
CHAPTER 2
Introducing the Corporate Information Factory
As discussed in Chapter 1, the corporate information factory (CIF) is an architecture—an infrastructure—for the information ecosystem, consisting of the following components:
![]() External world
External world
![]() Applications
Applications
![]() Integration and transformation layer (I & T layer)
Integration and transformation layer (I & T layer)
![]() Operational data store (ODS)
Operational data store (ODS)
![]() Data warehouse
Data warehouse
![]() Data mart(s)
Data mart(s)
![]() Internet and intranet
Internet and intranet
![]() Metadata repository
Metadata repository
![]() Exploration and data mining data warehouse
Exploration and data mining data warehouse
![]() Alternative storage
Alternative storage
![]() Decision Support Systems (DSS)
Decision Support Systems (DSS)
The simplest way to understand the CIF is in terms of the data that flows in and the information that flows out of the corporate information factory. Data enters the CIF as detailed, raw data collected by the applications. The raw detailed data is refined by the applications and then passes into a layer of programs that fundamentally integrates and transforms functional data into corporate data. The data passes from the integration and transformation layer into the ODS and the data warehouse. The data warehouse can be fed data from either the ODS or the integration and transformation layer. After the data passes through the data warehouse, data is accessed, analyzed, and transformed into information for various purposes.
The architecture and the flow of data that have been described are very similar to that of an actual factory. Raw and assembly goods enter a factory and are immediately collected by inventory and store management processors. Assembly lines then turn the raw goods into a product. Throughout the manufacturing process, different products are made. Some products are completely finished products; others represent a partial assembly that can be further assembled into many finished products.
Data in the Corporate Information Factory
Key components of the corporate information factory are shown in Figure 2.1. Let’s begin with external data. External data enters the corporate information factory from the world outside of the corporation. It is not generated internally, nor is it captured and manipulated at a detailed level internally. Instead, external data represents events and objects outside of the corporation in which the corporation is interested. External data can be used throughout the corporate information factory—at the data mart, data warehouse, ODS, and/or application levels.
Reference data is data that is stored in a shorthand fashion that serves to tie together multiple and diverse users. It is used to speed and standardize processing across many different departments and is typically found at the application level. As reference data passes into the architectural components of the corporate information factory, it takes on a slightly different form, that of historical reference data. The difference between reference data and historical reference data is that reference data represents information that is current and accurate as of the moment of usage. Historical reference data is the historical record of that same reference data, except that it is collected and managed over time. As current reference data changes over time, those changes are collected along with the effective change date in order to create historical reference data. Historical reference data is of great use to the data mart and the data warehouse analyst in that it provides details that help describe data in the data warehouse and data marts.

Figure 2.1 The basic structure of the corporate information factory.
A third type of data is raw detailed data. This data is generally captured at the application level and loaded into the data warehouse and ODS via the I & T layer. However, some raw detailed data may be captured and managed directly in the ODS. This happens when the end-user community needs access to data that is not currently being managed by an application. In effect, the ODS becomes the authoritative source of this data and source system to the data warehouse. Some may try to manage this data directly in the data warehouse; however, this is not recommended. This would be like trying to bulldoze a large mound of dirt with a Ferrari. The data warehouse is designed for strategic decision support and lacks the form and function to effectively store and access transaction-level data in real time. Additionally, if the data warehouse became the authoritative source of this raw detail data, it is likely that it would quickly become pressured to support operational activities for which it was designed to augment. This is likely to be a terminal condition for the information ecosystem.
Let’s take a closer look at external, reference, and historical data.
External Data
A key source of data found in the CIF is that of external data (see Figure 2.2). External data is data originating outside the CIF. Typically, external data is purchased or created by another corporation. It can be of almost any type and volume and can be either structured or unstructured, detailed or summarized. In short, as many types of external data exist as there are internal data.
One fundamental way in which external data differs from internal data is in its capability to be manipulated. When internal data needs to be changed, the programs that capture and shape it can always be altered. In that sense internal data is very malleable.
However, external data is pretty much what you see is what you get. Because the sources for the external data lie beyond the CIF, it is beyond the scope of the CIF architect to effect such a change in it. About the only real choice the CIF architect has to make is to either use the external data as is or to reject its use altogether.
The one exception to the alteration of external data is that of modifying a key structure to the external data as it enters the CIF. This happens quite often when trying to match external data to an existing customer. Generally, an attempt is made to match the name and address associated with the external data to a name and address in the customer database. If a match is made, the external key is replaced with the internal customer ID, and the external data is stored.
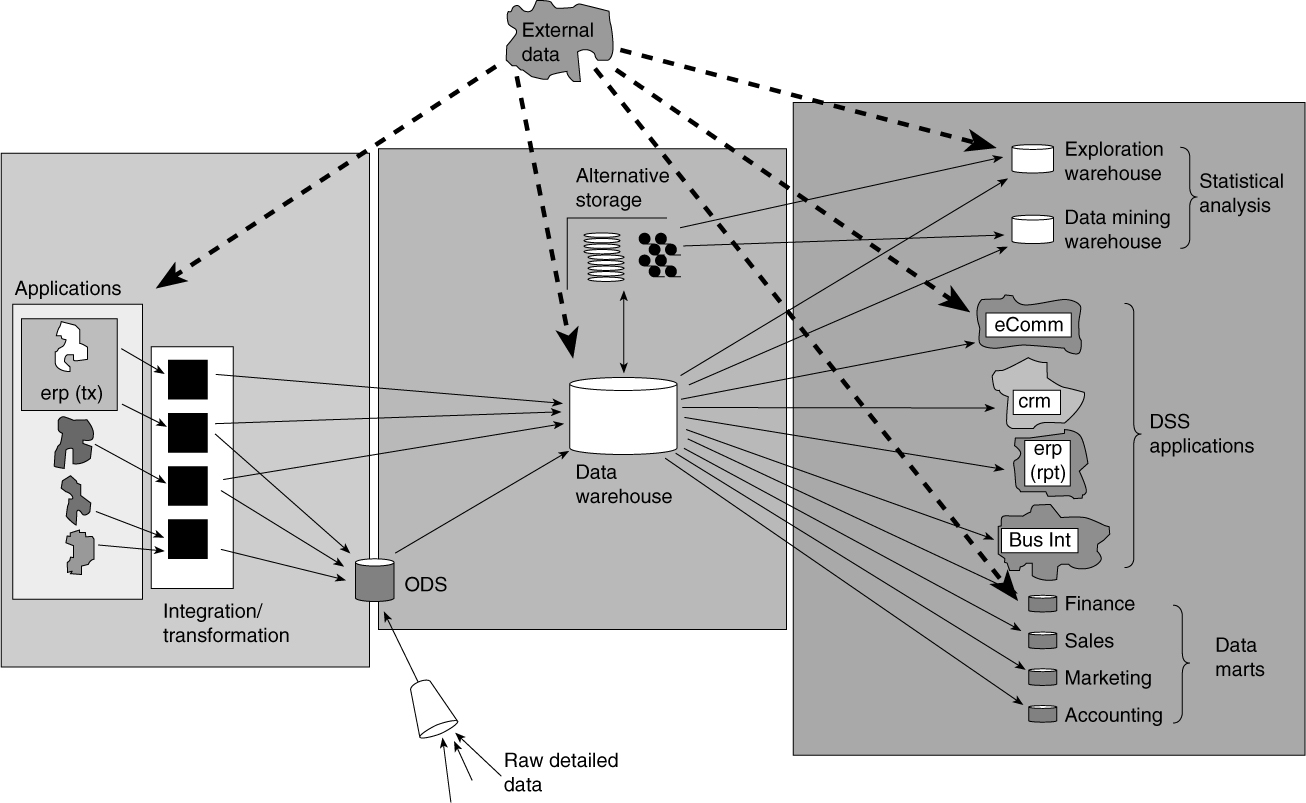
Figure 2.2 External data is an integral part of the CIF environment.
In many cases, the external data will have a key structure that is quite different from the key structure used within the CIF. The external data needs to have its keys modified in order to be used meaningfully within the confines of the CIF.
The modification of the external key can be a simple or a difficult thing to accomplish. In some cases, the external key goes through a simple algorithm to convert it to the CIF key. In other cases, reference tables are used in conjunction with an algorithm. And in the worst case, the conversion is made manually, on a record-by-record basis. The manual approach to key resolution is not viable for massive amounts of data and/or where the manual conversion must be done repeatedly.
External data can be made available to any and all components of the CIF. If the external data is to be used in multiple data marts, it is a good policy to place the external data first in the data warehouse and then transport it individually to the data mart. By placing it first inside the data warehouse, reconcilability of the data is maintained.
The component in which external data is most prominent is the exploration warehouse. In this environment, analysts endeavor to gain new insight about the business that cannot be distilled using internal transactional data. It is not uncommon for these analysts to use the exploration warehouse to identify new market opportunities or to characterize customers so that the business can better respond to their needs.
Reference Data
Some of the most important data any corporation has is reference data. One very popular type of reference data describes valid products and product hierarchies for a company. Reference data fulfills the following roles:
![]() It allows a corporation to standardize on a commonly used name for important and frequently used information, such as product, state, country, organization, customer segment, and so forth.
It allows a corporation to standardize on a commonly used name for important and frequently used information, such as product, state, country, organization, customer segment, and so forth.
![]() It allows commonly used names to be stored and accessed in a short-hand fashion, which saves disk space.
It allows commonly used names to be stored and accessed in a short-hand fashion, which saves disk space.
![]() It provides the basis for consistent interpretation of corporate data across departments. For example, if reference data existed, we could be reasonably assured that three separate departments analyzing sales volumes for dog food would come up with the same answer. Without this reference data, each department is likely to roll-up products differently, resulting in different sales volumes for dog food.
It provides the basis for consistent interpretation of corporate data across departments. For example, if reference data existed, we could be reasonably assured that three separate departments analyzing sales volumes for dog food would come up with the same answer. Without this reference data, each department is likely to roll-up products differently, resulting in different sales volumes for dog food.
In short, reference data is one of the most important kinds of data that a corporation has. Figure 2.3 shows the presence of reference data in the CIF.
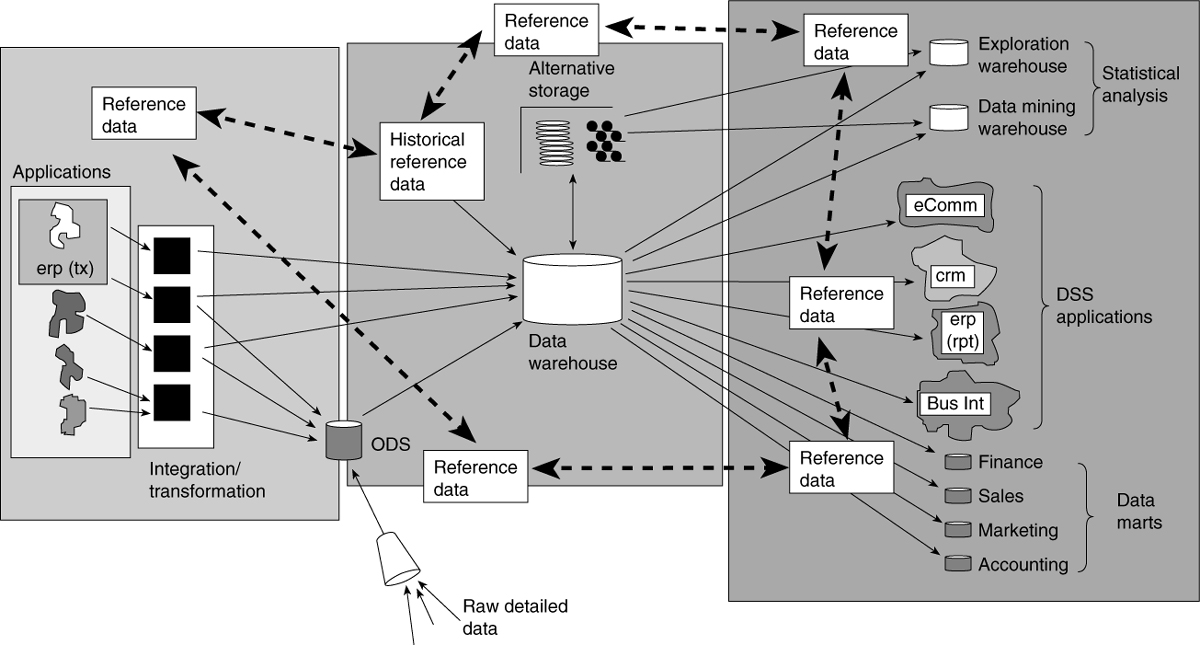
Figure 2.3 Reference data makes up an important part of the CIF. Note that reference data contained in the data warehouse is historical.
Reference data is notoriously unstructured and is, at best, a hit-and-miss proposition. This is in contrast to other forms of data, which are core to running the day-to-day businesses that require and receive great care in systematization. For example, data is needed to invoice a customer correctly. Programs and procedures are written for the update, creation, and deletion of nonreference data. But because reference data is so commonly used, programs and procedures needed for the systematization of reference data are not formalized. Several reasons exist for the lack of formalization:
![]() The volume of data that constitutes reference data is usually very small compared to other types of data found in the corporation. Reference data consumes only a fraction of a fraction of the space required for regular data. Because of its small size, reference data is often treated as an afterthought.
The volume of data that constitutes reference data is usually very small compared to other types of data found in the corporation. Reference data consumes only a fraction of a fraction of the space required for regular data. Because of its small size, reference data is often treated as an afterthought.
![]() Reference data is usually very slow to change. Unlike other types of data, which are constantly being created, deleted, and updated, reference data is very stable. Because of this stability, no one pays attention to the need for systematization of reference data.
Reference data is usually very slow to change. Unlike other types of data, which are constantly being created, deleted, and updated, reference data is very stable. Because of this stability, no one pays attention to the need for systematization of reference data.
![]() Reference data is often dictated by external sources. There are standard abbreviations for states, countries, and so on. There is no need for systematization of these types of reference data.
Reference data is often dictated by external sources. There are standard abbreviations for states, countries, and so on. There is no need for systematization of these types of reference data.
![]() Reference data often belongs to the entire corporation, not just a single department. Because reference data is a common corporate property, no one steps forward to own and manage the reference data.
Reference data often belongs to the entire corporation, not just a single department. Because reference data is a common corporate property, no one steps forward to own and manage the reference data.
For these reasons and more, reference data is often not managed with the same discipline that other data in the CIF is managed, yet it still requires as careful attention as any other type of data. For at least three reasons, reference data plays a very important role in the world of the CIF:
Reference data can simplify I & T layer processing. If reference data in an application is the same as reference data in the data warehouse, then the task of I & T is made much simpler. However, if the I & T layer must completely discard one approach to reference data and create an entirely brand new reference system (which can be done in extreme cases), then the logic of I & T processing becomes very complex and cumbersome.
Reference data is one of the primary ways that the different components of the CIF communicate and maintain continuity with each other. Whether you have implemented a data mart, exploration warehouse, ODS, or any other component of the CIF, well-formed and maintained reference data will help to ensure that such measures as revenue by product group and households by customer segment are consistent across the CIF.
Reference data ages over time. In the data warehouse, as reference data ages, a historical record must be kept so that the historical data that resides in the warehouse can have references made to the data that are accurate as of the moment of the creation of the data warehouse record. In other words, because historical data is stored in the data warehouse, an historical reference needs to be kept. If the DSS analyst is going back to 1995 to look at data in the data warehouse, he needs to know what the reference data was for 1995. It will not do to have the DSS analyst looking at 1995 data from the data warehouse where the DSS is trying to use reference tables from 1997. The need for historical referencability is one of the important and peculiar needs of the data warehouse within the context of the CIF.
Historical Data
Even when data has been entered onto a computer system and it is ten seconds old, it is historical in the sense that it represents events now passed. Of course, the event that has passed is much more current than events that may have occurred a week ago or a month ago. Nevertheless, all data entered into a computer system can be thought of as historical data (with the exception of forecast data). The issue is not whether data is historical, but just how historical the data is. The implications of historical data are many, including:
Volume of data. The longer the history is kept, the greater the amount of data.
Business usefulness. The more current a unit of information, the greater the likelihood that it is relevant to current business.
Aggregation of data. The more current the data, the greater the chance that the data will be used at the detailed level. The older the data, the greater the chance that the data will be used at the summary level.
Many other implications of history exist. These are merely the obvious ones. Figure 2.4 shows that the components of the CIF contain different phases of corporate information history.
The applications environment contains very current information, up to 30 days. Of course, the actual time parameters vary across industries and businesses. Some industries may have more than 30 days worth of information; other industries may have less.
The ODS environment has a time period identical to that of the applications. The difference between the ODS and the applications is that the ODS contains integrated corporate data, and the applications do not.
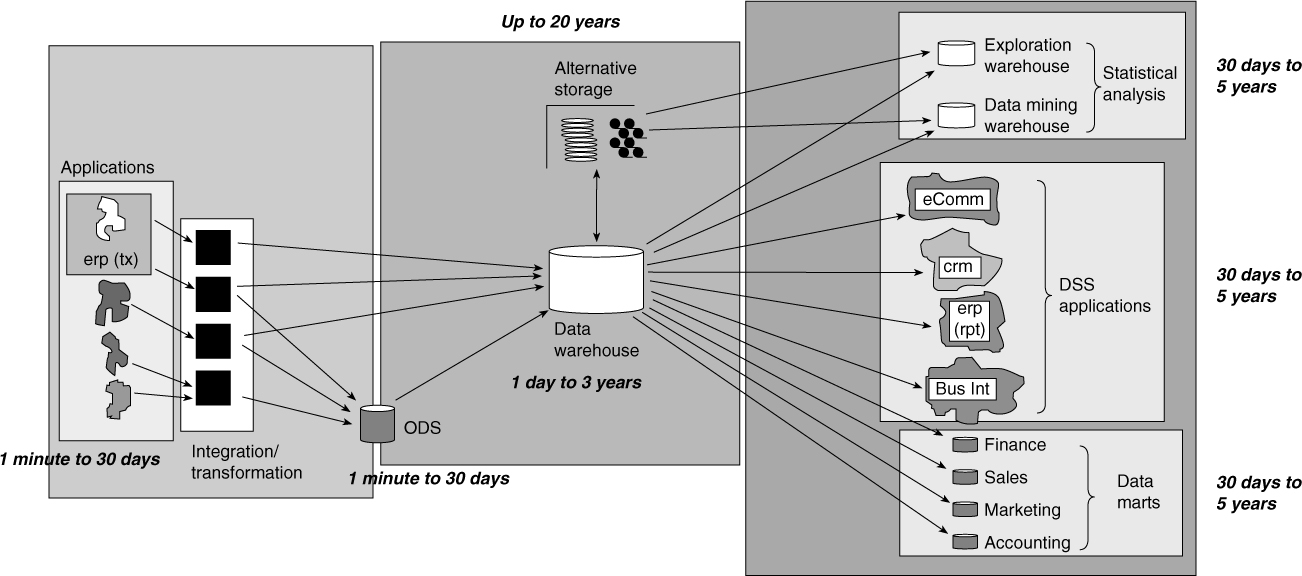
Figure 2.4 The amount of historical data that is found in the CIF differs from component to component.
The data warehouse contains data that is at least 24 hours old, up to 5 to 10 years worth of history. The actual length of time found here is highly dependent on the industry that is being represented by the data warehouse.
The data mart contains the widest variety of data found in the environment. The amount of history contained by a data mart is dependent on:
![]() The industry the corporation is in
The industry the corporation is in
![]() The company within the industry
The company within the industry
![]() The department within the company
The department within the company
By far the greatest volume of historical data is found in alternative storage. This is where much of the historical transaction data from the data warehouse is archived. Historical data is even found in the exploration and data mining warehouses. Fortunately, use of historical data in these environments is project oriented so history is fairly pruned and temporary. As a result, the exploration and data mining warehouses don’t require the large amounts of long-term storage or I & T layer processing to maintain history as do many of the other components of the CIF (data warehouses, alternative storage, data mart, etc.)
Of special interest is where different components overlap. The first overlap is between the applications arena and the ODS. As previously stated, the ODS contains corporate collective data, and the applications contain application-detailed (generally unintegrated or at best functionally integrated) data. There is overlap in the time frame, but no overlap in terms of the integration of the data.
The second overlap is between the data warehouse and the applications. An application may have data stored within it, up to 30 days or so. The data warehouse may have that same data stored. There are a few differences, however. The data warehouse contains data that has been passed through the I & T layer. As such, the data warehouse data may or may not be physically the same as the applications data. The second difference is that the data warehouse historical data is stored along with other historical data of the same ilk. The applications data is stored in an isolated manner.
The Decision-Support System to Operational Feedback Loop
The standard flow of data throughout the CIF is from left to right, that is, from the consumer to the application, from the application to the I & T layer, from the I & T layer to the ODS or the data warehouse, from the ODS to the data warehouse, and from the data warehouse to the data marts. The flow occurs as described in a regular and normal manner. However, another feedback loop is at work, as depicted in Figure 2.5.
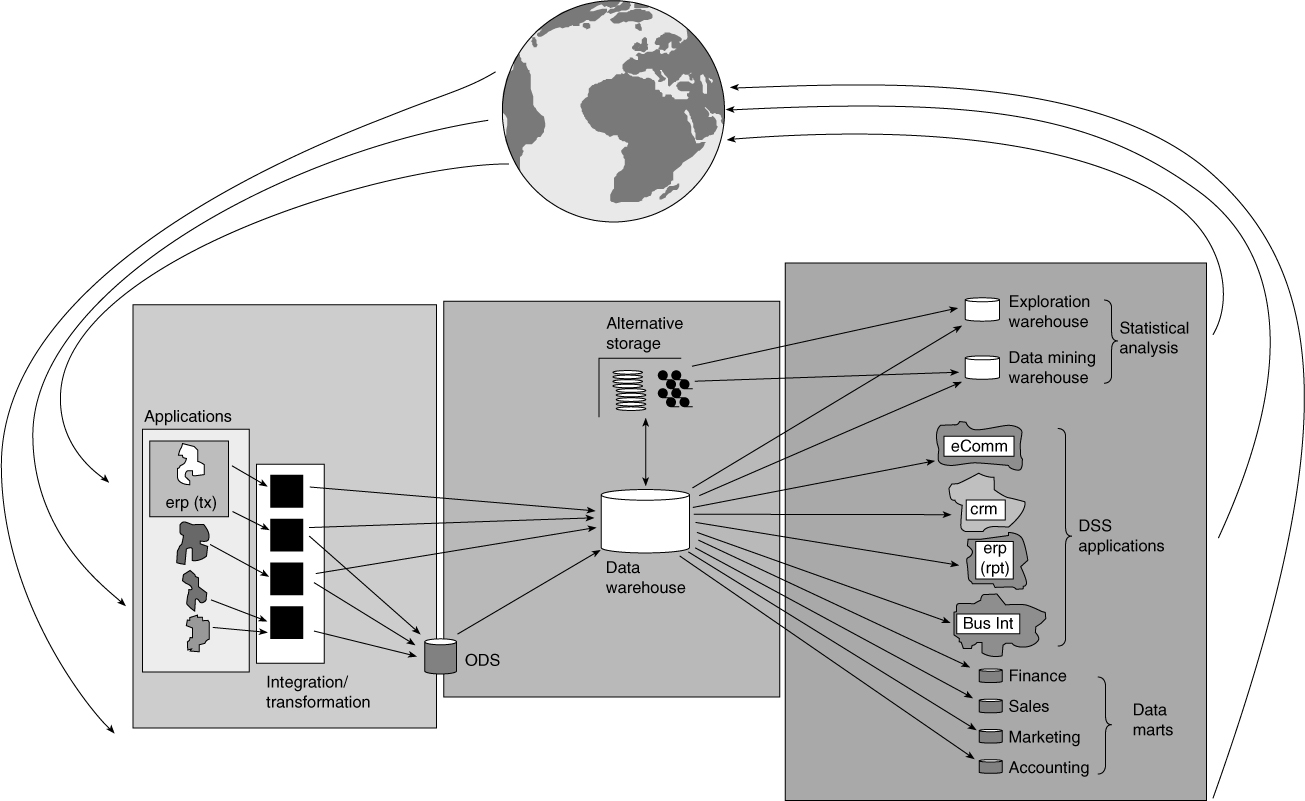
Figure 2.5 The feedback loop from the DSS/informational environment to the applications environment.
Figure 2.5 shows that as data is used in the DSS (or information) environment, decisions are made. As an example, a manager in the insurance environment decides to raise rates on a certain kind of policy based on the information derived from the DSS environment. Perhaps a bank manager decides to raise rates on car loans. Another example is a retailer deciding to produce more of product ABC based on strong demand detected in the DSS environment. In short, the DSS environment provides a basis for making business decisions.
However, after those business decisions have been made, they have an impact, which is first detected by the applications environment. For example, when the retailer decides to produce more of product ABC, sales are boosted across the United States, and the increase in sales is measured by the applications systems having a direct interaction with the consumer. Likewise, when an insurance executive decides to lower rates for a policy type, more policies are sold, which in turn is measured by the applications environment. In any case, the CIF operates as part of a holistic system. This ecosystem is regulated by the feedback loop shown in Figure 2.5. It is through this feedback loop that the different components of the CIF find a balance and constantly adjust to each other.
The Flow of Data
A predictable or normal-flow of data moves throughout the corporate information factory. The normal flow is indicated by the solid lines with arrows that connect the different components of the corporate information factory in Figure 2.6.
In general the flow of data is from left to right. Usually, 95 to 99 percent of the data in the corporate information factory flows as indicated in Figure 2.6. For example, a large amount of data flows from the legacy environment into the integration and transformation component, or a large amount of data flows from the data warehouse to the data mart environment.
Another very important flow of data in the corporate information factory is not along the lines of the normal flow. Data back flow exists in the corporate information factory. In Figure 2.6, dotted lines indicate the back flow of data, which is normally not voluminous. In fact, the back flow of data is minuscule to the point that in some cases it is so small as to be unmeasurable. But, just because it is small in volume does not mean that it is not important to the business.
Examples of back flow include:
![]() The marketing department deciding to raise the rates for certain lines of insurance. The raise itself is a small amount of data that has a large consequence for the business.
The marketing department deciding to raise the rates for certain lines of insurance. The raise itself is a small amount of data that has a large consequence for the business.
![]() The exploration statistician notes that there appears to be a growing market for goods for consumers from the ages of 15 to 20. The decision is made to price certain articles aimed at that marketplace even lower in order to attract market share.
The exploration statistician notes that there appears to be a growing market for goods for consumers from the ages of 15 to 20. The decision is made to price certain articles aimed at that marketplace even lower in order to attract market share.
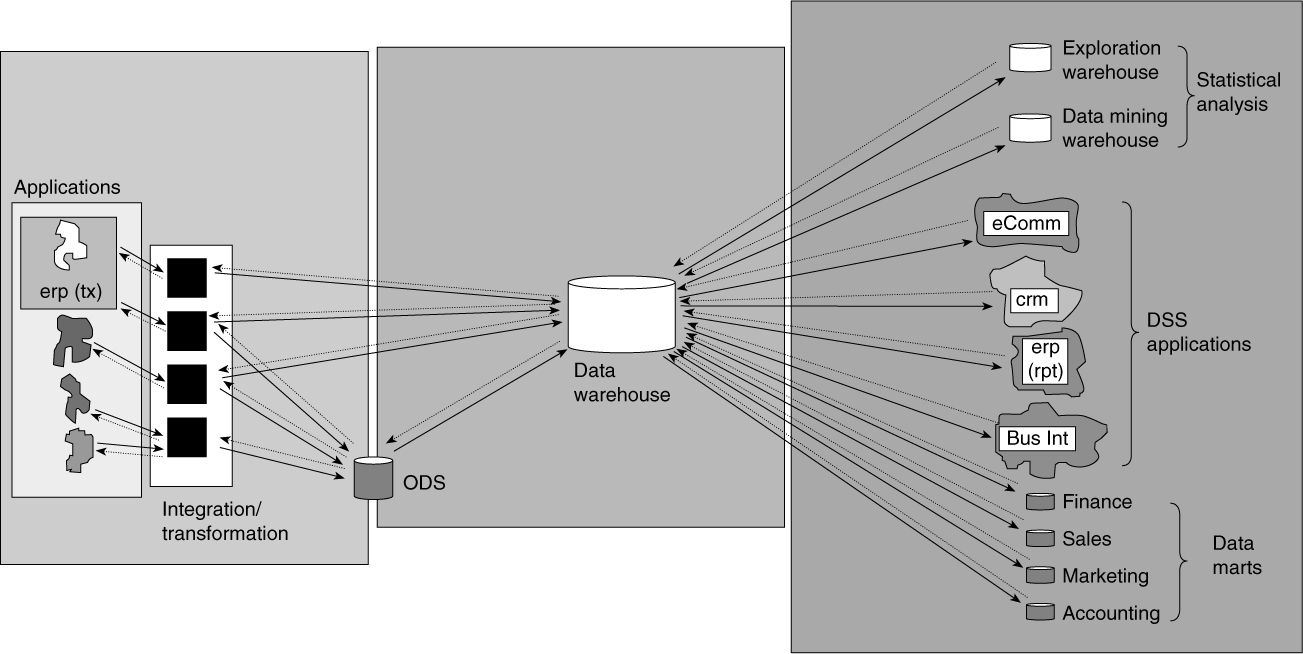
Figure 2.6 The normal flow of data in the CIF is shown with solid lines. Back flow is represented by dotted lines.
![]() The enterprise resource planning (ERP) application produces information that indicates certain assembly lines are more productive than other lines. The decision is made to monitor the less productive lines carefully.
The enterprise resource planning (ERP) application produces information that indicates certain assembly lines are more productive than other lines. The decision is made to monitor the less productive lines carefully.
![]() The banking sales and product department notes that loans for homes are slowing down. The decision is made to reduce home loan rates by ½ percent. The movement of data characterizing the lowering of rates is minuscule, but the business impact is enormous.
The banking sales and product department notes that loans for homes are slowing down. The decision is made to reduce home loan rates by ½ percent. The movement of data characterizing the lowering of rates is minuscule, but the business impact is enormous.
![]() Analysis is done in the data warehouse to select certain customers for preferred treatment. The list of preferred customers is sent to the ODS so that when those customers call in, they are immediately identified. The list of preferred customers is a short list that flows from the data warehouse to the ODS, but the business impact is large.
Analysis is done in the data warehouse to select certain customers for preferred treatment. The list of preferred customers is sent to the ODS so that when those customers call in, they are immediately identified. The list of preferred customers is a short list that flows from the data warehouse to the ODS, but the business impact is large.
The one place where there is a regular back and forth flow of data in the corporate information factory is from the data warehouse to and from alternative storage. The flow here depends on query activity and the nature of the queries. The more detail history required to supports a query, the more likely the alternative storage will need to be accessed.
Variations to the Corporate Information Factory
One of the common and valid variations to the corporate information factory occurs when there is no ODS. The ODS is peculiar in that many organizations find that they do not need an ODS to run their business. An ODS can be:
![]() Expensive and difficult to build
Expensive and difficult to build
![]() Expensive to operate
Expensive to operate
![]() Challenging to maintain
Challenging to maintain
There must be a very sound business case for an ODS. Of course, when an ODS is needed, there is nothing to replace it. Typically, large, decentralized businesses that require product integration and businesses that do a lot of high-performance transaction processing are candidates for an ODS.
Because many corporations operate successfully without an ODS, one valid variation of the classical corporate information factory architecture, as shown in Figure 2.1, is an architecture without an ODS. When there is no ODS, the flow of all data is from the I & T layer directly to the data warehouse.
Other variations exist to the corporate information factory. One variation is having no data in alternative storage. Data warehouses do not start out as large databases. Even the largest data warehouse started small at some point in time and as long as a data warehouse is of a small to modest size, no need exists for alternative storage. But as a data warehouse grows large, the need for alternative storage becomes apparent.
Another variation on the classic architecture of a corporate information factory is a no exploration warehouse. Only when a corporation starts to do a significant amount of exploration does the exploration warehouse become a standard part of the CIF. In addition, the exploration warehouse services both data mining and exploration needs until the company starts to do a really large amount of exploration.
Yet another variation to the CIF is multiple exploration warehouses. Exploration warehouses are typically project driven, with definite beginnings and endings. Having two or three exploration warehouses up and running is normal for a large corporation.
These are only a few variations of the corporate information factory. The classic CIF is never fully built. Instead, parts of the CIF are constantly being constructed, modified, reconstructed, and so forth.
Operational Processing and DSS Processing
Where operational processing ends and DSS/informational processing begins is clearly delineated. Figure 2.7 depicts that demarcation. The figure shows that the applications environment is entirely in the world of operational processing. Data marts and the data warehouse are completely in the world of DSS/informational processing. The ODS sits squarely in the middle of the world of informational and operational processing. With an ODS, both operational and informational processing are in the same structure. This is one of the reasons why the ODS is the most complex part of the information ecosystem. Every other part of the infrastructure can be optimized to suit one style of processing or the other, but the ODS must be optimal (or at least acceptable!) for more than one style of processing. This factor greatly complicates the life of the builder and the manager of the ODS environment.
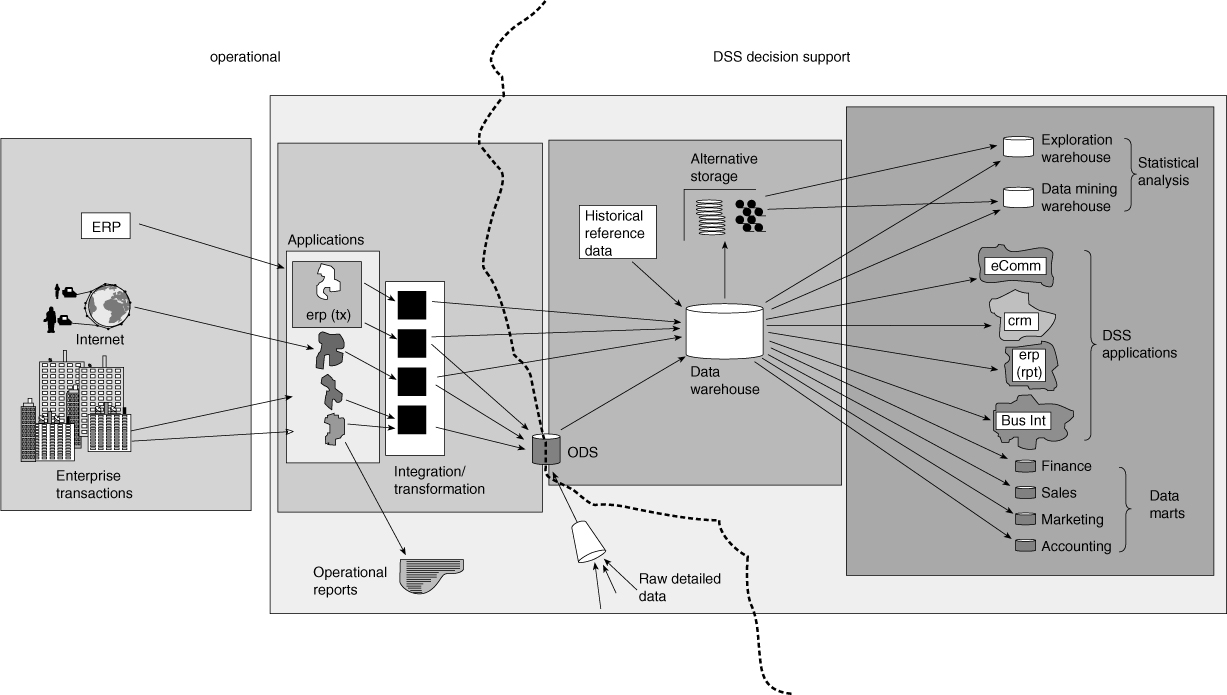
Figure 2.7 A very clearcut dividing line exists between operational processing and DSS informational processing in the CIF.
Reporting in the Corporate Information Factory
Analysis of data and reporting can be done throughout the corporate information factory. There is no point at which data is locked up and becomes unavailable. But at each different component of the architecture, the reporting that is done is quite different. The different kinds of reporting are:
![]() Operational reporting—ODS reporting for collective integrated data
Operational reporting—ODS reporting for collective integrated data
![]() Data warehouse reporting
Data warehouse reporting
![]() Data mart departmental reporting
Data mart departmental reporting
Each of the types of reporting has its own unique characteristics.
Corporate Information Factory Users
Different types of users access the corporate information factory at different places. Figure 2.8 shows the typical users of the applications of the CIF.
Applications Users
The users of applications are primarily clerical workers or sales/service professionals and, in some cases, the customers of the corporation themselves. Occasionally, the customers have direct interaction with the corporate applications through facilities such as ATMs, kiosks, Web sites, and even through direct entry using their personal computer. In other cases, a clerk is required to enter detailed data taken from the customer. The kind of data that is handled at the application level is:
![]() Detailed
Detailed
![]() Immediate
Immediate
![]() Application-oriented
Application-oriented
The user of the technology at the application level can expect immediate feedback in the form of transactions. High-performance transactions are the order here with one second response time as the norm. A high degree of availability across the network supports that type of application.
The nature of the applications in the corporate information factory includes:
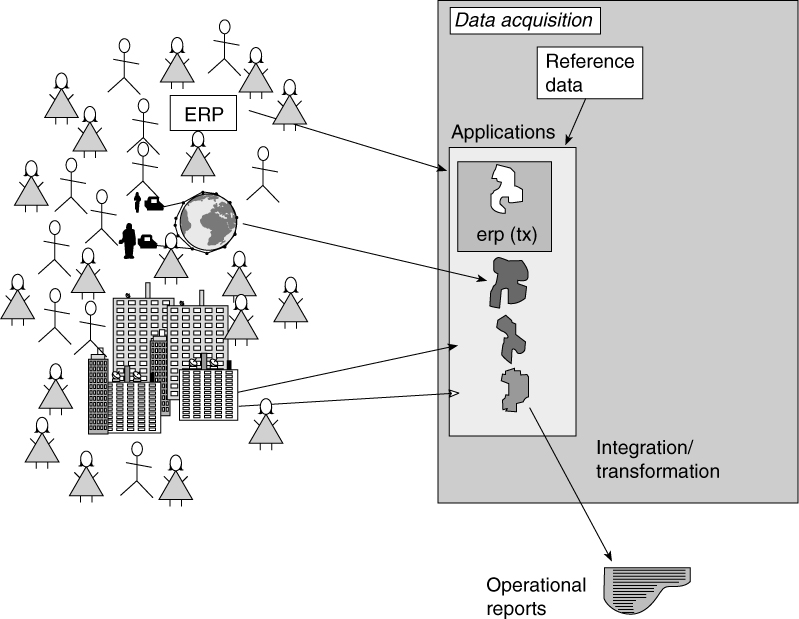
Figure 2.8 The users of the applications expect detailed information that is accurate up to the second and down to the last penny.
![]() Interacting with the end user
Interacting with the end user
![]() Collecting data
Collecting data
![]() Editing data
Editing data
![]() Auditing data
Auditing data
![]() Allowing adjustments and corrections to be made
Allowing adjustments and corrections to be made
![]() Verifying transactions
Verifying transactions
![]() Keeping an accurate record of events
Keeping an accurate record of events
![]() Keeping online data accurate with a high degree of integrity
Keeping online data accurate with a high degree of integrity
![]() Allowing small units of data to be accessed very rapidly
Allowing small units of data to be accessed very rapidly
![]() Securing data and transactions, etc.
Securing data and transactions, etc.
The interaction with the end users at the application level is through reports and terminals (usually preprogrammed and tightly controlled). The applications have their own store of data, which is augmented by reference data and external data. As a rule, the applications environment is unintegrated, where each application serves a particular need and a unique set of requirements.
Decision-Support System/Informational Users
DSS/information users are very different from operational users. They are solving or investigating longer-term questions. Operational users are concerned with very immediate and very direct decisions, such as:
![]() How much money is in an account right now?
How much money is in an account right now?
![]() Where is a shipment right now?
Where is a shipment right now?
![]() What coverage is there for a policy right now?
What coverage is there for a policy right now?
![]() When is an order due?
When is an order due?
DSS users are concerned with decisions that are much broader and long term, such as:
![]() What type of customer is the most profitable for our business?
What type of customer is the most profitable for our business?
![]() Over the years, how has transaction activity changed?
Over the years, how has transaction activity changed?
![]() Where has sales activity been highest in the springtime for the past three years?
Where has sales activity been highest in the springtime for the past three years?
![]() When we change prices, how much elasticity is there in the marketplace?
When we change prices, how much elasticity is there in the marketplace?
The DSS analysts have a whole different perspective on the use and value of information. They look at:
![]() Information that has been integrated across the corporation
Information that has been integrated across the corporation
![]() Broad vistas of information, instead of small divisions of information
Broad vistas of information, instead of small divisions of information
![]() Information over a lengthy period of time, rather than very current data
Information over a lengthy period of time, rather than very current data
Some very different characteristics are found between the use of information by DSS analysts and operational analysts, such as:
![]() The DSS analyst often looks at very large amounts of information as opposed to the operational analyst who looks at tiny bits of information.
The DSS analyst often looks at very large amounts of information as opposed to the operational analyst who looks at tiny bits of information.
![]() The DSS analyst does not need to have information returned immediately. Five minutes, 30 minutes, or even overnight in many cases is just fine for the DSS analyst, as opposed to the operational analyst who needs two to three seconds response time.
The DSS analyst does not need to have information returned immediately. Five minutes, 30 minutes, or even overnight in many cases is just fine for the DSS analyst, as opposed to the operational analyst who needs two to three seconds response time.
In addition, the very way that information is sought is different between the DSS analyst and the operational analyst. The DSS analyst looks for information heuristically, where the next step of analysis is profoundly shaped by the results obtained in the previous step of analysis and where the exact shape or even the extent of an analysis cannot be determined at the outset.
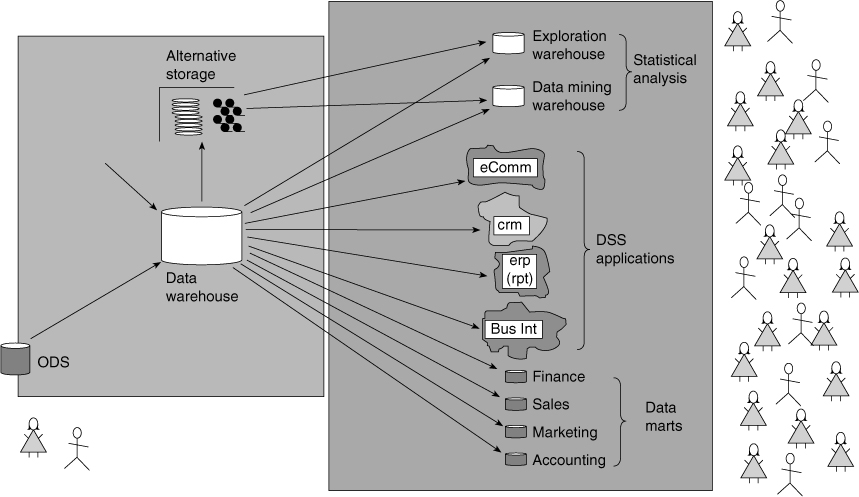
Figure 2.9 DSS/informational users’ needs are very broad as compared to operational users.
The operational analyst operates in a mode where queries and questions are preformatted into a very structured format. The same activity is repeated over and over again, where all that changes is the data that is being operated on in the world of the operational user.
Figure 2.9 shows that many different kinds of DSS analysts exist. At the departmental level are data mart analysts who do decision support through the eyes of their department. Typical departments are finance, marketing, and sales. The customized summary/subset data that is found in the data mart is exactly what the data mart analyst needs to satisfy their unique needs of data mart DSS processing.
Exploratory analysis is done at the data warehouse. The integrated, detailed data and the robust amount of history found at the data warehouse are ideal for this type of analysis.
Collective integrated operational analysis can be done at the ODS. Admittedly, much true operational processing is done at the ODS. But, occasionally, a need presents itself to do operational DSS processing. When that need arises, the ODS is the ideal place for processing.
Different types of DSS users are scattered throughout the corporate information factory. The four most common types of DSS users are tourists, farmers, explorers, and miners.
Tourists
Tourists are those DSS analysts who specialize in being able to find a breadth of information, as illustrated in Figure 2.10.
In the figure, a tourist is seen as an individual who uses the Internet/intranet and knows where to find many things. A tourist understands the structure of the corporate information factory and knows where in the structure of things to find almost anything. However, the tourist is an unpredictable analyst, sort of a walking directory of information.

Figure 2.10 One type of DSS user is the tourist.
Farmers
A farmer is a very different kind of DSS analyst than a tourist, as shown in Figure 2.11.

Figure 2.11 A second type of DSS user is a farmer.
A farmer is someone who is predictable and knows what he or she wants before setting out to do a query. A farmer looks at small amounts of data because the farmer knows where to find the data. The farmer is somewhat repetitive in the search for information and seldom wanders far from data that is familiar. The farmer operates as comfortably on detailed data as on summary data. In many regards, because summary data is compact and concise, summary data suits the needs of the farmer quite nicely. In addition, the data the farmer is looking for is almost always here.
Explorers
A third type of DSS analyst is someone known as an explorer, as shown in Figure 2.12.
Explorers have some traits similar to both the tourist and the farmer but are unique unto themselves. The explorer is someone who operates with a great degree of unpredictability and irregularity and looks over massive amounts of detail. The explorer seldom has much use for summary data and frequently makes requests that seem to be farfetched. Often times the explorer finds nothing, but occasionally the explorer finds huge nuggets in the most unexpected places. The explorer becomes an expert in one arena within the corporate information factory.

Figure 2.12 A third type of DSS user is an explorer.

Figure 2.13 A fourth type of DSS user is the data miner.
Miners
The fourth type of DSS analyst is an individual known as a miner, shown in Figure 2.13.
Miners have a great affinity to the explorer, and they form a symbiotic relationship. The explorer creates assertions and hypotheses. The miner proves the validity or invalidity of those assertions and hypotheses. The miner is a statistician. The miner begins by testing one or more hypotheses against a large body of data, usually transaction data. The miner then comes up with a statistically based opinion about the strength of the hypotheses. In many cases, examining one hypothesis leads the miner to discover other hypotheses. These newly discovered hypotheses are then reported back to the explorer for further examination.
Queries submitted by the miner are the largest found in the corporate information factory. A miner will typically look over many, many rows of data to discern the truth about a hypothesis.
Types of DSS Usage in the Corporate Information Factory Environment
Understanding that there are different kinds of DSS users with very different goals and techniques is the first step in resolving many seemingly complex and contradictory facets of the corporate information factory. Without this perspective, many DSS components of the corporate information factory do not make sense.
As an example of the perspective provided, consider that different parts of the DSS environment within the corporate information factory attract and apply to different types of users, as seen in Figure 2.14.
The figure shows that data mart and departmental analysis apply to farmers and the occasional tourist. Explorers are attracted to the data warehouse and, once in a while, the tourist finds his or her way into it. The ODS environment is almost exclusively the domain of farmers. It is worthwhile noting that the farmers found at the ODS environment are quite different from the farmers found at the data mart. The data mart farmers are those people who are analyzing a problem for possible future action. The farmers at the ODS environment are those who are interested in an immediate short-term tactical corporate decision, not some long-term consideration. For example, is this customer a good credit risk?
One of the reasons why the separation of the DSS analyst community into different audiences is important is that it explains why there are such diverse design and development practices throughout the DSS portion of the corporate information factory.
Centralized or Distributed?
One of the most important issues of the corporate information factory is whether the underlying component of the architecture is (under normal circumstances) centralized or distributed. This issue is salient to the implementation, functionality, and economics of the ultimate deployment of the corporate information factory. It needs to be considered on a case-by-case basis for each of the different components of the architecture. Figure 2.15 addresses centralization of the applications environment.
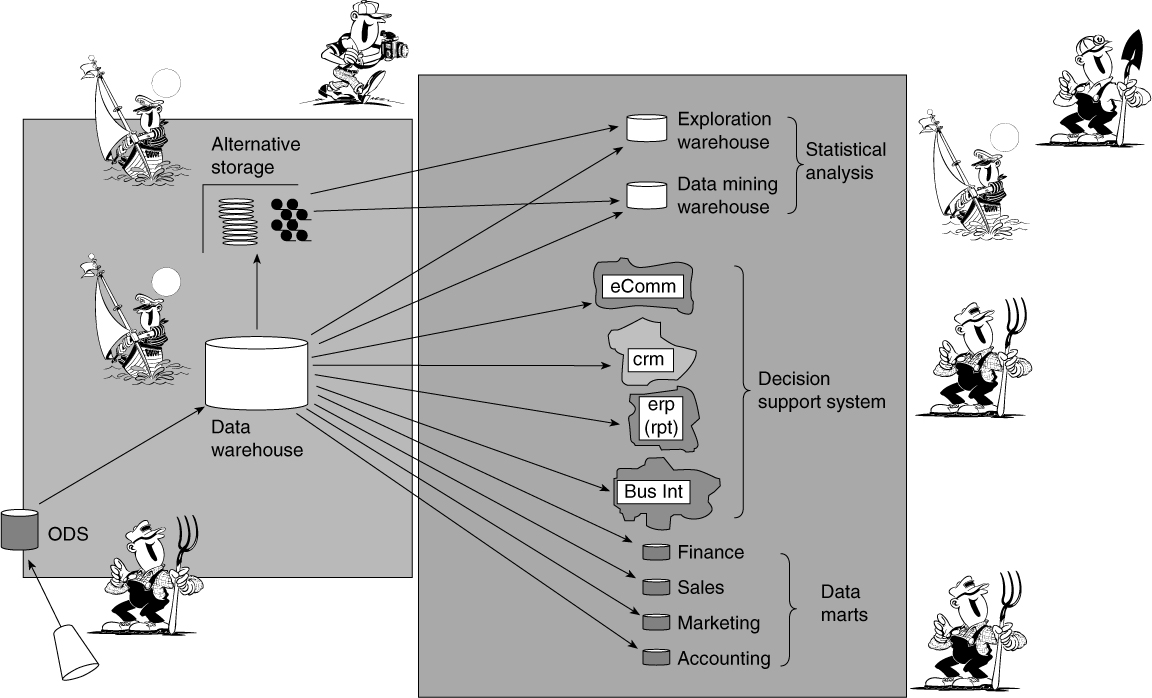
Figure 2.14 Different types of users fit in different places in the DSS/informational component of the CIF.
Because the applications environment can be either centralized or distributed, the decision is usually made by history: The hardware, and the past development and deployment of the application environment determine whether the applications are centralized or distributed.
As a rule, large transaction-processing applications are centralized, and smaller offline, sequential applications tend to be distributed. The ODS is almost always centralized, as seen in Figure 2.16.
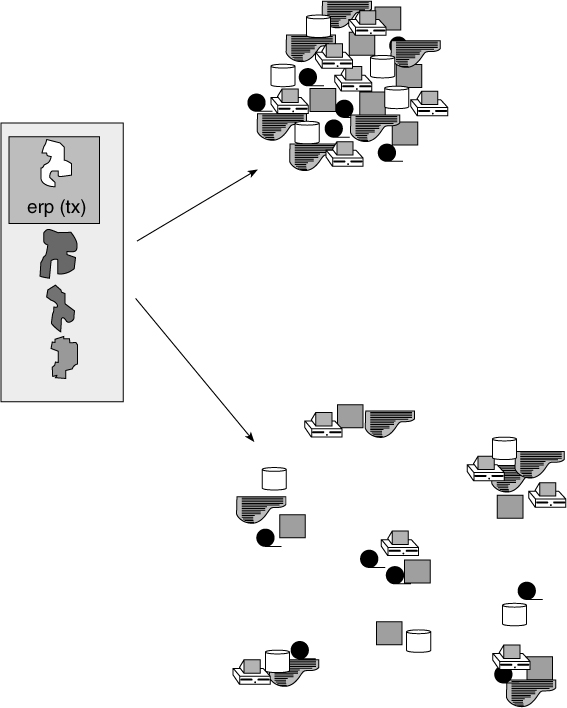
Figure 2.15 Applications can be either distributed or centralized.
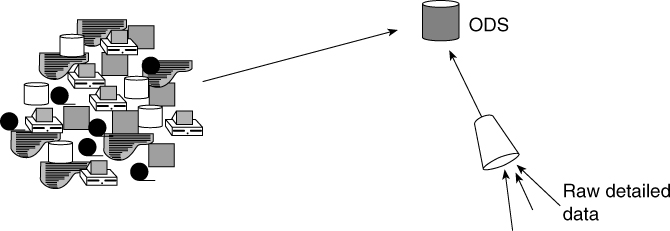
Figure 2.16 The ODS is almost always centralized.
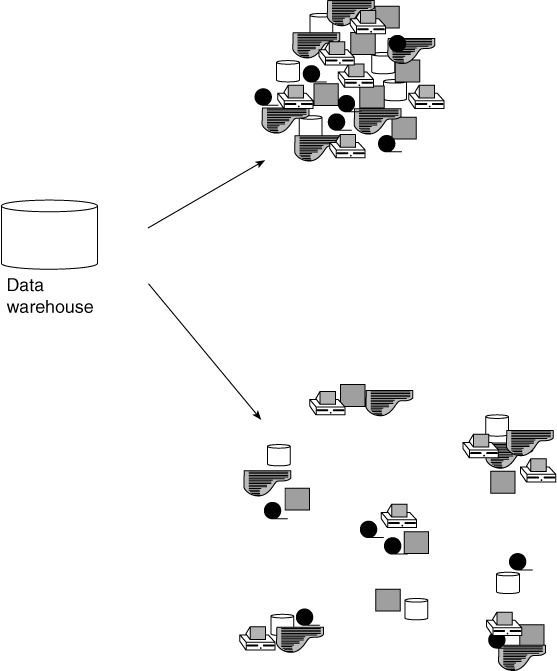
Figure 2.17 The data warehouse can be either distributed or centralized.
While in theory it may be possible to have a distributed ODS environment, in practice all ODS are centralized.
The data warehouse is another matter. The data warehouse can be either centralized or distributed, as shown in Figure 2.17.
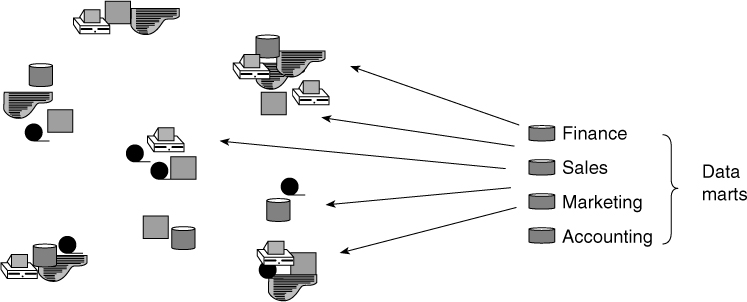
Figure 2.18 The data mart environment is distributed and decentralized.
In general, most data warehouses are centralized. But some very notable and successful examples of distributed data warehouses do exist. These have a slightly different form from a classic centralized data warehouse. When a data warehouse is distributed, the detail of the system is left at the local level. The architectural construct known as the distributed data warehouse is really centered around a lightly summarized level of data. This level of data becomes the corporate data warehouse. In this regard, the distributed data warehouse is a mutant form of a more standard data warehouse.
Data marts are exclusively distributed, as seen in Figure 2.18.
The very nature of data marts is that they be unique to the environment that owns or controls them. As such, data marts are distributed around the different departments of the corporation in many shapes and forms.
Data Modeling and the Corporate Information Factory
The CIF has many disparate parts. Although an overall dynamic pervades the corporate information factory, each component has its own parts and internal interactions. Therefore, some mechanism or technique must allow the CIF to function in a coordinated, cohesive manner. The structure of the different components is unified by means of a data model. The data model allows each of the architectural components of the corporate information factory to have as much autonomy as it needs, and at the same time allows the CIF to operate in a unified manner. The data model is the data blueprint and intellectually unifies the data warehouse. Figure 2.19 shows the role of the data model to the corporate information factory.
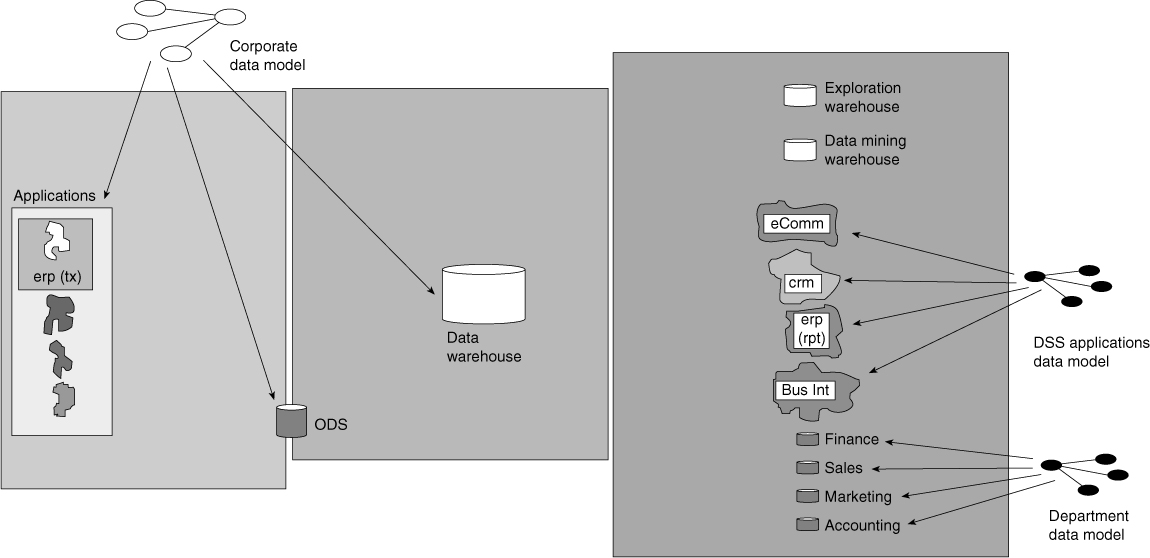
Figure 2.19 Different data models form the structural basis of the different components found in the CIF.
The data model exists for the entire organization and plays a different role for each of the architectural components in the corporate information factory:
![]() Serves as a guide for the ongoing reconstruction of the applications environment. Because the applications environment is notoriously unintegrated, the data model serves as a basis for bringing together the different applications as they are rewritten or as they are modified.
Serves as a guide for the ongoing reconstruction of the applications environment. Because the applications environment is notoriously unintegrated, the data model serves as a basis for bringing together the different applications as they are rewritten or as they are modified.
![]() Is the basis for subject-area design for both the ODS and the data warehouse. The general structuring of the ODS and the data warehouse begins with an orientation towards the major subject areas of the corporation. The orientation corresponds precisely to the entities that are defined in the high-level logical data model.
Is the basis for subject-area design for both the ODS and the data warehouse. The general structuring of the ODS and the data warehouse begins with an orientation towards the major subject areas of the corporation. The orientation corresponds precisely to the entities that are defined in the high-level logical data model.
But the corporate data model does not directly serve the needs of the departments that have data marts. The departmental data marts are patterned after the requirements that apply and are unique to a particular department. As such, their data models are shaped by their processing requirements. Finance will have its data model; accounting will have its data model; sales will have its data model; and so forth. The data models at the department level typically represent data that is denormalized and summarized. With that said, the departmental data model is a subset of or is profoundly shaped by the corporate data model.
Because all departments are a smaller part of a larger whole, an indirect relationship exists between the corporate data model and the individual departmental data models that shapes the design of the various data marts.
Migrating to the Corporate Information Factory
The size and complexity of the corporate information factory dictates that the fully matured architecture be achieved a step at a time. For all practical purposes, it is impossible to build the corporate information factory all at once. In fact, many good reasons support a step-at-a-time approach to the building of the corporate information factory, such as:
Cost. The cost of the infrastructure and the cost of development are simply prohibitive to consider the building of the corporate information factory at anything but a step at a time.
Complexity. The corporate information factory entails the usage of many different kinds of technologies. An organization can absorb only so many technologies at once.
Nature of the environment. The DSS portion of the environment is built iteratively in any case. It does not make sense to build the DSS environment in a “big bang” approach.
Value. Above all else, the implementation of the corporate information factory must demonstrate incremental value to the business. This is best accomplished through a series of three- to six-month iterations.
For these reasons the corporate information factory emerges from the information systems of a corporation over time, not all at once.
There is a typical progression to the building of the corporate information factory, as shown in Figures 2.20 and 2.21.
Figure 2.20 shows that on Day 1 is a chaotic information systems environment without shape and form. On Day 2, the data warehouse begins to emerge and grows incrementally. With each advance in the data warehouse, data is removed and integrated from the amorphous information systems environment. On Day 3, data marts start to grow from the data warehouse. Indirectly, more processing and data is removed from the information systems environment as different departments begin to rely on their data marts for DSS processing.
Figure 2.21 shows that on Day 4, integrated applications start to appear. The integrated applications require an integration and transformation layer in order to feed the data to the data warehouse. The emergence of the integrated applications comes slowly and, in many cases, imperceptibly.
On Day 5, the ODS is built. The ODS is fed from the integration and transformation layer and, in turn, feeds its data to the data warehouse. By this time, the systems that were once known as the production systems environment have almost disappeared. The legacy environment is only a very small vestige of its former invincible self.
The path to the building of the corporate information factory is seldom linear. Different parts of the corporate information factory are being built simultaneously and independently. For example, a finance data mart is being built while an exploration warehouse is being built, or an ODS is being built while the alternative storage component is being constructed.
Plenty of other migration paths are possible other than the one that has been shown. However, the path that has been suggested is one that is:
![]() Proven
Proven
![]() Least risky
Least risky
![]() Fastest
Fastest
![]() Avoids many pitfalls
Avoids many pitfalls
![]() Least expensive with the greatest probability of success
Least expensive with the greatest probability of success
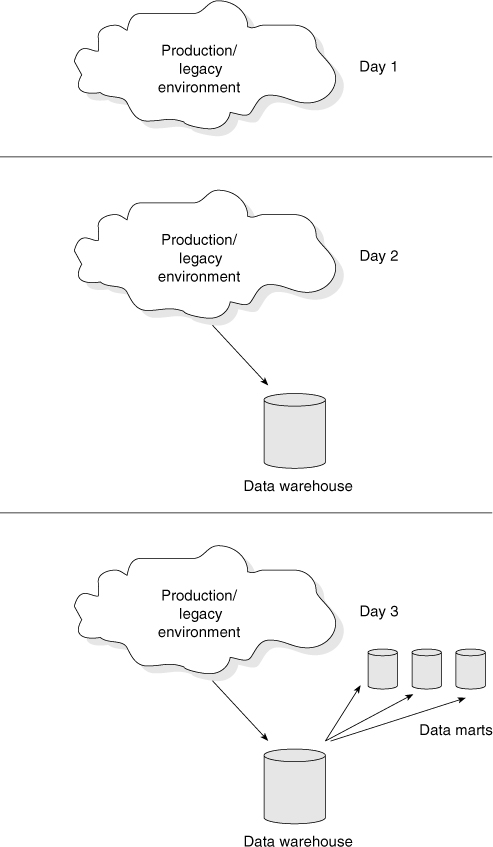
Figure 2.20 The typical first three steps to building the corporate information factory from the production/legacy environment.
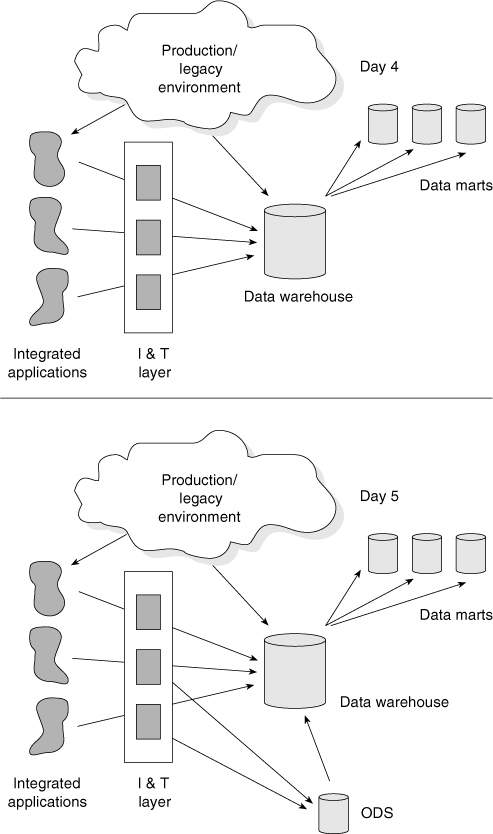
Figure 2.21 Migrating to the corporate information factory—latter phases.
Structuring Data in the Corporate Information Factory
One of the interesting features of the corporate information factory is the diversity of data structures that are found there. Figure 2.22 shows the different types of data structures found in the CIF.

Figure 2.22 Different design approaches can be seen throughout the CIF.
Common types of structural design techniques are:
![]() Flat, repetitive files, where the same structure type is represented again and again for different occurrences of data
Flat, repetitive files, where the same structure type is represented again and again for different occurrences of data
![]() Application transaction databases, where online transactions are supported in the face of application requirements
Application transaction databases, where online transactions are supported in the face of application requirements
![]() Star joins/snowflake structures, where data is denormalized and aggregated for the purpose of optimizing application requirements
Star joins/snowflake structures, where data is denormalized and aggregated for the purpose of optimizing application requirements
![]() Normalized structures, where data is separated according to its natural data relationships
Normalized structures, where data is separated according to its natural data relationships
The world of applications naturally sees a lot of application database design. The world of the ODS contains a mixture of star joins and normalized structures. The data warehouse is essentially a normalized structure. The alternative storage environment is one in which data is best stored in a normalized manner. When doing statistical analysis, a flat file with a repetitive structure is optimal. And star join/snowflake structures are optimal for DSS applications and data marts.
The diversity of design approaches is one of the hallmarks of the corporate information factory. No one design approach is optimal everywhere, primarily because very different requirements exist across the CIF when it comes to:
![]() Volumes of data found in the component of the corporate information factory
Volumes of data found in the component of the corporate information factory
![]() Performance
Performance
![]() The ability or inability to understand the requirements for processing prior to the creation of the structure
The ability or inability to understand the requirements for processing prior to the creation of the structure
![]() The volume of data needed for transaction processing
The volume of data needed for transaction processing
![]() The nature of the workload being processed
The nature of the workload being processed
![]() The age of the data
The age of the data
Summary
The corporate information factory has several recognizable and predictable components:
![]() External world
External world
![]() Applications
Applications
![]() Integration and transformation layer (I & T layer)
Integration and transformation layer (I & T layer)
![]() Operational data store (ODS)
Operational data store (ODS)
![]() Data warehouse
Data warehouse
![]() Data mart(s)
Data mart(s)
![]() Internet/intranet
Internet/intranet
![]() Metadata repository
Metadata repository
![]() Exploration/data mining warehouses
Exploration/data mining warehouses
![]() Alternative storage
Alternative storage
![]() Decision Support Systems (DSS)
Decision Support Systems (DSS)
The applications play the role of gathering raw data from interactions with customers. The applications level is a transaction-processing environment.
The data warehouse is where historical integrated information for the corporation is stored. The data warehouse typically contains huge amounts of data and represents the essence of corporate data.
Data marts exist for the many different departments that need to do DSS processing. Data marts are a customized, summarized subset of the data that resides in the data warehouse.
The ODS environment is the place where collective, corporate online operational integration occurs. The ODS is the most challenging environment to build and operate because it sometimes needs to support both informational and operational processing.
The world of the CIF is split along the lines of operational processing and DSS/informational processing. Applications belong in the domain of operational processing. Data marts and data warehouses are clearly in the DSS/informational world. The ODS is split into information and operational aspects.
The community of DSS users can be divided into four classifications: tourists, explorers, farmers, and miners. Each of the different classifications of DSS users has its own distinct set of characteristics.
There is a standard progression from the classical production, legacy environment to the corporate information factory. First, the data warehouse is built; next the data marts are built; and finally, the ODS is built, if the ODS is built at all. Many corporations do not need an ODS.
So far, we have talked about the heart of the information ecosystem, the corporate information factory. In the next chapter, we will talk about the force that justifies and shapes the CIF, the external world.