
8
SOFTWARE‐DEFINED ENVIRONMENTS
Chung‐Sheng Li1 and Hubertus Franke2
1 PwC, San Jose, California, United States of America
2 IBM, Yorktown Heights, New York, United States of America
8.1 INTRODUCTION
The worldwide public cloud services market, which includes business process as a service, software as a service, platform as a service, and infrastructure as a service, is projected to grow 17.5% in 2019 to total $214.3 billion, up from $182.4 billion in 2018, and is projected to grow to $331.2 billion by 2022.1 The hybrid cloud market, which often includes simultaneous deployment of on premise and public cloud services, is expected to grow from $44.60 billion in 2018 to $97.64 billion by 2023, at a compound annual growth rate (CAGR) of 17.0% during the forecast period.2 Most enterprises are taking cloud first or cloud only strategy and are migrating both of their mission‐critical and performance‐sensitive workloads to either public or hybrid cloud deployment models. Furthermore, the convergence of mobile, social, analytics, and artificial intelligence workloads on the cloud definitely gave strong indications shift of the value proposition of cloud computing from cost reduction to simultaneous efficiency, agility, and resilience.
Simultaneous requirements on agility, efficiency, and resilience impose potentially conflicting design objectives for the computing infrastructures. While cost reduction largely focused on the virtualization of infrastructure (IaaS, or infrastructure as a service), agility focuses on the ability to rapidly react to changes in the cloud environment and workload requirements. Resilience focuses on minimizing the risk of failure in an unpredictable environment and providing maximal availability. This requires a high degree of automation and programmability of the infrastructure itself. Hence, this shift led to the recent disruptive trend of software‐defined computing for which the entire system infrastructure—compute, storage, and network—is becoming software defined and dynamically programmable. As a result, software‐defined computing receives considerable focus across academia [1, 2] and every major infrastructure company in the computing industry [3–12].
Software‐defined computing originated from the compute environment in which the computing resources are virtualized and managed as virtual machines [13–16]. This enabled mobility and higher resource utilization as several virtual machines are colocated on the same server, and variable resource requirements can be mitigated by being shared among the virtual machines. Software‐defined networks (SDNs) move the network control and management planes (functions) away from the hardware packet switches and routers to the server for improved programmability, efficiency, extensibility, and security [17–21]. Software‐defined storage (SDS), similarly, separates the control and management planes from the data plane of a storage system and dynamically leverages heterogeneous storage to respond to changing workload demands [22, 23]. Software‐defined environments (SDEs) bring together software‐defined compute, network, and storage and unify the control and management planes from each individual software‐defined component.
The SDE concept was first coined at IBM Research during 2012 [24] and was cited in the 2012 IBM Annual report [25] at the beginning of 2013. In SDE, the unified control planes are assembled from programmable resource abstractions of the compute, network, and storage resources of a system (also known as fit‐for‐purpose systems or workload‐optimized systems) that meet the specific requirements of individual workloads and enable dynamic optimization in response to changing business requirements. For example, a workload can specify the abstracted compute and storage resources of its various workload components and their operational requirements (e.g. I/O [input/output] operations per second) and how these components are interconnected via an abstract wiring that will have to be realized using the programmable network. The decoupling of the control/management plane from the data/compute plane and virtualization of available compute, storage, and networking resources also lead to the possibility of resource pooling at the physical layer known as disaggregated or composable systems and datacenter [26–28].
In this chapter, we provide an overview of the vision, architecture, and current incarnation of SDEs within industry, as shown in Figure 8.1. At the top, workload abstractions and related tools provide the means to construct workloads and services based on preexisting patterns and to capture the functional and nonfunctional requirements of the workloads. At the bottom, heterogeneous compute, storage, and networking resources are pooled based on their capabilities, potentially using composable system concept. The workloads and their contexts are then mapped to the best‐suited resources. The unified control plane dynamically constructs, configures, continuously optimizes, and proactively orchestrates the mapping between the workload and the resources based on the desired outcome specified by the workload and the operational conditions of the cloud environment. We also demonstrate at a high level how this architecture achieves agility, efficiency, and continuous outcome optimized infrastructure with proactive resiliency and security.
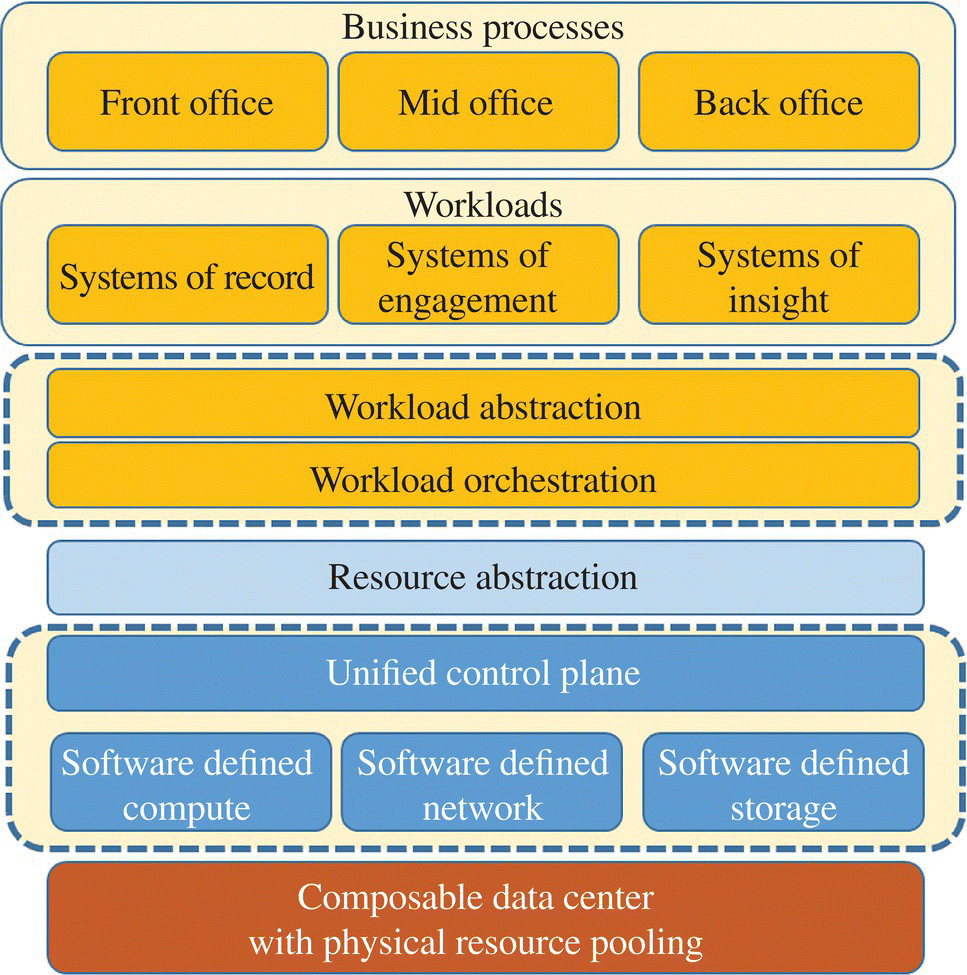
FIGURE 8.1 Architecture of software‐defined environments. Workloads are complex wirings of components and are represented through abstractions. Given a set of abstract resources the workloads are continuously mapped (orchestrated) into the environment through the unified control plane. The individual resource controllers program the underlying virtual resources (compute, network, and storage).
Source: © 2020 Chung‐Sheng Li.
8.2 SOFTWARE‐DEFINED ENVIRONMENTS ARCHITECTURE
Traditional virtualization and cloud solutions only allow basic abstraction of the computing, storage, and network resources in terms of their capacity [29]. These approaches often call for standardization of the underlying system architecture to simplify the abstraction of these resources. The convenience offered by the elasticity for scaling the provisioned resources based on the workload requirements, however, is often achieved at the expense of overlooking capability differences inherent in these resources. Capability differences in the computing domain could be:
- Differences in the instruction set architecture (ISA), e.g. Intel x86 versus ARM versus IBM POWER architectures
- Different implementations of the same ISA, e.g. Xeon by Intel versus EPYC by AMD
- Different generations of the same ISA by the same vendor, e.g. POWER7 versus POWER8 versus POWER9 from IBM and Nehalem versus Westmere versus Sandy Bridge versus Ivy Bridge versus Coffee Lake from Intel.
- Availability of various on‐chip or off‐chip accelerators including graphics processing units (GPUs) such as those from Nvidia, Tensor Processing Unit (TPU) from Google, and other accelerators such as those based on FPGA or ASIC for encryption, compression, extensible markup language (XML) acceleration, machine learning, deep learning, or other scalar/vector functions.
The workload‐optimized system approaches often call for tight integration of the workload with the tuning of the underlying system architecture for the specific workload. The fit‐for‐purpose approaches tightly couple the special capabilities offered by each micro‐architecture and by the system level capabilities at the expense of potentially labor‐intensive tuning required. These workload‐optimized approaches are not sustainable in an environment where the workload might be unpredictable or evolve rapidly as a result of growth of the user population or the continuous changing usage patterns.
The conundrum created by these conflicting requirements in terms of standardized infrastructure vs. workload‐optimized infrastructure is further exacerbated by the increasing demand for agility and efficiency as more enterprise applications from systems of record, systems of engagement, and systems of insight require fast deployment while continuously being optimized based on the available resources and unpredictable usage patterns. Systems of record usually refer to enterprise resource planning (ERP) or operational database systems that conduct online transaction processing (OLTP). Systems of engagement usually focused on engagement with large set of end users, including those applications supporting collaboration, mobile, and social computing. Systems of insight often refer to online analytic processing (OLAP), data warehouse, business intelligence, predictive/prescriptive analytics, and artificial intelligence solutions and applications. Emerging applications including chatbot, natural language processing, knowledge representation and reasoning, speech recognition/synthesis, computer vision and machine learning/deep learning all fall into this category.
Systems of records, engagement, and insight can be mapped to one of the enterprise applications areas:
- Front office: Including most of the customer facing functions such as corporate web portal, sales and marketing, trading desk, and customer and employee support,
- Mid office: Including most of the risk management, and compliance areas,
- Back office: The engine room of the corporation and often includes corporate finance, legal, HR, procurement, and supply chain.
Systems of engagement, insight, and records are deployed into front, mid, and back office application areas, respectively. Emerging applications such as chatbot based on artificial intelligence and KYC (know your customer) banking solutions based on advanced analytics, however, blurred the line among front, mid, and back offices. Chatbot, whether it is based on Google DialogFlow, IBM Watson Conversation, Amazon Lex, or Microsoft Azure Luis, is now widely deployed for customer support in the front office and HR & procurement in the back office area. KYC solutions, primarily deployed in front office, often leverage customer data from back office to develop comprehensive customer profiling and are also connected to most of the major compliance areas including anti‐money laundering (AML) and Foreign Account Tax Compliance Act (FATCA) in the mid office area.
It was observed in [30] that a fundamental change in the axis of IT innovation happened around 2000. Prior to 2000, new systems were introduced at the very high end of the economic spectrum (large public agencies and Fortune 500 companies). These innovations trickled down to smaller businesses, then to home office applications, and finally to consumers, students, and even children. This innovation flow reversed after 2000 and often started with the consumers, students, and children leading the way, especially due to the proliferation of mobile devices. These innovations are then adopted by nimble small‐to‐medium‐size businesses. Larger institutions are often the last to embrace these innovations. The author of [30] coined the term systems of engagement for the new kinds of systems that are more focused on engagement with the large set of end users in the consumer space. Many systems of engagement such as Facebook, Twitter, Netflix, Instagram, Snap, and many others are born on the cloud using public cloud services from Amazon Web Services (AWS), Google Cloud Platform (GCP), Microsoft Azure, etc. These systems of engagement often follow the agility trajectory. On the other hand, the workload‐optimized system concept is introduced to the systems of record environment, which occurred with the rise of client–server ERP systems on top of the Internet. Here the entire system, from top to bottom, is tuned for the database or data warehouse environment.
SDEs intended to address the challenge created from the desire for simultaneous agility, efficiency, and resilience. SDEs decouple the abstraction of resources from the real resources and only focus on the salient capabilities of the resources that really matter for the desired performance of the workload. SDEs also establish the workload definition and decouple this definition from the actual workloads so that the matching between the workload characteristics and the capabilities of the resources can be done efficiently and continuously. Simultaneous abstraction of both resources and workloads to enable late binding and flexible coupling among workload definitions, workload runtime, and available resources is fundamental to addressing the challenge created by the desire for both agility and optimization in deploying workloads while maintaining nearly maximal utilization of available resources.
8.3 SOFTWARE‐DEFINED ENVIRONMENTS FRAMEWORK
8.3.1 Policy‐Based and Goal‐Based Workload Abstraction
Workloads are generated by the execution of business processes and activities involving systems of record, systems of engagement, and systems of insight applications and solutions within an enterprise. Using the order‐to‐cash (OTC) process—a common corporate finance function as an example—the business process involves (i) generating quote after receiving the RFQ/RFP or after receiving a sales order, (ii) recording trade agreement or contract, (iii) receiving purchase order from client, (iv) preparing and shipping the order, (v) invoicing the client, (vi) recording invoice on account receivable within general ledger, (vii) receiving and allocating customer payment against account receivable, (viii) processing customer return as needed, and (ix) conducting collection on those delinquent invoices. Most of these steps within the OTC process can be automated through, for example, robotic process automation (RPA) [31]. The business process or workflow is often captured by an automation script within the RPA environment, where the script is executed by the orchestration engine of the RPA environment. This script will either invoke through direct API call or perform screen scraping of a VDI client (such as Citrix client) of those systems of records (the ERP system) that store and track the sales order, trade agreement, and purchase order, invoice, and account receivable; systems of engagement (email or SMS) for sending invoice and payment reminders; and systems of insight such as prediction of which invoices are likely to encounter challenges in collection. The execution of these applications in turn contributes to the workloads that need to be orchestrated within the infrastructure.
Executing workloads involves mapping and scheduling the tasks that need to be performed, as specified by the workload definition, to the available compute, storage, and networking resources. In order to optimize the mapping and scheduling, workload modeling is often used to achieve evenly distributed manageable workloads, to avoid overload, and to satisfy service level objectives.
The workload definition has been previously and extensively studied in the context of the Object Management Group (OMG) Model‐Driven Architecture (MDA) initiative during the late 1990s as an approach to system specification and interoperability based on the use of formal models. In MDA, platform‐independent models are described in a platform‐independent modeling language such as Unified Modeling Language (UML). The platform‐independent model is then translated into a platform‐specific model by mapping the platform independent models to implementation languages such as Java, XML, SOAP (Simple Object Access Protocol), or various dynamic scripting languages such as Python using formal rules.
Workload concepts were heavily used in the grid computing era, for example, IBM Spectrum Symphony, for defining and specifying tasks and resources and predicting and optimizing the resources for the tasks in order to achieve optimal performance. IBM Enterprise Workload Manager (eWLM) allows the user to monitor application‐level transactions and operating system processes, allows the user to define specific performance goals with respect to specific work, and allows adjusting the processing power among partitions in a partition workload group to ensure that performance goals are met. More recently, workload automation and development for deployment have received considerable interests as the development and operations (DevOps) concept becomes widely deployed. These workload automation environments often include programmable infrastructures that describe the available resources and characterization of the workloads (topology, service‐level agreements, and various functional and nonfunctional requirements). Examples of such environments include Amazon Cloud Formation, Oracle Virtual Assembly Builder, and VMware vFabric.
A workload, in the context of SDEs, is often composed of a complex wiring of services, applications, middleware components, management agents, and distributed data stores. Correct execution of a workload requires that these elements be wired and mapped to appropriate logical infrastructure according to workload‐specific policies and goals. Workload experts create workload definitions for specific workloads, which codify the best practices for deploying and managing the workloads. The workload abstraction specifies all of the workload components including services, applications, middleware components, management agents, and data. It also specifies the relationships among components and policies/goals defining how the workload should be managed and orchestrated. These policies represent examples of workload context embedded in a workload definition. They are derived based on expert knowledge of a specific workload or are learned in the course of running the workload in SDE. These policies may include requirements on continuous availability, minimum throughput, maximum latency, automatic load balancing, automatic migration, and auto‐scaling in order to satisfy the service‐level objectives. These contexts for the execution of the workload need to be incorporated during the translation from workload definition to an optimal infrastructure pattern that satisfies as many of the policies, constraints, and goals that are pertinent to this workload as possible.
In the OTC business process example, the ERP system (which serves as the systems of record) will need to have very high availability and low latency to be able to sustain high transaction throughput needed to support mission‐critical functions such as sales order capturing, shipping, invoicing, account receivable, and general ledger. In contrast, the email server (which is part of the systems of engagement) still need high availability but can tolerate lower throughput and higher latency. The analytic engine (which is part of the systems of insight) might not need to have high availability nor high throughput.
8.3.2 Capability‐Based Resource Abstraction and Software‐Defined Infrastructure
The abstraction of resources is based on the capabilities of these resources. Capability‐based pooling of heterogeneous resources requires classification of these resources based on workload characteristics. Using compute as an example, server design is often based on the thread speed, thread count, and effective cache/thread. The fitness of the compute resources (servers in this case) for the workload can then be measured by the serial fitness (in terms of thread speed), the parallel fitness (in terms of thread count), and the data fitness (in terms of cache/thread).
Capability‐based resource abstraction is an important step toward decoupling heterogeneous resources provisioning from the workload specification. Traditional resource provisioning is mostly based on capacity, and hence the differences in characteristics of the resource are often ignored. The Pfister framework [32] has been used to describe workload characteristics [1] in a two‐dimensional space where one axis describes the amount of thread contention and the other axis describes the amount of data contention. We can categorize the workload into four categories based on the Pfister framework: Type 1 (mixed workload updating shared data or queues), Type 2 (highly threaded applications, including WebSphere* applications), Type 3 (parallel data structures with analytics, including Big Data, Hadoop, etc.), and Type 4 (small discrete applications, such as Web 2.0 apps).
Servers are usually optimized to one of the corners of this two‐dimensional space, but not all four corners. For instance, the IBM System z [33] is best known for its single‐thread performance, while IBM Blue Gene [34] is best known for its ability to carry many parallel threads. Some of the systems (IBM System x3950 [Intel based] and IBM POWER 575) were designed to have better I/O capabilities. Eventually there is not a single server that can fit all workloads described above while delivering required performance by the workloads.
This leads to a very important observation: the majority of workloads (whether they are systems of record or systems of engagement or systems of insight) always consist of multiple workload types and are best addressed by a combination of heterogeneous servers rather than homogeneous servers.
We envision resource abstractions based on different computing capabilities that are pertinent to the subsequent workload deployments. These capabilities could include high memory bandwidth resources, high single thread performance resources, high I/O throughout resources, high cache/thread resources, and resources with strong graphics capabilities. Capability‐based resource abstraction eliminates the dependency on specific instruction‐set architectures (e.g. Intel x86 versus IBM POWER versus ARM) while focusing on the true capability differences (AMD Epyc versus Intel Xeon, and IBM POWER8 versus POWER9 may be represented as different capabilities).
Previously, it was reported [35] that up to 70% throughput improvement can be achieved through careful selection of the resources (AMD Opteron versus Intel Xeon) to run Google's workloads (content analytics, Big Table, and web search) in its heterogeneous warehouse scale computer center. Likewise, storage resources can be abstracted beyond the capacity and block versus file versus objects. Additional characteristics of storage such as high I/O throughput, high resiliency, and low latency can all be brought to the surface as part of storage abstraction. Networking resources can be abstracted beyond the basic connectivity and bandwidth. Additional characteristics of networking such as latency, resiliency, and support for remote direct memory access (RDMA) can be brought to the surface as part of the networking abstraction.
The combination of capability‐based resource abstraction for software‐defined compute, storage, and networking forms the software‐defined infrastructure, as shown in Figure 8.2. This is essentially an abstract view of the available compute and storage resources interconnected by the networking resources. This abstract view of the resources includes the pooling of resources with similar capabilities (for compute and storage), connectivity among these resources (within one hop or multiple hops), and additional functional or nonfunctional capabilities attached to the connectivity (load balancing, firewall, security, etc.). Additional physical characteristics of the datacenter are often captured in the resource abstraction model as well. These characteristics include clustering (for nodes and storage sharing the same top‐of‐the‐rack switches and that can be reached within one hop), point of delivery (POD) (for nodes and storage area network (SAN)‐attached storage sharing the same aggregation switch and can be reached within four hops), availability zones (for nodes sharing the same uninterrupted power supply (UPS) and A/C), and physical data center (for nodes that might be subject to the same natural or man‐made disasters). These characteristics are often needed during the process of matching workload requirements to available resources in order to address various performance, throughput, and resiliency requirements.
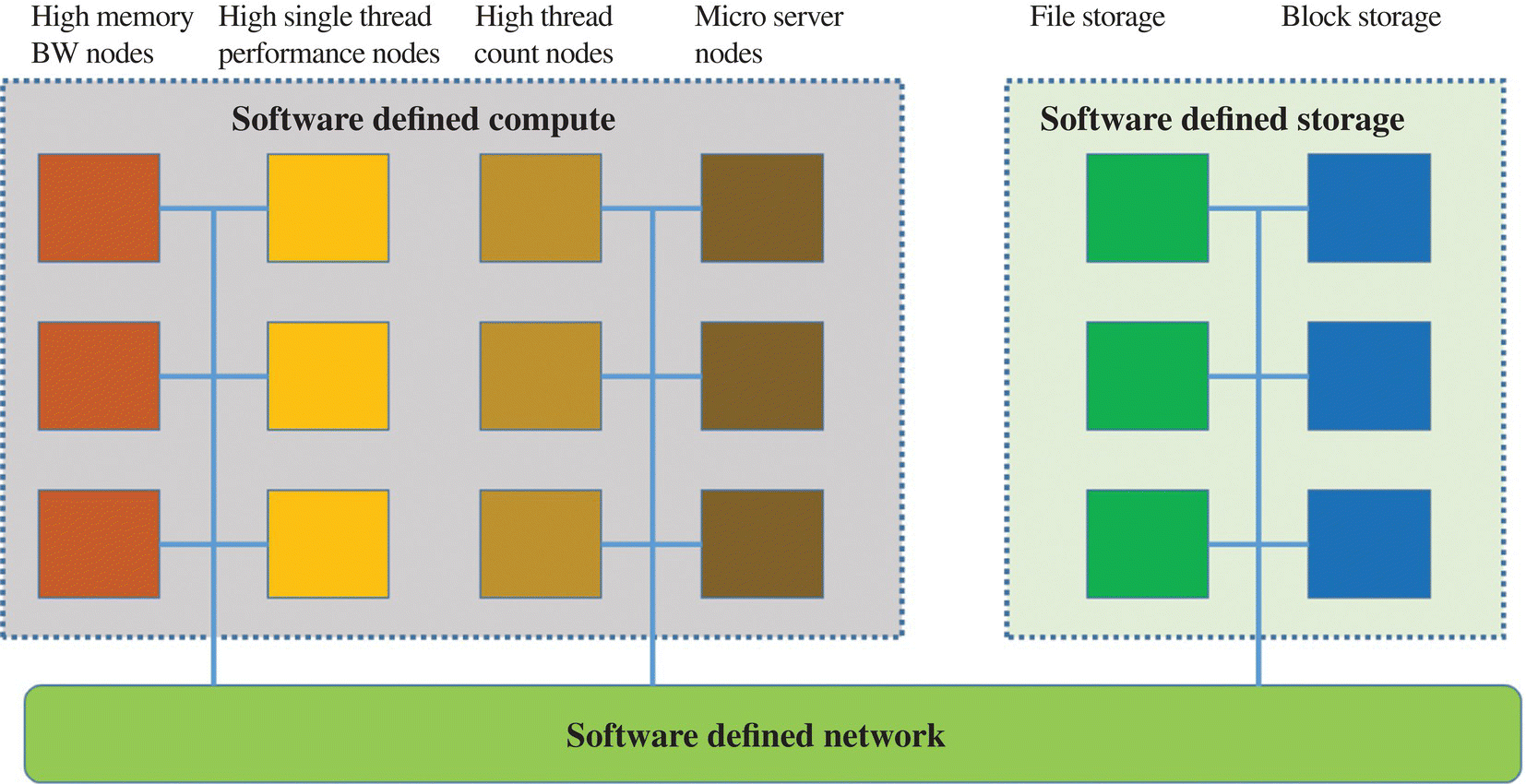
FIGURE 8.2 Capability‐based resource abstraction.
Source: © 2020 Chung‐Sheng Li.
8.3.3 Continuous Optimization
As a business increasingly relies on the availability and efficiency of its IT infrastructure, linking the business operations to the agility and performance of the deployment and continuous operation of IT becomes crucial for the overall business optimization. SDEs provide an overall framework for directly linking the business operation to the underlying IT as described below. Each business operation can be decomposed into multiple tasks, each of which has a priority. Each task has a set of key performance indicators (KPIs), which could include confidentiality, integrity, availability, correctness/precision, quality of service (QoS) (latency, throughput, etc.), and potentially other KPIs.
As an example, a procure‐to‐pay (PTP) business operation might include the following tasks: (i) send out request for quote (RFQ) or request for proposal (RFP); (ii) evaluate and select one of the proposals or bids to issue purchase order based on the past performance, company financial health, and competitiveness of the product in the marketplace; (iii) take delivery of the product (or services); (iv) receive the invoice for the goods or services rendered; (v) perform three‐way matching among purchase order, invoice, and goods received; (vi) issue payment based on the payment policy and deadline of the invoice. Each of these tasks may be measured by different KPIs: the KPI for the task of sending out RFP/RFQ or PO might focus on availability, while the KPI for the task of performing three‐way matching and issue payment might focus on integrity. The specification of the task decomposition of a business operation, the priority of each task, and KPIs for each task allow trade‐offs being made among these tasks when necessary. Using RFP/RFQ as an example, availability might have to be reduced when there is insufficient capacity until the capacity is increased or the load is reduced.
The KPIs for the task often are translated to the architecture and KPIs for the infrastructure. Confidentiality usually translates to required isolation for the infrastructure. Availability potentially translates into redundant instantiation of the runtime for each task using active–active or active–passive configurations—and may need to take advantage of the underlying availability zones provided by all major cloud service providers. Integrity of transactions, data, processes, and policies is managed at the application level, while the integrity of the executables and virtual machine images is managed at the infrastructure level. Correctness and precision need to be managed at the application level, and QoS (latency, throughput, etc.) usually translates directly to the implications for infrastructures. Continuous optimization of the business operation is performed to ensure optimal business operation during both normal time (best utilization of the available resources) and abnormal time (ensures the business operation continues in spite of potential system outages). This potentially requires trade‐offs among KPIs in order to ensure the overall business performance does not drop to zero due to outages. The overall closed‐loop framework for continuous optimizing is as follows:
- The KPIs of the service are continuously monitored and evaluated at each layer (the application layer and the infrastructure layer) so that the overall utility function (value of the business operation, cost of resource, and risk to potential failures) can be continuously evaluated based on the probabilities of success and failure. Deep introspection, i.e. a detailed understanding of resource usage and resource interactions, within each layer is used to facilitate the monitoring. The data is fed into the behavior models for the SDE (which includes the workload, the data (usage patterns), the infrastructure, and the people and processes).
- When triggering events occur, what‐if scenarios for deploying different amount of resources against each task will be evaluated to determine whether KPIs can be potentially improved.
- The scenario that maximizes the overall utility function is selected, and the orchestration engine will orchestrate the SDE through the following: (i) adjustment to resource provisioning (scale up or down), (ii) quarantine of the resources (in various resiliency and security scenarios), (iii) task/workload migration, and (iv) server rejuvenation.
8.4 CONTINUOUS ASSURANCE ON RESILIENCY
The resiliency of a service is often measured by the availability of this service in spite of hardware failures, software defects, human errors, and malicious cybersecurity threats. The overall framework on continuous assurance of resiliency is directly related to the continual optimization of the services performed within the SDEs, taking into account the value created by the delivery of service, subtracting the cost for delivering the service and the cost associated with a potential failure due to unavailability of the service (weighted by the probability of such failure). This framework enables proper calibration of the value at risk for any given service so that the overall metric will be risk‐adjusted cost performance. Continuous assurance on resiliency, as shown in Figure 8.3, ensures that the value at risk (VAR) is always optimal while maintaining the risk of service unavailability due to service failures and cybersecurity threats below the threshold defined by the service level agreement (SLA).
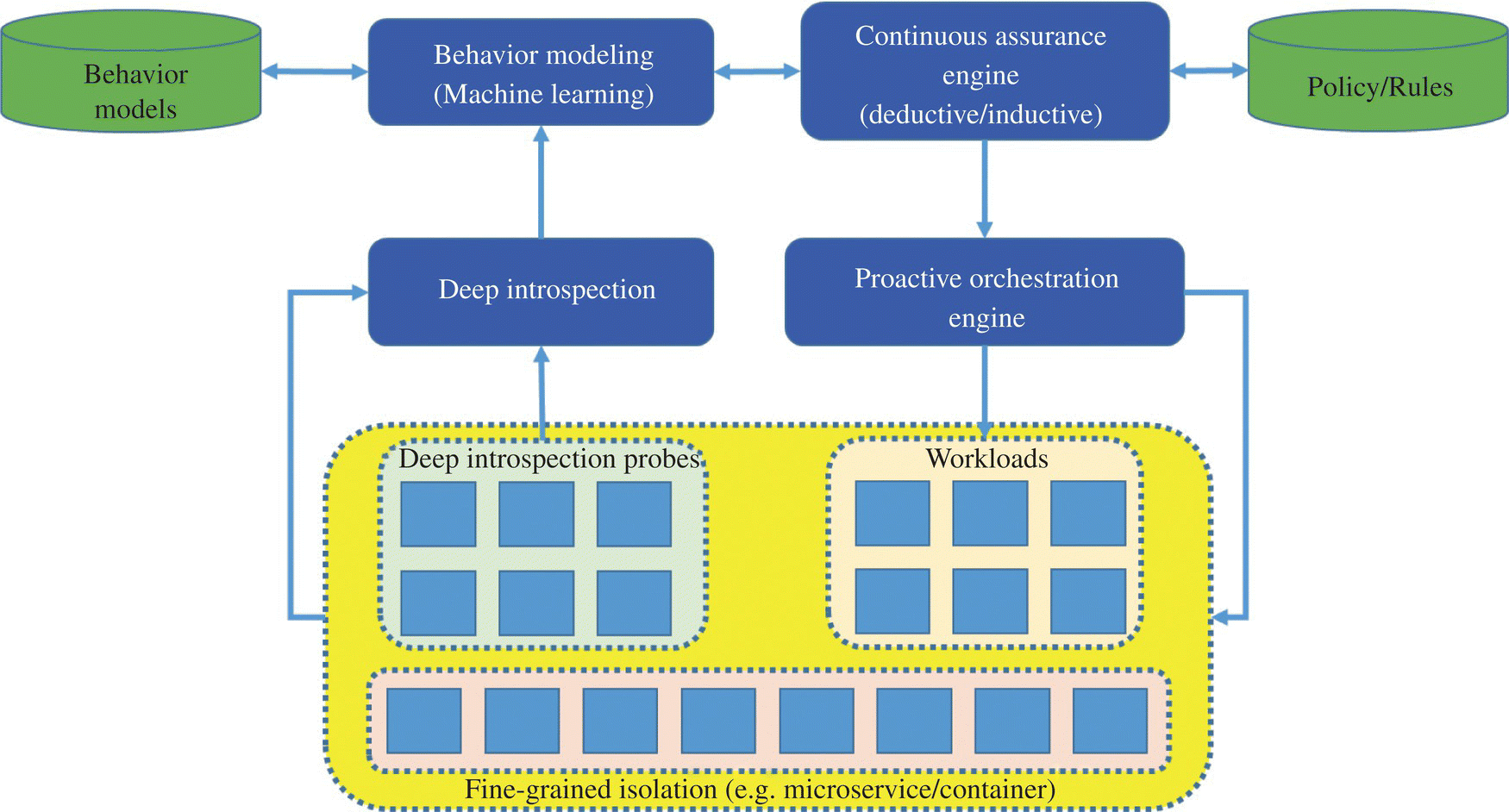
FIGURE 8.3 Continuous assurance for resiliency and security helps enable continuous deep introspection, advanced early warning, and proactive quarantine and orchestration for software‐defined environments.
Source: © 2020 Chung‐Sheng Li.
Increased virtualization, agility and resource heterogeneity within SDE on one hand improves the flexibility for providing resilience assurance and on the other hand also introduces new challenges, especially in the security area:
- Increased virtualization obfuscates monitoring: Traditional security architectures are often physically based, as IT security relies on the identities of the machine and the network. This model is less effective when there are multiple layers of virtualization and abstractions, which could result in many virtual systems being created within the same physical system or multiple physical systems virtualized into a single virtual system. This challenge is further compounded by the use of dedicated or virtual appliances in the computing environment.
- Dynamic binding complicates accountability: SDEs enable standing up and tearing down computing, storage, and networking resources quickly as the entire computing environment becomes programmable and breaks the long‐term association between security policies and the underlying hardware and software environment. The SDE environment requires the ability to quickly set up and continuously evolve security policies directly related to users, workloads, and the software‐defined infrastructure. There are no permanent associations (or bindings) between the logical resources and physical resources as software‐defined systems can be continuously created from scratch and can be continuously evolved and destroyed at the end. As a result, the challenge will be to provide a low‐overhead approach for capturing the provenance (who has done what, at what time, to whom, in what context), to identify the suspicious events in a rapidly changing virtual topology.
- Resource abstraction mask vulnerability: In order to accommodate heterogeneous compute, storage, and network resources in an SDE, resources are abstracted in terms of capability and capacity. This normalization of the capability across multiple types of resources masks the potential differences in various nonfunctional aspects such as the vulnerabilities to outages and security risk.
To ensure continuous assurance and address the challenges mentioned above, the continuous assurance framework within SDEs includes the following design considerations:
- Fine‐grained isolation: By leveraging the fine‐grained virtualization environments such as those provided by the microservice and Docker container framework, it is possible to minimize the potential interference between microservices within different containers so that the failure of one microservice in a Docker container will not propagate to the other containers. Meanwhile, fine‐grained isolation is feasible to contain the cybersecurity breach or penetration within a container while maintaining the continuous availability of other containers and maximize the resilience of the services.
- Deep introspection: Works with probes (often in the form of agents) inserted into the governed system to collect additional information that cannot be easily obtained simply by observing network traffic. These probes could be inserted into the hardware, hypervisors, guest virtual machines, middleware, or applications. Additional approaches include micro‐checkpoints and periodic snapshots of the virtual machine or container images when they are active. The key challenge is to avoid introducing unnecessary overhead while providing comprehensive capabilities for monitoring and rollback when abnormal behaviors are found.
- Behavior modeling: The data collected from deep introspection are assimilated with user, system, workload, threat, and business behavior models. Known causalities among these behavior models allow early detection of unusual behaviors. Being able to provide early warning of these abnormal behaviors from users, systems, and workloads, as well as various cybersecurity threats, is crucial for taking proactive actions against these threats and ensuring continuous business operations.
- Proactive failure discovery: Complementing deep introspection and behavior modeling is active fault (or chaos) injection. Introduced originally as chaos monkey for Netflix [36] and subsequently generalized into chaos engineering [37], pseudo‐random failures can be injected into an SDE environment to discover potential failure modes proactively and ensure that the SDE can survive the type of failures that are being tested. Coupling with the containment structures such as Docker container for microservices defined within SDE, the “blast radius” of the failure injection can be controlled without impacting the availability of the services.
- Policy‐based Adjudication: The behavior model assimilated from the workloads and their environments—including the network traffic—can be adjudicated based on the policies derived from the obligations extracted from pertinent regulations to ensure continuous assurance with respect to these regulations.
- Self‐healing with automatic Investigation and remediation: A case for subsequent follow‐up is created whenever an anomaly (such as microservice failure or network traffic anomaly) is detected from behavior modeling or an exception (such as SSAE 16 violation) is determined from the policy‐based adjudication. Automatic mechanisms can be used to collect the evidence, formulate multiple hypothesis, and evaluate the likelihood of each hypothesis based on the available evidence. The most likely hypothesis will then be used to generate recommendation and remediation. A properly designed microservice architecture within an SDE enables fault isolation so that crashed microservices can be detected and restarted automatically without human intervention to ensure continuous availability of the application.
- Intelligent orchestration: The assurance engine will continuously evaluate the predicted trajectory of the user, system, workload, and threats and compare against the business objectives and policies to determine whether proactive actions need to be taken by the orchestration engine. The orchestration engine receives instructions from the assurance engine and orchestrates defensive or offensive actions including taking evasive maneuvers as necessary. Examples of these defensive or offensive actions includes fast workload migration from infected areas, fine‐grained isolation and quarantine of infected areas of the system, server rejuvenation of those server images when the risk of server image contamination due to malware is found to be unacceptable, and Internet Protocol (IP) address randomization of the workload, making it much more difficult to accurately pinpoint an exact target for attacks.
8.5 COMPOSABLE/DISAGGREGATED DATACENTER ARCHITECTURE
Capability‐based resource abstraction within SDE not only decouples the resource requirements of workloads from the details of the computing architecture but also drives the resource pooling at the physical layers for optimal resource utilization within cloud datacenters. Systems in a cloud computing environment often have to be configured according to workload specifications. Nodes within a traditional datacenter are interconnected in a spine–leaf model—first by top‐of‐rack (TOR) switches within the same racks, then interconnected through the spine switches among racks. There is a conundrum between performance and resource utilization (and hence the cost of computation) when statically configuring these nodes across a wide spectrum of big data & AI workloads, as nodes optimally configured for CPU‐intensive workloads could leave CPUs underutilized for I/O intensive workloads. Traditional systems also impose identical life cycle for every hardware component inside the system. As a result, all of the components within a system (whether it is a server, storage, or switches) are replaced or upgraded at the same time. The “synchronous” nature of replacing the whole system at the same time prevents earlier adoption of newer technology at the component level, whether it is memory, SSD, GPU, or FPGA.
Composable/disaggregated datacenters achieve resource pooling at the physical layer through constructing each system at a coarser granularity so that individual resources such as CPU, memory, HDD, SSD, and GPU can be pooled together and dynamically composed into workload execution units on demand. A composable datacenter architecture is ideal for SDE with heterogeneous and fast evolving workloads as SDEs often have dynamic resource requirements and can benefit from the improved elasticity of the physical resource pooling offered by the composable architecture. From the simulations reported in [28], it was shown that the composable system sustains nearly up to 1.6 times stronger workload intensity than that of traditional systems, and it is insensitive to the distribution of workload demands.
Composable resources can be exposed through hardware‐based, hypervisor/operating system based, and middleware‐/application‐based approaches. Directly expose resource composability through capability‐based resource abstraction methodology within SDE to policy‐based workload abstractions that allow applications to manage the resources using application‐level knowledge is likely to achieve the best flexibility and performance gain.
Using Cassandra (a distributed NoSQL database) as an example, it is shown in [26] that accessing data from across multiple disks connected via Ethernet poses less of a bandwidth restriction than SATA and thus improves throughput and latency of data access and obviates the need for data locality. Overall composable storage systems are cheaper to build and manage and incrementally scalable and offer superior performance than traditional setups.
The primary concern for the composable architecture is the potential performance impacts arising from accessing resources such as memory, GPU, and I/O from nonlocal shared resource pools. Retaining sufficient local DRAM serving as the cache for the pooled memory as opposed to full disaggregation of memory resources and retain no local memory for the CPU is always recommended to minimize the performance impact due to latency incurred from accessing remote memory. Higher SMT levels and/or explicit management by applications that maximize thread level parallelism are also essential to further minimize the performance impact. It was shown in [26] that there is negligible latency and throughput penalty incurred in the Memcached experiments for the read/update operations if these operations are 75% local and the data size is 64 KB. Smaller data sizes result in larger latency penalty, while larger data sizes result in larger throughput penalty when the ratio of nonlocal operations is increased to 50 and 75%.
Frequent underutilization of memory is observed, while CPU is more fully utilized across the cluster in the Giraph experiments. However, introducing composable system architecture in this environment is not straightforward as sharing memory resources among nodes within a cluster through configuring RamDisk presents very high overhead. Consequently, it is stipulated that sharing unused memory across the entire compute cluster instead of through a swap device to a remote memory location is likely to be more promising in minimizing the overhead. In this case, rapid allocation and deallocation of remote memory is imperative to be effective.
It is reported in [38] that there is the notion of effective memory resource requirements for most of the big data analytic applications running inside JVMs in distributed Spark environments. Provisioning memory less than the effective memory requirement may result in rapid deterioration of the application execution in terms of its total execution time. A machine learning‐based prediction model proposed in [38] forecasts the effective memory requirement of an application in an SDE like environment given its SLA. This model captures the memory consumption behavior of big data applications and the dynamics of memory utilization in a distributed cluster environment. With an accurate prediction of the effective memory requirement, it is shown in [38] that up to 60% savings of the memory resource is feasible if an execution time penalty of 10% is acceptable.
8.6 SUMMARY
As the industry is quickly moving toward converged systems of record and systems of engagement, enterprises are increasingly aggressive in moving mission‐critical and performance‐sensitive applications to the cloud. Meanwhile, many new mobile, social, and analytics applications are directly developed and operated on the cloud. These converged systems of records and systems of engagement will demand simultaneous agility and optimization and will inevitably require SDEs for which the entire system infrastructure—compute, storage, and network—is becoming software defined and dynamically programmable and composable.
In this chapter, we described an SDE framework that includes capability‐based resource abstraction, goal‐/policy‐based workload definition, and continuous optimization of the mapping of the workload to the available resources. These elements enable SDEs to achieve agility, efficiency, continuously optimized provisioning and management, and continuous assurance for resiliency and security.
REFERENCES
- [1] Temple J, Lebsack R. Fit for purpose: workload based platform selection. Journal of Computing Resource Management 2011; 129:20–43.
- [2] Prodan R, Ostermann S. BA survey and taxonomy of infrastructure as a service and web hosting cloud providers. Proceedings of the 10th IEEE/ACM International Conference on Grid Computing, Banff, Alberta, Canada; 2009. p 17–25.
- [3] Data Center and Virtualization. Available at http://www.cisco.com/en/US/netsol/ns340/ns394/ns224/index.html. Accessed on June 24, 2020.
- [4] RackSpace. Available at http://www.rackspace.com/. Accessed on June 24, 2020.
- [5] Wipro. Available at https://www.wipro.com/en‐US/themes/software‐defined‐everything‐‐sdx‐/software‐defined‐compute‐‐sdc‐/. Accessed on June 24, 2020.
- [6] Intel. Available at https://www.intel.com/content/www/us/en/data‐center/software‐defined‐infrastructure‐101‐video.html. Accessed on June 24, 2020.
- [7] HP. Available at https://www.hpe.com/us/en/solutions/software‐defined.html. Accessed on June 24, 2020.
- [8] Dell. Available at https://www.dellemc.com/en‐us/solutions/software‐defined/index.htm. Accessed on June 24, 2020.
- [9] VMware. Available at https://www.vmware.com/solutions/software‐defined‐datacenter.html. Accessed on June 24, 2020.
- [10] Amazon Web Services. Available at http://aws.amazon.com/. Accessed on June 24, 2020.
- [11] IBM Corporation. IBM Cloud Computing Overview, Armonk, NY, USA. Available at http://www.ibm.com/cloud‐computing/us/en/. Accessed on June 24, 2020.
- [12] Cloud Computing with VMWare Virtualization and Cloud Technology. Available at http://www.vmware.com/cloud‐computing.html. Accessed on June 24, 2020.
- [13] Madnick SE. Time‐sharing systems: virtual machine concept vs. conventional approach. Mod Data 1969; 2(3):34–36.
- [14] Popek GJ, Goldberg RP. Formal requirements for virtualizable third generation architectures. Commun ACM 1974; 17(7):412–421.
- [15] Barman P, Dragovic B, Fraser K, Hand S, Harris T, Ho A, Neugebauer R, Pratt I, Warfield A. Xen and the art of virtualization. Proceedings of ACM Symposium on Operating Systems Principles, Farmington, PA; October 2013. p 164–177.
- [16] Bugnion E, Devine S, Rosenblum M, Sugerman J, Wang EY. Bringing virtualization to the x86 architecture with the original VMware workstation. ACM Trans Comput Syst 2012; 30(4):12:1–12:51.
- [17] Li CS, Liao W. Software defined networks [guest editorial]. IEEE Commun Mag 2013; 51(2):113.
- [18] Casado M, Freedman MJ, Pettit J, Luo J, Gude N, McKeown N, Shenker S. Rethinking enterprise network control. IEEE/ACM Trans Netw 2009; 17(4):1270–1283.
- [19] Kreutz D, Ramos F, Verissimo P. Towards secure and dependable software‐defined networks. Proceedings of 2nd ACM SIGCOMM Workshop Hot Topics in Software Design Networking; August 2013. p 55–60.
- [20] Stallings W. Software‐defined networks and openflow. Internet Protocol J 2013; 16(1). Available at https://wxcafe.net/pub/IPJ/ipj16‐1.pdf. Accessed on June 24, 2020.
- [21] Security Requirements in the Software Defined Networking Model. Available at https://tools.ietf.org/html/draft‐hartman‐sdnsec‐requirements‐00. Accessed on June 24, 2020.
- [22] ViPR: Software Defined Storage. Available at http://www.emc.com/data‐center‐management/vipr/index.htm. Accessed on June 24, 2020.
- [23] Singh A, Korupolu M, Mohapatra D. BServer‐storage virtualization: integration and load balancing in data centers. Proceedings of the 2008 ACM/IEEE Conferenceon Supercomputing, Austin, TX; November 15–21, 2008; Piscataway, NJ, USA: IEEE Press. p 53:1–53:12.
- [24] Li CS, Brech BL, Crowder S, Dias DM, Franke H, Hogstrom M, Lindquist D, Pacifici G, Pappe S, Rajaraman B, Rao J. Software defined environments: an introduction. IBM J Res Dev 2014; 58(2/3):1–11.
- [25] 2012 IBM Annual Report. p 25. Available at https://www.ibm.com/annualreport/2012/bin/assets/2012_ibm_annual.pdf. Accessed on June 24, 2020.
- [26] Li CS, Franke H, Parris C, Abali B, Kesavan M, Chang V. Composable architecture for rack scale big data computing. Future Gener Comput Syst 2017; 67:180–193.
- [27] Abali B, Eickemeyer RJ, Franke H, Li CS, Taubenblatt MA. 2015. Disaggregated and optically interconnected memory: when will it be cost effective?. arXiv preprint arXiv:1503.01416.
- [28] Lin AD, Li CS, Liao W, Franke H. Capacity optimization for resource pooling in virtualized data centers with composable systems. IEEE Trans Parallel Distrib Syst 2017; 29(2):324–337.
- [29] Armbrust M, Fox A, Griffith R, Joseph AD, Katz RH, Konwinski A, Lee G, Patterson DA, Rabkin A, Stoica I, Zaharia M. BAbove the Clouds: A Berkeley View of Cloud Computing. University of California, Berkeley, CA, USA. Technical Report No. UCB/EECS‐2009‐28; February 10, 2009. Available at http://www.eecs.berkeley.edu/Pubs/TechRpts/2009/EECS‐2009‐28.html. Accessed on June 24, 2020.
- [30] Moore J. System of engagement and the future of enterprise IT: a sea change in enterprise IT. AIIM White Paper; 2012. Available at http://www.aiim.org/~/media/Files/AIIM%20White%20Papers/Systems‐of‐Engagement‐Future‐of‐Enterprise‐IT.ashx. Accessed on June 24, 2020.
- [31] IBM blue gene. IBM J Res Dev 2005; 49(2/3).
- [32] Mars J, Tang L, Hundt R. Heterogeneity in homogeneous warehouse‐scale computers: a performance opportunity. Comput Archit Lett 2011; 10(2):29–32.
- [33] Basiri A, Behnam N, De Rooij R, Hochstein L, Kosewski L, Reynolds J, Rosenthal C. Chaos engineering. IEEE Softw 2016; 33(3):35–41.
- [34] Bennett C, Tseitlin A. Chaos monkey released into the wild. Netflix Tech Blog, 2012. p. 30.
- [35] Darema‐Rogers F, Pfister G, So K. Memory access patterns of parallel scientific programs. Proceedings of the ACM SIGMETRICS International Conference on Measurement and Modeling of Computer System, Banff, Alberta, Canada; May 11–14, 1987. p 46–58.
- [36] van der Aalst WMP, Bichler M, Heinzl A. Bus Inf Syst Eng 2018; 60:269. doi: https://doi.org/10.1007/s12599‐018‐0542‐4.
- [37] Haas J, Wallner R. IBM zEnterprise systems and technology. IBM J Res Dev 2012; 56(1/2):1–6.
- [38] Tsai L, Franke H, Li CS, Liao W. Learning‐based memory allocation optimization for delay‐sensitive big data processing. IEEE Trans Parallel Distrib Syst 2018; 29(6):1332–1341.