
System.out.println ("Message: "
+ ex.getMessage());
System.out.println ("Vendor: "
+ ex.getErrorCode());
ex = ex.getNextException();
System.out.println ("");
}
}
catch (java.lang.Exception ex)
{ System.out.println("Exception: " + ex);
ex.printStackTrace ();
}
}
private static String[] readLine(BufferedReader in)
throws IOException
{ String line = in.readLine();
Vector result = new Vector();
if (line != null)
{ StringTokenizer t = new StringTokenizer(line, "|");
while (t.hasMoreTokens())
result.addElement(t.nextToken().trim());
}
String[] retval = new String[result.size()];
result.copyInto(retval);
return retval;
}
private static void createTable(Statement stmt,
String tableName, String[] columnNames,
String[] columnTypes) throws SQLException
{ String command = "CREATE TABLE " + tableName + "(
";
String primary = "";
for (int i = 0; i < columnNames.length; i++)
{ if (i > 0) command += ",
";
String columnName = columnNames[i];
if (columnName.charAt(0) == '*')
{ if (primary.length() > 0) primary += ", ";
columnName = columnName.substring(1,
columnName.length());
primary += columnName;
}
command += columnName + " " + columnTypes[i];
}
if (primary.length() > 0)
command += "
PRIMARY KEY (" + primary + ")";
command += ")
";
stmt.executeUpdate(command);
}
private static void insertInto(Statement stmt,
String tableName, String[] columnTypes, String[] values)
throws SQLException
{ String command = "INSERT INTO " + tableName
+ " VALUES (";
for (int i = 0; i < columnTypes.length; i++)
{ if (i > 0) command += ", ";
String columnType = columnTypes[i].toUpperCase();
String value = "";
if (i < values.length) value = values[i];
if (columnType.startsWith("CHAR")
|| columnType.startsWith("VARCHAR"))
{ int from = 0;
int to = 0;
command += "'";
while ((to = value.indexOf(''', from)) >= 0)
{ command += value.substring(from, to) + "''";
from = to + 1;
}
command += value.substring(from) + "'";
}
else command += value;
}
command += ")";
stmt.executeUpdate(command);
}
private static void showTable(Statement stmt,
String tableName, int numCols) throws SQLException
{ String query = "SELECT * FROM " + tableName;
ResultSet rs = stmt.executeQuery(query);
while (rs.next())
{ for (int i = 1; i <= numCols; i++)
{ if (i > 1) System.out.print("|");
System.out.print(rs.getString(i));
}
System.out.println("");
}
rs.close();
}
}In this section, we will write a program that executes queries against the book database. For this program to work, you must have populated the corejava database with tables, as described in the preceding section. Figure 4-4 shows the query application.
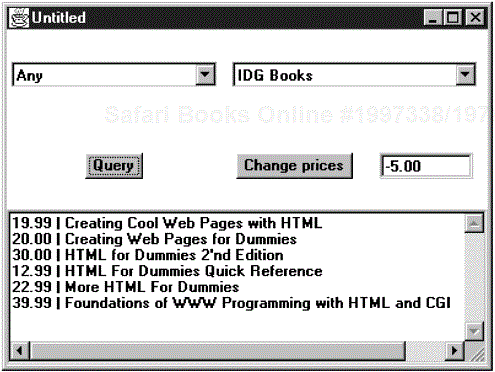
You can select the author and the publisher or leave either of them as Any. Click on Query; all books matching your selection will be displayed in the text box.
You can also change the data in the database. Select a publisher and type an amount into the textbox next to the Change prices button. When you click on the button, all prices of that publisher are adjusted by the amount you entered, and the text area contains a message indicating how many records were changed. However, to minimize unintended changes to the database, you can’t change all prices at once. The author field is ignored when you change prices. After a price change, you may want to run a query to verify the new prices.
In this program, we use one new feature, prepared statements. Consider the query for all books by a particular publisher, independent of the author. The SQL query is
SELECT Books.Price, Books.Title
FROM Books, Publishers
WHERE Books.Publisher_Id = Publishers.Publisher_Id
AND Publishers.Name = the name from the list boxRather than build a separate query command every time the user launches such a query, we can prepare a query with a host variable and use it many times, each time filling in a different string for the variable. That technique gives us a performance benefit. Whenever the database executes a query, it first computes a strategy of how to efficiently execute the query. By preparing the query and reusing it, that planning step is done only once. (The reason you do not always want to prepare a query is that the optimal strategy may change as your data changes. You have to balance the expense of optimization versus the expense of querying your data less efficiently.)
Each host variable in a prepared query is indicated with a ?. If there is more than one variable, then you must keep track of the positions of the ? when setting the values. For example, our prepared query becomes
String publisherQuery = "SELECT Books.Price, Books.Title " + "FROM Books, Publishers " + "WHERE Books.Publisher_Id = Publishers.Publisher_Id " + "AND Publishers.Name = ?"; PreparedStatement publisherQueryStmt = con.prepareStatement(publisherQuery);
Before executing the prepared statement, we must bind the host variables to actual values with a set method. As with the ResultSet get methods, there are different set methods for the various types. Here, we want to set a string.
publisherQueryStmt.setString(1, publisher);
The first argument is the host variable that we want to set. The position 1 denotes the first ?. The second argument is the value that we want to assign to the host variable.
If you reuse a prepared query that you have already executed and the query has more than one host variable, all host variables stay bound as you set them unless you change them with a set method. That means you only need to call set on those host variables that change from one query to the next.
Once all variables have been bound to values, you can execute the query
ResultSet rs = publisherQueryStmt.executeQuery();
You process the result set in the usual way. Here, we add the information to the text area result.
result.setText("");
while (rs.next())
result.appendText(rs.getString(1) + " | " +
rs.getString(2) + "
");
rs.close();There are a total of four prepared queries in this program, one each for the cases shown in Table 4-3.
Table 4-3. Selected queries
|
Author |
Publisher |
|---|---|
|
any |
any |
|
any |
specified |
|
specified |
any |
|
specified |
specified |
The price update feature is implemented as a simple UPDATE statement. For variety, we did not choose to make a prepared statement in this case. Note that we call executeUpdate, not executeQuery, since the UPDATE statement does not return a result set and we don’t need one. The return value of executeUpdate is the count of changed rows. We display the count in the text area.
String updateStatement = "UPDATE Books ..."; int r = stmt.executeUpdate(updateStatement); result.setText(r + " records updated");
The following steps provide an overview of the program.
Arrange the components in the frame, using a grid bag layout (see Chapter 7 in Volume 1).
Populate the author and publisher text boxes by running two queries that return all author and publisher names in the database.
When the user selects Query, find which of the four query types needs to be executed. If this is the first time this query type is executed, then the prepared statement variable is
null, and the prepared statement is constructed. Then, the values are bound to the query and the query is executed.The queries involving authors are more complex. Because a book can have multiple authors, the
BooksAuthorstable gives the correspondence between authors and books. For example, the book with ISBN number 1-56-604288-7 has two authors with codesHARRandKIDD. TheBooksAuthorstable has the rows1-56-604288-7 | HARR | 1 1-56-604288-7 | KIDD | 2
to indicate this fact. The third column lists the order of the authors. (We can’t just use the position of the records in the table. There is no fixed row ordering in a relational table.) Thus, the query has to snake (join) itself from the
Bookstable to theBooksAuthorstable, then to theAuthorstable to compare the author name with the one selected by the user.SELECT Books.Price, Books.Title FROM Books, Publishers, BooksAuthors, Authors WHERE Books.Publisher_Id = Publishers.Publisher_Id AND Publishers.Name = ? AND Books.ISBN = BooksAuthors.ISBN AND BooksAuthors.Author = Authors.Author AND Authors.Name = ?
The results of the query are displayed in the results text box.
When the user selects Change price, then the update query is constructed and executed. The query is quite complex because the
WHEREclause of theUPDATEstatement needs the publisher code and we know only the publisher name. This problem is solved with a nested subquery:UPDATE Books SET Price = Price + price change WHERE Books.Publisher_Id = (SELECT Publisher_Id FROM Publishers WHERE Name = publisher name)
We initialize the connection and statement objects in the constructor. We hang on to them for the life of the program. Just before the program exits, we call the
disposemethod, and Java closes these objects.class QueryDB extends Frame { QueryDB() { con = DriverManager.getConnection(url, user, password); stmt = con.createStatement(); . . . } . . . void dispose() { stmt.close(); con.close(); } . . . Connection con; Statement stmt; }
Example 4-2 is the complete program code.
Example 4-2. QueryDB.java
import java.net.*;
import java.sql.*;
import java.awt.*;
import java.awt.event.*;
import java.util.*;
import corejava.*;
public class QueryDB extends CloseableFrame
implements ActionListener
{ public QueryDB()
{ setLayout(new GridBagLayout());
GridBagConstraints gbc = new GridBagConstraints();
authors = new Choice();
authors.addItem("Any");
publishers = new Choice();
publishers.addItem("Any");
result = new TextArea(4, 50);
result.setEditable(false);
priceChange = new TextField(8);
priceChange.setText("-5.00");
try
{ Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
// force loading of driver
String url = "jdbc:odbc:corejava";
String user = "Cay";
String password = "password";
con = DriverManager.getConnection(url, user,
password);
stmt = con.createStatement();
String query = "SELECT Name FROM Authors";
ResultSet rs = stmt.executeQuery(query);
while (rs.next())
authors.addItem(rs.getString(1));
query = "SELECT Name FROM Publishers";
rs = stmt.executeQuery(query);
while (rs.next())
publishers.addItem(rs.getString(1));
}
catch(Exception e)
{ result.setText("Error " + e);
}
gbc.fill = GridBagConstraints.NONE;
gbc.weightx = 100;
gbc.weighty = 100;
add(authors, gbc, 0, 0, 2, 1);
add(publishers, gbc, 2, 0, 2, 1);
gbc.fill = GridBagConstraints.NONE;
Button queryButton = new Button("Query");
add(queryButton, gbc, 0, 1, 1, 1);
queryButton.addActionListener(this);
Button changeButton = new Button("Change prices");
add(changeButton, gbc, 2, 1, 1, 1);
changeButton.addActionListener(this);
add(priceChange, gbc, 3, 1, 1, 1);
gbc.fill = GridBagConstraints.BOTH;
add(result, gbc, 0, 2, 4, 1);
}
private void add(Component c, GridBagConstraints gbc,
int x, int y, int w, int h)
{ gbc.gridx = x;
gbc.gridy = y;
gbc.gridwidth = w;
gbc.gridheight = h;
add(c, gbc);
}
public void actionPerformed(ActionEvent evt)
{ String arg = evt.getActionCommand();
if (arg.equals("Query"))
{ ResultSet rs = null;
try
{ String author = authors.getSelectedItem();
String publisher = publishers.getSelectedItem();
if (!author.equals("Any")
&& !publisher.equals("Any"))
{ if (authorPublisherQueryStmt == null)
{ String authorPublisherQuery =
"SELECT Books.Price, Books.Title " +
"FROM Books, BooksAuthors, Authors, Publishers " +
"WHERE Authors.Author_Id = BooksAuthors.Author_Id AND " +
"BooksAuthors.ISBN = Books.ISBN AND " +
"Books.Publisher_Id = Publishers.Publisher_Id AND " +
"Authors.Name = ? AND " +
"Publishers.Name = ?";
authorPublisherQueryStmt =
con.prepareStatement(authorPublisherQuery);
}
authorPublisherQueryStmt.setString(1, author);
authorPublisherQueryStmt.setString(2, publisher);
rs = authorPublisherQueryStmt.executeQuery();
}
else if (!author.equals("Any")
&& publisher.equals("Any"))
{ if (authorQueryStmt == null)
{ String authorQuery =
"SELECT Books.Price, Books.Title " +
"FROM Books, BooksAuthors, Authors " +
"WHERE Authors.Author_Id = BooksAuthors.Author_Id AND " +
"BooksAuthors.ISBN = Books.ISBN AND " +
"Authors.Name = ?";
authorQueryStmt
= con.prepareStatement(authorQuery);
}
authorQueryStmt.setString(1, author);
rs = authorQueryStmt.executeQuery();
}
else if (author.equals("Any")
&& !publisher.equals("Any"))
{ if (publisherQueryStmt == null)
{ String publisherQuery =
"SELECT Books.Price, Books.Title " +
"FROM Books, Publishers " +
"WHERE Books.Publisher_Id = Publishers.Publisher_Id AND " +
"Publishers.Name = ?";
publisherQueryStmt
= con.prepareStatement(publisherQuery);
}
publisherQueryStmt.setString(1, publisher);
rs = publisherQueryStmt.executeQuery();
}
else
{ if (allQueryStmt == null)
{ String allQuery =
"SELECT Books.Price, Books.Title FROM Books";
allQueryStmt
= con.prepareStatement(allQuery);
}
rs = allQueryStmt.executeQuery();
}
result.setText("");
while (rs.next())
result.append(rs.getString(1)
+ " | " + rs.getString(2) + "
");
rs.close();
}
catch(Exception e)
{ result.setText("Error " + e);
}
}
else if (arg.equals("Change prices"))
{ String publisher = publishers.getSelectedItem();
if (publisher.equals("Any"))
result.setText
("I am sorry, but I cannot do that.");
else
try
{ String updateStatement =
"UPDATE Books " +
"SET Price = Price + " + priceChange.getText() +
" WHERE Books.Publisher_Id = " +
"(SELECT Publisher_Id FROM Publishers WHERE Name = '" +
publisher + "')";
int r = stmt.executeUpdate(updateStatement);
result.setText(r + " records updated.");
}
catch(Exception e)
{ result.setText("Error " + e);
}
}
}
public void dispose()
{ try
{ stmt.close();
con.close();
}
catch(SQLException e) {}
}
public static void main (String args[])
{ Frame f = new QueryDB();
f.setSize(400, 300);
f.show();
}
private Choice authors;
private Choice publishers;
private TextField priceChange;
private TextArea result;
private Connection con;
private Statement stmt;
private PreparedStatement authorQueryStmt;
private PreparedStatement authorPublisherQueryStmt;
private PreparedStatement publisherQueryStmt;
private PreparedStatement allQueryStmt;
}java.sql.Connection
PreparedStatement prepareStatement(String sql)returns a
PreparedStatementobject containing the precompiled statement. The stringsqlcontains an SQL statement that may contain one or more?parameter placeholders.
java.sql.PreparedStatement
void setXXX(int n,XXXx)(
XXXis a type such asint,double,String,Date, etc.)sets the value of the
nth parameter tox.void clearParameters()clears all current parameters in the prepared statement.
ResultSet executeQuery()executes a prepared SQL query and returns a
ResultSetobject.int executeUpdate()executes the prepared SQL
INSERT,UPDATE, orDELETEstatement represented by thePreparedStatementobject. Returns the number of rows affected or 0 for DDL statements.
In the last two sections, you saw how to populate, query, and update database tables. However, JDBC can give you additional information about the structure of a database and its tables. For example, you can get a list of the tables in a particular database or the column names and types of a table. This information is not useful when you are implementing a particular database. After all, if you design the tables, you know the tables and their structure. Structural information is, however, extremely useful for programmers who write tools that work with any database.
In this section, we will show you how to write such a simple tool. This tool lets you browse all tables in a database.
The choice box on top displays all tables in the database. Select one of them, and the center of the frame is filled with the field names of that table and the values of the first record, as shown in Figure 4-5. Click on Next to scroll through the records in the table.
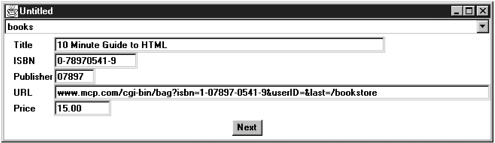
We fully expect tool vendors to develop much more sophisticated versions of programs like this one. For example, it then clearly would be possible to let the user edit the values or add new ones, and then update the database. We developed this program mostly to show you how such tools can be built.
In SQL, data that describes the database or one of its parts is called metadata (to distinguish it from the actual data that is stored in the database). JDBC reports to us two kinds of metadata: about a database and about a result set.
To find out more about the database, you need to request an object of type DatabaseMetaData from the database connection.
DatabaseMetaData md = con.getMetaData();
Databases are complex, and the SQL standard leaves plenty of room for variability. There are well over a hundred methods in the DatabaseMetaData class to inquire about the database, including calls with exotic names such as
md.supportsCatalogsInPrivilegeDefinitions()
and
md.nullPlusNonNullIsNull()
Clearly, these are geared toward advanced users with special needs, in particular, those who need to write highly portable code. In this section, we will study only one method that lets you list all tables in a database, and we won’t even look at all its options. The call
ResultSet rs = md.getTables(null, null, null, new String[]
{ "TABLE" })returns a result set that contains information about all tables in the database. (See the API note for other parameters to this method.)
Each row in the result set contains information about the table. We only care about the third entry, the name of the table. (Again, see the API note for the other columns.) Thus, rs.getString(3) is the table name. Here is the code that populates the choice box.
while (rs.next()) tableNames.addItem(rs.getString(3)); rs.close();
The more interesting metadata is reported about result sets. Whenever you have a result set from a query, you can inquire about the number of columns and each column’s name, type, and field width.
We will make use of this information to make a label for each name and a text field of sufficient size for each value.
ResultSet rs = stmt.executeQuery("SELECT * FROM " + tableName);
ResultSetMetaData rsmd = rs.getMetaData();
for (int i = 1; i <= rsmd.getColumnCount(); i++)
{ String columnName = rsmd.getColumnLabel(i);
int columnWidth = rsmd.getColumnDisplaySize(i);
Label l = new Label(columnName);
TextField tf = new TextField(columnWidth);
. . .
}The following steps provide a brief overview of the program.
Have the border layout put the table name choice component on the top, the table values in the center, and the Next button on the bottom.
Connect to the database. Get the table names and fill them into the choice component.
When the user selects a table, make a query to see all its values. Get the metadata. Throw out the old components from the center panel. Create a grid bag layout of labels and text boxes. Store the text boxes in a vector. Call the
packmethod to have the window resize itself to exactly hold the newly added components. Then, callshowNextRowto show the first row.The
showNextRowmethod is called to show the first record, and is also called whenever the Next button is clicked. It gets the next row from the table and fills the column values into the text boxes. When at the end of the table, the result set is closed.
Example 4-3 is the program.
Example 4-3. ViewDB.java
import java.net.*;
import java.sql.*;
import java.awt.*;
import java.awt.event.*;
import java.util.*;
import corejava.*;
public class ViewDB extends CloseableFrame
implements ActionListener, ItemListener
{ public ViewDB()
{ tableNames = new Choice();
tableNames.addItemListener(this);
dataPanel = new Panel();
add(dataPanel, "Center");
Panel p = new Panel();
Button nextButton = new Button("Next");
p.add(nextButton);
nextButton.addActionListener(this);
add(p, "South");
fields = new Vector();
try
{ Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
// force loading of driver
String url = "jdbc:odbc:corejava";
String user = "Cay";
String password = "password";
con = DriverManager.getConnection(url, user,
password);
stmt = con.createStatement();
md = con.getMetaData();
ResultSet mrs = md.getTables(null, null, null,
new String[] { "TABLE" });
while (mrs.next())
tableNames.addItem(mrs.getString(3));
mrs.close();
}
catch(Exception e)
{ System.out.println("Error " + e);
}
add(tableNames, "North");
}
private void add(Container p, Component c,
GridBagConstraints gbc, int x, int y, int w, int h)
{ gbc.gridx = x;
gbc.gridy = y;
gbc.gridwidth = w;
gbc.gridheight = h;
p.add(c, gbc);
}
public void itemStateChanged(ItemEvent evt)
{ if (evt.getStateChange() == ItemEvent.SELECTED)
{ remove(dataPanel);
dataPanel = new Panel();
fields.removeAllElements();
dataPanel.setLayout(new GridBagLayout());
GridBagConstraints gbc = new GridBagConstraints();
gbc.fill = GridBagConstraints.NONE;
gbc.anchor = GridBagConstraints.WEST;
gbc.weightx = 100;
gbc.weighty = 100;
try
{ String tableName = (String)evt.getItem();
if (rs != null) rs.close();
rs = stmt.executeQuery("SELECT * FROM "
+ tableName);
ResultSetMetaData rsmd = rs.getMetaData();
for (int i = 1; i <= rsmd.getColumnCount(); i++)
{ String columnName = rsmd.getColumnLabel(i);
int columnWidth = rsmd.getColumnDisplaySize(i);
TextField tb = new TextField(columnWidth);
fields.addElement(tb);
add(dataPanel, new Label(columnName),
gbc, 0, i - 1, 1, 1);
add(dataPanel, tb, gbc, 1, i - 1, 1, 1);
}
}
catch(Exception e)
{ System.out.println("Error " + e);
}
add(dataPanel, "Center");
doLayout();
pack();
showNextRow();
}
}
public void actionPerformed(ActionEvent evt)
{ if (evt.getActionCommand().equals("Next"))
{ showNextRow();
}
}
public void showNextRow()
{ if (rs == null) return;
{ try
{ if (rs.next())
{ for (int i = 1; i <= fields.size(); i++)
{ String field = rs.getString(i);
TextField tb
= (TextField)fields.elementAt(i - 1);
tb.setText(field);
}
}
else
{ rs.close();
rs = null;
}
}
catch(Exception e)
{ System.out.println("Error " + e);
}
}
}
public static void main (String args[])
{ Frame f = new ViewDB();
f.show();
}
private Panel dataPanel;
private Choice tableNames;
private Vector fields;
private Connection con;
private Statement stmt;
private DatabaseMetaData md;
private ResultSet rs;
}java.sql.Connection
DatabaseMetaData getMetaData()returns the metadata for the connection as a
DataBaseMetaDataobject.
java.sql.DatabaseMetaData
ResultSet getTables(String catalog, String schemaPattern, String tableNamePattern, String types[])gets a description of all tables in a catalog that match the schema and table name patterns and the type criteria. (A schema describes a group of related tables and access permissions. A catalog describes a related group of schemas. These concepts are important for structuring large databases.)
Parameters:
catalogschema Patterntable Name Patterntypes []The
catalogandschemaparameters can be " " to retrieve those tables without a catalog or schema, ornullto return tables regardless of catalog or schema.The
typesarray contains the names of the table types to include. Typical types areTABLE,VIEW,SYSTEM TABLE,GLOBAL TEMPORARY,LOCAL TEMPORARY,ALIAS, andSYNONYM. Iftypesisnull, then tables of all types are returned.The result set has five columns, all of which are of type
String, as shown in Table 4-4.
Table 4-4. Five columns of the result set
|
|
|
table catalog (may be |
|
|
|
table schema (may be |
|
|
|
table name |
|
|
|
table type |
|
|
|
comment on the table |
java.sql.ResultSet
resultSetMetaData getMetaData()gives you the metadata associated with the current
ResultSetcolumns.
interface java.sql.ResultSetMetaData
int getColumnCount()returns the number of columns in the current
ResultSetobject.int getColumnDisplaySize(int column)tells you the usual maximum width of the column specified by the index parameter.
Parameters:
columnthe column number
String getColumnLabel(int column)gives you the suggested title for the column.
Parameters:
columnthe column number
String getColumnName(int column)gives the column name associated with the column index specified.
Parameters:
columnthe column number