
Chapter 6: Applying Data Governance in the Data Lakehouse
The journey so far has covered five layers of Data Lakehouse. This chapter will focus on the final two layers, that is, data governance and data security layers. Data governance and security is an essential aspect of the modern data analytics platform. We will start this chapter by discussing the need for a data governance framework and how the 3-3-3 framework outlines the three components of data governance. The next section of the chapter will discuss implementing the data governance components in the Data Lakehouse. The sections will first cover implementing the three data governance components. Then, the sections will include key constructs for each of the data governance components and practical methods to implement them.
We will cover the following topics in the chapter:
- The 3-3-3 framework for data governance
- The three components of data governance
The 3-3-3 framework for data governance
The data landscape of any organization changes rapidly as more and more organizations embark on the digital transformation journey, and more and more data footprints are created.
Efficiently collecting, managing, and harnessing this data footprint is pivotal for an organization's success. Therefore, data needs to be treated as a strategic asset. However, according to a survey conducted by McKinsey in 2019, on average, an employee spends around 29 percent of the time on non-value-added tasks due to poor data quality and availability. The lack of quality of data and the lack of proper data availability is a function of data governance. As more and more data becomes available for analysis, the principle of garbage in, garbage out begins to manifest.
The 3-3-3 framework creates a structure that is a great starting point:
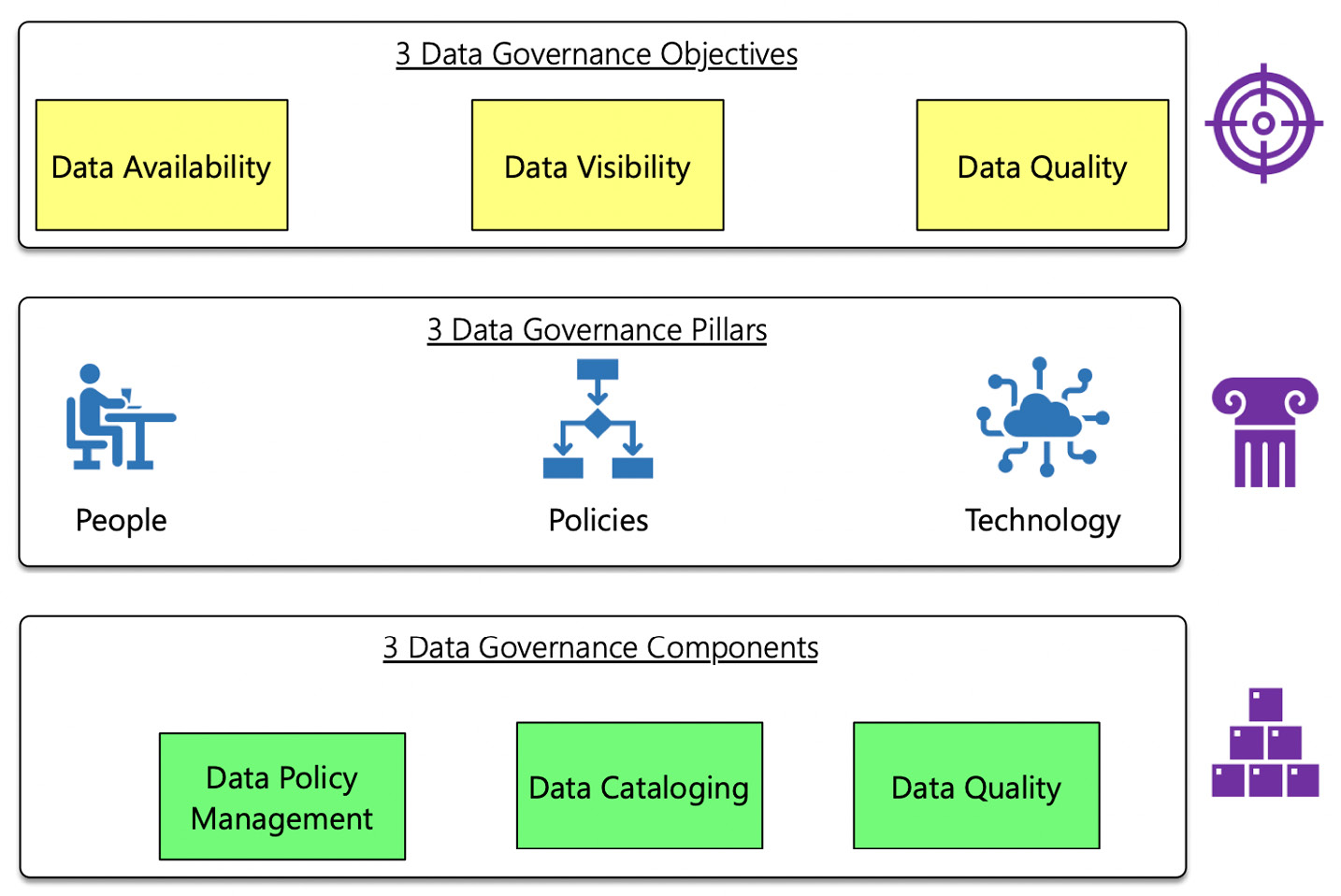
Figure 6.1 – 3-3-3 framework for data governance
This framework focuses on the following three aspects:
- Objectives
- Pillars
- Components
Let's discuss each of these aspects in detail.
The three objectives of data governance
Holistic data governance starts with a well-defined vision and clear objectives that define what data governance should achieve. The goals of data governance are specific to the organization. In this chapter, we will discuss only three objectives that are common and a must-have for any organization. The three must-have data governance objectives are as follows:
- Data Availability: Data availability ensures that a platform is provided to the right stakeholders for finding the correct data on time.
- Data Visibility: Data visibility ensures an intuitive catalog of data assets available across the organization.
- Data Quality: Data quality ensures that the appropriate quality of data is maintained throughout the data life cycle.
The three pillars of data governance
Now that we have defined the objectives, let's now discuss the three pillars of data governance.
People
The first pillar of data governance is the people. People embody personnel who perform three tasks:
- Creating: Ensuring that proper data governance policies are created, periodically reviewed, and updated as required. You should create these policies based on the strategic vision that the organization has for its data.
- Monitoring: Ensuring that the organization uses the data under the policy that has been created.
- Maintaining: Ensuring that proper processes are implemented to maintain data quality and make data accessible within and outside the organization.
Many roles fulfill these three tasks, and their responsibilities may vary from organization to organization. However, the following table represents the key roles that are generally required in any data governance framework:
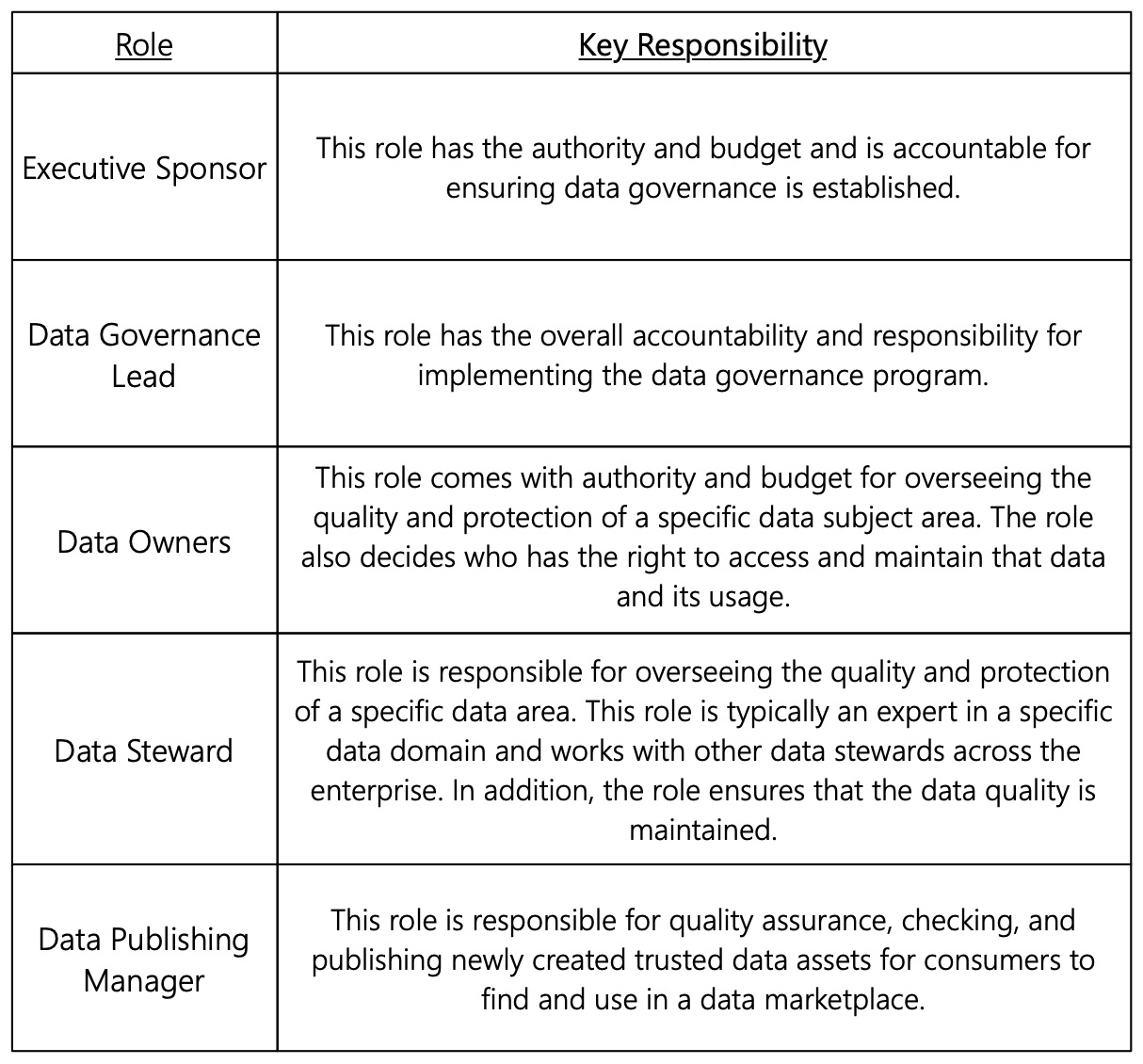
Figure 6.2 – Key roles for data governance
Now, let's discuss the second pillar of data governance, that is, policy.
Creating data policy
The second pillar of data governance is policy. The data goes through many stages of the life cycle throughout its journey in the Data Lakehouse. For each data life cycle stage, specific rules need to be defined that cater to data discovery, usage, and monitoring. The following figure depicts stages of the data life cycle and the implementation of policies:
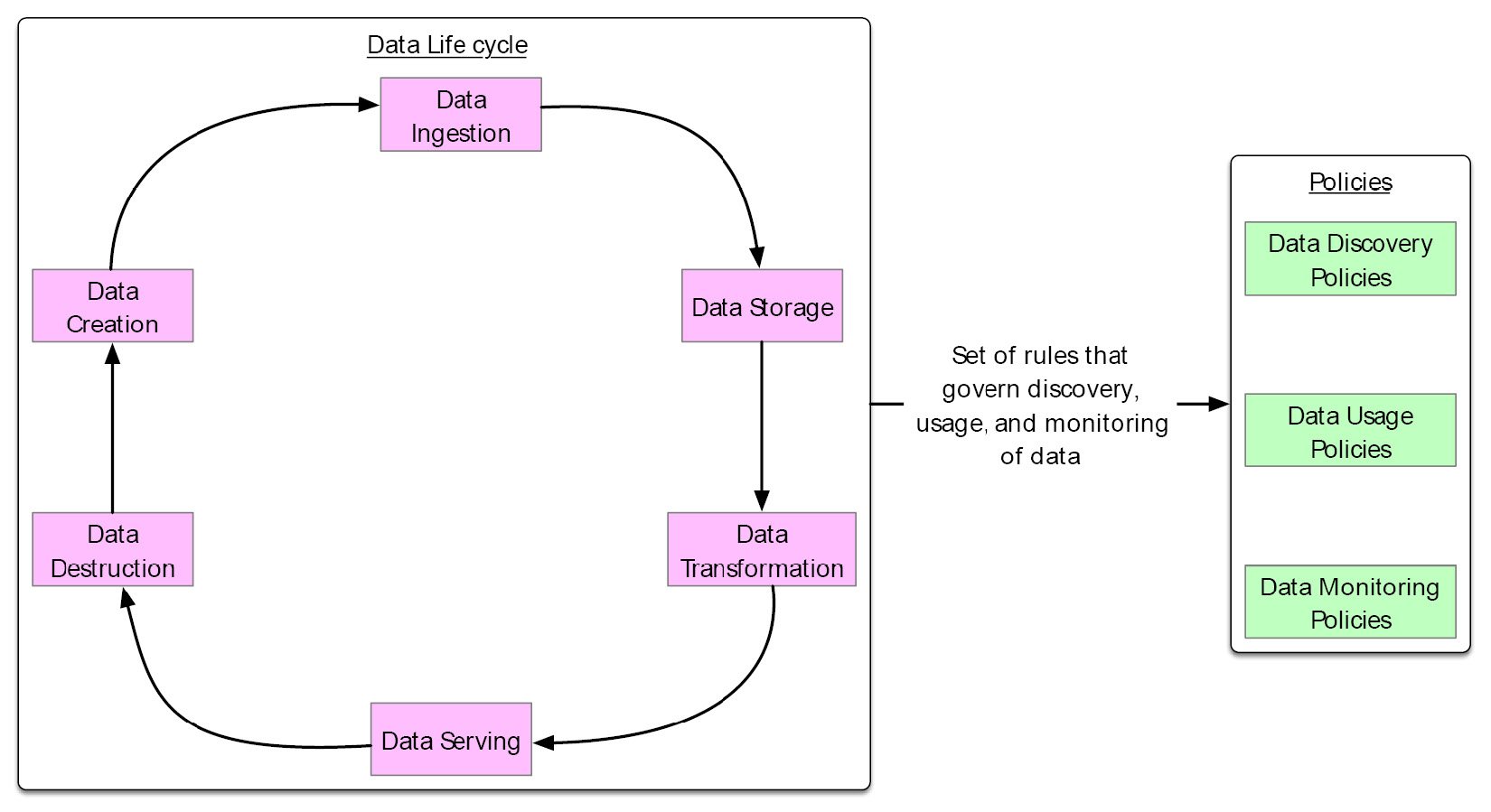
Figure 6.3 – Stages of the data life cycle and implementation of policies
The three categories of policies applied across the data life cycle are as follows:
- Data Discovery Policies: The data discovery policies are a set of rules that cater to the process of data discovery, profiling, and cataloging. These policies may vary based on the organization. These policies dictate how the data in the Data Lakehouse is cataloged and discovered.
- Data Usage Policies: The data usage policies are a set of rules that cater to data usage in the Data Lakehouse. It spans across the entire life cycle of the data and clarifies three key aspects:
- First, who can see the data?
- Second, how is the data transformed during its entire life cycle?
- Third, how is the data supposed to be used?
- Data Monitoring Policies: The data monitoring policies are rules that cater to the monitoring and auditing of data. These policies create a view of the data usage activities, data quality, and how data is maintained and retained. This set of rules also outlines how any policy violation is detected, documented, and resolved.
Now, let's discuss the third pillar of data governance, that is, technology.
Technology
The third pillar of data governance is technology. Technology is an integral part of any data governance framework. Technology implies the product or service that is used for performing the aspects of data governance. The three components of data governance come to fruition by appropriate use of technologies. A plethora of technologies can be used to implement data governance. However, the technology choice should enable the following at the minimum:
- Enables implementation of policy workflow: As discussed in the previous sections, data governance is policy-driven. Therefore, these policies need to be implemented using a technology that allows the creation of policies and provides a workflow for proper policy management.
- Enables implementation of data cataloging: The technology used should perform data cataloging of multiple data assets across the organization's data ecosystem. It should also be able to facilitate the easy discovery of the data through intuitive search. The data cataloging tool should also be able to classify the data and provide insights on data usage.
- Enables implementation of data quality: The technology used should be able to check the data quality aspects of the data. In addition, it should be able to configure data quality rules and ensure that you can create a data quality map across multiple data quality dimensions.
Let's now move on to the three components of the data governance layer.
The three components of the data governance layer
Recall that in Chapter 2, Data Lakehouse Architecture Overview, we briefly discussed the three components of the data governance layer. The following figure provides a recap of the three components of data governance:
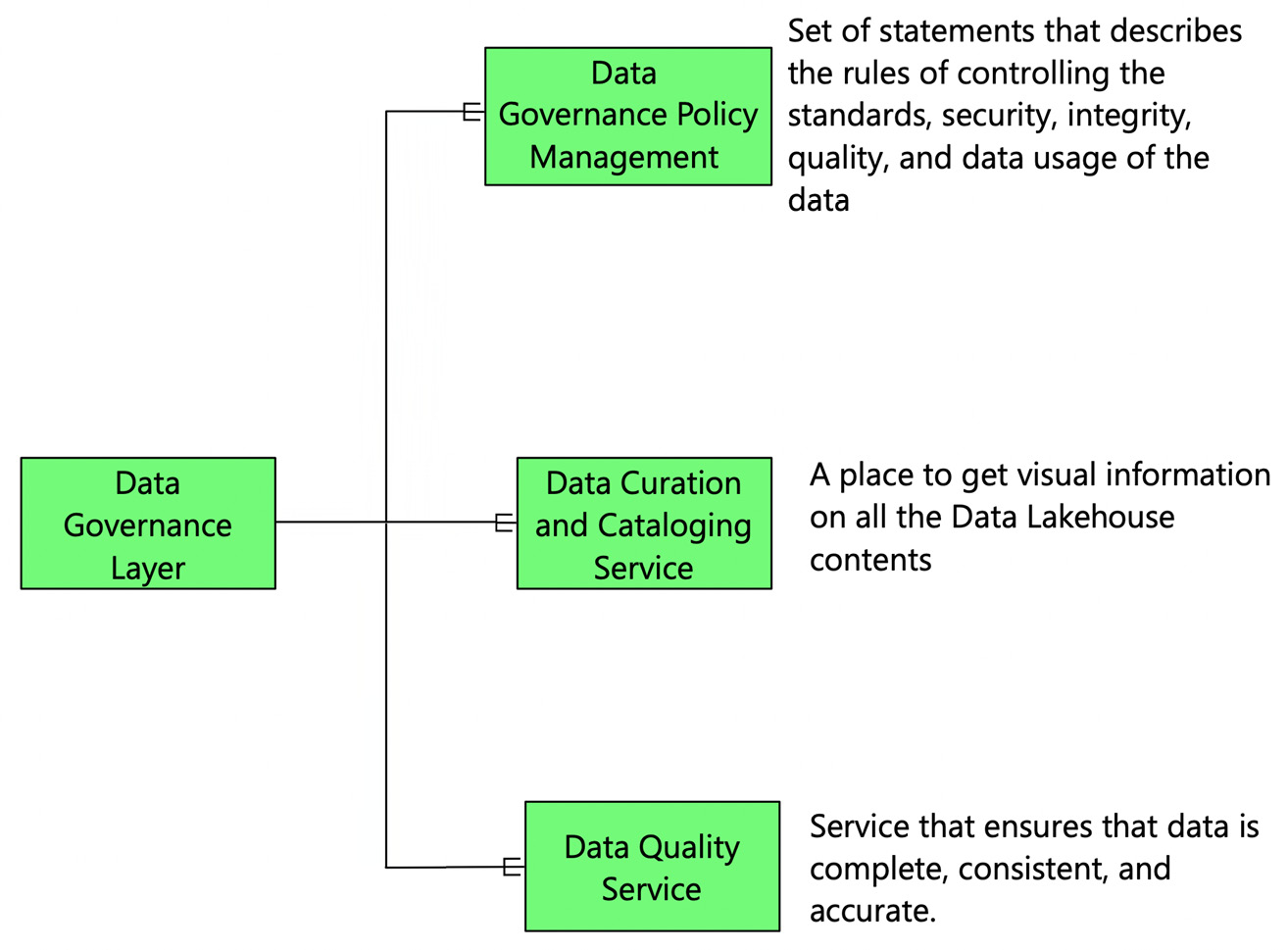
Figure 6.4 – The three components of the data governance layer
The three components of data governance are as follows:
- Data Governance Policy Management: The first component is not a technology component; it is a set of data policies and standards. The data policy is a set of statements describing the rules of controlling the standards, security, integrity, quality, and data usage in the Data Lakehouse.
- Data Curation and Cataloging Service: Data cataloging is the process of organizing an inventory of data so that it can be easily identified. This service ensures that all the source data, the data in the data lake, the data in the data warehouse, the data processing pipelines, and the outputs extracted from the Data Lakehouse are appropriately cataloged. Think of data cataloging services as the Facebook of data – a place to get visual information on all the Data Lakehouse's contents, including information about the relationships between the data and the lineage of transformations that the data has gone through. This service also provides insights about the metadata in the form of dashboards or reports.
- Data Quality Service: Any data stored or ingested in the Data Lakehouse must have a data quality score that determines the reliability and usability of the data. There are many parameters on which the quality of data is determined. A few of these parameters include the completeness of data, the consistency of data, and the accuracy of the data. The data quality service ensures that data is complete, consistent, and accurate.
Now that we have clarified the 3-3-3 framework for data governance, let's deep-dive into how you can use this framework to implement holistic data governance for the Data Lakehouse.
Implementing data governance policy management
The implementation of data governance policy management goes through two stages, which are as follows:
- The first stage is to define what the data policy is and the components of data policies.
- The last stage is to answer how the data policies are implemented.
Let's explore each of these stages in detail:
Defining data governance policy
A data governance policy is a documented set of guidelines that ensures that an organization's data and information assets are managed consistently and used correctly. The data components of a data governance policy include the following:
- Charter: A data governance charter is a statement of intent for the organization to follow as it designs and implements its data governance program. This charter defines the over-management of data availability, usability, integrity, and security. It establishes the parameters around data, so there is consistency in how it is published and how consumers use it.
- Tenets: Tenets are a set of architectural principles focused on ingestion, storage, processing, serving, and securing the data. The tenets may differ based on the organization's maturity and its vision. A few examples of tenets are as follows:
- Have purpose-driven storage layers – a data lake to store all raw and interim data and serve data stores.
- There will be decoupling between the storage of data and the compute required to process the data.
- Use a Platform as a Service (PaaS) offering to leverage demand scalability, built-in High Availability (HA), and minimal maintenance.
- Architect in a modular manner. While architecting, focus on the functionality rather than on the technology.
- All data and its transformation lineage needs to be captured in the Data Lakehouse.
Let's now discuss how organizations can realize data governance policies.
Realizing data governance policy
This stage covers the process of implementing and monitoring the data governance policies that are defined. The data governance policies are not cast in stone. It is a continuous cycle, and they need to be tweaked as the organization evolves and new information comes to light. The following figure depicts the continuous process of realizing the data governance policy:
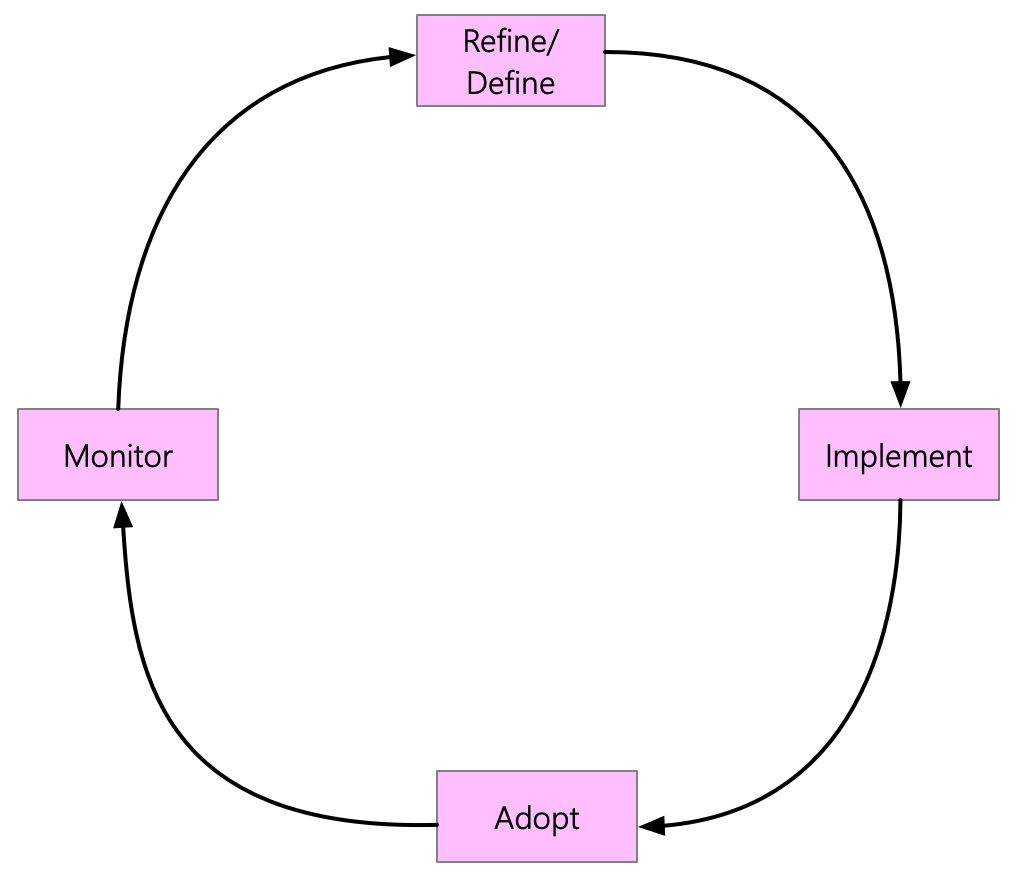
Figure 6.5 – A cycle to realize data governance
Let's zoom into each of the stages of the cycle.
- Refine/Define: In the refine/define stage for realizing the data governance policy, the goal is to determine the policies suited to the organization. Typically, a data governance committee has representation from all the critical stakeholders and the roles depicted in the preceding section will be part of the committee. They will define the policies and refine them as they go through different stages of the life cycle.
- Implement: In the implementation stage for realizing the data governance policy, a project or program is initiated to roll out the data governance policy across different functions of the organizations. The program team members, delivery methodology, and program milestones are crafted in this stage. Technical tools that you will employ to realize these policies are also identified.
- Adopt: Adoption of the data governance process is essential. Without the right adoption, the prudent realization of data governance policy is not possible. Furthermore, once the program has been rolled out, the various stakeholders who need to be aware of the usage process should be trained and enabled. Finally, focusing on adoption ensures that the organization is aware of the benefits of data governance and how it helps drive towards a more data-driven organization.
- Monitor: The last stage of the cycle is to monitor the adoption of data governance policy. This stage aims to identify which policies are effective and which ones are ineffective. The ineffective policies need to be revisited and refined to be more helpful.
Now that we have explored how to implement the data governance policy component, let's implement the data catalog component.
Implementing the data catalog
As described in Chapter 2, The Data Lakehouse Architecture Overview, data cataloging and curation is the process of organizing an inventory of data so that it can be easily identified. Data cataloging ensures that all the source system data, data in the data lake, the data warehouse, the data processing pipelines, and the outputs extracted from the Data Lakehouse are appropriately cataloged.
For implementing the data catalog, we will follow a similar thought process to implementing the data governance policies:
- First, we will identify the guidelines for determining the elements to be cataloged. These elements define what needs to be cataloged.
- Next, we will focus on how to implement the data catalog.
Let's cover the elements of cataloging next.
The elements of cataloging
The elements of cataloging can be explained using a catalog map. This provides potential metadata that can be cataloged. The following diagram provides a view of the catalog map, describing the minimum elements that need to be cataloged:
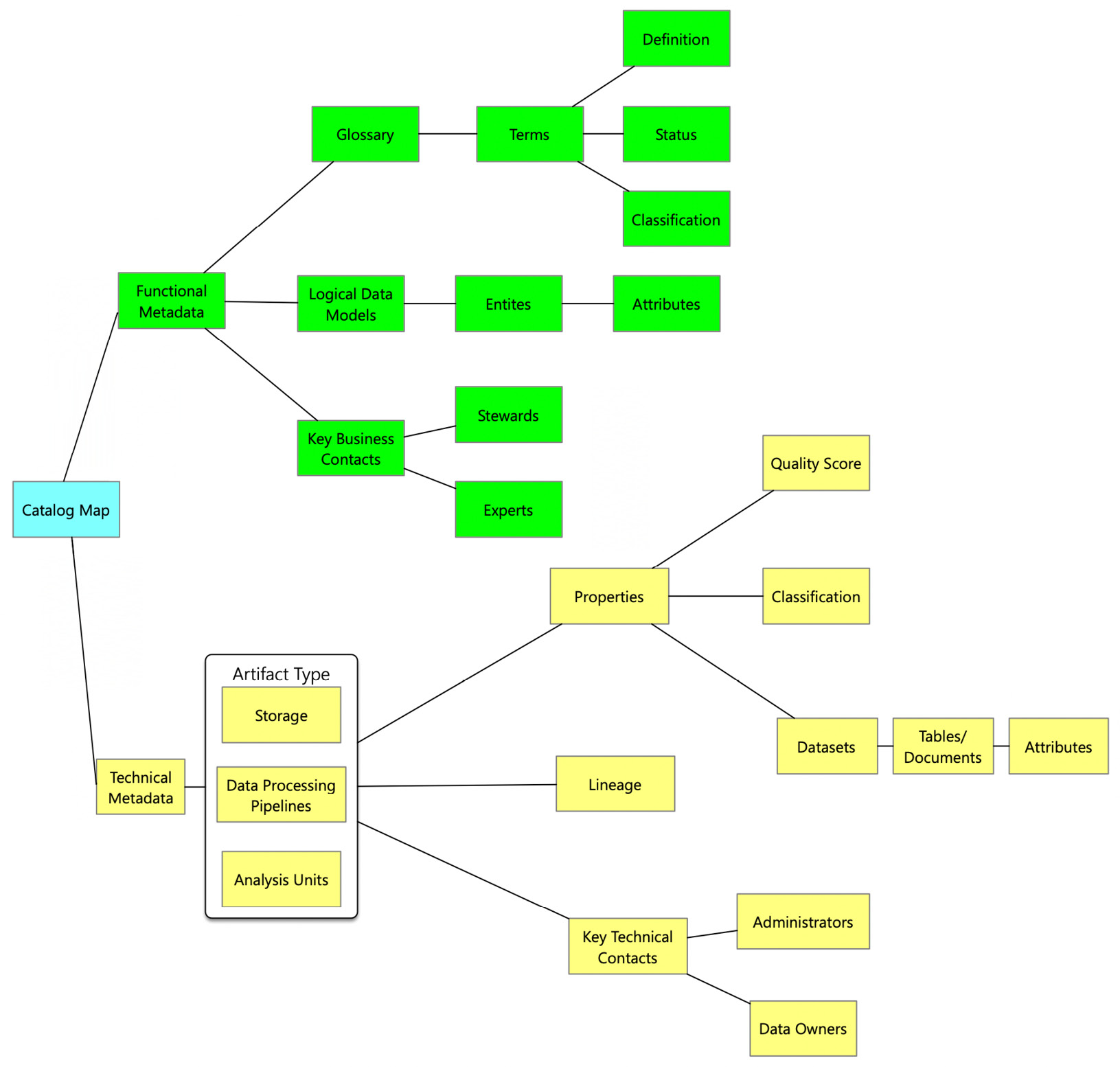
Figure 6.6 – Elements of the catalog map
The two types of metadata that need to be cataloged include Functional and Technical. Let's briefly describe each type of metadata.
- Functional Metadata: As the name suggests, functional metadata captures the metadata from a functional perspective and is technology agnostic. Functional metadata is an essential piece of cataloging as functional definitions change based on the view of an organizational unit. The key elements that need to be cataloged from a functional perspective are as follows:
- Glossary: A glossary is meant to be the de facto source of commonly used terms that stakeholders across the organization can assess. A glossary captures terms, definitions of the term under different contexts, and its status within the cataloging function, that is, whether the term is in review, approved, or a new entrant. The glossary also documents the classification of a term, such as whether the term is personal information.
- Logical Data Models: A logical data model is a blueprint that provides a functional view of the organization divided into subject areas, entities, and relationships between entities. The logical data models are helpful to get a high-level view of different entities in an organization, such as a customer in any industry. The logical data model should be cataloged. It enables the users to search for such blueprints and understand the various cogs that are elemental to the organization.
- Key Business Contacts: Each business term in the glossary needs an owner who owns the definition of the term in the organization's context. These owners are called Stewards. Typically, these owners are assigned to each functional area and the one multiple term within that functional area. In addition, the key business contacts may also include Experts who are Subject Matter Experts (SMEs) in a particular functional area.
- Technical Metadata: As the name suggests, technical metadata captures the metadata from a technical perspective. It is particular to the technical components of the Data Lakehouse, such as storage files, databases, or transformation pipelines. The key elements that need to be cataloged from a technical perspective are as follows:
- Artifact Type: The artifact type signifies the types of technical artifacts that need to be cataloged. It can be a database, different types of data processing pipelines, or a unit of analysis, such as a report or a machine learning model. The source can be a structured or unstructured data source that can reside outside or within the purview of the Data Lakehouse. Within the ambit of the Data Lakehouse, the components in the data lake layer, the data-serving layer, the processing layer, and the analytics layer need to be cataloged.
- Properties: Each cataloged source has a set of properties that vary depending on the source type. For example, suppose it is a database. In that case, you can catalog information about the database type, the physical tables within it, and the columns for each table. Another example could be a data pipeline. Properties of the data pipelines include the source information, the data transformation information, and the target of the data pipeline. Properties can also have the Quality Score of a specific table or column. For example, if the data is in the raw data store of the data lake, it may be cleaned or filtered. As a result, such datasets will have a low quality score. On the other hand, if the data is in the serving layer, it will have been cleansed, filtered, and made ready for consumption. Hence its relative quality score will be higher.
- Lineage: The data cataloging should be able to support data lineage. Data lineage provides a view of how data has been transformed from the source to the analysis unit, such as a report. It gives an idea of the data journey.
- Key Technical Contacts: Like the key business contacts, each piece of technical metadata also has an owner. This owner can be the source system owner or a database administrator. The key contacts also include Experts who can provide insights into how data units are used and transformed.
Let's now discuss the process of implementing the data catalog.
The process of implementing the data catalog
The following figure illustrates the process of implementing the data catalog. It depicts the subcomponents of a data catalog service and its interaction with other components of the Data Lakehouse. Let's look into them in detail:
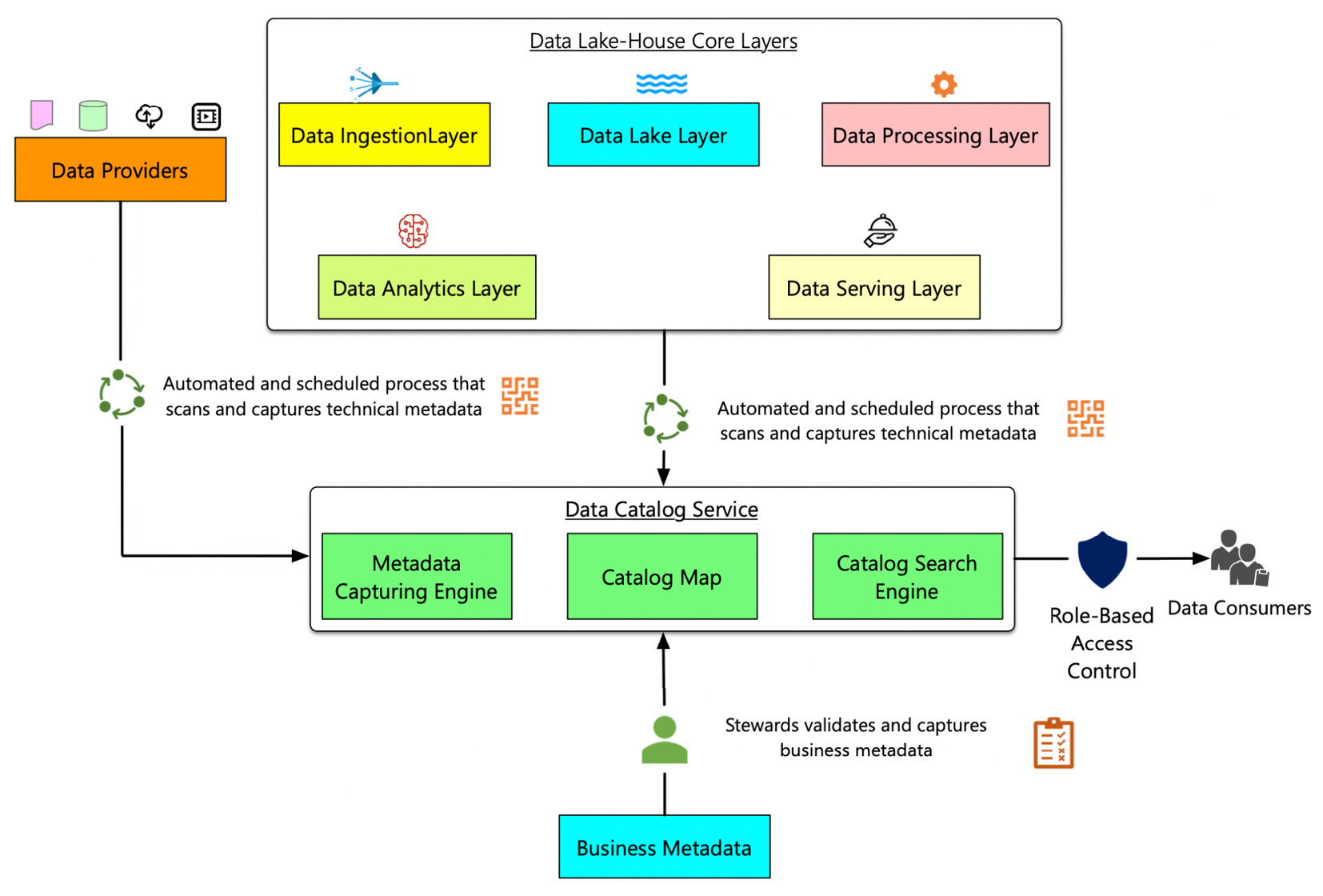
Figure 6.7 – The process of implementing the data catalog
The data cataloging process performs three steps to enable the catalog to be used for discovery. The steps are as follows:
- Metadata Capturing Engine: The metadata capturing engine is the first component. It captures metadata through either data scanning or a manual process. Typically, a data scan process scans technical metadata from both the data providers, that is, data sources of the Data Lakehouse and the layers of the Data Lakehouse, that is, the data lake layer, the data serving layer, and so on. Data scanning is an automated process that taps into components such as databases and data pipelines to capture the metadata they provide. The method of scanning can be periodically scheduled so that any metadata changes can be automatically cataloged. The metadata information is captured, processed, and converted into a Catalog Map. Along with this technical metadata, the data steward also catalogs business metadata.
- Catalog Map: The data scan results in a Catalog Map. The catalog map provides a map of metadata that the data consumers can browse to discover data elements that may be of interest to them. The catalog map enables the data consumers to explore the properties of data, such as its definition, lineage, and quality score. The catalog map can also have other features, such as providing insights about the data that is cataloged. For example, the catalog map may provide a report showing how many cataloged attributes have sensitive information. Once the catalog map is created, it is then exposed to the data consumers through the component of the Catalog Search Engine.
- Catalog Search Engine: The Catalog Search Engine is the window to the catalog. It is the component through which the data consumers interact with the catalog. It provides the ability to search artifacts that are cataloged using keywords, concepts, and artifact types, and so on. Proper Role-Based Access Control (RBAC) is employed to ensure that access to the data catalog is restricted and allowed to only the data consumer who needs it.
Now that we have covered how to elaborate on the data catalog component, let's implement the data quality component.
Implementing data quality
As in any other analytics platform, data quality plays an important role even in the Data Lakehouse. The garbage in, garbage out philosophy is applicable. For a practical implementation of data quality in the Data Lakehouse, the first step is to create a data quality framework. The next step entails implementing the framework that you can apply to data in the Data Lakehouse. This framework then needs to be adopted and monitored continuously. Let's look into these steps in detail.
The data quality framework
Before creating the data quality framework, it is essential to define data quality. The data quality rules are applicable for any data stored in the Data Lakehouse, that is, in the data lake and serving layers.
Quality of data is defined as the ability of the data to be fit for practical usage.
The data in the Data Lakehouse will have many levels of quality. However, it is impractical to always have data of the utmost quality. As more and more processing and rules are applied to improve data quality, the cost of achieving that quality goes up. There is an inflection point somewhere, and the cost of achieving quality no longer justifies the value it brings in. Hence, there needs to be a balance in achieving data quality. The following figure shows the cyclical stages of a data quality framework. Let's explore each of these stages in detail:
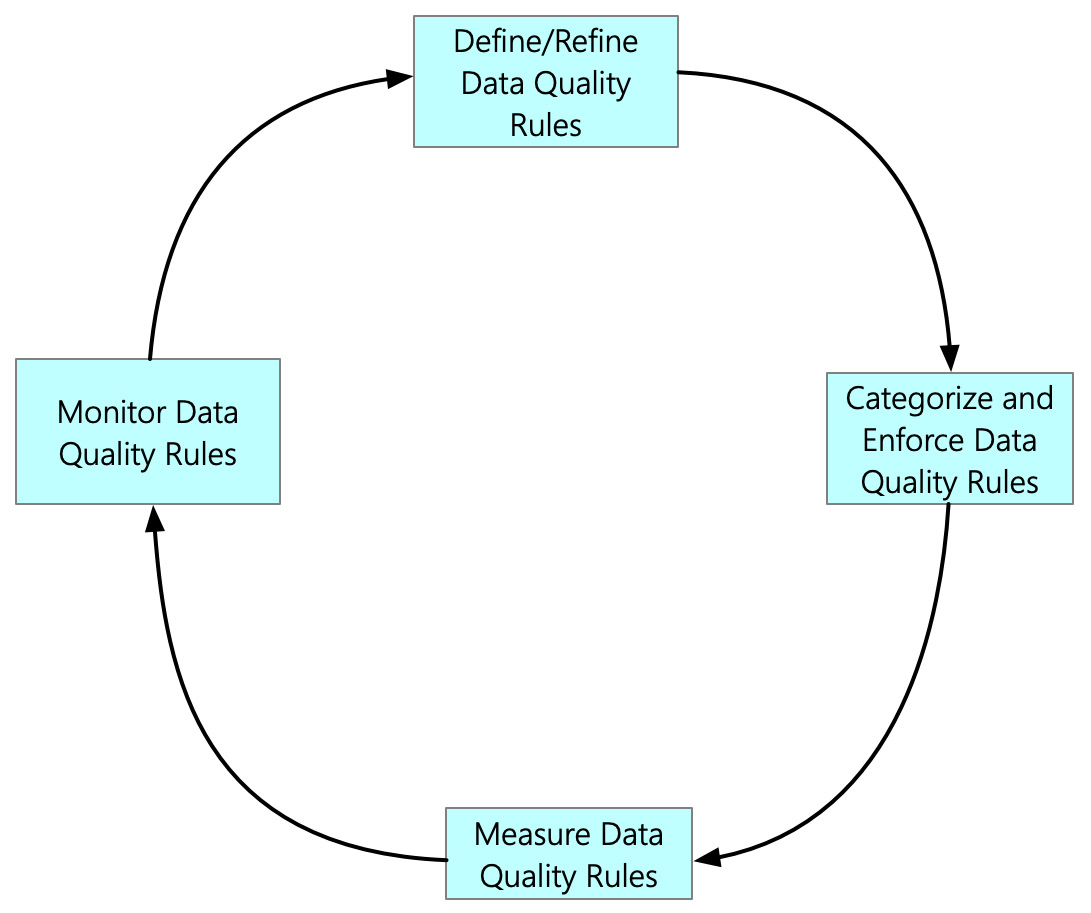
Figure 6.8 – The process of implementing the data catalog
Let's discuss how the data quality rules are defined and refined.
Defining/refining data quality rules
The first stage is to define the data quality rules and provide guidance on the potential methods of tackling aberrations of these rules. As shown in the following figure, you can define data quality rules at three levels:
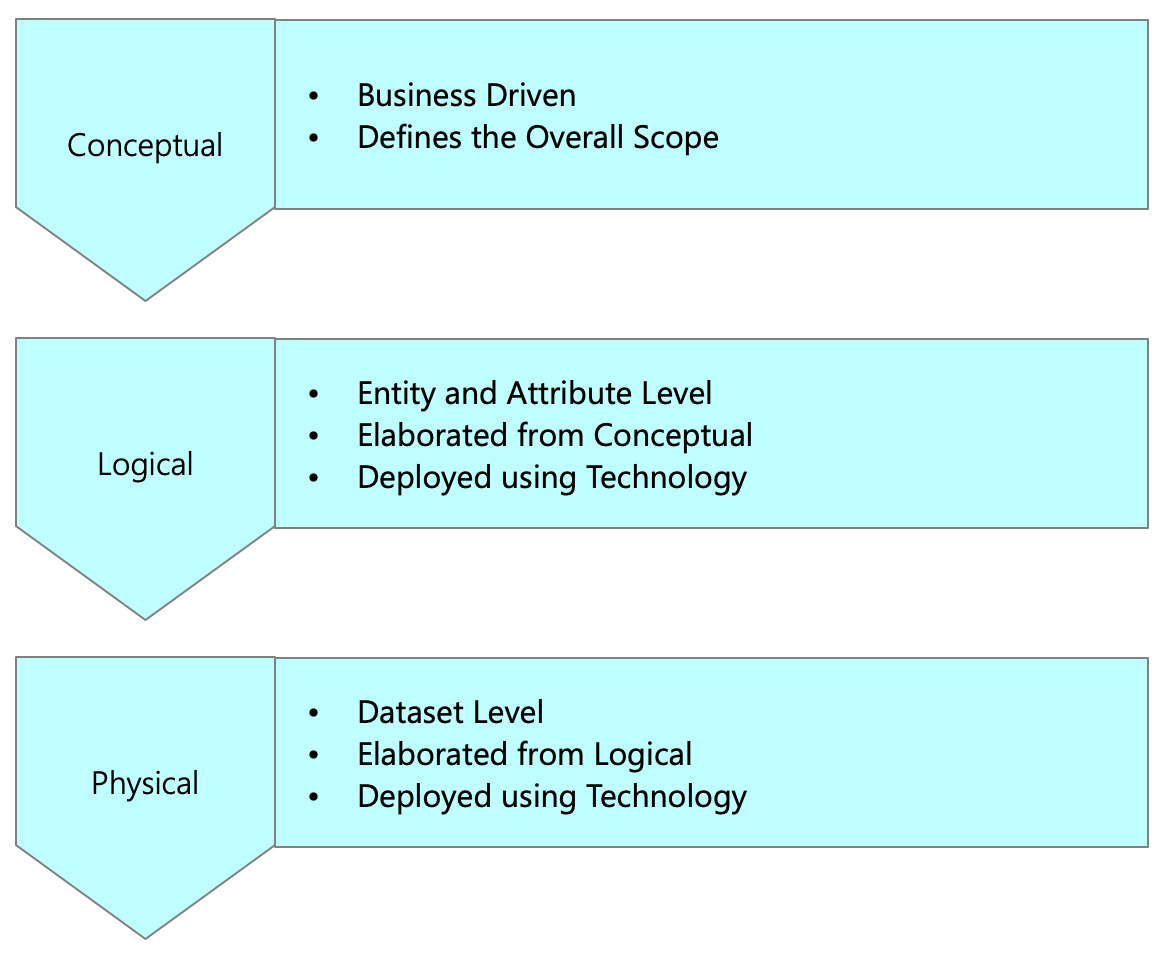
Figure 6.9 – The levels of data quality rules
Let's discuss each of these levels in detail.
- Conceptual: Defining data quality rules at a conceptual level involves providing a high-level data quality requirement. As a general guideline, data quality rules should be developed for the data elements showing the following characteristics:
- A data element is visual to the functional unit.
- A data element forms part of a functional key performance indicator.
- A data element is part of a functional rule.
- A data element is a user input in the application.
- Logical: Defining data quality rules at a logical level involves decomposing the conceptual-level data quality requirements into rules defined at a logical level. Each conceptual-data quality rule requirement can be split into one logical validation that you would eventually apply in a physical data object.
- Physical: Defining data quality rules at a physical level involves decomposing the data quality requirements defined at the logical level into data quality rules defined in a data quality tool.
For a better understanding of this concept, let's take an example of defining the data quality rule for a manufacturing plant:
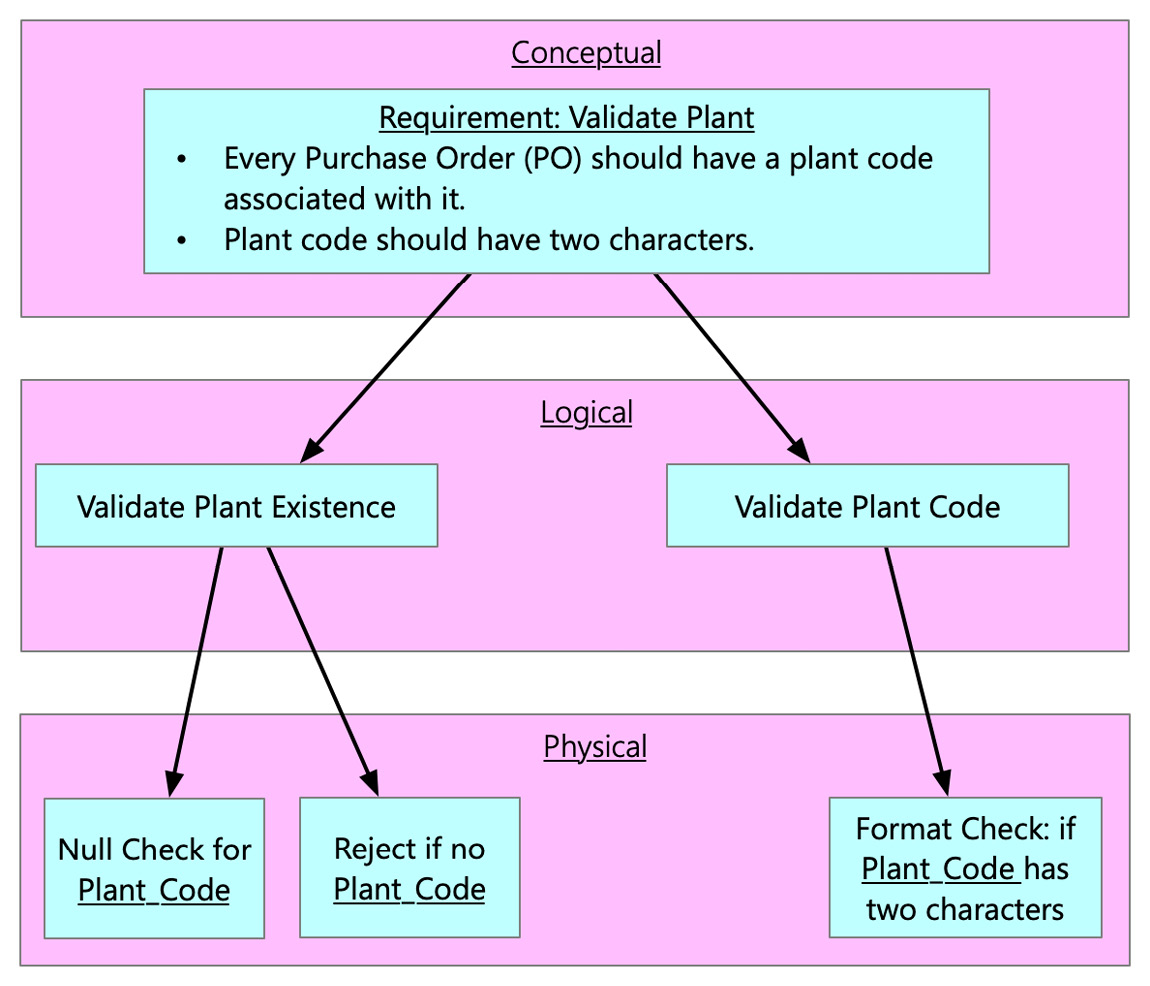
Figure 6.10 – An example of implementing data quality rules
Let's now discuss how to enforce the data quality rules.
Enforcing data quality rules
The second stage is to enforce the data quality rules as defined in step 1. Again, there are different dimensions through which you can enforce the data quality rules. The six dimensions are as follows:
- Completeness: Completeness of data implies the extent to which the required data has been recorded. A prudent data quality rule checks the completeness of data.
- Timeliness: Timeliness measures how frequently the recorded value is updated and verified to reflect the current value. Timeliness enforces keeping data current. Timeliness also includes accessibility, being able to gain access to the correct data when needed. The data quality rule should check the timeliness of data.
- Uniqueness: Uniqueness implies the presence of duplicate values of data emanating from multiple sources. The data quality rule should check the uniqueness of data.
- Consistency: Consistency implies the degree to which a data element contains the same types of information from record to record, based on its definition. The data quality rule should check for data consistency.
- Validity: The validity implies the degree to which the description of the data element and its business rules are appropriate and of high quality. The data quality rule should check for data validity.
- Accuracy: The accuracy of a data element implies the degree to which the data value reflects reality in conforming to the standard definition and business rules related to the creation, maintenance, and use of the data.
Measuring data quality rules
The third stage measures how the data is performing against the laid-out dimensions of data quality rules. Some frequently used metrics for measuring the quality score include the following:
- Completeness score: This is a measurement of how complete the data element is. An example of measuring the completeness score for a table can be the following: count of relevant records / count of relevant records + count of missing records.
- Accuracy score: The accuracy score is a measurement of how accurate the data element is. An example of measuring the accuracy score for a table can be the following: count of relevant records – count of erroneous records / count of relevant records.
- Timeliness score: A measurement of how timely or stale the data is. This measurement depends on the non-functional requirements and how much staleness is acceptable in a specific dataset.
- Overall quality score: The overall quality score is a weighted average of completeness, accuracy, and timeliness.
Monitoring data quality rules
The last stage of the cycle is to monitor the outcome of the data quality rules and their impact on the organization's data element. In practice, achieving a perfect overall quality score is extremely difficult. However, an organization should strive to estimate the overall quality score for each data element and continuously improve it to reach the goal. The data quality rules need to be constantly redefined to better the overall quality score.
Summary
We have covered a lot of ground in this chapter. The data governance layer, one of the vital layers in the Data Lakehouse, was covered in depth. We started by emphasizing the importance of data governance. The 3-3-3 framework for data governance provides a holistic framework for looking into data governance in a structured manner. As part of the 3-3-3 framework, must-have objectives for data governance were covered. The section also covered the key roles that enable data governance and the critical aspects of data governance policies, and the characteristics of technologies that allow it.
The next section of the chapter focused on the three components of the data governance layer, that is, data governance policy management, the data cataloging service, and the data quality service. The section then drilled down into what each component means and how the parts come to fruition in the Data Lakehouse architecture.
The next chapter will focus on the final layer of the Data Lakehouse, that is, the Data Security Layer.
Further reading
- Data governance: The best practices framework for managing data assets (cio.com): https://www.cio.com/article/202183/what-is-data-governance-a-best-practices-framework-for-managing-data-assets.html
- Designing data governance that delivers value | McKinsey: https://www.mckinsey.com/business-functions/mckinsey-digital/our-insights/designing-data-governance-that-delivers-value
- The TOGAF Standard, Version 9.2 - Architecture Governance (opengroup.org): https://pubs.opengroup.org/architecture/togaf9-doc/arch/chap44.html
- Data Quality Dimensions: https://www.precisely.com/blog/data-quality/data-quality-dimensions-measure
- Data Quality Dimensions: https://www.collibra.com/blog/the-6-dimensions-of-data-quality