
3
BLU Acceleration: Next-Generation Analytics Technology Will Leave Others “BLU” with Envy
BLU Acceleration technology finds its DB2 debut in the DB2 10.5 release. This market-disruptive technology is inspired by some pretty hot trending topics in today’s IT marketplace, including in-memory analytics and columnar storage. BLU Acceleration uses innovative and leading-edge technology to optimize the underlying hardware stack of your data server and squarely addresses many of the shortcomings of existing columnar and in-memory solutions.
The first question we always get asked about BLU Acceleration is “What does ‘BLU’ stand for?” The answer: nothing. We’re sure it’s somewhat related to IBM’s “Big Blue” nickname, and we like that, because it’s suggestive of big ideas and leading-edge solutions. The IBM research project behind it was called Blink Ultra, so perhaps that’s it, but don’t let trying to figure out the name as an acronym keep you up at night; this technology is going to let you sleep like a baby.
Now let’s dive into BLU Acceleration and answer the rest of the questions that we know you have and that we know how to answer. In this chapter, we introduce you to the BLU Acceleration technology. We discuss it from a business value perspective, covering the benefits our clients are seeing and also what we’ve personally observed. That said, we don’t skip over how we got here. There are a number of ideas—really big ideas—that you need to be aware of to fully appreciate just how groundbreaking BLU Acceleration really is, so we detail those from a technical perspective as well.
What Is BLU Acceleration?
BLU Acceleration is all about capturing unrealized (or deriving new) value to your business from your existing (and future) analytics-focused hardware, software, and your human capital investments. BLU Acceleration is also about letting you ask questions and do stuff you’ve not been able to do in the past. If you asked us to sum up all of the BLU Acceleration value propositions that we cover in this chapter by placing them into just three buckets (that we will call pillars), they’d be Next-Generation Database for Analytics, Seamlessly Integrated, and Hardware Optimized.
Next-Generation Database for Analytics
The value that’s associated with this first pillar was identified by a self-challenge for our organization to define what technologies or attributes would be worthy of a bucket called Next-Generation Database for Analytics (Next-Gen). For example, you hear a lot these days about in-memory analytics, a proven mechanism to drive higher levels of performance. BLU Acceleration is about dynamic in-memory analytics—its optimizations extend well beyond memory so that, unlike some alternative technologies, all of the data required by the query doesn’t have to fit into memory to avoid massive performance issues. Some alternative technologies return query errors if the data can’t fit into memory (which isn’t the case with BLU Acceleration); others are worse. BLU Acceleration uses in-memory processing to provide support for the dynamic movement of data from storage with intelligent prefetching. After all, we’re in a Big Data era; if the cost of memory drops by
X% every year, but the amount of data we’re trying to store and analyze increases by Y%(>X%), a nondynamic memory-only solution isn’t going to cut it—you’re going to come up short. This is why a NextGen technology needs to avoid the rigid requirement that all of the query’s data has to fit into memory to experience super-easy, super-fast analytics. Of course, better compression can help to get more data into your memory heaps, but NextGen analytics can’t be bound by memory alone; it needs to understand I/O. For this reason, we like to think of BLU Acceleration as in-memory optimized, not main memory constrained.Columnar processing has been around for a while and is attracting renewed interest, but it has some drawbacks that a NextGen platform must address. BLU Acceleration is about enhanced columnar storage techniques, including supporting the coexistence of row-organized and column-organized tables in the same database, and even in the same workload and SQL. In fact, if both an in-memory and traditional database could be contained in the same database technology’s process model, using the same application programming interfaces (APIs), skills, backup and recovery (BaR) protocols, and more, that would also be a NextGen technology list item. BLU Acceleration does all of this.
A NextGen database should have what IBM refers to as actionable compression. BLU Acceleration has patented compression techniques that preserve order such that the DB2 engine can (in most cases) work with the compressed data without having to decompress it first. In fact, BLU Acceleration has a very broad range of operations that can be run on compressed data without first having to decompress it. These include, but are not limited to, equality processing (
=, <>), range processing (BETWEEN, <=, <, =>, >), grouping, joins, and more.A NextGen database that’s geared toward analytics must find new and innovative ways to optimize storage that not only finds disk space savings, but optimizes the I/O pipe, and more. Although it’s fair to note that the power and cooling costs associated with database storage have experienced double-digit compounded annual growth rates over the last few years, and that mitigation of these costs is an imperative in our Big Data world, that’s not the whole story. Finding higher and higher compression ratios enables you to get more data into memory—effectively driving up in-memory yields since more data is in the memory-optimized part of the database. BLU Acceleration does this too.
Finally, making things easy to use and consume is a requirement for any NextGen technology. In our Big Data world, companies are facing steep learning curves to adopt new technologies (something that IBM is aggressively addressing with its toolkits and accelerators, but that’s outside of the scope of this book). You want to get all of the benefits of a NextGen analytics engine with minimum disruption, and that’s going to mean ensuring that impressive NextGen technology is consumable and simple to use, but at the same time delivers amazing performance and incredible compression ratios. We cover this topic in the next section.
To sum up, a NextGen database needs to deliver out-of-the-box high performance for complex queries, deliver groundbreaking storage savings, and ultimately flatten the cost of the analytics curve with an unapologetic focus on consumability. We think a NextGen database has to be disruptive in quantum benefits without interfering with your operations. We’re sure by the time you are done reading this chapter, you’ll conclude that DB2 10.5 with BLU Acceleration is a NextGen analytics database.
Seamlessly Integrated
BLU Acceleration isn’t an add-on to DB2; it’s part of DB2. There are lots of inmemory database technologies in the marketplace—some risky newcomers, some requiring new skills—but BLU Acceleration is seamlessly built into DB2. It’s in its DNA, and this is not only going to give you administrative efficiencies and economies of scale, but risk mitigation as well. Seamless integration means that the SQL language interfaces surfaced to your applications are the same no matter how the table is organized. It means that backup and restore strategies and utilities like
LOAD and EXPORT are consistent, and so on.Think about it: BLU Acceleration is exposed to you as a simple table object in DB2 10.5. It’s not a new engine; it’s not bolted on; it’s simply a new format for storing table data. Don’t overlook this fact: We could have brought this technology to market sooner, but we intentionally chose to make BLU Acceleration part of DB2, not a layer on top of DB2. DB2 with BLU Acceleration looks and feels just like the DB2 you’ve known for years, except that a lot of the complexity around tuning your analytic workloads has disappeared; in addition, performance takes a quantum leap forward and the storage foot-print of your data is slashed to a fraction. If you’re new to DB2, after you start to use it, you’ll get a sense of how easy it is to use and why it doesn’t leave DBAs “seeing red,” as does one of our competitors.
Another compelling fact that resonates with clients and analysts (and makes our competitors jealous) is that you don’t have to rip and replace hardware to get all the benefits of BLU Acceleration.
Hardware Optimized
The degree to which BLU Acceleration technology is optimized for the entire hardware stack is a very strong, industry-leading value proposition. BLU Acceleration takes advantage of the latest processing technologies, such as parallel vector processing, which we detail later in this chapter. If you think about the traditional approaches to performance tuning, you’re likely to focus on three areas: memory, CPU, and I/O. We don’t know of any other vendor who has put as much engineering effort into optimizing all three hardware-provisioned computing resources for their in-memory database technology as IBM.
Sure, there are other products in the marketplace that have an in-memory analytics solution, but our experience (and that of the clients we’ve been talking to) is that as soon as the data exceeds the memory allocation by a few bytes, those products keel over from a performance perspective, some “error out,” and others do even worse! We’ve seen other database systems that claim they are I/O optimized; however, as more and more data is placed into memory, their advantage is mitigated. If your solution is focused on optimizing a single performance factor, you’re going to end up with limitations and trade-offs.
BLU Acceleration optimizes the entire hardware stack, and it seeks every opportunity (memory, CPU, and I/O) to squeeze all that it can out of your hardware investment. As an analogy, think about your home computer, laptop, or even your smart phone. They all have multicore processing capabilities. How much of the software you’ve paid for has been developed from the ground up to fully exploit those cores? BLU Acceleration is designed to fully exploit all the computing resources provisioned to the DB2 server (we detail this in the section “How BLU Acceleration Came to Be: The Seven Big Ideas” later in the chapter).
Convince Me to Take BLU Acceleration for a Test Drive
In this section, we share some of our findings and some of our customers’ experiences, which serve to illustrate just how disruptive (in a good way) the DB2 10.5 BLU Acceleration technology really is.
Pedal to the Floor: How Fast Is BLU Acceleration?
It’s fast. Remember this motto: Super analytics, super easy. In both our internal and client performance tests, we’ve seen anywhere from single-digit to quadruple-digit performance speed-ups. Although your results are subject to a lot of variance (depending on your workload, your data, what server you’re running on, and other things you can imagine our lawyers want us to write here), you are going to hear about—and likely experience for yourself—head-shaking performance speed-ups with minimal effort.
We asked a highly regarded DBA that we know, Andrew Juarez (Lead SAP Basis and DBA at Coca-Cola Bottling Consolidated), to try BLU Acceleration, and he found that “it makes our analytical queries run 4–15x faster.”
Intel publicly shared their experience with BLU Acceleration’s exploitation of leading chipset technologies, like their Advanced Vector Extensions (ACX) instruction set on their E5-based processing cores. Not only did Pauline Nist (GM, Enterprise Software Alliances, Datacenter, and Connected Systems Group) conclude that “customers running this hardware can now immediately realize dramatically greater performance boosts at lower cost per query,” her team quantified that statement by noting that they’re “excited to see a 88x improvement in query processing performance using DB2 10.5 with BLU Acceleration over DB2 10.1.”
As a final reference point (we’re just giving you samples here because there are a lot more), we invited another highly regarded DBA, Kent Collins (Database Solution Architect, BNSF Railway), to put BLU Acceleration through its paces. Kent told us that he was going to bring some of his most troublesome queries to BLU Acceleration and then tell us what he thought. When he finished the tests, Kent noted that “it was amazing to see the faster query times compared to the performance results with our row-organized tables. The performance of four of our queries improved by over 100x, with the best outcome being a query that finished 137x faster! On average, our analytic queries were running 74x faster when using BLU Acceleration.”
It just gets better from there. At Taikang Life, workloads improved by 30x; Triton saw a 45x performance boost, and Mindray 50x! With that in mind, we’re pretty comfortable suggesting that if you use BLU Acceleration for the right analytical workloads, you should expect to see, on average, an 8- to 25-fold performance—or better—improvement for your queries. (Ensure you realize what we mean by average—some clients see triple-digit and beyond performance speed-up for single queries (often the most troublesome) but it’s important to appreciate the average speed-up of the query set, which is what we are referring to here.)
From Minimized to Minuscule: BLU Acceleration Compression Ratios
You’re going to hear a lot about the NextGen columnar technology being used in BLU Acceleration, and you’ll likely correlate that with storage savings. Indeed, column organization can greatly reduce the database footprint for the right kinds of tables, but there’s more to it than that.
BLU Acceleration is as much about what you don’t get as what you do get. With BLU Acceleration, you don’t get to create indexes or create aggregate tables—quite simply, all the storage that would have been required for secondary indexes and aggregates is no longer needed. In fact, if your trusted extract, transform, load (ETL) processes have validated the uniqueness of your data, you don’t even need to use storage to enforce it because we’ve extended the informational constraints capabilities introduced in DB2 9 to include uniqueness; this allows you to use this enhancement to inform the DB2 optimizer about the uniqueness of a row without persisting a secondary table object to strictly enforce that uniqueness. The bottom line is that all of these objects take up space, and because you’re not going to need these objects when you use column-organized tables (and if you’re not enforcing uniqueness because a reliable ETL process has cleansed and validated the data), you’re going to save lots of space. This all said, if you want the database to enforce uniqueness, it does that too! You can still create uniqueness constraints and primary keys as you always have in the past and they’ll be enforced with BLU Acceleration tables as they are with regular DB2 tables today—nothing is different.
We asked three of our customers (a famous investment brokerage house, a popular independent software vendor [ISV], and a well-known manufacturer whose products you likely see everytime you go for a country drive) to take tables in their database schemas that support query workloads and load them three times for comparison: once in DB2 10.1 without any compression, once in DB2 10.1 with automatic adaptive compression, and once using DB2 10.5 with BLU Acceleration. Their results are shown in Figure 3-1.
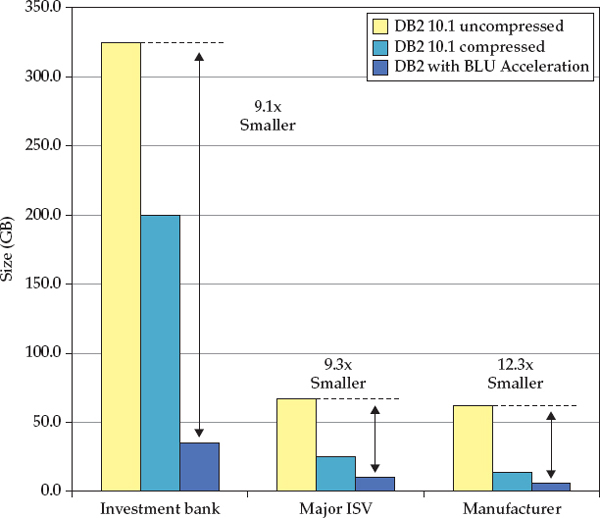
Figure 3-1 A sample of BLU Acceleration experiences from a table compression perspective
Many vendors communicate storage measurements that are based solely on data compression ratios, but we’ve taken a much broader view. Figure 3-1 reflects the total number of pages that are being used for a table, including all the data, indexes, compression dictionaries, and table metadata—in short, the entire footprint of the schema.
In Figure 3-1, the lightly shaded bar on the far left of each data set shows the result of loading the schema into a regular DB2 10.1 database without any compression. The darker filled bar in the middle of each data set shows the result of loading the same schema on the same server (everything is the same here; that’s important to remember) using the automatic adaptive compression capabilities first introduced in the DB2 10.1 release. Finally, the darkest shaded bar on the far right of each data set shows the schema’s footprint using DB2 with BLU Acceleration.
Don’t forget: DB2 has a wide spectrum of runtime optimizations for your analytics environment, and it has a holistic approach that we’ve yet to see anyone else adopt. For example, the more concurrency you need, the more temp space you’re going to need. If a table spills into temp storage, DB2 may choose to automatically compress it if the database manager deems it beneficial to the query; if DB2 hypothesizes that it’ll need to reference a large temporary table again, it might compress it as well. So, although temp space is a definite requirement in an analytics environment, we want you to know that those unique benefits aren’t even shown in Figure 3-1.
Andrew Juarez, Lead SAP Basis and DBA at Coca-Cola Bottling Consolidated, told us that “in our mixed environment (it includes both row- and column-organized tables in the same database), we realized an amazing 10–25x reduction in the storage requirements for the database when taking into account the compression ratios, along with all the things I no longer need to worry about: indexes, aggregates, and so on.” And Kent Collins, Database Solution Architect for BNSF Railway, stated that when “using DB2 10.5 with BLU Acceleration, our storage consumption went down by about 10x compared to our storage requirements for uncompressed tables and indexes. In fact, I was surprised to find a 3x increase in storage savings compared to the great compression that we already observed with DB2 Adaptive Compression.”
Where Will I Use BLU Acceleration?
Considering the value proposition that we shared with you in the last couple of sections, we’re sure that you’re eager to see what BLU Acceleration can do for you. As with any technology, there are areas in which you’ll want to use BLU Acceleration and areas in which you won’t.
As enterprises begin to see that the limits of their current enterprise data warehouse (EDW) and data mart technologies affect applications that are used to drive decision making, they’re desperately looking for solutions. Typical challenges include latency, synchronization, or concurrency problems, and scalability or availability issues. The off-loading of data that supports online analytical processing (OLAP) applications from an EDW into a data mart environment is an excellent opportunity to remedy these types of problems through the power of BLU Acceleration and your off-the-shelf analytics toolset.
BLU Acceleration simplifies and accelerates the analysis of data in support of business decisions because it empowers DBAs to effortlessly transform poorly performing analytic databases into super-performing ones, while at the same time insulating the business from front-end application changes and toolset changes. From a DBA perspective, it’s an instant performance boost—just load up the data in BLU Acceleration and go…analyze. One of our clients at a DB2 10.5 announcement event told the press that “…I thought my database had abended because a multimillion row query was processed so fast.” Think of that impact on your end users.
BLU Acceleration makes your business agile too. Typical data marts require architecture changes, capacity planning, storage choices, tooling decisions, and optimization and index tuning; with BLU Acceleration, the simplicity of create, load, and go becomes a reality—it’s not a dream.
We’ve done a lot of integration work with Cognos Business Intelligence (Cognos BI) and BLU Acceleration. For example, deploying a Cognos-based front end is done by simply modeling business and dimensional characteristics of the database and then deploying them for consumption using Cognos BI’s interactive exploration, dashboards, and managed reporting. BLU Acceleration technology flattens the time-to-value curve for Cognos BI (or any analytics toolsets for that matter) by decreasing the complexity of loading, massaging, and managing the data at the data mart level. We think perhaps one of the most attractive features in what we’ve done with BLU Acceleration and Cognos is that the Cognos engine looks at a DB2 column-organized table just like it does a row-organized one. Since they are both just DB2 tables to Cognos, a Cognos power user can convert underlying row-organized tables to BLU Acceleration without changing anything in the Cognos definitions (all the steps we just outlined); that’s very cool! Finally, DB2 10.5 includes five user licenses of Cognos BI, so you can get started right away and experience this integration for yourself.
Almost all lines of business find that although transactional data systems are sufficient to support the business, the data from these online transaction processing (OLTP) or enterprise resource planning (ERP) systems isn’t surfaced to their units as actionable information; the data is “mysterious” because it isn’t organized in a way that would suit an analytical workload. This quandary gives way to a second popular use case: create data marts directly off transactional databases for fast line-of-business reporting. Because we’ve made BLU Acceleration so simple, DBAs can effortlessly spin up line-of-business–oriented data marts to rapidly react to business requirements. For example, consider a division’s CMO who’s sponsoring a certain marketing promotion. She wants to know how it’s progressing and to analyze the information in a timely manner. DB2 with BLU Acceleration empowers this use case.
Given the columnar nature of BLU Acceleration, data doesn’t have to be indexed and organized to support business queries. As well, the data mart can now contain and handle the historical data that’s continuously being spawned out of a system of record, such as a transactional database.
As you can see, BLU Acceleration is designed for data mart–like analytic workloads that are characterized by activities such as grouping, aggregation, range scans, and so on. These workloads are typically processing more than 1 percent of the active data and accessing less than 25 percent of the table’s columns in a single query. Although not required, star and snowflake schemas are going to be commonplace in leading BLU Acceleration candidates’ schema design. DB2 10.5 with BLU Acceleration is also cloud-ready, so if you’re provisioning analytic services in this manner, it’s a nice deployment fit as well. You will even find DB2 with BLU Acceleration offered via various cloud vendors through their respective Software-as-a-Service (SaaS) procurement channels.
Finally, although it feels like magic, BLU Acceleration isn’t for all workloads and use cases. For example, operational queries that access a single row or a few rows (likely by using an index) aren’t the right fit for BLU Acceleration. If your environment continually processes fewer than 100 rows per commit, BLU Acceleration isn’t the best choice because the commit scope compromises the analysis that can be done on the data for optimal compression rates. There are some other reasons not to use BLU Acceleration, but they tend to be related to shorter-term restrictions so they’re not worth mentioning because by the time you are reading this book, they will likely be gone.
How BLU Acceleration Came to Be: The Seven Big Ideas
The number seven is pretty special in almost any domain. If you’re a numbers person, it’s a base and double Mersenne prime, a factorial prime, and a safe prime. If you study the Christian bible, you’ll find the seven days of Genesis, the seven Seals of Revelation, and more. Artist? The Group of Seven means something to you. Mythologists have their seven heavens, and if you’re a music lover and fan of Queen, you’ve undoubtedly heard their “Seven Seas of Rye” hit song. There also happen to be seven “big ideas” that served as guiding principles behind the BLU Acceleration design points, which we cover in this section.
Big Idea Number 1: KISS It
Although we’re sure that you’re going to want to kiss the development team behind BLU Acceleration when you get a chance to take it for a test drive, the core idea behind BLU Acceleration was to ensure our development teams gave it a KISS—“Kept it simple, Sweetie.” (We may have used a different word than Sweetie in our decree, but we’ll leave it at that.) The point was to keep it super easy for you—we didn’t want dozens of new parameter controls, additional software to install, make you change your application, forklift migrate your hardware, and so on. After all, if you look at traditional relational database management systems (RDBMS) and the kinds of complexity that they’ve introduced, you can begin to see why much of the proportional cost of administration and management of servers and software has risen relative to total IT spending in the last decade.
Keeping it simple was the key behind our Super Analytics, Super Easy BLU Acceleration tagline. In fact, the simplicity of DB2 with BLU Acceleration is one of its key value propositions. When we talk about administration of the BLU Acceleration technology, we tell you more about what you don’t have to do than what you have to do. How cool is that?
First and foremost, there’s no physical design tuning to be done. In addition, operational memory and storage attributes are automatically configured for you right out of the box (more on that in a bit). Think about the kinds of things that reside in a DB2 DBA’s toolkit when it comes to performance tuning and maintenance: these are the things you’re not going to do with BLU Acceleration. You’re not going to spend time creating indexes, creating materialized query tables (MQTs), dimensioning data using multidimensional clustering (MDC) tables, distributing data with a partitioning key, reclaiming space, collecting statistics, and more. None of this is needed to derive instant value from BLU Acceleration technology. From a DBA’s perspective, you just load and go and instantly start enjoying performance gains. Now compare that to some of our competitors who make you face design decisions like the ones we’ve just outlined.
One of the reasons that BLU Acceleration is easy to use is related to the fact that it uses the same DB2 process model that you’re used to, the same storage constructs, the same buffer pools, the same SQL language interfaces, the same administration tools, and so on—but with seriously enhanced algorithms inside. It’s not bolted-on DB2 technology; it is DB2 technology. The beautiful thing here is that you can have your column-organized tables in the same table space—and even in the same buffer pool for that matter—as your row-organized tables, and the same query can access all of that data. Don’t overlook this point; it’s really important and unique, and deserves repeating in this book—which we do. We delve into the details of how DB2 BLU Acceleration is really just a part of DB2 in the section “Under the Hood: A Quick Peek Behind the Scenes of BLU Acceleration” later in this chapter.
Looking back at this authoring team’s collective century-plus experience in the database world, we can’t help but take note of all the tuning papers we’ve read (or written) and courses we’ve attended (or taught). We’ve allocated memory and tuned it. We’ve built covering indexes, used various kinds of compression options (thankfully even for row-organized tables, DB2 automates almost all of this with a single switch), tuned I/O, invoked specialized buffer pool algorithms, and more. You’ll find all of this work pretty much eliminated in DB2 with BLU Acceleration, replaced with a management-by-intent policy in which you tell DB2 to run in analytics mode; and once set, the process model, workload management, memory allocations, almost everything is pretty much automatically configured for DB2 to operate with an analytics persona.
Have you ever cooked microwavable popcorn, followed the instructions (cook for 3 to 4 minutes), and then found that some of the kernels were perfectly popped, some were kind of burnt, and others didn’t pop at all? We have a microwave oven in our development lab that has a “Popcorn” button. We’re not really sure how it does what it does, but if we put a bag of popcorn in the oven and press this button, we end up with a late-night “hackathon” snack that would make Orville Redenbacher proud. Although DB2 with BLU Acceleration won’t make popcorn for you, it’s essentially the same approach. You “press the button,” load the data, and run queries. It’s hard to imagine things getting any simpler than that, and that’s why we call BLU Acceleration Super Analytics, Super Easy.
Big Idea Number 2: Actionable Compression and Computer-Friendly Encoding
The second big idea behind BLU Acceleration pertains to how DB2 encodes and compresses data and the way that it “packs” the CPU registers. DB2 with BLU Acceleration also has the ability to operate on the data while it’s still compressed (yes, you read that right).
Now, why would you want to do this, and more so, why is this such a big idea? First, if the data is smaller, you can obviously put more of it into memory. However, if you can save the most space on the data that’s repeated the most (more on this in a bit), you’re going to expend even less computing resource to work on the data that you use the most. Now, if DB2 can operate on the data while it’s still compressed, not only will the engine realize more memory savings, but it’ll also save on all that CPU that would have gone into decompressing the data just to evaluate predicates, for example. (We’re sure you’ve figured this out by now, but DB2 with BLU Acceleration does both.)
Let’s illustrate this benefit by thinking about a typical analytic query that might have to mass scan over several of a table’s columns, decompressing and evaluating all the values for the predicate columns, even though perhaps only 1 to 10 percent of that data satisfies the predicates in the query. In a BLU Acceleration environment, if only 5 percent of the data actually satisfies the query, the database engine needs to decompress only about 5 percent of the data in order to return it to the client application, effectively avoiding 95 percent of the decompression cycles that would have been consumed by typical compression technologies.
For example, DB2 with BLU Acceleration technology can apply equality and inequality predicates on compressed data without spending CPU cycles to decompress that data; as you can imagine, this is very valuable for range queries (for example, “Give me the run rate percentage and year-over-year dollar growth of revenue for area A between year X and year Y”).
The way that BLU Acceleration is able to work on compressed data comes from the way it’s encoded—both on disk and in memory. BLU Acceleration’s fundamental approach to compression is a variation of Huffman encoding. Huffman encoding looks for the symbols that occur most frequently and gives them a shorter representation. Think of it this way: Something that appears many times should be compressed more than other things that do not appear as often. For example, if you’re compressing the complete works of Shakespeare and the most frequent symbol is the letter “e,” Huffman encoding would compress it with just one bit. The letter “z” occurs much less frequently, and therefore a Huffman encoding scheme might compress it with seven bits. This encoding method yields very impressive compression ratios. Using approximate Huffman encoding as its base, BLU Acceleration adds several other compression methods to eke out a super-tight form factor for its data.
Now let’s show you how this actually works because BLU Acceleration doesn’t really encode on a per-letter basis. In fact, the scope of BLU Acceleration encoding is at the column-value level. Consider a compressed
Last_Name column in a table that tracks complaints for a certain airline carrier. The name of a frequent complainer (with four registered complaints), Zikopoulos, has ten characters in it, but as you can see on the left side of Figure 3-2, it’s using a smaller encoding scheme than Huras, which has only five characters and two registered complaints. Notice that Lightstone is the same length as Zikopoulos, but he has only one complaint and therefore has the largest bit-encoded representation.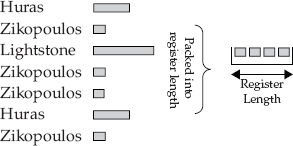
Figure 3-2 A representation of how BLU Acceleration encodes and packs the CPU register for optimal performance and compression
This encoding is dynamic in nature. This is a really important point: Consumability is in the DNA of all our technologies. For example, in DB2 9.7 we introduced index compression, which was designed to enable the DB2 engine to automatically detect, define, and dynamically adapt the prefix that it compresses as one of its three auto-selected and possible combined index compression techniques. This is something that a major competitor’s technology can’t do; that technology requires DBAs to drop and manually redefine the compression prefix to adapt to new data. The key point is that BLU Acceleration can dynamically alter the compression bias using adaptive compression for new data loads that changes the distribution of common symbols, thereby ensuring continuous optimization.
Offset coding is another compression optimization technique that’s used in BLU Acceleration. Offset coding is very useful with numeric data, the kind of data you’d typically see in financial applications. Think about an options chain for a traded stock and its corresponding open interest on contracts for sale.
IBM might show 100 interested contracts for a certain price, 101 for a call in the following month, and 102 of a call that is even further out, and so on. With offset coding, instead of trying to compress 100, 101, and 102, DB2 stores a single value (100) and then stores the offsets to that value (1, 2, …). This technique is actually very similar to how DB2 compresses index record IDs (RIDs), one of the three autonomic index compression algorithms that DB2 can dynamically apply to indexes. There are other compression optimization techniques used in BLU Acceleration, such as prefix compression, and other things that we’re not allowed to talk about, but they all combine to provide multifaceted, complete, and impactfully obvious compression capabilities.Values in BLU Acceleration are compressed to be order preserving, which means that they can be compared to each other while they are still compressed. For example, let’s assume the value
50000 compresses to a symbol like 10 (for simplicity’s sake) and 20000 compresses to 01. These two values are ordered (01 is less than 10, as 20000 is less than 50000). As a result, DB2 can perform a lot of predicate evaluations without decompressing the values. A query such as select * … where C1 < 50000 using this example becomes select * … where C1 < 10. In this example, DB2 could filter out the values that are greater than 50000 without having to decompress (materialize) the data. Quite simply, the fact that DB2 only has to decompress qualifying rows is a tremendous performance boost. Notice how instead of decompressing all the data to see if it matches the predicate (< 50000), which could require decompressing billions of values, BLU Acceleration will simply compress the predicate into the encoding space of the column. That’s just cool!The final tenet of this big idea pertains to the actual encoding: BLU Acceleration takes the symbols’ bits and packs them as tightly as possible into vectors: collections of bits that match (as closely as possible) the width of the CPU register; this is what you see on the right side of Figure 3-2 (although the figure is intentionally oversimplified and intended to not reveal all of our secrets, we think you’ll get the gist of what we’re doing). This is a big deal because it enables DB2 to flow the data (in its compressed form) into the CPU with maximum efficiency.
To sum up, all of the big idea components in this section will yield a synergistic combination of effects: better I/O because the data is smaller, which leads to more density in the RAM, optimized storage, and more efficient CPU because we’re operating on the data without decompressing it and packing that data in the CPU “registered aligned.” This is all going to result in much better (we’ll call it blistering) performance gains for the right workloads.
Big Idea Number 3: Multiplying the Power of the CPU
The third big idea has its genesis in the exploitation of a leading-edge CPU technology found in today’s modern processors: Single Instruction Multiple Data (SIMD). SIMD instructions are low-level CPU instructions that enable you to perform the same operation on multiple data points at the same time. If you’ve got a relatively new processor in your laptop or home computer, chances are it’s SIMD-enabled, because this technology was an inflection point for driving rich multimedia applications. For example, you’ll find SIMD exploitation for tasks such as adjusting the saturation, contrast, or brightness in your photo-editing applications; adjusting the volume in digital audio applications; and so on. DB2 10.5 with BLU Acceleration will auto-detect whether it’s running on an SIMD-enabled CPU (for example, a qualifying Power or Intel chip) and automatically exploit SIMD to effectively multiply the power of the CPU. Automation is a recurring theme in DB2; it automatically detects and senses its environment and dynamically optimizes the runtime accordingly. For example, DB2 pureScale will detect whether your storage subsystem is enabled with SCSI3 PR and use an alternative time-to-recovery technology with faster fencing of disks if it detects this kind of storage at engine start time, DB2 can tell that it’s running in a Power environment and exploit decimal floating-point arithmetic on the processor core for specific math functions; and during data prefetch, DB2 can detect the kind of prefetching that’s happening and adjust its prefetch accordingly. These are just a handful of the many examples where DB2 operates as a sensory mechanism where it can dynamically detect and react to its environment—without DBA intervention—for optimal results.
Now, you might be thinking that SIMD exploitation is like hyper-threading, in which the server is “tricked” into thinking that it has more cores, but that’s not it at all. Multithreading actually weaves work items between pauses, so although it’s definitely an optimization, SIMD is something completely different. Because SIMD instructions are very low-level specific CPU instructions, DB2 can use a single SIMD instruction to get results from multiple data elements (perform equality predicate processing, for example) as long as they are in the same register. DB2 can put 128 bits into an SIMD register and evaluate all of that data with a single instruction, and this is why this big idea is so important: Being able to compress data as much as possible, compress the most commonly occurring data, and then optimally pack it at register widths reveals the synergy that lies at the core of this big idea. You can also run DB2 with BLU Acceleration on a server that doesn’t include SIMD-enabled CPUs; you just won’t realize the full benefits of what we’ve done. That said, even if your server isn’t SIMD enabled, DB2 can “fake out” the CPU to provide some of the SIMD benefits. For example, BLU Acceleration is supported on Power 6, but SIMD isn’t supported on that platform; instead, when BLU Acceleration is used on Power 6, it will emulate hardware SIMD with software SIMD (using bitmasking to achieve some parallelism) to deliver some of the SIMD benefits, even when the CPU does naturally support it.
We’ll use Figure 3-3 to illustrate the power of SIMD using a scan operation that involves a predicate evaluation. (Although Figure 3-3 shows a predicate evaluation, we want you to be aware that SIMD exploitation can be used for join operations, arithmetic, and more—it’s not just a scan optimization.) On the right side of this figure, we show four column values being processed at one time—this is only for illustration purposes, as it’s quite possible to have more than four data elements processed by a single instruction with this technology.
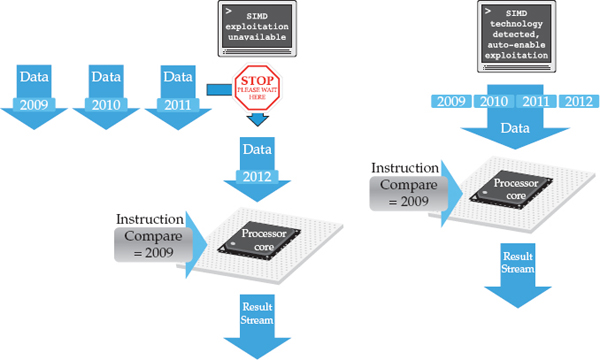
Figure 3-3 Comparing predicate evaluations with and without SIMD in a CPU packing optimized processing environment like DB2 10.5 with BLU Acceleration
Contrast the right side of Figure 3-3 with the left, which shows an example of how predicate evaluation processing would work if we didn’t take the time to engineer BLU Acceleration to automatically detect, exploit, and optimize SIMD technology, or implement big idea number 2 to optimally encode and pack the CPU register with data. In such an environment, instead of optimally packing the register width, things just happen the way they do in so many competing technologies. Each value is loaded one at a time into its own register for predicate evaluation. As you can see on the left side of Figure 3-3, other data elements queue up for predicate evaluation, each requiring distinct processing cycles.
When the same operation is executed in a DB2 with BLU Acceleration environment (the right side of Figure 3-3), the efficiency is obvious. We like to think of it as a four-for-one sale: DB2 can get multiple results from multiple data elements with a single instruction, thereby multiplying the performance of these operations. Of course, in a DB2 environment, there’s also no wasted runtime cycles spent aligning the data to pack the CPU register.
Now imagine that your query is matching a primary key to a foreign key—it could use SIMD for grouping or mathematical operations, and more. These kinds of operations are critical in exactly the kinds of workloads for which BLU Acceleration was designed: scanning, joining, grouping, and so on.
In summary, big idea number 3 is about multiplying the power of the CPU for the key operations typically associated with analytic query processing, such as scanning, joining, grouping, and arithmetic. By exploiting low-level instructions available on modern CPUs and matching that with optimizations for how the data is encoded and packed on the register (big idea 2), DB2 literally multiplies the power of the CPU: A single instruction can get results on multiple data elements with relatively little runtime processing.
At this point, our big ideas compress and encode the data, then pack it into a set of vectors that matches the width of the CPU register as closely as possible. This literally gives you the biggest “bang” for every CPU “buck” (cycles that the server consumes); we literally squeeze out every last drop of CPU power. Have you heard the expression “squeezing blood from a stone”? In most cases, that’s not a good thing, but with your hardware and software investments, it’s a very good thing.
Big Idea Number 4: Parallel Vector Processing
Multicore parallelism and operating on vectors of data with extreme efficiencies when it comes to memory access is a very powerful idea about actually delivering on something in which you’ve invested for a long time: exploiting the growing number of processing cores on a server’s socket.
Central to this big idea is that we want DB2 to be extraordinarily diligent in leveraging the processing cores that are available on a server. Where should data be placed in a cache that will be revisited? How should work be shipped across sockets? Now we know what you’re thinking: “What’s the big deal here? Every vendor says that they’ve been exploiting multicore parallelism for years.” Our response to such a question? Sure. Everyone says they do it, but do they really? Consider your own personal computing environment. For all the cores that you have in your system, don’t you find it odd that performance seems to be getting worse? And as applications get more feature rich and require more computing resources, the question that you really should be asking yourself is: “Was my software specifically written to parallelize operations?” Hint: This is not an easy thing to do, especially well, so ensure you look past the veneer of typical vendor claims.
In our experience, almost every vendor that we can think of has had only a moderate amount of success using core-friendly parallelism. For analytics parallelism, one approach has been to create a massively parallel processing (MPP) shared-nothing database cluster. The PureData System for Analytics (powered by Netezza technology) leverages this topology; so does the DB2 Database Partitioning Feature (DPF)—the technology behind the PureData System for Operational Analytics—as does Teradata’s architecture (which strongly resembles DB2 DPF). In such environments, you’re able to distribute a query across a cluster of machines. That’s been the prescription for driving parallelism in very large databases (VLDBs), and it will continue to be so.
But think about smaller warehouses and marts that contain raw data in the 10TB or less range, which could reach 30TB in a fully loaded warehouse when you include indexes, aggregates, and so on (even higher if that data isn’t compressed, perhaps over 100TB). Why can’t they fit into a single system? Well, in a shared-everything, single-server system (and for increased efficiencies in an MPP cluster where more and more CPU cores are available on an individual node), processing occurs in a single slice of memory. The entire system is sharing the same heaps and RAM buffer allocations. What you typically find is that when you scale within the system from one to two threads, the results are generally pretty good; with two to four threads, they are not too shabby. Above that, you have diminishing returns—in fact, in our client testing observations of commonplace in-market databases, we found that parallelism trails off pretty badly.
Why? Because of the physics of the system, which suggests that as you scale across sockets, and as your data starts to exceed what’s sitting in the level 2 (L2) cache, you start to incur more and more latency. That means it’s taking more time for the CPU to access data in memory. Servers try to minimize this latency through CPU advancements. For example, prefetching the data and trying to keep it in the L2 cache versus L3 cache, which is an order of magnitude (or more) faster to access than data in RAM. But the hardware can only guess at what data to prefetch and what data to keep in these fast caches.
There’s also the concept of false sharing, which occurs when memory is updated in one L1 cache, causing the corresponding L1 cache of another CPU to be invalidated. Once the L1 cacheline is invalidated, all of the data in that cacheline needs to be refreshed, causing further delays for that CPU. Only extremely careful programming techniques can help avoid this problem. The more sockets and memory channels on the server, the worse this problem gets.
These are just some of the reasons why single systems traditionally don’t scale well for analytics beyond four- to eight-way parallelism, and that’s part of the reason why almost every BI vendor has a shared-nothing architecture. You may never have heard of some of these problems. Indeed, they’re pretty esoteric. That’s exactly why they are hard to solve. This is why we call memory the new disk. (Traditionally, while you performance tuned your database, if a query spilled to disk, it would typically slow down performance. However, in BLU Acceleration, we kind of raise it up a level and view “query spills to in-line memory out of the CPU caches” as a performance inhibitor and that’s what we mean when we say “memory is the new disk.”)
So, what if your software could do better? We talked about making analytics super-easy in our first big idea. What if BLU Acceleration could change the inflection point where you need to leverage MPP technologies? Would that keep costs down and make it easier? If you could fit your marts on a singleserver solution and not have to manage a cluster, wouldn’t that make things easier and you can still leverage the power of MPP scale-out when needed? We believe that your existing server has the power to shift the “when to scale out or scale up” inflection point because the processing power is already there. The problem is that most analytic database engines haven’t been written to fully exploit those resources—we mean to really exploit those resources.
In DB2 with BLU Acceleration, we’ve done a lot of hard work so that you can truly “Kill It with Iron” (KIWI). KIWI starts with the premise that we know that the CPU core counts on today’s (and tomorrow’s) servers are going to continue to increase. We wanted to ensure that BLU Acceleration is available where it can be used the most and to keep things very easy. (Remember our Super Analytics, Super Easy tagline?) The secret for us has been to realize that memory is the new disk. For BLU Acceleration, main memory access is too slow. It is something to be avoided. BLU Acceleration is designed to access data on disk very rarely, access RAM only occasionally, and do the overwhelming bulk of its processing from data and instructions that reside in a CPU cache. Super easy from an administrative perspective means within the confines of one server, which means we aren’t going to ask DBAs to divide their data into logical partitions. To do this, we had to engineer DB2 to pay very careful attention to CPU cache affinity and memory management so that the majority of memory access occurs in a CPU cache and not by accessing data from RAM over and over again. By operating almost exclusively on data in a CPU cache and not in RAM, BLU Acceleration minimizes the “latency” and is able to keep your CPUs busy. We’ve seen a lot of benefit from the work we’ve done in this area, and have personally seen excellent scalability between 32- and 64-way parallelism—where even a single query can exploit 64 cores in shared memory with almost perfect scalability. It just gets easier as workload concurrency increases with more queries running at once.
In summary, big idea number 4 recognizes that servers have an increasingly larger numbers of cores. DB2 with BLU Acceleration is designed from the ground up to take advantage of the cores that you have and to always drive multicore parallelism for your queries. This is all done in shared memory—it is not DPF parallelism. Our focus on efficient parallel processing with memory-conscious algorithms enables us to fully utilize the power of multiple CPU cores.
Big Idea Number 5: Get Organized…by Column
Big idea number 5 revolves around something that’s become pretty trendy (despite being around for a long time) and commonplace in the last couple of years: column store. Essentially, the idea is to bring all of the typical benefits attributed to columnar stores, such as I/O minimization through elimination, improved memory density, scan-based optimizations, compelling compression ratios, and so on, to DB2. Again, we ask you to consider that what makes BLU Acceleration so special isn’t just that it’s an in-memory column store; rather, it’s how we implemented it as a dynamic in-memory column store with the other big ideas.
What Is a Column Store?
We’ll assume you’ve got the gist of what a column-organized table is because there are so many technologies using this approach in today’s marketplace, so we won’t spend too much time describing it. To ensure that we are all on the same page, however, Figure 3-4 shows a simplification of a row-organized table (on the left) and a column-organized table (on the right). As you can see, a column-organized table orients and stores its data by column instead of by row. This technique is well suited to specific warehousing scenarios.

Figure 3-4 Comparing row-organized and column-organized tables
With a columnar format, a single page stores the values of just a single column, which means that when the database engine performs I/O to retrieve data, it just performs I/O for only the columns that satisfy the query. This can save a lot of resources when processing certain kinds of queries.
On disk, you see a single page dedicated to a particular column’s data. Because in an analytics environment data (because there’s a high probability of repeated data on a page—like the
Skill column) within a column is more self-similar, we’ve observed better compression ratios with column stores than with traditional row-store compression technology. That said, the DB2 compression technology that’s available for row organized tables has been seen to achieve levels as good as columnar for many environments, and unlike columnar, is very well suited for transactional environments too. This is what makes DB2 so special: All this stuff is used side by side, shared in many cases, complementary, and integrated.Columnar Is Good—BLU Acceleration Engineering Makes It Great
BLU Acceleration uses columnar technology to store a table on disk and in memory. However, by combining that with all the big ideas detailed so far, we think it gives DB2 10.5 big advantages over our competitors.
By using a column store with encoding, DB2 is able to get an additional level of compression that leads to even more downstream I/O minimization. In addition, recall that DB2 is able to perform predicate evaluation (among other operations) against compressed data by using its actionable compression capabilities, and that even further reduces the amount of I/O and processing that needs to be performed.
Of course, overall I/O is reduced with columnar technology because you only read what the query needs. This can often make 95 percent of the I/O go away because most analytic workloads access only a subset of the columns. For example, if you’re only accessing 20 columns of a 50-column table in a traditional row store, you end up having to do I/O and consume server memory even for data in columns that are of no interest to the task of satisfying the query.
With BLU Acceleration column-organized tables, the rows are not accessed or even “stitched” back together until absolutely necessary—and at the latest possible moment in a query’s processing, for that matter. In most cases, this will occur when the answer set is returned to the end user, or when you join a column-organized table with a row-organized table. This process of combining the columns as late as possible is called late materialization.
Let’s use a simple example to explain why this helps. Consider a query on a 20-column table that has 1 billion rows; the query has predicates on columns A, B and C, and 1 percent of each column’s data satisfies these predicates. For example:
In a row store, this kind of query would only run well if the user had designed system indexes on columns A, B, and C. Failing that, all 1 billion rows would need to be read. In a column store that has late materialization, such as BLU Acceleration, the database starts by scanning only the column that’s likely to be the most selective (has the fewest qualifying values). Let’s assume that after scanning the first column, only 1 percent of the data remains. (Remember that BLU Acceleration can scan and operate on compressed data without needing to decompress it.) Next, DB2 accesses the second column, but only those qualifying 1 percent of records that survived the first column scan are looked at, leaving 1 percent of 1 percent (0.01 percent) of data that passes through the engine; finally, the third column is processed and that leaves just 1 percent of 1 percent of 1 percent (0.0001 percent) of the original data set.
Now consider just how much data was really accessed to satisfy this query. You can see that the total data accessed is dominated by the initial column scan, which is just 1/20th of the table’s data (1 of the 20 columns), and it didn’t even require decompression, and this is why it pays to access the columnar data as late in the processing as possible—as the query progresses, the data gets increasingly filtered.
To sum up, column store is a part of BLU Acceleration. DB2 with BLU Acceleration leverages columnar technology to help deliver minimal I/O (performing I/O only on those columns and values that satisfy the query), better memory density (column data is kept compressed in memory), and extreme compression. However, when it’s mixed with other big ideas, such as packing the data into scan-friendly structures, and more, BLU Acceleration really sets itself apart from the rest of the industry.
Big Idea Number 6: Dynamic In-Memory Processing
Dynamic in-memory processing covers a set of innovative technologies to ensure that BLU Acceleration is truly optimized for memory access, but not limited to the size of RAM—just in case your active data is (or may one day become) bigger than the buffer pool. We like to think of BLU Acceleration as being better than in-memory processing. Two major technologies are at play in this concept: scan-friendly memory caching and dynamic list prefetching.
Scan-friendly memory caching is a powerful idea, which, to the best of our knowledge, is unique to BLU Acceleration. Effectively caching data in memory has historically been difficult for systems that have more data than memory. Many database systems have memory caches, but they tend to work great for transaction processing and not very well for analytic workloads. That’s because their algorithm’s access patterns are radically different. Transaction-processing systems process a lot of random access patterns on highly skewed data patterns because in these environments, some data is much hotter than other data. For those workloads, databases have traditionally used variations of the Least Recently Used (LRU) and Most Recently Used (MRU) paging algorithms, which had the effect of keeping the data used most recently in memory (the MRU algorithm) while evicting the old data (the LRU algorithm).
Now it’s fair to note that analytic workloads have some elements of skew as well. For example, recent data (within the past month) is usually hotter than older data (often referred to as cold—perhaps in your environment, that’s five years old or more). That said, for analytic workloads, the pattern of data access is much more egalitarian (it’s likely not to favor a set of pages, thereby creating a “hot” page) within the active data set, as queries are bound to touch a lot of data while performing scans, aggregations, and joins. Egalitarian access presents quite the challenge for a database system; after all, how can you optimally decide what to keep in memory when all pages in a range are more or less equal? This presents a conundrum: The database manager wants to have some elements of the traditional caching approach that favors hot data, but also requires a new approach that recognizes that even the hot data may be larger than RAM and have fairly even access patterns. With BLU Acceleration, not only can the data be larger than allocated RAM, what’s more, DB2 is very effective at keeping the data in memory, which allows for efficient reuse and minimizing I/O; this is true even in cases where the working set and individual scans are larger than the available memory. DB2’s scan-friendly memory caching is an automatically triggered cache-replacement algorithm that provides egalitarian access, and it’s something new and powerful for analytics. Our tagline for this is “DB2 performance doesn’t fall off a cliff when the query’s data requirements are bigger than the RAM.”
Consider what happens when a database tries to use a transactional algorithm to decide what to keep in memory with heavy scan-based analytic workloads. An analytic query in such a workload is likely to start at the top of the table and scan its way to the bottom. However, with a transactional optimized page-cleaning algorithm, by the time the scanner gets to the bottom of the table, the least recently used pages that were read at the start of the scan become the victims. In other words, because the table scan is reading so many pages into the buffer pool, some of the required pages are going to get flushed out. The next time a scan begins on this table, the incoming query is going to start scanning the pages at the beginning of the table and find that the target pages are no longer in memory; what a shame, because this will not only trigger I/O, but lots of I/O. This scenario plays itself out continually because such a database is trying to use an algorithm for cache replacement that was designed fundamentally for transaction processing and use it for analytics.
The analytics-optimized page replacement algorithm that’s associated with BLU Acceleration assumes that the data is going to be highly compressed and will require columnar access, and that it’s likely the case that all of this active data (or at least 70 to 80 percent of it) is going to be put into memory.
When surveying our clients, we found that the most common memory-to-disk ratio was about 15 to 50 percent. Assuming a conservative 10-fold compression rate, there’s still a high probability that you’re going to be able to fit most (if not all) of your active data in memory when you use DB2 10.5 with BLU Acceleration. But while we expect most, if not all, of the active data to fit in memory for the majority of environments, we don’t require it. When DB2 accesses column-organized data, it’ll automatically use its scan-friendly memory-caching algorithm to decide which pages should stay in memory in order to minimize I/O, as opposed to using an algorithm based on LRU, which is good for OLTP and not as optimized for analytics.
What makes this big idea so unique is that DB2 automatically adapts the way it operates based on the organization of the table (row-organized or column-organized) being accessed. Remember the DBA doesn’t have to do anything here; there are no optimization hints to give, configuration parameters to set; it just happens automatically.
The second aspect of dynamic in-memory processing is the new prefetch technology called dynamic list prefetching. The prefetching algorithms for BLU Acceleration have been completely redesigned for its columnar parallel vector processing engine. These algorithms take a very different approach because BLU Acceleration doesn’t have indexes to tell it what pages are interesting to the query (list prefetching), which would be a common case with a row-organized table. Of course, DB2 could simply prefetch every page of every column that appears in a query, but that would be wasteful, as we saw with the previous late materialization example where each predicate filtered 99 percent of the remaining data. With 0.0001 percent of the data qualifying, prefetching 100 percent of the data for all columns would be a massive waste of I/O. BLU Acceleration addresses this challenge with an innovative strategy to prefetch only a subset of pages that are interesting (from a query perspective), without the ability to know far in advance what they are. We call this dynamic list prefetching because the specific list of pages can’t be known in advance via an index.
To sum up, remember that one of the special benefits of BLU Acceleration in comparison to traditional in-memory columnar technologies is that performance doesn’t “fall off the cliff” if your data sets are so large that they won’t fit into memory. If all of your data does fit into memory, it’s going to benefit you, but in a Big Data world, that isn’t always going to be the case, and this important BLU Acceleration benefit should not be overlooked.
Big Idea Number 7: Data Skipping
The seventh (but not final! …we don’t like saying final because more are coming as we enhance this technology in subsequent releases) big idea that inspired BLU Acceleration is data skipping. The idea is very simple: We wanted DB2 to be able to skip over data that’s of no interest to the active query workload. For example, if a query was to calculate the sum of last month’s sales, there’s no need to look at any data that’s older than last month that’s sitting in the warehouse. With data-skipping technology, DB2 10.5 can automatically skip over the nonqualifying data because it keeps metadata that describes the minimum and maximum range of data values on “chunks” of the data. This enables DB2 to automatically detect large sections of data that don’t qualify for a query and to effectively ignore them. Data skipping can deliver an order of magnitude in savings across compute resources (CPU, RAM, and I/O). Of course, in keeping with the “Super Easy” part of the BLU Acceleration mantra we’ve been chanting throughout this book, this metadata is automatically maintained during
INSERT, UPDATE, and DELETE activity, so you don’t have to worry about defining or maintaining it.BLU Acceleration’s data skipping is conceptually similar to the Zone Map technology found in the PureData System for Analytics (formerly known as Netezza) family. We say similar because unlike Zone Maps, this metadata isn’t tied to any particular page or extent boundary—it’s tied to a certain “chunk” of data records (about 1,000). Because data skipping allows a query to skip over ranges of uninteresting data, DB2 is able to avoid touching this data, whether it’s on disk or in memory, during query execution.
DB2’s data-skipping metadata is actually kept in a tiny column-organized table called a synopsis table, which is automatically maintained, loaded, and persisted into memory when needed. This metadata is extremely valuable because it empowers DB2 to save precious compute resources by enabling the database engine to intelligently and accurately skip over data that’s not needed; this saves I/O and keeps the system’s memory filled with useful active data rather than filling it up with data that the query doesn’t actually need. Of course, all this means that more memory is available for the important data you really want to run analytics on.
Seven Big Ideas Optimize the Hardware Stack
If you’ve spent any amount of time performance tuning a database, you know that there are three things you always care about: memory, CPU, and I/O. You iterate through various approaches to remove bottlenecks in any of these hardware attributes to find higher and higher levels of performance.
The driving force behind many of the amazing results coming from BLU Acceleration technology was a relentless focus on hardware utilization. (BLU Acceleration aside, DB2 10.5 contains lots of technologies for enhanced exploitation of memory, processors, and I/O, which leads to lower total cost of ownership, better resource utilization, better performance, and so on.)
Figure 3-5 presents a summary of the seven big ideas from the perspective of squeezing every last ounce of compute resources from your hardware stack.

Figure 3-5 Looking at BLU Acceleration’s seven big ideas from a compute resource perspective: the hardware stack
When Seven Big Ideas Deliver One Incredible Opportunity
Let’s see how these diverse ideas have been integrated into a single offering by working through a typical example in analytics processing. As always, “your mileage will vary,” depending on the kind of data you’re storing, your server, the queries you’re running, and so on.
With that said, let’s start with the assumption that you have a 32-core server and you’ve got 10 years of data (2004 to 2013) that’s ready to be loaded into a relatively wide (100-column) table. Before loading the data, the on-disk raw footprint of this data is 10TB. An analyst wants to run a simple query that counts all of the new customers that were added to your company’s loyalty program through the various campaigns (Web, mailings, and so on) run in a specific year. Using a favorite BI tool, such as Cognos BI, and without any idea what BLU Acceleration is, the analyst composes the following query:
select count(*) from LOYALTYCLIENTS where year = '2012'. Our goal? To provide the analyst with subsecond response times from this single nonpartitioned, 32-core server without creating any indexes or aggregates, partitioning the data, and so on.When we tabled this scenario with our testing team (without mentioning the BLU Acceleration technology), they laughed at us. We did the same thing in front of a seasoned DBA with one of our biggest clients, and she told us, “Impossible, not without an index!” Figure 3-6 shows how the seven big ideas worked together to take an incredible opportunity and turn it into something truly special.
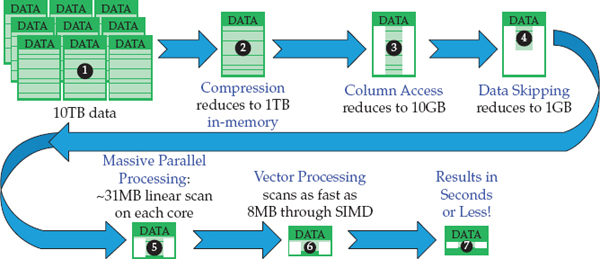
Figure 3-6 Watching how some of the seven big ideas that went into BLU Acceleration manifest into incredible performance opportunities
The example starts with 10TB of data  that’s sitting on a file system waiting to be loaded into a DB2 database with BLU Acceleration. Although we’ve seen much higher compression ratios, in many cases, we saw, on average, an order of magnitude (10x) reduction in the raw data storage requirements when just the BLU Acceleration encoding and compression techniques were taken into account, so now we have 1TB
that’s sitting on a file system waiting to be loaded into a DB2 database with BLU Acceleration. Although we’ve seen much higher compression ratios, in many cases, we saw, on average, an order of magnitude (10x) reduction in the raw data storage requirements when just the BLU Acceleration encoding and compression techniques were taken into account, so now we have 1TB  of data. Note that there aren’t any indexes or summary tables here. In a typical data warehouse, 10TB of raw data is going to turn into a 15- to 30-TB footprint by the time these traditional kinds of performance optimizations are taken into account. In this example, the 10TB of data is raw data. It’s the size before the data is aggregated, indexed, materialized, and so on. When it’s loaded into a BLU Acceleration table, that 10TB becomes 1TB.
of data. Note that there aren’t any indexes or summary tables here. In a typical data warehouse, 10TB of raw data is going to turn into a 15- to 30-TB footprint by the time these traditional kinds of performance optimizations are taken into account. In this example, the 10TB of data is raw data. It’s the size before the data is aggregated, indexed, materialized, and so on. When it’s loaded into a BLU Acceleration table, that 10TB becomes 1TB.
The analyst’s query is looking only for loyalty members acquired in 2012. YEAR is just one column in the 100-column LOYALTYCLIENTS table. Since DB2 needs to only access a single column in this column-organized table, you can therefore divide the 1TB of loaded data by 100. Now we’re down to 10GB  of data that needs to be processed. However, BLU Acceleration isn’t finished applying its seven big ideas yet!
of data that needs to be processed. However, BLU Acceleration isn’t finished applying its seven big ideas yet!
While DB2 is accessing this 10GB of data by using its columnar algorithms, it also applies the data-skipping big idea to skip over the other nine years of data in the YEAR column. At this point, DB2 skips over the nonqualifying data without any decompression or evaluation processing. Now we’re down to 1GB  : DB2 is now left solely looking at a single column of data, and within that column, a single discrete interval. Thanks to scan-friendly memory caching, it’s likely all of that data can be accessed at main memory speeds. Now DB2 with BLU Acceleration takes that 1GB and parallelizes it across the 32 cores on the server
: DB2 is now left solely looking at a single column of data, and within that column, a single discrete interval. Thanks to scan-friendly memory caching, it’s likely all of that data can be accessed at main memory speeds. Now DB2 with BLU Acceleration takes that 1GB and parallelizes it across the 32 cores on the server  , with incredible results because of the work that was done to implement the fourth big idea: parallel vector processing. This means that each server core only has to work on about 31MB of data (1GB = 1000MB/32 cores = 31.25MB). DB2 is still operating on compressed data at this point, and nothing has been materialized. It’s really important to remember this because all of the CPU, memory density, and I/O benefits still apply.
, with incredible results because of the work that was done to implement the fourth big idea: parallel vector processing. This means that each server core only has to work on about 31MB of data (1GB = 1000MB/32 cores = 31.25MB). DB2 is still operating on compressed data at this point, and nothing has been materialized. It’s really important to remember this because all of the CPU, memory density, and I/O benefits still apply.
DB2 now applies the other big ideas, namely actionable compression (operating on the compressed data, carefully organized as vectors that match the register width of the CPU) and leveraging SIMD optimization  . These big ideas take the required scanning activity to be performed on the remaining 32MB of data and make it run several times faster than on traditional systems. How fast? We think you already know the answer to that one—it depends. The combined benefits of actionable compression and SIMD can be very profound. For the sake of this illustration, let’s say the speed-up over traditional row-based systems is 4 times faster per byte (we think it’s often much higher, but we are being conservative—or rather being told to be). With this in mind, the DB2 server, from a performance perspective, only has to scan about 8MB (~32MB/4 speedup factor = 8MB) of data compared to a traditional system. Think about that for a moment. Eight megabytes is about the size of a high-quality digital image that you can capture with your camera. A modern CPU can chew through that amount of data in less than a second…no problem. The end result? We accepted a seemingly impossible challenge on 10TB of raw data and were able to run a typical analytic query on it in less than a second using the application of seven big ideas
. These big ideas take the required scanning activity to be performed on the remaining 32MB of data and make it run several times faster than on traditional systems. How fast? We think you already know the answer to that one—it depends. The combined benefits of actionable compression and SIMD can be very profound. For the sake of this illustration, let’s say the speed-up over traditional row-based systems is 4 times faster per byte (we think it’s often much higher, but we are being conservative—or rather being told to be). With this in mind, the DB2 server, from a performance perspective, only has to scan about 8MB (~32MB/4 speedup factor = 8MB) of data compared to a traditional system. Think about that for a moment. Eight megabytes is about the size of a high-quality digital image that you can capture with your camera. A modern CPU can chew through that amount of data in less than a second…no problem. The end result? We accepted a seemingly impossible challenge on 10TB of raw data and were able to run a typical analytic query on it in less than a second using the application of seven big ideas  .
.
Under the Hood: A Quick Peek Behind the Scenes of BLU Acceleration
BLU Acceleration comes with a number of DB2 optimizations that provide a platform for the incredible results we’ve detailed in this chapter. There’s a “knob” to run DB2 in analytics mode, and automatic workload management provides unlimited concurrency without your having to worry about resource pressures. There’s a new capability around uniqueness that lets you avoid storage and overhead for unique indexes when data is trusted, a utility to easily convert row-organized tables to column-organized tables, a query workload advisor that suggests how to organize a table based on a query set, and much more.
In this section, we discuss some of the things that go on “behind the scenes,” as well as some higher-level details on how things work in a BLU Acceleration environment. (If you’re not a propeller head, you can stop reading here—the remainder of the chapter may not interest you; that said, by all means, feel free to read on.)
BLU Acceleration Is a New Format for the Bytes in a Table, NOT a New Database Engine
Because BLU Acceleration is part of the DB2 DNA, its developmental context is not so much that of a new product, but one that draws benefits from the maturity and stability of a decades-long robust, proven, and familiar DB2 kernel. In fact, considerably less than 1 percent of the DB2 engine code was changed to bring BLU Acceleration to market because the process model stayed the same, the buffer pools stayed the same, as did the locking structures, package cache, recovery, and much more. And because BLU Acceleration is seamlessly built into the DB2 kernel, from an external perspective, the technology all looks the same. But what does this have to do with stability and maturity? Over the last 20 years, our labs have built up a mind-boggling collection of test cases that we run against every new release of DB2. We didn’t have to write a lot of new QA for BLU Acceleration; we just ran the thousands of existing test cases and bucket regression tests against tables using BLU Acceleration with the result that this is, by far, the most test cases and coverage that we’ve ever had for a new feature. Quite simply, a BLU Accelerated table is just a new database object that interfaces with the rest of DB2 in more or less the same manner as a conventional row-organized table did before, and this mitigates risk for those folks who might be tempted to view this as completely new technology.
How much a part of DB2 is BLU Acceleration? Well, relatively early in the project, one of us was writing code for BLU Acceleration’s integration into the DB2 kernel. He wondered whether he could get
BACKUP to work. After all, why wouldn’t it work? These tables are just using regular DB2 pages. Although this was very early code, it ran successfully. Looking at the backup image, sure enough, all of the data pages were there. Of course, the most important backup image is the one you can restore (always, always test recovery), so he decided to restore the data. That, too, worked! Even a query against the restored tables worked. He didn’t have to change a single line of code to get this scenario working in the prototype, one of the tangible benefits of building BLU Acceleration right into the DB2 kernel.The Day In and Day Out of BLU Acceleration
From a Data Definition Language (DDL) perspective, when you create a column-organized table, you just specify
ORGANIZE BY COLUMN instead of ORGANIZE BY ROW. (You can use the DFT_TABLE_ORG database configuration parameter to set the default table organization in lieu of specifying the ORGANIZE BY COLUMN clause on the CREATE TABLE statement.) If DB2_WORKLOAD=ANALYTICS, the DFT_TABLE_ORG value is set to COLUMN. Uniqueness and nullability are enforced, just as they are in a row-organized DB2 table, but there aren’t options for compression with BLU Acceleration because compression is always on. You still access the SYSCAT.TABLES view to look at table metadata; we just added a new column (TABLEORG) with R (row organized) and C (column organized) descriptors. As you can see, working with BLU Acceleration objects is pretty much the same as other objects and so we cut this section short.Informational Constraints, Uniqueness, and BLU Acceleration
Informational constraints, first introduced in DB2 9, provide DBAs with a mechanism to inform the DB2 optimizer about certain data characteristics without having to enforce them in the database. For example, if your data set has two discrete values for gender (
M|F) and the data has come from a trusted source, you could define this as a NOT ENFORCED informational constraint and bypass the database manager overhead and on-disk footprint associated with enforcing such a business rule. However, the DB2 optimizer could still take advantage of understanding the data distribution during query rewrite or access plan generation.Informational uniqueness is the enhancement to informational constraints that debuts in the DB2 10.5 release in support of BLU Acceleration. Imagine if you could tell the database manager that a row is unique without requiring enforcement. DB2 would save compute resources but still be able to generate superior query execution plans. This enhancement was delivered in support of BLU Acceleration because unique indexes (needed to enforce uniqueness) don’t really compress that well (compression is about the processing of repeating patterns, not unique ones), they occupy considerable space, and they must be maintained. Informational uniqueness is an optional optimization—the default in DB2 10.5 is to still enforce uniqueness. If you’re going to use this optimization, and there’s no reason not to—in fact, we recommend it if applicable—just be sure that your data is truly unique.
The following code snippets show you how to define informational uniqueness (or primary key) constraints on a new or existing table:

Getting the Data to BLU: Ingestion in a BLU Acceleration Environment
Data ingest is an important concept in today’s analytics landscape: We can’t tell you how many times we hear about companies wanting to flatten the latency of their analytics. BLU Acceleration dramatically reduces the time it takes to go from raw data sitting in some kind of flat file (such as an ASCII file) on the system to making that data queryable, a process that includes the time that’s required to load the data, build covering indexes, collect and plot data statistics, compress the data, and apply other optimizations.
BLU Acceleration supports the typical ways in which you get data in and out of a DB2 table, namely
LOAD, INGEST, IMPORT, EXPORT, and Data Manipulation Language (DML) operations such as INSERT, UPDATE, and DELETE. BLU Acceleration is heavily optimized (it comes with highly effective multicore parallelism for both INSERT and LOAD processing) to achieve rates that are similar (not identical) to the performance of these operations against row-organized tables. That said, you’re likely to find that the time to load from file to query is usually faster than loading a comparable row-organized table; we estimate anywhere from 1.3x to as high as 3.7x faster when you take into consideration all the activities that are performed to make raw data performance queryable when all is said and done. Of course, your mileage is going to vary, depending on the specific characteristics of your environment. How’s all of this possible? After all, aren’t column stores more computationally complex to format during load processing? While it’s true that getting the data into a column-organized table can require a bit more processing (mostly due to the advanced compression algorithms), the extra time spent compressing the data is more than saved by the avoidance that a row store spends building and maintaining indexes, collecting statistics, and more.Automated Workload Management That Is BLU-Aware
If you studied computer science, you’ve likely been exposed to the “movie theater” problem (and if you’ve ever gone shopping for Black Friday or Boxing Day Christmas-time clear-out sales, you’ll have your own analogy to draw from). Think about it: A movie theater has a big entrance door that could probably accommodate groups, four abreast, at any one time. If you had a movie theater filled with thousands of people and everybody tried to leave all at once, you’d end up with a big stampede for the door that would effectively “jam” the exit because all of the moviegoers are competing for the same resource (the door that leads out of the theater).
Now imagine a scenario in which you had the ability to instruct those moviegoers to act in a civilized manner (which would definitely be helpful during the Christmas shopping season) such that they leave the theater in an orderly fashion…four at a time. That would provide a great form of workload management for this problem domain. While bargain hunters and moviegoers likely won’t listen to you, one cool thing about computers is that they do exactly what you tell them to do! The movie theater problem is the idea behind the automated workload management that’s part of BLU Acceleration. The inspiration behind workload management for BLU Acceleration is you’ve got a server with some set number of processing cores and a certain amount of memory; let’s not let everyone’s queries try to fight each other for those resources all at once because we know they are going to run really fast, like really fast, so we just need to keep order and everyone will be happy.
DB2 10.5 with BLU Acceleration includes built-in and automated query resource consumption controls to deliver even higher performance to your analytic database environments. Analytic queries are typically resource-intensive and compete for CPU cycles and memory. Workload management for BLU Acceleration is yet another optimization that’s automatically enabled when DB2 is running in
ANALYTICS mode. When in this mode, the DB2 engine automatically enforces a workload management policy that regulates the number of queries that are going to be consuming resources at any given time. Specifically, DB2 10.5 automatically allows a high level of analytic query concurrency but limits the number of queries that consume resources simultaneously. When the database server is optimized for analytics concurrency, other workloads can still connect to the database server and they can still issue queries, but a finite number are going to be allowed to execute at any one time to keep the entire process running at peak efficiency.In DB2 10.5, workload management for BLU Acceleration is implemented by creating a new default workload manager (WLM) threshold object on the database server. When this policy is created, DB2 actually fine-tunes it for the underlying hardware architecture. This auto-created policy is the same kind of policy you could create manually using the
CREATE THRESHOLD command in DB2. In DB2 10.5, this auto-created policy exists even if you’re not using BLU Acceleration. If you set DB2_WORKLOAD=ANALYTICS, this policy will be enabled by default; if the database isn’t in this mode, while this policy still exists, it won’t be enabled and you’ll have to explicitly enable it to use it. We want to note that while there are default WLM objects that you’re likely aware of in previous versions of DB2 (for example, service classes), this throughput policy marks the first time we’ve included default concurrency control in DB2.Before DB2 10.5, unless you explicitly created a WLM policy, by default, all queries ran in the
SYSDEFAULTSUBCLASS. In DB2 10.5, read-oriented SQL that’s over an estimated cost will be mapped to run in the new SYSDEFAULTMANAGEDSUBCLASS, which has a default BLU Acceleration–tuned concurrency limit that’s auto-configured in consideration of the underlying hardware stack. Of course, you can augment these prebuilt workload management policies for BLU Acceleration with your own custom policies, or build all of your policies from scratch.Querying Column-Organized and Row-Organized Tables
One of the design points for BLU Acceleration was the seamless mixing and matching of table types (row-organized or column-organized) in the same database, table spaces, buffer pools, and queries. Mixing table types is key to some workloads and their underlying schemas. For example, point queries with highly selective index access favor row-organized tables, as do small, frequent write operations.
You should be aware that analytic queries are definitely going to run better if all the tables being accessed are column organized, because internal casting operations have to be done when you join row-organized and column-organized tables.
The Maintenance-Free Life of a BLU Acceleration Table
When we told you that BLU Acceleration tables are virtually maintenance free, we weren’t kidding; there’s a lot of “automatic” stuff in here, such as automatic configuration and tuning, automatic statistics collection, automatic workload management, and automatic space reclamation. In the area of space reclamation, there’s simply no need for typical (and costly) DBA space management tasks or
REORG operations—space is freed up while work continues.BLU Acceleration supports automatic space reclamation. Extents with no active values are freed and subsequently returned for reuse by any table (row-organized or column-organized) in its associated table space. This is a significant benefit. If you’re familiar with the pseudo delete mechanisms introduced for MDC tables in the DB2 9 release, you’ll understand this process very well.
Let’s work through a simple example. Consider a table with a number of key columns that stores data from different years. Over time, you want to roll out the older data and roll in new data; some folks have two-year rolling ranges, some use days or weeks, and some as much as a decade—it all depends on your business. Figure 3-7 illustrates a typical scenario in which you want to roll out a year of data from a BLU-Accelerated table named SALES. To do so, you would issue a SQL statement, such as:
DELETE * FROM sales WHERE year = '2012'.
Figure 3-7 Space reclamation of empty extents in a BLU-Accelerated table
In Figure 3-7, each box represents a data extent for a specific year. From a storage footprint perspective, after you run this statement, all of the data still exists on disk and is allocated to the table. But to database scanners, data associated with 2012 appears to have been deleted (these extents are tagged with a pseudo-deletion marker,  in Figure 3-7), and from an application perspective, this data no longer exists.
in Figure 3-7), and from an application perspective, this data no longer exists.
BLU Acceleration has a daemon that wakes up from time to time to search for those pseudo-deleted extents () using DB2’s automatic table maintenance (ATM), first introduced in DB2 8.2 and now extended with this capability for column-organized tables. When the daemon has done its work, those extents will have been removed from the table and returned to the table space so that they’re available for reuse by any table in that table space. In our tests, the overhead from this daemon was miniscule (~1 percent), so we don’t think you’re going to find it disruptive; in fact, we don’t even think you’re going to notice it, but you’ll appreciate what it does for you.
Getting to BLU-Accelerated Tables
You’ll find BLU Acceleration in any of the advanced DB2 editions, the newly announced DB2 Advanced Workgroup Server Edition (DB2 AWSE), and DB2 Advanced Enterprise Server Edition (DB2 AESE). Assuming that you’ve got entitlement to either of these editions (there are several nuances if you are upgrading from a previous DB2 version, but that's outside the scope of this book), and you want to keep things simple and effective, you really just need DB2 running in
ANALYTICS mode (DB2_WORKLOAD=ANALYTICS) before you Load and Go!It’s a great idea to have DB2 set to run in
ANALYTICS mode before creating the database, because DB2 will configure itself for analytic processing. For example, when a database is created in this persona, it makes column-organized tables the default table type; puts in place an in-memory, columnarcognizant prefetching and cleaning algorithm; enables the BLU-optimized automatic workload management and automatic space reclamation features that are detailed in the last sections; configures page and extent sizes for analytics; and automatically initializes memory for caching, sorting, hashing, and utilities based on the server’s detected compute resources.We understand that it’s not going to be practical for everyone to create a new database in
ANALYTICS mode, so if you can’t (or don’t want to)—not to worry! All of the automation that you get when creating a new DB2 database in ANALYTICS mode can be enabled with a few commands in just a few minutes. We cover this in the upcoming section “Ready, Set, Go! Hints and Tips We Learned Along the Way.”If you have some existing tables that you want to convert to BLU Acceleration tables, there’s a utility (
db2convert) to help you get there. You can run this operation online (it’s based on the online table move features that first appeared in the DB2 9 time frame). You can access this utility through the command line or the Optim Data Studio management toolset (select the Migrate to Column Storage option when right-clicking a row-organized table) as shown in Figure 3-8.
Figure 3-8 Space reclamation of empty extents in a BLU-Accelerated table
Note that there are no utilities or tools that support the conversion of column-organized tables to row-organized tables. If you want to manually convert a table in this manner, you need to unload the column-organized data and then reload it into a new row-organized table.
Optim Query Workload Tuner has been extended such that it can be used to examine your workload and suggest whether a column-organized table is likely to enhance performance. An example is shown in Figure 3-9. Notice how if you select recommendations for Table Organization the options for additional optimizations aren’t available. That’s because these technologies aren’t needed if the table was recommended as column-organized. If the advisor suggests organizing the table by row, you could then rerun the advisor and select these other options and deselect the Table Organization option.

Figure 3-9 Optim Query Workload Tuner includes the ability to evaluate captured query sets and recommend BLU Acceleration tables for performance enhancements.
Ready, Set, Go! Hints and Tips We Learned Along the Way
We believe that BLU Acceleration is such an incredible market-leading move forward, we strongly recommend trying it out (assuming that your environment meets the criteria that we’ve outlined in this chapter) before trying other partitioning strategies or approaches to get your analytical marts to scale. In this final section, we leave you with some of the tricks and tips that we’ve learned along the way. The hints and tips in this section come from some of our own observations while we were writing this book, and working with customers. The important BLU Acceleration-related bookmark you'll make for the next year is going to be to the "Best Practice: Optimizing Analytics Workloads using DB2 10.5 with BLU Acceleration" paper at https://ibm.biz/BdDrnq.
First Things First: Do This!
db2set DB2_WORKLOAD=ANALYTICS. A simple setting, but it’s the key to all the magic. If your database will be used purely for analytic workloads, this registry setting takes care of most of the system configuration for you. Because it configures some characteristics that are defined at database creation time (ensure that your database is enabled for AUTOCONFIGURE), for best results, you should set DB2_WORKLOAD=ANALYTICS prior to creating your database. This setting makes column-organized tables the default table type and configures page size, extent size, memory (buffer pools, sort, lock list, application heap, and so on), automatic workload management, new page cleaning and prefetching algorithms specifically designed for BLU Acceleration technology, automatic space reclamation, automatic statistics collection, and more. We repeated this here because it’s so important. We also want to note that if you access a row-organized table sitting in the same database schema, DB2 can use its traditional page-cleaning and prefetching algorithms too.If you can’t set
DB2_WORKLOAD=ANALYTICS before creating your database, you can still set it and run the AUTOCONFIGURE command to achieve many of the tuning benefits (it configures optimizations such as automatic workload management, space reclamation, page size, and extent size).Unable to Set DB2_WORKLOAD=ANALYTICS?
You might not be able to set
DB2_WORKLOAD=ANALYTICS prior to creating the database for various reasons. Perhaps you’re migrating an existing database from an earlier version of DB2, or perhaps your database supports mixed workloads and will include combinations of column-organized and row-organized tables. In a mixed environment where you have a significant amount of transaction processing occurring, you probably don’t want to configure the database as though it is running an entirely analytic workload. Whatever the reason, if you can’t create a new database in ANALYTICS mode, here’s what setting DB2_WORKLOAD=ANALYTICS does, so you can pick and choose which optimizations best suit your environment:• The page size (in KB) is set to 32.
• Extent size is set to 4.
• The default table organization (
DFT_TABLE_ORG) database configuration parameter is set to COLUMN.• Memory is divided (roughly) equally between the buffer pool and shared sort heap threshold (
SHEAPTHRESH_SHR).• The sort heap (
SORTHEAP) is set to a moderate fraction (for example, 5 percent) of SHEAPTHRESH_SHR. (See the “Automated Memory Tuning” section that follows.)• Intrapartition parallelism is enabled.
• Sets the default degree of parallelism (
DFT_DEGREE) to ANY.• Automatic statistics collection is enabled.
• Sets
UTIL_HEAP_SZ to a sizeable value. (This gives the load utility elbow room to generate high-quality compression dictionaries. We have some specific recommendations in the later section “For Optimal Compression Results….”)• Self-tuning memory manager (STMM), buffer pools, the lock list, and package cache are all enabled.
Finally, as a general rule of thumb, if you are using DB2’s sophisticated workload management capabilities, we recommend a concurrency threshold no larger than the number of cores available on the system and a timeron threshold of
75,000.Automated Memory Tuning
DB2’s self-tuning memory management (STMM) is an incredible piece of technology. However, in the first release of DB2 with BLU Acceleration, sort memory is not self-tuning for column-organized tables, so you have to watch out for this. Specifically, both the short heap (
SORTHEAP) and shared sort heap threshold (SHEAPTHRESH_SHR) should be set to static values; if DB2_WORKLOAD=ANALYTICS, this will have been done for you.In addition, you should know that BLU Acceleration makes heavy use of sort memory because it’s used for grouping, joins, and vector memory processing; therefore, the requirements are higher than for row-organized processing. Of course, as is the case with traditional row-organized tables, when sort memory gets constrained, the database will start spilling to disk. We recommend setting
SHEAPTHRESH_SHR to a value that’s similar to your buffer pool memory. This is considerably more generous than what’s usually recommended for row-organized tables, but the results are worth it. Trust us, because SORTHEAP is usually configured as a fraction of SHEAPTHRESH_SHR; 10 percent is common. Remember, BLU Acceleration is a dynamic in-memory database, and as its name would suggest, it’s going to rely on memory; you’re not going to have constraints if all your data won’t fit into memory like some of the alternative technologies available in today’s marketplace, but be prepared for more memory requirements.For Optimal Compression Results…
Compression is a hallmark of BLU Acceleration technology, not just because of the storage savings delivered, but because its vector-processing engine operates on compressed values. Better compression often results in better query performance.
In a BLU Acceleration environment, you should expect to see temporary increases in DB2’s utility heap requirements. This is because the
LOAD utility is designed to optimize compression encoding by doing a first pass over the data in what’s known as the analyze phase; this phase is used to scan the data, construct histograms, and build the compression dictionaries. Therefore, the more memory that you make available to LOAD, the deeper this analysis can be, which will result in better compression ratios. For this reason, consider increasing the UTIL_HEAP_SZ while the LOAD utility is running (you can reduce it again when it’s finished). For sizeable tables, several gigabytes of utility heap are likely suitable. If you’re loading terabyte-class tables, tens of gigabytes of utility heap are likely more appropriate. For these reasons, we also recommend that you avoid a large number of concurrent LOAD operations.For optimal compression results, you should be thinking about initially loading as much data as possible—a large initial load operation is healthy. Column compression dictionaries are built by analyzing the data during the first load operation against a table, and therefore, it’s extremely valuable for that initial load operation to contain a representative and reasonably large amount of data. Following the initial load operation, new data values not found in the dictionary are compressed using page-level dictionaries.
Data Statistics? Don’t Bother, We’ve Got It Covered
Many of you are accustomed to performing periodic
RUNSTATS jobs to collect statistics on tables and indexes, especially after tasks such as LOAD, IMPORT, or INGEST. With BLU Acceleration, it’s all automated! You can still execute those tasks, but there’s a lot less need to. The LOAD utility collects statistics automatically, and automatic table statistics are enabled by default on all new databases. At this point, you might be wondering if there’s really any need to issue a RUNSTATS job. Yes, if you’ve populated a table with a process that uses INSERT (such as IMPORT or INGEST) and you want to start running queries immediately after the task, then you’ve got a good reason to invoke RUNSTATS because automatic statistics collection will not likely have been initiated by the time you want to immediately run your query after ingesting the new data into the target table (but it will be initiated when it wakes up at its next interval).INSERT Performance
We think you’ll be pleased with
INSERT performance for column-organized tables. That said, keep in mind that BLU Acceleration is optimized for bulk processing. For this reason, we recommend commit rates of 10,000 rows or more. If you perform tasks using INSERT (including IMPORT or INGEST) and commit more frequently (such as every 1,000 rows or less), your INSERT performance might suffer.How to Skip More: Get the Most Out of Data Skipping
Every column-organized table maintains a child synopsis table, which is also column organized and stores encoded vectors of data. The synopsis tables store metadata about the columns of their parent tables and are used at query runtime to perform data skipping. They work best when data in the parent tables is clustered on predicate columns.
Now, there’s no need to sort your data, as is the case with many competing technologies. However, if you’re looking for a little extra “boost,” sorting your data before a
LOAD can give a nice jolt to the database engine. The sorting doesn’t need to be exact. For example, consider a table with predicates on a DATE column; sorting the entire table by DATE might be prohibitive. Sorting by month or quarter will usually be more than sufficient to achieve great data-skipping benefits.A NextGen Database Does Best with the Latest Hardware
BLU Acceleration is designed to leverage the latest microprocessor architectures in a very intimate way. Although our algorithms can run on readily available microprocessors, we’re constantly on the lookout for ways to optimize newer instruction sets and topologies, which provide facilities to maximize memory bandwidth, advanced SIMD instructions, larger CPU caches, and more. If you have a choice, go with the latest processors available.
Memory, Memory, and More Memory
By now you can fully appreciate how DB2 with BLU Acceleration is better than a typical in-memory database because you don’t have to size a buffer pool with enough memory for all of the active data. What’s more, any I/O will be performed with high efficiency by using the new dynamic list prefetching technique. After data is fetched into memory, it’s processed with all of DB2’s advanced processing power. Nevertheless, it certainly helps to keep the most active data in RAM, which begs the question: “How much RAM is ideal for my data?”
When sizing your server for memory, consider what fraction of the columns in your largest tables are active; this should give you a good rule of thumb for sizing your buffer pools. For example, consider a 40-column table with ten years of data that BLU Acceleration technology has reduced from 10TB to 1TB. When examining this table from an “activity” perspective, only the most recent five years are considered “warm” or “hot,” and only 8 of the 40 columns are active. In this example, we’d recommend an ideal buffer pool size of 100GB: 1TB * (5/10) * (8/40). And remember, if you’re implementing in-memory technology, it’s nice to have more memory. It seems obvious, but you are going to want more memory than you would typically allocate to your database.
Converting Your Row-Organized Tables into Column-Organized Tables
If you’re converting tables from a row-organized format into a column-organized format with BLU Acceleration using the
db2convert utility, we want you to know that this conversion process requires temporary space for both the source and target tables—so make any adjustments necessary. In addition, because there’s no online process to convert a column-organized table back into a row-organized table, we strongly recommend that you run BACKUP before converting any tables.Wrapping It Up…
In this chapter we introduced you to the “crown jewel” in the DB2 10.5 release: BLU Acceleration. We talked about seven big ideas that are the technical inspirations behind BLU Acceleration’s four pillars: dynamic in-memory processing, actionable compression, parallel vector processing, and data skipping. The pillars combine to greatly accelerate, simplify, and conserve your environment’s resources.
A plethora of clients have noticed. For example, LIS.TEC’s Joachim Klassen observed one of the key benefits of BLU Acceleration when he noted: “Even if your data does not completely fit into memory, you still have great performance gains. In the tests we ran we were seeing queries run up to 100x faster with BLU Acceleration.” It’s a very different approach than what’s been taken by some other vendors. After all, if the price of memory drops by about 30 percent every 18 months, yet the amount of data grows by 50 percent, and in a Big Data world data is being used to move from transactions to interactions, you’re not going to be able to fit all your data in memory—and that’s why BLU Acceleration is so different.
It should be clear by now that simplicity and “Load and Go” rule supreme when it comes to BLU Acceleration descriptors. Indeed, we commented that BLU Acceleration was more about what you no longer do than what you need to do. Randy Wilson, a top-notch DBA who works for Blue Cross/Blue Shield of Tennessee, sums up this point best when he tried his workload running on a partitioned database environment and ran it on a single DB2 server with BLU Acceleration: “We’ve tested DB2 10.5 with BLU Acceleration and found that it can be up to 43x faster with an analytic workload than our existing multiserver partitioned database environment. Without having to build indexes, we can just load and go. The performance out of the box is outstanding.”
We could brag some more, but don’t take our word for it, don’t take our customers’ world for it (but be jealous if you’re not using BLU Acceleration): We invite you to try it for yourself. It won’t take long; you just Load and Go!
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.