
6
DB2 10.5: New Era Applications
It seems that everywhere you turn, people talk about “NoSQL” databases and how they will ultimately replace traditional databases. In fact, many people believe that there is no more innovation in the relational world and that Big Data projects can only work with often creatively named “NoSQL” databases. DB2 10.5 is here to prove them wrong and help their applications scale and stay up and running! It is true that the flexibility associated with the NoSQL model is extremely well suited for certain kinds of applications, especially in the mobile-social-cloud world. After all, getting an accurate count of the “likes” on your Facebook page at any one time or the number of Twitter followers you have isn’t something that is typically considered mission critical. At the same time, relational database management systems (RDBMS) are critical for other kinds of transactional operations. (Are you getting the feeling early on that modern era information management architectures will have a mix of NoSQL and SQL style applications, depending on the data need?)
A good data management foundation requires both approaches, depending on the tasks at hand. Here is how we see it: NoSQL and SQL databases both have characteristics that are well suited to specific application styles, but availability, scalability, and governance are relevant to both. The great thing about DB2 is that release after release, it’s folding a NoSQL agile style of data management into its rock-solid and proven foundation. The DB2 10.5 release continues to evolve its NoSQL capabilities with new JSON-document store services that are designed in the same style as MongoDB; in fact, you can even run MongoDB applications in DB2 by simply embedding a driver and pointing it to a DB2 10.5 server! And this is the point: DB2 is becoming agile. In baseball, a player doesn’t use the same hand to catch and throw a ball—unless they only have one hand—because it isn’t efficient or agile. To the contrary, a baseball player uses each arm in a highly optimized and coordinated fashion: one for the task of throwing and the other for catching. You can use DB2 in this matter from a database persistence perspective. If you can use its services that are fine tuned for agility (NoSQL) and those that are fine tuned for traditional database needs (SQL)—you’re not trying to do everything with a single limb. The end result is a more agile platform that is robust, governed, available, and reliable.
What’s in the NoSQL Name?
So what exactly is a “NoSQL” database? NoSQL doesn’t mean “no SQL”; it means “not only SQL.” In fact, it’s kind of ironic that the biggest movement during the last year or so in the world of NoSQL is the push to get SQL there.
NoSQL developed out of the necessity to store and manipulate a variety of data that doesn’t fit rigorous RDBMS requirements and would often rather trade-off traditional benefits associated with databases for a new one: extreme flexibility. Sometimes folks refer to NoSQL as “schema later” or “schema on read”; in contrast, the classic RDBMS model could aptly be dubbed “schema first” or “schema on write.” Some folks say that NoSQL databases are created to avoid the need for DBAs. After all, it’s fair to assume that in most cases, when developers think performance, they think “How fast can I build my application?” whereas DBAs think “Am I meeting my service-level agreements?”
For example, if a developer on a whim wanted to model a new data entity and add new attributes, that’s dead simple in JavaScript Object Notation (JSON); just use one of the base data types and instantly evolve the application. In the RDBMS world, the developer goes to the DBA team, which then has to evolve the schema, and the whole “performance means how fast can I build an application” idea hits a roadblock. It’s not that application developers hate DBAs—this isn’t an example of Mets and Yankees fans in Major League Baseball; rather, it’s a value proposition that each group relies upon to do its job. The good news is that DB2 10.5 is here to give these communities the best of both worlds! In the tech community, this is often referred to as polyglot persistence.
There are many different ways to classify NoSQL technology, and we think that the following makes the most sense out of the NoSQL style taxonomies we’ve seen:
• Document databases pair each key with a complex data structure known as a document. Documents can contain many different key-value pairs, or key-array pairs, or even nested documents. The most popular document databases in today’s marketplace are JSON-based; MongoDB, Couchbase, CouchDB, and Apache Jackrabbit are among the more popular ones—oh ya, and soon to be DB2!
• Graph databases store information about networks, such as social connections, by using directed or undirected relationships, mixes, and multigraphs. The focus for these databases is on the connections between data. Some of the more popular ones include Jena, InfiniteGraph, and Neo4j. DB2 10 implemented a Jena graph store that provides users with a first-class graph database and support for the native Resource Description Framework (RDF) query language, SPARQL. If you are thinking that the following people seem to be connected to this influential person via a set of Facebook interactions (often called leaders and followers), you’ve got a feel for this style.
• Key-value stores contain data whereby every single item in the database is stored as an attribute name, or key, together with its value. It’s kind of like a hash table, or your file system, where the file is the content and the path is the key to getting to that content. This design is very popular for applications where performance is the name of the game, as well as for web sessionization applications, among many others. It’s the second most popular NoSQL design after document databases. With that said, more and more NoSQL styles are being combined. Some popular names in this style include Dynamo, Riak, the 600 pound yellow elephant in the room … Hadoop, and Voldemort (we aren’t afraid to say that word out loud).
• Column stores (sometimes called wide-column stores) place columns of data together, instead of rows, and are optimized for queries over large data sets. This technology is starting to get blurred with both traditional RDBMS and NoSQL style data stores; for example, many key-value stores have columnar store services. Column stores are very well suited to storing sparse data sets, which are very popular in a social-mobile-cloud world, because there is no incurred storage cost for NULL values. Column stores are also great at supporting applications where only a subset of the data is needed. In the NoSQL world, HBase is perhaps the most popular, with Accumulo (think HBase with cell-level security) and Cassandra also seeing their share of popularity. Of course, DB2 with BLU Acceleration has column store capabilities, as do other RDBMS players—although admittedly we don’t think they are as good and you can find out why in Chapter 3.
The development of these database styles helps us to answer two questions: “What are we trying to accomplish?” and “What kind of data do we need to address the business problems that we are trying to solve?” Many business problems involve a mixture of data, and we ultimately need to combine a number of different approaches to tackle them.
In the SQL world, consistency is of utmost importance; it’s the foundation of relational database technology. With NoSQL databases, consistency is more often than not an after-the-fact consideration, and the ACID (atomic, consistent, isolated, and durable) properties of the relational world are not found at the top of requirements list. This difference shows why both styles are needed and why neither is going away. If it’s a transaction order, statement, or record, consistency matters, but if you’re trolling through log data trying to discover why someone abandoned her online shopping cart, consistency isn’t as important.
Organizations that use DB2 can gain flexibility and the agility benefits of NoSQL deployment while retaining (if needed) the ACID properties, availability, and performance advantages of the well-proven DB2 relational database technology. Think about those DB2 enterprise-class attributes such as transaction control, or governance controls such as separation of duty or concern, label- or row-based access control, and more; these are the kinds of benefits that open-source projects typically don’t provide (or provide with the level of sophistication found in the DB2 implementation), and this is why we know that some of the technologies found in DB2 have a place in the NoSQL database world.
DB2 pureXML: Where DB2 First Dipped Its “Toe” in the NoSQL Pool
If years ago we asked you to think about the term Big Data, before it became the hot catch phrase that it’s become, Extensible Markup Language (XML) would likely come to mind. DB2 9 delivered a truly native XML engine called DB2 pureXML. This really caught the industry by storm because, unlike its counterparts at the time, pureXML was a genuinely pure and native XML framework. DB2 didn’t shred the XML or stuff it into a large object (LOB) under the guise of a “native” data type that made its XML services appear native, solely to application developers; DB2 pureXML kept the XML services purely inside the database as well. Specifically, IBM built from the ground up a pure, native XML storage capability and reworked the DB2 engine into a hybrid engine that understands and processes both XML and relational data.
The DB2 pureXML technology, which is freely available in all DB2 editions, treats XML data as a tree of XML elements and attributes and stores it that way (with no fidelity loss), thereby enabling faster insertion and retrieval of this semistructured format. This approach differs from those taken by most other database vendors, who under the covers typically store the XML as a string of characters stuffed into a character large object (CLOB), or shred away the XML tags and store it relationally. When most other vendors refer to their XML support as native, they are talking from the application programming interface (API) point of view. In practice, they shred or stuff the XML into the relational model, or provide you with a dizzying array of options. DB2 actually has a native compiler for XML—it’s why we called it pure.
Of course, when you don’t store your XML in a pure format like the one used by DB2, there’s always a trade-off. You typically need to choose one of two evils: performance loss or reduced flexibility. The good news is that with DB2’s pureXML, you never have to make such trade-offs.
DB2 pureXML technology has enabled DB2 customers to extend DB2 functionality well beyond traditional transaction processing and data warehousing tasks. DB2 was dealing with Big Data long before many of the NoSQL databases were all the rage. For more details on DB2 pureXML, refer to the DB2 documentation on this topic (http://tinyurl.com/mag5bfp).
DB2 as a Graph Database: RDF, SPARQL, and Other Shiny Things
The Resource Description Framework (RDF) is a World Wide Web Consortium (W3C) standard for describing web resources. The RDF describes web resources in the form of subject-predicate-object. For example, a simple web page might have a title, an author, creation and modification dates, and attribution information, all of which can be of significant value if machines could be enabled to search for and discover “connected” resources on the Web. The ability of computers to use such metadata to understand information about web resources is the idea behind the Semantic Web.
DB2 10.1 included the ability to function as a native triplestore database that could be used to store and query RDF data. DB2’s triplestore services are implemented as a set of five DB2 tables and includes an access API (based on Jena, the open-source Semantic Web framework for Java) that’s entirely client-based and provides commands and interfaces for working with RDF data.
A triplestore, as its name implies, is a database that is optimized for the storage and retrieval of triples. A triple is a data entity that is composed of the aforementioned subject-predicate-object: for example, “Paul works at IBM” or “George knows Matt.” Structuring data in compliance with RDF enables software programs to understand how disparate pieces of information fit together.
Because a triplestore is implemented inside of DB2, many of the features within the DB2 engine can be used to provide reliability and scalability services to the triplestore. This NoSQL technology in DB2 opened up new opportunities for organizations to seize some of the benefits of a NoSQL approach above and beyond the XML document store capabilities first introduced in DB2 9.
After an RDF triplestore has been implemented in DB2, the data can be retrieved using SPARQL, the RDF query language that is much like SQL. SPARQL is a W3C standard that is not tied to any particular RDF data store. To use SPARQL, you typically write a Java application and leverage the Jena API. Jena’s support for SPARQL is contained in a module called ARQ (ARQ is the query engine for Jena). These are all of the pieces that you need to work with an RDF data store in DB2.
With triple graph store support in DB2 10.1, you don’t have to lose the quality assurance of SQL or make expensive and risky architectural changes to gain NoSQL graph style capabilities. Instead, use NoSQL APIs to extend DB2 and implement a paradigm that many of the NoSQL proponents are promoting. We covered this topic extensively in Warp Speed, Time Travel, Big Data, and More: DB2 10 New Features (McGraw-Hill Education, 2012), available at http://tinyurl.com/l2dtlbf.
DB2 as a JSON Document Store
With the rise of social media and mobile applications, there are new opportunities for businesses to engage with their customers. Applications need to be developed quickly to respond to business problems or opportunities. There are many different technologies being assembled to rapidly deliver solutions, and JavaScript with JSON is common across most.
Applications and database schemas might need to change frequently, and some applications require flexible data interchange. JSON is an open standard whose specification can be found in the IETF RFC 4627. You can also find a wealth of information at www.JSON.org. JSON, a subset of JavaScript, is designed to be minimal, portable, and textual. It has only six kinds of data values (which keeps it simple), it’s easy to implement and easy to use, and it’s language independent (most programming languages today have features that map easily to JSON). JSON is commonly used to exchange data between programs that are written in all modern programming languages, and it comes in a human-readable text format, just like XML.
JSON is all the rage these days, and it’s not because XML is gone. Hardly: There are many standards that are based on XML. But in the social-mobile-cloud world, JSON seems to get all the attention, mainly because it’s less verbose and results in smaller document sizes; it’s tightly integrated with JavaScript, which has a lot of focus in this space; and most new development tools support JSON.
What Does JSON Look Like? JSON Document Structure
In JSON, there are four primitive types (string, number, boolean, and NULL) and two structured types (object and array) that are pretty common to most programming languages.
Objects are the primary concept in JSON (think “row” if you are an RDBMS aficionado): an unordered collection of name/value pairs in which the value can be any JSON value; objects can also contain other objects or arrays. Arrays are ordered sequences of any primitive type and can also contain an object.
JSON objects can be nested, but nesting isn’t normally more than a few levels deep. The following code is an example of a JSON document:

Every JSON document starts with an open brace (
{) and ends with a close brace (}). The document contains a series of name/value pairs, each pair separated by a comma:The name of each field is enclosed by double quotation marks (for example,
“firstname”). Names and values are separated by a colon (:). String values must be enclosed by double quotation marks (for example, “John”). A JSON object doesn’t place any restrictions on what is contained in your name/value pairs. That’s up to the application. Remember, it’s all about simplicity here. Contrast this with XML, which has all sorts of rules for tags, data types, and positional parameters.Other JSON objects can be embedded within a JSON object. An address field is a perfect example of an embedded object within the document:

As you can see, the
address name/value pair is made up of the container name “address” followed by another JSON object (“streetAddress”) rather than a primitive data type. Within this embedded object you will find primitive types that help to make up a complete address object.The phone number field is made up of an array type. An array starts with an open bracket (
[) and ends with a close bracket (]). For example:
With nesting and arrays, a lot of information about an entity can be contained within a JSON document.
If you’re a DBA, you might start to get slightly uncomfortable about these arrays and objects. Are you wondering whether this approach leads to a higher level of complexity and overhead when dealing with such documents? Well… you might be right, because in a relational model, multiple phone numbers would probably have been handled as a separate telephone table, rather than multiple columns in one main table. (Besides, how can you possibly know how many telephone columns that you will eventually need in a table?) A JSON document would contain any number of phone numbers and retrieving the document would return all phone numbers (whether you needed them or not!). So while JSON documents may look complex, implementing multi-valued fields is extremely easy. Contrast that with SQL, where you would need to split the table into two and then use join statements to retrieve the phone numbers you need.
All of this highlights one of the fundamental differences between document stores and relational databases when it comes to retrieving records: With document stores, there is no notion of a “join.” A JSON developer needs to write code to join records between two or more collections (“tables” for you relational people), and that’s why JSON developers might stuff everything into an object. The idea behind this is that you’re dealing with an entire entity (you never know what you might need—or need to add—from a document) and that two applications trying to update the same object simultaneously would be extremely rare.
Is this inability to join documents in NoSQL stores a real limitation? It really comes down to the complexity of the application. Many JSON applications are written with a focus on “customer” or “user,” with almost all (if not all) interactions being handled through the application. In other words, there’s rarely a need to access this data through anything but a customer view. Contrast this with an inventory application, which has multiple sources of input (warehouse feeds, returns, deliveries, and so on) and output. There are many ways to look at and update the data, so the complexity of the relationships becomes much greater. Think about it: From a document perspective, do you really want to place the name and address of a product supplier in every product document?
As JSON applications become more complex, developers will place nested structures (or arrays) in their own collections. An additional key field would be added to the new collections to identify where these documents belong. Doesn’t sound so different from a relational table, does it? This restructuring will help to manage the document collections, but it still places the burden of joining multiple collections on the shoulders of the application developer. That’s the price of flexibility!
Frequent Application Changes
Relational databases require that schemas be defined before you can add data. For example, you might want to store customer data such as first and last name, phone numbers, e-mail address, and so on. In the SQL world, the database needs to know the data fields and the data format in advance.
Having to predefine data types doesn’t make for agile development! For example, let’s assume that you suddenly decide to store the “Ship To” address along with the “Bill To” address. You’ll need to add that column to an RDBMS database (which, as a developer, means getting some time with the DBA) and then migrate the entire database to the new schema. If you frequently change your application in response to new requirements or during prototyping, for example, this slow paradigm ultimately becomes unacceptable. There’s no easy and efficient way to use a relational database with data that is completely unstructured or unknown in advance.
NoSQL databases are designed to allow the insertion of data without any predefined schema. Application changes can be made without worrying about back-end database evolution, which means that development is faster and less database administration is required.
Flexible Data Interchange
One of the benefits of JSON is that it’s text-based and position-independent, exactly like XML. XML has been in the marketplace for a long time, but JSON is winning greater mindshare among developers when it comes to a data interchange construct. It all comes down to simplicity. JSON is simpler to use because it is focused on working with objects only. XML is a document markup language in addition to being a data exchange language. This duality of purpose makes it much harder to work with XML. JSON also tends to be more compact, requiring fewer bytes to store and flow across the network—for example,
<Mytag>value</Mytag> versus Mytag:value.Another important factor in JSON’s favor is its relationship to JavaScript. JavaScript works in all browsers, is available on smart phones, and is perhaps becoming most popular because of its ubiquity around server-side applications that use JavaScript frameworks like
node.js; remember, developers love anything that makes their lives easier and that lets them program faster, and JavaScript is all that. JSON also gives developers greater synergy with their programming language of choice. The majority of application development languages support JSON because most languages have features that map easily to JSON concepts like object, structure, and record.Given the popularity of JSON, it’s not surprising that JSON-based document store databases like MongoDB began to emerge. MongoDB (from “humongous”) is a scalable, high-performance, open-source database. It is a document store; each document is written as a unit with its own individual structure. MongoDB’s API is a native mixture of JSON objects and JavaScript functions.
To support customers in their use of NoSQL document stores, DB2 10.5 introduces the DB2 JSON Document Store by implementing a popular JSON API, MongoDB API, into the DB2 product. JSON support in DB2 10.5 is surfaced to application developers through a set of tools and API interfaces, as shown in Figure 6-1, and can be be summed up by the following components:
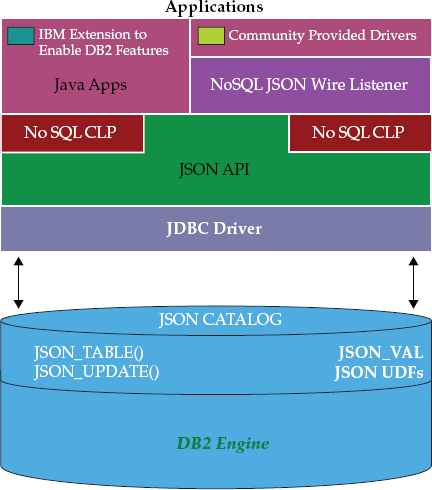
Figure 6-1 How DB2 10.5 supports JSON with both a Java-based API and a MongoDB-compliant wire listener; the choice is yours!
• A command-line shell to administer and query JSON data The DB2 JSON command-line shell provides an interactive way to work with JSON objects. The shell enables a user to create, modify, and drop collections, as well as manipulate records within the collections themselves (we detail this feature in the next section).
• A Java API for application development The DB2 NoSQL JSON Java API provides a set of methods for storing, retrieving, and manipulating JSON documents. These methods can be called by native Java applications directly through the API to work with JSON documents stored in the DB2 database’s JSON services. Developers can work with data that was selected from collections by using
INSERT, UPDATE, or DELETE operations, and so on. However, when you write JSON applications to the DB2-provided JSON API, you also boost your applications with a host of features that made DB2 what it is, thereby reaping all of the benefits of this JSON integration: joins, multistatement transaction boundary support, security, high availability, management/operations, and more.• A NoSQL (MongoDB-compliant) wire listener to accept and respond to requests that are sent over the network The DB2 NoSQL for JSON wire listener is a server application that intercepts the MongoDB Wire Protocol over Binary JSON (BSON). BSON is a binary-encoded serialization of JSON documents; it contains extensions that enable the representation of data types of the JSON specification. The wire listener leverages the DB2 NoSQL for JSON API to interface with DB2 as the data store. You can execute a MongoDB application written in the preferred application programming language (Java, NodeJS, PHP, Ruby, and so on), or use the MongoDB command-line interface (CLI) to communicate directly with DB2.
The following sections provide an introduction to JSON document stores, along with a glimpse into the DB2 JSON command-line shell and how you can use it to manipulate JSON objects.
Document Store Databases
As much as a few NoSQL pundits would like to distance themselves from relational databases, they can’t help but acknowledge the many similarities between the two database technologies. For example:
• A MongoDB instance contains zero or more databases.
• A database can have zero or more collections; you can think of a collection as a table in the relational world.
• A document sits inside of a collection and is composed of multiple fields; you can think of a document as a row in the relational world.
• Fields contain name/value pairs and are analogous to columns.
• Indexes are used to improve query performance.
If there are so many similarities between these two technologies, why bother using JSON? Because the objects are not manipulated in the same way. A relational database stores a value at the intersection of a particular table column and row, whereas a document-oriented database stores its values at the document level. Each document in the collection can have its own unique set of fields, and trying to model this in a relational database would require that a column be created to represent every possible field. This approach would result in a waste of space because many of these fields might be absent from a particular document; this challenge is often referred to as sparse data sets and is common in a social-mobile-cloud world.
Another significant drawback is that a developer needs to know all possible column values at design time; otherwise, the table would need to be modified every time the design changes. This doesn’t fit well into an agile development environment where a developer might choose to add or drop attributes (columns) on the fly or evolve them over time. Indeed, understanding the nature of a JSON document and how it fits into today’s modernera applications helps to clarify why it’s so popular with developers. But application developers must also understand the DBA’s needs—DB2 helps these communities live in harmony!
Manipulating JSON Documents with DB2
This section takes you through the
insert, update, delete, and find commands that are part of the JSON support in DB2 10.5. There are certainly more features than what we can cover in this short chapter, so we include some good references at the end if you want more details about how DB2 and JSON work together.Creating a Database
If you want to create JSON objects inside a DB2 database, you need a Java Runtime Environment (JRE) of 1.5+ (or a JDK), the DB2 JDBC drivers (
db2jcc.jar or db2jcc4.jar) in the CLASSPATH, and a suitable DB2 10.5 database.TIP Although DB2 10.5 lets you mix column-organized and row-organized tables in the same database, we’ve found it best to set
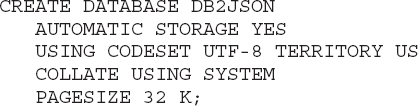
DB2_WORKLOAD to the NULL value (db2set DB2_WORKLOAD=) because JSON objects need to be in row format.Let’s start our example by creating the following database:
TIP You might need to specify the database server host name or IP address and the port number if they are different from the default (
localhost : 50000).After you’ve created the
DB2JSON database, you can start the command-line JSON processor by using the db2nosql.sh script that is located in the /sqllib/home/json/bin directory. The db2nosql command has a number of options, some of which are described in the following list:•
-DB database_name (if none is provided, DB2 prompts you for a value)•
-user username (default is the connected user)•
-hostname host_URL (default is localhost)•
-port db_port_no (default is 50000)•
-password password for database and user (if none is provided, DB2 prompts you for the proper authentication values)•
-setup enable/disable (enable creates JSON artifacts; disable removes them)For example, running the
db2nosql.sh script without any parameters elicits a prompt for the database name (entering a NULL value causes the command line to exit):
If this is the first time that the
db2nosql command processor has connected to this database, it will prompt you to issue the enable command. This command updates the database with specific functions and tables that support the NoSQL JSON implementation in DB2, some of which are shown in Figure 6-1.
A DB2 NoSQL JSON document store allows the definition of multiple JSON namespaces by using DB2 schemas as qualifiers. When you connect to an enabled database for the first time, the default namespace is the currently connected user and will remain as such for the duration of the active session unless you explicitly change the JSON namespace by invoking the
use command; for example:The schema name is case-insensitive. You can check your current connection by using the
db command, as shown in the following example:The
db qualifier represents the currently connected database (DB2JSON) and the schema (CUSTOMER), and any JSON documents that are created by using this connection are organized in collections that exist under this namespace. Note that although NoSQL collections do not enforce any document structure, documents in a collection generally share common characteristics.Inserting Documents
You can insert a document into a collection by using the
insert command. For example:In this example,
CUSTOMERS is the name of the collection, and it’s found under the CUSTOMER schema. If this collection didn’t already exist, DB2 would automatically create it, which is behavior that is consistent with MongoDB in the NoSQL world.Documents typically have a unique identifier associated with them; after all, you want to find the record again, don’t you? If a field that is tagged with the attribute name
_id is found, that field is used as a unique identifier, and it’s expected that all new documents will contain an _id of the same data type. If no _id is present, the system generates unique object identifiers for each document.As you might expect at this point, deleting a collection is pretty simple too.
You can use the find command to list all of the records in the
CUSTOMERS collection.
The records contain the
_id identifier to uniquely identify each record. Although automatic _id generation is useful, it’s not particularly easy to remember. As an alternative, you could create another field that uniquely identifies the customer, or replace the _id with the real customer ID. To use a different unique identifier, the collection has to be explicitly created by using the createCollection command:
The
createCollection command lets you specify other settings to enable DB2 features such as compression, time travel query, and table space settings, among others.The previous sample document contains only three different data types: string (
“firstname”:“Fred”), number (“age” : 45), and long integer (“_id” : 1). Keep in mind, however, that DB2 does support additional data types, such as date, timestamp, binary, and integer, so you’re not stuck with just these three.Importing Documents
Inserting documents into a JSON store can be really inefficient if you do it one record at a time. Luckily, DB2 also allows records to be imported from a file. Of course, the imported file must be in a valid JSON notation, because any records that aren’t in the proper JSON notation are rejected by DB2 during this operation. You can improve throughput by specifying how often the utility should commit records during processing, a familiar concept for DBAs who manage relational data in DB2.
The following example shows you how to import a valid input file into the DB2 JSON document store:

You can use the
sampleSchema command to retrieve information about the structure of a collection that’s been imported. This command analyzes a subset of documents and returns a list of attributes and their frequency. For example:
This information is similar to the DB2
DESCRIBE command, and can be useful in determining what name/value pairs are in the schema. You can also use this information to check whether any name/value pairs are very rarely used, perhaps because of a spelling mistake in one of the fields.Updating and Deleting Documents
You can use the
update command to update one or more documents. Several optional arguments let you specify the scope of the update. Here is the command syntax:The
upsertFlag and multiRowFlag options can be set to either true or false; the default is false. When upsertFlag is set to true, the system inserts a record into the collection even if an existing record is not found. When multiRowFlag is set to false, only the first matched record is updated. When multiRowFlag is set to true, the update applies to all matching records.If you want to replace the value of an individual field, you must use the
$set function. For example, the following command updates Fred’s age to 49:
What happens if you try to update the record without using the
$set function? Your entire record is replaced!
Selecting Documents
So far, the
find command has been used to return all records in a collection. A find operation can be much more selective by using conditions to limit the records that are returned and a projection list to return only specific name/value pairs—a list of the most popular comparison and logical operators that you can use in DB2, when working with JSON documents is shown in Table 6-1.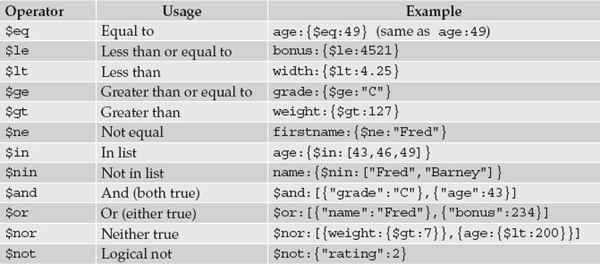
Table 6-1 Comparison and Logic Operators
The following
find command returns only the names of customers called Barney and their current ages. A projection list contains the names of attributes and, for each attribute, a value of 1 (to include it) or 0 (to exclude it). The only attribute that you can exclude when using a projection list is the record identifier (_id).
The
find command also has options to limit result sets, find the first matching document, aggregate data, count documents, find distinct values, find distinct values within groupings, calculate averages, sort values in ascending or descending order, and select a substring of an attribute. The find command offers plenty of other features to keep even the most skeptical NoSQL developers happy. In fact, there are features that can even improve query performance!Indexes serve NoSQL and relational engines well for certain kinds of applications. To help speed up queries, you can create indexes on frequently searched attributes. In DB2, you can create indexes on single or multiple JSON attributes, and these indexes that can be sorted in ascending or descending order. Note that an index is always created on the
_id column, which is used to ensure uniqueness and fast retrieval times for individual records.You can use the
ensureIndex command to create an index on a field in DB2. For example, the following command creates an index on “lastname” in ascending order:JSON indexes are automatically maintained by DB2 and provide a faster way of searching for this field.
Wrapping It Up…
So do you still think that you need a separate document-store database? Truth is, developers have been choosing their document stores based on agility and the whole “performance is speed to project delivery” bit. Now DBAs can offer that value proposition to them while applying the enterprise-grade principles that they require. And if they don’t want to exploit some amazing “above and beyond” capabilities that DB2 provides, they don’t even have to change their application.
The DB2 NoSQL JSON solution provides you with the flexibility of the JSON data representation within the proven DB2 database—the best of both worlds. DB2 10.5 helps you to develop modern-era applications by using a JSON programming paradigm that is patterned after the MongoDB data model and query language … without sacrificing agility.
You can administer and interactively query JSON data by using a command-line shell, develop Java applications by using an IBM-provided Java driver for JSON, and use any driver that implements the MongoDB protocol. This last feature gives you access to the DB2 NoSQL JSON store from a variety of modern languages, including
node.js, PHP, Python, and Ruby, as well as more traditional languages such as C, C++, and Perl.And that’s why DB2 is a great relational and NoSQL database!
For more details about DB2 NoSQL JSON support, visit the IBM developerWorks JSON zone (www.ibm.com/developerworks/topics/json/) or see the DB2 JSON documentation.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.