
Chapter 7: Applying Data Security in a Data Lakehouse
Six layers of the data lakehouse have been covered so far. This chapter will cover the last layer of Data Security. It is the most crucial layer that ensures that data is secured in all the layers of a data lakehouse; this chapter will cover the ways to secure the data lakehouse. We will start by formulating a framework for data security, which will elucidate the key dimensions you need to consider for data security. The next section of the chapter will focus on three components of the data security layer that help secure the lake and provide the right access.
In summary, this chapter will cover the following:
- Realizing the data security components in a data lakehouse
- Using an identity and access management service in a data lakehouse
- Methods of data encryption in a data lakehouse
- Methods of data masking in a data lakehouse
- Methods of implementing network security in a data lakehouse
Let's begin by discussing the methods for realizing the data security components in a data lakehouse.
Realizing the data security components in a data lakehouse
We covered the elements of data security briefly in Chapter 2, The Data Lakehouse Architecture Overview. Recall that, in that chapter, we discussed the four key components of the data security layer. The following figure summarizes the four components of the data security layer:
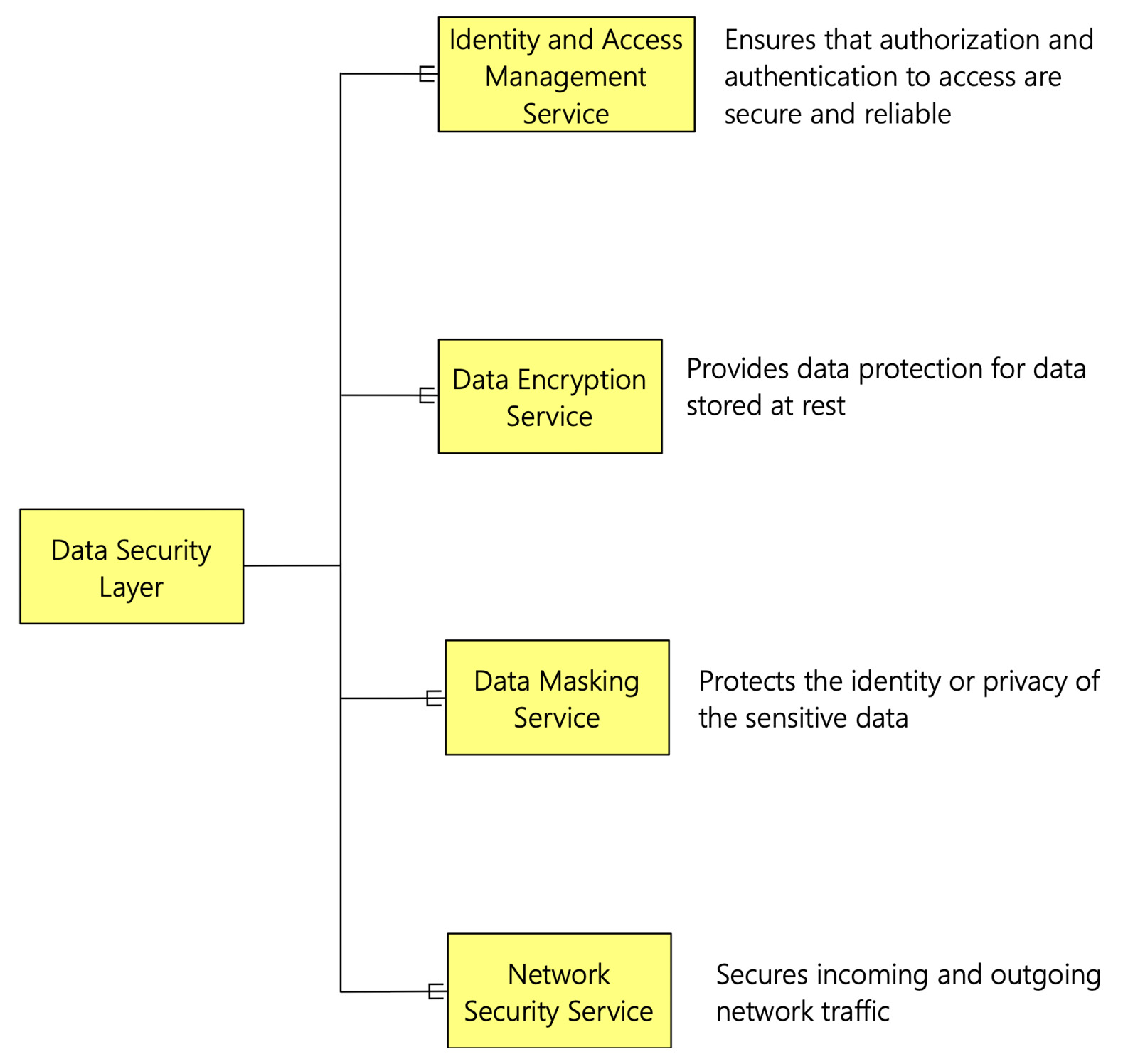
Figure 7.1 – Data security components
These four components ensure that data is well secured and that access to data is controlled. They work together in securing the data lakehouse. The following figure depicts how these four components orchestrate protected data:
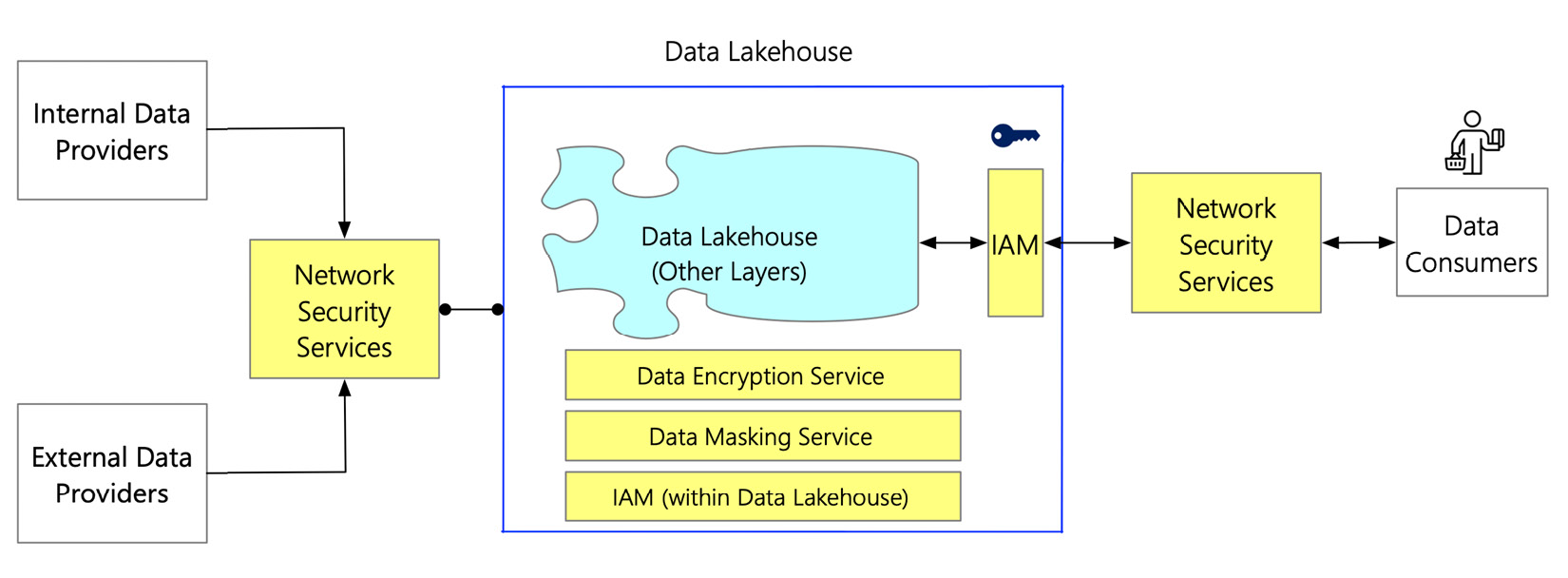
Figure 7.2 – Orchestration of various data security components in the data lakehouse
Whenever any interaction needs to be done with the data lakehouse layers, it must go through the network security service. The network security service filters the traffic to the data lakehouse layer. The network traffic to and from the data lakehouse layer is encrypted within the data lakehouse, using the data encryption service; specific sensitive data is masked using the data masking service. The Identity and Access Management (IAM) service ensures that Role-Based Access Control (RBAC) is applied. With RBAC, access to the data lakehouse components is provided with the right level of authentication and authorization.
Now that we have covered the overall flow, let's discuss each of these components in detail.
Using IAM in a data lakehouse
The first component for the data security layer is IAM, which ensures that the right principal gets access to the right component with the correct authorization level. For example, the principal could be a range of identities, including a person, a device, or an application, that can request an action or operation on a data lakehouse component. The IAM component determines who gets access to what and how.
IAM employs a Zero-Trust architecture. Zero trust means that any organization should have no trust in anything or anyone when accessing resources. With zero trust, a breach is assumed. Every user and device is treated as a threat. Therefore, its access level needs to be verified before being granted. The principles of least-privilege access and identity-based security policies are the cornerstone of a zero-trust architecture.
The following figure shows that an organization should have a holistic IAM implementation strategy with at least five elements:
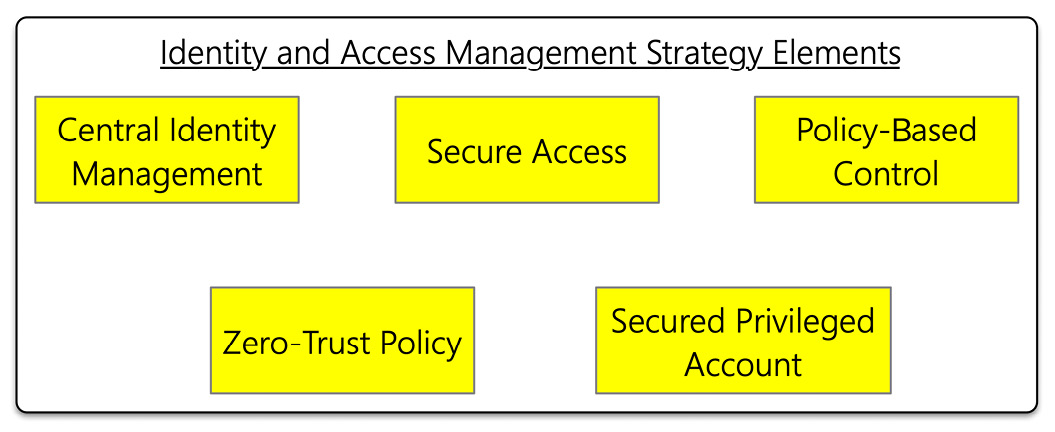
Figure 7.3 – Elements of a holistic IAM strategy
Let's briefly discuss these six elements.
- Central Identity Management: One of the critical principles of a zero-trust architecture is managing access to resources at the identity level. Having a central place to manage identities makes IAM implementation straightforward.
- Secure Access: In a zero-trust architecture, securing at the identity level is critical. An IAM should make sure that it confirms those who are logging in. Secure access should also consider the context of the login attempt, that is, parameters such as location, time, and devices.
- Policy-Based Control: A zero-trust architecture follows the Principle of Least Privilege (POLP). POLP signifies that the users should only be given enough authorization to perform their required tasks – no more or no less. These policies should also be managed centrally. Managing the policies centrally will ensure that the resources are secure no matter where they are accessed.
- Zero-Trust Policy: A zero-trust policy sees an organization with an IAM solution constantly monitor and secure its users' identities and access points. The zero-trust policies ensure that each identity is continuously identified and has its access managed.
- Secured Privileged Account: Secured privileged accounts imply that not all identities are created equal. The policy should provide the identities with special tools or access to sensitive information in the appropriate tier of security and support.
Now that we have covered the elements of the IAM implementation strategy, let's discuss how IAM works. The following diagram depicts the working and tasks of IAM:
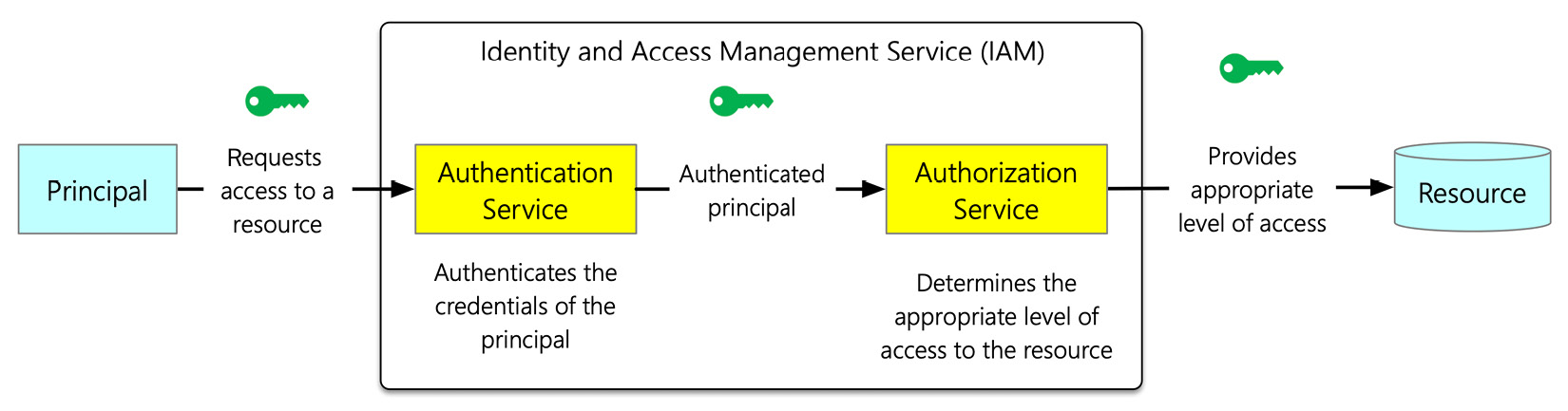
Figure 7.4 – The working of the IAM component
IAM performs a two-step process, authentication and authorization, which is as follows:
- In the first step, the principal who needs access to a resource sends a request to the authentication service of the IAM. Next, the authentication service checks the principal's credentials and recognizes the principal's identity by comparing the credentials with its database. If the credentials are valid, then the principal is authenticated.
- Once the principal is authenticated, the request goes to the authorization service. The authorization service checks the policies of permissions associated with the principal. It determines what level of access needs to be provided to the principal for the resource.
Tools such as password-management tools, provisioning software, security-policy enforcement applications, reporting and monitoring apps, and identity repositories are required to implement a holistic IAM policy. Typical capabilities of an IAM component include the following:
- Single Sign-On (SSO): SSO means accessing all the applications and resources with one sign-in.
- Multi-Factor Authentication (MFA): MFA authenticates using more than one verification method. It adds a second layer of security to user sign-ins.
- Role-Based Access Control (RBAC): RBAC provides fine-grained access management of resources based on specific roles. RBAC assigns roles such as owner, contributor, reader, administrator, and so on, and allows you to granularly control users' level of access.
- Monitoring and alerts: This IAM functionality enables security monitoring alerts, and machine learning-based reports identifying inconsistent access patterns.
- Device registration: Device registration provides conditional access to devices. When a device is registered, IAM offers the device an identity to authenticate the device.
- Identity protection: Identity protection facilitates monitoring potential risks and vulnerabilities that affect the organization's identities.
- Privileged identity management: IAM should perform privileged identity management that enables the management, control, and monitoring of privileged identities and access to resources.
Now that we have covered the first component of the data security layer, let's discuss the second component, the data encryption service.
Methods of data encryption in a data lakehouse
The second data security component is the data encryption service. Encryption is the most common form of protecting data. When data is encrypted, it cannot be deciphered even if someone gains unauthorized access to it. It becomes the second line of defense. However, hackers have their methods as well. They are getting more and more sophisticated in breaching data. The standard method of attacking encryption is through brute force. Brute force tries multiple keys to gain access to data until the right one is found. The encryption algorithms that encrypt the data prevent this by employing sophisticated algorithms and smartly managing its keys.
The following figure depicts the data encryption process:
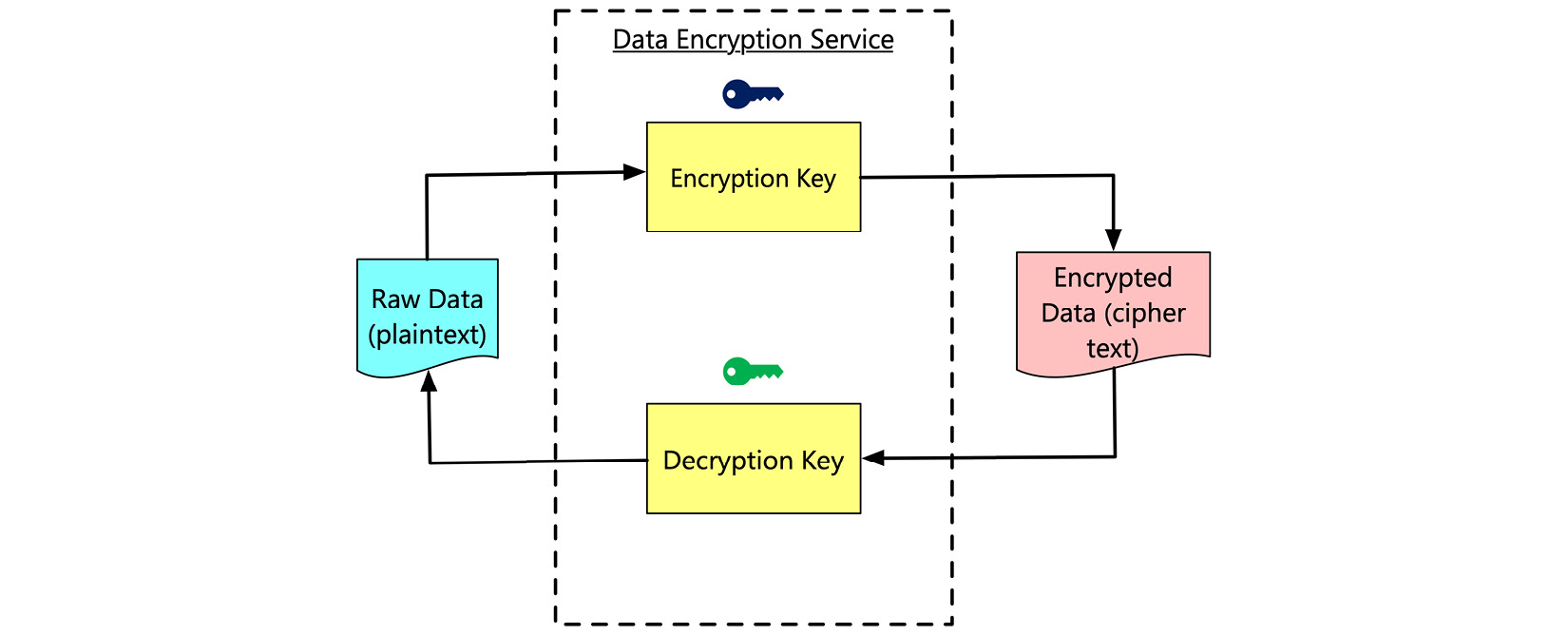
Figure 7.5 – The high-level process of data encryption
Data encryption is the process of translating data from typical data in human-readable format (plaintext) into a format that is unreadable by humans (ciphertext). An encryption algorithm performs this translation. Once the data is encrypted, it needs to be decrypted to be human-readable again. A decryption key decodes the ciphertext back into plaintext.
There are two types of encryption algorithms – symmetric and asymmetric:
- Symmetric encryption: In symmetric encryption, both the encryption and decryption keys are the same. Therefore, you must use the same key to enable secure communication. Symmetric algorithms are fast and can be easily implemented, and hence they are used for bulk data encryption. However, since both the encryption and decryption keys are the same, they can be read by anyone who has the key. The key will also need to be shared for it to be used to decrypt data.
- Asymmetric encryption: Asymmetric algorithms have a more complex implementation. The working of an asymmetric algorithm differs from that of a symmetric algorithm. In asymmetric algorithm encryption, two separate keys that are mathematically linked are used. One key, a public key, is used to encrypt the data and can be distributed. The other key is a private key used to decrypt the data. Using a private key means the need to exchange secret keys is eliminated, making it more secure. However, it is slower than the symmetric algorithm and requires greater computational power.
You can use many sophisticated algorithms to encrypt data. A few algorithms that are commonly used are as follows:
- The Advanced Encryption Standard (AES): AES is the trusted standard algorithm used by the United States government and other organizations. AES can use different bits of keys for encryption. A 128-bit key is considered very sophisticated, and 256-bit keys are used for a demanding encryption process. Therefore, many cloud computing vendors use AES 256-bit encryption to encrypt data. In addition, AES is broadly considered immune to all attacks except for brute force.
- Rivest-Shamir-Adleman (RSA): RSA is another asymmetric encryption algorithm. It uses a factorization method that uses factors of the product of two large prime numbers. This technique means hackers find decoding the data more challenging. To decrypt the message, the hacker or the user needs to be aware of these prime numbers. However, the challenge with RSA is the speed of encryption. It slows down as the volume of data grows.
- Blowfish: The Data Encryption Standard (DES) algorithm was a symmetric-key block cipher created in the early 1970s. The working of the algorithm includes taking plaintext in 64-bit blocks and converting it into ciphertext using 48-bit keys. However, since it's a symmetric-key algorithm, it employs the same key in encrypting and decrypting the data. Over time, DES's popularity declined as it was found that hackers could repeatedly breach it. As a result, many new sophisticated algorithms were designed to replace DES, and Blowfish is one of them. Blowfish is a symmetric algorithm as well. This algorithm breaks the messages into 64-bit blocks. Once broken, each block is encrypted individually. Blowfish has established a reputation for speed and flexibility and is unbreakable. It is commonly found on e-commerce platforms, for securing payments and password management tools.
- Twofish: Twofish is Blowfish's successor and is license-free, symmetric encryption. Unlike Blowfish, it deciphers 128-bit data blocks instead of 64-bit blocks. On top of that, Twofish encrypts data in 16 rounds irrespective of the critical size. As a result, Twofish is perfect for both software and hardware environments and is considered one of the fastest of its type.
In the context of the data lakehouse, these encryption algorithms are used to protect the data in the data lake layer and data serving layer, that is, data at rest. In addition, you can protect data in motion by applying Transport Layer Security (TLS). TLS provides three layers of security – encryption, data integrity, and authentication. The Hypertext Transfer Protocol Secure (HTTPS) protocol uses TLS to secure communication over various networks, including the internet.
Let's now move on to the next component used to mask data.
Methods of data masking in a data lakehouse
A data lakehouse can contain a lot of sensitive data that needs protection from unauthorized access. This could include Personally Identifiable Information (PII) such as social security numbers, email, or phone numbers, or sensitive information such as credit card or bank account numbers. Not everyone needs to access this sensitive data. A data masking service adds a layer of protection to ensure that sensitive data is only accessed by the most privileged users with the need to access it. Data masking is a way to create an artificial but practical version of data. It protects sensitive data without sacrificing the functionality that it offers. There are several reasons why data masking is vital for an organization:
- Data masking mitigates external and internal threats. For example, data exfiltration, insider threats or account compromise, and insecure interfaces with third-party systems are some threats mitigated by data masking.
- Data masking makes data useless to the attacker, as it veils its actual content without compromising the inherent functional properties.
- Data masking enables secured data sharing between the production version of data and the data required to test or develop software.
Data masking is different from encryption. Encryption is done at the data store level, whereas data masking is only applied to the specific data elements that are deemed sensitive. Let's now discuss different types of data masking:
- Static Data Masking: The first type of data masking is Static Data Masking (SDM). The following figure depicts the process of SDM:
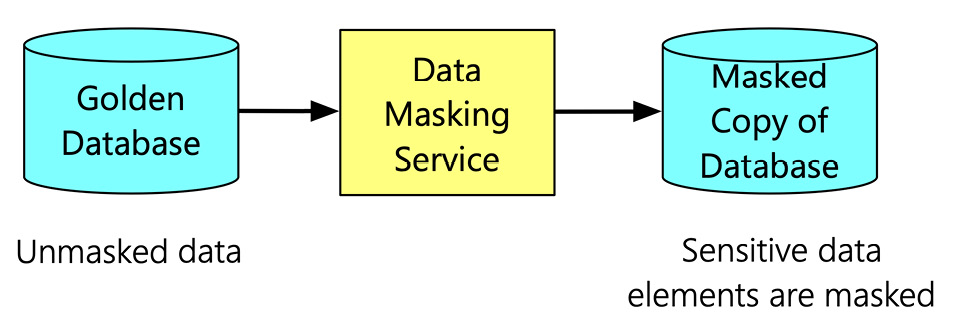
Figure 7.6 – The process of SDM
The golden database has unmasked data. The data masking service creates a copy of the database by masking the sensitive information. You can then use this masked copy of the database for other purposes. Typically, the golden database is the production copy. The masked version of the database is used for development and testing.
- Dynamic Data Masking: Another type of data masking is Dynamic Data Masking (DDM). The following figure depicts the process of DDM:
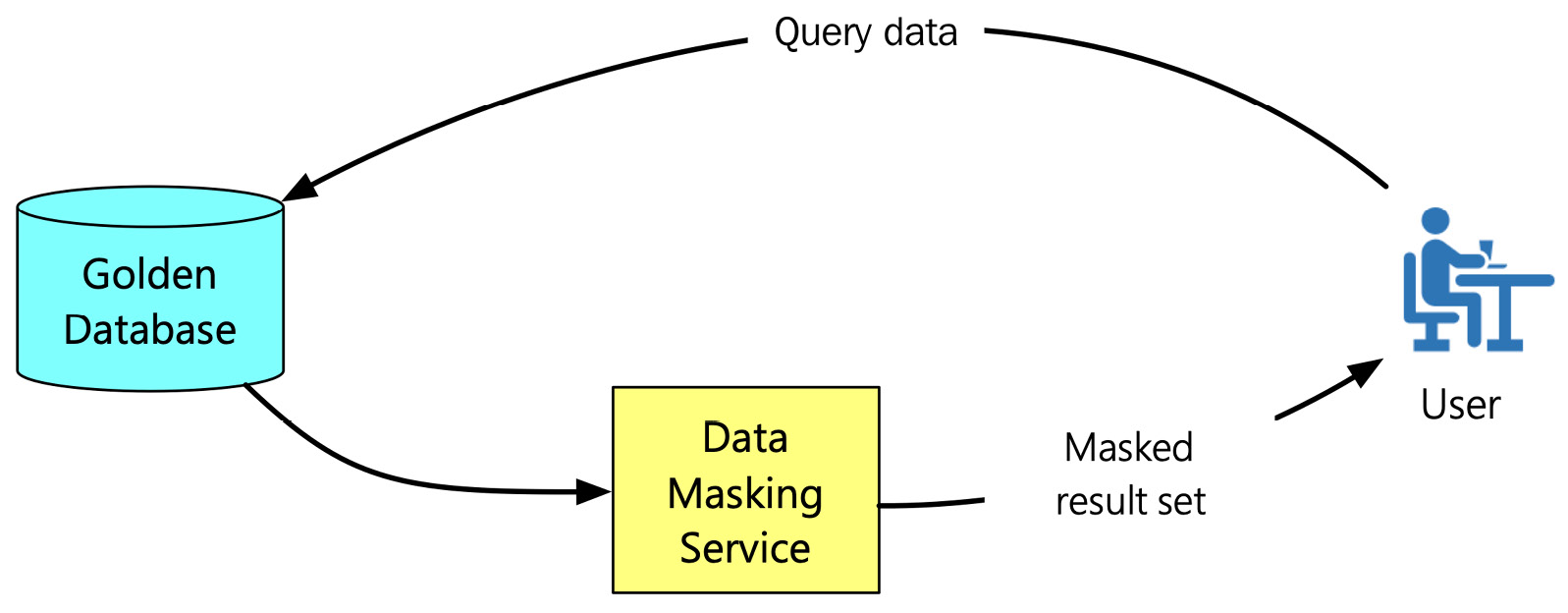
Figure 7.7 – The process of DDM
DDM happens at runtime. First, the data is streamed from the golden database. While the data is streamed, data masking services mask the sensitive data on the fly. DDM employs RBAC, which determines whether the user accessing the data has the privilege to see the sensitive data. If the user doesn't have the privilege to see the data, the data masking service masks the data before providing access to the user. DDM applies to read-only scenarios to prevent writing the masked data back to the production system.
- Deterministic data masking: Deterministic data masking maps two sets of data. Then, the original dataset is replaced by another dataset with the same data type. For example, Jack Reacher might always be replaced with Tom Cruise in all the columns of a database.
- On-the-fly data masking: As the name suggests, on-the-fly data masking masks data while it is transferred from production systems to test or development systems. The masking activity is performed before the data is saved to disk. This type of data masking is used by organizations that frequently deploy software. Creating a backup copy of the source database for every deployment is not feasible. Instead, they need to continuously stream data from production to other environments such as development and testing.
Now that we have discussed the different types of data masking, let's look into different techniques that you can use to mask data. The following figure depicts commonly used data masking techniques:
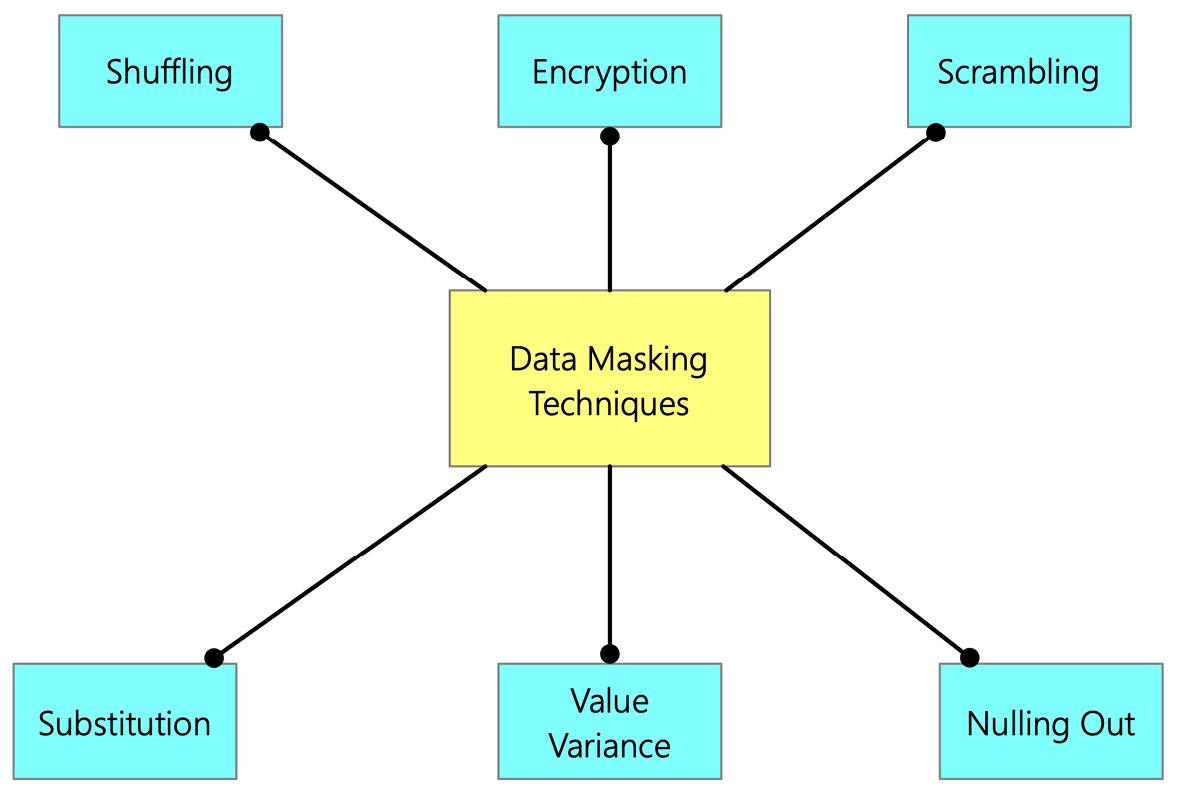
Figure 7.8 – Commonly used methods of data masking
Let's discuss these techniques briefly:
- Encryption: We covered encryption in detail in the last section. You can also use any of those encryption methods for data masking.
- Scrambling: Scrambling is a basic masking technique that jumbles the characters and numbers into a random order, thus hiding the original content. For example, an ID number of 1234 in a production database could be replaced by 4321 in a test database.
- Nulling Out: The nulling out data masking technique replaces the sensitive data with a null value so that unauthorized users don't see the actual data. The data appears to be null or missing.
- Value Variance: Original data values are replaced by a function that replaces the original data with the output value of the function. For example, suppose a customer purchases several products. In that case, the masking method can replace the purchase price with a range between the highest and lowest price paid.
- Substitution: In the substitution data masking technique, the sensitive data is substituted with another value. The substitution technique is one of the most effective data masking methods, which preserves the original look, such asthe look and feel of the data.
- Shuffling: The data shuffling technique involves moving data within rows in the same column. This technique is like substitution. However, the data values are switched within the same dataset in this case. The data is rearranged in each column using a random sequence.
Now that we have covered data masking, let's move on to the last component of the data security layer, that is, the network security service.
Methods of implementing network security in a data lakehouse
The network is the lifeline of the data lakehouse. The data flows in and out of the data lakehouse through the network. The network acts as a conduit to other systems as well. Therefore, it is paramount to ensure that the network is well protected. All other data security components work in tandem with network security services. Network security aims to protect the usability and integrity of your network. It effectively manages access to the network and mitigates various threats and stops them from entering or spreading on your network.
In the previous section, we covered the network security layer at a high level. So, let's further drill down to the network security service and discuss what it entails. The following figure dives deeper into the subcomponents of network security services:
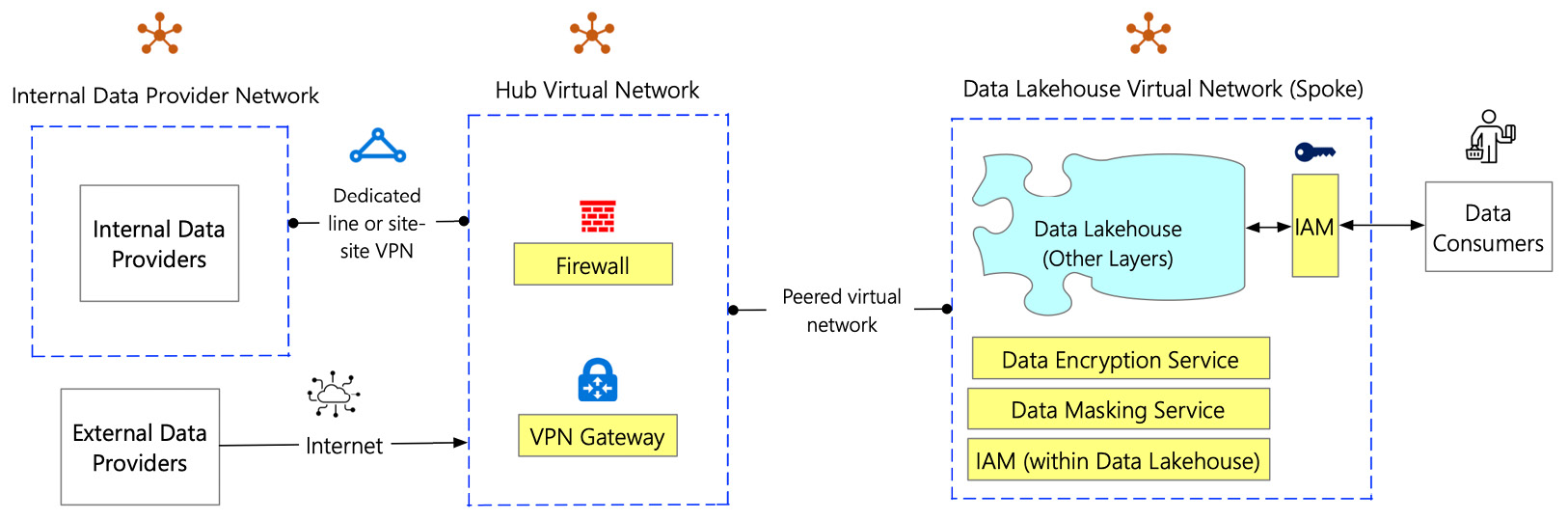
Figure 7.9 – The subcomponents of network security services
Let's break down this figure based on the subcomponents:
- Virtual Network: The first subcomponent of the network security service is the Virtual Network (VNET). A virtual network connects all devices, servers, virtual machines, and data centers through software and wireless technology. A typical implementation of VNETs includes a hub-spoke network topology. The virtual hub network is the central point of connectivity to the external network. It is a place to host services that are consumed by different workloads that are hosted in the virtual spoke networks. The spoke virtual networks isolate workloads in their virtual networks and are managed separately from other spokes. For example, the components of the data lakehouse are secured within its spoke VNET.
- Firewall: A hub VNET has specialized network security subcomponents that control the access to the spoke VNETs, including the data lakehouse VNET. That brings us to the second subcomponent of the network security layer, the firewall. A firewall is a network security component that watches and filters incoming and outgoing network traffic. Its primary purpose is to allow non-threatening traffic and keep dangerous traffic out. It screens this traffic based on an organization's previously established security policies. It acts as a barrier between a private internal network and the public internet. It also prevents malicious software from accessing a computer or network via the internet. Firewalls can also be configured to allow only specific devices, applications, or ports to allow communication.
- Virtual Private Network (VPN) gateway: The network traffic flows between the external and the data lakehouse networks. The data packets that flow through these networks need to be encrypted. That brings us to the third subcomponent of the network security layer, the VPN gateway. A VPN gateway is used to send encrypted traffic between the data lakehouse's virtual network and other networks that are external to the data lakehouse networks. These networks can be an organization's own data center networks or locations over the public internet.
We have covered all the components of the data security layer. Let's now conclude by summarizing the key aspects of this chapter.
Summary
This chapter covered the components of the data security layer, one of the essential layers of a data lakehouse. Data security is paramount in any system. Its importance is accentuated when it comes to protecting data access, usage, and storage. This chapter covered how to secure data and ensure that the right access is provided at the right layer to the right stakeholder. The chapter began by giving an overview of the four components of the data security layer. Then, we discussed how these four layers interact with each other. The following sections of the chapter delved deeper into each component. The first component discussed was IAM. IAM ensures that the right user gets access to the right component with the correct authorization level. We also discussed the principles of zero-trust architecture. The following section discussed the ways data can be encrypted in a data lakehouse using a data encryption service. When the data is encrypted, it cannot be deciphered, even if someone gains unauthorized access to data. Then, we discussed the various encryption methods that can be employed to secure data, and we also covered the ways data can be masked in a data lakehouse using a data masking service. Data masking allows us to hide sensitive information and ensures that access to such information is provided prudently. We discussed various methods used in data masking in this section.
The final section of the chapter focused on network security services. Network security binds the data flow within and outside of the data lakehouse. This section discussed three key subcomponents of network security services that protect data and its access.
We have covered all seven layers of the data lakehouse with this chapter. The next chapter will focus on the practical implementation of a data lakehouse using a cloud computing platform.
Further reading
For more information regarding the topics that were covered in this chapter, take a look at the following resources:
- Identity and Access Management: https://digitalguardian.com/blog/what-identity-and-access-management-iam
- Identity and Access Management 101: https://www.okta.com/identity-101/identity-and-access-management/
- Identity and Access Management: https://docs.microsoft.com/en-us/azure/security/fundamentals/identity-management-overview
- Identity and Access Management: https://www.onelogin.com/learn
- Data Encryption: https://digitalguardian.com/blog/what-data-encryption
- Data Encryption: https://www.forcepoint.com/cyber-edu/data-encryption
- Fundamentals of Data Encryption: https://docs.microsoft.com/en-us/azure/security/fundamentals/encryption-atrest
- What is Encryption: https://us.norton.com/internetsecurity-privacy-what-is-encryption.html
- Common Storage Encryption: https://docs.microsoft.com/en-us/azure/storage/common/storage-service-encryption?toc=/azure/storage/blobs/toc.json
- Symmetric Key Encryption: https://www.cryptomathic.com/news-events/blog/symmetric-key-encryption-why-where-and-how-its-used-in-banking
- Encryption Methods: https://www.simplilearn.com/data-encryption-methods-article
- Encryption Overview: https://docs.microsoft.com/en-us/azure/security/fundamentals/encryption-overview
- Transport Layer Security: https://en.wikipedia.org/wiki/Transport_Layer_Security
- Securing with HTTPS: https://developers.google.com/search/docs/advanced/security/https
- Data Masking: https://www.imperva.com/learn/data-security/data-masking/
- Data Masking: https://www.bmc.com/blogs/data-masking/
- Data Masking: https://www.datprof.com/solutions/deterministic-data-masking/
- Data Masking: https://www.delphix.com/glossary/data-masking
- Virtual Networks: https://docs.microsoft.com/en-us/azure/virtual-network/virtual-networks-overview
- Firewall: https://us.norton.com/internetsecurity-emerging-threats-what-is-firewall
- Understanding Firewalls: https://us-cert.cisa.gov/ncas/tips/ST04-004
- Virtual Networks: https://www.bmc.com/blogs/virtual-network/#
- Network Hub-Spoke: https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/hybrid-networking/hub-spoke?tabs=cli
- Firewalls: https://www.checkpoint.com/cyber-hub/network-security/what-is-firewall/
- VPN Gateway: https://www.techopedia.com/definition/30755/vpn-gateway