
As they say, data is the new oil. This current decade has set a steep trajectory of data growth, and organizations have been greatly successful by harnessing the power of this data. Not only that, with the democratization of Artificial Intelligence and Machine Learning , building predictions has become easier. The infusion of AI/ML with data has given lots of advantages to plan future requirements or actions. Some of the classic use cases are customer churn analysis, fraud analytics, social media analytics, and predictive maintenance. In this chapter, the focus is on how the evolution of data happened and how it disrupted the data analytics space. Moreover, there will be a brief description of the concepts of relational and nonrelational data stores, enterprise data warehouse and big data systems.
What’s Data Analytics?
- 1.
Descriptive: What happened?
- 2.
Diagnostic: Why did it happen?
- 3.
Predictive: What will happen?
- 4.
Prescriptive: What should I do?
Traditional business intelligence (BI) systems have been catering to descriptive and diagnostic analytics, a.k.a. data analytics. However, when machine learning is added into the data analytics pipeline, predictive and prescriptive analytics becomes possible and it’s called advanced data analytics, which is synonymous with traditional data mining solutions. Various use cases like fraud analytics, predictive maintenance, weather forecast, and optimizing production are examples of advanced data analytics. Data analytics has two major fields, which are called data Engineers and data scientists. To briefly describe these two fields, data engineering deals with extraction, transformation, and loading of data from data sources like relational and nonrelational. These data sources can be from IOT applications, ecommerce websites, or even finance applications. The data engineer needs to have a deep understanding of these data sources and the technologies that can help to extract and transform this data. However, data scientists use this data to build predictions using machine learning models and improve the accuracy of these models. Let’s discuss relational and nonrelational data stores in the next section.
Relational and Nonrelational Data Stores
Organizations have been building applications on both relational and nonrelational data stores. In fact, there are applications based on polyglot persistence—that is, multiple data stores like relational, key value pair, or document store in a single application. In other words, relational and nonrelational databases are two personas of data. The journey of relational will be completely different than nonrelational data; for example, to analyze large amount of relational data, enterprise data warehouses are built, or massively parallel processing is used. However, to analyze nonrelational data, data analytics solutions are built on distributed computing technologies like Hadoop. Moreover, now companies want to analyze both relational and nonrelational data on a single platform and build 360-degree analytics solutions. Let’s explore what relational and nonrelational data stores are, as follows.
Relational Data Stores
Atomicity means all the changes in a transaction will either be committed or rolled back.
Consistency means that all the data in the database will be consistent all the time; none of the constraints will ever be violated.
Isolation means that transaction data, which is not yet committed, can’t be accessed outside of the transaction.
Durability means that the committed data, once saved on the database, will be available even after failure or restart of the database server.
ACID principles are natively built into RDBMS database solutions, and it’s much easier to manage the transaction processing with such solutions. However, scalability is the biggest challenge in RDBMS technologies. RDBMS systems are designed to scale up/scale vertically—that is, more computing can be added to the server rather than adding more servers. However, there are options to scale horizontally or scale out, but issues of write conflicts make it a less preferred option. Microsoft SQL Server, Oracle, PostgreSQL, and MySQL are examples of relational data stores.
Nonrelational Data Stores
- 1.
Basically available: The system appears to be available most of the time.
- 2.
Soft state: The version of data may not be consistent all the time.
- 3.
Eventual consistency: Writes across the services will be done over a period of time.
- 1.
Document store: MongoDB, Cosmos DB
- 2.
Column family store: Cassandra, Cosmos DB
- 3.
Graph store: Gremlin, Cosmos DB
- 4.
Key value pair: Table, Cosmos DB
Consistency : Every read must receive the most recent write or an error.
Availability : Every request must receive a response, without a guarantee of it being the most recent write.
Partition tolerance : The system must continue to work during network failures between components—that is, the system will continue to function even if one of the nodes fails.

CAP theorem
CAP theorem describes that any distributed application can achieve only two functionalities out of these three, at the same time. Depending upon the nature of the application, one can choose an intersection of two functionalities: consistency and partition tolerance, or consistency and availability, or availability and partition tolerance. Most NoSQL technologies implement eventual consistency and prefer availability over consistency. However, this is customizable, and one can choose any two functionalities depending on the nature of application. Therefore, a NoSQL database can support more than one thousand nodes in a cluster, which is not possible with RDBMS databases.
Evolution of Data Analytics Systems
- 1.
Enterprise data warehouse (EDW)
- 2.
Big data analytics
Enterprise Data Warehouse

EDW architecture built on SQL server
- 1.
Consolidate data from different data sources using ETL tools like SSIS (SQL Server Integration Services) packages.
- 2.
Build centralized data stores to feed data to SSAS (SQL Server Analysis Services) data models.
- 3.
Understand KPIs and build data models.
- 4.
Build a caching layer using OLAP(SSAS) platforms to precalculate KPIs.
- 5.
Consume these KPIs to build dashboards.
However, due to SOA or microservices applications and especially with new types of data like JSON data, key value pair, columnar, and graph, there was a need that standard enterprise data warehouses were not able to fulfill. That’s where big data technologies played a key role.
Big Data Systems
Volume
Platforms like gaming, ecommerce, social media, and IOT, etc. generate large amounts of data. Let’s take an example of IOT: connected cars where a car manufacturing company may have millions of cars across the globe. When these cars are sending telemetry to the back-end systems, it can be of high volume; it can be hundreds of GBs of data per day. That’s the volume challenge that big data systems solve.
Variety
Traditionally, data has been in a structured format of data types like text, date, time, or number. To store this type of data, relational systems have always been a perfect fit. However, with the emergence of unstructured data like Twitter feeds, images, streaming audios, videos, web pages, and logs, etc., it was challenging to have a data analytics system that can analyze all these types of data. That’s the variety challenge that big data systems solve.
Veracity
Data veracity is another critical aspect, as it considers accuracy, precision, and trustworthiness of data. Given that this data would be used to make analytical decisions, it’s something that should always be truthful and reliable. Veracity of data is really critical to consider before designing any big data systems. Since the entire solution is based on data, understanding validity, volatility, and reliability of data is critical for meaningful output.
Velocity
Data velocity refers to the high speed of incoming data that needs to be processed. As discussed earlier, with scenarios like IOT, social media, etc., speed of incoming data will be high and there should be systems available that can handle this kind of data. That’s the velocity challenge that big data solves.
To support the aforementioned challenges of the four Vs and cost effectiveness, big data technology platforms use distributed processing to build scalability, fault tolerance, and high throughputs. In distributed processing, there are multiple different compute resources that work together to execute a task. Hadoop is a big data solution that is built on distributed processing concepts, where thousands of computer nodes can work together on PBs of data to execute a query task. For example, HDInsight (managed Hadoop on Microsoft Azure) and Databricks are heavily used platforms on Microsoft Azure.
So far, there has been a brief mention of enterprise data warehouse and big data concepts. While big data technologies were emerging, there was another concept called massively parallel processing (MPP) that came into light. It helped to analyze large amount of structured data. However, building an enterprise data warehouse took a long time considering the ETL, building centralized data stores, and OLAP layer, etc. involved. This solution was cumbersome, especially when the data size was in dozens to hundreds of TBs. There was a need for technology that could analyze this amount of data without the overhead of going through the long cycle. With MPP technologies, SQL queries can be executed on TBs of data within seconds to minutes, which could take days to run on traditional EDW systems.
Massively Parallel Processing
In MPP systems, all the compute nodes participate in coordinated operations, yet are built on shared nothing architecture. These nodes are independent units of compute, storage, and memory; to reduce the contention between nodes, there is no resource sharing between the nodes. This approach relies on parallelism to execute the queries on large data. In MPP, all the data is split into multiple nodes to run the queries locally and in parallel with all the other nodes. This helps to execute queries faster on TBs of data. Examples of MPP solutions are SQL pools in Synapse Analytics (earlier known as SQL DW) and Redshift, etc.
So far, there has been a discussion of three major types of analytics systems: enterprise data warehouse, big data, and MPP systems. Now, let’s understand where the word data lake analytics comes from.
Data Lake Analytics Rationale
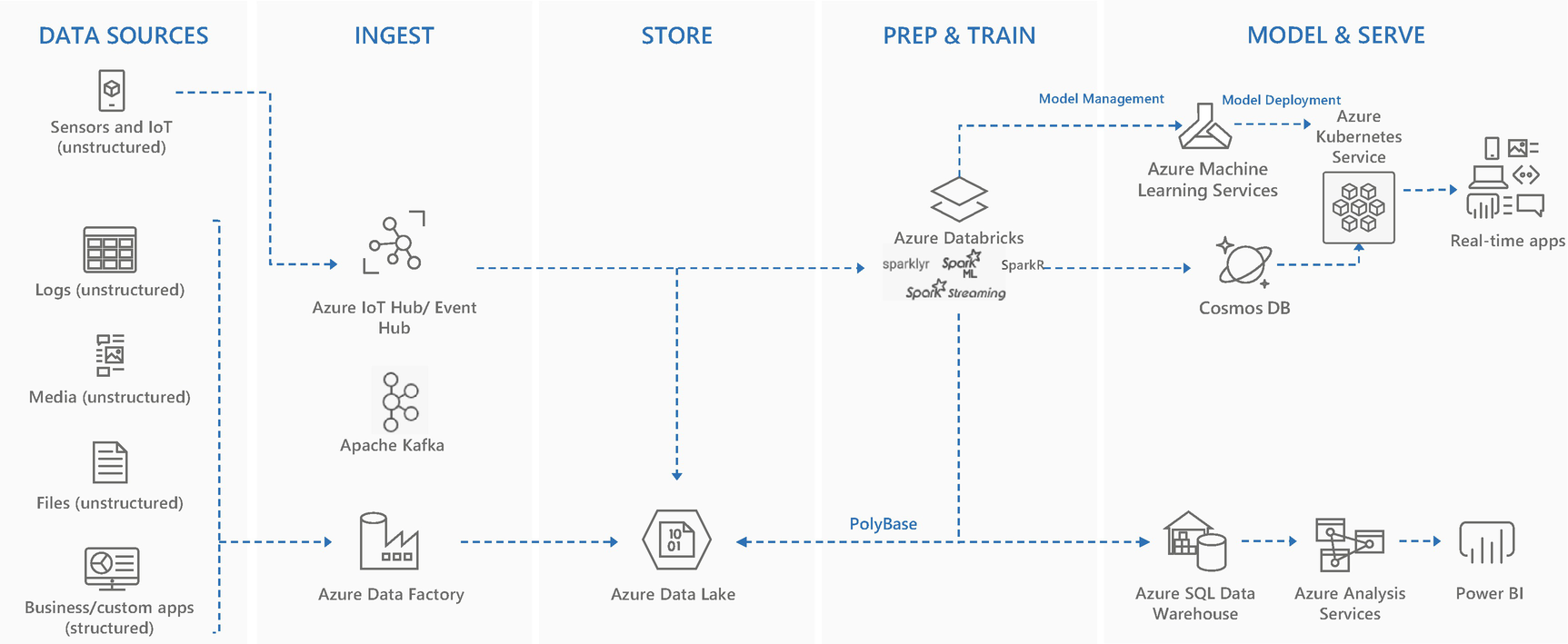
Modern data warehouse and advanced analytics architecture
- 1.
Data sources
- 2.
Data ingestion
- 3.
Data storage
- 4.
Preparation and training
- 5.
Model and serve
In the coming chapters, these steps are discussed in detail.
Conclusion
This chapter is about the basics of data analytics and how the evolution of data analytics platforms happened. The chapter is important for both data engineers and other DB profiles who are trying to get into this field. It briefly covers relational and nonrelational data stores and how the application landscape has changed from monolithic to microservices architectures. Moreover, there is a discussion on how these changes have brought a shift from enterprise data warehouses to big data analytics and massively parallel processing solutions. Fast-forward to the cloud world, where the enterprise data warehouse has been merged with big data analytics solutions into modern data warehouses; and when ML is infused into this solution, it becomes advanced analytics solutions. In the next chapter, there is a deeper discussion of the basic building blocks of data analytics solutions.