
CHAPTER 10
The Alternative Storage Component
We have now talked about the components of the Corporate Information Factory (CIF) that help us analyze data contained in the data warehouse: data marts, operational data store, and exploration/data mining warehouse. These components also enable the warehouse to scale and extend its reach across the corporation. Now let’s take a look at a component of the CIF that enables vast amounts of detail and history to be maintained in the warehouse efficiently and cost effectively—alternative storage.
Before we talk about alternative storage, we must first understand what is driving the need. As time passes, two realities strike corporations. The first reality is that the data volumes that collect in the data warehouse are overwhelming. The second reality is that as the volume of data grows, so does the cost of the infrastructure.
There are some powerful reasons why data in the warehouse grows at a rate never before witnessed by most corporations:
![]() Detailed data takes up more space than summarized or aggregated data.
Detailed data takes up more space than summarized or aggregated data.
![]() Deep history found in the data warehouses multiplies the size of the warehouse.
Deep history found in the data warehouses multiplies the size of the warehouse.
![]() Data warehouses are built with unknown requirements. This means that some data put into the warehouse will never be used.
Data warehouses are built with unknown requirements. This means that some data put into the warehouse will never be used.
![]() Summarized data is as important as detailed data. Summarized data is stored in data marts as well as the data warehouse.
Summarized data is as important as detailed data. Summarized data is stored in data marts as well as the data warehouse.
As you can see, there are some very good reasons why data warehouses attract a lot of data. With the growth in data volumes come a host of new issues, including:
![]() Cost of the infrastructure
Cost of the infrastructure
![]() Query and load performance issues
Query and load performance issues
![]() System availability issues
System availability issues
Another issue related to growth of data is organizational acceptance and understanding of how to manage this data. The techniques and technology that worked well in the operational world, where there was only a modicum of data, simply do not apply to the world of data warehousing. The organization finds that it must learn how to function on a whole new terrain to cope with the data warehouse environment.
Growth of Dormant Data
Dormant data is data that is placed inside a data warehouse and is either never infrequently accessed. Dormant data exists at various levels of granularity—table, column, and row. In the early days of a data warehouse, when the volume of data is small, there is very little, if any, dormant data. But as the volume of data grows, the percentage of data used actually decreases and the amount of dormant data grows quite large, as depicted in Figure 10.1.

Figure 10.1 As data volume grows, the actual amount of disk storage being used decreases.
There are some fairly powerful reasons that data grows dormant in a data warehouse. Some of those reasons are:
Overestimation of the need for historical data. When the warehouse is first designed, the data demand is for five years of historical data. After the designer delivers five years of history, the user learns that for most processing only one or two years of history are needed.
Inclusion of data that is never needed for analysis. The data warehouse is designed to handle one sort of analysis that never bears fruit. As a consequence certain types of data are simply never accessed.
Creation of summary data that is used only once. It is very common for summary data to be placed in the warehouse. Unfortunately, few plan for managing these summary tables. As a result, the DWA doesn’t know what summary tables to remove and plays it safe by not removing any of them.
The phenomenon of dormant data is one that is a normal and natural phenomenon. It simply happens that as the data volume grows, some data becomes dormant. At the rate that warehouses grow, a large amount of data grows dormant rather quickly. Now lets take look at a strategy for managing dormant data.
Managing Dormant Data
The solution to this problem is for the company to identify what data is dormant and move it away from data that is being actively used. Figure 10.2 shows that the bulk of the data is getting in the way of a small portion of the data that is being actively used.

Figure 10.2 Dormant data gets in the way of data that is being actively used.
There are many benefits to performing the physical separation of active and inactive data including:
![]() Performance is greatly improved by moving dormant data away from actively used data.
Performance is greatly improved by moving dormant data away from actively used data.
![]() The cost of the warehouse drops dramatically by moving dormant data to a low-cost storage medium.
The cost of the warehouse drops dramatically by moving dormant data to a low-cost storage medium.
![]() The data can be designed to accommodate a very fine granularity of data.
The data can be designed to accommodate a very fine granularity of data.
![]() The warehouse can effectively extended to infinity.
The warehouse can effectively extended to infinity.
These benefits will be examined in depth later in this chapter. But first, an important question must be answered: Where is the dividing line between actively and inactively used data?
Finding the Dividing Line
One approach to moving data to alternative storage is to simply pick an arbitrary dividing line and move all data over the line to alternative storage. For example, a company may pick 18 months as the dividing line. Any data earlier than 18 months stays in actively used storage and any data older than 18 months goes to alternative storage. Such a strategy is better than nothing at all. But picking an arbitrary dividing line is a very crude, and ultimately inefficient, thing to do. A much better approach to determining what should and should not be in actively used storage is to use an activity monitor. The activity monitor provides insight into data usage so that a more quantitative decision can be made regarding what data belongs in active storage versus inactive storage.
In order to be effective, the activity monitor needs to track data usage a several levels:
![]() Row level
Row level
![]() Table level
Table level
![]() Column level
Column level
There are implications to each of the different ways of examining dormant data. If a dormant table is found, then the table can be moved whole, to alternative storage. In the case of summary data, indeed, whole tables are found to be dormant. But the more normal case for dormant data is that rows of data and/or columns of data become dormant.
If rows of data are found to be dormant, they can be moved to alternative storage. But when rows of data are moved across multiple media, then the table exists on multiple media. There are some fairly severe technical implications to this splitting of data within the same table across different types of storage.
The third case is where entire columns of data are dormant. This is very common. Unfortunately, removing a column (or columns) of data very difficult in most database management systems (DBMSs) because such a removal requires a complete reorganization and redefinition of the data residing in the table. However, in some cases this type of reorganization is easily worth the resources expended.
One of the issues of monitoring the actively used storage component is the overhead and complexity of the monitoring itself. As a rule, every data unit needs to be monitored. Monitoring only sample information really does not do the job. In addition, if the monitoring software is complex, the software ends up needing as much management as the data warehouse itself. When looking at monitoring software, keep in mind the efficiency and simplicity of execution. The less intrusive the monitoring software the better.
Where the Activity Monitor Fits
Figure 10.3 shows that the activity monitor sits between the users of the system and the DBMS. The activity monitor looks at Structure Query Language (SQL) queries entering the DBMS and looks at the result set as it passes back to the end user.
When selecting an activity monitor, it is important to consider these questions:
![]() How much overhead does it require?
How much overhead does it require?
![]() How simple or complex is it to use?
How simple or complex is it to use?
![]() What level of detail and types of detail does it tape into?
What level of detail and types of detail does it tape into?
![]() What technology does it work on?
What technology does it work on?
![]() What does it cost?
What does it cost?
![]() Can it be turned on permanently or only at selected moments?
Can it be turned on permanently or only at selected moments?
![]() How many administrative resources are required to use it, and at what skill level?
How many administrative resources are required to use it, and at what skill level?

Figure 10.3 The activity monitor fits between the data warehouse and end user.

Figure 10.4 Moving dormant data to alternate storage.
Once the activity monitor is in place, the next step is to identify and move dormant data to alternative storage. This step is shown in Figure 10.4.
The activity monitor is used by the data warehouse administrator to identify dormant data. The dormant data is then moved to alternative storage. Once the data is moved to alternative storage, the high-performance disk environment is freed up. The only data left on high-performance disk storage is data that has a high probability of access.
Alternative Storage Technology
The alternative storage environment can be made up of (at least!) two types of technology, as depicted in Figure 10.5. These technologies can be classified as:
![]() Secondary storage (or “fat storage”)
Secondary storage (or “fat storage”)
![]() Near-line storage
Near-line storage
Secondary storage is disk storage that is slower, less cached, and less expensive than high-performance disk storage. Near-line storage is siloed tape storage, which has its origins in the mounted tape drives of yesterday. However, today’s siloed tape is managed robotically and is much more compact and reliable than the tape drives of yesteryear. Siloed tape storage is less expensive than secondary storage. And both siloed tape storage and secondary storage are less expensive than high performance disk storage. One of the components necessary to managing data on alternative storage is that of a contents directory. A contents directory is an index as to where the data content is located inside alternative storage. In order for alternative storage to function properly, a contents directory must be part of the environment.
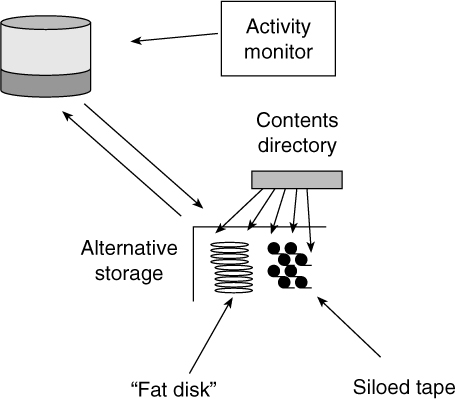
Figure 10.5 Alternative storage technology has one of two forms—secondary disk storage (also known as “fat storage”) and near-line storage.
Meta Content Data
In order for alternative storage to be effective there needs to be a special type of data—meta content data. Meta content data describes the contents of data inside alternative storage. In many ways meta content data is like an index into the contents of alternative storage. The contents need to be made available to the cross media storage manager. It is through the meta content data that a query knows where to go inside alternative storage.
Cross Media Storage Manager
Although alternative storage is a powerful concept on its own, another technology is required in order for alternative storage to function. That component is generically called the cross media storage manager. Figure 10.6 shows where the cross media storage manager fits in the corporate information factory.
Cross media storage management entails seamlessly crossing the high-performance disk to alternative storage boundary. The cross media storage manager has the job of managing the flow of traffic to and from high-performance disk to alternative storage. When data is not being used frequently, the cross media storage manager moves the data to alternative storage. When there is a request for data from alternative storage, the cross media storage manager finds the data and makes it available to the requesting party.
Figure 10.6 illustrates how the cross media storage manager operates. Note: This example shows one way that cross media storage management can be done. There are many variations to the implementation of cross media storage management.

Figure 10.6 An essential component of the alternative storage environment is the cross media manager.

Figure 10.7 How data can be accessed inside alternative storage.
In Figure 10.7, a query is submitted. The query sends its text to the DBMS. Once at the DBMS, the DBMS decides what data needs to be accessed. The DBMS sends different fetches to get the data. At this point the cross media storage manager intercepts those requests for data and adjusts the addresses for those pieces of data that reside in alternative storage. The requests are then sent either to the disk manager or to the alternative storage manager depending on where the data is located.
Figure 10.8 shows that after the data is located, the data is sent to the DBMS, which in turn sends it back to the query initiator as a result set.
Of course, if the request for data had not included data residing in alternative storage, then there would be no need to go to alternative storage. The effect of the activity monitor is to ensure that a minimum number of trips will have to be made to alternative storage.
Alternative Storage and Exploration Processing
The primary interface to alternative storage is to the data warehouse. This enables data to move back and forth between active and inactive storage mediums as usage should dictate. However, another important interface for alternative storage exists, between alternative storage and the exploration warehouse. Figure 10.9 shows this interface.
Data can be passed directly from alternative storage to the exploration warehouse. There is no need to place the data inside the data warehouse from alternative storage then move the data to the exploration warehouse.
Availability of data from alternative storage directly to the exploration warehouse greatly simplifies the job of the data warehouse administrator (DWA). The DWA does not have to worry about requests for data, which are used only once in a blue moon, passing through high performance disk storage in order to get to the exploration warehouse. Instead, when explorers have their own environment, the high performance data warehouse remains free to process regularly occurring queries.
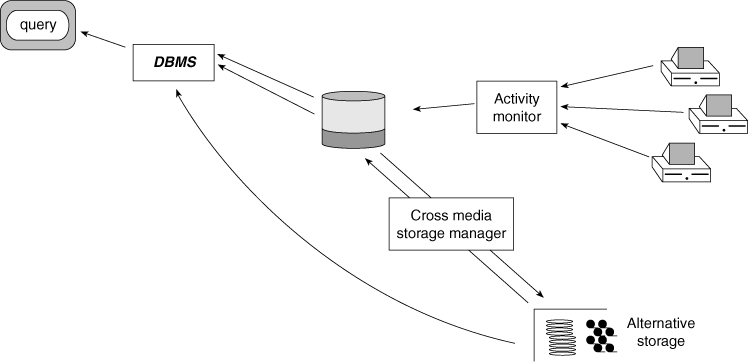
Figure 10.8 When located in alternative storage, data is returned directly to the DBMS.

Figure 10.9 Interface between alternative storage and the exploration warehouse.
Why Use Alternative Storage?
Companies look at a variety of factors when determining whether or not to use alternative storage, including:
![]() Cost
Cost
![]() Optimizing query performance
Optimizing query performance
![]() Level of granularity needed
Level of granularity needed
The following sections look at these factors and demonstrate the advantages of moving to alternative storage.
Saving Money
The first reason companies use alternative storage is the cost differential between a large high-performance disk implementation of a data warehouse and an implementation where data is spread across high-performance disk storage and alternative storage. Depending on the type of alternative storage, there may be as much as two orders of magnitude difference between the costs of the two implementations. In a word, going to alternative storage for the placement of dormant data brings the cost of data warehousing down dramatically.
But significant cost savings is not the only reason that alternative storage is so appealing.
Better Query Performance
The stage is now set for optimal performance for the data warehouse. Figure 10.10 illustrates what happens when alternative storage has been loaded with dormant data and the space formerly occupied by dormant data is freed up.
The two queries shown in Figure 10.10 do exactly the same thing. The only difference is that they operate on different foundations of data. One query operates where all data is maintained on high-performance disk storage. The other query operates in an environment where dormant data has been moved off of the high-performance disk storage to alternative storage.

Figure 10.10 Contrast a query performance accessing active data in an environment with and without alternative storage. The latter is substantially faster.
The query that operates on all high-performance disk storage uses a large percentage of its resources looking at and passing over dormant data. As much as 95 percent of the resources expended by this query is used scanning through data that is not germane to the analysis.
The query that operates on high-performance disk storage where dormant data has been removed operates much more efficiently than the other query. This query operates in an environment that does not contain dormant data; as a result the response time for queries in this environment is much faster.
Keeping Lowest Level of Granularity
Cost and performance are not the only reasons why companies go to alternative storage. Another important reason is its ability to store data at the lowest level of granularity. To control costs, it is common for a data warehouse implementation—without alternative storage—to limit detail history to the last twelve months and to summarize history beyond that point. Unfortunately, our ability to trend history beyond the last 12 months is constrained by what we knew about the business at the time the summary data was created. As time passes on, it is inevitable that summaries that were useful 12 months ago are no longer relevant business indicators worth tracking in the data warehouse. This leaves the company with summary data that is out of context and only marginally useful.
However, when alternative disk storage is used, the designer of the data warehouse has much more freedom to design the system at the lowest level of granularity. There are a number of industries that face this issue of granularity:
![]() Telecommunications, with their call-level detail records
Telecommunications, with their call-level detail records
![]() Retailing, with their sales and sku records
Retailing, with their sales and sku records
![]() Banking and finance, with their transaction records
Banking and finance, with their transaction records
![]() Airlines, with their passenger and flight records
Airlines, with their passenger and flight records
With alternative storage, the data warehouse designer is free to go to as low a level of detail as is desired. This ability, in some ways, is the most important reason that organizations must include alternative storage as a foundation technology for their corporate information factory. Stated differently, an organization building a corporate information factory that chooses to use only high performance storage as a basis for storing data greatly limits the potential of their corporate information factory.
Vendor Implementations
Now that we have spent a bit of time discussing alternative storage and cross media management, let’s take a look at some vendors have implemented these technologies.
Alternative Storage: Filetek
Alternative storage would only be a dream were it not for the software that allows data to be stored and managed on both disk storage and alternative storage. Following is a description of one of the software vendors for alternative storage.
FileTek’s StorHouse® fits strategically in the corporate information factory architecture by uniquely combining relational database technology with the management of multi-level storage media. It is comprised of two components, StorHouse/SM and StorHouse/RM. Together the components comprise a comprehensive system for automating the management of massive amounts of detailed data and providing selective, row-level access to data through industry standard methods. Customer relationship management (CRM), e-business, enterprise resource planning (ERP), and enterprise data warehousing initiatives put ever-increasing demands on conventional database technologies. With the demand for data projected to grow over 100 percent per year for next several years, enterprises are searching for new approaches to managing and accessing information. StorHouse addresses the performance, data management, and economic challenges facing enterprises that need to deliver the right information to decision-makers, customer-care personnel, vendors, and customers too.
The corporate information factory architecture identifies databases and tools designed for specific functions. Operational data stores (ODS), data warehouses, exploration databases, data marts, on-line analytical processing (OLAP) tools, and alternative storage systems, among other technologies, comprise the CIF. StorHouse fits in the CIF architecture as the atomic data repository that uses alternative storage technologies. And detailed, atomic-level data—the fundamental transactions of the business—are at the heart of the CIF. Atomic data is defined as the detailed transaction data generated during the course of every business day. Atomic data appears in many places in the world of corporate business.
For a telecommunications company, call detail records represent atomic data. Retailers collect point-of-sale transactions and banks generate atomic data in the form of ATM, credit card, and teller transactions, to name a few. Increasingly, e-businesses are collecting clickstream details that identify customer patterns of interacting with Web sites. Atomic data is generated and collected in large volumes—typically date specific—may be structured or unstructured, and is most valuable when retained over time. An effective data storage strategy for the CIF will make these transaction-level details affordable, available, and manageable.
Affordability
StorHouse manages a hierarchy of storage devices, including cache, redundant arrays of independent disks (RAID), erasable and write-once-read-many (WORM) optical jukeboxes, and automated tape libraries. However, unlike conventional hierarchical storage management (HSM) systems, StorHouse provides direct, row-level access to data it manages, even when that data is stored on removable media such as tape. The financial benefits of managing large amounts of transaction-level details and other types of relational data that are infrequently used are significant. The current economics of storage media suggest that storing data on tape is approximately seven percent of the cost of magnetic disk. Automated tape library systems offer a practical way to store historical atomic data for many years if necessary. But it is not enough merely to store data. Applications that use the CIF architecture need to access data quickly and efficiently. Traditional database implementations use tape to back up and restore entire databases or portions of the database system. In this sense, tape is a “passive” medium that it is not used for direct data storage and querying. In contrast, StorHouse closely integrates the relational database management system (RDBMS) with storage management to make “near-line” storage behave as online devices.
Compatibility with an organization’s investments in other databases and analytical tools also affects affordability. StorHouse integrates with the most commonly used relational database systems such as Oracle, DB2, and SQL Server. For instance, StorHouse transparently extends Oracle databases to give users access to StorHouse tables from Oracle-based applications. StorHouse tables can be defined as database links to the Oracle database using standard Oracle database administration and ODBC tools. As with other Oracle database links, administrators can build views of StorHouse tables and use table synonyms. Views and synonyms shield the user from having to know where database tables actually reside.
Similarly, StorHouse can extend a DB2 database using IBM’s Data Joiner. DB2/Data Joiner manages metadata that describes the location of different data items and the capabilities of the StorHouse data source. When it receives a DB2 query, Data Joiner parses the query and develops a query access plan. Elements of this plan become queries to DB2 and StorHouse. Data Joiner then combines and further refines the result sets returned by the data sources and passes the answer set back to the application. Database transparency protects an organization’s investments in applications as well as database administration tools and methods.
Availability
StorHouse processes industry-standard SQL ‘92. SQL is used to selectively “filter” the data required to satisfy an application or user’s request for information. When StorHouse processes a query, it does not reload complete files to a database. Rather, it accesses rows directly from the storage media upon which they are stored. In many cases, a single large table may span more than one type of storage media such as RAID and tape. The StorHouse architecture greatly improves the availability of corporate data by making it accessible from multiple diverse applications and platforms. StorHouse supports industry-standard gateways such as ODBC, JDBC, and OLE/DB ADO. Commonly used ETL, OLAP, and query generation tools use these standard APIs. StorHouse also supports the IBM DRDA interface so that mainframe-based DB2 applications can transparently access StorHouse-managed data.
StorHouse-managed data is accessible through a variety of interfaces and applications. But it is not enough to bring tape online as a part of the CIF architecture. Data is a corporate asset that needs to be protected over long periods of time in spite of hardware failures that inevitably occur in storage devices of all kinds. StorHouse automatically duplexes data across multiple storage libraries. Even when a failure to an optical or tape library or drive occurs, a second copy of data is available to the application. A third, backup copy can also be created. StorHouse does not require any other backup procedures since they are handled automatically by the system.
Routine database maintenance can also make the data managed by those databases unavailable for extended periods of time. Database reorganization, backups, and database version upgrades that require data conversion are among the maintenance events that take data offline. StorHouse databases avoid these issues. StorHouse does not require database reorganization and automatically creates its own backup copies. Data written to a StorHouse server can be copied, rather than converted, to storage devices with new form factors. These capabilities and others are designed to maximize the availability of StorHouse-managed data.
Manageability
In addition to making data available through standard relational database techniques, StorHouse is a comprehensive data management solution. StorHouse/Control Center is the system administration interface for systems and database administrators. It continually monitors the performance and reliability of the StorHouse server and its storage hardware devices. Administrators use Control Center to create databases and their schema, set storage management policies, and generate usage statistics and reports.
StorHouse differs from HSM systems in many respects. One of the storage management policies StorHouse administers is the automatic movement of data through the storage hierarchy. StorHouse migrates data from high-performance, higher cost storage media, to lower cost storage devices based upon the age and usage characteristics of the data. Data that is most frequently used is retained in the StorHouse performance buffer or on RAID while less active data moves to optical or tape. Likewise, when the StorHouse system detects that data stored on tape is becoming more frequently accessed, it will temporarily move it to RAID to improve its performance characteristics. StorHouse also provides the flexibility to separate indexes from the data those indexes represent. Indexes typically require rapid access and can be retained on higher performance storage longer than the data if necessary.
StorHouse solves other management issues associated with large data volumes. One of these is the sheer data volume that an atomic data store component in the CIF must load and index every day. StorHouse is capable of loading data in multiple parallel streams to meet throughput requirements. StorHouse supports concurrent loading of a single StorHouse table and can also load separate tables from a single load stream. StorHouse also builds its indexes “on-the-fly” to speed the data loading and indexing process. Other databases first load data, then create indexes in place. While this method is satisfactory for smaller data volume systems, it usually does not meet the needs of the enterprise CIF atomic data store. StorHouse loads data and builds indexes an order of magnitude faster than other conventional RDBMSs.
StorHouse includes other features that enhance its performance and manageability. These include a patented range index that speeds access to other indexes (i.e., value and hash). The system also sorts indexes based on data placement on storage volumes so that all the data required to satisfy a query is read from a volume before it is unmounted. Without this level of intelligent indexing and look-ahead queuing, systems that use removable media storage thrash as volumes are randomly mounted and unmounted while data is accessed.
StorHouse is a specialized server for managing and providing access to corporate information. It combines the flexibility and openness of a relational database with comprehensive data management capabilities. Enterprises use StorHouse to manage historical atomic data that “fuels” other informational and operational systems. For example, a telecommunications company uses StorHouse to feed data to an exploration warehouse that models customer network usage habits. Another company uses StorHouse to transparently extend a primary database for customer care applications. In both cases, the StorHouse system stores, manages, and provides access to the enterprise transactions—the atomic data. It sits at the heart of the CIF architecture to deliver economical and timely access to enterprise data assets of all types.
Cross Media Management: Unitree
There has been the notion of managing data on multiple storage media for many years. It is not a new idea. What is new is the notion of the granularity at which data has to be managed over the different media. For a number of years there has been what is called hierarchical storage management (HSM). In HSM, data resides on different storage media based on its probability of access.
But data is moved to one storage media or another based on entire tables or databases of data. The tables and databases that are found in a data warehouse are so large that it is simply unthinkable to manage them at this very gross level of granularity.
Instead, it makes much more sense to manage the movement of data at the row or block level. In a given table or database there will be many, many rows and blocks of data. An example of this style of data management across multiple storage media comes from Unitree. With Unitree, a row of data or a block of data can be moved from one storage media to another if its probability of access warrants. In doing so, a table or a database can be managed where some of the data resides on disk storage and other parts of the table or database reside on near line or secondary storage.
The Unitree software allows queries to be executed in a transparent manner. When issued the query it has no idea that the data it is looking for resides on anything but disk storage. The DBMS simply thinks that it is going to get data. Only the system software knows that some of the data being retrieved resides one place and other of the data resides elsewhere.
Of course, data still needs to be managed with the Unitree software. Data with a high probability of access needs to be placed in disk storage and data with a low probability of access needs to be placed elsewhere. And there needs to be constant monitoring of data to make sure the balance is kept equal over time.
Summary
In this chapter, the concept of alternative storage was introduced. Alternative storage becomes critical to the performance and cost effectiveness as the amount of dormant data grows in your data warehouse environment. Benefits to alternative storage include:
![]() Lowering the cost of ownership
Lowering the cost of ownership
![]() Extending the depth and breath of historical detail data that can be managed
Extending the depth and breath of historical detail data that can be managed
![]() Improving query performance for everyone
Improving query performance for everyone
Alternative storage takes two forms: secondary storage and near-line storage. Each of the physical form of storage has its own set of considerations.
Now that you are familiar with the components of the corporate information factory responsible for collecting, storing, and using data, let’s take a look at the communication fabric that binds these components together—the Internet/intranet.