
Solution architecture is a practice of defining and describing an architecture of a system defined in the context of a specific business domain solution and it may encompass the description of an entire system or only its sub-parts. The creation and definition of a solution architecture is led by solutions architects.
A solution architect is a practitioner of solution architecture. Typically part of the solution development team, the solution architect translates business requirements defined by business analysts into solution architecture describing it through architecture and design assets. The development team leverages these assets to implement and deploy the solution. The solution architect's process typically involves selecting the most appropriate technology framework for the problem.
This chapter covers the Q&As for solution architecture and the design domain. The Q&As cover the following areas: the JEE framework, OOAD - UML, session management, distributed DB, replication, performance issues, the Spring framework, Hibernate, the agile model, MVC, and design patterns.
The capabilities of Java EE 7.0 are as follows:
- Components are logically divided into three tiers: the business, middle, and web tier. This is the logical grouping, and components can be mapped to different tiers based upon business requirements.
- JPA and JMS provide services for messaging and databases. JCA facilitates integration with legacy applications.
- Enterprise Beans provide a simplified model leveraging POJOs to use basic services.
- CDI, interceptors, and common annotations provide type-safe dependency injection, addressing cross-cutting concerns and a set of annotations.
- CDI extensions facilitate extending the framework beyond its existing capabilities.
- Web services such as JAX-RS and JAX-WS, JSP, JSF, and EL enable models for web applications. Web fragments facilitate the registration of third-party frameworks in a natural manner.
- JSON provides parsing and generation of JSON structures in the web layer.
- Web sockets facilitate bi-directional, full-duplex communication over a TCP connection.
- Bean validation provides a means to declare constraints and validates them across different technologies.
This following diagram depicts the JEE framework 7.0 capabilities:

Figure 1: Capabilities of Java EE 7.0
Probability indicator: ![]()
SMEs have observed that EJB 3 is an entirely different ball game. It includes configuration, annotations, dependency injection, and aspect orientation making EJBs a lean alternative to JAR-heavy frameworks. EJB technology is lean and weightless. There is no longer a need for JARs, XML configuration, or added frameworks. They integrate Java persistence API, are scalable on multicore machines; and are only vendor-neutral solution for enterprise applications. EJB 2.1 specification was not concise and violated the Don't Repeat Yourself (DRY) principle. The EJB component was spread across remote, home interfaces, bean classes, and the deployment descriptor. Without tools, refactoring was tedious and IDEs weren't good at refactoring.
The following are the list of improvements in EJB 3 over the previous implementations:
- It simplifies the process of developing EJB. It reduce significantly the overhead of using Java language annotations as configuration, improving developers' productivity.
- The specification of programmatic defaults and metadata reduces the need to specify expected behaviors and requirements of the container.
- Encapsulation of dependencies and JNDI access through the use of annotations, dependency injection mechanisms, and simple lookup mechanisms.
- EJB support inheritance and polymorphism.
- Lightweight CRUD operations with the JPA entity manager API.
- Enhanced query JPA capabilities.
- A life cycle's callback methods can be defined in EJB itself or in a bean listener class.
- Interceptor facility listeners for session beans and message-driven beans. An interceptor method may be defined on the bean class or on an interceptor class associated with the bean.
Probability indicator: ![]()
Separation of Concerns (SoC) is a design principle for separating a program into different sections, so that each section addresses a different concern. A concern is a set of information that affects the code of a program. A concern can be as general as the details of the hardware the code is optimized for, or as specific as the name of the class to instantiate.
A program that embodies SoC is called a modular program. Modularity, and hence separation of concerns, is achieved by encapsulating information inside a section of the program having well-defined interfaces. Encapsulation facilitates information hiding. Layered designs are another embodiment of separation of concerns (for example, presentation, business, data access, and persistence).
Benefits of SoC
The value of separation of concerns is in simplifying the development and maintenance of implementations. Well-separated, concerned facilitates the reuse of individual sections, as well as independent development, with the ability to modify one section of a program without having to know the details of other sections.
Probability indicator: ![]()
HTTP is a stateless protocol, and a web server in a cluster can potentially process an application client request. Session management allows a user's session state to be persisted.
For example, after a user has been authenticated by the web server, there is no need to re-authenticate at the next HTTP request if the user's authentication persists in the user's session state. The convenience of session management, however, comes with a price. Applications that use session management must maintain each user's session state, which is usually stored in memory. This can greatly increase an application's run-time memory footprint and tends to link user sessions to specific servers, requiring those sessions to be migrated to another node if the server is taken offline or fails. If session management is not implemented, applications can have a smaller footprint, and any cluster node can service requests from any user.
Approach
The user sessions are stored in cookies or in a hidden entries on a HTML page. An application can allocate a unique identifier to a user and then track the user's progress on the site. A user's interaction spans across multiple web pages by archiving the user's session state, and the application can capture the user's recent interaction with the website. In some instances, the user's session state is persisted to moderate subsequent visits. Some applications apply the user's session state to dynamically pages based on a user's preferences and patterns. Session cookies are stored often in a cryptographically signed format, but the data is usually unencrypted. Session data stored in cookies should not contain any sensitive information such as credit card data or other personal data. User sessions are also stored in a database or via Memcached. There are scripting frameworks such as PHP WASP and Zend that offer session management features.
Probability indicator: ![]()
Session tracking is a technique leveraged by application servlets to maintain the state of user requests across a time span. The different techniques for session tracking are:
- User authentication is enabled through a web server to the resources to those clients logging using authorized credentials.
- Hidden fields are added to HTML and are not displayed in the browser. When the HTML with the fields is submitted, these fields are sent to the server.
- All the URLs the user clicks is dynamically re-written to include extra session data. The extra data is in the form of path information, parameters, or some URL updates.
- Cookies are the data that is sent from the web server to the browser and can later be read from the browser.
- HTTP session objects are also leveraged for session data but they put a maximum cap on the number of sessions that can co-exist in the memory.
Probability indicator: ![]()
Sessions and cookies are leveraged to store the user data. A cookies stores user information on the client side and a session does it on the server side and this is the key difference between cookies and sessions. Sessions and cookies are leveraged in the application for preferences, authentication, and application parameters across multiple user requests. Both sessions and cookies are meant for the same purpose. A cookie is leveraged for storing only textual information. The session can be used to store both textual information and objects.
Probability indicator: ![]()
Configuring the distributable tag in web XML enables an application to support session replication but it may not guarantee it will work fine in a session replicated environment.
A JEE application needs to enable the following during application development:
- All the attributes saved in HTTP session including all custom objects should be made serializable.
- Session APIs must be leveraged for making changes to session attributes. A reference to Java objects set in a session previously must call session APIs every time you make any amendments.
Options for enabling session replication
Session replication between clusters can be done in a variety of ways but the efficient approach depends on the type of application. The following are a few common techniques that are leveraged:
- Leveraging session persistence and saving sessions to a shared filesystem allows all nodes in a cluster to access the persisted session
- Leveraging in-memory-replication will create an in-memory copy of a session in all the cluster nodes
Probability indicator: ![]()
There may be a requirement to modify service logic or to add a functional scope of the services. In these cases, a new version of the service logic or service contract will need to be introduced. To ensure that the versioning of a service can be carried out with minimal impact and disruption to consumers that are dependent on the service, a formal service versioning technique needs to be in place which is the service inventory.
Approach
There are different versioning strategies, each of which introduces its own set of rules and priorities when it comes to managing the services compatibilities including the contracts. The service versioning phase is associated with SOA governance because it is a recurring part of the overall service life-cycle processes. Governance processes guide the service versioning and will have a significant influence on a service which will evolve over time. Because this stage also encompasses the retirement of a service, these influences are further factored into the service's overall life-span.
Probability indicator: ![]()
The explanation is as follows:
A library is a collection of routines or class and facilitates simple code reuse. The routines or classes define specific operations in a specific domain area. For example, there are libraries of mathematics call the function without redo the implementation algorithm.
In the framework, all the control flow is already there, and there's are pre-defined white spots that one should fill out with custom implementation. A framework is more complex than a library and defines a skeleton where the application needs to fill out this skeleton. The benefit is that we do not worry about whether a design is good or not, but just about implementing domain-specific features.
The key difference between a framework and a library is inversion of control. When one calls a method from a library, one is in control but with a framework, the control is inverted, that is, the framework calls you.
Probability indicator: ![]()
Applications have a tendency to increase in complexity over a period of time and thus become difficult to maintain and modify. They also become difficult to articulate. Refactoring is a modularization technique that deals with the separation of responsibilities. Refactored implementation makes code more reusable by virtue of loose coupling and minimum dependencies.
Refactoring has merits in terms of correctness and quality, but refactoring pays off the most with software maintenance and upgrades. Often a mechanism to add new requirements to a poorly factored implementation is to refactor the code and then add these features. This takes less effort than trying to add the new feature without refactoring, and it's an excellent way to enhance code quality.
Benefits
Refactoring can have multiples incentives:
- Improved code readability
- Simplified code structure
- Improved maintainability
- Improved extensibility
Probability indicator: ![]()
Object Oriented Programming (OOP):
- OOP enables applications as a set of collaborating objects. OOP code scatters system code such as logging and security with business logic code.
- OOP works on entities such as classes, objects, interfaces, and so on.
- OOP provides benefits such as reuse, flexibility, maintainability, modularity, time, and effort, with the help of OO principles.
Aspect Oriented Programming (AOP):
- AOP works in complex software as a combined implementation of multiple concerns such as business logic, persistence, logging, security, thread safety, errors, and exception handling. It bifurcates business logic from the system code and one concern remains unaware of the other.
- AOP has join points, point cuts, advice, and aspects.
- AOP implementation coexists with OOP by leveraging OOP as the foundation
Probability indicator: ![]()
The domain model is a conceptual or logical model of the specific domain related to a specific business domain. It explains entities, attributes, roles, relationships, and constraints that govern the problem domain but not the solutions to the problem. The domain model is defined as the vocabulary and concepts of the problem domain or the business domain. The domain model establishes the relationships between the entities in the scope of the problem domain and identifies their properties. The domain model encapsulates methods within entities and is properly associated with object oriented models. The domain model enables a structural view of the domain complemented with other dynamic views, such as use cases.
Probability indicator: ![]()
This will be based on your past expertise and be prepared with a key engagement as a case study and to answer details pertaining to the following:
- Design decision made or options considered or rejected
- Frameworks leveraged and why
- Methodology or process that was leveraged to arrive at the target architecture or solution
- Security considerations/mechanism recommended
- Addressing non-functional requirements pertaining to availability, scalability, performance and reliability, and so on
Probability indicator: ![]()
A distributed database is an architecture in which parts of the database are stored on a different server in a network. Users have access to part of the database at their location to access data relevant to their processes. A centralized distributed database management system (DBMS) manages the database as a single entity. DBMS syncs all data at regular time intervals. In cases where multiple users access the same data, DBMS ensures that updates that are performed on the data at one location are reflected in the data stored in others.
The following are the benefits of distributed databases:
- Efficient handling of distributed data with varied levels of transparency such as networks, fragmentation, replication, and so on
- Increased availability, reliability, and flexibility
- Database fragments relating to organizational structure are stored within the departments
- Autonomy is enabled as departments can control the data they work with and they own data
- During a catastrophe such as an earthquake, the data will not be in one place, but will be distributed in multiple locations, thus providing protection
- Data is located near the site of demand, and databases are parallelized, enabling load balancing and providing excellent performance
- Due to architecture modularity, the components can be modified without affecting other modules in the DBMS
- Reliable transactions are enabled due to database replication and location independence
- As the model is distributed, a single-site failure does not affect the performance of the overall system, thus facilitating continuous operation, even if nodes go offline
Probability indicator: ![]()
Database sharding means horizontal partitioning in a database. The purpose is to split data between multiple nodes while ensuring that the data is accessed from the correct location. Sharding is sometimes referred to as horizontal scaling or horizontal partitioning. Sharding is a proven database scalability technique and is leveraged in some of the world's most popular web applications. With sharding, instead of storing data in just one database instance, it's distributed across multiple instances.
Sharding is an architectural technique that distributes one logical database system into a cluster of machines. In sharded database systems, the database rows of a table are stored separately, instead of being split into columns like normalization or vertical partitioning. Each partition is then a shard, and is independently locatable on a separate database node.
The total number of rows in a database table is reduced since the tables are distributed across multiple nodes. This also reduces the index size, providing excellent performance. Hashing of a unique ID in the application is the most common approach for defining shards.
The downsides of sharding include:
- The application has to be aware of the multiple data locations
- Any addition or deletion of nodes from the system will require re-balancing in the architecture
- Where there are a lot of cross-node join queries, performance will be poor and thus a knowledge of the data purpose and the way it will be leveraged for querying will be the key
- An incorrect sharding technique will result in poor performance
The difference is as follows:
A master/slave approach is only for replication. This method only improves performance for applications dealing with static data since only the master can receive and update information. Sharding does not replicate anything. It simply partitions the data in different files, which may be located in different folders, filesystems, or even machines.
Probability indicator: ![]()
The two popular techniques to achieve this are to use clustering to deal with failover and load balancing. The Active/Active mode is enabled to provide for database or session replication and redundancy. Load balancers can be deployed to route requests according to server performance and on the basis of the algorithm.
Active/Passive mode
Active/Passive configuration offers advantages in that the primary load balancer distributes the network traffic to a suitable server while the second load balancer operates in listening mode to monitor the performance of the primary load balancer, ready to take over the load balancing duties should the primary load balancer fail.
Load balancers, when configured in Active/Passive mode, provide the ability to sustain uninterrupted customer services. One more advantage is the ability to deal with either planned or unplanned outages. Business today requires a 24/7 service for customers and any outage is costly in terms of lost as well as damage to the reputation.
Active/Active mode
In the Active/Active mode, two or more servers aggregate the network traffic and, working as a team, distributes it to the server clusters. The load balancers remember information requests from users and keep this information in the cache. Should the user return, the user will be locked onto the load balancer that previously served them and the information provided again from the cache, therefore reducing network traffic load. One potential disadvantage is that you run them near full capacity.
Probability indicator: ![]()
The following are the performance issues:
- Too many database calls due to many database queries triggered by request response transactions
- In a high work-load environment, over-synchronization will lead to poor performance and scalability issues
- Multiple calls across these remote boundaries and too chatty applications will result in poor performance and scalability issues
- Unexpected performance and scalability issues will result from the wrong usage of O/R-Mappers or frameworks
- As a best practice implementation, it is key to release object references as soon as they are no longer needed, as GC does not prevent such memory leaks
- At times, there are issues with third-party frameworks and components and therefore validation of frameworks is mandatory.
- Wasteful handling of scarce resources such as memory, CPU, and I/O databases is costly and thus the lack of resource access by others will ultimately leads to performance and scalability
- There may be bloated web tiers as many pack unwanted stuff
- It is necessary to verify which objects to cache and which not to cache as incorrect cache strategy leads to excessive garbage collection
- Intermittent problems are the hardest to locate as they occur with specific parameters or are sporadic
- Different serialization types will have different impact on performance, scalability, memory usage, and network traffic.
Probability indicator: ![]()
The descriptions are explained in the following table:
|
Tools |
Description |
|
Thread and dump analyzer |
Analyzes Java core dump files.
Locates bottlenecks, deadlocks, and resource contention |
|
Garbage collection and memory visualizer |
Analyzes and visualizes verbose GC logs.
Identifies memory leaks, the size of Java heaps, and selects GC policy. |
|
Heap-analyzer |
Analyzes dumps to find memory leaks. |
|
Performance monitoring infrastructure PMI |
Dashboards can be viewed in the performance viewer
Monitors JDBC pools, JVM runtime, heap size, request counts, and average time by servlet |
Table 1: Performance Tools
Probability indicator: ![]()
DB resolution: Query optimization, restructuring indexes, DB caching tuning leveraging ORM frameworks
- Tacking bottlenecks:
- Reduce demand: Caching, tuning code, tuning database, and tuning application server
- Increase available resources: Horizontal or vertical scaling, memory, CPU
- Reduce slowdown due to synchronization: Effective collections and effective locking
Probability indicator: ![]()
Java EE provides various ways and APIs to facilitate async capabilities. The following table illustrates the Java EE spec capabilities that provide the async feature:
|
Async Capabilities |
Description |
|
JAX-RS 2.0 |
Async processing of requests is a new feature in edition 2.0 of JAX-RS in Java EE 7. To execute an aysnc request using JAX-RS APIs, one needs to inject a reference to an AsyncResponse interface in the JAX-RS resource method. The parameter puts the request execution in async mode and the method proceeds with its execution. |
|
Websocket 1.0 |
Websocket API is a new addition to Java EE 7. It facilitates bi-directional full duplex communication |
|
Concurrency utilities 1.0 |
Java concurrency utilities is a great addition to Java EE 7. It provides a standard way of spawning threads that are managed by containers and not just isolated/orphan threads |
|
Servlet 3.0 |
Asynchronous HTTP was introduced in Servlet 3.0, basically providing the capability to execute the request in a separate thread and suspend the original thread to handle client invocation. |
|
EJB 3.1 |
EJB message driven beans were leveraged to fulfill async related requirements. MDB listens to messages sent to a queue/topic and executes business logic. The important thing to understand is that the client which sends the message to the queue/topic is unaware of the decoupled MDB and does not wait/remain blocked until the end of the execution |
Table 2: Asynchronous Options JEE
Probability indicator: ![]()
Persisting data and querying it back is a major consideration. Here are a few ways of designing your persistence tier:
- Using JEE JPA and Object Relational Mapping (ORM) frameworks such as Hibernate
- Creating DB stored procedures and then leveraging a data tier to consume them in the EIS layer
- Generating strongly typed classes, basic database tables, leveraging code generation techniques, and JDBC
Probability indicator: ![]()
Performance testing: Performance testing is done to establish how the application components are performing, under a simulated situation. Resource usage, scalability, and reliability are validated under this testing. This testing may be a spin-off of performance engineering, which is focused on tackling the performance issues architecture of software applications.
The primary goal of performance testing is establishing the benchmark behavior of the application.
Load testing: Load testing tests the application by constantly and incrementally increasing the work load on the application until it reaches the threshold limit. It is the easiest form of testing and leverages automation tools such as Load Runner. Load testing is also known as volume or endurance testing. The purpose of load testing is to assign the largest job to the application so that it can test the endurance results.
The target of load testing is to determine the upper limit of all the components of the applications such as databases, hardware, networks, and so on, so that it can manage the anticipated load in future.
Stress testing: In stress testing, various tasks to overload the applications are executed in an attempt to break the application. Negative testing, including the removal of components from the application is also done as a part of stress testing. This is also known as fatigue testing. This testing establishes the stability of the application by testing it beyond its bandwidth capacity. The objective of stress testing is to ascertain the failure and to monitor the recovery gracefully.
The goal is to analyze crash reports to define the behavior of the application post-failure. The challenge is to ensure that the application does not compromise the security of sensitive data after the failure.
Best practices for load and performance testing include:
- Set precise performance objectives or parameters and define peak load, expected response time, and availability
- An application does not work on its own as it needs to interconnect with external interfaces and hence establish performance goals with external interfaces
- Validate early and ensure performance testing early in the life cycle
- A testing environment and the production environment should be identical
- Make it a practice to leverage application profilers in the IDE (for example, JProfiler)
- Optimization decisions should be based on past experience and should not be premature optimizations
- Set a strategy for expected and peak load, server configuration, clustered environments, and load balancers
Probability indicator: ![]()
Use case diagram explains IT application objectives from the user perspective. Use cases are added in requirement specifications to depict clarity regarding an application. There are three key parts to use cases: scenario, actor, and use case:
- Scenario: This is a sequence of events than are triggered when a user interacts with the IT application.
- Actor: The actor is the end user of the IT system.
- Use case: The use case is a goal performed by the end user. As use cases represent action, they are normally defined by strong verbs.
Primary and secondary actors
Actors are represented by a stick man symbol and use cases by an oval shape. Actors are further classified into two categories: primary and secondary. Primary actors are the users that are active participants, and they trigger the use case, while secondary actors passively participate in the use case.
Probability indicator: ![]()
The explanation is as stated as follows:
- An abstraction resolves the design level problems while encapsulation solves problems at implementation levels
- An abstraction is leveraged for hiding unsolicited data and providing relevant data while, to protect from external entities, encapsulation is about hiding the code and data in a single unit
- Encapsulation means hiding the internal mechanics of an object while abstraction puts emphasis on the object interface
Probability indicator: ![]()
There are two types of association: aggregation and composition:
- Aggregation: An association establishes that the entire object exists without the aggregated object. For example, in the diagram there are three classes: university, department, and professor. The university cannot exist without the department; the university will be shut as the department is shut. This means that the lifespan of the university depends on the lifespan of the department. The filled diamond represents the aggregation.
- Composition: The diagram also defines the second association between the department and the professor. In this case, if the professor leaves the department the department still continues to exist, meaning the department is not dependent on the professor. The empty diamond represents the composition.

Figure 2: Aggregation and composition in action
Probability indicator: ![]()
Specialization and generalizations define parent-child relationships between the classes. In many instances, classes may have the same operation and properties and these classes are called super classes and later one inherits from the super class to create sub-classes with their own custom properties. In the diagram, there are three classes for showing generalization and specialization relationships. All the phone types have a phone number as a generalized property, but depending upon landline or mobile you can have wired or sim card connectivity as a specialized property. In this diagram, the cell-phone represents generalization whereas clslandline and clsmobile represent specialization.

Figure 3: Generalization and specialization
Probability indicator: ![]()
- Inheritance is a relationship whereas composition has a relationship
- In inheritance there is only one object in the memory, the derived object, whereas in composition , the parent object holds references to many other objects
- Inheritance is an object inheriting reusable properties of the super class and composition is an object that holds another object.
Probability indicator: ![]()
The Spring framework helps build simple, portable, fast, and flexible JVM-based applications. Spring is a lightweight open source framework for developing enterprise applications. The Spring framework resolves the complexity of enterprise application development and provides a cohesive framework for application development based on dependency injection and inversion of control and design patterns.
The benefits of the Spring framework include:
- The Spring framework enables building enterprise-class applications using POJOs. The benefit of using only POJOs is that one does not need an EJB container and it is not complex.
- The Spring framework is structured in a modular manner. In Spring, even though the number of packages is substantial, one is to understand one the few they need while ignoring the rest.
- The Spring framework doesn't reinvent the wheel as it makes use of the existing technologies such as ORM frameworks, logging frameworks, and timers.
- Spring's framework also has a well architected MVC framework, providing an alternative to web frameworks such as Struts or other less popular web frameworks.
- Spring provides a simple API for translating technology-specific exceptions into consistent, unchecked exceptions.
- The Spring framework provides a consistent transaction API that can scale down to a local transaction.
- Testing an application written with the Spring framework is easy because the environment-dependent code is moved into this framework.
Probability indicator: ![]()
When multiple entities are trying to access the DB locks they go into the cyclic wait state, making it unresponsive. Deadlock is a condition that occurs with multiple threads for any applications, not just on a RDBMS.
For example, a thread in multithreaded an OS might acquire one or more resources, such as blocks of memory. If the resource being acquired is currently owned by another thread, the first thread will have to wait for the owning thread to release the resources. The waiting thread is said to have a dependency on the owning thread. In the instance of the database engine, sessions can deadlock when acquiring non-database resources, such as memory or threads.
Few listed as follows:
- Creating a queue can verify and order the requests to the DB.
- Ensure that the transactionsh are small
- Keep transactions short and in one batch.
- Avoid user interaction in transactions.
- Efficiently leverage DB cursors as they lock the tables for a long time.
Probability indicator: ![]()
The Document Object Model (DOM) parser creates a tree structure in memory from a document. In a DOM, the parser serves the application with the entire document. In contrast, the Simple API for XML SAX parser does not create any internal structure. A SAX parser always serves the client application only with part of the document at any given time.
The SAX parser, however, is much more space efficient if dealing with a big document whereas the DOM parser is rich in functionality. Leverage the DOM parser if you need to refer to different document areas before giving back the information. Leverage a SAX parser if you just need unrelated nuclear information from different areas.
Examples: Crimson are SAX Parsers whereas XercesDOM, SunDOM, and OracleDOM are DOM parsers.
Probability indicator: ![]()
The connection pooling technique allows multiple clients to make use of cached shared and reusable connection objects, providing access to a database. Connecting to a database consists of several time-consuming steps. A physical channel such as a socket or a named pipe must be established, the handshake must occur, the connection string information needs to be parsed, and the connection must be authenticated by the server.
In practice, applications leverage only a few configurations for connections. This means that during the application execution, many similar connections will be repeatedly created and closed. To minimize the cost of connections management, an optimization technique called connection pooling is leveraged. Connection pooling reduces the times that new connections need to be opened. The pool maintains ownership of these physical connection. It manages connections by ensuring a set of active connections for different connection configurations.
Connection pooling provides the following benefits:
- Reduces the number of times new connection entities are created
- Promotes connection object reuse
- Fastens the process of getting a connection
- Reduces the effort to manually manage connection objects
- Minimizes the number of stale connections
- Reduces the amount of resources spent on maintaining connections
Probability indicator: ![]()
Hibernate is an ORM framework and has numerous pros and cons. This section mainly lists the advantages of using Hibernate.
The advantages are as follows:
- Hibernate is independent of the database engine. A list of Hibernate dialect is leveraged for connecting to different databases.
- Java Persistence API - JPA is a specification. Hibernate is a standard ORM solution, and has a JPA capability. Hence, leveraging Hibernate will help you leverage all capabilities of ORM and JPA.
- Hibernate has integrated automatically with most reliable connection pool mechanisms.
- Hibernate is a layered architecture so that we are not bound to leverage everything provided by Hibernate. We just leverage those features that are needed for the project.
- Hibernate supports inheritance, associations, and collections.
- Hibernate supports relationships such as Many-to-One, One-to-Many, Many-to-Many-to-Many, and One-to-One.
- Hibernate also supports collections such as lists, sets, and maps.
The following are differences between Hibernate and JPA.
Java Persistence API is a specification for ORM implementations whereas Hibernate is the actual ORM framework implementation. JPA is a specification that guides the implementation of ORM frameworks. Implementations abiding by the specification would mean that one can be replaced with others in an application without much hassle. Only the features that are added to the specification need to be taken care of if any such change is made.
Probability indicator: ![]()
String is immutable for several reasons; here is a summary:
- Security: Parameters are leveraged as String in network connections, database connection usernames/passwords, and so on. As they are immutable, they cannot be changed easily.
- Synchronization and concurrency, by making String objects immutable, automatically make them thread safe, thus solving the synchronization issues.
- When a compiler optimizes the String objects, if two objects have the same value, you need only one string object.
- String is leveraged as arguments for class loading but if it is mutable, it could result in the wrong class being loaded.
Probability indicator: ![]()
Garbage collection does not guarantee that a program will not run out of memory. It is possible for programs to use up memory resources faster than they are garbage collected and it is possible for programs to create objects that are not garbage collected.
The methodology used is as follows.
The Java runtime environment deletes objects when it determines that they are no longer leveraged and this is known as garbage collection. The Java runtime environment provides a garbage collector that periodically frees the memory used by objects that are no longer needed. The Java garbage collector scans Java's dynamic memory areas for objects, marking those that are referenced. After all possible paths to objects are investigated, those objects that are not referenced are garbage collected.
Probability indicator: ![]()
Java doesn't support multiple inheritances. Interfaces don't facilitate inheritance and hence the implementation of multiple interfaces doesn't make multiple inheritances.
Checked exceptions are checked at compile time. If some code within a function throws a checked exception, then the function must either handle the exception or it must specify the exception using the throws keyword.
Unchecked exceptions are not checked at compile time. In C++, all exceptions are unchecked, so it is not forced by the compiler to either handle or specify the exception. It is up to the programmers to decide and catch these exceptions.
Probability indicator:![]()
Casting means taking an object of one type and turning it into another type. There are two types of casting, casting between object references and casting between primitive numeric types. Casting between numeric types is leveraged to convert larger values, such as double values, to smaller values, such as byte values. Casting between object references is leveraged to refer to an object by a compatible class, interface, or array type reference.
Probability indicator: ![]()
The final variable is a constant variable. The variable value can't be changed after instantiation. A method that cannot be overridden in the subclass. A class that cannot be sub-classed. A class using only immutable; objects cannot be changed after initialization can be created.
Probability indicator: ![]()
The thread is a lightweight process, the smallest unit of a scheduled execution. An instance of the Thread class in Java could be in one of the following states. A thread can only be in one state at a given time. These states are virtual machine states which do not reflect any operating system thread states.
The following diagram depicts different thread states:

- Runnable: The thread is waiting for its turn to be picked for execution by the thread scheduler based on priority
- Running: The CPU is actively executing the thread and will run until it becomes blocked, or voluntarily gives up
- Waiting: The thread is in a blocked state while it waits for external processing, such as a file I/O, to complete
- Sleeping: Threads are forcibly put to sleep or suspended and resume using Thread API
- Blocked on I/O: The thread will become runnable after an I/O condition is complete
- Blocked on synchronization: The thread will move to Runnable when a lock is acquired
- Dead: The thread is finished working
Probability indicator: ![]()
The advantages are as follows:
Arrays: An array is a collection of objects of similar type. Because arrays can be any length, they are leveraged to store thousands of objects, but the size is fixed when the array is created. Each item in the array is accessed by an index, which is a number that indicates the position where the object is stored. Arrays can be leveraged to store both value or reference types.
Collections: An array is just one of the different options for storing data. The option selected depends on various factors, such as how you manipulate or access the data. For example, a list is generally faster than an array if you must insert items at the beginning or in the middle of the collection. Other types of collections include maps, trees, and stacks; each one has its own advantages:
- Collections are re-sizable and can increase or decrease the size as per requirements
- Collections can hold both homogeneous and heterogeneous data
- Every collection follows standard data structures
- The collection provides built-in methods for traversing, sorting and, search
Probability indicator: ![]()
Java is a portable language because without any modification we can use Java byte code in any platform (which supports Java). So this byte code is portable, and we can use it in any other major platform.
Probability indicator:![]()
The differences are as follows:
Processes: Processes are often synonymous with applications, but what the user sees as a single application is, in fact, a set of cooperating processes. A process has a self-contained execution environment which includes a private set of basic runtime resources and its own memory space.
Threads: Threads are lightweight processes and both processes and threads provide an execution environment, but creating a new thread requires fewer resources than processes. Threads exist within a process; every process has at least one thread. Threads share the process's resources, including memory and files.
Comparison:
- When an OS wants to start running the program, it creates a new process and every process has at least one thread running.
- A thread is a path of execution in a program, which has its own local variables, a program counter (a pointer to the current execution being executed), and lifetime.
- When the Java VM is started by the OS, a new process is created. Within that process, many threads can be created.
- Within a process, every thread has an independent path of execution, but there may be a situation where two threads can interfere causing concurrency and deadlock.
- As two process can communicate, in the same way two threads can also communicate with each other.
- Every thread in Java is created and controlled by a unique object of the Thread class.
Probability indicator:![]()
A string buffer creates a mutable sequence of characters. A string buffer is a string but can be modified. It contains some sequence of characters, but the length and content of the sequence can be changed through method calls. The String class represents character strings. All string literals in Java, such as "xyz", are constants and implemented as instances of the string class; their values cannot be changed after the initial creation.
Probability indicator:![]()
Object Relational Mapping (ORM) and O/R mapping is a technique for converting data between incompatible types in OO languages. This creates, in effect, a "virtual database" that can be leveraged from the programming language.
The benefits of ORM include:
- Productivity
- Application design
- Code reuse
- Application maintainability
Probability indicator:![]()
In JEE applications, the modules are packaged as WAR, JAR and EAR based on functionality:
- JAR: EJB modules containing enterprise Java beans, class files, and EJB deployment descriptors are packed as JAR files with the
.jarextension - WAR: Web modules containing Servlet class files, JSPs, GIF, and HTML are packaged as JAR
file.warextensions - EAR: All the
.jarand.warfiles are packaged as JAR files with.ear(enterprise archive) extensions and deployed into a container
Probability indicator:![]()
JavaServer Pages (JSP) is a technology that helps create dynamically generated web pages based on HTML, XML, or other types. Released in 1999 by Sun Microsystems, JSP is similar to PHP, but it uses the Java language.
Probability indicator:![]()
ACID is an acronym commonly used to define the properties of a RDBMS; it stands for the following terms:
- Atomicity: This guarantees that if one part of a transaction fails, the entire transaction will fail, and the database state will be left unchanged
- Consistency: This ensures that any transaction will bring the database from one valid state to another
- Isolation: This ensures that the concurrent execution of transactions results in a system state that would be obtained if transactions were executed serially
- Durable: This means that once a transaction has been committed, it will remain so, even in the event of a power failure.
Probability indicator:![]()
A shared nothing architecture is a distributed approach in which each node is independent and self-reliant, and there is no single point of failure across the landscape:
- This means no resources are shared between nodes
- The nodes are able to work independently without depending on one another
- Failure on one node affects only the users of that node and other nodes continue to work without disruption
This approach is highly scalable since it avoids the existence of bottlenecks. Shared nothing is popular for web development due to its linear scalability. Google has been leveraging it for a long time. A shared nothing architecture can scale almost infinitely by adding nodes in the form of inexpensive machines.
Probability indicator:![]()
Deploying a newer version of a live website can be a challenging task when a website has heavy traffic. Any small downtime is going to affect the end users. There are a few best practices that we can follow.
Before deploying on production:
- Thoroughly test the fixes and ensure they are working in a test environment (identical to the production environment).
- Perform automation of test cases as much as possible and one can leverage selenium functional testing.
- Create an automated sanity testing script/smoke test that can be run on production. These are typically the read-only type of test cases and ensure they can run quickly by keeping them short.
- Create scripts for all manual tasks, avoiding any mistakes during the deployment day.
- Test these script to make sure they work in a non-production environment.
- Build artifacts should be ready which includes application deployment files, database scripts, config files, and so on.
- Deploy in a non-production environment first and with production data. Please note the time for tasks so you can plan accordingly.
When deploying on a production environment, keep these things in mind:
- Keep a backup of current data in case of rollback.
- Use sanity test cases before doing a lot of in-depth testing.
Probability indicator:![]()
The core competencies of architects are illustrated in the following diagram:
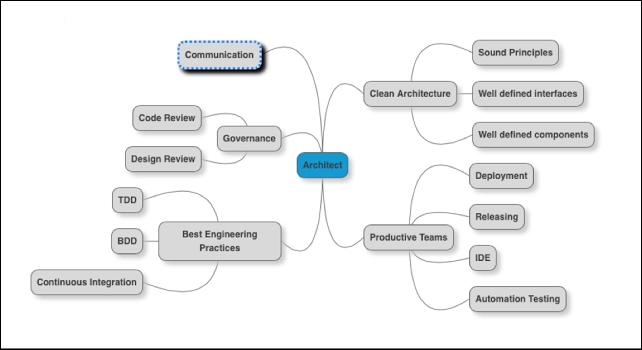
Figure 5: Competencies and soft skills of architects
- Creating a simple architecture basis, sound principles, and covering all non-functional requirements
- The framework should having good governance and review processes in place for SDLC
- Ensuring teams' productivity and empowering them with the correct frameworks and tools
- Ensuring teams are following the industry standards, frameworks, and practices
- Ensuring crisp and clear communication
The following diagram illustrates the key soft qualities of architects:

Figure 6: Key soft qualities of architects
- Impeccable credibility, to which the team looks up to and aspires to
- Excellent diagnostic ability to deep dive on a challenging issue
- Futuristic thinker, proactive, and identifies opportunities to add value to work
- Great communication in the widest sense. Communicating every aspect to the stakeholders, management, software engineers, and testers

Figure 7: Modern programming practices
Probability indicator:![]()
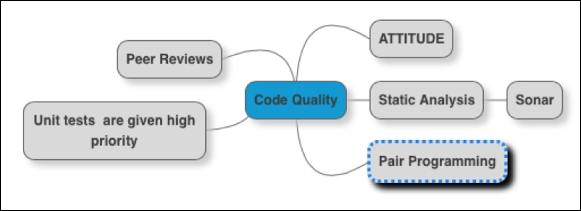
Figure 8: Code quality
Code quality is an attitude to refactor things that are wrong. The attitude to be a boy scout. An architect has to encourage an environment where such an attitude is appreciated. There are bad sheep, who take the code quality to such a level that it is not fun anymore. Have a good static analysis tool which is part of continuous integration. Understand the limits of static analysis. Results from static analysis are a signal and help to decide where to look during architect reviews. Every user story has to be reviewed. Put focus on peer reviews when there is a new developer or there is a new change being done and make the best use of pair programming.
Probability indicator: ![]()
Agile and architecture do go hand in hand. Agile brings in the need to separate architecture and design and the architecture is about things which are difficult to change, such as technology, frameworks, communication, and so on. It a best practice if a big chunk of architectural decisions is done before the team starts. There will be things that are uncertain. Inputs to these can come from spikes as part of the scrum team but it is better to plan ahead.
Architecture choices should be well thought out. It's good to spend time thinking before you make an architectural choice. Change is continuous only when the team is sure nothing is broken. And automation test suites play a great role in providing immediate feedback. Important principles are tested early, fail fast, and automate.
Probability indicator:![]()
Figure 7: Modern programming practices
- FUnit testing: This is the age of continuous integration and delivery, and the thing that enables this is having a set of unit tests in place. Understand the concept of Mocking and JUnit.
- Automated tests: An automated integration test is the second important factor enabling continuous delivery. For example, Fitnesse, Cucumber, and Protractor.
- TDD: This a software development methodology that relies on the repetition of very short development sprints: requirements are turned into specific test cases, then the software is improved to pass these tests
- Continuous integration: Every project today has continuous integration. Compilations, unit tests, code quality gate, integration, and chain tests. But make sure the build does not take long. Immediate feedback is important. If needed, create a separate build scheduled less frequently for slower tests. Jenkins is the most popular continuous integration tool today.
- BDD: Business-driven development is a methodology for developing solutions that directly satisfy business requirements. This is achieved by adopting a model-driven approach that starts with the business strategy, requirements, and goals and then transforms them into a solution.
Probability indicator:![]()
- Let's look into this stepwise: Do we want a modern JavaScript framework?
- Should we leverage an MVC framework such as Spring MVC or Struts, or should we use a Java-based framework like Wicket?
- What should be the view technology? JSP, JSF, or template-based?
- Do you need AJAX functionality?
- How do you map a view to business objects? Do you want to have a View and business assemblers?
- What kind of data is put in the user session? Do we need additional control mechanisms to ensure small session sizes?
- How do we authenticate and authorize? Do we need to integrate external frameworks like Spring security?
- Do we need to expose web services?
Probability indicator:![]()
The following lis are the important considerations:
- Should there be a service layer as a facade to the business layer?
- How do we implement transaction management? JTA or Spring transactions or container managed transactions?
- Can we separate business logic into separate components?
- Do we use a domain object model?
- Do we need caching and at what level?
- Does the service layer or web layer need to handle all exceptions?
- Is there any specific logging or auditing needed?
- Do we need to validate the data that is coming into the business layer? Or is the validation done by the web layer?
Probability indicator: ![]()
- Listed below are essentials things that are needed: Do we leverage a JPA based object mapping framework, such as Hibernate, or a query based mapping framework, such asiBatis or simple DO?
- How do we communicate with external systems? Web services or JMS? How do we handle XML mapping: JAXB or XMLBeans?
- How do you handle connections to a database? These days, it's an easy answer: leave it to the application server configuration of the data source.
- What are the kinds of exceptions that you want to throw to the business layer? Should they be checked or unchecked exceptions?
- Ensure that performance and scalability is taken care of in all the decisions.
Probability indicator:![]()

Figure 9: Traditional web applications
Web applications are based on HTTP requests and responses. Following are the steps:
- When the user initiates an action in the browser, an HTTP request is created by the browser.
- The web server creates an
HTTPServletRequestbased on the content of the HTTP request. - The web application (based on the framework used) handles the
HTTPServletRequest. Controllers, the business layer, the database, and interfaces) HTTPServletResponseis returned and is converted to an HTTP response.- The HTTP response is rendered by the browser.
Probability indicator:![]()
Various layers of web applications can be implemented using different Spring modules. The beauty of the Spring framework is that Spring provides great integration support with other non-Spring open source frameworks.
|
Layer |
Description |
|
Web layer |
Spring MVC to implement MVC pattern.
Spring WS to expose web services |
|
Service and business layers |
Core Business Logic using POJOs, managed by Spring's container
Transaction management leveraging Spring AOP |
|
Integration layer |
Spring ORM to integrate databases (JPA and iBatis).
Spring JMS to integrate with external interfaces using JMS
Spring WS to consume web services. |
Table 3: Spring Capabilities
Probability indicator:![]()
A design pattern is a reusable solution to a commonly occurring problem within a context in software design. A design pattern is not a finalized design that can be transformed into a machine code. It is a template for solving a problem that can be leveraged in different situations. Patterns are best practices that can be used to solve common problems when designing an application. Object-oriented patterns typically show interactions between objects, without specifying the final application classes that are involved. Patterns that imply object-orientation or a more generally mutable state are not as applicable in functional programming languages.
Benefits of design patterns
Please refer the table for a detailed description:
|
Benefit |
Description |
|
Enhances code readability |
Design patterns help to speed up development by providing tested development paradigms. Reusable design patterns help correct subtle problems and enhance code readability. |
|
Robust |
Besides improving readability, design patterns allow us to communicate clearly with well-defined names enhancing interaction. |
|
Solutions to specific problems |
Often, people know to use specific software tools to solve certain problems. Although design patterns offer solutions to aid in the implementation process, few techniques may be tailored to suit specific needs. |
|
Simplify the coding process |
Since it is difficult to understand code without prior knowledge of web development and object oriented design, you need to familiarize yourself with basic design patterns. |
|
Enhances software development |
A design pattern is a main component in software development. And a better understanding of design patterns will help enhance software development. |
Table 4: Benefits of design patterns
Probability indicator:![]()
MVC stands for model, view, and controller and is a software architectural pattern for implementing UIs:
- Controller: Controls the flow, sends commands to the model to update the state, and sends commands to the view to change the presentation of the model
- Model: Represents the state of the application, notifies associated views and controllers if there is a change in the state
- View: Visual representation of the model for the end user
Probability indicator:![]()
- In Spring web MVC, any POJO can be leveraged as a command or form-backing object.
- Highly flexible data binding: If there is a mismatch, it is shown as a validation error. Business POJOs can directly be leveraged as form-backing objects.
- Flexible view resolution: Controller can either select a view name and prepare a model map for it or write directly to the response stream.
- Supports JSP, Velocity, and Freemarker view technologies.
- Can directly generate XML, JSON, Atom, and many other types of content.
- Highly convenient tag library.
Probability indicator:![]()

Figure 10: Hibernate best practices
Java Persistence API (JPA) is a specification of how the object-relational mapping should be done. Java is an object-oriented language. Data from Java objects need to be stored in relational SQL tables. JPA defines the interface of how mapping should be done. JPA is a specification with no implementation. Hibernate is an implementation of JPA. All annotations specified in JPA are implemented in Hibernate. The main benefit of using JPA is that at a later point in time, you can switch to another implementation of JPA. If I directly leverage Hibernate annotations, I'm locked into Hibernate. I cannot easily switch to other ORM frameworks.
Probability indicator:![]()
There are three basic classifications of patterns: creational, structural, and behavioral.
Creational patterns include:
- Abstract factory: Creates an instance of several families of classes
- Builder: Separates object construction from its representation
- Factory method: Creates an instance of several derived classes
- Prototype: A fully initialized instance to be copied or cloned
- Singleton: A class in which only a single instance can exist
Structural patterns include:
- Adapter: Matches interfaces of different classes
- Bridge: Separates an object's abstraction from its implementation
- Composite: A tree structure of simple and composite objects
- Decorator: Adds responsibilities to objects dynamically
- Facade: A single class that represents an entire subsystem
- Flyweight: A fine-grained instance used for efficient sharing
- Proxy: An object is representing another object
Behavioral patterns include:
- Mediator: Defines simplified communication between classes
- Memento: Captures and restores an object's internal state
- Interpreter: A way to include language elements in a program
- Iterator: Sequentially accesses the elements of a collection
- Chain of Resp: A way of passing a request between a chain of objects
- Command: Encapsulates a command request as an object.
- State: Alters an object's behavior when its state changes
- Strategy: Encapsulates an algorithm inside a class
- Observer: A way of notifying a change to a number of classes
- Template method: Defers the exact steps of an algorithm to a subclass
- Visitor: Defines a new operation to a class without change
Probability indicator: ![]()
There are various avenues to keep abreast with the technology and domain which are:
- Attending seminar, webinar, and industry events that are organized by organizations and bodies
- Reading white papers, knowledge papers, and thought papers based on your domain/competencies
- Writing white papers gives you an opportunity to do a market scan and research on various topics
- Reading books relevant for your domain/competencies
- Reading analyst reports (Gartner/Forrester/IDC ) that provide data on the key players in the industry and is a crucial piece of information
- Following the recent trends in the business and technology landscape (for example, SMAC)
- Participation in forums based on your area of expertise and competencies
- Planning for certifications based on your area of expertise and competencies
- Attending training and discussions from various product vendors, standards bodies, and so on.
Probability indicator: ![]()